Spark предоставляет API для Scala, Java, Python и R. Система поддерживает повторное использование кода между рабочими задачами, пакетную обработку данных, интерактивные запросы, аналитику в реальном времени, машинное обучение и вычисления на графах. Она использует кэширование в памяти и оптимизированное выполнение запросов к данным любого размера.
У нее нет одной собственной файловой системы, такой как Hadoop Distributed File System (HDFS), вместо этого Spark поддерживает множество популярных файловых систем, таких как HDFS, HBase, Cassandra, Amazon S3, Amazon Redshift, Couchbase и т. д.
Преимущества использования Apache Spark:
- Он запускает программы в памяти до 100 раз быстрее, чем Hadoop MapReduce, и в 10 раз быстрее на диске, потому что Spark выполняет обработку в основной памяти рабочих узлов и предотвращает ненужные операции ввода-вывода.
- Spark крайне удобен для пользователя, поскольку имеет API-интерфейсы, написанные на популярных языках, что упрощает задачу для разработчиков: такой подход скрывает сложность распределенной обработки за простыми высокоуровневыми операторами, что значительно снижает объем необходимого кода.
- Систему можно развернуть, используя Mesos, Hadoop через Yarn или собственный диспетчер кластеров Spark.
- Spark производит вычисления в реальном времени и обеспечивает низкую задержку благодаря их резидентному выполнению (в памяти).
Давайте приступим.
Настройка среды в Google Colab
Чтобы запустить pyspark на локальной машине, нам понадобится Java и еще некоторое программное обеспечение. Поэтому вместо сложной процедуры установки мы используем Google Colaboratory, который идеально удовлетворяет наши требования к оборудованию, и также поставляется с широким набором библиотек для анализа данных и машинного обучения. Таким образом, нам остается только установить пакеты pyspark и Py4J. Py4J позволяет программам Python, работающим в интерпретаторе Python, динамически обращаться к объектам Java из виртуальной машины Java.
Итоговый ноутбук можно скачать в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/pyspark_beginner.ipynb
Команда для установки вышеуказанных пакетов:
!pip install pyspark==3.0.1 py4j==0.10.9Spark Session
SparkSession стал точкой входа в PySpark, начиная с версии 2.0: ранее для этого использовался SparkContext. SparkSession — это способ инициализации базовой функциональности PySpark для программного создания PySpark RDD, DataFrame и Dataset. Его можно использовать вместо SQLContext, HiveContext и других контекстов, определенных до 2.0.
Вы также должны знать, что SparkSession внутренне создает SparkConfig и SparkContext с конфигурацией, предоставленной с SparkSession. SparkSession можно создать с помощью SparkSession.builder, который представляет собой реализацию шаблона проектирования Builder (Строитель).
Создание SparkSession
Чтобы создать SparkSession, вам необходимо использовать метод builder().
getOrCreate()возвращает уже существующий SparkSession; если он не существует, создается новый SparkSession.master(): если вы работаете с кластером, вам нужно передать имя своего кластерного менеджера в качестве аргумента. Обычно это будет либоyarn, либоmesosв зависимости от настройки вашего кластера, а при работе в автономном режиме используетсяlocal[x]. Здесь X должно быть целым числом, большим 0. Данное значение указывает, сколько разделов будет создано при использовании RDD, DataFrame и Dataset. В идеалеXдолжно соответствовать количеству ядер ЦП.appName()используется для установки имени вашего приложения.
Пример создания SparkSession:
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark_Tutorial')\
.getOrCreate()
# где "*" обозначает все ядра процессора.
Чтение данных
Используя spark.read мы может считывать данные из файлов различных форматов, таких как CSV, JSON, Parquet и других. Вот несколько примеров получения данных из файлов:
# Чтение CSV файла
csv_file = 'data/stocks_price_final.csv'
df = spark.read.csv(csv_file)
# Чтение JSON файла
json_file = 'data/stocks_price_final.json'
data = spark.read.json(json_file)
# Чтение parquet файла
parquet_file = 'data/stocks_price_final.parquet'
data1 = spark.read.parquet(parquet_file)
Структурирование данных с помощью схемы Spark
Давайте прочитаем данные о ценах на акции в США с января 2019 года по июль 2020 года, которые доступны в датасетах Kaggle.
Код для чтения данных в формате файла CSV:
data = spark.read.csv(
'stocks_price_final.csv',
sep=',',
header=True,
)
data.printSchema()
Теперь посмотрим на схему данных с помощью метода PrintSchema.
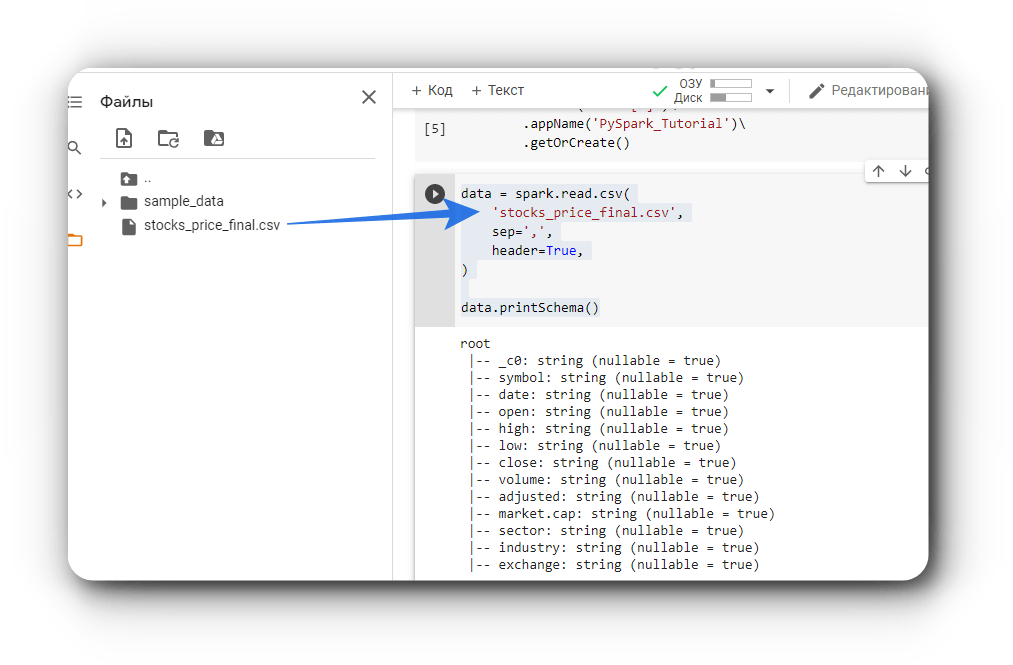
Схема Spark отображает структуру фрейма данных или датасета. Мы можем определить ее с помощью класса StructType, который представляет собой коллекцию объектов StructField. Они в свою очередь устанавливают имя столбца (String), его тип (DataType), допускает ли он значение NULL (Boolean), и метаданные (MetaData).
Это бывает довольно полезно, даже учитывая, что Spark автоматически выводит схему из данных, так как иногда предполагаемый им тип может быть неверным, или нам необходимо определить собственные имена столбцов и типы данных. Такое часто случается при работе с полностью или частично неструктурированными данными.
Давайте посмотрим, как мы можем структурировать наши данные:
from pyspark.sql.types import *
data_schema = [
StructField('_c0', IntegerType(), True),
StructField('symbol', StringType(), True),
StructField('data', DateType(), True),
StructField('open', DoubleType(), True),
StructField('high', DoubleType(), True),
StructField('low', DoubleType(), True),
StructField('close', DoubleType(), True),
StructField('volume', IntegerType(), True),
StructField('adjusted', DoubleType(), True),
StructField('market.cap', StringType(), True),
StructField('sector', StringType(), True),
StructField('industry', StringType(), True),
StructField('exchange', StringType(), True),
]
final_struc = StructType(fields = data_schema)
data = spark.read.csv(
'stocks_price_final.csv',
sep=',',
header=True,
schema=final_struc
)
data.printSchema()
В приведенном выше коде создается структура данных с помощью StructType и StructField. Затем она передается в качестве параметра schema методу spark.read.csv(). Давайте взглянем на полученную в результате схему структурированных данных:
root
|-- _c0: integer (nullable = true)
|-- symbol: string (nullable = true)
|-- data: date (nullable = true)
|-- open: double (nullable = true)
|-- high: double (nullable = true)
|-- low: double (nullable = true)
|-- close: double (nullable = true)
|-- volume: integer (nullable = true)
|-- adjusted: double (nullable = true)
|-- market.cap: string (nullable = true)
|-- sector: string (nullable = true)
|-- industry: string (nullable = true)
|-- exchange: string (nullable = true)Различные методы инспекции данных
Существуют следующие методы инспекции данных: schema, dtypes, show, head, first, take, describe, columns, count, distinct, printSchema. Давайте разберемся в них на примере.
schema(): этот метод возвращает схему данных (фрейма данных). Ниже показан пример с ценами на акции.
data.schema
# -------------- Вывод ------------------
# StructType(
# List(
# StructField(_c0,IntegerType,true),
# StructField(symbol,StringType,true),
# StructField(data,DateType,true),
# StructField(open,DoubleType,true),
# StructField(high,DoubleType,true),
# StructField(low,DoubleType,true),
# StructField(close,DoubleType,true),
# StructField(volume,IntegerType,true),
# StructField(adjusted,DoubleType,true),
# StructField(market_cap,StringType,true),
# StructField(sector,StringType,true),
# StructField(industry,StringType,true),
# StructField(exchange,StringType,true)
# )
# )
dtypesвозвращает список кортежей с именами столбцов и типами данных.
data.dtypes
#------------- Вывод ------------
# [('_c0', 'int'),
# ('symbol', 'string'),
# ('data', 'date'),
# ('open', 'double'),
# ('high', 'double'),
# ('low', 'double'),
# ('close', 'double'),
# ('volume', 'int'),
# ('adjusted', 'double'),
# ('market_cap', 'string'),
# ('sector', 'string'),
# ('industry', 'string'),
# ('exchange', 'string')]
head(n)возвращает n строк в виде списка. Вот пример:
data.head(3)
# ---------- Вывод ---------
# [
# Row(_c0=1, symbol='TXG', data=datetime.date(2019, 9, 12), open=54.0, high=58.0, low=51.0, close=52.75, volume=7326300, adjusted=52.75, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ'),
# Row(_c0=2, symbol='TXG', data=datetime.date(2019, 9, 13), open=52.75, high=54.355, low=49.150002, close=52.27, volume=1025200, adjusted=52.27, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ'),
# Row(_c0=3, symbol='TXG', data=datetime.date(2019, 9, 16), open=52.450001, high=56.0, low=52.009998, close=55.200001, volume=269900, adjusted=55.200001, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ')
# ]
show()по умолчанию отображает первые 20 строк, а также принимает число в качестве параметра для выбора их количества.first()возвращает первую строку данных.
data.first()
# ----------- Вывод -------------
# Row(_c0=1, symbol='TXG', data=datetime.date(2019, 9, 12), open=54.0, high=58.0, low=51.0,
# close=52.75, volume=7326300, adjusted=52.75, market_cap='$9.31B', sector='Capital Goods',
# industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ')
take(n)возвращает первые n строк.describe()вычисляет некоторые статистические значения для столбцов с числовым типом данных.columnsвозвращает список, содержащий названия столбцов.
data.columns
# --------------- Вывод --------------
# ['_c0',
# 'symbol',
# 'data',
# 'open',
# 'high',
# 'low',
# 'close',
# 'volume',
# 'adjusted',
# 'market_cap',
# 'sector',
# 'industry',
# 'exchange']count()возвращает общее число строк в датасете.
data.count()
# возвращает количество строк данных
# -------- Вывод ---------
# 1292361distinct()— количество различных строк в используемом наборе данных.printSchema()отображает схему данных.
df.printSchema()
# ------------ Вывод ------------
# root
# |-- _c0: integer (nullable = true)
# |-- symbol: string (nullable = true)
# |-- data: date (nullable = true)
# |-- open: double (nullable = true)
# |-- high: double (nullable = true)
# |-- low: double (nullable = true)
# |-- close: double (nullable = true)
# |-- volume: integer (nullable = true)
# |-- adjusted: double (nullable = true)
# |-- market_cap: string (nullable = true)
# |-- sector: string (nullable = true)
# |-- industry: string (nullable = true)
# |-- exchange: string (nullable = true)Манипуляции со столбцами
Давайте посмотрим, какие методы используются для добавления, обновления и удаления столбцов данных.
1. Добавление столбца: используйте withColumn, чтобы добавить новый столбец к существующим. Метод принимает два параметра: имя столбца и данные. Пример:
data = data.withColumn('date', data.data)
data.show(5)
2. Обновление столбца: используйте withColumnRenamed, чтобы переименовать существующий столбец. Метод принимает два параметра: название существующего столбца и его новое имя. Пример:
data = data.withColumnRenamed('date', 'data_changed')
data.show(5)
3. Удаление столбца: используйте метод drop, который принимает имя столбца и возвращает данные.
data = data.drop('data_changed')
data.show(5)
Работа с недостающими значениями
Мы часто сталкиваемся с отсутствующими значениями при работе с данными реального времени. Эти пропущенные значения обозначаются как NaN, пробелы или другие заполнители. Существуют различные методы работы с пропущенными значениями, некоторые из самых популярных:
- Удаление: удалить строки с пропущенными значениями в любом из столбцов.
- Замена средним/медианным значением: замените отсутствующие значения, используя среднее или медиану соответствующего столбца. Это просто, быстро и хорошо работает с небольшими наборами числовых данных.
- Замена на наиболее частые значения: как следует из названия, используйте наиболее часто встречающееся значение в столбце, чтобы заменить отсутствующие. Это хорошо работает с категориальными признаками, но также может вносить смещение (bias) в данные.
- Замена с использованием KNN: метод K-ближайших соседей — это алгоритм классификации, который рассчитывает сходство признаков новых точек данных с уже существующими, используя различные метрики расстояния, такие как Евклидова, Махаланобиса, Манхэттена, Минковского, Хэмминга и другие. Такой подход более точен по сравнению с вышеупомянутыми методами, но он требует больших вычислительных ресурсов и довольно чувствителен к выбросам.
Давайте посмотрим, как мы можем использовать PySpark для решения проблемы отсутствующих значений:
# Удаление строк с пропущенными значениями
data.na.drop()
# Замена отсутствующих значений средним
data.na.fill(data.select(f.mean(data['open'])).collect()[0][0])
# Замена отсутствующих значений новыми
data.na.replace(old_value, new_vallue)
Получение данных
PySpark и PySpark SQL предоставляют широкий спектр методов и функций для удобного запроса данных. Вот список наиболее часто используемых методов:
- Select
- Filter
- Between
- When
- Like
- GroupBy
- Агрегирование
Select
Он используется для выбора одного или нескольких столбцов, используя их имена. Вот простой пример:
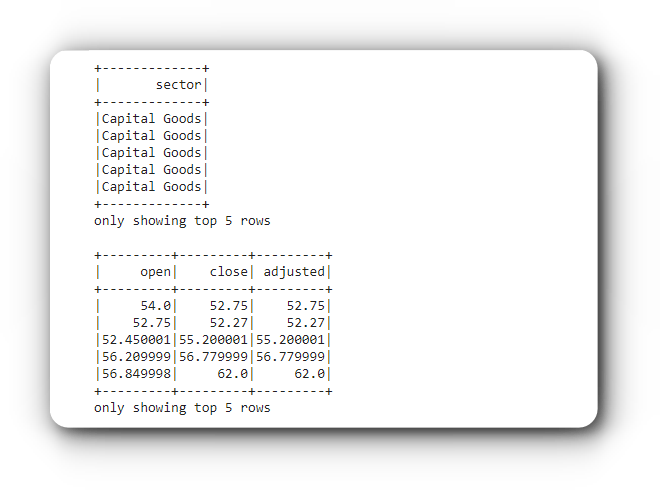
# Выбор одного столбца
data.select('sector').show(5)
# Выбор нескольких столбцов
data.select(['open', 'close', 'adjusted']).show(5)
Filter
Данный метод фильтрует данные на основе заданного условия. Вы также можете указать несколько условий, используя операторы AND (&), OR (|) и NOT (~). Вот пример получения данных о ценах на акции за январь 2020 года.
from pyspark.sql.functions import col, lit
data.filter( (col('data') >= lit('2020-01-01')) & (col('data') <= lit('2020-01-31')) ).show(5)
Between
Этот метод возвращает True, если проверяемое значение принадлежит указанному отрезку, иначе — False. Давайте посмотрим на пример отбора данных, в которых значения adjusted находятся в диапазоне от 100 до 500.
data.filter(data.adjusted.between(100.0, 500.0)).show()
When
Он возвращает 0 или 1 в зависимости от заданного условия. В приведенном ниже примере показано, как выбрать такие цены на момент открытия и закрытия торгов, при которых скорректированная цена была больше или равна 200.
data.select('open', 'close',
f.when(data.adjusted >= 200.0, 1).otherwise(0)
).show(5)
Like
Этот метод похож на оператор Like в SQL. Приведенный ниже код демонстрирует использование rlike() для извлечения имен секторов, которые начинаются с букв M или C.
data.select(
'sector',
data.sector.rlike('^[B,C]').alias('Колонка sector начинается с B или C')
).distinct().show()
GourpBy
Само название подсказывает, что данная функция группирует данные по выбранному столбцу и выполняет различные операции, такие как вычисление суммы, среднего, минимального, максимального значения и т. д. В приведенном ниже примере объясняется, как получить среднюю цену открытия, закрытия и скорректированную цену акций по отраслям.
data.select(['industry', 'open', 'close', 'adjusted'])\
.groupBy('industry')\
.mean()\
.show()
Агрегирование
PySpark предоставляет встроенные стандартные функции агрегации, определенные в API DataFrame, они могут пригодится, когда нам нужно выполнить агрегирование значений ваших столбцов. Другими словами, такие функции работают с группами строк и вычисляют единственное возвращаемое значение для каждой группы.
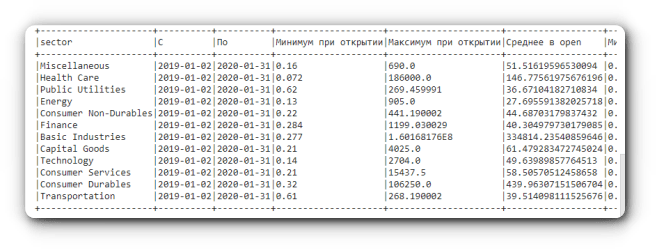
В приведенном ниже примере показано, как отобразить минимальные, максимальные и средние значения цен открытия, закрытия и скорректированных цен акций в промежутке с января 2019 года по январь 2020 года для каждого сектора.
from pyspark.sql import functions as f
data.filter((col('data') >= lit('2019-01-02')) & (col('data') <= lit('2020-01-31')))\
.groupBy("sector") \
.agg(f.min("data").alias("С"),
f.max("data").alias("По"),
f.min("open").alias("Минимум при открытии"),
f.max("open").alias("Максимум при открытии"),
f.avg("open").alias("Среднее в open"),
f.min("close").alias("Минимум при закрытии"),
f.max("close").alias("Максимум при закрытии"),
f.avg("close").alias("Среднее в close"),
f.min("adjusted").alias("Скорректированный минимум"),
f.max("adjusted").alias("Скорректированный максимум"),
f.avg("adjusted").alias("Среднее в adjusted"),
).show(truncate=False)
Визуализация данных
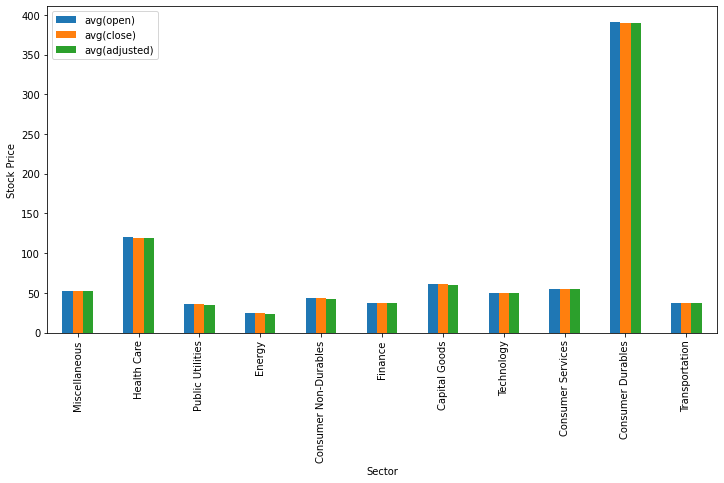
Для визуализации данных мы воспользуемся библиотеками matplotlib и pandas. Метод toPandas() позволяет нам осуществить преобразование данных в dataframe pandas, который мы используем при вызове метода визуализации plot(). В приведенном ниже коде показано, как отобразить гистограмму, отображающую средние значения цен открытия, закрытия и скорректированных цен акций для каждого сектора.
from matplotlib import pyplot as plt
sec_df = data.select(['sector',
'open',
'close',
'adjusted']
)\
.groupBy('sector')\
.mean()\
.toPandas()
ind = list(range(12))
ind.pop(6)
sec_df.iloc[ind ,:].plot(kind='bar', x='sector', y=sec_df.columns.tolist()[1:],
figsize=(12, 6), ylabel='Stock Price', xlabel='Sector')
plt.show()
Теперь давайте визуализируем те же средние показатели, но уже по отраслям.
industries_x = data.select(['industry', 'open', 'close', 'adjusted']).groupBy('industry').mean().toPandas()
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')]
q.plot(kind='barh', x='industry', y=q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel='Industry')
plt.show()
Также построим временные ряды для средних цен открытия, закрытия и скорректированных цен акций технологического сектора.
industries_x = data.select(['industry', 'open', 'close', 'adjusted']).groupBy('industry').mean().toPandas()
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')]
q.plot(kind='barh', x='industry', y=q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel='Industry')
plt.show()
Запись/сохранение данных в файл
Метод write.save() используется для сохранения данных в различных форматах, таких как CSV, JSVON, Parquet и других. Давайте рассмотрим, как записать данные в файлы разных форматов. Мы можем сохранить как все строки, так и только выбранные с помощью метода select().
# CSV
data.write.csv('dataset.csv')
# JSON
data.write.save('dataset.json', format='json')
# Parquet
data.write.save('dataset.parquet', format='parquet')
# Запись выбранных данных в различные форматы файлов
# CSV
data.select(['data', 'open', 'close', 'adjusted'])\
.write.csv('dataset.csv')
# JSON
data.select(['data', 'open', 'close', 'adjusted'])\
.write.save('dataset.json', format='json')
# Parquet
data.select(['data', 'open', 'close', 'adjusted'])\
.write.save('dataset.parquet', format='parquet')
Заключение
PySpark — отличный инструмент для специалистов по данным, поскольку он обеспечивает масштабируемые анализ и ML-пайплайны. Если вы уже знакомы с Python, SQL и Pandas, тогда PySpark — хороший вариант для быстрого старта.
В этой статье было показано, как следует выполнять широкий спектр операций, начиная с чтения файлов и заканчивая записью результатов с помощью PySpark. Также мы охватили основные методы визуализации с использованием библиотеки matplotlib.
Мы узнали, что Google Colaboratory Notebooks — это удобное место для начала изучения PySpark без долгой установки необходимого программного обеспечения. Не забудьте ознакомиться с представленными ниже ссылками на ресурсы, которые могут помочь вам быстрее и проще изучить PySpark.
Также не стесняйтесь использовать предоставленный в статье код, доступ к которому можно получить, перейдя на Gitlab. Удачного обучения.
]]>Случайный лес имеет множество применений, таких как механизмы рекомендаций, классификация изображений и отбор признаков. Его можно использовать для классификации добросовестных соискателей кредита, выявления мошенничества и прогнозирования заболеваний. Он лежит в основе алгоритма Борута, который определяет наиболее значимые показатели датасета.
Алгоритм Random Forest
Давайте разберемся в алгоритме случайного леса, используя нетехническую аналогию. Предположим, вы решили отправиться в путешествие и хотите попасть в туда, где вам точно понравится.
Итак, что вы делаете, чтобы выбрать подходящее место? Ищите информацию в Интернете: вы можете прочитать множество различных отзывов и мнений в блогах о путешествиях, на сайтах, подобных Кью, туристических порталах, — или же просто спросить своих друзей.
Предположим, вы решили узнать у своих знакомых об их опыте путешествий. Вы, вероятно, получите рекомендации от каждого друга и составите из них список возможных локаций. Затем вы попросите своих знакомых проголосовать, то есть выбрать лучший вариант для поездки из составленного вами перечня. Место, набравшее наибольшее количество голосов, станет вашим окончательным выбором для путешествия.
Вышеупомянутый процесс принятия решения состоит из двух частей.
- Первая заключается в опросе друзей об их индивидуальном опыте и получении рекомендации на основе тех мест, которые посетил конкретный друг. В этой части используется алгоритм дерева решений. Каждый участник выбирает только один вариант среди знакомых ему локаций.
- Второй частью является процедура голосования для определения лучшего места, проведенная после сбора всех рекомендаций. Голосование означает выбор наиболее оптимального места из предоставленных на основе опыта ваших друзей. Весь этот процесс (первая и вторая части) от сбора рекомендаций до голосования за наиболее подходящий вариант представляет собой алгоритм случайного леса.
Технически Random forest — это метод (основанный на подходе «разделяй и властвуй»), использующий ансамбль деревьев решений, созданных на случайно разделенном датасете. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака.
Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс. В случае регрессии конечным результатом считается среднее значение всех выходных данных ансамбля. Метод случайного леса является более простым и эффективным по сравнению с другими алгоритмами нелинейной классификации.
Как работает случайный лес?
Алгоритм состоит из четырех этапов:
- Создайте случайные выборки из заданного набора данных.
- Для каждой выборки постройте дерево решений и получите результат предсказания, используя данное дерево.
- Проведите голосование за каждый полученный прогноз.
- Выберите предсказание с наибольшим количеством голосов в качестве окончательного результата.
Поиск важных признаков
Random forest также предлагает хороший критерий отбора признаков. Scikit-learn предоставляет дополнительную переменную при использовании модели случайного леса, которая показывает относительную важность, то есть вклад каждого показателя в прогноз. Библиотека автоматически вычисляет оценку релевантности каждого признака на этапе обучения. Затем полученное значение нормализируется так, чтобы сумма всех оценок равнялась 1.
Такая оценка поможет выбрать наиболее значимые показатели и отбросить наименее важные для построения модели.
Случайный лес использует критерий Джини, также известный как среднее уменьшение неопределенности (MDI), для расчета важности каждого признака. Кроме того, критерий Джини иногда называют общим уменьшением неопределенности в узлах. Он показывает, насколько снижается точность модели, когда вы отбрасываете переменную. Чем больше уменьшение, тем значительнее отброшенный признак. Таким образом, среднее уменьшение является необходимым параметром для выбора переменной. Также с помощью данного критерия можете быть отображена общая описательная способность признаков.
Сравнение случайных лесов и деревьев решений
- Случайный лес — это набор из множества деревьев решений.
- Глубокие деревья решений могут страдать от переобучения, но случайный лес предотвращает переобучение, создавая деревья на случайных выборках.
- Деревья решений вычислительно быстрее, чем случайные леса.
- Случайный лес сложно интерпретировать, а дерево решений легко интерпретировать и преобразовать в правила.
Создание классификатора с использованием Scikit-learn
Вы будете строить модель на основе набора данных о цветках ириса, который является очень известным классификационным датасетом. Он включает длину и ширину чашелистика, длину и ширину лепестка, и тип цветка. Существуют три вида (класса) ирисов: Setosa, Versicolor и Virginica. Вы построите модель, определяющую тип цветка из вышеперечисленных. Этот датасет доступен в библиотеке scikit-learn или вы можете загрузить его из репозитория машинного обучения UCI.
Начнем с импорта datasets из scikit-learn и загрузим набор данных iris с помощью load_iris().
from sklearn import datasets
# загрузка датасета
iris = datasets.load_iris()
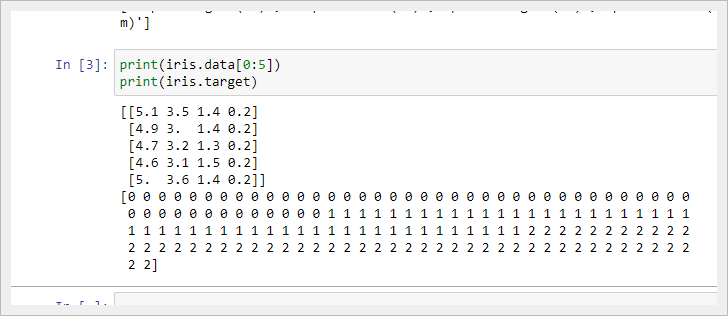
Вы можете отобразить имена целевого класса и признаков, чтобы убедиться, что это нужный вам датасет:
print(iris.target_names)
print(iris.feature_names)
['setosa' 'versicolor' 'virginica']
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']Рекомендуется всегда хотя бы немного изучить свои данные, чтобы знать, с чем вы работаете. Здесь вы можете увидеть результат вывода первых пяти строк используемого набора данных, а также всех значений целевой переменной датасета.
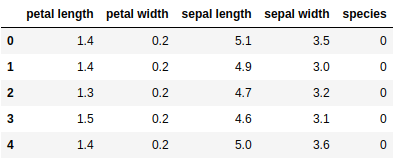
Ниже мы создаем dataframe из нашего набора данных об ирисах.
import pandas as pd
data=pd.DataFrame({
'sepal length':iris.data[:,0],
'sepal width':iris.data[:,1],
'petal length':iris.data[:,2],
'petal width':iris.data[:,3],
'species':iris.target
})
data.head()
Далее мы разделяем столбцы на зависимые и независимые переменные (признаки и метки целевых классов). Затем давайте создадим выборки для обучения и тестирования из исходных данных.
from sklearn.model_selection import train_test_split
X = data[['sepal length', 'sepal width', 'petal length', 'petal width']]
y = data['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=85)
После этого мы сгенерируем модель случайного леса на обучающем наборе и выполним предсказания на тестовом.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
После создания модели стоит проверить ее точность, используя фактические и спрогнозированные значения.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
Accuracy: 0.9333333333333333Вы также можете сделать предсказание для единственного наблюдения. Предположим, sepal length=3, sepal width=5, petal length=4, petal width=2.
Мы можем определить, к какому типу цветка относится выбранный, следующим образом:
clf.predict([[3, 5, 4, 2]])
# результат - 2
Выше цифра 2 указывает на класс цветка «virginica».
Поиск важных признаков с помощью scikit-learn
В этом разделе вы определяете наиболее значимые признаки или выполняете их отбор в датасете iris. В scikit-learn мы можем решить эту задачу, выполнив перечисленные шаги:
- Создадим модель случайного леса.
- Используем переменную
feature_importances_, чтобы увидеть соответствующие оценки значимости показателей. - Визуализируем полученные оценочные значения с помощью библиотеки seaborn.
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
feature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)
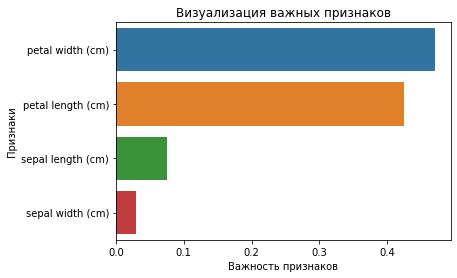
feature_imp
petal width (cm) 0.470224
petal length (cm) 0.424776
sepal length (cm) 0.075913
sepal width (cm) 0.029087Вы также можете визуализировать значимость признаков. Такое графическое отображение легко понять и интерпретировать. Кроме того, визуальное представление информации является самым быстрым способом ее усвоения человеческим мозгом.
Для построения необходимых диаграмм вы можете использовать библиотеки matplotlib и seaborn совместно, потому что seaborn, построенная поверх matplotlib, предлагает множество специальных тем и дополнительных графиков. Matplotlib — это надмножество seaborn, и обе библиотеки одинаково необходимы для хорошей визуализации.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.barplot(x=feature_imp, y=feature_imp.index)
plt.xlabel('Важность признаков')
plt.ylabel('Признаки')
plt.title('Визуализация важных признаков')
plt.show()
Повторная генерация модели с отобранными признаками
Далее мы удаляем показатель «sepal width» и используем оставшиеся 3 признака, поскольку ширина чашелистика имеет очень низкую важность.
from sklearn.model_selection import train_test_split
X = data[['petal length', 'petal width','sepal length']]
y = data['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=85)
После разделения вы сгенерируете модель случайного леса для выбранных признаков обучающей выборки, выполните прогноз на тестовом наборе и сравните фактические и предсказанные значения.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
from sklearn import metrics
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.9619047619047619
Вы можете заметить, что после удаления наименее важных показателей (ширины чашелистика) точность увеличилась, поскольку мы устранили вводящие в заблуждение данные и уменьшили шум. Кроме того, ограничив количество значимых признаков, мы сократили время обучения модели.
Преимущества Random Forest:
- Случайный лес считается высокоточным и надежным методом, поскольку в процессе прогнозирования участвует множество деревьев решений.
- Random forest не страдает проблемой переобучения. Основная причина в том, что случайный лес использует среднее значение всех прогнозов, что устраняет смещения.
- RF может использоваться в обоих типах задач (задачах классификации и регрессии).
- Случайный лес также может работать с отсутствующими значениями. Есть два способа решения такой проблемы в Random forest. В первом используется медианное значение для заполнения непрерывных переменных, а во втором вычисляется среднее взвешенное пропущенных значений.
- RF также рассчитывает относительную важность показателей, которая помогает в выборе наиболее значимых признаков для классификатора.
Недостатки Random Forest:
- Случайный лес довольно медленный, так как для работы алгоритм использует множество деревьев: каждому дереву в лесу передаются одни и те же входные данные, на основании которых оно должно вернуть свое предсказание. После чего также происходит голосование на полученных прогнозах. Весь этот процесс занимает много времени.
- Модель случайного леса сложнее интерпретировать по сравнению с деревом решений, где вы легко определяете результат, следуя по пути в дереве.
Заключение
Вы узнали об алгоритме Random forest и принципе его работы, о поиске важных признаков, о главных отличиях случайного леса от дерева решений, о преимуществах и недостатках данного метода. Также научились создавать и оценивать модели, находить наиболее значимые показатели в scikit-learn. Не останавливайся на этом!
Я рекомендую вам попробовать RF на разных наборах данных и прочитать больше о матрице ошибок.
]]>Известный пример — спам-фильтр для электронной почты. Gmail использует методы машинного обучения с учителем, чтобы автоматически помещать электронные письма в папку для спама в зависимости от их содержания, темы и других характеристик.
Две модели машинного обучения выполняют большую часть работы, когда дело доходит до задач классификации:
- Метод K-ближайших соседей
- Метод К-средних
Из этого руководства вы узнаете, как применять алгоритмы K-ближайших соседей и K-средних в коде на Python.
Модели K-ближайших соседей
Алгоритм K-ближайших соседей является одним из самых популярных среди ML-моделей для решения задач классификации.
Обычным упражнением для студентов, изучающих машинное обучение, является применение алгоритма K-ближайших соседей к датасету, категории которого неизвестны. Реальным примером такой ситуации может быть случай, когда вам нужно делать предсказания, используя ML-модели, обученные на секретных правительственных данных.
В этом руководстве вы изучите алгоритм машинного обучения K-ближайших соседей и напишите его реализацию на Python. Мы будем работать с анонимным набором данных, как в описанной выше ситуации.
Используемый датасет
Первое, что вам нужно сделать, это скачать набор данных, который мы будем использовать в этом руководстве. Вы можете скачать его на Gitlab.
Далее вам нужно переместить загруженный файл с датасетом в рабочий каталог. После этого откройте Jupyter Notebook — теперь мы можем приступить к написанию кода на Python!
Необходимые библиотеки
Чтобы написать алгоритм K-ближайших соседей, мы воспользуемся преимуществами многих Python-библиотек с открытым исходным кодом, включая NumPy, pandas и scikit-learn.
Начните работу, добавив следующие инструкции импорта:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Импорт датасета
Следующий шаг — добавление файла classified_data.csv в наш код на Python. Библиотека pandas позволяет довольно просто импортировать данные в DataFrame.
Поскольку датасет хранится в файле csv, мы будем использовать метод read_csv:
raw_data = pd.read_csv('classified_data.csv')
Отобразив полученный DataFrame в Jupyter Notebook, вы увидите, что представляют собой наши данные:
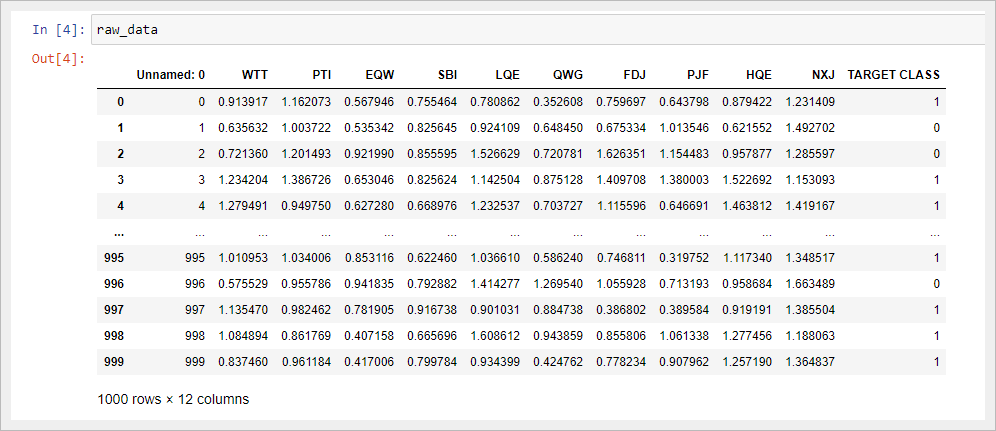
Стоит заметить, что таблица начинается с безымянного столбца, значения которого равны номерам строк DataFrame. Мы можем исправить это, немного изменив команду, которая импортировала наш набор данных в скрипт Python:
raw_data = pd.read_csv('classified_data.csv', index_col = 0)
Затем давайте посмотрим на показатели (признаки), содержащиеся в этом датасете. Вы можете вывести список имен столбцов с помощью следующей инструкции:
raw_data.columns
Получаем:
Index(['WTT', 'PTI', 'EQW', 'SBI', 'LQE', 'QWG', 'FDJ', 'PJF', 'HQE', 'NXJ',
'TARGET CLASS'],
dtype='object')Поскольку этот набор содержит секретные данные, мы понятия не имеем, что означает любой из этих столбцов. На данный момент достаточно признать, что каждый столбец является числовым по своей природе и поэтому хорошо подходит для моделирования с помощью методов машинного обучения.
Стандартизация датасета
Поскольку алгоритм K-ближайших соседей делает прогнозы относительно точки данных (семпла), используя наиболее близкие к ней наблюдения, существующий масштаб показателей в датасете имеет большое значение.
Из-за этого специалисты по машинному обучению обычно стандартизируют набор данных, что означает корректировку каждого значения x так, чтобы они находились примерно в одном диапазоне.
К счастью, библиотека scikit-learn позволяет сделать это без особых проблем.
Для начала нам нужно будет импортировать класс StandardScaler из scikit-learn. Для этого добавьте в свой скрипт Python следующую команду:
from sklearn.preprocessing import StandardScaler
Этот класс во многом похож на классы LinearRegression и LogisticRegression, которые мы использовали ранее в этом курсе. Нам нужно создать экземпляр StandardScaler, а затем использовать этот объект для преобразования наших данных.
Во-первых, давайте создадим экземпляр класса StandardScaler с именем scaler следующей инструкцией:
scaler = StandardScaler()
Теперь мы можем обучить scaler на нашем датасете, используя метод fit:
scaler.fit(raw_data.drop('TARGET CLASS', axis=1))
Теперь мы можем применить метод transform для стандартизации всех признаков, чтобы они имели примерно одинаковый масштаб. Мы сохраним преобразованные семплы в переменной scaled_features:
scaled_features = scaler.transform(raw_data.drop('TARGET CLASS', axis=1))
В качестве результата мы получили массив NumPy со всеми точками данных из датасета, но нам желательно преобразовать его в формат DataFrame библиотеки pandas.
К счастью, сделать это довольно легко. Мы просто обернем переменную scaled_features в метод pd.DataFrame и назначим этот DataFrame новой переменной scaled_data с соответствующим аргументом для указания имен столбцов:
scaled_data = pd.DataFrame(scaled_features, columns = raw_data.drop('TARGET CLASS', axis=1).columns)
Теперь, когда мы импортировали наш датасет и стандартизировали его показатели, мы готовы разделить этот набор данных на обучающую и тестовую выборки.
Разделение датасета на обучающие и тестовые данные
Мы будем использовать функцию train_test_split библиотеки scikit-learn в сочетании с распаковкой списка для создания обучающих и тестовых датасетов из нашего набора секретных данных.
Во-первых, вам нужно импортировать train_test_split из модуля model_validation библиотеки scikit-learn:
from sklearn.model_selection import train_test_split
Затем нам необходимо указать значения x и y, которые будут переданы в функцию train_test_split.
Значения x представляют собой DataFrame scaled_data, который мы создали ранее. Значения y хранятся в столбце "TARGET CLASS" нашей исходной таблицы raw_data.
Вы можете создать эти переменные следующим образом:
x = scaled_data
y = raw_data['TARGET CLASS']
Затем вам нужно запустить функцию train_test_split, используя эти два аргумента и разумный test_size. Мы будем использовать test_size 30%, что дает следующие параметры функции:
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, y, test_size = 0.3)
Теперь, когда наш датасет разделен на данные для обучения и данные для тестирования, мы готовы приступить к обучению нашей модели!
Обучение модели K-ближайших соседей
Начнем с импорта KNeighborsClassifier из scikit-learn:
from sklearn.neighbors import KNeighborsClassifier
Затем давайте создадим экземпляр класса KNeighborsClassifier и назначим его переменной model.
Для этого требуется передать параметр n_neighbors, который равен выбранному вами значению K алгоритма K-ближайших соседей. Для начала укажем n_neighbors = 1:
model = KNeighborsClassifier(n_neighbors = 1)
Теперь мы можем обучить нашу модель, используя метод fit и переменные x_training_data и y_training_data:
model.fit(x_training_data, y_training_data)
Теперь давайте сделаем несколько прогнозов с помощью полученной модели!
Делаем предсказания с помощью алгоритма K-ближайших соседей
Способ получения прогнозов на основе алгоритма K-ближайших соседей такой же, как и у моделей линейной и логистической регрессий, построенных нами ранее в этом курсе: для предсказания достаточно вызвать метод predict, передав в него переменную x_test_data.
В частности, вот так вы можете делать предсказания и присваивать их переменной predictions:
predictions = model.predict(x_test_data)
Давайте посмотрим, насколько точны наши прогнозы, в следующем разделе этого руководства.
Оценка точности нашей модели
В руководстве по логистической регрессии мы видели, что scikit-learn поставляется со встроенными функциями, которые упрощают измерение эффективности классификационных моделей машинного обучения.
Для начала импортируем в наш отчет две функции classification_report и confusion_matrix:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
Теперь давайте поработаем с каждой из них по очереди, начиная с classification_report. С ее помощью вы можете создать отчет следующим образом:
print(classification_report(y_test_data, predictions))
Полученный вывод:
precision recall f1-score support
0 0.92 0.91 0.91 148
1 0.91 0.92 0.92 152
accuracy 0.91 300
macro avg 0.91 0.91 0.91 300
weighted avg 0.91 0.91 0.91 300Точно так же вы можете сгенерировать матрицу ошибок:
print(confusion_matrix(y_test_data, predictions))
# Вывод:
# [[134 14]
# [ 12 140]]
Глядя на такие метрики производительности, похоже, что наша модель уже достаточно эффективна. Но ее еще можно улучшить.
В следующем разделе будет показано, как мы можем повлиять на работу модели K-ближайших соседей, выбрав более подходящее значение для K.
Выбор оптимального значения для K с помощью метода «Локтя»
В этом разделе мы будем использовать метод «локтя», чтобы выбрать оптимальное значение K для нашего алгоритма K-ближайших соседей.
Метод локтя включает в себя итерацию по различным значениям K и выбор значения с наименьшей частотой ошибок при применении к нашим тестовым данным.
Для начала создадим пустой список error_rates. Мы пройдемся по различным значениям K и добавим их частоту ошибок в этот список.
error_rates = []
Затем нам нужно создать цикл Python, который перебирает различные значения K, которые мы хотим протестировать, и на каждой итерации выполняет следующее:
- Создает новый экземпляр класса
KNeighborsClassifierиз scikit-learn. - Тренирует эту модель, используя наши обучающие данные.
- Делает прогнозы на основе наших тестовых данных.
- Вычисляет долю неверных предсказаний (чем она ниже, тем точнее наша модель).
Реализация описанного цикла для значений K от 1 до 100:
for i in np.arange(1, 101):
new_model = KNeighborsClassifier(n_neighbors = i)
new_model.fit(x_training_data, y_training_data)
new_predictions = new_model.predict(x_test_data)
error_rates.append(np.mean(new_predictions != y_test_data))
Давайте визуализируем, как изменяется частота ошибок при различных K, используя matplotlib — plt.plot(error_rates):
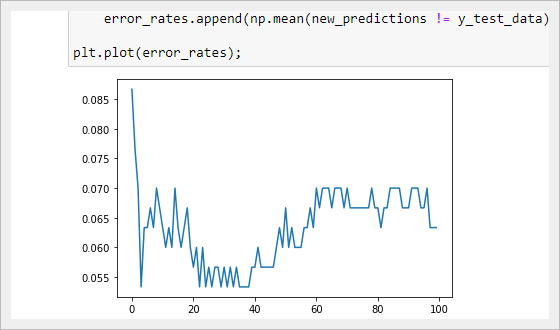
Как видно из графика, мы достигаем минимальной частоты ошибок при значении K, равном приблизительно 35. Это означает, что 35 является подходящим выбором для K, который сочетает в себе простоту и точность предсказаний.
Вы можете найти весь код в ноутбуке на GitLab:
https://gitlab.com/PythonRu/notebooks/-/blob/master/sklearn_kmeans_and_knn.ipynb
Модели кластеризации методом K-средних
Алгоритм кластеризации K-средних обычно является первой моделью машинного обучения без учителя, которую изучают студенты.
Он позволяет специалистам по машинному обучению создавать группы точек данных со схожими количественными характеристиками в датасете. Это полезно для решения таких задач, как формирование клиентских сегментов или определение городских районов с высоким уровнем преступности.
В этом разделе вы узнаете, как создать свой первый алгоритм кластеризации K-средних на Python.
Используемый датасет
В этом руководстве мы будем использовать набор данных, созданный с помощью scikit-learn.
Давайте импортируем функцию make_blobs из scikit-learn, чтобы сгенерировать необходимые данные. Откройте Jupyter Notebook и запустите свой скрипт Python со следующей инструкцией:
from sklearn.datasets import make_blobs
Теперь давайте воспользуемся функцией make_blobs, чтобы получить фиктивные данные!
В частности, вот как вы можете создать набор данных из 200 семплов, который имеет 2 показателя и 4 кластерных центров. Стандартное отклонение для каждого кластера будет равно 1.8.
raw_data = make_blobs(
n_samples = 200,
n_features = 2,
centers = 4,
cluster_std = 1.8
)
Если вы выведите объект raw_data, то заметите, что на самом деле он представляет собой кортеж Python. Первым его элементом является массив NumPy с 200 наблюдениями. Каждое наблюдение содержит 2 признака (как мы и указали в нашей функции make_blobs).
Теперь, когда наши данные созданы, мы можем перейти к импорту других необходимых библиотек с открытым исходным кодом в наш скрипт Python.
Импортируемые библиотеки
В этом руководстве будет использоваться ряд популярных библиотек Python с открытым исходным кодом, включая pandas, NumPy и matplotlib. Продолжим написание скрипта, добавив следующие импорты:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Первая группа библиотек в этом блоке кода предназначена для работы с большими наборами данных. Вторая группа предназначена для визуализации результатов.
Теперь перейдем к созданию визуального представления нашего датасета.
Визуализация датасета
В функции make_blobs мы указали, что в нашем наборе данных должно быть 4 кластерных центра. Лучший способ убедиться, что все действительно так, — это создать несколько простых точечных диаграмм.
Для этого мы воспользуемся функцией plt.scatter, передав в нее все значения из первого столбца нашего набора данных в качестве X и соответствующие значения из второго столбца в качестве Y:
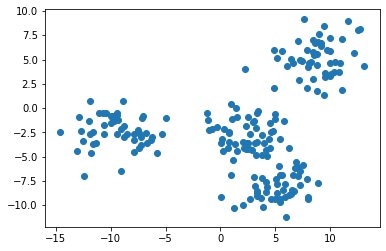
Примечание: ваш датасет будет отличаться от моего, поскольку его данные сгенерированы случайным образом.
Представленное изображение, похоже, указывает на то, что в нашем датасете всего три кластера. Нам так кажется потому, что два кластера расположены очень близко друг к другу.
Чтобы исправить это, нужно сослаться на второй элемент кортежа raw_data, представляющий собой массив NumPy: он содержит индекс кластера, которому принадлежит каждое наблюдение.
Если при построении мы будем использовать уникальный цвет для каждого кластера, то мы легко различим 4 группы наблюдений. Вот код для этого:
plt.scatter(raw_data[0][:,0], raw_data[0][:,1], c=raw_data[1]);
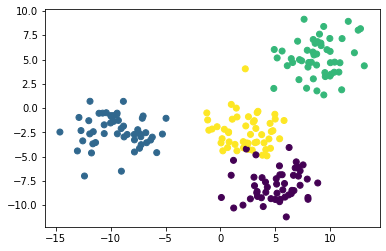
Теперь мы видим, что в нашем наборе данных есть четыре уникальных кластера. Давайте перейдем к построению нашей модели на основе метода K-средних на Python!
Создание и обучение модели кластеризации K-средних
Для того, чтобы начать использовать метод K-средних, импортируем соответствующий класс из scikit-learn. Для этого добавьте в свой скрипт следующую команду:
from sklearn.cluster import KMeans
Затем давайте создадим экземпляр класса KMeans с параметром n_clusters=4 и присвоим его переменной model:
model = KMeans(n_clusters=4)
Теперь обучим нашу модель, вызвав на ней метод fit и передав первый элемент нашего кортежа raw_data:
model.fit(raw_data[0])
В следующем разделе мы рассмотрим, как делать прогнозы с помощью модели кластеризации K-средних.
Прежде чем двигаться дальше, я хотел бы указать на одно различие, которое вы, возможно заметили, между процессом построения модели, используя метод K-средних (он является алгоритмом кластеризации без учителя), и алгоритмами машинного обучения с учителем, с которыми мы работали ранее в данном курсе.
Оно заключается в том, что нам не нужно разбивать набор данных на обучающую и тестовую выборки. Это важное различие, так как вам никогда не нужно разделять таким образом датасет при построении моделей машинного обучения без учителя!
Применяем нашу модель кластеризации K-средних для получения предсказаний
Специалисты по машинному обучению обычно используют алгоритмы кластеризации, чтобы делать два типа прогнозов:
- К какому кластеру принадлежит каждая точка данных.
- Где находится центр каждого кластера.
Теперь, когда наша модель обучена, мы можем легко сгенерировать такие предсказания.
Во-первых, давайте предскажем, к какому кластеру принадлежит каждая точка данных. Для этого обратимся к атрибуту labels_ из объекта model с помощью оператора точки:
model.labels_
Таким образом мы получаем массив NumPy с прогнозами для каждого семпла:
array([3, 2, 1, 1, 3, 2, 1, 0, 0, 0, 0, 0, 3, 2, 1, 2, 1, 3, 3, 3, 3, 1,
1, 1, 2, 2, 3, 1, 3, 2, 1, 0, 1, 3, 1, 1, 3, 2, 0, 1, 3, 2, 3, 3,
0, 3, 2, 2, 3, 0, 0, 0, 1, 1, 2, 1, 2, 0, 1, 2, 2, 1, 2, 3, 0, 3,
0, 2, 0, 0, 1, 1, 0, 3, 2, 3, 2, 0, 1, 2, 0, 2, 0, 3, 3, 0, 3, 3,
0, 3, 2, 3, 2, 1, 2, 1, 3, 3, 2, 2, 0, 2, 0, 2, 0, 2, 1, 0, 0, 2,
3, 2, 1, 2, 3, 0, 1, 1, 1, 3, 2, 2, 3, 3, 2, 1, 3, 0, 0, 3, 0, 1,
1, 3, 1, 0, 1, 1, 0, 3, 2, 0, 3, 0, 1, 2, 1, 2, 1, 2, 2, 3, 2, 1,
0, 2, 3, 3, 2, 0, 1, 3, 3, 2, 0, 0, 0, 3, 1, 2, 0, 2, 3, 3, 2, 2,
3, 1, 0, 1, 2, 3, 1, 3, 1, 1, 0, 2, 1, 0, 2, 1, 3, 1, 3, 3, 1, 3,
0, 3])Чтобы узнать, где находится центр каждого кластера, аналогичным способом обратитесь к атрибуту cluster_centers_:
model.cluster_centers_
Получаем двумерный массив NumPy, содержащий координаты центра каждого кластера. Он будет выглядеть так:
array([[ 5.2662658 , -8.20493969],
[-9.39837945, -2.36452588],
[ 8.78032251, 5.1722511 ],
[ 2.40247618, -2.78480268]])Визуализация точности предсказаний модели
Последнее, что мы сделаем в этом руководстве, — это визуализируем точность нашей модели. Для этого можно использовать следующий код:
f, (ax1, ax2) = plt.subplots(1, 2, sharey=True,figsize=(10,6))
ax1.set_title('Наши предсказания')
ax1.scatter(raw_data[0][:,0], raw_data[0][:,1],c=model.labels_)
ax2.set_title('Реальные значения')
ax2.scatter(raw_data[0][:,0], raw_data[0][:,1],c=raw_data[1]);
Он генерирует две точечные диаграммы. Первая показывает кластеры, используя фактические метки из нашего датасета, а вторая основана на предсказаниях, сделанных нашей моделью. Вот как выглядит результат:
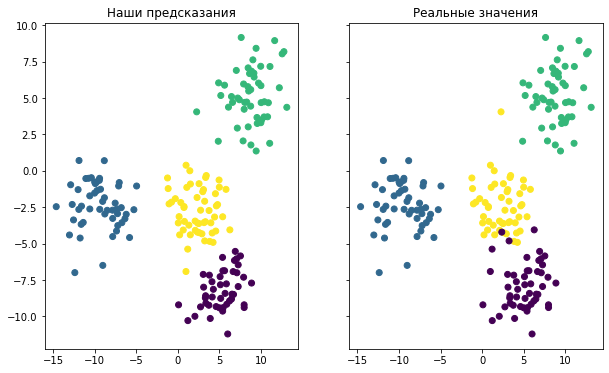
Хотя окраска двух графиков разная, вы можете видеть, что созданная модель довольно хорошо справилась с предсказанием кластеров в нашем наборе данных. Вы также можете заметить, что модель не идеальна: точки данных, расположенные на краях кластеров, в некоторых случаях классифицируются неверно.
И последнее, о чем следует упомянуть, говоря об оценке точности нашей модели. В этом примере мы знали, к какому кластеру принадлежит каждое наблюдение, потому что мы сами создали этот набор данных.
Такая ситуация встречается крайне редко. Метод К-средних обычно применяется, когда не известны ни количество кластеров, ни присущие им качества. Таким образом, специалисты по машинному обучению используют данный алгоритм, чтобы обнаружить закономерности в датасете, о которых они еще ничего не знают.
Вы можете найти весь код в ноутбуке на GitLab:
https://gitlab.com/PythonRu/notebooks/-/blob/master/sklearn_kmeans_and_knn.ipynb
Заключительные мысли
В этом руководстве вы научились создавать модели машинного обучения на Python, используя методы K-ближайших соседей и K-средних.
Вот краткое изложение того, что вы узнали о моделях K-ближайших соседей в Python:
- Как засекреченные данные являются распространенным инструментом для обучения студентов решению задач K-ближайших соседей.
- Почему важно стандартизировать набор данных при построении моделей K-ближайших соседей.
- Как разделить датасет на обучающую и тестирующую выборки с помощью функции
train_test_split. - Способ обучить вашу первую модель K-ближайших соседей и как получить сделанные ее прогнозы.
- Как оценить эффективность модели K-ближайших соседей.
- Метод локтя для выбора оптимального значения K в модели K-ближайших соседей.
А вот краткое изложение того, что вы узнали о моделях кластеризации K-средних в Python:
- Как сгенерировать фиктивные данные в scikit-learn с помощью функции
make_blobs. - Как создать и обучить модель кластеризации K-средних.
- То, что ML-методы без учителя не требуют, чтобы вы разделяли датасет на данные для обучения и данные для тестирования.
- Как создать и обучить модель кластеризации K-средних с помощью scikit-learn.
- Как визуализировать эффективность алгоритма K-средних, если вы изначально владеете информацией о кластерах.
Gensim может работать с большими текстовыми коллекциями. Этим она отличается от других программных библиотек машинного обучения, ориентированных на обработку в памяти. GenSim также предоставляет эффективные многоядерные реализации различных алгоритмов для увеличения скорости обработки. В нее добавлены более удобные средства для обработки текста, чем у конкурентов, таких как Scikit-learn, R и т. д.
В этом руководстве будут рассмотрены следующие концепции:
- Создание корпуса из заданного датасета.
- Матрицы TFIDF в Gensim.
- Создание биграммы и триграммы с помощью Gensim.
- Модели Word2Vec, с использованием Gensim.
- Модели Doc2Vec, с использованием Gensim.
- Создание тематической модели с LDA.
- Создание тематической модели с LSI.
Прежде чем двигаться дальше, давайте разберемся, что означают следующие термины:
- Корпус: коллекция текстовых документов.
- Вектор: форма представления текста.
- Модель: алгоритм, используемый для генерации представления данных.
- Тематическое моделирование: инструмент интеллектуального анализа информации, который используется для извлечения семантических тем из документов.
- Тема: повторяющаяся группа слов, часто встречающихся вместе.
Например:
У вас есть документ, состоящий из таких слов, как:
bat, car, racquet, score, glass, drive, cup, keys, water, game, steering, liquid.
Их можно сгруппировать по разным темам:
| Тема 1 | Тема 2 | Тема 3 |
|---|---|---|
| glass | bat | car |
| cup | racquet | drive |
| water | score | keys |
| liquid | game | sterring |
Некоторые из методов тематического моделирования:
- Латентно-семантический анализ (LSI)
- Латентное размещение Дирихле (LDA)
Теперь, когда у нас есть базовое понимание терминологии, давайте перейдем к использованию пакета Gensim. Сначала установите библиотеку с помощью следующих команд:
pip install gensim
# или
conda install gensimШаг 1. Создайте корпус из заданного датасета
Вам необходимо выполнить следующие шаги, чтобы создать свою коллекцию документов:
- Загрузите выбранный датасет.
- Проведите предварительную обработку вашего набора данных.
- Создайте словарь.
- Создайте Bag of Words.
1.1 Загрузите выбранный датасет:
У вас может быть файл .txt в качестве набора данных или вы также можете загрузить необходимые датасеты с помощью API Gensim Downloader.
import os
# прочитать текстовый файл как объект
doc = open('sample_data.txt', encoding ='utf-8')
Gensim Downloader API – это модуль, доступный в библиотеке Gensim, который представляет собой API для скачивания, получения информации и загрузки датасетов/моделей.
import gensim.downloader as api
# проверка имеющихся моделей и датасетов
info_datasets = api.info()
print(info_datasets)
# информация ы конкретном наборе данных
dataset_info = api.info("text8")
# загрузка набора данных "text8"
dataset = api.load("text8")
# загрузка предварительно обученной модели
word2vec_model = api.load('word2vec-google-news-300')
Здесь мы будем использовать текстовый файл как необработанный набор данных, которые представляют собой текст со страницы Википедии.
1.2 Предварительная обработка набора данных
В NLP под предварительной обработкой текста понимают процесс очистки и подготовки текстовых данных. Для этого мы воспользуемся функцией simple_preprocess(), которая возвращает список токенов после их токенизации и нормализации.
import gensim
import os
from gensim.utils import simple_preprocess
# прочитать текстовый файл как объект
doc = open('nlp-wiki.txt', encoding ='utf-8')
# предварительная обработка файла для получения списка токенов
tokenized = []
for sentence in doc.read().split('.'):
# функция simple_preprocess возвращает список слов каждого предложения
tokenized.append(simple_preprocess(sentence, deacc = True))
print(tokenized)
doc.close()
Токенизированный вывод:
[['the', 'history', 'of', 'natural', 'language', 'processing', 'generally', 'started', 'in', 'the', 'although', 'work', 'can', 'be', 'found', 'from', 'earlier', 'periods'], ['in', 'alan', 'turing', 'published', 'an', 'article', 'titled', 'intelligence', 'which', 'proposed', 'what', 'is', 'now', 'called', 'the', 'turing', 'test', 'as', 'criterion', 'of', 'intelligence'], ['the', 'georgetown', 'experiment', 'in', 'involved', 'fully', 'automatic', 'translation', 'of', 'more', 'than', 'sixty', 'russian', 'sentences', 'into', 'english'], ['the', 'authors', 'claimed', 'that', 'within', 'three', 'or', 'five', 'years', 'machine', 'translation', 'would', 'be', 'solved', 'problem'],
...1.3 Создание словаря
Теперь у нас есть предварительно обработанные данные, которые можно преобразовать в словарь с помощью функции corpora.Dictionary(). Этот словарь представляет собой коллекцию уникальных токенов.
from gensim import corpora
# сохранение извлеченных токенов в словарь
my_dictionary = corpora.Dictionary(tokenized)
print(my_dictionary)
Dictionary(410 unique tokens: ['although', 'be', 'can', 'earlier', 'found']...)
1.3.1 Сохранение словаря
Вы можете сохранить (или загрузить) свой словарь на диске напрямую, а также в виде текстового файла, как показано ниже:
# сохраните словарь на диске
my_dictionary.save('my_dictionary.dict')
# загрузите обратно
load_dict = corpora.Dictionary.load('my_dictionary.dict')
# сохраните словарь в текстовом файле
from gensim.test.utils import get_tmpfile
tmp_fname = get_tmpfile("dictionary")
my_dictionary.save_as_text(tmp_fname)
# загрузите текстовый файл с вашим словарем
load_dict = corpora.Dictionary.load_from_text(tmp_fname)
1.4 Создание Bag of Words
Когда у нас есть словарь, мы можем создать корпус Bag of Words с помощью функции doc2bow(). Эта функция подсчитывает число вхождений и генерирует целочисленный идентификатор для каждого слова. Результат возвращается в виде разреженного вектора.
# преобразование в слов Bag of Word
bow_corpus =[my_dictionary.doc2bow(doc, allow_update = True) for doc in tokenized]
print(bow_corpus)
[[(0, 1), (1, 1), (2, 1),
...
(407, 1), (408, 1), (409, 1)], []]
1.4.1 Сохранение корпуса на диск
Код для сохранения/загрузки вашего корпуса:
from gensim.corpora import MmCorpus
from gensim.test.utils import get_tmpfile
output_fname = get_tmpfile("BoW_corpus.mm")
# сохранение корпуса на диск
MmCorpus.serialize(output_fname, bow_corpus)
# загрузка корпуса
load_corpus = MmCorpus(output_fname)
Шаг 2: Создание матрицы TF-IDF в Gensim
TF-IDF (Term Frequency – Inverse Document Frequency) – это часто используемая модель обработки естественного языка, которая помогает вам определять самые важные слова для каждого документа в корпусе. Она была разработана для коллекций небольшого размера.
Некоторые слова могут не являться стоп-словами, но при этом довольно часто встречаться в документах, имея малую значимость. Следовательно, эти слова необходимо удалить или снизить их важность. Модель TFIDF берет текст, написанный на одном языке, и гарантирует, что наиболее распространенные слова во всем корпусе не будут отображаться в качестве ключевых слов.
Вы можете построить модель TFIDF, используя Gensim и корпус, который вы разработали ранее, следующий образом:
from gensim import models
import numpy as np
# Вес слова в корпусе Bag of Word
word_weight =[]
for doc in bow_corpus:
for id, freq in doc:
word_weight.append([my_dictionary[id], freq])
print(word_weight)
Вес слов перед применением TF-IDF:
[['although', 1], ['be', 1], ['can', 1], ['earlier', 1],
...
['steps', 1], ['term', 1], ['transformations', 1]]Код (применение модели TF-IDF):
# создать модель TF-IDF
tfIdf = models.TfidfModel(bow_corpus, smartirs ='ntc')
# TF-IDF вес слова
weight_tfidf =[]
for doc in tfIdf[bow_corpus]:
for id, freq in doc:
weight_tfidf.append([my_dictionary[id], np.around(freq, decimals=3)])
print(weight_tfidf)
Вес слов после применением TF-IDF:
[['although', 0.339], ['be', 0.19], ['can', 0.237], ['earlier', 0.339],
...
['steps', 0.191], ['term', 0.191], ['transformations', 0.191]]
Вы можете видеть, что словам, часто встречающимся в документах, теперь присвоены более низкие веса.
Шаг 3. Создание биграмм и триграмм с помощью Gensim
Многие слова употребляются в тексте вместе. Такие сочетания имеют другое значение, чем составляющие их слова по отдельности.
Например:
Beatboxing -> слова beat и boxing имеют собственные смысловые вариации, но вместе они представляют совсем иное значение.
Биграмма — группа из двух слов.
Триграмма — группа из трех слов.
Здесь мы будем использовать датасет text8, который можно загрузить с помощью API downloader Gensim. Код построения биграмм и триграмм:
import gensim.downloader as api
from gensim.models.phrases import Phrases
# загрузка набора данных "text8"
dataset = api.load("text8")
# извлечь список слов из датасета
data =[]
for word in dataset:
data.append(word)
# Биграм с использованием модели фразера
bigram_model = Phrases(data, min_count=3, threshold=10)
print(bigram_model[data[0]])
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working_class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans_culottes', 'of', 'the', 'french_revolution', 'whilst', 'the', 'term', 'is', 'still' ...Для создания триграмм мы просто передаем полученную выше биграммную модель той же функции.
# Триграмма с использованием модели фразы
trigram_model = Phrases(bigram_model[data], threshold=10)
# Триграмма
print(trigram_model[bigram_model[data[0]]])
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early' ...Шаг 4: Создайте модель Word2Vec с помощью Gensim
Алгоритмы ML/DL не могут использовать текст напрямую, поэтому нам нужно некоторое числовое представление, чтобы эти алгоритмы могли обрабатывать данные. В простых приложениях машинного обучения используются CountVectorizer и TFIDF, которые не сохраняют связь между словами.
Word2Vec — метод преобразования текста для создания векторных представлений (Word Embeddings), которые отображают все слова, присутствующие в языке, в векторное пространство заданной размерности. Мы можем выполнять математические операции с этими векторами, которые помогают сохранить связь между словами.
Пример: queen — women + man = king.
Готовые векторно-семантические модели, такие как word2vec, GloVe, fasttext и другие можно загрузить с помощью API загрузчика Gensim. Иногда векторные представления определенных слов из вашего документа могут отсутствовать в упомянутых пакетах. Но вы можете решить данную проблему, обучив свою модель.
4.1) Обучение модели
import gensim.downloader as api
from multiprocessing import cpu_count
from gensim.models.word2vec import Word2Vec
# загрузка набора данных "text8"
dataset = api.load("text8")
# извлечь список слов из датасета
data =[]
for word in dataset:
data.append(word)
# Разделим данные на две части
data_1 = data[:1200] # используется для обучения модели
data_2 = data[1200:] # используется для обновления модели
# Обучение модели Word2Vec
w2v_model = Word2Vec(data_1, min_count=0, workers=cpu_count())
# вектор слов для слова "время"
print(w2v_model.wv['time'])
Вектор для слова «time»:
[-0.04681756 -0.08213229 1.0628034 -1.0186515 1.0779341 -0.89710116
0.6538859 -0.81849015 -0.29984367 0.55887854 2.138567 -0.93843514
...
-1.4128548 -1.3084044 0.94601256 0.27390406 0.6346426 -0.46116787
0.91097695 -3.597664 0.6901859 1.0902803 ]Вы также можете использовать функцию most_similar(), чтобы найти слова, похожие на переданное.
# слова, похожие на "time"
print(w2v_model.wv.most_similar('time'))
# сохранение и загрузка модели
w2v_model.save('Word2VecModel')
model = Word2Vec.load('Word2VecModel')
Cлова, наиболее похожие на «time»:
[('moment', 0.6137239933013916), ('period', 0.5904807448387146), ('stage', 0.5393826961517334), ('decade', 0.51670902967453), ('lifetime', 0.4878680109977722), ('once', 0.4843854010105133), ('distance', 0.4821343719959259), ('breteuil', 0.4815649390220642), ('preestablished', 0.47662678360939026), ('point', 0.4757876396179199)]4.2) Обновление модели
# построим словарный запас по образцу из последовательности предложений
w2v_model.build_vocab(data_2, update=True)
# обучение вектора слов
w2v_model.train(data_2, total_examples=w2v_model.corpus_count, epochs=w2v_model.epochs)
print(w2v_model.wv['time'])
На выходе вы получите новые веса для слов.
Шаг 5: Создание модели Doc2Vec с помощью Gensim
В отличие от модели Word2Vec, модель Doc2Vec генерирует векторное представление для всего документа или группы слов. С помощью этой модели мы можем найти взаимосвязь между различными документами, как показано ниже:
Если натренировать модель на литературе типа «Алиса в Зазеркалье». Мы можем сказать, что
Алиса в Зазеркалье == Алиса в Стране чудес.
5.1) Обучите модель
import gensim
import gensim.downloader as api
from gensim.models import doc2vec
# получить датасета
dataset = api.load("text8")
data =[]
for w in dataset:
data.append(w)
# Для обучения модели нам нужен список целевых документов
def tagged_document(list_of_ListOfWords):
for x, ListOfWords in enumerate(list_of_ListOfWords):
yield doc2vec.TaggedDocument(ListOfWords, [x])
# тренировочные данные
data_train = list(tagged_document(data))
# вывести обученный набор данных
print(data_train[:1])
Вывод – обученный датасет.
5.2) Обновите модель
# Инициализация модели
d2v_model = doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)
# расширить словарный запас
d2v_model.build_vocab(data_train)
# Обучение модели Doc2Vec
d2v_model.train(data_train, total_examples=d2v_model.corpus_count, epochs=d2v_model.epochs)
# Анализ выходных данных
analyze = d2v_model.infer_vector(['violent', 'means', 'to', 'destroy'])
print(analyze)
Вывод обновленной модели:
[-3.79053354e-02 -1.03341974e-01 -2.85615563e-01 1.37473553e-01
1.79868549e-01 3.42468806e-02 -1.68495290e-02 -1.86038092e-01
...
-1.20517321e-01 -1.48323074e-01 -5.70210926e-02 -2.15077385e-01]Шаг 6. Создание тематической модели с помощью LDA
LDA – популярный метод тематического моделирования, при котором каждый документ рассматривается как совокупность тем в определенной пропорции. Нам нужно вывести полезные качества тем, например, насколько они разделены и значимы. Темы хорошего качества зависят от:
- качества обработки текста,
- нахождения оптимального количества тем,
- настройки параметров алгоритма.
Выполните следующие шаги, чтобы создать модель.
6.1 Подготовка данных
Это делается путем удаления стоп-слов и последующей лемматизации ваших данных. Чтобы выполнить лемматизацию с помощью Gensim, нам нужно сначала загрузить пакет шаблонов и стоп-слова.
pip install pattern
# в python консоле
>>> import nltk
>>> nltk.download('stopwords')import gensim
from gensim import corpora
from gensim.models import LdaModel, LdaMulticore
import gensim.downloader as api
from gensim.utils import simple_preprocess
import nltk
from nltk.stem.wordnet import WordNetLemmatizer
# nltk.download('stopwords')
from nltk.corpus import stopwords
import re
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s')
logging.root.setLevel(level=logging.INFO)
# загрузка stopwords
stop_words = stopwords.words('english')
# добавление stopwords
stop_words = stop_words + ['subject', 'com', 'are', 'edu', 'would', 'could']
lemmatizer = WordNetLemmatizer()
# загрузка датасета
dataset = api.load("text8")
data = [w for w in dataset]
# подготовка данных
processed_data = []
for x, doc in enumerate(data[:100]):
doc_out = []
for word in doc:
if word not in stop_words: # для удаления стоп-слов
lemmatized_word = lemmatizer.lemmatize(word) # лемматизация
if lemmatized_word:
print
doc_out.append(lemmatized_word)
else:
continue
processed_data.append(doc_out) # processed_data это список слов
# вывод образца
print(processed_data[0][:10])
['anarchism', 'originated', 'term', 'abuse', 'first', 'used', 'early', 'working', 'class', 'radical']6.2 Создание словаря и корпуса
Обработанные данные теперь будут использоваться для создания словаря и корпуса.
dictionary = corpora.Dictionary(processed_data)
corpus = [dictionary.doc2bow(l) for l in processed_data]
6.3 Обучение LDA-модели
Мы будем обучать модель LDA с 5 темами, используя словарь и корпус, созданные ранее. Здесь используется функция LdaModel(), но вы также можете использовать функцию LdaMulticore(), поскольку она позволяет выполнять параллельную обработку.
# Обучение
LDA_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=5)
# сохранение модели
LDA_model.save('LDA_model.model')
# показать темы
print(LDA_model.print_topics(-1))
Слова, которые встречаются в более чем одной теме и имеют малое значение, могут быть добавлены в список запрещенных слов.
6.4 Интерпретация вывода
Модель LDA в основном дает нам информацию по трем направлениям:
- Темы в документе
- К какой теме принадлежит каждое слово
- Значение фи
Значением фи является вероятность того, что слово относится к определенной теме. Для выбранного слова сумма значений фи дает количество раз, оно встречается в документе.
# вероятность принадлежности слова к теме
LDA_model.get_term_topics('fire')
bow_list =['time', 'space', 'car']
# сначала преобразуйте в bag of words
bow = LDA_model.id2word.doc2bow(bow_list)
# интерпретация данных
doc_topics, word_topics, phi_values = LDA_model.get_document_topics(bow, per_word_topics=True)
Шаг 7. Создание тематической модели с помощью LSI
Чтобы создать модель с LSI, просто выполните те же шаги, что и с LDA.
Только для обучения используйте функцию LsiModel() вместо LdaMulticore() или LdaModel().
from gensim.models import LsiModel
# Обучение модели с помощью LSI
LSI_model = LsiModel(corpus=corpus, id2word=dictionary, num_topics=7, decay=0.5)
# темы
print(LSI_model.print_topics(-1))
Заключение
Это только некоторые из возможностей библиотеки Gensim. Пользоваться ими очень удобно, особенно когда вы занимаетесь NLP. Вы, конечно, можете применять их по своему усмотрению.
]]>Теория ROC-кривой
Полное название ROC — Receiver Operating Characteristic (рабочая характеристика приёмника). Впервые она была создана для использования радиолокационного обнаружения сигналов во время Второй мировой войны. США использовали ROC для повышения точности обнаружения японских самолетов с помощью радара. Поэтому ее называют рабочей характеристикой приемника.
AUC или area under curve — это просто площадь под кривой ROC. Прежде чем мы перейдем к тому, что такое ROC-кривая, нужно вспомнить, что такое матрица ошибок.
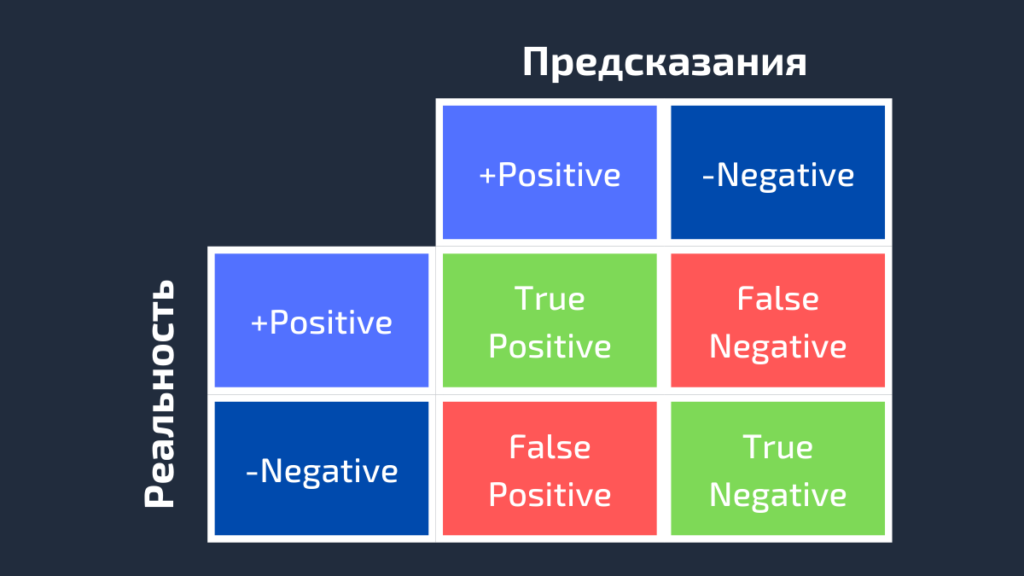
Как видно из рисунка выше, матрица ошибок — это комбинация вашего прогноза (1 или 0) и фактического значения (1 или 0). В зависимости от результата предсказания и того, корректна ли была проведена классификация, матрица разделена на 4 части. Например, true positive (истинно положительный) результат — это количество случаев, в которых вы правильно классифицируете семпл как положительный. А false positive (ложноположительный) — это число случаев, в которых вы ошибочно классифицируете семпл как положительный.
Матрица ошибок содержит только абсолютные числа. Однако, используя их, мы можем получить множество других метрик, основанных на процентных соотношениях. True Positive Rate (TPR) и False Positive Rate (FPR) — две из них.
True Positive Rate (TPR) показывает, какой процент среди всех positive верно предсказан моделью.
TPR = TP / (TP + FN).
False Positive Rate (FPR): какой процент среди всех negative неверно предсказан моделью.
FPR = FP / (FP + TN).
Хорошо, давайте теперь перейдем к кривой ROC!
Что такое ROC-кривая?
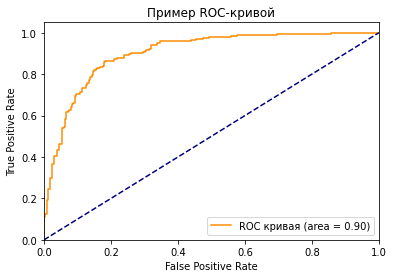
Как вы можете видеть на графике, кривая ROC — это просто отношение TPR к FPR. Теперь вам все понятно, в заключение…
Поверили?
Если серьезно, вы можете прочитать намного больше информации из диаграммы. Первый вопрос, который я хочу здесь обсудить: у нас же есть только один набор TPR, FPR, посчитанный на основе сделанных моделью предсказаний. Так откуда взялось такое количество точек для построения целого графика?
Все следует из того, как работает модель классификации. Когда вы строите классификационную модель, такую как дерево решений, и хотите определить, будут ли акции расти в цене или падать на основе входных данных. Модель сначала рассчитает вероятность увеличения или уменьшения, используя предоставленные вами исторические данные. После этого, основываясь на пороговом значении, она решит, будет ли результат увеличиваться или уменьшаться.
Да, ключевое слово здесь — порог. Разные пороговые значения создают разные TPR и FPR. Они представляют те самые точки, что образуют кривую ROC. Вы можете выбрать «Увеличение» в качестве предсказания модели, если полученная на основе исторических данных вероятность роста акций больше 50%. Также можете изменить пороговое значение и отобразить «Увеличение», только если соответствующая вероятность больше 90%. Если вы установите 90% порог вместо 50%, вы будете более уверены в том, что выбранные для «Увеличения» акции действительно вырастут. Но так вы можете упустить некоторые потенциально выгодные варианты.
Что значит синяя пунктирная линия на графике?
Как мы знаем, чем больше площадь под кривой (AUC), тем лучше классификация. Идеальная или наилучшая кривая — это вертикальная линия от (0,0) до (0,1), которая тянется до (1,1). Это означает: модель всегда может различить положительные и отрицательные случаи. Однако, если вы выбираете класс случайным образом для каждого семпла, TPR и FPR должны увеличиваться с одинаковой скоростью. Синяя пунктирная линия показывает кривую TPR и FPR при случайном определении positive или negative для каждого случая. Для этой диагональной линии площадь под кривой (AUC) составляет 0.5.
Что произойдет с TPR, FPR и ROC-кривой, если изменить пороговое значение?
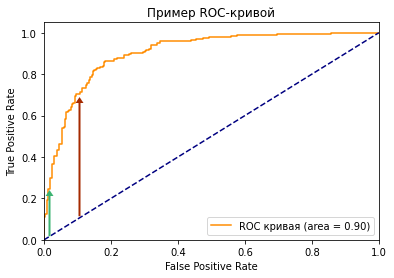
Посмотрите на две точки на ROC-кривой. Зеленая точка имеет очень высокий порог, это означает, что только если вы уверены на 99%, можете классифицировать случай как positive. Красная точка имеет относительно более низкий порог. Это означает, что вы можете классифицировать случай как positive, если вы уверены на 90%.
Как изменяются TPR и FPR при движении от зеленой точки к красной?
И TPR, и FPR увеличиваются. Когда вы уменьшаете порог, модель будет определять больше положительных случаев. Таким образом, TP увеличивается, как и TP/(TP + FN). С другой стороны, вы неизбежно ошибочно классифицируете некоторые отрицательные случаи как положительные из-за снижения порога, и поэтому FP и FP/(FP + TN) также увеличиваются.
Мы видим, что TPR и FPR положительно коррелируют. Вам нужно балансировать между максимальным охватом positive случаев и минимизацией неправильной классификации negative случаев.
Как выбрать оптимальную точку на кривой ROC?
Трудно определить оптимальную точку, потому что нужно выбрать наиболее подходящее пороговое значение, учитывая сферу применения модели. Однако общее правило — максимизировать разницу (TPR-FPR), которая на графике представлена вертикальным расстоянием между оранжевой и синей пунктирной линией.
Почему площадь под кривой ROC – хорошая метрика для оценки модели классификации?
Хорошая метрика модели машинного обучения должна отображать истинную и постоянную способность модели к прогнозированию. Это означает, что, если я изменю тестовый набор данных, он не должен давать другой результат.
ROC-кривая учитывает не только результаты классификации, но и вероятность предсказания всех классов. Например, если результат корректно классифицирован на основе 51% вероятности, то он, скорее всего, будет классифицирован неверно, если вы воспользуетесь другим тестовым датасетом. Кроме того, ROC-кривая также учитывает эффективность модели при различных пороговых значениях. Она является комплексной метрикой для оценки того, насколько хорошо разделяются случаи в разных группах.
Какое значение AUC является приемлемым для модели классификации?
Как я показал ранее, для задачи двоичной классификации при определении классов случайным образом, вы можете получить 0.5 AUC. Следовательно, если вы решаете задачу бинарной классификации, разумное значение AUC должно быть > 0.5. У хорошей модели классификации показатель AUC > 0.9, но это значение сильно зависит от сферы ее применения.
Как рассчитать AUC и построить ROC-кривую в Python?
Если вы просто хотите рассчитать AUC, вы можете воспользоваться пакетом metrics библиотеки sklearn (ссылка).
Если вы хотите построить ROC-кривую для результатов вашей модели, вам стоит перейти сюда.
Вот код для построения графика ROC, который я использовал в этой статье.
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import roc_auc_score
from matplotlib import pyplot as plt
# генерируем датасет на 2 класса
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# разделяем его на 2 выборки
trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2)
# обучаем модель
model = LogisticRegression(solver='lbfgs')
model.fit(trainX, trainy)
# получаем предказания
lr_probs = model.predict_proba(testX)
# сохраняем вероятности только для положительного исхода
lr_probs = lr_probs[:, 1]
# рассчитываем ROC AUC
lr_auc = roc_auc_score(testy, lr_probs)
print('LogisticRegression: ROC AUC=%.3f' % (lr_auc))
# рассчитываем roc-кривую
fpr, tpr, treshold = roc_curve(testy, lr_probs)
roc_auc = auc(fpr, tpr)
# строим график
plt.plot(fpr, tpr, color='darkorange',
label='ROC кривая (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Пример ROC-кривой')
plt.legend(loc="lower right")
plt.show()
Вам нужны следующие входные данные: фактическое значение y и вероятность предсказания. Обратите внимание, что функция roc_curve требует только вероятность для положительного случая, а не для обоих классов. Если вам нужно решить задачу мультиклассовой классификации, вы также можете использовать этот пакет, и в приведенной выше ссылке есть пример того, как построить график.
]]>Для работы с LightGBM доступны API на C, Python или R. Фреймворк также предоставляет CLI, который позволяет нам использовать библиотеку из командной строки. Оценщики (estimators) LightGBM оснащены множеством гиперпараметров для настройки модели. Кроме этого, в нем уже реализован большой набор функций оптимизации/потерь и оценочных метрики.
В рамках данного руководства мы рассмотрим Python API данного фреймворка. Мы постараемся объяснить и охватить большую часть этого API. Основная цель работы — ознакомить читателей с основными функциональными возможностями lightgbm, необходимыми для начала работы с ним.
Существуют и другие библиотеки (xgboost, catboost, scikit-learn), которые также обеспечивают реализацию деревьев решений с градиентным бустингом.
Давайте начнем.
Ноутбук с кодом в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/LightGBM_python.ipynb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import lightgbm as lgb
import sklearn
import warnings
warnings.filterwarnings("ignore")
print("Версия LightGBM : ", lgb.__version__)
print("Версия Scikit-Learn : ", sklearn.__version__)
Версия LightGBM : 3.2.1
Версия Scikit-Learn : 0.23.2Загрузка датасетов
Мы будем использовать доступные в sklearn три набора данных (показаны ниже) для этого руководства.
- Boston Housing Dataset — это выборка для задач регрессии, которая содержит информацию о различных характеристиках домов в Бостоне и их цене в долларах. Она будет использоваться нами при решении регрессионных проблем.
- Breast Cancer Dataset — это датасет для задач классификации, содержащий информацию о двух типах опухолей. Он будет применяться для объяснения методов бинарной классификации.
- Wine Dataset — это набор данных классификации, содержащий информацию об ингредиентах, используемых в создании вин трех типов. Используется нами для объяснения задач мультиклассификации.
Ниже мы загрузили все три упомянутых датасета, вывели их описания для ознакомления с признаками(features) и размерами соответствующих выборок. Каждый датасет как pandas DataFrame. Посмотрим на них:
Boston Housing Dataset
from sklearn.datasets import load_boston
boston = load_boston()
for line in boston.DESCR.split("\n")[5:29]:
print(line)
boston_df = pd.DataFrame(data=boston.data, columns = boston.feature_names)
boston_df["Price"] = boston.target
boston_df.head()
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | Price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
Breast Cancer Dataset
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
for line in breast_cancer.DESCR.split("\n")[5:31]:
print(line)
breast_cancer_df = pd.DataFrame(data=breast_cancer.data, columns = breast_cancer.feature_names)
breast_cancer_df["TumorType"] = breast_cancer.target
breast_cancer_df.head()
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
The mean, standard error, and "worst" or largest (mean of the three
worst/largest values) of these features were computed for each image,
resulting in 30 features. For instance, field 0 is Mean Radius, field
10 is Radius SE, field 20 is Worst Radius.
- class:
- WDBC-Malignant
- WDBC-Benign| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | … | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | TumorType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | … | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | … | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | … | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | … | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | … | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Wine Dataset
from sklearn.datasets import load_wine
wine = load_wine()
for line in wine.DESCR.split("\n")[5:29]:
print(line)
wine_df = pd.DataFrame(data=wine.data, columns = wine.feature_names)
wine_df["WineType"] = wine.target
wine_df.head()
**Data Set Characteristics:**
:Number of Instances: 178 (50 in each of three classes)
:Number of Attributes: 13 numeric, predictive attributes and the class
:Attribute Information:
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
- class:
- class_0
- class_1
- class_2| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | WineType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 | 0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 | 0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 | 0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 | 0 |
Обучение модели на train()
Самый простой способ создать оценщик (estimator) в lightgbm — использовать метод train(). Он принимает на вход оценочный параметр в виде словаря и обучающий датасет. Затем train тренирует оценщик и возвращает объект типа Booster, который является обученным оценщиком: его можно использовать для будущих предсказаний.
Ниже приведены некоторые из важных параметров метода train().
params— это словарь, определяющий параметры алгоритма деревьев решений с градиентным бустингом. Нам просто нужно предоставить целевую функцию для начала работы в зависимости от типа задачи (классификация/регрессия). Позже мы ознакомимся с часто используемым списком параметров, которые можно передать в этот словарь.train_set— этот параметр принимает объект типаDatasetфреймворка lightgbm, который содержит информацию о показателях и целевых значениях. Это внутренняя структура данных, разработанная lightgbm для обертывания данных.num_boost_round— указывает количество деревьев бустинга, которые будут использоваться в ансамбле. Ансамбль — это группа деревьев с градиентным бустингом, которую мы обычно называем оценщиком. Значение по умолчанию равно 100.valid_sets— принимает списокDatasetобъектов, которые являются выборками для валидации. Эти проверочные датасеты оцениваются после каждого цикла обучения.valid_names— принимает список строк той же длины, что и уvalid_sets, определяющих имена для каждой проверочной выборки. Эти имена будут использоваться при выводе оценочных метрик для валидационных наборов данных, а также при их построении.categorical_feature— принимает список строк/целых чисел или строку auto. Если мы передадим список строк/целых чисел, тогда указанные столбцы из набора данных будут рассматриваться как категориальные.verbose_eval— принимает значения типаboolилиint. Если мы установим значениеFalseили 0, тоtrainне будет выводить результаты расчета метрик на проверочных выборках, которые мы передали. Если нами было указано True, он будет печатать их для каждого раунда. При передаче целого числа, большего 1,trainотобразит результаты повторно после указанного количества раундов.
Dataset
Dataset представляет собой внутреннюю структуру данных lightgbm для хранения данных и меток. Ниже приведены важные параметры класса.
data— принимает массив библиотеки numpy, dataframe pandas, разреженные матрицы (sparse matrix) scipy, список массивов numpy, фрейм таблицы данных h2o в качестве входного значения, хранящего значения признаков (features).label— принимает массив numpy, pandas series или dataframe с одним столбцом. Данный параметр определяет целевые значения. Мы также можем установить дляlabelзначениеNone, если у нас нет таких значений. По умолчанию —None.feature_name— принимает список строк, определяющих имена показателей.categorical_feature— имеет то же значение, что и указанное выше в параметре методаtrain(). Мы можем определить категориальный показатель здесь или вtrain.
Регрессия
Первая проблема, которую мы решим с помощью lightgbm, — это простая задача регрессии с использованием датасета Boston housing, который был загружен нами ранее. Мы разделили этот набор данных на обучающую/тестовую выборки и создали из них экземпляр Dataset. Затем мы вызвали метод lightgbm.train(), предоставив ему датасеты для обучения и проверки. Мы установили количество итераций бустинга равным 10, поэтому для решения задачи будет создано 10 деревьев.
После завершения обучения train вернет экземпляр типа Booster, который мы позже сможем использовать для будущих предсказаний. Поскольку мы передали проверочный датасет в качестве входных данных, метод выведет значение l2 для валидации после каждой итерации обучения. Обратите внимание, что по умолчанию lightgbm минимизирует потерю l2 для задачи регрессии.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression"},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Размеры Train/Test: (379, 13) (127, 13) (379,) (127,)
[LightGBM] [Warning] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000840 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 961
[LightGBM] [Info] Number of data points in the train set: 379, number of used features: 13
[LightGBM] [Info] Start training from score 22.134565
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[1] valid_0's l2: 92.7815
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[2] valid_0's l2: 80.7846
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[3] valid_0's l2: 70.6207
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[4] valid_0's l2: 61.6287
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[5] valid_0's l2: 55.0184
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[6] valid_0's l2: 49.3809
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[7] valid_0's l2: 44.3784
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[8] valid_0's l2: 40.2941
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[9] valid_0's l2: 36.8559
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[10] valid_0's l2: 33.9026Ниже мы сделали прогнозы по тренировочным и тестовым данным с использованием обученной модели. Затем рассчитали R2 метрики для них, используя соответствующий метод sklearn. Обратите внимание, метод predict() принимает массив numpy, dataframe pandas, scipy sparse matrix или фрейм таблицы данных h2o в качестве входных данных для предсказаний.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression"},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Test R2 Score : 0.68
Train R2 Score : 0.74raw_score— это логический параметр, при котором, если он установлен вTrue, результатом выполнения будут необработанные прогнозы. Для задач регрессии это не имеет никакого значения, но при классификации predict вернет значения функции, а не вероятности.pred_leaf— этот параметр принимает логические значения. Если заданоTrue, то будет возвращаться индекс листа каждого дерева, который был спрогнозирован для конкретного семпла. Размер вывода будетn_samples x n_trees.pred_contrib— возвращает массив показателей для каждого наблюдения. Результатом будет являться массив размера(n_features + 1)для каждого семпла, где последнее значение является ожидаемым значением, а первые n_features являются вкладом показателей в этот прогноз. Мы можем добавить вклад каждого показателя к последнему ожидаемому значению и получить фактический прогноз. Обычно такие значения называют SHAP.
idxs = booster.predict(X_test, pred_leaf=True)
print("Размерность: ", idxs.shape)
idxs
Размерность: (127, 10)
array([[10, 11, 12, ..., 5, 13, 6],
[ 3, 3, 3, ..., 3, 4, 2],
[ 2, 8, 2, ..., 2, 2, 3],
...,
[ 3, 3, 3, ..., 3, 4, 2],
[ 5, 0, 0, ..., 13, 0, 13],
[ 0, 5, 14, ..., 0, 3, 1]])shap_vals = booster.predict(X_test, pred_contrib=True)
print("Размерность: ", shap_vals.shape)
print("\nЗначения Shap для нулевого семпла: ", shap_vals[0])
print("\nПредсказания с использованием значений SHAP: ", shap_vals[0].sum())
print("Предсказания без SHAP: ", test_preds[0])
Размерность: (127, 14)
Значения Shap для нулевого семпла: [-1.04268359e+00 0.00000000e+00 5.78385997e-02 0.00000000e+00
-5.09776692e-01 -1.81771187e+00 -5.44789659e-02 -2.41017058e-02
9.10266200e-03 -6.42845196e-03 5.32678196e-03 0.00000000e+00
-4.62999363e+00 2.21345647e+01]
Предсказания с использованием значений SHAP: 14.121657826104853
Предсказания без SHAP: 14.121657826104858Мы можем вызвать метод num_trees() в экземпляре бустера, чтобы получить количество деревьев в ансамбле. Обратите внимание: если мы не прекратим обучение раньше, число деревьев будет таким же, как num_boost_round. Но если мы прервем тренировку, тогда их количество будет отличаться от num_boost_round.
Позже в этом руководстве мы объясним, как можно остановить обучение, если производительность ансамбля не улучшается при оценке на проверочном наборе.
Экземпляр бустера имеет еще один важный метод feature_importance(), который может возвращать нам важность признаков на основе значений выигрыша (booster.feature_importance(importance_type="gain")) и разделения (booster.feature_importance(importance_type="split")) деревьев.
(array([4.56516126e+03, 0.00000000e+00, 1.49124010e+03, 0.00000000e+00,
1.20125020e+03, 6.15448327e+04, 4.08311499e+02, 8.27205796e+02,
2.62632999e+01, 4.70000000e+01, 2.03512299e+02, 0.00000000e+00,
4.28531050e+04])
array([21, 0, 7, 0, 9, 29, 7, 15, 1, 1, 4, 0, 44]))Бинарная классификация
В этом разделе объясняется, как мы можем, используя метод train(), создать бустер для задачи бинарной классификации. Обучаем модель на наборе данных о раке груди, а затем оцениваем ее точность, используя метрику из sklearn. Мы установили objective значение binary для информирования метода train() о том, что предоставленные нами данные предназначены для решения задачи бинарной классификации. Также установили параметр verbosity равным -1, чтобы предотвратить вывод сообщений во время обучения. Он по-прежнему будет печатать результаты оценки проверочного датасета, которые тоже можно отключить, передав для параметра verbose_eval значение False.
Обратите внимание, что для задач классификации метод бустера predict() возвращает вероятности. Мы добавили логику для преобразования вероятностей в целевой класс.
По умолчанию при решении задач бинарной классификации LightGBM использует для оценки бинарную логистическую функцию потери на проверочной выборке. Мы можем добавить параметр metric в словарь, который передается методу train(), с названиями любых метрик, доступных в lightgbm, и он будет использовать эти метрики. Позже мы более подробно обсудим перечень предоставляемых lightgbm метрик.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=breast_cancer.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=breast_cancer.feature_names.tolist())
booster = lgb.train({"objective": "binary", "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's binary_logloss: 0.600128
[2] valid_0's binary_logloss: 0.537151
[3] valid_0's binary_logloss: 0.48676
[4] valid_0's binary_logloss: 0.443296
[5] valid_0's binary_logloss: 0.402604
[6] valid_0's binary_logloss: 0.37053
[7] valid_0's binary_logloss: 0.339712
[8] valid_0's binary_logloss: 0.316836
[9] valid_0's binary_logloss: 0.297812
[10] valid_0's binary_logloss: 0.278683
Test Accuracy: 0.95
Train Accuracy: 0.97Мультиклассовая классификация
В рамках этого раздела объясняется, как использовать метод train() для задач мультиклассовой классификации. Мы применяем его на выборке данных о вине, которая имеет три разных типа вина в качестве целевой переменной. Мы установили objective в значение multiclass. Всякий раз, когда нами используется метод train() для решения такой задачи, нам необходимо предоставить целочисленный параметр num_class, определяющим количество классов.
Метод predict() возвращает вероятности для каждого класса в случае мультиклассовых задач. Мы добавили логику для выбора класса с наибольшим значением вероятности в качестве фактического предсказания.
LightGBM по умолчанию использует для оценки мультиклассовую логистическую функцию потери на проверочном датасете при решении проблем бинарной классификации.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=wine.feature_names)
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=wine.feature_names)
booster = lgb.train({"objective": "multiclass", "num_class":3, "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = np.argmax(test_preds, axis=1)
train_preds = np.argmax(train_preds, axis=1)
print("\nTest Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (133, 13) (45, 13) (133,) (45,)
[1] valid_0's multi_logloss: 0.951806
[2] valid_0's multi_logloss: 0.837812
[3] valid_0's multi_logloss: 0.746033
[4] valid_0's multi_logloss: 0.671446
[5] valid_0's multi_logloss: 0.60648
[6] valid_0's multi_logloss: 0.54967
[7] valid_0's multi_logloss: 0.499026
[8] valid_0's multi_logloss: 0.458936
[9] valid_0's multi_logloss: 0.419804
[10] valid_0's multi_logloss: 0.385265
Test Accuracy: 0.98
Train Accuracy: 1.00Список важных параметров LightGBM
Теперь мы перечислим важные параметры lightgbm, которые могут быть предоставлены в виде словаря при вызове метода train(). Мы можем использовать те же параметры для оценщиков (LGBMModel, LGBMRegressor и LGBMClassifier), которые доступны в lightgbm, с той лишь разницей, что нам не нужно формировать словарь — мы можем передать их напрямую при создании экземпляра. Мы рассмотрим работу с оценщиками в следующем разделе.
objective— этот параметр позволяет нам определить целевую функцию, используемую для текущей задачи. Его значением по умолчанию является regression. Ниже приведен список часто используемых значений этого параметра.regressionregression_l1tweediebinarymulticlassmulticlassovacross_entropy- Другие доступные целевые функции
metric— данный параметр принимает метрики для расчета на оценочных наборах данных (в случае если эти выборки предоставлены как значение параметраeval_set/validation_sets). Мы можем предоставить более одной метрики, и все они будут посчитаны на проверочных датасетах. Ниже приведен список наиболее часто используемых значений этого параметра.rmsel2l1tweediebinary_loglossmulti_loglossauccross_entropy- Другие доступные метрики
boosting— этот параметр принимает одну из нижеперечисленных строк, определяющих, какой алгоритм использовать.gbdt— значение по умолчанию. Дерево решений с градиентным бустингомrf— Случайный лесdart— Dropout на множественных аддитивных регрессионных деревьяхgoss— Односторонняя выборка на основе градиента
num_iterations— данный параметр является псевдонимом дляnum_boost_round, который позволяет нам указать число деревьев в ансамбле для создания оценщика. По умолчанию 100.learning_rate— этот параметр используется для определения скорости обучения. По умолчанию 0.1.num_class— если мы работаем с задачей мультиклассовой классификации, то этот параметр должен содержать количество классов.num_leaves— данный параметр принимает целое число, определяющее максимальное количество листьев, разрешенное для каждого дерева. По умолчанию 31.num_threads— принимает целое число, указывающее количество потоков, используемых для обучения. Мы можем установить его равным числу ядер системы.seed— позволяет нам указать инициализирующее значение для процесса обучения, что предоставляет нам возможность повторно генерировать те же результаты.max_depth— этот параметр позволяет нам указать максимальную глубину, разрешенную для деревьев в ансамбле. По умолчанию -1, что позволяет деревьям расти как можно глубже. Мы можем ограничить это поведение, установив этот параметр.min_data_in_leaf— данный параметр принимает целочисленное значение, определяющее минимальное количество точек данных (семплов), которые могут храниться в одном листе дерева. Этот параметр можно использовать для контроля переобучения. Значение по умолчанию 20.bagging_fraction— этот параметр принимает значение с плавающей запятой от 0 до 1, которое позволяет указать, насколько большая часть данных будет случайно отбираться при обучении. Этот параметр может помочь предотвратить переобучение. По умолчанию 1.0.feature_fraction— данный параметр принимает значение с плавающей запятой от 0 до 1, которое информирует алгоритм о выборе этой доли показателей из общего числа для обучения на каждой итерации. По умолчанию 1.0, поэтому используются все показатели.extra_trees— этот параметр принимает логические значения, определяющие, следует ли использовать чрезвычайно рандомизированное дерево или нет.early_stopping_round— принимает целое число, указывающее, что мы должны остановить обучение, если оценочная метрика, рассчитанная на последнем проверочном датасете, не улучшается на протяжении определенного параметром числа итераций.monotone_constraints— этот параметр позволяет нам указать, должна ли наша модель обеспечивать увеличение, уменьшение или отсутствие связи отдельного показателя с целевым значением. Использование данного параметра объясняется в разделе «Монотонные ограничения».monotone_constraints_method— этот параметр принимает одну из нижеперечисленных строк, определяющих тип накладываемых монотонных ограничений.basic— базовый метод монотонных ограничений, который может чрезмерно ограничивать модель.intermediate— это более сложный метод ограничений, который немного менее ограничивает, чем базовый метод, но может занять больше времени.advanced— это расширенный метод ограничений, который менее ограничивает, чем базовый и промежуточный методы, но может занять больше времени.
interaction_constraints— этот параметр принимает список списков, в которых отдельные списки определяют индексы показателей, которым разрешено взаимодействовать друг с другом. Такое взаимодействие подробно объясняется в разделе «Ограничения взаимодействия показателей».verbosity— этот параметр принимает целочисленное значение для управления логированием сообщений при обучении.- < 0 — отображаются только фатальные ошибки.
- 0 — отображаются сообщения об ошибках/предупреждениях и перечисленные выше.
- 1 — отображаются информационные сообщения и перечисленные выше.
- > 1 — отображается отладочная информация и перечисленные выше.
is_unbalance— это логический параметр, который должен иметь значениеTrue, если данные не сбалансированы. Его следует использовать с задачами бинарной и мультиклассовой классификации.device_type— принимает одну из следующих строк, определяющих тип используемого для обучения оборудования.cpugpucuda
force_col_wise— этот параметр принимает логическое значение, определяющее, следует ли принудительно строить гистограмму по столбцам при обучении. Если в данных слишком много столбцов, установка для этого параметра значенияTrueповысит скорость процесса обучения за счет уменьшения использования памяти.force_row_wise— этот параметр принимает логическое значение, определяющее, следует ли принудительно строить гистограмму по строкам при обучении. Если в данных слишком много строк, установка для этого параметра значенияTrueповысит скорость процесса обучения за счет уменьшения использования памяти.
Стоит учитывать, что это не полный список параметров, доступных при работе с lightgbm, а только перечисление некоторых наиболее важных. Если вы хотите узнать обо всех параметрах, перейдите по ссылке ниже.
Полный список параметров LightGBM.
LGBMModel
Класс LGBMModel — это обертка для класса Booster, которая предоставляет подобный scikit-learn API для обучения и прогнозирования в lightgbm. Он позволяет нам создать объект оценщика со списком параметров в качестве входных данных. Затем мы можем вызвать метод fit() для обучения, передав ему тренировочные данные, и метод predict() для предсказания.
Параметры, которые мы передали в виде словаря аргументу params функции train(), теперь можно напрямую передать конструктору LGBMModel для создания модели. LGBMModel позволяет нам выполнять задачи как классификации, так и регрессии, указав цель (objective) задачи.
Регрессия
Ниже на простом примере объясняется, как мы можем использовать LGBMModel для выполнения задач регрессии с данными о жилье в Бостоне. Сначала нами был создан экземпляр LGBMModel с целью (objective) регрессии и числом деревьев, равным 10. Параметр n_estimators является псевдонимом параметра num_boost_round метода train().
Затем мы вызвали метод fit() для обучения модели, передав ему тренировочные данные. Обратите внимание, что он принимает в качестве входных данных массивы numpy, а не объект Dataset фреймворка lightgbm. Мы также предоставили набор данных, который будет использоваться в качестве оценочного датасета, и метрики, которые будут рассчитываться на нем. Параметры метода fit() почти такие же, как и у train().
Наконец, мы вызвали метод predict(), чтобы сделать прогнозы.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="regression", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
from sklearn.metrics import r2_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("\nTest R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Размеры Train/Test Sizes: (379, 13) (127, 13) (379,) (127,)
[1] valid_0's rmse: 9.70598 valid_0's l2: 94.206
[2] valid_0's rmse: 9.04855 valid_0's l2: 81.8763
[3] valid_0's rmse: 8.51309 valid_0's l2: 72.4727
[4] valid_0's rmse: 8.04785 valid_0's l2: 64.7678
[5] valid_0's rmse: 7.6032 valid_0's l2: 57.8086
[6] valid_0's rmse: 7.21651 valid_0's l2: 52.078
[7] valid_0's rmse: 6.88971 valid_0's l2: 47.4681
[8] valid_0's rmse: 6.63273 valid_0's l2: 43.9931
[9] valid_0's rmse: 6.40727 valid_0's l2: 41.0532
[10] valid_0's rmse: 6.21095 valid_0's l2: 38.5759
Test R2 Score: 0.65
Train R2 Score: 0.74Бинарная классификация
Ниже мы объясняем на простом примере, как мы можем использовать LGBMModel для задач классификации. У нас есть обученная модель с набором данных по раку груди. Обратите внимание, что метод predict() возвращает вероятности. Мы включили логику для вычисления класса по вероятностям.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="regression", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
from sklearn.metrics import r2_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("\nTest R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Размеры Train/Test Sizes: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's binary_logloss: 0.578847
[2] valid_0's binary_logloss: 0.524271
[3] valid_0's binary_logloss: 0.480868
[4] valid_0's binary_logloss: 0.441691
[5] valid_0's binary_logloss: 0.410361
[6] valid_0's binary_logloss: 0.381543
[7] valid_0's binary_logloss: 0.353827
[8] valid_0's binary_logloss: 0.33609
[9] valid_0's binary_logloss: 0.319685
[10] valid_0's binary_logloss: 0.30735
Test Accuracy: 0.90
Train Accuracy: 0.98LGBMRegressor
LGBMRegressor — еще одна обертка-оценщик вокруг класса Booster, предоставляемая lightgbm и имеющая тот же API, что и у оценщиков sklearn. Как следует из названия, он предназначен для задач регрессии.
LGBMRegressor почти такой же, как LGBMModel, с той лишь разницей, что он предназначен только для задач регрессии. Ниже мы объяснили использование LGBMRegressor на простом примере с использованием набора данных о жилье в Бостоне. Обратите внимание, что LGBMRegressor предоставляет метод score(), который рассчитывает для нас оценку R2, которую мы до сих пор получали с использованием метрик sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMRegressor(objective="regression_l2", n_estimators=10,)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric=["rmse", "l2", "l1"])
print("Test R2 Score: %.2f"%booster.score(X_train, Y_train))
print("Train R2 Score: %.2f"%booster.score(X_test, Y_test))
Размеры Train/Test Sizes: (379, 13) (127, 13) (379,) (127,)
[1] valid_0's rmse: 8.31421 valid_0's l2: 69.1262 valid_0's l1: 6.0334
[2] valid_0's rmse: 7.61825 valid_0's l2: 58.0377 valid_0's l1: 5.54499
[3] valid_0's rmse: 7.00797 valid_0's l2: 49.1116 valid_0's l1: 5.14472
[4] valid_0's rmse: 6.45103 valid_0's l2: 41.6158 valid_0's l1: 4.7527
[5] valid_0's rmse: 5.97644 valid_0's l2: 35.7178 valid_0's l1: 4.41064
[6] valid_0's rmse: 5.55884 valid_0's l2: 30.9007 valid_0's l1: 4.11807
[7] valid_0's rmse: 5.20092 valid_0's l2: 27.0495 valid_0's l1: 3.85392
[8] valid_0's rmse: 4.88393 valid_0's l2: 23.8528 valid_0's l1: 3.63833
[9] valid_0's rmse: 4.63603 valid_0's l2: 21.4928 valid_0's l1: 3.45951
[10] valid_0's rmse: 4.40797 valid_0's l2: 19.4302 valid_0's l1: 3.27911
Test R2 Score: 0.75
Train R2 Score: 0.76LGBMClassifier
LGBMClassifier — еще одна обертка-оценщик вокруг класса Booster, которая предоставляет API, подобный sklearn, для задач классификации. Он работает точно так же, как LGBMModel, но только для задач классификации. Он также предоставляет метод score(), который оценивает точность переданных ему данных.
Обратите внимание, что LGBMClassifier предсказывает фактические метки классов для задач классификации с помощью метода predict(). Он предоставляет метод pred_proba(), если нам нужны вероятности целевых классов.
Бинарная классификация
Ниже мы приводим простой пример того, как мы можем использовать LGBMClassifier для задач бинарной классификации. Наше объяснение основано на его применении к датасету по раку груди.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
booster = lgb.LGBMClassifier(objective="binary", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),])
print("Test Accuracy: %.2f"%booster.score(X_test, Y_test))
print("Train Accuracy: %.2f"%booster.score(X_train, Y_train))
Test Accuracy: 0.97
Train Accuracy: 0.97Мультиклассовая классификация
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target)
booster = lgb.LGBMClassifier(objective="multiclassova", n_estimators=10, num_class=3)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),])
print("Test Accuracy: %.2f"%booster.score(X_test, Y_test))
print("Train Accuracy: %.2f"%booster.score(X_train, Y_train))
Test Accuracy: 0.96
Train Accuracy: 1.00Далее мы объясняем использование LGBMClassifier для задач мультиклассовой классификации с использованием набора данных Wine.
Обратите внимание, что LGBMModel, LGBMRegressor и LGBMClassifier предоставляют атрибут с названием booster_, возвращающий экземпляр класса Booster, который мы можем сохранить на диск после обучения и позже загрузить для прогнозирования.
Сохранение и загрузка модели
Теперь мы покажем, как сохранить обученную модель на диск, чтобы использовать ее позже для прогнозов. Lightgbm предоставляет нижеперечисленные методы для сохранения и загрузки моделей.
save_model()— этот метод принимает имя файла, в котором сохраняется модель.model_to_string()— данный метод возвращает строковое представление модели, которое мы затем можем сохранить в текстовый файл.lightgbm.Booster()— этот конструктор позволяет нам создать экземпляр классаBooster. У него есть два важных параметра, которые могут помочь нам загрузить модель из файла или из строки.model_file— этот параметр принимает имя файла, из которого загружается обученная модель.model_str— данный параметр принимает строку, содержащую информацию об обученной модели. Нам нужно передать этому параметру строку, которая была сгенерирована с помощьюmodel_to_string()после загрузки из файла.
Ниже мы объясняем на простых примерах, как использовать вышеупомянутые методы для сохранения моделей на диск, а затем загрузки с него.
Обратите внимание, что для сохранения модели, обученной с использованием LGBMModel, LGBMRegressor и LGBMClassifier, нам сначала нужно получить их экземпляр Booster с помощью атрибута booster_ оценщика, а затем сохранить его. LGBMModel, LGBMRegressor и LGBMClassifier не предоставляют функций сохранения и загрузки. Они доступны только с экземпляром Booster.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression", "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
verbose_eval=False,
feature_name=boston.feature_names.tolist(),
num_boost_round=10)
booster.save_model("lgb.model")
loaded_booster = lgb.Booster(model_file="lgb.model")
test_preds = loaded_booster.predict(X_test)
train_preds = loaded_booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.62
Train R2 Score: 0.76Кросс-валидация
Lightgbm позволяет нам выполнять кросс-валидацию с помощью метода cv(). Он принимает параметры модели в виде словаря, как метод train(). Затем мы можем предоставить набор данных для выполнения перекрестной проверки. По умолчанию данный метод производит 5-кратную кросс-валидацию. Мы можем изменить кратность, установив параметр nfold. Он также принимает разделитель данных sklearn, такой как KFold, StratifiedKFold, ShuffleSplit и StratifiedShuffleSplit. Мы можем предоставить эти разделители данных параметру folds метода cv().
Метод cv() возвращает словарь, содержащий информацию о среднем значении и стандартном отклонении потерь для каждого цикла обучения. Мы даже можем попросить метод вернуть экземпляр CVBooster, установив для параметра return_cvbooster значение True. Объект CVBooster содержит информацию о кросс-валидации.
from sklearn.model_selection import StratifiedShuffleSplit
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=breast_cancer.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=breast_cancer.feature_names.tolist())
lgb.cv({"objective": "binary", "verbosity": -1},
train_set=test_dataset, num_boost_round=10,
nfold=5, stratified=True, shuffle=True,
verbose_eval=True)
cv_output = lgb.cv({"objective": "binary", "verbosity": -1},
train_set=test_dataset, num_boost_round=10,
metrics=["auc", "average_precision"],
folds=StratifiedShuffleSplit(n_splits=3),
verbose_eval=True,
return_cvbooster=True)
for key, val in cv_output.items():
print("\n" + key, " : ", val)
auc-mean : [0.9766666666666666, 0.9833333333333334, 0.9833333333333334, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
auc-stdv : [0.020548046676563275, 0.023570226039551608, 0.023570226039551608, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
average_precision-mean : [0.9833333333333334, 0.9888888888888889, 0.9888888888888889, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
average_precision-stdv : [0.013608276348795476, 0.015713484026367772, 0.015713484026367772, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
cvbooster : <lightgbm.engine.CVBooster object at 0x000001CDFDA4FA00>Построение графиков
Lightgbm предоставляет нижеперечисленные функции для построения графиков — plot_importance().
Этот метод принимает экземпляр класса Booster и с его помощью отображает важность показателей. Ниже мы создали график важности показателей, используя бустер, ранее обученный для задачи регрессии. У данного метода есть параметр important_type. Если он установлен в значение split, то график будет отображать количество раз каждый показатель использовался для разбиения. Также если установлено значение gain, то будет показан выигрыш от соответствующих разделений. Значение параметра important_type по умолчанию split.
Метод plot_importance() имеет еще один важный параметр max_num_features, который принимает целое число, определяющее, сколько признаков включить в график. Мы можем ограничить их количество с помощью этого параметра. Таким образом, на графике будет показано только указанное количество основных показателей.
lgb.plot_importance(booster, figsize=(8,6));
plot_metric()
Этот метод отображает результаты расчета метрики. Нам нужно предоставить экземпляр бустера методу, чтобы построить оценочною метрику, рассчитанную на наборе данных для оценки.
plot_split_value_histogram()
Этот метод принимает на вход экземпляр класса Booster и имя/индекс показателя. Затем он строит гистограмму значений разделения (split value) для выбранного признака.
plot_tree()
Этот метод позволяет построить отдельное дерево ансамбля. Нам нужно указать экземпляр бустера и индекс дерева, которое мы хотим построить.
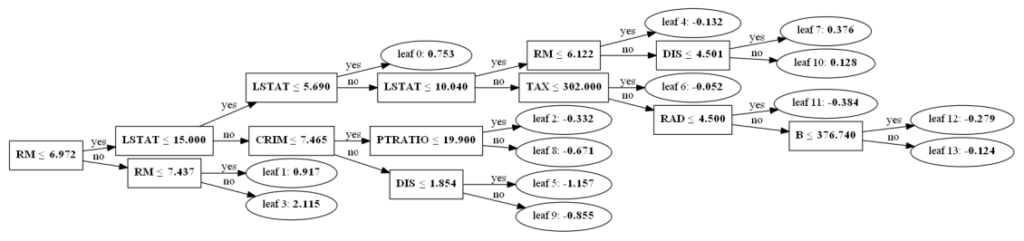
Ранняя остановка обучения
Ранняя остановка обучения — это процесс, при котором мы прекращаем обучение, если оценочная метрика, рассчитанная на оценочном датасете, не улучшается в течение указанного числа раундов. Lightgbm предоставляет параметр early_stopping_rounds как часть методов train() и fit(). Этот параметр принимает целочисленное значение, указывающее, что процесс обучения должен остановится, если результаты вычисления метрики не улучшились за указанное число итераций.
Обратите внимание, что для того, чтобы данный процесс работал, нам нужен набор данных для оценки, поскольку принятие решения об остановке обучения основано на результатах расчета метрики на оценочном датасете.
Ниже мы показываем использование параметра early_stopping_rounds для задач регрессии и классификации на простых примерах.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="binary", n_estimators=100, metric="auc")
booster.fit(X_train, Y_train,
eval_set=[(X_test, Y_test),],
early_stopping_rounds=3)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's auc: 0.979158
Training until validation scores don't improve for 3 rounds
[2] valid_0's auc: 0.979592
[3] valid_0's auc: 0.979592
[4] valid_0's auc: 0.988168
[5] valid_0's auc: 0.988602
[6] valid_0's auc: 0.98947
[7] valid_0's auc: 0.992727
[8] valid_0's auc: 0.995766
[9] valid_0's auc: 0.994572
[10] valid_0's auc: 0.995115
[11] valid_0's auc: 0.995332
Early stopping, best iteration is:
[8] valid_0's auc: 0.995766
Test Accuracy: 0.92
Train Accuracy: 0.96Lightgbm также предоставляет возможность ранней остановки обучения с помощью функции early_stopping(). Мы можем передать число раундов в функцию early_stopping() и использовать возвращаемую ее функцию обратного вызова в качестве входного параметра callbacks методов train() или fit(). Обратные вызовы рассматриваются более подробно в одном из следующих разделов.
Ограничения взаимодействия показателей
Когда lightgbm завершил обучение на датасете, отдельный узел в этих деревьях представляет некоторое условие, основанное на некотором значении показателя. Когда во время предсказания мы используем отдельное дерево, мы начинаем с его корневого узла, проверяя условие конкретного показателя, указанное в данном узле, с соответствующим значением показателя из нашего семпла. Решения принимаются нами на основе значений признаков из наблюдения и условий, представленных в дереве. Таким образом, мы идем по определенному пути, пока не достигнем листа дерева, где сможем сделать окончательный прогноз.
По умолчанию любой узел может быть связан с любым показателем в качестве условия. Этот процесс принятия окончательного решения путем прохождения узлов дерева, проверяя условие на соответствующих признаках, называется взаимодействием показателей, так как предиктор пришел к конкретному узлу после оценки условия предыдущего узла. Lightgbm позволяет нам определять ограничения на то, какой признак взаимодействует с каким. Мы можем предоставить список индексов, и указанные показатели будут взаимодействовать только друг с другом. Этим признакам не будет разрешено взаимодействовать с другими, и это ограничение будет применяться при создании деревьев в процессе обучения.
Ниже мы объясняем на простом примере, как наложить ограничение взаимодействия показателей на оценщик в lightgbm. Оценщики Lightgbm предоставляют параметр с названием interaction_constraints, который принимает список списков, где отдельные списки являются индексами признаков, которым разрешено взаимодействовать друг с другом.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse",
'interaction_constraints':[[0,1,2,11,12], [3, 4],[6,10], [5,9], [7,8]]},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Монотонные ограничения
Lightgbm позволяет нам указывать монотонные ограничения для модели, которые определяют, связан ли отдельный показатель с увеличением/уменьшением целевого значения, или не связан вовсе. Таким образом, у нас есть возможность использовать монотонные значения -1, 0 и 1, тем самым заставляя модель устанавливать уменьшающуюся, нулевую и увеличивающуюся взаимосвязь показателя с целью. Мы можем предоставить список той же длины, что и количество признаков, указав 1, 0 или -1 для монотонной связи, используя параметр monotone_constraints. Ниже объясняется, как обеспечить монотонные ограничения в lightgbm.
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse",
'monotone_constraints':(1,0,1,-1,1,0,1,0,-1,1,1, -1, 1)},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Пользовательская функция цели/потерь
Lightgbm также позволяет определить целевую функцию, подходящую именно нам. Для этого нужно создать функцию, которая принимает список прогнозируемых и фактических меток в качестве входных данных и возвращает первую и вторую производные функции потерь, вычисленные с использованием предсказанных и фактических значений. Далее мы можем передать параметру objective оценщика определенную нами функцию цели/потерь. В случае использования метода train() мы должны предоставить ее через параметр fobj.
Ниже нами была разработана целевая функция средней квадратической ошибки (MSE). Затем мы передали ее параметру objective LGBMModel.
def first_grad(predt, dmat):
'''Вычисли первую производную для MSE.'''
y = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
return 2*(y-predt)
def second_grad(predt, dmat):
'''Вычисли вторую производную для MSE.'''
y = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
return [1] * len(predt)
def mean_sqaured_error(predt, dmat):
''''Функция MSE.'''
predt[predt < -1] = -1 + 1e-6
grad = first_grad(predt, dmat)
hess = second_grad(predt, dmat)
return grad, hess
booster = lgb.LGBMModel(objective=mean_sqaured_error, n_estimators=10,)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.78
Train R2 Score: 0.82Пользовательская функция оценки
Lightgbm позволяет нам определять нашу собственную оценочную метрику, если мы не хотим использовать метрики, предоставленные фреймворком. Для этого мы должны написать функцию, которая принимает на вход список предсказаний и фактических целевых значений. Она будет возвращать строку, определяющую название метрики, результат ее расчета и логическое значение, выражающее, стоит ли стремится к максимизации данной метрики или к ее минимизации. В случае, когда чем выше значение метрики, тем лучше, должно быть возвращено True, иначе — False.
Нам нужно указать ссылку на эту функцию в параметре feval, если мы используем метод train() для разработки нашего оценщика. При передаче в fit() нам нужно присвоить данную ссылку параметру eval_metric.
Далее объясняется на простых примерах, как можно использовать пользовательские оценочные метрики с lightgbm.
def mean_absolute_error(preds, dmat):
actuals = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
err = (actuals - preds).sum()
is_higher_better = False
return "MAE", err, is_higher_better
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse"},
feval=mean_absolute_error,
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.71
Train R2 Score: 0.76Функции обратного вызова
Lightgbm предоставляет пользователям список функций обратного вызова для разных целей, которые выполняются после каждой итерации обучения. Ниже приведен список доступных колбэков:
early_stopping(stopping_rounds)— эта функция обратного вызова принимает целое число, указывающее, следует ли останавливать обучение, если результаты расчета метрики на последнем оценочном датасете не улучшаются на протяжении указанного числа итераций.print_evaluation(period, show_stdv)— данный колбэк принимает целочисленные значения, определяющие, как часто должны выводиться результаты оценки. Полученные значения оценочной метрики печатаются через указанное число итераций.record_evaluation(eval_result)— эта функция получает на вход словарь, в котором будут записаны результаты оценки.reset_parameter()— данная функция обратного вызова позволяет нам сбрасывать скорость обучения после каждой итерации. Она принимает массив, размер которого совпадает с их количеством, или функцию, возвращающую новую скорость обучения для каждой итерации.
Параметр callbacks методов train() и fit() принимает список функций обратного вызова.
Ниже на простых примерах показано, как мы можем использовать различные колбэки. Функция обратного вызова early_stopping() также была рассмотрена в разделе «Ранняя остановка обучения» этого руководства.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
booster = lgb.LGBMModel(objective=mean_sqaured_error, n_estimators=10,)
booster.fit(X_train, Y_train,
eval_set=[(X_test, Y_test),], eval_metric="rmse",
callbacks=[lgb.reset_parameter(learning_rate=np.linspace(0.1,1,10).tolist())])
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score : %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score : %.2f"%r2_score(Y_train, train_preds))
[1] valid_0's rmse: 20.8416
[2] valid_0's rmse: 12.9706
[3] valid_0's rmse: 6.60998
[4] valid_0's rmse: 4.28918
[5] valid_0's rmse: 3.96958
[6] valid_0's rmse: 3.89009
[7] valid_0's rmse: 3.80177
[8] valid_0's rmse: 3.88698
[9] valid_0's rmse: 4.2917
[10] valid_0's rmse: 4.39651
Test R2 Score : 0.82
Train R2 Score : 0.94На этом заканчивается наше небольшое руководство, объясняющее API LightGBM. Не стесняйтесь поделиться с нами своим мнением в разделе комментариев.
]]>В бой. Импортируем рабочие библиотеки и датасет:
from sklearn.datasets import load_boston
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import learning_curve
from sklearn.metrics import make_scorer
%matplotlib inline
np.random.seed(42)
boston_data = load_boston()
boston_df = pd.DataFrame(boston_data.data, columns=boston_data.feature_names)
target = boston_data.target
Вот краткое описание нашего датасета:
- CRIM — уровень преступности на душу населения по городам.
- ZN — доля земли под жилую застройку, разделенная на участки площадью более 25 000 кв. футов.
- INDUS — доля акров, которые принадлежат предприятиям, не связанным с розничной торговлей, на город.
- CHAS — фиктивная переменная реки Чарльз (1, если участок соединен с рекой; 0 в противном случае).
- NOX — концентрация оксидов азота (в десятимиллионных долях).
- RM — среднее количество комнат в доме.
- AGE — доля занимаемых зданий, построенных до 1940 г.
- DIS — взвешенные расстояния до пяти бостонских центров занятости.
- RAD — индекс доступности радиальных автомобильных дорог.
- TAX — полная ставка налога на имущество за каждые 10000 долларов стоимости.
- PTRATIO — соотношение учеников и учителей по городам.
- B — 1000 (Bk — 0,63) , где Bk — доля граждан афроамериканского происхождения по городам.
- LSTAT — процент более низкого статуса населения.
- TARGET —медианное значение стоимости занимаемых домов в тысячах долларов США.
Задача данной выборки сводится к прогнозированию целевого показателя (медианной стоимости недвижимости), используя приведенные выше показатели (все, кроме TARGET).
Полный ноутбук с кодом статьи: https://gitlab.com/PythonRu/notebooks/-/blob/master/linear_regression_sklearn.ipynb
Линейная регрессия
Как мы можем подойти к этой проблеме?
Для нашего первого прохода давайте упростим задачу. Допустим, мы просто хотим использовать признак LSAT для прогнозирования TARGET.
plt.scatter(boston_df['LSTAT'], target);

По оси X у нас есть LSTAT, а по оси Y — TARGET. Просто взглянув на это, можно увидеть отрицательную взаимосвязь: когда LSTAT растет, TARGET падает.
Функция оценки/стоимости
Как мы можем решить проблему предсказания TARGET на основе LSTAT? Хорошая отправная точка для размышлений: допустим, мы разрабатываем множество моделей для прогнозирования целевого показателя, как нам выбрать лучшую из них? Как только мы найдем подходящее для сравнения значение, наша задача — минимизировать/максимизировать его.
Это чрезвычайно полезно, если вы можете свести проблему к единственной оценочной метрике. Тогда это очень упрощает цикл разработки модели. Однако в реальном мире прийти к такому упрощению может быть непросто. Иногда не совсем понятно, что вы хотите, чтобы ваша модель максимизировала/минимизировала. Но это проблема для другой статьи.
Поэтому для нашей задачи предлагаю использовать среднюю квадратическую ошибку (mean squared error) в качестве оценочной метрики. Для лучшего понимания смысла MSE, давайте определимся с терминологией:

Таким образом, MSE:

По сути, для каждой точки мы вычитаем предсказанное нами значение из фактического. Затем, поскольку нас не волнует направление ошибки, мы возводим разницу в квадрат. Наконец, мы вычисляем среднее всех этих значений. Таким образом, мы хотим, чтобы среднее расстояние между предсказанными и фактическими показателями было минимальным.
Вам может быть интересно, почему мы возводили разницу в квадрат вместо того, чтобы брать абсолютное значение. Оказывается, что для некоторых из представленных ниже математических операций возведение в квадрат работает лучше. Кроме того, это метод максимального правдоподобия. Тем не менее, такой подход приводит к тому, что крупные ошибки имеют более сильное влияние на среднее значение, поскольку мы возводим в квадрат каждое отклонение.
Наша модель
Теперь, когда у нас есть функция оценки, как найти способ ее минимизировать? В этом посте мы рассмотрим модель линейной регрессии. Она выглядит следующим образом:

Где j — количество имеющихся у нас предсказателей (независимых переменных), значения бета — это наши коэффициенты. А бета 0 является смещением (intercept). По сути, данная модель представляет собой линейную комбинацию наших предсказателей с intercept.
Теперь, когда у нас есть модель и функция оценки, наша задача состоит в том, чтобы найти бета-значения, которые минимизируют MSE для наших данных. Для линейной регрессии на самом деле существует решение в замкнутой форме, называемое нормальным уравнением. Однако в этом посте мы собираемся использовать другую технику — градиентный спуск.
Градиентный спуск
Градиентный спуск — это метод, который мы позаимствовали из оптимизации. Очень простой, но мощный алгоритм, который можно использовать для поиска минимума функции.
- Выберите случайное начальное значение.
- Делайте шаги, пропорциональные отрицательному градиенту в текущей точке.
- Повторяйте, пока не достигните предела.
Этот метод найдет глобальный минимум, если функция выпуклая. В противном случае мы можем быть уверены только в том, что достигнем локальный минимум.
Первый вопрос, на который нам нужно ответить: является ли наша функция оценки выпуклой? Давайте посмотрим:
mses = []
lstat_coef = range(-20, 23)
for coef in lstat_coef:
pred_values = np.array([coef * lstat for lstat in boston_df.LSTAT.values])
mses.append(np.sum((target - pred_values)**2))
plt.plot(lstat_coef, mses);
Для построения графика выше мы взяли диапазон значений коэффициентов для LSTAT, и для каждого из них рассчитали MSE на основе наших данных. Если мы затем отобразим полученные значения, мы получим приведенную выше кривую — выглядит довольно выпуклой! И оказывается, что наша функция MSE с нашей моделью линейной регрессии всегда будет выпуклой! Это означает: мы можем использовать градиентный спуск, чтобы найти оптимальные коэффициенты для нашей модели!
Одна из причин того, что градиентный спуск более распространен, чем нормальное уравнение для машинного обучения, заключается в том, что он намного лучше масштабируется по мере увеличения количества показателей. Это также стандартный метод оптимизации, который используется повсюду в машинном обучении. Поэтому понимание того, как он работает, чрезвычайно важно.
Градиенты
Если вы снова посмотрите на наш псевдокод для градиентного спуска, вы увидите, что на самом деле все, что нам нужно сделать, это вычислить градиенты. Итак, что такое градиенты? Это просто частные производные по коэффициентам. Для каждого имеющегося коэффициента нам нужно будет вычислить производную MSE по этому коэффициенту. Давайте начнем!
Для начала запишем выражение для MSE, подставив функцию оценки со смещением и единственной переменной LSTAT:
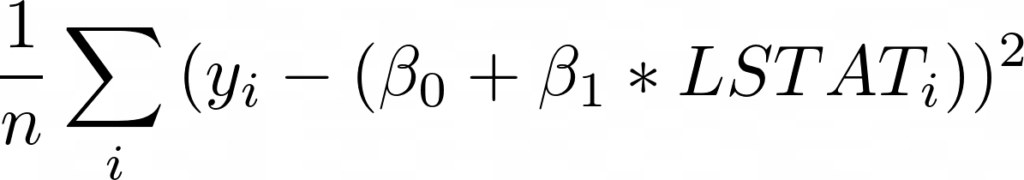
Теперь, взяв производную по бета 0, мы получим (умноженное на -1):

И для бета 1:
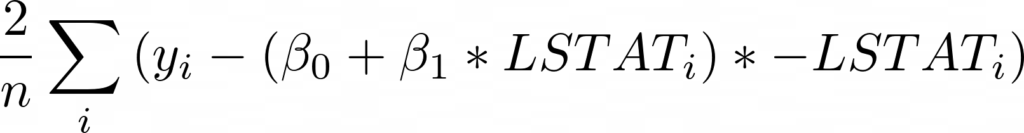
Теперь давайте запустим наш алгоритм градиентного спуска и убедимся, что MSE действительно уменьшается:
beta_0 = 0
beta_1 = 0
learning_rate = 0.001
lstat_values = boston_df.LSTAT.values
n = len(lstat_values)
all_mse = []
for _ in range(10000):
predicted = beta_0 + beta_1 * lstat_values
residuals = target - predicted
all_mse.append(np.sum(residuals**2))
beta_0 = beta_0 - learning_rate * ((2/n) * np.sum(residuals) * -1)
beta_1 = beta_1 - learning_rate * ((2/n) * residuals.dot(lstat_values) * -1)
plt.plot(range(len(all_mse)), all_mse);
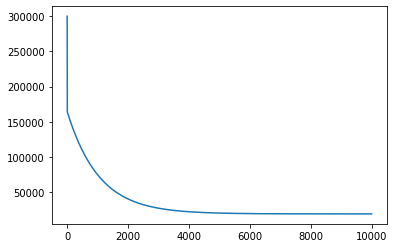
Первый график, представленный выше, показывает значение MSE, когда мы запускаем градиентный спуск. Как и следовало ожидать, MSE уменьшается со временем по мере выполнения алгоритма. Это означает, что мы постоянно приближаемся к оптимальному решению.
На графике видно, что мы вполне могли завершить работу раньше. MSE переходит в прямую (почти не изменяется) примерно после 4000 итераций.
print(f"Beta 0: {beta_0}")
print(f"Beta 1: {beta_1}")
plt.scatter(boston_df['LSTAT'], target)
x = range(0, 40)
plt.plot(x, [beta_0 + beta_1 * l for l in x]);
Итак, запуск градиентного спуска показал, что оптимальное смещение составляет 34.55, а оптимальный наклон равен -0,95. На приведенном выше графике эта линия показана поверх наших данных, она выглядит как аппроксимирующая прямая.
Скорость обучения
Один параметр, который нам еще предстоит обсудить, — это скорость обучения. Эта скорость — гиперпараметр, используемый для определения того, насколько большие шаги мы делаем от направления градиента. Как узнать, какое значение выбрать? Как правило, можно попробовать множество вариантов. Вот некоторые из них, которые были предложены Andrew Ng: .001, .003, .01, .03, .1, .3, 1, 3.
Выбор слишком малого значения приводит к более медленной сходимости. Выбор слишком большого значения может привести к перешагиванию через минимум и расхождению.
Существуют также другие оптимизаторы градиентного спуска, которые более сложны и адаптируют скорость обучения за вас. Это также то, что вы можете делать самостоятельно, постепенно снижая скорость обучения.
Когда прекратить итерацию?
В моем коде я просто выполняю наш цикл 10000 раз. Почему 10000? Никакой реальной причины, кроме моей уверенности в том, что этого достаточно, чтобы достичь минимума. Такой подход точно нельзя назвать лучшей практикой. Вот несколько более разумных идей:
- Следите за оценкой после каждого цикла, и когда ее очередное изменение меньше некоторого граничного значения — скажем, 0.001 — останавливайтесь.
- Используйте проверочный датасет (validation set) и отслеживайте число ошибок, например, с помощью MSE. Когда метрика перестанет уменьшаться, остановитесь.
Нормализация данных
При работе с градиентным спуском вы хотите, чтобы все ваши данные были нормализованы. Вычтите среднее значение и разделите на стандартное отклонение для всех ваших тренировочных показателей. Обычно это ускоряет обучение и снижает вероятность застревания в локальном оптимуме, если функция оценки не является выпуклой.
Другие виды градиентного спуска
Показанный здесь градиентный спуск представляет собой классическую форму, что означает: каждое обновление коэффициента использует все данные для вычисления градиентов. Существует также стохастический градиентный спуск. Ему необходима только 1 строка данных (1 наблюдение) для пересчета коэффициентов в каждом цикле.
Такой способ намного лучше масштабируется, так как нужно обработать только одну строку данных за раз перед обновлением. Также он является более неопределенным, поскольку вы пытаетесь перемещаться с использованием градиента, рассчитанного на основе единственного наблюдения.
Другой тип градиентного спуска — это мини-пакетный градиентный спуск. Эта форма представляет собой компромисс между двумя, где вы выбираете размер пакета. Скажем, 32 (или, что еще лучше, пакетный график, который начинается с небольших пакетов и увеличивается с увеличением количества эпох), и каждая итерация вашего градиентного спуска использует 32 случайные строки данных для вычисления градиента (алгоритм воспользуется всеми строками перед повторной выборкой раннее обработанных). В результате мы получаем некоторую масштабируемость, но и некоторую неопределенность.
Такое случайное поведение оказывается полезным для функций оценки, которые не являются выпуклыми (глубокое обучение), поскольку оно может помочь модели избежать локального минимума. Это наиболее распространенный метод для невыпуклых функций оценки.
Допущения нашей модели
Всякий раз, когда вы имеете дело с моделью, хорошо знать, какие допущения она делает. Университет Дьюка написал об этом целую статью:
https://people.duke.edu/~rnau/testing.htm
Реализация линейной регрессии в Scikit-Learn
Теперь, когда мы немного разбираемся в теории и реализации, давайте обратимся к библиотеке scikit-learn, чтобы на самом деле использовать линейную регрессию на наших данных. Написание моделей с нуля довольно полезно для обучения, но на практике вам, как правило, гораздо лучше использовать проверенную и широко используемую библиотеку.
Для начала нужно нормализовать данные:
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(boston_df)
scaled_df = scaler.transform(boston_df)
У Scikit-learn довольно удобный API. Он предоставляет множество моделей, и все они имеют функции fit и predict. Вы можете вызвать fit с вашими X и y данными для обучения модели, а затем использовать predict для получения предсказанных значений на основе новых данных. Scikit-learn также предоставляет множество метрик, которые вы можете использовать для оценки, такие как MSE. Здесь я вычисляю среднеквадратическую ошибку (RMSE). Так мы можем использовать шкалу нашего целевого показателя, что, легче для понимания.
SGDRegressor выполняет линейную регрессию с использованием градиентного спуска и принимает следующие аргументы: tol(сообщает модели, когда следует прекратить итерацию) и eta0(начальная скорость обучения).
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
linear_regression_model.fit(scaled_df, target)
predictions = linear_regression_model.predict(scaled_df)
mse = mean_squared_error(target, predictions)
print("RMSE: {}".format(np.sqrt(mse)))
RMSE в итоге составила 4.68… для нашей обучающей выборки с использованием scikit-learn.
Полиномиальные переменные
Рассматривая построенный выше график стоимости от LSTAT, вы могли заметить, что между данными показателями существует полиномиальная связь. Линейная регрессия хорошо подходит в случае линейной зависимости, но, если вы добавите полиномиальные показатели, такие как LSTAT, вы сможете установить более сложные отношения. SKLearn упрощает данный процесс:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(2, include_bias=False)
poly_df = poly.fit_transform(boston_df)
scaled_poly_df = scaler.fit_transform(poly_df)
print(f"shape: {scaled_poly_df.shape}")
linear_regression_model.fit(scaled_poly_df, target)
predictions = linear_regression_model.predict(scaled_poly_df)
mse = mean_squared_error(target, predictions)
print("RMSE: {}".format(np.sqrt(mse)))
shape: (506, 104)
RMSE: 3.243477309312183Функция PolynomialFeatures сгенерировала новую матрицу показателей, состоящую из всех их полиномиальных комбинаций со степенью меньше или равной указанной (в нашем примере 2). Затем мы нормализовали эти данные и скормили их нашей модели. Так мы получили улучшенную тренировочную RMSE, равную 3.24. Однако обратите внимание, что эти результаты, представленные в иллюстративных целях, используют только тренировочную выборку.
Категориальные переменные
Линейная регрессия — одна из моделей, с которой нужно быть осторожным, когда у вас есть качественные данные. Если у вас переменные со значениями 1, 2 и 3, которые на самом деле означают «Мужской», «Женский», «Нет ответа», не передавайте их модели таким образом, даже если они являются числами.
Если бы вы это сделали, модель присвоила бы такому показателю коэффициент — возможно, 0.1. Это будет означать, что принадлежность к женскому полу увеличивает предсказанное значение на 0.1. А отсутствие ответа — на 0.2. Но, возможно, метка «Женский» должна повысить результат на 1.2, а «Нет ответа» — всего на 0.001. Чтобы решить данную проблему, вы должны преобразовать такие значения в фиктивные переменные, чтобы каждая категория имела свой собственный вес. Вы можете узнать, как это сделать с помощью scikit-learn, здесь.
Интерпретация вашей модели
Линейная регрессия — это отличная статистическая модель, которая существует уже давно. Есть много статистических методов, которые можно использовать для ее оценки и интерпретации. Мы не будем рассматривать их все и на самом деле сосредоточимся на очень простых подходах, которые, возможно, более распространены в машинном обучении, чем в статистике.
Во-первых, давайте посмотрим на коэффициенты, которым научилась наша модель (по всем показателям):
linear_regression_model.fit(scaled_df, target)
sorted(list(zip(boston_df.columns, linear_regression_model.coef_)),
key=lambda x: abs(x[1]))
[('AGE', -0.09572161737815363),
('INDUS', -0.21745291834072922),
('CHAS', 0.7410105153873195),
('B', 0.8435653632801421),
('CRIM', -0.850480180062872),
('ZN', 0.9500420835249525),
('TAX', -1.1871976153182786),
('RAD', 1.7832553590229068),
('NOX', -1.8352515775847786),
('PTRATIO', -2.0059298125382456),
('RM', 2.8526547965775757),
('DIS', -2.9865347158079887),
('LSTAT', -3.724642983604627)]Что они означают? Каждый коэффициент представляет собой среднее изменение цены на жилье при изменении соответствующего показателя на единицу с условием, что все остальные показатели остаются неизменными. Например, если значения других показателей не затрагиваются, то увеличение LSTAT на единицу снижает наш целевой показатель (цену на жилье) на 3.72, а увеличение RM увеличивает его на 2.85.
Таким образом, если вы хотите повысить стоимость дома, то может быть стоит начать с увеличения RM и уменьшения LSTAT. Я говорю «может быть», потому что линейная регрессия рассматривает корреляции. Судя по нашим данным, такая взаимосвязь имеет место быть, что само по себе не означает обязательное наличие причинно-следственной связи между показателями.
Доверительные интервалы
Часто в машинном обучении очень полезно иметь доверительный интервал вокруг ваших оценок. Есть разные способы сделать это, но одним довольно общим методом является использование bootstrap.
Bootstrap — это случайная выборка на основе наших данных, и эта выборка того же размера, что и исходные данные. Так мы можем создать несколько представлений одних и тех же данных. Давайте создадим 1000 bootstrap-семплов наших данных.
from sklearn.utils import resample
n_bootstraps = 1000
bootstrap_X = []
bootstrap_y = []
for _ in range(n_bootstraps):
sample_X, sample_y = resample(scaled_df, target)
bootstrap_X.append(sample_X)
bootstrap_y.append(sample_y)
Затем мы обучим модель на каждом из полученных датасетов и получим следующие коэффициенты:
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
coeffs = []
for i, data in enumerate(bootstrap_X):
linear_regression_model.fit(data, bootstrap_y[i])
coeffs.append(linear_regression_model.coef_)
coef_df = pd.DataFrame(coeffs, columns=boston_df.columns)
coef_df.plot(kind='box')
plt.xticks(rotation=90);
На представленной диаграмме размаха показан диапазон значений коэффициентов, которые мы получили для каждого показателя для всех моделей, которые мы обучили. AGE — особенно интересен, потому что значения коэффициентов были как положительными, так и отрицательными, что является хорошим признаком того, что, вероятно, нет никакой связи между возрастом и стоимостью.
Кроме того, мы можем увидеть, что LSTAT имеет большой разброс в значениях коэффициентов, в то время как PTRATIO имеет относительно небольшую дисперсию, что повышает доверие к нашей оценке этого коэффициента.
Мы даже можем немного углубиться в полученные коэффициенты для LSTAT:
print(coef_df['LSTAT'].describe())
coef_df['LSTAT'].plot(kind='hist');
count 1000.000000
mean -3.686064
std 0.713812
min -6.032298
25% -4.166195
50% -3.671628
75% -3.202391
max -1.574986
Name: LSTAT, dtype: float64
Теперь мы можем с большой уверенностью сказать, что фактический коэффициент LSTAT отрицателен и почти наверняка находится между -2 и -5.5.
Разделение на обучающий/тестовый датасеты и кросс-валидация
До этого момента мы тренировались на всех имеющихся данных. Это может иметь смысл, потому что мы хотим максимизировать их полезность, используя как можно больше данных для обучения. С другой стороны, из-за такого подхода нам становится труднее оценивать, насколько хорошо работает наша модель. Причина этого в том, что, если мы продолжим рассчитывать MSE, используя тренировочные данные, мы можем обнаружить, что при применении модели на незнакомых ей данных, она работает довольно плохо.
Эта идея называется переобучением (overfitting). По сути, такая модель работает намного лучше с обучающими данными, чем с новыми. Она была чрезмерно натренирована на обнаружение уникальных характеристик обучающего множества, которые не являются общими закономерностями, присущими генеральной совокупности.
Другая сторона проблемы называется bias. Модель имеет высокий bias, когда она плохо обучена. В этом случае MSE будет высокой как для тренировочных данных, так и для данных, не показанных во время обучения.
В ML всегда существует компромисс между смещением (bias) и дисперсией (overfitting). По мере того, как ваши модели становятся более сложными, возрастает риск переобучения на тренировочных данных.
Теперь, когда мы знаем о проблемах с вычислением MSE, используя только обучающее множество, что мы можем сделать, чтобы лучше судить о способности модели к обобщению? А также диагностировать overfitting и bias? Типичным решением является разделение наших данных на две части: обучающий и тестовый датасеты.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled_df,
target,
test_size=0.33,
random_state=42)
Теперь, когда у нас есть два отдельных набора данных, мы можем тренировать модель на обучающем множестве и вычислять метрики, используя оба датасета (лучше всего использовать ваши тестовые данные после настройки модели):
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
linear_regression_model.fit(X_train, y_train)
train_predictions = linear_regression_model.predict(X_train)
test_predictions = linear_regression_model.predict(X_test)
train_mse = mean_squared_error(y_train, train_predictions)
test_mse = mean_squared_error(y_test, test_predictions)
print("Train MSE: {}".format(train_mse))
print("Test MSE: {}".format(test_mse))
Train MSE: 23.068773005090424
Test MSE: 21.243935754712375Отлично! Теперь у нас есть MSE как для тренировочных данных, так и для данных тестирования. И оба значения довольно близки, что говорит об отсутствии проблемы с переобучением. Но достаточно ли они низкие? Большие значения предполагают наличие высокого bias.
Один из способов разобраться в этом — построить график обучения. Кривая обучения отображает нашу функцию ошибок (MSE) с различными объемами данных, используемых для тренировки. Вот наш график:
# Источник: http://scikit-learn.org/0.15/auto_examples/plot_learning_curve.html
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Train примеры")
plt.ylabel("Оценка")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, scoring=make_scorer(mean_squared_error))
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Train score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="C-V score")
plt.legend(loc="best")
return plt
plot_learning_curve(linear_regression_model,
"Кривая обучения",
X_train,
y_train,
cv=5);

Вы можете видеть, что с менее чем 50 обучающими примерами тренировочная MSE неплохая, а кросс-валидация оставляет желать лучшего — довольно плохая (мы еще не говорили о кросс-валидации, так что пока думайте об этом как о тестировании). Если бы у нас было только такое количество данных, это выглядело бы как явная проблема высокой дисперсии (переобучения).
По мере увеличения наших данных мы начинаем улучшать оба результата, и они становятся очень похожими, что говорит о том, что у нас нет проблемы переобучения. Как правило, при высокой дисперсии на этом графике две линии будут находится довольно далеко друг от друга, и кажется, что, если мы продолжим добавлять больше данных, они могут сойтись.
Этот график больше похож на проблему с большим смещением (bias), поскольку две наши кривые очень близки и сглаживаются. Однако трудно сказать наверняка, потому что, возможно, мы только что достигли наилучшего возможного MSE. В таком случае это не будет проблемой высокого смещения. Такой результат был бы ей только в том случае, если бы наши кривые выровнялись при значении MSE выше оптимального. В реальной жизни вы не знаете, какова оптимальная MSE, поэтому вам нужно немного поразмышлять, считаете ли вы, что уменьшение bias улучшит ваш результат — но лучше просто попробуйте!
Устранение проблем высоких bias/variance
Итак, теперь, когда вы диагностировали проблему смещения или дисперсии, как ее исправить?
Для высокой дисперсии:
- Получите больше данных для обучения
- Попробуйте меньший набор показателей
- Используйте менее сложную модель
- Добавьте регуляризацию
Для высокого смещения:
- Попробуйте увеличить число показателей
- Перейдите на более сложную модель
Кросс-валидация и настройка гиперпараметров
Ранее мы упоминали этот термин: кросс-валидация. Давайте поговорим об этом сейчас. На данный момент мы узнали, что неплохо разделить данные на наборы для обучения и тестирования, чтобы лучше понять, насколько хорошо работает модель. Это замечательно, но представьте, что мы хотим протестировать несколько разных моделей или протестировать разные параметры нашей модели — например, другую скорость обучения или толерантность. Как бы нам решить, какая модель или какой параметр лучше? Будем ли мы обучать все на тренировочных данных и тестировать все на наших тестовых данных?
Надеюсь, вы понимаете, что это не имеет смысла, потому что тогда мы, по сути, оказались бы в том же месте, что и раньше, без возможности проверить, насколько хорошо мы справляемся с ранее неизвестными данными. Итак, мы хотим сохранить датасет для тестирования незапятнанным в том смысле, что в идеальном мире мы бы запускали наши тесты на нем только после того, как провели все необходимые эксперименты и были уверены в том, что нашли самую лучшую модель.
Похоже, нам нужен третий набор данных – датасет для валидации. По сути, мы можем разбить наши обучающие данные на две части: обучающий и проверочный датасеты. Все модели будут обучены на тренировочном множестве, а затем протестированы на нашем проверочном наборе. Затем мы выберем модель, которая лучше всего справляется с проверкой, и посмотрим, насколько удачно она пройдет тестирование. Результаты тестирования покажут, как хорошо наша модель будет работать с незнакомыми данными, и на этом мы завершим процесс разработки.
Примечание: в статье предполагается, что используемые тестовые и проверочные датасеты представляют собой репрезентативные выборки из нашей совокупности. Например, если средняя цена дома в вашем проверочном множестве составляет 1 миллион, а для генеральной совокупности соответствующее значение равно 300 тысячам, у вас плохая выборка. Часто мы случайным образом делим имеющиеся данные на три выборки, но всегда полезно подтвердить, что эти наборы являются репрезентативными. В противном случае вы обнаружите, что ваша модель, которая хорошо зарекомендовала себя при проверке и тестировании, плохо работает на реальных данных.
На практике вместо создания единого множества для проверки мы часто используем k-блочную кросс-валидацию.
Это означает, что мы выбираем значение k, скажем 3. Затем мы берем наши обучающие данные и делим их на 3 части. Мы случайным образом выбираем 2 блока для тренировки, а затем используем оставшийся для тестирования. Повторяем этот процесс еще 2 раза, так чтобы все наблюдения были использованы как для обучения, так и для проверки, и каждое из них применялось для валидации только один раз. После этого усредняем все три оценки (в нашем случае MSE), чтобы получить общую оценку для конкретной модели. Затем мы можем повторить этот процесс для других моделей, чтобы найти лучшую.
Вот видео, которое более наглядно описывает этот подход (с русскими субтитрами): https://www.youtube.com/watch?v=TIgfjmp-4BA
Этот процесс довольно просто реализуется с помощью sklearn:
from sklearn.model_selection import RandomizedSearchCV
param_dist = {"eta0": [ .001, .003, .01, .03, .1, .3, 1, 3]}
linear_regression_model = SGDRegressor(tol=.0001)
n_iter_search = 8
random_search = RandomizedSearchCV(linear_regression_model,
param_distributions=param_dist,
n_iter=n_iter_search,
cv=3,
scoring='neg_mean_squared_error')
random_search.fit(X_train, y_train)
print("Лучшие параметры: {}".format(random_search.best_params_))
print("Лучшая оценка MSE: {}".format(random_search.best_score_))
Лучшие параметры: {'eta0': 0.001}
Лучшая оценка MSE: -25.64219216972172Здесь мы фактически использовали рандомизированный поиск (RandomizedSearchCV), который обычно лучше, чем поиск по всем возможным значениям. Часто вы хотите попробовать много разных параметров для множества различных регуляторов, и сеточный поиск (перебор всех возможных комбинаций) вам не подходит.
Обычно вы хотите использовать рандомизированный поиск (случайный выбор комбинаций), как мы сделали выше. Хотя, поскольку у нас было только небольшое количество значений, мы заставили его работать как сеточный поиск, установив n_iter_search равным числу вариантов, которые мы хотели попробовать.
Мы также установили cv=3, чтобы иметь 3 блока и использовали отрицательную MSE, потому что функции CV в scikit-learn пытаются максимизировать значение.
Вы можете узнать больше о случайном и «сеточном» вариантах поиска здесь: https://scikit-learn.org/stable/modules/grid_search.html.
Кроме того, в scikit-learn есть много других CV функций, которые полезны, особенно если вы хотите протестировать разные модели с одинаковыми блоками. Вот некоторая документация: https://scikit-learn.org/stable/modules/cross_validation.html.
Регуляризация
В качестве средства борьбы с высокой дисперсией я упомянул регуляризацию. Вы можете думать о ней как о методе, который используется для наказания модели за обучение сложным взаимосвязям. Для линейной регрессии она принимает форму трех популярных подходов. Все эти методы сосредоточены на идее ограничения того, насколько большими могут быть коэффициенты наших показателей.
Идея состоит в том, что если мы переоцениваем влияние предсказателя (большое значение коэффициента), то, вероятно, мы переобучаемся. Примечание: у нас все еще могут быть просто большие коэффициенты. Регуляризация говорит о том, что уменьшение MSE должно оправдывать увеличение значений коэффициентов.
- Регуляризация L1 (Lasso): вы добавляете сумму абсолютных значений коэффициентов к функции оценки. Этот метод может принудительно обнулить коэффициенты, что затем может быть средством выбора показателей.
- Регуляризация L2 (Ridge): вы добавляете сумму квадратов значений коэффициентов к функции оценки.
- Эластичная сетка: вы добавляете обе и выбираете, как их утяжелить.
Каждый из этих методов принимает весовой множитель, который говорит вам, насколько сильное влияние регуляризация будет иметь на функцию оценки. В scikit-learn такой параметр называется альфа. Альфа равный 0 не добавит штрафа, в то время как высокое его значение будет сильно наказывать модель за наличие больших коэффициентов. Вы можете использовать кросс-валидацию, чтобы найти хорошее значение для альфа.
Sklearn упрощает это:
from sklearn.linear_model import ElasticNetCV
clf = ElasticNetCV(l1_ratio=[.1, .5, .7, .9, .95, .99, 1], alphas=[.1, 1, 10])
clf.fit(X_train, y_train)
train_predictions = clf.predict(X_train)
test_predictions = clf.predict(X_test)
print("Train MSE: {}".format(mean_squared_error(y_train, train_predictions)))
print("Test MSE: {}".format(mean_squared_error(y_test, test_predictions)))
Train MSE: 23.58766002758097
Test MSE: 21.54591803491954Здесь мы использовали функцию ElasticNetCV, которая имеет встроенную кросс-валидацию, чтобы выбрать лучшее значение для альфы. l1_ratio — это вес, который придается регуляризации L1. Оставшийся вес применяется к L2.
Итог
Если вы зашли так далеко, поздравляю! Это была тонна информации, но я обещаю, что, если вы потратите время на ее усвоение, у вас будет очень твердое понимание линейной регрессии и многих вещей, которые она может делать!
Кроме того, здесь вы можете найти весь код статьи.
]]>Наличие готовых датасетов является огромным преимуществом, потому что вы можете сразу приступить к созданию моделей, не тратя время на получение, очистку и преобразование данных — на что специалисты по данным тратят много времени.
Даже после того, как вся подготовительная работа выполнена, применение выборок Scikit-Learn поначалу может показаться вам немного запутанным. Не волнуйтесь, через несколько минут вы точно узнаете, как использовать датасеты, и встанете на путь исследования мира искусственного интеллекта. В этой статье предполагается, что у вас установлены python, scikit-learn, pandas и Jupyter Notebook (или вы можете воспользоваться Google Collab). Давайте начнем.
Введение в Scikit-Learn datasets
Scikit-Learn предоставляет семь наборов данных, которые они называют игровыми датасетами. Не дайте себя обмануть словом «игровой». Эти выборки довольно объемны и служат хорошей отправной точкой для изучения машинного обучения (далее ML). Вот несколько примеров доступных наборов данных и способы их использования:
- Цены на жилье в Бостоне — используйте ML для прогнозирования цен на жилье на основе таких атрибутов, как количество комнат, уровень преступности в городе.
- Датасет диагностики рака молочной железы (Висконсин) — используйте ML для диагностики рака как доброкачественного (не распространяется на остальную часть тела) или злокачественного (распространяется).
- Распознавание вина — используйте ML для определения типа вина по химическим свойствам.
В этой статье мы будем работать с “Breast Cancer Wisconsin” (рак молочной железы, штат Висконсин) датасетом. Мы импортируем данные и разберем, как их читать. В качестве бонуса мы построим простую модель машинного обучения, которая сможет классифицировать сканированные изображения рака как злокачественные или доброкачественные.
Чтобы узнать больше о предоставленных выборках, нажмите здесь для перехода на документацию Scikit-Learn.
Как импортировать модуль datasets?
Доступные датасеты можно найти в sklearn.datasets. Давайте импортируем необходимые данные. Сначала мы добавим модуль datasets, который содержит все семь выборок.
from sklearn import datasets
У каждого датасета есть соответствующая функция, используемая для его загрузки. Эти функции имеют единый формат: «load_DATASET()», где DATASET — названием выборки. Для загрузки набора данных о раке груди мы используем load_breast_cancer(). Точно так же при распознавании вина мы вызовем load_wine(). Давайте загрузим выбранные данные и сохраним их в переменной data.
data = datasets.load_breast_cancer()
До этого момента мы не встретили никаких проблем. Но упомянутые выше функции загрузки (такие как load_breast_cancer()) не возвращают данные в табличном формате, который мы привыкли ожидать. Вместо этого они передают нам объект Bunch.
Не знаете, что такое Bunch? Не волнуйтесь. Считайте объект Bunch причудливым аналогом словаря от библиотеки Scikit-Learn.
Давайте быстро освежим память. Словарь — это структура данных, в которой данные хранятся в виде ключей и значений. Думайте о нем как о книге с аналогичным названием, к которой мы привыкли. Вы ищете интересующее вас слово (ключ) и получаете его определение (значение). У программистов есть возможность делать ключи и соответствующие значения какими угодно (могут быть словами, числами и так далее).
Например, в случае хранения персональных контактов ключами являются имена, а значениями — телефонные номера. Таким образом, словарь в Python не ограничивается его типичной репрезентацией, но может быть применен ко всему, что вам нравится.
Что в нашем Bunch-словаре?
Предоставленный Sklearn словарь Bunch — достаточно мощный инструмент. Давайте узнаем, какие ключи нам доступны.
print(data.keys())
Получаем следующие ключи:
data— это необходимые для предсказания данные (показатели, полученные при сканировании, такие как радиус, площадь и другие) в массиве NumPy.target— это целевые данные (переменная, которую вы хотите предсказать, в данном случае является ли опухоль злокачественной или доброкачественной) в массиве NumPy.
Значения этих двух ключей предоставляют нам необходимые для обучения данные. Остальные ключи (смотри ниже) имеют пояснительное предназначение. Важно отметить, что все датасеты в Scikit-Learn разделены на data и target. data представляет собой показатели, переменные, которые используются моделью для тренировки. target включает в себя фактические метки классов. В нашем случае целевые данные — это один столбец, в котором опухоль классифицируется как 0 (злокачественная) или 1 (доброкачественная).
feature_names— это названия показателей, другими словами, имена столбцов вdata.target_names— это имя целевой переменной или переменных, другими словами, название целевого столбца или столбцов.DESCR— сокращение от DESCRIPTION, представляет собой описание выборки.filename— это путь к файлу с данными в формате CSV.
Чтобы посмотреть значение ключа, вы можете ввести data.KEYNAME, где KEYNAME — интересующий ключ. Итак, если мы хотим увидеть описание датасета:
print(data.DESCR)
Вот небольшая часть полученного результата (полная версия слишком длинная для добавления в статью):
.. _breast_cancer_dataset:
Breast cancer wisconsin (diagnostic) dataset
--------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
...Вы также можете узнать информацию о выборке, посетив документацию Scikit-Learn. Их документация намного более читабельна и точна.
Работа с датасетом
Теперь, когда мы понимаем, что возвращает функция загрузки, давайте посмотрим, как можно использовать датасет в нашей модели машинного обучения. Прежде всего, если вы хотите изучить выбранный набор данных, используйте для этого pandas. Вот так:
# импорт pandas
import pandas as pd
# Считайте DataFrame, используя данные функции
df = pd.DataFrame(data.data, columns=data.feature_names)
# Добавьте столбец "target" и заполните его данными.
df['target'] = data.target
# Посмотрим первые пять строк
df.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | … | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | … | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | … | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | … | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | … | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | … | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Вы загрузили обучающую выборку в Pandas DataFrame, которая теперь полностью готова к изучению и использованию. Чтобы действительно увидеть возможности этого датасета, запустите:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 569 entries, 0 to 568
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mean radius 569 non-null float64
1 mean texture 569 non-null float64
2 mean perimeter 569 non-null float64
3 mean area 569 non-null float64
4 mean smoothness 569 non-null float64
5 mean compactness 569 non-null float64
6 mean concavity 569 non-null float64
7 mean concave points 569 non-null float64
8 mean symmetry 569 non-null float64
9 mean fractal dimension 569 non-null float64
10 radius error 569 non-null float64
11 texture error 569 non-null float64
12 perimeter error 569 non-null float64
13 area error 569 non-null float64
14 smoothness error 569 non-null float64
15 compactness error 569 non-null float64
16 concavity error 569 non-null float64
17 concave points error 569 non-null float64
18 symmetry error 569 non-null float64
19 fractal dimension error 569 non-null float64
20 worst radius 569 non-null float64
21 worst texture 569 non-null float64
22 worst perimeter 569 non-null float64
23 worst area 569 non-null float64
24 worst smoothness 569 non-null float64
25 worst compactness 569 non-null float64
26 worst concavity 569 non-null float64
27 worst concave points 569 non-null float64
28 worst symmetry 569 non-null float64
29 worst fractal dimension 569 non-null float64
30 target 569 non-null int32
dtypes: float64(30), int32(1)
memory usage: 135.7 KBНесколько вещей, на которые следует обратить внимание:
- Нет пропущенных данных, все столбцы содержат 569 значений. Это избавляет нас от необходимости учитывать отсутствующие значения.
- Все типы данных числовые. Это важно, потому что модели Scikit-Learn не принимают качественные переменные. В реальном мире, когда получаем такие переменные, мы преобразуем их в числовые. Датасеты Scikit-Learn не содержат качественных значений.
Следовательно, Scikit-Learn берет на себя работу по очистке данных. Эти наборы данных чрезвычайно удобны. Вы получите удовольствие от изучения машинного обучения, используя их.
Обучение на датесете из sklearn.datasets
Наконец, самое интересное. Далее мы построим модель, которая классифицирует раковые опухоли как злокачественные и доброкачественные. Это покажет вам, как использовать данные для ваших собственных моделей. Мы построим простую модель K-ближайших соседей.
Во-первых, давайте разделим выборку на две: одну для тренировки модели — предоставление ей данных для обучения, а вторую — для тестирования, чтобы посмотреть, насколько хорошо модель работает с данными (результаты сканирования), которые она раньше не видела.
X = data.data
y = data.target
# разделим данные с помощью Scikit-Learn's train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
Это дает нам два датасета — один для обучения и один для тестирования. Приступим к тренировке модели.
from sklearn.neighbors import KNeighborsClassifier
logreg = KNeighborsClassifier(n_neighbors=6)
logreg.fit(X_train, y_train)
logreg.score(X_test, y_test)
Получили на выходе 0.923? Это означает, что модель точна на 92%! Всего за несколько минут вы создали модель, которая классифицирует результаты сканирования опухолей с точностью 90%. Конечно, в реальном мире все сложнее, но это хорошее начало.
Ноутбук с кодом вы можете скачать здесь.
Вы многому научитесь, пытаясь построить модели с использованием datasets из Scikit-Learn. Удачного обучения искусственному интеллекту!
]]>В этом руководстве обсуждается матрица ошибок и то, как рассчитываются precision, recall и accuracy метрики.
Здесь мы рассмотрим:
- Матрицу ошибок для двоичной классификации.
- Матрицу ошибок для мультиклассовой классификации.
- Расчет матрицы ошибок с помощью Scikit-learn.
- Accuracy, Precision и Recall.
- Precision или Recall?
Матрица ошибок для бинарной классификации
В бинарной классификации каждая выборка относится к одному из двух классов. Обычно им присваиваются такие метки, как 1 и 0, или положительный и отрицательный (Positive и Negative). Также могут использоваться более конкретные обозначения для классов: злокачественный или доброкачественный (например, если проблема связана с классификацией рака), успех или неудача (если речь идет о классификации результатов тестов учащихся).
Предположим, что существует проблема бинарной классификации с классами positive и negative. Вот пример достоверных или эталонных меток для семи выборок, используемых для обучения модели.
positive, negative, negative, positive, positive, positive, negativeТакие наименования нужны в первую очередь для того, чтобы нам, людям, было проще различать классы. Для модели более важна числовая оценка. Обычно при передаче очередного набора данных на выходе вы получите не метку класса, а числовой результат. Например, когда эти семь семплов вводятся в модель, каждому классу будут назначены следующие значения:
0.6, 0.2, 0.55, 0.9, 0.4, 0.8, 0.5На основании полученных оценок каждой выборке присваивается соответствующий класс. Такое преобразование числовых результатов в метки происходит с помощью порогового значения. Данное граничное условие является гиперпараметром модели и может быть определено пользователем. Например, если порог равен 0.5, тогда любая оценка, которая больше или равна 0.5, получает положительную метку. В противном случае — отрицательную. Вот предсказанные алгоритмом классы:
positive (0.6), negative (0.2), positive (0.55), positive (0.9), negative (0.4), positive (0.8), positive (0.5)Сравните достоверные и полученные метки — мы имеем 4 верных и 3 неверных предсказания. Стоит добавить, что изменение граничного условия отражается на результатах. Например, установка порога, равного 0.6, оставляет только два неверных прогноза.
Реальность: positive, negative, negative, positive, positive, positive, negative
Предсказания: positive, negative, positive, positive, negative, positive, positiveДля получения дополнительной информации о характеристиках модели используется матрица ошибок (confusion matrix). Матрица ошибок помогает нам визуализировать, «ошиблась» ли модель при различении двух классов. Как видно на следующем рисунке, это матрица 2х2. Названия строк представляют собой эталонные метки, а названия столбцов — предсказанные.
Четыре элемента матрицы (клетки красного и зеленого цвета) представляют собой четыре метрики, которые подсчитывают количество правильных и неправильных прогнозов, сделанных моделью. Каждому элементу дается метка, состоящая из двух слов:
- True или False.
- Positive или Negative.
True, если получено верное предсказание, то есть эталонные и предсказанные метки классов совпадают, и False, когда они не совпадают. Positive или Negative — названия предсказанных меток.
Таким образом, всякий раз, когда прогноз неверен, первое слово в ячейке False, когда верен — True. Наша цель состоит в том, чтобы максимизировать показатели со словом «True» (True Positive и True Negative) и минимизировать два других (False Positive и False Negative). Четыре метрики в матрице ошибок представляют собой следующее:
- Верхний левый элемент (True Positive): сколько раз модель правильно классифицировала Positive как Positive?
- Верхний правый (False Negative): сколько раз модель неправильно классифицировала Positive как Negative?
- Нижний левый (False Positive): сколько раз модель неправильно классифицировала Negative как Positive?
- Нижний правый (True Negative): сколько раз модель правильно классифицировала Negative как Negative?
Мы можем рассчитать эти четыре показателя для семи предсказаний, использованных нами ранее. Полученная матрица ошибок представлена на следующем рисунке.
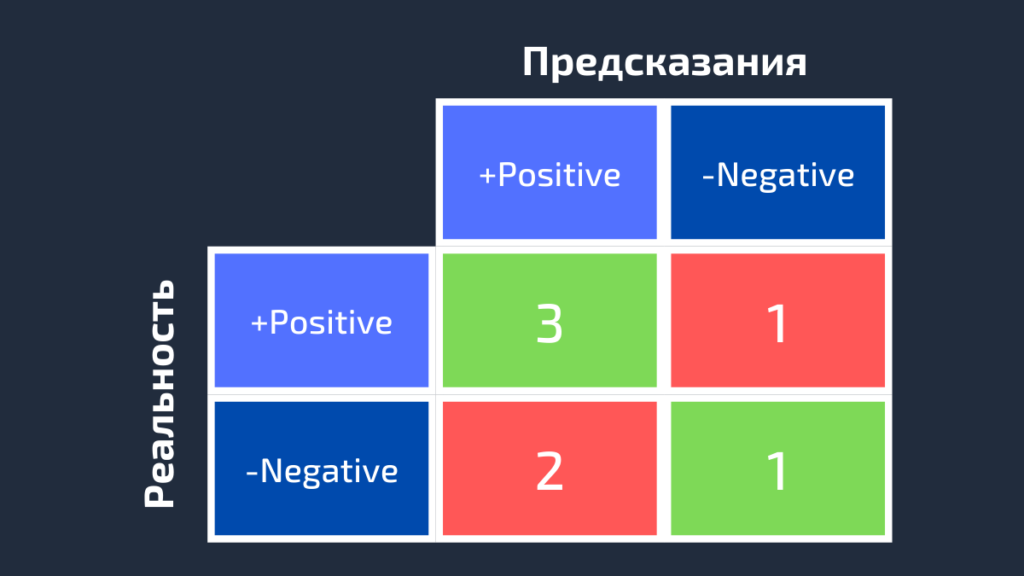
Вот так вычисляется матрица ошибок для задачи двоичной классификации. Теперь посмотрим, как решить данную проблему для большего числа классов.
Матрица ошибок для мультиклассовой классификации
Что, если у нас более двух классов? Как вычислить эти четыре метрики в матрице ошибок для задачи мультиклассовой классификации? Очень просто!
Предположим, имеется 9 семплов, каждый из которых относится к одному из трех классов: White, Black или Red. Вот достоверные метки для 9 выборок:
Red, Black, Red, White, White, Red, Black, Red, WhiteПосле загрузки данных модель делает следующее предсказание:
Red, White, Black, White, Red, Red, Black, White, RedДля удобства сравнения здесь они расположены рядом.
Реальность: Red, Black, Red, White, White, Red, Black, Red, White Предсказания: Red, White, Black, White, Red, Red, Black, White, RedПеред вычислением матрицы ошибок необходимо выбрать целевой класс. Давайте назначим на эту роль класс Red. Он будет отмечен как Positive, а все остальные отмечены как Negative.
Positive, Negative, Positive, Negative, Negative, Positive, Negative, Positive, Negative Positive, Negative, Negative, Negative, Positive, Positive, Negative, Negative, Positive11111111111111111111111После замены остались только два класса (Positive и Negative), что позволяет нам рассчитать матрицу ошибок, как было показано в предыдущем разделе. Стоит заметить, что полученная матрица предназначена только для класса Red.
Далее для класса White заменим каждое его вхождение на Positive, а метки всех остальных классов на Negative. Мы получим такие достоверные и предсказанные метки:
Negative, Negative, Negative, Positive, Positive, Negative, Negative, Negative, Positive Negative, Positive, Negative, Positive, Negative, Negative, Negative, Positive, NegativeНа следующей схеме показана матрица ошибок для класса White.
Точно так же может быть получена матрица ошибок для Black.
Расчет матрицы ошибок с помощью Scikit-Learn
В популярной Python-библиотеке Scikit-learn есть модуль metrics, который можно использовать для вычисления метрик в матрице ошибок.
Для задач с двумя классами используется функция confusion_matrix(). Мы передадим в функцию следующие параметры:
y_true: эталонные метки.y_pred: предсказанные метки.
Следующий код вычисляет матрицу ошибок для примера двоичной классификации, который мы обсуждали ранее.
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
print(r)
array([[1, 2],
[1, 3]], dtype=int64)Обратите внимание, что порядок метрик отличается от описанного выше. Например, показатель True Positive находится в правом нижнем углу, а True Negative — в верхнем левом углу. Чтобы исправить это, мы можем перевернуть матрицу.
import numpy
r = numpy.flip(r)
print(r)
array([[3, 1],
[2, 1]], dtype=int64)Чтобы вычислить матрицу ошибок для задачи с большим числом классов, используется функция multilabel_confusion_matrix(), как показано ниже. В дополнение к параметрам y_true и y_pred третий параметр labels принимает список классовых меток.
import sklearn.metrics
import numpy
y_true = ["Red", "Black", "Red", "White", "White", "Red", "Black", "Red", "White"]
y_pred = ["Red", "White", "Black", "White", "Red", "Red", "Black", "White", "Red"]
r = sklearn.metrics.multilabel_confusion_matrix(y_true, y_pred, labels=["White", "Black", "Red"])
print(r)
array([
[[4 2]
[2 1]]
[[6 1]
[1 1]]
[[3 2]
[2 2]]], dtype=int64)Функция вычисляет матрицу ошибок для каждого класса и возвращает все матрицы. Их порядок соответствует порядку меток в параметре labels. Чтобы изменить последовательность метрик в матрицах, мы будем снова использовать функцию numpy.flip().
print(numpy.flip(r[0])) # матрица ошибок для класса White
print(numpy.flip(r[1])) # матрица ошибок для класса Black
print(numpy.flip(r[2])) # матрица ошибок для класса Red
# матрица ошибок для класса White
[[1 2]
[2 4]]
# матрица ошибок для класса Black
[[1 1]
[1 6]]
# матрица ошибок для класса Red
[[2 2]
[2 3]]В оставшейся части этого текста мы сосредоточимся только на двух классах. В следующем разделе обсуждаются три ключевых показателя, которые рассчитываются на основе матрицы ошибок.
Accuracy, Precision и Recall
Как мы уже видели, матрица ошибок предлагает четыре индивидуальных показателя. На их основе можно рассчитать другие метрики, которые предоставляют дополнительную информацию о поведении модели:
- Accuracy
- Precision
- Recall
В следующих подразделах обсуждается каждый из этих трех показателей.
Метрика Accuracy
Accuracy — это показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен. Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Рассчитаем accuracy с помощью Scikit-learn на основе ранее полученной матрицы ошибок. Переменная acc содержит результат деления суммы True Positive и True Negative метрик на сумму всех значений матрицы. Таким образом, accuracy, равная 0.5714, означает, что модель с точностью 57,14% делает верный прогноз.
import numpy
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
r = numpy.flip(r)
acc = (r[0][0] + r[-1][-1]) / numpy.sum(r)
print(acc)
# вывод будет 0.571
В модуле sklearn.metrics есть функция precision_score(), которая также может вычислять accuracy. Она принимает в качестве аргументов достоверные и предсказанные метки.
acc = sklearn.metrics.accuracy_score(y_true, y_pred)
Стоит учесть, что метрика accuracy может быть обманчивой. Один из таких случаев — это несбалансированные данные. Предположим, у нас есть всего 600 единиц данных, из которых 550 относятся к классу Positive и только 50 — к Negative. Поскольку большинство семплов принадлежит к одному классу, accuracy для этого класса будет выше, чем для другого.
Если модель сделала 530 правильных прогнозов из 550 для класса Positive, по сравнению с 5 из 50 для Negative, то общая accuracy равна (530 + 5) / 600 = 0.8917. Это означает, что точность модели составляет 89.17%. Полагаясь на это значение, вы можете подумать, что для любой выборки (независимо от ее класса) модель сделает правильный прогноз в 89.17% случаев. Это неверно, так как для класса Negative модель работает очень плохо.
Precision
Precision представляет собой отношение числа семплов, верно классифицированных как Positive, к общему числу выборок с меткой Positive (распознанных правильно и неправильно). Precision измеряет точность модели при определении класса Positive.
Когда модель делает много неверных Positive классификаций, это увеличивает знаменатель и снижает precision. С другой стороны, precision высока, когда:
- Модель делает много корректных предсказаний класса Positive (максимизирует True Positive метрику).
- Модель делает меньше неверных Positive классификаций (минимизирует False Positive).
Представьте себе человека, который пользуется всеобщим доверием; когда он что-то предсказывает, окружающие ему верят. Метрика precision похожа на такого персонажа. Если она высока, вы можете доверять решению модели по определению очередной выборки как Positive. Таким образом, precision помогает узнать, насколько точна модель, когда она говорит, что семпл имеет класс Positive.
Основываясь на предыдущем обсуждении, вот определение precision:
Precision отражает, насколько надежна модель при классификации Positive-меток.
На следующем изображении зеленая метка означает, что зеленый семпл классифицирован как Positive, а красный крест – как Negative. Модель корректно распознала две Positive выборки, но неверно классифицировала один Negative семпл как Positive. Из этого следует, что метрика True Positive равна 2, когда False Positive имеет значение 1, а precision составляет 2 / (2 + 1) = 0.667. Другими словами, процент доверия к решению модели, что выборка относится к классу Positive, составляет 66.7%.
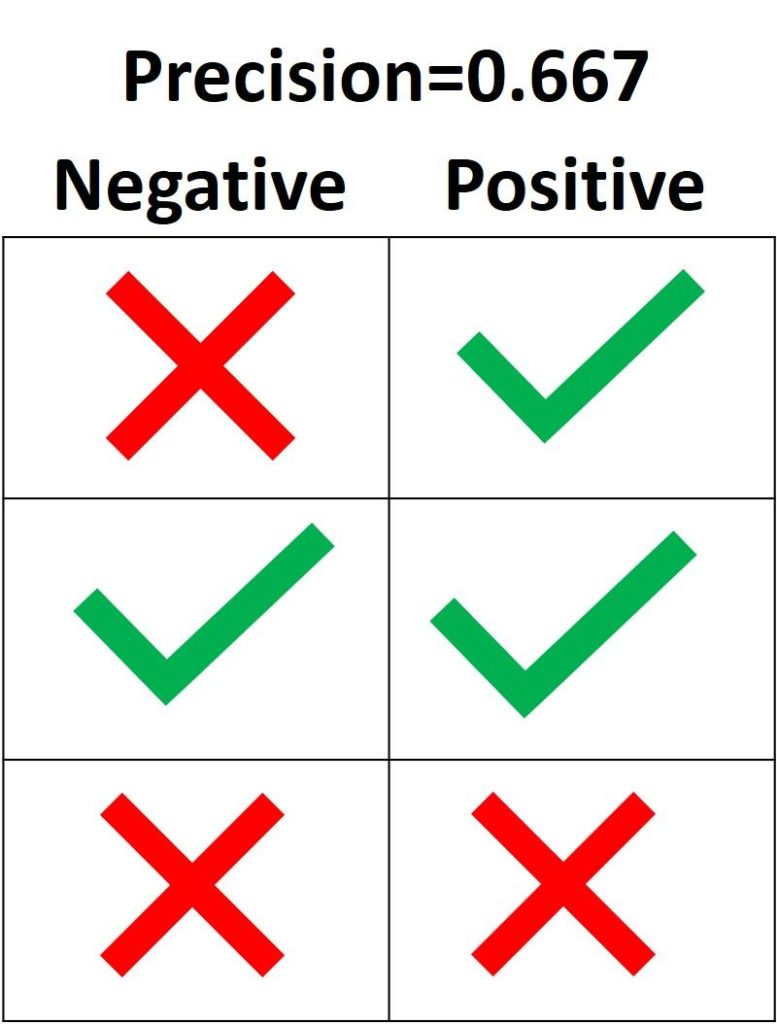
Цель precision – классифицировать все Positive семплы как Positive, не допуская ложных определений Negative как Positive. Согласно следующему рисунку, если все три Positive выборки предсказаны правильно, но один Negative семпл классифицирован неверно, precision составляет 3 / (3 + 1) = 0.75. Таким образом, утверждения модели о том, что выборка относится к классу Positive, корректны с точностью 75%.
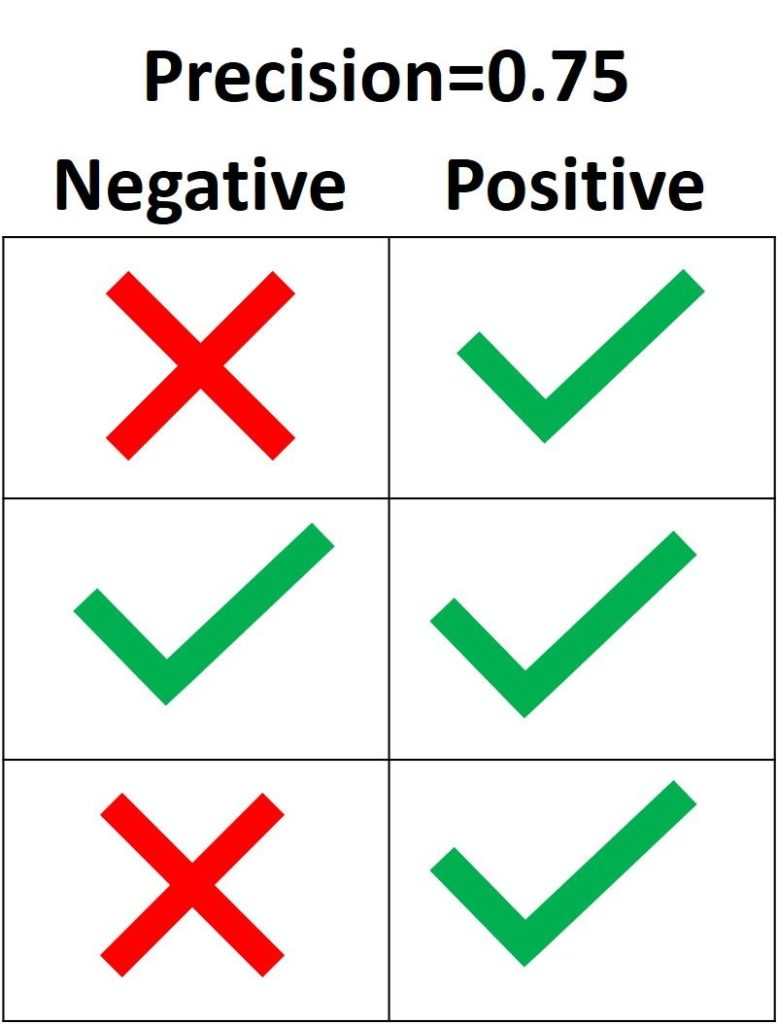
Единственный способ получить 100% precision — это классифицировать все Positive выборки как Positive без классификации Negative как Positive.
В Scikit-learn модуль sklearn.metrics имеет функцию precision_score(), которая получает в качестве аргументов эталонные и предсказанные метки и возвращает precision. Параметр pos_label принимает метку класса Positive (по умолчанию 1).
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
precision = sklearn.metrics.precision_score(y_true, y_pred, pos_label="positive")
print(precision)
Вывод: 0.6666666666666666.
Recall
Recall рассчитывается как отношение числа Positive выборок, корректно классифицированных как Positive, к общему количеству Positive семплов. Recall измеряет способность модели обнаруживать выборки, относящиеся к классу Positive. Чем выше recall, тем больше Positive семплов было найдено.
Recall заботится только о том, как классифицируются Positive выборки. Эта метрика не зависит от того, как предсказываются Negative семплы, в отличие от precision. Когда модель верно классифицирует все Positive выборки, recall будет 100%, даже если все представители класса Negative были ошибочно определены как Positive. Давайте посмотрим на несколько примеров.
На следующем изображении представлены 4 разных случая (от A до D), и все они имеют одинаковый recall, равный 0.667. Представленные примеры отличаются только тем, как классифицируются Negative семплы. Например, в случае A все Negative выборки корректно определены, а в случае D – наоборот. Независимо от того, как модель предсказывает класс Negative, recall касается только семплов относящихся к Positive.

Из 4 случаев, показанных выше, только 2 Positive выборки определены верно. Таким образом, метрика True Positive равна 2. False Negative имеет значение 1, потому что только один Positive семпл классифицируется как Negative. В результате recall будет равен 2 / (2 + 1) = 2/3 = 0.667.
Поскольку не имеет значения, как предсказываются объекты класса Negative, лучше их просто игнорировать, как показано на следующей схеме. При расчете recall необходимо учитывать только Positive выборки.

Что означает, когда recall высокий или низкий? Если recall имеет большое значение, все Positive семплы классифицируются верно. Следовательно, модели можно доверять в ее способности обнаруживать представителей класса Positive.
На следующем изображении recall равен 1.0, потому что все Positive семплы были правильно классифицированы. Показатель True Positive равен 3, а False Negative – 0. Таким образом, recall вычисляется как 3 / (3 + 0) = 1. Это означает, что модель обнаружила все Positive выборки. Поскольку recall не учитывает, как предсказываются представители класса Negative, могут присутствовать множество неверно определенных Negative семплов (высокая False Positive метрика).

С другой стороны, recall равен 0.0, если не удается обнаружить ни одной Positive выборки. Это означает, что модель обнаружила 0% представителей класса Positive. Показатель True Positive равен 0, а False Negative имеет значение 3. Recall будет равен 0 / (0 + 3) = 0.
Когда recall имеет значение от 0.0 до 1.0, это число отражает процент Positive семплов, которые модель верно классифицировала. Например, если имеется 10 экземпляров Positive и recall равен 0.6, получается, что модель корректно определила 60% объектов класса Positive (т.е. 0.6 * 10 = 6).
Подобно precision_score(), функция repl_score() из модуля sklearn.metrics вычисляет recall. В следующем блоке кода показан пример ее использования.
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
recall = sklearn.metrics.recall_score(y_true, y_pred, pos_label="positive")
print(recall)
Вывод: 0.6666666666666666.
После определения precision и recall давайте кратко подведем итоги:
- Precision измеряет надежность модели при классификации Positive семплов, а recall определяет, сколько Positive выборок было корректно предсказано моделью.
- Precision учитывает классификацию как Positive, так и Negative семплов. Recall же использует при расчете только представителей класса Positive. Другими словами, precision зависит как от Negative, так и от Positive-выборок, но recall — только от Positive.
- Precision принимает во внимание, когда семпл определяется как Positive, но не заботится о верной классификации всех объектов класса Positive. Recall в свою очередь учитывает корректность предсказания всех Positive выборок, но не заботится об ошибочной классификации представителей Negative как Positive.
- Когда модель имеет высокий уровень recall метрики, но низкую precision, такая модель правильно определяет большинство Positive семплов, но имеет много ложных срабатываний (классификаций Negative выборок как Positive). Если модель имеет большую precision, но низкий recall, то она делает высокоточные предсказания, определяя класс Positive, но производит всего несколько таких прогнозов.
Некоторые вопросы для проверки понимания:
- Если recall равен 1.0, а в датасете имеются 5 объектов класса Positive, сколько Positive семплов было правильно классифицировано моделью?
- Учитывая, что recall составляет 0.3, когда в наборе данных 30 Positive семплов, сколько представителей класса Positive будет предсказано верно?
- Если recall равен 0.0 и в датасете14 Positive-семплов, сколько корректных предсказаний класса Positive было сделано моделью?
Precision или Recall?
Решение о том, следует ли использовать precision или recall, зависит от типа вашей проблемы. Если цель состоит в том, чтобы обнаружить все positive выборки (не заботясь о том, будут ли negative семплы классифицированы как positive), используйте recall. Используйте precision, если ваша задача связана с комплексным предсказанием класса Positive, то есть учитывая Negative семплы, которые были ошибочно классифицированы как Positive.
Представьте, что вам дали изображение и попросили определить все автомобили внутри него. Какой показатель вы используете? Поскольку цель состоит в том, чтобы обнаружить все автомобили, используйте recall. Такой подход может ошибочно классифицировать некоторые объекты как целевые, но в конечном итоге сработает для предсказания всех автомобилей.
Теперь предположим, что вам дали снимок с результатами маммографии, и вас попросили определить наличие рака. Какой показатель вы используете? Поскольку он обязан быть чувствителен к неверной идентификации изображения как злокачественного, мы должны быть уверены, когда классифицируем снимок как Positive (то есть с раком). Таким образом, предпочтительным показателем в данном случае является precision.
Вывод
В этом руководстве обсуждалась матрица ошибок, вычисление ее 4 метрик (true/false positive/negative) для задач бинарной и мультиклассовой классификации. Используя модуль metrics библиотеки Scikit-learn, мы увидели, как получить матрицу ошибок в Python.
Основываясь на этих 4 показателях, мы перешли к обсуждению accuracy, precision и recall метрик. Каждая из них была определена и использована в нескольких примерах. Модуль sklearn.metrics применяется для расчета каждого вышеперечисленного показателя.
]]>В данной статье обсуждаются три конкретных особенности, которые следует учитывать при разделении набора данных, подходы к решению связанных проблем и практическая реализация на Python.
Для наших примеров мы будем использовать модуль train_test_split библиотеки Scikit-learn, который очень полезен для разделения датасетов, независимо от того, будете ли вы применять Scikit-learn для выполнения других задач машинного обучения. Конечно, можно выполнить такие разбиения каким-либо другим способом (возможно, используя только Numpy). Библиотека Scikit-learn включает полезные функции, позволяющее сделать это немного проще.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.67,
random_state=42)
Возможно, вы использовали этот модуль для разделения данных в прошлом, но при этом не приняли во внимание некоторые детали.
Случайное перемешивание строк
Первое, на что следует обратить внимание: перемешаны ли ваши экземпляры? Это следует делать пока нет причин не перетасовывать данные (например, они представляют собой временные интервалы). Мы должны убедиться в том, что наши экземпляры не разбиты на выборки по классам. Это потенциально вносит в нашу модель некоторую нежелательную предвзятость.
Например, посмотрите, как одна из версий набора данных iris, упорядочивает свои экземпляры при загрузке:
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
print(f"Классы датасета: {iris.target}")
Классы датасета: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]Если такой набор данных с тремя классами при равном числе экземпляров в каждом разделить на две выборки: 2/3 для обучения и 1/3 для тестирования, то полученные поднаборы будут иметь нулевое пересечение классовых меток. Это, очевидно, недопустимо при изучении признаков для предсказания классов. К счастью, функция train_test_split по умолчанию автоматически перемешивает данные (вы можете переопределить это, установив для параметра shuffle значение False).
- В функцию должны быть переданы как вектор признаков, так и целевой вектор (X и y).
- Для воспроизводимости вы должны установить аргумент
random_state. - Также необходимо определить либо
train_size, либоtest_size, но оба они не нужны. Если вы явно устанавливаете оба параметра, они должны составлять в сумме 1.
Вы можете убедится, что теперь наши классы перемешаны.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.67,
random_state=42)
print(f"Классы в y_train:\n{y_train}")
print(f"Классы в y_test:\n{y_test}")
Классы в y_train:
[1 2 1 0 2 1 0 0 0 1 2 0 0 0 1 0 1 2 0 1 2 0 2 2 1 1 2 1 0 1 2 0 0 1 1 0 2
0 0 1 1 2 1 2 2 1 0 0 2 2 0 0 0 1 2 0 2 2 0 1 1 2 1 2 0 2 1 2 1 1 1 0 1 1
0 1 2 2 0 1 2 2 0 2 0 1 2 2 1 2 1 1 2 2 0 1 2 0 1 2]
Классы в y_test:
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0 1 2 2 1 2]Стратификация (равномерное распределение) классов
Данное размышление заключается в следующем. Равномерно ли распределено количество классов в наборах данных, разделенных для обучения и тестирования?
import numpy as np
print(f"Количество строк в y_train по классам: {np.bincount(y_train)}")
print(f"Количество строк в y_test по классам: {np.bincount(y_test)}")
Количество строк в y_train по классам: [31 35 34]
Количество строк в y_test по классам: [19 15 16]Это не равная разбивка. Главная идея заключается в том, получает ли наш алгоритм равные возможности для изучения признаков каждого из представленных классов и последующего тестирования результатов обучения, на равном числе экземпляров каждого класса. Хотя это особенно важно для небольших наборов данных, желательно постоянно уделять внимание данному вопросу.
Мы можем задать пропорцию классов при разделении на обучающий и проверяющий датасеты с помощью параметра stratify функции train_test_split. Стоит отметить, что мы будем стратифицировать в соответствии распределению по классам в y.
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.67,
random_state=42,
stratify=y)
print(f"Количество строк в y_train по классам: {np.bincount(y_train)}")
print(f"Количество строк в y_test по классам: {np.bincount(y_test)}")
Количество строк в y_train по классам: [34 33 33]
Количество строк в y_test по классам: [16 17 17]Сейчас это выглядит лучше, и представленные числа говорят нам, что это наиболее оптимально возможное разделение.
Дополнительное разделение
Третье соображение относится к проверочным данным (выборке валидации). Есть ли смысл для нашей задачи иметь только один тестовый датасет. Или мы должны подготовить два таких набора — один для проверки наших моделей во время их точной настройки, а еще один — в качестве окончательного датасета для сравнения моделей и выбора лучшей.
Если мы определим 2 таких набора, это будет означать, что одна выборка, будет храниться до тех пор, пока все предположения не будут проверены, все гиперпараметры не настроены, а все модели обучены для достижения максимальной производительности. Затем она будет показана моделям только один раз в качестве последнего шага в наших экспериментах.
Если вы хотите использовать датасеты для тестирования и валидации, создать их с помощью train_test_split легко. Для этого мы разделяем весь набор данных один раз для выделения обучающей выборки. Затем еще раз, чтобы разбить оставшиеся данные на датасеты для тестирования и валидации.
Ниже, используя набор данных digits, мы разделяем 70% для обучения и временно назначаем остаток для тестирования. Не забывайте применять методы, описанные выше.
from sklearn.datasets import load_digits
digits = load_digits()
X, y = digits.data, digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.7,
random_state=42,
stratify=y)
print(f"Количество строк в y_train по классам: {np.bincount(y_train)}")
print(f"Количество строк в y_test по классам: {np.bincount(y_test)}")
Количество строк в y_train по классам: [124 127 124 128 127 127 127 125 122 126]
Количество строк в y_test по классам: [54 55 53 55 54 55 54 54 52 54]Обратите внимание на стратифицированные классы в полученных наборах. Затем мы повторно делим тестовый датасет.
X_test, X_val, y_test, y_val = train_test_split(X_test, y_test,
train_size=0.5,
random_state=42,
stratify=y_test)
print(f"Количество строк в y_test по классам: {np.bincount(y_test)}")
print(f"Количество строк в y_val по классам: {np.bincount(y_val)}")
Количество строк в y_test по классам: [27 27 27 27 27 28 27 27 26 27]
Количество строк в y_val по классам: [27 28 26 28 27 27 27 27 26 27]Обратите внимание на стратификацию классов по всем наборам данных, которая является оптимальной.
Теперь вы готовы обучать, проверять и тестировать столько моделей машинного обучения, сколько вы сочтете нужным для ваших данных.
Еще один совет: вы можете подумать об использовании перекрестной валидации вместо простой стратегии обучение/тестирование или обучение/валидация/тестирование. Мы рассмотрим вопросы кросс-валидации в следующий раз.
]]>В библиотеке Pandas есть несколько функций для решения этой проблемы, и value_counts — одна из них. Она возвращает объект, содержащий уникальные значения из dataframe Pandas в отсортированном порядке. Однако многие забывают об этой возможности и используют параметры по умолчанию. В этом материале посмотрим, как получить максимум пользы от value_counts, изменив параметры по умолчанию.
Что такое функция value_counts()?
Функция value_counts() используется для получения Series, содержащего уникальные значения. Она вернет результат, отсортированный в порядке убывания, так что первый элемент в коллекции будет самым встречаемым. NA-значения не включены в результат.
Синтаксисdf['your_column'].value_counts() — вернет количество уникальных совпадений в определенной колонке.
Важно заметить, что value_counts работает только с series, но не dataframe. Поэтому нужно указать одни квадратные скобки df['your_column'], а не пару df[['your_column']].
Параметры:
normalize(bool, по умолчанию False) — еслиTrue, то возвращаемый объект будет содержать значения относительно частоты встречаемых значений.sort(bool, по умолчанию True) — сортировка по частоте.ascending(bool, по умолчанию False) — сортировка по возрастанию.bins(int) — вместе подсчета значений группирует их по отрезкам, но это работает только с числовыми данными.- dropna (bool, по умолчанию True) — не включать количество NaN.
Загрузка данных для демонстрации
Рассмотрим, как использовать этот метод на реальных данных. Возьмем в качестве примера датасет из курса Coursera на Kaggle.
Для начала импортируем нужные библиотеки и сами данные. Это нужно в любом проекте. После этого проанализируем данные в notebook Jupyter.
# импорт библиотеки
import pandas as pd
# Загрузка данных
df = pd.read_csv('Downloads/coursea_data.csv', index_col=0)
# проверка данных из csv
df.head(10)
Проверьте, сколько записей в датасете и есть ли у нас пропуски.
df.info()
Результат показывает, что в наборе 981 запись, и нет ни одного NA.
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 134 to 163
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 course_title 891 non-null object
1 course_organization 891 non-null object
2 course_Certificate_type 891 non-null object
3 course_rating 891 non-null float64
4 course_difficulty 891 non-null object
5 course_students_enrolled 891 non-null object
dtypes: float64(1), object(5)
memory usage: 48.7+ KB1. value_counts с параметрами по умолчанию
Теперь можно начинать использовать функцию value_counts. Начнем с базового применения функции.
Синтаксис: df['your_column'].value_counts().
Получим количество каждого значения для колонки «course_difficulty».
Функция value_counts вернет количество совпадений всех уникальных значений по заданному индексу без пропусков. Это позволит увидеть, что больше всего курсов с уровнем сложности «Начинающий», после этого идут «Средний» и «Смешанный». А «Сложный» на последнем месте.
df['course_difficulty'].value_counts()
---------------------------------------------------
Beginner 487
Intermediate 198
Mixed 187
Advanced 19
Name: course_difficulty, dtype: int64Теперь время поработать с параметрами.
2. Сортировка по возрастанию
По умолчанию value_counts() возвращает данные по убыванию. Изменит поведение можно, задав значение True для параметра ascending.
Синтаксис: df['your_column'].value_counts(ascending=True).
df['course_difficulty'].value_counts(ascending=True)
---------------------------------------------------
Advanced 19
Mixed 187
Intermediate 198
Beginner 487
Name: course_difficulty, dtype: int643. Сортировка в алфавитном порядке
В определенных случаях может существовать необходимость отсортировать записи в алфавитном порядке. Это делается с помощью добавления sort_index(ascending=True) после value_counts().
По умолчанию функция сортирует «course_difficulty» по количеству совпадений, а с sort_index сортирует по индексу (имени колонки, для которой и используется функция):
df['course_difficulty'].value_counts().sort_index(ascending=True)
---------------------------------------------------
Advanced 19
Beginner 487
Intermediate 198
Mixed 187
Name: course_difficulty, dtype: int64Если же требуется отобразить value_counts() в обратном алфавитном порядке, то нужно изменить направление сортировки: .sort_index(ascending=False).
4. Сортировка по значению, а затем по алфавиту
Для этого примера используем другой датасет.
df_fruit = pd.DataFrame({
'fruit':
['хурма']*5 + ['яблоки']*5 + ['бананы']*3 +
['персики']*3 + ['морковь']*3 + ['абрикосы'] + ['манго']*2
})
Так, нужно получить вывод, отсортированный в первую очередь по количеству совпадений значений, а потом уже и по алфавиту. Это можно сделать, объединив value_counts() c sort_index(ascending=False) и sort_values(ascending=False).
df_fruit['fruit'].value_counts()\
.sort_index(ascending=False)\
.sort_values(ascending=False)
-------------------------------------------------
хурма 5
яблоки 5
бананы 3
морковь 3
персики 3
манго 2
абрикосы 1
Name: fruit, dtype: int645. Относительная частота уникальных значений
Иногда нужно получить относительные значения, а не просто количество. С параметром normalize=True объект вернет относительную частоту уникальных значений. По умолчанию значение этого параметра равно False.
Синтаксис: df['your_column'].value_counts(normalize=True).
df['course_difficulty'].value_counts(normalize=True)
-------------------------------------------------
Beginner 0.546577
Intermediate 0.222222
Mixed 0.209877
Advanced 0.021324
Name: course_difficulty, dtype: float646. value_counts() для разбивки данных на дискретные интервалы
Еще один трюк, который часто игнорируют. value_counts() можно использовать для разбивки данных на дискретные интервалы с помощью параметра bin. Это работает только с числовыми данными. Принцип напоминает pd.cut. Посмотрим как это работает на примере колонки «course_rating». Сгруппируем значения колонки на 4 группы.
Синтаксис: df['your_column'].value_counts(bin=количество групп).
df['course_rating'].value_counts(bins=4)
-------------------------------------------------
(4.575, 5.0] 745
(4.15, 4.575] 139
(3.725, 4.15] 5
(3.297, 3.725] 2
Name: course_rating, dtype: int64Бинниг позволяет легко получить инсайты. Так, можно увидеть, что большая часть людей оценивает курс на 4.5. И лишь несколько курсов имеют оценку ниже 4.15.
7. value_counts() с пропусками
По умолчанию количество значений NaN не включается в результат. Но это поведение можно изменить, задав значение False для параметра dropna. Поскольку в наборе данных нет нулевых значений, в этом примере это ни на что не повлияет. Но сам параметр следует запомнить.
Синтаксис: df['your_column'].value_counts(dropna=False).
8. value_counts() как dataframe
Как уже было отмечено, value_counts() возвращает Series, а не Dataframe. Если же нужно получить результаты в последнем виде, то для этого можно использовать функцию .to_frame() после .value_counts().
Синтаксис: df['your_column'].value_counts().to_frame().
Это будет выглядеть следующим образом:
Если нужно задать имя для колонки или переименовать существующую, то эту конвертацию можно реализовать другим путем.
value_counts = df['course_difficulty'].value_counts()
# преобразование в df и присвоение новых имен колонкам
df_value_counts = pd.DataFrame(value_counts)
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = ['unique_values', 'counts for course_difficulty']
df_value_counts
Groupby и value_counts
Groupby — очень популярный метод в Pandas. С его помощью можно сгруппировать результат по одной колонке и посчитать значения в другой.
Синтаксис: df.groupby('your_column_1')['your_column_2'].value_counts().
Так, с помощью groupby и value_counts можно посчитать количество типов сертификатов для каждого уровня сложности курсов.
df.groupby('course_difficulty')['course_Certificate_type'].value_counts()
-------------------------------------------------
course_difficulty course_Certificate_type
Advanced SPECIALIZATION 10
COURSE 9
Beginner COURSE 282
SPECIALIZATION 196
PROFESSIONAL CERTIFICATE 9
Intermediate COURSE 104
SPECIALIZATION 91
PROFESSIONAL CERTIFICATE 3
Mixed COURSE 187
Name: course_Certificate_type, dtype: int64Это мульти-индекс, позволяющий иметь несколько уровней индексов в dataframe. В этом случае сложность курса соответствует нулевому уровню индекса, а тип сертификата — первому.
Фильтрация значений по минимум и максимум
Работая с набором данных, может потребоваться вернуть количество ограниченных вхождений с помощью value_counts().
Синтаксис: df['your_column'].value_counts().loc[lambda x : x > 1].
Этот код отфильтрует все значения уникальных данных и покажет только те, где значение больше единицы.
Для примера ограничим рейтинг курса значением 4.
df.groupby('course_difficulty')['coudf['course_rating']\
.value_counts().loc[lambda x: x > 4]
-------------------------------------------------
4.8 256
4.7 251
4.6 168
4.5 80
4.9 68
4.4 34
4.3 15
4.2 10
Name: course_rating, dtype: int64value_counts() — удобный инструмент, позволяющий делать удобный анализ в одну строку.
Тест на знание функции value_counts
Фреймворк — это интерфейс или инструмент, позволяющий разработчикам просто создавать модели машинного обучения, не погружаясь в лежащие в основе алгоритмы.
Библиотека — это набор файлов, содержащих код, который можно импортировать в свое приложение.
Фреймворк может быть набором библиотек, необходимых для построения модели без понимания особенностей лежащих в основе алгоритмов. Однако разработчикам нужно знать, каким образом эти алгоритмы работают, чтобы корректно интерпретировать результат.
#10 Matplotlib
Matplotlib — это интерактивная кроссплатформенная библиотека для создания двумерных диаграмм. С ее помощью можно создавать качественные графики и диаграммы в нескольких форматах.
Преимущества:
- Гибкость. Поддерживает Python и IPython, скрипты Python, Jupyter Notebook, сервера веб-приложений и многие инструменты с интерфейсом (GTK+, Tkinter, Qt и wxPython).
- Предоставляет интерфейс в стиле MATLAB для создания диаграмм
- Объектно-ориентированный интерфейс предоставляет полный контроль над свойствами осей, шрифтов, стилями линий и так далее.
- Совместим с разными графическими движками и операционными системами.
- Часто используется в других библиотеках, таких как Pandas.
Недостатки:
- Наличие двух разных интерфейсов (объектно-ориентированного и в стиле MATLAB) может запутать начинающего разработчика.
- Matplotlib — это библиотека для визуализации, а не для анализа данных. Для последнего ее нужно совмещать с другими, например, Pandas.
Официальная документация: https://matplotlib.org/stable/index.html.
Уроки по matplotlib на русском: Установка matplotlib и архитектура графиков / plt 1.
#9 Natural Language Toolkit (NLTK)

NLTK — это фреймворк и набор библиотек для разработки системы символической и статистической обработки естественного языка (natural language processing, NLP). Стандартный инструмент для NLP в Python.
Преимущества:
- Библиотека содержит графические инструменты, а также примеры данных.
- Включает книгу и набор примеров для начинающих.
- Предоставляет поддержку разных ML-операций, таких как классификация, парсинг, токенизация и так далее.
- Работает как платформа для прототипирования и создания исследовательских систем.
- Совместима с несколькими языками.
Недостатки:
- Для работы с NLTK нужно понимать, как работать со строками. Однако в этом может помочь документация.
- Токенизация происходит за счет разбития текста на предложения. Это отрицательно влияет на производительность.
Официальная документация: https://www.nltk.org/.
#8 Pandas

Это библиотека Python для высокопроизводительных и одновременно понятных структур данных и инструментов анализа данных в Python.
Преимущества:
- Выразительные, быстрые и гибкие структуры данных.
- Поддерживает операции агрегации, конкатенации, итерации, переиндексации и визуализации.
- Гибкая и совместимая с другими библиотеками Python.
- Интуитивное управление данными с минимальным набором команд.
- Поддерживает широкий спектр коммерческих и академических областей.
- Производительная.
Недостатки:
- Построена на основе matplotlib, что значит, что начинающий должен быть знаком с обеими, чтобы понимать, что лучше использовать для решения конкретной проблемы.
- Меньше подходит для n-размерных массивов и статистического моделирования. Для этого лучше использовать NumPy, SciPy или SciKit Learn.
Официальная документация: https://pandas.pydata.org/pandas-docs/stable/index.html.
Краткая документация с примерами: Введение в библиотеку pandas: установка и первые шаги / pd 1.
Уроки по Pandas на русском: Основы Pandas №1 // Чтение файлов, DataFrame, отбор данных.
#7 Scikit-Learn

Эта библиотека построена на основе matplotlib, NumPy и SciPy. Она предоставляет несколько инструментов для анализа и добычи данных.
Преимущества:
- Простая и эффективная.
- Быстро улучшается и обновляется.
- Разнообразие алгоритмов, включая кластерный и факторный анализ, а также метод главных компонент.
- Может извлекать данные из изображений и текста.
- Может использоваться для NLP.
Недостатки:
- Предназначена для обучения с учителем и не очень хорошо работает в обучении без учителя (например, в Deep Learning).
Официальная документация: https://scikit-learn.org/stable/.
#6 Seaborn

Библиотека для создания статистических графиков в Python. Построена на базе matplotlib и имеет интеграцию со структурами данных pandas.
Преимущества
- Предлагает более визуально привлекательные графики по сравнению с matplotlib.
- Предлагает встроенные графики, которых нет в matplotlib.
- Использует меньше кода для визуализации.
- Отличная интеграция с Pandas: комбинация из визуализации данных и анализа.
Недостатки:
- Построена на основе matplotlib, поэтому нужно понимать, какую из библиотек использовать в том или ином случае.
- Полагается на темы по умолчанию, поэтому результат не настолько настраиваемый, как у matplotlib.
Официальная документация: https://seaborn.pydata.org/.
#5 NumPy

NumPy добавляет обработку многомерных массивов и матриц в Python, а также крупные наборов данных для высокоуровневых математических функций. Обычно используется для научных вычислений. Следовательно, это один из самых используемых пакетов Python для машинного обучения.
Преимущества:
- Интуитивная и интерактивная.
- Предлагает преобразования Фурье, возможности для генерации сложных чисел и другие инструменты для интеграции таких компьютерных языков, как C/C++ и Fortran.
- Универсальность — другие библиотеки для машинного обучения, такие как scikit-learn и TensorFlow, используют массивы NumPy в качестве исходных значений; а у Pandas — NumPy под капотом.
- Серьезный вклад сообщества в развитие.
- Упрощает сложные математические реализации.
Недостатки:
- Может быть чересчур сложным — не стоит использовать, если вам с головой хватает обычных списков Python.
Официальная документация: https://numpy.org/.
Уроки по NumPy на русском: Введение и установка библиотеки NumPy / np 1.
#4 Keras

Очень популярная библиотека для машинного обучения в Python, предоставляющая высокоуровневое API нейронной сети, работающее поверх TensorFlow, CNTK или Theano.
Преимущества:
- Отличное решение для экспериментов и быстрого прототипирования.
- Портативная.
- Предлагает легкое представление нейронных сетей.
- Удобно использовать для моделирования и визуализации.
Недостатки:
- Медленная, поскольку требует создания вычислительного графа перед выполнением операций.
Официальная документация: https://keras.io/.
Уроки по Keras на русском: Преимущества и ограничения Keras / keras 1.
#3 SciPy

Популярная библиотека с разными модулями для оптимизации, линейной алгебры, интеграции и статистики.
Преимущества:
- Подходит для управления изображениями.
- Предоставляет простую обработку математических операций.
- Предлагает эффективные математические операции, включая интеграцию и оптимизацию.
- Поддерживает сигнальную обработку.
Недостатки:
- Под названием SciPy скрываются как стек, так и библиотека. При этом библиотека является частью стека. Это может сбивать с толку.
Официальная документация: https://www.scipy.org/.
Введение в SciPy на русском: Руководство по SciPy: что это, и как ее использовать.
#2 Pytorch

Популярная библиотека, построенная на базе Torch, которая, в свою очередь, сделана на C и завернута в Lua. Изначально создавалась Facebook, но сейчас используется в Twitter, Salefsorce и многих других организациях.
Преимущества:
- Содержит инструменты и библиотеки компьютерного зрения, натуральной обработки речи, глубокого обучения и другого.
- Разработчики могут выполнять вычисления на тензорах с помощью ускорения GPU.
- Помогает создавать вычислительные диаграммы.
- Процесс моделирования простой и прозрачный.
- Стандартный режим «define-by-run» больше напоминает классическое программирование.
- Использует привычные инструменты отладки, такие как pdb, ipdb или отладчик PyCharm.
- Использует массу готовых моделей и модулей, которые можно комбинировать между собой.
Недостатки:
- Поскольку PyTorch относительно новый, не так много онлайн-ресурсов. Это усложняет процесс обучения с нуля, хотя он все равно достаточно интуитивный.
- Не настолько готов к полноценной работе в сравнении с TensorFlow.
Официальная документация: https://pytorch.org/.
#1 TensorFlow

Изначально разработанная Google, TensorFlow — это высокопроизводительная библиотека для вычислений с помощью графа потока данных.
Под капотом это в большей степени фреймворк для создания и работы вычислений, использующих тензоры. Чаще всего TensorFlow используется в нейронных сетях и глубоком обучении. Это делает библиотеку одной из самых популярных.
Преимущества:
- Поддерживает обучение с подкреплением и другие алгоритмы.
- Предоставляет абстракцию вычислительного графа.
- Огромное сообщество.
- Предоставляет TensorBoard — инструмент для визуализации моделей прямо в браузере.
- Готов к работе.
- Может быть развернут на нескольких CPU и GPU.
Недостатки:
- Намного медленнее остальных фреймворков, использующих CPU/GPU.
- Крутая кривая обучения по сравнению с PyTorch.
- Вычислительные графы могут быть медленными.
- Не поддерживается коммерчески.
- Не слишком большой набор инструментов.
Официальная документация: https://www.tensorflow.org/.

Выводы
Теперь вы знаете разницу в библиотеках и фреймворках Python. Можете оценить преимущества и недостатки самых популярных библиотек машинного обучения.
]]>Благодаря богатому пользовательскому опыту, возможности повторно использовать код и расширяемости Keras делает процесс написания кода простым и гибким. Помимо этого он также предлагает дополнительные возможности в составе приложений Keras.
Основные приложения — это модели глубокого обучения с натренированными весами.
Пользователь может использовать их для составления прогнозов или использования отдельных признаков в своей работе без необходимости создавать и тренировать собственные модели.
В этой статье речь пойдет о таких натренированных моделях, а также о том, как их использовать.
Натренированные модели Keras
В Keras доступны 10 натренированных моделей. Они используются для классификации изображений, а их веса натренированы с помощью набора данных ImageNet.
Эти модели доступны в модуле applications в Keras. Для работы с ними их нужно импортировать с помощью keras.applications._model_name_
Далее список доступных моделей:
| Xception | InceptionResNetV2 |
| VGG16 | MobileNet |
| VGG19 | MobileNetV2 |
| ResNet, ResNetV2 | DenseNet |
| InceptionV3 | NASNet |
Например: для загрузки и начала работы с моделью ResNet50
from keras.applications.resnet50 import ResNet50
model=ResNet50(weights='imagenet')
У всех моделей разные размеры весов и при создании экземпляра модели они загружаются автоматически. В зависимости от размеров процесс загрузки может занять некоторое время.

Что такое ImageNet?
ImageNet — это крупный набор данных с аннотированными объектами. Цель создания ImageNet — развития алгоритмов компьютерного зрения. Это коллекция объектов-изображений, включающая около 1000 категорий изображений с примечаниями.
С 2010 года проект ежегодно организовывает конкурс ImageNet Large Scale Visual Recognition Challenge, в рамках которого участники должны создавать модели на основе этой базы для классификации объектов или изображений.
Вот примеры популярных классов изображений в наборе:
- Животные:
- Рыбы,
- Птицы,
- Млекопитающие.
- Растения:
- Деревья,
- Цветы,
- Овощи.
- Материалы:
- Ткани.
- Инструменты:
- Посуда,
- Инструменты,
- Приборы.
- Место действия:
- Комнаты.
Эти категории в свою очередь делятся на подкатегории
Реализация натренированных моделей Keras
- Импорт модели и необходимых библиотек.
from keras.preprocessing import image from keras.applications.resnet50 import ResNet50 from keras.applications.resnet50 import preprocess_input from keras.applications.resnet50 import decode_predictions import numpy as np - Создание экземпляра модели.
model=ResNet50(weights='imagenet') - Анализ модели с помощью:
model.summary() - Изображение на ввод для прогноза.
path='./….../...png' # путь к изображению img=image.load_img(path,target_size=(224,224)) x=image.img_to_array(img) x=np.expand_dims(x,axis=0) x=preprocess_input(x) - Прогноз
res=model.predict(x) print(decode_predictions(res,top=5)[0])
Вот топ-5 прогнозов модели. Вывод модели:

Можно увидеть, что модель предсказывает изображения таких птиц, как щегол, якамар, дрозд, вьюрок или американская оляпка.
Имеющиеся модели можно использовать и для классификации изображений без натренированной модели.
Также существует способ использования моделей на собственных изображениях и составления прогнозов на основе своих классов. Это называется трансферным обучением, где используются отдельные признаки модели для конкретной проблемы.
Выводы
Статья иллюстрирует основную сферу применения Keras, то есть, натренированные модели. Рассматривает ImageNet и его классы. Также на примерах показывается, насколько легко классифицировать изображения с помощью имеющихся моделей, а также обозначается термин трансферного обучения. Имеющиеся модели — одни из лучших структур нейронных сетей для точной классификации изображений и объектов.
]]>Помимо классических графиков, таких как столбчатые и круговые, можно представлять данные и другими способами. В интернете и разных источниках можно найти самые разные примеры визуализации данных, некоторые из которых выглядят невероятно. В этом разделе речь пойдет только о графических представлениях, но не о подробных способах их реализации. Можете считать это введением в мир визуализации данных.
Для выполнения кода импортируйте pyplot и numpy
import matplotlib.pyplot as plt import numpy as np
Контурные графики
В научном мире часто встречается тип контурных графиков или контурных карт. Они подходят для представления трехмерных поверхностей с помощью контурных карт, составленных из кривых, которые, в свою очередь, являются точками на поверхности на одном уровне (с одним и тем же значением z).
Хотя визуально контурный график — довольно сложная структура, ее реализация не так сложна, и все благодаря matplotlib. Во-первых, нужна функция z = f(x, y) для генерации трехмерной поверхности. Затем, имея значения x и y, определяющие площадь карты для вывода, можно вычислять значения z для каждой пары x и y с помощью функции f(x, y), которая и используется для этих целей. Наконец, благодаря функции contour() можно сгенерировать контурную карту на поверхности. Также часто требуется добавить цветную карту. Это площади, ограниченные кривыми уровней, заполненные цветным градиентом. Например, следующее изображения показывает отрицательные значения с помощью темных оттенков синего, а приближение к желтому и красному указывает на более высокие значения.
dx = 0.01; dy = 0.01
x = np.arange(-2.0,2.0,dx)
y = np.arange(-2.0,2.0,dy)
X,Y = np.meshgrid(x,y)
def f(x,y):
return (1 - y**5 + x**5)*np.exp(-x**2-y**2)
C = plt.contour(X,Y,f(X,Y),8,colors='black')
plt.contourf(X,Y,f(X,Y),8)
plt.clabel(C, inline=1, fontsize=10)
plt.show()

Это стандартный цветовой градиент. Но с помощью именованного аргумента cmap можно выбрать из большого число цветных карт.
Более того при работе с таким визуальным представлением добавление градации цвета сторонам графа — это прямо необходимость. Для этого есть функция colorbar() в конце кода. В следующем изображении можно увидеть другой пример карты, которая начинается с черного, проходит через красный и затем превращается в желтый и белый на максимальных значениях. Это карта plt.cm.hot.
dx = 0.01; dy = 0.01
x = np.arange(-2.0,2.0,dx)
y = np.arange(-2.0,2.0,dy)
X,Y = np.meshgrid(x,y)
def f(x,y):
return (1 - y**5 + x**5)*np.exp(-x**2-y**2)
C = plt.contour(X,Y,f(X,Y),8,colors='black')
plt.contourf(X,Y,f(X,Y),8,cmap=plt.cm.hot)
plt.clabel(C, inline=1, fontsize=10)
plt.colorbar()
plt.show()

Лепестковые диаграммы
Еще один продвинутый тип диаграмм — лепестковые диаграммы. Он представляет собой набор круговых секторов, каждый из которых занимает определенный угол. Таким образом можно изобразить два значения, присвоив их величинам, обозначающим диаграмму: радиус r и угол θ. На самом деле, это полярные координаты — альтернативный способ представления функций на осях координат. С графической точки зрения такая диаграмма имеет свойства круговой и столбчатой. Как и в круговой диаграмме каждый сектор здесь указывает на значение в процентах по отношению к целому. Как и в столбчатой, расширение по радиусу — это числовое значение категории.
До сих пор в примерах использовался стандартный набор цветов, обозначаемых кодами (например, r — это красный). Однако есть возможность использовать любую последовательность цветов. Нужно лишь определить список строковых значений, содержащих RGB-коды в формате #rrggbb, которые будут соответствовать нужным цветам.
Странно, но для вывода лепестковой диаграммы нужно использовать функцию bar() и передать ей список углов θ и список радиальных расширений для каждого сектора.
N = 8
theta = np.arange(0.,2 * np.pi, 2 * np.pi / N)
radii = np.array([4,7,5,3,1,5,6,7])
plt.axes([0.025, 0.025, 0.95, 0.95], polar=True)
colors = np.array(['#4bb2c5','#c5b47f','#EAA228','#579575','#839557','#958c12','#953579','#4b5de4'])
bars = plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors)
plt.show()

В этом примере определена последовательность цветов в формате #rrggbb, но ничто не мешает использовать строки с реальными названиями цветов.
N = 8
theta = np.arange(0.,2 * np.pi, 2 * np.pi / N)
radii = np.array([4,7,5,3,1,5,6,7])
plt.axes([0.025, 0.025, 0.95, 0.95], polar=True)
colors = np.array(['lightgreen','darkred','navy','brown','violet','plum','yellow','darkgreen'])
bars = plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors)
plt.show()

Набор инструментов mplot3d
Набор mplot3d включен во все стандартные версии matplotlib и позволят расширить возможности создания трехмерных визуализаций данных. Если объект Figure выводится в отдельном окне, можно вращать оси трехмерного представления с помощью мыши.
Даже с этим пакетом продолжает использоваться объект Figure, но вместо объектов Axes определяется новый тип, Axes3D из этого набора. Поэтому нужно добавить один импорт в код.
from mpl_toolkits.mplot3d import Axes3D
Трехмерные поверхности
В прошлом разделе для представления трехмерных поверхностей использовался контурный график. Но с помощью mplot3D поверхности можно рисовать прямо в 3D. В этом примере используем ту же функцию z = f(x, y), что и в прошлом.
Когда meshgrid вычислена, можно вывести поверхность графика с помощью функции plot_surface().
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
X = np.arange(-2,2,0.1)
Y = np.arange(-2,2,0.1)
X,Y = np.meshgrid(X,Y)
def f(x,y):
return (1 - y**5 + x**5)*np.exp(-x**2-y**2)
ax.plot_surface(X,Y,f(X,Y), rstride=1, cstride=1)
plt.show()

Трехмерная поверхность выделяется за счет изменения карты с помощью именованного аргумента cmap. Поверхность также можно вращать с помощью функции view_unit(). На самом деле, эта функция подстраивает точку обзора, откуда можно будет рассмотреть поверхность, изменяя аргументы elev и azim. С помощью их комбинирования можно получить поверхность, изображенную с любого угла. Первый аргумент настраивает высоту, а второй — угол поворота поверхности.
Например, можно поменять карту с помощью plt.cm.hot и повернуть угол на elev=30 и azim=125.
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
X = np.arange(-2,2,0.1)
Y = np.arange(-2,2,0.1)
X,Y = np.meshgrid(X,Y)
def f(x,y):
return (1 - y**5 + x**5)*np.exp(-x**2-y**2)
ax.plot_surface(X,Y,f(X,Y), rstride=1, cstride=1, cmap=plt.cm.hot)
ax.view_init(elev=30,azim=125)
plt.show()

Диаграмма рассеяния
Самым используемым трехмерным графиком остается 3D график рассеяния. С его помощью можно определить, следуют ли точки определенным трендам и, что самое важное, скапливаются ли они.
В этом случае используется функция scatter() как и при построении обычного двумерного графика, но на объекте Axed3D. Таким образом можно визуализировать разные объекты Series, представленные через вызовы функции scatter() в единой трехмерной форме.
from mpl_toolkits.mplot3d import Axes3D
xs = np.random.randint(30,40,100)
ys = np.random.randint(20,30,100)
zs = np.random.randint(10,20,100)
xs2 = np.random.randint(50,60,100)
ys2 = np.random.randint(30,40,100)
zs2 = np.random.randint(50,70,100)
xs3 = np.random.randint(10,30,100)
ys3 = np.random.randint(40,50,100)
zs3 = np.random.randint(40,50,100)
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(xs,ys,zs)
ax.scatter(xs2,ys2,zs2,c='r',marker='^')
ax.scatter(xs3,ys3,zs3,c='g',marker='*')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_xlabel('X Label')
plt.show()

Столбчатые диаграммы в 3D
Также в анализе данных используются трехмерные столбчатые диаграммы. Здесь тоже нужно применять функцию bar() к объекту Axes3D. Если же определить несколько Series, то их можно накопить в нескольких вызовах функции bar() для одной 3D-визуализации.
from mpl_toolkits.mplot3d import Axes3D
x = np.arange(8)
y = np.random.randint(0,10,8)
y2 = y + np.random.randint(0,3,8)
y3 = y2 + np.random.randint(0,3,8)
y4 = y3 + np.random.randint(0,3,8)
y5 = y4 + np.random.randint(0,3,8)
clr = ['#4bb2c5','#c5b47f','#EAA228','#579575','#839557','#958c12','#953579','#4b5de4']
fig = plt.figure()
ax = Axes3D(fig)
ax.bar(x,y,0,zdir='y',color=clr)
ax.bar(x,y2,10,zdir='y',color=clr)
ax.bar(x,y3,20,zdir='y',color=clr)
ax.bar(x,y4,30,zdir='y',color=clr)
ax.bar(x,y5,40,zdir='y',color=clr)
ax.set_xlabel('X Axis')
ax.set_ylabel('Y Axis')
ax.set_zlabel('Z Axis')
ax.view_init(elev=40)
plt.show()

Многопанельные графики
Были рассмотрены самые разные способы представления данных на графике, в том числе и случаи, когда несколько наборов данных разделены в одном объекте Figure на нескольких подграфиках. В этом разделе речь пойдет о более сложных случаях.
Подграфики внутри графиков
Есть возможность рассматривать графики внутри других ограниченных рамками. Поскольку речь идет о границах — объектах Axes — то есть необходимость разделять основные (основного графика) от тех, которые принадлежат добавляемому графику. Для этого используется функция figures(). С ее помощью нужно получить объект Figure, где будут определены два разных объекта Axes с помощью add_axes().
fig = plt.figure()
ax = fig.add_axes([0.1,0.1,0.8,0.8])
inner_ax = fig.add_axes([0.6,0.6,0.25,0.25])
plt.show()

Чтобы лучше понять эффект этого режима, лучше заполнить предыдущий объект Axes с помощью реальных данных.
fig = plt.figure()
ax = fig.add_axes([0.1,0.1,0.8,0.8])
inner_ax = fig.add_axes([0.6,0.6,0.25,0.25])
x1 = np.arange(10)
y1 = np.array([1,2,7,1,5,2,4,2,3,1])
x2 = np.arange(10)
y2 = np.array([1,3,4,5,4,5,2,6,4,3])
ax.plot(x1,y1)
inner_ax.plot(x2,y2)
plt.show()

Сетка подграфиков
Есть другой способ создания подграфиков. С помощью функции subplots() их нужно добавить, разбив таким образом график на секторы. matplotlib позволяет работать даже с более сложными случаями с помощью функции GridSpec(). Это подразделение позволяет разбить область на сетку подграфиков, каждому из которых можно присвоить свой график, так что результатом будет сетка с подграфиками разных размеров с разными направлениями.
gs = plt.GridSpec(3,3)
fig = plt.figure(figsize=(6,6))
fig.add_subplot(gs[1,:2])
fig.add_subplot(gs[0,:2])
fig.add_subplot(gs[2,0])
fig.add_subplot(gs[:2,2])
fig.add_subplot(gs[2,1:])
plt.show()

Создать такую сетку несложно. Осталось разобраться, как заполнить ее данными. Для этого нужно использовать объект Axes, который возвращает каждая функция add_subplot(). В конце остается вызвать plot() для вывода конкретного графика.
gs = plt.GridSpec(3,3)
fig = plt.figure(figsize=(6,6))
x1 = np.array([1,3,2,5])
y1 = np.array([4,3,7,2])
x2 = np.arange(5)
y2 = np.array([3,2,4,6,4])
s1 = fig.add_subplot(gs[1,:2])
s1.plot(x,y,'r')
s2 = fig.add_subplot(gs[0,:2])
s2.bar(x2,y2)
s3 = fig.add_subplot(gs[2,0])
s3.barh(x2,y2,color='g')
s4 = fig.add_subplot(gs[:2,2])
s4.plot(x2,y2,'k')
s5 = fig.add_subplot(gs[2,1:])
s5.plot(x1,y1,'b^',x2,y2,'yo')
plt.show()

В прошлых материалах вы встречали примеры, демонстрирующие архитектуру библиотеки matplotlib. После знакомства с основными графическими элементами для графиков время рассмотреть примеры разных типов графиков, начиная с самых распространенных, таких как линейные графики, гистограммы и круговые диаграммы, и заканчивая более сложными, но все равно часто используемыми.
Поскольку визуализация — основная цель библиотеки, то этот раздел является очень важным. Умение выбрать правильный тип графика является фундаментальным навыком, ведь неправильная репрезентация может привести к тому, что данные, полученные в результате качественного анализа данных, будет интерпретированы неверно.
Для выполнения кода импортируйте pyplot и numpy
import matplotlib.pyplot as plt import numpy as np
Линейные графики
Линейные графики являются самыми простыми из всех. Такой график — это последовательность точек данных на линии. Каждая точка состоит из пары значений (x, y), которые перенесены на график в соответствии с масштабами осей (x и y).
В качестве примера можно вывести точки, сгенерированные математической функцией. Возьмем такую: y = sin (3 * x) / x
Таким образом для создания последовательности точек данных нужно создать два массива NumPy. Сначала создадим массив со значениями x для оси x. Для определения последовательности увеличивающихся значений используем функцию np.arrange(). Поскольку функция синусоидальная, то значениями должны быть числа кратные π (np.pi). Затем с помощью этой последовательности можно получить значения y, применив для них функцию np.sin() (и все благодаря NumPy).
После этого остается лишь вывести все точки на график с помощью функции plot(). Результатом будет линейный график.
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
plt.plot(x,y)
plt.show()

Этот пример можно расширить для демонстрации семейства функций, например, такого (с разными значениями n):
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y)
plt.plot(x,y2)
plt.plot(x,y3)
plt.show()

Как можно увидеть на изображении, каждой линии автоматически присваивается свой цвет. При этом все графики представлены в одном масштабе. Это значит, что точки данных связаны с одними и теми же осями x и y. Вот почему каждый вызов функции plot() учитывает предыдущие вызовы, так что объект Figure применяет изменения с учетом прошлых команд еще до вывода (для вывода используется show()).
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y,'k--',linewidth=3)
plt.plot(x,y2,'m-.')
plt.plot(x,y3,color='#87a3cc',linestyle='--')
plt.show()

Как уже говорилось в прошлых в разделах, вне зависимости от настроек по умолчанию можно выбрать тип начертания, цвет и так далее. Третьим аргументом функции plot() можно указать коды цветов, типы линий и все этой в одной строке. Также можно использовать два именованных аргумента отдельно: color — для цвета и linestyle — для типа линии.
| Код | Цвет |
|---|---|
| b | голубой |
| g | зеленый |
| r | красный |
| c | сине-зеленый |
| m | пурпурный |
| y | желтый |
| k | черный |
| w | белый |
На графике определен диапазон от — 2π до 2π на оси x, но по умолчанию деления обозначены в числовой форме. Поэтому их нужно заменить на множители числа π. Также можно поменять делители на оси y. Для этого используются функции xticks() и yticks(). Им нужно передать список значений. Первый список содержит значения, соответствующие позициям, где деления будут находиться, а второй — их метки. В этом случае будут использоваться LaTeX-выражения, что нужно для корректного отображения π. Важно не забыть добавить знаки $ в начале и конце, а также символ r в качестве префикса.
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y,color='b')
plt.plot(x,y2,color='r')
plt.plot(x,y3,color='g')
plt.xticks([-2*np.pi,-np.pi,0, np.pi, 2*np.pi],
[r'$-2\pi$',r'$-\pi$',r'$0$',r'$+\pi$',r'$+2\pi$'])
plt.yticks([-1,0,1,2,3],
[r'$-1$',r'$0$',r'$+1$',r'$+2$',r'$+3$'])
plt.show()

Пока что на всех рассмотренных графиках оси x и y изображались на краях объекта Figure (по границе рамки). Но их же можно провести так, чтобы они пересекались — то есть, получит декартову система координат.
Для этого нужно сперва получить объект Axes с помощью функцию gca. Затем с его помощью можно выбрать любую из четырех сторон, создав область с границами и определив положение каждой: справа, слева, сверху и снизу. Ненужные части обрезаются (справа и снизу), а с помощью функции set_color() задается значение none. Затем стороны, которые соответствуют осям x и y, проходят через начало координат (0, 0) с помощью функции set_position().
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y,color='b')
plt.plot(x,y2,color='r')
plt.plot(x,y3,color='g')
plt.xticks([-2*np.pi,-np.pi,0, np.pi, 2*np.pi],
[r'$-2\pi$',r'$-\pi$',r'$0$',r'$+\pi$',r'$+2\pi$'])
plt.yticks([-1,0,1,2,3],
[r'$-1$',r'$0$',r'$+1$',r'$+2$',r'$+3$'])
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
plt.show()
Теперь график будет состоять из двух пересекающихся в центре осей, который представляет собой начало декартовой системы координат.

Также есть возможность указать на определенную точку с помощью дополнительных обозначений и стрелки. Обозначением может выступать LaTeX-выражение, например, формула предела функции sinx/x, стремящейся к 0.
Для этого в matplotlib есть функция annotate(). Ее настройка кажется сложной, но большое количество kwargs обеспечивает требуемый результат. Первый аргумент — строка, представляющая собой LaTeX-выражение, а все остальные — опциональные. Точка, которую нужно отметить на графике представлена в виде списка, включающего ее координаты (x и y), переданные в аргумент xy. Расстояние заметки до точки определено в xytext, а стрелка — с помощью arrowprops.
x = np.arange(-2*np.pi,2*np.pi,0.01)
y = np.sin(3*x)/x
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
plt.plot(x,y,color='b')
plt.plot(x,y2,color='r')
plt.plot(x,y3,color='g')
plt.xticks([-2*np.pi,-np.pi,0, np.pi, 2*np.pi],
[r'$-2\pi$',r'$-\pi$',r'$0$',r'$+\pi$',r'$+2\pi$'])
plt.yticks([-1,0,1,2,3],
[r'$-1$',r'$0$',r'$+1$',r'$+2$',r'$+3$'])
plt.annotate(r'$\lim_{x\to 0}\frac{\sin(x)}{x}= 1$', xy=[0,1],xycoords='data',
xytext=[30,30],fontsize=16, textcoords='offset points', arrowprops=dict(arrowstyle="->",
connectionstyle="arc3,rad=.2"))
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
plt.show()
В итоге этот код сгенерирует график с математической формулой предела, представленной точкой, на которую указывает стрелка.

Линейные графики с pandas
Рассмотрим более практический и приближенный к анализу данных пример. С ним будет видно, насколько просто использовать библиотеку matplotlib для объектов Dataframe из библиотеки pandas. Визуализация данных в виде линейного графика — максимально простая задача. Достаточно передать объект в качестве аргумента функции plot() для получения графика с несколькими линиями.
import pandas as pd
data = {'series1':[1,3,4,3,5],
'series2':[2,4,5,2,4],
'series3':[3,2,3,1,3]}
df = pd.DataFrame(data)
x = np.arange(5)
plt.axis([0,5,0,7])
plt.plot(x,df)
plt.legend(data, loc=2)
plt.show()

Гистограммы
Гистограмма состоит из примыкающих прямоугольников, расположенных вдоль оси x, которые разбиты на дискретные интервалы, их называют bins. Их площадь пропорциональна частоте конкретного интервала. Такой способ визуализации часто используют в статистике для демонстрации распределения.
Для представления гистограммы в pyplot есть функция hist(). У нее также есть особенности, которых не найти у других функций, отвечающих за создание графиков. hist() не только рисует гистограмму, но также возвращает кортеж значений, представляющих собой результат вычислений гистограммы. Функция hist() может реализовывать вычисление гистограммы, чего достаточно для предоставления набора значений и количества интервалов, на которых их нужно разбить. Наконец hist() отвечает за разделение интервала на множество и вычисление частоты каждого. Результат этой операции не только выводится в графической форме, но и возвращается в виде кортежа.
Для понимания операции лучше всего воспользоваться практическим примером. Сгенерируем набор из 100 случайных чисел от 0 до 100 с помощью random.randint().
pop = np.random.randint(0,100,100)
pop
array([33, 90, 10, 68, 18, 67, 6, 54, 32, 25, 90, 6, 48, 34, 59, 70, 37,
50, 86, 7, 49, 40, 54, 94, 95, 20, 83, 59, 33, 0, 81, 18, 26, 69,
2, 42, 51, 7, 42, 90, 94, 63, 14, 14, 71, 25, 85, 99, 40, 62, 29,
42, 27, 98, 30, 89, 21, 78, 17, 33, 63, 80, 61, 50, 79, 38, 96, 8,
85, 19, 76, 32, 19, 14, 37, 62, 24, 30, 19, 80, 55, 5, 94, 74, 85,
59, 65, 17, 80, 11, 81, 84, 81, 46, 82, 66, 46, 78, 29, 40])
Дальше создаем гистограмму из этих данных, передавая аргумент функции hist(). Например, нужно разделить данные на 20 интервалов (значение по умолчанию — 10 интервалов). Для этого используется именованный аргумент bin.
n, bin, patches = plt.hist(pop, bins=20)
plt.show()

Столбчатые диаграммы
Еще один распространенный тип графиков — столбчатые диаграммы. Они похожа на гистограммы, но на оси x тут располагаются не числовые значения, а категории. В matplotlib для реализации столбчатых диаграмм используется функция bin().
index = [0,1,2,3,4]
values = [5,7,3,4,6]
plt.bar(index,values)
plt.show()
Всего нескольких строк кода достаточно для получения такой столбчатой диаграммы.

На последней диаграмме видно, что метки на оси x написаны под каждым столбцом. Поскольку каждый из них относится к отдельной категории, правильнее обозначать их строками. Для этого используется функция xticks(). А для правильного размещения нужно передать список со значениями позиций в качестве первого аргумента в той же функции. Результатом будет такая диаграмма.
index = np.arange(5)
values1 = [5,7,3,4,6]
plt.bar(index, values1)
plt.xticks(index+0.4,['A','B','C','D','E'])
plt.show()

Есть и множество других операций, которые можно выполнить для улучшения диаграммы. Каждая из них выполняется за счет добавления конкретного именованного аргумента в bar(). Например, можно добавить величины стандартного отклонения с помощью аргумента yerr вместе с соответствующими значениями. Часто этот аргумент используется вместе с error_kw, который принимает друге аргументы, отвечающие за представление погрешностей. Два из них — это eColor, который определяет цвета колонок погрешностей и capsize — ширину поперечных линий, обозначающих окончания этих колонок.
Еще один именованный аргумент — alpha. Он определяет степень прозрачности цветной колонки. Его значением может быть число от 0 до 1, где 0 — полностью прозрачный объект.
Также крайне рекомендуется использовать легенду, за которую отвечает аргумент label.
Результат — следующая столбчатая диаграмма с колонками погрешностей.
index = np.arange(5)
values1 = [5,7,3,4,6]
std1 = [0.8,1,0.4,0.9,1.3]
plt.title('A Bar Chart')
plt.bar(index, values1, yerr=std1, error_kw={'ecolor':'0.1','capsize':6},alpha=0.7,label='First')
plt.xticks(index+0.4,['A','B','C','D','E'])
plt.legend(loc=2)
plt.show()

Горизонтальные столбчатые диаграммы
В предыдущем разделе столбчатая диаграмма была вертикальной. Но блоки могут располагаться и горизонтально. Для этого режима есть специальная функция barh(). Аргументы и именованные аргументы, которые использовались для bar() будут работать и здесь. Единственное изменение в том, что поменялись роли осей. Категории теперь представлены на оси y, а числовые значения — на x.
index = np.arange(5)
values1 = [5,7,3,4,6]
std1 = [0.8,1,0.4,0.9,1.3]
plt.title('A Horizontal Bar Chart')
plt.barh(index, values1, xerr=std1, error_kw={'ecolor':'0.1','capsize':6},alpha=0.7,label='First')
plt.yticks(index+0.4,['A','B','C','D','E'])
plt.legend(loc=5)
plt.show()

Многорядные столбчатые диаграммы
Как и линейные графики, столбчатые диаграммы широко используются для одновременного отображения больших наборов данных. Но в случае с многорядными работает особая структура. До сих пор во всех примерах определялись последовательности индексов, каждый из которых соответствует столбцу, относящемуся к оси x. Индексы представляют собой и категории. В таком случае столбцов, которые относятся к одной и той же категории, даже больше.
Один из способов решения этой проблемы — разделение пространства индекса (для удобства его ширина равна 1) на то количество столбцов, которые к нему относятся. Также рекомендуется добавлять пустое пространство, которое будет выступать пропусками между категориями.
index = np.arange(5)
values1 = [5,7,3,4,6]
values2 = [6,6,4,5,7]
values3 = [5,6,5,4,6]
bw = 0.3
plt.axis([0,5,0,8])
plt.title('A Multiseries Bar Chart', fontsize=20)
plt.bar(index, values1, bw, color='b')
plt.bar(index+bw, values2, bw, color='g')
plt.bar(index+2*bw, values3, bw, color='r')
plt.xticks(index+1.5*bw,['A','B','C','D','E'])
plt.show()

В случае с горизонтальными многорядными столбчатыми диаграммами все работает по тому же принципу. Функцию bar() нужно заменить на соответствующую barh(), а также не забыть заменить xticks() на yticks(). И нужно развернуть диапазон значений на осях с помощью функции axis().
index = np.arange(5)
values1 = [5,7,3,4,6]
values2 = [6,6,4,5,7]
values3 = [5,6,5,4,6]
bw = 0.3
plt.axis([0,8,0,5])
plt.title('A Multiseries Bar Chart', fontsize=20)
plt.barh(index, values1, bw, color='b')
plt.barh(index+bw, values2, bw, color='g')
plt.barh(index+2*bw, values3, bw, color='r')
plt.yticks(index+0.4,['A','B','C','D','E'])
plt.show()

Многорядные столбчатые диаграммы с Dataframe из pandas
Как и в случае с линейными графиками matplotlib предоставляет возможность представлять объекты Dataframe с результатами анализа данных в форме столбчатых графиков. В этом случае все происходит даже быстрее и проще. Нужно лишь использовать функцию plot() по отношению к объекту Dataframe и указать внутри именованный аргумент kind, ему требуется присвоить тип графика, который будет выводиться. В данном случае это bar. Без дополнительных настроек результат должен выглядеть как на следующем изображении.
import pandas as pd
index = np.arange(5)
data = {'series1': [1,3,4,3,5],
'series2': [2,4,5,2,4],
'series3': [3,2,3,1,3]}
df = pd.DataFrame(data)
df.plot(kind='bar')
plt.show()

Но для еще большего контроля (или просто при необходимости) можно брать части Dataframe в виде массивов NumPy и описывать их так, как в предыдущем примере. Для этого каждый нужно передать в качестве аргумента функциям matplotlib.
К горизонтальной диаграмме применимы те же правила, но нужно не забыть указать значение barh для аргумента kind. Результатом будет горизонтальная столбчатая диаграмма как на следующем изображении.

Многорядные сложенные столбчатые графики
Еще один способ представления многорядного столбчатого графика — сложенная форма, где каждый столбец установлен поверх другого. Это особенно полезно в том случае, когда нужно показать общее значение суммы всех столбцов.
Для превращения обычного многорядного столбчатого графика в сложенный нужно добавить именованный аргумент bottom в каждую функцию bar(). Каждый объект Series должен быть присвоен соответствующему аргументу bottom. Результатом будет сложенный столбчатый график.
series1 = np.array([3,4,5,3])
series2 = np.array([1,2,2,5])
series3 = np.array([2,3,3,4])
index = np.arange(4)
plt.axis([-0.5,3.5,0,15])
plt.title('A Multiseries Stacked Bar Chart')
plt.bar(index,series1,color='r')
plt.bar(index,series2,color='b',bottom=series1)
plt.bar(index,series3,color='g',bottom=(series2+series1))
plt.xticks(index,['Jan18','Feb18','Mar18','Apr18'])
plt.show()

Здесь для создания аналогичного горизонтального графика нужно заменить bar() на barh(), не забыв про остальные параметры. Функцию xticks() необходимо поменять местами с yticks(), потому что метки категорий теперь будут расположены по оси y. После этого будет создан следующий горизонтальный график.
series1 = np.array([3,4,5,3])
series2 = np.array([1,2,2,5])
series3 = np.array([2,3,3,4])
index = np.arange(4)
plt.axis([0,15,-0.5,3.5])
plt.title('A Multiseries Horizontal Stacked Bar Chart')
plt.barh(index,series1,color='r')
plt.barh(index,series2,color='b',left=series1)
plt.barh(index,series3,color='g',left=(series2+series1))
plt.yticks(index,['Jan18','Feb18','Mar18','Apr18'])
plt.show()

До сих пор объекты Series разделялись только по цветам. Но можно использовать, например, разную штриховку. Для этого сперва необходимо сделать цвет столбца белым и использовать именованный аргумент hatch для определения типа штриховки. Все они выполнены с помощью символов (|, /, -, \, *), соответствующих стилю столбца. Чем чаще он повторяется, тем теснее будут расположены линии. Так, /// — более плотный вариант чем //, а этот, в свою очередь, плотнее /.
series1 = np.array([3,4,5,3])
series2 = np.array([1,2,2,5])
series3 = np.array([2,3,3,4])
index = np.arange(4)
plt.axis([0,15,-0.5,3.5])
plt.title('A Multiseries Horizontal Stacked Bar Chart')
plt.barh(index,series1,color='w',hatch='xx')
plt.barh(index,series2,color='w',hatch='///',left=series1)
plt.barh(index,series3,color='w',hatch='\\\\\\',left=(series2+series1))
plt.yticks(index,['Jan18','Feb18','Mar18','Apr18'])
plt.show()

Сложенные столбчатые графики с Dataframe из padans
В случае со сложенными столбчатыми графиками очень легко представлять значения объектов Dataframe с помощью функции plot(). Нужно лишь добавить в качестве аргумента stacked со значением True.
import pandas as pd
data = {'series1': [1,3,4,3,5],
'series2': [2,4,5,2,4],
'series3': [3,2,3,1,3]}
df = pd.DataFrame(data)
df.plot(kind='bar',stacked=True)
plt.show()

Другие представления столбчатых графиков
Еще один удобный тип представления данных в столбчатом графике — с использованием двух Series из одних и тех же категорий, где они сравниваются путем размещения друг напротив друга вдоль оси y. Для этого нужно разместить значения y одного из графиков в отрицательной форме. Также в этом примере показано, как поменять внутренний цвет другим способом. Это делается с помощью задания значения для аргумента facecolor.
Также вы увидите, как добавить значение y с меткой в конце каждого столбца. Это поможет улучшить читаемость всего графика. Это делается с помощью цикла for, в котором функция text() показывает значение y. Настроить положение метки можно с помощью именованных аргументов ha и va, которые контролируют горизонтальное и вертикальное выравнивание соответственно. Результатом будет следующий график.
x0 = np.arange(8)
y1 = np.array([1,3,4,5,4,3,2,1])
y2 = np.array([1,2,5,4,3,3,2,1])
plt.ylim(-7,7)
plt.bar(x0,y1,0.9, facecolor='g')
plt.bar(x0,-y2,0.9,facecolor='b')
plt.xticks(())
plt.grid(True)
for x, y in zip(x0, y1):
plt.text(x, y + 0.05, '%d' % y, ha='center', va = 'bottom')
for x, y in zip(x0, y2):
plt.text(x, -y - 0.05, '%d' % y, ha='center', va = 'top')
plt.show()

Круговая диаграмма
Еще один способ представления данных — круговая диаграмма, которую можно получить с помощью функции pie().
Даже для нее нужно передать основной аргумент, представляющий собой список значений. Пусть это будут проценты (где максимально значение — 100), но это может быть любое значение. А уже сама функция определит, сколько будет занимать каждое значение.
Также в случае с этими графиками есть другие особенности, которые определяются именованными аргументами. Например, если нужно задать последовательность цветов, используется аргумент colors. В таком случае придется присвоить список строк, каждая из которых будет содержать название цвета. Еще одна возможность — добавление меток каждой доле. Для этого есть labels, которой присваивает список строк с метками в последовательности.
А чтобы диаграмма была идеально круглой, необходимо в конце добавить функцию axix() со строкой equal в качестве аргумента. Результатом будет такая диаграмма.
labels = ['Nokia','Samsung','Apple','Lumia']
values = [10,30,45,15]
colors = ['yellow','green','red','blue']
plt.pie(values,labels=labels,colors=colors)
plt.axis('equal')
plt.show()

Чтобы сделать диаграмму более сложной, можно «вытащить» одну из частей. Обычно это делается с целью акцентировать на ней внимание. В этом графике, например, для выделения Nokia. Для этого используется аргумент explode. Он представляет собой всего лишь последовательность чисел с плавающей точкой от 0 до 1, где 1 — положение целиком вне диаграмма, а 0 — полностью внутри. Значение между соответствуют среднему градусу извлечения.
Заголовок добавляется с помощью функции title(). Также можно настроить угол поворота с помощью аргумента startangle, который принимает значение между 0 и 360, обозначающее угол поворота (0 – значение по умолчанию). Следующий график показывает все изменения.
labels = ['Nokia','Samsung','Apple','Lumia']
values = [10,30,45,15]
colors = ['yellow','green','red','blue']
explode = [0.3,0,0,0]
plt.title('A Pie Chart')
plt.pie(values,labels=labels,colors=colors,explode=explode,startangle=180)
plt.axis('equal')
plt.show()

Но и это не все, что может быть на диаграмме. У нее нет осей, поэтому сложно передать точное разделение. Чтобы решить эту проблему, можно использовать autopct, который добавляет в центр каждой части текст с соответствующим значением.
Чтобы сделать диаграмму еще более привлекательной визуально, можно добавить тень с помощью shadow со значением True. Результат — следующее изображение.
labels = ['Nokia','Samsung','Apple','Lumia']
values = [10,30,45,15]
colors = ['yellow','green','red','blue']
explode = [0.3,0,0,0]
plt.title('A Pie Chart')
plt.pie(values,labels=labels,colors=colors,explode=explode,shadow=True,autopct='%1.1f%%',startangle=180)
plt.axis('equal')
plt.show()

Круговые диаграммы с Dataframe из pandas
Даже в случае с круговыми диаграммами можно передавать значения из Dataframe. Однако каждая диаграмма будет представлять собой один Series, поэтому в примере изобразим только один объект, выделив его через df['series1'].
Указать тип графика можно с помощью аргумента kind в функции plot(), который в этом случае получит значение pie. Также поскольку он должен быть идеально круглым, обязательно задать figsize. Получится следующая диаграмма.
import pandas as pd
data = {'series1': [1,3,4,3,5],
'series2': [2,4,5,2,4],
'series3': [3,2,3,1,3]}
df = pd.DataFrame(data)
df['series1'].plot(kind='pie', figsize=(6,6))
plt.show()

В этом материале обсудим некоторые особенности Keras. Также выполним классификацию рукописных цифр с помощью набора данных MNIST, используя Keras и его возможности.
Что такое Keras?
Keras — это библиотека нейронной сети в Python, использующая в качестве бэкенда TensorFlow, Microsoft CNTK или Theano. Ее можно установить вместе с движком с помощью PyPl.
pip install Keras
pip install tensorFlow
Зачем учить Keras?
Keras делает акцент на пользовательском опыте. С ее помощью пользователь может писать минимум кода для выполнения основных операций. Библиотека модульная и расширяемая. Модели и части кода можно использовать повторно и расширять в будущем.
Особенности Keras
Рассмотрим главные особенности Keras, из-за которых ее стоит учить:
1. Наборы помеченных данных
В Keras много помеченных наборов данных, которые можно импортировать и загрузить.
Пример: классификация небольших изображений CIFAR10, определение тональности рецензий IMDB, классификация новостных тем Reuters, рукописные цифры MNIST и некоторые другие (это лишь примеры самых известных наборов).
Для загрузки набора MNIST нужны следующие команды:
from Keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
2. Многочисленные реализованные слои и параметры
Keras содержит многочисленные слои и параметры, такие как функции потерь, оптимизаторы, метрики оценки. Они используются для создания, настройки, тренировки и оценки нейронных сетей.
Загрузим эти требуемые слои для построения классификатора цифр.
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.optimizers import Adam
from keras.utils import np_utils
Keras также поддерживает одно- и двухмерные сверточные и рекуррентные нейронные сети. Для классификатора используем сверточную нейронную сеть (слой Conv2D).
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
3. Методы для предварительной обработки данных
В Keras также масса методов для предварительной обработки. Будем использовать метод Keras.np_utils.to_categorical() для унитарной кодировки y_train и y_test.
Перед этим изменим форму и нормализуем данные в соответствии с требованиями.
# изменение размерности
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], X_train.shape[2], 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], X_test.shape[2], 1).astype('float32')
# нормализация, чтобы получить данные в диапазоне 0-1
X_train/=255
X_test/=255
number_of_classes = 10
y_train = np_utils.to_categorical(y_train, number_of_classes)
y_test = np_utils.to_categorical(y_test, number_of_classes)
4. Метод add() в Keras
Для добавления импортированных слоев используется метод add() с дополнительными параметрами.
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(X_train.shape[1], X_train.shape[2], 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(number_of_classes, activation='softmax')
5. Метод compile()
Перед тренировкой нужно настроить процесс обучения, что делается с помощью метода compile().
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
6. Метод fit()
Тренировка моделей Keras происходит с помощью массивов и метода fit().
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=5, batch_size=200)
Тренировка занимает некоторое время. В данном случае прошло всего 5 epocs, но их число можно увеличить.
Тренировка выглядит вот так:

7. Оценка модели
После тренировки модели результаты проверяются на новых данных или с помощью predict_classes() или evaluate().
Проверим модель рукописных цифр. Можете взять в качестве примера это изображение.

Но сперва его нужно конвертировать в формат набора MNIST.
Этот формат представляет собой черно-белые изображения 28*28*1.
import cv2
img = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
resized = cv2.resize(img, (28,28), interpolation = cv2.INTER_AREA)
img = np.resize(resized, (28,28,1))
im2arr = np.array(img)
im2arr = im2arr.reshape(1,28,28,1)
y_pred = model.predict_classes(im2arr)
print(y_pred)
7
8. Модульность
Keras является модульным, поэтому можно сохранить модель и тренировать ее позже.
Это делается вот так:
model.save('model.h5')
Выводы
Это основные особенности Keras. Рассмотрели их на примере базовых операций: загрузки набора данных, построения модели, добавления параметров, компиляции, тренировки и оценки. С помощью этой статьи у вас была возможность создать собственный классификатор рукописных цифр на основе набора данных MNIST. Этот пример показывает, что проекты глубокого обучения могут состоять всего из 10 строк кода.
]]>Разработчики используют машинное обучение и глубокое обучение, чтобы делать компьютеры более умными. Человек учится, выполняя определенную задачу, практикуясь и повторяя ее раз за разом, запоминая, как именно это делается. После этого нейроны в мозге срабатывают автоматически и могут быстро выполнить выученную задачу.
Глубокое обучение работает по похожему принципу. В нем используются разные типы архитектуры нейронной сети в зависимости от типов проблем. Например, распознавание объектов, классификация изображений и звуков, определение объектов, сегментация изображений и так далее.
Что такое распознавание рукописных цифр?
Распознавание рукописных цифр — это способность компьютера узнавать написанные от руки цифры. Для машины это не самая простая задача, ведь каждая написанная цифра может отличаться от эталонного написания. В случае с распознаванием решением является то, что машина способна узнавать цифру на изображении.
О Python-проекте
В этом материале реализуем приложение для распознавания написанных от руки цифр с помощью набора данных MNIST. Используем специальный тип глубокой нейронной сети, которая называется сверточной нейронной сетью. А в конце создадим графический интерфейс, в котором можно будет рисовать цифру и тут же ее узнавать.
Требования
Для этого проекта нужны базовые знания программирования на Python, библиотеки Keras для глубокого обучения и библиотеки Tkinter для создания графического интерфейса.
Установим требуемые библиотеки для проекта с помощью pip install.
Библиотеки: numpy, tensorflow, keras, pillow.
Набор данных MNIST
Это, наверное, один из самых популярных наборов данных среди энтузиастов, работающих в сфера машинного обучения и глубокого обучения. Он содержит 60 000 тренировочных изображений написанных от руки цифр от 0 до 9, а также 10 000 картинок для тестирования. В наборе есть 10 разных классов. Изображения с цифрами представлены в виде матриц 28 х 28, где каждая ячейка содержит определенный оттенок серого.
Создание проекта на Python для распознавания рукописных цифр
Скачайте файлы проекта
1. Импорт библиотек и загрузка набор данных
Сначала нужно импортировать все модули, которые потребуются для тренировки модели. Библиотека Keras уже включает некоторые из них. В их числе и MNIST. Таким образом можно запросто импортировать набор и начать работать с ним. Метод mnist.load_data() возвращает тренировочные данные, их метки и тестовые данные с метками.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
# скачиваем данные и разделяем на надор для обучения и тесовый
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape, y_train.shape)
2. Предварительная обработка данных
Данные с изображения нельзя прямо передать в модель, поэтому сперва нужно выполнить определенные операции, обработав данные, чтобы нейронная сеть с ними работала. Размерность тренировочных данных — (60000, 28, 28). Модель сверточной нейронной сети требует одну размерность, поэтому потребуется перестроить форму (60000, 28, 28, 1).
num_classes = 10
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
input_shape = (28, 28, 1)
# преобразование векторных классов в бинарные матрицы
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('Размерность x_train:', x_train.shape)
print(x_train.shape[0], 'Размер train')
print(x_test.shape[0], 'Размер test')
3. Создание модели
Следующий этап – создание модели сверточной нейронной сети. Она преимущественно состоит из сверточных и слоев подвыборки. Модель лучше работает с данными, представленными в качестве сеточных структур. Вот почему такая сеть отлично подходит для задач с классификацией изображений. Слой исключения используется для отключения отдельных нейронов и во время тренировки. Он уменьшает вероятность переобучения. Затем происходит компиляция модели с помощью оптимизатора Adadelta.
batch_size = 128
epochs = 10
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,optimizer=keras.optimizers.Adadelta(),metrics=['accuracy'])
4. Тренировка модели
Функция model.fit() в Keras начнет тренировку модели. Она принимает тренировочные, валидационные данные, эпохи (epoch) и размер батча (batch).
Тренировка модели занимает некоторое время. После этого веса и определение модели сохраняются в файле mnist.h5.
hist = model.fit(x_train, y_train, batch_size = batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
print("Модель успешно обучена")
model.save('mnist.h5')
print("Модель сохранена как mnist.h5")
5. Оценка модели
В наборе данных есть 10 000 изображений, которые используются для оценки качества работы модели. Тестовые данные не используются во время тренировки, поэтому являются новыми для модели. Набор MNIST хорошо сбалансирован, поэтому можно рассчитывать на точность около 99%.
score = model.evaluate(x_test, y_test, verbose=0)
print('Потери на тесте:', score[0])
print('Точность на тесте:', score[1])
6. Создание графического интерфейса для предсказания цифр
Для графического интерфейса создадим новый файл, в котором будет интерактивное окно для рисования цифр на полотне и кнопка, отвечающая за процесс распознавания. Библиотека Tkinter является частью стандартной библиотеки Python. Функция predict_digit() принимает входящее изображение и затем использует натренированную сеть для предсказания.
Затем создаем класс App, который будет отвечать за построение графического интерфейса приложения. Создаем полотно, на котором можно рисовать, захватывая события мыши. Кнопка же будет активировать функцию predict_digit() и отображать результат.
Дальше весь код из файла gui_digit_recognizer.py:
from keras.models import load_model
from tkinter import *
import tkinter as tk
import win32gui
from PIL import ImageGrab, Image
import numpy as np
model = load_model('mnist.h5')
def predict_digit(img):
# изменение рзмера изобржений на 28x28
img = img.resize((28,28))
# конвертируем rgb в grayscale
img = img.convert('L')
img = np.array(img)
# изменение размерности для поддержки модели ввода и нормализации
img = img.reshape(1,28,28,1)
img = img/255.0
# предстказание цифры
res = model.predict([img])[0]
return np.argmax(res), max(res)
class App(tk.Tk):
def __init__(self):
tk.Tk.__init__(self)
self.x = self.y = 0
# Создание элементов
self.canvas = tk.Canvas(self, width=300, height=300, bg = "white", cursor="cross")
self.label = tk.Label(self, text="Думаю..", font=("Helvetica", 48))
self.classify_btn = tk.Button(self, text = "Распознать", command = self.classify_handwriting)
self.button_clear = tk.Button(self, text = "Очистить", command = self.clear_all)
# Сетка окна
self.canvas.grid(row=0, column=0, pady=2, sticky=W, )
self.label.grid(row=0, column=1,pady=2, padx=2)
self.classify_btn.grid(row=1, column=1, pady=2, padx=2)
self.button_clear.grid(row=1, column=0, pady=2)
# self.canvas.bind("<Motion>", self.start_pos)
self.canvas.bind("<B1-Motion>", self.draw_lines)
def clear_all(self):
self.canvas.delete("all")
def classify_handwriting(self):
HWND = self.canvas.winfo_id()
rect = win32gui.GetWindowRect(HWND) # получаем координату холста
im = ImageGrab.grab(rect)
digit, acc = predict_digit(im)
self.label.configure(text= str(digit)+', '+ str(int(acc*100))+'%')
def draw_lines(self, event):
self.x = event.x
self.y = event.y
r=8
self.canvas.create_oval(self.x-r, self.y-r, self.x + r, self.y + r, fill='black')
app = App()
mainloop()
Получится:
Выводы
Проект для распознавания рукописных цифр на Python готов. Была создана и натренирована сверточная нейронная сеть, которая идеально подходит для классификации изображений. Наконец, был реализован графический интерфейс, который используется для рисования и представления результата предсказания цифры.
]]>Модуль pyplot — это коллекция функций в стиле команд, которая позволяет использовать matplotlib почти так же, как MATLAB. Каждая функция pyplot работает с объектами Figure и позволяет их изменять. Например, есть функции для создания объекта Figure, для создания области построения, представления линии, добавления метки и так далее.
pyplot является зависимым от состояния (stateful). Он отслеживает статус объекта Figure и его области построения. Функции выполняются на текущем объекте.
Простой интерактивный график
Для знакомства с библиотекой matplotlib и с самим pyplot начнем создавать простой интерактивный график. В matplotlib эта операция выполняется очень просто. Достаточно трех строчек кода.
Но сначала нужно импортировать пакет pyplot и обозначить его как plt.
import matplotlib.pyplot as plt
В Python конструкторы обычно не нужны. Все определяется неявно. Так, при импорте пакета уже создается экземпляр plt со всеми его графическими возможностями, который готов к работе. Нужно всего лишь использовать функцию plot() для передачи функций, по которым требуется построить график.
Поэтому достаточно передать значения, которые нужно представить в виде последовательности целых чисел.
plt.plot([1,2,3,4])
[<matplotlib.lines.Line2D at 0xa3eb438>]
В этом случае генерируется объект Line2D. Это линия, представляющая собой линейный тренд точек, нанесенных на график.
Теперь все настроено. Осталось лишь дать команду показать график с помощью функции show().
plt.show()
Результат должен соответствовать показанному на изображении. Он будет отображаться в окне, которое называется plotting window с панелью инструментов. Прямо как в MATLAB.

Окно графика
В этом окне есть панель управления, состоящая из нескольких кнопок.

Код в консоли IPython передается в консоль Python в виде набора команд:
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.show()
Если же вы используете IPython QtConsole, то могли заметить, что после вызова plot() график сразу отображается без необходимости вызывать show().
Если функции plt.plot() передать только список или массив чисел, matplotlib предположит, что это последовательность значений y на графике и свяжет ее с последовательностью натуральных чисел x: 0, 1, 2, 3, ….
Обычно график представляет собой пару значений (x, y), поэтому, если нужно определить его правильно, требуется два массива: в первом будут значения для оси x, а втором — для y. Функция plot() принимает и третий аргумент, описывающий то, как нужно представить точку на графике.
Свойства графика
На последнем изображении точки были представлены синей линией. Если не указывать явно, то график возьмет настройку функции plt.plot() по умолчанию:
- Размер осей соответствует диапазону введенных данных
- У осей нет ни меток, ни заголовков
- Легенды нет
- Соединяющая точки линия синяя
Для получения настоящего графика, где каждая пара значений (x, y) будет представлена в виде красной точки, нужно поменять это представление.
Если вы работаете в IPython, закройте окно, чтобы вернуться в консоль для введения новых команд. Затем нужно будет вызывать функцию show(), чтобы увидеть внесенные изменения.
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()
Если же вы используете Jupyter QtConsole, то для каждой введенной команды будет появляться новый график.
в будущем в примерах средой разработки будет выступать IPython QtConsole.
Можно определить диапазон для осей x и y, задав значения в список [xmin, xmax, ymin, ymax] и передав его в качестве аргумента в функцию axis().
в IPython QtConsole для создания графика иногда нужно ввести несколько строк команд. Чтобы график при этом не генерировался с каждым нажатием Enter (перевод на новую строку), необходимо нажимать Ctrl + Enter. А когда график будет готов, остается лишь нажать Enter дважды.
Можно задать несколько свойств. Одно из них — заголовок, который задается через функцию title().
plt.axis([0,5,0,20])
plt.title('My first plot')
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()
На следующем изображении видно, как новые настройки делают график более читаемым. Так, конечные точки набора данных теперь распределены по графику, а не находятся на краях. А сверху есть заголовок.

matplotlib и NumPy
Даже matplot, которая является полностью графической библиотекой, основана на NumPy. Вы видели на примерах, как передавать списки в качестве аргументов. Это нужно как для представления данных, так и для того, чтобы задавать границы осей. Внутри эти списки конвертируются в массивы NumPy.
Таким образом можно прямо добавлять в качестве входящих данных массивы NumPy. Массив данных, обработанный pandas, может быть использован matplotlib без дальнейшей обработки.
В качестве примера рассмотрим, как перенести на один график три тренда. Возьмем функцию sin из модуля math. Последний сперва нужно импортировать. Для генерации точек по синусоиде нужно использовать библиотеку NumPy. Сгенерируем набор точек по оси x с помощью функции arrange(), а для оси y воспользуемся функцией map(). С ее помощью применим sin() ко всем элементам массива (без цикла for).
import math
import numpy as np
t = np.arange(0,2.5,0.1)
y1 = np.sin(math.pi*t)
y2 = np.sin(math.pi*t+math.pi/2)
y3 = np.sin(math.pi*t-math.pi/2)
plt.plot(t,y1,'b*',t,y2,'g^',t,y3,'ys')
plt.show()

Как видно на прошлом изображении, график представляет три разных тренда с помощью разных цветов и меток. В таких случаях когда тренд функции очевиден, график является не самой подходящим представлением — лучше использовать линии. Чтобы разделить их не только цветами, можно использовать паттерны, состоящие из комбинаций точек и дефисов.
plt.plot(t,y1,'b--',t,y2,'g',t,y3,'r-.')
plt.show()
если вы не пользуетесь IPython QtConsole со встроенной matplotlib или работаете с этим кодом в обычной сессии Python, используйте команду
plt.show()в конце кода для получения объекта графика со следующего изображения.

Использование kwargs
Объекты, которые создают график, имеют разные характеризующие их атрибуты. Все они являются значениями по умолчанию, но их можно настроить с помощью аргументов-ключевых слов — kwargs.
Эти ключевые слова передаются в качестве аргументов в функции. В документации по разным функциям библиотеки matplotlib они всегда упоминаются последними вместе с kwargs. Например, функция plot() описана следующим образом.
matplotlib.pyplot.plot(*args, **kwargs)
В качестве примера с помощью аргумента linewidth можно поменять толщину линии.
plt.plot([1,2,4,2,1,0,1,2,1,4], linewidth=2.0)
plt.show()

Работа с несколькими объектами Figure и осями
До сих пор во всех примерах команды pyplot были направлены на отображение в пределах одного объекта. Но matplotlib позволяет управлять несколькими Figure одновременно, а внутри одного объекта можно выводить подграфики.
Работая с pyplot, нужно помнить о концепции текущего объекта Figure и текущих осей (графика на объекте).
Дальше будет пример с двумя подграфиками на одном Figure. Функция subplot(), помимо разделения объекта на разные зоны для рисования, используется для фокусировки команды на конкретном подграфике.
Аргументы, переданные subplot(), задают режим разделения и определяют текущий подграфик. Этот график будет единственным, на который воздействуют команды. Аргумент функции subplot() состоит из трех целых чисел. Первое определяет количество частей, на которое нужно разбить объект по вертикали. Второе — горизонтальное разделение. А третье число указывает на текущий подграфик, для которого будут актуальны команды.
Дальше будут отображаться тренды синусоиды (синус и косинус), и лучше всего разделить полотно по вертикали на два горизонтальных подграфика. В график передают числа 211 и 212.
t = np.arange(0,5,0.1)
y1 = np.sin(2*np.pi*t)
y2 = np.sin(2*np.pi*t)
plt.subplot(211)
plt.plot(t,y1,'b-.')
plt.subplot(212)
plt.plot(t,y2,'r--')
plt.show()

Теперь — то же самое для двух вертикальных подграфиков. Передаем в качестве аргументов 121 и 122.
t = np.arange(0.,1.,0.05)
y1 = np.sin(2*np.pi*t)
y2 = np.cos(2*np.pi*t)
plt.subplot(121)
plt.plot(t,y1,'b-.')
plt.subplot(122)
plt.plot(t,y2,'r--')
plt.show()

Добавление элементов на график
Чтобы сделать график более информативным, недостаточно просто представлять данные с помощью линий и маркеров и присваивать диапазон значений с помощью двух осей. Есть и множество других элементов, которые можно добавить на график, чтобы наполнить его дополнительной информацией.
В этом разделе добавим на график текстовые блоки, легенду и так далее.
Добавление текста
Вы уже видели, как добавить заголовок с помощью функции title(). Два других текстовых индикатора можно добавить с помощью меток осей. Для этого используются функции xlabel() и ylabel(). В качестве аргумента они принимают строку, которая будет выведена.
количество команд для представления графика постоянно растет. Но их не нужно переписывать каждый раз. Достаточно использовать стрелки на клавиатуре, вызывая раннее введенные команды и редактируя их с помощью новых строк (в тексте они выделены жирным).
Теперь добавим две метки на график. Они будут описывать тип значений на каждой из осей.
plt.axis([0,5,0,20])
plt.title('My first plot')
plt.xlabel('Counting')
plt.ylabel('Square values')
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()

Благодаря ключевым словам можно менять характеристики текста. Например, можно поменять заголовок, выбрав другой шрифт и увеличив его размер. Также можно менять цвета меток осей, чтобы акцентировать внимание на заголовке всего графика.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()

Но в matplotlib можно делать даже больше: pyplot позволяет добавлять текст в любом месте графика. Это делается с помощью специальной функции text().
text(x,y,s, fontdict=None, **kwargs)
Первые два аргумента — это координаты, в которых нужно разметить текст. s — это строка с текстом, а fontdict (опционально) — желаемый шрифт. Разрешается использовать и ключевые слова.
Добавим метку для каждой точки графика. Поскольку первые два аргумента в функции являются координатами, координаты всех точек по оси y немного сдвинутся.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()
Теперь у каждой точки есть своя метка.

Поскольку matplotlib — это графическая библиотека, созданная для использования в научных кругах, она должна быть способна в полной мере использовать научный язык, включая математические выражения. matplotlib предоставляет возможность интегрировать выражения LaTeX, что позволяет добавлять выражения прямо на график.
Для этого их нужно заключить в два символа $. Интерпретатор распознает их как выражения LaTeX и конвертирует соответствующий график. Это могут быть математические выражения, формулы, математические символы или греческие буквы. Перед LaTeX нужно добавлять r, что означает сырой текст. Это позволит избежать появления исключающих последовательностей.
Также разрешается использовать ключевые слова, чтобы дополнить текст графика. Например, можно добавить формулу, описывающую тренд и цветную рамку.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()

Добавление сетки
Также на график можно добавить сетку. Часто это необходимо, чтобы лучше понимать положение каждой точки на графике.
Это простая операция. Достаточно воспользоваться функцией grid(), передав в качестве аргумента True.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.show()

Добавление легенды
Также на графике должна присутствовать легенда. pyplot предлагает функцию legend() для добавления этого элемента.
В функцию нужно передать строку, которая будет отображаться в легенде. В этом примере текст First series характеризует входящий массив данных.
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.legend(['First series'])
plt.show()

По умолчанию легенда добавляется в правом верхнем углу. Чтобы поменять это поведение, нужно использовать несколько аргументов-ключевых слов. Так, для выбора положения достаточно передать аргумент loc со значением от 0 до 10. Каждая из цифр обозначает один из углов. Значение 1 — значение по умолчанию, то есть, верхний правый угол. В следующем примере переместим легенду в левый верхний угол, чтобы она не пересекалась с точками на графике.
| Код положения | Положение |
|---|---|
| 0 | лучшее |
| 1 | Верхний правый угол |
| 2 | Верхний левый угол |
| 3 | Нижний левый угол |
| 4 | Нижний правый угол |
| 5 | Справа |
| 6 | Слева по центру |
| 7 | Справа по центру |
| 8 | Снизу по центру |
| 9 | Сверху по центру |
| 10 | По центру |
Тут важно сделать одну ремарку. Легенды используются для указания определения набора данных с помощью меток, ассоциированных с определенным цветом и/или маркером. До сих пор в примерах использовался лишь один набор данных, переданный с помощью одной функции plot(). Но куда чаще один график может использоваться для нескольких наборов данных. С точки зрения кода каждый такой набор будет характеризоваться вызовом одной функции plot(), а порядок их определения будет соответствовать порядку текстовых меток, переданных в качестве аргумента функции legend().
import matplotlib.pyplot as plt
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.plot([1,2,3,4],[0.8,3.5,8,15],'g^')
plt.plot([1,2,3,4],[0.5,2.5,4,12],'b*')
plt.legend(['First series','Second series','Third series'], loc=2)
plt.show()

Сохранение графиков
В этом разделе разберемся, как сохранять график разными способами. Если в будущем потребуется использовать график в разных Notebook или сессиях Python, то лучший способ — сохранять графики в виде кода Python. С другой стороны, если они нужны в отчетах или презентациях, то подойдет сохранение в виде изображения. Можно даже сохранить график в виде HTML-страницы, что пригодится при работе в интернете.
Сохранение кода
Как уже стало понятно, объем кода, отвечающего за представление одного графика, постоянно растет. Когда финальный результат удовлетворяет, его можно сохранить в файле .py, который затем вызывается в любой момент.
Также можно использовать команду %save [имя файла] [количество строк кода], чтобы явно указать, сколько строк нужно сохранить. Если весь код написан одним запросом, тогда нужно добавить лишь номер его строки. Если же использовалось несколько команд, например, от 10 до 20, то эти числа и нужно записать, разделив их дефисом (10-20).
В этом примере сохранить весь код, отвечающий за формирование графика, можно с помощью ввода со строки 171.
In [171]: import matplotlib.pyplot as plt
Такую команду потребуется ввести для сохранения в файл .py.
%save my_first_chart 171
После запуска команды файл my_first_chart.py окажется в рабочей директории.
# %load my_first_chart.py
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.plot([1,2,3,4],[0.8,3.5,8,15],'g^')
plt.plot([1,2,3,4],[0.5,2.5,4,12],'b*')
plt.legend(['First series','Second series','Third series'], loc=2)
plt.show()
Позже, когда вы откроете сессию IPython, у вас уже будет готовый график и его можно редактировать с момента сохранения этой командой:
ipython qtconsole --matplotlib inline -m my_first_chart.py
Либо его можно загрузить заново в один запрос в QtConsole с помощью команды %load.
%load my_first_chart.py
Или запустить в уже активной сессии с помощью %run.
%run my_first_chart.py
в определенных случаях последняя команда будет работать только после ввода двух предыдущих.
Сохранение сессии в HTML-файл
С помощью IPython QtConsole вы можете конвертировать весь код и графику, представленные в текущей сессии, в одну HTML-страницу. Просто выберите File → Save to HTML/XHTML в верхнем меню.
Будет предложено сохранить сессию в одном из двух форматов: HTML и XHTML. Разница между ними заключается в типе сжатия изображения. Если выбрать HTML, то все картинки конвертируются в PNG. В случае с XHTML будет выбран формат SVG.
В этом примере сохраним сессию в формате HTML в файле my_session.html.
Дальше программа спросит, сохранить ли изображения во внешней директории или прямо в тексте. В первом случае все картинки будут храниться в папке my_session_files, а во втором — будут встроены в HTML-код.
Сохранение графика в виде изображения
График можно сохранить и виде файла-изображения, забыв обо всем написанном коде. Для этого используется функция savefig(). В аргументы нужно передать желаемое название будущего файла. Также важно, чтобы эта команда шла в конце, после всех остальных (иначе сохранится пустой PNG-файл).
plt.axis([0,5,0,20])
plt.title('My first plot', fontsize=20, fontname='Times New Roman')
plt.xlabel('Counting', color='gray')
plt.ylabel('Square values',color='gray')
plt.text(1,1.5,'First')
plt.text(2,4.5,'Second')
plt.text(3,9.5,'Third')
plt.text(4,16.5,'Fourth')
plt.text(1.1,12,r'$y = x^2$', fontsize=20, bbox={'facecolor':'yellow','alpha':0.2})
plt.grid(True)
plt.plot([1,2,3,4],[1,4,9,16],'ro')
plt.plot([1,2,3,4],[0.8,3.5,8,15],'g^')
plt.plot([1,2,3,4],[0.5,2.5,4,12],'b*')
plt.legend(['First series','Second series','Third series'], loc=2)
plt.savefig('my_chart.png')
Файл появится в рабочей директории. Он будет называться my_chart.png и включать изображение графика.
Обработка значений дат
Одна из основных проблем при анализе данных — обработка значений дат. Отображение даты по оси (обычно это ось x) часто становится проблемой.
Возьмем в качестве примера линейный график с набором данных, который включает 8 точек, где каждая представляет точку даты на оси x в следующем формате: день-месяц-год.
import datetime
import numpy as np
import matplotlib.pyplot as plt
events = [datetime.date(2015,1,23),
datetime.date(2015,1,28),
datetime.date(2015,2,3),
datetime.date(2015,2,21),
datetime.date(2015,3,15),
datetime.date(2015,3,24),
datetime.date(2015,4,8),
datetime.date(2015,4,24)]
readings = [12,22,25,20,18,15,17,14]
plt.plot(events,readings)
plt.show()

Автоматическая расстановка отметок в этом случае — настоящая катастрофа. Даты сложно читать, ведь между ними нет интервалов, и они наслаиваются друг на друга.
Для управления датами нужно определить временную шкалу. Сперва необходимо импортировать matplotlib.dates — модуль, предназначенный для работы с этим типом дат. Затем указываются шкалы для дней и месяцев с помощью MonthLocator() и DayLocator(). В этом случае форматирование играет важную роль, и чтобы не получить наслоение текста, нужно ограничить количество отметок, оставив только год-месяц. Такой формат передается в качестве аргумента функции DateFormatter().
Когда шкалы определены (один — для дней, второй — для месяцев) можно определить два вида пометок на оси x с помощью set_major_locator() и set_minor_locator() для объекта xaxis. Для определения формата текста отметок месяцев используется set_major_formatter.
Задав все эти изменения, можно получить график как на следующем изображении.
import matplotlib.dates as mdates
months = mdates.MonthLocator()
days = mdates.DayLocator()
timeFmt = mdates.DateFormatter('%Y-%m')
events = [datetime.date(2015,1,23),
datetime.date(2015,1,28),
datetime.date(2015,2,3),
datetime.date(2015,2,21),
datetime.date(2015,3,15),
datetime.date(2015,3,24),
datetime.date(2015,4,8),
datetime.date(2015,4,24)]
readings = [12,22,25,20,18,15,17,14]
fig, ax = plt.subplots()
plt.plot(events, readings)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_major_formatter(timeFmt)
ax.xaxis.set_minor_locator(days)
plt.show()

matplotlib — это библиотека, предназначенная для разработки двумерных графиков (включая 3D-представления). За последнее время она широко распространилась в научных и инженерных кругах (http://matplotlib.org):
Среди всех ее функций особо выделяются следующие:
- Простота в использовании
- Постепенное развитие и интерактивная визуализация данных
- Выражения и текст в LaTeX
- Широкие возможности по контролю графических элементов
- Экспорт в разные форматы, включая PNG, PDF, SVG и EPS
О Matplotlib
matplotlib спроектирована с целью максимально точно воссоздать среду MATLAB в плане графического интерфейса и синтаксической формы. Этот подход оказался успешным, ведь он позволил задействовать особенности уже проверенного ПО (MATLAB), распространив библиотеку в среду технологий и науки. Более того, она включает тот объем работы по оптимизации, который был проделан за много лет. Результат — простота в использовании, что особенно важно для тех, у кого нет опыта работы в этой сфере.
Помимо простоты библиотека matplotlib также унаследовала от MATLAB интерактивность. Это значит, что специалист можно вставлять команду за командой для постепенной разработки графического представления данных. Этот режим отлично подходит для более интерактивных режимов работы с Python, таких как IPython, QtConsole и Jupyter Notebook, предоставляя среду для анализа данных, где есть все, что можно найти, например в Mathematica, IDL или MATLAB.
Гений создателей этой библиотеки в использовании уже доступных, зарекомендовавших себя инструментов из области науки. И это не ограничивается лишь режимом исполнения MATLAB, но также моделями текстового представления научных выражений и символов LaTeX. Благодаря своим возможностям по представлению научных выражений LaTeX был незаменимым элементом научных публикаций и документаций, в которых требуются такие визуальные репрезентации, как интегралы, объединения и производные. А matplotlib интегрирует этот инструмент для улучшения качества отображения.
Не стоит забывать о том, что matplotlib — это не отдельное приложение, а библиотека такого языка программирования, как Python. Поэтому она на полную использует его возможности. Matplotlib воспринимается как графическая библиотека, позволяющая программными средствами настраивать визуальные элементы, из которых состоят графики, и управлять ими. Способность запрограммировать визуальное представление позволяет управлять воспроизводимостью данных в разных средах особенно при изменениях или обновлениях.
А поскольку matplotlib — это библиотека Python, она позволяет на полную использовать потенциал остальных библиотек языка. Чаще всего работе с анализом данных matplotlib взаимодействует с набором других библиотек, таких как NumPy и pandas, но можно добавлять и другие.
Наконец, графическое представление из этой библиотеки можно экспортировать в самые распространенные графические форматы (PNG и SVG) и затем использовать в других приложениях, документах, в сети и так далее.
Установка
Есть много вариантов установки matplotlib. Если это дистрибутив пакетов, такой как Anaconda или Enthought Canopy, то процесс очень простой. Например, используя пакетный менеджер conda, достаточно ввести следующее:
conda install matplotlib
Если его нужно установить прямо, то команды зависят от операционной системы
В системах Debian-Ubuntu:
sudo apt-get install python-matplotlib
В Fedora-Redhat:
sudo yum install python-matplotlib
В macOS или Windows нужно использовать pip
IPython и IPython QtConsole
Для знакомства со всеми инструментами мира Python часто используют IPython из терминала или QtConsole. Все благодаря тому, что IPython позволяет использовать интерактивность улучшенного терминала и интегрировать графику прямо в консоль.
Для запуска сессии IPython нужно использовать следующую команду:
ipython
Python 3.6.3 (default, Oct 15 2017, 03:27:45) [MSC v.1900 64 bit (AMD64)]
Type "copyright", "credits" or "license" for more information.
IPython 3.6.3 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
Если же используется Jupyter QtConsole с возможностью отображения графики вместе с командами, то нужна эта:
jupyter qtconsole
На экране тут же отобразится новое окно с запущенной сессией IPython.
Однако ничто не мешает использовать стандартную сессию Python. Все примеры дальше будут работать и в таком случае.
Архитектура matplotlib
Одна из основных задач, которую выполняет matplotlib — предоставление набора функций и инструментов для представления и управления Figure (так называется основной объект) вместе со всеми внутренними объектами, из которого он состоит. Но в matplotlib есть также инструменты для обработки событий и, например, анимации. Благодаря им эта библиотека способна создавать интерактивные графики на основе событий по нажатию кнопки или движению мыши.
Архитектура matplotlib логически разделена на три слоя, расположенных на трех уровнях. Коммуникация непрямая — каждый слой может взаимодействовать только с тем, что расположен под ним, но не над.
Вот эти слои:
- Слой сценария
- Художественный слой
- Слой бэкенда
Слой бэкенда
Слой Backend является нижним на диаграмме с архитектурой всей библиотеки. Он содержит все API и набор классов, отвечающих за реализацию графических элементов на низком уровне.
FigureCanvas— это объект, олицетворяющий область рисования.Renderer— объект, который рисует поFigureCanvas.Event— объект, обрабатывающий ввод от пользователя (события с клавиатуры и мыши)
Художественный слой
Средним слоем выступает художественный (artist). Все элементы, составляющие график, такие как название, метки осей, маркеры и так далее, являются экземплярами этого объекта. Каждый из них играет свою роль в иерархической структуре.
Есть два художественных класса: примитивный и составной.
- Примитивный — это объекты, которые представляют собой базовые элементы для формирования графического представления графика, например, Line2D, или геометрические фигуры, такие как прямоугольник круг или даже текст.
- Составные — объекты, состоящие из нескольких базовых (примитивных). Это оси, шкалы и диаграммы.
На этом уровне часто приходится иметь дело с объектами, занимающими высокое положение в иерархии: график, система координат, оси. Поэтому важно полностью понимать, какую роль они играют. Следующее изображение показывает три основных художественных (составных объекта), которые часто используются на этом уровне.
Figure— объект, занимающий верхнюю позицию в иерархии. Он соответствует всему графическому представлению и может содержать много систем координат.Axes— это тот самый график. Каждая система координат принадлежит только одному объектуFigureи имеет два объектаAxis(или три, если речь идет о трехмерном графике). Другие объекты, такие как название, меткиxиy, принадлежат отдельно осям.Axisучитывает числовые значения в системе координат, определяет пределы и управляет обозначениями на осях, а также соответствующим каждому из них текстом. Положение шкал определяется объектомLocator, а внешний вид —Formatter.
Слой сценария (pyplot)
Художественные классы и связанные с ними функции (API matplotlib) подходят всем разработчикам, особенно тем, кто работает с серверами веб-приложений или разрабатывает графические интерфейсы. Но для вычислений, в частности для анализа и визуализации данных, лучше всего подходит слой сценария. Он включает интерфейс pyplot.
pylab и pyplot
Существуют две библиотеки: pylab и pyplot. Но в чем между ними разница? Pylab — это модуль, устанавливаемый вместе с matplotlib, а pyplot — внутренний модуль matplotlib. На оба часто ссылаются.
from pylab import *
# и
import matplotlib.pyplot as plt
import numpy as np
Pylab объединяет функциональность pyplot с возможностями NumPy в одном пространстве имен, поэтому отдельно импортировать NumPy не нужно. Более того, при импорте pylab функции из pyplot и NumPy можно вызывать без ссылки на модуль (пространство имен), что похоже на MATLAB.
plot(x,y)
array([1,2,3,4])
# вместо
plt.plot()
np.array([1,2,3,4]
Пакет pyplot предлагает классический интерфейс Python для программирования, имеет собственное пространство имеет и требует отдельного импорта NumPy. В последующих материалах используется этот подход. Его же применяет большая часть программистов на Python.
Модули Keras предоставляют различные классы и алгоритмы глубокого обучения. Дальше о них и пойдет речь.
Модули Keras
В Keras представлены следующие модули:
- Бэкенд
- Утилиты
- Обработка изображений
- Последовательная последовательности
- Обработка текста
- Обратный вызов
Модуль бэкенда в Keras
Keras — это высокоуровневый API, который не заостряет внимание на вычислениях на бэкенде. Однако он позволяет пользователям изучать свой бэкенд и делать изменения на этом уровне. Для этого есть специальный модуль.
Его конфигурация по умолчанию хранится в файле $Home/keras/keras.json.
Он выглядит вот так:
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Можно дописать код, совместимый с этим бэкендом.
from Keras import backend as K
b=K.random_uniform_variable(shape=(3,4),low=0,high=1)
c=K.random_uniform_variable(shape=(3,4),mean=0,scale=1)
d=K.random_uniform_variable(shape=(3,4),mean=0,scale=1)
a=b + c * K.abs(d)
c=K.dot(a,K.transpose(b))
a=K.sum(b,axis=1)
a=K.softmax(b)
a=K.concatenate([b,c],axis=1)
Модуль утилит в Keras
Этот модуль предоставляет утилиты для операций глубокого обучения. Вот некоторые из них.
HDF5Matrix
Для преобразования входящих данных в формат HDF5.
from.utils import HDF5Matrix data=HDF5Matrix('data.hdf5','data')
to_categorical
Для унитарной кодировки (one hot encoding) векторов класса.
from keras.utils import to_categorical
labels = [0,1,2,3,4,5]
to_categorical(labels)
print_summary
Для вывода сводки по модели.
from keras.utils import print_summary
print_summary(model)
Модуль обработки изображений в Keras
Содержит методы для конвертации изображений в массивы NumPy. Также есть функции для представления данных.
Класс ImageDataGenerator
Используется для дополнения данных в реальном времени.
keras.preprocessing.image.ImageDataGenerator(featurewise_center, samplewise_center, featurewise_std_normalization, samplewise_std_normalization, zca_whitening, zca_epsilon=1e-06, rotation_range=0, width_shift_range=0.0, height_shift_range=0.0, brightness_range, shear_range=0.0, zoom_range=0.0, channel_shift_range=0.0, fill_mode='nearest', cval=0.0, horizontal_flip, vertical_flip)
Методы ImageDataGenerator
apply_transform:
Для применения изменений к изображению
apply_transform(x, transform_parameters)
flow
Для генерации серий дополнительных данных.
flow(x, y, batch_size=32, shuffle, sample_weight, seed, save_to_dir, save_prefix='', save_format='png', subset)
standardize
Для нормализации входящего пакета.
standardize(x)
Модуль обработки последовательности
Методы для генерации основанных на времени данных из ввода. Также есть функции для представления данных.
TimeseriesGenerator
Для генерации временных данных.
keras.preprocessing.sequence.TimeseriesGenerator(data, targets, length, sampling_rate, stride, start_index, end_index)
skipgrams
Конвертирует последовательность слов в кортежи слов.
keras.preprocessing.sequence.skipgrams(sequence, vocabulary_size, window_size=4, negative_samples=1.0, shuffle, categorical, sampling_table, seed)
Модуль предварительной обработки текста
Методы для конвертации текста в массивы NumPy. Есть также методы для подготовки данных.
Tokenizer
Используется для конвертации основного текста в векторы.
keras.preprocessing.text.Tokenizer(num_words, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower, split=' ', char_level, oov_token=, document_count=0)
one_hot
Для кодировки текста в список слов.
keras.preprocessing.text.one_hot(text, n, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower, split=' ')
text_to_word_sequence
Для конвертации текста в последовательность слов.
keras.preprocessing.text.text_to_word_sequence(text, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower, split=' ')
Модуль обратного вызова
Предоставляет функции обратного вызова. Используется для изучения промежуточных результатов.
Callback
Для создания новых обратных вызовов.
keras.callbacks.callbacks.Callback()
BaseLogger
Для вычисления среднего значения метрик.
keras.callbacks.callbacks.BaseLogger(stateful_metrics)
History
Для записи событий.
keras.callbacks.callbacks.History()
ModelCheckpoint
Для сохранения модели после каждого временного промежутка.
keras.callbacks.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only, save_weights_only, mode='auto', period=1)
Выводы
Теперь вы знакомы с разными модулями Keras и знаете, для чего они нужны.
]]>Манипуляция строками
Python — это популярный язык, который благодаря своей простоте часто используется для обработки строк и текста. Большая часть операций может быть выполнена даже с помощью встроенных функций. А для более сложных используются регулярные выражения.
Встроенные методы для работы со строками
В большинстве случаев имеются сложные строки, которые желательно разделять на части и присваивать их правильным переменным. Функция split() позволяет разбить тексты на части, используя разделитель в качестве ориентира. Им может быть, например, запятая.
>>> text = '16 Bolton Avenue , Boston'
>>> text.split(',')
['16 Bolton Avenue ', 'Boston']
По первому элементу видно, что в конце у него остается пробел. Чтобы решить эту проблему, вместе со split() нужно также использовать функцию strip(), которая обрезает пустое пространство (включая символы новой строки)
>>> tokens = [s.strip() for s in text.split(',')]
>>> tokens
['16 Bolton Avenue', 'Boston']
Результат — массив строк. Если элементов не много, то можно выполнить присваивание вот так:
>>> address, city = [s.strip() for s in text.split(',')]
>>> address
'16 Bolton Avenue'
>>> city
'Boston'
Помимо разбития текста на части часто требуется сделать обратное — конкатенировать разные строки, получив в результате текст большого объема. Самый простой способ — использовать оператор +.
>>> address + ',' + city
'16 Bolton Avenue, Boston'
Но это сработает только в том случае, если строк не больше двух-трех. Если же их больше, то есть метод join(). Его нужно применять к желаемому разделителю, передав в качестве аргумента список строк.
>>> strings = ['A+','A','A-','B','BB','BBB','C+']
>>> ';'.join(strings)
'A+;A;A-;B;BB;BBB;C+'
Еще один тип операции, которую можно выполнять со строкой — поиск отдельных частей, подстрок. В Python для этого есть ключевое слово, используемое для обнаружения подстрок.
>>> 'Boston' in text
True
Но имеются и две функции, которые выполняют ту же задачу: index() и find().
>>> text.index('Boston')
19
>>> text.find('Boston')
19
В обоих случаях возвращаемое значение — наименьший индекс, где встречаются искомые символы. Разница лишь в поведении функций в случае, если подстрока не была найдена:
>>> text.index('New York')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
>>> text.find('New York')
-1
Если index() вернет сообщение с ошибкой, то find() – -1. Также можно посчитать, как часто символ или комбинация из нескольких (подстрока) встречаются в тексте. За это отвечает функция count().
>>> text.count('e')
2
>>> text.count('Avenue')
1
Еще одна доступная операция — замена или удаление подстроки (или отдельного символа). В обоих случаях применяется функция replace(), где удаление подстроки — это то же самое, что и замена ее на пустой символ.
Регулярные выражения
Регулярные выражения предоставляют гибкий способ поиска совпадающих паттернов в тексте. Выражение regex — это строка, написанная с помощью языка регулярных выражений. В Python есть встроенный модуль re, который отвечает за работу с регулярными выражениями.
В первую очередь его нужно импортировать:
>>> import re
Модуль re предоставляет набор функций, которые можно поделить на три категории:
- Поиск совпадающих паттернов
- Замена
- Разбиение
Теперь разберем на примерах. Регулярное выражение для поиска одного или последовательности пробельных символов — \s+. В прошлом разделе вы видели, как для разделения текста на части с помощью split() используется символ разделения. В модуле re есть такая же функция. Она выполняет аналогичную задачу, но в качестве аргумента условия разделения принимает паттерн с регулярным выражением, что делает ее более гибкой.
>>> text = "This is an\t odd \n text!"
>>> re.split('\s+', text)
['This', 'is', 'an', 'odd', 'text!']
Разберемся чуть подробнее с принципом работы модуля re. При вызове функции re.split() сперва компилируется регулярное выражение, а только потом вызывается split() с готовым текстовым аргументом. Можно скомпилировать функцию регулярного выражения с помощью re.compile() и получить объект, который будет использоваться повторно, сэкономив таким образом циклы CPU.
Это особенно важно для операций последовательного поиска подстроки во множестве или массиве строк.
>>> regex = re.compile('\s+')
Создав объект regex с помощью функции compile(), вы сможете прямо использовать split() следующим образом.
>>> regex.split(text)
['This', 'is', 'an', 'odd', 'text!']
Для поиска совпадений паттерна с другими подстроками в тексте используется функция findall(). Она возвращает список всех подстрок, которые соответствуют условиям.
Например, если нужно найти в строке все слова, начинающиеся с латинской «A» в верхнем регистре, или, например, с «a» в любом регистре, необходимо ввести следующее:
>>> text = 'This is my address: 16 Bolton Avenue, Boston'
>>> re.findall('A\w+',text)
['Avenue']
>>> re.findall('[A,a]\w+',text)
['address', 'Avenue']
Есть еще две функции, которые связаны с findall():match() и search(). И если findall() возвращает все совпадения в списке, то search() — только первое. Более того, он является конкретным объектом.
>>> re.search('[A,a]\w+',text)
<_sre.SRE_Match object; span=(11, 18), match='address'>
Этот объект не содержит значение подстроки, соответствующей паттерну, а всего лишь индексы начала и окончания.
>>> search = re.search('[A,a]\w+',text)
>>> search.start()
11
>>> search.end()
18
>>> text[search.start():search.end()]
'address'
Функция match() ищет совпадение в начале строке; если его нет для первого символа, то двигается дальше и ищет в самой строке. Если совпадений не найдено вовсе, то она ничего не вернет.
>>> re.match('[A,a]\w+',text)
В случае успеха же она возвращает то же, что и функция search().
>>> re.match('T\w+',text)
<_sre.SRE_Match object; span=(0, 4), match='This'>
>>> match = re.match('T\w+',text)
>>> text[match.start():match.end()]
'This'
Агрегация данных
Последний этап работы с данными — агрегация. Он включает в себя преобразование, в результате которого из массива получается целое число. На самом деле, ранее упоминаемые функции sum(), mean() и count() — это тоже агрегация. Они работают с наборами данных и выполняют вычисления, результатом которых всегда является одно значение. Однако более формальный способ, дающий больше контроля над агрегацией, включает категоризацию наборов данных.
Категоризация набора, необходимая для группировки, — это важный этап в процессе обработки данных. Это тоже процесс преобразования, ведь после разделения на группы, применяется функция, которая конвертирует или преобразовывает данные определенным образом в зависимости от того, к какой группе они принадлежат. Часто фазы группировки и применения функции происходит в один шаг.
Также для этого этапа анализа данных pandas предоставляет гибкий и производительный инструмент — GroupBy.
Как и в случае с join те, кто знаком с реляционными базами данных и языком SQL, увидят знакомые вещи. Однако языки, такие как SQL, довольно ограничены, когда их применяют к группам. А вот гибкость таких языков, как Python, со всеми доступными библиотеками, особенно pandas, дает возможность выполнять очень сложные операции.
GroupBy
Теперь разберем в подробностях механизм работы GroupBy. Он использует внутренний механизм, процесс под названием split-apply-combine. Это паттерн, который можно разбить на три фазы, выделив отдельные операции:
- Разделение — разделение на группы датасетов
- Применение — применение функции к каждой группе
- Комбинирование — комбинирование результатов разных групп
Рассмотрите процесс подробно на следующей схеме. На первом этапе, разделении, данные из структуры (Dataframe или Series) разделяются на несколько групп в соответствии с заданными критериями: индексами или значениями в колонках. На жаргоне SQL значения в этой колонке называются ключами. Если же вы работаете с двухмерными объектами, такими как Dataframe, критерий группировки может быть применен и к строке (axis = 0), и колонке (axis = 1).
Вторая фаза состоит из применения функции или, если быть точнее, — вычисления, основанного на функции, результатом которого является одно значение, характерное для этой группы.
Последний этап собирает результаты каждой группы и комбинирует их в один объект.
Практический пример
Теперь вы знаете, что процесс агрегации данных в pandas разделен на несколько этапов: разделение-применение-комбинирование. И пусть в библиотеке они не выражены явно конкретными функциями, функция groupby() генерирует объект GroupBy, который является ядром целого процесса.
Для лучшего понимания этого механизма стоит обратиться к реальному примеру. Сперва создадим Dataframe с разными числовыми и текстовыми значениями.
>>> frame = pd.DataFrame({ 'color': ['white','red','green','red','green'],
... 'object': ['pen','pencil','pencil','ashtray','pen'],
... 'price1' : [5.56,4.20,1.30,0.56,2.75],
... 'price2' : [4.75,4.12,1.60,0.75,3.15]})
>>> frame
| | color | object | price1 | price2 |
|---|-------|---------|--------|--------|
| 0 | white | pen | 5.56 | 4.75 |
| 1 | red | pencil | 4.20 | 4.12 |
| 2 | green | pencil | 1.30 | 1.60 |
| 3 | red | ashtray | 0.56 | 0.75 |
| 4 | green | pen | 2.75 | 3.15 |
Предположим, нужно посчитать среднюю стоимость в колонке price1 с помощью меток из колонки color. Есть несколько способов, как этого можно добиться. Например, можно получить доступ к колонке price1 и затем вызвать groupby(), где колонка color будет выступать аргументом.
>>> group = frame['price1'].groupby(frame['color'])
>>> group
<pandas.core.groupby.SeriesGroupBy object at 0x00000000098A2A20>
Результат — объект GroupBy. Однако в этой операции не было никаких вычислений; пока что была лишь собрана информация, которая необходима для вычисления среднего значения. Теперь у нас есть group, где все строки с одинаковым значением цвета сгруппированы в один объект.
Чтобы понять, как произошло такое разделение на группы, вызовите атрибут groups для объекта GroupBy.
>>> group.groups
{'green': Int64Index([2, 4], dtype='int64'),
'red': Int64Index([1, 3], dtype='int64'),
'white': Int64Index([0], dtype='int64')}
Как видите, здесь перечислены все группы и явно обозначены строки Dataframe в них. Теперь нужно применить операцию для получения результатов каждой из групп.
>>> group.mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> group.sum()
color
green 4.05
red 4.76
white 5.56
Name: price1, dtype: float64
Группировка по иерархии
В прошлом разделе данные были сгруппированы по значениям колонки-ключа. Тот же подход можно использовать и для нескольких колонок, сделав группировку нескольких ключей иерархической.
>>> ggroup = frame['price1'].groupby([frame['color'],frame['object']])
>>> ggroup.groups
{('green', 'pen'): Int64Index([4], dtype='int64'),
('green', 'pencil'): Int64Index([2], dtype='int64'),
('red', 'ashtray'): Int64Index([3], dtype='int64'),
('red', 'pencil'): Int64Index([1], dtype='int64'),
('white', 'pen'): Int64Index([0], dtype='int64')}
>>> ggroup.sum()
color object
green pen 2.75
pencil 1.30
red ashtray 0.56
pencil 4.20
white pen 5.56
Name: price1, dtype: float64
Группировка может работать не только с одной колонкой, но и с несколькими или целым Dataframe. Также если объект GroupBy не потребуется использовать несколько раз, просто удобно выполнять группировки и расчеты за раз, без объявления дополнительных переменных.
>>> frame[['price1','price2']].groupby(frame['color']).mean()
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
>>> frame.groupby(frame['color']).mean()
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
Итерация с группировкой
Объект GroupBy поддерживает операцию итерации для генерации последовательности из двух кортежей, содержащих названия групп и их данных.
>>> for name, group in frame.groupby('color'):
... print(name)
... print(group)
green
color object price1 price2
2 green pencil 1.30 1.60
4 green pen 2.75 3.15
red
color object price1 price2
1 red pencil 4.20 4.12
3 red ashtray 0.56 0.75
white
color object price1 price2
0 white pen 5.56 4.75
В последнем примере для иллюстрации был применен вывод переменных. Но операцию вывода на экран можно заменить на функцию, которую требуется применить.
Цепочка преобразований
Из этих примеров должно стать понятно, что при передаче функциям вычисления или другим операциям группировок (вне зависимости от способа их получения) результатом всегда является Series (если была выбрана одна колонка) или Dataframe, сохраняющий систему индексов и названия колонок.
>>> result1 = frame['price1'].groupby(frame['color']).mean()
>>> type(result1)
<class 'pandas.core.series.Series'>
>>> result2 = frame.groupby(frame['color']).mean()
>>> type(result2)
<class 'pandas.core.frame.DataFrame'>
Таким образом становится возможным выбрать одну колонку на разных этапах процесса. Дальше три примера выбора одной колонки на трех разных этапах. Они иллюстрируют гибкость такой системы группировки в pandas.
>>> frame['price1'].groupby(frame['color']).mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> frame.groupby(frame['color'])['price1'].mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> (frame.groupby(frame['color']).mean())['price1']
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
Но также после операции агрегации имена некоторых колонок могут не нести нужное значение. Поэтому часто оказывается полезным добавлять префикс, объясняющий бизнес-логику такого объединения. Добавление префикса (вместо использования полностью нового имени) помогает отслеживать источник данных. Это важно в случае применения процесса цепочки преобразований (когда Series или Dataframe генерируются друг из друга), где важно отслеживать исходные данные.
>>> means = frame.groupby('color').mean().add_prefix('mean_')
>>> means
| | mean_price1 | mean_price2 |
|-------|-------------|-------------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
Функции для групп
Хотя многие методы не были реализованы специально для GroupBy, они корректно работают с Series. В прошлых примерах было видно, насколько просто получить Series на основе объекта GroupBy, указав имя колонки и применив метод для вычислений. Например, можно использование вычисление квантилей с помощью функции quantiles().
>>> group = frame.groupby('color')
>>> group['price1'].quantile(0.6)
color
green 2.170
red 2.744
white 5.560
Name: price1, dtype: float64
Также можно определять собственные функции агрегации. Для этого функцию нужно создать и передать в качестве аргумента функции mark(). Например, можно вычислить диапазон значений для каждой группы.
>>> def range(series):
... return series.max() - series.min()
...
>>> group['price1'].agg(range)
color
green 1.45
red 3.64
white 0.00
Name: price1, dtype: float64
Функция agg() позволяет использовать функции агрегации для всего объекта Dataframe.
>>> group.agg(range)
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 1.45 | 1.55 |
| red | 3.64 | 3.37 |
| white | 0.00 | 0.00 |
Также можно использовать больше функций агрегации одновременно с помощью mark(), передав массив со списком операций для выполнения. Они станут новыми колонками.
>>> group['price1'].agg(['mean','std',range])
| | mean | std | range |
|-------|-------|----------|-------|
| color | | | |
| green | 2.025 | 1.025305 | 1.45 |
| red | 2.380 | 2.573869 | 3.64 |
| white | 5.560 | NaN | 0.00 |
Продвинутая агрегация данных
В этом разделе речь пойдет о функциях transform() и apply(), которые позволяют выполнять разные виды операций, включая очень сложные.
Предположим, что в одном Dataframe нужно получить следующее: оригинальный объект (с данными) и полученный с помощью вычисления агрегации, например, сложения.
>>> frame = pd.DataFrame({ 'color':['white','red','green','red','green'],
... 'price1':[5.56,4.20,1.30,0.56,2.75],
... 'price2':[4.75,4.12,1.60,0.75,3.15]})
>>> frame
| | color | price1 | price2 |
|---|-------|--------|--------|
| 0 | white | 5.56 | 4.75 |
| 1 | red | 4.20 | 4.12 |
| 2 | green | 1.30 | 1.60 |
| 3 | red | 0.56 | 0.75 |
| 4 | green | 2.75 | 3.15 |
>>> sums = frame.groupby('color').sum().add_prefix('tot_')
>>> sums
| | tot_price1 | tot_price2 | price2 |
|-------|------------|------------|--------|
| color | | | 4.75 |
| green | 4.05 | 4.75 | 4.12 |
| red | 4.76 | 4.87 | 1.60 |
| white | 5.56 | 4.75 | 0.75 |
>>> merge(frame,sums,left_on='color',right_index=True)
| | color | price1 | price2 | tot_price1 | tot_price2 |
|---|-------|--------|--------|------------|------------|
| 0 | white | 5.56 | 4.75 | 5.56 | 4.75 |
| 1 | red | 4.20 | 4.12 | 4.76 | 4.87 |
| 3 | red | 0.56 | 0.75 | 4.76 | 4.87 |
| 2 | green | 1.30 | 1.60 | 4.05 | 4.75 |
| 4 | green | 2.75 | 3.15 | 4.05 | 4.75 |
Благодаря merge() можно сложить результаты агрегации в каждой строке. Но есть и другой способ, работающий за счет transform(). Эта функция выполняет агрегацию, но в то же время показывает значения, сделанные с помощью вычислений на основе ключевого значения в каждой строке Dataframe.
>>> frame.groupby('color').transform(np.sum).add_prefix('tot_')
| | tot_price1 | tot_price2 |
|---|------------|------------|
| 0 | 5.56 | 4.75 |
| 1 | 4.76 | 4.87 |
| 2 | 4.05 | 4.75 |
| 3 | 4.76 | 4.87 |
| 4 | 4.05 | 4.75 |
Метод transform() — более специализированная функция с конкретными условиями: передаваемая в качестве аргумента функция должна возвращать одно скалярное значение (агрегацию).
Метод для более привычных GroupBy — это apply(). Он в полной мере реализует схему разделение-применение-комбинирование. Функция разделяет объект на части для преобразования, вызывает функцию для каждой из частей и затем пытается связать их между собой.
>>> frame = pd.DataFrame( { 'color':['white','black','white','white','black','black'],
... 'status':['up','up','down','down','down','up'],
... 'value1':[12.33,14.55,22.34,27.84,23.40,18.33],
... 'value2':[11.23,31.80,29.99,31.18,18.25,22.44]})
>>> frame
| | color | price1 | price2 | status |
|---|-------|--------|--------|--------|
| 0 | white | 12.33 | 11.23 | up |
| 1 | black | 14.55 | 31.80 | up |
| 2 | white | 22.34 | 29.99 | down |
| 3 | white | 27.84 | 31.18 | down |
| 4 | black | 23.40 | 18.25 | down |
| 5 | black | 18.33 | 22.44 | up |
>>> frame.groupby(['color','status']).apply( lambda x: x.max())
| | | color | price1 | price2 | status |
|-------|--------|-------|--------|--------|--------|
| color | status | | | | |
| black | down | black | 23.40 | 18.25 | down |
| | up | black | 18.33 | 31.80 | up |
| white | down | white | 27.84 | 31.18 | down |
| | up | white | 12.33 | 11.23 | up |
>>> frame.rename(index=reindex, columns=recolumn)
| | color | price1 | price2 | status |
|--------|-------|--------|--------|--------|
| first | white | 12.33 | 11.23 | up |
| second | black | 14.55 | 31.80 | up |
| third | white | 22.34 | 29.99 | down |
| fourth | white | 27.84 | 31.18 | down |
| fifth | black | 23.40 | 18.25 | down |
| 5 | black | 18.33 | 22.44 | up |
>>> temp = pd.date_range('1/1/2015', periods=10, freq= 'H')
>>> temp
DatetimeIndex(['2015-01-01 00:00:00', '2015-01-01 01:00:00',
'2015-01-01 02:00:00', '2015-01-01 03:00:00',
'2015-01-01 04:00:00', '2015-01-01 05:00:00',
'2015-01-01 06:00:00', '2015-01-01 07:00:00',
'2015-01-01 08:00:00', '2015-01-01 09:00:00'],
dtype='datetime64[ns]', freq='H')
>>> timeseries = pd.Series(np.random.rand(10), index=temp)
>>> timeseries
2015-01-01 00:00:00 0.317051
2015-01-01 01:00:00 0.628468
2015-01-01 02:00:00 0.829405
2015-01-01 03:00:00 0.792059
2015-01-01 04:00:00 0.486475
2015-01-01 05:00:00 0.707027
2015-01-01 06:00:00 0.293156
2015-01-01 07:00:00 0.091072
2015-01-01 08:00:00 0.146105
2015-01-01 09:00:00 0.500388
Freq: H, dtype: float64
>>> timetable = pd.DataFrame( {'date': temp, 'value1' : np.random.rand(10),
... 'value2' : np.random.rand(10)})
>>> timetable
| | date | value1 | value2 |
|---|---------------------|----------|----------|
| 0 | 2015-01-01 00:00:00 | 0.125229 | 0.995517 |
| 1 | 2015-01-01 01:00:00 | 0.597289 | 0.160828 |
| 2 | 2015-01-01 02:00:00 | 0.231104 | 0.076982 |
| 3 | 2015-01-01 03:00:00 | 0.862940 | 0.270581 |
| 4 | 2015-01-01 04:00:00 | 0.534056 | 0.306486 |
| 5 | 2015-01-01 05:00:00 | 0.162040 | 0.979835 |
| 6 | 2015-01-01 06:00:00 | 0.400413 | 0.486397 |
| 7 | 2015-01-01 07:00:00 | 0.157052 | 0.246959 |
| 8 | 2015-01-01 08:00:00 | 0.835632 | 0.572664 |
| 9 | 2015-01-01 09:00:00 | 0.812283 | 0.388435 |
Затем Dataframe добавляется колонка с набором текстовых значений, которые будут выступать ключевыми значениями.
>>> timetable['cat'] = ['up','down','left','left','up','up','down','right',
'right','up']
>>> timetable
| | date | value1 | value2 | cat |
|---|---------------------|----------|----------|-------|
| 0 | 2015-01-01 00:00:00 | 0.125229 | 0.995517 | up |
| 1 | 2015-01-01 01:00:00 | 0.597289 | 0.160828 | down |
| 2 | 2015-01-01 02:00:00 | 0.231104 | 0.076982 | left |
| 3 | 2015-01-01 03:00:00 | 0.862940 | 0.270581 | left |
| 4 | 2015-01-01 04:00:00 | 0.534056 | 0.306486 | up |
| 5 | 2015-01-01 05:00:00 | 0.162040 | 0.979835 | up |
| 6 | 2015-01-01 06:00:00 | 0.400413 | 0.486397 | down |
| 7 | 2015-01-01 07:00:00 | 0.157052 | 0.246959 | right |
| 8 | 2015-01-01 08:00:00 | 0.835632 | 0.572664 | right |
| 9 | 2015-01-01 09:00:00 | 0.812283 | 0.388435 | up |
Но в этом примере все равно есть повторяющиеся ключи.
]]>Нейронная сеть — это стек из слоев. Каждый из них получает входящие данные, делает вычисления и передает результат следующему. В Keras есть много встроенных слоев. Например, Conv2D, MaxPooling2D, Dense и Flatten имеют по несколько сценариев использования, но их нужно применять в соответствии с определенными требованиями. Однако иногда может потребоваться делать вычисления, которые не связаны с тем, что умеет Keras.
В таком случае нужно будет создать собственный слой и определить алгоритм для вычислений на основе входящих данных. В Keras есть инструмент для создания кастомных слоев. В этом материале разберемся, что они собой представляют и рассмотрим примеры построения таких слоев.
Кастомные слои Keras можно добавить двумя путями:
- Лямбда-слой
- Кастомный слой класса
Лямбда-слой в Keras
Лямбда-слои используются в Keras в тех случаях, когда нет нужды добавлять веса предыдущему слою. Этот слой создается для простых операций. Он напоминает лямбда-функции.
Сперва определяется функция, принимающая предыдущий слой в качестве источника входящих данных, затем выполняются вычисления, и возвращаются обновленные тензоры. После этого функция передается кастомному лямбда-слою.
Самое распространенное применение лямбда-слоя — определение собственной функции активации.
Предположим, нужно определить собственную функцию активации ReLU с помощью лямбда-слоя.
from keras.layer import Lambda
from keras import backend as K
def custom_function(input):
return K.maximum(0.,input)
lambda_output = Lambda(custom_function)(input)
Этого достаточно для создания.
После этого слой добавляется в модель тем же способом, что и остальные.
model.add(lambda_output)
Кастомный слой класса в Keras
А теперь создадим собственный слой с весами. Для этого нужно реализовать четыре метода:
__init__— инициализируется переменная класса и переменная суперклассаbuild(input_shape)— определяются весаcall(x)— определяется алгоритм вычислений. В качестве аргумента принимается тензорcompute_output_shape(input_shape)— определяется форма вывода слоя
Рассмотрим получившуюся реализацию:
from keras import backend as K
from keras.layers import Layer
class custom_layer(Layer):
def __init__(self,output_dim,**kwargs):
self.output_dim=output_dim
super(custom_layer,self).__init__(**kwargs)
def build(self,input_shape):
self.W=self.add_weight(name=’kernel’,
shape=(input_shape[1],
self.output_dim),
initializer=’uniform’,
trainable=True)
self.built = True
def call(self,x):
return K.dot(x,self.W)
def compute_output_shape(self,input_shape):
return (input_shape[0], self.output_dim)
Здесь используется всего один тензор, но их можно передать несколько в одном списке.
Выводы
Эта статья посвящена принципам создания кастомных слоев Keras. Есть два способа: лямбда-слои и слои класса. Первые нужны для базовых операций, а вторые — для применения весов ко входящим данным.
]]>Процесс подготовки данных для анализа включает сборку данных в Dataframe с возможными добавлениями из других объектов и удалением ненужных частей. Следующий этап — трансформация. После того как данные внутри структуры организованы, нужно преобразовать ее значения. Этот раздел будет посвящен распространенным проблемам и процессам, которые требуются для их решения с помощью функций библиотеки pandas.
Среди них удаление элементов с повторяющимися значениями, изменение индексов, обработка числовых значений данных и строк.
Удаление повторов
Дубликаты строк могут присутствовать в Dataframe по разным причинам. И в объектах особо крупного размера их может быть сложно обнаружить. Для этого в pandas есть инструменты анализа повторяющихся данных для крупных структур.
Для начала создадим простой Dataframe с повторяющимися строками.
>>> dframe = pd.DataFrame({'color': ['white','white','red','red','white'],
... 'value': [2,1,3,3,2]})
>>> dframe
| | color | value |
|---|-------|-------|
| 0 | white | 2 |
| 1 | white | 1 |
| 2 | red | 3 |
| 3 | red | 3 |
| 4 | white | 2 |
Функция duplicated() способна обнаружить дубликаты. Она вернет объект Series, состоящий из булевых значений, где каждый элемент соответствует строке. Их значения равны True, если строка является дубликатом (все повторения за исключением первого) и False, если повторов этого элемента не было.
>>> dframe.duplicated()
0 False
1 False
2 False
3 True
4 True
dtype: bool
Объект с булевыми элементами может быть особенно полезен, например, для фильтрации. Так, чтобы увидеть строки-дубликаты, нужно просто написать следующее:
>>> dframe[dframe.duplicated()]
| | color | value |
|---|-------|-------|
| 3 | red | 3 |
| 4 | white | 2 |
Обычно повторяющиеся строки удаляются. Для этого в pandas есть функция drop_duplicates(), которая возвращает Dataframe без дубликатов.
>>> dframe = dframe.drop_duplicates()
>>> dframe
| | color | value |
|---|-------|-------|
| 0 | white | 2 |
| 2 | red | 3 |
Маппинг
Библиотека pandas предоставляет набор функций, использующих маппинг для выполнения определенных операций. Маппинг — это всего лишь создание списка совпадений двух разных значений, что позволяет привязывать значение определенной метке или строке.
Для определения маппинга лучше всего подходит объект dict:
map = {
'label1' : 'value1,
'label2' : 'value2,
...
}
Функции, которые будут дальше встречаться в этом разделе, выполняют конкретные операции, но всегда принимают объект dict.
• replace() — Заменяет значения
• map() — Создает новый столбец
• rename() — Заменяет значения индекса
Замена значений с помощью маппинга
Часто бывает так, что в готовой структуре данных присутствуют значения, не соответствующие конкретным требованиям. Например, текст может быть написан на другом языке, являться синонимом или, например, выраженным в другом виде. В таких случаях используется операция замены разных значений.
Для примера определим Dataframe с разными объектами и их цветами, включая два названия цветов не на английском.
>>> frame = pd.DataFrame({'item':['ball','mug','pen','pencil','ashtray'],
... 'color':['white','rosso','verde','black','yellow'],
... 'price':[5.56,4.20,1.30,0.56,2.75]})
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | rosso | mug | 4.20 |
| 2 | verde | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Для замены некорректных значений новыми нужно определить маппинг соответствий, где ключами будут выступать новые значения.
>>> newcolors = {
... 'rosso': 'red',
... 'verde': 'green'
... }
Теперь осталось использовать функцию replace(), задав маппинг в качестве аргумента.
>>> frame.replace(newcolors)
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Как видно выше, два цвета были заменены на корректные значения в Dataframe. Распространенный пример — замена значений NaN на другие, например, на 0. Функция replace() отлично справляется и с этим.
>>> ser = pd.Series([1,3,np.nan,4,6,np.nan,3])
>>> ser
0 1.0
1 3.0
2 NaN
3 4.0
4 6.0
5 NaN
6 3.0
dtype: float64
>>> ser.replace(np.nan,0)
0 1.0
1 3.0
2 0.0
3 4.0
4 6.0
5 0.0
6 3.0
dtype: float64
Добавление значений с помощью маппинга
В предыдущем примере вы узнали, как менять значения с помощью маппинга. Теперь попробуем использовать маппинг на другом примере — для добавления новых значений в колонку на основе значений в другой. Маппинг всегда определяется отдельно.
>>> frame = pd.DataFrame({'item':['ball','mug','pen','pencil','ashtray'],
... 'color':['white','red','green','black','yellow']})
>>> frame
| | color | item |
|---|--------|---------|
| 0 | white | ball |
| 1 | red | mug |
| 2 | green | pen |
| 3 | black | pencil |
| 4 | yellow | ashtray |
Предположим, что нужно добавить колонку с ценой вещи из объекта. Также предположим, что имеется список цен. Определим его в виде объекта dict с ценами для каждого типа объекта.
>>> prices = {
... 'ball' : 5.56,
... 'mug' : 4.20,
... 'bottle' : 1.30,
... 'scissors' : 3.41,
... 'pen' : 1.30,
... 'pencil' : 0.56,
... 'ashtray' : 2.75
... }
Функция map(), примененная к Series или колонке объекта Dataframe принимает функцию или объект с маппингом dict. В этому случае можно применить маппинг цен для элементов колонки, добавив еще одну колонку price в Dataframe.
>>> frame['price'] = frame['item'].map(prices)
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Переименование индексов осей
По примеру того, как работает изменение значений в Series и Dataframe, можно трансформировать метки оси с помощью маппинга. Для замены меток индексов в pandas есть функция rename(), которая принимает маппинг (объект dict) в качестве аргумента.
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
>>> reindex = {
... 0: 'first',
... 1: 'second',
... 2: 'third',
... 3: 'fourth',
... 4: 'fifth'}
>>> frame.rename(reindex)
| | color | item | price |
|--------|--------|---------|-------|
| first | white | ball | 5.56 |
| second | red | mug | 4.20 |
| third | green | pen | 1.30 |
| fourth | black | pencil | 0.56 |
| fifth | yellow | ashtray | 2.75 |
По умолчанию переименовываются индексы. Если же нужно поменять названия колонок, то используется параметр columns. В следующем примере присвоим несколько маппингов двум индексам с параметром columns.
>>> recolumn = {
... 'item':'object',
... 'price': 'value'}
>>> frame.rename(index=reindex, columns=recolumn)
| | color | object | price |
|--------|--------|---------|-------|
| first | white | ball | 5.56 |
| second | red | mug | 4.20 |
| third | green | pen | 1.30 |
| fourth | black | pencil | 0.56 |
| fifth | yellow | ashtray | 2.75 |
В тех случаях когда заменить нужно только одно значение, все можно и не писать.
>>> frame.rename(index={1:'first'}, columns={'item':'object'})
| | color | object | price |
|-------|--------|---------|-------|
| 0 | white | ball | 5.56 |
| first | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Пока что функция rename() возвращала объект Dataframe с изменениями, не трогая оригинальный объект. Но если нужно поменять его, то необходимо передать значение True параметру inplace.
>>> frame.rename(columns={'item':'object'}, inplace=True)
>>> frame
| | color | object | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Дискретизация и биннинг
Более сложный процесс преобразования называется дискретизацией. Он используется для обработки большим объемов данных. Для анализа их необходимо разделять на дискретные категории, например, распределив диапазон значений на меньшие интервалы и посчитав статистику для каждого. Еще один пример — большое количество образцов. Даже здесь необходимо разделять весь диапазон по категориям и внутри них считать вхождения и статистику.
В следующем случае, например, нужно работать с экспериментальными значениями, лежащими в диапазоне от 0 до 100. Эти данные собраны в список.
>>> results = [12,34,67,55,28,90,99,12,3,56,74,44,87,23,49,89,87]
Вы знаете, что все значения лежат в диапазоне от 0 до 100, а это значит, что их можно разделить на 4 одинаковых части, бины. В первом будут элементы от 0 до 25, во втором — от 26 до 50, в третьем — от 51 до 75, а в последнем — от 75 до 100.
Для этого в pandas сначала нужно определить массив со значениями разделения:
>>> bins = [0,25,50,75,100]
Затем используется специальная функция cut(), которая применяется к массиву. В нее нужно добавить и бины.
>>> cat = pd.cut(results, bins)
>>> cat
(0, 25]
(25, 50]
(50, 75]
(50, 75]
(25, 50]
(75, 100]
(75, 100]
(0, 25]
(0, 25]
(50, 75]
(50, 75]
(25, 50]
(75, 100]
(0, 25]
(25, 50]
(75, 100]
(75, 100]
Levels (4): Index(['(0, 25]', '(25, 50]', '(50, 75]', '(75, 100]'],
dtype=object)
Функция cut() возвращает специальный объект типа Categorical. Его можно считать массивом строк с названиями бинов. Внутри каждая содержит массив categories, включающий названия разных внутренних категорий и массив codes со списком чисел, равных элементам results. Число соответствует бину, которому был присвоен соответствующий элемент results.
>>> cat.categories
IntervalIndex([0, 25], (25, 50], (50, 75], (75, 100]]
closed='right'
dtype='interval[int64]')
>>> cat.codes
array([0, 1, 2, 2, 1, 3, 3, 0, 0, 2, 2, 1, 3, 0, 1, 3, 3], dtype=int8)
Чтобы узнать число вхождений каждого бина, то есть, результаты для всех категорий, нужно использовать функцию value_counts().
>>> pd.value_counts(cat)
(75, 100] 5
(50, 75] 4
(25, 50] 4
(0, 25] 4
dtype: int64
У каждого класса есть нижний предел с круглой скобкой и верхний — с квадратной. Такая запись соответствует математической, используемой для записи интервалов. Если скобка квадратная, то число лежит в диапазоне, а если круглая — то нет.
Бинам можно задавать имена, передав их в массив строк, а затем присвоив его параметру labels в функции cut(), которая используется для создания объекта Categorical.
>>> bin_names = ['unlikely','less likely','likely','highly likely']
>>> pd.cut(results, bins, labels=bin_names)
unlikely
less likely
likely
likely
less likely
highly likely
highly likely
unlikely
unlikely
likely
likely
less likely
highly likely
unlikely
less likely
highly likely
highly likely
Levels (4): Index(['unlikely', 'less likely', 'likely', 'highly likely'],
dtype=object)
Если функции cut() передать в качестве аргумента целое число, а не границы бина, то диапазон значений будет разделен на указанное количество интервалов.
Пределы будут основаны на минимуме и максимуме данных.
>>> pd.cut(results, 5)
(2.904, 22.2]
(22.2, 41.4]
(60.6, 79.8]
(41.4, 60.6]
(22.2, 41.4]
(79.8, 99]
(79.8, 99]
(2.904, 22.2]
(2.904, 22.2]
(41.4, 60.6]
(60.6, 79.8]
(41.4, 60.6]
(79.8, 99]
(22.2, 41.4]
(41.4, 60.6]
(79.8, 99]
(79.8, 99]
Levels (5): Index(['(2.904, 22.2]', '(22.2, 41.4]', '(41.4, 60.6]',
'(60.6, 79.8]', '(79.8, 99]'], dtype=object)
Также в pandas есть еще одна функция для биннинга, qcut(). Она делит весь набор на квантили. Так, в зависимости от имеющихся данных cut() обеспечит разное количество данных для каждого бина. А qcut() позаботится о том, чтобы количество вхождений было одинаковым. Могут отличаться только границы.
>>> quintiles = pd.qcut(results, 5)
>>> quintiles
[3, 24]
(24, 46]
(62.6, 87]
(46, 62.6]
(24, 46]
(87, 99]
(87, 99]
[3, 24]
[3, 24]
(46, 62.6]
(62.6, 87]
(24, 46]
(62.6, 87]
[3, 24]
(46, 62.6]
(87, 99]
(62.6, 87]
Levels (5): Index(['[3, 24]', '(24, 46]', '(46, 62.6]', '(62.6, 87]',
'(87, 99]'], dtype=object)
>>> pd.value_counts(quintiles)
[3, 24] 4
(62.6, 87] 4
(87, 99] 3
(46, 62.6] 3
(24, 46] 3
dtype: int64
В этом примере видно, что интервалы отличаются от тех, что получились в результате использования функции cut(). Также можно обратить внимание на то, что qcut() попыталась стандартизировать вхождения для каждого бина, поэтому в первых двух больше вхождений. Это связано с тем, что количество объектов не делится на 5.
Определение и фильтрация лишних данных
При анализе данных часто приходится находить аномальные значения в структуре данных. Для примера создайте Dataframe с тремя колонками целиком случайных чисел.
>>> randframe = pd.DataFrame(np.random.randn(1000,3))
С помощью функции describe() можно увидеть статистику для каждой колонки.
>>> randframe.describe()
| | 0 | 1 | 2 |
|-------|-------------|-------------|-------------|
| count | 1000.000000 | 1000.000000 | 1000.000000 |
| mean | -0.036163 | 0.037203 | 0.018722 |
| std | 1.038703 | 0.986338 | 1.011587 |
| min | -3.591217 | -3.816239 | -3.586733 |
| 25% | -0.729458 | -0.581396 | -0.665261 |
| 50% | -0.025864 | 0.005155 | -0.002774 |
| 75% | 0.674396 | 0.706958 | 0.731404 |
| max | 3.115554 | 2.899073 | 3.425400 |
Лишними можно считать значения, которые более чем в три раза больше стандартного отклонения. Чтобы оставить только подходящие, нужно использовать функцию std().
>>> randframe.std()
0 1.038703
1 0.986338
2 1.011587
dtype: float64
Теперь используйте фильтр для всех значений Dataframe, применив соответствующее стандартное отклонение для каждой колонки. Функция any() позволит использовать фильтр для каждой колонки.
>>> randframe[(np.abs(randframe) > (3*randframe.std())).any(1)]
| | 0 | 1 | 2 |
|-----|-----------|-----------|-----------|
| 87 | -2.106846 | -3.408329 | -0.067435 |
| 129 | -3.591217 | 0.791474 | 0.243038 |
| 133 | 1.149396 | -3.816239 | 0.328653 |
| 717 | 0.434665 | -1.248411 | -3.586733 |
| 726 | 1.682330 | 1.252479 | -3.090042 |
| 955 | 0.272374 | 2.224856 | 3.425400 |
Перестановка
Операции перестановки (случайного изменения порядка) в объекте Series или строках Dataframe можно выполнить с помощью функции numpy.random.permutation().
Для этого примера создайте Dataframe с числами в порядке возрастания.
>>> nframe = pd.DataFrame(np.arange(25).reshape(5,5))
>>> nframe
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 4 | 20 | 21 | 22 | 23 | 24 |
Теперь создайте массив из пяти чисел от 0 до 4 в случайном порядке с функцией permutation(). Этот массив будет новым порядком, в котором потребуется разместить и значения строк из Dataframe.
>>> new_order = np.random.permutation(5)
>>> new_order
array([2, 3, 0, 1, 4])
Теперь примените его ко всем строкам Dataframe с помощью функции take().
>>> nframe.take(new_order)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 0 | 0 | 1 | 2 | 3 | 4 |
| 4 | 20 | 21 | 22 | 23 | 24 |
| 1 | 5 | 6 | 7 | 8 | 9 |
Как видите, порядок строк поменялся, а индексы соответствуют порядку в массиве new_order.
Перестановку можно произвести и для отдельной части Dataframe. Это сгенерирует массив с последовательностью, ограниченной конкретным диапазоном, например, от 2 до 4.
>>> new_order = [3,4,2]
>>> nframe.take(new_order)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 3 | 15 | 16 | 17 | 18 | 19 |
| 4 | 20 | 21 | 22 | 23 | 24 |
| 2 | 10 | 11 | 12 | 13 | 14 |
Случайная выборка
Вы уже знаете, как доставать отдельные части Dataframe для последующей перестановки. Но иногда ее потребуется отобрать случайным образом. Проще всего сделать это с помощью функции np.random.randint().
>>> sample = np.random.randint(0, len(nframe), size=3)
>>> sample
array([1, 4, 4])
>>> nframe.take(sample)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 3 | 15 | 16 | 17 | 18 | 19 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 3 | 15 | 16 | 17 | 18 | 19 |
В этом случае один и тот же участок попадается даже чаще.
]]>Слои являются основными элементами, необходимыми при создании нейронных сетей. Последовательные слои отвечают за архитектуру модели глубокого обучения. Каждый из них выполняет вычисления на основе данных, полученных из предыдущего. Затем информация передается дальше. В конце концов, последний слой выдает требуемый результат. В этом материале разберем типы слоев Keras, их свойства и параметры.
Слои Keras
Для определения или создания слоя Keras нужна следующая информация:
- Форма ввода: для понимания структуры входящей информации
- Количество: для определения количества узлов/нейронов в слое
- Инициализатор: для определения весов каждого входа, что важно для выполнения вычислений
- Активаторы: для преобразования входных данных в нелинейный формат, чтобы каждый нейрон мог обучаться эффективнее
- Ограничители: для наложения ограничений на веса при оптимизации
- Регуляторы: для применения штрафов к параметрам во время оптимизации
Различные слои в Keras
Основные слои Keras
Dense
Вычисляет вывод следующим образом:
output=activation(dot(input,kernel)+bias)
Здесь activation — это активатор, а kernel — взвешенная матрица, применяемая к входящим тензорам. bias — это константа, помогающая настроить модель наилучшим образом.
Dense-слой получает информацию со всех узлов предыдущего слоя. Вот его аргументы и значения по умолчанию:
Dense(units, activation=NULL, use_bias=TRUE,kernel_initializer='glorot_uniform',
bias_regularizer=NULL, activity_regularizer=NULL,
kernel_constraint=NULL, bias_constrain=NULL)
Activation
Используется для применения функции активации к выводу. То же самое, что передача активации в Dense-слой. Имеет следующие аргументы:
Activation(activation_function)
Если функцию активации не передать, то будет выполнена линейная активация.
Dropout
Dropout применяется в нейронных сетях для решения проблемы переобучения. Для этого он случайным образом выбирает доли единиц и при каждом обновлении назначает им значение 0.
Аргументы:
Dropout(rate, noise_shape=NULL, seed=NULL)
Flatten
Flatten используется для конвертации входящих данных в меньшую размерность.
Например, входящий слой размерности (batch_size, 3,2) «выравнивается» для вывода размерности (batch_size, 6). Он имеет следующие аргументы.
Flatten(data_format=None)
Input
Этот слой используется в Keras для создания модели на основе ввода и вывода модели. Он является точкой входа в модель графа.
Аргументы:
Input(shape, batch_shape, name, dtype,
sparse=FALSE,tensor=NULL)
Reshape
Изменить вывод под конкретную размерность
Аргумент:
Reshape(target_shape)
Выдаст следующий результат:
(batch_size,)+ target_shape
Permute
Поменять ввод для соответствия конкретному шаблону. Этот же слой используется для изменения формы ввода с помощью определенных шаблонов.
Аргументы:
Permute(dims)
Lambda
Слои Lambda используются для создания дополнительных признаков слоев, которых нет в Keras.
Аргументы:
Lambda(lambda_fun,output_shape=None, mask=None, arguments=None)
Masking
Пропустить временной промежуток, если все признаки равны mask_value.
Аргументы:
Masking(mask_value=0.0)
Сверточные сети Keras
Conv1D и Conv2D
Здесь определяется взвешенное ядро. Производится операция свертки, результатом которой становятся тензоры.
Аргументы:
Conv1D(filters,kernel_size,strides=1, padding='valid',
data_format='channels_last', dilation_rate=1, activation=None,
use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None)
Conv2D(filters,kernel_size,strides=(1,1) , padding='valid',
data_format='channels_last', dilation_rate=(1,1) ,
activation=None, use_bias=True,
kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None,
activity_regularizer=None, kernel_constraint=None,
bias_constraint=None)
Слои пулинга (подвыборки)
Они используются для уменьшения размера ввода и извлечения важной информации.
MaxPooling1D и MaxPooling2D
Извлекаем максимум
Аргументы:
MaxPooling1D(pool_size=2, strides=None, padding='valid',
data_format='channels_last')
MaxPooling2D(pool_size=(2,2), strides=None, padding='valid',
data_format='channels_last')
AveragePooling1D и AveragePooling2D
Извлекаем среднее
Аргументы:
AveragePooling1D(pool_size=2, strides=None, padding='valid',
data_format='channels_last')
AveragePooling1D(pool_size=(2,2), strides=None, padding='valid',
data_format=None)
Рекуррентный слой
Этот слой используется для вычисления последовательных данных — временного ряда или естественного языка.
SimpleRNN
Это полностью связанная RNN (рекуррентная нейронная сеть), где вывод подается обратно в качестве входящих данных
Аргументы:
SimpleRNN(units, activation, use_bias, kernel_initializer,
recurrent_initializer, bias_initializer, kernel_regularizer,
recurrent_regularizer, bias_regularizer, activity_regularizer,
kernel_constraint, recurrent_constraint, bias_constraint,
dropout, recurrent_dropout, return_sequences, return_state)
LSTM
Это увеличенная форма RNN с хранилищем для информации.
LSTM(units, activation , recurrent_activation, use_bias,
kernel_initializer, recurrent_initializer, bias_initializer,
unit_forget_bias, kernel_regularizer, recurrent_regularizer,
bias_regularizer, activity_regularizer, kernel_constraint,
recurrent_constraint, bias_constraint, dropout,
recurrent_dropout, implementation, return_sequences,
return_state)
В Keras есть и другие слои, но чаще всего используются описанные выше.
Выводы
Этот материал посвящен концепции слоев в моделях Keras. Вы узнали о требованиях для построения слоя, а также об их типах: основные слои, сверточные слои, подвыборки, рекуррентные слои, а также их свойства и параметры.
]]>Это руководство посвящено глубокому обучению и важным алгоритмам в Keras. Разберем сферы применение алгоритма и его реализацию в Keras.
Глубокое обучение — это подраздел машинного обучения, использующий алгоритмы, вдохновленные работой человеческого мозга. В последнем десятилетии было несколько важных разработок в этой области. Библиотека Keras – результат одной из них. Она позволяет создавать модели нейронных сетей в несколько строк кода.
В свое время был бум в исследовании алгоритмов глубокого обучения, а Keras обеспечивает простоту их создания для пользователей.
Но прежде чем переходить к глубокому обучению, осуществим установку Keras.
Популярные алгоритмы глубокого обучения с Keras
Вот самые популярные алгоритмы глубокого обучения:
- Автокодировщики
- Сверточные нейронные сети
- Рекурентные нейронные сети
- Долгая краткосрочная память
- Глубокая машина Больцмана
- Глубокие сети доверия
В этом материале рассмотрим автокодировщики глубокого обучения
Автокодировщики
Эти типы нейронных сетей способны сжимать входящие данные и воссоздавать их заново. Это очень старые алгоритмы глубокого обучения. Они кодируют ввод в до уровня узкого места («бутылочного горлышка»), а затем декодируют для получения исходных данных. Таким образом на уровне «бутылочного горлышка» образуется сжатая форма ввода.
Определение аномалий и устранение шумов на изображении — основные сферы применения автокодировщиков.
Типы автокодировщиков
Есть 7 типов автокодировщиков глубокого обучения:
- Шумоподавляющие автокодировщики
- Глубокие автокодировщики
- Разреженные автокодировщики
- Сжимающие автокодировщики
- Сверточные автокодировщики
- Вариационные автокодировщики
- Неполные автокодировщики
Для примера будет создан шумоподавляющий автокодировщик
Реализации шумоподавляющего автокодировщика в Keras
В целях реализации на Keras будем работать с базой данных цифр MNIST.
Для начала добавим на изображения шумы. Затем создадим автокодировщик для удаления шума и воссоздания оригинальных изображений.
- Импортируем требуемые модули
import numpy as np import matplotlib.pyplot as plt from keras.datasets import mnist from keras.layers import Input,Dense,Conv2D,MaxPooling2D,UpSampling2D from keras.models import Model from keras import backend as K - Загружаем изображения MNIST из модуля datasetes
from keras.datasets import mnist (x_train,y_train),(x_test,y_test)=mnist.load_data() - Конвертируем набор в диапазон от 0 до 1
x_train=x_train.astype('float32')/255 x_test=x_test.astype('float32')/255 x_train=np.reshape(x_train,(len(x_train),28,28,1)) x_test=np.reshape(x_test,(len(x_test),28,28,1)) - Добавляем шум на изображения с помощью Гауссового распределения
noise_factor=0.5 x_train_noisy=x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0,size=x_train.shape) x_test_noisy=x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0,size=x_test.shape) x_train_noisy= np.clip(x_train_noisy,0.,1.) x_test_noisy= np.clip(x_test_noisy,0.,1.) - Визуализируем добавленный шум
n=5 plt.figure(figsize=(20,2)) for i in range(n): ax=plt.subplot(1,n,i+1) plt.imshow(x_test_noisy[i].reshape(28,28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show() - Определяем входящий слой и создаем модель
input_img=Input(shape=(28,28,1)) x=Conv2D(128,(7,7),activation='relu',padding='same')(input_img) x=MaxPooling2D((2,2),padding='same')(x) x = Conv2D(32, (2, 2), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) encoded = Conv2D(1, (7, 7), activation='relu', padding='same')(x) - «Бутылочное горлышко» закодировано и состоит из сжатых изображений
input_encoded = Input(shape=(7, 7, 1)) x = Conv2D(32, (7, 7), activation='relu', padding='same')(input_encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(128, (2, 2), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (7, 7), activation='sigmoid', padding='same')(x) - Тренируем автокодировщик
encoder = Model(input_img, encoded, name="encoder") decoder = Model(input_encoded, decoded, name="decoder") autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder") autoencoder.compile(optimizer='adam', loss='binary_crossentropy') autoencoder.summary() autoencoder.fit(x_train, x_train, epochs=20, batch_size=256, shuffle=True, validation_data=(x_test, x_test))В этом примере модель тренировалась в течение 20
epoch. Лучшего результата можно добиться, увеличив это значение до 100. - Получаем предсказания по шумным данным
x_test_result = autoencoder.predict(x_test_noisy, batch_size=128) - Заново визуализируем воссозданные изображения
n=5
plt.figure(figsize=(20,2))
for i in range(n):
ax=plt.subplot(1,n,i+1)
plt.imshow(x_test_result[i].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
Как видите, автокодировщик способен воссоздать изображения и избавиться от шумов. Можно добиться лучших результатов, увеличив количество epoch.
Вывод
Этот материал представляет собой пример реализации глубокого обучения на Keras. Теперь вы знаете, что такое автокодировщики, какими они бывают, зачем они нужны, и как именно работают. В примере мы разобрали построение нейронной сети для устранения шума из данных.
]]>Прежде чем приступать к работе с данными, их нужно подготовить и собрать в виде структуры, так чтобы они поддавались обработке с помощью инструментов из библиотеки pandas. Дальше перечислены некоторые из этапов подготовки.
- Загрузка
- Сборка
- Объединение (merge)
- Конкатенация (concatenating)
- Комбинирование (combining)
- Изменение
- Удаление
Прошлый материал был посвящен загрузке. На этом этапе происходит конвертация из разных форматов в одну структуру данных, такую как Dataframe. Но даже после этого требуются дополнительные этапы подготовки. Поэтому дальше речь пойдет о том, как выполнять операции получения данных в объединенной структуре данных.
Данные из объектов pandas можно собрать несколькими путями:
- Объединение — функция
pandas.merge()соединяет строки вDataframeна основе одного или нескольких ключей. Этот вариант будет знаком всем, кто работал с языком SQL, поскольку там есть аналогичная операция. - Конкатенация — функция
pandas.concat()конкатенирует объекты по оси. - Комбинирование — функция
pandas.DataFrame.combine_first()является методом, который позволяет соединять пересекающиеся данные для заполнения недостающих значений в структуре, используя данные другой структуры.
Более того, частью подготовки является поворот — процесс обмена строк и колонок.
Соединение
Операция соединения (merge), которая соответствует JOIN из SQL, состоит из объединения данных за счет соединения строк на основе одного или нескольких ключей.
На самом деле, любой, кто работал с реляционными базами данных, обычно использует запрос JOIN из SQL для получения данных из разных таблиц с помощью ссылочных значений (ключей) внутри них. На основе этих ключей можно получать новые данные в табличной форме как результат объединения других таблиц. Эта операция в библиотеке pandas называется соединением (merging), а merge() — функция для ее выполнения.
Сначала нужно импортировать библиотеку pandas и определить два объекта Dataframe, которые будут примерами в этом разделе.
>>> import numpy as np
>>> import pandas as pd
>>> frame1 = pd.DataFrame({'id':['ball','pencil','pen','mug','ashtray'],
... 'price': [12.33,11.44,33.21,13.23,33.62]})
>>> frame1
| | id | price |
|---|---------|-------|
| 0 | ball | 12.33 |
| 1 | pencil | 11.44 |
| 2 | pen | 33.21 |
| 3 | mug | 13.23 |
| 4 | ashtray | 33.62 |
>>> frame2 = pd.DataFrame({'id':['pencil','pencil','ball','pen'],
... 'color': ['white','red','red','black']})
>>> frame2
| | color | id |
|---|-------|--------|
| 0 | white | pencil |
| 1 | red | pencil |
| 2 | red | ball |
| 3 | black | pen |
Выполним соединение, применив функцию merge() к двум объектам.
>>> pd.merge(frame1,frame2)
| | id | price | color |
|---|--------|-------|-------|
| 0 | ball | 12.33 | red |
| 1 | pencil | 11.44 | white |
| 2 | pencil | 11.44 | red |
| 3 | pen | 33.21 | black |
Получившийся объект Dataframe состоит из всех строк с общим ID. В дополнение к общей колонке добавлены и те, что присутствуют только в первом и втором объектах.
В этом случае функция merge() была использована без явного определения колонок. Но чаще всего необходимо указывать, на основе какой колонки выполнять соединение.
Для этого нужно добавить свойство с названием колонки, которое будет ключом соединения.
>>> frame1 = pd.DataFrame({'id':['ball','pencil','pen','mug','ashtray'],
... 'color': ['white','red','red','black','green'],
... 'brand': ['OMG','ABC','ABC','POD','POD']})
>>> frame1
| | brand | color | id |
|---|-------|-------|---------|
| 0 | OMG | white | ball |
| 1 | ABC | red | pencil |
| 2 | ABC | red | pen |
| 3 | POD | black | mug |
| 4 | PPOD | green | ashtray |
>>> frame2 = pd.DataFrame({'id':['pencil','pencil','ball','pen'],
... 'brand': ['OMG','POD','ABC','POD']})
>>> frame2
| | brand | id |
|---|-------|--------|
| 0 | OMG | pencil |
| 1 | POD | pencil |
| 2 | ABC | ball |
| 3 | POD | pen |
В этом случае два объекта Dataframe имеют колонки с одинаковыми названиями. Поэтому при запуске merge результата не будет.
>>> pd.merge(frame1,frame2)
Empty DataFrame
Columns: [brand, color, id]
Index: []
Необходимо явно задавать условия соединения, которым pandas будет следовать, определяя название ключа в параметре on.
>>> pd.merge(frame1,frame2,on='id')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on='brand')
| | brand | color | id_x | id_y |
|---|-------|-------|--------|--------|
| 0 | OMG | white | ball | pencil |
| 1 | ABC | red | pencil | ball |
| 2 | ABC | red | pen | ball |
| 3 | POD | black | mug | pencil |
| 4 | POD | black | mug | pen |
Как и ожидалось, результаты отличаются в зависимости от условий соединения.
Но часто появляется другая проблема, когда есть два Dataframe без колонок с одинаковыми названиями. Для исправления ситуации нужно использовать left_on и right_on, которые определяют ключевые колонки для первого и второго объектов Dataframe. Дальше следует пример.
>>> frame2.columns = ['brand','sid']
>>> frame2
| | brand | sid |
|---|-------|--------|
| 0 | OMG | pencil |
| 1 | POD | pencil |
| 2 | ABC | ball |
| 3 | POD | pen |
>>> pd.merge(frame1, frame2, left_on='id', right_on='sid')
| | brand_x | color | id | brand_y | sid |
|---|---------|-------|--------|---------|--------|
| 0 | OMG | white | ball | ABC | ball |
| 1 | ABC | red | pencil | OMG | pencil |
| 2 | ABC | red | pencil | POD | pencil |
| 3 | ABC | red | pen | POD | pen |
По умолчанию функция merge() выполняет inner join (внутреннее соединение). Ключ в финальном объекте — результат пересечения.
Другие возможные варианты: left join, right join и outer join (левое, правое и внешнее соединение). Внешнее выполняет объединение всех ключей, комбинируя эффекты правого и левого соединений. Для выбора типа нужно использовать параметр how.
>>> frame2.columns = ['brand','id']
>>> pd.merge(frame1,frame2,on='id')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on='id',how='outer')
| | brand_x | color | id | brand_y |
|---|---------|-------|---------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
| 4 | POD | black | mug | NaN |
| 5 | PPOD | green | ashtray | NaN |
>>> pd.merge(frame1,frame2,on='id',how='left')
| | brand_x | color | id | brand_y |
|---|---------|-------|---------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
| 4 | POD | black | mug | NaN |
| 5 | PPOD | green | ashtray | NaN |
>>> pd.merge(frame1,frame2,on='id',how='right')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on=['id','brand'],how='outer')
| | brand | color | id |
|---|-------|-------|---------|
| 0 | OMG | white | ball |
| 1 | ABC | red | pencil |
| 2 | ABC | red | pen |
| 3 | POD | black | mug |
| 4 | PPOD | green | ashtray |
| 5 | OMG | NaN | pencil |
| 6 | POD | NaN | pencil |
| 7 | ABC | NaN | ball |
| 8 | POD | NaN | pen |
Для соединения нескольких ключей, нужно просто в параметр on добавить список.
Соединение по индексу
В некоторых случаях вместо использования колонок объекта Dataframe в качестве ключей для этих целей можно задействовать индексы. Затем для выбора конкретных индексов нужно задать значения True для left_join или right_join. Они могут быть использованы и вместе.
>>> pd.merge(frame1,frame2,right_index=True, left_index=True)
| | brand_x | color | id_x | brand_y | id_y |
|---|---------|-------|--------|---------|--------|
| 0 | OMG | white | ball | OMG | pencil |
| 1 | ABC | red | pencil | POD | pencil |
| 2 | ABC | red | pen | ABC | ball |
| 3 | POD | black | mug | POD | pen |
Но у объектов Dataframe есть и функция join(), которая оказывается особенно полезной, когда необходимо выполнить соединение по индексам. Она же может быть использована для объединения множества объектов с одинаковыми индексами, но без совпадающих колонок.
При запуске такого кода
>>> frame1.join(frame2)
Будет ошибка, потому что некоторые колонки в объекте frame1 называются так же, как и во frame2. Нужно переименовать их во втором объекте перед использованием join().
>>> frame2.columns = ['brand2','id2']
>>> frame1.join(frame2)
В этом примере соединение было выполнено на основе значений индексов, а не колонок. Также индекс 4 представлен только в объекте frame1, но соответствующие значения колонок во frame2 равняются NaN.
Конкатенация
Еще один тип объединения данных — конкатенация. NumPy предоставляет функцию concatenate() для ее выполнения.
>>> array1 = np.arange(9).reshape((3,3))
>>> array1
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> array2 = np.arange(9).reshape((3,3))+6
>>> array2
array([[6, 7, 8],
[9, 10, 11],
[12, 13, 14]])
>>> np.concatenate([array1,array2],axis=1)
array([[0, 1, 2, 6, 7, 8],
[3, 4, 5, 9, 10, 11],
[6, 7, 8, 12, 13, 14]])
>>> np.concatenate([array1,array2],axis=0)
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
[6, 7, 8],
[9, 10, 11],
[12, 13, 14]])
С библиотекой pandas и ее структурами данных, такими как Series и Dataframe, именованные оси позволяют и дальше обобщать конкатенацию массивов. Для этого в pandas есть функция concat().
>>> ser1 = pd.Series(np.random.rand(4), index=[1,2,3,4])
>>> ser1
1 0.636584
2 0.345030
3 0.157537
4 0.070351
dtype: float64
>>> ser2 = pd.Series(np.random.rand(4), index=[5,6,7,8])
>>> ser2
5 0.411319
6 0.359946
7 0.987651
8 0.329173
dtype: float64
>>> pd.concat([ser1,ser2])
1 0.636584
2 0.345030
3 0.157537
4 0.070351
5 0.411319
6 0.359946
7 0.987651
8 0.329173
dtype: float64
По умолчанию функция concat() работает на axis=0 и возвращает объект Series. Если задать 1 значением axis, то результатом будет объект Dataframe.
>>> pd.concat([ser1,ser2],axis=1)
| | 0 | 1 |
|---|----------|----------|
| 1 | 0.953608 | NaN |
| 2 | 0.929539 | NaN |
| 3 | 0.036994 | NaN |
| 4 | 0.010650 | NaN |
| 5 | NaN | 0.200771 |
| 6 | NaN | 0.709060 |
| 7 | NaN | 0.813766 |
| 8 | NaN | 0.218998 |
Проблема с этой операцией в том, что конкатенированные части не определяются в итоговом объекте. Например, нужно создать иерархический индекс на оси конкатенации. Для этого требуется использовать параметр keys.
>>> pd.concat([ser1,ser2], keys=[1,2])
1 1 0.953608
2 0.929539
3 0.036994
4 0.010650
2 5 0.200771
6 0.709060
7 0.813766
8 0.218998
dtype: float64
В случае объединения двух Series по axis=1 ключи становятся заголовками колонок объекта Dataframe.
>>> pd.concat([ser1,ser2], axis=1, keys=[1,2])
| | 1 | 2 |
|---|----------|----------|
| 1 | 0.953608 | NaN |
| 2 | 0.929539 | NaN |
| 3 | 0.036994 | NaN |
| 4 | 0.010650 | NaN |
| 5 | NaN | 0.200771 |
| 6 | NaN | 0.709060 |
| 7 | NaN | 0.813766 |
| 8 | NaN | 0.218998 |
Пока что в примерах конкатенация применялась только к объектам Series, но та же логика работает и с Dataframe.
>>> frame1 = pd.DataFrame(np.random.rand(9).reshape(3,3),
... index=[1,2,3], columns=['A','B','C'])
>>> frame2 = pd.DataFrame(np.random.rand(9).reshape(3,3),
... index=[4,5,6], columns=['A','B','C'])
>>> pd.concat([frame1, frame2])
| | A | B | C |
|---|----------|----------|----------|
| 1 | 0.231057 | 0.024329 | 0.843888 |
| 2 | 0.727480 | 0.296619 | 0.367309 |
| 3 | 0.282516 | 0.524227 | 0.462000 |
| 4 | 0.078044 | 0.751505 | 0.832853 |
| 5 | 0.843225 | 0.945914 | 0.141331 |
| 6 | 0.189217 | 0.799631 | 0.308749 |
>>> pd.concat([frame1, frame2], axis=1)
| | A | B | C | A | B | C |
|---|----------|----------|----------|----------|----------|----------|
| 1 | 0.231057 | 0.024329 | 0.843888 | NaN | NaN | NaN |
| 2 | 0.727480 | 0.296619 | 0.367309 | NaN | NaN | NaN |
| 3 | 0.282516 | 0.524227 | 0.462000 | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | 0.078044 | 0.751505 | 0.832853 |
| 5 | NaN | NaN | NaN | 0.843225 | 0.945914 | 0.141331 |
| 6 | NaN | NaN | NaN | 0.189217 | 0.799631 | 0.308749 |
Комбинирование
Есть еще одна ситуация, при которой объединение не работает за счет соединения или конкатенации. Например, если есть два набора данных с полностью или частично пересекающимися индексами.
Одна из функций для Series называется combine_first(). Она выполняет объединение с выравниваем данных.
>>> ser1 = pd.Series(np.random.rand(5),index=[1,2,3,4,5])
>>> ser1
1 0.075815
2 0.332282
3 0.884463
4 0.518336
5 0.089025
dtype: float64
>>> ser2 = pd.Series(np.random.rand(4),index=[2,4,5,6])
>>> ser2
2 0.315847
4 0.275937
5 0.352538
6 0.865549
dtype: float64
>>> ser1.combine_first(ser2)
1 0.075815
2 0.332282
3 0.884463
4 0.518336
5 0.089025
6 0.865549
dtype: float64
>>> ser2.combine_first(ser1)
1 0.075815
2 0.315847
3 0.884463
4 0.275937
5 0.352538
6 0.865549
dtype: float64
Если же требуется частичное пересечение, необходимо обозначить конкретные части Series.
>>> ser1[:3].combine_first(ser2[:3])
1 0.075815
2 0.332282
3 0.884463
4 0.275937
5 0.352538
dtype: float64
Pivoting — сводные таблицы
В дополнение к сборке данных для унификации собранных из разных источников значений часто применяется операция поворота. На самом деле, выравнивание данных по строке и колонке не всегда подходит под конкретную ситуацию. Иногда требуется перестроить данные по значениям колонок в строках или наоборот.
Поворот с иерархическим индексированием
Вы уже знаете, что Dataframe поддерживает иерархическое индексирование. Эта особенность может быть использована для перестраивания данных в объекте Dataframe. В контексте поворота есть две базовые операции:
- Укладка (stacking) — поворачивает структуру данных, превращая колонки в строки
- Обратный процесс укладки (unstacking) — конвертирует строки в колонки
>>> frame1 = pd.DataFrame(np.arange(9).reshape(3,3),
... index=['white','black','red'],
... columns=['ball','pen','pencil'])
>>> frame1
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
С помощью функции stack() в Dataframe можно развернуть данные и превратить колонки в строки, получив Series:
>>> ser5 = frame1.stack()
white ball 0
pen 1
pencil 2
black ball 3
pen 4
pencil 5
red ball 6
pen 7
pencil 8
dtype: int32
Из объекта Series с иерархическим индексировании можно выполнить пересборку в развернутую таблицу с помощью unstack().
>>> ser5.unstack()
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
Обратный процесс можно выполнить и на другом уровне, определив количество уровней или название в качестве аргумента функции.
>>> ser5.unstack(0)
| | white | black | red |
|--------|-------|-------|-----|
| ball | 0 | 3 | 6 |
| pen | 1 | 4 | 7 |
| pencil | 2 | 5 | 8 |
Поворот из «длинного» в «широкий» формат
Наиболее распространенный способ хранения наборов данных — точная регистрация данных, которые будут заполнять строки текстового файла: CSV или таблицы в базе данных. Это происходит особенно в таких случаях: чтение выполняется с помощью инструментов; результаты вычислений итерируются; или данные вводятся вручную. Похожий пример таких файлов — логи, заполняемые строка за строкой с помощью постоянно поступающих данных.
Необычная особенность этого типа набора данных — элементы разных колонок, часто повторяющиеся в последующих строках. Они всегда в табличной форме, поэтому их можно воспринимать как формат длинных или упакованных.
Чтобы лучше разобраться с этой концепцией, рассмотрим следующий Dataframe.
>>> longframe = pd.DataFrame({'color':['white','white','white',
... 'red','red','red',
... 'black','black','black'],
... 'item':['ball','pen','mug',
... 'ball','pen','mug',
... 'ball','pen','mug'],
... 'value': np.random.rand(9)})
>>> longframe
| | color | item | value |
|---|-------|------|----------|
| 0 | white | ball | 0.896313 |
| 1 | white | pen | 0.344864 |
| 2 | white | mug | 0.101891 |
| 3 | red | ball | 0.697267 |
| 4 | red | pen | 0.852835 |
| 5 | red | mug | 0.145385 |
| 6 | black | ball | 0.738799 |
| 7 | black | pen | 0.783870 |
| 8 | black | mug | 0.017153 |
Этот режим записи данных имеет свои недостатки. Первый — повторение некоторых полей. Если воспринимать колонки в качестве ключей, то данные в этом формате будет сложно читать, а особенно — понимать отношения между значениями ключей и остальными колонками.
Но существует замена для длинного формата — широкий способ организации данных в таблице. В таком режиме данные легче читать, а также налаживать связь между таблицами. Плюс, они занимают меньше места. Это более эффективный способ хранения данных, пусть и менее практичный, особенно на этапе заполнения объекта данными.
В качестве критерия нужно выбрать колонку или несколько из них как основной ключ. Значения в них должны быть уникальными.
pandas предоставляет функцию, которая позволяет выполнить трансформацию Dataframe из длинного типа в широкий. Она называется pivot(), а в качестве аргументов принимает одну или несколько колонок, которые будут выполнять роль ключа.
Еще с прошлого примера вы создавали Dataframe в широком формате. Колонка color выступала основным ключом, item – вторым, а их значения формировали новые колонки в объекте.
>>> wideframe = longframe.pivot('color','item')
>>> wideframe
| | value | | |
|-------|----------|----------|----------|
| item | ball | mug | pen |
| color | | | |
| black | 0.738799 | 0.017153 | 0.783870 |
| red | 0.697267 | 0.145385 | 0.852835 |
| white | 0.896313 | 0.101891 | 0.344864 |
В таком формате Dataframe более компактен, а данные в нем — куда более читаемые.
Удаление
Последний этап подготовки данных — удаление колонок и строк. Определим такой объект в качестве примера.
>>> frame1 = pd.DataFrame(np.arange(9).reshape(3,3),
... index=['white','black','red'],
... columns=['ball','pen','pencil'])
>>> frame1
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
Для удаления колонки используйте команду del к Dataframe с определенным названием колонки.
>>> del frame1['ball']
>>> frame1
| | pen | pencil |
|-------|-----|--------|
| white | 1 | 2 |
| black | 4 | 5 |
| red | 7 | 8 |
Для удаления нежеланной строки используйте функцию drop() с меткой соответствующего индекса в аргументе.
>>> frame1.drop('white')
| | pen | pencil |
|-------|-----|--------|
| black | 4 | 5 |
| red | 7 | 8 |
Модуль pickle предоставляет мощный алгоритм сериализации и десериализации структур данных Python. Pickling — это процесс, при котором иерархия объекта конвертируется в поток байтов.
Это позволяет переносить и хранить объект, так что получатель может восстановить его, сохранив все оригинальные черты.
В Python за этот процесс отвечает модуль pickle, но имеется и cPickle, который является результатом работы по оптимизации первого (написан на C). Он в некоторых случаях может быть быстрее оригинального pickle в тысячу раз. Однако интерфейс самих модулей почти не отличается.
Прежде чем переходить к функциям библиотеки, рассмотрим cPickle в подробностях .
Сериализация объекта с помощью cPickle
Формат данных, используемый pickle (или cPickle), универсален для Python. По умолчанию для превращения в человекочитаемый вид используется представление в виде ASCII. Затем, открыв файл в текстовом редакторе, можно понять его содержимое. Для использования модуля его сначала нужно импортировать:
>>> import pickle
Создадим объект с внутренней структурой, например, dict.
>>> data = { 'color': ['white','red'], 'value': [5, 7]}
Теперь выполним сериализацию с помощью функции dumps() модуля cPickle.
>>> pickled_data = pickle.dumps(data)
Чтобы увидеть, как прошла сериализация, необходимо изучить содержимое переменной pickled_data.
>>> print(pickled_data)
Когда данные сериализованы, их можно записать в файл, отправить через сокет, канал или другими способами.
А после передачи их можно пересобрать (выполнить десериализацию) с помощью функции loads() из модуля cPickle.
>>> nframe = pickle.loads(pickled_data)
>>> nframe
{'color': ['white', 'red'], 'value': [5, 7]}
Процесс “pickling” в pandas
Когда дело доходит до сериализации (или десериализации), то pandas с легкостью справляется с задачей. Не нужно даже импортировать модуль cPickle, а все операции выполняются неявно.
Также формат сериализации в pandas не целиком в ASCII.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
index=['up','down','left','right'])
>>> frame.to_pickle('frame.pkl')
Теперь у вас есть файл frame.pkl, содержащий всю информацию об объекте Dataframe.
Для его открытия используется следующая команда:
>>> pd.read_pickle('frame.pkl')
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| up | 0 | 1 | 2 | 3 |
| down | 4 | 5 | 6 | 7 |
| left | 8 | 9 | 10 | 11 |
| right | 12 | 13 | 14 | 15 |
На этом примере видно, что все нюансы скрыты от пользователя pandas, что делает работу простой и понятной, особенно для тех, кто занимается непосредственно анализом данных.
]]>Примечание. При использовании формата важно убедиться, что открываемый файл безопасен. Формат не очень защищен от вредоносных данных.
Keras поддерживает разный бэкенд и его производительность сильно зависит от сделанного выбора. В этом материале речь пойдет о двух самых распространенных вариантах: TensorFlow и Theano. Создадим модель нейронной сети и проверим ее производительность на примерах.
Бэкенд Keras
Keras — это высокоуровневый API для разработки нейронных сетей, поэтому низкоуровневыми вычислениями он не занимается. Для этих целей он опирается на «бэкенд-движки». Поддержка реализована в модульном виде, что значит, что к Keras можно присоединить несколько движков.
TensorFlow и Theano — самые распространенные варианты
TensorFlow
Это платформа для машинного обучения с открытым исходным кодом, разработанная в Google и выпущенная в ноябре 2015 году.
Theano
Это библиотека Python, созданная для управления и оценки математических выражений, созданная Университетом Монреаля и выпущенная в 2007 году.
Изменения движка Keras
По умолчанию движком бэкенда Keras является TensorFlow. Чтобы убедиться в этом, проверьте конфигурационный файл по этому пути:
$HOME/.keras/keras.json
Он выглядит следующим образом:
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Или импортируйте Keras и введите:
keras.backend.backend()
Для изменения движка выполните следующие шаги:
- Откройте конфигурационный файл в любом текстовом редакторе.
subl $HOME/.keras/keras.json - Измените значение
backendнаtheano - Проверьте используемый движок
Движок в игре меняется в один шаг. Не нужно ничего менять в самом коде, а дальше мы увидим, как можно запускать модели Keras на разных движках.
Проверим модель на разных движках Keras
Создадим нейронную сеть типа многослойный перцептрон для бинарной классификации. Проверим производительность модели на основе времени тренировки и ее точности.
Сначала используем TensorFlow.
В этом примере использовалось железо со следующей конфигурацией:
- Процессор Intel Core i5 7-го поколения
- Keras 2.3.1
- Python 3.6.0
- TensorFlow 1.14.0
- Theano 1.0.4
Результаты относительны и могут отличаться в зависимости от конфигураций систем и разных версий библиотек.
Создадим нейронную сеть
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
Сгенерируем случайный ввод для тестирования
x_train=np.random.random((1000,20))
y_train=np.random.randint(2,size=(100,1))
x_test=np.random.random((100,20))
y_test=np.random.randint(2,size=(100,1))
Создадим модель
model=Sequential()
model.add(Dense(64, input_dim=20,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
Скомпилируем модель
model.compile(loss='binary_crossentropy', optimizer='rmsprop',metrics=['accuracy'])
Для вычисления времени тренировки используем модуль Time из Python.
Добавим переменные до и после тренировки.
import time
start=time.time()
model.fit(x_train,y_tarin,epochs=20,batch_size=128)
end=time.time()
print("running time: ",end-start)
Посчитаем величину потерь и точность модели
score=model.evaluate(x_test,y_test,batch_size=128)
print("score: ",score)
Можно увидеть, что тренировка этой модели заняла 0,5446 секунд, величина потерь — 0,6998, а точность — 0,4199
Теперь переключимся на Theano и выполним те же шаги.
Тренировка этой модели заняла 1,066 секунд, величина потерь — 0,6747, а точность — 0,6700. В системе с этим примером TensorFlow сработал быстрее, но у Theano выше точность.
Выводы
Этот материал объясняет поддержку разных движков в Keras и показывает, как между ними переключаться. В качестве примеров были использованы TensorFlow и Theano. Также было показано сравнение эффективности модели нейронной сети на обоих движках.
]]>Чтение и запись в файлы Microsoft Excel
Данные очень легко читать из файлов CSV, но они часто хранятся в табличной форме в формате Excel.
pandas предоставляет специальные функции для работы с ним:
to_excel()read_excel()
Функция read_excel() может читать из файлов Excel 2003 (.xls) и Excel 2007 (.xlsx). Это возможно благодаря модулю xlrd.
Для начала откроем файл Excel и введем данные со следующий таблиц. Разместим их в листах sheet1 и sheet2. Сохраним файл как ch05_data.xlsx.
| white | red | green | black | |
|---|---|---|---|---|
| a | 12 | 23 | 17 | 18 |
| b | 22 | 16 | 19 | 18 |
| c | 14 | 23 | 22 | 21 |
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
Для чтения данных из файла XLS нужно всего лишь конвертировать его в Dataframe, используя для этого функцию read_excel().
>>> pd.read_excel('ch05_data.xlsx')
По умолчанию готовый объект pandas Dataframe будет состоять из данных первого листа файла. Но если нужно загрузить и второй, то достаточно просто указать его номер (индекс) или название в качестве второго аргумента.
>>> pd.read_excel('ch05_data.xlsx','Sheet2')
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
>>> pd.read_excel('ch05_data.xlsx',1)
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
Запись работает по тому же принципу. Для конвертации объекта Dataframe в Excel нужно написать следующее.
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index = ['exp1','exp2','exp3','exp4'],
... columns = ['Jan2015','Fab2015','Mar2015','Apr2005'])
>>> frame.to_excel('data2.xlsx')
>>> frame
| Jan2015 | Feb2015 | Mar2015 | Apr2015 | |
|---|---|---|---|---|
| exp1 | 0.671044 | 0.437715 | 0.497103 | 0.070595 |
| exp2 | 0.864018 | 0.575196 | 0.240343 | 0.471081 |
| exp3 | 0.957986 | 0.311648 | 0.381975 | 0.622556 |
| exp4 | 0.407909 | 0.015926 | 0.180611 | 0.579783 |
В рабочей директории будет создан файл с соответствующими данными.
Данные JSON
JSON (JavaScript Object Notation) стал одним из самых распространенных стандартных форматов для передачи данных в сети.
Одна из главных его особенностей — гибкость, хотя структура и не похожа на привычные таблицы.
В этом разделе вы узнаете, как использовать функции read_json() и to_json() для использования API. А в следующем — познакомитесь с другим примером взаимодействия со структурированными данными формата, который чаще встречается в реальной жизни.
http://jsonviewer.stack.hu/ — полезный онлайн-инструмент для проверки формата JSON. Нужно вставить данные в этом формате, и сайт покажет, представлены ли они в корректной форме, а также покажет дерево структуры.
{
"up": {
"white": 0,
"black": 4,
"red": 8,
"blue": 12
},
"down": {
"white": 1,
"black": 5,
"red": 9,
"blue": 13
},
"right": {
"white": 2,
"black": 6,
"red": 10,
"blue": 14
},
"left": {
"white": 3,
"black": 7,
"red": 11,
"blue": 15
}
}
Начнем с самого полезного примера, когда есть объект Dataframe и его нужно конвертировать в файл JSON. Определим такой объект и используем его для вызова функции to_json(), указав название для итогового файла.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
... index=['white','black','red','blue'],
... columns=['up','down','right','left'])
>>> frame.to_json('frame.json')
Он будет находится в рабочей папке и включать все данные в формате JSON.
Обратную операцию можно выполнить с помощью функции read_json(). Параметром здесь должен выступать файл с данными.
>>> pd.read_json('frame.json')
| down | left | right | up | |
|---|---|---|---|---|
| black | 5 | 7 | 6 | 4 |
| blue | 13 | 15 | 14 | 12 |
| red | 9 | 11 | 10 | 8 |
| white | 1 | 3 | 2 | 0 |
Это был простейший пример, где данные JSON представлены в табличной форме (поскольку источником файла frame.json служил именно такой объект — Dataframe). Но в большинстве случаев у JSON-файлов нет такой четкой структуры. Поэтому нужно конвертировать файл в табличную форму. Этот процесс называется нормализацией.
Библиотека pandas предоставляет функцию json_normalize(), которая умеет конвертировать объект dict или список в таблицу. Для начала ее нужно импортировать:
>>> from pandas.io.json import json_normalize
Создадим JSON-файл как в следующем примере с помощью любого текстового редактора и сохраним его в рабочей директории как books.json.
[{"writer": "Mark Ross",
"nationality": "USA",
"books": [
{"title": "XML Cookbook", "price": 23.56},
{"title": "Python Fundamentals", "price": 50.70},
{"title": "The NumPy library", "price": 12.30}
]
},
{"writer": "Barbara Bracket",
"nationality": "UK",
"books": [
{"title": "Java Enterprise", "price": 28.60},
{"title": "HTML5", "price": 31.35},
{"title": "Python for Dummies", "price": 28.00}
]
}]
Как видите, структура файла более сложная и не похожа на таблицу. В таком случае функция read_json() уже не сработает. Однако данные в нужной форме все еще можно получить. Во-первых, нужно загрузить содержимое файла и конвертировать его в строку.
>>> import json
>>> file = open('books.json','r')
>>> text = file.read()
>>> text = json.loads(text)
После этого можно использовать функцию json_normalize(). Например, можно получить список книг. Для этого необходимо указать ключ books в качестве второго параметра.
>>> json_normalize(text,'books')
| price | title | |
|---|---|---|
| 0 | 23.56 | XML Cookbook |
| 1 | 50.70 | Python Fundamentals |
| 2 | 12.30 | The NumPy library |
| 3 | 28.60 | Java Enterprise |
| 4 | 31.35 | HTML5 |
| 5 | 28.30 | Python for Dummies |
Функция считает содержимое всех элементов, у которых ключом является books. Все свойства будут конвертированы в имена вложенных колонок, а соответствующие значения заполнят объект Dataframe. В качестве индексов будет использоваться возрастающая последовательность чисел.
Однако в этом случае Dataframe включает только внутреннюю информацию. Не лишним было бы добавить и значения остальных ключей на том же уровне. Для этого необходимо добавить другие колонки, вставив список ключей в качестве третьего элемента функции.
>>> json_normalize(text,'books',['nationality','writer'])
| price | title | writer | nationality | |
|---|---|---|---|---|
| 0 | 23.56 | XML Cookbook | Mark Ross | USA |
| 1 | 50.70 | Python Fundamentals | Mark Ross | USA |
| 2 | 12.30 | The NumPy library | Mark Ross | USA |
| 3 | 28.60 | Java Enterprise | Barbara Bracket | UK |
| 4 | 31.35 | HTML5 | Barbara Bracket | UK |
| 5 | 28.30 | Python for Dummies | Barbara Bracket | UK |
Результатом будет Dataframe с готовой структурой.
Формат HDF5
До сих пор в примерах использовалась запись данных лишь в текстовом формате. Но когда речь заходит о больших объемах, то предпочтительнее использовать бинарный. Для этого в Python есть несколько инструментов. Один из них — библиотека HDF5.
HDF расшифровывается как hierarchical data format (иерархический формат данных), а сама библиотека используется для чтения и записи файлов HDF5, содержащих структуру с узлами и возможностью хранить несколько наборов данных.
Библиотека разработана на C, но предусматривает интерфейсы для других языков: Python, MATLAB и Java. Она особенно эффективна при сохранении больших объемов данных. В сравнении с остальными форматами, работающими в бинарном виде, HDF5 поддерживает сжатие в реальном времени, используя преимущества повторяющихся паттернов в структуре для уменьшения размера файла.
Возможные варианты в Python — это PyTables и h5py. Они отличаются по нескольким аспектам, а выбирать их стоит, основываясь на том, что нужно программисту.
h5py предоставляет прямой интерфейс с высокоуровневыми API HDF5, а PyTables скрывает за абстракциями многие детали HDF5 с более гибкими контейнерами данных, индексированные таблицы, запросы и другие способы вычислений.
В pandas есть классовый dict под названием HDFStore, который использует PyTables для хранения объектов pandas. Поэтому перед началом работы с форматом необходимо импортировать класс HDFStore:
>>> from pandas.io.pytables import HDFStore
Теперь данные объекта Dataframe можно хранить в файле с расширением .h5. Для начала создадим Dataframe.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
... index=['white','black','red','blue'],
... columns=['up','down','right','left'])
Дальше нужен файл HDF5 под названием mydata.h5. Добавим в него содержимое объекта Dataframe.
>>> store = HDFStore('mydata.h5')
>>> store['obj1'] = frame
Можете догадаться, как хранить несколько структур данных в одном файле HDF5, указав для каждой из них метку. С помощью этого формата можно хранить несколько структур данных в одном файле, при том что он будет представлен переменной store.
>>> store
<class 'pandas.io.pytables.HDFStore'>
File path: ch05_data.h5
Обратный процесс также прост. Учитывая наличие файла HDF5 с разными структурами данных вызвать их можно следующим путем.
Взаимодействие с базами данных
В большинстве приложений текстовые файлы редко выступают источниками данных, просто потому что это не эффективно. Они хранятся в реляционных базах данных (SQL) или альтернативных (NoSQL), которые стали особо популярными в последнее время.
Загрузка из SQL в Dataframe — это простой процесс, а pandas предлагает дополнительные функции для еще большего упрощения.
Модуль pandas.io.sql предоставляет объединенный интерфейс, независимый от базы данных, под названием sqlalchemy. Он упрощает режим соединения, поскольку команды неизменны вне зависимости от типа базы. Для создания соединения используется функция create_engine(). Это же позволяет настроить все необходимые свойства: ввести имя пользователя, пароль и порт, а также создать экземпляр базы данных.
Вот список разных типов баз данных:
>>> from sqlalchemy import create_engine
# For PostgreSQL:
>>> engine = create_engine('postgresql://scott:tiger@localhost:5432/mydatabase')
# For MySQL
>>> engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# For Oracle
>>> engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
# For MSSQL
>>> engine = create_engine('mssql+pyodbc://mydsn')
# For SQLite
>>> engine = create_engine('sqlite:///foo.db')
Загрузка и запись данных с SQLite3
Для первого примера используем базу данных SQLite, применив встроенный Python sqlite3. SQLite3 — это инструмент, реализующий реляционную базу данных очень простым путем. Это самый легкий способ добавить ее в любое приложение на Python. С помощью SQLite фактически можно создать встроенную базу данных в одном файле.
Идеальный вариант для тех, кому нужна база, но нет желания устанавливать реальную. SQLite3 же можно использовать для тренировки или для использования функций базы при сборе данных, не выходя за рамки программы.
Создадим объект Dataframe, который будет использоваться для создания новой таблицы в базе данных SQLite3.
>>> frame = pd.DataFrame(np.arange(20).reshape(4,5),
... columns=['white','red','blue','black','green'])
>>> frame
| white | red | blue | black | green | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
Теперь нужно реализовать соединение с базой.
>>> engine = create_engine('sqlite:///foo.db')
Конвертируем объект в таблицу внутри базы данных.
>>> frame.to_sql('colors',engine)
А вот для чтения базы нужно использовать функцию read_sql(), указав название таблицы и движок.
>>> pd.read_sql('colors',engine)
| index | white | red | blue | black | green | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 3 | 15 | 16 | 17 | 18 | 19 |
На примере видно, что даже в этом случае процесс записи очень прост благодаря API библиотеки pandas.
Однако того же можно добиться и без них. Это покажет, почему pandas считается эффективным инструментом для работы с базой данных.
Во-первых, нужно установить соединение и создать таблицу, определив правильные типы данных, которые впоследствии будут загружаться.
>>> import sqlite3
>>> query = """
... CREATE TABLE test
... (a VARCHAR(20), b VARCHAR(20),
... c REAL, d INTEGER
... );"""
>>> con = sqlite3.connect(':memory:')
>>> con.execute(query)
<sqlite3.Cursor object at 0x0000000009E7D730>
>>> con.commit()
Теперь можно добавлять сами данные с помощью SQL INSERT.
>>> data = [('white','up',1,3),
... ('black','down',2,8),
... ('green','up',4,4),
... ('red','down',5,5)]
>>> stmt = "INSERT INTO test VALUES(?,?,?,?)"
>>> con.executemany(stmt, data)
<sqlite3.Cursor object at 0x0000000009E7D8F0>
>>> con.commit()
Наконец, можно перейти к запросам из базы данных. Это делается с помощью SQL SELECT.
>>> cursor = con.execute('select * from test')
>>> cursor
<sqlite3.Cursor object at 0x0000000009E7D730>
>>> rows = cursor.fetchall()
>>> rows
[('white', 'up', 1.0, 3),
('black', 'down', 2.0, 8),
('green', 'up', 4.0, 4),
('red', 'down', 5.0, 5)]
Конструктору Dataframe можно передать список кортежей, а если нужны названия колонок, то их можно найти в атрибуте description своего cursor.
>>> cursor.description
(('a', None, None, None, None, None, None),
('b', None, None, None, None, None, None),
('c', None, None, None, None, None, None),
('d', None, None, None, None, None, None))
>>> pd.DataFrame(rows, columns=zip(*cursor.description)[0])
Этот подход куда сложнее.
Загрузка и запись с помощью PostgreSQL
Начиная с pandas 0.14, PostgreSQL также поддерживается. Для начала нужно проверить версию библиотеки.
>>> pd.__version__
>>> '0.22.0'
Для запуска примера база PostgreSQL должна быть установлена в системе. В этом примере была создана база postgres, где пользователя зовут postgres, а пароль — password. Замените значения на соответствующие в вашей системе.
Сначала нужно установить библиотеку psycopg2, которая предназначена для управления соединениями с базой данных.
В Anaconda:
conda install psycopg2
Или с помощью PyPl:
pip install psycopg2
Теперь можно установить соединение:
>>> import psycopg2
>>> engine = create_engine('postgresql://postgres:password@localhost:5432/
postgres')
Примечание. В этом примере вне зависимости от установленной версии в Windows может возникать ошибка:
from psycopg2._psycopg import BINARY, NUMBER, STRING,
DATETIME, ROWID
ImportError: DLL load failed: The specified module could not
be found.
Это почти наверняка значит, что DLL для PostgreSQL (в частности, libpq.dll) не установлены в PATH. Добавьте одну из папок
postgres\x.x\binв PATH и теперь соединение Python с базой данных PostgreSQL должно работать без проблем.
Создайте объект Dataframe:
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index=['exp1','exp2','exp3','exp4'],
... columns=['feb','mar','apr','may']);
Вот как просто переносить данные в таблицу. С помощью to_sql() вы без проблем запишите их в таблицу dataframe.
>>> frame.to_sql('dataframe',engine)
pgAdmin III — это графическое приложение для управления базами данных PostgreSQL. Крайне удобный инструмент для Windows и Linux. С его помощью можно легко изучить созданную базу данных.
Если вы хорошо знаете язык SQL, то есть и классический способ рассмотреть созданную таблицу с помощью сессии psql.
>>> psql -U postgres
В этом случае соединение произошло от имени пользователя postgres. Оно может отличаться. После соединения просто осуществите SQL-запрос к таблице.
postgres=# SELECT * FROM DATAFRAME;
index| feb | mar | apr | may
-----+-----------------+-----------------+-----------------+-----------------
exp1 |0.757871296789076|0.422582915331819|0.979085739226726|0.332288515791064
exp2 |0.124353978978927|0.273461421503087|0.049433776453223|0.0271413946693556
exp3 |0.538089036334938|0.097041417119426|0.905979807772598|0.123448718583967
exp4 |0.736585422687497|0.982331931474687|0.958014824504186|0.448063967996436
(4 righe)
Даже конвертация таблицы в объект Dataframe — тривиальная задача. Для этого есть функция read_sql_table(), которая считывает данные из таблицы и записывает их в новый объект.
>>> pd.read_sql_table('dataframe',engine)
Но когда нужно считать данные из базы, конвертация целой таблицы в Dataframe — не самая полезная операция. Те, кто работают с реляционными базами данных, предпочитают использовать для этих целей SQL. Он подходит для выбора того. какие данные и в каком виде требуется получить с помощью SQL-запроса.
Текст запроса может быть использован в функции read_sql_query().
>>> pd.read_sql_query('SELECT index,apr,may FROM DATAFRAME WHERE apr >
0.5',engine)
Чтение и запись данных в базу данных NoSQL: MongoDB
Среди всех баз данных NoSQL (BerkeleyDB, Tokyo Cabinet и MongoDB) MongoDB — одна из самых распространенных. Она доступна в разных системах и подходит для чтения и записи данных при анализе данных.
Работу нужно начать с того, что указать на конкретную директорию.
mongod --dbpath C:\MongoDB_data
Теперь, когда сервис случает порт 27017, к базе можно подключиться, используя официальный драйвер для MongoDB, pymongo.
>>> import pymongo
>>> client = MongoClient('localhost',27017)
Один экземпляр MongoDB способен поддерживать несколько баз данных одновременно. Поэтому нужно указать на конкретную.
>>> db = client.mydatabase
>>> db
Database(MongoClient('localhost', 27017), 'mycollection')
>>> # Чтобы ссылаться на этот объект, используйте
>>> client['mydatabase']
Database(MongoClient('localhost', 27017), 'mydatabase')
Когда база данных определена, нужно определить коллекцию. Она представляет собой группу документов, сохраненных в MongoDB. Ее можно воспринимать как эквивалент таблиц из SQL.
>>> collection = db.mycollection
>>> db['mycollection']
Collection(Database(MongoClient('localhost', 27017), 'mydatabase'),
'mycollection')
>>> collection
Collection(Database(MongoClient('localhost', 27017), 'mydatabase'),
'mycollection')
Теперь нужно добавить данные в коллекцию. Создайте Dataframe.
>>> frame = pd.DataFrame(np.arange(20).reshape(4,5),
... columns=['white','red','blue','black','green'])
>>> frame
| white | red | blue | black | green | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
Перед добавлением его нужно конвертировать в формат JSON. Процесс конвертации не такой простой, потому что нужно задать данные, которые будут записаны в базу, чтобы потом с легкостью извлекать их снова в объекте.
>>> import json
>>> record = json.loads(frame.T.to_json()).values()
>>> record
[{'blue': 7, 'green': 9, 'white': 5, 'black': 8, 'red': 6},
{'blue': 2, 'green': 4, 'white': 0, 'black': 3, 'red': 1},
{'blue': 17, 'green': 19, 'white': 15, 'black': 18, 'red': 16},
{'blue': 12, 'green': 14, 'white': 10, 'black': 13, 'red': 11}]
Теперь все готово для добавления документа в коллекцию. Для этого используется функция insert().
>>> collection.mydocument.insert(record)
[ObjectId('54fc3afb9bfbee47f4260357'), ObjectId('54fc3afb9bfbee47f4260358'),
ObjectId('54fc3afb9bfbee47f4260359'), ObjectId('54fc3afb9bfbee47f426035a')]
В этом случае каждый объект представлен на отдельной строке. Когда данные загружены в документ базы данных, можно выполнить и обратный процесс, то есть, прочитать данные и конвертировать их в Dataframe.
>>> cursor = collection['mydocument'].find()
>>> dataframe = (list(cursor))
>>> del dataframe['_id']
>>> dataframe
Была удалена колонка с ID для внутренней навигации по MongoDB.
В этом материале вы узнаете, как установить Keras на ОС Linux и Windows, а также ознакомитесь с проблемами, которые могут возникнуть в процессе, и требованиями для установки.
Как установить Keras на Linux
Keras — это фреймворк Python для глубокого обучения, поэтому в первую очередь нужно, чтобы Python был установлен в системе.
В Ubuntu он есть по умолчанию. Рекомендуется использовать последнюю версию, то есть python3. Для проверки наличия его в системе выполните следующее:
- Откройте терминал (Ctrl+Alt+T)
- Введите
python3 -Vилиpython3 –version
Выводом будет версия Python 3.
Python 3.6.9
Если Python 3 не установлен, воспользуйтесь следующими инструкциями:
- Добавьте
PPA, запустив следующую командуsudo add-apt-repository ppa:jonathonf/python-3.6Введите пароль суперпользователя.
- Проверьте обновления и установите Python 3.6 или больше
sudo apt-get update sudo apt-get install python3.6 - Снова проверьте версию Python 3.
Теперь пришло время устанавливать Keras.
Но сначала нужно установить один из бэкенд-движков: Tensorflow, Theano или Microsoft CNTK. Лучше всего использовать первый.
Установите Tensorflow из PyPl:
pip3 install tensorflow
Теперь установка Keras:
- Установите Keras из PyPl:
pip3 install Keras
- Или установите его из Github:
- Клонируйте репозиторий
git clone https://github.com/keras-team/keras.git - Перейдите в папку keras
cd Keras - Запустите команду install
sudo python3 setup.py install
Keras установлен.
Как установить Keras на Windows?
Прежде чем переходить к установке Keras, нужно убедиться, что в системе есть Python. Нужна версия как минимум Python 3.5+.
Для проверки установленной версии:
- Откройте
cmd - Введите
python -Vилиpython –version
Отобразится текущая версия Python.
Python 3.7.3
Если Python не установлен или загружена более старая версия:
- Зайдите на сайт python.org
- Выберите последнюю версию Python для Windows
- В нижней части страницы выберите установочный файл
Windows x86-для 64-битной версии системы илиWindows x86— для 32-битной. - После загрузки программы установки дважды кликните по файлу.
- Снова проверьте версию Python в
cmd
Теперь нужно установить один из движков: Tensorflow, Theano или Microsoft CNTK. Рекомендуется использовать первый.
Установите Tensofrflow с помощью пакетного менеджера pip3:
pip3 install tensorflow
Теперь установите Keras
- Установите Keras из PyPl:
pip3 install Keras - Установите Keras из Github
Клонируйте git-репозиторийgit clone https://github.com/keras-team/keras.git - Перейдите в папку
kerascd keras - Запустите команду
installpython3 setup.py install
Создайте первую программу в Keras
Создадим регрессионную предсказательную модель на основе данных о ценах Boston Housing с помощью Keras. Данные включают 13 признаков домов и включают 506 объектов. Задача — предсказать цены.
Это классическая регрессионная проблема машинного обучения, а набор данных доступен в модуле Keras.dataset.
Реализация:
import numpy as np
import pandas as pd
# загрузить набор данных, это может занять некоторое время
from keras.datasets import boston_housing
(train_x,train_y),(test_x,test_y)=boston_housing.load_data()
Нормализация данных
mean=train_x.mean(axis=0)
train_x-=mean
std=train_x.std(axis=0)
train_x/=std
test_x-=mean
test_x/=std
Построение нейронной сети
from keras import models, layers
def build_model():
model=models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(train_x.shape[1],)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop',loss='mse',metrics=['mae'])
return model
Тренировка модели
model=build_model()
model.fit(train_x,train_y,epochs=80,batch_size=16,verbose=0)
Оценка модели с помощью среднеквадратической ошибки модели и средней абсолютной ошибки
test_mse, test_mae=model.evaluate(test_x, test_y)
test_mae
2.6441757678985596
Модель получает довольно высокую среднюю ошибку с этими данными. Лучшие результаты можно получить за счет дальнейшей предварительной обработки данных.
Выводы
Статья посвящена пошаговой установке Keras в Linux (Ubuntu) и Windows. Она также включает базовую реализацию предсказательной модели ценообразования Boston Housing, которая является хорошо исследованной регрессионной проблемой моделирования в машинном обучении.
]]>Вы уже знакомы с библиотекой pandas и ее базовой функциональностью по анализу данных. Также знаете, что в ее основе лежат два типа данных: Dataframe и Series. На их основе выполняется большая часть взаимодействия с данными, вычислений и анализа.
В этом материале вы познакомитесь с инструментами, предназначенными для чтения данных, сохраненных в разных источниках (файлах и базах данных). Также научитесь записывать структуры в эти форматы, не задумываясь об используемых технологиях.
Этот раздел посвящен функциям API I/O (ввода/вывода), которые pandas предоставляет для чтения и записи данных прямо в виде объектов Dataframe. Начнем с текстовых файлов, а затем перейдем к более сложным бинарным форматам.
А в конце узнаем, как взаимодействовать с распространенными базами данных, такими как SQL и NoSQL, используя для этого реальные примеры. Разберем, как считывать данные из базы данных, сохраняя их в виде Dataframe.
Инструменты API I/O
pandas — библиотека, предназначенная для анализа данных, поэтому логично предположить, что она в первую очередь используется для вычислений и обработки данных. Процесс записи и чтения данных на/с внешние файлы — это часть обработки. Даже на этом этапе можно выполнять определенные операции, готовя данные к взаимодействию.
Первый шаг очень важен, поэтому для него представлен полноценный инструмент в библиотеке, называемый API I/O. Функции из него можно разделить на две категории: для чтения и для записи.
| Чтение | Запись |
|---|---|
| read_csv | to_csv |
| read_excel | to_excel |
| read_hdf | to_hdf |
| read_sql | to_sql |
| read_json | to_json |
| read_html | to_html |
| read_stata | to_stata |
| read_clipboard | to_clipboard |
| read_pickle | to_pickle |
| read_msgpack | to_msgpack (экспериментальный) |
| read_gbq | to_gbq (экспериментальный) |
CSV и текстовые файлы
Все привыкли к записи и чтению файлов в текстовой форме. Чаще всего они представлены в табличной форме. Если значения в колонке разделены запятыми, то это формат CSV (значения, разделенные запятыми), который является, наверное, самым известным форматом.
Другие формы табличных данных могут использовать в качестве разделителей пробелы или отступы. Они хранятся в текстовых файлах разных типов (обычно с расширением .txt).
Такой тип файлов — самый распространенный источник данных, который легко расшифровывать и интерпретировать. Для этого pandas предлагает набор функций:
read_csvread_tableto_csv
Чтение данных из CSV или текстовых файлов
Самая распространенная операция по взаимодействию с данными при анализе данных — чтение их из файла CSV или как минимум текстового файла.
Для этого сперва нужно импортировать отдельные библиотеки.
>>> import numpy as np
>>> import pandas as pd
Чтобы сначала увидеть, как pandas работает с этими данными, создадим маленький файл CSV в рабочем каталоге, как показано на следующем изображении и сохраним его как ch05_01.csv.
white,red,blue,green,animal
1,5,2,3,cat
2,7,8,5,dog
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
Поскольку разделителем в файле выступают запятые, можно использовать функцию read_csv() для чтения его содержимого и добавления в объект Dataframe.
>>> csvframe = pd.read_csv('ch05_01.csv')
>>> csvframe
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Это простая операция. Файлы CSV — это табличные данные, где значения одной колонки разделены запятыми. Поскольку это все еще текстовые файлы, то подойдет и функция read_table(), но в таком случае нужно явно указывать разделитель.
>>> pd.read_table('ch05_01.csv',sep=',')
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
В этом примере все заголовки, обозначающие названия колонок, определены в первой строчке. Но это не всегда работает именно так. Иногда сами данные начинаются с первой строки.
Создадим файл ch05_02.csv
1,5,2,3,cat
2,7,8,5,dog
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
>>> pd.read_csv('ch05_02.csv')
| 1 | 5 | 2 | 3 | cat | |
|---|---|---|---|---|---|
| 0 | 2 | 7 | 8 | 5 | dog |
| 1 | 3 | 3 | 6 | 7 | horse |
| 2 | 2 | 2 | 8 | 3 | duck |
| 3 | 4 | 4 | 2 | 1 | mouse |
| 4 | 4 | 4 | 2 | 1 | mouse |
В таком случае нужно убедиться, что pandas не присвоит названиям колонок значения первой строки, передав None параметру header.
>>> pd.read_csv('ch05_02.csv', header=None)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Также можно самостоятельно определить названия, присвоив список меток параметру names.
>>> pd.read_csv('ch05_02.csv', names=['white','red','blue','green','animal'])
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
В более сложных случаях когда нужно создать Dataframe с иерархической структурой на основе данных из файла CSV, можно расширить возможности функции read_csv() добавив параметр index_col, который конвертирует колонки в значения индексов.
Чтобы лучше разобраться с этой особенностью, создайте новый CSV-файл с двумя колонками, которые будут индексами в иерархии. Затем сохраните его в рабочую директорию под именем ch05_03.csv.
Создадим файл ch05_03.csv
color,status,item1,item2,item3
black,up,3,4,6
black,down,2,6,7
white,up,5,5,5
white,down,3,3,2
white,left,1,2,1
red,up,2,2,2
red,down,1,1,4
>>> pd.read_csv('ch05_03.csv', index_col=['color','status'])
| item1 | item2 | item3 | ||
|---|---|---|---|---|
| color | status | |||
| black | up | 3 | 4 | 6 |
| down | 2 | 6 | 7 | |
| white | up | 5 | 5 | 5 |
| down | 3 | 3 | 2 | |
| left | 1 | 2 | 1 | |
| red | up | 2 | 2 | 2 |
| down | 1 | 1 | 4 |
Использованием RegExp для парсинга файлов TXT
Иногда бывает так, что в файлах, из которых нужно получить данные, нет разделителей, таких как запятая или двоеточие. В таких случаях на помощь приходят регулярные выражения. Задать такое выражение можно в функции read_table() с помощью параметра sep.
Чтобы лучше понимать regexp и то, как их использовать для разделения данных, начнем с простого примера. Например, предположим, что файл TXT имеет значения, разделенные пробелами и отступами хаотично. В таком случае regexp подойдут идеально, ведь они позволяют учитывать оба вида разделителей. Подстановочный символ /s* отвечает за все символы пробелов и отступов (если нужны только отступы, то используется /t), а * указывает на то, что символов может быть несколько. Таким образом значения могут быть разделены большим количеством пробелов.
| . | Любой символ за исключением новой строки |
| \d | Цифра |
| \D | Не-цифровое значение |
| \s | Пробел |
| \S | Не-пробельное значение |
| \n | Новая строка |
| \t | Отступ |
| \uxxxx | Символ Unicode в шестнадцатеричном виде |
Возьмем в качестве примера случай, где значения разделены отступами или пробелами в хаотическом порядке.
Создадим файл ch05_04.txt
white red blue green
1 5 2 3
2 7 8 5
3 3 6 7
>>> pd.read_table('ch05_04.txt',sep='\s+', engine='python')
| white | red | blue | green | |
|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 |
| 1 | 2 | 7 | 8 | 5 |
| 2 | 3 | 3 | 6 | 7 |
Результатом будет идеальный Dataframe, в котором все значения корректно отсортированы.
Дальше будет пример, который может показаться странным, но на практике он встречается не так уж и редко. Он пригодится для понимания принципов работы regexp. На самом деле, о разделителях (запятых, пробелах, отступах и так далее) часто думают как о специальных символах, но иногда ими выступают и буквенно-цифровые символы, например, целые числа.
В следующем примере необходимо извлечь цифровую часть из файла TXT, в котором последовательность символов перемешана с буквами.
Не забудьте задать параметр None для параметра header, если в файле нет заголовков колонок.
Создадим файл ch05_05.txt
000END123AAA122
001END124BBB321
002END125CCC333
>>> pd.read_table('ch05_05.txt', sep='\D+', header=None, engine='python')
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 123 | 122 |
| 1 | 1 | 124 | 321 |
| 2 | 2 | 125 | 333 |
Еще один распространенный пример — удаление из данных отдельных строк при извлечении. Так, не всегда нужны заголовки или комментарии. Благодаря параметру skiprows можно исключить любые строки, просто присвоим ему массив с номерами строк, которые не нужно парсить.
Обратите внимание на способ использования параметра. Если нужно исключить первые пять строк, то необходимо писать skiprows = 5, но для удаления только пятой строки — [5].
Создадим файл ch05_06.txt
########### LOG FILE ############
This file has been generated by automatic system
white,red,blue,green,animal
12-Feb-2015: Counting of animals inside the house
1,5,2,3,cat
2,7,8,5,dog
13-Feb-2015: Counting of animals outside the house
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
>>> pd.read_table('ch05_06.txt',sep=',',skiprows=[0,1,3,6])
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Чтение файлов TXT с разделением на части
При обработке крупных файлов или необходимости использовать только отдельные их части часто требуется считывать их кусками. Это может пригодится, если необходимо воспользоваться перебором или же целый файл не нужен.
Если требуется получить лишь часть файла, можно явно указать количество требуемых строк. Благодаря параметрам nrows и skiprows можно выбрать стартовую строку n (n = SkipRows) и количество строк, которые нужно считать после (nrows = 1).
>>> pd.read_csv('ch05_02.csv',skiprows=[2],nrows=3,header=None)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 2 | 2 | 8 | 3 | duck |
Еще одна интересная и распространенная операция — разбитие на части того куска текста, который требуется парсить. Затем для каждой части может быть выполнена конкретная операция для получения перебора части за частью.
Например, нужно суммировать значения в колонке каждой третьей строки и затем вставить результат в объект Series. Это простой и непрактичный пример, но с его помощью легко разобраться, а поняв механизм работы, его проще будет применять в сложных ситуациях.
>>> out = pd.Series()
>>> i = 0
>>> pieces = pd.read_csv('ch05_01.csv',chunksize=3)
>>> for piece in pieces:
... out.set_value(i,piece['white'].sum())
... i = i + 1
...
>>> out
0 6
1 6
dtype: int64
Запись данных в CSV
В дополнение к чтению данных из файла, распространенной операцией является запись в файл данных, полученных, например, в результате вычислений или просто из структуры данных.
Например, нужно записать данные из объекта Dataframe в файл CSV. Для этого используется функция to_csv(), принимающая в качестве аргумента имя файла, который будет сгенерирован.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
index = ['red', 'blue', 'yellow', 'white'],
columns = ['ball', 'pen', 'pencil', 'paper'])
>>> frame.to_csv('ch05_07.csv')
Если открыть новый файл ch05_07.csv, сгенерированный библиотекой pandas, то он будет напоминать следующее:
,ball,pen,pencil,paper
0,1,2,3
4,5,6,7
8,9,10,11
12,13,14,15
На предыдущем примере видно, что при записи Dataframe в файл индексы и колонки отмечаются в файле по умолчанию. Это поведение можно изменить с помощью параметров index и header. Им нужно передать значение False.
>>> frame.to_csv('ch05_07b.csv', index=False, header=False)
Файл ch05_07b.csv
1,2,3
5,6,7
9,10,11
13,14,15
Важно запомнить, что при записи файлов значения NaN из структуры данных представлены в виде пустых полей в файле.
>>> frame3 = pd.DataFrame([[6,np.nan,np.nan,6,np.nan],
... [np.nan,np.nan,np.nan,np.nan,np.nan],
... [np.nan,np.nan,np.nan,np.nan,np.nan],
... [20,np.nan,np.nan,20.0,np.nan],
... [19,np.nan,np.nan,19.0,np.nan]
... ],
... index=['blue','green','red','white','yellow'],
... columns=['ball','mug','paper','pen','pencil'])
>>> frame3
| Unnamed: 0 | ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|---|
| 0 | blue | 6.0 | NaN | NaN | 6.0 | NaN |
| 1 | green | NaN | NaN | NaN | NaN | NaN |
| 2 | red | NaN | NaN | NaN | NaN | NaN |
| 3 | white | 20.0 | NaN | NaN | 20.0 | NaN |
| 4 | yellow | 19.0 | NaN | NaN | 19.0 | NaN |
>>> frame3.to_csv('ch05_08.csv')
,ball,mug,paper,pen,pencil
blue,6.0,,,6.0,
green,,,,,
red,,,,,
white,20.0,,,20.0,
yellow,19.0,,,19.0,
Но их можно заменить на любое значение, воспользовавшись параметром na_rep из функции to_csv. Это может быть NULL, 0 или то же NaN.
>>> frame3.to_csv('ch05_09.csv', na_rep ='NaN')
,ball,mug,paper,pen,pencil
blue,6.0,NaN,NaN,6.0,NaN
green,NaN,NaN,NaN,NaN,NaN
red,NaN,NaN,NaN,NaN,NaN
white,20.0,NaN,NaN,20.0,NaN
yellow,19.0,NaN,NaN,19.0,NaN
Примечание: в предыдущих примерах использовались только объекты
Dataframe, но все функции применимы и по отношению кSeries.
Чтение и запись файлов HTML
pandas предоставляет соответствующую пару функций API I/O для формата HTML.
read_html()to_html()
Эти две функции очень полезны. С их помощью можно просто конвертировать сложные структуры данных, такие как Dataframe, прямо в таблицы HTML, не углубляясь в синтаксис.
Обратная операция тоже очень полезна, потому что сегодня веб является одним из основных источников информации. При этом большая часть информации не является «готовой к использованию», будучи упакованной в форматы TXT или CSV. Необходимые данные чаще всего представлены лишь на части страницы. Так что функция для чтения окажется полезной очень часто.
Такая деятельность называется парсингом (веб-скрапингом). Этот процесс становится фундаментальным элементом первого этапа анализа данных: поиска и подготовки.
Примечание: многие сайты используют
HTML5для предотвращения ошибок недостающих модулей или сообщений об ошибках. Настоятельно рекомендуется использовать модульhtml5libв Anaconda.
conda install html5lib
Запись данных в HTML
При записи Dataframe в HTML-таблицу внутренняя структура объекта автоматически конвертируется в сетку вложенных тегов <th>, <tr> и <td>, сохраняя иерархию. Для этой функции даже не нужно знать HTML.
Поскольку структуры данных, такие как Dataframe, могут быть большими и сложными, это очень удобно иметь функцию, которая сама создает таблицу на странице. Вот пример.
Сначала создадим простейший Dataframe. Дальше с помощью функции to_html() прямо конвертируем его в таблицу HTML.
>>> frame = pd.DataFrame(np.arange(4).reshape(2,2))
Поскольку функции API I/O определены в структуре данных pandas, вызывать to_html() можно прямо к экземпляру Dataframe.
>>> print(frame.to_html())
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>0</th>
<th>1</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>0</td>
<td>1</td>
</tr>
<tr>
<th>1</th>
<td>2</td>
<td>3</td>
</tr>
</tbody>
</table>
Результат — готовая таблица HTML, сохранившая всю внутреннюю структуру.
В следующем примере вы увидите, как таблицы автоматически появляются в файле HTML. В этот раз сделаем объект более сложным, добавив в него метки индексов и названия колонок.
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index = ['white','black','red','blue'],
... columns = ['up','down','right','left'])
>>> frame
| up | down | right | left | |
|---|---|---|---|---|
| white | 0.420378 | 0.533364 | 0.758968 | 0.132560 |
| black | 0.711775 | 0.375598 | 0.936847 | 0.495377 |
| red | 0.630547 | 0.998588 | 0.592496 | 0.076336 |
| blue | 0.308752 | 0.158057 | 0.647739 | 0.907514 |
Теперь попробуем написать страницу HTML с помощью генерации строк. Это простой пример, но он позволит разобраться с функциональностью pandas прямо в браузере.
Сначала создадим строку, которая содержит код HTML-страницы.
>>> s = ['<HTML>']
>>> s.append('<HEAD><TITLE>My DataFrame</TITLE></HEAD>')
>>> s.append('<BODY>')
>>> s.append(frame.to_html())
>>> s.append('</BODY></HTML>')
>>> html = ''.join(s)
Теперь когда метка html содержит всю необходимую разметку, можно писать прямо в файл myFrame.html:
>>> html_file = open('myFrame.html','w')
>>> html_file.write(html)
>>> html_file.close()
В рабочей директории появится новый файл, myFrame.html. Двойным кликом его можно открыть прямо в браузере. В левом верхнем углу будет следующая таблица:

Чтение данных из HTML-файла
pandas может с легкостью генерировать HTML-таблицы на основе данных Dataframe. Обратный процесс тоже возможен. Функция read_html() осуществляет парсинг HTML и ищет таблицу. В случае успеха она конвертирует ее в Dataframe, который можно использовать в процессе анализа данных.
Если точнее, то read_html() возвращает список объектов Dataframe, даже если таблица одна. Источник может быть разных типов. Например, может потребоваться прочитать HTML-файл в любой папке. Или попробовать парсить HTML из прошлого примера:
>>> web_frames = pd.read_html('myFrame.html')
>>> web_frames[0]
| Unnamed: 0 | up | down | right | left | |
|---|---|---|---|---|---|
| 0 | white | 0.420378 | 0.533364 | 0.758968 | 0.132560 |
| 1 | black | 0.711775 | 0.375598 | 0.936847 | 0.495377 |
| 2 | red | 0.630547 | 0.998588 | 0.592496 | 0.076336 |
| 3 | blue | 0.308752 | 0.158057 | 0.647739 | 0.907514 |
Все теги, отвечающие за формирование таблицы в HTML в финальном объекте не представлены. web_frames — это список Dataframe, хотя в этом случае объект был всего один. К нему можно обратиться стандартным путем. Здесь достаточно лишь указать на него через индекс 0.
Но самый распространенный режим работы функции read_html() — прямой парсинг ссылки. Таким образом страницы парсятся прямо, а из них извлекаются таблицы.
Например, дальше будет вызвана страница, на которой есть HTML-таблица, показывающая рейтинг с именами и баллами.
>>> ranking = pd.read_html('https://www.meccanismocomplesso.org/en/
meccanismo-complesso-sito-2/classifica-punteggio/')
>>> ranking[0]
| # | Nome | Exp | Livelli | right |
|---|---|---|---|---|
| 0 | 1 | Fabio Nelli | 17521 | NaN |
| 1 | 2 | admin | 9029 | NaN |
| 2 | 3 | BrunoOrsini | 2124 | NaN |
| … | … | … | … | … |
| 247 | 248 | emilibassi | 1 | NaN |
| 248 | 249 | mehrbano | 1 | NaN |
| 249 | 250 | NIKITA PANCHAL | 1 | NaN |
Чтение данных из XML
В списке функции API I/O нет конкретного инструмента для работы с форматом XML (Extensible Markup Language). Тем не менее он очень важный, поскольку многие структурированные данные представлены именно в нем. Но это и не проблема, ведь в Python есть много других библиотек (помимо pandas), которые подходят для чтения и записи данных в формате XML.
Одна их них называется lxml и она обеспечивает идеальную производительность при парсинге даже самых крупных файлов. Этот раздел будет посвящен ее использованию, интеграции с pandas и способам получения Dataframe с нужными данными. Больше подробностей о lxml есть на официальном сайте http://lxml.de/index.html.
Возьмем в качестве примера следующий файл. Сохраните его в рабочей директории с названием books.xml.
<?xml version="1.0"?>
<Catalog>
<Book id="ISBN9872122367564">
<Author>Ross, Mark</Author>
<Title>XML Cookbook</Title>
<Genre>Computer</Genre>
<Price>23.56</Price>
<PublishDate>2014-22-01</PublishDate>
</Book>
<Book id="ISBN9872122367564">
<Author>Bracket, Barbara</Author>
<Title>XML for Dummies</Title>
<Genre>Computer</Genre>
<Price>35.95</Price>
<PublishDate>2014-12-16</PublishDate>
</Book>
</Catalog>
В этом примере структура файла будет конвертирована и преподнесена в виде Dataframe. В первую очередь нужно импортировать субмодуль objectify из библиотеки.
>>> from lxml import objectify
Теперь нужно всего лишь использовать его функцию parse().
>>> xml = objectify.parse('books.xml')
>>> xml
<lxml.etree._ElementTree object at 0x0000000009734E08>
Результатом будет объект tree, который является внутренней структурой данных модуля lxml.
Чтобы познакомиться с деталями этого типа, пройтись по его структуре или выбирать элемент за элементом, в первую очередь нужно определить корень. Для этого используется функция getroot().
>>> root = xml.getroot()
Теперь можно получать доступ к разным узлам, каждый из которых соответствует тегам в оригинальном XML-файле. Их имена также будут соответствовать. Для выбора узлов нужно просто писать отдельные теги через точки, используя иерархию дерева.
>>> root.Book.Author
'Ross, Mark'
>>> root.Book.PublishDate
'2014-22-01'
В такой способ доступ к узлам можно получить индивидуально. А getchildren() обеспечит доступ ко всем дочерним элементами.
>>> root.getchildren()
[<Element Book at 0x9c66688>, <Element Book at 0x9c66e08>]
При использовании атрибута tag вы получаете название соответствующего тега из родительского узла.
>>> [child.tag for child in root.Book.getchildren()]
['Author', 'Title', 'Genre', 'Price', 'PublishDate']
А text покажет значения в этих тегах.
>>> [child.text for child in root.Book.getchildren()]
['Ross, Mark', 'XML Cookbook', 'Computer', '23.56', '2014-22-01']
Но вне зависимости от возможности двигаться по структуре lxml.etree, ее нужно конвертировать в Dataframe. Воспользуйтесь следующей функцией, которая анализирует содержимое eTree и заполняет им Dataframe строчка за строчкой.
>>> def etree2df(root):
... column_names = []
... for i in range(0, len(root.getchildren()[0].getchildren())):
... column_names.append(root.getchildren()[0].getchildren()[i].tag)
... xmlframe = pd.DataFrame(columns=column_names)
... for j in range(0, len(root.getchildren())):
... obj = root.getchildren()[j].getchildren()
... texts = []
... for k in range(0, len(column_names)):
... texts.append(obj[k].text)
... row = dict(zip(column_names, texts))
... row_s = pd.Series(row)
... row_s.name = j
... xmlframe = xmlframe.append(row_s)
... return xmlframe
>>> etree2df(root)
| Author | Title | Genre | Price | PublishDate | |
|---|---|---|---|---|---|
| 0 | Ross, Mark | XML Cookbook | Computer | 23.56 | 2014-01-22 |
| 1 | Bracket, Barbara | XML for Dummies | Computer | 35.95 | 2014-12-16 |
Keras — очень полезная библиотека для тех, кто только начинает свое знакомство с нейронными сетями. Это высокоуровневый фреймворк со скрытой бэкенд-реализацией, необходимый для построения моделей нейронных сетей. Из этого материала вы узнаете о достоинствах и ограничениях Keras.
Преимущества Keras
1. Простой в использовании с высокой скоростью развертывания
Keras — это простой в использовании API, с помощью которого очень легко создавать модели нейронных сетей. Он подходит для реализации алгоритмов глубокого обучения и обработки естественного языка. Модель нейронной сети можно построить с помощью всего нескольких строчек кода.
Вот пример:
from keras.models import Sequential
from keras.layers import Dense, Activation
model= Sequential()
model.add(Dense(64, activation=’relu’,input_dim=50))
model.add(Dense(28, activation=’relu’))
model.add(Dense(10,activation=’softmax’))
Здесь видно, что разобраться как с кодом, так и с потоком не составит труда. Функции и параметры очень простые, поэтому и писать их не сложно. Есть внушительный набор функций для обработки данных. Keras предоставляет несколько слоев, включая поддержку свертываемых и рекуррентных слоев.
2. Качественная документация и поддержка от сообщества
У Keras один из лучших примеров документации. Она представляет каждую функцию последовательно и очень подробно. Примеры кода также полезны и просты для понимания.
У Keras есть отличная поддержка со стороны сообщества. Многие разработчики предпочитают Keras для участия в соревнованиях по Data Science. Также многие исследователи публикуют свой код и руководства для широкой аудитории.
3. Поддержка разных движков и модульность
Keras предлагает поддержку несколько бэкенд-движков, включая Tensorflow, Theano и CNTK. Любой из них может быть выбран на основе требований проекта.
Можно также тренировать модель Keras на основе одного движка, а проверять результаты — на другом. Поменять движок в Keras также очень легко. Для этого его имя нужно просто записать в конфигурационном файле.
4. Натренированные модели
Keras предоставляет несколько моделей глубокого обучения с натренированными весами. Их можно использовать для предсказания или извлечения признаков.
У этих моделей встроенные веса, которые являются результатами тренировки модели на данных ImageNet.
Вот некоторые из представленных моделей:
- Xception
- VGG16
- VGG19
- ResNet, ResNetV2
- InceptionV3
- InceptionResNetV2
- MobileNet
- MobileNetV2
- DenseNet
- NASNet
5. Поддержка нескольких GPU
Keras позволяет тренировать модель как на одном, так и на нескольких GPU. Это обеспечивает поддержку параллелизма данных и позволяет обрабатывать большие объемы.
Ограничения Keras
Вот некоторые из недостатков инструмента.
1. Проблемы в низкоуровневом API
Иногда возникают низкоуровневые ошибки бэкенда. Это происходит в тех случаях, когда предпринимаются попытки выполнить операции, для которых Keras не предназначен.
Однако он не позволяет изменять что-либо в бэкенде. Следовательно, сложно заниматься отладкой на основе логов с ошибками.
2. Требуются улучшения некоторых особенностей
Инструменты Keras для подготовки данных не так хороши, как в случае с другими пакетами, например scikit-learn. Они не подходят для построения базовых алгоритмов машинного обучения: кластерного анализа или метода главных компонент. Нет и возможности динамического создания графиков.
3. Медленнее бэкенда
Иногда Keras очень медленный при работе на GPU, а его операции занимают больше времени в сравнении с бэкендом. Поэтому скоростью приходится жертвовать в угоду удобству использования.
Выводы
Этот материал — лишь основные достоинства и недостатки работы с Keras. На их основе вы должны решать, когда использовать фреймворк, а когда лучше отдать предпочтение альтернативам.
]]>Иерархическое индексирование — это важная особенность pandas, поскольку она позволяет иметь несколько уровней индексов в одной оси. С ее помощью можно работать с данными в большом количестве измерений, по-прежнему используя для этого структуру данных из двух измерений.
Начнем с простого примера, создав Series с двумя массивами индексов — структуру с двумя уровнями.
>>> mser = pd.Series(np.random.rand(8),
... index=[['white','white','white','blue','blue','red','red',
'red'],
... ['up','down','right','up','down','up','down','left']])
>>> mser
white up 0.661039
down 0.512268
right 0.639885
blue up 0.081480
down 0.408367
red up 0.465264
down 0.374153
left 0.325975
dtype: float64
>>> mser.index
MultiIndex(levels=[['blue', 'red', 'white'], ['down', 'left', 'right', 'up']],
labels=[[2, 2, 2, 0, 0, 1, 1, 1], [3, 0, 2, 3, 0, 3, 0, 1]])
За счет спецификации иерархического индексирования, выбор подмножеств значений в таком случае заметно упрощен. Можно выбрать значения для определенного значения первого индекса стандартным способом:
>>> mser['white']
up 0.661039
down 0.512268
right 0.639885
dtype: float64
Или же значения для конкретного значения во втором индекса — таким:
>>> mser[:,'up']
white 0.661039
blue 0.081480
red 0.465264
dtype: float64
Если необходимо конкретное значение, просто указываются оба индекса.
>>> mser['white','up']
0.66103875558038194
Иерархическое индексирование играет важную роль в изменении формы данных и групповых операциях, таких как сводные таблицы. Например, данные могут быть перестроены и использованы в объекте Dataframe с помощью функции unstack(). Она конвертирует Series с иерархическими индексами в простой Dataframe, где второй набор индексов превращается в новые колонки.
>>> mser.unstack()
| down | left | right | up | |
|---|---|---|---|---|
| blue | 0.408367 | NaN | NaN | 0.081480 |
| red | 0.374153 | 0.325975 | NaN | 0.465264 |
| white | 0.512268 | NaN | 0.639885 | 0.661039 |
Если необходимо выполнить обратную операцию — превратить Dataframe в Series, — используется функция stack().
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame.stack()
red ball 0
pen 1
pencil 2
paper 3
blue ball 4
pen 5
pencil 6
paper 7
yellow ball 8
pen 9
pencil 10
paper 11
white ball 12
pen 13
pencil 14
paper 15
dtype: int32
В Dataframe можно определить иерархическое индексирование для строк и колонок. Для этого необходимо определить массив массивов для параметров index и columns.
>>> mframe = pd.DataFrame(np.random.randn(16).reshape(4,4),
... index=[['white','white','red','red'], ['up','down','up','down']],
... columns=[['pen','pen','paper','paper'],[1,2,1,2]])
>>> mframe
| pen | paper | ||||
|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | ||
| white | up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | 0.580848 | 1.124744 | 0.741454 | -0.035455 | |
| red | up | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
Изменение порядка и сортировка уровней
Иногда потребуется поменять порядок уровней на оси или отсортировать значения на определенном уровне.
Функция swaplevel() принимает в качестве аргументов названия уровней, которые необходимо поменять относительно друг друга и возвращает новый объект с соответствующими изменениями, оставляя данные в том же состоянии.
>>> mframe.columns.names = ['objects','id']
>>> mframe.index.names = ['colors','status']
>>> mframe
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| colors | status | ||||
| white | up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | 0.580848 | 1.124744 | 0.741454 | -0.035455 | |
| red | up | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
>>> mframe.swaplevel('colors','status')
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| status | colors | ||||
| up | white | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | white | 0.580848 | 1.124744 | 0.741454 | -0.035455 |
| up | red | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | red | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
А функция sort_index() сортирует данные для конкретного уровня, указанного в параметрах.
>>> mframe.sort_index(level='colors')
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| colors | status | ||||
| red | down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
| up | -1.721348 | 0.989703 | -1.454304 | -0.249718 | |
| white | down | 0.580848 | 1.124744 | 0.741454 | -0.035455 |
| up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
Общая статистика по уровню
У многих статистических методов для Dataframe есть параметр level, в котором нужно определить, для какого уровня нужно определить статистику.
Например, если нужна статистика для первого уровня, его нужно указать в параметрах.
>>> mframe.sum(level='colors')
| objects | pen | paper | ||
|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 |
| colors | ||||
| white | 2.143731 | 2.044471 | 0.343945 | -0.349614 |
| red | -1.834594 | 0.548174 | -1.559332 | 0.036068 |
Если же она необходима для конкретного уровня колонки, например, id, тогда требуется задать параметр axis и указать значение 1.
>>> mframe.sum(level='id', axis=1)
| id | 1 | 2 | paper |
|---|---|---|---|
| colors | status | ||
| white | up | 1.165374 | 0.605568 |
| down | 1.322302 | 1.089289 | |
| red | up | -3.175653 | 0.739985 |
| down | -0.218274 | -0.155743 |
В предыдущих разделах вы видели, как легко могут образовываться недостающие данные. В структурах они определяются как значения NaN (Not a Value). Такой тип довольно распространен в анализе данных.
Но pandas спроектирован так, чтобы лучше с ними работать. Дальше вы узнаете, как взаимодействовать с NaN, чтобы избегать возможных проблем. Например, в библиотеке pandas вычисление описательной статистики неявно исключает все значения NaN.
Присваивание значения NaN
Если нужно специально присвоить значение NaN элементу структуры данных, для этого используется np.NaN (или np.nan) из библиотеки NumPy.
>>> ser = pd.Series([0,1,2,np.NaN,9],
... index=['red','blue','yellow','white','green'])
>>> ser
red 0.0
blue 1.0
yellow 2.0
white NaN
green 9.0
dtype: float64
>>> ser['white'] = None
>>> ser
red 0.0
blue 1.0
yellow 2.0
white NaN
green 9.0
dtype: float64
Фильтрование значений NaN
Есть несколько способов, как можно избавиться от значений NaN во время анализа данных. Это можно делать вручную, удаляя каждый элемент, но такая операция сложная и опасная, к тому же не гарантирует, что вы действительно избавились от всех таких значений. Здесь на помощь приходит функция dropna().
>>> ser.dropna()
red 0.0
blue 1.0
yellow 2.0
green 9.0
dtype: float64
Функцию фильтрации можно выполнить и прямо с помощью notnull() при выборе элементов.
>>> ser[ser.notnull()]
red 0.0
blue 1.0
yellow 2.0
green 9.0
dtype: float64
В случае с Dataframe это чуть сложнее. Если использовать функцию pandas dropna() на таком типе объекта, который содержит всего одно значение NaN в колонке или строке, то оно будет удалено.
>>> frame3 = pd.DataFrame([[6,np.nan,6],[np.nan,np.nan,np.nan],[2,np.nan,5]],
... index = ['blue','green','red'],
... columns = ['ball','mug','pen'])
>>> frame3
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| green | NaN | NaN | NaN |
| red | 2.0 | NaN | 5.0 |
>>> frame3.dropna()
Empty DataFrame
Columns: [ball, mug, pen]
Index: []
Таким образом чтобы избежать удаления целых строк или колонок нужно использовать параметр how, присвоив ему значение all. Это сообщит функции, чтобы она удаляла только строки или колонки, где все элементы равны NaN.
>>> frame3.dropna(how='all')
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| red | 2.0 | NaN | 5.0 |
Заполнение NaN
Вместо того чтобы отфильтровывать значения NaN в структурах данных, рискуя удалить вместе с ними важные элементы, можно заменять их на другие числа. Для этих целей подойдет fillna(). Она принимает один аргумент — значение, которым нужно заменить NaN.
>>> frame3.fillna(0)
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 0.0 | 0.0 | 0.0 |
| red | 2.0 | 0.0 | 5.0 |
Или же NaN можно заменить на разные значения в зависимости от колонки, указывая их и соответствующие значения.
>>> frame3.fillna({'ball':1,'mug':0,'pen':99})
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 1.0 | 0.0 | 99.0 |
| red | 2.0 | 0.0 | 5.0 |
Функции для элементов
Библиотека Pandas построена на базе NumPy и расширяет возможности последней, используя их по отношению к новым структурам данных: Series и Dataframe. В их числе универсальные функции, называемые ufunc. Они применяются к элементам структуры данных.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Например, можно найти квадратный корень для каждого значения в Dataframe с помощью функции np.sqrt().
>>> np.sqrt(frame)
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0.000000 | 1.000000 | 1.414214 | 1.732051 |
| blue | 2.000000 | 2.236068 | 2.449490 | 2.645751 |
| yellow | 2.828427 | 3.000000 | 3.162278 | 3.316625 |
| white | 3.464102 | 3.605551 | 3.741657 | 3.872983 |
Функции для строк и колонок
Применение функций не ограничивается универсальными, но включает и те, что были определены пользователем. Важно отметить, что они работают с одномерными массивами, выдавая в качестве результата единое число. Например, можно определить лямбда-функцию, которая вычисляет диапазон значений элементов в массиве.
>>> f = lambda x: x.max() - x.min()
Эту же функцию можно определить и следующим образом:
>>> def f(x):
... return x.max() - x.min()
С помощью apply() новая функция применяется к Dataframe.
>>> frame.apply(f)
ball 12
pen 12
pencil 12
paper 12
dtype: int64
В этот раз результатом является одно значение для каждой колонки, но если нужно применить функцию к строкам, а на колонкам, нужно лишь поменять значение параметра axis и указать 1.
>>> frame.apply(f, axis=1)
red 3
blue 3
yellow 3
white 3
dtype: int64
Метод apply() не обязательно вернет скалярную величину. Он может вернуть и объект Series. Можно также включить и применить несколько функций одновременно. Это делается следующим образом:
>>> def f(x):
... return pd.Series([x.min(), x.max()], index=['min','max'])
После этого функция используется как и в предыдущем примере. Но теперь результатом будет объект Dataframe, а не Series, в котором столько строк, сколько значений функция возвращает.
>>> frame.apply(f)
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| min | 0 | 1 | 2 | 3 |
| max | 12 | 13 | 14 | 15 |
Статистические функции
Большая часть статистических функций массивов работает и с Dataframe, поэтому для них не нужно использовать apply(). Например, sum() и mean() могут посчитать сумму или среднее значение соответственно для элементов внутри объекта Dataframe.
>>> frame.sum()
ball 24
pen 28
pencil 32
paper 36
dtype: int64
>>> frame.mean()
ball 6.0
pen 7.0
pencil 8.0
paper 9.0
dtype: float64
Есть даже функция describe(), которая позволяет получить всю статистику за раз.
>>> frame.describe()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| count | 4.000000 | 4.000000 | 4.000000 | 4.000000 |
| mean | 6.000000 | 7.000000 | 8.000000 | 9.000000 |
| std | 5.163978 | 5.163978 | 5.163978 | 5.163978 |
| min | 0.000000 | 1.000000 | 2.000000 | 3.000000 |
| 25% | 3.000000 | 4.000000 | 5.000000 | 6.000000 |
| 50% | 6.000000 | 7.000000 | 8.000000 | 9.000000 |
| 75% | 9.000000 | 10.000000 | 11.000000 | 12.000000 |
| max | 12.000000 | 13.000000 | 14.000000 | 15.000000 |
Сортировка и ранжирование
Еще одна операция, использующая индексирование pandas, — сортировка. Сортировка данных нужна часто, поэтому важно иметь возможность выполнять ее легко. Библиотека pandas предоставляет функцию sort_index(), которая возвращает новый объект, идентичный стартовому, но с отсортированными элементами.
Сначала рассмотрим варианты, как можно сортировать элементы Series. Операция простая, ведь сортируется всего один список индексов.
>>> ser = pd.Series([5,0,3,8,4],
... index=['red','blue','yellow','white','green'])
>>> ser
red 5
blue 0
yellow 3
white 8
green 4
dtype: int64
>>> ser.sort_index()
blue 0
green 4
red 5
white 8
yellow 3
dtype: int64
В этом примере элементы были отсортированы по алфавиту на основе ярлыков (от A до Z). Это поведение по умолчанию, но достаточно сделать значением параметра ascending False и элементы объекта отсортируются иначе.
>>> ser.sort_index(ascending=False)
yellow 3
white 8
red 5
green 4
blue 0
dtype: int64
В случае с Dataframe можно выполнить сортировку независимо для каждой из осей. Если требуется отсортировать элементы по индексам, то нужно просто использовать sort_index() как обычно. Если же требуется сортировка по колонкам, то необходимо задать значение 1 для параметра axis.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame.sort_index()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| blue | 4 | 5 | 6 | 7 |
| red | 0 | 1 | 2 | 3 |
| white | 12 | 13 | 14 | 15 |
| yellow | 8 | 9 | 10 | 11 |
>>> frame.sort_index(axis=1)
| ball | paper | pen | pencil | |
|---|---|---|---|---|
| red | 0 | 3 | 1 | 2 |
| blue | 4 | 7 | 5 | 6 |
| yellow | 8 | 11 | 9 | 10 |
| white | 12 | 15 | 13 | 14 |
Но это лишь то, что касается сортировки по индексам. Но часто приходится сортировать объект по значениям его элементов. В таком случае сперва нужно определить объект: Series или Dataframe.
Для первого подойдет функция sort_values().
>>> ser.sort_values()
blue 0
yellow 3
green 4
red 5
white 8
dtype: int64
А для второго — та же функция sort_values(), но с параметром by, значением которого должна быть колонка, по которой требуется отсортировать объект.
>>> frame.sort_values(by='pen')
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Если сортировка основана на двух или больше колонках, то by можно присвоить массив с именами колонок.
>>> frame.sort_values(by=['pen','pencil'])
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Ранжирование тесно связано с операцией сортировки. Оно состоит из присваивания ранга (то есть, значения, начинающегося с 0 и постепенно увеличивающегося) к каждому элементу Series. Он присваивается элементам, начиная с самого младшего значения.
>>> ser.rank()
red 4.0
blue 1.0
yellow 2.0
white 5.0
green 3.0
dtype: float64
Ранг может быть присвоен и согласно порядку, в котором элементы содержатся в структуре (без операции сортировки). В таком случае нужно добавить параметр method со значением first.
>>> ser.rank(method='first')
red 4.0
blue 1.0
yellow 2.0
white 5.0
green 3.0
dtype: float64
По умолчанию даже ранжирование происходит в возрастающем порядке. Для обратного нужно задать значение False для параметра ascending.
>>> ser.rank(ascending=False)
red 2.0
blue 5.0
yellow 4.0
white 1.0
green 3.0
dtype: float64
Корреляция и ковариантность
Два важных типа статистических вычислений — корреляция и вариантность. В pandas они представлены функциями corr() и cov(). Для их работы нужны два объекта Series.
>>> seq2 = pd.Series([3,4,3,4,5,4,3,2],['2006','2007','2008',
'2009','2010','2011','2012','2013'])
>>> seq = pd.Series([1,2,3,4,4,3,2,1],['2006','2007','2008',
'2009','2010','2011','2012','2013'])
>>> seq.corr(seq2)
0.7745966692414835
>>> seq.cov(seq2)
0.8571428571428571
Их же можно применить и по отношению к одному Dataframe. В таком случае функции вернут соответствующие матрицы в виде двух новых объектов Dataframe.
>>> frame2 = pd.DataFrame([[1,4,3,6],[4,5,6,1],[3,3,1,5],[4,1,6,4]],
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame2
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 1 | 4 | 3 | 6 |
| blue | 4 | 5 | 6 | 1 |
| yellow | 3 | 3 | 1 | 5 |
| white | 4 | 1 | 6 | 4 |
>>> frame2.corr()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| ball | 1.000000 | -0.276026 | 0.577350 | -0.763763 |
| pen | -0.276026 | 1.000000 | -0.079682 | -0.361403 |
| pencil | 0.577350 | -0.079682 | 1.000000 | -0.692935 |
| paper | -0.763763 | -0.361403 | -0.692935 | 1.000000 |
>>> frame2.cov()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| ball | 2.000000 | -0.666667 | 2.000000 | -2.333333 |
| pen | -0.666667 | 2.916667 | -0.333333 | -1.333333 |
| pencil | 2.000000 | -0.333333 | 6.000000 | -3.666667 |
| paper | -2.333333 | -1.333333 | -3.666667 | 4.666667 |
С помощью метода corwith() можно вычислить попарные корреляции между колонками и строками объекта Dataframe и Series или другим DataFrame().
>>> ser = pd.Series([0,1,2,3,9],
... index=['red','blue','yellow','white','green'])
>>> ser
red 0
blue 1
yellow 2
white 3
green 9
dtype: int64
>>> frame2.corrwith(ser)
ball 0.730297
pen -0.831522
pencil 0.210819
paper -0.119523
dtype: float64
>>> frame2.corrwith(frame)
ball 0.730297
pen -0.831522
pencil 0.210819
paper -0.119523
dtype: float64
В отличие от других структур данных в Python pandas не только пользуется преимуществами высокой производительности массивов NumPy, но и добавляет в них индексы.
Этот выбор оказался крайне удачным. Несмотря на и без того отличную гибкость, которая обеспечивается существующими динамическими структурами, внутренние ссылки на их элементы (а именно ими и являются метки) позволяют разработчикам еще сильнее упрощать операции.
В этом разделе речь пойдет о некоторых базовых функциях, использующих этот механизм:
- Переиндексирование
- Удаление
- Выравнивание
Переиндексирование df.reindex()
Вы уже знаете, что после объявления в структуре данных объект Index нельзя менять. Но с помощью операции переиндексирования это можно решить.
Существует даже возможность получить новую структуру из уже существующей, где правила индексирования заданы заново.
>>> ser = pd.Series([2,5,7,4], index=['one','two','three','four']) >>> ser
one 2
two 5
three 7
four 4
dtype: int64
Для того чтобы провести переиндексирование объекта Series библиотека pandas предоставляет функцию reindex(). Она создает новый объект Series со значениями из другого Series, которые теперь переставлены в соответствии с новой последовательностью меток.
При операции переиндексирования можно поменять порядок индексов, удалить некоторые из них или добавить новые. Если метка новая, pandas добавит NaN на место соответствующего значения.
>>> ser.reindex(['three','four','five','one'])
three 7.0
four 4.0
five NaN
one 2.0
dtype: float64
Как видно по выводу, порядок меток можно поменять полностью. Значение, которое раньше соответствовало метке two, удалено, зато есть новое с меткой five.
Тем не менее в случае, например, с большим Dataframe, не совсем удобно будет указывать новый список меток. Вместо этого можно использовать метод, который заполняет или интерполирует значения автоматически.
Для лучшего понимания механизма работы этого режима автоматического индексирования создадим следующий объект Series.
>>> ser3 = pd.Series([1,5,6,3],index=[0,3,5,6])
>>> ser3
0 1
3 5
5 6
6 3
dtype: int64
В этом примере видно, что колонка с индексами — это не идеальная последовательность чисел. Здесь пропущены цифры 1, 2 и 4. В таком случае нужно выполнить операцию интерполяции и получить полную последовательность чисел. Для этого можно использовать reindex с параметром method равным ffill. Более того, необходимо задать диапазон значений для индексов. Тут можно использовать range(6) в качестве аргумента.
>>> ser3.reindex(range(6),method='ffill')
0 1
1 1
2 1
3 5
4 5
5 6
dtype: int64
Теперь в объекте есть элементы, которых не было в оригинальном объекте Series. Операция интерполяции сделала так, что наименьшие индексы стали значениями в объекте. Так, индексы 1 и 2 имеют значение 1, принадлежащее индексу 0.
Если нужно присваивать значения индексов при интерполяции, необходимо использовать метод bfill.
>>> ser3.reindex(range(6),method='bfill')
0 1
1 5
2 5
3 5
4 6
5 6
dtype: int64
В этом случае значения индексов 1 и 2 равны 5, которое принадлежит индексу 3.
Операция отлично работает не только с Series, но и с Dataframe. Переиндексирование можно проводить не только на индексах (строках), но также и на колонках или на обоих. Как уже отмечалось, добавлять новые индексы и колонки возможно, но поскольку в оригинальной структуре есть недостающие значения, на их месте будет NaN.
>>> frame.reindex(range(5), method='ffill',columns=['colors','price','new', 'object'])
| item | colors | price | new | object |
|---|---|---|---|---|
| id | ||||
| 0 | blue | 1.2 | blue | ball |
| 1 | green | 1.0 | green | pen |
| 2 | yellow | 3.3 | yellow | pencil |
| 3 | red | 0.9 | red | paper |
| 4 | white | 1.7 | white | mug |
Удаление
Еще одна операция, связанная с объектами Index — удаление. Удалить строку или колонку не составит труда, потому что метки используются для обозначения индексов и названий колонок.
В этом случае pandas предоставляет специальную функцию для этой операции, которая называется drop(). Метод возвращает новый объект без элементов, которые необходимо было удалить.
Например, возьмем в качестве примера случай, где из объекта нужно удалить один элемент. Для этого определим базовый объект Series из четырех элементов с 4 отдельными метками.
>>> ser = pd.Series(np.arange(4.), index=['red','blue','yellow','white'])
>>> ser
red 0.0
blue 1.0
yellow 2.0
white 3.0
dtype: float64
Теперь, предположим, необходимо удалить объект с меткой yellow. Для этого нужно всего лишь указать ее в качестве аргумента функции drop().
>>> ser.drop('yellow')
red 0.0
blue 1.0
white 3.0
dtype: float64
Для удаления большего количества элементов, передайте массив с соответствующими индексами.
>>> ser.drop(['blue','white'])
red 0.0
yellow 2.0
dtype: float64
Если речь идет об объекте Dataframe, значения могут быть удалены с помощью ссылок на метки обеих осей. Возьмем в качестве примера следующий объект.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball', 'pen', 'pencil', 'paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Для удаления строк просто передайте индексы строк.
>>> frame.drop(['blue','yellow'])
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| white | 12 | 13 | 14 | 15 |
Для удаления колонок необходимо указывать индексы колонок, а также ось, с которой требуется удалить элементы. Для этого используется параметр axis. Чтобы сослаться на название колонки, нужно написать axis=1.
>>> frame.drop(['pen','pencil'],axis=1)
| ball | paper | |
|---|---|---|
| red | 0 | 3 |
| blue | 4 | 7 |
| yellow | 8 | 11 |
| white | 12 | 15 |
Арифметика и выравнивание данных
Наверное, самая важная особенность индексов в этой структуре данных — тот факт, что pandas может выравнивать индексы двух разных структур. Это особенно важно при выполнении арифметических операций на их значениях. В этом случае индексы могут быть не только в разном порядке, но и присутствовать лишь в одной из двух структур.
В качестве примера можно взять два объекта Series с разными метками.
>>> s1 = pd.Series([3,2,5,1],['white','yellow','green','blue'])
>>> s2 = pd.Series([1,4,7,2,1],['white','yellow','black','blue','brown'])
Теперь воспользуемся базовой операцией сложения. Как видно по примеру, некоторые метки есть в обоих структурах, а остальные — только в одной. Если они есть в обоих случаях, их значения складываются, а если только в одном — то значением будет NaN.
>>> s1 + s2
black NaN
blue 3.0
brown NaN
green NaN
white 4.0
yellow 6.0
dtype: float64
При использовании Dataframe выравнивание работает по тому же принципу, но проводится и для рядов, и для колонок.
>>> frame1 = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame2 = pd.DataFrame(np.arange(12).reshape((4,3)),
... index=['blue','green','white','yellow'],
... columns=['mug','pen','ball'])
>>> frame1
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame2
| mug | pen | ball | |
|---|---|---|---|
| blue | 0 | 1 | 2 |
| green | 3 | 4 | 5 |
| white | 6 | 7 | 8 |
| yellow | 9 | 10 | 11 |
>>> frame1 + frame2
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Ядром pandas являются две структуры данных, в которых происходят все операции:
- Series
- Dataframes
Series — это структура, используемая для работы с последовательностью одномерных данных, а Dataframe — более сложная и подходит для нескольких измерений.
Пусть они и не являются универсальными для решения всех проблем, предоставляют отличный инструмент для большинства приложений. При этом их легко использовать, а множество более сложных структур можно упросить до одной из этих двух.
Однако особенности этих структур основаны на одной черте — интеграции в их структуру объектов index и labels (метки). С их помощью структурами становится очень легко манипулировать.
Series (серии)
Series — это объект библиотеки pandas, спроектированный для представления одномерных структур данных, похожих на массивы, но с дополнительными возможностями. Его структура проста, ведь он состоит из двух связанных между собой массивов. Основной содержит данные (данные любого типа NumPy), а в дополнительном, index, хранятся метки.

Создание объекта Series
Для создания объекта Series с предыдущего изображения необходимо вызвать конструктор Series() и передать в качестве аргумента массив, содержащий значения, которые необходимо включить.
>>> s = pd.Series([12,-4,7,9])
>>> s
0 12
1 -4
2 7
3 9
dtype: int64
Как можно увидеть по выводу, слева отображаются значения индексов, а справа — сами значения (данные).
Если не определить индекс при объявлении объекта, метки будут соответствовать индексам (положению в массиве) элементов объекта Series.
Однако лучше создавать Series, используя метки с неким смыслом, чтобы в будущем отделять и идентифицировать данные вне зависимости от того, в каком порядке они хранятся.
В таком случае необходимо будет при вызове конструктора включить параметр index и присвоить ему массив строк с метками.
>>> s = pd.Series([12,-4,7,9], index=['a','b','c','d'])
>>> s
a 12
b -4
c 7
d 9
dtype: int64
Если необходимо увидеть оба массива, из которых состоит структура, можно вызвать два атрибута: index и values.
>>> s.values
array([12, -4, 7, 9], dtype=int64)
>>> s.index
Index(['a', 'b', 'c', 'd'], dtype='object')
Выбор элементов по индексу или метке
Выбирать отдельные элементы можно по принципу обычных массивов numpy, используя для этого индекс.
>>> s[2]
7
Или же можно выбрать метку, соответствующую положению индекса.
>>> s['b']
-4
Таким же образом можно выбрать несколько элементов массива numpy с помощью следующей команды:
>>> s[0:2]
a 12
b -4
dtype: int64
В этом случае можно использовать соответствующие метки, но указать их список в массиве.
>>> s[['b','c']]
b -4
c 7
dtype: int64
Присваивание значений элементам
Понимая как выбирать отдельные элементы, важно знать и то, как присваивать им новые значения. Можно делать это по индексу или по метке.
>>> s[1] = 0
>>> s
a 12
b 0
c 7
d 9
dtype: int64
>>> s['b'] = 1
>>> s
a 12
b 1
c 7
d 9
dtype: int64
Создание Series из массивов NumPy
Новый объект Series можно создать из массивов NumPy и уже существующих Series.
>>> arr = np.array([1,2,3,4])
>>> s3 = pd.Series(arr)
>>> s3
0 1
1 2
2 3
3 4
dtype: int32
>>> s4 = pd.Series(s)
>>> s4
a 12
b 1
c 7
d 9
dtype: int64
Важно запомнить, что значения в массиве NumPy или оригинальном объекте Series не копируются, а передаются по ссылке. Это значит, что элементы объекта вставляются динамически в новый Series. Если меняется оригинальный объект, то меняются и его значения в новом.
>>> s3
0 1
1 2
2 3
3 4
dtype: int32
>>> arr[2] = -2
>>> s3
0 1
1 2
2 -2
3 4
dtype: int32
На этом примере можно увидеть, что при изменении третьего элемента массива arr, меняется соответствующий элемент и в s3.
Фильтрация значений
Благодаря тому что основной библиотекой в pandas является NumPy, многие операции, применяемые к массивам NumPy, могут быть использованы и в случае с Series. Одна из таких — фильтрация значений в структуре данных с помощью условий.
Например, если нужно узнать, какие элементы в Series больше 8, то можно написать следующее:
>>> s[s > 8]
a 12
d 9
dtype: int64
Операции и математические функции
Другие операции, такие как операторы (+, -, * и /), а также математические функции, работающие с массивами NumPy, могут использоваться и для Series.
Для операторов можно написать простое арифметическое уравнение.
>>> s / 2
a 6.0
b 0.5
c 3.5
d 4.5
dtype: float64
Но в случае с математическими функциями NumPy необходимо указать функцию через np, а Series передать в качестве аргумента.
>>> np.log(s)
a 2.484907
b 0.000000
c 1.945910
d 2.197225
dtype: float64
Количество значений
В Series часто встречаются повторения значений. Поэтому важно иметь информацию, которая бы указывала на то, есть ли дубликаты или конкретное значение в объекте.
Так, можно объявить Series, в котором будут повторяющиеся значения.
>>> serd = pd.Series([1,0,2,1,2,3], index=['white','white','blue','green',' green','yellow'])
>>> serd
white 1
white 0
blue 2
green 1
green 2
yellow 3
dtype: int64
Чтобы узнать обо всех значениях в Series, не включая дубли, можно использовать функцию unique(). Возвращаемое значение — массив с уникальными значениями, необязательно в том же порядке.
>>> serd.unique()
array([1, 0, 2, 3], dtype=int64)
На unique() похожа функция value_counts(), которая возвращает не только уникальное значение, но и показывает, как часто элементы встречаются в Series.
>>> serd.value_counts()
2 2
1 2
3 1
0 1
dtype: int64
Наконец, isin() показывает, есть ли элементы на основе списка значений. Она возвращает булевые значения, которые очень полезны при фильтрации данных в Series или в колонке Dataframe.
>>> serd.isin([0,3])
white False
white True
blue False
green False
green False
yellow True
dtype: bool
>>> serd[serd.isin([0,3])]
white 0
yellow 3
dtype: int64
Значения NaN
В предыдущем примере мы попробовали получить логарифм отрицательного числа и результатом стало значение NaN. Это значение (Not a Number) используется в структурах данных pandas для обозначения наличия пустого поля или чего-то, что невозможно обозначить в числовой форме.
Как правило, NaN — это проблема, для которой нужно найти определенное решение, особенно при работе с анализом данных. Эти данные часто появляются при извлечении информации из непроверенных источников или когда в самом источнике недостает данных. Также значения NaN могут генерироваться в специальных случаях, например, при вычислении логарифмов для отрицательных значений, в случае исключений при вычислениях или при использовании функций. Есть разные стратегии работы со значениями NaN.
Несмотря на свою «проблемность» pandas позволяет явно определять NaN и добавлять это значение в структуры, например, в Series. Для этого внутри массива достаточно ввести np.NaN в том месте, где требуется определить недостающее значение.
>>> s2 = pd.Series([5,-3,np.NaN,14])
>>> s2
0 5.0
1 -3.0
2 NaN
3 14.0
dtype: float64
Функции isnull() и notnull() очень полезны для определения индексов без значения.
>>> s2.isnull()
0 False
1 False
2 True
3 False
dtype: bool
>>> s2.notnull()
0 True
1 True
2 False
3 True
dtype: bool
Они возвращают два объекта Series с булевыми значениями, где True указывает на наличие значение, а NaN — на его отсутствие. Функция isnull() возвращает True для значений NaN в Series, а notnull() — True в тех местах, где значение не равно NaN. Эти функции часто используются в фильтрах для создания условий.
>>> s2[s2.notnull()]
0 5.0
1 -3.0
3 14.0
dtype: float64
s2[s2.isnull()]
2 NaN
dtype: float64
Series из словарей
Series можно воспринимать как объект dict (словарь). Эта схожесть может быть использована на этапе объявления объекта. Даже создавать Series можно на основе существующего dict.
>>> mydict = {'red': 2000, 'blue': 1000, 'yellow': 500,
'orange': 1000}
>>> myseries = pd.Series(mydict)
>>> myseries
blue 1000
orange 1000
red 2000
yellow 500
dtype: int64
На этом примере можно увидеть, что массив индексов заполнен ключами, а данные — соответствующими значениями. В таком случае соотношение будет установлено между ключами dict и метками массива индексов. Если есть несоответствие, pandas заменит его на NaN.
>>> colors = ['red','yellow','orange','blue','green']
>>> myseries = pd.Series(mydict, index=colors)
>>> myseries
red 2000.0
yellow 500.0
orange 1000.0
blue 1000.0
green NaN
dtype: float64
Операции с сериями
Вы уже видели, как выполнить арифметические операции на объектах Series и скалярных величинах. То же возможно и для двух объектов Series, но в таком случае в дело вступают и метки.
Одно из главных достоинств этого типа структур данных в том, что он может выравнивать данные, определяя соответствующие метки.
В следующем примере добавляются два объекта Series, у которых только некоторые метки совпадают.
>>> mydict2 = {'red':400,'yellow':1000,'black':700}
>>> myseries2 = pd.Series(mydict2)
>>> myseries + myseries2
black NaN
blue NaN
green NaN
orange NaN
red 2400.0
yellow 1500.0
dtype: float64
Новый объект получает только те элементы, где метки совпали. Все остальные тоже присутствуют, но со значением NaN.
DataFrame (датафрейм)
Dataframe — это табличная структура данных, напоминающая таблицы из Microsoft Excel. Ее главная задача — позволить использовать многомерные Series. Dataframe состоит из упорядоченной коллекции колонок, каждая из которых содержит значение разных типов (числовое, строковое, булевое и так далее).

В отличие от Series у которого есть массив индексов с метками, ассоциированных с каждым из элементов, Dataframe имеет сразу два таких. Первый ассоциирован со строками (рядами) и напоминает таковой из Series. Каждая метка ассоциирована со всеми значениями в ряду. Второй содержит метки для каждой из колонок.
Dataframe можно воспринимать как dict, состоящий из Series, где ключи — названия колонок, а значения — объекты Series, которые формируют колонки самого объекта Dataframe. Наконец, все элементы в каждом объекте Series связаны в соответствии с массивом меток, называемым index.
Создание Dataframe
Простейший способ создания Dataframe — передать объект dict в конструктор DataFrame(). Объект dict содержит ключ для каждой колонки, которую требуется определить, а также массив значений для них.
Если объект dict содержит больше данных, чем требуется, можно сделать выборку. Для этого в конструкторе Dataframe нужно определить последовательность колонок с помощью параметра column. Колонки будут созданы в заданном порядке вне зависимости от того, как они расположены в объекте dict.
>> data = {'color' : ['blue', 'green', 'yellow', 'red', 'white'],
'object' : ['ball', 'pen', 'pencil', 'paper', 'mug'],
'price' : [1.2, 1.0, 0.6, 0.9, 1.7]}
>>> frame = pd.DataFrame(data)
>>> frame
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Даже для объектов Dataframe если метки явно не заданы в массиве index, pandas автоматически присваивает числовую последовательность, начиная с нуля. Если же индексам Dataframe нужно присвоить метки, необходимо использовать параметр index и присвоить ему массив с метками.
>>> frame2 = pd.DataFrame(data, columns=['object', 'price'])
>>> frame2
| object | price | |
|---|---|---|
| 0 | ball | 1.2 |
| 1 | pen | 1.0 |
| 2 | pencil | 0.6 |
| 3 | paper | 0.9 |
| 4 | mug | 1.7 |
Теперь, зная о параметрах index и columns, проще использовать другой способ определения Dataframe. Вместо использования объекта dict можно определить три аргумента в конструкторе в следующем порядке: матрицу данных, массив значений для параметра index и массив с названиями колонок для параметра columns.
В большинстве случаев простейший способ создать матрицу значений — использовать np.arrange(16).reshape((4,4)). Это формирует матрицу размером 4х4 из чисел от 0 до 15.
>>> frame3 = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball', 'pen', 'pencil', 'paper'])
>>> frame3
Выбор элементов
Если нужно узнать названия всех колонок Dataframe, можно вызвать атрибут columns для экземпляра объекта.
>>> frame.columns
Index(['color', 'object', 'price'], dtype='object')
То же можно проделать и для получения списка индексов.
>>> frame.index
RangeIndex(start=0, stop=5, step=1)
Весь же набор данных можно получить с помощью атрибута values.
>>> frame.values
array([['blue', 'ball', 1.2],
['green', 'pen', 1.0],
['yellow', 'pencil', 0.6],
['red', 'paper', 0.9],
['white', 'mug', 1.7]], dtype=object)
Указав в квадратных скобках название колонки, можно получить значений в ней.
>>> frame['price']
0 1.2
1 1.0
2 0.6
3 0.9
4 1.7
Name: price, dtype: float64
Возвращаемое значение — объект Series. Название колонки можно использовать и в качестве атрибута.
>>> frame.price
0 1.2
1 1.0
2 0.6
3 0.9
4 1.7
Name: price, dtype: float64
Для строк внутри Dataframe используется атрибут loc со значением индекса нужной строки.
>>> frame.loc[2]
color yellow
object pencil
price 0.6
Name: 2, dtype: object
Возвращаемый объект — это снова Series, где названия колонок — это уже метки массива индексов, а значения — данные Series.
Для выбора нескольких строк можно указать массив с их последовательностью.
>>> frame.loc[[2,4]]
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Если необходимо извлечь часть Dataframe с конкретными строками, для этого можно использовать номера индексов. Она выведет данные из соответствующей строки и названия колонок.
>>> frame[0:1]
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Возвращаемое значение — объект Dataframe с одной строкой. Если нужно больше одной строки, необходимо просто указать диапазон.
>>> frame[1:3]
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
Наконец, если необходимо получить одно значение из объекта, сперва нужно указать название колонки, а потом — индекс или метку строки.
>>> frame['object'][3]
'paper'
Присваивание и замена значений
Разобравшись с логикой получения доступа к разным элементам Dataframe, можно следовать ей же для добавления новых или изменения уже существующих значений.
Например, в структуре Dataframe массив индексов определен атрибутом index, а строка с названиями колонок — columns. Можно присвоить метку с помощью атрибута name для этих двух подструктур, чтобы идентифицировать их.
>>> frame.index.name = 'id'
>>> frame.columns.name = 'item'
>>> frame
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Одна из главных особенностей структур данных pandas — их гибкость. Можно вмешаться на любом уровне для изменения внутренней структуры данных. Например, добавление новой колонки — крайне распространенная операция.
Ее можно выполнить, присвоив значение экземпляру Dataframe и определив новое имя колонки.
>>> frame['new'] = 12
>>> frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 12 |
| 1 | green | pen | 1.0 | 12 |
| 2 | yellow | pencil | 0.6 | 12 |
| 3 | red | paper | 0.9 | 12 |
| 4 | white | mug | 1.7 | 12 |
Здесь видно, что появилась новая колонка new со значениями 12 для каждого элемента.
Для обновления значений можно использовать массив.
frame['new'] = [3.0, 1.3, 2.2, 0.8, 1.1]
frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 3.0 |
| 1 | green | pen | 1.0 | 1.3 |
| 2 | yellow | pencil | 0.6 | 2.2 |
| 3 | red | paper | 0.9 | 0.8 |
| 4 | white | mug | 1.7 | 1.1 |
Тот же подход используется для обновления целой колонки. Например, можно применить функцию np.arrange() для обновления значений колонки с помощью заранее заданной последовательности.
Колонки Dataframe также могут быть созданы с помощью присваивания объекта Series одной из них, например, определив объект Series, содержащий набор увеличивающихся значений с помощью np.arrange().
>>> ser = pd.Series(np.arange(5))
>>> ser
0 0
1 1
2 2
3 3
4 4
dtype: int32
frame['new'] = ser
frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 0 |
| 1 | green | pen | 1.0 | 1 |
| 2 | yellow | pencil | 0.6 | 2 |
| 3 | red | paper | 0.9 | 3 |
| 4 | white | mug | 1.7 | 4 |
Наконец, для изменения одного значения нужно лишь выбрать элемент и присвоить ему новое значение.
>>> frame['price'][2] = 3.3
Вхождение значений
Функция isin() используется с объектами Series для определения вхождения значений в колонку. Она же подходит и для объектов Dataframe.
>>> frame.isin([1.0,'pen'])
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | False | False | False | False |
| 1 | False | True | True | True |
| 2 | False | False | False | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
Возвращается Dataframe с булевыми значениями, где True указывает на те значения, где членство подтверждено. Если передать это значение в виде условия, тогда вернется Dataframe, где будут только значения, удовлетворяющие условию.
>>> frame[frame.isin([1.0,'pen'])]
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | pen | 1.0 | 1.0 |
| 2 | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
Удаление колонки
Для удаления целой колонки и всего ее содержимого используется команда del.
>>> del frame['new']
>>> frame
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 3.3 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Фильтрация
Даже для Dataframe можно применять фильтры, используя определенные условия. Например, вам нужно получить все значения меньше определенного числа (допустим, 1,2).
>>> frame[frame < 1.2]
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | NaN |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | NaN |
| 3 | red | paper | 0.9 |
| 4 | white | mug | NaN |
Результатом будет Dataframe со значениями меньше 1,2 на своих местах. На месте остальных будет NaN.
Dataframe из вложенного словаря
В Python часто используется вложенный dict:
>>> nestdict = {'red': { 2012: 22, 2013: 33},
... 'white': { 2011: 13, 2012: 22, 2013: 16},
... 'blue': { 2011: 17, 2012: 27, 2013: 18}}
Эта структура данных, будучи переданной в качестве аргумента в DataFrame(), интерпретируется pandas так, что внешние ключи становятся названиями колонок, а внутренние — метками индексов.
При интерпретации вложенный структуры возможно такое, что не все поля будут совпадать. pandas компенсирует это несоответствие, добавляя NaN на место недостающих значений.
>>> nestdict = {'red': { 2012: 22, 2013: 33},
... 'white': { 2011: 13, 2012: 22, 2013: 16},
... 'blue': { 2011: 17, 2012: 27, 2013: 18}}
>>> frame2 = pd.DataFrame(nestdict)
>>> frame2
| blue | red | white | |
|---|---|---|---|
| 2011 | 17 | NaN | 13 |
| 2012 | 27 | 22.0 | 22 |
| 2013 | 18 | 33.0 | 16 |
Транспонирование Dataframe
При работе с табличным структурами данных иногда появляется необходимость выполнить операцию перестановки (сделать так, чтобы колонки стали рядами и наоборот). pandas позволяет добиться этого очень просто. Достаточно добавить атрибут T.
>>> frame2.T
| 2011 | 2012 | 2013 | |
|---|---|---|---|
| blue | 17.0 | 27.0 | 18.0 |
| red | NaN | 22.0 | 33.0 |
| white | 13.0 | 22.0 | 16.0 |
Объекты Index
Зная, что такое Series и Dataframes, и понимая как они устроены, проще разобраться со всеми их достоинствами. Главная особенность этих структур — наличие объекта Index, который в них интегрирован.
Объекты Index являются метками осей и содержат другие метаданные. Вы уже знаете, как массив с метками превращается в объект Index, и что для него нужно определить параметр index в конструкторе.
>>> ser = pd.Series([5,0,3,8,4], index=['red','blue','yellow','white','green'])
>>> ser.index
Index(['red', 'blue', 'yellow', 'white', 'green'], dtype='object')
В отличие от других элементов в структурах данных pandas (Series и Dataframe) объекты index — неизменяемые. Это обеспечивает безопасность, когда нужно передавать данные между разными структурами.
У каждого объекта Index есть методы и свойства, которые нужны, чтобы узнавать значения.
Методы Index
Есть методы для получения информации об индексах из структуры данных. Например, idmin() и idmax() — структуры, возвращающие индексы с самым маленьким и большим значениями.
>>> ser.idxmin()
'blue'
>>> ser.idxmax()
'white'
Индекс с повторяющимися метками
Пока что были только те случаи, когда у индексов одной структуры лишь одна, уникальная метка. Для большинства функций это обязательное условие, но не для структур данных pandas.
Определим, например, Series с повторяющимися метками.
>>> serd = pd.Series(range(6), index=['white','white','blue','green', 'green','yellow'])
>>> serd
white 0
white 1
blue 2
green 3
green 4
yellow 5
dtype: int64
Если метке соответствует несколько значений, то она вернет не один элемент, а объект Series.
>>> serd['white']
white 0
white 1
dtype: int64
То же применимо и к Dataframe. При повторяющихся индексах он возвращает Dataframe.
В случае с маленькими структурами легко определять любые повторяющиеся индексы, но если структура большая, то растет и сложность этой операции. Для этого в pandas у объектов Index есть атрибут is_unique. Он сообщает, есть ли индексы с повторяющимися метками в структуре (Series или Dataframe).
>>> serd.index.is_unique
False
>>> frame.index.is_unique
True
Операции между структурами данных
Теперь когда вы знакомы со структурами данных, Series и Dataframe, а также базовыми операциями для работы с ними, стоит рассмотреть операции, включающие две или более структур.
Гибкие арифметические методы
Уже рассмотренные операции можно выполнять с помощью гибких арифметических методов:
add()sub()div()mul()
Для их вызова нужно использовать другую спецификацию. Например, вместо того чтобы выполнять операцию для двух объектов Dataframe по примеру frame1 + frame2, потребуется следующий формат:
>>> frame1.add(frame2)
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Результат такой же, как при использовании оператора сложения +. Также стоит обратить внимание, что если названия индексов и колонок сильно отличаются, то результатом станет новый объект Dataframe, состоящий только из значений NaN.
Операции между Dataframe и Series
Pandas позволяет выполнять переносы между разными структурами, например, между Dataframe и Series. Определить две структуры можно следующим образом.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> ser = pd.Series(np.arange(4), index=['ball','pen','pencil','paper'])
>>> ser
ball 0
pen 1
pencil 2
paper 3
dtype: int32
Они были специально созданы так, чтобы индексы в Series совпадали с названиями колонок в Dataframe. В таком случае можно выполнить прямую операцию.
>>> frame - ser
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 0 | 0 | 0 |
| blue | 4 | 4 | 4 | 4 |
| yellow | 8 | 8 | 8 | 8 |
| white | 12 | 12 | 12 | 12 |
По результату видно, что элементы Series были вычтены из соответствующих тому же индексу в колонках значений Dataframe.
Если индекс не представлен ни в одной из структур, то появится новая колонка с этим индексом и значениями NaN.
>>> ser['mug'] = 9
>>> ser
ball 0
pen 1
pencil 2
paper 3
mug 9
dtype: int64
>>> frame - ser
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| red | 0 | NaN | 0 | 0 | 0 |
| blue | 4 | NaN | 4 | 4 | 4 |
| yellow | 8 | NaN | 8 | 8 | 8 |
| white | 12 | NaN | 12 | 12 | 12 |
Библиотека pandas в Python — это идеальный инструмент для тех, кто занимается анализом данных, используя для этого язык программирования Python.
В этом материале речь сначала пойдет об основных аспектах библиотеки и о том, как установить ее в систему. Потом вы познакомитесь с двумя структурам данных: series и dataframes. Сможете поработать с базовым набором функций, предоставленных библиотекой pandas, для выполнения основных операций по обработке. Знакомство с ними — ключевой навык для специалиста в этой сфере. Поэтому так важно перечитать материал до тех, пока он не станет понятен на 100%.
А на примерах сможете разобраться с новыми концепциями, появившимися в библиотеке — индексацией структур данных. Научитесь правильно ее использовать для управления данными. В конце концов, разберетесь с тем, как расширить возможности индексации для работы с несколькими уровнями одновременно, используя для этого иерархическую индексацию.
Библиотека Python для анализа данных
Pandas — это библиотека Python с открытым исходным кодом для специализированного анализа данных. Сегодня все, кто использует Python для изучения статистических целей анализа и принятия решений, должны быть с ней знакомы.
Библиотека была спроектирована и разработана преимущественно Уэсом Маккини в 2008 году. В 2012 к нему присоединился коллега Чан Шэ. Вместе они создали одну из самых используемых библиотек в сообществе Python.
Pandas появилась из необходимости в простом инструменте для обработки, извлечения и управления данными.
Этот пакет Python спроектирован на основе библиотеки NumPy. Такой выбор обуславливает успех и быстрое распространение pandas. Он также пользуется всеми преимуществами NumPy и делает pandas совместимой с большинством другим модулей.
Еще одно важное решение — разработка специальных структур для анализа данных. Вместо того, чтобы использовать встроенные в Python или предоставляемые другими библиотеками структуры, были разработаны две новых.
Они спроектированы для работы с реляционными и классифицированными данными, что позволяет управлять данными способом, похожим на тот, что используется в реляционных базах SQL и таблицах Excel.
Дальше вы встретите примеры базовых операций для анализа данных, которые обычно используются на реляционных или таблицах Excel. Pandas предоставляет даже более расширенный набор функций и методов, позволяющих выполнять эти операции эффективнее.
Основная задача pandas — предоставить все строительные блоки для всех, кто погружается в мир анализа данных.
Установка pandas
Простейший способ установки библиотеки pandas — использование собранного решения, то есть установка через Anaconda или Enthought.
Установка в Anaconda
В Anaconda установка занимает пару минут. В первую очередь нужно проверить, не установлен ли уже pandas, и если да, то какая это версия. Для этого введите следующую команду в терминале:
conda list pandas
Если модуль уже установлен (например в Windows), вы получите приблизительно следующий результат:
# packages in environment at C:\Users\Fabio\Anaconda:
#
pandas 0.20.3 py36hce827b7_2
Если pandas не установлена, ее необходимо установить. Введите следующую команду:
conda install pandas
Anaconda тут же проверит все зависимости и установит дополнительные модули.
Solving environment: done
## Package Plan ##
Environment location: C:\Users\Fabio\Anaconda3
added / updated specs:
- pandas
The following new packages will be installed:
Pandas: 0.22.0-py36h6538335_0
Proceed ([y]/n)?
Press the y key on your keyboard to continue the installation.
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
Если требуется обновить пакет до более новой версии, используется эта интуитивная команда:
conda update pandas
Система проверит версию pandas и версию всех модулей, а затем предложит соответствующие обновления. Затем предложит перейти к обновлению.
Установка из PyPI
Pandas можно установить и с помощью PyPI, используя эту команду:
pip install pandas
Установка в Linux
Если вы работаете в дистрибутиве Linux и решили не использовать эти решения, то pandas можно установить как и любой другой пакет.
В Debian и Ubuntu используется команда:
sudo apt-get install python-pandas
А для OpenSuse и Fedora — эта:
zypper in python-pandas
Установка из источника
Если есть желание скомпилировать модуль pandas из исходного кода, тогда его можно найти на GitHub по ссылке https://github.com/pandas-dev/pandas:
git clone git://github.com/pydata/pandas.git
cd pandas
python setup.py install
Убедитесь, что Cython установлен. Больше об этом способе можно прочесть в документации: (http://pandas.pydata.org/pandas-docs/stable/install.html).
Репозиторий для Windows
Если вы работаете в Windows и предпочитаете управлять пакетами так, чтобы всегда была установлена последняя версия, то существует ресурс, где всегда можно загрузить модули для Windows: Christoph Gohlke’s Python Extension Packages for Windows (www.lfd.uci.edu/~gohlke/pythonlibs/). Каждый модуль поставляется в формате WHL для 32 и 64-битных систем. Для установки нужно использовать приложение pip:
pip install SomePackage-1.0.whl
Например, для установки pandas потребуется найти и загрузить следующий пакет:
pip install pandas-0.22.0-cp36-cp36m-win_amd64.whl
При выборе модуля важно выбрать нужную версию Python и архитектуру. Более того, если для NumPy пакеты не требуются, то у pandas есть зависимости. Их также необходимо установить. Порядок установки не имеет значения.
Недостаток такого подхода в том, что нужно устанавливать пакеты отдельно без менеджера, который бы помог подобрать нужные версии и зависимости между разными пакетами. Плюс же в том, что появляется возможность освоиться с модулями и получить последние версии вне зависимости от того, что выберет дистрибутив.
Проверка установки pandas
Библиотека pandas может запустить проверку после установки для верификации управляющих элементов (документация утверждает, что тест покрывает 97% всего кода).
Во-первых, нужно убедиться, что установлен модуль nose. Если он имеется, то тестирование проводится с помощью следующей команды:
nosetests pandas
Оно займет несколько минут и в конце покажет список проблем.
Модуль Nose
Этот модуль спроектирован для проверки кода Python во время этапов разработки проекта или модуля Python. Он расширяет возможности модуль
unittest. Nose используется для проверки кода и упрощает процесс.Здесь о нем можно почитать подробнее: _http://pythontesting.net/framework/nose/nose-introduction/.
Первые шаги с pandas
Лучший способ начать знакомство с pandas — открыть консоль Python и вводить команды одна за одной. Таким образом вы познакомитесь со всеми функциями и структурами данных.
Более того, данные и функции, определенные здесь, будут работать и в примерах будущих материалов. Однако в конце каждого примера вы вольны экспериментировать с ними.
Для начала откройте терминал Python и импортируйте библиотеку pandas. Стандартная практика для импорта модуля pandas следующая:
>>> import pandas as pd
>>> import numpy as np
Теперь, каждый раз встречая pd и np вы будете ссылаться на объект или метод, связанный с этими двумя библиотеками, хотя часто будет возникать желание импортировать модуль таким образом:
>>> from pandas import *
В таком случае ссылаться на функцию, объект или метод с помощью pd уже не нужно, а это считается не очень хорошей практикой в среде разработчиков Python.
Важный аспект NumPy, которому пока не уделялось внимание — процесс чтения данных из файла. Это очень важный момент, особенно когда нужно работать с большим количеством данных в массивах. Это базовая операция анализа данных, поскольку размер набора данных почти всегда огромен, и в большинстве случаев не рекомендуется работать с ним вручную.NumPy предлагает набор функций, позволяющих специалисту сохранять результаты вычислений в текстовый или бинарный файл. Таким же образом можно считывать и конвертировать текстовые данные из файла в массив.
Загрузка и сохранение данных в бинарных файлах
NumPy предлагает пару функций, save() и load(), которые позволяют сохранять, а позже и получать данные, сохраненные в бинарном формате.
При наличии массива, который нужно сохранить, содержащего, например, результаты анализа данных, остается лишь вызвать функцию call() и определить аргументы: название файла и аргументы. Файл автоматически получит расширение .npy.
>>> data=([[ 0.86466285, 0.76943895, 0.22678279],
[ 0.12452825, 0.54751384, 0.06499123],
[ 0.06216566, 0.85045125, 0.92093862],
[ 0.58401239, 0.93455057, 0.28972379]])
>>> np.save('saved_data',data)
Когда нужно восстановить данные из файла .npy, используется функция load(). Она требует определить имя файла в качестве аргумента с расширением .npy.
>>> loaded_data = np.load('saved_data.npy')
>>> loaded_data
array([[ 0.86466285, 0.76943895, 0.22678279],
[ 0.12452825, 0.54751384, 0.06499123],
[ 0.06216566, 0.85045125, 0.92093862],
[ 0.58401239, 0.93455057, 0.28972379]])
Чтение файлов с табличными данными
Часто данные для чтения или сохранения представлены в текстовом формате (TXT или CSV). Их можно сохранить в такой формат вместо двоичного, потому что таким образом к ним можно будет получать доступ даже вне NumPy, с помощью других приложений. Возьмем в качестве примера набор данных в формате CSV (Comma-Separated Values — значения, разделенные запятыми). Данные здесь хранятся в табличной форме, а значения разделены запятыми.
id,value1,value2,value3
1,123,1.4,23
2,110,0.5,18
3,164,2.1,19
Для чтения данных в текстовом файле и получения значений в массив NumPy предлагает функцию genfromtxt(). Обычно она принимает три аргумента: имя файла, символ-разделитель и указание, содержат ли данные заголовки колонок.
>>> data = np.genfromtxt('ch3_data.csv', delimiter=',', names=True)
>>> data
array([(1.0, 123.0, 1.4, 23.0), (2.0, 110.0, 0.5, 18.0),
(3.0, 164.0, 2.1, 19.0)],
dtype=[('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'), ('value3', '<f8')])
Как видно по результату, можно запросто получить структурированный массив, где заголовки колонок станут именами полей.
Эта функция неявно выполняет два цикла: первый перебирает строки одна за одной, а вторая — разделяет и конвертирует значения в них, вставляя специально созданные последовательные элементы. Плюс в том, что даже при недостатке данных функция их дополнит.
Возьмем в качестве примера предыдущий файл с удаленными элементами. Сохраним его как data2.csv.
id,value1,value2,value3
1,123,1.4,23
2,110,,18
3,,2.1,19
Выполнение этих команд приведет к тому, что genfromtxt() заменит пустые области на значения nan.
>>> data2 = np.genfromtxt('ch3_data2.csv', delimiter=',', names=True)
>>> data2 array([(1.0, 123.0, 1.4, 23.0), (2.0, 110.0, nan, 18.0),
(3.0, nan, 2.1, 19.0)],
dtype=[('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'),
('value3', '<f8')])
В нижней части массива указаны заголовки колонок из файла. Их можно использовать как ярлыки-индексы, используемые для получения данных по колонкам.
>>> data2['id']
array([ 1., 2., 3.])
А с помощью числовых значений можно получать данные из конкретных строк.
>>> data2[0]
(1.0, 123.0, 1.4, 23.0)
В предыдущих примерах вы видели только одно- или двухмерные массивы. Но NumPy позволяет создавать массивы, которые будут более сложными не только в плане размера, но и по своей структуре. Они называются структурированными массивами. В них вместо отдельных элементов содержатся structs или записи.
Например, можно создать простой массив, состоящий из structs в качестве элементов. Благодаря параметру dtype можно определить условия, которые будут представлять элементы struct, а также тип данных и порядок.
| byte | b1 |
| int | i1, i2, i4, i8 |
| float | f2, f4, f8 |
| complex | c8, c16 |
| string | a<n> |
Например, если необходимо определить struct, содержащий целое число, строку длиной 6 символов и булево значение, потребуется обозначить три типа данных в dtype в нужном порядке.
Примечание: результат
dtypeи другие атрибуты формата могут отличаться на разных операционных системах и дистрибутивах Python.
>>> structured = np.array([(1, 'First', 0.5, 1+2j),(2, 'Second', 1.3, 2-2j), (3, 'Third', 0.8, 1+3j)], dtype=('i2, a6, f4, c8'))
>>> structured
array([(1, b'First', 0.5, 1+2.j),
(2, b'Second', 1.3, 2.-2.j),
(3, b'Third', 0.8, 1.+3.j)],
dtype=[('f0', '<i2'), ('f1', 'S6'), ('f2', '<f4'), ('f3', '<c8')])
Тип данных можно указать и явно с помощью int8, uint8, float16, complex16 и так далее.
>>> structured = np.array([(1, 'First', 0.5, 1+2j),(2, 'Second', 1.3,2-2j), (3, 'Third', 0.8, 1+3j)],dtype=('int16, a6, float32, complex64'))
>>> structured
array([(1, b'First', 0.5, 1.+2.j),
(2, b'Second', 1.3, 2.-2.j),
(3, b'Third', 0.8, 1.+3.j)],
dtype=[('f0', '<i2'), ('f1', 'S6'), ('f2', '<f4'), ('f3', '<c8')])
В обоих случаях будет одинаковый результат. В массиве имеется последовательность dtype, содержащая название каждого элемента struct с соответствующим типом данных.
Указывая соответствующий индекс, вы получаете нужную строку, включающую struct.
>>> structured[1]
(2, 'bSecond', 1.3, 2.-2.j)
Имена, присваиваемые каждому элементу struct автоматически, по сути, представляют собой имена колонок массива. Используя их как структурированный указатель, можно ссылаться на все элементы одного типа или одной и той же колонки.
>>> structured['f1']
array([b'First', b'Second', b'Third'],
dtype='|S6')
Имена присваиваются автоматически с символом f (он значит field (поле)) и увеличивающимся целым числом, обозначающим позицию в последовательности. Но было бы куда удобнее иметь более логичные имена. Это можно сделать в момент создания массива:
>>> structured = np.array([(1,'First',0.5,1+2j),
(2,'Second',1.3,2-2j), (3,'Third',0.8,1+3j)],
dtype=[('id','i2'),('position','a6'),('value','f4'),('complex','c8')])
>>> structured
array([(1, b'First', 0.5, 1.+2.j),
(2, b'Second', 1.3, 2.-2.j),
(3, b'Third', 0.8, 1.+3.j)],
dtype=[('id', '<i2'), ('position', 'S6'), ('value', '<f4'), ('complex', '<c8')])
Или позже, переопределив кортежи имен, присвоенных атрибуту dtype структурированного массива:
>>> structured.dtype.names = ('id','order','value','complex')
Теперь можно использовать понятные имена для разных типов полей:
>>> structured['order']
array([b'First', b'Second', b'Third'], dtype='|S6')
В этом разделе описываются общие понятия, лежащие в основе библиотеки NumPy. Разница между копиями и представлениями при возвращении значений. Также рассмотрим механизм “broadcasting”, который неявно происходит во многих функциях NumPy.
Копии или представления объектов
Как вы могли заметить, при управлении массивом в NumPy можно возвращать его копию или представление. Но ни один из видов присваивания в NumPy не приводит к появлению копий самого массива или его элементов.
>>> a = np.array([1, 2, 3, 4])
>>> b = a
>>> b
array([1, 2, 3, 4])
>>> a[2] = 0
>>> b
array([1, 2, 0, 4])
Если присвоить один массив a переменной b, то это будет не операция копирования; массив b — это всего лишь еще один способ вызова a. Изменяя значение третьего элемента в a, вы изменяете его же и в b.
>>> c = a[0:2]
>>> c
array([1, 2])
>>> a[0] = 0
>>> c
array([0, 2])
Даже получая срез, вы все равно указываете на один и тот же массив. Если же нужно сгенерировать отдельный массив, необходимо использовать функцию copy().
>>> a = np.array([1, 2, 3, 4])
>>> c = a.copy()
>>> c
array([1, 2, 3, 4])
>>> a[0] = 0
>>> c
array([1, 2, 3, 4])
В этом случае даже при изменении объектов в массиве a, массив c будет оставаться неизменным.
Векторизация
Векторизация, как и транслирование, — это основа внутренней реализации NumPy. Векторизация — это отсутствие явного цикла при разработке кода. Самих циклов избежать не выйдет, но их внутренняя реализация заменяется на другие конструкции в коде. Приложение векторизации делает код более емким и читаемым. Можно сказать, что он становится более «Pythonic» внешне. Благодаря векторизации многие операции принимают более математический вид. Например, NumPy позволяет выражать умножение двух массивов вот так:
a * b
Или даже умножение двух матриц:
A * B
В других языках подобные операции выражаются за счет нескольких вложенных циклов и конструкции for. Например, так бы выглядела первая операция:
for (i = 0; i < rows; i++){
c[i] = a[i]*b[i];
}
А произведение матриц может быть выражено следующим образом:
for( i=0; i < rows; i++){
for(j=0; j < columns; j++){
c[i][j] = a[i][j]*b[i][j];
}
}
Использование NumPy делает код более читаемым и математическим.
Транслирование (Broadcasting)
Транслирование позволяет оператору или функции применяться по отношению к двум или большему количеству массивов, даже если они не одной формы. Тем не менее не все размерности поддаются транслированию; они должны соответствовать определенным правилам.
С помощью NumPy многомерные массивы можно классифицировать через форму (shape) — кортеж, каждый элемент которого представляет длину каждой размерности.
Транслирование может работать для двух массивов в том случае, если их размерности совместимы: их длина равна, или длина одной из них — 1. Если эти условия не соблюдены, возникает исключение, сообщающее, что два массива не совместимы.
>>> A = np.arange(16).reshape(4, 4)
>>> b = np.arange(4)
>>> A
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> b
array([0, 1, 2, 3])
В таком случае вы получаете два массива:
4 x 4
4
Есть два правила транслирования. В первую очередь нужно добавить 1 к каждой недостающей размерности. Если правила совместимости соблюдены, можно использовать транслирование и переходить ко второму правилу. Например:
4 x 4
4 x 1
Правило транслирования соблюдено. Можно переходить ко второму. Оно объясняет, как увеличить размер меньшего массива, чтобы он соответствовал большему, и можно было применить функцию или оператор поэлементно.
Второе правило предполагает, что недостающие элементы заполняются копиями заданных значений.

Когда у двух массивов одинаковые размерности, их значения можно суммировать.
>>> A + b
array([[ 0, 2, 4, 6],
[ 4, 6, 8, 10],
[ 8, 10, 12, 14],
[12, 14, 16, 18]])
Это простой случай, в котором один из массивов меньше второго. Могут быть и более сложные, когда у двух массивов разные размеры, и каждый меньше второго в конкретных размерностях.
>>> m = np.arange(6).reshape(3, 1, 2)
>>> n = np.arange(6).reshape(3, 2, 1)
>>> m
array([[[0, 1]],
[[2, 3]],
[[4, 5]]])
>>> n
array([[[0],
[1]],
[[2],
[3]],
[[4],
[5]]])
Даже в таком случае, анализируя форму двух массивов, можно увидеть, что они совместимы, а правила транслирования могут быть применены.
3 x 1 x 2
3 x 2 x 1
В этом случае размерности обоих массивов расширяются (транслирование).
m* = [[[0,1], n* = [[[0,0],
[0,1]], [1,1]],
[[2,3], [[2,2],
[2,3]], [3,3]],
[[4,5], [[4,4],
[4,5]]] [5,5]]]
Затем можно использовать, например, оператор сложения для двух массивов поэлементно.
>>> m + n
array([[[ 0, 1],
[ 1, 2]],
[[ 4, 5],
[ 5, 6]],
[[ 8, 9],
[ 9, 10]]])
Часто требуется создать новый массив на основе уже существующих. В этом разделе речь пойдет о процессе создания массивов за счет объединения или разделения ранее определенных.
Объединение массивов
Можно осуществить слияние массивов для создания нового, который будет содержать все элементы объединенных. NumPy использует концепцию стекинга и предлагает для этого кое-какие функции. Например, можно осуществить вертикальный стекинг с помощью функции vstack(), которая добавит второй массив в первый с помощью новых рядов. А функция hstack() осуществляет горизонтальная стекинг, добавляя второй массив в виде колонок.
>>> A = np.ones((3, 3))
>>> B = np.zeros((3, 3))
>>> np.vstack((A, B))
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.],
[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> np.hstack((A,B))
array([[ 1., 1., 1., 0., 0., 0.],
[ 1., 1., 1., 0., 0., 0.],
[ 1., 1., 1., 0., 0., 0.]])
Еще две функции, которые выполняют стекинг для нескольких массивов — это column_stack() и row_stack(). Они работают независимо от первых двух. Их используют для одномерных массивов, для объединения значения в ряды или колонки и формирования двумерного массива.
>>> a = np.array([0, 1, 2])
>>> b = np.array([3, 4, 5])
>>> c = np.array([6, 7, 8])
>>> np.column_stack((a, b, c))
array([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]])
>>> np.row_stack((a, b, c))
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
Разделение массивов
Из прошлого раздела вы узнали, как собирать массивы с помощью стекинга. Теперь разберемся с разделением их на части. В NumPy для этого используется разделение. Также имеется набор функций, который работают в горизонтальной (hsplit()) и вертикальной (vsplit()) ориентациях.
>>> A = np.arange(16).reshape((4, 4))
>>> A
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
Так, если нужно разбить массив горизонтально, то есть, поделить ширину массива на две части, то матрица A размером 4×4 превратится в две матрицы 2×4.
>>> [B,C] = np.hsplit(A, 2)
>>> B
array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]])
>>> C
array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])
Если же нужно разбить массив вертикально, то есть поделить высоту на две части, то матрица A размером 4×4 превратится в 2 размерами 4×2.
>>> [B,C] = np.vsplit(A, 2)
>>> B
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
>>> C
array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])
Более сложная команда — функция split(). Она позволяет разбить массив на несимметричные части. Массив передается в качестве аргумента, но вместе с ним необходимо указать и индексы частей, на которые его требуется разбить. Если указать параметр axis = 1, то индексами будут колонки, а если axis = 0 — ряды.
Например, необходимо разбить матрицу на три части. Первая из которых будет включать первую колонку, вторая — вторую и третью колонки, а третья — последнюю. Здесь нужно указать следующие индексы.
>>> [A1,A2,A3] = np.split(A,[1,3],axis=1)
>>> A1
array([[ 0],
[ 4],
[ 8],
[12]])
>>> A2
array([[ 1, 2],
[ 5, 6],
[ 9, 10],
[13, 14]])
>>> A3
array([[ 3],
[ 7],
[11],
[15]])
То же самое можно проделать и для рядов.
>>> [A1,A2,A3] = np.split(A,[1,3],axis=0)
>>> A1
array([[0, 1, 2, 3]])
>>> A2
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> A3
array([[12, 13, 14, 15]])
Эта же особенность включает функции vsplit() и hsplit().
До этого момента индексы и срезы использовать для извлечения подмножеств. В этих методах используются числовые значения. Но есть альтернативный путь получения элементов — с помощью условий и булевых операторов.
Предположим, что нужно выбрать все значения меньше 0,5 в матрице размером 4х4, которая содержит случайные значения между 0 и 1.
>>> A = np.random.random((4, 4))
>>> A
array([[ 0.03536295, 0.0035115 , 0.54742404, 0.68960999],
[ 0.21264709, 0.17121982, 0.81090212, 0.43408927],
[ 0.77116263, 0.04523647, 0.84632378, 0.54450749],
[ 0.86964585, 0.6470581 , 0.42582897, 0.22286282]])
Когда матрица из случайных значений определена, можно применить оператор условия. Результатом будет матрица из булевых значений: True, если элемент соответствовал условию и False — если нет. В этом примере можно видеть все элементы со значениями меньше 0,5.
>>> A < 0.5
array([[ True, True, False, False],
[ True, True, False, True],
[False, True, False, False],
[False, False, True, True]], dtype=bool)
На самом деле, булевы массивы используются для неявного извлечения частей массивов. Добавив прошлое условие в квадратные скобки, можно получить новый массив, который будет включать все элементы меньше 0,5 из предыдущего.
>>> A[A < 0.5]
array([ 0.03536295, 0.0035115 , 0.21264709, 0.17121982, 0.43408927,
0.04523647, 0.42582897, 0.22286282])
Управление размерностью
Вы уже видели, как можно превращать одномерный массив в матрицу с помощью функции reshape().
>>> a = np.random.random(12)
>>> a
array([ 0.77841574, 0.39654203, 0.38188665, 0.26704305, 0.27519705,
0.78115866, 0.96019214, 0.59328414, 0.52008642, 0.10862692,
0.41894881, 0.73581471])
>>> A = a.reshape(3, 4)
>>> A
array([[ 0.77841574, 0.39654203, 0.38188665, 0.26704305],
[ 0.27519705, 0.78115866, 0.96019214, 0.59328414],
[ 0.52008642, 0.10862692, 0.41894881, 0.73581471]])
Функция reshape() возвращает новый массив и таким образом может создавать новые объекты. Но если необходимо изменить объект, поменяв его форму, нужно присвоить кортеж с новыми размерностями атрибуту shape массива.
>>> a.shape = (3, 4)
>>> a
array([[ 0.77841574, 0.39654203, 0.38188665, 0.26704305],
[ 0.27519705, 0.78115866, 0.96019214, 0.59328414],
[ 0.52008642, 0.10862692, 0.41894881, 0.73581471]])
Как видно на примере, в этот раз оригинальный массив изменил форму, и ничего не возвращается. Обратная операция также возможна. Можно конвертировать двухмерный массив в одномерный с помощью функции ravel().
>>> a = a.ravel()
array([ 0.77841574, 0.39654203, 0.38188665, 0.26704305, 0.27519705,
0.78115866, 0.96019214, 0.59328414, 0.52008642, 0.10862692,
0.41894881, 0.73581471])
Или прямо повлиять на атрибут shape самого массива.
>>> a.shape = (12)
>>> a
array([ 0.77841574, 0.39654203, 0.38188665, 0.26704305, 0.27519705,
0.78115866, 0.96019214, 0.59328414, 0.52008642, 0.10862692,
0.41894881, 0.73581471])
Еще одна важная операция — транспонирование матрицы. Это инверсия колонок и рядов. NumPy предоставляет такую функциональность в функции transpose().
>>> A.transpose()
array([[ 0.77841574, 0.27519705, 0.52008642],
[ 0.39654203, 0.78115866, 0.10862692],
[ 0.38188665, 0.96019214, 0.41894881],
[ 0.26704305, 0.59328414, 0.73581471]])
В прошлых разделах вы узнали, как создавать массив и выполнять операции с ним. В этом — речь пойдет о манипуляции массивами: о выборе элементов по индексам и срезам, а также о присваивании для изменения отдельных значений. Наконец, узнаете, как перебирать их.
Индексы
При работе с индексами массивов всегда используются квадратные скобки ([ ]). С помощью индексирования можно ссылаться на отдельные элементы, выделяя их или даже меняя значения.
При создании нового массива шкала с индексами создается автоматически.

Для получения доступа к одному элементу на него нужно сослаться через его индекс.
>>> a = np.arange(10, 16)
>>> a
array([10, 11, 12, 13, 14, 15])
>>> a[4]
14
NumPy также принимает отрицательные значения. Такие индексы представляют собой аналогичную последовательность, где первым элемент будет представлен самым большим отрицательным значением.
>>> a[–1]
15
>>> a[–6]
10
Для выбора нескольких элементов в квадратных скобках можно передать массив индексов.
>>> a[[1, 3, 4]]
array([11, 13, 14])
Двухмерные массивы, матрицы, представлены в виде прямоугольного массива, состоящего из строк и колонок, определенных двумя осями, где ось 0 представлена строками, а ось 1 — колонками. Таким образом индексация происходит через пару значений; первое — это значение ряда, а второе — колонки. И если нужно получить доступ к определенному элементу матрицы, необходимо все еще использовать квадратные скобки, но уже с двумя значениями.
>>> A = np.arange(10, 19).reshape((3, 3))
>>> A
array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
Если нужно удалить элемент третьей колонки во второй строке, необходимо ввести пару [1, 2].
>>> A[1, 2]
15
Срезы
Срезы позволяют извлекать части массива для создания новых массивов. Когда вы используете срезы для списков Python, результирующие массивы — это копии, но в NumPy они являются представлениями одного и того же лежащего в основе буфера.
В зависимости от части массива, которую необходимо извлечь, нужно использовать синтаксис среза; это последовательность числовых значений, разделенная двоеточием (:) в квадратных скобках.
Чтобы получить, например, часть массива от второго до шестого элемента, необходимо ввести индекс первого элемента — 1 и индекса последнего — 5, разделив их :.
>>> a = np.arange(10, 16)
>>> a
array([10, 11, 12, 13, 14, 15])
>>> a[1:5]
array([11, 12, 13, 14])
Если нужно извлечь элемент из предыдущего отрезка и пропустить один или несколько элементов, можно использовать третье число, которое представляет собой интервал последовательности. Например, со значением 2 результат будет такой.
>>> a[1:5:2]
array([11, 13])
Чтобы лучше понять синтаксис среза, необходимо рассматривать и случаи, когда явные числовые значения не используются. Если не ввести первое число, NumPy неявно интерпретирует его как 0 (то есть, первый элемент массива). Если пропустить второй — он будет заменен на максимальный индекс, а если последний — представлен как 1. То есть, все элементы будут перебираться без интервалов.
>>> a[::2]
array([10, 12, 14])
>>> a[:5:2]
array([10, 12, 14])
>>> a[:5:]
array([10, 11, 12, 13, 14]
В случае с двухмерными массивами срезы тоже работают, но их нужно определять отдельно для рядов и колонок. Например, если нужно получить только первую строку:
>>> A = np.arange(10, 19).reshape((3, 3))
>>> A
array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
>>> A[0,:]
array([10, 11, 12])
Как видно по второму индексу, если оставить только двоеточие без числа, будут выбраны все колонки. А если нужно выбрать все значения первой колонки, то необходимо писать обратное.
>>> A[:,0]
array([10, 13, 16])
Если же необходимо извлечь матрицу меньшего размера, то нужно явно указать все интервалы с соответствующими индексами.
>>> A[0:2, 0:2]
array([[10, 11],
[13, 14]])
Если индексы рядов или колонок не последовательны, нужно указывать массив индексов.
>>> A[[0,2], 0:2]
array([[10, 11],
[16, 17]])
Итерация по массиву
В Python для перебора по элементам массива достаточно использовать такую конструкцию.
>>> for i in a:
... print(i)
...
10
11
12
13
14
15
Но даже здесь в случае с двухмерным массивом можно использовать вложенные циклы внутри for. Первый цикл будет сканировать ряды массива, а второй — колонки. Если применить цикл for к матрице, она всегда будет перебирать в первую очередь по строкам.
>>> for row in A:
... print(row)
...
[10 11 12]
[13 14 15]
[16 17 18]
Если необходимо перебирать элемент за элементом можно использовать следующую конструкцию, применив цикл for для A.flat:
>>> for item in A.flat:
... print(item)
...
10
11
12
13
14
15
68
16
17
18
Но NumPy предлагает и альтернативный, более элегантный способ. Как правило, требуется использовать перебор для применения функции для конкретных рядов, колонок или отдельных элементов. Можно запустить функцию агрегации, которая вернет значение для каждой колонки или даже каждой строки, но есть оптимальный способ, когда NumPy перебирает процесс итерации на себя: функция apply_along_axis().
Она принимает три аргумента: функцию, ось, для которой нужно применить перебор и сам массив. Если ось равна 0, тогда функция будет применена к элементам по колонкам, а если 1 — то по рядам. Например, можно посчитать среднее значение сперва по колонкам, а потом и по рядам.
>>> np.apply_along_axis(np.mean, axis=0, arr=A)
array([ 13., 14., 15.])
>>> np.apply_along_axis(np.mean, axis=1, arr=A)
array([ 11., 14., 17.])
В прошлом примере использовались функции из библиотеки NumPy, но ничто не мешает определять собственные. Можно использовать и ufunc. В таком случае перебор по колонкам и по рядам выдает один и тот же результат. На самом деле, ufunc выполняет перебор элемент за элементом.
>>> def foo(x):
... return x/2
...
>>> np.apply_along_axis(foo, axis=1, arr=A)
array([[5., 5.5, 6. ],
[6.5, 7., 7.5],
[8., 8.5, 9. ]])
>>> np.apply_along_axis(foo, axis=0, arr=A)
array([[5., 5.5, 6.],
[6.5, 7., 7.5],
[8., 8.5, 9.]])
В этом случае функция ufunct делит значение каждого элемента надвое вне зависимости от того, был ли применен перебор к ряду или колонке.
Вы уже знаете, как создавать массив NumPy и как определять его элементы. Теперь пришло время разобраться с тем, как применять к ним различные операции.
Арифметические операторы
Арифметические операторы — первые, которые предстоит использовать. К числу наиболее очевидных относятся прибавление и умножение на скаляр.
>>> a = np.arange(4)
>>> a
array([0, 1, 2, 3])
>>> a+4
array([4, 5, 6, 7])
>>> a*2
array([0, 2, 4, 6])
Их можно использовать для двух массивов. В NumPy эти операции поэлементные, то есть, они применяются только к соответствующим друг другу элементам. Это должны быть объекты, которые занимают одно и то же положение, так что результатом станет новый массив, содержащий итоговые величины в тех же местах, что и операнды.
>>> b = np.arange(4,8)
>>> b
array([4, 5, 6, 7])
>>> a + b
array([ 4, 6, 8, 10])
>>> a – b
array([–4, –4, –4, –4])
>>> a * b
array([ 0, 5, 12, 21])
Более того, эти операторы доступны и для функций, если те возвращают массив NumPy. Например, можно перемножить массив на синус или квадратный корень элементов массива b.
>>> a * np.sin(b)
array([–0. , –0.95892427, –0.558831 , 1.9709598 ])
>>> a * np.sqrt(b)
array([ 0. , 2.23606798, 4.89897949, 7.93725393])
И даже в случае с многомерными массивами можно применять арифметические операторы поэлементно.
>>> A = np.arange(0, 9).reshape(3, 3)
>>> A
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> B = np.ones((3, 3))
>>> B
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
>>> A * B
array([[ 0., 1., 2.],
[ 3., 4., 5.],
[ 6., 7., 8.]])
Произведение матриц
Выбор оператора для поэлементного применения — это странный аспект работы с библиотекой NumPy. В большинстве инструментов для анализа данных оператор * обозначает произведение матриц. Он применяется к обоим массивам. В NumPy же подобное произведение обозначается функцией dot(). Эта операция не поэлементная.
>>> np.dot(A,B)
array([[ 3., 3., 3.],
[ 12., 12., 12.],
[ 21., 21., 21.]])
Каждый элемент результирующей матрицы — сумма произведений каждого элемента соответствующей строки в первой матрице с соответствующим элементом из колонки второй. Рисунок ниже показывает процесс произведения матриц (для двух элементов).

Еще один вариант записи произведения матриц — использование одной из двух матриц в качестве объекта функции dot().
>>> A.dot(B)
array([[ 3., 3., 3.],
[ 12., 12., 12.],
[ 21., 21., 21.]])
Но поскольку произведение матриц — это не коммутативная операция, порядок операндов имеет значение. В данном случае A*B не равняется B*A.
>>> np.dot(B,A)
array([[ 9., 12., 15.],
[ 9., 12., 15.],
[ 9., 12., 15.]])
Операторы инкремента и декремента
На самом деле, в Python таких операторов нет, поскольку нет операторов ++ или --. Для увеличения или уменьшения значения используются += и -=. Они не отличаются от предыдущих, но вместо создания нового массива с результатами присваивают новое значение тому же массиву.
>>> a = np.arange(4)
>>> a
array([0, 1, 2, 3])
>>> a += 1
>>> a
array([1, 2, 3, 4])
>>> a –= 1
>>> a
array([0, 1, 2, 3])
Таким образом использование этих операторов дает возможность получать более масштабные результаты, чем в случае с обычными операторами инкремента, увеличивающими значения на один. Их можно использовать в самых разных ситуациях. Например, они подходят для изменения значений без создания нового массива.
array([0, 1, 2, 3])
>>> a += 4
>>> a
array([4, 5, 6, 7])
>>> a *= 2
>>> a
array([ 8, 10, 12, 14])
Универсальные функции (ufunc)
Универсальная функция, известная также как ufunc, — это функция, которая применяется в массиве к каждому элементу. Это значит, что она воздействует на каждый элемент массива ввода, генерируя соответствующий результат в массив вывода. Финальный массив соответствует по размеру массиву ввода.
Под это определение подпадает множество математических и тригонометрических операций; например, вычисление квадратного корня с помощью sqrt(), логарифма с log() или синуса с sin().
>>> a = np.arange(1, 5)
>>> a
array([1, 2, 3, 4])
>>> np.sqrt(a)
array([ 1. , 1.41421356, 1.73205081, 2. ])
>>> np.log(a)
array([ 0. , 0.69314718, 1.09861229, 1.38629436])
>>> np.sin(a)
array([ 0.84147098, 0.90929743, 0.14112001, –0.7568025 ])
Многие функции уже реализованы в библиотеке NumPy.
Функции агрегации
Функции агрегации выполняют операцию на наборе значений, например, на массиве, и выдают один результат. Таким образом, сумма всех элементов массива — это результат работы функции агрегации. Многие из таких функций реализованы в классе ndarray.
>>> a = np.array([3.3, 4.5, 1.2, 5.7, 0.3])
>>> a.sum()
15.0
>>> a.min()
0.29999999999999999
>>> a.max()
5.7000000000000002
>>> a.mean()
3.0
>>> a.std()
2.0079840636817816
Основной элемент библиотеки NumPy — объект ndarray (что значит N-размерный массив). Этот объект является многомерным однородным массивом с заранее заданным количеством элементов. Однородный — потому что практически все объекты в нем одного размера или типа. На самом деле, тип данных определен другим объектом NumPy, который называется dtype (тип-данных). Каждый ndarray ассоциирован только с одним типом dtype.
Количество размерностей и объектов массива определяются его размерностью (shape), кортежем N-положительных целых чисел. Они указывают размер каждой размерности. Размерности определяются как оси, а количество осей — как ранг.
Еще одна странность массивов NumPy в том, что их размер фиксирован, а это значит, что после создания объекта его уже нельзя поменять. Это поведение отличается от такового у списков Python, которые могут увеличиваться и уменьшаться в размерах.
Простейший способ определить новый объект ndarray — использовать функцию array(), передав в качестве аргумента Python-список элементов.
>>> a = np.array([1, 2, 3])
>>> a
array([1, 2, 3])
Можно легко проверить, что новый объект — это ndarray, передав его функции type().
>>> type(a)
<type 'numpy.ndarray'>
Чтобы узнать ассоциированный тип dtype, необходимо использовать атрибут dtype.
Примечание: результат
dtype,shapeи других может быть разным для разных операционных систем и дистрибутивов Python.
>>> a.dtype
dtype('int64')
Только что созданный массив имеет одну ось, а его ранг равняется 1, то есть его форма — (3,1). Для получения этих значений из массива необходимо использовать следующие атрибуты: ndim — для осей, size — для длины массива, shape — для его формы.
>>> a.ndim
1
>>> a.size
3
>>> a.shape
(3,)
Это был пример простейшего одномерного массива. Но функциональность массивов может быть расширена и до нескольких размерностей. Например, при определении двумерного массива 2×2:
>>> b = np.array([[1.3, 2.4],[0.3, 4.1]])
>>> b.dtype
dtype('float64')
>>> b.ndim
2
>>> b.size
4
>>> b.shape
(2, 2)
Ранг этого массива — 2, поскольку у него 2 оси, длина каждой из которых также равняется 2.
Еще один важный атрибут — itemsize. Он может быть использован с объектами ndarray. Он определяет размер каждого элемента массива в байтах, а data — это буфер, содержащий все элементы массива. Второй атрибут пока не используется, потому что для получения данных из массива применяется механизм индексов, речь о котором подробно пойдет в следующих разделах.
>>> b.itemsize
8
>>> b.data
<read-write buffer for 0x0000000002D34DF0, size 32, offset 0 at
0x0000000002D5FEA0>
Создание массива
Есть несколько вариантов создания массива. Самый распространенный — список из списков, выступающий аргументом функции array().
>>> c = np.array([[1, 2, 3],[4, 5, 6]])
>>> c
array([[1, 2, 3],
[4, 5, 6]])
Функция array() также может принимать кортежи и последовательности кортежей.
>>> d = np.array(((1, 2, 3),(4, 5, 6)))
>>> d
array([[1, 2, 3],
[4, 5, 6]])
Она также может принимать последовательности кортежей и взаимосвязанных списков.
>>> e = np.array([(1, 2, 3), [4, 5, 6], (7, 8, 9)])
>>> e
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
Типы данных
Пока что рассматривались только значения простого целого числа и числа с плавающей запятой, но массивы NumPy сделаны так, чтобы включать самые разные типы данных. Например, можно включать строки:
Типы данных, поддерживаемые NumPy
| Тип данных | Описание |
|---|---|
bool |
Булевы значения (True или False) хранятся в виде байтов |
int |
Тип по умолчанию — целое число (то же, что long в C; обычно int64 или int32) |
intc |
Идентичный int в C (обычно int32 или int64) |
intp |
Целое число для использования в качестве индексов (то же, что и size_t в C, обычно int32 или int64) |
int8 |
Байт (от — 128 до 127) |
int16 |
Целое число (от -32768 до 32767) |
int32 |
Целое число (от -2147483648 до 2147483647) |
int64 |
Целое число (от -9223372036854775808 до 9223372036854775807) |
uint8 |
Целое число без знака (от 0 до 255) |
uint16 |
Целое число без знака (от 0 до 65535) |
uint32 |
Целое число без знака (от 0 до 4294967295) |
uint64 |
Целое число без знака (от 0 до 18446744073709551615) |
float |
Обозначение float64 |
float16 |
Число с плавающей точкой половинной точности; бит на знак, 5-битная экспонента, 10-битная мантисса |
float32 |
Число с плавающей точкой единичной точности; бит на знак, 8-битная экспонента, 23-битная мантисса |
float64 |
Число с плавающей точкой двойной точности; бит на знак, 11-битная экспонента, 52-битная мантисса |
complex |
Обозначение complex128 |
complex64 |
Комплексное число, представленное двумя 32-битными float (с действительной и мнимой частями) |
complex128 |
Комплексное число, представленное двумя 64-битными float (с действительной и мнимой частями) |
Параметр dtype
Функция array() не принимает один аргумент. На примерах видно, что каждый объект ndarray ассоциирован с объектом dtype, определяющим тип данных, которые будут в массиве. По умолчанию функция array() можно ассоциировать самый подходящий тип в соответствии со значениями в последовательностях списков или кортежей. Их можно определить явно с помощью параметра dtype в качестве аргумента.
Например, если нужно определить массив с комплексными числами в качестве значений, необходимо использовать параметр dtype следующим образом:
>>> f = np.array([[1, 2, 3],[4, 5, 6]], dtype=complex)
>>> f
array([[ 1.+0.j, 2.+0.j, 3.+0.j],
[ 4.+0.j, 5.+0.j, 6.+0.j]])
Функции генерации массива
Библиотека NumPy предоставляет набор функций, которые генерируют ndarray с начальным содержимым. Они создаются с разным значениями в зависимости от функции. Это очень полезная особенность. С помощью всего одной строки кода можно сгенерировать большой объем данных.
Функция zeros(), например, создает полный массив нулей с размерностями, определенными аргументом shape. Например, для создания двумерного массива 3×3, можно использовать:
>>> np.zeros((3, 3))
array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
А функция ones() создает массив, состоящий из единиц.
>>> np.ones((3, 3))
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
По умолчанию две функции создают массивы с типом данных float64. Полезная фишка — arrange(). Она генерирует массивы NumPy с числовыми последовательностями, которые соответствуют конкретным требованиям в зависимости от переданных аргументов. Например, для генерации последовательности значений между 0 и 10, нужно передать всего один аргумент — значение, которое закончит последовательность.
>>> np.arange(0, 10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
Если в начале нужен не ноль, то необходимо обозначить уже два аргумента: первый и последний.
>>> np.arange(4, 10)
array([4, 5, 6, 7, 8, 9])
Также можно сгенерировать последовательность значений с точным интервалом между ними. Если определено и третье значение в arrange(), оно будет представлять собой промежуток между каждым элементом.
>>> np.arange(0, 12, 3)
array([0, 3, 6, 9])
Оно может быть и числом с плавающей точкой.
>>> np.arange(0, 6, 0.6)
array([ 0. , 0.6, 1.2, 1.8, 2.4, 3. , 3.6, 4.2, 4.8, 5.4])
Пока что в примерах были только одномерные массивы. Для генерации двумерных массивов все еще можно использовать функцию arrange(), но вместе с reshape(). Она делит линейный массив на части способом, который указан в аргументе shape.
>>> np.arange(0, 12).reshape(3, 4)
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
Похожая на arrange() функция — linspace(). Она также принимает в качестве первых двух аргументов первое и последнее значения последовательности, но третьим аргументом является не интервал, а количество элементов, на которое нужно разбить последовательность.
>>> np.linspace(0,10,5)
array([ 0. , 2.5, 5. , 7.5, 10. ])
Еще один способ получения массива — заполнение его случайными значениями. Это можно сделать с помощью функции random() из модуля numpy.random. Эта функция генерирует массив с тем количеством элементов, которые указаны в качестве аргумента.
>>> np.random.random(3)
array([ 0.78610272, 0.90630642, 0.80007102])
Полученные числа будут отличаться с каждым запуском. Для создания многомерного массива, нужно передать его размер в виде аргумента.
>>> np.random.random((3,3))
array([[ 0.07878569, 0.7176506 , 0.05662501],
[ 0.82919021, 0.80349121, 0.30254079],
[ 0.93347404, 0.65868278, 0.37379618]])
Что такое машинное обучение и почему это важно?
Машинное обучение — это область искусственного интеллекта, использующая статистические методы, чтобы предоставить компьютерным системам способность «учиться». То есть постепенно улучшать производительность в конкретной задаче, с помощью данных без явного программирования. Хороший пример — то, насколько эффективно (или не очень) Gmail распознает спам или насколько совершеннее стали системы распознавания голоса с приходом Siri, Alex и Google Home.
С помощью машинного обучения решаются следующие задачи:
- Распознавание мошенничества — отслеживание необычных шаблонов в транзакциях кредитных карт или банковских счетов
- Предсказание — предсказание будущей цены акций, курса обмена валюты или криптовалюты
- Распознавание изображений — определение объектов и лиц на картинках
Машинное обучение — огромная область, и сегодня речь пойдет лишь об одной из ее составляющих.
Обучение с учителем
Обучение с учителем — один из видов машинного обучения. Его идея заключается в том, что систему сначала учат понимать прошлые данные, предлагая много примеров конкретной проблемы и желаемый вывод. Затем, когда система «натренирована», ей можно давать новые входные данные для предсказания выводов.
Например, как создать спам-детектор? Один из способов — интуиция. Можно вручную определять правила: например «содержит слово деньги» или «включает фразу Western Union». И пусть иногда такие системы работают, в большинстве случаев все-таки сложно создать или определить шаблоны, опираясь исключительно на интуицию.
С помощью обучения с учителем можно тренировать системы изучать лежащие в основе правила и шаблоны за счет предоставления примеров с большим количеством спама. Когда такой детектор натренирован, ему можно дать новое письмо, чтобы он попытался предсказать, является ли оно спамом.
Обучение с учителем можно использовать для предсказания вывода. Есть два типа проблем, которые решаются с его помощью: регрессия и классификация.
- В регрессионных проблемах мы пытаемся предсказать непрерывный вывод. Например, предсказание цены дома на основе данных о его размере
- В классификационных — предсказываем дискретное число качественных меток. Например, попытка предсказать, является ли письмо спамом на основе количества слов в нем.

Невозможно говорить о машинном обучении с учителем, не затронув модели обучения с учителем. Это как говорить о программировании, не касаясь языков программирования или структур данных. Модели обучения — это те самые структуры, что поддаются тренировке. Их вес (или структура) меняется по мере того, как они формируют понимание того, что нужно предсказывать. Есть несколько видов моделей обучения, например:
- Случайный лес (random forest)
- Наивный байесовский классификатор (naive Bayes)
- Логистическая регрессия (logistic regression)
- Метод k-ближайших соседей (k nearest neighbors)
В этом материале в качестве модели будет использоваться нейронная сеть.
Понимание работы нейронных сетей
Нейронные сети получили такое название, потому что их внутренняя структура должна имитировать человеческий мозг. Последний состоит из нейронов и синапсов, которые их соединяют. В момент стимуляции нейроны «активируют» другие с помощью электричества.
Каждый нейрон «активируется» в первую очередь за счет вычисления взвешенной суммы вводных данных и последующего результата с помощью результирующей функции. Когда нейрон активируется, он в свою очередь активирует остальные, которые выполняют похожие вычисления, вызывая цепную реакцию между всеми нейронами всех слоев.
Стоит отметить, что пусть нейронные сети и вдохновлены биологическими, сравнивать их все-таки нельзя.

- Эта диаграмма иллюстрирует процесс активации, через который проходит каждый нейрон. Рассмотрим схему слева направо.
- Все вводные данные (числовые значения) из входящих нейронов считываются. Они определяются как x1…xn.
- Каждый ввод умножается на взвешенную сумму, ассоциированную с этим соединением. Ассоциированные веса обозначены как W1j…Wnj.
- Все взвешенные вводы суммируются и передаются активирующей функции. Она читает этот ввод и трансформирует его в числовое значение k-ближайших соседей.
- В итоге числовое значение, которое возвращает эта функция, будет вводом для другого нейрона в другом слое.
Слои нейронной сети
Нейроны внутри нейронной сети организованы в слои. Слои — это способ создать структуру, где каждый содержит 1 или большее количество нейронов. В нейронной сети обычно 3 или больше слоев. Также всегда определяются 2 специальных слоя, которые выполняют роль ввода и вывода.
- Слой ввода является точкой входа в нейронную сеть. В рамках программировании его можно воспринимать как аргумент функции.
- Вывод — это результат работы нейронной сети. В терминах программирования это возвращаемое функцией значение.
Слои между ними описываются как «скрытые слои». Именно там происходят все вычисления. Все слои в нейронной сети кодируются как признаковые описания.
Выбор количества скрытых слоев и нейронов
Нет золотого правила, которым стоит руководствоваться при выборе количества слоев и их размера (или числа нейронов). Как правило, стоит попробовать как минимум 1 такой слой и дальше настраивать размер, проверяя, что работает лучше всего.

Использование библиотеки Keras для тренировки простой нейронной сети, которая распознает рукописные цифры
Программистам на Python нет необходимости заново изобретать колесо. Такие библиотеки, как Tensorflow, Torch, Theano и Keras уже определили основные структуры данных для нейронной сети, оставив необходимость лишь декларативно описать структуру нейронной сети.
Keras предоставляет еще и определенную свободу: возможность выбрать количество слоев, число нейронов, тип слоя и функцию активации. На практике элементов довольно много, но в этот раз обойдемся более простыми примерами.
Как уже упоминалось, есть два специальных уровня, которые должны быть определены на основе конкретной проблемы: размер слоя ввода и размер слоя вывода. Все остальные «скрытые слои» используются для изучения сложных нелинейных абстракций задачи.
В этом материале будем использовать Python и библиотеку Keras для предсказания рукописных цифр из базы данных MNIST.
Запуск Jupyter Notebook локально
Если вы еще не работали с Jupyter Notebook, сначало изучите Руководство по Jupyter Notebook для начинающих
Список необходимых библиотек:
- numpy
- matplotlib
- sklearn
- tensorflow
Запуск из интерпретатора Python
Для запуска чистой установки Python (любой версии старше 3.6) установите требуемые модули с помощью pip.
Рекомендую (но не обязательно) запускать код в виртуальной среде.
!pip install matplotlib
!pip install sklearn
!pip install tensorflow
Если эти модули установлены, то теперь можно запускать весь код в проекте.
Импортируем модули и библиотеки:
import numpy as np
import matplotlib.pyplot as plt
import gzip
from typing import List
from sklearn.preprocessing import OneHotEncoder
import tensorflow.keras as keras
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import itertools
%matplotlib inline
База данных MNIST
MNIST — это огромная база данных рукописных цифр, которая используется как бенчмарк и точка знакомства с машинным обучением и системами обработки изображений. Она идеально подходит, чтобы сосредоточиться именно на процессе обучения нейронной сети. MNIST — очень чистая база данных, а это роскошь в мире машинного обучения.
Цель
Натренировать систему, классифицировать каждое соответствующим ярлыком (изображенной цифрой). С помощью набора данных из 60 000 изображений рукописных цифр (представленных в виде изображений 28х28 пикселей, каждый из которых является градацией серого от 0 до 255).
Набор данных
Набор данных состоит из тренировочных и тестовых данных, но для упрощения здесь будет использоваться только тренировочный. Вот так его загрузить:
%%bash
rm -Rf train-images-idx3-ubyte.gz
rm -Rf train-labels-idx1-ubyte.gz
wget -q http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
wget -q http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz

Чтение меток
Есть 10 цифр: (0-9), поэтому каждая метка должна быть цифрой от 0 до 9. Загруженный файл, train-labels-idx1-ubyte.gz, кодирует метки следующим образом:
Файл ярлыка тренировочного набора (train-labels-idx1-ubyte):
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | label |
Значения меток от 0 до 9.
Первые 8 байт (или первые 2 32-битных целых числа) можно пропустить, потому что они содержат метаданные файлы, необходимые для низкоуровневых языков программирования. Для парсинга файла нужно проделать следующие операции:
- Открыть файл с помощью библиотеки gzip, чтобы его можно было распаковать
- Прочитать весь массив байтов в память
- Пропустить первые 8 байт
- Перебирать каждый байт и приводить его к целому числу
Примечание: если этот файл из непроверенного источника, понадобится куда больше проверок. Но предположим, что этот конкретный является надежным и подходит для целей материала.
with gzip.open('train-labels-idx1-ubyte.gz') as train_labels:
data_from_train_file = train_labels.read()
# Пропускаем первые 8 байт
label_data = data_from_train_file[8:]
assert len(label_data) == 60000
# Конвертируем каждый байт в целое число.
# Это будет число от 0 до 9
labels = [int(label_byte) for label_byte in label_data]
assert min(labels) == 0 and max(labels) == 9
assert len(labels) == 60000
Чтение изображений
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 0017 | unsigned byte | ?? | pixel |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | pixel |
Чтение изображений немного отличается от чтения меток. Первые 16 байт содержат уже известные метаданные. Их можно пропустить и переходить сразу к чтению изображений. Каждое из них представлено в виде массива 28*28 из байтов без знака. Все что требуется — читать по одному изображению за раз и сохранять их в массив.
SIZE_OF_ONE_IMAGE = 28 ** 2
images = []
# Перебор тренировочного файла и читение одного изображения за раз
with gzip.open('train-images-idx3-ubyte.gz') as train_images:
train_images.read(4 * 4)
ctr = 0
for _ in range(60000):
image = train_images.read(size=SIZE_OF_ONE_IMAGE)
assert len(image) == SIZE_OF_ONE_IMAGE
# Конвертировать в NumPy
image_np = np.frombuffer(image, dtype='uint8') / 255
images.append(image_np)
images = np.array(images)
images.shape
Вывод: (60000, 784)
В списке 60000 изображений. Каждое из них представлено битовым вектором размером SIZE_OF_ONE_IMAGE. Попробуем построить изображение с помощью библиотеки matplotlib:
def plot_image(pixels: np.array):
plt.imshow(pixels.reshape((28, 28)), cmap='gray')
plt.show()
plot_image(images[25])

Кодирование меток изображения с помощью One-hot encoding
Будем использовать one-hot encoding для превращения целевых меток в вектор.
labels_np = np.array(labels).reshape((-1, 1))
encoder = OneHotEncoder(categories='auto')
labels_np_onehot = encoder.fit_transform(labels_np).toarray()
labels_np_onehot
array([[0., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]])
Были успешно созданы входные данные и векторный вывод, который будет поступать на входной и выходной слои нейронной сети. Вектор ввода с индексом i будет отвечать вектору вывода с индексом i.
Вводные данные:
labels_np_onehot[999]
Вывод:
array([0., 0., 0., 0., 0., 0., 1., 0., 0., 0.])
Вводные данные:
plot_image(images[999])
Вывод:

В примере выше явно видно, что изображение с индексом 999 представляет цифру 6. Ассоциированный с ним вектор содержит 10 цифр (поскольку имеется 10 меток), а цифра с индексом 6 равно 1. Это значит, что метка правильная.
Разделение датасета на тренировочный и тестовый
Для проверки того, что нейронная сеть была натренирована правильно, берем определенный процент тренировочного набора (60 000 изображений) и используем его в тестовых целях.
Вводные данные:
X_train, X_test, y_train, y_test = train_test_split(images, labels_np_onehot)
print(y_train.shape)
print(y_test.shape)
(45000, 10)
(15000, 10)
Здесь видно, что весь набор из 60 000 изображений бал разбит на два: один с 45 000, а другой с 15 000 изображений.
Тренировка нейронной сети с помощью Keras
model = keras.Sequential()
model.add(keras.layers.Dense(input_shape=(SIZE_OF_ONE_IMAGE,), units=128, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
Вывод:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 128) 100480
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
Для обучения нейронной сети, выполним этот код.
model.fit(X_train, y_train, epochs=20, batch_size=128)
Вывод:
Train on 45000 samples
Epoch 1/20
45000/45000 [==============================] - 2s 54us/sample - loss: 1.3391 - accuracy: 0.6710
Epoch 2/20
45000/45000 [==============================] - 2s 39us/sample - loss: 0.6489 - accuracy: 0.8454
...
Epoch 20/20
45000/45000 [==============================] - 2s 40us/sample - loss: 0.2584 - accuracy: 0.9279
Проверяем точность на тренировочных данных.
model.evaluate(X_test, y_test)
Вывод:
[0.2567395991722743, 0.9264]
Посмотрим результаты
Вот вы и натренировали нейронную сеть для предсказания рукописных цифры с точностью выше 90%. Проверим ее с помощью изображения из тестового набора.
Возьмем случайное изображение — картинку с индексом 1010. Берем предсказанную метку (в данном случае — 4, потому что на пятой позиции стоит цифра 1)
y_test[1010]
Вывод:
array([0., 0., 0., 0., 1., 0., 0., 0., 0., 0.])
Построим изображения соответствующей картинки
plot_image(X_test[1010])

Понимание вывода активационного слоя softmax
Пропустим цифру через нейронную сеть и посмотрим, какой вывод она предскажет.
Вводные данные:
predicted_results = model.predict(X_test[1010].reshape((1, -1)))
Вывод слоя softmax — это распределение вероятностей для каждого вывода. В этом случае их может быть 10 (цифры от 0 до 9). Но ожидается, что каждое изображение будет соответствовать лишь одному.
Поскольку это распределение вероятностей, их сумма приблизительно равна 1 (единице).
predicted_results.sum()
1.0000001
Чтение вывода слоя softmax для конкретной цифры
Как можно видеть дальше, 5-ой индекс действительно близок к 1 (0,99), а это значит, что он с большой долей вероятности является
4… а это так и есть!
predicted_results
array([[1.2202066e-06, 3.4432333e-08, 3.5151488e-06, 1.2011528e-06, 9.9889344e-01, 3.5855610e-05, 1.6140550e-05, 7.6822333e-05, 1.0446112e-04, 8.6736667e-04]], dtype=float32)
Просмотр матрицы ошибок
predicted_outputs = np.argmax(model.predict(X_test), axis=1)
expected_outputs = np.argmax(y_test, axis=1)
predicted_confusion_matrix = confusion_matrix(expected_outputs, predicted_outputs)
predicted_confusion_matrix
array([[1402, 0, 4, 3, 1, 6, 20, 2, 21, 2],
[ 1, 1684, 9, 5, 4, 9, 1, 3, 9, 3],
[ 13, 8, 1280, 9, 19, 5, 12, 15, 17, 8],
[ 6, 8, 37, 1404, 1, 53, 3, 17, 33, 15],
[ 4, 7, 8, 0, 1345, 1, 18, 3, 8, 54],
[ 17, 8, 9, 31, 25, 1157, 25, 3, 24, 12],
[ 9, 6, 10, 0, 10, 12, 1431, 0, 6, 1],
[ 3, 11, 17, 4, 23, 2, 1, 1484, 5, 40],
[ 11, 16, 24, 40, 9, 25, 13, 3, 1348, 25],
[ 5, 5, 6, 16, 31, 6, 0, 43, 7, 1381]],
dtype=int64)
# это код из https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
# Compute confusion matrix
class_names = [str(idx) for idx in range(10)]
cnf_matrix = confusion_matrix(expected_outputs, predicted_outputs)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names,
title='Confusion matrix, without normalization')
plt.show()

Выводы
В течение этого руководства вы должны были разобраться с основными концепциями, которые составляют основу машинного обучения, а также научиться:
- Кодировать и декодировать изображения в наборе данных MNIST
- Кодировать категориальные значения с помощью “one-hot encoding”
- Определять нейронную сеть с двумя скрытыми слоями, а также слой вывода, использующий функцию активации softmax
- Изучать результаты вывода функции активации softmax
- Строить матрицу ошибок классификатора
Библиотеки Sci-Kit Learn и Keras значительно понизили порог входа в машинное обучение — так же, как Python снизил порог знакомства с программированием. Однако потребуются годы (или десятилетия), чтобы достичь экспертного уровня!
Программисты, обладающие навыками машинного обучения, очень востребованы. С помощью упомянутых библиотек и вводных материалов о практических аспектах машинного обучения у всех должна быть возможность познакомиться с этой областью знаний. Даже если теоретических знаний о модели, библиотеке или фреймворке нет.
Затем навыки нужно использовать на практике, разрабатывая более умные продукты, что сделает потребителей более вовлеченными.
Попробуйте сами
Вот что вы можете попробовать сделать сами, чтобы углубиться в мир машинного обучения с Python:
- Поэкспериментируйте с количеством нейронов в скрытом слое. Сможете ли вы увеличить точность?
- Попробуйте добавить больше слоев. Тренируется ли сеть от этого медленнее? Понимаете ли вы, почему?
- Попробуйте RandomForestClassifier (нужна библиотека scikit-learn) вместо нейронной сети. Увеличилась ли точность?
Немного истории
В ранние годы существования Python разработчикам необходимо было проводить сложные вычисления, особенно когда язык использовался в научном сообществе.
Первой попыткой упростить задачу был модуль Numeric. Его разработал программист по имени Джим Хагунин в 1995 году. Следом за ней появился пакет Numarray. Оба решения специализировались на вычислениях массивов. У каждого свои преимущества в зависимости от сценария. Поэтому и использовались они по обстоятельствам. Такая неопределенность привела к тому, что приняли решение объединить два пакета. Для этих целей Трэвис Олифант начал разработку библиотеки NumPy, первая версия которой вышла в 2006 году.
С тех пор NumPy стала библиотекой №1 в Python для научных вычислений и по сегодняшний день она является самым популярным пакетом для вычислений многомерных и просто крупных массивов. Он также включает множество функций, которые позволяют эффективно проводить операции и выполнять высокоуровневые математические расчеты.
Сейчас NumPy — это проект с открытым исходным кодом, который распространяется по лицензии BSD. В его развитии внесли свою лепту множество разработчиков.
Установка NumPy
Модуль представлен как пакет по умолчанию во множестве дистрибутивов Python, но если его нет, то для установки используйте одну из следующих команд.
В Linux (Ubuntu и Debian):
sudo apt-get install python-numpy
Для Linux (Fedora):
sudo yum install numpy scipy
В Windows с Anaconda или pip:
conda install numpy
pip install numpy
Когда NumPy установлен, импортируйте модуль с помощью этой команды.
import numpy as np
Для поддержки растущей необходимости в данных в интернете сегодня доступно множество источников. Они предлагают информацию всем, кто в ней нуждаются. Такая информация называется открытыми данными.
Вот список основных источников.
- DataHub (https://datahub.io/dataset)
- Всемирная организация здравоохранения (https://www.who.int/research/en/)
- Data.gov (https://data.gov)
- Портал открытых данных ЕС (https://open-data.europa.eu/en/data/)
- Открытые наборы данных Amazon Web Service (https://aws.amazon.com/datasets)
- Facebook Graph (https://developers.facebook.com/docs/graph-api)
- Healthdata.gov (https://www.healthdata.gov)
- Google Тренды (https://www.google.com/trends/explore)
- Google Finance (https://www.google.com/finance)
- Google Books Ngrams (https://storage.googleapis.com/books/ngrams/books/datasetsv2.html)
- Репозитории для Машинного обучения (https://archive.ics.uci.edu/ml/)
Политические и правительственные данные
- Socrata https://www.socrata.com/resources/
Socrata хороший сайт для изучения данных, связанных с правительством. Кроме того, он дает инструменты визуализации для исследования данных. - Бюро переписей США https://www.census.gov/data.html
Этот сайт предоставляет информацию о гражданах США, охватывающую данные о населении, географические и об образовании. - Данные баз ООН https://data.un.org/
UNdata — это интернет-служба данных, которая предоставляет статистические базы данных ООН. - Портал открытых данных ЕС https://open-data.europa.eu/en/data/
Этот сайт предоставляет много данных из учреждений Европейского Союза. - Data.gov.uk https://data.gov.uk/
Этот сайт правительства Великобритании включает Британскую национальную библиографию: метаданные всех британских книг и публикаций с 1950 года. - Всемирная книга фактов ЦРУ https://www.cia.gov/library/publications/the-world-factbook/
Этот сайт Центрального разведывательного управления предоставляет много информации об истории, населении, экономике, правительстве, инфраструктуре и вооруженных силах 267 стран.
Медицинские данные
- Информационный центр здравоохранения и социального обеспечения https://www.hscic.gov.uk/home
Наборы данных о здоровье от Национальной службы здравоохранения Великобритании.
Социальные данные
- Topsy https://topsy.com/
Topsy предоставляет доступную для поиска по базе данных публичных твитов, начиная с 2006 года, а также несколько инструментов для анализа. - Likebutton https://likebutton.com/
Публикует общедоступные данные Facebook, чтобы дать представление о том, что людям «нравится» в данный момент.
Общедоступные наборы данных
- DBPedia https://wiki.dbpedia.org
Википедия содержит миллионы данных, структурированных и неструктурированных, по каждой теме. DBPedia — это амбициозный проект по каталогизации и созданию публичной, свободной
базы данных, позволяющей любому анализировать эти данные. - Freebase https://www.freebase.com/
Эта база данных предоставляет информацию по нескольким темам с более чем 45 миллионами записей. - Gapminder https://www.gapminder.org/data/
Этот сайт предоставляет данные, поступающие от Всемирной организации здравоохранения и Всемирного банка, которые охватывают экономическую, медицинскую и социальную статистику со всего мира.
Климатические данные
- Национальный центр климатических данных https://www.ncdc.noaa.gov/data-access/quick-links#loc-clim
Огромный набор экологических, метеорологических и климатических данных из Национального центра климатических данных США. Самый большой в мире архив данных о погоде. - WeatherBase https://www.weatherbase.com/
На этом сайте представлены средние значения погодных условий, прогнозы и текущие условия для более чем 40 000 городов по всему миру. - Wunderground https://www.wunderground.com/
Этот сайт предоставляет климатические данные со спутников и метеостанций, что позволяет получать всю информацию о температуре, ветре и других измерениях.


Спортивные данные
- Pro-Football-Reference https://www.pro-football-reference.com/
Этот сайт предоставляет данные о футболе и некоторых других видах спорта.
Газеты
- New York Times https://developer.nytimes.com/docs
Поисковой, проиндексированный архив новостных статей, начиная с 1851 года.
Музыкальные данные
- Датасет с миллионом песен
https://aws.amazon.com/datasets/6468931156960467
Метаданные о более чем миллионе песен и музыкальных произведений. Часть Amazon Web Services
Многие источники с открытыми данными можно найти на диаграмме LOD cloud (https://lod-coud.net). Она показывает связи между разными источниками открытых данных, которые доступны в сети.

Анализ данных полностью сосредоточен на данных. В зависимости от их происхождения можно проводить различия.
Когда анализируемые данные строго числовые или имеют структуру категорий, тогда речь идет о количественном анализе. Но если значения выражены описательно, естественным языком, то это качественный анализ.
Именно из-за разной природы данных, для анализа которых используются эти два типа анализа, можно и наблюдать их различия.
Количественный анализ
Количественный анализ связан с данными, в которых наблюдается логический порядок. Данными которые можно разбить на определенные категории. Это приводит к появлению структуры.
Порядок, классификация и структуры, в свою очередь, дают новую информацию и позволяют дальше обрабатывать ее более математическим путем. Это приводит к появлению моделей, которые создают количественные предсказания. А они уже позволяют специалисту в области анализа данных делать более объективные выводы.
Качественный анализ
Качественный анализ работает с данными, в которых нет структуры или она не очевидна, а их природа — не числа и не какие-либо категории. Например, такие данные могут быть текстовыми, визуальными или звуковыми.
Такой анализ должен быть построен на методологиях, часто отличающихся от случая к случаю. Это позволяет извлекать информацию, которая создает модели, предлагающие качественные предсказания. А выводы на их основе будут включать субъективные интерпретации специалиста.
С другой стороны, качественный анализ может привести к исследованию новых систем и выводам, которые невозможны в случае со строгим математическим подходом. Часто такой вид анализа задействует изучение такие систем, как социальные феномены или сложных структур, не поддающихся измерению.

Выводы
Теперь вы знаете, что такое анализ данных, и какие процессы он включает. Также вы наверняка начали видеть, какую роль играют данные в построении предсказательной модели, и как правильный их отбор влияет на аккуратный и точный анализ данных. В будущем речь пойдет о Python и тех инструментах, которые он предлагает для работы в сфере анализа данных.
]]>Анализ данных можно описать как процесс, состоящий из нескольких шагов, в которых сырые данные превращаются и обрабатываются с целью создать визуализации и сделать предсказания на основе математической модели.
Анализ данных — это всего лишь последовательность шагов, каждый из которых играет ключевую роль для последующих. Этот процесс похож на цепь последовательных, связанных между собой этапов:
- Определение проблемы;
- Извлечение данных;
- Подготовка данных — очистка данных;
- Подготовка данных — преобразование данных;
- Исследование и визуализация данных;
- Предсказательная модель;
- Проверка модели, тестирование;
- Развертывание — визуализация и интерпретация результатов;
- Развертывание — развертывание решения.

Определение проблемы
Процесс анализа данных начинается задолго до сбора сырых данных. Он начинается с проблемы, которую необходимо сперва определить, а затем и решить.
Определить ее можно только сосредоточившись на изучаемой системе: механизме, приложении или процессе в целом. Исследование может быть предназначено для лучшего понимания функционирования системы, но его лучше спроектировать так, чтобы понять принципы поведения и впоследствии делать предсказания или выбор (осознанный).
Процессы определения и документации результатов научной проблемы или бизнеса нужны для того, чтобы сосредоточить анализ на получении результатов.
На самом деле, всеобъемлющее и исчерпывающее исследование системы — это сложный процесс, и почти всегда нет достаточного количества информации, с которой можно начать. Поэтому определение проблемы и особенно планирование приводят к появлению руководящих принципов, которым необходимо следовать в течение всего проекта.
Когда проблема определена и задокументирована, можно двигаться к этапу планирования проекта анализа данных. Планирование необходимо для понимания того, какие профессионалы и ресурсы понадобятся для выполнения требований проекта максимально эффективно. Таким образом задача — рассмотреть те вопросы в области, которые касаются решения этой проблемы Необходимо найти специалистов с разными интересами и установить ПО, нужное для анализа данных.
Построение хорошей команды — один из ключевых факторов успешного анализа данных.
Также во время фазы планировки выбирается эффективная команда. Такие команды должны быть междисциплинарными, чтобы у них была возможность решать проблемы, рассматривая данные с разных точек зрения.
Извлечение данных
Когда проблема определена, первый шаг для проведения анализа — получение данных. Они должны быть выбраны с одной базовой целью — построение предсказательной модели. Поэтому выбор данных — также важный момент для успешного анализа.
Данные должны максимально отражать реальный мир — то, как система реагирует на него. Например, использовании больших наборов сырых данных, которые были собраны неграмотно, это привести либо к неудаче, либо к неопределенности.
Поэтому недостаточное внимание, уделенное выбору данных или выбор таких, которые не представляют систему, приведет к тому, что модели не будут соответствовать изучаемым системам.
Поиск и извлечение данных часто требует интуиции, границы которой лежат за пределами технических исследований и извлечения данных. Этот процесс также требует понимания природы и формы данных, предоставить которое может только опыт и знания практической области проблемы.
Вне зависимости от количества и качества необходимых данных важный вопрос — использование лучших источников данных.
Если средой изучения выступает лаборатория (техническая или научная), а сгенерированные данные экспериментальные, то источник данных легко определить. В этом случае речь идет исключительно о самих экспериментах.
Но при анализе данных невозможно воспроизводить системы, в которых данные собираются исключительно экспериментальным путем, во всех областях применения. Многие области требуют поиска данных в окружающем мире, часто полагаясь на внешние экспериментальные данные или даже на сбор их с помощью интервью и опросов.
В таких случаях поиск хорошего источника данных, способного предоставить все необходимые данные, — задача не из легких. Часто необходимо получать данные из нескольких источников данных для устранения недостатков, выявления расхождений и с целью сделать данные максимально общими.
Интернет — хорошее место для начала поиска данных. Но большую часть из них не так просто взять. Не все данные хранятся в виде файла или базы данных. Они могут содержаться в файле HTML или другом формате. Тут на помощь приходит техника парсинга. Он позволяет собирать данные с помощью поиска определенных HTML-тегов на страницах. При появлении таких совпадений специальный софт извлекает нужные данные. Когда поиск завершен, у вас есть список данных, которые необходимо проанализировать.
Подготовка данных
Из всех этапов анализа подготовка данных кажется наименее проблемным шагом, но на самом деле требует наибольшего количества ресурсов и времени для завершения. Данные часто собираются из разных источников, каждый из которых может предлагать их в собственном виде или формате. Их нужно подготовить для процесса анализа.
Подготовка данных включает такие процессы:
- получение,
- очистка,
- нормализация,
- превращение в оптимизированный набор данных.
Обычно это табличная форма, которая идеально подходит для этих методов, что были запланированы на этапе проектировки.
Многие проблемы могут возникнуть при появлении недействительных, двусмысленных или недостающих значений, повторении полей или данных, несоответствующих допустимому интервалу.
Изучение данных/визуализация
Изучение данных — это их анализ в графической или статистической репрезентации с целью поиска моделей или взаимосвязей. Визуализация — лучший инструмент для выделения подобных моделей.
За последние годы визуализация данных развилась так сильно, что стала независимой дисциплиной. Многочисленные технологии используются исключительно для отображения данных, а многие типы отображения работают так, чтобы получать только лучшую информацию из набора данных.
Исследование данных состоит из предварительного изучения, которое необходимо для понимания типа и значения собранной информации. Вместе с информацией, собранной при определении проблемы, такая категоризация определяет, какой метод анализа данных лучше всего подойдет для определения модели.
Эта фаза, в дополнение к изучению графиков, состоит из следующих шагов:
- Обобщение данных;
- Группировка данных;
- Исследование отношений между разными атрибутами;
- Определение моделей и тенденций;
- Построение моделей регрессионного анализа;
- Построение моделей классификации.
Как правило, анализ данных требует обобщения заявлений касательно изучаемых данных.
Обобщение — процесс, при котором количество данных для интерпретации уменьшается без потери важной информации.
Кластерный анализ — метод анализа данных, используемый для поиска групп, объединенных общими атрибутами (также называется группировкой).
Еще один важный этап анализа — идентификация отношений, тенденций и аномалий в данных. Для поиска такой информации часто нужно использовать инструменты и проводить дополнительные этапы анализа, но уже на визуализациях.
Другие методы поиска данных, такие как деревья решений и ассоциативные правила, автоматически извлекают важные факты или правила из данных. Эти подходы используются параллельно с визуализацией для поиска взаимоотношений данных.
Предсказательная (предиктивная) модель
Предсказательная аналитика — это процесс в анализе данных, который нужен для создания или поиска подходящей статистической модели для предсказания вероятности результата.
После изучения данных у вас есть вся необходимая информация для развития математической модели, которая кодирует отношения между данными. Эти модели полезны для понимания изучаемой системы и используются в двух направлениях.
Первое — предсказания о значениях данных, которые создает система. В этом случае речь идет о регрессионных моделях.
Второе — классификация новых продуктов. Это уже модели классификации или модели кластерного анализа. На самом деле, можно разделить модели в соответствии с типом результатов, к которым те приводят:
- Модели классификации: если полученный результат — качественная переменная.
- Регрессионные модели: если полученный результат числовой.
- Кластерные модели: если полученный результат описательный.
Простые методы генерации этих моделей включают такие техники:
- линейная регрессия,
- логистическая регрессия,
- классификация,
- дерево решений,
- метод k-ближайших соседей.
Но таких методов много, и у каждого есть свои характеристики, которые делают их подходящими для определенных типов данных и анализа. Каждый из них приводит к появлению определенной модели, а их выбор соответствует природе модели продукта.
Некоторые из методов будут предоставлять значения, относящиеся к реальной системе и их структурам. Они смогут объяснить некоторые характеристики изучаемой системы простым способом. Другие будут делать хорошие предсказания, но их структура будет оставаться «черным ящиком» с ограниченной способностью объяснить характеристики системы.
Проверка модели
Проверка (валидация) модели, то есть фаза тестирования, — это важный этап. Он позволяет проверить модель, построенную на основе начальных данных. Он важен, потому что позволяет узнать достоверность данных, созданных моделью, сравнив их с реальной системой. Но в этот раз вы берете за основу начальные данные, которые использовались для анализа.
Как правило, при использовании данных для построения модели вы будете воспринимать их как тренировочный набор данных (датасет), а для проверки — как валидационный набор данных.
Таким образом сравнивая данные, созданные моделью и созданные системой, вы сможете оценивать ошибки. С помощью разных наборов данных оценивать пределы достоверности созданной модели. Правильно предсказанные значения могут быть достоверны только в определенном диапазоне или иметь разные уровни соответствия в зависимости от диапазона учитываемых значений.
Этот процесс позволяет не только в числовом виде оценивать эффективность модели, но также сравнивать ее с другими. Есть несколько подобных техник; самая известная — перекрестная проверка (кросс-валидация). Она основана на разделении учебного набора на разные части. Каждая из них, в свою очередь, будет использоваться в качестве валидационного набора. Все остальные — как тренировочного. Так вы получите модель, которая постепенно совершенствуется.
Развертывание (деплой)
Это финальный шаг процесса анализа, задача которого — предоставить результаты, то есть выводы анализа. В процессе развертывания бизнес-среды анализ является выгодой, которую получит клиент, заказавший анализ. В технической или научной средах результат выдает конструкционные решения или научные публикации.
Развертывание — это процесс использования на практике результатов анализа данных.
Есть несколько способов развертывания результатов анализа данных или майнинга данных. Обычно развертывание состоит из написания отчета для руководства или клиента. Этот документ концептуально описывает полученные результаты. Он должен быть направлен руководству, которое будет принимать решения. Затем оно использует выводы на практике.
В документации от аналитика должны быть подробно рассмотрены следующие темы:
- Результаты анализа;
- Развертывание решения;
- Анализ рисков;
- Измерения влияния на бизнес.
Когда результаты проекта включают генерацию предсказательных моделей, они могут быть использованы в качестве отдельных приложений или встроены в ПО.
]]>Данные можно поделить на две категории:
- Качественные (номинальные и порядковые);
- Количественные (дискретные и непрерывные);
Качественные данные — это значения наблюдений, которые можно разделить на группы или категории. Есть два типа качественных данных: номинальные и порядковые. Номинальная переменная не имеет внутреннего порядка, определенного в категории. Порядковая переменная наоборот имеет определенный порядок.
Количественные данные — значения наблюдений из измерений. Они могут быть дискретными и непрерывными. Дискретные значения можно посчитать, они отличны друг от друга. Непрерывные происходят от измерений или наблюдений, которые предполагают значения в заданном диапазоне.
]]>Еще один важный момент — сфера компетенции данных. Ее источник — биология, физика, финансы, испытания материалов, статистика населения и т. д. На самом деле, пусть у аналитиков есть подготовка в области статистики, они должны уметь задокументировать источник данных. Это помогает лучше понимать механизмы, которые их сгенерировали.
Данные — это не просто строки или цифры. Они являются выражениями или измерениями наблюдаемых параметров. Таким образом лучшее понимание источника данных может улучшить качество интерпретации. Но часто это дорого обходится, поэтому куда практичнее найти консультантов или ключевых фигур. Им можно задать правильные вопросы.
Понимание природы данных
Объект исследования анализа данных — это, собственно, данные. Они — ключевой игрок во всех процессах. Представляют собой сырой материал для обработки. Благодаря этому процессу и анализу появляется возможность извлекать разную информацию, чтобы увеличить уровень знаний изучаемой системы — той, которая является источником данных.
Когда данные становятся информацией
Данные — события, произошедшие в мире.
Все, что можно категоризировать и измерить, можно и конвертировать в данные.
После сбора их изучают и анализируют, чтобы понять природу событий и, в большинстве случаев, сделать прогнозы или хотя бы принять осмысленные решения.
Когда информация становится знанием
О знании можно говорить тогда, когда информация превращается в набор правил, которые помогают лучше понимать определенные механизмы и таким образом делать предсказания о развитии определенных событий.
]]>Анализ данных — дисциплина, которая подходит для изучения проблем, возникающих в самых разных сферах. Более того, она включает разные инструменты и методологии, требующие знания компьютерных технологий, математики и статистики.
Хороший специалист должен уметь ориентироваться в разных областях этой дисциплины.
Многие из них являются основой методов анализа данных, и их знание обязательно. С остальными стоит знакомиться в зависимости от сферы применения и изучения конкретного проекта в сфере анализа данных. В общем, достаточный опыт в этих областях позволит лучше понимать проблемы и тип необходимых данных.
Часто при работе с крупными проблемами в сфере анализа данных необходимо иметь нескольких специалистов, обладающих знаниями разных дисциплин. Таким образом они смогут внести свой вклад в соответствующие составляющие проекта.
В более мелких проектах хороший аналитик должен уметь распознавать возникающие проблемы, определять навыки, требуемые для их решения, осваивать их и, возможно, даже советоваться с другими специалистами. Хороший аналитик должен знать не только как искать данные, но и как с ними обращаться.
Компьютерные науки
Знание компьютерных наук — базовое требование к любому специалисту в области анализа данных. Только с ними можно эффективно управлять необходимыми инструментами. Каждый шаг в процессе анализа данных задействует программное обеспечение для расчетов (IDL, MATLAB и другие), а также языки программирования (C++, Java и Python).
Большое количество доступных сегодня благодаря информационным технологиям данных требуют особых навыков для управления ими максимально эффективно. Исследование данных и их извлечение требуют знаний разных форматов. Данные структурированы и хранятся в файлах, а также таблицах баз данных таких форматов, как XML, JSON, XLS или CSV.
Многие приложения позволяют читать такие файлы и управлять информацией в них. Когда дело касается извлечения данных из базы данных, необходимо знание языка запросов SQL или специальных программных инструментов.
Для определенных видов исследованиях данных, такие форматы не используются. Вместо них информация хранится в текстовых файлах (документах или логах) или веб-страницах, а демонстрируется с помощью графиков, измерений, количества посетителей или таблиц HTML. Для парсинга таких данных нужны определенные технические знания (такая техника называется веб-скрапинг или парсинг).
Знание информационных технологий необходимо для понимания того, как использовать различные инструменты: приложения и языки программирования. Они в свою очередь используются для анализа данных и их визуализации.
Цель этого и последующих материалов — предоставить необходимые знания касательно разработки и методологий анализа данных.
Язык программирования Python и различные специализированные библиотеки используются, потому что они вносят решающий вклад в процесс анализа данных: от исследований до публикации результатов предсказательной модели.
Математика и статистика
Анализ данных также требует сложной математики для работы с информацией. В ней необходимо разбираться, как минимум понимая, что вы делаете. Знакомство с основными методами статистики также необходимы, потому что все применяемые методы основаны на них. Как компьютер предлагает инструменты для анализа данных, так и статистика — концепции, которые составляют основу дисциплины.
Она предлагает множество инструментов для специалиста. Знание того, как их использовать наилучшим образом, требует многих лет опыта. К числу самых популярных статистических методов в анализе данных относятся:
- Байесовский вывод;
- Регрессионный анализ;
- Кластерный анализ;
Познакомившись с этими примерами, вы лучше поймете, как сильно связаны математика и статистика. Благодаря отдельным библиотекам Python сможете ими управлять.
Машинное обучение и искусственный интеллект
Один из самых продвинутых инструментов анализа данных — машинное обучение. Даже при использовании визуализации данных и таких методов, как кластерный или регрессионный анализ, во время исследования часто есть смысл использовать специализированные средства для поиска моделей (паттернов) в определенном наборе данных.
Машинное обучение — это область, использующая набор приемов и алгоритмов для анализа данных с целью выявить модели, кластеры или тенденции, а затем извлечь нужную информацию автоматически.
Она становится все более фундаментальным инструментом анализа данных. Ее знание, по крайней мере в общих чертах, играет важную роль для специалиста.
]]>В мире, который столь сильно сосредоточен на информационных технологиях, огромные объемы информации и данных производятся и сохраняются каждый день.
Часто их источником являются системы автоматического обнаружения, сенсоры и инструменты ученых. Как вариант — вы создаете их самостоятельно, даже не осознавая: снимаете деньги с банковского счета, осуществляете покупку, делаете запись в блоге или социальной сети.
Но что такое данные?
Данные — это не информация, по крайне мере, по меркам их формы. В бесформенном потоке байтов на первый взгляд сложно понять их суть вне чисел, слов или времени, которое они представляют.
Информация — это результат обработки с учетом определенного набора данных.
Она предлагает определенные выводы, которые затем разными способами могут быть использованы. Этот процесс извлечения информации из сырых данных и называется анализом данных.
Цель анализа данных — извлекать информацию, которую не просто истолковать, но которая, если ее понять, поможет проводить исследования. Такие исследования в свою очередь дадут возможность понять системы, ответственные за создание данных и в будущем делать прогнозы относительно работы систем и их развития.
Будучи изначально простым методичным подходом к защите данных, анализ данных превратился в полноценную дисциплину, которая привела к появлению сложных методологий и полноценных моделей.
фотоМодели
Модель — это перевод изучаемой системы в математическую форму.
Когда есть математическая или логическая форма, которая может описывать реакции системы на разные уровни давления, появляется возможность делать предсказания о ее развитии или ответах на определенные вводные данные. Поэтому цель анализа данных — это не модель, а качество силы предсказания.
Сила предсказания модели зависит не только от качества техник создания моделей, но и от возможности выбрать хороший набор данных, на основе которого и будет построен процесс анализа.
Так, поиск данных, их извлечение и последующая обработка, которые являются подготовительными этапами анализа, также относятся к дисциплине. Причина тому — влияние результатов этих процессов на конечный результат.
Визуализация данных
Пока что речь шла только о данных, работе с ними и обработке с помощью математических операций. Параллельно этим этапам анализа данных развивались различные способы визуализации данных.
Чтобы понять данные — конкретно и то, какую роль они играют в общей картине — нет лучшего способа, чем разработка графического представления.
Такая репрезентация способна превращать информацию, иногда неявно скрытую, в схемы, которые помогают проще ее понять. В течение лет было разработано множество моделей отображения. Они получили название графиков.
Проверка модели
В конце процесса анализа данных у вас есть модель и набор графиков. На их основе можно делать прогнозы изучаемой системы, а после этого переходить к тестовой фазе. Модель будет проверена с помощью другого набора данных, для которого есть правильные ответы.
Эти данные не будут использованы для предсказательной модели. В зависимости от возможности модели повторять реальные ответы, у вас будут расчеты ошибок. Также знание о действительности модели и ее рабочих пределах.
Эти результаты можно сравнить с любыми другими моделями, чтобы понять, являются ли новые более эффективными.
Внедрение результатов анализа
После оценки нужно переходить к последней фазе анализа данных — развертыванию. Этот этап включает внедрение результатов анализа — фактически использованию решений, принятых на основе предсказаний модели и связанных рисков.
Анализ данных отлично вписывается в разные виды профессиональной деятельности. Поэтому знание этой дисциплины и умение использовать ее на практике является очень полезным. Она позволяет проверять гипотезы и лучше понимать анализируемые системы.
]]>Это небольшая аналитика, чтобы получить некоторое представление о хаосе, вызванном коронавирусом. Немного графики и статистики для общего представления.
Данные — Novel Corona Virus 2019 Dataset
Импортируем необходимые библиотеки.
import numpy as np # линейная алгебра
import pandas as pd # обработка данных, CSV afqk I/O (например pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context('paper')
import random
def random_colours(number_of_colors):
'''
Простая функция для генерации случайных цветов.
Входные данные:
number_of_colors - целочисленное значение, указывающее
количество цветов, которые будут сгенерированы.
Выход:
Цвет в следующем формате: ['#E86DA4'].
'''
colors = []
for i in range(number_of_colors):
colors.append("#"+''.join([random.choice('0123456789ABCDEF') for j in range(6)]))
return colors
Статистический анализ
data = pd.read_csv('/novel-corona-virus-2019-dataset/2019_nCoV_data.csv')
data.head()
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | Anhui | China | 1/22/2020 12:00 | 1.0 | 0.0 | 0.0 |
| 1 | 2 | Beijing | China | 1/22/2020 12:00 | 14.0 | 0.0 | 0.0 |
| 2 | 3 | Chongqing | China | 1/22/2020 12:00 | 6.0 | 0.0 | 0.0 |
| 3 | 4 | Fujian | China | 1/22/2020 12:00 | 1.0 | 0.0 | 0.0 |
| 4 | 5 | Gansu | China | 1/22/2020 12:00 | 0.0 | 0.0 | 0.0 |
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 497 entries, 0 to 496
Data columns (total 7 columns):
Sno 497 non-null int64
Province/State 393 non-null object
Country 497 non-null object
Last Update 497 non-null object
Confirmed 497 non-null float64
Deaths 497 non-null float64
Recovered 497 non-null float64
dtypes: float64(3), int64(1), object(3)
memory usage: 27.3+ KB
Растет метрик по числовым колонкам.
data.describe()
| Sno | Confirmed | Deaths | Recovered | |
|---|---|---|---|---|
| count | 434.000000 | 434.000000 | 434.000000 | 434.000000 |
| mean | 217.500000 | 80.762673 | 1.847926 | 1.525346 |
| std | 125.429263 | 424.706068 | 15.302792 | 9.038054 |
| min | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 109.250000 | 2.000000 | 0.000000 | 0.000000 |
| 50% | 217.500000 | 7.000000 | 0.000000 | 0.000000 |
| 75% | 325.750000 | 36.000000 | 0.000000 | 0.000000 |
| max | 434.000000 | 5806.000000 | 204.000000 | 116.000000 |
Растет метрик по не числовым колонкам.
data.describe(include="O")
| Province/State | Country | Last Update | |
|---|---|---|---|
| count | 393 | 497 | 497 |
| unique | 45 | 31 | 13 |
| top | Ningxia | Mainland China | 1/31/2020 19:00 |
| freq | 10 | 274 | 63 |
Преобразуем данные Last Update в datetime
data['Last Update'] = pd.to_datetime(data['Last Update'])
Добавляем колонки Day и Hour
data['Day'] = data['Last Update'].apply(lambda x:x.day)
data['Hour'] = data['Last Update'].apply(lambda x:x.hour)
Данные только за 30 день января.
data[data['Day'] == 30]
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 375 | 376 | Hubei | Mainland China | 2020-01-30 21:30:00 | 5806.0 | 204.0 | 116.0 | 30 | 21 |
| 376 | 377 | Zhejiang | Mainland China | 2020-01-30 21:30:00 | 537.0 | 0.0 | 9.0 | 30 | 21 |
| 377 | 378 | Guangdong | Mainland China | 2020-01-30 21:30:00 | 393.0 | 0.0 | 11.0 | 30 | 21 |
| 378 | 379 | Henan | Mainland China | 2020-01-30 21:30:00 | 352.0 | 2.0 | 3.0 | 30 | 21 |
| 379 | 380 | Hunan | Mainland China | 2020-01-30 21:30:00 | 332.0 | 0.0 | 2.0 | 30 | 21 |
| 380 | 381 | Jiangxi | Mainland China | 2020-01-30 21:30:00 | 240.0 | 0.0 | 7.0 | 30 | 21 |
| 381 | 382 | Anhui | Mainland China | 2020-01-30 21:30:00 | 237.0 | 0.0 | 3.0 | 30 | 21 |
| 382 | 383 | Chongqing | Mainland China | 2020-01-30 21:30:00 | 206.0 | 0.0 | 1.0 | 30 | 21 |
| 383 | 384 | Shandong | Mainland China | 2020-01-30 21:30:00 | 178.0 | 0.0 | 2.0 | 30 | 21 |
| 384 | 385 | Sichuan | Mainland China | 2020-01-30 21:30:00 | 177.0 | 1.0 | 1.0 | 30 | 21 |
| 385 | 386 | Jiangsu | Mainland China | 2020-01-30 21:30:00 | 168.0 | 0.0 | 2.0 | 30 | 21 |
| 386 | 387 | Shanghai | Mainland China | 2020-01-30 21:30:00 | 128.0 | 1.0 | 9.0 | 30 | 21 |
| 387 | 388 | Beijing | Mainland China | 2020-01-30 21:30:00 | 121.0 | 1.0 | 5.0 | 30 | 21 |
| 388 | 389 | Fujian | Mainland China | 2020-01-30 21:30:00 | 101.0 | 0.0 | 0.0 | 30 | 21 |
| 389 | 390 | Guangxi | Mainland China | 2020-01-30 21:30:00 | 87.0 | 0.0 | 2.0 | 30 | 21 |
| 390 | 391 | Hebei | Mainland China | 2020-01-30 21:30:00 | 82.0 | 1.0 | 0.0 | 30 | 21 |
| 391 | 392 | Yunnan | Mainland China | 2020-01-30 21:30:00 | 76.0 | 0.0 | 0.0 | 30 | 21 |
| 392 | 393 | Shaanxi | Mainland China | 2020-01-30 21:30:00 | 87.0 | 0.0 | 0.0 | 30 | 21 |
| 393 | 394 | Heilongjiang | Mainland China | 2020-01-30 21:30:00 | 59.0 | 2.0 | 0.0 | 30 | 21 |
| 394 | 395 | Hainan | Mainland China | 2020-01-30 21:30:00 | 50.0 | 1.0 | 1.0 | 30 | 21 |
| 395 | 396 | Liaoning | Mainland China | 2020-01-30 21:30:00 | 45.0 | 0.0 | 1.0 | 30 | 21 |
| 396 | 397 | Shanxi | Mainland China | 2020-01-30 21:30:00 | 39.0 | 0.0 | 1.0 | 30 | 21 |
| 397 | 398 | Tianjin | Mainland China | 2020-01-30 21:30:00 | 32.0 | 0.0 | 0.0 | 30 | 21 |
| 398 | 399 | Gansu | Mainland China | 2020-01-30 21:30:00 | 29.0 | 0.0 | 0.0 | 30 | 21 |
| 399 | 400 | Ningxia | Mainland China | 2020-01-30 21:30:00 | 21.0 | 0.0 | 1.0 | 30 | 21 |
| 400 | 401 | Inner Mongolia | Mainland China | 2020-01-30 21:30:00 | 20.0 | 0.0 | 0.0 | 30 | 21 |
| 401 | 402 | Xinjiang | Mainland China | 2020-01-30 21:30:00 | 17.0 | 0.0 | 0.0 | 30 | 21 |
| 402 | 403 | Guizhou | Mainland China | 2020-01-30 21:30:00 | 15.0 | 0.0 | 1.0 | 30 | 21 |
| 403 | 404 | Jilin | Mainland China | 2020-01-30 21:30:00 | 14.0 | 0.0 | 1.0 | 30 | 21 |
| 404 | 405 | Hong Kong | Hong Kong | 2020-01-30 21:30:00 | 12.0 | 0.0 | 0.0 | 30 | 21 |
| 405 | 406 | Taiwan | Taiwan | 2020-01-30 21:30:00 | 9.0 | 0.0 | 0.0 | 30 | 21 |
| 406 | 407 | Qinghai | Mainland China | 2020-01-30 21:30:00 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| 407 | 408 | Macau | Macau | 2020-01-30 21:30:00 | 7.0 | 0.0 | 0.0 | 30 | 21 |
| 408 | 409 | Tibet | Mainland China | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 409 | 410 | Washington | US | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 410 | 411 | Illinois | US | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 411 | 412 | California | US | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 412 | 413 | Arizona | US | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 413 | 414 | NaN | Japan | 2020-01-30 21:30:00 | 11.0 | 0.0 | 1.0 | 30 | 21 |
| 414 | 415 | NaN | Thailand | 2020-01-30 21:30:00 | 14.0 | 0.0 | 5.0 | 30 | 21 |
| 415 | 416 | NaN | South Korea | 2020-01-30 21:30:00 | 6.0 | 0.0 | 0.0 | 30 | 21 |
| 416 | 417 | NaN | Singapore | 2020-01-30 21:30:00 | 10.0 | 0.0 | 0.0 | 30 | 21 |
| 417 | 418 | NaN | Vietnam | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 418 | 419 | NaN | France | 2020-01-30 21:30:00 | 5.0 | 0.0 | 0.0 | 30 | 21 |
| 419 | 420 | NaN | Nepal | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 420 | 421 | NaN | Malaysia | 2020-01-30 21:30:00 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| 421 | 422 | Ontario | Canada | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 422 | 423 | British Columbia | Canada | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 423 | 424 | NaN | Cambodia | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 424 | 425 | NaN | Sri Lanka | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 425 | 426 | New South Wales | Australia | 2020-01-30 21:30:00 | 4.0 | 0.0 | 2.0 | 30 | 21 |
| 426 | 427 | Victoria | Australia | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 427 | 428 | Queensland | Australia | 2020-01-30 21:30:00 | 3.0 | 0.0 | 0.0 | 30 | 21 |
| 428 | 429 | Bavaria | Germany | 2020-01-30 21:30:00 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| 429 | 430 | NaN | Finland | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 430 | 431 | NaN | United Arab Emirates | 2020-01-30 21:30:00 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| 431 | 432 | NaN | Philippines | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 432 | 433 | NaN | India | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 433 | 434 | NaN | Italy | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
data[data['Day'] == 30].sum()
Sno 23895
Country Mainland ChinaMainland ChinaMainland ChinaMain...
Confirmed 9776
Deaths 213
Recovered 187
Day 1770
Hour 1239
dtype: object
Мы можем видеть, что число подтвержденных случаев для провинции Хубэй в Китае — 5806 на 30-е число. Количества смертей, выздоровевших и пострадавших, соответствует официальным на 30 января. Это означает, что в Confirmed уже включены люди, затронуте в предыдущие даты.
Создаем датасета с данными только за 30 января.
latest_data = data[data['Day'] == 30]
latest_data.head()
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 375 | 376 | Hubei | Mainland China | 2020-01-30 21:30:00 | 5806.0 | 204.0 | 116.0 | 30 | 21 |
| 376 | 377 | Zhejiang | Mainland China | 2020-01-30 21:30:00 | 537.0 | 0.0 | 9.0 | 30 | 21 |
| 377 | 378 | Guangdong | Mainland China | 2020-01-30 21:30:00 | 393.0 | 0.0 | 11.0 | 30 | 21 |
| 378 | 379 | Henan | Mainland China | 2020-01-30 21:30:00 | 352.0 | 2.0 | 3.0 | 30 | 21 |
| 379 | 380 | Hunan | Mainland China | 2020-01-30 21:30:00 | 332.0 | 0.0 | 2.0 | 30 | 21 |
print('Подтвержденные случаи (весь мир): ', latest_data['Confirmed'].sum())
print('Смерти (весь мир): ', latest_data['Deaths'].sum())
print('Выздоровления (весь мир): ', latest_data['Recovered'].sum())
Подтвержденные случаи (весь мир): 9776.0
Смерти (весь мир): 213.0
Выздоровления (весь мир): 187.0
Данные датасета соответствуют официальным данным.
Посмотрим как коронавирус распространялся с течением времени.
plt.figure(figsize=(16,6))
data.groupby('Day').sum()['Confirmed'].plot();

Со временем наблюдается экспоненциальный рост числа жертв короновируса.
plt.figure(figsize=(16,6))
sns.barplot(x='Day',y='Confirmed',data=data);

Глубокий разведочный анализ данных (EDA)
latest_data.groupby('Country').sum()
| Sno | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|
| Country | ||||||
| Australia | 1281 | 9.0 | 0.0 | 2.0 | 90 | 63 |
| Cambodia | 424 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Canada | 845 | 3.0 | 0.0 | 0.0 | 60 | 42 |
| Finland | 430 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| France | 419 | 5.0 | 0.0 | 0.0 | 30 | 21 |
| Germany | 429 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| Hong Kong | 405 | 12.0 | 0.0 | 0.0 | 30 | 21 |
| India | 433 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Italy | 434 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| Japan | 414 | 11.0 | 0.0 | 1.0 | 30 | 21 |
| Macau | 408 | 7.0 | 0.0 | 0.0 | 30 | 21 |
| Mainland China | 12126 | 9658.0 | 213.0 | 179.0 | 930 | 651 |
| Malaysia | 421 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| Nepal | 420 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Philippines | 432 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Singapore | 417 | 10.0 | 0.0 | 0.0 | 30 | 21 |
| South Korea | 416 | 6.0 | 0.0 | 0.0 | 30 | 21 |
| Sri Lanka | 425 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Taiwan | 406 | 9.0 | 0.0 | 0.0 | 30 | 21 |
| Thailand | 415 | 14.0 | 0.0 | 5.0 | 30 | 21 |
| US | 1646 | 6.0 | 0.0 | 0.0 | 120 | 84 |
| United Arab Emirates | 431 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| Vietnam | 418 | 2.0 | 0.0 | 0.0 | 30 | 21 |
- Материковый Китай имеет ненулевые значения выздоровлений и смертей, которые можно изучить позже, создав отдельный набор данных
Провинции и регионы в которых нет зарегистрированных случаев заболевания.
data[data['Confirmed']==0]
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 5 | Gansu | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 10 | 11 | Heilongjiang | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 12 | 13 | Hong Kong | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 15 | 16 | Inner Mongolia | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 18 | 19 | Jilin | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 22 | 23 | Qinghai | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 23 | 24 | Shaanxi | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 30 | 31 | Tibet | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 32 | 33 | Xinjiang | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 53 | 54 | Inner Mongolia | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 60 | 61 | Qinghai | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 68 | 69 | Tibet | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 77 | 78 | NaN | Philippines | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 78 | 79 | NaN | Malaysia | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 80 | 81 | NaN | Australia | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 81 | 82 | NaN | Mexico | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 82 | 83 | NaN | Brazil | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 115 | 116 | Qinghai | Mainland China | 2020-01-24 12:00:00 | 0.0 | 0.0 | 0.0 | 24 | 12 |
| 263 | 264 | NaN | Ivory Coast | 2020-01-27 20:30:00 | 0.0 | 0.0 | 0.0 | 27 | 20 |
- Интересно, что есть части материкового Китая, которые еще не были затронуты вирусом.
- Есть страны без подтвержденных случаев заражения, и мы отбросим их.
Провинции и регионы в которых есть минимум 1 зарегистрированный случай заболевания.
data = data[data['Confirmed'] != 0]
Количество зараженных в разных странах.
plt.figure(figsize=(18,8))
sns.barplot(x='Country',y='Confirmed',data=data)
plt.tight_layout()

- На графике показано то, что мы все знаем. Вирус больше всего затронул материковый Китай, однако есть сообщения о жертвах в соседних странах, что говорит о распространении вируса.
- Есть также случаи, подтвержденные в странах, которые далеко, таких как США, Таиланд, Япония и т. Д. Интересно, как вирус попал туда. Я предполагаю, что кто-то был в Ухане или близлежащем районе во время распространения вируса и увез его с собой домой, эта вспышка действительно опасна.
Количество зараженных в разных регионах.
import plotly.express as px
fig = px.bar(data, x='Province/State', y='Confirmed')
fig.show()

Анализ роста коронавируса в каждой стране
pivoted = pd.pivot_table(data, values='Confirmed', columns='Country', index='Day')
pivoted.plot(figsize=(16,10));

Визуализация вспышки в провинциях/регионах
pivoted = pd.pivot_table(data, values='Confirmed', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15));

- Hubei, наиболее пострадавшая провинция.
- Также в подтвержденных случаях наблюдается тенденция к росту, и кажется, что состояние ухудшается.
Теперь давайте посмотрим на страны, которые были затронуты изначально, и страны, в которые сейчас проник коронный вирус.
data[data['Day'] == 22]['Country'].unique()
array(['China', 'US', 'Japan', 'Thailand', 'South Korea'], dtype=object)
Итак, в первый день, 22 января заражения были обнаружены в Китае, США, Японии, Таиланде
temp = data[data['Day'] == 22]
temp.groupby('Country').sum()['Confirmed'].plot.bar()

Посмотрим на последние данные.
data[data['Day'] == 30]['Country'].unique()
array(['Mainland China', 'Hong Kong', 'Taiwan', 'Macau', 'US', 'Japan',
'Thailand', 'South Korea', 'Singapore', 'Vietnam', 'France',
'Nepal', 'Malaysia', 'Canada', 'Cambodia', 'Sri Lanka',
'Australia', 'Germany', 'Finland', 'United Arab Emirates',
'Philippines', 'India', 'Italy'], dtype=object)
Здесь мы видим, что вспышка распространилась в 23 странах к 30 января.
Рассмотрим только материковый Китай
data_main_china = latest_data[latest_data['Country']=='Mainland China']
Рассчитаем процент смертей.
(data_main_china['Deaths'].sum() / data_main_china['Confirmed'].sum())*100
2.205425553944916
Теперь процент выздоровлений.
(data_main_china['Recovered'].sum() / data_main_china['Confirmed'].sum())*100
1.8533857941602818
- Мы можем видеть, что процент смертности от коронавируса — 2%, поэтому он не такой смертоносный, как другие вирусные вспышки.
- Поскольку зарегистрировано мало случаев излечения, процент выздоровления составляет 1,87, это страшно. Хотя цифра может сильно вырасти, ведь 96% сейчас не попадают ни в одну из групп.

Где произошло большинство смертей
data_main_china.groupby('Province/State')['Deaths'].sum().reset_index(
).sort_values(by=['Deaths'],ascending=False).head()
| Province/State | Deaths | |
|---|---|---|
| 12 | Hubei | 204.0 |
| 10 | Heilongjiang | 2.0 |
| 11 | Henan | 2.0 |
| 9 | Hebei | 1.0 |
| 1 | Beijing | 1.0 |
Количество смертей по дням.
plt.figure(figsize=(16,6))
data.groupby('Day').sum()['Deaths'].plot();

График заболеваний в материковом Китае.
pivoted = pd.pivot_table(data[data['Country']=='Mainland China'] , values='Confirmed', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15))

pivoted = pd.pivot_table(data, values='Deaths', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15));

Что дальше
Скачайте coronavirus.ipynb и данные по ссылке в начале статьи. Попробуйте построить свои графики и таблицы.
]]>Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации.
Такой пошаговый подход обеспечивает быстрый, последовательный процесс разработки, поскольку вывод для каждого блока показывается сразу же. Именно поэтому инструмент стал настолько популярным в среде Data Science за последнее время. Большая часть Kaggle Kernels (работы участников конкурсов на платформе Kaggle) сегодня созданы с помощью Jupyter Notebook.

Этот материал предназначен для новичков, которые только знакомятся с Jupyter Notebook, и охватывает все этапы работы с ним: установку, азы использования и процесс создания интерактивного проекта Data Science.
Настройка Jupyter Notebook
Чтобы начать работать с Jupyter Notebook, библиотеку Jupyter необходимо установить для Python. Проще всего это сделать с помощью pip:
pip3 install jupyter
Лучше использовать pip3, потому что pip2 работает с Python 2, поддержка которого прекратится уже 1 января 2020 года.
Теперь нужно разобраться с тем, как пользоваться библиотекой. С помощью команды cd в командной строке (в Linux и Mac) в первую очередь нужно переместиться в папку, в которой вы планируете работать. Затем запустите Jupyter с помощью следующей команды:
jupyter notebook
Это запустит сервер Jupyter, а браузер откроет новую вкладку со следующим URL: https://localhost:8888/tree. Она будет выглядеть приблизительно вот так:

Отлично. Сервер Jupyter работает. Теперь пришло время создать первый notebook и заполнять его кодом.
Основы Jupyter Notebook
Для создания notebook выберите «New» в верхнем меню, а потом «Python 3». Теперь страница в браузере будет выглядеть вот так:

Обратите внимание на то, что в верхней части страницы, рядом с логотипом Jupyter, есть надпись Untitled — это название notebook. Его лучше поменять на что-то более понятное. Просто наведите мышью и кликните по тексту. Теперь можно выбрать новое название. Например, George's Notebook.
Теперь напишем какой-нибудь код!
Перед первой строкой написано In []. Это ключевое слово значит, что дальше будет ввод. Попробуйте написать простое выражение вывода. Не забывайте, что нужно пользоваться синтаксисом Python 3. После этого нажмите «Run».

Вывод должен отобразиться прямо в notebook. Это и позволяет заниматься программированием в интерактивном формате, имея возможность отслеживать вывод каждого шага.
Также обратите внимание на то, что In [] изменилась и вместе нее теперь In [1]. Число в скобках означает порядок, в котором эта ячейка будет запущена. В первой цифра 1, потому что она была первой запущенной ячейкой. Каждую ячейку можно запускать индивидуально и цифры в скобках будут менять соответственно.
Рассмотрим пример. Настроим 2 ячейки, в каждой из которых будет разное выражение print. Сперва запустим вторую, а потом первую. Можно увидеть, как в результате цифры в скобках меняются.

Если есть несколько ячеек, то между ними можно делиться переменными и импортами. Это позволяет проще разбивать весь код на связанные блоки, не создавая переменную каждый раз. Главное убедиться в запуске ячеек в правильном порядке, чтобы переменные не использовались до того, как были созданы.
Добавление описания к notebook
В Jupyter Notebook есть несколько инструментов, используемых для добавления описания. С их помощью можно не только оставлять комментарии, но также добавлять заголовки, списки и форматировать текст. Это делается с помощью Markdown.
Первым делом нужно поменять тип ячейки. Нажмите на выпадающее меню с текстом «Code» и выберите «Markdown». Это поменяет тип ячейки.
Попробуем несколько вариантов. Заголовки можно создавать с помощью символа #. Один такой символ создаст самый крупный заголовок верхнего уровня. Чем больше #, тем меньше будет текст.
Сделать текст курсивным можно с помощью символов * с двух сторон текста. Если с каждой стороны добавить по два *, то текст станет полужирным. Список создается с помощью тире и пробела для каждого пункта.

Интерактивная наука о данных
Соорудим простой пример проекта Data Science. Этот notebook и код взяты из реального проекта.
Начнем с ячейки Markdown с самым крупным текстом, который делается с помощью одного #. Затем список и описание всех библиотек, которые необходимо импортировать.
Следом идет первая ячейка, в которой происходит импорт библиотек. Это стандартный код для Python Data Science с одним исключение: чтобы прямо видеть визуализации Matplotlib в notebook, нужна следующая строчка: %matplotlib inline.

Следом нужно импортировать набор данных из файла CSV и вывести первые 10 пунктов. Обратите внимание, как Jupyter автоматически показывает вывод функции .head() в виде таблицы. Jupyter отлично работает с библиотекой Pandas!

Теперь нарисуем диаграмму прямо в notebook. Поскольку наверху есть строка %matplotlib inline, при написании plt.show() диаграмма будет выводиться в notebook!
Также обратите внимание на то, как переменные из предыдущих ячеек, содержащие данные из CSV-файла, используются в последующих ячейках в том случае, если по отношению к первым была нажата кнопка «Run».

Это простейший способ создания интерактивного проекта Data Science!
Меню
На сервере Jupyter есть несколько меню, с помощью которых от проекта можно получить максимум. С их помощью можно взаимодействовать с notebook, читать документацию популярных библиотек Python и экспортировать проект для последующей демонстрации.
Файл (File): отвечает за создание, копирование, переименование и сохранение notebook в файл. Самый важный пункт в этом разделе — выпадающее меню Download, с помощью которого можно скачать notebook в разных форматах, включая pdf, html и slides для презентаций.
Редактировать (Edit): используется, чтобы вырезать, копировать и вставлять код. Здесь же можно поменять порядок ячеек, что понадобится для демонстрации проекта.
Вид (View): здесь можно настроить способ отображения номеров строк и панель инструментов. Самый примечательный пункт — Cell Toolbar, к каждой ячейке можно добавлять теги, заметки и другие приложения. Можно даже выбрать способ форматирования для ячейки, что потребуется для использования notebook в презентации.
Вставить (Insert): для добавления ячеек перед или после выбранной.
Ячейка (Cell): отсюда можно запускать ячейки в определенном порядке или менять их тип.
Помощь (Help): в этом разделе можно получить доступ к важной документации. Здесь же упоминаются горячие клавиши для ускорения процесса работы. Наконец, тут можно найти ссылки на документацию для самых важных библиотек Python: Numpy, Scipy, Matplotlib и Pandas.
]]>Предок NumPy, Numeric, был разработан Джимом Хугунином. Также был создан пакет Numarray с дополнительной функциональностью. В 2005 году Трэвис Олифант выпустил пакет NumPy, добавив особенности Numarray в Numeric. Это проект с исходным кодом, и в его развитии поучаствовало уже много человек.
NumPy или Numerical Python — это библиотека Python, которая предлагает следующее:
- Мощный N-мерный массив
- Высокоуровневые функции
- Инструменты для интеграции кода C/C++ и Fortran
- Использование линейной алгебры, Преобразований Фурье и возможностей случайных чисел
Она также предлагает эффективный многомерный контейнер общих данных. С ее помощью можно определять произвольные типы данных. Официальный сайт библиотеки — www.numpy.org
Установка NumPy в Python
-
Ubuntu Linux
sudo apt update -y sudo apt upgrade -y sudo apt install python3-tk python3-pip -y sudo pip install numpy -y -
Anaconda
conda install -c anaconda numpy
Массив NumPy
Это мощный многомерный массив в форме строк и колонок. С помощью библиотеки можно создавать массивы NumPy из вложенного списка Python и получать доступ к его элементам.
Массив NumPy — это не то же самое, что и класс array.array из Стандартной библиотеки Python, который работает только с одномерными массивами.
-
Одномерный массив NumPy.
import numpy as np a = np.array([1,2,3]) print(a)Результатом кода выше будет
[1 2 3]. -
Многомерные массивы.
import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a)Результат —
[[1 2 3] [4 5 6]].
Атрибуты массива NumPy
-
ndarray.ndim
Возвращает количество измерений массива.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.ndim)Вывод кода сверху будет 2, поскольку «a» — это 2-мерный массив.
-
ndarray.shape
Возвращает кортеж размера массива, то есть (n,m), где n — это количество строк, а m — количество колонок.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.shape)Вывод кода — (2,3), то есть 2 строки и 3 колонки.
-
ndarray.size
Возвращает общее количество элементов в массиве.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.size)Вывод — 6, потому что 2 х 3.
-
ndarray.dtype
Возвращает объект, описывающий тип элементов в массиве.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.dtype)Вывод — «int32», поскольку это 32-битное целое число.
Можно явно определить тип данных массива NumPy.import numpy as np a = np.array([[1,2,3],[4,5,6]], dtype = float) print(a.dtype)Этот код вернет
float64, потому что это 64-битное число с плавающей точкой. -
ndarray.itemsize
Возвращает размер каждого элемента в массиве в байтах.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.itemsize)Вывод — 4, потому что 32/8.
-
ndarray.data
Возвращает буфер с актуальными элементами массива. Это альтернативный способ получения доступа к элементам через их индексы.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a.data)Этот код вернет список элементов.
-
ndarray.sum()
Функция вернет сумму все элементов ndarray.import numpy as np a = np.random.random((2,3)) print(a) print(a.sum())Сгенерированная в этом примере матрица —
[[0.46541517 0.66668157 0.36277909] [0.7115755 0.57306008 0.64267163]], следовательно код вернет3.422183052180838. Поскольку используется генератор случайных чисел, ваш результат будет отличаться. -
ndarray.min()
Функция вернет элемент с минимальным значением из ndarray.import numpy as np a = np.random.random((2,3)) print(a.min())Сгенерированная в этом примере матрица —
[[0.46541517 0.66668157 0.36277909] [0.7115755 0.57306008 0.64267163]], следовательно код вернет0.36277909. Поскольку используется генератор случайных чисел, ваш результат будет отличаться. -
ndarray.max()
Функция вернет элемент с максимальным значением из ndarray.import numpy as np a = np.random.random((2,3)) print(a.min())Сгенерированная в этом примере матрица —
[[0.46541517 0.66668157 0.36277909] [0.7115755 0.57306008 0.64267163]], следовательно код вернет0.7115755. Поскольку используется генератор случайных чисел, ваш результат будет отличаться
Функции NumPy
-
type(numpy.ndarray)
Это функция Python, используемая, чтобы вернуть тип переданного параметра. В случае с массивом numpy, она вернетnumpy.ndarray.import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(type(a))Код выше вернет
numpy.ndarray. -
numpy.zeroes()numpy.zeros((rows, columns), dtype)
Эта функция создаст массив numpy с заданным количеством измерений, где каждый элемент будет равняться 0. Если dtype не указан, по умолчанию будет использоваться dtype.import numpy as np np.zeros((3,3)) print(a)Код вернет массив numpy 3×3, где каждый элемент равен 0.
-
numpy.ones()numpy.ones((rows,columns), dtype)
Эта функция создаст массив numpy с заданным количеством измерений, где каждый элемент будет равняться 1. Если dtype не указан, по умолчанию будет использоваться dtype.import numpy as np np.ones((3,3)) print(a)Код вернет массив numpy 3 x 3, где каждый элемент равен 1.
-
numpy.empty()numpy.empty((rows,columns))
Эта функция создаст массив, содержимое которого будет случайным — оно зависит от состояния памяти.import numpy as np np.empty((3,3)) print(a)Код вернет массив numpy 3×3, где каждый элемент будет случайным.
-
numpy.arrange()numpy.arrange(start, stop, step)
Эта функция используется для создания массива numpy, элементы которого лежат в диапазоне значений отstartдоstopс разницей равнойstep.import numpy as np a=np.arange(5,25,4) print(a)Вывод этого кода —
[5 9 13 17 21] -
numpy.linspace()numpy.linspace(start, stop, num_of_elements)
Эта функция создаст массив numpy, элементы которого лежат в диапазоне значений междуstartдоstop, аnum_of_elements— это размер массива. Тип по умолчанию —float64.import numpy as np a=np.linspace(5,25,5) print(a)Вывод —
[5 10 15 20 25]. -
numpy.logspace()numpy.logspace(start, stop, num_of_elements)
Эта функция используется для создания массива numpy, элементы которого лежат в диапазоне значений отstartдоstop, аnum_of_elements— это размер массива. Тип по умолчанию — float64. Все элементы находятся в пределах логарифмической шкалы, то есть представляют собой логарифмы соответствующих элементов.import numpy as np a = np.logspace(5,25,5) print(a)Вывод —
[1.e+05 1.e+10 1.e+15 1.e+20 1.e+25]. -
numpy.sin()numpy.sin(numpy.ndarray)
Этот код вернет синус параметра.import numpy as np a = np.logspace(5,25,2) print(np.sin(a))Вывод кода сверху равен
[0.0357488 -0.3052578]. Также естьcos(),tan()и так далее. -
numpy.reshape()numpy.reshape(dimensions)
Эта функция используется для изменения количества измерений массива numpy. От количества аргументов вreshapeзависит, сколько измерений будет в массиве numpy.import numpy as np a = np.arange(9).reshape(3,3) print(a)Вывод этого года — 2-мерный массив 3×3.
-
numpy.random.random()numpy.random.random((rows, column))
Эта функция возвращает массив с заданным количеством измерений, где каждый элемент генерируется случайным образом.a = np.random.random((2,2))Этот код вернет ndarray 2×2.
-
numpy.exp()numpy.exp(numpy.ndarray)
Функция вернет ndarray с экспоненциальной величиной каждого элемента.b = np.exp([10])Значением кода выше будет
22025.4657948. -
numpy.sqrt()numpy.sqrt(numpy.ndarray)
Эта функция вернет ndarray с квадратным корнем каждого элемента.b = np.sqrt([16])Этот код вернет значение 4.
Базовые операции NumPy
a = np.array([5, 10, 15, 20, 25])
b = np.array([0, 1, 2, 3])
-
Этот код вернет разницу двух массивов
c = a - b. -
Этот код вернет массив, где каждое значение возведено в квадрат
b**2. -
Этот код вернет значение в соответствии с заданным выражением
10 * np.sin(a). -
Этот код вернет
Trueдля каждого элемента, чье значение удовлетворяет условиеa < 15.
Базовые операции с массивом NumPy
a = np.array([[1,1], [0,1]])
b = np.array([[2,0],[3,4]])
-
Этот код вернет произведение элементов обоих массивов
a * b. -
Этот код вернет матричное произведение обоих массивов
a @ b
илиa.dot(b).
Выводы
Из этого материала вы узнали, что такое numpy и как его устанавливать, познакомились с массивов numpy, атрибутами и операциями массива numpy, а также базовыми операциями numpy.
]]>Существуют миллионы сайтов, обещающих научить Python с нуля. Но вы наверняка знаете, насколько сложно начать и как еще сложнее не останавливаться. Возможно, даже думали, что код — это не для вас. Но реальность такова, что Python с нуля может выучить каждый, совсем не имея опыта в программировании. А если вы пробовали и что-то не получилось, то проблему стоит искать где-то еще. Есть три основные причины, почему новички терпят неудачи в начале и бросают, так и не почувствовав прогресса.
Причина №1: хорошие программисты, плохие учителя

Большинство ресурсов для изучения программирования созданы самими программистами, которые хотят помочь остальным учиться. К сожалению, хороший программист не всегда будет хорошим учителем. Для тех, кто работает с Python годами, может оказаться сложным поставить себя на место новичка.
А на практике при первом знакомстве действительно сложно понять некоторые концепции в программировании. Например, способ индексации данных, таких как списки, в Python. Люди с опытом работы с кодом знают, что первый пункт в списке — это нулевой элемент. Но обычные люди привыкли считать, начиная с единицы.
Конечно, есть конкретные объяснения, почему в Python используется индексация с нуля. Но в программировании полно таких концепций. Начинающим они могут показаться не только сложными в начале, но и просто неинтуитивными.
Опытные специалисты обычно не помнят, как сами справлялись с подобными проблемами, поэтому ожидают от начинающих «просто запомнить, как есть». Однако такой подход подойдет лишь некоторым. Остальные же разочаровываются и бросают заниматься раньше времени.
Большинству требуются подробные объяснения, контекст и практика, чтобы освоить сложные вещи. Большинство ресурсов, посвященных обучению и обещающих научить Python с нуля, предлагают такие объяснения, которые будут понятны только программистам с опытом, но их сложно осознать остальным. Это и заставляет сдаваться.
Причина №2: недостаток мотивации
В традиционном образовании утрата мотивации считается проблемой и провалом студента, но на самом деле это недостаток метода обучения и самого учителя.
Сложно изучать что угодно без должной мотивации. Одним из главных мотивирующих факторов в сфере программирования является возможность использовать полученные навыки. И на этом моменте многие ресурсы по обучению претерпевают неудачу. Они учат синтаксису с помощью механических упражнений или заставляют создавать бесполезные программы, которые не имеют ничего общего с причинами, из-за которых люди начали изучать Python.
Легко бросить начатое, если вы взялись изучать Python для data science, но не работаете с данными в процессе обучения.
Причина №3: «учить», но не применять

Использование на практике приобретенных навыков критически необходимо, что они закрепились и остались надолго. Это доказывают даже исследования.
Это важно, потому что многие пытаются изучать Python, используя книги или видеоуроки. Они часто предлагают исчерпывающее освещение темы, но не могут заставить использовать полученные знания. И даже если вы используете, все равно оставляйте время для написания собственного кода.
Это не значит, что не нужно использовать книги или видео для обучения. Но именно они могут создать ложное ощущение, что вы что-то понимаете, хотя на самом деле это не так. Пройдут дни или недели, прежде чем вы напишите код, используя новые знания, осознав, что не разобрались с новым материалом так хорошо, как думали.
Решение: как выучить Python с нуля
Если вы хотите увеличить свои шансы на успешное изучение Python, то нужно использовать подход, который поможет избежать эти трех ловушек. Python нужно не просто учить, его нужно учить правильно. Следующие шаги помогут в этом:
-
Понять, зачем вы учите Python. Все вытекает из этой мотивации и очень важно понимать, изучаете ли вы Python для data science, робототехники, разработки игр или чего-то еще.
-
Изучить основы синтаксиса языка. Именно основы! Не нужно учить все. Изучение синтаксиса — важная часть, но она может быть скучной, и желательно минимизировать потраченное на нее время. Главное — взять то, что понадобится для начала работы над собственными проектами. Этот этап будет еще проще, если удастся найти ресурсы или обучающие материалы, которые рассказывают основы, но с упором на ту сферу, которая интересует в первую очередь. Например, при изучении data science полезно использовать реальные данные в своих экспериментальных проектах.
-
Создавать проекты с четкой структурой. В этом плане помогут руководства, в которых расписаны все шаги. Важно начать работать над интересующим проектом как можно раньше.
-
Создавать уникальные и все более сложные вещи по мере приобретения новых способностей. После работы над несколькими проектами у вас должны появиться идеи для собственных. Приступайте к ним, даже если кажется, что навыков недостаточно. Они появятся в процессе работы.
Нужно всего лишь разбить проект на маленькие и понятные часты. Предположим, есть идея для приложения, которое будет анализировать настроение в Твиттере. Это очень крупный проект, но его можно разделить на элементы и работать с каждым по отдельности. Сначала нужно разобраться, как получить доступ и использовать API сайта. Дальше нужно переходить к фильтрованию твитов и сохранению тех, которые потребуется проанализировать. Потом — очистить данные и искать методы, которые подойдут для анализа настроения.
Такой подход подойдет для проекта любого типа. Не обязательно знать все, прежде чем браться за работу. Разбейте ее на части, учитесь и совершенствуйтесь в процессе.
Много времени уйдет на поиск ответов в Google, StackOverflow и официальной документации Python, и это абсолютно нормально! Один из не-секретов индустрии в том, что даже профессионалы проводят большую часть времени в поисках ответов на свои вопросы.
-
Это продолжение четвертого шага, которое предусматривает увеличивающуюся сложность с каждым новым проектом. Если же вы с самого начала знаете, как реализовать каждую из частей проекта, то это, наверное, не лучшая идея — будет слишком легко, а процесс ничему не научит.
Важно, чтобы задания были сложными, но не казались невозможными. При изучении игровой разработки не стоит после первой «Змейки» переходить к разработке трехмерной RPG в открытом мире. Это слишком сложно. Но игра должна быть сложнее той же «Змейки».
]]>Это дополнение к «Основы Pandas». Вместо теоретического вступления в миллион особенностей Pandas — 2 примера:
- Данные с космического телескопа «Хаббл».
- Датасет о заработной плате экономически активного населения США.
Данные «Хаббла»
Начнем с данных «Хаббла». В первую очередь речь пойдет о том, как читать простой csv-файл и строить данные:
Начнем с данных с космического телескопа «Хаббл», одного из известнейших телескопов.
Данные очень простые. Файл называется hubble_data.csv. Его можно открыть даже в Microsoft Excel или OpenOffice. Вот как он будет выглядеть в этих программах:

Данные в формате CSV. Это очень популярный формат в первую очередь из-за своей простоты. Его можно открыть в любом текстовом редакторе. Попробуйте.
Будет видно, что CSV-файлы — это всего лишь разные значения, разделенные запятой (что, собственно, и подразумевается в названии — comma-separated values).
Это основная причина популярности формата. Для него не нужно никакое специальное ПО, даже Excel. Это также значит, что данные можно будет прочесть и через 10 лет, когда появятся новые версии электронных таблиц.
Начнем. Откройте экземпляр Ipython (Jupyter) и запустите следующий код.
import pandas as pd
import matplotlib.pyplot as plt
%pylab inline
Это импортирует pandas — основную библиотеку в Python для анализа данных. Также импортируется matplotlib для построения графиков.
%pylan inline — это команда Ipython, которая позволяет использовать графики в работе.
data = pd.read_csv("hubble_data.csv")
data.head()
Pandas значительно упрощает жизнь. Прочесть файл csv можно с помощью одной функции: read_csv().
Теперь можно вызвать функцию head(), чтобы вывести первые пять строк.
| distance | recession_velocity | |
|---|---|---|
| 0 | 0.032 | 170 |
| 1 | 0.034 | 290 |
| 2 | 0.214 | -130 |
| 3 | 0.263 | -70 |
| 4 | 0.275 | -185 |
Pandas — довольно умная библиотека. Это проявляется в том, что она понимает, что первая строка файла — это заголовок. Вот как выглядят первые 3 строки CSV-файла:
distance,recession_velocity
.032,170
.034,290
Теперь можно увидеть, что заголовок в верхней части действительно есть. Он называет две колонки: distance и recession_velocity.
Pandas корректно распознает это.
А что делать, если заголовка нет? Можно прочесть файл, вручную указав заголовки. Есть еще один файл hubble_data_no_headers.csv без заголовков. Он не отличается от предыдущего за исключением отсутствующих заголовков.
Вот как читать такой файл:
headers = ["dist","rec_vel"]
data_no_headers = pd.read_csv("hubble_data_no_headers.csv", names=headers)
data_no_headers.head()
Здесь объявляются собственные заголовки (headers). У них другие имена (dist и rec_vel), чтобы было явно видно, что это другой файл.
Данные читаются таким же способом, но в этот раз передаются новые переменные names=headers. Это сообщает Pandas, что нужно использовать их, поскольку в файле заголовков нет. Затем выводятся первые пять строк.
| dist | rec_vel | |
|---|---|---|
| 0 | 0.032 | 170 |
| 1 | 0.034 | 290 |
| 2 | 0.214 | -130 |
| 3 | 0.263 | -70 |
| 4 | 0.275 | -185 |
Pandas позволяет увидеть только одну колонку:
data_no_headers["dist"]
0 0.032
1 0.034
2 0.214
3 0.263
4 0.275
Теперь, когда данные есть, на их основе нужно построить график.
Проще всего добиться этого, избавившись от индексов. Pandas по умолчанию добавляет номера (как и Excel). Если посмотреть на структуру данных, будет видно, что левая строка имеет значения 0,1,2,3,4....
Если заменить номера на distance, тогда построение графиков станет еще проще. distance станет осью x, а velocity — осью y.
Но как заменить индексы?
data.set_index("distance", inplace=True)
data.head()
| distance | recession_velocity |
|---|---|
| 0.032 | 170 |
| 0.034 | 290 |
| 0.214 | -130 |
| 0.263 | -70 |
| 0.275 | -185 |
При сравнении с прошлым примером можно увидеть, что номера пропали. Более того, данные теперь расположены в соотношении x — y.
Создать график теперь еще проще:
data.plot()
plt.show()

Данные о заработной плате
Теперь данные о заработной плате. Этот пример построен на предыдущем и показывает, как добавлять собственные заголовки, работать с файлами, разделенными отступами, и извлекать колонки из данных:
Этот пример посложнее.
Откройте ноутбук. Начнем, как и раньше, с импорта необходимых модулей и чтения CSV-файла. В данном случае речь идет о файле wages_hours.csv.
import pandas as pd
import matplotlib.pyplot as plt
%pylab inline
data = pd.read_csv("wages_hours.csv")
data.head()
Все как раньше. Нужно ведь просто прочесть файл? Но результат получается следующий:
| HRS RATE ERSP ERNO NEIN ASSET AGE DEP RACE SCHOOL | |
|---|---|
| 0 | 2157\t2.905\t1121\t291\t380\t7250\t38.5\t2.340… |
| 1 | 2174\t2.970\t1128\t301\t398\t7744\t39.3\t2.335… |
| 2 | 2062\t2.350\t1214\t326\t185\t3068\t40.1\t2.851… |
| 3 | 2111\t2.511\t1203\t49\t117\t1632\t22.4\t1.159\… |
| 4 | 2134\t2.791\t1013\t594\t730\t12710\t57.7\t1.22… |
Выглядит непонятно. И совсем не похоже на оригинальный файл.
Что же случилось?
В CSV-файле нет запятых
Хотя название подразумевает «Значения, Разделенные Запятыми», данные могут быть разделены чем угодно. Например, отступами.
\t в тексте означает отступы. Pandas не может разобрать файл, потому что библиотека рассчитывала на запятые, а не на отступы.
Нужно прочитать файл еще раз, в этот раз передав новую переменную sep='\t'. Это сообщит, что разделителями выступают отступы, а не запятые.
data = pd.read_csv("wages_hours.csv", sep="\t")
data.head()
| HRS | RATE | ERSP | ERNO | NEIN | ASSET | AGE | DEP | RACE | SCHOOL | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2157 | 2.905 | 1121 | 291 | 380 | 7250 | 38.5 | 2.340 | 32.1 | 10.5 |
| 1 | 2174 | 2.970 | 1128 | 301 | 398 | 7744 | 39.3 | 2.335 | 31.2 | 10.5 |
| 2 | 2062 | 2.350 | 1214 | 326 | 185 | 3068 | 40.1 | 2.851 | * | 8.9 |
| 3 | 2111 | 2.511 | 1203 | 49 | 117 | 1632 | 22.4 | 1.159 | 27.5 | 11.5 |
| 4 | 2134 | 2.791 | 1013 | 594 | 730 | 12710 | 57.7 | 1.229 | 32.5 | 8.8 |
Сработало.
Но тут довольно много данных. Нужны ли они все?
В этом проекте необходимы только AGE (возраст) и RACE (ставка заработной платы). В первую очередь необходимо извлечь только эти две колонки.
data2 = data[["AGE", "RATE"]]
data2.head()
| AGE | RATE | |
|---|---|---|
| 0 | 38.5 | 2.905 |
| 1 | 39.3 | 2.970 |
| 2 | 40.1 | 2.350 |
| 3 | 22.4 | 2.511 |
| 4 | 57.7 | 2.791 |
Чтобы составить грамотный график, необходимо расположить возраст по порядку: возрастания или убывания.
Сделаем в порядке убывания (потому что это поведение по умолчанию для функции sort()).
data_sorted = data2.sort(["AGE"])
data_sorted.head()
Как и в прошлый раз, нужно убрать числа, а вместо них использовать значения возраста, чтобы упростить процесс построения графика.
data_sorted.set_index("AGE", inplace=True)
data_sorted.head()
| AGE | RATE |
|---|---|
| 22.4 | 2.511 |
| 37.2 | 3.015 |
| 37.4 | 1.901 |
| 37.5 | 1.899 |
| 37.5 | 3.009 |
И сам график:
data_sorted.plot()
plt.show()

Можно увидеть, что ставка повышается до 35 лет, а потом начинает сильно меняться.
Конечно, это общий универсальный показатель. Из этого набора данных можно сделать лишь отдельные выводы.
]]>В предыдущих материалах этого руководства мы обсудили базовые концепции Python: переменные, структуры данных, встроенные функции и методы, циклы for и инструкции if. Это все — семантическое ядро языка. Но это лишь основа того, что есть в Python. Самое интересное ждет впереди. У Python есть море модулей и пакетов, которые можно импортировать в свой проект. Что это значит? Об этом вы узнаете в статье: о том, как использовать инструкцию import и о самых важных встроенных модулях для работы в сфере data science.
Инструкция import в Python
Итак, что такое инструкция import, и почему она так важна?
Представьте LEGO.
Пока что в руководствах использовались только базовые элементы набора LEGO. Но если нужно построить что-то более сложное, необходимо задействовать более сложные инструменты.
С помощью import можно получить доступ к «инструментам» Python, которые называются модулями.
Они делятся на три группы:
- Модули стандартной библиотеки Python:
Получить к ним доступ проще простого, потому что они поставляются с языком Python3 по умолчанию. Все что нужно — ввестиimportи название модуля. С этого момента выбранный модуль можно использовать в коде. О том, как это делать, дальше в статье. - Другие более продвинутые и специализированные модули:
Эти модули не являются частью стандартной библиотеки. Для их использования нужно установить новыепакетына сервер данных. В проектах data science такие «внешние» пакеты будут использоваться часто. (Вы могли слышать, например, о pandas, numpy, matplotlib, scikit-learn и так далее). Этой теме будет посвящен отдельный материал - Собственные модули:
Да, их можно писать и самостоятельно (об этом в более продвинутых руководствах по Python)
import — очень мощный элемент Python, потому что именно с его помощью можно постоянно и почти бесконечно расширять свой набор инструментов, особенно в процессе работы с особенно сложными задачами.
Самые важные встроенные модули Python для специалистов Data Science
Теперь, когда вы понимаете, о чем идет речь, можно переходить к практике. В стандартной библиотеке Python есть десятки встроенных модулей. Одними из самых важных для проектов data science являются следующие:
- random
- statistics
- math
- datetime
- csv
Импортировать их можно, используя следующий синтаксис:
import [module_name]
Например: import random
Примечание: это импортирует весь модуль целиком со всеми его элементами. Можно взять и отдельную его часть: from [module_name] import [item_name]. Но пока лучше не переусложнять.
Разберем эти пять модулей.
Встроенный модуль №1: random
Рандомизация (случайности) очень важна в data science… например, A/B тестирование. С помощью модуля random можно генерировать случайные числа, следуя разным правилам:
Введем следующее в Jupyter Notebook:
import random
Затем в отдельную ячейку:
random.random()
Это сгенерирует случайное число с плавающей точкой от 0 до 1.
Стоит попробовать и так тоже:
random.randint(1, 10)
Это создаст случайное целое число от 1 до 10.

Больше о random можно узнать здесь.
Встроенный модуль №2: statistics
Если рандомизация важна, то статистика неизбежна. К счастью, в библиотеке есть встроенный модуль со следующими функциями: среднее значение, медиана, деление с остатком, среднеквадратичное отклонение, дисперсия и многие другие…
Начинаем стандартно:
import statistics
Дальше нужно создать список:
a = [0, 1, 1, 3, 4, 9, 15]
Теперь посчитать все значения для этого списка:

Больше о statistics можно узнать здесь.
Встроенный модуль №3: math
Есть несколько функций, которые относятся больше к математике, чем к статистике. Для них есть отдельный модуль. Он включает факториал, возведение в степень, логарифмические функции, а также тригонометрию и константы.
import math
И сам код:
math.factorial(5)
math.pi
math.sqrt(5)
math.log(256, 2)

Больше о math можно узнать здесь.
Встроенный модуль №4: datetime
Планируете работать в интернет-стартапе? Тогда вы наверняка столкнетесь с журналами данных. В их основе лежат дата и время. По умолчанию Python 3 не работает с датой и временем, но если импортировать модуль datatime, то эти функции тоже станут доступны.
import datetime
На самом деле, модуль datetime слегка переусложнен. Как минимум для новичков. Чтобы разобраться с ним, нужен отдельный материал. Но начать можно с этих двух функций:
datetime.datetime.now()
datetime.datetime.now().strftime("%F")

Встроенный модуль №5: csv
«csv» расшифровывается как «comma-separated values». Это один из самых распространенных форматов файлов для хранения журналов данных в виде текстовых данных (простого текста). Поэтому очень важно знать, как открыть файл с расширением .csv в Python. Есть конкретный способ, как это можно сделать.
Предположим, имеется маленький .csv-файл (его даже в Jupyter можно создать) под названием fruits.csv:
2018-04-10;1001;banana
2018-04-11;1002;orange
2018-04-12;1003;apple
Чтобы открыть его в Jupyter Notebook, нужно использовать следующий код:
import csv
with open('fruits.csv') as csvfile:
my_csv_file = csv.reader(csvfile, delimiter=';')
for row in my_csv_file:
print(row)

Он возвращает списки Python. С помощью функций выбора списков и методами списка, изученными раньше, можно реорганизовать набор данных.
Больше о модуле csv можно узнать здесь.
Больше встроенных модулей
Неплохое начало, но полный список встроенных модулей Python намного объемнее. С их помощью можно запаковывать и распаковывать файлы, собирать сетевые данные, отправлять email, декодировать файлы JSON и многое другое. Чтобы взглянуть на этот список, нужно перейти на страницу стандартной библиотеки Python — это часть официальной документации языка.
Есть и другие библиотеки и пакеты, не являющиеся частью стандартной библиотеки (pandas, numpy, scipy и другие). О них чуть позже.
Синтаксис
При обсуждении синтаксиса нужно выделить три вещи:
- В скриптах Python все инструкции
importнужно оставлять в начале. Почему? Чтобы видеть, какие модули нужны коду. Это также гарантирует, что импорт произойдет до того, как отдельные части модуля будут использованы. Поэтому просто запомните: инструкцииimportдолжны находиться в начале.
- В статье функции модуля использовались с помощью такого синтаксиса:
module_name.function_name(parameters)
Например,statistics.median(a)
или
csv.reader(csvfile, delimiter=';')Это логично. Перед использованием функции нужно сообщить Python, в каком модуле ее можно найти. Иногда бывают даже более сложные выражения, как функции класса в модуле (например,datetime.datetime.now()), но сейчас об этом можно не думать. Лучше просто составить список любимых модулей и функций и изучать, как они работают. Если нужен новый — посмотрите в документации Python, как создать его вместе с определенными функциями. - При использовании модуля (или пакета) его можно переименовать с помощью ключевого слова
as:
Если ввести:
import statistics as stat, в дальнейшем ссылаться на модуль можно с помощью «stat». Например,stat.median(a), а неstatistics.median(a). По традиции две библиотеки, используемые почти во всех проектах Data Science, импортируются с укороченными именами: numpy (import numpy as np) и pandas (import pandas as pd). Об этом также будет отдельный материал.
Так что это? Пакет? Модуль? Функция? Библиотека?
Поначалу вам может быть сложно даже понять, что именно импортируете. Иногда эти элементы называют «модулями», иногда — «пакетами», «функциями» или даже «библиотеками».
Примечание: даже если проверить сайты numpy и pandas, можно обнаружить, что один из них называют библиотекой, а второй — пакетом.
Не все любят теорию в программировании. Но если вы хотите участвовать в осмысленных беседах с другими разработчиками (или как минимум задавать грамотные вопросы на Stackoverflow), нужно хотя бы иметь представление о том, что и как называется.
Вот как можно попытаться классифицировать эти вещи:
- Функция: это блок кода, который можно использовать по несколько раз, вызывая его с помощью ключевого слова. Например,
print()— это функция. - Модуль: это файл с расширением .py, который содержит список функций (также — переменных и классов). Например, в
statisctics.mean(a),mean— это функция, которую можно найти в модулеstatistics. - Пакет: это коллекция модулей Python. Например,
numpy.random.randint(2, size=10).randint()— это функция в модулеrandomв пакете numpy. - Библиотека: это обобщенное название для определенной коллекции кода в Python.
Эта информация взята из вопроса на Stackoverflow.
Выводы
import — это важная составляющая Python. Чем больше вы будете узнавать о data science, тем лучше будете понимать, как постоянно расширять собственный набор инструментов в зависимости от поставленной задачи. import — это основной инструмент для этих целей. Он открывает тысячи дверей.
Для новичков в программировании синтаксис оказывается одной из самых сложных вещей. Он очень строг и может казаться противоречивым. Поэтому в этом материале собраны основы синтаксиса Python, которые важны даже для профессионалов. Здесь же упомянуты лучшие практики форматирования, которые помогут делать код опрятным.
Это основы. Ссылки на более сложные вещи будут в конце материала.
3 важных правила о синтаксисе Python
#1. Разрывы строк имеют значение
В отличие от SQL, в Python разрывы имеют значение. В 99% случаев если добавить разрыв туда, где его быть не должно, появится ошибка. Странно? Зато точку с запятой в конце каждой строки добавлять не нужно.
Поэтому вот правило №1 в Python: одно выражение на строку.
Есть и исключения. Выражения могут быть разбиты на несколько строк, если они записаны:
- в скобках (например, функции или методы),
- в квадратных скобках (например, списки),
- в фигурных скобках (например, словари).
Это называется неявным объединением строк и очень помогает при работе с более крупными структурами данных.

Также можно разбивать любое выражение на несколько строк, если написать обратную черту (\) в конце строки. Обратное также допустимо — ввести несколько выражений на одной строке, добавляя точку с запятой (;) после каждого. Но эти способы не используются слишком часто. Применять их нужно только при сильной необходимости. (Например, с выражениями, которые состоят из более чем 80 символов).


#2. Отступы важны
Ненавидите отступы? Вы не одиноки в этом. Многие начинающие Python-программисты не любят это понятие. У людей, которые только знакомятся с азами программирования, именно из-за отступов возникает больше всего ошибок в коде. Но вы привыкнете. А если ответственно проходили примеры из прошлых частей руководства, то, возможно, уже привыкли.
Зачем нужны отступы? Простыми словами, это способ показать, какие части кода связаны между собой — например, где начало и конец инструкции if или цикла for. В других языках, где отступов нет, для этих целей используются другие методы: в Javascript блоки кода окружают дополнительные скобки, а в bash — ключевые слова. В Python используются отступы и по мнению многих — это самый элегантный способ решения проблемы.
И это правило №2 в Python: убедитесь, что используете отступы правильно и последовательно.
Примечание: об этих же правилах речь шла в руководствах, посвященных циклам for и инструкциям if.

И вот еще: если вы смотрели сериал «Кремниевая долина», то наверняка слышали о споре «отступы против пробелов»:
Так отступы или пробелы? Вот что говорится в Руководстве по стилю Python:
Табы или пробелы?
Пробелы являются предпочтительным методом отступа.
Табы должны использоваться исключительно для соответствия с кодом, который уже имеет отступы табуляцией.
Все понятно!
#3. Чувствительность к регистру
Python чувствителен к регистру. Есть разница в том, чтоб ввести and (правильно) или AND (не сработает). Как показывает практика, большинство ключевых слов в Python пишутся с маленькой буквы. Известное исключение (из-за которого у многих новичков возникают проблемы) — булевы значения. Их нужно вводить только так: True и False. (Не TRUE или true).
Правило №3 в Python: Python чувствителен к регистру.
Другие практики Python
Есть и другие необязательные особенности Python, которые сделают код более приятным и читаемым.
1. Используйте комментарии
В код Python можно добавлять комментарии. Для этого нужно всего лишь добавить символ #. Все, что будет написано после символа #, не исполнится.
# Это комментарий перед циклом for.
for i in range(0, 100, 2):
print(i)
#2. Названия переменных
Традиционно переменные нужно писать буквами в нижнем регистре, разделяя их символами нижнего подчеркивания (_). Также не рекомендуется использовать переменные длиной в один символ. Понятные и легко различимые переменные помогают и другим программистам, когда те разбираются в вашем коде.
my_meaningful_variable = 100
#3. Используйте пустые строки
Если вы хотите визуально разделить блоки кода (например, есть скрипт на 100 строк, состоящий из 10-12 блоков), используйте пустые строки. Или даже несколько. Это никак не повлияет на сам код.

#4. Добавляйте пробелы вокруг операторов и оператора присваивания
Чтобы получить более чистый код, рекомендуется использовать пробелы вокруг знаков =, математических и операторов сравнения (>, <, +, - и так далее). Без этих пробелов код все равно будет работать: но чем он чище, тем проще его читать и тем проще использовать повторно.
number_x = 10
number_y = 100
number_mult = number_x * number_y
#5. Максимальная длина строки — 79 символов
Если в вашей строке больше 79 символов, рекомендуется разбить код на несколько с помощью знака \. Python его проигнорирует и прочитает так, будто бы это одна строка.
(В некоторых же случаях можно использовать неявное объединение строк).
#6. Будьте последовательны
Одно из самых важных правил — оставайтесь последовательны. Даже если всегда следовать правилам выше, в определенных ситуациях придется придумывать собственные. Главное — неукоснительно придерживаться уже их. При идеальном сценарии спустя 6 месяцев вы откроете код и быстро поймете, для чего он нужен. Если вы будете без причины менять правила оформления или способ именования переменных, создадите ненужную головную боль для будущего себя.
Дзен Python — приятное пасхальное яйцо
Что еще могло бы быть в конце этой статьи, как не пасхальное яйцо?
Если ввести import this в Jupyter Notebook, то выведутся 19 «заповедей» Python:
>>> import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Используйте их с умом!
Выводы
Следуйте этим советам, а если хотите узнать еще больше о синтаксисе Python и лучших практиках, обратитесь к следующим материалам:
В последней части речь пойдет о библиотеках Python.
]]>В прошлый раз вы узнали, как работают инструкции if и циклы for в Python. В этот раз стоит поговорить о том, как объединять их. На практических примерах вы узнаете, как совмещать несколько циклов for, а также — один цикл for с инструкцией if.
Это практическое руководство! Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам.
Цикл for внутри цикла for — или просто вложенный цикл for
Чем сложнее проект, над которым ведется работа, тем больше вероятность, что придется работать с вложенным циклом for. Это значит, что будет одна итерация с другой итерацией внутри нее.
Предположим, что есть 9 сериалов в трех категориях: комедии, мультфильмы и драмы. Они представлены во вложенном списке Python («списки в списке»):
my_movies = [['How I Met Your Mother', 'Friends', 'Silicon Valley'],
['Family Guy', 'South Park', 'Rick and Morty'],
['Breaking Bad', 'Game of Thrones', 'The Wire']]
Необходимо посчитать символы в этих названиях и вывести результаты один за одним на экране в таком формате:
"The title [movie_title] is [X] characters long."
Как это можно сделать? Поскольку в основном списке есть три списка, чтобы получить их названия нужно перебрать элементы my_movies. Это нужно сделать и в основном списке, и в каждом вложенном:
for sublist in my_movies:
for movie_name in sublist:
char_num = len(movie_name)
print("The title " + movie_name + " is " + str(char_num) + " characters long.")
Примечание:
len()— это функция Python, которая выводит целое число. Чтобы сделать его «выводимым», нужно превратить число в строку. О том, как это сделать, говорилось в прошлом руководстве.

Циклы for в Python может быть сложно понять вначале, а с вложенными циклами все еще сложнее. Поэтому чтобы разобраться с тем, что происходит, нужно взять ручку и бумагу и попробовать воспроизвести скрипт так, будто вы компьютер — пройти через каждый шаг и выписать результаты.
И еще кое-что:
Синтаксис! Правила те же, что были при изучении простых циклов for. Единственное, на чем важно сделать акцент — отступы. Только используя корректные отступы в Python, вы сможете сообщить языку, в каком именно блоке цикла (внешнем или внутреннем) нужно применить тот или иной код. Попробуйте сделать следующее и обнаружить отличия в этих примерах:

Инструкции if в цикле for
Внутри цикла for также можно использовать инструкции if.
В качестве примера можно привести известное упражнение, которое предлагают junior-специалистам в сфере data science:
Переберите числа до 99. Выводите «fizz» для каждого числа, которое делится на 3, «buzz» — для тех, что делятся на 5 и «fizzbuzz» — для тех, что делятся на 3 и на 5! Если число не делится, выводите тире (’-’)
Вот решение:
for i in range(100):
if i % 3 == 0 and i % 5 == 0:
print('fizzbuzz')
elif i % 3 == 0:
print('fizz')
elif i % 5 == 0:
print('buzz')
else:
print('-')
Как видно в примере, инструкция if в цикле for отлично подходит, чтобы оценить диапазон чисел (или, например, элементы списка) и разбить их по категориям. Таким же образом к ним можно применить функции или просто вывести.
Важно: при использовании инструкции if в цикле for будьте особенно внимательно с отступами, потому что если что-то упустить, то программа работать не будет.
Break
В Python есть удобный инструмент потока, который идеально подходит для управления инструкциями if в циклах for. Это инструкция break.
Найдете первое 7-значное число, которое делится на 137? (Только одно — первое).
Решение:
for i in range(0, 10000000, 137):
if len(str(i)) == 7:
print(i)
break
Этот цикл берет каждое 137-е число (for i in range (0, 10000000, 137)) и проверяет, используется ли в нем 7 цифр или нет (if len(str(i) == 7). Как только он получит первое 7-значное число, инструкция if станет истинной (True), и произойдут две вещи:
print(i)— число выведется на экранbreakпрервет цикл, чтобы первое 7-значное число было также и последним на экране.
Узнать больше о break (и его брате близнеце, continue) можно в статье: Синтаксис, возможности и подводные камни цикла for Python 3.
Примечание: эту задачу можно решить еще проще с помощью цикла
while. Но поскольку руководства по этому циклу еще нет, здесь был использован подход цикл for +break.
Проверьте себя!
Пришло время узнать, насколько вы разобрались с инструкцией if, циклами for и их объединением. Попробуйте решить следующее задание.
Создайте скрипт на Python, который узнает ваш возраст максимум с 8 попыток. Он должен задавать только один вопрос: угадывать возраст (например, «Вам 67 лет?»). Отвечать же можно одним из трех вариантов:
- correct
- less
- more
Основываясь на ответе, компьютер должен делать новые попытки до тех пор, пока не узнает корректный возраст.
Примечание: для решения задачи нужно изучить новую функцию
input(). Больше о ней здесь.
Готовы? Вперед!
Решение
Вот код решения.
Примечание: решить задачу можно и с помощью цикла while. Но поскольку он еще не рассматривался, был выбран вариант с for.
down = 0
up = 100
for i in range(1,10):
guessed_age = int((up + down) / 2)
answer = input('Are you ' + str(guessed_age) + " years old?")
if answer == 'correct':
print("Nice")
break
elif answer == 'less':
up = guessed_age
elif answer == 'more':
down = guessed_age
else:
print('wrong answer')
Логика решения следующая:
- Устанавливаем диапазон от 0 до 100, предполагая, что возраст «игрока» будет где-то посередине.
down = 0 up = 100 - Скрипт всегда спрашивает среднее значение диапазона (первой попыткой будет 50):
guessed_age = int((up + down) / 2) answer = input('Are you ' + str(guessed_age) + " years old?") - После получения ответа от «игрока» могут быть 4 возможных сценария:
- Если возраст угадан, скрипт заканчивается и возвращает определенный ответ.
if answer == 'correct': print("Nice") break- Если ответ «меньше», тогда цикл начинается сначала, но перед этим максимальное значение диапазона устанавливается на уровне последнего предположения (Так, вторая итерация будет искать середину между 0 и 50).
elif answer == 'less': up = guessed_age - То же самое для «больше» — только в этом случае меняется минимум:
elif answer == 'more': down = guessed_age - И в конце обрабатываются ошибки или опечатки:
else: print('wrong answer')
Итого
Теперь вы знаете о:
- Вложенных циклах for в Python
- Объединении циклов for и инструкций if
Это уже не базовый уровень Python, а переход к среднему. Использование этих инструментов предполагает понимание логики Python 3 и постоянной практики.
В серии этих руководств осталось всего два урока. Продолжайте, чтобы узнать все об основах синтаксиса Python.
]]>Помните, как в предыдущей части инструкции if в Python сравнивались с тем, как принимает решения мозг человека, основываясь на неких условиях в повседневной жизни? В случае с циклами for ситуация та же. Человек перебирает весь список покупок, пока не купит все, что в нем указано. Дилер раздает карты до тех пор, пока каждый игрок не получит 5 штук. Спортсмен делает отжимания, пока не доберется до сотни… Циклы повсюду. Касательно циклов for в Python — они нужны для выполнения повторяющихся задач. В этот статье вы узнаете все, что нужно знать об этих циклах: синтаксис, логику и лучшие примеры.
Это практическое руководство!
Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам, если вы еще не ознакомились с ними.
- #1 Python для Data Science – Руководство для начинающих
- #2 Python для Data Science — Структуры данных
- #3 Python для Data Science — встроенные функции и методы Python
- #4 Python для Data Science — инструкции if в Python
Циклы for в Python — два простых примеры
Перво-наперво: циклы for нужны для перебора (итерации) итерируемых объектов. В большинстве случаев ими будут выступать уже знакомые списки, строки и словари. Иногда это могут быть объекты range() (об этом в конце статьи).
Начнем с простейшего примера — списка!
В прошлых руководствах неоднократно использовался пес Фредди. И вот он снова здесь для иллюстрации примера. Создадим список:
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]
Теперь, когда есть готовый список, можно перебрать все его элементы, выводя их один за одним с помощью простейшего цикла for:
for i in dog:
print(i)

Результатом будут элементы списка, выведенные один за одним на разных строках:
Freddie
9
True
1.1
2001
['bone', 'little ball']
Но в чем преимущество такого способа? Используем другой пример — список чисел:
numbers = [1, 5, 12, 91, 102]
Предположим, что нужно возвести в квадрат каждое из них.
Примечание: к сожалению, формула
numbers * numbersне сработает… Это кажется логичным, но, узнав Python лучше, станет понятно, что это совсем не логично.
Нужно сделать следующее:
for i in numbers:
print(i * i)
Результат будет такой:

Вот что происходит по шагам:
- Есть список (
numbers) с 5 элементами. - Берем первый элемент (из-за индексации с нуля, это будет 0 (нулевой) элемент) списка (
1) и сохраняем его в переменнуюi. - Исполняем функцию
print(i * i), которая возвращает значение1в квадрате. Это1. - Затем весь процесс начинается заново…
- Берем новый элемент и присваиваем его переменной
i. - Снова исполняем функцию
print (i * i)и получаем значение второго элемента в квадрате:25 - Повторяем процесс…
… пока не получим последний элемент, возведенный в квадрат.
Это базовый пример работы цикла в Python, но сильно сложнее он не будет становиться — только комплекснее.
Логика, лежащая в основе циклов for в Python
Теперь, когда стала понятна польза циклов for, нужно разобраться с логикой в их основе.
Примечание: это одна из важнейших частей руководства. Многие люди без проблем используют базовые циклы, но затрудняются применять те что посложнее. Проблема в том, что они изучают синтаксис, но забывают разобраться в логике. Поэтому желательно перечитывать этот раздел до тех пор, пока не станет понятно что к чему. В будущем вы поблагодарите себя за то, что когда-то потратили на это время.
Это блок-схема с визуализацией процесса работы цикла:

Разобьем ее и изучим все в деталях. В качестве примера будем использовать предыдущий код со списком numbers и их значениями, возведенными в квадрат:
numbers = [1, 5, 12, 91, 102]
for i in numbers:
print(i * i)
- Определяем итерируемый объект (то есть, уже имеющийся список
numbers = [1, 5, 12, 91, 102]). - При создании цикла for первая строка всегда будет выглядеть как-то так:
for i in numbers:forиin— это ключевые слова Python, аnumber— название списка. Но куда важнее переменнаяi. Это «временная» переменная, и ее единственная роль заключается в хранении конкретного элемента списка, который будет работать в момент каждой отдельной итерации цикла. Хотя в большинстве случаев эта переменная обозначается какi(в онлайн-курсах и даже книгах), важно знать, что можно выбрать любое имя. Это может быть не толькоi(for i in numbers), но, напримерx(for x in numbers) илиhello(for hello in numbers). Или любое другое значение. Суть в том, что это переменная и нужно не забывать ссылаться на нее внутри цикла. - Продолжаем использовать числа в качестве примеров. Берем первый элемент итерируемого объекта (технически, из-за индексации с нуля — это 0 (нулевой) объект. Запустится первая итерация цикла. Нулевой элемент — это
1. Значением переменнойiбудет1. - Функция в цикле была
print(i * i). Поскольку i = 1, результатомi * iбудет1.1выведется на экран. - Цикл начинается заново.
- Берется следующий элемент, и начинается вторая итерация цикла. Первый элемент
number— это5. iравняется5. Снова запуститсяprint(i * i), а на экран выведется25.- Цикл начнется заново. Следующий элемент.
- Еще один элемент. Это уже третья итерация. Второй элемент —
12. print(i * i)выведет144.- Цикл стартует заново. Следующий элемент присутствует. Новая итерация.
- Третий элемент —
91. Значение в квадрате —8281. - Цикл стартует заново. Следующий элемент присутствует. Новая итерация.
iравняется102. Значение в квадрате —10404.- Цикл стартует заново. Но «следующего элемента» нет. Цикл завершается.
Это очень-очень подробное объяснение третьей строки. Но такой разбор нужен лишь первый раз. Уже в следующий раз вся логика будет у вас в голове. Но важно было рассмотреть все таким вот образом, потому что у начинающих специалистов именно этой логики и не достает, а такой недостаток прямо влияет на качество кода.
Итерация по строкам
Для цикла можно использовать и другие последовательности, а не только списки. Попробуем строку:
my_list = "Hello World!"
for i in my_list:
print(i)

Все просто. Буквы выводятся одна за одной. Важно запомнить, что строки всегда обрабатываются как последовательности символов, поэтому цикл for и работает с ними так же, как и со списками.
Итерация по объектам range()
range() — это встроенная функция Python и она используется почти всегда только в циклах for. Но для чего? Если говорить простым языком — она генерирует список чисел. Вот как это работает:
my_list = range(0,10)
for i in my_list:
print(i)
")
Она принимает три аргумента:
")
- the first element: первый элемент диапазона
- the last element: можно было бы предположить, что это последний элемент диапазона, но это не так. На самом деле здесь определяется элемент, который будет идти после последнего. Если ввести 10, то диапазон будет от 0 до 9. Если 11 — от 0 до 10 и так далее.
- the step: это разница между элементами диапазона. Если это 2, то будет выводиться только каждый второй элемент.
Можете теперь угадать, каким будет результат диапазона сверху?
Вот он:

Примечание: атрибуты first element и step опциональны. Если их не определить, тогда первым элементом будет 0, а шаг по умолчанию — это 1. Попробуйте следующее в Jupyter Notebook и проверьте результат:
my_list = range(10)
for i in my_list:
print(i)
Зачем нужна range()? В двух случаях:
- Необходимо перебрать числа. Например, нужно возвести в куб нечетные числа между 1 и 9. Без проблем:
my_list = range(1, 10, 2) for i in my_list: print(i * i * i) - Необходимо перебрать список, сохранив индексы элементов.
my_list = [1, 5, 12, 91, 102] my_list_length = len(my_list) for i in range(0,my_list_length): print(i, my_list[i] * my_list[i])В этом случае
i— это индекс, а элементами списка будутmy_list[i].
В любом случае, range() упростит работу с циклами в Python.
Лучшие примеры и распространенные ошибки
- Циклы for — это не самая простая тема для начинающих. Чтобы работать с ними, нужно алгоритмическое мышление. Но с практикой понимание приходит… Если же попалась действительно сложна задача, лучше нарисовать схему а бумаге. Просто пройти первые итерации на бумаге и записать результаты. Так будет понятнее.
- Как и в случае с инструкциями if, нужно быть внимательными с синтаксисом. Двоеточие обязательно в конце строки
for. А перед строкой в теле цикла должны быть 4 отступа. - Нельзя выводить строки и числа в функции
print()с помощью знака+. Это больше особенность функцииprint, а не цикла for, но чаще всего такая проблема будет встречать в циклах. Например:
Если встречается такое, лучше всего превратить числа в строки с помощью функции str(). Вот предыдущий пример с правильным синтаксисом:

Вот и все. Пришло время упражнений.
Проверьте себя
Вот отличное упражнение для цикла for:
Возьмите переменную и присвойте ей случайную строку.
Затем выведите пирамиду из элементов строки как в этом примере:
my_string = "python"
Вывод:
p
py
pyt
pyth
pytho
python
pytho
pyth
pyt
py
p
Напишите код, который бы делал подобное для любого значения my_string.
Решение
Примечание: есть несколько способов решения этой задачи. Дальше будет относительно простое, но вы можете использовать и посложнее.
my_string = "python"
x = 0
for i in my_string:
x = x + 1
print(my_string[0:x])
for i in my_string:
x = x - 1
print(my_string[0:x])

Решение говорит само за себя. Единственная хитрость заключается в использовании переменной-счетчика «x», которая показывает количество символов, необходимых для вывода в этой итерации. В первом цикле for значение увеличивается, пока не доберется до значения количества символов в слове. Во втором — опускается до нуля, пока на экране не останется ни одного символа.
Итого
Циклы for в Python очень важны. Они широко используются в data science. Синтаксис довольно простой, но для понимания логики нужно постараться. Этой статьи должно быть достаточно, чтобы разобраться в основах, поэтому все, что остается, — практиковаться.
В следующем материале вы узнаете, как объединять циклы for между собой и циклы for с инструкциями if.
]]>Инструкции if (если) используются в повседневной жизни постоянно, пусть она и не написана на Python. Если горит зеленый, тогда можно переходить дорогу; в противном случае нужно подождать. Если солнце встало, тогда нужно выбираться из постели; в противном случае можно продолжать спать. Возможно, все не настолько строго, но когда действия выполняются на основе условий, мозг делает то же самое, что и компьютер — оценивает условия и действует в зависимости от результата.
Однако у компьютера нет подсознания, поэтому для занятий data science нужно понимать, как работает инструкция if, и как ее использовать в Python!
Это практическое руководство! Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам, если вы еще не ознакомились с ними:
- #1 Python для Data Science – Руководство для начинающих
- #2 Python для Data Science — Структуры данных
- #3 Python для Data Science — встроенные функции и методы Python
Основы инструкций if в Python
Логика инструкции if очень проста.

Предположим, что есть два значения: a = 10 и b = 20. Сравниваем эти два значения. Сравнение даст один из двух выводов: True или False. (Проверьте в своем Jupyter Notebook)

Можно пойти дальше и написать условие: if a == b вернет True, тогда вывести 'yes'. Если False — тогда 'no'. И это все — это логика инструкций if в Python. Синтаксис следующий:
a = 10
b = 20
if a == b:
print('yes')
else:
print('no')

Запустите этот скрипт в Jupyter Notebook. Очевидно, что результат будет 'no'.
Теперь попробуйте то же самое, но со значением b равным 10.
a = 10
b = 10
if a == b:
print('yes')
else:
print('no')
На этот раз сообщение будет 'yes'.
Синтаксис инструкции if в Python
Нужно рассмотреть синтаксис подробно, потому что в нем есть строгие правила. Основы просты:

Имеются:
- ключевое слово
if - условие
- инструкция
- ключевое слово
else - другая инструкция
Но есть две вещи, о которых нужно всегда помнить:
- Никогда не пропускать двоеточие в конце строк
ifиelse!

- Никогда не пропускать отступы в начале строк с инструкциями!

Если что-то из этого пропустить, вернется сообщение об ошибке с текстом «invalid syntax», а скрипт не будет работать.
Инструкции if в Python — 2-й уровень
Теперь, когда вы знаете основы, пришло время сделать условия более сложными: с помощью арифметики, сравнений и логических операторов. (Примечание: если слово «оператор» ни о чем не говорит, лучше вернуться к первому материалу из серии).
Вот пример:
a = 10
b = 20
c = 30
if (a + b) / c == 1 and c - b - a == 0:
print('yes')
else:
print('no')
Код вернет yes, поскольку оба условия, (a + b) / c == 1 и c - b - a == 0 вернут True, а логический оператор между ними — это and.

Конечно, код можно сделать еще более сложным, но суть в том, что в инструкции if легко можно использовать несколько операторов — подобное часто встречается на практике.
Инструкции if в Python — 3-й уровень
Можно перейти на еще один уровень выше, используя ключевое слово elif (это короткая форма фразы «else if») для создания последовательностей условий. «Последовательность условий» звучит красиво, но на самом деле — это всего лишь инструкция if, вложенная в другую инструкцию if:

Другой пример:
a = 10
b = 11
c = 10
if a == b:
print('first condition is true')
elif a == c:
print('second condition is true')
else:
print('nothing is true. existence is pain.')
Очевидно, что результат будет "second condition is true".

Это можно делать миллионы раз и построить огромную последовательность if-elif-elif-elif, если хочется, конечно.
И это более-менее все, что нужно знать об инструкциях if в Python. А теперь:
Проверьте себя
Вот случайное целое число: 918652728452151.
Нужно узнать две вещи о нем:
- Делится ли оно на 17 без остатка?
- В нем больше 12 цифр?
Если оба условия верны, тогда вернем super17.
Если одно из них ложно, тогда стоит запустить второй тест:
- Делится ли оно без остатка на 13?
- В нем больше 10 цифр?
Если оба условия верны, тогда вернем awesome13.
Если оригинальное число не определяется ни как super17, ни как awesome13, тогда выведем просто meh, this is just an average random number.
Итак: является ли число 918652728452151 super 17 или awesome13 или это просто случайное число?
Решение
918652728452151 — это число super17.

Рассмотрим подробнее код:
my_number = 918652728452151
if my_number % 17 == 0 and len(str(my_number)) > 12:
print("super17")
elif my_number % 13 == 0 and len(str(my_number)) > 10:
print("awesome13")
else:
print("meh, this is just a random number")
В первой строке число 918652728452151 сохраняется в переменную, так что его не придется записывать каждый раз, а код будет смотреться изящнее: my_number = 918652728452151.
После этого создается последовательность условия if-elif-else.
В строке if есть два условия. Первое — проверка, делится ли my_number на 17 без остатка. Это часть my_number % 17 == 0. Во втором нужно подсчитать количество цифр в my_number. Из-за ограничений языка сделать это нельзя, поэтому нужно преобразовать число в строку с помощью функции str(). После этого необходимо использовать функцию len() и узнать количество символов. Это часть len(str(my_number)).
Выходит, что оба оригинальных условия были верны, потому что на экран вывелось super17. Но если бы это было не так, следующая строка elif проделала бы то же самое, но проверяла, делится ли число на 13 (а не 17), а символов должно было быть больше 10 (не 12).
Если бы и это условие оказалось ложным, инструкция else запустила бы print("meh, this is just an average random number").
Не так уж и сложно, не правда ли?
Итого
Инструкции if широко используются в каждом языке программирования. Теперь вы тоже знаете, как пользоваться ими. Логика их работы проста, а синтаксис можно даже пересказать обычными словами.
В следующий раз речь пойдет о циклах for в Python.
]]>Это третья часть руководства по pandas, в которой речь пойдет о методах форматирования данных, часто используемых в проектах data science: merge, sort, reset_index и fillna. Конечно, есть и другие, поэтому в конце статьи будет шпаргалка с функциями и методами, которые также могут пригодиться.
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Merge в pandas («объединение» Data Frames)
В реальных проектах данные обычно не хранятся в одной таблице. Вместо нее используется много маленьких. И на то есть несколько причин. С помощью нескольких таблиц данными легче управлять, проще избегать «многословия», можно экономить место на диске, а запросы к таблицам обрабатываются быстрее.
Суть в том, что при работе с данными довольно часто придется вытаскивать данные из двух и более разных страниц. Это делается с помощью merge.
Примечание: хотя в pandas это называется merge, метод почти не отличается от JOIN в SQL.
Рассмотрим пример. Для этого можно взять DataFrame zoo (из предыдущих частей руководства), в котором есть разные животные. Но в этот раз нужен еще один DataFrame — zoo_eats, в котором будет описаны пищевые требования каждого вида.

Теперь нужно объединить два эти Data Frames в один. Чтобы получилось нечто подобное:

В этой таблице можно проанализировать, например, сколько животных в зоопарке едят мясо или овощи.
Как делается merge?
В первую очередь нужно создать DataFrame zoo_eats, потому что zoo уже имеется из прошлых частей. Для упрощения задачи вот исходные данные:
animal;food
elephant;vegetables
tiger;meat
kangaroo;vegetables
zebra;vegetables
giraffe;vegetables
О том, как превратить этот набор в DataFrame, написано в первом уроке по pandas. Но есть способ для ленивых. Нужно лишь скопировать эту длинную строку в Jupyter Notebook pandas_tutorial_1, который был создан еще в первой части руководства.
zoo_eats = pd.DataFrame([['elephant','vegetables'], ['tiger','meat'], ['kangaroo','vegetables'], ['zebra','vegetables'], ['giraffe','vegetables']], columns=['animal', 'food'])
И вот готов DataFrame zoo_eats.

Теперь пришло время метода merge:
zoo.merge(zoo_eats)
(А где же все львы? К этому вернемся чуть позже).
Это было просто, не так ли? Но стоит разобрать, что сейчас произошло:
Сначала был указан первый DataFrame (zoo). Потом к нему применен метод .merge(). В качестве его параметра выступает новый DataFrame (zoo_eats). Можно было сделать и наоборот:
zoo_eats.merge(zoo)
Это то же самое, что и:
zoo.merge(zoo_eats)
Разница будет лишь в порядке колонок в финальной таблице.
Способы объединения: inner, outer, left, right
Базовый метод merge довольно прост. Но иногда к нему нужно добавить несколько параметров.
Один из самых важных вопросов — как именно нужно объединять эти таблицы. В SQL есть 4 типа JOIN.

В случае с merge в pandas в теории это работает аналогичным образом.
При выборе INNER JOIN (вид по умолчанию в SQL и pandas) объединяются только те значения, которые можно найти в обеих таблицах. В случае же с OUTER JOIN объединяются все значения, даже если некоторые из них есть только в одной таблице.
Конкретный пример: в zoo_eats нет значения lion. А в zoo нет значения giraffe. По умолчанию использовался метод INNER, поэтому и львы, и жирафы пропали из таблицы. Но бывают случаи, когда нужно, чтобы все значения оставались в объединенном DataFrame. Этого можно добиться следующим образом:
zoo.merge(zoo_eats, how='outer')

В этот раз львы и жирафы вернулись. Но поскольку вторая таблица не предоставила конкретных данных, то вместо значения ставится пропуск (NaN).
Логичнее всего было бы оставить в таблице львов, но не жирафов. В таком случае будет три типа еды: vegetables, meat и NaN (что, фактически, значит, «информации нет»). Если же в таблице останутся жирафы, это может запутать, потому что в зоопарке-то этого вида животных все равно нет. Поэтому следует воспользоваться параметром how='left' при объединении.
Вот так:
zoo.merge(zoo_eats, how='left')
Теперь в таблице есть вся необходимая информация, и ничего лишнего. how = 'left' заберет все значения из левой таблицы (zoo), но из правой (zoo_eats) использует только те значения, которые есть в левой.
Еще раз взглянем на типы объединения:
Примечание: «Какой метод merge является самым безопасным?» — самый распространенный вопрос. Но на него нет однозначного ответа. Нужно решать в зависимости от конкретной задачи.
Merge в pandas. По какой колонке?
Для использования merge библиотеке pandas нужны ключевые колонки, на основе которых будет проходить объединение (в случае с примером это колонка animal). Иногда pandas не сможет распознать их автоматически, и тогда нужно указать названия колонок. Для этого нужны параметры left_on и right_on.
Например, последний merge мог бы выглядеть следующим образом:
zoo.merge(zoo_eats, how = 'left', left_on='animal', right_on='animal')
Примечание: в примере pandas автоматически нашел ключевые колонки, но часто бывает так, что этого не происходит. Поэтому о
left_onиright_onне стоит забывать.
Merge в pandas — довольно сложный метод, но остальные будут намного проще.
Сортировка в pandas
Сортировка необходима. Базовый метод сортировки в pandas совсем не сложный. Функция называется sort_values() и работает она следующим образом:
zoo.sort_values('water_need')

Примечание: в прошлых версиях pandas была функция
sort(), работающая подобным образом. Но в новых версиях ее заменили наsort_values(), поэтому пользоваться нужно именно новым вариантом.
Единственный используемый параметр — название колонки, water_need в этом случае. Довольно часто приходится сортировать на основе нескольких колонок. В таком случае для них нужно использовать ключевое слово by:
zoo.sort_values(by=['animal', 'water_need'])

Примечание: ключевое слово
byможно использовать и для одной колонкиzoo.sort_values(by = ['water_need'].
sort_values сортирует в порядке возрастания, но это можно поменять на убывание:
zoo.sort_values(by=['water_need'], ascending=False)

reset_index()
Заметили ли вы, какой беспорядок теперь в нумерации после последней сортировки?

Это не просто выглядит некрасиво… неправильная индексация может испортить визуализации или повлиять на то, как работают модели машинного обучения.
В случае изменения DataFrame нужно переиндексировать строки. Для этого можно использовать метод reset_index(). Например:
zoo.sort_values(by=['water_need'], ascending=False).reset_index()

Можно заметить, что новый DataFrame также хранит старые индексы. Если они не нужны, их можно удалить с помощью параметра drop=True в функции:
zoo.sort_values(by = ['water_need'], ascending = False).reset_index(drop = True)

Fillna
Примечание: fillna — это слова fill( заполнить) и na(не доступно).
Запустим еще раз метод left-merge:
zoo.merge(zoo_eats, how='left')
Это все животные. Проблема только в том, что для львов есть значение NaN. Само по себе это значение может отвлекать, поэтому лучше заменять его на что-то более осмысленное. Иногда это может быть 0, в других случаях — строка. Но в этот раз обойдемся unknown. Функция fillna() автоматически найдет и заменит все значения NaN в DataFrame:
zoo.merge(zoo_eats, how='left').fillna('unknown')

Примечание: зная, что львы едят мясо, можно было также написать
zoo.merge(zoo_eats, how='left').fillna('meat').
Проверьте себя
Вернемся к набору данных article_read.
Примечание: в этом наборе хранятся данные из блога о путешествиях. Загрузить его можно здесь. Или пройти весь процесс загрузки, открытия и установки из первой части руководства pandas.
Скачайте еще один набор данных: blog_buy. Это можно сделать с помощью следующих двух строк в Jupyter Notebook:
!wget https://pythonru.com/downloads/pandas_tutorial_buy.csv
blog_buy = pd.read_csv('pandas_tutorial_buy.csv', delimiter=';', names=['my_date_time', 'event', 'user_id', 'amount'])
Набор article_read показывает всех пользователей, которые читают блог, а blog_buy — тех, купил что-то в этом блоге за период с 2018-01-01 по 2018-01-07.
Два вопроса:
- Какой средний доход в период с
2018-01-01по2018-01-07от пользователей изarticle_read? - Выведите топ-3 страны по общему уровню дохода за период с
2018-01-01по2018-01-07. (Пользователей изarticle_readздесь тоже нужно использовать).
Решение задания №1
Средний доход — 1,0852
Для вычисления использовался следующий код:
step_1 = article_read.merge(blog_buy, how='left', left_on='user_id', right_on='user_id')
step_2=step_1.amount
step_3=step_2.fillna(0)
result=step_3.mean()
result

Примечание: шаги использовались, чтобы внести ясность. Описанные функции можно записать и в одну строку.`
Краткое объяснение:
- На скриншоте также есть две строки с импортом pandas и numpy, а также чтением файлов csv в Jupyter Notebook.
- На шаге №1 объединены две таблицы (
article_readиblog_buy) на основе колонкиuser_id. В таблицеarticle_readхранятся все пользователи, даже если они ничего не покупают, потому что ноли (0) также должны учитываться при подсчете среднего дохода. Из таблицы удалены те, кто покупали, но кого нет в набореarticle_read. Все вместе привело к left-merge. - Шаг №2 — удаление ненужных колонок с сохранением только
amount. - На шаге №3 все значения
NaNзаменены на0. - В конце концов проводится подсчет с помощью
.mean().
Решение задания №2
step_1 = article_read.merge(blog_buy, how = 'left', left_on = 'user_id', right_on = 'user_id')
step_2 = step_1.fillna(0)
step_3 = step_2.groupby('country').sum()
step_4 = step_3.amount
step_5 = step_4.sort_values(ascending = False)
step_5.head(3)

Найдите топ-3 страны на скриншоте.
Краткое объяснение:
- Тот же метод
merge, что и в первом задании. - Замена всех
NaNна0. - Суммирование всех числовых значений по странам.
- Удаление всех колонок кроме
amount. - Сортировка результатов в убывающем порядке так, чтобы можно было видеть топ.
- Вывод только первых 3 строк.
Итого
Это был третий эпизод руководства pandas с важными и часто используемыми методами: merge, sort, reset_index и fillna.
Функции — одно из главных преимуществ языка Python как минимум при использовании их в проектах Data Science. Это третья часть серии материалов «Python для Data Science», в которой речь пойдет о функциях и методах.
Из нее вы узнаете не только о базовых концепциях, но познакомитесь с наиболее важными функциями и методами, которые будете использовать в будущем.
Это практическое руководство!
Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам, если вы еще не ознакомились с ними.
Что такое функции и методы Python?
Начнем с основ. Предположим, что существует переменная:
a = 'Hello!'
Вот простейший пример функции Python:
len(a)
# Результат: 6
А вот пример метода Python:
a.upper()
# Результат: HELLO!

Так что такое функции и методы Python? По сути, они превращают что-то в нечто другое. В случае этого примера ввод 'Hello!' дал вывод длины строки (6) и версию строки, переписанную с большой буквы: 'HELLO!'. Конечно, это не единственные функции. Их намного больше. Их комбинация пригодится в разных частях проекта — от очистки данных до машинного обучения.
Встроенные vs. пользовательские методы и функции
Круто то, что помимо огромного списка встроенных функций/методов, пользователи могут создавать собственные. Также они поставляются с различными Python-библиотеками. Для доступа к ним библиотеку нужно скачать и импортировать. Выходит, что возможности безграничны. Но к этому стоит вернуться позже, а сейчас сосредоточимся на встроенных элементах.
Самые важные встроенные функции Python для проектов Data Science
Функция в Python работают очень просто — ее нужно вызвать с заданными аргументами, а она вернет результат. Тип аргумента (например, строка, число, логическое значение и так далее) может быть ограничен (например, иногда нужно, чтобы это было именно целое число), но чаще аргументом может выступать значение любого типа. Рассмотрим самые важные встроенные функции Python:
print()
Эта функция уже использовалась в прошлых статьях. Она выводит различные значения на экран.
print("Hello, World!")

abs()
Возвращает абсолютную величину числа (то есть, целое число или число с плавающей точкой). Результат не может быть строкой, а только числовым значением.
abs(-4/3)

round()
Возвращает округленное значение числа
round(-4/3)

min()
Возвращает наименьший объект в списке или из общего числа введенных аргументов. Это может быть в том числе и строка.
min(3,2,5)
min('c','a','b')

max()
Несложно догадаться, что это противоположность min().
sorted()
Сортирует список по возрастанию. Он может содержать и строки и числа.
a = [3, 2, 1]
sorted(a)

sum()
Суммирует значения списка. Он может содержать разные типы числовых значений, но стоит понимать, что с числами с плавающей запятой функция справляется не всегда корректно.
a = [3, 2, 1]
sum(a)
b = [4/3 , 2/3, 1/3, 1/3, 1/3]
sum(b)

len()
Возвращает количество элементов в списке или количество символов в строке.
len('Hello!')
type()
Возвращает тип переменной
a = True
type(a)
b = 2
type(b)

Это встроенные функции Python, которые придется использовать регулярно. Со всем списком можно ознакомиться здесь: https://docs.python.org/3/library/functions.html
С многими другими вы познакомитесь в следующих руководствах.
Самые важные встроенные методы Python
Большую часть методов Python необходимо применять по отношению к конкретному типу. Например, upper() работает со строками, но не с целыми числами. А append() можно использовать на списках, но со строками, числами и логическими значениями он бесполезен. Поэтому дальше будет список методов, разбитый по типам.
Методы для строк Python
Строковые методы используются на этапе очистки данных проекта. Например, представьте, что вы собираете информацию о том, что ищут пользователи на сайте, и получили следующие строки: 'mug', 'mug ', 'Mug'. Человеку известно, что речь идет об одном и том же, но для Python это три уникальные строки. И здесь ему нужно помочь. Для этого используются самые важные строковые методы Python:
a.lower()
Возвращает версию строки с символами в нижнем регистре.
a = 'MuG'
a.lower()

a.upper()
Противоположность lower()
a.strip()
Если в строке есть пробелы в начале или в конце, метод их удалит.
a = ' Mug '
a.strip()

a.replace(‘old’, ‘new’)
Заменяет выбранную строку другой строкой. Метод чувствителен к регистру.
a = 'muh'
a.replace('h', 'g')

a.split(‘delimiter’)
Разбивает строку и делает из нее список. Аргумент выступает разделителем.
a = 'Hello World'
a.split(' ')
Примечание: в этом случае разделителем выступает пробел.

’delimeter’.join(a)
Объединяет элементы списка в строку. Разделитель можно указать заново.
a = ['Hello', 'World']
' '.join(a)

Это были самые важные методы, для работы со строками в Python.
Методы Python для работы со списками
В прошлом материале речь шла о структурах данных Python. И вот к ним нужно вернуться снова. Вы уже знаете, как создавать списки и получать доступ к их элементам. Теперь узнаете, как менять их.
Используем уже знакомую собаку Freddie:
[dog] = ['Freddie', 9 , True, 1.1, 2001, ['bone', 'little ball']]
Теперь посмотрим, как можно изменять список.
a.append(arg)
Метод append добавляет элемент к концу списка. Предположим, что нужно добавить количество лап Freddie (4).
dog.append(4)
dog

a.remove(arg)
Удалить любой из элементов можно с помощью метода .remove(). Для этого нужно указать элемент, который необходимо удалить, а Python уберет первый такой элемент в списке.
dog.remove(2001)
dog

a.count(arg)
Возвращает количество указанных элементов в списке.
dog.count('Freddie')

a.clear()
Удаляет все элементы списка. По сути, он полностью удалит Freddie. Но не стоит волноваться, потом его можно вернуть.
dog.clear()
dog

Список всех методов для работы с Python можно найти здесь: https://docs.python.org/3/tutorial/datastructures.html
Методы Python для работы со словарями
Как и в случае со списками, есть набор важных методов для работы со словарями, о которых нужно знать.
И снова Freddie:
dog_dict = {'name': 'Freddie',
'age': 9,
'is_vaccinated': True,
'height': 1.1,
'birth_year': 2001,
'belongings': ['bone', 'little ball']}
dog_dict.keys()
Вернет все ключи словаря.

dog_dict.values()
Вернет все значения словаря.

dog_dict.clear()
Удалит все из словаря.

Для добавления элемента в словарь не обязательно использовать метод; достаточно просто указать пару ключ-значение следующим образом:
dog_dict['key'] = 'value'
dog_dict['name'] = 'Freddie'

Это все методы на сегодня.
Проверьте себя
В этом задании вам нужно использовать не только то, что узнали сегодня, но и знания о структурах данных из прошлого материала, а также о переменных — из первого.
- Есть список:
test_yourself = [1, 1, 2, 2, 3, 3, 3, 3, 4, 5, 5] - Посчитайте среднее значение элементов списка, используя знания, полученные из прошлых частей руководства.
- Посчитайте медиану, следуя тем же условиям.
.
.
.
.
.
.
Решение
sum(test_yourself) / len(test_yourself)
sum() суммирует значения элементов, а len() подсчитывает их количество. Если поделить одно значение на другое, то выйдет среднее. Результат: 2.909090

test_yourself[round(len(test_yourself) / 2) - 1]
Повезло, что в списке нечетное количество элементов.
Примечание: эта формула не сработает, если элементов будет четное количество.
len(test_yourself) / 2 подскажет, где в списке искать среднее число — это и будет медиана. Результат равен 5,5, но результат len() / 2 всегда будет на 0,5 меньше, чем реальное число, если в списке нечетное количество элементов (можете проверить на списке с 3 или 5 элементами). Округлим 5,5 до 6 с помощью round(len(test_yourself) / 2). Все верно — в данном случае внутри функции используется другая функция. Затем нужно вычесть единицу, потому что индексация начинается с нуля: round(len(test_yourself) / 2) - 1.
В конце концов результат можно подставить в качестве индекса для поиска его в списке: test_yourself[round(len(test_yourself) / 2 - 1]; или взять полученное число: test_yourself[5]. Результат — 3.

В чем разница между функциями и методами в Python?
После прочтения этой статьи у вас наверняка появился вопрос: «Зачем нужны и функции и методы, если они делают одно и то же?»
Это один из самых сложных вопросов для тех, кто только знакомится с Python, а ответ включает много технических деталей, поэтому вот некоторые подсказки, чтобы начать разбираться.
Сперва очевидное. Отличается синтаксис. Функция выглядит вот так: function(something), а метод вот так: something.method().
Так зачем и методы и функции нужны в Python? Официальный ответ заключается в том, что между ними есть небольшие отличия. Так, метод всегда относится к объекту (например, в dog.append(4) методу append() нужно объект dog). В функции объект не нужно использовать. Если еще проще, метод — это определенная функция. Все методы — это функции, но не все функции являются методами.
Если все равно не понятно, но стоит волноваться. Работая с Python и дальше, вы разберетесь в различиях, особенно, когда начнете создавать собственные методы и функции.
Вот еще один дополнительный совет: функции и методы — это как артикли (der, die, das) в немецком языке. Нужно просто выучить синтаксис и использовать их по правилам.
Как и в немецком, есть эмпирические правила, которые также должны помочь. Так, функции можно применять к разным типам объектов, а методы — нет. Например, sorted() — это функция, которая работает со строками, списками, числами и так далее. Метод upper() работает исключительно со строками.
Но главный совет в том, чтобы не пытаться понять различия, а учиться их использовать.
Итого
Теперь вы знакомы более чем с 20 методами и функциями Python. Неплохое начало, но это только основы. В следующих руководствах их количество будет расти в том числе за счет функций и методов из сторонних библиотек.
Далее нужно будет разобраться с циклами и инструкциями if.
Во втором уроке руководства по работе с pandas речь пойдет об агрегации (min, max, sum, count и дргуих) и группировке. Это популярные методы в аналитике и проектах data science, поэтому убедитесь, что понимаете все в деталях!
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Агрегация данных — теория
Агрегация — это процесс превращения значений набора данных в одно значение. Например, у вас есть следующий набор данных…
| animal | water_need |
|---|---|
| zebra | 100 |
| lion | 350 |
| elephant | 670 |
| kangaroo | 200 |
…простейший метод агрегации для него — суммирование water_needs, то есть 100 + 350 + 670 + 200 = 1320. Как вариант, можно посчитать количество животных — 4. Теория не так сложна. Но пора переходить к практике.
Агрегация данных — практика
Где мы остановились в последний раз? Открыли Jupyter Notebook, импортировали pandas и numpy и загрузили два набора данных: zoo.csv и article_reads. Продолжим с этого же места. Если вы не прошли первую часть, вернитесь и начните с нее.
Начнем с набора zoo. Он был загружен следующим образом:
pd.read_csv('zoo.csv', delimiter = ',')

Дальше сохраним набор данных в переменную zoo.
zoo = pd.read_csv('zoo.csv', delimiter = ',')
Теперь нужно проделать пять шагов:
- Посчитать количество строк (количество животных) в
zoo. - Посчитать общее значение
water_needживотных. - Найти наименьшее значение
water_need. - И самое большое значение
water_need. - Наконец, среднее
water_need.
Агрегация данных pandas №1: .count()
Посчитать количество животных — то же самое, что применить функцию count к набору данных zoo:
zoo.count()

А что это за строки? На самом деле, функция count() считает количество значений в каждой колонке. В случае с zoo было 3 колонки, в каждой из которых по 22 значения.
Чтобы сделать вывод понятнее, можно выбрать колонку animal с помощью оператора выбора из предыдущей статьи:
zoo[['animal']].count()
В этом случае результат будет даже лучше, если написать следующим образом:
zoo.animal.count()
Также будет выбрана одна колонка, но набор данных pandas превратится в объект series (а это значит, что формат вывода будет отличаться).

Агрегация данных pandas №2: .sum()
Следуя той же логике, можно с легкостью найти сумму значений в колонке water_need с помощью:
zoo.water_need.sum()

Просто из любопытства можно попробовать найти сумму во всех колонках:
zoo.sum()

Примечание: интересно, как
.sum()превращает слова из колонкиanimalв строку названий животных. (Кстати, это соответствует всей логике языка Python).
Агрегация данных pandas №3 и №4: .min() и .max()
Какое наименьшее значение в колонке water_need? Определить это несложно:
zoo.water_need.min()

То же и с максимальным значением:
zoo.water_need.max()

Агрегация данных pandas №5 и №6: .mean() и .median()
Наконец, стоит посчитать среднестатистические показатели, например среднее и медиану:
zoo.water_need.mean()

zoo.water_need.median()

Это было просто. Намного проще, чем агрегация в SQL.
Но можно усложнить все немного с помощью группировки.
Группировка в pandas
Работая аналитиком или специалистом Data Science, вы наверняка постоянно будете заниматься сегментациями. Например, хорошо знать количество необходимой воды (water_need) для всех животных (это 347,72). Но удобнее разбить это число по типу животных.
Вот упрощенная репрезентация того, как pandas осуществляет «сегментацию» (группировку и агрегацию) на основе значений колонок!
Функция .groupby в действии
Проделаем эту же группировку с DataFrame zoo.
Между переменной zoo и функцией .mean() нужно вставить ключевое слово groupby:
zoo.groupby('animal').mean()

Как и раньше, pandas автоматически проведет расчеты .mean() для оставшихся колонок (колонка animal пропала, потому что по ней проводилась группировка). Можно или игнорировать колонку uniq_id или удалить ее одним из следующих способов:
zoo.groupby('animal').mean()[['water_need']] — возвращает объект DataFrame.
zoo.groupby('animal').mean().water_need — возвращает объект Series.
Можно поменять метод агрегации с .mean() на любой изученный до этого.
Пришло время…
Проверить себя №1
Вернемся к набору данных article_read.
Примечание: стоит напомнить, что в этом наборе хранятся данные из блога о путешествиях. Скачать его можно отсюда. Пошаговый процесс загрузки, открытия и сохранения есть в прошлом материале руководства.
Если все готово, вот первое задание:
Какой источник используется в article_read чаще остальных?
.
.
.
.
.
.
Правильный ответ:
Reddit!
Получить его можно было с помощью кода:
article_read.groupby('source').count()
Взять набор данных article_read, создать сегменты по значениям колонки source (groupby('source')) и в конце концов посчитать значения по источникам (.count()).

Также можно удалить ненужные колонки и сохранить только user_id:
article_read.groupby('source').count()[['user_id']]
Проверить себя №2
Вот еще одна, более сложная задача:
Какие самые популярные источник и страна для пользователей country_2? Другими словами, какая тема из какого источника принесла больше всего просмотров из country_2?
.
.
.
.
.
.
Правильный ответ: Reddit (источник) и Азия (тема) с 139 прочтениями.
Вот Python-код для получения результата:
article_read[article_read.country == 'country_2'].groupby(['source', 'topic']).count()

Вот краткое объяснение:
В первую очередь отфильтровали пользователей из country_2 (article_read[article_read.country == 'country_2']). Затем для этого подмножества был использован метод groupby. (Да, группировку можно осуществлять для нескольких колонок. Для этого их названия нужно собрать в список. Поэтому квадратные скобки используются между круглыми. Это что касается части groupby(['source', 'topic'])).
А функция count() — заключительный элемент пазла.
Итого
Это была вторая часть руководства по работе с pandas. Теперь вы знаете, что агрегация и группировка в pandas— это простые операции, а использовать их придется часто.
Примечание: если вы ранее пользовались SQL, сделайте перерыв и сравните методы агрегации в SQL и pandas. Так лучше станет понятна разница между языками.
В следующем материале вы узнаете о четырех распространенных методах форматирования данных: merge, sort, reset_index и fillna.
В предыдущей статье речь шла о переменных в Python. Теперь нужно обсудить вторую важную тему, без которой невозможно работать с этим языком в Data Science — структуры данных в Python.
Это практическое руководство!
Желательно повторять те части, где нужно писать код, и решать задачи в конце статьи! Также рекомендуется вернуться к прошлым материалам, если вы еще не ознакомились с ними.
Почему структуры данных в Python так важны?
Представьте книгу. Пусть это будет «Практическая статистика для специалистов Data Science» П. Брюса и Э. Брюса. Сохранить эту информацию можно, поместив ее в переменную.
my_book = "Практическая статистика для специалистов Data Science"
Готово!
А если рядом лежат также «Цифровая крепость» Дэна Брауна и «Игра престолов» Джорджа Мартина? Как сохранить их? Можно снова воспользоваться переменными:
my_book2 = "Цифровая крепость"
my_book3 = "Игра престолов"
А если позади целый книжный шкаф? Вот здесь и появляется проблема. Иногда в Python нужно хранить релевантную информацию в одном объекте, а не разбивать ее по переменным.
Вот зачем нужны структуры данных!
Структуры данных Python
В Python 3 основные структуры данных:
- Списки
book_list = ['Игра престолов', 'Цифровая крепость', 'Практическая статистика для специалистов Data Science'] - Кортежи
book_tuple = ('Игра престолов', 'Цифровая крепость', 'Практическая статистика для специалистов Data Science') - Словари
book_dictionary = {'Джордж Мартин': 'Игра престолов', 'Дэн Браун': 'Цифровая крепость', 'П. & Э. Брюсы': 'Практическая статистика для специалистов Data Science'}
Все три нужны для разных ситуаций и использовать их необходимо по-разному.
Перейдем к деталям!
Первая структура данных Python: Список
Начнем с самого простого — списков в Python.
Список — это последовательность значений. Это данные, заключенные в квадратные скобки и разделенные запятыми. Простой пример — список целых чисел:
[3, 4, 1, 4, 5, 2, 7]
Важно понимать, что в Python список является объектом, поэтому работать с ним можно так же, как и с любыми другими типами данных (например, целыми числами, строками, булевыми операторами и так далее). Это значит, что список можно присвоить переменной, чтобы хранить ее таким образом и получать доступ в дальнейшем более простым способом:
my_first_list = [3, 4, 1, 4, 5, 2, 7]
my_first_list

Список может содержать другие типы данных, включая строки, логические значения и даже другие списки. Помните собаку Freddie из прошлой статьи?

Ее параметры можно сохранить в одном списке, а не разбивать на 5 разных переменных:
dog = ['Freddie', 9, True, 1.1, 2001]

Теперь предположим, что Freddie принадлежит две вещи: кость и маленький мяч. Их можно сохранить внутри списка отдельным списком.
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]
На самом деле, вот так углубляться в дерево списков можно бесконечно. Этот прием (официально он называется «вложенными списками») будет важен при работе с Data Science в Python — например, при создании многомерных массивов numpy для запуска корреляционных анализов… но сейчас не об этом! Главное, что нужно запомнить — списки можно хранить внутри других списков.
Попробуйте:
sample_matrix = [[1, 4, 9], [1, 8, 27], [1, 16, 81]]

Чувствуете себя ученым? Стоило бы, потому что вы создали двухмерный массив размерами 3-на-3.
Как получить доступ к конкретному элементу в списке Python?
Теперь, когда значения сохранены, нужно разобраться, как получать к ним доступ в будущем. Вернуть целый список можно с помощью имени переменной. Например dog
Но как вызвать один элемент из списка? Сперва подумайте, как можно обратиться к одному из элементов в теории? Единственное, что приходит в голову, — положение значения. Так, если нужно вернуть первый элемент из списка dog, необходимо ввести его название и номер элемента в скобках: [1]. Попробуйте: dog[1]

Что??? Цифра 9 была вторым элементом списка, а не первым. Однако в Python это работает иначе. Python использует так называемое «индексирование с нуля». Это значит, что номер первого элемента — это всегда [0], второго — [1], третьего — [2] и так далее. Это важно помнить, работая со структурами данных в Python.
Если вам кажется, что это слишком сложно, просто почитайте открытое письмо известного ученого Дейкстра, написанное в 1982 году: https://www.cs.utexas.edu/users/EWD/transcriptions/EWD08xx/EWD831.html. А теперь просто перестаньте думать об этом и запомните, что так будет всегда!
Вот подробный пример!
Собака Freddie:
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]

Попробуйте вывести все элементы списка один за одним:
dog[0]
dog[1]
dog[2]
dog[3]
dog[4]
dog[5]

Запутанно… Но к этому можно привыкнуть.
Как получить доступ к определенному элементу вложенного списка в Python
Еще один важный момент о Freddie. Нужно вывести его вещи друг за другом
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]
Догадаетесь, как получить элемент bone, заключенный во вложенный список? Это максимально интуитивно.
Он будет нулевым элементом пятого элемента:
dog[5][0]Если на 100% не понятно, почему все работает именно так, поиграйтесь с этим набором данных и вы разберетесь: sample_matrix = [[1, 4, 9], [1, 8, 27], [1, 16, 81]].
Как получить доступ к нескольким элементам списка Python
Вот еще один трюк. Можно использовать двоеточие между двумя числами в скобках, чтобы получить последовательность значений.
dog[1:4]

Пока это все, что вам нужно знать о списках Python.
Вторая структура данных Python: Кортежи
Что такое кортеж в Python? Во-первых, начинающий специалист Data Science не должен много думать об этой структуре. Можете и вовсе пропустить этот раздел.
Если все-таки остались:
Кортеж в Python — почти то же самое, что и список в Python с небольшими отличиями.
- Синтаксис: при объявлении используются не квадратные скобки, а круглые.
Список:book_list = ['Игра престолов', 'Цифровая крепость', 'Практическая статистика для специалистов Data Science']Кортежи
book_tuple = ('Игра престолов', 'Цифровая крепость', 'Практическая статистика для специалистов Data Science') - Список — изменяемый тип данных, поэтому в нем можно добавлять, удалять или изменять элементы. Кортеж — неизменяемый тип данных. Он остается таким, каким был и объявлен. Это строгость пригодится, чтобы сделать код безопаснее.
- Кортежи работают быстрее, чем списки в Python в одних и тех же операциях.
В остальном кортежи можно использовать так же, как и списки. Даже возвращать отдельный элемент нужно с помощью квадратных скобок. (Попробуйте book_tuple[1] на новом кортеже).
book_tuple[1]
'Цифровая крепость'
Еще раз: ничего из вышесказанного не будет вас заботить первое время, но хорошо знать хотя бы что-нибудь о кортежах.
Третья структура данных Python: Словари
Словари — это совсем другая история. Они сильно отличаются от списков и очень часто используются в проектах data science.
Особенность словарей в том, что у каждого значения есть уникальный ключ. Взглянем еще раз на собаку Freddie:
dog = ['Freddie', 9, True, 1.1, 2001, ['bone', 'little ball']]
Это значения с параметрами собаки, которые нужно сохранить. В словаре для каждого значения можно назначить свой ключ так, чтобы понимать, что они обозначают.
`dog_dict = {'name': 'Freddie', 'age': 9, 'is_vaccinated': True, 'height': 1.1, 'birth_year': 2001, 'belongings': ['bone', 'little ball']}`

Вывод заранее форматируется Python. Чтобы лучше разобраться, то же самое можно сделать изначально, перенеся каждое значение на новую строку:
dog_dict = {'name': 'Freddie',
'age': 9,
'is_vaccinated': True,
'height': 1.1,
'birth_year': 2001,
'belongings': ['bone', 'little ball']}
Как можно видеть, вложенный список (в этом примере belongings) как значение словаря не является проблемой.
Это что касается внешнего вида словарей в Python.
Как получить доступ к конкретному элементу словаря Python
Самое важное, что нужно запомнить о получении доступа к элементу любого типа в любой структуре данных Python, это то, что вне зависимости от структуры (список, кортеж или словарь), нужно всего лишь ввести название структуры и универсальный идентификатор элемента в квадратных скобках (например, [1]).
То же касается и словарей.
Единственное отличие в том, что для списков и кортежей идентификатором выступает номер элемента, а здесь ключ. Попробуйте:
dog_dict['name']

Примечание: наверняка возникает вопрос, а можно ли использовать число для доступа к значению словаря. Нет, потому что словари в Python по умолчанию не упорядочены — это значит, что ни у одной пары ключ-значение нет своего номера.
Примечание: нельзя также вывести ключ с помощью значения. Python попросту не предназначен для этого.
Проверьте себя
Вы многое узнали о структурах данных. Даже если вы не выполняли прошлые уроки в конце статей, сделайте исключение для этой. Структуры — это то, что придется использовать постоянно, поэтому сделайте себе одолжение и попробуйте разобраться во всем на 100%
Упражнение:
- Скопируйте этот супер-вложенный список-словарь Python в Jupyter Notebook и присвойте его переменной
test.test = [{'Arizona': 'Phoenix', 'California': 'Sacramento', 'Hawaii': 'Honolulu'}, 1000, 2000, 3000, ['hat', 't-shirt', 'jeans', {'socks1': 'red', 'socks2': 'blue'}]] - Выполните эти 6 небольших заданий, выводя конкретные значения из списка-словаря! Каждое следующее будет немного сложнее.2.1. Верните
20002.2. Верните словарь с городами и штатами{'Arizona': 'Phoenix', 'California': 'Sacramento', 'Hawaii': 'Honolulu'}2.3. Верните список вещей['hat', 't-shirt', 'jeans', {'socks1': 'red', 'socks2': 'blue'}]2.4. Верните слово'Phoenix'2.5. Верните слово'jeans'2.6. Верните слово
'blue'
.
.
.
.
.
.
Решения
test[2]— главная сложность в том, чтобы запомнить, что индексирование начинается с нуля, а это значит, что2000— второй элемент.test[0]— это выведет весь словарь из основного списка.test[4]— как и в предыдущих примерах, будет выведен вложенный список.test[0]['Arizona"]— следующий этап для второго задания. Здесь с помощью ключа'Arizona'вызывается значение'Phoenix'.test[4][2]— это решение связано с третьим заданием. Обращаемся к'jeans'по номеру. Главное не забыть об индексировании с нуля.test[4][3]['socks2']— последний шаг — вызов элемента из словаря в списке, вложенного в другой список

Итог
Итак, вы справились с еще одним руководством по Python! Это почти все, что нужно знать о структурах данных. Впереди будет еще много небольших, но важных деталей (например, о том, как добавлять, удалять и изменять элементы в списке или словаре)… но до этого необходимо разобраться с функциями и методами.
]]>Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».

- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:
import numpy as np import pandas as pd
Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть
as pd, Jupyter Notebook понимает, что в будущем, при вводеpdподразумевается именно библиотека pandas.
Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.

DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.

В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv().
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
animal,uniq_id,water_need
elephant,1001,500
elephant,1002,600
elephant,1003,550
tiger,1004,300
tiger,1005,320
tiger,1006,330
tiger,1007,290
tiger,1008,310
zebra,1009,200
zebra,1010,220
zebra,1011,240
zebra,1012,230
zebra,1013,220
zebra,1014,100
zebra,1015,80
lion,1016,420
lion,1017,600
lion,1018,500
lion,1019,390
kangaroo,1020,410
kangaroo,1021,430
kangaroo,1022,410
Вернемся во вкладку “Home” https://you_ip:you_port/tree Jupyter для создания нового текстового файла…

затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…

…и назовем его zoo.csv!

Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
pd.read_csv('zoo.csv', delimiter=',')

Готово! Это файл zoo.csv, перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv
Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:

Если кликнуть на него…

…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
pd.read_csv('pandas_tutorial_read.csv', delimete=';')
Данные загружены в pandas!

Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
pd.read_csv('pandas_tutorial_read.csv', delimiter=';',
names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'])

Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл
.csvчерез URL напрямую. В этом случае данные не загрузятся на сервер данных.
pd.read_csv(
'https://pythonru.com/downloads/pandas_tutorial_read.csv',
delimiter=';',
names=['my_datetime', 'event', 'country',
'user_id', 'source', 'topic']
)
Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
article_read = pd.read_csv(
'pandas_tutorial_read.csv',
delimiter=';',
names = ['my_datetime', 'event', 'country',
'user_id', 'source', 'topic']
)
После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!

Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
article_read.head()

Или последние 5 строк:
article_read.tail()

Или 5 случайных строк:
article_read.sample(5)

Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
article_read[['country', 'user_id']]

Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
- article_read.user_id
- article_read[‘user_id’]

Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
article_read[article_read.source == 'SEO']
Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли 'SEO' значением колонки article_read.source? Результат всегда будет булевым значением (True или False).

Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read.

Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
article_read.head()[['country', 'user_id']]
Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
article_read[['country', 'user_id']].head()
В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
pd.read_csv(
'pandas_tutorial_read.csv',
delimiter=';',
names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic']
)[['country', 'user_id']].head()
Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2. Выведите первые 5 строк!
Вперед!
.
.
.
.
.
А вот и решение!
Его можно преподнести одной строкой:
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head()
Или, чтобы было понятнее, можно разбить на несколько строк:
ar_filtered = article_read[article_read.country == 'country_2']
ar_filtered_cols = ar_filtered[['user_id','topic', 'country']]
ar_filtered_cols.head()
В любом случае, логика не отличается. Сначала берется оригинальный dataframe (article_read), затем отфильтровываются строки со значением для колонки country — country_2 ([article_read.country == 'country_2']). Потому берутся три нужные колонки ([['user_id', 'topic', 'country']]) и в конечном итоге выбираются только первые пять строк (.head()).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
]]>Если вы изучаете Data Science (науку о данных), то довольно быстро встретитесь с Python. Почему? Потому что это один из самых используемых языков программирования для работы с данными. Он популярен по 3 основным причинам:
- Его легко изучать, с ним легко работать
- Python прекрасно работает с разными структурами данных
- Существуют мощные библиотеки языка для визуализации данных и статистики
В этом руководстве речь пойдет обо всем, что нужно знать, начиная с основ. Даже если вы никогда не работали с кодом, то точно оказались в нужном месте. Затрагиваться будет только та часть языка, которая имеет отношение к data science — ненужные и непрактичные нюансы пропустим. А в конце обязательно создадим что-то интересное, например, прогнозную аналитику.
Это практическое руководство!
Делать что-то, следуя инструкциям, всегда полезнее, чем просто читать. Если те части, в которых есть код, вы будете повторять самостоятельно, набирая его на своем ПК, то разберетесь и запомните все в 10 раз лучше. А в конце статьи обязательно будет одно-два упражнения для проверки!
Это значит, что для практики нужна некоторая подготовка. Установите:
- Python 3.6+
- Jupyter (с iPython)
- Библиотеки: pandas, numpy, scikit, matplotlib
Зачем учить Python для Data Science?
Когда настает время изучать код для работы с данными, стоит сосредоточиться на этих 4 языках:
- SQL
- Python
- R
- Bash
Конечно, хорошо бы изучить все четыре. Но если вы только начинаете, то стоит начать с одного или двух. Чаще всего рекомендуют выбирать Python и SQL. С их помощью удастся охватить 99% процесса работы с данными и аналитических проблем.
Но почему стоит изучать Python для Data Science?
- Это легко и весело.
- Есть много библиотек для простых аналитических проектов (например, сегментация, групповой анализ, исследовательская аналитика и так далее) и более сложных (например, построение моделей машинного обучения).
- Рынок труда требует профессионалов в сфере работы с данными, у которых хорошие знания Python. Это значит, что Python в резюме будет чрезвычайно конкурентоспособным пунктом.
Что такое Python? Он подходит только для Data Science?
Теоретическая часть будет короткой. Но вам нужно знать две вещи о языке, прежде чем начинать использовать его.
- Python — язык общего назначения и он используется не только для Data Science. Это значит, что его не нужно знать идеально, чтобы быть экспертом в сфере работы с данными. В то же время даже основ будет достаточно, чтобы понимать и другие языки, а это очень удобно для работы в IT.
- Python — высокоуровневый язык. Это значит, что в отношении процессорного времени он не самый эффективный. С другой же стороны, он был создан очень простым, «удобным для использования» и понятным. Так, пусть вы и проиграете в процессорном времени, но сможете отыграться в процессе разработки.
Python 2 vs Python 3 – какой выбрать для Data Science?
Многие слышали о противостоянии Python 2.x и Python 3.x. Суть его в том, что Python 3 существует с 2008 года, и 95% функций и библиотек для data science уже перекочевали из Python 2. Также Python 2 перестанет поддерживаться после 2020 года. Учить его — то же самое, что учить латынь — иногда полезно, но будущее все равно за Python 3.
По этой причине все эти руководства написаны на Python 3.
Примечание: тем не менее почти всегда используется код, который будет работать в обеих версиях.
Достаточно теории! Пора программировать!
Как открыть Jupyter Notebook
Когда Jupyter Notebook установлен, следуйте этим 4 шагам каждый раз, когда нужно будет его запустить:
Есть вы работаете локально, достаточно запустить программу Jupyter Notebook и перейти к пункту 4.
- Войти на сервер! Для этого нужно открыть терминал и ввести следующее в командную строку:
ssh [ваш_логин]@[ваш ip-адрес]
и пароль.
(Например:ssh dataguy@178.62.1.214)

- Запустить Jupyter Notebeook на сервере с помощью команды:
jupyter notebook --browser any

- Получить доступ к Jupyter из браузера! Для этого нужно открыть Google Chrome (или любой другой) и ввести следующее в адресную строку:
[IP адрес удаленного сервера]:8888
(Например: 178.62.1.214:8888)
На экране отобразится следующее:

Нужно будет ввести “password” (пароль) или “token” (токен). Поскольку пароля пока нет, сначала нужно использовать токен, который можно найти в окне терминала:

- Готово! Теперь нужно создать новый Jupyter Notebook! (Если он создан, осталось его открыть).

Важно! Во время работы в браузере окно терминал сдолжен работать в фоне. Если его закрыть, Jupyter в браузере тоже закроется.
Вот и все. Запомните порядок действий, потому что их придется повторять часто в этом руководстве по Python для Data Science.
Как использовать Jupyter Notebeook
Теперь разберем, как пользоваться Jupyter Notebook!

- Введите команду Python! Это может быть команда на несколько строк — если нажать Enter, ничего не запустится, а в этой же ячейке появится новая строка!

- Для запуска команды Python нужно нажать
SHIFT + ENTER!

- Введите что-то и нажмите
TAB. Если это возможно, Jupyter автоматически закончит выражение (для команд Python и указанных переменных). Если вариантов несколько, появится выпадающее меню.

Основы Python
Прекрасно! Вы знаете все, что может понадобиться с технической стороны. Дальше речь пойдет об основных концепциях, которые нужно изучить, прежде чем переходить к использованию Python в Data Science. Вот эти 6 концепций:
- Переменные и типы данных
- Структуры данных в Python
- Функции и методы
- Инструкция (оператор) if
- Циклы
- Основы синтаксиса Python
Чтобы упростить процесс изучения и практики, эти 6 тем разбиты на 6 статей. Вот первая.
Основы Python №1: переменные и типы данных
В Python значения присваиваются переменным. Почему? Потому что это улучшает код — делает его более гибким, понятным и позволяет легко использовать повторно. В то же время «концепция присваивания» является одной из самых сложных в программировании. Когда код ссылается на элемент, который в свою очередь ссылается на другой элемент… это непросто. Но как только привыкаете, это начинает нравиться!
Посмотрим, как это работает!
Предположим, что есть собака (“Freddie”), и нужно сохранить ее черты (name, age, is_vaccinated, birth_year и так далее) в переменных Python. В ячейке Jupyter Notebook нужно ввести следующее:
dog_name = 'Freddie'
age = 9
is_vaccinated = True
height = 1.1
birth_year = 2001
Примечание: это же можно сделать по одной переменной для каждой ячейки. Но такое решение все-в-одном проще и изящнее.
С этого момент если вводить названия переменных, то те будут возвращать соответствующие значения:

Как и в SQL в Python есть несколько типов данных.
Например, переменная dog_name хранит строку: 'Freddie'. В Python 3 строка — это последовательность символов в кодировке Unicode (например, цифры, буквы, знаки препинания и так далее), поэтому она может содержать цифры, знаки восклицания и почти все что угодно (например, ‘R2-D2’ — допустимая строка). В Python легко определить строку — она записывается в кавычках.
age и birth_year хранят целые числа (9 и 2001) — это числовой тип данных Python. Другой тип данных — числа с плавающей точкой (float). В примере это height со значением 1.1.
Значение True переменной is_vaccinated — это логический тип (или булевый тип). В этом типе есть только два значения: True и False.
Резюме в таблице:
| Имя переменной | Значение | Тип данных |
|---|---|---|
dog_name |
'Freddie' |
str (сокр. от ‘string’ — строка) |
age |
9 |
int (сокр. от ‘integer’ — целое число) |
is_vaccinated |
True |
bool (сокр. от Boolean — булев тип) |
height |
1.1 |
float (сокр. от floating — с плавающей запятой) |
birth_year |
2001 |
int (сокр. от integer) |
Есть и другие типы данных, но для начала этих четырех будет достаточно.
Важно знать, что любую переменную Python можно перезаписать. Например, если запустить:
_dog_name = 'Eddie'
в Jupyter Notebook, тогда имя пса больше не будет ‘Freddie’…

Переменные Python — основные операторы
Вы знаете, что такое переменные. Пора поэкспериментировать с ними! Определим две переменные: a и b:
a = 3
b = 4
Что можно сделать с a и b? В первую очередь, есть набор арифметических операций! Ничего необычного, но вот список:
| Оператор | Что делает? | Результат |
|---|---|---|
a + b |
Складывает a и b | 7 |
a - b |
Вычитает b из a | -1 |
a * b |
Умножает a на b | 12 |
a / b |
Делит a на b | 0.75 |
b % a |
Делит b на a и возвращает остаток | 1 |
a ** b |
Возводит a в степень b | 81 |
Вот как это выглядит в Jupyter:

Примечание: попробуйте самостоятельно со своими переменными в Jupyter Notebook.
Можно использовать переменные с операторами сравнения. Результатом всегда будут логические True или False. a и b все еще 3 и 4.
| Оператор | Что делает? | Результат |
|---|---|---|
a > b |
Оценивает, больше ли a чем b |
False |
a < b |
Оценивает, меньше ли a чем b |
True |
a == b |
Оценивает, равны ли a и b |
False |
В Jupyter Notebook:

В итоге, переменные сами могут быть логическими операторами. Определим c и d:
c = True
d = False
| Оператор | Что делает? | Результат |
|---|---|---|
c and d |
True, если c и d — True |
False |
c or d |
True, если c или d — True |
True |
not c |
Противоположное c |
False |

Это легко и, возможно, не так интересно, но все-таки: попробуйте ввести все это в Jupyter Notebook, запустите команды и начните соединять элементы — будет интереснее.
Время переходить к заданиям.
Проверьте себя №1
Вот несколько переменных:
a = 1
b = 2
c = 3
d = True
e = 'cool'
Какой тип данных вернется, и каким будет результат всей операции?
a == e or d and c > b
Примечание: сперва попробуйте ответить на этот вопрос без Python — а затем проверьте, правильно ли вы определили!
.
.
.
Ответ: это будет логический тип данных со значением True.
Почему? Потому что:
- Значение
a == eравноFalse, поскольку 1 не равняется ‘cool’ - Значение
dравноTrueпо определению - Значение
c > bравноTrue, потому что 3 больше 2
Таким образом, a == e or d and c > b превращается в False or True and True, что в итоге приводит к True.
Проверьте себя №2
Используйте переменные из прошлого задания:
a = 1
b = 2
c = 3
d = True
e = 'cool'
Но в этот раз попробуйте определить результат слегка измененного выражения:
not a == e or d and not c > b
Чтобы правильно решить эту задачку, нужно знать порядок исполнения логических операторов:
- not
- and
- or
.
.
.
Ответ: True.
Почему? Разберем.
Пользуясь логикой прошлого задания, можно прийти к выводу, что выражение равняется: not False or True and not True.
Первым исполняется оператор not. После того как все not оценены, остается: True or True and False.
Второй шаг — определить оператор and. Переводим и получаем True or (True and False), что приводит к True or False.
И финальный шаг — or:
True or False → True
Выводы
Осознали ли вы, что программировали на Python 3? Не правда ли, что было легко и весело?
Хорошие новости в том, что в остальном Python настолько же прост. Сложность появляется от объединения простых вещей… Именно поэтому так важно знать основы!
В следующей части «Python для Data Science» вы узнаете о самых важных структурах данных в Python.
]]>