

В этом материале рассмотрим обработку аудио в Python на примере библиотеки librosa.
Что такое librosa?
Librosa — это пакет Python для анализа музыки и аудио. Он предоставляет строительные блоки для создания структур, которые помогают получать информацию о музыке.
Установка librosa в Python
Установим библиотеку с помощью команды pip:
pip install librosa
Для примера я скачал файл mp3-файл из https://www.bensound.com/ и конвертировал его в ogg для комфортной работы. Загрузим короткий ogg-файл (это может быть любой музыкальный файл в формате ogg):
import librosa
y, sr = librosa.load('bensound-happyrock.ogg')
Обработка аудио в виде временных рядов
В последней строке функция load считывает ogg-файл в виде временного рядя. Где, sr обозначает sample_rate.
- Time series (временной ряд) представлен массивом.
sample_rate— это количество сэмплов на секунду аудио.
По умолчанию звук микшируется в моно. Но его можно передискретизировать во время загрузки до 22050 Гц. Это делается с помощью дополнительных параметров в функции librosa.load.
Извлечение признаков из аудиофайла
У сэмпла есть несколько важных признаков. Есть фундаментальное понятие ритма в некоторых формах, а остальные либо имеют свою нюансы, либо связаны:
- Темп: скорость, с которой паттерны повторяются. Темп измеряется в битах в минуту (BPM). Если у музыки 120 BPM, это значит, что каждую минуту в ней 120 битов (ударов).
- Бит: отрезок времени. Это ритм, выстукиваемый в песне. Так, в одном такте 4 бита, например.
- Такт: логичное деление битов. Обычно в такте 3 или 4 бита, хотя возможны и другие варианты.
- Интервал: в программах для редактирования чаще всего встречаются интервалы. Обычно есть последовательность нот, например, 8 шестнадцатых одинаковой длины. Обычно интервал — 8 нот, триплеты или четверные.
- Ритм: список музыкальных звуков. Все ноты и являются ритмом.
Из аудио можно получить темп и биты:
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
print(tempo)
print(beat_frames)
89.10290948275862
[ 3 40 75 97 132 153 183 211 246 275 303 332 361 389
...
4438 4466]Мел-кепстральные коэффициенты (MFCC)
Мел-кепстральные коэффициенты — один из важнейших признаков в обработке аудио.
MFCC — это матрица значений, которая захватывает тембральные аспекты музыкального инструменты: например, отличия в звучании металлической и деревянной гитары. Другими метриками эта разница не захватывается, но это ближайшее к тому, что может различать человек.
mfcc = librosa.feature.mfcc(y=y, sr=sr, hop_length=8192, n_mfcc=12)
# pip install seaborn matplotlib
import seaborn as sns
from matplotlib import pyplot as plt
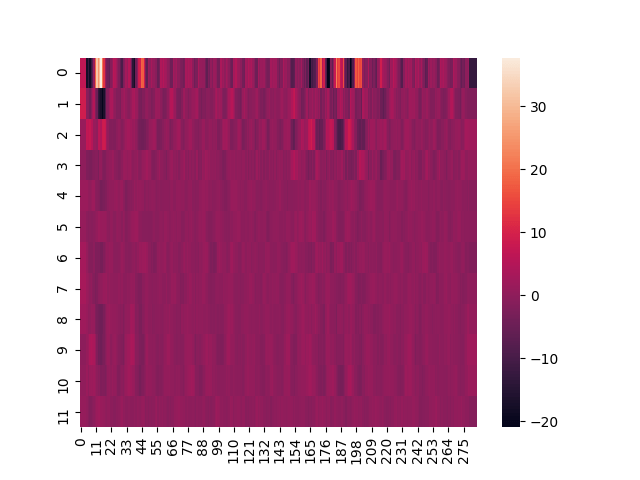
mfcc_delta = librosa.feature.delta(mfcc)
sns.heatmap(mfcc_delta)
plt.show()
Здесь мы создаем тепловую карту данных MFCC, которая обеспечивает такой результат:
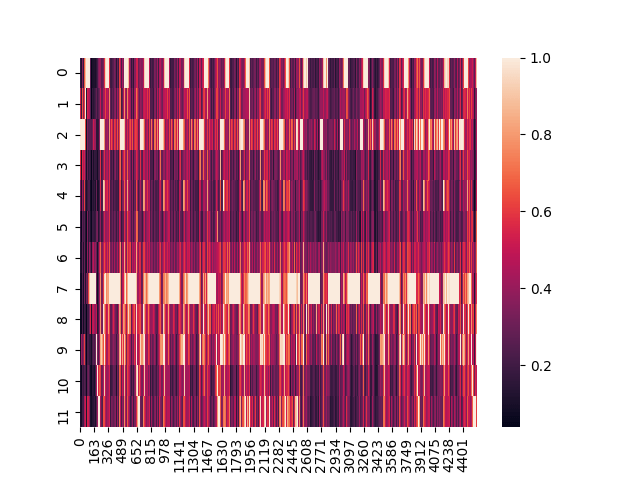
Нормализация ее в хроматограмму даст такой результат:
chromagram = librosa.feature.chroma_cqt(y=y, sr=sr)
sns.heatmap(chromagram)
plt.show()
Это лишь основы о том, что можно получить из аудиоданных для обучаемых алгоритмов. Много продвинутых примеров есть в документации librosa.





