

Прежде чем начинать работать над проектом, связанным с данными, нужно посмотреть на набор данных. Разведочный анализ данных (EDA) — очень важный этап, ведь данные могут быть запутанными, и очень многое может пойти не по плану в процессе работы.
В библиотеке Pandas есть несколько функций для решения этой проблемы, и value_counts — одна из них. Она возвращает объект, содержащий уникальные значения из dataframe Pandas в отсортированном порядке. Однако многие забывают об этой возможности и используют параметры по умолчанию. В этом материале посмотрим, как получить максимум пользы от value_counts, изменив параметры по умолчанию.
Что такое функция value_counts()?
Функция value_counts() используется для получения Series, содержащего уникальные значения. Она вернет результат, отсортированный в порядке убывания, так что первый элемент в коллекции будет самым встречаемым. NA-значения не включены в результат.
Синтаксисdf['your_column'].value_counts() — вернет количество уникальных совпадений в определенной колонке.
Важно заметить, что value_counts работает только с series, но не dataframe. Поэтому нужно указать одни квадратные скобки df['your_column'], а не пару df[['your_column']].
Параметры:
normalize(bool, по умолчанию False) — еслиTrue, то возвращаемый объект будет содержать значения относительно частоты встречаемых значений.sort(bool, по умолчанию True) — сортировка по частоте.ascending(bool, по умолчанию False) — сортировка по возрастанию.bins(int) — вместе подсчета значений группирует их по отрезкам, но это работает только с числовыми данными.- dropna (bool, по умолчанию True) — не включать количество NaN.
Загрузка данных для демонстрации
Рассмотрим, как использовать этот метод на реальных данных. Возьмем в качестве примера датасет из курса Coursera на Kaggle.
Для начала импортируем нужные библиотеки и сами данные. Это нужно в любом проекте. После этого проанализируем данные в notebook Jupyter.
# импорт библиотеки
import pandas as pd
# Загрузка данных
df = pd.read_csv('Downloads/coursea_data.csv', index_col=0)
# проверка данных из csv
df.head(10)
Проверьте, сколько записей в датасете и есть ли у нас пропуски.
df.info()
Результат показывает, что в наборе 981 запись, и нет ни одного NA.
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 134 to 163
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 course_title 891 non-null object
1 course_organization 891 non-null object
2 course_Certificate_type 891 non-null object
3 course_rating 891 non-null float64
4 course_difficulty 891 non-null object
5 course_students_enrolled 891 non-null object
dtypes: float64(1), object(5)
memory usage: 48.7+ KB1. value_counts с параметрами по умолчанию
Теперь можно начинать использовать функцию value_counts. Начнем с базового применения функции.
Синтаксис: df['your_column'].value_counts().
Получим количество каждого значения для колонки «course_difficulty».
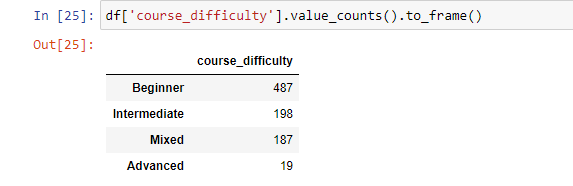
Функция value_counts вернет количество совпадений всех уникальных значений по заданному индексу без пропусков. Это позволит увидеть, что больше всего курсов с уровнем сложности «Начинающий», после этого идут «Средний» и «Смешанный». А «Сложный» на последнем месте.
df['course_difficulty'].value_counts()
---------------------------------------------------
Beginner 487
Intermediate 198
Mixed 187
Advanced 19
Name: course_difficulty, dtype: int64Теперь время поработать с параметрами.
2. Сортировка по возрастанию
По умолчанию value_counts() возвращает данные по убыванию. Изменит поведение можно, задав значение True для параметра ascending.
Синтаксис: df['your_column'].value_counts(ascending=True).
df['course_difficulty'].value_counts(ascending=True)
---------------------------------------------------
Advanced 19
Mixed 187
Intermediate 198
Beginner 487
Name: course_difficulty, dtype: int643. Сортировка в алфавитном порядке
В определенных случаях может существовать необходимость отсортировать записи в алфавитном порядке. Это делается с помощью добавления sort_index(ascending=True) после value_counts().
По умолчанию функция сортирует «course_difficulty» по количеству совпадений, а с sort_index сортирует по индексу (имени колонки, для которой и используется функция):
df['course_difficulty'].value_counts().sort_index(ascending=True)
---------------------------------------------------
Advanced 19
Beginner 487
Intermediate 198
Mixed 187
Name: course_difficulty, dtype: int64Если же требуется отобразить value_counts() в обратном алфавитном порядке, то нужно изменить направление сортировки: .sort_index(ascending=False).
4. Сортировка по значению, а затем по алфавиту
Для этого примера используем другой датасет.
df_fruit = pd.DataFrame({
'fruit':
['хурма']*5 + ['яблоки']*5 + ['бананы']*3 +
['персики']*3 + ['морковь']*3 + ['абрикосы'] + ['манго']*2
})
Так, нужно получить вывод, отсортированный в первую очередь по количеству совпадений значений, а потом уже и по алфавиту. Это можно сделать, объединив value_counts() c sort_index(ascending=False) и sort_values(ascending=False).
df_fruit['fruit'].value_counts()\
.sort_index(ascending=False)\
.sort_values(ascending=False)
-------------------------------------------------
хурма 5
яблоки 5
бананы 3
морковь 3
персики 3
манго 2
абрикосы 1
Name: fruit, dtype: int645. Относительная частота уникальных значений
Иногда нужно получить относительные значения, а не просто количество. С параметром normalize=True объект вернет относительную частоту уникальных значений. По умолчанию значение этого параметра равно False.
Синтаксис: df['your_column'].value_counts(normalize=True).
df['course_difficulty'].value_counts(normalize=True)
-------------------------------------------------
Beginner 0.546577
Intermediate 0.222222
Mixed 0.209877
Advanced 0.021324
Name: course_difficulty, dtype: float646. value_counts() для разбивки данных на дискретные интервалы
Еще один трюк, который часто игнорируют. value_counts() можно использовать для разбивки данных на дискретные интервалы с помощью параметра bin. Это работает только с числовыми данными. Принцип напоминает pd.cut. Посмотрим как это работает на примере колонки «course_rating». Сгруппируем значения колонки на 4 группы.
Синтаксис: df['your_column'].value_counts(bin=количество групп).
df['course_rating'].value_counts(bins=4)
-------------------------------------------------
(4.575, 5.0] 745
(4.15, 4.575] 139
(3.725, 4.15] 5
(3.297, 3.725] 2
Name: course_rating, dtype: int64Бинниг позволяет легко получить инсайты. Так, можно увидеть, что большая часть людей оценивает курс на 4.5. И лишь несколько курсов имеют оценку ниже 4.15.
7. value_counts() с пропусками
По умолчанию количество значений NaN не включается в результат. Но это поведение можно изменить, задав значение False для параметра dropna. Поскольку в наборе данных нет нулевых значений, в этом примере это ни на что не повлияет. Но сам параметр следует запомнить.
Синтаксис: df['your_column'].value_counts(dropna=False).
8. value_counts() как dataframe
Как уже было отмечено, value_counts() возвращает Series, а не Dataframe. Если же нужно получить результаты в последнем виде, то для этого можно использовать функцию .to_frame() после .value_counts().
Синтаксис: df['your_column'].value_counts().to_frame().
Это будет выглядеть следующим образом:
Если нужно задать имя для колонки или переименовать существующую, то эту конвертацию можно реализовать другим путем.
value_counts = df['course_difficulty'].value_counts()
# преобразование в df и присвоение новых имен колонкам
df_value_counts = pd.DataFrame(value_counts)
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = ['unique_values', 'counts for course_difficulty']
df_value_counts
Groupby и value_counts
Groupby — очень популярный метод в Pandas. С его помощью можно сгруппировать результат по одной колонке и посчитать значения в другой.
Синтаксис: df.groupby('your_column_1')['your_column_2'].value_counts().
Так, с помощью groupby и value_counts можно посчитать количество типов сертификатов для каждого уровня сложности курсов.
df.groupby('course_difficulty')['course_Certificate_type'].value_counts()
-------------------------------------------------
course_difficulty course_Certificate_type
Advanced SPECIALIZATION 10
COURSE 9
Beginner COURSE 282
SPECIALIZATION 196
PROFESSIONAL CERTIFICATE 9
Intermediate COURSE 104
SPECIALIZATION 91
PROFESSIONAL CERTIFICATE 3
Mixed COURSE 187
Name: course_Certificate_type, dtype: int64Это мульти-индекс, позволяющий иметь несколько уровней индексов в dataframe. В этом случае сложность курса соответствует нулевому уровню индекса, а тип сертификата — первому.
Фильтрация значений по минимум и максимум
Работая с набором данных, может потребоваться вернуть количество ограниченных вхождений с помощью value_counts().
Синтаксис: df['your_column'].value_counts().loc[lambda x : x > 1].
Этот код отфильтрует все значения уникальных данных и покажет только те, где значение больше единицы.
Для примера ограничим рейтинг курса значением 4.
df.groupby('course_difficulty')['coudf['course_rating']\
.value_counts().loc[lambda x: x > 4]
-------------------------------------------------
4.8 256
4.7 251
4.6 168
4.5 80
4.9 68
4.4 34
4.3 15
4.2 10
Name: course_rating, dtype: int64value_counts() — удобный инструмент, позволяющий делать удобный анализ в одну строку.





