

LightGBM — это фреймворк, который предоставляет реализацию деревьев принятия решений с градиентным бустингом. Он создан группой исследователей и разработчиков Microsoft. LightGBM известен своей более высокой скоростью обучения, хорошей точностью с параметрами по умолчанию, параллельным и GPU обучением, малым использованием памяти и возможностью обработки больших датасетов, которые не всегда помещаются в ней.
Для работы с LightGBM доступны API на C, Python или R. Фреймворк также предоставляет CLI, который позволяет нам использовать библиотеку из командной строки. Оценщики (estimators) LightGBM оснащены множеством гиперпараметров для настройки модели. Кроме этого, в нем уже реализован большой набор функций оптимизации/потерь и оценочных метрики.
В рамках данного руководства мы рассмотрим Python API данного фреймворка. Мы постараемся объяснить и охватить большую часть этого API. Основная цель работы — ознакомить читателей с основными функциональными возможностями lightgbm, необходимыми для начала работы с ним.
Существуют и другие библиотеки (xgboost, catboost, scikit-learn), которые также обеспечивают реализацию деревьев решений с градиентным бустингом.
Давайте начнем.
Ноутбук с кодом в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/LightGBM_python.ipynb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import lightgbm as lgb
import sklearn
import warnings
warnings.filterwarnings("ignore")
print("Версия LightGBM : ", lgb.__version__)
print("Версия Scikit-Learn : ", sklearn.__version__)
Версия LightGBM : 3.2.1
Версия Scikit-Learn : 0.23.2Загрузка датасетов
Мы будем использовать доступные в sklearn три набора данных (показаны ниже) для этого руководства.
- Boston Housing Dataset — это выборка для задач регрессии, которая содержит информацию о различных характеристиках домов в Бостоне и их цене в долларах. Она будет использоваться нами при решении регрессионных проблем.
- Breast Cancer Dataset — это датасет для задач классификации, содержащий информацию о двух типах опухолей. Он будет применяться для объяснения методов бинарной классификации.
- Wine Dataset — это набор данных классификации, содержащий информацию об ингредиентах, используемых в создании вин трех типов. Используется нами для объяснения задач мультиклассификации.
Ниже мы загрузили все три упомянутых датасета, вывели их описания для ознакомления с признаками(features) и размерами соответствующих выборок. Каждый датасет как pandas DataFrame. Посмотрим на них:
Boston Housing Dataset
from sklearn.datasets import load_boston
boston = load_boston()
for line in boston.DESCR.split("\n")[5:29]:
print(line)
boston_df = pd.DataFrame(data=boston.data, columns = boston.feature_names)
boston_df["Price"] = boston.target
boston_df.head()
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | Price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
Breast Cancer Dataset
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
for line in breast_cancer.DESCR.split("\n")[5:31]:
print(line)
breast_cancer_df = pd.DataFrame(data=breast_cancer.data, columns = breast_cancer.feature_names)
breast_cancer_df["TumorType"] = breast_cancer.target
breast_cancer_df.head()
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
The mean, standard error, and "worst" or largest (mean of the three
worst/largest values) of these features were computed for each image,
resulting in 30 features. For instance, field 0 is Mean Radius, field
10 is Radius SE, field 20 is Worst Radius.
- class:
- WDBC-Malignant
- WDBC-Benign| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | … | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | TumorType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | … | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | … | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | … | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | … | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | … | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Wine Dataset
from sklearn.datasets import load_wine
wine = load_wine()
for line in wine.DESCR.split("\n")[5:29]:
print(line)
wine_df = pd.DataFrame(data=wine.data, columns = wine.feature_names)
wine_df["WineType"] = wine.target
wine_df.head()
**Data Set Characteristics:**
:Number of Instances: 178 (50 in each of three classes)
:Number of Attributes: 13 numeric, predictive attributes and the class
:Attribute Information:
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
- class:
- class_0
- class_1
- class_2| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | WineType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 | 0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 | 0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 | 0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 | 0 |
Обучение модели на train()
Самый простой способ создать оценщик (estimator) в lightgbm — использовать метод train(). Он принимает на вход оценочный параметр в виде словаря и обучающий датасет. Затем train тренирует оценщик и возвращает объект типа Booster, который является обученным оценщиком: его можно использовать для будущих предсказаний.
Ниже приведены некоторые из важных параметров метода train().
params— это словарь, определяющий параметры алгоритма деревьев решений с градиентным бустингом. Нам просто нужно предоставить целевую функцию для начала работы в зависимости от типа задачи (классификация/регрессия). Позже мы ознакомимся с часто используемым списком параметров, которые можно передать в этот словарь.train_set— этот параметр принимает объект типаDatasetфреймворка lightgbm, который содержит информацию о показателях и целевых значениях. Это внутренняя структура данных, разработанная lightgbm для обертывания данных.num_boost_round— указывает количество деревьев бустинга, которые будут использоваться в ансамбле. Ансамбль — это группа деревьев с градиентным бустингом, которую мы обычно называем оценщиком. Значение по умолчанию равно 100.valid_sets— принимает списокDatasetобъектов, которые являются выборками для валидации. Эти проверочные датасеты оцениваются после каждого цикла обучения.valid_names— принимает список строк той же длины, что и уvalid_sets, определяющих имена для каждой проверочной выборки. Эти имена будут использоваться при выводе оценочных метрик для валидационных наборов данных, а также при их построении.categorical_feature— принимает список строк/целых чисел или строку auto. Если мы передадим список строк/целых чисел, тогда указанные столбцы из набора данных будут рассматриваться как категориальные.verbose_eval— принимает значения типаboolилиint. Если мы установим значениеFalseили 0, тоtrainне будет выводить результаты расчета метрик на проверочных выборках, которые мы передали. Если нами было указано True, он будет печатать их для каждого раунда. При передаче целого числа, большего 1,trainотобразит результаты повторно после указанного количества раундов.
Dataset
Dataset представляет собой внутреннюю структуру данных lightgbm для хранения данных и меток. Ниже приведены важные параметры класса.
data— принимает массив библиотеки numpy, dataframe pandas, разреженные матрицы (sparse matrix) scipy, список массивов numpy, фрейм таблицы данных h2o в качестве входного значения, хранящего значения признаков (features).label— принимает массив numpy, pandas series или dataframe с одним столбцом. Данный параметр определяет целевые значения. Мы также можем установить дляlabelзначениеNone, если у нас нет таких значений. По умолчанию —None.feature_name— принимает список строк, определяющих имена показателей.categorical_feature— имеет то же значение, что и указанное выше в параметре методаtrain(). Мы можем определить категориальный показатель здесь или вtrain.
Регрессия
Первая проблема, которую мы решим с помощью lightgbm, — это простая задача регрессии с использованием датасета Boston housing, который был загружен нами ранее. Мы разделили этот набор данных на обучающую/тестовую выборки и создали из них экземпляр Dataset. Затем мы вызвали метод lightgbm.train(), предоставив ему датасеты для обучения и проверки. Мы установили количество итераций бустинга равным 10, поэтому для решения задачи будет создано 10 деревьев.
После завершения обучения train вернет экземпляр типа Booster, который мы позже сможем использовать для будущих предсказаний. Поскольку мы передали проверочный датасет в качестве входных данных, метод выведет значение l2 для валидации после каждой итерации обучения. Обратите внимание, что по умолчанию lightgbm минимизирует потерю l2 для задачи регрессии.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression"},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Размеры Train/Test: (379, 13) (127, 13) (379,) (127,)
[LightGBM] [Warning] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000840 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 961
[LightGBM] [Info] Number of data points in the train set: 379, number of used features: 13
[LightGBM] [Info] Start training from score 22.134565
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[1] valid_0's l2: 92.7815
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[2] valid_0's l2: 80.7846
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[3] valid_0's l2: 70.6207
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[4] valid_0's l2: 61.6287
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[5] valid_0's l2: 55.0184
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[6] valid_0's l2: 49.3809
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[7] valid_0's l2: 44.3784
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[8] valid_0's l2: 40.2941
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[9] valid_0's l2: 36.8559
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[10] valid_0's l2: 33.9026Ниже мы сделали прогнозы по тренировочным и тестовым данным с использованием обученной модели. Затем рассчитали R2 метрики для них, используя соответствующий метод sklearn. Обратите внимание, метод predict() принимает массив numpy, dataframe pandas, scipy sparse matrix или фрейм таблицы данных h2o в качестве входных данных для предсказаний.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression"},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Test R2 Score : 0.68
Train R2 Score : 0.74raw_score— это логический параметр, при котором, если он установлен вTrue, результатом выполнения будут необработанные прогнозы. Для задач регрессии это не имеет никакого значения, но при классификации predict вернет значения функции, а не вероятности.pred_leaf— этот параметр принимает логические значения. Если заданоTrue, то будет возвращаться индекс листа каждого дерева, который был спрогнозирован для конкретного семпла. Размер вывода будетn_samples x n_trees.pred_contrib— возвращает массив показателей для каждого наблюдения. Результатом будет являться массив размера(n_features + 1)для каждого семпла, где последнее значение является ожидаемым значением, а первые n_features являются вкладом показателей в этот прогноз. Мы можем добавить вклад каждого показателя к последнему ожидаемому значению и получить фактический прогноз. Обычно такие значения называют SHAP.
idxs = booster.predict(X_test, pred_leaf=True)
print("Размерность: ", idxs.shape)
idxs
Размерность: (127, 10)
array([[10, 11, 12, ..., 5, 13, 6],
[ 3, 3, 3, ..., 3, 4, 2],
[ 2, 8, 2, ..., 2, 2, 3],
...,
[ 3, 3, 3, ..., 3, 4, 2],
[ 5, 0, 0, ..., 13, 0, 13],
[ 0, 5, 14, ..., 0, 3, 1]])
shap_vals = booster.predict(X_test, pred_contrib=True)
print("Размерность: ", shap_vals.shape)
print("\nЗначения Shap для нулевого семпла: ", shap_vals[0])
print("\nПредсказания с использованием значений SHAP: ", shap_vals[0].sum())
print("Предсказания без SHAP: ", test_preds[0])
Размерность: (127, 14)
Значения Shap для нулевого семпла: [-1.04268359e+00 0.00000000e+00 5.78385997e-02 0.00000000e+00
-5.09776692e-01 -1.81771187e+00 -5.44789659e-02 -2.41017058e-02
9.10266200e-03 -6.42845196e-03 5.32678196e-03 0.00000000e+00
-4.62999363e+00 2.21345647e+01]
Предсказания с использованием значений SHAP: 14.121657826104853
Предсказания без SHAP: 14.121657826104858Мы можем вызвать метод num_trees() в экземпляре бустера, чтобы получить количество деревьев в ансамбле. Обратите внимание: если мы не прекратим обучение раньше, число деревьев будет таким же, как num_boost_round. Но если мы прервем тренировку, тогда их количество будет отличаться от num_boost_round.
Позже в этом руководстве мы объясним, как можно остановить обучение, если производительность ансамбля не улучшается при оценке на проверочном наборе.
Экземпляр бустера имеет еще один важный метод feature_importance(), который может возвращать нам важность признаков на основе значений выигрыша (booster.feature_importance(importance_type="gain")) и разделения (booster.feature_importance(importance_type="split")) деревьев.
(array([4.56516126e+03, 0.00000000e+00, 1.49124010e+03, 0.00000000e+00,
1.20125020e+03, 6.15448327e+04, 4.08311499e+02, 8.27205796e+02,
2.62632999e+01, 4.70000000e+01, 2.03512299e+02, 0.00000000e+00,
4.28531050e+04])
array([21, 0, 7, 0, 9, 29, 7, 15, 1, 1, 4, 0, 44]))Бинарная классификация
В этом разделе объясняется, как мы можем, используя метод train(), создать бустер для задачи бинарной классификации. Обучаем модель на наборе данных о раке груди, а затем оцениваем ее точность, используя метрику из sklearn. Мы установили objective значение binary для информирования метода train() о том, что предоставленные нами данные предназначены для решения задачи бинарной классификации. Также установили параметр verbosity равным -1, чтобы предотвратить вывод сообщений во время обучения. Он по-прежнему будет печатать результаты оценки проверочного датасета, которые тоже можно отключить, передав для параметра verbose_eval значение False.
Обратите внимание, что для задач классификации метод бустера predict() возвращает вероятности. Мы добавили логику для преобразования вероятностей в целевой класс.
По умолчанию при решении задач бинарной классификации LightGBM использует для оценки бинарную логистическую функцию потери на проверочной выборке. Мы можем добавить параметр metric в словарь, который передается методу train(), с названиями любых метрик, доступных в lightgbm, и он будет использовать эти метрики. Позже мы более подробно обсудим перечень предоставляемых lightgbm метрик.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=breast_cancer.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=breast_cancer.feature_names.tolist())
booster = lgb.train({"objective": "binary", "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's binary_logloss: 0.600128
[2] valid_0's binary_logloss: 0.537151
[3] valid_0's binary_logloss: 0.48676
[4] valid_0's binary_logloss: 0.443296
[5] valid_0's binary_logloss: 0.402604
[6] valid_0's binary_logloss: 0.37053
[7] valid_0's binary_logloss: 0.339712
[8] valid_0's binary_logloss: 0.316836
[9] valid_0's binary_logloss: 0.297812
[10] valid_0's binary_logloss: 0.278683
Test Accuracy: 0.95
Train Accuracy: 0.97Мультиклассовая классификация
В рамках этого раздела объясняется, как использовать метод train() для задач мультиклассовой классификации. Мы применяем его на выборке данных о вине, которая имеет три разных типа вина в качестве целевой переменной. Мы установили objective в значение multiclass. Всякий раз, когда нами используется метод train() для решения такой задачи, нам необходимо предоставить целочисленный параметр num_class, определяющим количество классов.
Метод predict() возвращает вероятности для каждого класса в случае мультиклассовых задач. Мы добавили логику для выбора класса с наибольшим значением вероятности в качестве фактического предсказания.
LightGBM по умолчанию использует для оценки мультиклассовую логистическую функцию потери на проверочном датасете при решении проблем бинарной классификации.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=wine.feature_names)
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=wine.feature_names)
booster = lgb.train({"objective": "multiclass", "num_class":3, "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = np.argmax(test_preds, axis=1)
train_preds = np.argmax(train_preds, axis=1)
print("\nTest Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (133, 13) (45, 13) (133,) (45,)
[1] valid_0's multi_logloss: 0.951806
[2] valid_0's multi_logloss: 0.837812
[3] valid_0's multi_logloss: 0.746033
[4] valid_0's multi_logloss: 0.671446
[5] valid_0's multi_logloss: 0.60648
[6] valid_0's multi_logloss: 0.54967
[7] valid_0's multi_logloss: 0.499026
[8] valid_0's multi_logloss: 0.458936
[9] valid_0's multi_logloss: 0.419804
[10] valid_0's multi_logloss: 0.385265
Test Accuracy: 0.98
Train Accuracy: 1.00Список важных параметров LightGBM
Теперь мы перечислим важные параметры lightgbm, которые могут быть предоставлены в виде словаря при вызове метода train(). Мы можем использовать те же параметры для оценщиков (LGBMModel, LGBMRegressor и LGBMClassifier), которые доступны в lightgbm, с той лишь разницей, что нам не нужно формировать словарь — мы можем передать их напрямую при создании экземпляра. Мы рассмотрим работу с оценщиками в следующем разделе.
objective— этот параметр позволяет нам определить целевую функцию, используемую для текущей задачи. Его значением по умолчанию является regression. Ниже приведен список часто используемых значений этого параметра.regressionregression_l1tweediebinarymulticlassmulticlassovacross_entropy- Другие доступные целевые функции
metric— данный параметр принимает метрики для расчета на оценочных наборах данных (в случае если эти выборки предоставлены как значение параметраeval_set/validation_sets). Мы можем предоставить более одной метрики, и все они будут посчитаны на проверочных датасетах. Ниже приведен список наиболее часто используемых значений этого параметра.rmsel2l1tweediebinary_loglossmulti_loglossauccross_entropy- Другие доступные метрики
boosting— этот параметр принимает одну из нижеперечисленных строк, определяющих, какой алгоритм использовать.gbdt— значение по умолчанию. Дерево решений с градиентным бустингомrf— Случайный лесdart— Dropout на множественных аддитивных регрессионных деревьяхgoss— Односторонняя выборка на основе градиента
num_iterations— данный параметр является псевдонимом дляnum_boost_round, который позволяет нам указать число деревьев в ансамбле для создания оценщика. По умолчанию 100.learning_rate— этот параметр используется для определения скорости обучения. По умолчанию 0.1.num_class— если мы работаем с задачей мультиклассовой классификации, то этот параметр должен содержать количество классов.num_leaves— данный параметр принимает целое число, определяющее максимальное количество листьев, разрешенное для каждого дерева. По умолчанию 31.num_threads— принимает целое число, указывающее количество потоков, используемых для обучения. Мы можем установить его равным числу ядер системы.seed— позволяет нам указать инициализирующее значение для процесса обучения, что предоставляет нам возможность повторно генерировать те же результаты.max_depth— этот параметр позволяет нам указать максимальную глубину, разрешенную для деревьев в ансамбле. По умолчанию -1, что позволяет деревьям расти как можно глубже. Мы можем ограничить это поведение, установив этот параметр.min_data_in_leaf— данный параметр принимает целочисленное значение, определяющее минимальное количество точек данных (семплов), которые могут храниться в одном листе дерева. Этот параметр можно использовать для контроля переобучения. Значение по умолчанию 20.bagging_fraction— этот параметр принимает значение с плавающей запятой от 0 до 1, которое позволяет указать, насколько большая часть данных будет случайно отбираться при обучении. Этот параметр может помочь предотвратить переобучение. По умолчанию 1.0.feature_fraction— данный параметр принимает значение с плавающей запятой от 0 до 1, которое информирует алгоритм о выборе этой доли показателей из общего числа для обучения на каждой итерации. По умолчанию 1.0, поэтому используются все показатели.extra_trees— этот параметр принимает логические значения, определяющие, следует ли использовать чрезвычайно рандомизированное дерево или нет.early_stopping_round— принимает целое число, указывающее, что мы должны остановить обучение, если оценочная метрика, рассчитанная на последнем проверочном датасете, не улучшается на протяжении определенного параметром числа итераций.monotone_constraints— этот параметр позволяет нам указать, должна ли наша модель обеспечивать увеличение, уменьшение или отсутствие связи отдельного показателя с целевым значением. Использование данного параметра объясняется в разделе «Монотонные ограничения».monotone_constraints_method— этот параметр принимает одну из нижеперечисленных строк, определяющих тип накладываемых монотонных ограничений.basic— базовый метод монотонных ограничений, который может чрезмерно ограничивать модель.intermediate— это более сложный метод ограничений, который немного менее ограничивает, чем базовый метод, но может занять больше времени.advanced— это расширенный метод ограничений, который менее ограничивает, чем базовый и промежуточный методы, но может занять больше времени.
interaction_constraints— этот параметр принимает список списков, в которых отдельные списки определяют индексы показателей, которым разрешено взаимодействовать друг с другом. Такое взаимодействие подробно объясняется в разделе «Ограничения взаимодействия показателей».verbosity— этот параметр принимает целочисленное значение для управления логированием сообщений при обучении.- < 0 — отображаются только фатальные ошибки.
- 0 — отображаются сообщения об ошибках/предупреждениях и перечисленные выше.
- 1 — отображаются информационные сообщения и перечисленные выше.
- > 1 — отображается отладочная информация и перечисленные выше.
is_unbalance— это логический параметр, который должен иметь значениеTrue, если данные не сбалансированы. Его следует использовать с задачами бинарной и мультиклассовой классификации.device_type— принимает одну из следующих строк, определяющих тип используемого для обучения оборудования.cpugpucuda
force_col_wise— этот параметр принимает логическое значение, определяющее, следует ли принудительно строить гистограмму по столбцам при обучении. Если в данных слишком много столбцов, установка для этого параметра значенияTrueповысит скорость процесса обучения за счет уменьшения использования памяти.force_row_wise— этот параметр принимает логическое значение, определяющее, следует ли принудительно строить гистограмму по строкам при обучении. Если в данных слишком много строк, установка для этого параметра значенияTrueповысит скорость процесса обучения за счет уменьшения использования памяти.
Стоит учитывать, что это не полный список параметров, доступных при работе с lightgbm, а только перечисление некоторых наиболее важных. Если вы хотите узнать обо всех параметрах, перейдите по ссылке ниже.
Полный список параметров LightGBM.
LGBMModel
Класс LGBMModel — это обертка для класса Booster, которая предоставляет подобный scikit-learn API для обучения и прогнозирования в lightgbm. Он позволяет нам создать объект оценщика со списком параметров в качестве входных данных. Затем мы можем вызвать метод fit() для обучения, передав ему тренировочные данные, и метод predict() для предсказания.
Параметры, которые мы передали в виде словаря аргументу params функции train(), теперь можно напрямую передать конструктору LGBMModel для создания модели. LGBMModel позволяет нам выполнять задачи как классификации, так и регрессии, указав цель (objective) задачи.
Регрессия
Ниже на простом примере объясняется, как мы можем использовать LGBMModel для выполнения задач регрессии с данными о жилье в Бостоне. Сначала нами был создан экземпляр LGBMModel с целью (objective) регрессии и числом деревьев, равным 10. Параметр n_estimators является псевдонимом параметра num_boost_round метода train().
Затем мы вызвали метод fit() для обучения модели, передав ему тренировочные данные. Обратите внимание, что он принимает в качестве входных данных массивы numpy, а не объект Dataset фреймворка lightgbm. Мы также предоставили набор данных, который будет использоваться в качестве оценочного датасета, и метрики, которые будут рассчитываться на нем. Параметры метода fit() почти такие же, как и у train().
Наконец, мы вызвали метод predict(), чтобы сделать прогнозы.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="regression", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
from sklearn.metrics import r2_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("\nTest R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Размеры Train/Test Sizes: (379, 13) (127, 13) (379,) (127,)
[1] valid_0's rmse: 9.70598 valid_0's l2: 94.206
[2] valid_0's rmse: 9.04855 valid_0's l2: 81.8763
[3] valid_0's rmse: 8.51309 valid_0's l2: 72.4727
[4] valid_0's rmse: 8.04785 valid_0's l2: 64.7678
[5] valid_0's rmse: 7.6032 valid_0's l2: 57.8086
[6] valid_0's rmse: 7.21651 valid_0's l2: 52.078
[7] valid_0's rmse: 6.88971 valid_0's l2: 47.4681
[8] valid_0's rmse: 6.63273 valid_0's l2: 43.9931
[9] valid_0's rmse: 6.40727 valid_0's l2: 41.0532
[10] valid_0's rmse: 6.21095 valid_0's l2: 38.5759
Test R2 Score: 0.65
Train R2 Score: 0.74Бинарная классификация
Ниже мы объясняем на простом примере, как мы можем использовать LGBMModel для задач классификации. У нас есть обученная модель с набором данных по раку груди. Обратите внимание, что метод predict() возвращает вероятности. Мы включили логику для вычисления класса по вероятностям.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="regression", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
from sklearn.metrics import r2_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("\nTest R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Размеры Train/Test Sizes: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's binary_logloss: 0.578847
[2] valid_0's binary_logloss: 0.524271
[3] valid_0's binary_logloss: 0.480868
[4] valid_0's binary_logloss: 0.441691
[5] valid_0's binary_logloss: 0.410361
[6] valid_0's binary_logloss: 0.381543
[7] valid_0's binary_logloss: 0.353827
[8] valid_0's binary_logloss: 0.33609
[9] valid_0's binary_logloss: 0.319685
[10] valid_0's binary_logloss: 0.30735
Test Accuracy: 0.90
Train Accuracy: 0.98LGBMRegressor
LGBMRegressor — еще одна обертка-оценщик вокруг класса Booster, предоставляемая lightgbm и имеющая тот же API, что и у оценщиков sklearn. Как следует из названия, он предназначен для задач регрессии.
LGBMRegressor почти такой же, как LGBMModel, с той лишь разницей, что он предназначен только для задач регрессии. Ниже мы объяснили использование LGBMRegressor на простом примере с использованием набора данных о жилье в Бостоне. Обратите внимание, что LGBMRegressor предоставляет метод score(), который рассчитывает для нас оценку R2, которую мы до сих пор получали с использованием метрик sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMRegressor(objective="regression_l2", n_estimators=10,)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric=["rmse", "l2", "l1"])
print("Test R2 Score: %.2f"%booster.score(X_train, Y_train))
print("Train R2 Score: %.2f"%booster.score(X_test, Y_test))
Размеры Train/Test Sizes: (379, 13) (127, 13) (379,) (127,)
[1] valid_0's rmse: 8.31421 valid_0's l2: 69.1262 valid_0's l1: 6.0334
[2] valid_0's rmse: 7.61825 valid_0's l2: 58.0377 valid_0's l1: 5.54499
[3] valid_0's rmse: 7.00797 valid_0's l2: 49.1116 valid_0's l1: 5.14472
[4] valid_0's rmse: 6.45103 valid_0's l2: 41.6158 valid_0's l1: 4.7527
[5] valid_0's rmse: 5.97644 valid_0's l2: 35.7178 valid_0's l1: 4.41064
[6] valid_0's rmse: 5.55884 valid_0's l2: 30.9007 valid_0's l1: 4.11807
[7] valid_0's rmse: 5.20092 valid_0's l2: 27.0495 valid_0's l1: 3.85392
[8] valid_0's rmse: 4.88393 valid_0's l2: 23.8528 valid_0's l1: 3.63833
[9] valid_0's rmse: 4.63603 valid_0's l2: 21.4928 valid_0's l1: 3.45951
[10] valid_0's rmse: 4.40797 valid_0's l2: 19.4302 valid_0's l1: 3.27911
Test R2 Score: 0.75
Train R2 Score: 0.76LGBMClassifier
LGBMClassifier — еще одна обертка-оценщик вокруг класса Booster, которая предоставляет API, подобный sklearn, для задач классификации. Он работает точно так же, как LGBMModel, но только для задач классификации. Он также предоставляет метод score(), который оценивает точность переданных ему данных.
Обратите внимание, что LGBMClassifier предсказывает фактические метки классов для задач классификации с помощью метода predict(). Он предоставляет метод pred_proba(), если нам нужны вероятности целевых классов.
Бинарная классификация
Ниже мы приводим простой пример того, как мы можем использовать LGBMClassifier для задач бинарной классификации. Наше объяснение основано на его применении к датасету по раку груди.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
booster = lgb.LGBMClassifier(objective="binary", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),])
print("Test Accuracy: %.2f"%booster.score(X_test, Y_test))
print("Train Accuracy: %.2f"%booster.score(X_train, Y_train))
Test Accuracy: 0.97
Train Accuracy: 0.97Мультиклассовая классификация
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target)
booster = lgb.LGBMClassifier(objective="multiclassova", n_estimators=10, num_class=3)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),])
print("Test Accuracy: %.2f"%booster.score(X_test, Y_test))
print("Train Accuracy: %.2f"%booster.score(X_train, Y_train))
Test Accuracy: 0.96
Train Accuracy: 1.00Далее мы объясняем использование LGBMClassifier для задач мультиклассовой классификации с использованием набора данных Wine.
Обратите внимание, что LGBMModel, LGBMRegressor и LGBMClassifier предоставляют атрибут с названием booster_, возвращающий экземпляр класса Booster, который мы можем сохранить на диск после обучения и позже загрузить для прогнозирования.
Сохранение и загрузка модели
Теперь мы покажем, как сохранить обученную модель на диск, чтобы использовать ее позже для прогнозов. Lightgbm предоставляет нижеперечисленные методы для сохранения и загрузки моделей.
save_model()— этот метод принимает имя файла, в котором сохраняется модель.model_to_string()— данный метод возвращает строковое представление модели, которое мы затем можем сохранить в текстовый файл.lightgbm.Booster()— этот конструктор позволяет нам создать экземпляр классаBooster. У него есть два важных параметра, которые могут помочь нам загрузить модель из файла или из строки.model_file— этот параметр принимает имя файла, из которого загружается обученная модель.model_str— данный параметр принимает строку, содержащую информацию об обученной модели. Нам нужно передать этому параметру строку, которая была сгенерирована с помощьюmodel_to_string()после загрузки из файла.
Ниже мы объясняем на простых примерах, как использовать вышеупомянутые методы для сохранения моделей на диск, а затем загрузки с него.
Обратите внимание, что для сохранения модели, обученной с использованием LGBMModel, LGBMRegressor и LGBMClassifier, нам сначала нужно получить их экземпляр Booster с помощью атрибута booster_ оценщика, а затем сохранить его. LGBMModel, LGBMRegressor и LGBMClassifier не предоставляют функций сохранения и загрузки. Они доступны только с экземпляром Booster.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression", "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
verbose_eval=False,
feature_name=boston.feature_names.tolist(),
num_boost_round=10)
booster.save_model("lgb.model")
loaded_booster = lgb.Booster(model_file="lgb.model")
test_preds = loaded_booster.predict(X_test)
train_preds = loaded_booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.62
Train R2 Score: 0.76Кросс-валидация
Lightgbm позволяет нам выполнять кросс-валидацию с помощью метода cv(). Он принимает параметры модели в виде словаря, как метод train(). Затем мы можем предоставить набор данных для выполнения перекрестной проверки. По умолчанию данный метод производит 5-кратную кросс-валидацию. Мы можем изменить кратность, установив параметр nfold. Он также принимает разделитель данных sklearn, такой как KFold, StratifiedKFold, ShuffleSplit и StratifiedShuffleSplit. Мы можем предоставить эти разделители данных параметру folds метода cv().
Метод cv() возвращает словарь, содержащий информацию о среднем значении и стандартном отклонении потерь для каждого цикла обучения. Мы даже можем попросить метод вернуть экземпляр CVBooster, установив для параметра return_cvbooster значение True. Объект CVBooster содержит информацию о кросс-валидации.
from sklearn.model_selection import StratifiedShuffleSplit
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=breast_cancer.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=breast_cancer.feature_names.tolist())
lgb.cv({"objective": "binary", "verbosity": -1},
train_set=test_dataset, num_boost_round=10,
nfold=5, stratified=True, shuffle=True,
verbose_eval=True)
cv_output = lgb.cv({"objective": "binary", "verbosity": -1},
train_set=test_dataset, num_boost_round=10,
metrics=["auc", "average_precision"],
folds=StratifiedShuffleSplit(n_splits=3),
verbose_eval=True,
return_cvbooster=True)
for key, val in cv_output.items():
print("\n" + key, " : ", val)
auc-mean : [0.9766666666666666, 0.9833333333333334, 0.9833333333333334, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
auc-stdv : [0.020548046676563275, 0.023570226039551608, 0.023570226039551608, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
average_precision-mean : [0.9833333333333334, 0.9888888888888889, 0.9888888888888889, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
average_precision-stdv : [0.013608276348795476, 0.015713484026367772, 0.015713484026367772, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
cvbooster : <lightgbm.engine.CVBooster object at 0x000001CDFDA4FA00>Построение графиков
Lightgbm предоставляет нижеперечисленные функции для построения графиков — plot_importance().
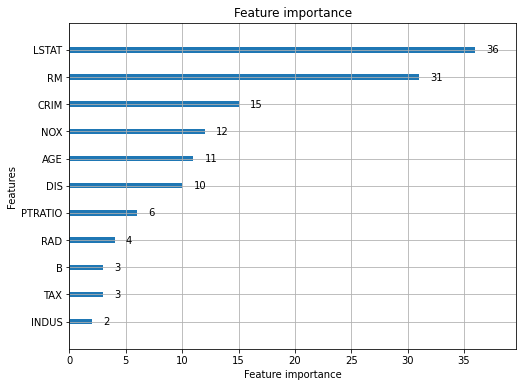
Этот метод принимает экземпляр класса Booster и с его помощью отображает важность показателей. Ниже мы создали график важности показателей, используя бустер, ранее обученный для задачи регрессии. У данного метода есть параметр important_type. Если он установлен в значение split, то график будет отображать количество раз каждый показатель использовался для разбиения. Также если установлено значение gain, то будет показан выигрыш от соответствующих разделений. Значение параметра important_type по умолчанию split.
Метод plot_importance() имеет еще один важный параметр max_num_features, который принимает целое число, определяющее, сколько признаков включить в график. Мы можем ограничить их количество с помощью этого параметра. Таким образом, на графике будет показано только указанное количество основных показателей.
lgb.plot_importance(booster, figsize=(8,6));
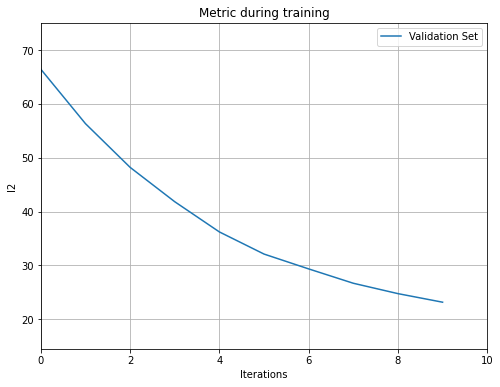
plot_metric()
Этот метод отображает результаты расчета метрики. Нам нужно предоставить экземпляр бустера методу, чтобы построить оценочною метрику, рассчитанную на наборе данных для оценки.
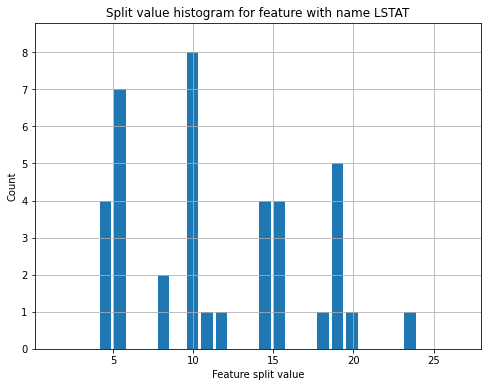
plot_split_value_histogram()
Этот метод принимает на вход экземпляр класса Booster и имя/индекс показателя. Затем он строит гистограмму значений разделения (split value) для выбранного признака.
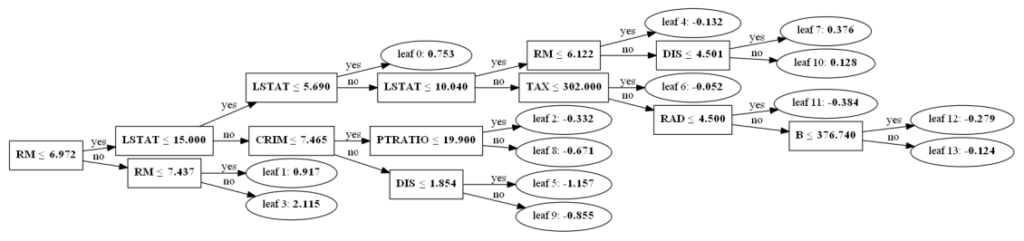
plot_tree()
Этот метод позволяет построить отдельное дерево ансамбля. Нам нужно указать экземпляр бустера и индекс дерева, которое мы хотим построить.
Ранняя остановка обучения
Ранняя остановка обучения — это процесс, при котором мы прекращаем обучение, если оценочная метрика, рассчитанная на оценочном датасете, не улучшается в течение указанного числа раундов. Lightgbm предоставляет параметр early_stopping_rounds как часть методов train() и fit(). Этот параметр принимает целочисленное значение, указывающее, что процесс обучения должен остановится, если результаты вычисления метрики не улучшились за указанное число итераций.
Обратите внимание, что для того, чтобы данный процесс работал, нам нужен набор данных для оценки, поскольку принятие решения об остановке обучения основано на результатах расчета метрики на оценочном датасете.
Ниже мы показываем использование параметра early_stopping_rounds для задач регрессии и классификации на простых примерах.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="binary", n_estimators=100, metric="auc")
booster.fit(X_train, Y_train,
eval_set=[(X_test, Y_test),],
early_stopping_rounds=3)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's auc: 0.979158
Training until validation scores don't improve for 3 rounds
[2] valid_0's auc: 0.979592
[3] valid_0's auc: 0.979592
[4] valid_0's auc: 0.988168
[5] valid_0's auc: 0.988602
[6] valid_0's auc: 0.98947
[7] valid_0's auc: 0.992727
[8] valid_0's auc: 0.995766
[9] valid_0's auc: 0.994572
[10] valid_0's auc: 0.995115
[11] valid_0's auc: 0.995332
Early stopping, best iteration is:
[8] valid_0's auc: 0.995766
Test Accuracy: 0.92
Train Accuracy: 0.96Lightgbm также предоставляет возможность ранней остановки обучения с помощью функции early_stopping(). Мы можем передать число раундов в функцию early_stopping() и использовать возвращаемую ее функцию обратного вызова в качестве входного параметра callbacks методов train() или fit(). Обратные вызовы рассматриваются более подробно в одном из следующих разделов.
Ограничения взаимодействия показателей
Когда lightgbm завершил обучение на датасете, отдельный узел в этих деревьях представляет некоторое условие, основанное на некотором значении показателя. Когда во время предсказания мы используем отдельное дерево, мы начинаем с его корневого узла, проверяя условие конкретного показателя, указанное в данном узле, с соответствующим значением показателя из нашего семпла. Решения принимаются нами на основе значений признаков из наблюдения и условий, представленных в дереве. Таким образом, мы идем по определенному пути, пока не достигнем листа дерева, где сможем сделать окончательный прогноз.
По умолчанию любой узел может быть связан с любым показателем в качестве условия. Этот процесс принятия окончательного решения путем прохождения узлов дерева, проверяя условие на соответствующих признаках, называется взаимодействием показателей, так как предиктор пришел к конкретному узлу после оценки условия предыдущего узла. Lightgbm позволяет нам определять ограничения на то, какой признак взаимодействует с каким. Мы можем предоставить список индексов, и указанные показатели будут взаимодействовать только друг с другом. Этим признакам не будет разрешено взаимодействовать с другими, и это ограничение будет применяться при создании деревьев в процессе обучения.
Ниже мы объясняем на простом примере, как наложить ограничение взаимодействия показателей на оценщик в lightgbm. Оценщики Lightgbm предоставляют параметр с названием interaction_constraints, который принимает список списков, где отдельные списки являются индексами признаков, которым разрешено взаимодействовать друг с другом.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse",
'interaction_constraints':[[0,1,2,11,12], [3, 4],[6,10], [5,9], [7,8]]},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Монотонные ограничения
Lightgbm позволяет нам указывать монотонные ограничения для модели, которые определяют, связан ли отдельный показатель с увеличением/уменьшением целевого значения, или не связан вовсе. Таким образом, у нас есть возможность использовать монотонные значения -1, 0 и 1, тем самым заставляя модель устанавливать уменьшающуюся, нулевую и увеличивающуюся взаимосвязь показателя с целью. Мы можем предоставить список той же длины, что и количество признаков, указав 1, 0 или -1 для монотонной связи, используя параметр monotone_constraints. Ниже объясняется, как обеспечить монотонные ограничения в lightgbm.
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse",
'monotone_constraints':(1,0,1,-1,1,0,1,0,-1,1,1, -1, 1)},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Пользовательская функция цели/потерь
Lightgbm также позволяет определить целевую функцию, подходящую именно нам. Для этого нужно создать функцию, которая принимает список прогнозируемых и фактических меток в качестве входных данных и возвращает первую и вторую производные функции потерь, вычисленные с использованием предсказанных и фактических значений. Далее мы можем передать параметру objective оценщика определенную нами функцию цели/потерь. В случае использования метода train() мы должны предоставить ее через параметр fobj.
Ниже нами была разработана целевая функция средней квадратической ошибки (MSE). Затем мы передали ее параметру objective LGBMModel.
def first_grad(predt, dmat):
'''Вычисли первую производную для MSE.'''
y = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
return 2*(y-predt)
def second_grad(predt, dmat):
'''Вычисли вторую производную для MSE.'''
y = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
return [1] * len(predt)
def mean_sqaured_error(predt, dmat):
''''Функция MSE.'''
predt[predt < -1] = -1 + 1e-6
grad = first_grad(predt, dmat)
hess = second_grad(predt, dmat)
return grad, hess
booster = lgb.LGBMModel(objective=mean_sqaured_error, n_estimators=10,)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.78
Train R2 Score: 0.82Пользовательская функция оценки
Lightgbm позволяет нам определять нашу собственную оценочную метрику, если мы не хотим использовать метрики, предоставленные фреймворком. Для этого мы должны написать функцию, которая принимает на вход список предсказаний и фактических целевых значений. Она будет возвращать строку, определяющую название метрики, результат ее расчета и логическое значение, выражающее, стоит ли стремится к максимизации данной метрики или к ее минимизации. В случае, когда чем выше значение метрики, тем лучше, должно быть возвращено True, иначе — False.
Нам нужно указать ссылку на эту функцию в параметре feval, если мы используем метод train() для разработки нашего оценщика. При передаче в fit() нам нужно присвоить данную ссылку параметру eval_metric.
Далее объясняется на простых примерах, как можно использовать пользовательские оценочные метрики с lightgbm.
def mean_absolute_error(preds, dmat):
actuals = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
err = (actuals - preds).sum()
is_higher_better = False
return "MAE", err, is_higher_better
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse"},
feval=mean_absolute_error,
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.71
Train R2 Score: 0.76Функции обратного вызова
Lightgbm предоставляет пользователям список функций обратного вызова для разных целей, которые выполняются после каждой итерации обучения. Ниже приведен список доступных колбэков:
early_stopping(stopping_rounds)— эта функция обратного вызова принимает целое число, указывающее, следует ли останавливать обучение, если результаты расчета метрики на последнем оценочном датасете не улучшаются на протяжении указанного числа итераций.print_evaluation(period, show_stdv)— данный колбэк принимает целочисленные значения, определяющие, как часто должны выводиться результаты оценки. Полученные значения оценочной метрики печатаются через указанное число итераций.record_evaluation(eval_result)— эта функция получает на вход словарь, в котором будут записаны результаты оценки.reset_parameter()— данная функция обратного вызова позволяет нам сбрасывать скорость обучения после каждой итерации. Она принимает массив, размер которого совпадает с их количеством, или функцию, возвращающую новую скорость обучения для каждой итерации.
Параметр callbacks методов train() и fit() принимает список функций обратного вызова.
Ниже на простых примерах показано, как мы можем использовать различные колбэки. Функция обратного вызова early_stopping() также была рассмотрена в разделе «Ранняя остановка обучения» этого руководства.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
booster = lgb.LGBMModel(objective=mean_sqaured_error, n_estimators=10,)
booster.fit(X_train, Y_train,
eval_set=[(X_test, Y_test),], eval_metric="rmse",
callbacks=[lgb.reset_parameter(learning_rate=np.linspace(0.1,1,10).tolist())])
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score : %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score : %.2f"%r2_score(Y_train, train_preds))
[1] valid_0's rmse: 20.8416
[2] valid_0's rmse: 12.9706
[3] valid_0's rmse: 6.60998
[4] valid_0's rmse: 4.28918
[5] valid_0's rmse: 3.96958
[6] valid_0's rmse: 3.89009
[7] valid_0's rmse: 3.80177
[8] valid_0's rmse: 3.88698
[9] valid_0's rmse: 4.2917
[10] valid_0's rmse: 4.39651
Test R2 Score : 0.82
Train R2 Score : 0.94На этом заканчивается наше небольшое руководство, объясняющее API LightGBM. Не стесняйтесь поделиться с нами своим мнением в разделе комментариев.





