

Одно из самых популярных приложений машинного обучения — решение задач классификации. Задачи классификации — это ситуации, когда у вас есть набор данных, и вы хотите классифицировать наблюдения из этого набора в определенную категорию.
Известный пример — спам-фильтр для электронной почты. Gmail использует методы машинного обучения с учителем, чтобы автоматически помещать электронные письма в папку для спама в зависимости от их содержания, темы и других характеристик.
Две модели машинного обучения выполняют большую часть работы, когда дело доходит до задач классификации:
- Метод K-ближайших соседей
- Метод К-средних
Из этого руководства вы узнаете, как применять алгоритмы K-ближайших соседей и K-средних в коде на Python.
Модели K-ближайших соседей
Алгоритм K-ближайших соседей является одним из самых популярных среди ML-моделей для решения задач классификации.
Обычным упражнением для студентов, изучающих машинное обучение, является применение алгоритма K-ближайших соседей к датасету, категории которого неизвестны. Реальным примером такой ситуации может быть случай, когда вам нужно делать предсказания, используя ML-модели, обученные на секретных правительственных данных.
В этом руководстве вы изучите алгоритм машинного обучения K-ближайших соседей и напишите его реализацию на Python. Мы будем работать с анонимным набором данных, как в описанной выше ситуации.
Используемый датасет
Первое, что вам нужно сделать, это скачать набор данных, который мы будем использовать в этом руководстве. Вы можете скачать его на Gitlab.
Далее вам нужно переместить загруженный файл с датасетом в рабочий каталог. После этого откройте Jupyter Notebook — теперь мы можем приступить к написанию кода на Python!
Необходимые библиотеки
Чтобы написать алгоритм K-ближайших соседей, мы воспользуемся преимуществами многих Python-библиотек с открытым исходным кодом, включая NumPy, pandas и scikit-learn.
Начните работу, добавив следующие инструкции импорта:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Импорт датасета
Следующий шаг — добавление файла classified_data.csv в наш код на Python. Библиотека pandas позволяет довольно просто импортировать данные в DataFrame.
Поскольку датасет хранится в файле csv, мы будем использовать метод read_csv:
raw_data = pd.read_csv('classified_data.csv')
Отобразив полученный DataFrame в Jupyter Notebook, вы увидите, что представляют собой наши данные:
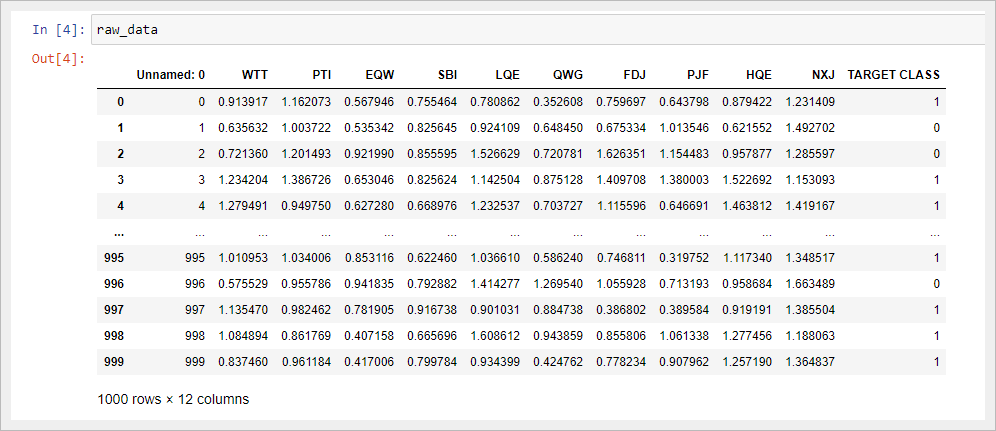
Стоит заметить, что таблица начинается с безымянного столбца, значения которого равны номерам строк DataFrame. Мы можем исправить это, немного изменив команду, которая импортировала наш набор данных в скрипт Python:
raw_data = pd.read_csv('classified_data.csv', index_col = 0)
Затем давайте посмотрим на показатели (признаки), содержащиеся в этом датасете. Вы можете вывести список имен столбцов с помощью следующей инструкции:
raw_data.columns
Получаем:
Index(['WTT', 'PTI', 'EQW', 'SBI', 'LQE', 'QWG', 'FDJ', 'PJF', 'HQE', 'NXJ',
'TARGET CLASS'],
dtype='object')Поскольку этот набор содержит секретные данные, мы понятия не имеем, что означает любой из этих столбцов. На данный момент достаточно признать, что каждый столбец является числовым по своей природе и поэтому хорошо подходит для моделирования с помощью методов машинного обучения.
Стандартизация датасета
Поскольку алгоритм K-ближайших соседей делает прогнозы относительно точки данных (семпла), используя наиболее близкие к ней наблюдения, существующий масштаб показателей в датасете имеет большое значение.
Из-за этого специалисты по машинному обучению обычно стандартизируют набор данных, что означает корректировку каждого значения x так, чтобы они находились примерно в одном диапазоне.
К счастью, библиотека scikit-learn позволяет сделать это без особых проблем.
Для начала нам нужно будет импортировать класс StandardScaler из scikit-learn. Для этого добавьте в свой скрипт Python следующую команду:
from sklearn.preprocessing import StandardScaler
Этот класс во многом похож на классы LinearRegression и LogisticRegression, которые мы использовали ранее в этом курсе. Нам нужно создать экземпляр StandardScaler, а затем использовать этот объект для преобразования наших данных.
Во-первых, давайте создадим экземпляр класса StandardScaler с именем scaler следующей инструкцией:
scaler = StandardScaler()
Теперь мы можем обучить scaler на нашем датасете, используя метод fit:
scaler.fit(raw_data.drop('TARGET CLASS', axis=1))
Теперь мы можем применить метод transform для стандартизации всех признаков, чтобы они имели примерно одинаковый масштаб. Мы сохраним преобразованные семплы в переменной scaled_features:
scaled_features = scaler.transform(raw_data.drop('TARGET CLASS', axis=1))
В качестве результата мы получили массив NumPy со всеми точками данных из датасета, но нам желательно преобразовать его в формат DataFrame библиотеки pandas.
К счастью, сделать это довольно легко. Мы просто обернем переменную scaled_features в метод pd.DataFrame и назначим этот DataFrame новой переменной scaled_data с соответствующим аргументом для указания имен столбцов:
scaled_data = pd.DataFrame(scaled_features, columns = raw_data.drop('TARGET CLASS', axis=1).columns)
Теперь, когда мы импортировали наш датасет и стандартизировали его показатели, мы готовы разделить этот набор данных на обучающую и тестовую выборки.
Разделение датасета на обучающие и тестовые данные
Мы будем использовать функцию train_test_split библиотеки scikit-learn в сочетании с распаковкой списка для создания обучающих и тестовых датасетов из нашего набора секретных данных.
Во-первых, вам нужно импортировать train_test_split из модуля model_validation библиотеки scikit-learn:
from sklearn.model_selection import train_test_split
Затем нам необходимо указать значения x и y, которые будут переданы в функцию train_test_split.
Значения x представляют собой DataFrame scaled_data, который мы создали ранее. Значения y хранятся в столбце "TARGET CLASS" нашей исходной таблицы raw_data.
Вы можете создать эти переменные следующим образом:
x = scaled_data
y = raw_data['TARGET CLASS']
Затем вам нужно запустить функцию train_test_split, используя эти два аргумента и разумный test_size. Мы будем использовать test_size 30%, что дает следующие параметры функции:
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, y, test_size = 0.3)
Теперь, когда наш датасет разделен на данные для обучения и данные для тестирования, мы готовы приступить к обучению нашей модели!
Обучение модели K-ближайших соседей
Начнем с импорта KNeighborsClassifier из scikit-learn:
from sklearn.neighbors import KNeighborsClassifier
Затем давайте создадим экземпляр класса KNeighborsClassifier и назначим его переменной model.
Для этого требуется передать параметр n_neighbors, который равен выбранному вами значению K алгоритма K-ближайших соседей. Для начала укажем n_neighbors = 1:
model = KNeighborsClassifier(n_neighbors = 1)
Теперь мы можем обучить нашу модель, используя метод fit и переменные x_training_data и y_training_data:
model.fit(x_training_data, y_training_data)
Теперь давайте сделаем несколько прогнозов с помощью полученной модели!
Делаем предсказания с помощью алгоритма K-ближайших соседей
Способ получения прогнозов на основе алгоритма K-ближайших соседей такой же, как и у моделей линейной и логистической регрессий, построенных нами ранее в этом курсе: для предсказания достаточно вызвать метод predict, передав в него переменную x_test_data.
В частности, вот так вы можете делать предсказания и присваивать их переменной predictions:
predictions = model.predict(x_test_data)
Давайте посмотрим, насколько точны наши прогнозы, в следующем разделе этого руководства.
Оценка точности нашей модели
В руководстве по логистической регрессии мы видели, что scikit-learn поставляется со встроенными функциями, которые упрощают измерение эффективности классификационных моделей машинного обучения.
Для начала импортируем в наш отчет две функции classification_report и confusion_matrix:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
Теперь давайте поработаем с каждой из них по очереди, начиная с classification_report. С ее помощью вы можете создать отчет следующим образом:
print(classification_report(y_test_data, predictions))
Полученный вывод:
precision recall f1-score support
0 0.92 0.91 0.91 148
1 0.91 0.92 0.92 152
accuracy 0.91 300
macro avg 0.91 0.91 0.91 300
weighted avg 0.91 0.91 0.91 300Точно так же вы можете сгенерировать матрицу ошибок:
print(confusion_matrix(y_test_data, predictions))
# Вывод:
# [[134 14]
# [ 12 140]]
Глядя на такие метрики производительности, похоже, что наша модель уже достаточно эффективна. Но ее еще можно улучшить.
В следующем разделе будет показано, как мы можем повлиять на работу модели K-ближайших соседей, выбрав более подходящее значение для K.
Выбор оптимального значения для K с помощью метода «Локтя»
В этом разделе мы будем использовать метод «локтя», чтобы выбрать оптимальное значение K для нашего алгоритма K-ближайших соседей.
Метод локтя включает в себя итерацию по различным значениям K и выбор значения с наименьшей частотой ошибок при применении к нашим тестовым данным.
Для начала создадим пустой список error_rates. Мы пройдемся по различным значениям K и добавим их частоту ошибок в этот список.
error_rates = []
Затем нам нужно создать цикл Python, который перебирает различные значения K, которые мы хотим протестировать, и на каждой итерации выполняет следующее:
- Создает новый экземпляр класса
KNeighborsClassifierиз scikit-learn. - Тренирует эту модель, используя наши обучающие данные.
- Делает прогнозы на основе наших тестовых данных.
- Вычисляет долю неверных предсказаний (чем она ниже, тем точнее наша модель).
Реализация описанного цикла для значений K от 1 до 100:
for i in np.arange(1, 101):
new_model = KNeighborsClassifier(n_neighbors = i)
new_model.fit(x_training_data, y_training_data)
new_predictions = new_model.predict(x_test_data)
error_rates.append(np.mean(new_predictions != y_test_data))
Давайте визуализируем, как изменяется частота ошибок при различных K, используя matplotlib — plt.plot(error_rates):
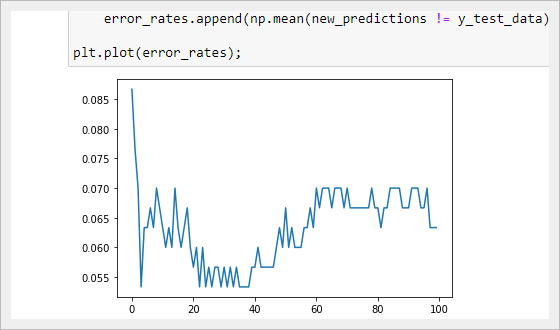
Как видно из графика, мы достигаем минимальной частоты ошибок при значении K, равном приблизительно 35. Это означает, что 35 является подходящим выбором для K, который сочетает в себе простоту и точность предсказаний.
Вы можете найти весь код в ноутбуке на GitLab:
https://gitlab.com/PythonRu/notebooks/-/blob/master/sklearn_kmeans_and_knn.ipynb
Модели кластеризации методом K-средних
Алгоритм кластеризации K-средних обычно является первой моделью машинного обучения без учителя, которую изучают студенты.
Он позволяет специалистам по машинному обучению создавать группы точек данных со схожими количественными характеристиками в датасете. Это полезно для решения таких задач, как формирование клиентских сегментов или определение городских районов с высоким уровнем преступности.
В этом разделе вы узнаете, как создать свой первый алгоритм кластеризации K-средних на Python.
Используемый датасет
В этом руководстве мы будем использовать набор данных, созданный с помощью scikit-learn.
Давайте импортируем функцию make_blobs из scikit-learn, чтобы сгенерировать необходимые данные. Откройте Jupyter Notebook и запустите свой скрипт Python со следующей инструкцией:
from sklearn.datasets import make_blobs
Теперь давайте воспользуемся функцией make_blobs, чтобы получить фиктивные данные!
В частности, вот как вы можете создать набор данных из 200 семплов, который имеет 2 показателя и 4 кластерных центров. Стандартное отклонение для каждого кластера будет равно 1.8.
raw_data = make_blobs(
n_samples = 200,
n_features = 2,
centers = 4,
cluster_std = 1.8
)
Если вы выведите объект raw_data, то заметите, что на самом деле он представляет собой кортеж Python. Первым его элементом является массив NumPy с 200 наблюдениями. Каждое наблюдение содержит 2 признака (как мы и указали в нашей функции make_blobs).
Теперь, когда наши данные созданы, мы можем перейти к импорту других необходимых библиотек с открытым исходным кодом в наш скрипт Python.
Импортируемые библиотеки
В этом руководстве будет использоваться ряд популярных библиотек Python с открытым исходным кодом, включая pandas, NumPy и matplotlib. Продолжим написание скрипта, добавив следующие импорты:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Первая группа библиотек в этом блоке кода предназначена для работы с большими наборами данных. Вторая группа предназначена для визуализации результатов.
Теперь перейдем к созданию визуального представления нашего датасета.
Визуализация датасета
В функции make_blobs мы указали, что в нашем наборе данных должно быть 4 кластерных центра. Лучший способ убедиться, что все действительно так, — это создать несколько простых точечных диаграмм.
Для этого мы воспользуемся функцией plt.scatter, передав в нее все значения из первого столбца нашего набора данных в качестве X и соответствующие значения из второго столбца в качестве Y:
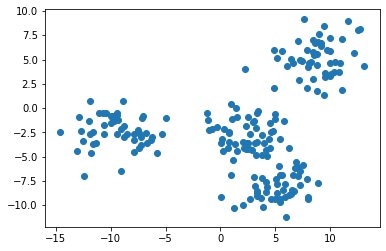
Примечание: ваш датасет будет отличаться от моего, поскольку его данные сгенерированы случайным образом.
Представленное изображение, похоже, указывает на то, что в нашем датасете всего три кластера. Нам так кажется потому, что два кластера расположены очень близко друг к другу.
Чтобы исправить это, нужно сослаться на второй элемент кортежа raw_data, представляющий собой массив NumPy: он содержит индекс кластера, которому принадлежит каждое наблюдение.
Если при построении мы будем использовать уникальный цвет для каждого кластера, то мы легко различим 4 группы наблюдений. Вот код для этого:
plt.scatter(raw_data[0][:,0], raw_data[0][:,1], c=raw_data[1]);
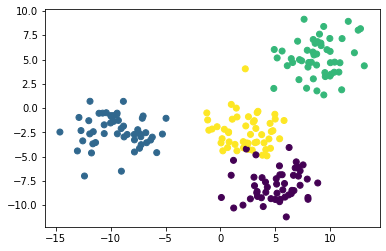
Теперь мы видим, что в нашем наборе данных есть четыре уникальных кластера. Давайте перейдем к построению нашей модели на основе метода K-средних на Python!
Создание и обучение модели кластеризации K-средних
Для того, чтобы начать использовать метод K-средних, импортируем соответствующий класс из scikit-learn. Для этого добавьте в свой скрипт следующую команду:
from sklearn.cluster import KMeans
Затем давайте создадим экземпляр класса KMeans с параметром n_clusters=4 и присвоим его переменной model:
model = KMeans(n_clusters=4)
Теперь обучим нашу модель, вызвав на ней метод fit и передав первый элемент нашего кортежа raw_data:
model.fit(raw_data[0])
В следующем разделе мы рассмотрим, как делать прогнозы с помощью модели кластеризации K-средних.
Прежде чем двигаться дальше, я хотел бы указать на одно различие, которое вы, возможно заметили, между процессом построения модели, используя метод K-средних (он является алгоритмом кластеризации без учителя), и алгоритмами машинного обучения с учителем, с которыми мы работали ранее в данном курсе.
Оно заключается в том, что нам не нужно разбивать набор данных на обучающую и тестовую выборки. Это важное различие, так как вам никогда не нужно разделять таким образом датасет при построении моделей машинного обучения без учителя!
Применяем нашу модель кластеризации K-средних для получения предсказаний
Специалисты по машинному обучению обычно используют алгоритмы кластеризации, чтобы делать два типа прогнозов:
- К какому кластеру принадлежит каждая точка данных.
- Где находится центр каждого кластера.
Теперь, когда наша модель обучена, мы можем легко сгенерировать такие предсказания.
Во-первых, давайте предскажем, к какому кластеру принадлежит каждая точка данных. Для этого обратимся к атрибуту labels_ из объекта model с помощью оператора точки:
model.labels_
Таким образом мы получаем массив NumPy с прогнозами для каждого семпла:
array([3, 2, 1, 1, 3, 2, 1, 0, 0, 0, 0, 0, 3, 2, 1, 2, 1, 3, 3, 3, 3, 1,
1, 1, 2, 2, 3, 1, 3, 2, 1, 0, 1, 3, 1, 1, 3, 2, 0, 1, 3, 2, 3, 3,
0, 3, 2, 2, 3, 0, 0, 0, 1, 1, 2, 1, 2, 0, 1, 2, 2, 1, 2, 3, 0, 3,
0, 2, 0, 0, 1, 1, 0, 3, 2, 3, 2, 0, 1, 2, 0, 2, 0, 3, 3, 0, 3, 3,
0, 3, 2, 3, 2, 1, 2, 1, 3, 3, 2, 2, 0, 2, 0, 2, 0, 2, 1, 0, 0, 2,
3, 2, 1, 2, 3, 0, 1, 1, 1, 3, 2, 2, 3, 3, 2, 1, 3, 0, 0, 3, 0, 1,
1, 3, 1, 0, 1, 1, 0, 3, 2, 0, 3, 0, 1, 2, 1, 2, 1, 2, 2, 3, 2, 1,
0, 2, 3, 3, 2, 0, 1, 3, 3, 2, 0, 0, 0, 3, 1, 2, 0, 2, 3, 3, 2, 2,
3, 1, 0, 1, 2, 3, 1, 3, 1, 1, 0, 2, 1, 0, 2, 1, 3, 1, 3, 3, 1, 3,
0, 3])Чтобы узнать, где находится центр каждого кластера, аналогичным способом обратитесь к атрибуту cluster_centers_:
model.cluster_centers_
Получаем двумерный массив NumPy, содержащий координаты центра каждого кластера. Он будет выглядеть так:
array([[ 5.2662658 , -8.20493969],
[-9.39837945, -2.36452588],
[ 8.78032251, 5.1722511 ],
[ 2.40247618, -2.78480268]])Визуализация точности предсказаний модели
Последнее, что мы сделаем в этом руководстве, — это визуализируем точность нашей модели. Для этого можно использовать следующий код:
f, (ax1, ax2) = plt.subplots(1, 2, sharey=True,figsize=(10,6))
ax1.set_title('Наши предсказания')
ax1.scatter(raw_data[0][:,0], raw_data[0][:,1],c=model.labels_)
ax2.set_title('Реальные значения')
ax2.scatter(raw_data[0][:,0], raw_data[0][:,1],c=raw_data[1]);
Он генерирует две точечные диаграммы. Первая показывает кластеры, используя фактические метки из нашего датасета, а вторая основана на предсказаниях, сделанных нашей моделью. Вот как выглядит результат:
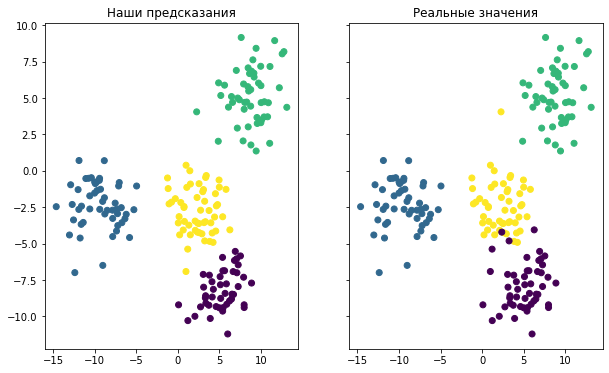
Хотя окраска двух графиков разная, вы можете видеть, что созданная модель довольно хорошо справилась с предсказанием кластеров в нашем наборе данных. Вы также можете заметить, что модель не идеальна: точки данных, расположенные на краях кластеров, в некоторых случаях классифицируются неверно.
И последнее, о чем следует упомянуть, говоря об оценке точности нашей модели. В этом примере мы знали, к какому кластеру принадлежит каждое наблюдение, потому что мы сами создали этот набор данных.
Такая ситуация встречается крайне редко. Метод К-средних обычно применяется, когда не известны ни количество кластеров, ни присущие им качества. Таким образом, специалисты по машинному обучению используют данный алгоритм, чтобы обнаружить закономерности в датасете, о которых они еще ничего не знают.
Вы можете найти весь код в ноутбуке на GitLab:
https://gitlab.com/PythonRu/notebooks/-/blob/master/sklearn_kmeans_and_knn.ipynb
Заключительные мысли
В этом руководстве вы научились создавать модели машинного обучения на Python, используя методы K-ближайших соседей и K-средних.
Вот краткое изложение того, что вы узнали о моделях K-ближайших соседей в Python:
- Как засекреченные данные являются распространенным инструментом для обучения студентов решению задач K-ближайших соседей.
- Почему важно стандартизировать набор данных при построении моделей K-ближайших соседей.
- Как разделить датасет на обучающую и тестирующую выборки с помощью функции
train_test_split. - Способ обучить вашу первую модель K-ближайших соседей и как получить сделанные ее прогнозы.
- Как оценить эффективность модели K-ближайших соседей.
- Метод локтя для выбора оптимального значения K в модели K-ближайших соседей.
А вот краткое изложение того, что вы узнали о моделях кластеризации K-средних в Python:
- Как сгенерировать фиктивные данные в scikit-learn с помощью функции
make_blobs. - Как создать и обучить модель кластеризации K-средних.
- То, что ML-методы без учителя не требуют, чтобы вы разделяли датасет на данные для обучения и данные для тестирования.
- Как создать и обучить модель кластеризации K-средних с помощью scikit-learn.
- Как визуализировать эффективность алгоритма K-средних, если вы изначально владеете информацией о кластерах.





