

Scrapy — это продвинутый Python-фреймворк для веб-скрапинга, который помогает разработчикам извлекать данные с разных сайтов. Scrapy использует веб-краулеров, называемых Spider. Они могут доставать, обрабатывать и сохранять данные. Поскольку Scrapy построен на базе Twitsted, асинхронного сетевого фреймворка, он отправляет запросы без блокировки потока. Это влияет на скорость.
Преимущества Scrapy
- Имеется встроенный механизм под названием Selector, который отвечает за поиск и извлечение данные со страниц с помощью Xpath и CSS.
- Для работы Scrapy не нужно много дополнительного кода как в случае с остальными фреймворками. Достаточно лишь указать сайт и данные, которые требуется получить. Scrapy сделает все остальное.
- Scrapy — это бесплатный, кроссплатформенный проект с открытым исходным кодом.
- Он является быстрым, мощным и легко расширяемым за счет асинхронной обработки запросов.
- Используется для создания скраперов для крупных проектов.
- С помощью Scrapy можно извлекать данные с любых страниц вне зависимости от их доступности.
- Куда меньшее потребление памяти и мощности процессора в сравнении с другими библиотеками.
- Поддерживает экспорт данных в разные форматы, включая CSV, XML, JSON и JSON Line.
- Отличное сообщество для разработчиков.
Установка Scrapy
Scrapy работает в обеих версиях Python (2 и 3), но в этом руководстве будет использоваться Python 3. Есть два способа установки. Если имеется Anaconda, то нужно использовать канал conda-forge. Сама платформа доступна по ссылке.
Второй вариант — использовать пакетный менеджер pip. С его помощью можно установить Scrapy прямо на компьютер.
conda install -c conda-forge scrapy
pip install scrapy
В обоих случаях будет загружена и установлена последняя версия.
Создание проекта Scrapy
Архив с кодом проекта. Весь код протестирован на: python 3.8 / scrapy 2.3.0 / ubuntu 16.04
Для создания проекта нужно переместиться в папку с ним. Дальше создается проект Scrapy. В этом руководстве он будет называться scrapy_tutorial.
scrapy startproject scrapy_tutorial
Есть вы получили ошибку No module named ‘_cffi_backend’, установите cffi — pip install cffi
Когда проект создан, появляются папка и конфигурационный файл. Новая директория содержит различные компоненты поискового роботы, который будут созданы позже. Внутри проекта следующая структура.

Рассмотрим в подробностях.
| Файл | Описание |
| spiders | Эта папка содержит всех Spider в формате класса Python. Если запустить Scrapy, то он выполнит поиск именно в этой папке |
| items.py | Содержит контейнер, который будет загружаться вместе с извлеченными данными |
| middleware.py | Содержит механизм обработки для работы с запросами и ответами |
| pipeline.py | Набор классов Python для последующей обработки классов |
| settings.py | Здесь находятся все настройки |
Создание Spider
Spider — это класс, содержащий методологию извлечения данных с указанного сайта. Другими словами, он определяет, как именно должен проходить процесс.
Для создания Spider используется такая команда.
scrapy genspider spidername your-link-here
В качестве spidername можно задать любое название, а на месте ссылки — URL сайта или домена, с которого требуется извлечь данные. В этом руководстве попробуем достать пользовательские обзоры на Apple iPhone XS Max с сайта Amazon.com.
Поэтому Spider будет называться reviewspider.
scrapy genspider reviewspider amazon.com/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S
Scrapy Shell
Scrapy Shell — это интерактивная оболочка, напоминающая Python Shell, где можно проверять свой код. С помощью нее можно протестировать выражения Xpath и CSS, убедившись, что данные извлекаются. Spider при этом даже не будет запускаться. Это быстрый и важный инструмент для разработки и отладки.
scrapy shell https://www.amazon.com/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S
Определение структуры HTML
Прежде чем переходить к написанию кода самого Spider нужно проанализировать структуру страницы.
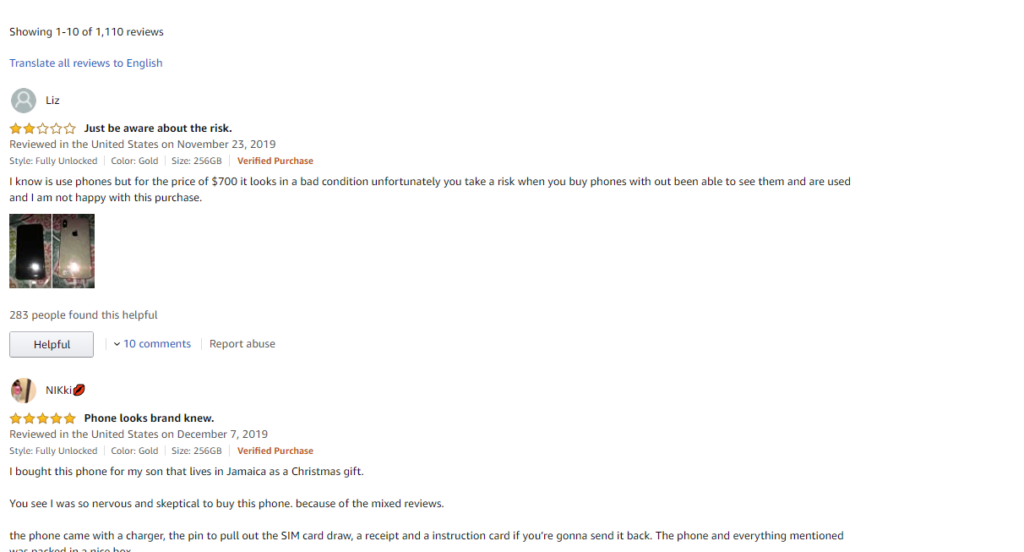
На изображении видно, что у каждого обзора есть текст и оценка в звездах. Будет извлекать оба элемента.
Для просмотра структуры нужно кликнуть правой кнопкой по странице и нажать «Посмотреть код» или посмотреть код с помощью инструментов разработчика в браузере.
Согласно структуре все отзывы заключены в блок с id cm_cr-review_list, у которого есть внутренние блоки для каждого отзыва.
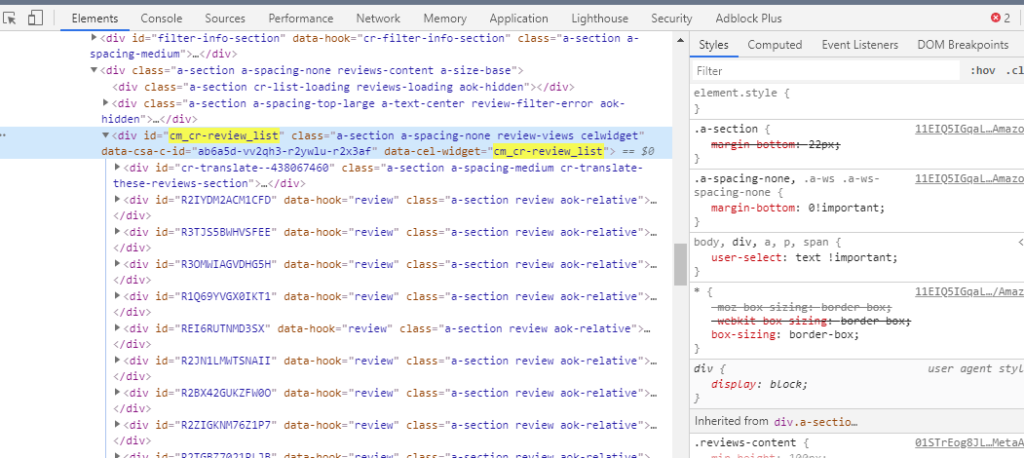
Если раскрывать их, то можно увидеть отдельные блоки для каждого компонента обзора. Однако сейчас важны только рейтинг в звездочках и текст.
<i data-hook="review-star-rating" class="a-icon a-icon-star a-star-2 review-rating">
<span class="a-icon-alt">2.0 out of 5 stars</span>
</i>Здесь рейтинг определяется классом a-icon-alt.
<span data-hook="review-body" class="a-size-base review-text review-text-content">
<span>
I know is use phones but for the price of $700 it looks in
a bad condition unfortunately you take a risk when you buy
phones with out been able to see them and are used and I am
not happy with this purchase.
</span>
</span>Текст же заключен в класс a-size-base. Эта информация пригодится для создания Spider.
Создание парсера Scrapy
Если открыть Spider, который был создан раньше, то внутри будет такой класс.
import scrapy
class ReviewspiderSpider(scrapy.Spider):
name = 'reviewspider'
allowed_domains = ['amazon.com']
start_urls = ['https://www.amazon.com/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S/']
def parse(self, response):
pass
Это базовый шаблон, а allowed_domains и start_urls определены на основе переданных ссылок.
Логика извлечения данных будет прописана в функции parse, которая начнет работу после перехода на страницу, указанную в start_urls.
Scrapy предоставляет возможность поиска по нескольким URL одновременно. Для этого нужно определить базовый URL и те части, которые нужны присоединить к нему. Делается это с помощью urljoin(). Однако в этом примере достаточно будет лишь одной ссылки.
Далее код, который будет извлекать отзывы пользователей.
import scrapy
class ReviewspiderSpider(scrapy.Spider):
name = 'reviewspider'
allowed_domains = ['amazon.com']
start_urls = ['https://www.amazon.com/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S/']
def parse(self, response):
pass
В Scrapy есть собственный механизм, селекторы, для извлечения данных. Они используют выражения Xpath и CSS для выбора разных элементов в HTML-документах. В этом коде в качестве селектора используется Xpath.
star_rating=response.xpath('//span[@class="a-icon-alt"]/text()').extract()В последней строке Scrapy использует Xpath для получения узла в ответе и извлечения его данных в текстовом формате.
for item in zip(star_rating, comments):
# создаем словарь для хранения собранной информации
scraped_data = {
'Рейтинг': item[0],
'Отзыв': item[1],
}Здесь каждый элемент добавляется в словарь Python.
yield scraped_dataYield возвращает извлеченные данные для обработки и сохранения.
Обработка нескольких страниц
В примере выше функция parse работала для одной страницы. Но это неэффективно, когда обзоры расположены на нескольких. Поэтому нужно расширить код так, чтобы была возможность перемещаться по всем доступным страницам и извлекать данные тем же способом.
Перемещение по страницам происходит с помощью кнопки Next Page, и вот HTML-код для нее.
<li class="a-last">
<a href="/Apple-iPhone-Max-Fully-Unlocked/product-reviews/B07KFNRQ5S/ref=cm_cr_arp_d_paging_btm_2?ie=UTF8&pageNumber=2">
Next page
<span class="a-letter-space"></span>
<span class="a-letter-space"></span>
→
</a>
</li>Теперь осталось изменить Spider так, чтобы он мог определять кнопку и проверять, существует ли она. Если да, то он будет переходить по ней и снова вызывать парсер. Для этого достаточно добавить следующее в конец функции parse.
def parse(self, response):
star_rating = response.xpath('//span[@class="a-icon-alt"]/text()').extract()
comments = response.xpath('//span[@class="a-size-base review-text review-text-content"]/span/text()').extract()
count = 0
for item in zip(star_rating, comments):
# создаем словарь для хранения собранной информации
scraped_data = {
'Рейтинг': item[0],
'Отзыв': item[1],
}
# возвращаем собранную информацию
yield scraped_data
Здесь в качестве селектора для Next Page использовался CSS. После определения extract_first() ищет первое совпадение и проверяет, существует ли оно. Если да, то для нового URL вызывается метод self.parse.
Работа Spider
После создания Spider его нужно запустить с помощью следующей команды.
next_page = response.css('.a-last a ::attr(href)').extract_first()
if next_page:
yield scrapy.Request(
response.urljoin(next_page),
callback=self.parse
)
Команда runspider принимает reviewspider.py в качестве входящего файла и возвращает CSV-файл scraped_data.csv с собранными результатами.
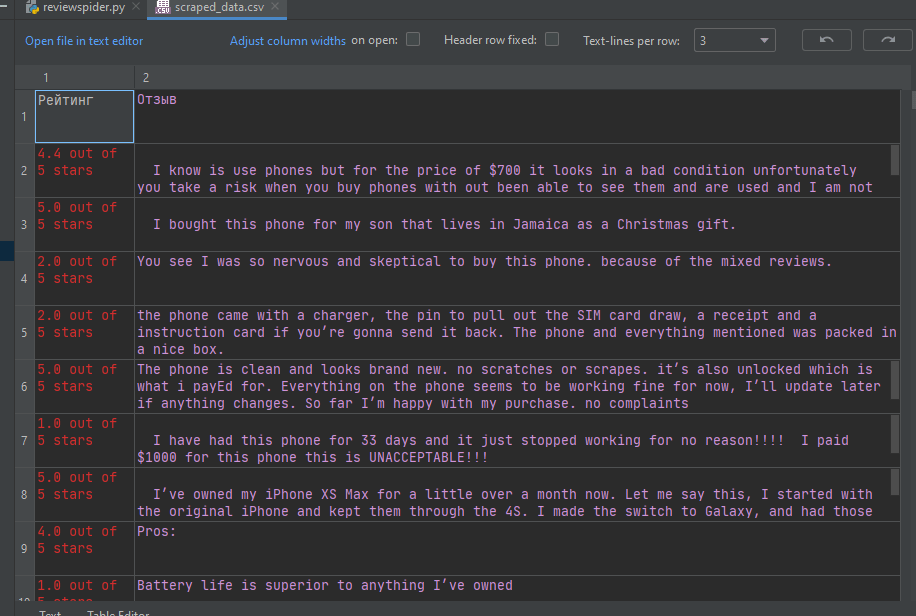
Экспорт данных Scrapy
Scrapy предоставляет возможность экспорта для сохранения извлеченных данных в разных форматах или методах сериализации. Поддерживаются форматы CSV, XML и JSON.
Например, для получения вывода в формате CSV нужно перейти в settings.py и ввести следующие строки.
scrapy runspider scrapy_tutorial/spiders/reviewspider.py -o scraped_data.csv
После этого сохраните файл и снова запустите Spider. Сгенерированный файл окажется в папке проекта.
Если нужны временная метка или имя, то их можно передать в FEED_URI так: %(time)s или %(name)s.
Например:
FEED_URI = "scraped_data_%(time)s.json"Выводы
Scrapy — это мощный фреймворк для веб-скрапинга. На примере из материала можно было увидеть, насколько просто с ним работать. Он предназначен в первую очередь для парсинга HTML-документов, но быстро и легко изучается для самых разных сценариев примнения. Все подробности есть в официальной документации.





