

PySpark — это API Apache Spark, который представляет собой систему с открытым исходным кодом, применяемую для распределенной обработки больших данных. Изначально она была разработана на языке программирования Scala в Калифорнийском университете Беркли.
Spark предоставляет API для Scala, Java, Python и R. Система поддерживает повторное использование кода между рабочими задачами, пакетную обработку данных, интерактивные запросы, аналитику в реальном времени, машинное обучение и вычисления на графах. Она использует кэширование в памяти и оптимизированное выполнение запросов к данным любого размера.
У нее нет одной собственной файловой системы, такой как Hadoop Distributed File System (HDFS), вместо этого Spark поддерживает множество популярных файловых систем, таких как HDFS, HBase, Cassandra, Amazon S3, Amazon Redshift, Couchbase и т. д.
Преимущества использования Apache Spark:
- Он запускает программы в памяти до 100 раз быстрее, чем Hadoop MapReduce, и в 10 раз быстрее на диске, потому что Spark выполняет обработку в основной памяти рабочих узлов и предотвращает ненужные операции ввода-вывода.
- Spark крайне удобен для пользователя, поскольку имеет API-интерфейсы, написанные на популярных языках, что упрощает задачу для разработчиков: такой подход скрывает сложность распределенной обработки за простыми высокоуровневыми операторами, что значительно снижает объем необходимого кода.
- Систему можно развернуть, используя Mesos, Hadoop через Yarn или собственный диспетчер кластеров Spark.
- Spark производит вычисления в реальном времени и обеспечивает низкую задержку благодаря их резидентному выполнению (в памяти).
Давайте приступим.
Настройка среды в Google Colab
Чтобы запустить pyspark на локальной машине, нам понадобится Java и еще некоторое программное обеспечение. Поэтому вместо сложной процедуры установки мы используем Google Colaboratory, который идеально удовлетворяет наши требования к оборудованию, и также поставляется с широким набором библиотек для анализа данных и машинного обучения. Таким образом, нам остается только установить пакеты pyspark и Py4J. Py4J позволяет программам Python, работающим в интерпретаторе Python, динамически обращаться к объектам Java из виртуальной машины Java.
Итоговый ноутбук можно скачать в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/pyspark_beginner.ipynb
Команда для установки вышеуказанных пакетов:
!pip install pyspark==3.0.1 py4j==0.10.9Spark Session
SparkSession стал точкой входа в PySpark, начиная с версии 2.0: ранее для этого использовался SparkContext. SparkSession — это способ инициализации базовой функциональности PySpark для программного создания PySpark RDD, DataFrame и Dataset. Его можно использовать вместо SQLContext, HiveContext и других контекстов, определенных до 2.0.
Вы также должны знать, что SparkSession внутренне создает SparkConfig и SparkContext с конфигурацией, предоставленной с SparkSession. SparkSession можно создать с помощью SparkSession.builder, который представляет собой реализацию шаблона проектирования Builder (Строитель).
Создание SparkSession
Чтобы создать SparkSession, вам необходимо использовать метод builder().
getOrCreate()возвращает уже существующий SparkSession; если он не существует, создается новый SparkSession.master(): если вы работаете с кластером, вам нужно передать имя своего кластерного менеджера в качестве аргумента. Обычно это будет либоyarn, либоmesosв зависимости от настройки вашего кластера, а при работе в автономном режиме используетсяlocal[x]. Здесь X должно быть целым числом, большим 0. Данное значение указывает, сколько разделов будет создано при использовании RDD, DataFrame и Dataset. В идеалеXдолжно соответствовать количеству ядер ЦП.appName()используется для установки имени вашего приложения.
Пример создания SparkSession:
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark_Tutorial')\
.getOrCreate()
# где "*" обозначает все ядра процессора.
Чтение данных
Используя spark.read мы может считывать данные из файлов различных форматов, таких как CSV, JSON, Parquet и других. Вот несколько примеров получения данных из файлов:
# Чтение CSV файла
csv_file = 'data/stocks_price_final.csv'
df = spark.read.csv(csv_file)
# Чтение JSON файла
json_file = 'data/stocks_price_final.json'
data = spark.read.json(json_file)
# Чтение parquet файла
parquet_file = 'data/stocks_price_final.parquet'
data1 = spark.read.parquet(parquet_file)
Структурирование данных с помощью схемы Spark
Давайте прочитаем данные о ценах на акции в США с января 2019 года по июль 2020 года, которые доступны в датасетах Kaggle.
Код для чтения данных в формате файла CSV:
data = spark.read.csv(
'stocks_price_final.csv',
sep=',',
header=True,
)
data.printSchema()
Теперь посмотрим на схему данных с помощью метода PrintSchema.
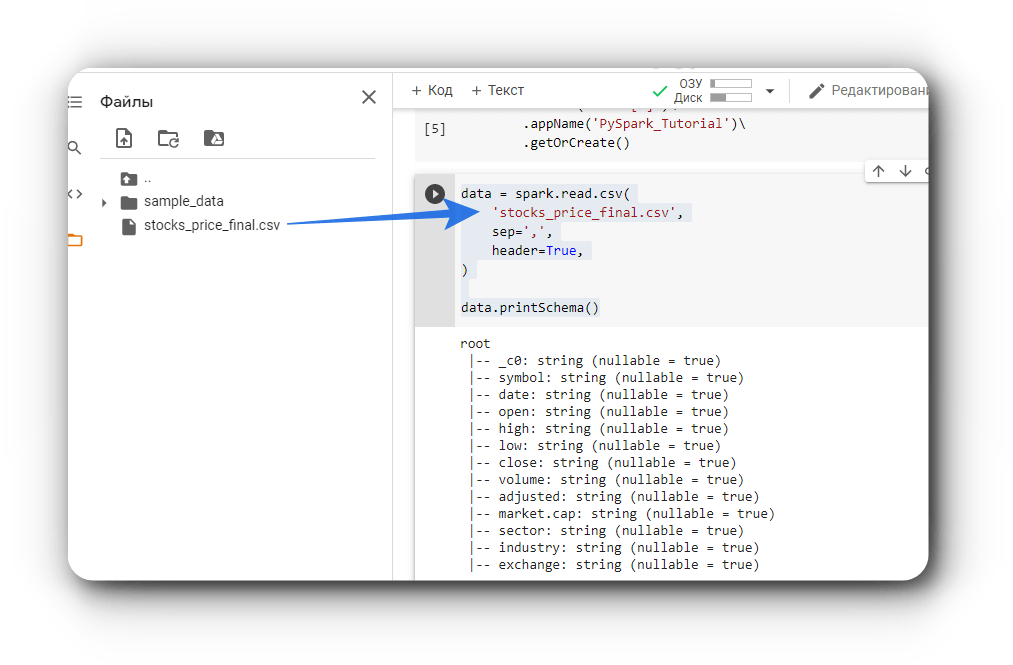
Схема Spark отображает структуру фрейма данных или датасета. Мы можем определить ее с помощью класса StructType, который представляет собой коллекцию объектов StructField. Они в свою очередь устанавливают имя столбца (String), его тип (DataType), допускает ли он значение NULL (Boolean), и метаданные (MetaData).
Это бывает довольно полезно, даже учитывая, что Spark автоматически выводит схему из данных, так как иногда предполагаемый им тип может быть неверным, или нам необходимо определить собственные имена столбцов и типы данных. Такое часто случается при работе с полностью или частично неструктурированными данными.
Давайте посмотрим, как мы можем структурировать наши данные:
from pyspark.sql.types import *
data_schema = [
StructField('_c0', IntegerType(), True),
StructField('symbol', StringType(), True),
StructField('data', DateType(), True),
StructField('open', DoubleType(), True),
StructField('high', DoubleType(), True),
StructField('low', DoubleType(), True),
StructField('close', DoubleType(), True),
StructField('volume', IntegerType(), True),
StructField('adjusted', DoubleType(), True),
StructField('market.cap', StringType(), True),
StructField('sector', StringType(), True),
StructField('industry', StringType(), True),
StructField('exchange', StringType(), True),
]
final_struc = StructType(fields = data_schema)
data = spark.read.csv(
'stocks_price_final.csv',
sep=',',
header=True,
schema=final_struc
)
data.printSchema()
В приведенном выше коде создается структура данных с помощью StructType и StructField. Затем она передается в качестве параметра schema методу spark.read.csv(). Давайте взглянем на полученную в результате схему структурированных данных:
root
|-- _c0: integer (nullable = true)
|-- symbol: string (nullable = true)
|-- data: date (nullable = true)
|-- open: double (nullable = true)
|-- high: double (nullable = true)
|-- low: double (nullable = true)
|-- close: double (nullable = true)
|-- volume: integer (nullable = true)
|-- adjusted: double (nullable = true)
|-- market.cap: string (nullable = true)
|-- sector: string (nullable = true)
|-- industry: string (nullable = true)
|-- exchange: string (nullable = true)Различные методы инспекции данных
Существуют следующие методы инспекции данных: schema, dtypes, show, head, first, take, describe, columns, count, distinct, printSchema. Давайте разберемся в них на примере.
schema(): этот метод возвращает схему данных (фрейма данных). Ниже показан пример с ценами на акции.
data.schema
# -------------- Вывод ------------------
# StructType(
# List(
# StructField(_c0,IntegerType,true),
# StructField(symbol,StringType,true),
# StructField(data,DateType,true),
# StructField(open,DoubleType,true),
# StructField(high,DoubleType,true),
# StructField(low,DoubleType,true),
# StructField(close,DoubleType,true),
# StructField(volume,IntegerType,true),
# StructField(adjusted,DoubleType,true),
# StructField(market_cap,StringType,true),
# StructField(sector,StringType,true),
# StructField(industry,StringType,true),
# StructField(exchange,StringType,true)
# )
# )
dtypesвозвращает список кортежей с именами столбцов и типами данных.
data.dtypes
#------------- Вывод ------------
# [('_c0', 'int'),
# ('symbol', 'string'),
# ('data', 'date'),
# ('open', 'double'),
# ('high', 'double'),
# ('low', 'double'),
# ('close', 'double'),
# ('volume', 'int'),
# ('adjusted', 'double'),
# ('market_cap', 'string'),
# ('sector', 'string'),
# ('industry', 'string'),
# ('exchange', 'string')]
head(n)возвращает n строк в виде списка. Вот пример:
data.head(3)
# ---------- Вывод ---------
# [
# Row(_c0=1, symbol='TXG', data=datetime.date(2019, 9, 12), open=54.0, high=58.0, low=51.0, close=52.75, volume=7326300, adjusted=52.75, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ'),
# Row(_c0=2, symbol='TXG', data=datetime.date(2019, 9, 13), open=52.75, high=54.355, low=49.150002, close=52.27, volume=1025200, adjusted=52.27, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ'),
# Row(_c0=3, symbol='TXG', data=datetime.date(2019, 9, 16), open=52.450001, high=56.0, low=52.009998, close=55.200001, volume=269900, adjusted=55.200001, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ')
# ]
show()по умолчанию отображает первые 20 строк, а также принимает число в качестве параметра для выбора их количества.first()возвращает первую строку данных.
data.first()
# ----------- Вывод -------------
# Row(_c0=1, symbol='TXG', data=datetime.date(2019, 9, 12), open=54.0, high=58.0, low=51.0,
# close=52.75, volume=7326300, adjusted=52.75, market_cap='$9.31B', sector='Capital Goods',
# industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ')
take(n)возвращает первые n строк.describe()вычисляет некоторые статистические значения для столбцов с числовым типом данных.columnsвозвращает список, содержащий названия столбцов.
data.columns
# --------------- Вывод --------------
# ['_c0',
# 'symbol',
# 'data',
# 'open',
# 'high',
# 'low',
# 'close',
# 'volume',
# 'adjusted',
# 'market_cap',
# 'sector',
# 'industry',
# 'exchange']count()возвращает общее число строк в датасете.
data.count()
# возвращает количество строк данных
# -------- Вывод ---------
# 1292361distinct()— количество различных строк в используемом наборе данных.printSchema()отображает схему данных.
df.printSchema()
# ------------ Вывод ------------
# root
# |-- _c0: integer (nullable = true)
# |-- symbol: string (nullable = true)
# |-- data: date (nullable = true)
# |-- open: double (nullable = true)
# |-- high: double (nullable = true)
# |-- low: double (nullable = true)
# |-- close: double (nullable = true)
# |-- volume: integer (nullable = true)
# |-- adjusted: double (nullable = true)
# |-- market_cap: string (nullable = true)
# |-- sector: string (nullable = true)
# |-- industry: string (nullable = true)
# |-- exchange: string (nullable = true)Манипуляции со столбцами
Давайте посмотрим, какие методы используются для добавления, обновления и удаления столбцов данных.
1. Добавление столбца: используйте withColumn, чтобы добавить новый столбец к существующим. Метод принимает два параметра: имя столбца и данные. Пример:
data = data.withColumn('date', data.data)
data.show(5)
2. Обновление столбца: используйте withColumnRenamed, чтобы переименовать существующий столбец. Метод принимает два параметра: название существующего столбца и его новое имя. Пример:
data = data.withColumnRenamed('date', 'data_changed')
data.show(5)
3. Удаление столбца: используйте метод drop, который принимает имя столбца и возвращает данные.
data = data.drop('data_changed')
data.show(5)
Работа с недостающими значениями
Мы часто сталкиваемся с отсутствующими значениями при работе с данными реального времени. Эти пропущенные значения обозначаются как NaN, пробелы или другие заполнители. Существуют различные методы работы с пропущенными значениями, некоторые из самых популярных:
- Удаление: удалить строки с пропущенными значениями в любом из столбцов.
- Замена средним/медианным значением: замените отсутствующие значения, используя среднее или медиану соответствующего столбца. Это просто, быстро и хорошо работает с небольшими наборами числовых данных.
- Замена на наиболее частые значения: как следует из названия, используйте наиболее часто встречающееся значение в столбце, чтобы заменить отсутствующие. Это хорошо работает с категориальными признаками, но также может вносить смещение (bias) в данные.
- Замена с использованием KNN: метод K-ближайших соседей — это алгоритм классификации, который рассчитывает сходство признаков новых точек данных с уже существующими, используя различные метрики расстояния, такие как Евклидова, Махаланобиса, Манхэттена, Минковского, Хэмминга и другие. Такой подход более точен по сравнению с вышеупомянутыми методами, но он требует больших вычислительных ресурсов и довольно чувствителен к выбросам.
Давайте посмотрим, как мы можем использовать PySpark для решения проблемы отсутствующих значений:
# Удаление строк с пропущенными значениями
data.na.drop()
# Замена отсутствующих значений средним
data.na.fill(data.select(f.mean(data['open'])).collect()[0][0])
# Замена отсутствующих значений новыми
data.na.replace(old_value, new_vallue)
Получение данных
PySpark и PySpark SQL предоставляют широкий спектр методов и функций для удобного запроса данных. Вот список наиболее часто используемых методов:
- Select
- Filter
- Between
- When
- Like
- GroupBy
- Агрегирование
Select
Он используется для выбора одного или нескольких столбцов, используя их имена. Вот простой пример:
# Выбор одного столбца
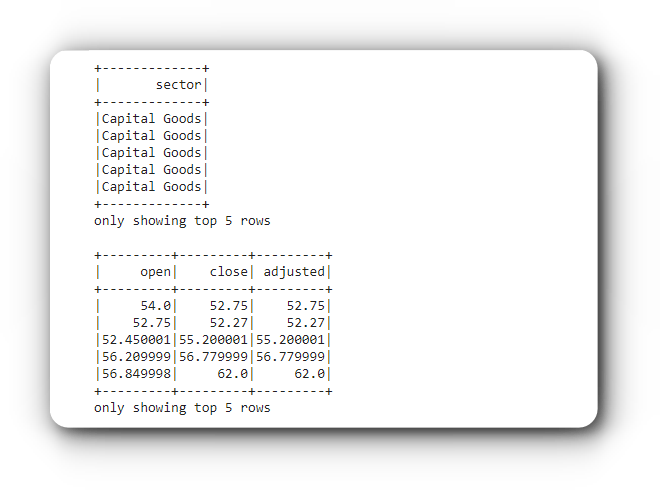
data.select('sector').show(5)
# Выбор нескольких столбцов
data.select(['open', 'close', 'adjusted']).show(5)
Filter
Данный метод фильтрует данные на основе заданного условия. Вы также можете указать несколько условий, используя операторы AND (&), OR (|) и NOT (~). Вот пример получения данных о ценах на акции за январь 2020 года.
from pyspark.sql.functions import col, lit
data.filter( (col('data') >= lit('2020-01-01')) & (col('data') <= lit('2020-01-31')) ).show(5)
Between
Этот метод возвращает True, если проверяемое значение принадлежит указанному отрезку, иначе — False. Давайте посмотрим на пример отбора данных, в которых значения adjusted находятся в диапазоне от 100 до 500.
data.filter(data.adjusted.between(100.0, 500.0)).show()
When
Он возвращает 0 или 1 в зависимости от заданного условия. В приведенном ниже примере показано, как выбрать такие цены на момент открытия и закрытия торгов, при которых скорректированная цена была больше или равна 200.
data.select('open', 'close',
f.when(data.adjusted >= 200.0, 1).otherwise(0)
).show(5)
Like
Этот метод похож на оператор Like в SQL. Приведенный ниже код демонстрирует использование rlike() для извлечения имен секторов, которые начинаются с букв M или C.
data.select(
'sector',
data.sector.rlike('^[B,C]').alias('Колонка sector начинается с B или C')
).distinct().show()
GourpBy
Само название подсказывает, что данная функция группирует данные по выбранному столбцу и выполняет различные операции, такие как вычисление суммы, среднего, минимального, максимального значения и т. д. В приведенном ниже примере объясняется, как получить среднюю цену открытия, закрытия и скорректированную цену акций по отраслям.
data.select(['industry', 'open', 'close', 'adjusted'])\
.groupBy('industry')\
.mean()\
.show()
Агрегирование
PySpark предоставляет встроенные стандартные функции агрегации, определенные в API DataFrame, они могут пригодится, когда нам нужно выполнить агрегирование значений ваших столбцов. Другими словами, такие функции работают с группами строк и вычисляют единственное возвращаемое значение для каждой группы.
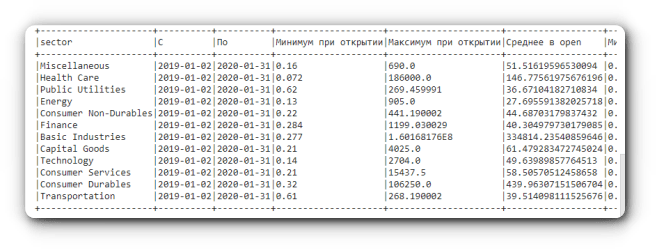
В приведенном ниже примере показано, как отобразить минимальные, максимальные и средние значения цен открытия, закрытия и скорректированных цен акций в промежутке с января 2019 года по январь 2020 года для каждого сектора.
from pyspark.sql import functions as f
data.filter((col('data') >= lit('2019-01-02')) & (col('data') <= lit('2020-01-31')))\
.groupBy("sector") \
.agg(f.min("data").alias("С"),
f.max("data").alias("По"),
f.min("open").alias("Минимум при открытии"),
f.max("open").alias("Максимум при открытии"),
f.avg("open").alias("Среднее в open"),
f.min("close").alias("Минимум при закрытии"),
f.max("close").alias("Максимум при закрытии"),
f.avg("close").alias("Среднее в close"),
f.min("adjusted").alias("Скорректированный минимум"),
f.max("adjusted").alias("Скорректированный максимум"),
f.avg("adjusted").alias("Среднее в adjusted"),
).show(truncate=False)
Визуализация данных
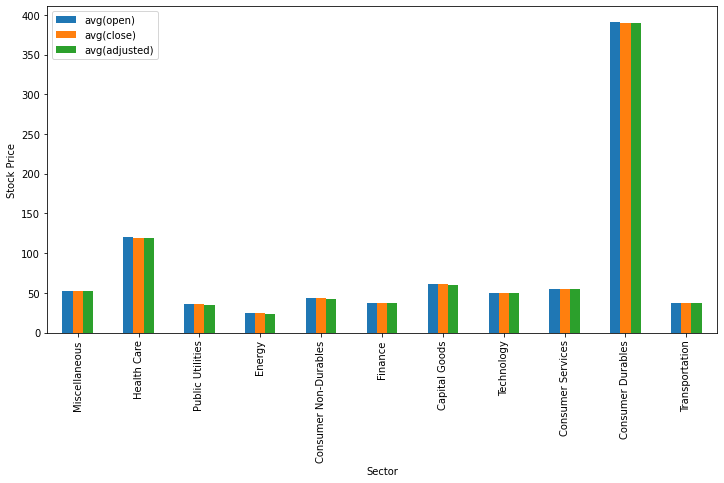
Для визуализации данных мы воспользуемся библиотеками matplotlib и pandas. Метод toPandas() позволяет нам осуществить преобразование данных в dataframe pandas, который мы используем при вызове метода визуализации plot(). В приведенном ниже коде показано, как отобразить гистограмму, отображающую средние значения цен открытия, закрытия и скорректированных цен акций для каждого сектора.
from matplotlib import pyplot as plt
sec_df = data.select(['sector',
'open',
'close',
'adjusted']
)\
.groupBy('sector')\
.mean()\
.toPandas()
ind = list(range(12))
ind.pop(6)
sec_df.iloc[ind ,:].plot(kind='bar', x='sector', y=sec_df.columns.tolist()[1:],
figsize=(12, 6), ylabel='Stock Price', xlabel='Sector')
plt.show()
Теперь давайте визуализируем те же средние показатели, но уже по отраслям.
industries_x = data.select(['industry', 'open', 'close', 'adjusted']).groupBy('industry').mean().toPandas()
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')]
q.plot(kind='barh', x='industry', y=q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel='Industry')
plt.show()
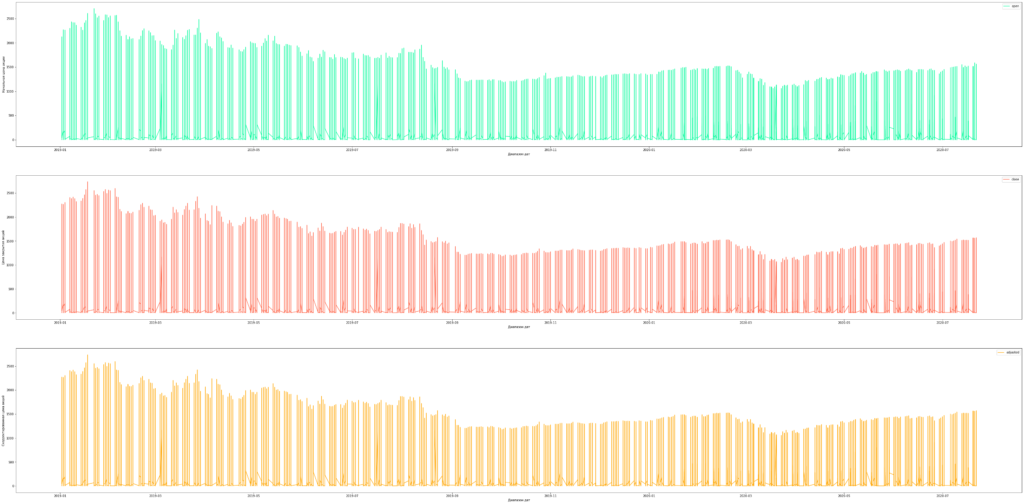
Также построим временные ряды для средних цен открытия, закрытия и скорректированных цен акций технологического сектора.
industries_x = data.select(['industry', 'open', 'close', 'adjusted']).groupBy('industry').mean().toPandas()
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')]
q.plot(kind='barh', x='industry', y=q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel='Industry')
plt.show()
Запись/сохранение данных в файл
Метод write.save() используется для сохранения данных в различных форматах, таких как CSV, JSVON, Parquet и других. Давайте рассмотрим, как записать данные в файлы разных форматов. Мы можем сохранить как все строки, так и только выбранные с помощью метода select().
# CSV
data.write.csv('dataset.csv')
# JSON
data.write.save('dataset.json', format='json')
# Parquet
data.write.save('dataset.parquet', format='parquet')
# Запись выбранных данных в различные форматы файлов
# CSV
data.select(['data', 'open', 'close', 'adjusted'])\
.write.csv('dataset.csv')
# JSON
data.select(['data', 'open', 'close', 'adjusted'])\
.write.save('dataset.json', format='json')
# Parquet
data.select(['data', 'open', 'close', 'adjusted'])\
.write.save('dataset.parquet', format='parquet')
Заключение
PySpark — отличный инструмент для специалистов по данным, поскольку он обеспечивает масштабируемые анализ и ML-пайплайны. Если вы уже знакомы с Python, SQL и Pandas, тогда PySpark — хороший вариант для быстрого старта.
В этой статье было показано, как следует выполнять широкий спектр операций, начиная с чтения файлов и заканчивая записью результатов с помощью PySpark. Также мы охватили основные методы визуализации с использованием библиотеки matplotlib.
Мы узнали, что Google Colaboratory Notebooks — это удобное место для начала изучения PySpark без долгой установки необходимого программного обеспечения. Не забудьте ознакомиться с представленными ниже ссылками на ресурсы, которые могут помочь вам быстрее и проще изучить PySpark.
Также не стесняйтесь использовать предоставленный в статье код, доступ к которому можно получить, перейдя на Gitlab. Удачного обучения.





