В библиотеке Pandas есть несколько функций для решения этой проблемы, и value_counts — одна из них. Она возвращает объект, содержащий уникальные значения из dataframe Pandas в отсортированном порядке. Однако многие забывают об этой возможности и используют параметры по умолчанию. В этом материале посмотрим, как получить максимум пользы от value_counts, изменив параметры по умолчанию.
Что такое функция value_counts()?
Функция value_counts() используется для получения Series, содержащего уникальные значения. Она вернет результат, отсортированный в порядке убывания, так что первый элемент в коллекции будет самым встречаемым. NA-значения не включены в результат.
Синтаксисdf['your_column'].value_counts() — вернет количество уникальных совпадений в определенной колонке.
Важно заметить, что value_counts работает только с series, но не dataframe. Поэтому нужно указать одни квадратные скобки df['your_column'], а не пару df[['your_column']].
Параметры:
normalize(bool, по умолчанию False) — еслиTrue, то возвращаемый объект будет содержать значения относительно частоты встречаемых значений.sort(bool, по умолчанию True) — сортировка по частоте.ascending(bool, по умолчанию False) — сортировка по возрастанию.bins(int) — вместе подсчета значений группирует их по отрезкам, но это работает только с числовыми данными.- dropna (bool, по умолчанию True) — не включать количество NaN.
Загрузка данных для демонстрации
Рассмотрим, как использовать этот метод на реальных данных. Возьмем в качестве примера датасет из курса Coursera на Kaggle.
Для начала импортируем нужные библиотеки и сами данные. Это нужно в любом проекте. После этого проанализируем данные в notebook Jupyter.
# импорт библиотеки
import pandas as pd
# Загрузка данных
df = pd.read_csv('Downloads/coursea_data.csv', index_col=0)
# проверка данных из csv
df.head(10)
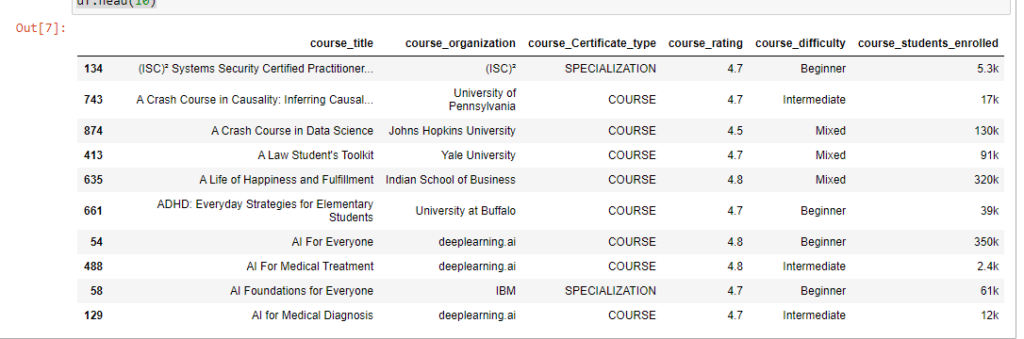
Проверьте, сколько записей в датасете и есть ли у нас пропуски.
df.info()
Результат показывает, что в наборе 981 запись, и нет ни одного NA.
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 134 to 163
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 course_title 891 non-null object
1 course_organization 891 non-null object
2 course_Certificate_type 891 non-null object
3 course_rating 891 non-null float64
4 course_difficulty 891 non-null object
5 course_students_enrolled 891 non-null object
dtypes: float64(1), object(5)
memory usage: 48.7+ KB1. value_counts с параметрами по умолчанию
Теперь можно начинать использовать функцию value_counts. Начнем с базового применения функции.
Синтаксис: df['your_column'].value_counts().
Получим количество каждого значения для колонки «course_difficulty».
Функция value_counts вернет количество совпадений всех уникальных значений по заданному индексу без пропусков. Это позволит увидеть, что больше всего курсов с уровнем сложности «Начинающий», после этого идут «Средний» и «Смешанный». А «Сложный» на последнем месте.
df['course_difficulty'].value_counts()
---------------------------------------------------
Beginner 487
Intermediate 198
Mixed 187
Advanced 19
Name: course_difficulty, dtype: int64Теперь время поработать с параметрами.
2. Сортировка по возрастанию
По умолчанию value_counts() возвращает данные по убыванию. Изменит поведение можно, задав значение True для параметра ascending.
Синтаксис: df['your_column'].value_counts(ascending=True).
df['course_difficulty'].value_counts(ascending=True)
---------------------------------------------------
Advanced 19
Mixed 187
Intermediate 198
Beginner 487
Name: course_difficulty, dtype: int643. Сортировка в алфавитном порядке
В определенных случаях может существовать необходимость отсортировать записи в алфавитном порядке. Это делается с помощью добавления sort_index(ascending=True) после value_counts().
По умолчанию функция сортирует «course_difficulty» по количеству совпадений, а с sort_index сортирует по индексу (имени колонки, для которой и используется функция):
df['course_difficulty'].value_counts().sort_index(ascending=True)
---------------------------------------------------
Advanced 19
Beginner 487
Intermediate 198
Mixed 187
Name: course_difficulty, dtype: int64Если же требуется отобразить value_counts() в обратном алфавитном порядке, то нужно изменить направление сортировки: .sort_index(ascending=False).
4. Сортировка по значению, а затем по алфавиту
Для этого примера используем другой датасет.
df_fruit = pd.DataFrame({
'fruit':
['хурма']*5 + ['яблоки']*5 + ['бананы']*3 +
['персики']*3 + ['морковь']*3 + ['абрикосы'] + ['манго']*2
})
Так, нужно получить вывод, отсортированный в первую очередь по количеству совпадений значений, а потом уже и по алфавиту. Это можно сделать, объединив value_counts() c sort_index(ascending=False) и sort_values(ascending=False).
df_fruit['fruit'].value_counts()\
.sort_index(ascending=False)\
.sort_values(ascending=False)
-------------------------------------------------
хурма 5
яблоки 5
бананы 3
морковь 3
персики 3
манго 2
абрикосы 1
Name: fruit, dtype: int645. Относительная частота уникальных значений
Иногда нужно получить относительные значения, а не просто количество. С параметром normalize=True объект вернет относительную частоту уникальных значений. По умолчанию значение этого параметра равно False.
Синтаксис: df['your_column'].value_counts(normalize=True).
df['course_difficulty'].value_counts(normalize=True)
-------------------------------------------------
Beginner 0.546577
Intermediate 0.222222
Mixed 0.209877
Advanced 0.021324
Name: course_difficulty, dtype: float646. value_counts() для разбивки данных на дискретные интервалы
Еще один трюк, который часто игнорируют. value_counts() можно использовать для разбивки данных на дискретные интервалы с помощью параметра bin. Это работает только с числовыми данными. Принцип напоминает pd.cut. Посмотрим как это работает на примере колонки «course_rating». Сгруппируем значения колонки на 4 группы.
Синтаксис: df['your_column'].value_counts(bin=количество групп).
df['course_rating'].value_counts(bins=4)
-------------------------------------------------
(4.575, 5.0] 745
(4.15, 4.575] 139
(3.725, 4.15] 5
(3.297, 3.725] 2
Name: course_rating, dtype: int64Бинниг позволяет легко получить инсайты. Так, можно увидеть, что большая часть людей оценивает курс на 4.5. И лишь несколько курсов имеют оценку ниже 4.15.
7. value_counts() с пропусками
По умолчанию количество значений NaN не включается в результат. Но это поведение можно изменить, задав значение False для параметра dropna. Поскольку в наборе данных нет нулевых значений, в этом примере это ни на что не повлияет. Но сам параметр следует запомнить.
Синтаксис: df['your_column'].value_counts(dropna=False).
8. value_counts() как dataframe
Как уже было отмечено, value_counts() возвращает Series, а не Dataframe. Если же нужно получить результаты в последнем виде, то для этого можно использовать функцию .to_frame() после .value_counts().
Синтаксис: df['your_column'].value_counts().to_frame().
Это будет выглядеть следующим образом:
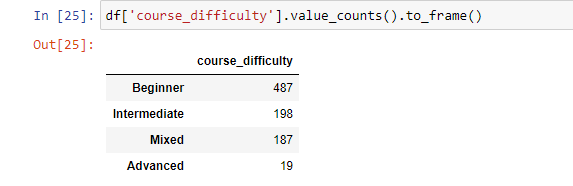
Если нужно задать имя для колонки или переименовать существующую, то эту конвертацию можно реализовать другим путем.
value_counts = df['course_difficulty'].value_counts()
# преобразование в df и присвоение новых имен колонкам
df_value_counts = pd.DataFrame(value_counts)
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = ['unique_values', 'counts for course_difficulty']
df_value_counts
Groupby и value_counts
Groupby — очень популярный метод в Pandas. С его помощью можно сгруппировать результат по одной колонке и посчитать значения в другой.
Синтаксис: df.groupby('your_column_1')['your_column_2'].value_counts().
Так, с помощью groupby и value_counts можно посчитать количество типов сертификатов для каждого уровня сложности курсов.
df.groupby('course_difficulty')['course_Certificate_type'].value_counts()
-------------------------------------------------
course_difficulty course_Certificate_type
Advanced SPECIALIZATION 10
COURSE 9
Beginner COURSE 282
SPECIALIZATION 196
PROFESSIONAL CERTIFICATE 9
Intermediate COURSE 104
SPECIALIZATION 91
PROFESSIONAL CERTIFICATE 3
Mixed COURSE 187
Name: course_Certificate_type, dtype: int64Это мульти-индекс, позволяющий иметь несколько уровней индексов в dataframe. В этом случае сложность курса соответствует нулевому уровню индекса, а тип сертификата — первому.
Фильтрация значений по минимум и максимум
Работая с набором данных, может потребоваться вернуть количество ограниченных вхождений с помощью value_counts().
Синтаксис: df['your_column'].value_counts().loc[lambda x : x > 1].
Этот код отфильтрует все значения уникальных данных и покажет только те, где значение больше единицы.
Для примера ограничим рейтинг курса значением 4.
df.groupby('course_difficulty')['coudf['course_rating']\
.value_counts().loc[lambda x: x > 4]
-------------------------------------------------
4.8 256
4.7 251
4.6 168
4.5 80
4.9 68
4.4 34
4.3 15
4.2 10
Name: course_rating, dtype: int64value_counts() — удобный инструмент, позволяющий делать удобный анализ в одну строку.
Тест на знание функции value_counts
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip.
Если у вас Windows, Linux или macOS:
pip install pandas # или pip3В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
ModuleNotFoundError: No module named 'openpyxl'В таком случае нужно установить недостающие модули:
pip install openpyxl xlsxwriter xlrd # или pip3Запись в файл Excel с python
Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame. А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas. Потом используем словарь для заполнения DataFrame:
import pandas as pd
df = pd.DataFrame({'Name': ['Manchester City', 'Real Madrid', 'Liverpool',
'FC Bayern München', 'FC Barcelona', 'Juventus'],
'League': ['English Premier League (1)', 'Spain Primera Division (1)',
'English Premier League (1)', 'German 1. Bundesliga (1)',
'Spain Primera Division (1)', 'Italian Serie A (1)'],
'TransferBudget': [176000000, 188500000, 90000000,
100000000, 180500000, 105000000]})
Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:
df.to_excel('./teams.xlsx')
А вот и созданный файл Excel:

Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel():
df.to_excel('./teams.xlsx', sheet_name='Budgets', index=False)
Также можно добавили параметр index со значением False, чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
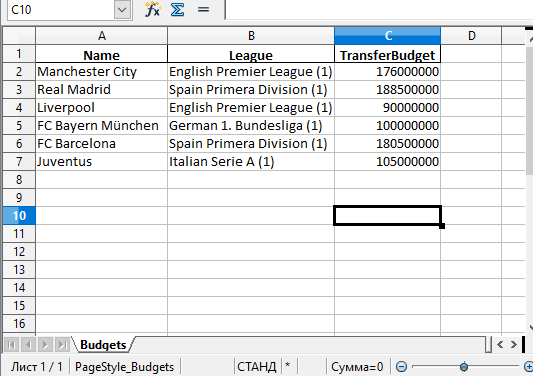
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
salaries1 = pd.DataFrame({'Name': ['L. Messi', 'Cristiano Ronaldo', 'J. Oblak'],
'Salary': [560000, 220000, 125000]})
salaries2 = pd.DataFrame({'Name': ['K. De Bruyne', 'Neymar Jr', 'R. Lewandowski'],
'Salary': [370000, 270000, 240000]})
salaries3 = pd.DataFrame({'Name': ['Alisson', 'M. ter Stegen', 'M. Salah'],
'Salary': [160000, 260000, 250000]})
salary_sheets = {'Group1': salaries1, 'Group2': salaries2, 'Group3': salaries3}
writer = pd.ExcelWriter('./salaries.xlsx', engine='xlsxwriter')
for sheet_name in salary_sheets.keys():
salary_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets, где каждый ключ будет названием листа, а значение — объектом DataFrame.
Дальше используем движок xlsxwriter для создания объекта writer. Он и передается функции to_excel().
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
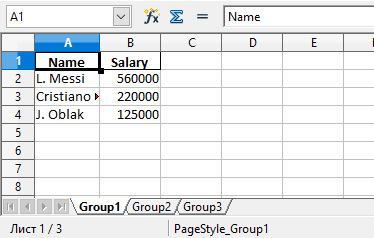
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter, который нужен для работы с классом ExcelWriter. Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save(), которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame. Для этого достаточно воспользоваться функцией read_excel():
top_players = pd.read_excel('./top_players.xlsx')
top_players.head()
Содержимое финального объекта можно посмотреть с помощью функции head().
Примечание:
Этот способ самый простой, но он и способен прочесть лишь содержимое первого листа.
Посмотрим на вывод функции head():
| Name | Age | Overall | Potential | Positions | Club | |
|---|---|---|---|---|---|---|
| 0 | L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| 1 | Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| 2 | J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| 3 | K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| 4 | Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
Pandas присваивает метку строки или числовой индекс объекту DataFrame по умолчанию при использовании функции read_excel().
Это поведение можно переписать, передав одну из колонок из файла в качестве параметра index_col:
top_players = pd.read_excel('./top_players.xlsx', index_col='Name')
top_players.head()
Результат будет следующим:
| Name | Age | Overall | Potential | Positions | Club |
|---|---|---|---|---|---|
| L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
В этом примере индекс по умолчанию был заменен на колонку «Name» из файла. Однако этот способ стоит использовать только при наличии колонки со значениями, которые могут стать заменой для индексов.
Чтение определенных колонок из файла Excel
Иногда удобно прочитать содержимое файла целиком, но бывают случаи, когда требуется получить доступ к определенному элементу. Например, нужно считать значение элемента и присвоить его полю объекта.
Это делается с помощью функции read_excel() и параметра usecols. Например, можно ограничить функцию, чтобы она читала только определенные колонки. Добавим параметр, чтобы он читал колонки, которые соответствуют значениям «Name», «Overall» и «Potential».
Для этого укажем числовой индекс каждой колонки:
cols = [0, 2, 3]
top_players = pd.read_excel('./top_players.xlsx', usecols=cols)
top_players.head()
Вот что выдаст этот код:
| Name | Overall | Potential | |
|---|---|---|---|
| 0 | L. Messi | 93 | 93 |
| 1 | Cristiano Ronaldo | 92 | 92 |
| 2 | J. Oblak | 91 | 93 |
| 3 | K. De Bruyne | 91 | 91 |
| 4 | Neymar Jr | 91 | 91 |
Таким образом возвращаются лишь колонки из списка cols.
В DataFrame много встроенных возможностей. Легко изменять, добавлять и агрегировать данные. Даже можно строить сводные таблицы. И все это сохраняется в Excel одной строкой кода.
Рекомендую изучить DataFrame в моих уроках по Pandas.
Выводы
В этом материале были рассмотрены функции read_excel() и to_excel() из библиотеки Pandas. С их помощью можно считывать данные из файлов Excel и выполнять запись в них. С помощью различных параметров есть возможность менять поведение функций, создавая нужные файлы, не просто копируя содержимое из объекта DataFrame.
Манипуляция строками
Python — это популярный язык, который благодаря своей простоте часто используется для обработки строк и текста. Большая часть операций может быть выполнена даже с помощью встроенных функций. А для более сложных используются регулярные выражения.
Встроенные методы для работы со строками
В большинстве случаев имеются сложные строки, которые желательно разделять на части и присваивать их правильным переменным. Функция split() позволяет разбить тексты на части, используя разделитель в качестве ориентира. Им может быть, например, запятая.
>>> text = '16 Bolton Avenue , Boston'
>>> text.split(',')
['16 Bolton Avenue ', 'Boston']
По первому элементу видно, что в конце у него остается пробел. Чтобы решить эту проблему, вместе со split() нужно также использовать функцию strip(), которая обрезает пустое пространство (включая символы новой строки)
>>> tokens = [s.strip() for s in text.split(',')]
>>> tokens
['16 Bolton Avenue', 'Boston']
Результат — массив строк. Если элементов не много, то можно выполнить присваивание вот так:
>>> address, city = [s.strip() for s in text.split(',')]
>>> address
'16 Bolton Avenue'
>>> city
'Boston'
Помимо разбития текста на части часто требуется сделать обратное — конкатенировать разные строки, получив в результате текст большого объема. Самый простой способ — использовать оператор +.
>>> address + ',' + city
'16 Bolton Avenue, Boston'
Но это сработает только в том случае, если строк не больше двух-трех. Если же их больше, то есть метод join(). Его нужно применять к желаемому разделителю, передав в качестве аргумента список строк.
>>> strings = ['A+','A','A-','B','BB','BBB','C+']
>>> ';'.join(strings)
'A+;A;A-;B;BB;BBB;C+'
Еще один тип операции, которую можно выполнять со строкой — поиск отдельных частей, подстрок. В Python для этого есть ключевое слово, используемое для обнаружения подстрок.
>>> 'Boston' in text
True
Но имеются и две функции, которые выполняют ту же задачу: index() и find().
>>> text.index('Boston')
19
>>> text.find('Boston')
19
В обоих случаях возвращаемое значение — наименьший индекс, где встречаются искомые символы. Разница лишь в поведении функций в случае, если подстрока не была найдена:
>>> text.index('New York')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
>>> text.find('New York')
-1
Если index() вернет сообщение с ошибкой, то find() – -1. Также можно посчитать, как часто символ или комбинация из нескольких (подстрока) встречаются в тексте. За это отвечает функция count().
>>> text.count('e')
2
>>> text.count('Avenue')
1
Еще одна доступная операция — замена или удаление подстроки (или отдельного символа). В обоих случаях применяется функция replace(), где удаление подстроки — это то же самое, что и замена ее на пустой символ.
Регулярные выражения
Регулярные выражения предоставляют гибкий способ поиска совпадающих паттернов в тексте. Выражение regex — это строка, написанная с помощью языка регулярных выражений. В Python есть встроенный модуль re, который отвечает за работу с регулярными выражениями.
В первую очередь его нужно импортировать:
>>> import re
Модуль re предоставляет набор функций, которые можно поделить на три категории:
- Поиск совпадающих паттернов
- Замена
- Разбиение
Теперь разберем на примерах. Регулярное выражение для поиска одного или последовательности пробельных символов — \s+. В прошлом разделе вы видели, как для разделения текста на части с помощью split() используется символ разделения. В модуле re есть такая же функция. Она выполняет аналогичную задачу, но в качестве аргумента условия разделения принимает паттерн с регулярным выражением, что делает ее более гибкой.
>>> text = "This is an\t odd \n text!"
>>> re.split('\s+', text)
['This', 'is', 'an', 'odd', 'text!']
Разберемся чуть подробнее с принципом работы модуля re. При вызове функции re.split() сперва компилируется регулярное выражение, а только потом вызывается split() с готовым текстовым аргументом. Можно скомпилировать функцию регулярного выражения с помощью re.compile() и получить объект, который будет использоваться повторно, сэкономив таким образом циклы CPU.
Это особенно важно для операций последовательного поиска подстроки во множестве или массиве строк.
>>> regex = re.compile('\s+')
Создав объект regex с помощью функции compile(), вы сможете прямо использовать split() следующим образом.
>>> regex.split(text)
['This', 'is', 'an', 'odd', 'text!']
Для поиска совпадений паттерна с другими подстроками в тексте используется функция findall(). Она возвращает список всех подстрок, которые соответствуют условиям.
Например, если нужно найти в строке все слова, начинающиеся с латинской «A» в верхнем регистре, или, например, с «a» в любом регистре, необходимо ввести следующее:
>>> text = 'This is my address: 16 Bolton Avenue, Boston'
>>> re.findall('A\w+',text)
['Avenue']
>>> re.findall('[A,a]\w+',text)
['address', 'Avenue']
Есть еще две функции, которые связаны с findall():match() и search(). И если findall() возвращает все совпадения в списке, то search() — только первое. Более того, он является конкретным объектом.
>>> re.search('[A,a]\w+',text)
<_sre.SRE_Match object; span=(11, 18), match='address'>
Этот объект не содержит значение подстроки, соответствующей паттерну, а всего лишь индексы начала и окончания.
>>> search = re.search('[A,a]\w+',text)
>>> search.start()
11
>>> search.end()
18
>>> text[search.start():search.end()]
'address'
Функция match() ищет совпадение в начале строке; если его нет для первого символа, то двигается дальше и ищет в самой строке. Если совпадений не найдено вовсе, то она ничего не вернет.
>>> re.match('[A,a]\w+',text)
В случае успеха же она возвращает то же, что и функция search().
>>> re.match('T\w+',text)
<_sre.SRE_Match object; span=(0, 4), match='This'>
>>> match = re.match('T\w+',text)
>>> text[match.start():match.end()]
'This'
Агрегация данных
Последний этап работы с данными — агрегация. Он включает в себя преобразование, в результате которого из массива получается целое число. На самом деле, ранее упоминаемые функции sum(), mean() и count() — это тоже агрегация. Они работают с наборами данных и выполняют вычисления, результатом которых всегда является одно значение. Однако более формальный способ, дающий больше контроля над агрегацией, включает категоризацию наборов данных.
Категоризация набора, необходимая для группировки, — это важный этап в процессе обработки данных. Это тоже процесс преобразования, ведь после разделения на группы, применяется функция, которая конвертирует или преобразовывает данные определенным образом в зависимости от того, к какой группе они принадлежат. Часто фазы группировки и применения функции происходит в один шаг.
Также для этого этапа анализа данных pandas предоставляет гибкий и производительный инструмент — GroupBy.
Как и в случае с join те, кто знаком с реляционными базами данных и языком SQL, увидят знакомые вещи. Однако языки, такие как SQL, довольно ограничены, когда их применяют к группам. А вот гибкость таких языков, как Python, со всеми доступными библиотеками, особенно pandas, дает возможность выполнять очень сложные операции.
GroupBy
Теперь разберем в подробностях механизм работы GroupBy. Он использует внутренний механизм, процесс под названием split-apply-combine. Это паттерн, который можно разбить на три фазы, выделив отдельные операции:
- Разделение — разделение на группы датасетов
- Применение — применение функции к каждой группе
- Комбинирование — комбинирование результатов разных групп
Рассмотрите процесс подробно на следующей схеме. На первом этапе, разделении, данные из структуры (Dataframe или Series) разделяются на несколько групп в соответствии с заданными критериями: индексами или значениями в колонках. На жаргоне SQL значения в этой колонке называются ключами. Если же вы работаете с двухмерными объектами, такими как Dataframe, критерий группировки может быть применен и к строке (axis = 0), и колонке (axis = 1).
Вторая фаза состоит из применения функции или, если быть точнее, — вычисления, основанного на функции, результатом которого является одно значение, характерное для этой группы.
Последний этап собирает результаты каждой группы и комбинирует их в один объект.
Практический пример
Теперь вы знаете, что процесс агрегации данных в pandas разделен на несколько этапов: разделение-применение-комбинирование. И пусть в библиотеке они не выражены явно конкретными функциями, функция groupby() генерирует объект GroupBy, который является ядром целого процесса.
Для лучшего понимания этого механизма стоит обратиться к реальному примеру. Сперва создадим Dataframe с разными числовыми и текстовыми значениями.
>>> frame = pd.DataFrame({ 'color': ['white','red','green','red','green'],
... 'object': ['pen','pencil','pencil','ashtray','pen'],
... 'price1' : [5.56,4.20,1.30,0.56,2.75],
... 'price2' : [4.75,4.12,1.60,0.75,3.15]})
>>> frame
| | color | object | price1 | price2 |
|---|-------|---------|--------|--------|
| 0 | white | pen | 5.56 | 4.75 |
| 1 | red | pencil | 4.20 | 4.12 |
| 2 | green | pencil | 1.30 | 1.60 |
| 3 | red | ashtray | 0.56 | 0.75 |
| 4 | green | pen | 2.75 | 3.15 |
Предположим, нужно посчитать среднюю стоимость в колонке price1 с помощью меток из колонки color. Есть несколько способов, как этого можно добиться. Например, можно получить доступ к колонке price1 и затем вызвать groupby(), где колонка color будет выступать аргументом.
>>> group = frame['price1'].groupby(frame['color'])
>>> group
<pandas.core.groupby.SeriesGroupBy object at 0x00000000098A2A20>
Результат — объект GroupBy. Однако в этой операции не было никаких вычислений; пока что была лишь собрана информация, которая необходима для вычисления среднего значения. Теперь у нас есть group, где все строки с одинаковым значением цвета сгруппированы в один объект.
Чтобы понять, как произошло такое разделение на группы, вызовите атрибут groups для объекта GroupBy.
>>> group.groups
{'green': Int64Index([2, 4], dtype='int64'),
'red': Int64Index([1, 3], dtype='int64'),
'white': Int64Index([0], dtype='int64')}
Как видите, здесь перечислены все группы и явно обозначены строки Dataframe в них. Теперь нужно применить операцию для получения результатов каждой из групп.
>>> group.mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> group.sum()
color
green 4.05
red 4.76
white 5.56
Name: price1, dtype: float64
Группировка по иерархии
В прошлом разделе данные были сгруппированы по значениям колонки-ключа. Тот же подход можно использовать и для нескольких колонок, сделав группировку нескольких ключей иерархической.
>>> ggroup = frame['price1'].groupby([frame['color'],frame['object']])
>>> ggroup.groups
{('green', 'pen'): Int64Index([4], dtype='int64'),
('green', 'pencil'): Int64Index([2], dtype='int64'),
('red', 'ashtray'): Int64Index([3], dtype='int64'),
('red', 'pencil'): Int64Index([1], dtype='int64'),
('white', 'pen'): Int64Index([0], dtype='int64')}
>>> ggroup.sum()
color object
green pen 2.75
pencil 1.30
red ashtray 0.56
pencil 4.20
white pen 5.56
Name: price1, dtype: float64
Группировка может работать не только с одной колонкой, но и с несколькими или целым Dataframe. Также если объект GroupBy не потребуется использовать несколько раз, просто удобно выполнять группировки и расчеты за раз, без объявления дополнительных переменных.
>>> frame[['price1','price2']].groupby(frame['color']).mean()
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
>>> frame.groupby(frame['color']).mean()
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
Итерация с группировкой
Объект GroupBy поддерживает операцию итерации для генерации последовательности из двух кортежей, содержащих названия групп и их данных.
>>> for name, group in frame.groupby('color'):
... print(name)
... print(group)
green
color object price1 price2
2 green pencil 1.30 1.60
4 green pen 2.75 3.15
red
color object price1 price2
1 red pencil 4.20 4.12
3 red ashtray 0.56 0.75
white
color object price1 price2
0 white pen 5.56 4.75
В последнем примере для иллюстрации был применен вывод переменных. Но операцию вывода на экран можно заменить на функцию, которую требуется применить.
Цепочка преобразований
Из этих примеров должно стать понятно, что при передаче функциям вычисления или другим операциям группировок (вне зависимости от способа их получения) результатом всегда является Series (если была выбрана одна колонка) или Dataframe, сохраняющий систему индексов и названия колонок.
>>> result1 = frame['price1'].groupby(frame['color']).mean()
>>> type(result1)
<class 'pandas.core.series.Series'>
>>> result2 = frame.groupby(frame['color']).mean()
>>> type(result2)
<class 'pandas.core.frame.DataFrame'>
Таким образом становится возможным выбрать одну колонку на разных этапах процесса. Дальше три примера выбора одной колонки на трех разных этапах. Они иллюстрируют гибкость такой системы группировки в pandas.
>>> frame['price1'].groupby(frame['color']).mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> frame.groupby(frame['color'])['price1'].mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
>>> (frame.groupby(frame['color']).mean())['price1']
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
Но также после операции агрегации имена некоторых колонок могут не нести нужное значение. Поэтому часто оказывается полезным добавлять префикс, объясняющий бизнес-логику такого объединения. Добавление префикса (вместо использования полностью нового имени) помогает отслеживать источник данных. Это важно в случае применения процесса цепочки преобразований (когда Series или Dataframe генерируются друг из друга), где важно отслеживать исходные данные.
>>> means = frame.groupby('color').mean().add_prefix('mean_')
>>> means
| | mean_price1 | mean_price2 |
|-------|-------------|-------------|
| color | | |
| green | 2.025 | 2.375 |
| red | 2.380 | 2.435 |
| white | 5.560 | 4.750 |
Функции для групп
Хотя многие методы не были реализованы специально для GroupBy, они корректно работают с Series. В прошлых примерах было видно, насколько просто получить Series на основе объекта GroupBy, указав имя колонки и применив метод для вычислений. Например, можно использование вычисление квантилей с помощью функции quantiles().
>>> group = frame.groupby('color')
>>> group['price1'].quantile(0.6)
color
green 2.170
red 2.744
white 5.560
Name: price1, dtype: float64
Также можно определять собственные функции агрегации. Для этого функцию нужно создать и передать в качестве аргумента функции mark(). Например, можно вычислить диапазон значений для каждой группы.
>>> def range(series):
... return series.max() - series.min()
...
>>> group['price1'].agg(range)
color
green 1.45
red 3.64
white 0.00
Name: price1, dtype: float64
Функция agg() позволяет использовать функции агрегации для всего объекта Dataframe.
>>> group.agg(range)
| | price1 | price2 |
|-------|--------|--------|
| color | | |
| green | 1.45 | 1.55 |
| red | 3.64 | 3.37 |
| white | 0.00 | 0.00 |
Также можно использовать больше функций агрегации одновременно с помощью mark(), передав массив со списком операций для выполнения. Они станут новыми колонками.
>>> group['price1'].agg(['mean','std',range])
| | mean | std | range |
|-------|-------|----------|-------|
| color | | | |
| green | 2.025 | 1.025305 | 1.45 |
| red | 2.380 | 2.573869 | 3.64 |
| white | 5.560 | NaN | 0.00 |
Продвинутая агрегация данных
В этом разделе речь пойдет о функциях transform() и apply(), которые позволяют выполнять разные виды операций, включая очень сложные.
Предположим, что в одном Dataframe нужно получить следующее: оригинальный объект (с данными) и полученный с помощью вычисления агрегации, например, сложения.
>>> frame = pd.DataFrame({ 'color':['white','red','green','red','green'],
... 'price1':[5.56,4.20,1.30,0.56,2.75],
... 'price2':[4.75,4.12,1.60,0.75,3.15]})
>>> frame
| | color | price1 | price2 |
|---|-------|--------|--------|
| 0 | white | 5.56 | 4.75 |
| 1 | red | 4.20 | 4.12 |
| 2 | green | 1.30 | 1.60 |
| 3 | red | 0.56 | 0.75 |
| 4 | green | 2.75 | 3.15 |
>>> sums = frame.groupby('color').sum().add_prefix('tot_')
>>> sums
| | tot_price1 | tot_price2 | price2 |
|-------|------------|------------|--------|
| color | | | 4.75 |
| green | 4.05 | 4.75 | 4.12 |
| red | 4.76 | 4.87 | 1.60 |
| white | 5.56 | 4.75 | 0.75 |
>>> merge(frame,sums,left_on='color',right_index=True)
| | color | price1 | price2 | tot_price1 | tot_price2 |
|---|-------|--------|--------|------------|------------|
| 0 | white | 5.56 | 4.75 | 5.56 | 4.75 |
| 1 | red | 4.20 | 4.12 | 4.76 | 4.87 |
| 3 | red | 0.56 | 0.75 | 4.76 | 4.87 |
| 2 | green | 1.30 | 1.60 | 4.05 | 4.75 |
| 4 | green | 2.75 | 3.15 | 4.05 | 4.75 |
Благодаря merge() можно сложить результаты агрегации в каждой строке. Но есть и другой способ, работающий за счет transform(). Эта функция выполняет агрегацию, но в то же время показывает значения, сделанные с помощью вычислений на основе ключевого значения в каждой строке Dataframe.
>>> frame.groupby('color').transform(np.sum).add_prefix('tot_')
| | tot_price1 | tot_price2 |
|---|------------|------------|
| 0 | 5.56 | 4.75 |
| 1 | 4.76 | 4.87 |
| 2 | 4.05 | 4.75 |
| 3 | 4.76 | 4.87 |
| 4 | 4.05 | 4.75 |
Метод transform() — более специализированная функция с конкретными условиями: передаваемая в качестве аргумента функция должна возвращать одно скалярное значение (агрегацию).
Метод для более привычных GroupBy — это apply(). Он в полной мере реализует схему разделение-применение-комбинирование. Функция разделяет объект на части для преобразования, вызывает функцию для каждой из частей и затем пытается связать их между собой.
>>> frame = pd.DataFrame( { 'color':['white','black','white','white','black','black'],
... 'status':['up','up','down','down','down','up'],
... 'value1':[12.33,14.55,22.34,27.84,23.40,18.33],
... 'value2':[11.23,31.80,29.99,31.18,18.25,22.44]})
>>> frame
| | color | price1 | price2 | status |
|---|-------|--------|--------|--------|
| 0 | white | 12.33 | 11.23 | up |
| 1 | black | 14.55 | 31.80 | up |
| 2 | white | 22.34 | 29.99 | down |
| 3 | white | 27.84 | 31.18 | down |
| 4 | black | 23.40 | 18.25 | down |
| 5 | black | 18.33 | 22.44 | up |
>>> frame.groupby(['color','status']).apply( lambda x: x.max())
| | | color | price1 | price2 | status |
|-------|--------|-------|--------|--------|--------|
| color | status | | | | |
| black | down | black | 23.40 | 18.25 | down |
| | up | black | 18.33 | 31.80 | up |
| white | down | white | 27.84 | 31.18 | down |
| | up | white | 12.33 | 11.23 | up |
>>> frame.rename(index=reindex, columns=recolumn)
| | color | price1 | price2 | status |
|--------|-------|--------|--------|--------|
| first | white | 12.33 | 11.23 | up |
| second | black | 14.55 | 31.80 | up |
| third | white | 22.34 | 29.99 | down |
| fourth | white | 27.84 | 31.18 | down |
| fifth | black | 23.40 | 18.25 | down |
| 5 | black | 18.33 | 22.44 | up |
>>> temp = pd.date_range('1/1/2015', periods=10, freq= 'H')
>>> temp
DatetimeIndex(['2015-01-01 00:00:00', '2015-01-01 01:00:00',
'2015-01-01 02:00:00', '2015-01-01 03:00:00',
'2015-01-01 04:00:00', '2015-01-01 05:00:00',
'2015-01-01 06:00:00', '2015-01-01 07:00:00',
'2015-01-01 08:00:00', '2015-01-01 09:00:00'],
dtype='datetime64[ns]', freq='H')
>>> timeseries = pd.Series(np.random.rand(10), index=temp)
>>> timeseries
2015-01-01 00:00:00 0.317051
2015-01-01 01:00:00 0.628468
2015-01-01 02:00:00 0.829405
2015-01-01 03:00:00 0.792059
2015-01-01 04:00:00 0.486475
2015-01-01 05:00:00 0.707027
2015-01-01 06:00:00 0.293156
2015-01-01 07:00:00 0.091072
2015-01-01 08:00:00 0.146105
2015-01-01 09:00:00 0.500388
Freq: H, dtype: float64
>>> timetable = pd.DataFrame( {'date': temp, 'value1' : np.random.rand(10),
... 'value2' : np.random.rand(10)})
>>> timetable
| | date | value1 | value2 |
|---|---------------------|----------|----------|
| 0 | 2015-01-01 00:00:00 | 0.125229 | 0.995517 |
| 1 | 2015-01-01 01:00:00 | 0.597289 | 0.160828 |
| 2 | 2015-01-01 02:00:00 | 0.231104 | 0.076982 |
| 3 | 2015-01-01 03:00:00 | 0.862940 | 0.270581 |
| 4 | 2015-01-01 04:00:00 | 0.534056 | 0.306486 |
| 5 | 2015-01-01 05:00:00 | 0.162040 | 0.979835 |
| 6 | 2015-01-01 06:00:00 | 0.400413 | 0.486397 |
| 7 | 2015-01-01 07:00:00 | 0.157052 | 0.246959 |
| 8 | 2015-01-01 08:00:00 | 0.835632 | 0.572664 |
| 9 | 2015-01-01 09:00:00 | 0.812283 | 0.388435 |
Затем Dataframe добавляется колонка с набором текстовых значений, которые будут выступать ключевыми значениями.
>>> timetable['cat'] = ['up','down','left','left','up','up','down','right',
'right','up']
>>> timetable
| | date | value1 | value2 | cat |
|---|---------------------|----------|----------|-------|
| 0 | 2015-01-01 00:00:00 | 0.125229 | 0.995517 | up |
| 1 | 2015-01-01 01:00:00 | 0.597289 | 0.160828 | down |
| 2 | 2015-01-01 02:00:00 | 0.231104 | 0.076982 | left |
| 3 | 2015-01-01 03:00:00 | 0.862940 | 0.270581 | left |
| 4 | 2015-01-01 04:00:00 | 0.534056 | 0.306486 | up |
| 5 | 2015-01-01 05:00:00 | 0.162040 | 0.979835 | up |
| 6 | 2015-01-01 06:00:00 | 0.400413 | 0.486397 | down |
| 7 | 2015-01-01 07:00:00 | 0.157052 | 0.246959 | right |
| 8 | 2015-01-01 08:00:00 | 0.835632 | 0.572664 | right |
| 9 | 2015-01-01 09:00:00 | 0.812283 | 0.388435 | up |
Но в этом примере все равно есть повторяющиеся ключи.
]]>Процесс подготовки данных для анализа включает сборку данных в Dataframe с возможными добавлениями из других объектов и удалением ненужных частей. Следующий этап — трансформация. После того как данные внутри структуры организованы, нужно преобразовать ее значения. Этот раздел будет посвящен распространенным проблемам и процессам, которые требуются для их решения с помощью функций библиотеки pandas.
Среди них удаление элементов с повторяющимися значениями, изменение индексов, обработка числовых значений данных и строк.
Удаление повторов
Дубликаты строк могут присутствовать в Dataframe по разным причинам. И в объектах особо крупного размера их может быть сложно обнаружить. Для этого в pandas есть инструменты анализа повторяющихся данных для крупных структур.
Для начала создадим простой Dataframe с повторяющимися строками.
>>> dframe = pd.DataFrame({'color': ['white','white','red','red','white'],
... 'value': [2,1,3,3,2]})
>>> dframe
| | color | value |
|---|-------|-------|
| 0 | white | 2 |
| 1 | white | 1 |
| 2 | red | 3 |
| 3 | red | 3 |
| 4 | white | 2 |
Функция duplicated() способна обнаружить дубликаты. Она вернет объект Series, состоящий из булевых значений, где каждый элемент соответствует строке. Их значения равны True, если строка является дубликатом (все повторения за исключением первого) и False, если повторов этого элемента не было.
>>> dframe.duplicated()
0 False
1 False
2 False
3 True
4 True
dtype: bool
Объект с булевыми элементами может быть особенно полезен, например, для фильтрации. Так, чтобы увидеть строки-дубликаты, нужно просто написать следующее:
>>> dframe[dframe.duplicated()]
| | color | value |
|---|-------|-------|
| 3 | red | 3 |
| 4 | white | 2 |
Обычно повторяющиеся строки удаляются. Для этого в pandas есть функция drop_duplicates(), которая возвращает Dataframe без дубликатов.
>>> dframe = dframe.drop_duplicates()
>>> dframe
| | color | value |
|---|-------|-------|
| 0 | white | 2 |
| 2 | red | 3 |
Маппинг
Библиотека pandas предоставляет набор функций, использующих маппинг для выполнения определенных операций. Маппинг — это всего лишь создание списка совпадений двух разных значений, что позволяет привязывать значение определенной метке или строке.
Для определения маппинга лучше всего подходит объект dict:
map = {
'label1' : 'value1,
'label2' : 'value2,
...
}
Функции, которые будут дальше встречаться в этом разделе, выполняют конкретные операции, но всегда принимают объект dict.
• replace() — Заменяет значения
• map() — Создает новый столбец
• rename() — Заменяет значения индекса
Замена значений с помощью маппинга
Часто бывает так, что в готовой структуре данных присутствуют значения, не соответствующие конкретным требованиям. Например, текст может быть написан на другом языке, являться синонимом или, например, выраженным в другом виде. В таких случаях используется операция замены разных значений.
Для примера определим Dataframe с разными объектами и их цветами, включая два названия цветов не на английском.
>>> frame = pd.DataFrame({'item':['ball','mug','pen','pencil','ashtray'],
... 'color':['white','rosso','verde','black','yellow'],
... 'price':[5.56,4.20,1.30,0.56,2.75]})
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | rosso | mug | 4.20 |
| 2 | verde | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Для замены некорректных значений новыми нужно определить маппинг соответствий, где ключами будут выступать новые значения.
>>> newcolors = {
... 'rosso': 'red',
... 'verde': 'green'
... }
Теперь осталось использовать функцию replace(), задав маппинг в качестве аргумента.
>>> frame.replace(newcolors)
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Как видно выше, два цвета были заменены на корректные значения в Dataframe. Распространенный пример — замена значений NaN на другие, например, на 0. Функция replace() отлично справляется и с этим.
>>> ser = pd.Series([1,3,np.nan,4,6,np.nan,3])
>>> ser
0 1.0
1 3.0
2 NaN
3 4.0
4 6.0
5 NaN
6 3.0
dtype: float64
>>> ser.replace(np.nan,0)
0 1.0
1 3.0
2 0.0
3 4.0
4 6.0
5 0.0
6 3.0
dtype: float64
Добавление значений с помощью маппинга
В предыдущем примере вы узнали, как менять значения с помощью маппинга. Теперь попробуем использовать маппинг на другом примере — для добавления новых значений в колонку на основе значений в другой. Маппинг всегда определяется отдельно.
>>> frame = pd.DataFrame({'item':['ball','mug','pen','pencil','ashtray'],
... 'color':['white','red','green','black','yellow']})
>>> frame
| | color | item |
|---|--------|---------|
| 0 | white | ball |
| 1 | red | mug |
| 2 | green | pen |
| 3 | black | pencil |
| 4 | yellow | ashtray |
Предположим, что нужно добавить колонку с ценой вещи из объекта. Также предположим, что имеется список цен. Определим его в виде объекта dict с ценами для каждого типа объекта.
>>> prices = {
... 'ball' : 5.56,
... 'mug' : 4.20,
... 'bottle' : 1.30,
... 'scissors' : 3.41,
... 'pen' : 1.30,
... 'pencil' : 0.56,
... 'ashtray' : 2.75
... }
Функция map(), примененная к Series или колонке объекта Dataframe принимает функцию или объект с маппингом dict. В этому случае можно применить маппинг цен для элементов колонки, добавив еще одну колонку price в Dataframe.
>>> frame['price'] = frame['item'].map(prices)
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Переименование индексов осей
По примеру того, как работает изменение значений в Series и Dataframe, можно трансформировать метки оси с помощью маппинга. Для замены меток индексов в pandas есть функция rename(), которая принимает маппинг (объект dict) в качестве аргумента.
>>> frame
| | color | item | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
>>> reindex = {
... 0: 'first',
... 1: 'second',
... 2: 'third',
... 3: 'fourth',
... 4: 'fifth'}
>>> frame.rename(reindex)
| | color | item | price |
|--------|--------|---------|-------|
| first | white | ball | 5.56 |
| second | red | mug | 4.20 |
| third | green | pen | 1.30 |
| fourth | black | pencil | 0.56 |
| fifth | yellow | ashtray | 2.75 |
По умолчанию переименовываются индексы. Если же нужно поменять названия колонок, то используется параметр columns. В следующем примере присвоим несколько маппингов двум индексам с параметром columns.
>>> recolumn = {
... 'item':'object',
... 'price': 'value'}
>>> frame.rename(index=reindex, columns=recolumn)
| | color | object | price |
|--------|--------|---------|-------|
| first | white | ball | 5.56 |
| second | red | mug | 4.20 |
| third | green | pen | 1.30 |
| fourth | black | pencil | 0.56 |
| fifth | yellow | ashtray | 2.75 |
В тех случаях когда заменить нужно только одно значение, все можно и не писать.
>>> frame.rename(index={1:'first'}, columns={'item':'object'})
| | color | object | price |
|-------|--------|---------|-------|
| 0 | white | ball | 5.56 |
| first | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Пока что функция rename() возвращала объект Dataframe с изменениями, не трогая оригинальный объект. Но если нужно поменять его, то необходимо передать значение True параметру inplace.
>>> frame.rename(columns={'item':'object'}, inplace=True)
>>> frame
| | color | object | price |
|---|--------|---------|-------|
| 0 | white | ball | 5.56 |
| 1 | red | mug | 4.20 |
| 2 | green | pen | 1.30 |
| 3 | black | pencil | 0.56 |
| 4 | yellow | ashtray | 2.75 |
Дискретизация и биннинг
Более сложный процесс преобразования называется дискретизацией. Он используется для обработки большим объемов данных. Для анализа их необходимо разделять на дискретные категории, например, распределив диапазон значений на меньшие интервалы и посчитав статистику для каждого. Еще один пример — большое количество образцов. Даже здесь необходимо разделять весь диапазон по категориям и внутри них считать вхождения и статистику.
В следующем случае, например, нужно работать с экспериментальными значениями, лежащими в диапазоне от 0 до 100. Эти данные собраны в список.
>>> results = [12,34,67,55,28,90,99,12,3,56,74,44,87,23,49,89,87]
Вы знаете, что все значения лежат в диапазоне от 0 до 100, а это значит, что их можно разделить на 4 одинаковых части, бины. В первом будут элементы от 0 до 25, во втором — от 26 до 50, в третьем — от 51 до 75, а в последнем — от 75 до 100.
Для этого в pandas сначала нужно определить массив со значениями разделения:
>>> bins = [0,25,50,75,100]
Затем используется специальная функция cut(), которая применяется к массиву. В нее нужно добавить и бины.
>>> cat = pd.cut(results, bins)
>>> cat
(0, 25]
(25, 50]
(50, 75]
(50, 75]
(25, 50]
(75, 100]
(75, 100]
(0, 25]
(0, 25]
(50, 75]
(50, 75]
(25, 50]
(75, 100]
(0, 25]
(25, 50]
(75, 100]
(75, 100]
Levels (4): Index(['(0, 25]', '(25, 50]', '(50, 75]', '(75, 100]'],
dtype=object)
Функция cut() возвращает специальный объект типа Categorical. Его можно считать массивом строк с названиями бинов. Внутри каждая содержит массив categories, включающий названия разных внутренних категорий и массив codes со списком чисел, равных элементам results. Число соответствует бину, которому был присвоен соответствующий элемент results.
>>> cat.categories
IntervalIndex([0, 25], (25, 50], (50, 75], (75, 100]]
closed='right'
dtype='interval[int64]')
>>> cat.codes
array([0, 1, 2, 2, 1, 3, 3, 0, 0, 2, 2, 1, 3, 0, 1, 3, 3], dtype=int8)
Чтобы узнать число вхождений каждого бина, то есть, результаты для всех категорий, нужно использовать функцию value_counts().
>>> pd.value_counts(cat)
(75, 100] 5
(50, 75] 4
(25, 50] 4
(0, 25] 4
dtype: int64
У каждого класса есть нижний предел с круглой скобкой и верхний — с квадратной. Такая запись соответствует математической, используемой для записи интервалов. Если скобка квадратная, то число лежит в диапазоне, а если круглая — то нет.
Бинам можно задавать имена, передав их в массив строк, а затем присвоив его параметру labels в функции cut(), которая используется для создания объекта Categorical.
>>> bin_names = ['unlikely','less likely','likely','highly likely']
>>> pd.cut(results, bins, labels=bin_names)
unlikely
less likely
likely
likely
less likely
highly likely
highly likely
unlikely
unlikely
likely
likely
less likely
highly likely
unlikely
less likely
highly likely
highly likely
Levels (4): Index(['unlikely', 'less likely', 'likely', 'highly likely'],
dtype=object)
Если функции cut() передать в качестве аргумента целое число, а не границы бина, то диапазон значений будет разделен на указанное количество интервалов.
Пределы будут основаны на минимуме и максимуме данных.
>>> pd.cut(results, 5)
(2.904, 22.2]
(22.2, 41.4]
(60.6, 79.8]
(41.4, 60.6]
(22.2, 41.4]
(79.8, 99]
(79.8, 99]
(2.904, 22.2]
(2.904, 22.2]
(41.4, 60.6]
(60.6, 79.8]
(41.4, 60.6]
(79.8, 99]
(22.2, 41.4]
(41.4, 60.6]
(79.8, 99]
(79.8, 99]
Levels (5): Index(['(2.904, 22.2]', '(22.2, 41.4]', '(41.4, 60.6]',
'(60.6, 79.8]', '(79.8, 99]'], dtype=object)
Также в pandas есть еще одна функция для биннинга, qcut(). Она делит весь набор на квантили. Так, в зависимости от имеющихся данных cut() обеспечит разное количество данных для каждого бина. А qcut() позаботится о том, чтобы количество вхождений было одинаковым. Могут отличаться только границы.
>>> quintiles = pd.qcut(results, 5)
>>> quintiles
[3, 24]
(24, 46]
(62.6, 87]
(46, 62.6]
(24, 46]
(87, 99]
(87, 99]
[3, 24]
[3, 24]
(46, 62.6]
(62.6, 87]
(24, 46]
(62.6, 87]
[3, 24]
(46, 62.6]
(87, 99]
(62.6, 87]
Levels (5): Index(['[3, 24]', '(24, 46]', '(46, 62.6]', '(62.6, 87]',
'(87, 99]'], dtype=object)
>>> pd.value_counts(quintiles)
[3, 24] 4
(62.6, 87] 4
(87, 99] 3
(46, 62.6] 3
(24, 46] 3
dtype: int64
В этом примере видно, что интервалы отличаются от тех, что получились в результате использования функции cut(). Также можно обратить внимание на то, что qcut() попыталась стандартизировать вхождения для каждого бина, поэтому в первых двух больше вхождений. Это связано с тем, что количество объектов не делится на 5.
Определение и фильтрация лишних данных
При анализе данных часто приходится находить аномальные значения в структуре данных. Для примера создайте Dataframe с тремя колонками целиком случайных чисел.
>>> randframe = pd.DataFrame(np.random.randn(1000,3))
С помощью функции describe() можно увидеть статистику для каждой колонки.
>>> randframe.describe()
| | 0 | 1 | 2 |
|-------|-------------|-------------|-------------|
| count | 1000.000000 | 1000.000000 | 1000.000000 |
| mean | -0.036163 | 0.037203 | 0.018722 |
| std | 1.038703 | 0.986338 | 1.011587 |
| min | -3.591217 | -3.816239 | -3.586733 |
| 25% | -0.729458 | -0.581396 | -0.665261 |
| 50% | -0.025864 | 0.005155 | -0.002774 |
| 75% | 0.674396 | 0.706958 | 0.731404 |
| max | 3.115554 | 2.899073 | 3.425400 |
Лишними можно считать значения, которые более чем в три раза больше стандартного отклонения. Чтобы оставить только подходящие, нужно использовать функцию std().
>>> randframe.std()
0 1.038703
1 0.986338
2 1.011587
dtype: float64
Теперь используйте фильтр для всех значений Dataframe, применив соответствующее стандартное отклонение для каждой колонки. Функция any() позволит использовать фильтр для каждой колонки.
>>> randframe[(np.abs(randframe) > (3*randframe.std())).any(1)]
| | 0 | 1 | 2 |
|-----|-----------|-----------|-----------|
| 87 | -2.106846 | -3.408329 | -0.067435 |
| 129 | -3.591217 | 0.791474 | 0.243038 |
| 133 | 1.149396 | -3.816239 | 0.328653 |
| 717 | 0.434665 | -1.248411 | -3.586733 |
| 726 | 1.682330 | 1.252479 | -3.090042 |
| 955 | 0.272374 | 2.224856 | 3.425400 |
Перестановка
Операции перестановки (случайного изменения порядка) в объекте Series или строках Dataframe можно выполнить с помощью функции numpy.random.permutation().
Для этого примера создайте Dataframe с числами в порядке возрастания.
>>> nframe = pd.DataFrame(np.arange(25).reshape(5,5))
>>> nframe
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 4 | 20 | 21 | 22 | 23 | 24 |
Теперь создайте массив из пяти чисел от 0 до 4 в случайном порядке с функцией permutation(). Этот массив будет новым порядком, в котором потребуется разместить и значения строк из Dataframe.
>>> new_order = np.random.permutation(5)
>>> new_order
array([2, 3, 0, 1, 4])
Теперь примените его ко всем строкам Dataframe с помощью функции take().
>>> nframe.take(new_order)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 0 | 0 | 1 | 2 | 3 | 4 |
| 4 | 20 | 21 | 22 | 23 | 24 |
| 1 | 5 | 6 | 7 | 8 | 9 |
Как видите, порядок строк поменялся, а индексы соответствуют порядку в массиве new_order.
Перестановку можно произвести и для отдельной части Dataframe. Это сгенерирует массив с последовательностью, ограниченной конкретным диапазоном, например, от 2 до 4.
>>> new_order = [3,4,2]
>>> nframe.take(new_order)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 3 | 15 | 16 | 17 | 18 | 19 |
| 4 | 20 | 21 | 22 | 23 | 24 |
| 2 | 10 | 11 | 12 | 13 | 14 |
Случайная выборка
Вы уже знаете, как доставать отдельные части Dataframe для последующей перестановки. Но иногда ее потребуется отобрать случайным образом. Проще всего сделать это с помощью функции np.random.randint().
>>> sample = np.random.randint(0, len(nframe), size=3)
>>> sample
array([1, 4, 4])
>>> nframe.take(sample)
| | 0 | 1 | 2 | 3 | 4 |
|---|----|----|----|----|----|
| 3 | 15 | 16 | 17 | 18 | 19 |
| 3 | 15 | 16 | 17 | 18 | 19 |
| 3 | 15 | 16 | 17 | 18 | 19 |
В этом случае один и тот же участок попадается даже чаще.
]]>Прежде чем приступать к работе с данными, их нужно подготовить и собрать в виде структуры, так чтобы они поддавались обработке с помощью инструментов из библиотеки pandas. Дальше перечислены некоторые из этапов подготовки.
- Загрузка
- Сборка
- Объединение (merge)
- Конкатенация (concatenating)
- Комбинирование (combining)
- Изменение
- Удаление
Прошлый материал был посвящен загрузке. На этом этапе происходит конвертация из разных форматов в одну структуру данных, такую как Dataframe. Но даже после этого требуются дополнительные этапы подготовки. Поэтому дальше речь пойдет о том, как выполнять операции получения данных в объединенной структуре данных.
Данные из объектов pandas можно собрать несколькими путями:
- Объединение — функция
pandas.merge()соединяет строки вDataframeна основе одного или нескольких ключей. Этот вариант будет знаком всем, кто работал с языком SQL, поскольку там есть аналогичная операция. - Конкатенация — функция
pandas.concat()конкатенирует объекты по оси. - Комбинирование — функция
pandas.DataFrame.combine_first()является методом, который позволяет соединять пересекающиеся данные для заполнения недостающих значений в структуре, используя данные другой структуры.
Более того, частью подготовки является поворот — процесс обмена строк и колонок.
Соединение
Операция соединения (merge), которая соответствует JOIN из SQL, состоит из объединения данных за счет соединения строк на основе одного или нескольких ключей.
На самом деле, любой, кто работал с реляционными базами данных, обычно использует запрос JOIN из SQL для получения данных из разных таблиц с помощью ссылочных значений (ключей) внутри них. На основе этих ключей можно получать новые данные в табличной форме как результат объединения других таблиц. Эта операция в библиотеке pandas называется соединением (merging), а merge() — функция для ее выполнения.
Сначала нужно импортировать библиотеку pandas и определить два объекта Dataframe, которые будут примерами в этом разделе.
>>> import numpy as np
>>> import pandas as pd
>>> frame1 = pd.DataFrame({'id':['ball','pencil','pen','mug','ashtray'],
... 'price': [12.33,11.44,33.21,13.23,33.62]})
>>> frame1
| | id | price |
|---|---------|-------|
| 0 | ball | 12.33 |
| 1 | pencil | 11.44 |
| 2 | pen | 33.21 |
| 3 | mug | 13.23 |
| 4 | ashtray | 33.62 |
>>> frame2 = pd.DataFrame({'id':['pencil','pencil','ball','pen'],
... 'color': ['white','red','red','black']})
>>> frame2
| | color | id |
|---|-------|--------|
| 0 | white | pencil |
| 1 | red | pencil |
| 2 | red | ball |
| 3 | black | pen |
Выполним соединение, применив функцию merge() к двум объектам.
>>> pd.merge(frame1,frame2)
| | id | price | color |
|---|--------|-------|-------|
| 0 | ball | 12.33 | red |
| 1 | pencil | 11.44 | white |
| 2 | pencil | 11.44 | red |
| 3 | pen | 33.21 | black |
Получившийся объект Dataframe состоит из всех строк с общим ID. В дополнение к общей колонке добавлены и те, что присутствуют только в первом и втором объектах.
В этом случае функция merge() была использована без явного определения колонок. Но чаще всего необходимо указывать, на основе какой колонки выполнять соединение.
Для этого нужно добавить свойство с названием колонки, которое будет ключом соединения.
>>> frame1 = pd.DataFrame({'id':['ball','pencil','pen','mug','ashtray'],
... 'color': ['white','red','red','black','green'],
... 'brand': ['OMG','ABC','ABC','POD','POD']})
>>> frame1
| | brand | color | id |
|---|-------|-------|---------|
| 0 | OMG | white | ball |
| 1 | ABC | red | pencil |
| 2 | ABC | red | pen |
| 3 | POD | black | mug |
| 4 | PPOD | green | ashtray |
>>> frame2 = pd.DataFrame({'id':['pencil','pencil','ball','pen'],
... 'brand': ['OMG','POD','ABC','POD']})
>>> frame2
| | brand | id |
|---|-------|--------|
| 0 | OMG | pencil |
| 1 | POD | pencil |
| 2 | ABC | ball |
| 3 | POD | pen |
В этом случае два объекта Dataframe имеют колонки с одинаковыми названиями. Поэтому при запуске merge результата не будет.
>>> pd.merge(frame1,frame2)
Empty DataFrame
Columns: [brand, color, id]
Index: []
Необходимо явно задавать условия соединения, которым pandas будет следовать, определяя название ключа в параметре on.
>>> pd.merge(frame1,frame2,on='id')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on='brand')
| | brand | color | id_x | id_y |
|---|-------|-------|--------|--------|
| 0 | OMG | white | ball | pencil |
| 1 | ABC | red | pencil | ball |
| 2 | ABC | red | pen | ball |
| 3 | POD | black | mug | pencil |
| 4 | POD | black | mug | pen |
Как и ожидалось, результаты отличаются в зависимости от условий соединения.
Но часто появляется другая проблема, когда есть два Dataframe без колонок с одинаковыми названиями. Для исправления ситуации нужно использовать left_on и right_on, которые определяют ключевые колонки для первого и второго объектов Dataframe. Дальше следует пример.
>>> frame2.columns = ['brand','sid']
>>> frame2
| | brand | sid |
|---|-------|--------|
| 0 | OMG | pencil |
| 1 | POD | pencil |
| 2 | ABC | ball |
| 3 | POD | pen |
>>> pd.merge(frame1, frame2, left_on='id', right_on='sid')
| | brand_x | color | id | brand_y | sid |
|---|---------|-------|--------|---------|--------|
| 0 | OMG | white | ball | ABC | ball |
| 1 | ABC | red | pencil | OMG | pencil |
| 2 | ABC | red | pencil | POD | pencil |
| 3 | ABC | red | pen | POD | pen |
По умолчанию функция merge() выполняет inner join (внутреннее соединение). Ключ в финальном объекте — результат пересечения.
Другие возможные варианты: left join, right join и outer join (левое, правое и внешнее соединение). Внешнее выполняет объединение всех ключей, комбинируя эффекты правого и левого соединений. Для выбора типа нужно использовать параметр how.
>>> frame2.columns = ['brand','id']
>>> pd.merge(frame1,frame2,on='id')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on='id',how='outer')
| | brand_x | color | id | brand_y |
|---|---------|-------|---------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
| 4 | POD | black | mug | NaN |
| 5 | PPOD | green | ashtray | NaN |
>>> pd.merge(frame1,frame2,on='id',how='left')
| | brand_x | color | id | brand_y |
|---|---------|-------|---------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
| 4 | POD | black | mug | NaN |
| 5 | PPOD | green | ashtray | NaN |
>>> pd.merge(frame1,frame2,on='id',how='right')
| | brand_x | color | id | brand_y |
|---|---------|-------|--------|---------|
| 0 | OMG | white | ball | ABC |
| 1 | ABC | red | pencil | OMG |
| 2 | ABC | red | pencil | POD |
| 3 | ABC | red | pen | POD |
>>> pd.merge(frame1,frame2,on=['id','brand'],how='outer')
| | brand | color | id |
|---|-------|-------|---------|
| 0 | OMG | white | ball |
| 1 | ABC | red | pencil |
| 2 | ABC | red | pen |
| 3 | POD | black | mug |
| 4 | PPOD | green | ashtray |
| 5 | OMG | NaN | pencil |
| 6 | POD | NaN | pencil |
| 7 | ABC | NaN | ball |
| 8 | POD | NaN | pen |
Для соединения нескольких ключей, нужно просто в параметр on добавить список.
Соединение по индексу
В некоторых случаях вместо использования колонок объекта Dataframe в качестве ключей для этих целей можно задействовать индексы. Затем для выбора конкретных индексов нужно задать значения True для left_join или right_join. Они могут быть использованы и вместе.
>>> pd.merge(frame1,frame2,right_index=True, left_index=True)
| | brand_x | color | id_x | brand_y | id_y |
|---|---------|-------|--------|---------|--------|
| 0 | OMG | white | ball | OMG | pencil |
| 1 | ABC | red | pencil | POD | pencil |
| 2 | ABC | red | pen | ABC | ball |
| 3 | POD | black | mug | POD | pen |
Но у объектов Dataframe есть и функция join(), которая оказывается особенно полезной, когда необходимо выполнить соединение по индексам. Она же может быть использована для объединения множества объектов с одинаковыми индексами, но без совпадающих колонок.
При запуске такого кода
>>> frame1.join(frame2)
Будет ошибка, потому что некоторые колонки в объекте frame1 называются так же, как и во frame2. Нужно переименовать их во втором объекте перед использованием join().
>>> frame2.columns = ['brand2','id2']
>>> frame1.join(frame2)
В этом примере соединение было выполнено на основе значений индексов, а не колонок. Также индекс 4 представлен только в объекте frame1, но соответствующие значения колонок во frame2 равняются NaN.
Конкатенация
Еще один тип объединения данных — конкатенация. NumPy предоставляет функцию concatenate() для ее выполнения.
>>> array1 = np.arange(9).reshape((3,3))
>>> array1
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> array2 = np.arange(9).reshape((3,3))+6
>>> array2
array([[6, 7, 8],
[9, 10, 11],
[12, 13, 14]])
>>> np.concatenate([array1,array2],axis=1)
array([[0, 1, 2, 6, 7, 8],
[3, 4, 5, 9, 10, 11],
[6, 7, 8, 12, 13, 14]])
>>> np.concatenate([array1,array2],axis=0)
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
[6, 7, 8],
[9, 10, 11],
[12, 13, 14]])
С библиотекой pandas и ее структурами данных, такими как Series и Dataframe, именованные оси позволяют и дальше обобщать конкатенацию массивов. Для этого в pandas есть функция concat().
>>> ser1 = pd.Series(np.random.rand(4), index=[1,2,3,4])
>>> ser1
1 0.636584
2 0.345030
3 0.157537
4 0.070351
dtype: float64
>>> ser2 = pd.Series(np.random.rand(4), index=[5,6,7,8])
>>> ser2
5 0.411319
6 0.359946
7 0.987651
8 0.329173
dtype: float64
>>> pd.concat([ser1,ser2])
1 0.636584
2 0.345030
3 0.157537
4 0.070351
5 0.411319
6 0.359946
7 0.987651
8 0.329173
dtype: float64
По умолчанию функция concat() работает на axis=0 и возвращает объект Series. Если задать 1 значением axis, то результатом будет объект Dataframe.
>>> pd.concat([ser1,ser2],axis=1)
| | 0 | 1 |
|---|----------|----------|
| 1 | 0.953608 | NaN |
| 2 | 0.929539 | NaN |
| 3 | 0.036994 | NaN |
| 4 | 0.010650 | NaN |
| 5 | NaN | 0.200771 |
| 6 | NaN | 0.709060 |
| 7 | NaN | 0.813766 |
| 8 | NaN | 0.218998 |
Проблема с этой операцией в том, что конкатенированные части не определяются в итоговом объекте. Например, нужно создать иерархический индекс на оси конкатенации. Для этого требуется использовать параметр keys.
>>> pd.concat([ser1,ser2], keys=[1,2])
1 1 0.953608
2 0.929539
3 0.036994
4 0.010650
2 5 0.200771
6 0.709060
7 0.813766
8 0.218998
dtype: float64
В случае объединения двух Series по axis=1 ключи становятся заголовками колонок объекта Dataframe.
>>> pd.concat([ser1,ser2], axis=1, keys=[1,2])
| | 1 | 2 |
|---|----------|----------|
| 1 | 0.953608 | NaN |
| 2 | 0.929539 | NaN |
| 3 | 0.036994 | NaN |
| 4 | 0.010650 | NaN |
| 5 | NaN | 0.200771 |
| 6 | NaN | 0.709060 |
| 7 | NaN | 0.813766 |
| 8 | NaN | 0.218998 |
Пока что в примерах конкатенация применялась только к объектам Series, но та же логика работает и с Dataframe.
>>> frame1 = pd.DataFrame(np.random.rand(9).reshape(3,3),
... index=[1,2,3], columns=['A','B','C'])
>>> frame2 = pd.DataFrame(np.random.rand(9).reshape(3,3),
... index=[4,5,6], columns=['A','B','C'])
>>> pd.concat([frame1, frame2])
| | A | B | C |
|---|----------|----------|----------|
| 1 | 0.231057 | 0.024329 | 0.843888 |
| 2 | 0.727480 | 0.296619 | 0.367309 |
| 3 | 0.282516 | 0.524227 | 0.462000 |
| 4 | 0.078044 | 0.751505 | 0.832853 |
| 5 | 0.843225 | 0.945914 | 0.141331 |
| 6 | 0.189217 | 0.799631 | 0.308749 |
>>> pd.concat([frame1, frame2], axis=1)
| | A | B | C | A | B | C |
|---|----------|----------|----------|----------|----------|----------|
| 1 | 0.231057 | 0.024329 | 0.843888 | NaN | NaN | NaN |
| 2 | 0.727480 | 0.296619 | 0.367309 | NaN | NaN | NaN |
| 3 | 0.282516 | 0.524227 | 0.462000 | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | 0.078044 | 0.751505 | 0.832853 |
| 5 | NaN | NaN | NaN | 0.843225 | 0.945914 | 0.141331 |
| 6 | NaN | NaN | NaN | 0.189217 | 0.799631 | 0.308749 |
Комбинирование
Есть еще одна ситуация, при которой объединение не работает за счет соединения или конкатенации. Например, если есть два набора данных с полностью или частично пересекающимися индексами.
Одна из функций для Series называется combine_first(). Она выполняет объединение с выравниваем данных.
>>> ser1 = pd.Series(np.random.rand(5),index=[1,2,3,4,5])
>>> ser1
1 0.075815
2 0.332282
3 0.884463
4 0.518336
5 0.089025
dtype: float64
>>> ser2 = pd.Series(np.random.rand(4),index=[2,4,5,6])
>>> ser2
2 0.315847
4 0.275937
5 0.352538
6 0.865549
dtype: float64
>>> ser1.combine_first(ser2)
1 0.075815
2 0.332282
3 0.884463
4 0.518336
5 0.089025
6 0.865549
dtype: float64
>>> ser2.combine_first(ser1)
1 0.075815
2 0.315847
3 0.884463
4 0.275937
5 0.352538
6 0.865549
dtype: float64
Если же требуется частичное пересечение, необходимо обозначить конкретные части Series.
>>> ser1[:3].combine_first(ser2[:3])
1 0.075815
2 0.332282
3 0.884463
4 0.275937
5 0.352538
dtype: float64
Pivoting — сводные таблицы
В дополнение к сборке данных для унификации собранных из разных источников значений часто применяется операция поворота. На самом деле, выравнивание данных по строке и колонке не всегда подходит под конкретную ситуацию. Иногда требуется перестроить данные по значениям колонок в строках или наоборот.
Поворот с иерархическим индексированием
Вы уже знаете, что Dataframe поддерживает иерархическое индексирование. Эта особенность может быть использована для перестраивания данных в объекте Dataframe. В контексте поворота есть две базовые операции:
- Укладка (stacking) — поворачивает структуру данных, превращая колонки в строки
- Обратный процесс укладки (unstacking) — конвертирует строки в колонки
>>> frame1 = pd.DataFrame(np.arange(9).reshape(3,3),
... index=['white','black','red'],
... columns=['ball','pen','pencil'])
>>> frame1
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
С помощью функции stack() в Dataframe можно развернуть данные и превратить колонки в строки, получив Series:
>>> ser5 = frame1.stack()
white ball 0
pen 1
pencil 2
black ball 3
pen 4
pencil 5
red ball 6
pen 7
pencil 8
dtype: int32
Из объекта Series с иерархическим индексировании можно выполнить пересборку в развернутую таблицу с помощью unstack().
>>> ser5.unstack()
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
Обратный процесс можно выполнить и на другом уровне, определив количество уровней или название в качестве аргумента функции.
>>> ser5.unstack(0)
| | white | black | red |
|--------|-------|-------|-----|
| ball | 0 | 3 | 6 |
| pen | 1 | 4 | 7 |
| pencil | 2 | 5 | 8 |
Поворот из «длинного» в «широкий» формат
Наиболее распространенный способ хранения наборов данных — точная регистрация данных, которые будут заполнять строки текстового файла: CSV или таблицы в базе данных. Это происходит особенно в таких случаях: чтение выполняется с помощью инструментов; результаты вычислений итерируются; или данные вводятся вручную. Похожий пример таких файлов — логи, заполняемые строка за строкой с помощью постоянно поступающих данных.
Необычная особенность этого типа набора данных — элементы разных колонок, часто повторяющиеся в последующих строках. Они всегда в табличной форме, поэтому их можно воспринимать как формат длинных или упакованных.
Чтобы лучше разобраться с этой концепцией, рассмотрим следующий Dataframe.
>>> longframe = pd.DataFrame({'color':['white','white','white',
... 'red','red','red',
... 'black','black','black'],
... 'item':['ball','pen','mug',
... 'ball','pen','mug',
... 'ball','pen','mug'],
... 'value': np.random.rand(9)})
>>> longframe
| | color | item | value |
|---|-------|------|----------|
| 0 | white | ball | 0.896313 |
| 1 | white | pen | 0.344864 |
| 2 | white | mug | 0.101891 |
| 3 | red | ball | 0.697267 |
| 4 | red | pen | 0.852835 |
| 5 | red | mug | 0.145385 |
| 6 | black | ball | 0.738799 |
| 7 | black | pen | 0.783870 |
| 8 | black | mug | 0.017153 |
Этот режим записи данных имеет свои недостатки. Первый — повторение некоторых полей. Если воспринимать колонки в качестве ключей, то данные в этом формате будет сложно читать, а особенно — понимать отношения между значениями ключей и остальными колонками.
Но существует замена для длинного формата — широкий способ организации данных в таблице. В таком режиме данные легче читать, а также налаживать связь между таблицами. Плюс, они занимают меньше места. Это более эффективный способ хранения данных, пусть и менее практичный, особенно на этапе заполнения объекта данными.
В качестве критерия нужно выбрать колонку или несколько из них как основной ключ. Значения в них должны быть уникальными.
pandas предоставляет функцию, которая позволяет выполнить трансформацию Dataframe из длинного типа в широкий. Она называется pivot(), а в качестве аргументов принимает одну или несколько колонок, которые будут выполнять роль ключа.
Еще с прошлого примера вы создавали Dataframe в широком формате. Колонка color выступала основным ключом, item – вторым, а их значения формировали новые колонки в объекте.
>>> wideframe = longframe.pivot('color','item')
>>> wideframe
| | value | | |
|-------|----------|----------|----------|
| item | ball | mug | pen |
| color | | | |
| black | 0.738799 | 0.017153 | 0.783870 |
| red | 0.697267 | 0.145385 | 0.852835 |
| white | 0.896313 | 0.101891 | 0.344864 |
В таком формате Dataframe более компактен, а данные в нем — куда более читаемые.
Удаление
Последний этап подготовки данных — удаление колонок и строк. Определим такой объект в качестве примера.
>>> frame1 = pd.DataFrame(np.arange(9).reshape(3,3),
... index=['white','black','red'],
... columns=['ball','pen','pencil'])
>>> frame1
| | ball | pen | pencil |
|-------|------|-----|--------|
| white | 0 | 1 | 2 |
| black | 3 | 4 | 5 |
| red | 6 | 7 | 8 |
Для удаления колонки используйте команду del к Dataframe с определенным названием колонки.
>>> del frame1['ball']
>>> frame1
| | pen | pencil |
|-------|-----|--------|
| white | 1 | 2 |
| black | 4 | 5 |
| red | 7 | 8 |
Для удаления нежеланной строки используйте функцию drop() с меткой соответствующего индекса в аргументе.
>>> frame1.drop('white')
| | pen | pencil |
|-------|-----|--------|
| black | 4 | 5 |
| red | 7 | 8 |
Модуль pickle предоставляет мощный алгоритм сериализации и десериализации структур данных Python. Pickling — это процесс, при котором иерархия объекта конвертируется в поток байтов.
Это позволяет переносить и хранить объект, так что получатель может восстановить его, сохранив все оригинальные черты.
В Python за этот процесс отвечает модуль pickle, но имеется и cPickle, который является результатом работы по оптимизации первого (написан на C). Он в некоторых случаях может быть быстрее оригинального pickle в тысячу раз. Однако интерфейс самих модулей почти не отличается.
Прежде чем переходить к функциям библиотеки, рассмотрим cPickle в подробностях .
Сериализация объекта с помощью cPickle
Формат данных, используемый pickle (или cPickle), универсален для Python. По умолчанию для превращения в человекочитаемый вид используется представление в виде ASCII. Затем, открыв файл в текстовом редакторе, можно понять его содержимое. Для использования модуля его сначала нужно импортировать:
>>> import pickle
Создадим объект с внутренней структурой, например, dict.
>>> data = { 'color': ['white','red'], 'value': [5, 7]}
Теперь выполним сериализацию с помощью функции dumps() модуля cPickle.
>>> pickled_data = pickle.dumps(data)
Чтобы увидеть, как прошла сериализация, необходимо изучить содержимое переменной pickled_data.
>>> print(pickled_data)
Когда данные сериализованы, их можно записать в файл, отправить через сокет, канал или другими способами.
А после передачи их можно пересобрать (выполнить десериализацию) с помощью функции loads() из модуля cPickle.
>>> nframe = pickle.loads(pickled_data)
>>> nframe
{'color': ['white', 'red'], 'value': [5, 7]}
Процесс “pickling” в pandas
Когда дело доходит до сериализации (или десериализации), то pandas с легкостью справляется с задачей. Не нужно даже импортировать модуль cPickle, а все операции выполняются неявно.
Также формат сериализации в pandas не целиком в ASCII.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
index=['up','down','left','right'])
>>> frame.to_pickle('frame.pkl')
Теперь у вас есть файл frame.pkl, содержащий всю информацию об объекте Dataframe.
Для его открытия используется следующая команда:
>>> pd.read_pickle('frame.pkl')
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| up | 0 | 1 | 2 | 3 |
| down | 4 | 5 | 6 | 7 |
| left | 8 | 9 | 10 | 11 |
| right | 12 | 13 | 14 | 15 |
На этом примере видно, что все нюансы скрыты от пользователя pandas, что делает работу простой и понятной, особенно для тех, кто занимается непосредственно анализом данных.
]]>Примечание. При использовании формата важно убедиться, что открываемый файл безопасен. Формат не очень защищен от вредоносных данных.
Чтение и запись в файлы Microsoft Excel
Данные очень легко читать из файлов CSV, но они часто хранятся в табличной форме в формате Excel.
pandas предоставляет специальные функции для работы с ним:
to_excel()read_excel()
Функция read_excel() может читать из файлов Excel 2003 (.xls) и Excel 2007 (.xlsx). Это возможно благодаря модулю xlrd.
Для начала откроем файл Excel и введем данные со следующий таблиц. Разместим их в листах sheet1 и sheet2. Сохраним файл как ch05_data.xlsx.
| white | red | green | black | |
|---|---|---|---|---|
| a | 12 | 23 | 17 | 18 |
| b | 22 | 16 | 19 | 18 |
| c | 14 | 23 | 22 | 21 |
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
Для чтения данных из файла XLS нужно всего лишь конвертировать его в Dataframe, используя для этого функцию read_excel().
>>> pd.read_excel('ch05_data.xlsx')
По умолчанию готовый объект pandas Dataframe будет состоять из данных первого листа файла. Но если нужно загрузить и второй, то достаточно просто указать его номер (индекс) или название в качестве второго аргумента.
>>> pd.read_excel('ch05_data.xlsx','Sheet2')
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
>>> pd.read_excel('ch05_data.xlsx',1)
| yellow | purple | blue | orange | |
|---|---|---|---|---|
| A | 11 | 16 | 44 | 22 |
| B | 20 | 22 | 23 | 44 |
| C | 30 | 31 | 37 | 32 |
Запись работает по тому же принципу. Для конвертации объекта Dataframe в Excel нужно написать следующее.
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index = ['exp1','exp2','exp3','exp4'],
... columns = ['Jan2015','Fab2015','Mar2015','Apr2005'])
>>> frame.to_excel('data2.xlsx')
>>> frame
| Jan2015 | Feb2015 | Mar2015 | Apr2015 | |
|---|---|---|---|---|
| exp1 | 0.671044 | 0.437715 | 0.497103 | 0.070595 |
| exp2 | 0.864018 | 0.575196 | 0.240343 | 0.471081 |
| exp3 | 0.957986 | 0.311648 | 0.381975 | 0.622556 |
| exp4 | 0.407909 | 0.015926 | 0.180611 | 0.579783 |
В рабочей директории будет создан файл с соответствующими данными.
Данные JSON
JSON (JavaScript Object Notation) стал одним из самых распространенных стандартных форматов для передачи данных в сети.
Одна из главных его особенностей — гибкость, хотя структура и не похожа на привычные таблицы.
В этом разделе вы узнаете, как использовать функции read_json() и to_json() для использования API. А в следующем — познакомитесь с другим примером взаимодействия со структурированными данными формата, который чаще встречается в реальной жизни.
http://jsonviewer.stack.hu/ — полезный онлайн-инструмент для проверки формата JSON. Нужно вставить данные в этом формате, и сайт покажет, представлены ли они в корректной форме, а также покажет дерево структуры.
{
"up": {
"white": 0,
"black": 4,
"red": 8,
"blue": 12
},
"down": {
"white": 1,
"black": 5,
"red": 9,
"blue": 13
},
"right": {
"white": 2,
"black": 6,
"red": 10,
"blue": 14
},
"left": {
"white": 3,
"black": 7,
"red": 11,
"blue": 15
}
}
Начнем с самого полезного примера, когда есть объект Dataframe и его нужно конвертировать в файл JSON. Определим такой объект и используем его для вызова функции to_json(), указав название для итогового файла.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
... index=['white','black','red','blue'],
... columns=['up','down','right','left'])
>>> frame.to_json('frame.json')
Он будет находится в рабочей папке и включать все данные в формате JSON.
Обратную операцию можно выполнить с помощью функции read_json(). Параметром здесь должен выступать файл с данными.
>>> pd.read_json('frame.json')
| down | left | right | up | |
|---|---|---|---|---|
| black | 5 | 7 | 6 | 4 |
| blue | 13 | 15 | 14 | 12 |
| red | 9 | 11 | 10 | 8 |
| white | 1 | 3 | 2 | 0 |
Это был простейший пример, где данные JSON представлены в табличной форме (поскольку источником файла frame.json служил именно такой объект — Dataframe). Но в большинстве случаев у JSON-файлов нет такой четкой структуры. Поэтому нужно конвертировать файл в табличную форму. Этот процесс называется нормализацией.
Библиотека pandas предоставляет функцию json_normalize(), которая умеет конвертировать объект dict или список в таблицу. Для начала ее нужно импортировать:
>>> from pandas.io.json import json_normalize
Создадим JSON-файл как в следующем примере с помощью любого текстового редактора и сохраним его в рабочей директории как books.json.
[{"writer": "Mark Ross",
"nationality": "USA",
"books": [
{"title": "XML Cookbook", "price": 23.56},
{"title": "Python Fundamentals", "price": 50.70},
{"title": "The NumPy library", "price": 12.30}
]
},
{"writer": "Barbara Bracket",
"nationality": "UK",
"books": [
{"title": "Java Enterprise", "price": 28.60},
{"title": "HTML5", "price": 31.35},
{"title": "Python for Dummies", "price": 28.00}
]
}]
Как видите, структура файла более сложная и не похожа на таблицу. В таком случае функция read_json() уже не сработает. Однако данные в нужной форме все еще можно получить. Во-первых, нужно загрузить содержимое файла и конвертировать его в строку.
>>> import json
>>> file = open('books.json','r')
>>> text = file.read()
>>> text = json.loads(text)
После этого можно использовать функцию json_normalize(). Например, можно получить список книг. Для этого необходимо указать ключ books в качестве второго параметра.
>>> json_normalize(text,'books')
| price | title | |
|---|---|---|
| 0 | 23.56 | XML Cookbook |
| 1 | 50.70 | Python Fundamentals |
| 2 | 12.30 | The NumPy library |
| 3 | 28.60 | Java Enterprise |
| 4 | 31.35 | HTML5 |
| 5 | 28.30 | Python for Dummies |
Функция считает содержимое всех элементов, у которых ключом является books. Все свойства будут конвертированы в имена вложенных колонок, а соответствующие значения заполнят объект Dataframe. В качестве индексов будет использоваться возрастающая последовательность чисел.
Однако в этом случае Dataframe включает только внутреннюю информацию. Не лишним было бы добавить и значения остальных ключей на том же уровне. Для этого необходимо добавить другие колонки, вставив список ключей в качестве третьего элемента функции.
>>> json_normalize(text,'books',['nationality','writer'])
| price | title | writer | nationality | |
|---|---|---|---|---|
| 0 | 23.56 | XML Cookbook | Mark Ross | USA |
| 1 | 50.70 | Python Fundamentals | Mark Ross | USA |
| 2 | 12.30 | The NumPy library | Mark Ross | USA |
| 3 | 28.60 | Java Enterprise | Barbara Bracket | UK |
| 4 | 31.35 | HTML5 | Barbara Bracket | UK |
| 5 | 28.30 | Python for Dummies | Barbara Bracket | UK |
Результатом будет Dataframe с готовой структурой.
Формат HDF5
До сих пор в примерах использовалась запись данных лишь в текстовом формате. Но когда речь заходит о больших объемах, то предпочтительнее использовать бинарный. Для этого в Python есть несколько инструментов. Один из них — библиотека HDF5.
HDF расшифровывается как hierarchical data format (иерархический формат данных), а сама библиотека используется для чтения и записи файлов HDF5, содержащих структуру с узлами и возможностью хранить несколько наборов данных.
Библиотека разработана на C, но предусматривает интерфейсы для других языков: Python, MATLAB и Java. Она особенно эффективна при сохранении больших объемов данных. В сравнении с остальными форматами, работающими в бинарном виде, HDF5 поддерживает сжатие в реальном времени, используя преимущества повторяющихся паттернов в структуре для уменьшения размера файла.
Возможные варианты в Python — это PyTables и h5py. Они отличаются по нескольким аспектам, а выбирать их стоит, основываясь на том, что нужно программисту.
h5py предоставляет прямой интерфейс с высокоуровневыми API HDF5, а PyTables скрывает за абстракциями многие детали HDF5 с более гибкими контейнерами данных, индексированные таблицы, запросы и другие способы вычислений.
В pandas есть классовый dict под названием HDFStore, который использует PyTables для хранения объектов pandas. Поэтому перед началом работы с форматом необходимо импортировать класс HDFStore:
>>> from pandas.io.pytables import HDFStore
Теперь данные объекта Dataframe можно хранить в файле с расширением .h5. Для начала создадим Dataframe.
>>> frame = pd.DataFrame(np.arange(16).reshape(4,4),
... index=['white','black','red','blue'],
... columns=['up','down','right','left'])
Дальше нужен файл HDF5 под названием mydata.h5. Добавим в него содержимое объекта Dataframe.
>>> store = HDFStore('mydata.h5')
>>> store['obj1'] = frame
Можете догадаться, как хранить несколько структур данных в одном файле HDF5, указав для каждой из них метку. С помощью этого формата можно хранить несколько структур данных в одном файле, при том что он будет представлен переменной store.
>>> store
<class 'pandas.io.pytables.HDFStore'>
File path: ch05_data.h5
Обратный процесс также прост. Учитывая наличие файла HDF5 с разными структурами данных вызвать их можно следующим путем.
Взаимодействие с базами данных
В большинстве приложений текстовые файлы редко выступают источниками данных, просто потому что это не эффективно. Они хранятся в реляционных базах данных (SQL) или альтернативных (NoSQL), которые стали особо популярными в последнее время.
Загрузка из SQL в Dataframe — это простой процесс, а pandas предлагает дополнительные функции для еще большего упрощения.
Модуль pandas.io.sql предоставляет объединенный интерфейс, независимый от базы данных, под названием sqlalchemy. Он упрощает режим соединения, поскольку команды неизменны вне зависимости от типа базы. Для создания соединения используется функция create_engine(). Это же позволяет настроить все необходимые свойства: ввести имя пользователя, пароль и порт, а также создать экземпляр базы данных.
Вот список разных типов баз данных:
>>> from sqlalchemy import create_engine
# For PostgreSQL:
>>> engine = create_engine('postgresql://scott:tiger@localhost:5432/mydatabase')
# For MySQL
>>> engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# For Oracle
>>> engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
# For MSSQL
>>> engine = create_engine('mssql+pyodbc://mydsn')
# For SQLite
>>> engine = create_engine('sqlite:///foo.db')
Загрузка и запись данных с SQLite3
Для первого примера используем базу данных SQLite, применив встроенный Python sqlite3. SQLite3 — это инструмент, реализующий реляционную базу данных очень простым путем. Это самый легкий способ добавить ее в любое приложение на Python. С помощью SQLite фактически можно создать встроенную базу данных в одном файле.
Идеальный вариант для тех, кому нужна база, но нет желания устанавливать реальную. SQLite3 же можно использовать для тренировки или для использования функций базы при сборе данных, не выходя за рамки программы.
Создадим объект Dataframe, который будет использоваться для создания новой таблицы в базе данных SQLite3.
>>> frame = pd.DataFrame(np.arange(20).reshape(4,5),
... columns=['white','red','blue','black','green'])
>>> frame
| white | red | blue | black | green | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
Теперь нужно реализовать соединение с базой.
>>> engine = create_engine('sqlite:///foo.db')
Конвертируем объект в таблицу внутри базы данных.
>>> frame.to_sql('colors',engine)
А вот для чтения базы нужно использовать функцию read_sql(), указав название таблицы и движок.
>>> pd.read_sql('colors',engine)
| index | white | red | blue | black | green | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 3 | 15 | 16 | 17 | 18 | 19 |
На примере видно, что даже в этом случае процесс записи очень прост благодаря API библиотеки pandas.
Однако того же можно добиться и без них. Это покажет, почему pandas считается эффективным инструментом для работы с базой данных.
Во-первых, нужно установить соединение и создать таблицу, определив правильные типы данных, которые впоследствии будут загружаться.
>>> import sqlite3
>>> query = """
... CREATE TABLE test
... (a VARCHAR(20), b VARCHAR(20),
... c REAL, d INTEGER
... );"""
>>> con = sqlite3.connect(':memory:')
>>> con.execute(query)
<sqlite3.Cursor object at 0x0000000009E7D730>
>>> con.commit()
Теперь можно добавлять сами данные с помощью SQL INSERT.
>>> data = [('white','up',1,3),
... ('black','down',2,8),
... ('green','up',4,4),
... ('red','down',5,5)]
>>> stmt = "INSERT INTO test VALUES(?,?,?,?)"
>>> con.executemany(stmt, data)
<sqlite3.Cursor object at 0x0000000009E7D8F0>
>>> con.commit()
Наконец, можно перейти к запросам из базы данных. Это делается с помощью SQL SELECT.
>>> cursor = con.execute('select * from test')
>>> cursor
<sqlite3.Cursor object at 0x0000000009E7D730>
>>> rows = cursor.fetchall()
>>> rows
[('white', 'up', 1.0, 3),
('black', 'down', 2.0, 8),
('green', 'up', 4.0, 4),
('red', 'down', 5.0, 5)]
Конструктору Dataframe можно передать список кортежей, а если нужны названия колонок, то их можно найти в атрибуте description своего cursor.
>>> cursor.description
(('a', None, None, None, None, None, None),
('b', None, None, None, None, None, None),
('c', None, None, None, None, None, None),
('d', None, None, None, None, None, None))
>>> pd.DataFrame(rows, columns=zip(*cursor.description)[0])
Этот подход куда сложнее.
Загрузка и запись с помощью PostgreSQL
Начиная с pandas 0.14, PostgreSQL также поддерживается. Для начала нужно проверить версию библиотеки.
>>> pd.__version__
>>> '0.22.0'
Для запуска примера база PostgreSQL должна быть установлена в системе. В этом примере была создана база postgres, где пользователя зовут postgres, а пароль — password. Замените значения на соответствующие в вашей системе.
Сначала нужно установить библиотеку psycopg2, которая предназначена для управления соединениями с базой данных.
В Anaconda:
conda install psycopg2
Или с помощью PyPl:
pip install psycopg2
Теперь можно установить соединение:
>>> import psycopg2
>>> engine = create_engine('postgresql://postgres:password@localhost:5432/
postgres')
Примечание. В этом примере вне зависимости от установленной версии в Windows может возникать ошибка:
from psycopg2._psycopg import BINARY, NUMBER, STRING,
DATETIME, ROWID
ImportError: DLL load failed: The specified module could not
be found.
Это почти наверняка значит, что DLL для PostgreSQL (в частности, libpq.dll) не установлены в PATH. Добавьте одну из папок
postgres\x.x\binв PATH и теперь соединение Python с базой данных PostgreSQL должно работать без проблем.
Создайте объект Dataframe:
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index=['exp1','exp2','exp3','exp4'],
... columns=['feb','mar','apr','may']);
Вот как просто переносить данные в таблицу. С помощью to_sql() вы без проблем запишите их в таблицу dataframe.
>>> frame.to_sql('dataframe',engine)
pgAdmin III — это графическое приложение для управления базами данных PostgreSQL. Крайне удобный инструмент для Windows и Linux. С его помощью можно легко изучить созданную базу данных.
Если вы хорошо знаете язык SQL, то есть и классический способ рассмотреть созданную таблицу с помощью сессии psql.
>>> psql -U postgres
В этом случае соединение произошло от имени пользователя postgres. Оно может отличаться. После соединения просто осуществите SQL-запрос к таблице.
postgres=# SELECT * FROM DATAFRAME;
index| feb | mar | apr | may
-----+-----------------+-----------------+-----------------+-----------------
exp1 |0.757871296789076|0.422582915331819|0.979085739226726|0.332288515791064
exp2 |0.124353978978927|0.273461421503087|0.049433776453223|0.0271413946693556
exp3 |0.538089036334938|0.097041417119426|0.905979807772598|0.123448718583967
exp4 |0.736585422687497|0.982331931474687|0.958014824504186|0.448063967996436
(4 righe)
Даже конвертация таблицы в объект Dataframe — тривиальная задача. Для этого есть функция read_sql_table(), которая считывает данные из таблицы и записывает их в новый объект.
>>> pd.read_sql_table('dataframe',engine)
Но когда нужно считать данные из базы, конвертация целой таблицы в Dataframe — не самая полезная операция. Те, кто работают с реляционными базами данных, предпочитают использовать для этих целей SQL. Он подходит для выбора того. какие данные и в каком виде требуется получить с помощью SQL-запроса.
Текст запроса может быть использован в функции read_sql_query().
>>> pd.read_sql_query('SELECT index,apr,may FROM DATAFRAME WHERE apr >
0.5',engine)
Чтение и запись данных в базу данных NoSQL: MongoDB
Среди всех баз данных NoSQL (BerkeleyDB, Tokyo Cabinet и MongoDB) MongoDB — одна из самых распространенных. Она доступна в разных системах и подходит для чтения и записи данных при анализе данных.
Работу нужно начать с того, что указать на конкретную директорию.
mongod --dbpath C:\MongoDB_data
Теперь, когда сервис случает порт 27017, к базе можно подключиться, используя официальный драйвер для MongoDB, pymongo.
>>> import pymongo
>>> client = MongoClient('localhost',27017)
Один экземпляр MongoDB способен поддерживать несколько баз данных одновременно. Поэтому нужно указать на конкретную.
>>> db = client.mydatabase
>>> db
Database(MongoClient('localhost', 27017), 'mycollection')
>>> # Чтобы ссылаться на этот объект, используйте
>>> client['mydatabase']
Database(MongoClient('localhost', 27017), 'mydatabase')
Когда база данных определена, нужно определить коллекцию. Она представляет собой группу документов, сохраненных в MongoDB. Ее можно воспринимать как эквивалент таблиц из SQL.
>>> collection = db.mycollection
>>> db['mycollection']
Collection(Database(MongoClient('localhost', 27017), 'mydatabase'),
'mycollection')
>>> collection
Collection(Database(MongoClient('localhost', 27017), 'mydatabase'),
'mycollection')
Теперь нужно добавить данные в коллекцию. Создайте Dataframe.
>>> frame = pd.DataFrame(np.arange(20).reshape(4,5),
... columns=['white','red','blue','black','green'])
>>> frame
| white | red | blue | black | green | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
Перед добавлением его нужно конвертировать в формат JSON. Процесс конвертации не такой простой, потому что нужно задать данные, которые будут записаны в базу, чтобы потом с легкостью извлекать их снова в объекте.
>>> import json
>>> record = json.loads(frame.T.to_json()).values()
>>> record
[{'blue': 7, 'green': 9, 'white': 5, 'black': 8, 'red': 6},
{'blue': 2, 'green': 4, 'white': 0, 'black': 3, 'red': 1},
{'blue': 17, 'green': 19, 'white': 15, 'black': 18, 'red': 16},
{'blue': 12, 'green': 14, 'white': 10, 'black': 13, 'red': 11}]
Теперь все готово для добавления документа в коллекцию. Для этого используется функция insert().
>>> collection.mydocument.insert(record)
[ObjectId('54fc3afb9bfbee47f4260357'), ObjectId('54fc3afb9bfbee47f4260358'),
ObjectId('54fc3afb9bfbee47f4260359'), ObjectId('54fc3afb9bfbee47f426035a')]
В этом случае каждый объект представлен на отдельной строке. Когда данные загружены в документ базы данных, можно выполнить и обратный процесс, то есть, прочитать данные и конвертировать их в Dataframe.
>>> cursor = collection['mydocument'].find()
>>> dataframe = (list(cursor))
>>> del dataframe['_id']
>>> dataframe
Была удалена колонка с ID для внутренней навигации по MongoDB.
Вы уже знакомы с библиотекой pandas и ее базовой функциональностью по анализу данных. Также знаете, что в ее основе лежат два типа данных: Dataframe и Series. На их основе выполняется большая часть взаимодействия с данными, вычислений и анализа.
В этом материале вы познакомитесь с инструментами, предназначенными для чтения данных, сохраненных в разных источниках (файлах и базах данных). Также научитесь записывать структуры в эти форматы, не задумываясь об используемых технологиях.
Этот раздел посвящен функциям API I/O (ввода/вывода), которые pandas предоставляет для чтения и записи данных прямо в виде объектов Dataframe. Начнем с текстовых файлов, а затем перейдем к более сложным бинарным форматам.
А в конце узнаем, как взаимодействовать с распространенными базами данных, такими как SQL и NoSQL, используя для этого реальные примеры. Разберем, как считывать данные из базы данных, сохраняя их в виде Dataframe.
Инструменты API I/O
pandas — библиотека, предназначенная для анализа данных, поэтому логично предположить, что она в первую очередь используется для вычислений и обработки данных. Процесс записи и чтения данных на/с внешние файлы — это часть обработки. Даже на этом этапе можно выполнять определенные операции, готовя данные к взаимодействию.
Первый шаг очень важен, поэтому для него представлен полноценный инструмент в библиотеке, называемый API I/O. Функции из него можно разделить на две категории: для чтения и для записи.
| Чтение | Запись |
|---|---|
| read_csv | to_csv |
| read_excel | to_excel |
| read_hdf | to_hdf |
| read_sql | to_sql |
| read_json | to_json |
| read_html | to_html |
| read_stata | to_stata |
| read_clipboard | to_clipboard |
| read_pickle | to_pickle |
| read_msgpack | to_msgpack (экспериментальный) |
| read_gbq | to_gbq (экспериментальный) |
CSV и текстовые файлы
Все привыкли к записи и чтению файлов в текстовой форме. Чаще всего они представлены в табличной форме. Если значения в колонке разделены запятыми, то это формат CSV (значения, разделенные запятыми), который является, наверное, самым известным форматом.
Другие формы табличных данных могут использовать в качестве разделителей пробелы или отступы. Они хранятся в текстовых файлах разных типов (обычно с расширением .txt).
Такой тип файлов — самый распространенный источник данных, который легко расшифровывать и интерпретировать. Для этого pandas предлагает набор функций:
read_csvread_tableto_csv
Чтение данных из CSV или текстовых файлов
Самая распространенная операция по взаимодействию с данными при анализе данных — чтение их из файла CSV или как минимум текстового файла.
Для этого сперва нужно импортировать отдельные библиотеки.
>>> import numpy as np
>>> import pandas as pd
Чтобы сначала увидеть, как pandas работает с этими данными, создадим маленький файл CSV в рабочем каталоге, как показано на следующем изображении и сохраним его как ch05_01.csv.
white,red,blue,green,animal
1,5,2,3,cat
2,7,8,5,dog
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
Поскольку разделителем в файле выступают запятые, можно использовать функцию read_csv() для чтения его содержимого и добавления в объект Dataframe.
>>> csvframe = pd.read_csv('ch05_01.csv')
>>> csvframe
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Это простая операция. Файлы CSV — это табличные данные, где значения одной колонки разделены запятыми. Поскольку это все еще текстовые файлы, то подойдет и функция read_table(), но в таком случае нужно явно указывать разделитель.
>>> pd.read_table('ch05_01.csv',sep=',')
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
В этом примере все заголовки, обозначающие названия колонок, определены в первой строчке. Но это не всегда работает именно так. Иногда сами данные начинаются с первой строки.
Создадим файл ch05_02.csv
1,5,2,3,cat
2,7,8,5,dog
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
>>> pd.read_csv('ch05_02.csv')
| 1 | 5 | 2 | 3 | cat | |
|---|---|---|---|---|---|
| 0 | 2 | 7 | 8 | 5 | dog |
| 1 | 3 | 3 | 6 | 7 | horse |
| 2 | 2 | 2 | 8 | 3 | duck |
| 3 | 4 | 4 | 2 | 1 | mouse |
| 4 | 4 | 4 | 2 | 1 | mouse |
В таком случае нужно убедиться, что pandas не присвоит названиям колонок значения первой строки, передав None параметру header.
>>> pd.read_csv('ch05_02.csv', header=None)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Также можно самостоятельно определить названия, присвоив список меток параметру names.
>>> pd.read_csv('ch05_02.csv', names=['white','red','blue','green','animal'])
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
В более сложных случаях когда нужно создать Dataframe с иерархической структурой на основе данных из файла CSV, можно расширить возможности функции read_csv() добавив параметр index_col, который конвертирует колонки в значения индексов.
Чтобы лучше разобраться с этой особенностью, создайте новый CSV-файл с двумя колонками, которые будут индексами в иерархии. Затем сохраните его в рабочую директорию под именем ch05_03.csv.
Создадим файл ch05_03.csv
color,status,item1,item2,item3
black,up,3,4,6
black,down,2,6,7
white,up,5,5,5
white,down,3,3,2
white,left,1,2,1
red,up,2,2,2
red,down,1,1,4
>>> pd.read_csv('ch05_03.csv', index_col=['color','status'])
| item1 | item2 | item3 | ||
|---|---|---|---|---|
| color | status | |||
| black | up | 3 | 4 | 6 |
| down | 2 | 6 | 7 | |
| white | up | 5 | 5 | 5 |
| down | 3 | 3 | 2 | |
| left | 1 | 2 | 1 | |
| red | up | 2 | 2 | 2 |
| down | 1 | 1 | 4 |
Использованием RegExp для парсинга файлов TXT
Иногда бывает так, что в файлах, из которых нужно получить данные, нет разделителей, таких как запятая или двоеточие. В таких случаях на помощь приходят регулярные выражения. Задать такое выражение можно в функции read_table() с помощью параметра sep.
Чтобы лучше понимать regexp и то, как их использовать для разделения данных, начнем с простого примера. Например, предположим, что файл TXT имеет значения, разделенные пробелами и отступами хаотично. В таком случае regexp подойдут идеально, ведь они позволяют учитывать оба вида разделителей. Подстановочный символ /s* отвечает за все символы пробелов и отступов (если нужны только отступы, то используется /t), а * указывает на то, что символов может быть несколько. Таким образом значения могут быть разделены большим количеством пробелов.
| . | Любой символ за исключением новой строки |
| \d | Цифра |
| \D | Не-цифровое значение |
| \s | Пробел |
| \S | Не-пробельное значение |
| \n | Новая строка |
| \t | Отступ |
| \uxxxx | Символ Unicode в шестнадцатеричном виде |
Возьмем в качестве примера случай, где значения разделены отступами или пробелами в хаотическом порядке.
Создадим файл ch05_04.txt
white red blue green
1 5 2 3
2 7 8 5
3 3 6 7
>>> pd.read_table('ch05_04.txt',sep='\s+', engine='python')
| white | red | blue | green | |
|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 |
| 1 | 2 | 7 | 8 | 5 |
| 2 | 3 | 3 | 6 | 7 |
Результатом будет идеальный Dataframe, в котором все значения корректно отсортированы.
Дальше будет пример, который может показаться странным, но на практике он встречается не так уж и редко. Он пригодится для понимания принципов работы regexp. На самом деле, о разделителях (запятых, пробелах, отступах и так далее) часто думают как о специальных символах, но иногда ими выступают и буквенно-цифровые символы, например, целые числа.
В следующем примере необходимо извлечь цифровую часть из файла TXT, в котором последовательность символов перемешана с буквами.
Не забудьте задать параметр None для параметра header, если в файле нет заголовков колонок.
Создадим файл ch05_05.txt
000END123AAA122
001END124BBB321
002END125CCC333
>>> pd.read_table('ch05_05.txt', sep='\D+', header=None, engine='python')
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 0 | 123 | 122 |
| 1 | 1 | 124 | 321 |
| 2 | 2 | 125 | 333 |
Еще один распространенный пример — удаление из данных отдельных строк при извлечении. Так, не всегда нужны заголовки или комментарии. Благодаря параметру skiprows можно исключить любые строки, просто присвоим ему массив с номерами строк, которые не нужно парсить.
Обратите внимание на способ использования параметра. Если нужно исключить первые пять строк, то необходимо писать skiprows = 5, но для удаления только пятой строки — [5].
Создадим файл ch05_06.txt
########### LOG FILE ############
This file has been generated by automatic system
white,red,blue,green,animal
12-Feb-2015: Counting of animals inside the house
1,5,2,3,cat
2,7,8,5,dog
13-Feb-2015: Counting of animals outside the house
3,3,6,7,horse
2,2,8,3,duck
4,4,2,1,mouse
>>> pd.read_table('ch05_06.txt',sep=',',skiprows=[0,1,3,6])
| white | red | blue | green | animal | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 3 | 3 | 6 | 7 | horse |
| 3 | 2 | 2 | 8 | 3 | duck |
| 4 | 4 | 4 | 2 | 1 | mouse |
Чтение файлов TXT с разделением на части
При обработке крупных файлов или необходимости использовать только отдельные их части часто требуется считывать их кусками. Это может пригодится, если необходимо воспользоваться перебором или же целый файл не нужен.
Если требуется получить лишь часть файла, можно явно указать количество требуемых строк. Благодаря параметрам nrows и skiprows можно выбрать стартовую строку n (n = SkipRows) и количество строк, которые нужно считать после (nrows = 1).
>>> pd.read_csv('ch05_02.csv',skiprows=[2],nrows=3,header=None)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 1 | 5 | 2 | 3 | cat |
| 1 | 2 | 7 | 8 | 5 | dog |
| 2 | 2 | 2 | 8 | 3 | duck |
Еще одна интересная и распространенная операция — разбитие на части того куска текста, который требуется парсить. Затем для каждой части может быть выполнена конкретная операция для получения перебора части за частью.
Например, нужно суммировать значения в колонке каждой третьей строки и затем вставить результат в объект Series. Это простой и непрактичный пример, но с его помощью легко разобраться, а поняв механизм работы, его проще будет применять в сложных ситуациях.
>>> out = pd.Series()
>>> i = 0
>>> pieces = pd.read_csv('ch05_01.csv',chunksize=3)
>>> for piece in pieces:
... out.set_value(i,piece['white'].sum())
... i = i + 1
...
>>> out
0 6
1 6
dtype: int64
Запись данных в CSV
В дополнение к чтению данных из файла, распространенной операцией является запись в файл данных, полученных, например, в результате вычислений или просто из структуры данных.
Например, нужно записать данные из объекта Dataframe в файл CSV. Для этого используется функция to_csv(), принимающая в качестве аргумента имя файла, который будет сгенерирован.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
index = ['red', 'blue', 'yellow', 'white'],
columns = ['ball', 'pen', 'pencil', 'paper'])
>>> frame.to_csv('ch05_07.csv')
Если открыть новый файл ch05_07.csv, сгенерированный библиотекой pandas, то он будет напоминать следующее:
,ball,pen,pencil,paper
0,1,2,3
4,5,6,7
8,9,10,11
12,13,14,15
На предыдущем примере видно, что при записи Dataframe в файл индексы и колонки отмечаются в файле по умолчанию. Это поведение можно изменить с помощью параметров index и header. Им нужно передать значение False.
>>> frame.to_csv('ch05_07b.csv', index=False, header=False)
Файл ch05_07b.csv
1,2,3
5,6,7
9,10,11
13,14,15
Важно запомнить, что при записи файлов значения NaN из структуры данных представлены в виде пустых полей в файле.
>>> frame3 = pd.DataFrame([[6,np.nan,np.nan,6,np.nan],
... [np.nan,np.nan,np.nan,np.nan,np.nan],
... [np.nan,np.nan,np.nan,np.nan,np.nan],
... [20,np.nan,np.nan,20.0,np.nan],
... [19,np.nan,np.nan,19.0,np.nan]
... ],
... index=['blue','green','red','white','yellow'],
... columns=['ball','mug','paper','pen','pencil'])
>>> frame3
| Unnamed: 0 | ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|---|
| 0 | blue | 6.0 | NaN | NaN | 6.0 | NaN |
| 1 | green | NaN | NaN | NaN | NaN | NaN |
| 2 | red | NaN | NaN | NaN | NaN | NaN |
| 3 | white | 20.0 | NaN | NaN | 20.0 | NaN |
| 4 | yellow | 19.0 | NaN | NaN | 19.0 | NaN |
>>> frame3.to_csv('ch05_08.csv')
,ball,mug,paper,pen,pencil
blue,6.0,,,6.0,
green,,,,,
red,,,,,
white,20.0,,,20.0,
yellow,19.0,,,19.0,
Но их можно заменить на любое значение, воспользовавшись параметром na_rep из функции to_csv. Это может быть NULL, 0 или то же NaN.
>>> frame3.to_csv('ch05_09.csv', na_rep ='NaN')
,ball,mug,paper,pen,pencil
blue,6.0,NaN,NaN,6.0,NaN
green,NaN,NaN,NaN,NaN,NaN
red,NaN,NaN,NaN,NaN,NaN
white,20.0,NaN,NaN,20.0,NaN
yellow,19.0,NaN,NaN,19.0,NaN
Примечание: в предыдущих примерах использовались только объекты
Dataframe, но все функции применимы и по отношению кSeries.
Чтение и запись файлов HTML
pandas предоставляет соответствующую пару функций API I/O для формата HTML.
read_html()to_html()
Эти две функции очень полезны. С их помощью можно просто конвертировать сложные структуры данных, такие как Dataframe, прямо в таблицы HTML, не углубляясь в синтаксис.
Обратная операция тоже очень полезна, потому что сегодня веб является одним из основных источников информации. При этом большая часть информации не является «готовой к использованию», будучи упакованной в форматы TXT или CSV. Необходимые данные чаще всего представлены лишь на части страницы. Так что функция для чтения окажется полезной очень часто.
Такая деятельность называется парсингом (веб-скрапингом). Этот процесс становится фундаментальным элементом первого этапа анализа данных: поиска и подготовки.
Примечание: многие сайты используют
HTML5для предотвращения ошибок недостающих модулей или сообщений об ошибках. Настоятельно рекомендуется использовать модульhtml5libв Anaconda.
conda install html5lib
Запись данных в HTML
При записи Dataframe в HTML-таблицу внутренняя структура объекта автоматически конвертируется в сетку вложенных тегов <th>, <tr> и <td>, сохраняя иерархию. Для этой функции даже не нужно знать HTML.
Поскольку структуры данных, такие как Dataframe, могут быть большими и сложными, это очень удобно иметь функцию, которая сама создает таблицу на странице. Вот пример.
Сначала создадим простейший Dataframe. Дальше с помощью функции to_html() прямо конвертируем его в таблицу HTML.
>>> frame = pd.DataFrame(np.arange(4).reshape(2,2))
Поскольку функции API I/O определены в структуре данных pandas, вызывать to_html() можно прямо к экземпляру Dataframe.
>>> print(frame.to_html())
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>0</th>
<th>1</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>0</td>
<td>1</td>
</tr>
<tr>
<th>1</th>
<td>2</td>
<td>3</td>
</tr>
</tbody>
</table>
Результат — готовая таблица HTML, сохранившая всю внутреннюю структуру.
В следующем примере вы увидите, как таблицы автоматически появляются в файле HTML. В этот раз сделаем объект более сложным, добавив в него метки индексов и названия колонок.
>>> frame = pd.DataFrame(np.random.random((4,4)),
... index = ['white','black','red','blue'],
... columns = ['up','down','right','left'])
>>> frame
| up | down | right | left | |
|---|---|---|---|---|
| white | 0.420378 | 0.533364 | 0.758968 | 0.132560 |
| black | 0.711775 | 0.375598 | 0.936847 | 0.495377 |
| red | 0.630547 | 0.998588 | 0.592496 | 0.076336 |
| blue | 0.308752 | 0.158057 | 0.647739 | 0.907514 |
Теперь попробуем написать страницу HTML с помощью генерации строк. Это простой пример, но он позволит разобраться с функциональностью pandas прямо в браузере.
Сначала создадим строку, которая содержит код HTML-страницы.
>>> s = ['<HTML>']
>>> s.append('<HEAD><TITLE>My DataFrame</TITLE></HEAD>')
>>> s.append('<BODY>')
>>> s.append(frame.to_html())
>>> s.append('</BODY></HTML>')
>>> html = ''.join(s)
Теперь когда метка html содержит всю необходимую разметку, можно писать прямо в файл myFrame.html:
>>> html_file = open('myFrame.html','w')
>>> html_file.write(html)
>>> html_file.close()
В рабочей директории появится новый файл, myFrame.html. Двойным кликом его можно открыть прямо в браузере. В левом верхнем углу будет следующая таблица:

Чтение данных из HTML-файла
pandas может с легкостью генерировать HTML-таблицы на основе данных Dataframe. Обратный процесс тоже возможен. Функция read_html() осуществляет парсинг HTML и ищет таблицу. В случае успеха она конвертирует ее в Dataframe, который можно использовать в процессе анализа данных.
Если точнее, то read_html() возвращает список объектов Dataframe, даже если таблица одна. Источник может быть разных типов. Например, может потребоваться прочитать HTML-файл в любой папке. Или попробовать парсить HTML из прошлого примера:
>>> web_frames = pd.read_html('myFrame.html')
>>> web_frames[0]
| Unnamed: 0 | up | down | right | left | |
|---|---|---|---|---|---|
| 0 | white | 0.420378 | 0.533364 | 0.758968 | 0.132560 |
| 1 | black | 0.711775 | 0.375598 | 0.936847 | 0.495377 |
| 2 | red | 0.630547 | 0.998588 | 0.592496 | 0.076336 |
| 3 | blue | 0.308752 | 0.158057 | 0.647739 | 0.907514 |
Все теги, отвечающие за формирование таблицы в HTML в финальном объекте не представлены. web_frames — это список Dataframe, хотя в этом случае объект был всего один. К нему можно обратиться стандартным путем. Здесь достаточно лишь указать на него через индекс 0.
Но самый распространенный режим работы функции read_html() — прямой парсинг ссылки. Таким образом страницы парсятся прямо, а из них извлекаются таблицы.
Например, дальше будет вызвана страница, на которой есть HTML-таблица, показывающая рейтинг с именами и баллами.
>>> ranking = pd.read_html('https://www.meccanismocomplesso.org/en/
meccanismo-complesso-sito-2/classifica-punteggio/')
>>> ranking[0]
| # | Nome | Exp | Livelli | right |
|---|---|---|---|---|
| 0 | 1 | Fabio Nelli | 17521 | NaN |
| 1 | 2 | admin | 9029 | NaN |
| 2 | 3 | BrunoOrsini | 2124 | NaN |
| … | … | … | … | … |
| 247 | 248 | emilibassi | 1 | NaN |
| 248 | 249 | mehrbano | 1 | NaN |
| 249 | 250 | NIKITA PANCHAL | 1 | NaN |
Чтение данных из XML
В списке функции API I/O нет конкретного инструмента для работы с форматом XML (Extensible Markup Language). Тем не менее он очень важный, поскольку многие структурированные данные представлены именно в нем. Но это и не проблема, ведь в Python есть много других библиотек (помимо pandas), которые подходят для чтения и записи данных в формате XML.
Одна их них называется lxml и она обеспечивает идеальную производительность при парсинге даже самых крупных файлов. Этот раздел будет посвящен ее использованию, интеграции с pandas и способам получения Dataframe с нужными данными. Больше подробностей о lxml есть на официальном сайте http://lxml.de/index.html.
Возьмем в качестве примера следующий файл. Сохраните его в рабочей директории с названием books.xml.
<?xml version="1.0"?>
<Catalog>
<Book id="ISBN9872122367564">
<Author>Ross, Mark</Author>
<Title>XML Cookbook</Title>
<Genre>Computer</Genre>
<Price>23.56</Price>
<PublishDate>2014-22-01</PublishDate>
</Book>
<Book id="ISBN9872122367564">
<Author>Bracket, Barbara</Author>
<Title>XML for Dummies</Title>
<Genre>Computer</Genre>
<Price>35.95</Price>
<PublishDate>2014-12-16</PublishDate>
</Book>
</Catalog>
В этом примере структура файла будет конвертирована и преподнесена в виде Dataframe. В первую очередь нужно импортировать субмодуль objectify из библиотеки.
>>> from lxml import objectify
Теперь нужно всего лишь использовать его функцию parse().
>>> xml = objectify.parse('books.xml')
>>> xml
<lxml.etree._ElementTree object at 0x0000000009734E08>
Результатом будет объект tree, который является внутренней структурой данных модуля lxml.
Чтобы познакомиться с деталями этого типа, пройтись по его структуре или выбирать элемент за элементом, в первую очередь нужно определить корень. Для этого используется функция getroot().
>>> root = xml.getroot()
Теперь можно получать доступ к разным узлам, каждый из которых соответствует тегам в оригинальном XML-файле. Их имена также будут соответствовать. Для выбора узлов нужно просто писать отдельные теги через точки, используя иерархию дерева.
>>> root.Book.Author
'Ross, Mark'
>>> root.Book.PublishDate
'2014-22-01'
В такой способ доступ к узлам можно получить индивидуально. А getchildren() обеспечит доступ ко всем дочерним элементами.
>>> root.getchildren()
[<Element Book at 0x9c66688>, <Element Book at 0x9c66e08>]
При использовании атрибута tag вы получаете название соответствующего тега из родительского узла.
>>> [child.tag for child in root.Book.getchildren()]
['Author', 'Title', 'Genre', 'Price', 'PublishDate']
А text покажет значения в этих тегах.
>>> [child.text for child in root.Book.getchildren()]
['Ross, Mark', 'XML Cookbook', 'Computer', '23.56', '2014-22-01']
Но вне зависимости от возможности двигаться по структуре lxml.etree, ее нужно конвертировать в Dataframe. Воспользуйтесь следующей функцией, которая анализирует содержимое eTree и заполняет им Dataframe строчка за строчкой.
>>> def etree2df(root):
... column_names = []
... for i in range(0, len(root.getchildren()[0].getchildren())):
... column_names.append(root.getchildren()[0].getchildren()[i].tag)
... xmlframe = pd.DataFrame(columns=column_names)
... for j in range(0, len(root.getchildren())):
... obj = root.getchildren()[j].getchildren()
... texts = []
... for k in range(0, len(column_names)):
... texts.append(obj[k].text)
... row = dict(zip(column_names, texts))
... row_s = pd.Series(row)
... row_s.name = j
... xmlframe = xmlframe.append(row_s)
... return xmlframe
>>> etree2df(root)
| Author | Title | Genre | Price | PublishDate | |
|---|---|---|---|---|---|
| 0 | Ross, Mark | XML Cookbook | Computer | 23.56 | 2014-01-22 |
| 1 | Bracket, Barbara | XML for Dummies | Computer | 35.95 | 2014-12-16 |
Иерархическое индексирование — это важная особенность pandas, поскольку она позволяет иметь несколько уровней индексов в одной оси. С ее помощью можно работать с данными в большом количестве измерений, по-прежнему используя для этого структуру данных из двух измерений.
Начнем с простого примера, создав Series с двумя массивами индексов — структуру с двумя уровнями.
>>> mser = pd.Series(np.random.rand(8),
... index=[['white','white','white','blue','blue','red','red',
'red'],
... ['up','down','right','up','down','up','down','left']])
>>> mser
white up 0.661039
down 0.512268
right 0.639885
blue up 0.081480
down 0.408367
red up 0.465264
down 0.374153
left 0.325975
dtype: float64
>>> mser.index
MultiIndex(levels=[['blue', 'red', 'white'], ['down', 'left', 'right', 'up']],
labels=[[2, 2, 2, 0, 0, 1, 1, 1], [3, 0, 2, 3, 0, 3, 0, 1]])
За счет спецификации иерархического индексирования, выбор подмножеств значений в таком случае заметно упрощен. Можно выбрать значения для определенного значения первого индекса стандартным способом:
>>> mser['white']
up 0.661039
down 0.512268
right 0.639885
dtype: float64
Или же значения для конкретного значения во втором индекса — таким:
>>> mser[:,'up']
white 0.661039
blue 0.081480
red 0.465264
dtype: float64
Если необходимо конкретное значение, просто указываются оба индекса.
>>> mser['white','up']
0.66103875558038194
Иерархическое индексирование играет важную роль в изменении формы данных и групповых операциях, таких как сводные таблицы. Например, данные могут быть перестроены и использованы в объекте Dataframe с помощью функции unstack(). Она конвертирует Series с иерархическими индексами в простой Dataframe, где второй набор индексов превращается в новые колонки.
>>> mser.unstack()
| down | left | right | up | |
|---|---|---|---|---|
| blue | 0.408367 | NaN | NaN | 0.081480 |
| red | 0.374153 | 0.325975 | NaN | 0.465264 |
| white | 0.512268 | NaN | 0.639885 | 0.661039 |
Если необходимо выполнить обратную операцию — превратить Dataframe в Series, — используется функция stack().
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame.stack()
red ball 0
pen 1
pencil 2
paper 3
blue ball 4
pen 5
pencil 6
paper 7
yellow ball 8
pen 9
pencil 10
paper 11
white ball 12
pen 13
pencil 14
paper 15
dtype: int32
В Dataframe можно определить иерархическое индексирование для строк и колонок. Для этого необходимо определить массив массивов для параметров index и columns.
>>> mframe = pd.DataFrame(np.random.randn(16).reshape(4,4),
... index=[['white','white','red','red'], ['up','down','up','down']],
... columns=[['pen','pen','paper','paper'],[1,2,1,2]])
>>> mframe
| pen | paper | ||||
|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | ||
| white | up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | 0.580848 | 1.124744 | 0.741454 | -0.035455 | |
| red | up | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
Изменение порядка и сортировка уровней
Иногда потребуется поменять порядок уровней на оси или отсортировать значения на определенном уровне.
Функция swaplevel() принимает в качестве аргументов названия уровней, которые необходимо поменять относительно друг друга и возвращает новый объект с соответствующими изменениями, оставляя данные в том же состоянии.
>>> mframe.columns.names = ['objects','id']
>>> mframe.index.names = ['colors','status']
>>> mframe
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| colors | status | ||||
| white | up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | 0.580848 | 1.124744 | 0.741454 | -0.035455 | |
| red | up | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
>>> mframe.swaplevel('colors','status')
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| status | colors | ||||
| up | white | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
| down | white | 0.580848 | 1.124744 | 0.741454 | -0.035455 |
| up | red | -1.721348 | 0.989703 | -1.454304 | -0.249718 |
| down | red | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
А функция sort_index() сортирует данные для конкретного уровня, указанного в параметрах.
>>> mframe.sort_index(level='colors')
| objects | pen | paper | |||
|---|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 | |
| colors | status | ||||
| red | down | -0.113246 | -0.441528 | -0.105028 | 0.285786 |
| up | -1.721348 | 0.989703 | -1.454304 | -0.249718 | |
| white | down | 0.580848 | 1.124744 | 0.741454 | -0.035455 |
| up | 1.562883 | 0.919727 | -0.397509 | -0.314159 |
Общая статистика по уровню
У многих статистических методов для Dataframe есть параметр level, в котором нужно определить, для какого уровня нужно определить статистику.
Например, если нужна статистика для первого уровня, его нужно указать в параметрах.
>>> mframe.sum(level='colors')
| objects | pen | paper | ||
|---|---|---|---|---|
| id | 1 | 2 | 1 | 2 |
| colors | ||||
| white | 2.143731 | 2.044471 | 0.343945 | -0.349614 |
| red | -1.834594 | 0.548174 | -1.559332 | 0.036068 |
Если же она необходима для конкретного уровня колонки, например, id, тогда требуется задать параметр axis и указать значение 1.
>>> mframe.sum(level='id', axis=1)
| id | 1 | 2 | paper |
|---|---|---|---|
| colors | status | ||
| white | up | 1.165374 | 0.605568 |
| down | 1.322302 | 1.089289 | |
| red | up | -3.175653 | 0.739985 |
| down | -0.218274 | -0.155743 |
В предыдущих разделах вы видели, как легко могут образовываться недостающие данные. В структурах они определяются как значения NaN (Not a Value). Такой тип довольно распространен в анализе данных.
Но pandas спроектирован так, чтобы лучше с ними работать. Дальше вы узнаете, как взаимодействовать с NaN, чтобы избегать возможных проблем. Например, в библиотеке pandas вычисление описательной статистики неявно исключает все значения NaN.
Присваивание значения NaN
Если нужно специально присвоить значение NaN элементу структуры данных, для этого используется np.NaN (или np.nan) из библиотеки NumPy.
>>> ser = pd.Series([0,1,2,np.NaN,9],
... index=['red','blue','yellow','white','green'])
>>> ser
red 0.0
blue 1.0
yellow 2.0
white NaN
green 9.0
dtype: float64
>>> ser['white'] = None
>>> ser
red 0.0
blue 1.0
yellow 2.0
white NaN
green 9.0
dtype: float64
Фильтрование значений NaN
Есть несколько способов, как можно избавиться от значений NaN во время анализа данных. Это можно делать вручную, удаляя каждый элемент, но такая операция сложная и опасная, к тому же не гарантирует, что вы действительно избавились от всех таких значений. Здесь на помощь приходит функция dropna().
>>> ser.dropna()
red 0.0
blue 1.0
yellow 2.0
green 9.0
dtype: float64
Функцию фильтрации можно выполнить и прямо с помощью notnull() при выборе элементов.
>>> ser[ser.notnull()]
red 0.0
blue 1.0
yellow 2.0
green 9.0
dtype: float64
В случае с Dataframe это чуть сложнее. Если использовать функцию pandas dropna() на таком типе объекта, который содержит всего одно значение NaN в колонке или строке, то оно будет удалено.
>>> frame3 = pd.DataFrame([[6,np.nan,6],[np.nan,np.nan,np.nan],[2,np.nan,5]],
... index = ['blue','green','red'],
... columns = ['ball','mug','pen'])
>>> frame3
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| green | NaN | NaN | NaN |
| red | 2.0 | NaN | 5.0 |
>>> frame3.dropna()
Empty DataFrame
Columns: [ball, mug, pen]
Index: []
Таким образом чтобы избежать удаления целых строк или колонок нужно использовать параметр how, присвоив ему значение all. Это сообщит функции, чтобы она удаляла только строки или колонки, где все элементы равны NaN.
>>> frame3.dropna(how='all')
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | NaN | 6.0 |
| red | 2.0 | NaN | 5.0 |
Заполнение NaN
Вместо того чтобы отфильтровывать значения NaN в структурах данных, рискуя удалить вместе с ними важные элементы, можно заменять их на другие числа. Для этих целей подойдет fillna(). Она принимает один аргумент — значение, которым нужно заменить NaN.
>>> frame3.fillna(0)
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 0.0 | 0.0 | 0.0 |
| red | 2.0 | 0.0 | 5.0 |
Или же NaN можно заменить на разные значения в зависимости от колонки, указывая их и соответствующие значения.
>>> frame3.fillna({'ball':1,'mug':0,'pen':99})
| ball | mug | pen | |
|---|---|---|---|
| blue | 6.0 | 0.0 | 6.0 |
| green | 1.0 | 0.0 | 99.0 |
| red | 2.0 | 0.0 | 5.0 |
Функции для элементов
Библиотека Pandas построена на базе NumPy и расширяет возможности последней, используя их по отношению к новым структурам данных: Series и Dataframe. В их числе универсальные функции, называемые ufunc. Они применяются к элементам структуры данных.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Например, можно найти квадратный корень для каждого значения в Dataframe с помощью функции np.sqrt().
>>> np.sqrt(frame)
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0.000000 | 1.000000 | 1.414214 | 1.732051 |
| blue | 2.000000 | 2.236068 | 2.449490 | 2.645751 |
| yellow | 2.828427 | 3.000000 | 3.162278 | 3.316625 |
| white | 3.464102 | 3.605551 | 3.741657 | 3.872983 |
Функции для строк и колонок
Применение функций не ограничивается универсальными, но включает и те, что были определены пользователем. Важно отметить, что они работают с одномерными массивами, выдавая в качестве результата единое число. Например, можно определить лямбда-функцию, которая вычисляет диапазон значений элементов в массиве.
>>> f = lambda x: x.max() - x.min()
Эту же функцию можно определить и следующим образом:
>>> def f(x):
... return x.max() - x.min()
С помощью apply() новая функция применяется к Dataframe.
>>> frame.apply(f)
ball 12
pen 12
pencil 12
paper 12
dtype: int64
В этот раз результатом является одно значение для каждой колонки, но если нужно применить функцию к строкам, а на колонкам, нужно лишь поменять значение параметра axis и указать 1.
>>> frame.apply(f, axis=1)
red 3
blue 3
yellow 3
white 3
dtype: int64
Метод apply() не обязательно вернет скалярную величину. Он может вернуть и объект Series. Можно также включить и применить несколько функций одновременно. Это делается следующим образом:
>>> def f(x):
... return pd.Series([x.min(), x.max()], index=['min','max'])
После этого функция используется как и в предыдущем примере. Но теперь результатом будет объект Dataframe, а не Series, в котором столько строк, сколько значений функция возвращает.
>>> frame.apply(f)
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| min | 0 | 1 | 2 | 3 |
| max | 12 | 13 | 14 | 15 |
Статистические функции
Большая часть статистических функций массивов работает и с Dataframe, поэтому для них не нужно использовать apply(). Например, sum() и mean() могут посчитать сумму или среднее значение соответственно для элементов внутри объекта Dataframe.
>>> frame.sum()
ball 24
pen 28
pencil 32
paper 36
dtype: int64
>>> frame.mean()
ball 6.0
pen 7.0
pencil 8.0
paper 9.0
dtype: float64
Есть даже функция describe(), которая позволяет получить всю статистику за раз.
>>> frame.describe()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| count | 4.000000 | 4.000000 | 4.000000 | 4.000000 |
| mean | 6.000000 | 7.000000 | 8.000000 | 9.000000 |
| std | 5.163978 | 5.163978 | 5.163978 | 5.163978 |
| min | 0.000000 | 1.000000 | 2.000000 | 3.000000 |
| 25% | 3.000000 | 4.000000 | 5.000000 | 6.000000 |
| 50% | 6.000000 | 7.000000 | 8.000000 | 9.000000 |
| 75% | 9.000000 | 10.000000 | 11.000000 | 12.000000 |
| max | 12.000000 | 13.000000 | 14.000000 | 15.000000 |
Сортировка и ранжирование
Еще одна операция, использующая индексирование pandas, — сортировка. Сортировка данных нужна часто, поэтому важно иметь возможность выполнять ее легко. Библиотека pandas предоставляет функцию sort_index(), которая возвращает новый объект, идентичный стартовому, но с отсортированными элементами.
Сначала рассмотрим варианты, как можно сортировать элементы Series. Операция простая, ведь сортируется всего один список индексов.
>>> ser = pd.Series([5,0,3,8,4],
... index=['red','blue','yellow','white','green'])
>>> ser
red 5
blue 0
yellow 3
white 8
green 4
dtype: int64
>>> ser.sort_index()
blue 0
green 4
red 5
white 8
yellow 3
dtype: int64
В этом примере элементы были отсортированы по алфавиту на основе ярлыков (от A до Z). Это поведение по умолчанию, но достаточно сделать значением параметра ascending False и элементы объекта отсортируются иначе.
>>> ser.sort_index(ascending=False)
yellow 3
white 8
red 5
green 4
blue 0
dtype: int64
В случае с Dataframe можно выполнить сортировку независимо для каждой из осей. Если требуется отсортировать элементы по индексам, то нужно просто использовать sort_index() как обычно. Если же требуется сортировка по колонкам, то необходимо задать значение 1 для параметра axis.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame.sort_index()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| blue | 4 | 5 | 6 | 7 |
| red | 0 | 1 | 2 | 3 |
| white | 12 | 13 | 14 | 15 |
| yellow | 8 | 9 | 10 | 11 |
>>> frame.sort_index(axis=1)
| ball | paper | pen | pencil | |
|---|---|---|---|---|
| red | 0 | 3 | 1 | 2 |
| blue | 4 | 7 | 5 | 6 |
| yellow | 8 | 11 | 9 | 10 |
| white | 12 | 15 | 13 | 14 |
Но это лишь то, что касается сортировки по индексам. Но часто приходится сортировать объект по значениям его элементов. В таком случае сперва нужно определить объект: Series или Dataframe.
Для первого подойдет функция sort_values().
>>> ser.sort_values()
blue 0
yellow 3
green 4
red 5
white 8
dtype: int64
А для второго — та же функция sort_values(), но с параметром by, значением которого должна быть колонка, по которой требуется отсортировать объект.
>>> frame.sort_values(by='pen')
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Если сортировка основана на двух или больше колонках, то by можно присвоить массив с именами колонок.
>>> frame.sort_values(by=['pen','pencil'])
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Ранжирование тесно связано с операцией сортировки. Оно состоит из присваивания ранга (то есть, значения, начинающегося с 0 и постепенно увеличивающегося) к каждому элементу Series. Он присваивается элементам, начиная с самого младшего значения.
>>> ser.rank()
red 4.0
blue 1.0
yellow 2.0
white 5.0
green 3.0
dtype: float64
Ранг может быть присвоен и согласно порядку, в котором элементы содержатся в структуре (без операции сортировки). В таком случае нужно добавить параметр method со значением first.
>>> ser.rank(method='first')
red 4.0
blue 1.0
yellow 2.0
white 5.0
green 3.0
dtype: float64
По умолчанию даже ранжирование происходит в возрастающем порядке. Для обратного нужно задать значение False для параметра ascending.
>>> ser.rank(ascending=False)
red 2.0
blue 5.0
yellow 4.0
white 1.0
green 3.0
dtype: float64
Корреляция и ковариантность
Два важных типа статистических вычислений — корреляция и вариантность. В pandas они представлены функциями corr() и cov(). Для их работы нужны два объекта Series.
>>> seq2 = pd.Series([3,4,3,4,5,4,3,2],['2006','2007','2008',
'2009','2010','2011','2012','2013'])
>>> seq = pd.Series([1,2,3,4,4,3,2,1],['2006','2007','2008',
'2009','2010','2011','2012','2013'])
>>> seq.corr(seq2)
0.7745966692414835
>>> seq.cov(seq2)
0.8571428571428571
Их же можно применить и по отношению к одному Dataframe. В таком случае функции вернут соответствующие матрицы в виде двух новых объектов Dataframe.
>>> frame2 = pd.DataFrame([[1,4,3,6],[4,5,6,1],[3,3,1,5],[4,1,6,4]],
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame2
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 1 | 4 | 3 | 6 |
| blue | 4 | 5 | 6 | 1 |
| yellow | 3 | 3 | 1 | 5 |
| white | 4 | 1 | 6 | 4 |
>>> frame2.corr()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| ball | 1.000000 | -0.276026 | 0.577350 | -0.763763 |
| pen | -0.276026 | 1.000000 | -0.079682 | -0.361403 |
| pencil | 0.577350 | -0.079682 | 1.000000 | -0.692935 |
| paper | -0.763763 | -0.361403 | -0.692935 | 1.000000 |
>>> frame2.cov()
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| ball | 2.000000 | -0.666667 | 2.000000 | -2.333333 |
| pen | -0.666667 | 2.916667 | -0.333333 | -1.333333 |
| pencil | 2.000000 | -0.333333 | 6.000000 | -3.666667 |
| paper | -2.333333 | -1.333333 | -3.666667 | 4.666667 |
С помощью метода corwith() можно вычислить попарные корреляции между колонками и строками объекта Dataframe и Series или другим DataFrame().
>>> ser = pd.Series([0,1,2,3,9],
... index=['red','blue','yellow','white','green'])
>>> ser
red 0
blue 1
yellow 2
white 3
green 9
dtype: int64
>>> frame2.corrwith(ser)
ball 0.730297
pen -0.831522
pencil 0.210819
paper -0.119523
dtype: float64
>>> frame2.corrwith(frame)
ball 0.730297
pen -0.831522
pencil 0.210819
paper -0.119523
dtype: float64
В отличие от других структур данных в Python pandas не только пользуется преимуществами высокой производительности массивов NumPy, но и добавляет в них индексы.
Этот выбор оказался крайне удачным. Несмотря на и без того отличную гибкость, которая обеспечивается существующими динамическими структурами, внутренние ссылки на их элементы (а именно ими и являются метки) позволяют разработчикам еще сильнее упрощать операции.
В этом разделе речь пойдет о некоторых базовых функциях, использующих этот механизм:
- Переиндексирование
- Удаление
- Выравнивание
Переиндексирование df.reindex()
Вы уже знаете, что после объявления в структуре данных объект Index нельзя менять. Но с помощью операции переиндексирования это можно решить.
Существует даже возможность получить новую структуру из уже существующей, где правила индексирования заданы заново.
>>> ser = pd.Series([2,5,7,4], index=['one','two','three','four']) >>> ser
one 2
two 5
three 7
four 4
dtype: int64
Для того чтобы провести переиндексирование объекта Series библиотека pandas предоставляет функцию reindex(). Она создает новый объект Series со значениями из другого Series, которые теперь переставлены в соответствии с новой последовательностью меток.
При операции переиндексирования можно поменять порядок индексов, удалить некоторые из них или добавить новые. Если метка новая, pandas добавит NaN на место соответствующего значения.
>>> ser.reindex(['three','four','five','one'])
three 7.0
four 4.0
five NaN
one 2.0
dtype: float64
Как видно по выводу, порядок меток можно поменять полностью. Значение, которое раньше соответствовало метке two, удалено, зато есть новое с меткой five.
Тем не менее в случае, например, с большим Dataframe, не совсем удобно будет указывать новый список меток. Вместо этого можно использовать метод, который заполняет или интерполирует значения автоматически.
Для лучшего понимания механизма работы этого режима автоматического индексирования создадим следующий объект Series.
>>> ser3 = pd.Series([1,5,6,3],index=[0,3,5,6])
>>> ser3
0 1
3 5
5 6
6 3
dtype: int64
В этом примере видно, что колонка с индексами — это не идеальная последовательность чисел. Здесь пропущены цифры 1, 2 и 4. В таком случае нужно выполнить операцию интерполяции и получить полную последовательность чисел. Для этого можно использовать reindex с параметром method равным ffill. Более того, необходимо задать диапазон значений для индексов. Тут можно использовать range(6) в качестве аргумента.
>>> ser3.reindex(range(6),method='ffill')
0 1
1 1
2 1
3 5
4 5
5 6
dtype: int64
Теперь в объекте есть элементы, которых не было в оригинальном объекте Series. Операция интерполяции сделала так, что наименьшие индексы стали значениями в объекте. Так, индексы 1 и 2 имеют значение 1, принадлежащее индексу 0.
Если нужно присваивать значения индексов при интерполяции, необходимо использовать метод bfill.
>>> ser3.reindex(range(6),method='bfill')
0 1
1 5
2 5
3 5
4 6
5 6
dtype: int64
В этом случае значения индексов 1 и 2 равны 5, которое принадлежит индексу 3.
Операция отлично работает не только с Series, но и с Dataframe. Переиндексирование можно проводить не только на индексах (строках), но также и на колонках или на обоих. Как уже отмечалось, добавлять новые индексы и колонки возможно, но поскольку в оригинальной структуре есть недостающие значения, на их месте будет NaN.
>>> frame.reindex(range(5), method='ffill',columns=['colors','price','new', 'object'])
| item | colors | price | new | object |
|---|---|---|---|---|
| id | ||||
| 0 | blue | 1.2 | blue | ball |
| 1 | green | 1.0 | green | pen |
| 2 | yellow | 3.3 | yellow | pencil |
| 3 | red | 0.9 | red | paper |
| 4 | white | 1.7 | white | mug |
Удаление
Еще одна операция, связанная с объектами Index — удаление. Удалить строку или колонку не составит труда, потому что метки используются для обозначения индексов и названий колонок.
В этом случае pandas предоставляет специальную функцию для этой операции, которая называется drop(). Метод возвращает новый объект без элементов, которые необходимо было удалить.
Например, возьмем в качестве примера случай, где из объекта нужно удалить один элемент. Для этого определим базовый объект Series из четырех элементов с 4 отдельными метками.
>>> ser = pd.Series(np.arange(4.), index=['red','blue','yellow','white'])
>>> ser
red 0.0
blue 1.0
yellow 2.0
white 3.0
dtype: float64
Теперь, предположим, необходимо удалить объект с меткой yellow. Для этого нужно всего лишь указать ее в качестве аргумента функции drop().
>>> ser.drop('yellow')
red 0.0
blue 1.0
white 3.0
dtype: float64
Для удаления большего количества элементов, передайте массив с соответствующими индексами.
>>> ser.drop(['blue','white'])
red 0.0
yellow 2.0
dtype: float64
Если речь идет об объекте Dataframe, значения могут быть удалены с помощью ссылок на метки обеих осей. Возьмем в качестве примера следующий объект.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball', 'pen', 'pencil', 'paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
Для удаления строк просто передайте индексы строк.
>>> frame.drop(['blue','yellow'])
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| white | 12 | 13 | 14 | 15 |
Для удаления колонок необходимо указывать индексы колонок, а также ось, с которой требуется удалить элементы. Для этого используется параметр axis. Чтобы сослаться на название колонки, нужно написать axis=1.
>>> frame.drop(['pen','pencil'],axis=1)
| ball | paper | |
|---|---|---|
| red | 0 | 3 |
| blue | 4 | 7 |
| yellow | 8 | 11 |
| white | 12 | 15 |
Арифметика и выравнивание данных
Наверное, самая важная особенность индексов в этой структуре данных — тот факт, что pandas может выравнивать индексы двух разных структур. Это особенно важно при выполнении арифметических операций на их значениях. В этом случае индексы могут быть не только в разном порядке, но и присутствовать лишь в одной из двух структур.
В качестве примера можно взять два объекта Series с разными метками.
>>> s1 = pd.Series([3,2,5,1],['white','yellow','green','blue'])
>>> s2 = pd.Series([1,4,7,2,1],['white','yellow','black','blue','brown'])
Теперь воспользуемся базовой операцией сложения. Как видно по примеру, некоторые метки есть в обоих структурах, а остальные — только в одной. Если они есть в обоих случаях, их значения складываются, а если только в одном — то значением будет NaN.
>>> s1 + s2
black NaN
blue 3.0
brown NaN
green NaN
white 4.0
yellow 6.0
dtype: float64
При использовании Dataframe выравнивание работает по тому же принципу, но проводится и для рядов, и для колонок.
>>> frame1 = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red','blue','yellow','white'],
... columns=['ball','pen','pencil','paper'])
>>> frame2 = pd.DataFrame(np.arange(12).reshape((4,3)),
... index=['blue','green','white','yellow'],
... columns=['mug','pen','ball'])
>>> frame1
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> frame2
| mug | pen | ball | |
|---|---|---|---|
| blue | 0 | 1 | 2 |
| green | 3 | 4 | 5 |
| white | 6 | 7 | 8 |
| yellow | 9 | 10 | 11 |
>>> frame1 + frame2
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Ядром pandas являются две структуры данных, в которых происходят все операции:
- Series
- Dataframes
Series — это структура, используемая для работы с последовательностью одномерных данных, а Dataframe — более сложная и подходит для нескольких измерений.
Пусть они и не являются универсальными для решения всех проблем, предоставляют отличный инструмент для большинства приложений. При этом их легко использовать, а множество более сложных структур можно упросить до одной из этих двух.
Однако особенности этих структур основаны на одной черте — интеграции в их структуру объектов index и labels (метки). С их помощью структурами становится очень легко манипулировать.
Series (серии)
Series — это объект библиотеки pandas, спроектированный для представления одномерных структур данных, похожих на массивы, но с дополнительными возможностями. Его структура проста, ведь он состоит из двух связанных между собой массивов. Основной содержит данные (данные любого типа NumPy), а в дополнительном, index, хранятся метки.

Создание объекта Series
Для создания объекта Series с предыдущего изображения необходимо вызвать конструктор Series() и передать в качестве аргумента массив, содержащий значения, которые необходимо включить.
>>> s = pd.Series([12,-4,7,9])
>>> s
0 12
1 -4
2 7
3 9
dtype: int64
Как можно увидеть по выводу, слева отображаются значения индексов, а справа — сами значения (данные).
Если не определить индекс при объявлении объекта, метки будут соответствовать индексам (положению в массиве) элементов объекта Series.
Однако лучше создавать Series, используя метки с неким смыслом, чтобы в будущем отделять и идентифицировать данные вне зависимости от того, в каком порядке они хранятся.
В таком случае необходимо будет при вызове конструктора включить параметр index и присвоить ему массив строк с метками.
>>> s = pd.Series([12,-4,7,9], index=['a','b','c','d'])
>>> s
a 12
b -4
c 7
d 9
dtype: int64
Если необходимо увидеть оба массива, из которых состоит структура, можно вызвать два атрибута: index и values.
>>> s.values
array([12, -4, 7, 9], dtype=int64)
>>> s.index
Index(['a', 'b', 'c', 'd'], dtype='object')
Выбор элементов по индексу или метке
Выбирать отдельные элементы можно по принципу обычных массивов numpy, используя для этого индекс.
>>> s[2]
7
Или же можно выбрать метку, соответствующую положению индекса.
>>> s['b']
-4
Таким же образом можно выбрать несколько элементов массива numpy с помощью следующей команды:
>>> s[0:2]
a 12
b -4
dtype: int64
В этом случае можно использовать соответствующие метки, но указать их список в массиве.
>>> s[['b','c']]
b -4
c 7
dtype: int64
Присваивание значений элементам
Понимая как выбирать отдельные элементы, важно знать и то, как присваивать им новые значения. Можно делать это по индексу или по метке.
>>> s[1] = 0
>>> s
a 12
b 0
c 7
d 9
dtype: int64
>>> s['b'] = 1
>>> s
a 12
b 1
c 7
d 9
dtype: int64
Создание Series из массивов NumPy
Новый объект Series можно создать из массивов NumPy и уже существующих Series.
>>> arr = np.array([1,2,3,4])
>>> s3 = pd.Series(arr)
>>> s3
0 1
1 2
2 3
3 4
dtype: int32
>>> s4 = pd.Series(s)
>>> s4
a 12
b 1
c 7
d 9
dtype: int64
Важно запомнить, что значения в массиве NumPy или оригинальном объекте Series не копируются, а передаются по ссылке. Это значит, что элементы объекта вставляются динамически в новый Series. Если меняется оригинальный объект, то меняются и его значения в новом.
>>> s3
0 1
1 2
2 3
3 4
dtype: int32
>>> arr[2] = -2
>>> s3
0 1
1 2
2 -2
3 4
dtype: int32
На этом примере можно увидеть, что при изменении третьего элемента массива arr, меняется соответствующий элемент и в s3.
Фильтрация значений
Благодаря тому что основной библиотекой в pandas является NumPy, многие операции, применяемые к массивам NumPy, могут быть использованы и в случае с Series. Одна из таких — фильтрация значений в структуре данных с помощью условий.
Например, если нужно узнать, какие элементы в Series больше 8, то можно написать следующее:
>>> s[s > 8]
a 12
d 9
dtype: int64
Операции и математические функции
Другие операции, такие как операторы (+, -, * и /), а также математические функции, работающие с массивами NumPy, могут использоваться и для Series.
Для операторов можно написать простое арифметическое уравнение.
>>> s / 2
a 6.0
b 0.5
c 3.5
d 4.5
dtype: float64
Но в случае с математическими функциями NumPy необходимо указать функцию через np, а Series передать в качестве аргумента.
>>> np.log(s)
a 2.484907
b 0.000000
c 1.945910
d 2.197225
dtype: float64
Количество значений
В Series часто встречаются повторения значений. Поэтому важно иметь информацию, которая бы указывала на то, есть ли дубликаты или конкретное значение в объекте.
Так, можно объявить Series, в котором будут повторяющиеся значения.
>>> serd = pd.Series([1,0,2,1,2,3], index=['white','white','blue','green',' green','yellow'])
>>> serd
white 1
white 0
blue 2
green 1
green 2
yellow 3
dtype: int64
Чтобы узнать обо всех значениях в Series, не включая дубли, можно использовать функцию unique(). Возвращаемое значение — массив с уникальными значениями, необязательно в том же порядке.
>>> serd.unique()
array([1, 0, 2, 3], dtype=int64)
На unique() похожа функция value_counts(), которая возвращает не только уникальное значение, но и показывает, как часто элементы встречаются в Series.
>>> serd.value_counts()
2 2
1 2
3 1
0 1
dtype: int64
Наконец, isin() показывает, есть ли элементы на основе списка значений. Она возвращает булевые значения, которые очень полезны при фильтрации данных в Series или в колонке Dataframe.
>>> serd.isin([0,3])
white False
white True
blue False
green False
green False
yellow True
dtype: bool
>>> serd[serd.isin([0,3])]
white 0
yellow 3
dtype: int64
Значения NaN
В предыдущем примере мы попробовали получить логарифм отрицательного числа и результатом стало значение NaN. Это значение (Not a Number) используется в структурах данных pandas для обозначения наличия пустого поля или чего-то, что невозможно обозначить в числовой форме.
Как правило, NaN — это проблема, для которой нужно найти определенное решение, особенно при работе с анализом данных. Эти данные часто появляются при извлечении информации из непроверенных источников или когда в самом источнике недостает данных. Также значения NaN могут генерироваться в специальных случаях, например, при вычислении логарифмов для отрицательных значений, в случае исключений при вычислениях или при использовании функций. Есть разные стратегии работы со значениями NaN.
Несмотря на свою «проблемность» pandas позволяет явно определять NaN и добавлять это значение в структуры, например, в Series. Для этого внутри массива достаточно ввести np.NaN в том месте, где требуется определить недостающее значение.
>>> s2 = pd.Series([5,-3,np.NaN,14])
>>> s2
0 5.0
1 -3.0
2 NaN
3 14.0
dtype: float64
Функции isnull() и notnull() очень полезны для определения индексов без значения.
>>> s2.isnull()
0 False
1 False
2 True
3 False
dtype: bool
>>> s2.notnull()
0 True
1 True
2 False
3 True
dtype: bool
Они возвращают два объекта Series с булевыми значениями, где True указывает на наличие значение, а NaN — на его отсутствие. Функция isnull() возвращает True для значений NaN в Series, а notnull() — True в тех местах, где значение не равно NaN. Эти функции часто используются в фильтрах для создания условий.
>>> s2[s2.notnull()]
0 5.0
1 -3.0
3 14.0
dtype: float64
s2[s2.isnull()]
2 NaN
dtype: float64
Series из словарей
Series можно воспринимать как объект dict (словарь). Эта схожесть может быть использована на этапе объявления объекта. Даже создавать Series можно на основе существующего dict.
>>> mydict = {'red': 2000, 'blue': 1000, 'yellow': 500,
'orange': 1000}
>>> myseries = pd.Series(mydict)
>>> myseries
blue 1000
orange 1000
red 2000
yellow 500
dtype: int64
На этом примере можно увидеть, что массив индексов заполнен ключами, а данные — соответствующими значениями. В таком случае соотношение будет установлено между ключами dict и метками массива индексов. Если есть несоответствие, pandas заменит его на NaN.
>>> colors = ['red','yellow','orange','blue','green']
>>> myseries = pd.Series(mydict, index=colors)
>>> myseries
red 2000.0
yellow 500.0
orange 1000.0
blue 1000.0
green NaN
dtype: float64
Операции с сериями
Вы уже видели, как выполнить арифметические операции на объектах Series и скалярных величинах. То же возможно и для двух объектов Series, но в таком случае в дело вступают и метки.
Одно из главных достоинств этого типа структур данных в том, что он может выравнивать данные, определяя соответствующие метки.
В следующем примере добавляются два объекта Series, у которых только некоторые метки совпадают.
>>> mydict2 = {'red':400,'yellow':1000,'black':700}
>>> myseries2 = pd.Series(mydict2)
>>> myseries + myseries2
black NaN
blue NaN
green NaN
orange NaN
red 2400.0
yellow 1500.0
dtype: float64
Новый объект получает только те элементы, где метки совпали. Все остальные тоже присутствуют, но со значением NaN.
DataFrame (датафрейм)
Dataframe — это табличная структура данных, напоминающая таблицы из Microsoft Excel. Ее главная задача — позволить использовать многомерные Series. Dataframe состоит из упорядоченной коллекции колонок, каждая из которых содержит значение разных типов (числовое, строковое, булевое и так далее).

В отличие от Series у которого есть массив индексов с метками, ассоциированных с каждым из элементов, Dataframe имеет сразу два таких. Первый ассоциирован со строками (рядами) и напоминает таковой из Series. Каждая метка ассоциирована со всеми значениями в ряду. Второй содержит метки для каждой из колонок.
Dataframe можно воспринимать как dict, состоящий из Series, где ключи — названия колонок, а значения — объекты Series, которые формируют колонки самого объекта Dataframe. Наконец, все элементы в каждом объекте Series связаны в соответствии с массивом меток, называемым index.
Создание Dataframe
Простейший способ создания Dataframe — передать объект dict в конструктор DataFrame(). Объект dict содержит ключ для каждой колонки, которую требуется определить, а также массив значений для них.
Если объект dict содержит больше данных, чем требуется, можно сделать выборку. Для этого в конструкторе Dataframe нужно определить последовательность колонок с помощью параметра column. Колонки будут созданы в заданном порядке вне зависимости от того, как они расположены в объекте dict.
>> data = {'color' : ['blue', 'green', 'yellow', 'red', 'white'],
'object' : ['ball', 'pen', 'pencil', 'paper', 'mug'],
'price' : [1.2, 1.0, 0.6, 0.9, 1.7]}
>>> frame = pd.DataFrame(data)
>>> frame
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Даже для объектов Dataframe если метки явно не заданы в массиве index, pandas автоматически присваивает числовую последовательность, начиная с нуля. Если же индексам Dataframe нужно присвоить метки, необходимо использовать параметр index и присвоить ему массив с метками.
>>> frame2 = pd.DataFrame(data, columns=['object', 'price'])
>>> frame2
| object | price | |
|---|---|---|
| 0 | ball | 1.2 |
| 1 | pen | 1.0 |
| 2 | pencil | 0.6 |
| 3 | paper | 0.9 |
| 4 | mug | 1.7 |
Теперь, зная о параметрах index и columns, проще использовать другой способ определения Dataframe. Вместо использования объекта dict можно определить три аргумента в конструкторе в следующем порядке: матрицу данных, массив значений для параметра index и массив с названиями колонок для параметра columns.
В большинстве случаев простейший способ создать матрицу значений — использовать np.arrange(16).reshape((4,4)). Это формирует матрицу размером 4х4 из чисел от 0 до 15.
>>> frame3 = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball', 'pen', 'pencil', 'paper'])
>>> frame3
Выбор элементов
Если нужно узнать названия всех колонок Dataframe, можно вызвать атрибут columns для экземпляра объекта.
>>> frame.columns
Index(['color', 'object', 'price'], dtype='object')
То же можно проделать и для получения списка индексов.
>>> frame.index
RangeIndex(start=0, stop=5, step=1)
Весь же набор данных можно получить с помощью атрибута values.
>>> frame.values
array([['blue', 'ball', 1.2],
['green', 'pen', 1.0],
['yellow', 'pencil', 0.6],
['red', 'paper', 0.9],
['white', 'mug', 1.7]], dtype=object)
Указав в квадратных скобках название колонки, можно получить значений в ней.
>>> frame['price']
0 1.2
1 1.0
2 0.6
3 0.9
4 1.7
Name: price, dtype: float64
Возвращаемое значение — объект Series. Название колонки можно использовать и в качестве атрибута.
>>> frame.price
0 1.2
1 1.0
2 0.6
3 0.9
4 1.7
Name: price, dtype: float64
Для строк внутри Dataframe используется атрибут loc со значением индекса нужной строки.
>>> frame.loc[2]
color yellow
object pencil
price 0.6
Name: 2, dtype: object
Возвращаемый объект — это снова Series, где названия колонок — это уже метки массива индексов, а значения — данные Series.
Для выбора нескольких строк можно указать массив с их последовательностью.
>>> frame.loc[[2,4]]
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Если необходимо извлечь часть Dataframe с конкретными строками, для этого можно использовать номера индексов. Она выведет данные из соответствующей строки и названия колонок.
>>> frame[0:1]
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Возвращаемое значение — объект Dataframe с одной строкой. Если нужно больше одной строки, необходимо просто указать диапазон.
>>> frame[1:3]
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
Наконец, если необходимо получить одно значение из объекта, сперва нужно указать название колонки, а потом — индекс или метку строки.
>>> frame['object'][3]
'paper'
Присваивание и замена значений
Разобравшись с логикой получения доступа к разным элементам Dataframe, можно следовать ей же для добавления новых или изменения уже существующих значений.
Например, в структуре Dataframe массив индексов определен атрибутом index, а строка с названиями колонок — columns. Можно присвоить метку с помощью атрибута name для этих двух подструктур, чтобы идентифицировать их.
>>> frame.index.name = 'id'
>>> frame.columns.name = 'item'
>>> frame
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Одна из главных особенностей структур данных pandas — их гибкость. Можно вмешаться на любом уровне для изменения внутренней структуры данных. Например, добавление новой колонки — крайне распространенная операция.
Ее можно выполнить, присвоив значение экземпляру Dataframe и определив новое имя колонки.
>>> frame['new'] = 12
>>> frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 12 |
| 1 | green | pen | 1.0 | 12 |
| 2 | yellow | pencil | 0.6 | 12 |
| 3 | red | paper | 0.9 | 12 |
| 4 | white | mug | 1.7 | 12 |
Здесь видно, что появилась новая колонка new со значениями 12 для каждого элемента.
Для обновления значений можно использовать массив.
frame['new'] = [3.0, 1.3, 2.2, 0.8, 1.1]
frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 3.0 |
| 1 | green | pen | 1.0 | 1.3 |
| 2 | yellow | pencil | 0.6 | 2.2 |
| 3 | red | paper | 0.9 | 0.8 |
| 4 | white | mug | 1.7 | 1.1 |
Тот же подход используется для обновления целой колонки. Например, можно применить функцию np.arrange() для обновления значений колонки с помощью заранее заданной последовательности.
Колонки Dataframe также могут быть созданы с помощью присваивания объекта Series одной из них, например, определив объект Series, содержащий набор увеличивающихся значений с помощью np.arrange().
>>> ser = pd.Series(np.arange(5))
>>> ser
0 0
1 1
2 2
3 3
4 4
dtype: int32
frame['new'] = ser
frame
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 0 |
| 1 | green | pen | 1.0 | 1 |
| 2 | yellow | pencil | 0.6 | 2 |
| 3 | red | paper | 0.9 | 3 |
| 4 | white | mug | 1.7 | 4 |
Наконец, для изменения одного значения нужно лишь выбрать элемент и присвоить ему новое значение.
>>> frame['price'][2] = 3.3
Вхождение значений
Функция isin() используется с объектами Series для определения вхождения значений в колонку. Она же подходит и для объектов Dataframe.
>>> frame.isin([1.0,'pen'])
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | False | False | False | False |
| 1 | False | True | True | True |
| 2 | False | False | False | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
Возвращается Dataframe с булевыми значениями, где True указывает на те значения, где членство подтверждено. Если передать это значение в виде условия, тогда вернется Dataframe, где будут только значения, удовлетворяющие условию.
>>> frame[frame.isin([1.0,'pen'])]
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | pen | 1.0 | 1.0 |
| 2 | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
Удаление колонки
Для удаления целой колонки и всего ее содержимого используется команда del.
>>> del frame['new']
>>> frame
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 3.3 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Фильтрация
Даже для Dataframe можно применять фильтры, используя определенные условия. Например, вам нужно получить все значения меньше определенного числа (допустим, 1,2).
>>> frame[frame < 1.2]
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | NaN |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | NaN |
| 3 | red | paper | 0.9 |
| 4 | white | mug | NaN |
Результатом будет Dataframe со значениями меньше 1,2 на своих местах. На месте остальных будет NaN.
Dataframe из вложенного словаря
В Python часто используется вложенный dict:
>>> nestdict = {'red': { 2012: 22, 2013: 33},
... 'white': { 2011: 13, 2012: 22, 2013: 16},
... 'blue': { 2011: 17, 2012: 27, 2013: 18}}
Эта структура данных, будучи переданной в качестве аргумента в DataFrame(), интерпретируется pandas так, что внешние ключи становятся названиями колонок, а внутренние — метками индексов.
При интерпретации вложенный структуры возможно такое, что не все поля будут совпадать. pandas компенсирует это несоответствие, добавляя NaN на место недостающих значений.
>>> nestdict = {'red': { 2012: 22, 2013: 33},
... 'white': { 2011: 13, 2012: 22, 2013: 16},
... 'blue': { 2011: 17, 2012: 27, 2013: 18}}
>>> frame2 = pd.DataFrame(nestdict)
>>> frame2
| blue | red | white | |
|---|---|---|---|
| 2011 | 17 | NaN | 13 |
| 2012 | 27 | 22.0 | 22 |
| 2013 | 18 | 33.0 | 16 |
Транспонирование Dataframe
При работе с табличным структурами данных иногда появляется необходимость выполнить операцию перестановки (сделать так, чтобы колонки стали рядами и наоборот). pandas позволяет добиться этого очень просто. Достаточно добавить атрибут T.
>>> frame2.T
| 2011 | 2012 | 2013 | |
|---|---|---|---|
| blue | 17.0 | 27.0 | 18.0 |
| red | NaN | 22.0 | 33.0 |
| white | 13.0 | 22.0 | 16.0 |
Объекты Index
Зная, что такое Series и Dataframes, и понимая как они устроены, проще разобраться со всеми их достоинствами. Главная особенность этих структур — наличие объекта Index, который в них интегрирован.
Объекты Index являются метками осей и содержат другие метаданные. Вы уже знаете, как массив с метками превращается в объект Index, и что для него нужно определить параметр index в конструкторе.
>>> ser = pd.Series([5,0,3,8,4], index=['red','blue','yellow','white','green'])
>>> ser.index
Index(['red', 'blue', 'yellow', 'white', 'green'], dtype='object')
В отличие от других элементов в структурах данных pandas (Series и Dataframe) объекты index — неизменяемые. Это обеспечивает безопасность, когда нужно передавать данные между разными структурами.
У каждого объекта Index есть методы и свойства, которые нужны, чтобы узнавать значения.
Методы Index
Есть методы для получения информации об индексах из структуры данных. Например, idmin() и idmax() — структуры, возвращающие индексы с самым маленьким и большим значениями.
>>> ser.idxmin()
'blue'
>>> ser.idxmax()
'white'
Индекс с повторяющимися метками
Пока что были только те случаи, когда у индексов одной структуры лишь одна, уникальная метка. Для большинства функций это обязательное условие, но не для структур данных pandas.
Определим, например, Series с повторяющимися метками.
>>> serd = pd.Series(range(6), index=['white','white','blue','green', 'green','yellow'])
>>> serd
white 0
white 1
blue 2
green 3
green 4
yellow 5
dtype: int64
Если метке соответствует несколько значений, то она вернет не один элемент, а объект Series.
>>> serd['white']
white 0
white 1
dtype: int64
То же применимо и к Dataframe. При повторяющихся индексах он возвращает Dataframe.
В случае с маленькими структурами легко определять любые повторяющиеся индексы, но если структура большая, то растет и сложность этой операции. Для этого в pandas у объектов Index есть атрибут is_unique. Он сообщает, есть ли индексы с повторяющимися метками в структуре (Series или Dataframe).
>>> serd.index.is_unique
False
>>> frame.index.is_unique
True
Операции между структурами данных
Теперь когда вы знакомы со структурами данных, Series и Dataframe, а также базовыми операциями для работы с ними, стоит рассмотреть операции, включающие две или более структур.
Гибкие арифметические методы
Уже рассмотренные операции можно выполнять с помощью гибких арифметических методов:
add()sub()div()mul()
Для их вызова нужно использовать другую спецификацию. Например, вместо того чтобы выполнять операцию для двух объектов Dataframe по примеру frame1 + frame2, потребуется следующий формат:
>>> frame1.add(frame2)
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Результат такой же, как при использовании оператора сложения +. Также стоит обратить внимание, что если названия индексов и колонок сильно отличаются, то результатом станет новый объект Dataframe, состоящий только из значений NaN.
Операции между Dataframe и Series
Pandas позволяет выполнять переносы между разными структурами, например, между Dataframe и Series. Определить две структуры можно следующим образом.
>>> frame = pd.DataFrame(np.arange(16).reshape((4,4)),
... index=['red', 'blue', 'yellow', 'white'],
... columns=['ball','pen','pencil','paper'])
>>> frame
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
>>> ser = pd.Series(np.arange(4), index=['ball','pen','pencil','paper'])
>>> ser
ball 0
pen 1
pencil 2
paper 3
dtype: int32
Они были специально созданы так, чтобы индексы в Series совпадали с названиями колонок в Dataframe. В таком случае можно выполнить прямую операцию.
>>> frame - ser
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 0 | 0 | 0 |
| blue | 4 | 4 | 4 | 4 |
| yellow | 8 | 8 | 8 | 8 |
| white | 12 | 12 | 12 | 12 |
По результату видно, что элементы Series были вычтены из соответствующих тому же индексу в колонках значений Dataframe.
Если индекс не представлен ни в одной из структур, то появится новая колонка с этим индексом и значениями NaN.
>>> ser['mug'] = 9
>>> ser
ball 0
pen 1
pencil 2
paper 3
mug 9
dtype: int64
>>> frame - ser
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| red | 0 | NaN | 0 | 0 | 0 |
| blue | 4 | NaN | 4 | 4 | 4 |
| yellow | 8 | NaN | 8 | 8 | 8 |
| white | 12 | NaN | 12 | 12 | 12 |
Библиотека pandas в Python — это идеальный инструмент для тех, кто занимается анализом данных, используя для этого язык программирования Python.
В этом материале речь сначала пойдет об основных аспектах библиотеки и о том, как установить ее в систему. Потом вы познакомитесь с двумя структурам данных: series и dataframes. Сможете поработать с базовым набором функций, предоставленных библиотекой pandas, для выполнения основных операций по обработке. Знакомство с ними — ключевой навык для специалиста в этой сфере. Поэтому так важно перечитать материал до тех, пока он не станет понятен на 100%.
А на примерах сможете разобраться с новыми концепциями, появившимися в библиотеке — индексацией структур данных. Научитесь правильно ее использовать для управления данными. В конце концов, разберетесь с тем, как расширить возможности индексации для работы с несколькими уровнями одновременно, используя для этого иерархическую индексацию.
Библиотека Python для анализа данных
Pandas — это библиотека Python с открытым исходным кодом для специализированного анализа данных. Сегодня все, кто использует Python для изучения статистических целей анализа и принятия решений, должны быть с ней знакомы.
Библиотека была спроектирована и разработана преимущественно Уэсом Маккини в 2008 году. В 2012 к нему присоединился коллега Чан Шэ. Вместе они создали одну из самых используемых библиотек в сообществе Python.
Pandas появилась из необходимости в простом инструменте для обработки, извлечения и управления данными.
Этот пакет Python спроектирован на основе библиотеки NumPy. Такой выбор обуславливает успех и быстрое распространение pandas. Он также пользуется всеми преимуществами NumPy и делает pandas совместимой с большинством другим модулей.
Еще одно важное решение — разработка специальных структур для анализа данных. Вместо того, чтобы использовать встроенные в Python или предоставляемые другими библиотеками структуры, были разработаны две новых.
Они спроектированы для работы с реляционными и классифицированными данными, что позволяет управлять данными способом, похожим на тот, что используется в реляционных базах SQL и таблицах Excel.
Дальше вы встретите примеры базовых операций для анализа данных, которые обычно используются на реляционных или таблицах Excel. Pandas предоставляет даже более расширенный набор функций и методов, позволяющих выполнять эти операции эффективнее.
Основная задача pandas — предоставить все строительные блоки для всех, кто погружается в мир анализа данных.
Установка pandas
Простейший способ установки библиотеки pandas — использование собранного решения, то есть установка через Anaconda или Enthought.
Установка в Anaconda
В Anaconda установка занимает пару минут. В первую очередь нужно проверить, не установлен ли уже pandas, и если да, то какая это версия. Для этого введите следующую команду в терминале:
conda list pandas
Если модуль уже установлен (например в Windows), вы получите приблизительно следующий результат:
# packages in environment at C:\Users\Fabio\Anaconda:
#
pandas 0.20.3 py36hce827b7_2
Если pandas не установлена, ее необходимо установить. Введите следующую команду:
conda install pandas
Anaconda тут же проверит все зависимости и установит дополнительные модули.
Solving environment: done
## Package Plan ##
Environment location: C:\Users\Fabio\Anaconda3
added / updated specs:
- pandas
The following new packages will be installed:
Pandas: 0.22.0-py36h6538335_0
Proceed ([y]/n)?
Press the y key on your keyboard to continue the installation.
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
Если требуется обновить пакет до более новой версии, используется эта интуитивная команда:
conda update pandas
Система проверит версию pandas и версию всех модулей, а затем предложит соответствующие обновления. Затем предложит перейти к обновлению.
Установка из PyPI
Pandas можно установить и с помощью PyPI, используя эту команду:
pip install pandas
Установка в Linux
Если вы работаете в дистрибутиве Linux и решили не использовать эти решения, то pandas можно установить как и любой другой пакет.
В Debian и Ubuntu используется команда:
sudo apt-get install python-pandas
А для OpenSuse и Fedora — эта:
zypper in python-pandas
Установка из источника
Если есть желание скомпилировать модуль pandas из исходного кода, тогда его можно найти на GitHub по ссылке https://github.com/pandas-dev/pandas:
git clone git://github.com/pydata/pandas.git
cd pandas
python setup.py install
Убедитесь, что Cython установлен. Больше об этом способе можно прочесть в документации: (http://pandas.pydata.org/pandas-docs/stable/install.html).
Репозиторий для Windows
Если вы работаете в Windows и предпочитаете управлять пакетами так, чтобы всегда была установлена последняя версия, то существует ресурс, где всегда можно загрузить модули для Windows: Christoph Gohlke’s Python Extension Packages for Windows (www.lfd.uci.edu/~gohlke/pythonlibs/). Каждый модуль поставляется в формате WHL для 32 и 64-битных систем. Для установки нужно использовать приложение pip:
pip install SomePackage-1.0.whl
Например, для установки pandas потребуется найти и загрузить следующий пакет:
pip install pandas-0.22.0-cp36-cp36m-win_amd64.whl
При выборе модуля важно выбрать нужную версию Python и архитектуру. Более того, если для NumPy пакеты не требуются, то у pandas есть зависимости. Их также необходимо установить. Порядок установки не имеет значения.
Недостаток такого подхода в том, что нужно устанавливать пакеты отдельно без менеджера, который бы помог подобрать нужные версии и зависимости между разными пакетами. Плюс же в том, что появляется возможность освоиться с модулями и получить последние версии вне зависимости от того, что выберет дистрибутив.
Проверка установки pandas
Библиотека pandas может запустить проверку после установки для верификации управляющих элементов (документация утверждает, что тест покрывает 97% всего кода).
Во-первых, нужно убедиться, что установлен модуль nose. Если он имеется, то тестирование проводится с помощью следующей команды:
nosetests pandas
Оно займет несколько минут и в конце покажет список проблем.
Модуль Nose
Этот модуль спроектирован для проверки кода Python во время этапов разработки проекта или модуля Python. Он расширяет возможности модуль
unittest. Nose используется для проверки кода и упрощает процесс.Здесь о нем можно почитать подробнее: _http://pythontesting.net/framework/nose/nose-introduction/.
Первые шаги с pandas
Лучший способ начать знакомство с pandas — открыть консоль Python и вводить команды одна за одной. Таким образом вы познакомитесь со всеми функциями и структурами данных.
Более того, данные и функции, определенные здесь, будут работать и в примерах будущих материалов. Однако в конце каждого примера вы вольны экспериментировать с ними.
Для начала откройте терминал Python и импортируйте библиотеку pandas. Стандартная практика для импорта модуля pandas следующая:
>>> import pandas as pd
>>> import numpy as np
Теперь, каждый раз встречая pd и np вы будете ссылаться на объект или метод, связанный с этими двумя библиотеками, хотя часто будет возникать желание импортировать модуль таким образом:
>>> from pandas import *
В таком случае ссылаться на функцию, объект или метод с помощью pd уже не нужно, а это считается не очень хорошей практикой в среде разработчиков Python.
Это небольшая аналитика, чтобы получить некоторое представление о хаосе, вызванном коронавирусом. Немного графики и статистики для общего представления.
Данные — Novel Corona Virus 2019 Dataset
Импортируем необходимые библиотеки.
import numpy as np # линейная алгебра
import pandas as pd # обработка данных, CSV afqk I/O (например pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context('paper')
import random
def random_colours(number_of_colors):
'''
Простая функция для генерации случайных цветов.
Входные данные:
number_of_colors - целочисленное значение, указывающее
количество цветов, которые будут сгенерированы.
Выход:
Цвет в следующем формате: ['#E86DA4'].
'''
colors = []
for i in range(number_of_colors):
colors.append("#"+''.join([random.choice('0123456789ABCDEF') for j in range(6)]))
return colors
Статистический анализ
data = pd.read_csv('/novel-corona-virus-2019-dataset/2019_nCoV_data.csv')
data.head()
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | Anhui | China | 1/22/2020 12:00 | 1.0 | 0.0 | 0.0 |
| 1 | 2 | Beijing | China | 1/22/2020 12:00 | 14.0 | 0.0 | 0.0 |
| 2 | 3 | Chongqing | China | 1/22/2020 12:00 | 6.0 | 0.0 | 0.0 |
| 3 | 4 | Fujian | China | 1/22/2020 12:00 | 1.0 | 0.0 | 0.0 |
| 4 | 5 | Gansu | China | 1/22/2020 12:00 | 0.0 | 0.0 | 0.0 |
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 497 entries, 0 to 496
Data columns (total 7 columns):
Sno 497 non-null int64
Province/State 393 non-null object
Country 497 non-null object
Last Update 497 non-null object
Confirmed 497 non-null float64
Deaths 497 non-null float64
Recovered 497 non-null float64
dtypes: float64(3), int64(1), object(3)
memory usage: 27.3+ KB
Растет метрик по числовым колонкам.
data.describe()
| Sno | Confirmed | Deaths | Recovered | |
|---|---|---|---|---|
| count | 434.000000 | 434.000000 | 434.000000 | 434.000000 |
| mean | 217.500000 | 80.762673 | 1.847926 | 1.525346 |
| std | 125.429263 | 424.706068 | 15.302792 | 9.038054 |
| min | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 109.250000 | 2.000000 | 0.000000 | 0.000000 |
| 50% | 217.500000 | 7.000000 | 0.000000 | 0.000000 |
| 75% | 325.750000 | 36.000000 | 0.000000 | 0.000000 |
| max | 434.000000 | 5806.000000 | 204.000000 | 116.000000 |
Растет метрик по не числовым колонкам.
data.describe(include="O")
| Province/State | Country | Last Update | |
|---|---|---|---|
| count | 393 | 497 | 497 |
| unique | 45 | 31 | 13 |
| top | Ningxia | Mainland China | 1/31/2020 19:00 |
| freq | 10 | 274 | 63 |
Преобразуем данные Last Update в datetime
data['Last Update'] = pd.to_datetime(data['Last Update'])
Добавляем колонки Day и Hour
data['Day'] = data['Last Update'].apply(lambda x:x.day)
data['Hour'] = data['Last Update'].apply(lambda x:x.hour)
Данные только за 30 день января.
data[data['Day'] == 30]
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 375 | 376 | Hubei | Mainland China | 2020-01-30 21:30:00 | 5806.0 | 204.0 | 116.0 | 30 | 21 |
| 376 | 377 | Zhejiang | Mainland China | 2020-01-30 21:30:00 | 537.0 | 0.0 | 9.0 | 30 | 21 |
| 377 | 378 | Guangdong | Mainland China | 2020-01-30 21:30:00 | 393.0 | 0.0 | 11.0 | 30 | 21 |
| 378 | 379 | Henan | Mainland China | 2020-01-30 21:30:00 | 352.0 | 2.0 | 3.0 | 30 | 21 |
| 379 | 380 | Hunan | Mainland China | 2020-01-30 21:30:00 | 332.0 | 0.0 | 2.0 | 30 | 21 |
| 380 | 381 | Jiangxi | Mainland China | 2020-01-30 21:30:00 | 240.0 | 0.0 | 7.0 | 30 | 21 |
| 381 | 382 | Anhui | Mainland China | 2020-01-30 21:30:00 | 237.0 | 0.0 | 3.0 | 30 | 21 |
| 382 | 383 | Chongqing | Mainland China | 2020-01-30 21:30:00 | 206.0 | 0.0 | 1.0 | 30 | 21 |
| 383 | 384 | Shandong | Mainland China | 2020-01-30 21:30:00 | 178.0 | 0.0 | 2.0 | 30 | 21 |
| 384 | 385 | Sichuan | Mainland China | 2020-01-30 21:30:00 | 177.0 | 1.0 | 1.0 | 30 | 21 |
| 385 | 386 | Jiangsu | Mainland China | 2020-01-30 21:30:00 | 168.0 | 0.0 | 2.0 | 30 | 21 |
| 386 | 387 | Shanghai | Mainland China | 2020-01-30 21:30:00 | 128.0 | 1.0 | 9.0 | 30 | 21 |
| 387 | 388 | Beijing | Mainland China | 2020-01-30 21:30:00 | 121.0 | 1.0 | 5.0 | 30 | 21 |
| 388 | 389 | Fujian | Mainland China | 2020-01-30 21:30:00 | 101.0 | 0.0 | 0.0 | 30 | 21 |
| 389 | 390 | Guangxi | Mainland China | 2020-01-30 21:30:00 | 87.0 | 0.0 | 2.0 | 30 | 21 |
| 390 | 391 | Hebei | Mainland China | 2020-01-30 21:30:00 | 82.0 | 1.0 | 0.0 | 30 | 21 |
| 391 | 392 | Yunnan | Mainland China | 2020-01-30 21:30:00 | 76.0 | 0.0 | 0.0 | 30 | 21 |
| 392 | 393 | Shaanxi | Mainland China | 2020-01-30 21:30:00 | 87.0 | 0.0 | 0.0 | 30 | 21 |
| 393 | 394 | Heilongjiang | Mainland China | 2020-01-30 21:30:00 | 59.0 | 2.0 | 0.0 | 30 | 21 |
| 394 | 395 | Hainan | Mainland China | 2020-01-30 21:30:00 | 50.0 | 1.0 | 1.0 | 30 | 21 |
| 395 | 396 | Liaoning | Mainland China | 2020-01-30 21:30:00 | 45.0 | 0.0 | 1.0 | 30 | 21 |
| 396 | 397 | Shanxi | Mainland China | 2020-01-30 21:30:00 | 39.0 | 0.0 | 1.0 | 30 | 21 |
| 397 | 398 | Tianjin | Mainland China | 2020-01-30 21:30:00 | 32.0 | 0.0 | 0.0 | 30 | 21 |
| 398 | 399 | Gansu | Mainland China | 2020-01-30 21:30:00 | 29.0 | 0.0 | 0.0 | 30 | 21 |
| 399 | 400 | Ningxia | Mainland China | 2020-01-30 21:30:00 | 21.0 | 0.0 | 1.0 | 30 | 21 |
| 400 | 401 | Inner Mongolia | Mainland China | 2020-01-30 21:30:00 | 20.0 | 0.0 | 0.0 | 30 | 21 |
| 401 | 402 | Xinjiang | Mainland China | 2020-01-30 21:30:00 | 17.0 | 0.0 | 0.0 | 30 | 21 |
| 402 | 403 | Guizhou | Mainland China | 2020-01-30 21:30:00 | 15.0 | 0.0 | 1.0 | 30 | 21 |
| 403 | 404 | Jilin | Mainland China | 2020-01-30 21:30:00 | 14.0 | 0.0 | 1.0 | 30 | 21 |
| 404 | 405 | Hong Kong | Hong Kong | 2020-01-30 21:30:00 | 12.0 | 0.0 | 0.0 | 30 | 21 |
| 405 | 406 | Taiwan | Taiwan | 2020-01-30 21:30:00 | 9.0 | 0.0 | 0.0 | 30 | 21 |
| 406 | 407 | Qinghai | Mainland China | 2020-01-30 21:30:00 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| 407 | 408 | Macau | Macau | 2020-01-30 21:30:00 | 7.0 | 0.0 | 0.0 | 30 | 21 |
| 408 | 409 | Tibet | Mainland China | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 409 | 410 | Washington | US | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 410 | 411 | Illinois | US | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 411 | 412 | California | US | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 412 | 413 | Arizona | US | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 413 | 414 | NaN | Japan | 2020-01-30 21:30:00 | 11.0 | 0.0 | 1.0 | 30 | 21 |
| 414 | 415 | NaN | Thailand | 2020-01-30 21:30:00 | 14.0 | 0.0 | 5.0 | 30 | 21 |
| 415 | 416 | NaN | South Korea | 2020-01-30 21:30:00 | 6.0 | 0.0 | 0.0 | 30 | 21 |
| 416 | 417 | NaN | Singapore | 2020-01-30 21:30:00 | 10.0 | 0.0 | 0.0 | 30 | 21 |
| 417 | 418 | NaN | Vietnam | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 418 | 419 | NaN | France | 2020-01-30 21:30:00 | 5.0 | 0.0 | 0.0 | 30 | 21 |
| 419 | 420 | NaN | Nepal | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 420 | 421 | NaN | Malaysia | 2020-01-30 21:30:00 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| 421 | 422 | Ontario | Canada | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 422 | 423 | British Columbia | Canada | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 423 | 424 | NaN | Cambodia | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 424 | 425 | NaN | Sri Lanka | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 425 | 426 | New South Wales | Australia | 2020-01-30 21:30:00 | 4.0 | 0.0 | 2.0 | 30 | 21 |
| 426 | 427 | Victoria | Australia | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| 427 | 428 | Queensland | Australia | 2020-01-30 21:30:00 | 3.0 | 0.0 | 0.0 | 30 | 21 |
| 428 | 429 | Bavaria | Germany | 2020-01-30 21:30:00 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| 429 | 430 | NaN | Finland | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 430 | 431 | NaN | United Arab Emirates | 2020-01-30 21:30:00 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| 431 | 432 | NaN | Philippines | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 432 | 433 | NaN | India | 2020-01-30 21:30:00 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| 433 | 434 | NaN | Italy | 2020-01-30 21:30:00 | 2.0 | 0.0 | 0.0 | 30 | 21 |
data[data['Day'] == 30].sum()
Sno 23895
Country Mainland ChinaMainland ChinaMainland ChinaMain...
Confirmed 9776
Deaths 213
Recovered 187
Day 1770
Hour 1239
dtype: object
Мы можем видеть, что число подтвержденных случаев для провинции Хубэй в Китае — 5806 на 30-е число. Количества смертей, выздоровевших и пострадавших, соответствует официальным на 30 января. Это означает, что в Confirmed уже включены люди, затронуте в предыдущие даты.
Создаем датасета с данными только за 30 января.
latest_data = data[data['Day'] == 30]
latest_data.head()
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 375 | 376 | Hubei | Mainland China | 2020-01-30 21:30:00 | 5806.0 | 204.0 | 116.0 | 30 | 21 |
| 376 | 377 | Zhejiang | Mainland China | 2020-01-30 21:30:00 | 537.0 | 0.0 | 9.0 | 30 | 21 |
| 377 | 378 | Guangdong | Mainland China | 2020-01-30 21:30:00 | 393.0 | 0.0 | 11.0 | 30 | 21 |
| 378 | 379 | Henan | Mainland China | 2020-01-30 21:30:00 | 352.0 | 2.0 | 3.0 | 30 | 21 |
| 379 | 380 | Hunan | Mainland China | 2020-01-30 21:30:00 | 332.0 | 0.0 | 2.0 | 30 | 21 |
print('Подтвержденные случаи (весь мир): ', latest_data['Confirmed'].sum())
print('Смерти (весь мир): ', latest_data['Deaths'].sum())
print('Выздоровления (весь мир): ', latest_data['Recovered'].sum())
Подтвержденные случаи (весь мир): 9776.0
Смерти (весь мир): 213.0
Выздоровления (весь мир): 187.0
Данные датасета соответствуют официальным данным.
Посмотрим как коронавирус распространялся с течением времени.
plt.figure(figsize=(16,6))
data.groupby('Day').sum()['Confirmed'].plot();

Со временем наблюдается экспоненциальный рост числа жертв короновируса.
plt.figure(figsize=(16,6))
sns.barplot(x='Day',y='Confirmed',data=data);

Глубокий разведочный анализ данных (EDA)
latest_data.groupby('Country').sum()
| Sno | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|
| Country | ||||||
| Australia | 1281 | 9.0 | 0.0 | 2.0 | 90 | 63 |
| Cambodia | 424 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Canada | 845 | 3.0 | 0.0 | 0.0 | 60 | 42 |
| Finland | 430 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| France | 419 | 5.0 | 0.0 | 0.0 | 30 | 21 |
| Germany | 429 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| Hong Kong | 405 | 12.0 | 0.0 | 0.0 | 30 | 21 |
| India | 433 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Italy | 434 | 2.0 | 0.0 | 0.0 | 30 | 21 |
| Japan | 414 | 11.0 | 0.0 | 1.0 | 30 | 21 |
| Macau | 408 | 7.0 | 0.0 | 0.0 | 30 | 21 |
| Mainland China | 12126 | 9658.0 | 213.0 | 179.0 | 930 | 651 |
| Malaysia | 421 | 8.0 | 0.0 | 0.0 | 30 | 21 |
| Nepal | 420 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Philippines | 432 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Singapore | 417 | 10.0 | 0.0 | 0.0 | 30 | 21 |
| South Korea | 416 | 6.0 | 0.0 | 0.0 | 30 | 21 |
| Sri Lanka | 425 | 1.0 | 0.0 | 0.0 | 30 | 21 |
| Taiwan | 406 | 9.0 | 0.0 | 0.0 | 30 | 21 |
| Thailand | 415 | 14.0 | 0.0 | 5.0 | 30 | 21 |
| US | 1646 | 6.0 | 0.0 | 0.0 | 120 | 84 |
| United Arab Emirates | 431 | 4.0 | 0.0 | 0.0 | 30 | 21 |
| Vietnam | 418 | 2.0 | 0.0 | 0.0 | 30 | 21 |
- Материковый Китай имеет ненулевые значения выздоровлений и смертей, которые можно изучить позже, создав отдельный набор данных
Провинции и регионы в которых нет зарегистрированных случаев заболевания.
data[data['Confirmed']==0]
| Sno | Province/State | Country | Last Update | Confirmed | Deaths | Recovered | Day | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 5 | Gansu | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 10 | 11 | Heilongjiang | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 12 | 13 | Hong Kong | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 15 | 16 | Inner Mongolia | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 18 | 19 | Jilin | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 22 | 23 | Qinghai | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 23 | 24 | Shaanxi | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 30 | 31 | Tibet | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 32 | 33 | Xinjiang | China | 2020-01-22 12:00:00 | 0.0 | 0.0 | 0.0 | 22 | 12 |
| 53 | 54 | Inner Mongolia | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 60 | 61 | Qinghai | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 68 | 69 | Tibet | Mainland China | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 77 | 78 | NaN | Philippines | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 78 | 79 | NaN | Malaysia | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 80 | 81 | NaN | Australia | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 81 | 82 | NaN | Mexico | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 82 | 83 | NaN | Brazil | 2020-01-23 12:00:00 | 0.0 | 0.0 | 0.0 | 23 | 12 |
| 115 | 116 | Qinghai | Mainland China | 2020-01-24 12:00:00 | 0.0 | 0.0 | 0.0 | 24 | 12 |
| 263 | 264 | NaN | Ivory Coast | 2020-01-27 20:30:00 | 0.0 | 0.0 | 0.0 | 27 | 20 |
- Интересно, что есть части материкового Китая, которые еще не были затронуты вирусом.
- Есть страны без подтвержденных случаев заражения, и мы отбросим их.
Провинции и регионы в которых есть минимум 1 зарегистрированный случай заболевания.
data = data[data['Confirmed'] != 0]
Количество зараженных в разных странах.
plt.figure(figsize=(18,8))
sns.barplot(x='Country',y='Confirmed',data=data)
plt.tight_layout()

- На графике показано то, что мы все знаем. Вирус больше всего затронул материковый Китай, однако есть сообщения о жертвах в соседних странах, что говорит о распространении вируса.
- Есть также случаи, подтвержденные в странах, которые далеко, таких как США, Таиланд, Япония и т. Д. Интересно, как вирус попал туда. Я предполагаю, что кто-то был в Ухане или близлежащем районе во время распространения вируса и увез его с собой домой, эта вспышка действительно опасна.
Количество зараженных в разных регионах.
import plotly.express as px
fig = px.bar(data, x='Province/State', y='Confirmed')
fig.show()

Анализ роста коронавируса в каждой стране
pivoted = pd.pivot_table(data, values='Confirmed', columns='Country', index='Day')
pivoted.plot(figsize=(16,10));

Визуализация вспышки в провинциях/регионах
pivoted = pd.pivot_table(data, values='Confirmed', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15));

- Hubei, наиболее пострадавшая провинция.
- Также в подтвержденных случаях наблюдается тенденция к росту, и кажется, что состояние ухудшается.
Теперь давайте посмотрим на страны, которые были затронуты изначально, и страны, в которые сейчас проник коронный вирус.
data[data['Day'] == 22]['Country'].unique()
array(['China', 'US', 'Japan', 'Thailand', 'South Korea'], dtype=object)
Итак, в первый день, 22 января заражения были обнаружены в Китае, США, Японии, Таиланде
temp = data[data['Day'] == 22]
temp.groupby('Country').sum()['Confirmed'].plot.bar()

Посмотрим на последние данные.
data[data['Day'] == 30]['Country'].unique()
array(['Mainland China', 'Hong Kong', 'Taiwan', 'Macau', 'US', 'Japan',
'Thailand', 'South Korea', 'Singapore', 'Vietnam', 'France',
'Nepal', 'Malaysia', 'Canada', 'Cambodia', 'Sri Lanka',
'Australia', 'Germany', 'Finland', 'United Arab Emirates',
'Philippines', 'India', 'Italy'], dtype=object)
Здесь мы видим, что вспышка распространилась в 23 странах к 30 января.
Рассмотрим только материковый Китай
data_main_china = latest_data[latest_data['Country']=='Mainland China']
Рассчитаем процент смертей.
(data_main_china['Deaths'].sum() / data_main_china['Confirmed'].sum())*100
2.205425553944916
Теперь процент выздоровлений.
(data_main_china['Recovered'].sum() / data_main_china['Confirmed'].sum())*100
1.8533857941602818
- Мы можем видеть, что процент смертности от коронавируса — 2%, поэтому он не такой смертоносный, как другие вирусные вспышки.
- Поскольку зарегистрировано мало случаев излечения, процент выздоровления составляет 1,87, это страшно. Хотя цифра может сильно вырасти, ведь 96% сейчас не попадают ни в одну из групп.

Где произошло большинство смертей
data_main_china.groupby('Province/State')['Deaths'].sum().reset_index(
).sort_values(by=['Deaths'],ascending=False).head()
| Province/State | Deaths | |
|---|---|---|
| 12 | Hubei | 204.0 |
| 10 | Heilongjiang | 2.0 |
| 11 | Henan | 2.0 |
| 9 | Hebei | 1.0 |
| 1 | Beijing | 1.0 |
Количество смертей по дням.
plt.figure(figsize=(16,6))
data.groupby('Day').sum()['Deaths'].plot();

График заболеваний в материковом Китае.
pivoted = pd.pivot_table(data[data['Country']=='Mainland China'] , values='Confirmed', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15))

pivoted = pd.pivot_table(data, values='Deaths', columns='Province/State', index='Day')
pivoted.plot(figsize=(20,15));

Что дальше
Скачайте coronavirus.ipynb и данные по ссылке в начале статьи. Попробуйте построить свои графики и таблицы.
]]>Это дополнение к «Основы Pandas». Вместо теоретического вступления в миллион особенностей Pandas — 2 примера:
- Данные с космического телескопа «Хаббл».
- Датасет о заработной плате экономически активного населения США.
Данные «Хаббла»
Начнем с данных «Хаббла». В первую очередь речь пойдет о том, как читать простой csv-файл и строить данные:
Начнем с данных с космического телескопа «Хаббл», одного из известнейших телескопов.
Данные очень простые. Файл называется hubble_data.csv. Его можно открыть даже в Microsoft Excel или OpenOffice. Вот как он будет выглядеть в этих программах:

Данные в формате CSV. Это очень популярный формат в первую очередь из-за своей простоты. Его можно открыть в любом текстовом редакторе. Попробуйте.
Будет видно, что CSV-файлы — это всего лишь разные значения, разделенные запятой (что, собственно, и подразумевается в названии — comma-separated values).
Это основная причина популярности формата. Для него не нужно никакое специальное ПО, даже Excel. Это также значит, что данные можно будет прочесть и через 10 лет, когда появятся новые версии электронных таблиц.
Начнем. Откройте экземпляр Ipython (Jupyter) и запустите следующий код.
import pandas as pd
import matplotlib.pyplot as plt
%pylab inline
Это импортирует pandas — основную библиотеку в Python для анализа данных. Также импортируется matplotlib для построения графиков.
%pylan inline — это команда Ipython, которая позволяет использовать графики в работе.
data = pd.read_csv("hubble_data.csv")
data.head()
Pandas значительно упрощает жизнь. Прочесть файл csv можно с помощью одной функции: read_csv().
Теперь можно вызвать функцию head(), чтобы вывести первые пять строк.
| distance | recession_velocity | |
|---|---|---|
| 0 | 0.032 | 170 |
| 1 | 0.034 | 290 |
| 2 | 0.214 | -130 |
| 3 | 0.263 | -70 |
| 4 | 0.275 | -185 |
Pandas — довольно умная библиотека. Это проявляется в том, что она понимает, что первая строка файла — это заголовок. Вот как выглядят первые 3 строки CSV-файла:
distance,recession_velocity
.032,170
.034,290
Теперь можно увидеть, что заголовок в верхней части действительно есть. Он называет две колонки: distance и recession_velocity.
Pandas корректно распознает это.
А что делать, если заголовка нет? Можно прочесть файл, вручную указав заголовки. Есть еще один файл hubble_data_no_headers.csv без заголовков. Он не отличается от предыдущего за исключением отсутствующих заголовков.
Вот как читать такой файл:
headers = ["dist","rec_vel"]
data_no_headers = pd.read_csv("hubble_data_no_headers.csv", names=headers)
data_no_headers.head()
Здесь объявляются собственные заголовки (headers). У них другие имена (dist и rec_vel), чтобы было явно видно, что это другой файл.
Данные читаются таким же способом, но в этот раз передаются новые переменные names=headers. Это сообщает Pandas, что нужно использовать их, поскольку в файле заголовков нет. Затем выводятся первые пять строк.
| dist | rec_vel | |
|---|---|---|
| 0 | 0.032 | 170 |
| 1 | 0.034 | 290 |
| 2 | 0.214 | -130 |
| 3 | 0.263 | -70 |
| 4 | 0.275 | -185 |
Pandas позволяет увидеть только одну колонку:
data_no_headers["dist"]
0 0.032
1 0.034
2 0.214
3 0.263
4 0.275
Теперь, когда данные есть, на их основе нужно построить график.
Проще всего добиться этого, избавившись от индексов. Pandas по умолчанию добавляет номера (как и Excel). Если посмотреть на структуру данных, будет видно, что левая строка имеет значения 0,1,2,3,4....
Если заменить номера на distance, тогда построение графиков станет еще проще. distance станет осью x, а velocity — осью y.
Но как заменить индексы?
data.set_index("distance", inplace=True)
data.head()
| distance | recession_velocity |
|---|---|
| 0.032 | 170 |
| 0.034 | 290 |
| 0.214 | -130 |
| 0.263 | -70 |
| 0.275 | -185 |
При сравнении с прошлым примером можно увидеть, что номера пропали. Более того, данные теперь расположены в соотношении x — y.
Создать график теперь еще проще:
data.plot()
plt.show()

Данные о заработной плате
Теперь данные о заработной плате. Этот пример построен на предыдущем и показывает, как добавлять собственные заголовки, работать с файлами, разделенными отступами, и извлекать колонки из данных:
Этот пример посложнее.
Откройте ноутбук. Начнем, как и раньше, с импорта необходимых модулей и чтения CSV-файла. В данном случае речь идет о файле wages_hours.csv.
import pandas as pd
import matplotlib.pyplot as plt
%pylab inline
data = pd.read_csv("wages_hours.csv")
data.head()
Все как раньше. Нужно ведь просто прочесть файл? Но результат получается следующий:
| HRS RATE ERSP ERNO NEIN ASSET AGE DEP RACE SCHOOL | |
|---|---|
| 0 | 2157\t2.905\t1121\t291\t380\t7250\t38.5\t2.340… |
| 1 | 2174\t2.970\t1128\t301\t398\t7744\t39.3\t2.335… |
| 2 | 2062\t2.350\t1214\t326\t185\t3068\t40.1\t2.851… |
| 3 | 2111\t2.511\t1203\t49\t117\t1632\t22.4\t1.159\… |
| 4 | 2134\t2.791\t1013\t594\t730\t12710\t57.7\t1.22… |
Выглядит непонятно. И совсем не похоже на оригинальный файл.
Что же случилось?
В CSV-файле нет запятых
Хотя название подразумевает «Значения, Разделенные Запятыми», данные могут быть разделены чем угодно. Например, отступами.
\t в тексте означает отступы. Pandas не может разобрать файл, потому что библиотека рассчитывала на запятые, а не на отступы.
Нужно прочитать файл еще раз, в этот раз передав новую переменную sep='\t'. Это сообщит, что разделителями выступают отступы, а не запятые.
data = pd.read_csv("wages_hours.csv", sep="\t")
data.head()
| HRS | RATE | ERSP | ERNO | NEIN | ASSET | AGE | DEP | RACE | SCHOOL | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2157 | 2.905 | 1121 | 291 | 380 | 7250 | 38.5 | 2.340 | 32.1 | 10.5 |
| 1 | 2174 | 2.970 | 1128 | 301 | 398 | 7744 | 39.3 | 2.335 | 31.2 | 10.5 |
| 2 | 2062 | 2.350 | 1214 | 326 | 185 | 3068 | 40.1 | 2.851 | * | 8.9 |
| 3 | 2111 | 2.511 | 1203 | 49 | 117 | 1632 | 22.4 | 1.159 | 27.5 | 11.5 |
| 4 | 2134 | 2.791 | 1013 | 594 | 730 | 12710 | 57.7 | 1.229 | 32.5 | 8.8 |
Сработало.
Но тут довольно много данных. Нужны ли они все?
В этом проекте необходимы только AGE (возраст) и RACE (ставка заработной платы). В первую очередь необходимо извлечь только эти две колонки.
data2 = data[["AGE", "RATE"]]
data2.head()
| AGE | RATE | |
|---|---|---|
| 0 | 38.5 | 2.905 |
| 1 | 39.3 | 2.970 |
| 2 | 40.1 | 2.350 |
| 3 | 22.4 | 2.511 |
| 4 | 57.7 | 2.791 |
Чтобы составить грамотный график, необходимо расположить возраст по порядку: возрастания или убывания.
Сделаем в порядке убывания (потому что это поведение по умолчанию для функции sort()).
data_sorted = data2.sort(["AGE"])
data_sorted.head()
Как и в прошлый раз, нужно убрать числа, а вместо них использовать значения возраста, чтобы упростить процесс построения графика.
data_sorted.set_index("AGE", inplace=True)
data_sorted.head()
| AGE | RATE |
|---|---|
| 22.4 | 2.511 |
| 37.2 | 3.015 |
| 37.4 | 1.901 |
| 37.5 | 1.899 |
| 37.5 | 3.009 |
И сам график:
data_sorted.plot()
plt.show()

Можно увидеть, что ставка повышается до 35 лет, а потом начинает сильно меняться.
Конечно, это общий универсальный показатель. Из этого набора данных можно сделать лишь отдельные выводы.
]]>Это третья часть руководства по pandas, в которой речь пойдет о методах форматирования данных, часто используемых в проектах data science: merge, sort, reset_index и fillna. Конечно, есть и другие, поэтому в конце статьи будет шпаргалка с функциями и методами, которые также могут пригодиться.
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Merge в pandas («объединение» Data Frames)
В реальных проектах данные обычно не хранятся в одной таблице. Вместо нее используется много маленьких. И на то есть несколько причин. С помощью нескольких таблиц данными легче управлять, проще избегать «многословия», можно экономить место на диске, а запросы к таблицам обрабатываются быстрее.
Суть в том, что при работе с данными довольно часто придется вытаскивать данные из двух и более разных страниц. Это делается с помощью merge.
Примечание: хотя в pandas это называется merge, метод почти не отличается от JOIN в SQL.
Рассмотрим пример. Для этого можно взять DataFrame zoo (из предыдущих частей руководства), в котором есть разные животные. Но в этот раз нужен еще один DataFrame — zoo_eats, в котором будет описаны пищевые требования каждого вида.

Теперь нужно объединить два эти Data Frames в один. Чтобы получилось нечто подобное:

В этой таблице можно проанализировать, например, сколько животных в зоопарке едят мясо или овощи.
Как делается merge?
В первую очередь нужно создать DataFrame zoo_eats, потому что zoo уже имеется из прошлых частей. Для упрощения задачи вот исходные данные:
animal;food
elephant;vegetables
tiger;meat
kangaroo;vegetables
zebra;vegetables
giraffe;vegetables
О том, как превратить этот набор в DataFrame, написано в первом уроке по pandas. Но есть способ для ленивых. Нужно лишь скопировать эту длинную строку в Jupyter Notebook pandas_tutorial_1, который был создан еще в первой части руководства.
zoo_eats = pd.DataFrame([['elephant','vegetables'], ['tiger','meat'], ['kangaroo','vegetables'], ['zebra','vegetables'], ['giraffe','vegetables']], columns=['animal', 'food'])
И вот готов DataFrame zoo_eats.

Теперь пришло время метода merge:
zoo.merge(zoo_eats)
(А где же все львы? К этому вернемся чуть позже).
Это было просто, не так ли? Но стоит разобрать, что сейчас произошло:
Сначала был указан первый DataFrame (zoo). Потом к нему применен метод .merge(). В качестве его параметра выступает новый DataFrame (zoo_eats). Можно было сделать и наоборот:
zoo_eats.merge(zoo)
Это то же самое, что и:
zoo.merge(zoo_eats)
Разница будет лишь в порядке колонок в финальной таблице.
Способы объединения: inner, outer, left, right
Базовый метод merge довольно прост. Но иногда к нему нужно добавить несколько параметров.
Один из самых важных вопросов — как именно нужно объединять эти таблицы. В SQL есть 4 типа JOIN.

В случае с merge в pandas в теории это работает аналогичным образом.
При выборе INNER JOIN (вид по умолчанию в SQL и pandas) объединяются только те значения, которые можно найти в обеих таблицах. В случае же с OUTER JOIN объединяются все значения, даже если некоторые из них есть только в одной таблице.
Конкретный пример: в zoo_eats нет значения lion. А в zoo нет значения giraffe. По умолчанию использовался метод INNER, поэтому и львы, и жирафы пропали из таблицы. Но бывают случаи, когда нужно, чтобы все значения оставались в объединенном DataFrame. Этого можно добиться следующим образом:
zoo.merge(zoo_eats, how='outer')

В этот раз львы и жирафы вернулись. Но поскольку вторая таблица не предоставила конкретных данных, то вместо значения ставится пропуск (NaN).
Логичнее всего было бы оставить в таблице львов, но не жирафов. В таком случае будет три типа еды: vegetables, meat и NaN (что, фактически, значит, «информации нет»). Если же в таблице останутся жирафы, это может запутать, потому что в зоопарке-то этого вида животных все равно нет. Поэтому следует воспользоваться параметром how='left' при объединении.
Вот так:
zoo.merge(zoo_eats, how='left')
Теперь в таблице есть вся необходимая информация, и ничего лишнего. how = 'left' заберет все значения из левой таблицы (zoo), но из правой (zoo_eats) использует только те значения, которые есть в левой.
Еще раз взглянем на типы объединения:
Примечание: «Какой метод merge является самым безопасным?» — самый распространенный вопрос. Но на него нет однозначного ответа. Нужно решать в зависимости от конкретной задачи.
Merge в pandas. По какой колонке?
Для использования merge библиотеке pandas нужны ключевые колонки, на основе которых будет проходить объединение (в случае с примером это колонка animal). Иногда pandas не сможет распознать их автоматически, и тогда нужно указать названия колонок. Для этого нужны параметры left_on и right_on.
Например, последний merge мог бы выглядеть следующим образом:
zoo.merge(zoo_eats, how = 'left', left_on='animal', right_on='animal')
Примечание: в примере pandas автоматически нашел ключевые колонки, но часто бывает так, что этого не происходит. Поэтому о
left_onиright_onне стоит забывать.
Merge в pandas — довольно сложный метод, но остальные будут намного проще.
Сортировка в pandas
Сортировка необходима. Базовый метод сортировки в pandas совсем не сложный. Функция называется sort_values() и работает она следующим образом:
zoo.sort_values('water_need')

Примечание: в прошлых версиях pandas была функция
sort(), работающая подобным образом. Но в новых версиях ее заменили наsort_values(), поэтому пользоваться нужно именно новым вариантом.
Единственный используемый параметр — название колонки, water_need в этом случае. Довольно часто приходится сортировать на основе нескольких колонок. В таком случае для них нужно использовать ключевое слово by:
zoo.sort_values(by=['animal', 'water_need'])

Примечание: ключевое слово
byможно использовать и для одной колонкиzoo.sort_values(by = ['water_need'].
sort_values сортирует в порядке возрастания, но это можно поменять на убывание:
zoo.sort_values(by=['water_need'], ascending=False)

reset_index()
Заметили ли вы, какой беспорядок теперь в нумерации после последней сортировки?

Это не просто выглядит некрасиво… неправильная индексация может испортить визуализации или повлиять на то, как работают модели машинного обучения.
В случае изменения DataFrame нужно переиндексировать строки. Для этого можно использовать метод reset_index(). Например:
zoo.sort_values(by=['water_need'], ascending=False).reset_index()

Можно заметить, что новый DataFrame также хранит старые индексы. Если они не нужны, их можно удалить с помощью параметра drop=True в функции:
zoo.sort_values(by = ['water_need'], ascending = False).reset_index(drop = True)

Fillna
Примечание: fillna — это слова fill( заполнить) и na(не доступно).
Запустим еще раз метод left-merge:
zoo.merge(zoo_eats, how='left')
Это все животные. Проблема только в том, что для львов есть значение NaN. Само по себе это значение может отвлекать, поэтому лучше заменять его на что-то более осмысленное. Иногда это может быть 0, в других случаях — строка. Но в этот раз обойдемся unknown. Функция fillna() автоматически найдет и заменит все значения NaN в DataFrame:
zoo.merge(zoo_eats, how='left').fillna('unknown')

Примечание: зная, что львы едят мясо, можно было также написать
zoo.merge(zoo_eats, how='left').fillna('meat').
Проверьте себя
Вернемся к набору данных article_read.
Примечание: в этом наборе хранятся данные из блога о путешествиях. Загрузить его можно здесь. Или пройти весь процесс загрузки, открытия и установки из первой части руководства pandas.
Скачайте еще один набор данных: blog_buy. Это можно сделать с помощью следующих двух строк в Jupyter Notebook:
!wget https://pythonru.com/downloads/pandas_tutorial_buy.csv
blog_buy = pd.read_csv('pandas_tutorial_buy.csv', delimiter=';', names=['my_date_time', 'event', 'user_id', 'amount'])
Набор article_read показывает всех пользователей, которые читают блог, а blog_buy — тех, купил что-то в этом блоге за период с 2018-01-01 по 2018-01-07.
Два вопроса:
- Какой средний доход в период с
2018-01-01по2018-01-07от пользователей изarticle_read? - Выведите топ-3 страны по общему уровню дохода за период с
2018-01-01по2018-01-07. (Пользователей изarticle_readздесь тоже нужно использовать).
Решение задания №1
Средний доход — 1,0852
Для вычисления использовался следующий код:
step_1 = article_read.merge(blog_buy, how='left', left_on='user_id', right_on='user_id')
step_2=step_1.amount
step_3=step_2.fillna(0)
result=step_3.mean()
result

Примечание: шаги использовались, чтобы внести ясность. Описанные функции можно записать и в одну строку.`
Краткое объяснение:
- На скриншоте также есть две строки с импортом pandas и numpy, а также чтением файлов csv в Jupyter Notebook.
- На шаге №1 объединены две таблицы (
article_readиblog_buy) на основе колонкиuser_id. В таблицеarticle_readхранятся все пользователи, даже если они ничего не покупают, потому что ноли (0) также должны учитываться при подсчете среднего дохода. Из таблицы удалены те, кто покупали, но кого нет в набореarticle_read. Все вместе привело к left-merge. - Шаг №2 — удаление ненужных колонок с сохранением только
amount. - На шаге №3 все значения
NaNзаменены на0. - В конце концов проводится подсчет с помощью
.mean().
Решение задания №2
step_1 = article_read.merge(blog_buy, how = 'left', left_on = 'user_id', right_on = 'user_id')
step_2 = step_1.fillna(0)
step_3 = step_2.groupby('country').sum()
step_4 = step_3.amount
step_5 = step_4.sort_values(ascending = False)
step_5.head(3)

Найдите топ-3 страны на скриншоте.
Краткое объяснение:
- Тот же метод
merge, что и в первом задании. - Замена всех
NaNна0. - Суммирование всех числовых значений по странам.
- Удаление всех колонок кроме
amount. - Сортировка результатов в убывающем порядке так, чтобы можно было видеть топ.
- Вывод только первых 3 строк.
Итого
Это был третий эпизод руководства pandas с важными и часто используемыми методами: merge, sort, reset_index и fillna.
Во втором уроке руководства по работе с pandas речь пойдет об агрегации (min, max, sum, count и дргуих) и группировке. Это популярные методы в аналитике и проектах data science, поэтому убедитесь, что понимаете все в деталях!
Примечание: это руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Агрегация данных — теория
Агрегация — это процесс превращения значений набора данных в одно значение. Например, у вас есть следующий набор данных…
| animal | water_need |
|---|---|
| zebra | 100 |
| lion | 350 |
| elephant | 670 |
| kangaroo | 200 |
…простейший метод агрегации для него — суммирование water_needs, то есть 100 + 350 + 670 + 200 = 1320. Как вариант, можно посчитать количество животных — 4. Теория не так сложна. Но пора переходить к практике.
Агрегация данных — практика
Где мы остановились в последний раз? Открыли Jupyter Notebook, импортировали pandas и numpy и загрузили два набора данных: zoo.csv и article_reads. Продолжим с этого же места. Если вы не прошли первую часть, вернитесь и начните с нее.
Начнем с набора zoo. Он был загружен следующим образом:
pd.read_csv('zoo.csv', delimiter = ',')

Дальше сохраним набор данных в переменную zoo.
zoo = pd.read_csv('zoo.csv', delimiter = ',')
Теперь нужно проделать пять шагов:
- Посчитать количество строк (количество животных) в
zoo. - Посчитать общее значение
water_needживотных. - Найти наименьшее значение
water_need. - И самое большое значение
water_need. - Наконец, среднее
water_need.
Агрегация данных pandas №1: .count()
Посчитать количество животных — то же самое, что применить функцию count к набору данных zoo:
zoo.count()

А что это за строки? На самом деле, функция count() считает количество значений в каждой колонке. В случае с zoo было 3 колонки, в каждой из которых по 22 значения.
Чтобы сделать вывод понятнее, можно выбрать колонку animal с помощью оператора выбора из предыдущей статьи:
zoo[['animal']].count()
В этом случае результат будет даже лучше, если написать следующим образом:
zoo.animal.count()
Также будет выбрана одна колонка, но набор данных pandas превратится в объект series (а это значит, что формат вывода будет отличаться).

Агрегация данных pandas №2: .sum()
Следуя той же логике, можно с легкостью найти сумму значений в колонке water_need с помощью:
zoo.water_need.sum()

Просто из любопытства можно попробовать найти сумму во всех колонках:
zoo.sum()

Примечание: интересно, как
.sum()превращает слова из колонкиanimalв строку названий животных. (Кстати, это соответствует всей логике языка Python).
Агрегация данных pandas №3 и №4: .min() и .max()
Какое наименьшее значение в колонке water_need? Определить это несложно:
zoo.water_need.min()

То же и с максимальным значением:
zoo.water_need.max()

Агрегация данных pandas №5 и №6: .mean() и .median()
Наконец, стоит посчитать среднестатистические показатели, например среднее и медиану:
zoo.water_need.mean()

zoo.water_need.median()

Это было просто. Намного проще, чем агрегация в SQL.
Но можно усложнить все немного с помощью группировки.
Группировка в pandas
Работая аналитиком или специалистом Data Science, вы наверняка постоянно будете заниматься сегментациями. Например, хорошо знать количество необходимой воды (water_need) для всех животных (это 347,72). Но удобнее разбить это число по типу животных.
Вот упрощенная репрезентация того, как pandas осуществляет «сегментацию» (группировку и агрегацию) на основе значений колонок!
Функция .groupby в действии
Проделаем эту же группировку с DataFrame zoo.
Между переменной zoo и функцией .mean() нужно вставить ключевое слово groupby:
zoo.groupby('animal').mean()

Как и раньше, pandas автоматически проведет расчеты .mean() для оставшихся колонок (колонка animal пропала, потому что по ней проводилась группировка). Можно или игнорировать колонку uniq_id или удалить ее одним из следующих способов:
zoo.groupby('animal').mean()[['water_need']] — возвращает объект DataFrame.
zoo.groupby('animal').mean().water_need — возвращает объект Series.
Можно поменять метод агрегации с .mean() на любой изученный до этого.
Пришло время…
Проверить себя №1
Вернемся к набору данных article_read.
Примечание: стоит напомнить, что в этом наборе хранятся данные из блога о путешествиях. Скачать его можно отсюда. Пошаговый процесс загрузки, открытия и сохранения есть в прошлом материале руководства.
Если все готово, вот первое задание:
Какой источник используется в article_read чаще остальных?
.
.
.
.
.
.
Правильный ответ:
Reddit!
Получить его можно было с помощью кода:
article_read.groupby('source').count()
Взять набор данных article_read, создать сегменты по значениям колонки source (groupby('source')) и в конце концов посчитать значения по источникам (.count()).

Также можно удалить ненужные колонки и сохранить только user_id:
article_read.groupby('source').count()[['user_id']]
Проверить себя №2
Вот еще одна, более сложная задача:
Какие самые популярные источник и страна для пользователей country_2? Другими словами, какая тема из какого источника принесла больше всего просмотров из country_2?
.
.
.
.
.
.
Правильный ответ: Reddit (источник) и Азия (тема) с 139 прочтениями.
Вот Python-код для получения результата:
article_read[article_read.country == 'country_2'].groupby(['source', 'topic']).count()

Вот краткое объяснение:
В первую очередь отфильтровали пользователей из country_2 (article_read[article_read.country == 'country_2']). Затем для этого подмножества был использован метод groupby. (Да, группировку можно осуществлять для нескольких колонок. Для этого их названия нужно собрать в список. Поэтому квадратные скобки используются между круглыми. Это что касается части groupby(['source', 'topic'])).
А функция count() — заключительный элемент пазла.
Итого
Это была вторая часть руководства по работе с pandas. Теперь вы знаете, что агрегация и группировка в pandas— это простые операции, а использовать их придется часто.
Примечание: если вы ранее пользовались SQL, сделайте перерыв и сравните методы агрегации в SQL и pandas. Так лучше станет понятна разница между языками.
В следующем материале вы узнаете о четырех распространенных методах форматирования данных: merge, sort, reset_index и fillna.
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».

- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:
import numpy as np import pandas as pd
Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть
as pd, Jupyter Notebook понимает, что в будущем, при вводеpdподразумевается именно библиотека pandas.
Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.

DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.

В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv().
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
animal,uniq_id,water_need
elephant,1001,500
elephant,1002,600
elephant,1003,550
tiger,1004,300
tiger,1005,320
tiger,1006,330
tiger,1007,290
tiger,1008,310
zebra,1009,200
zebra,1010,220
zebra,1011,240
zebra,1012,230
zebra,1013,220
zebra,1014,100
zebra,1015,80
lion,1016,420
lion,1017,600
lion,1018,500
lion,1019,390
kangaroo,1020,410
kangaroo,1021,430
kangaroo,1022,410
Вернемся во вкладку “Home” https://you_ip:you_port/tree Jupyter для создания нового текстового файла…

затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…

…и назовем его zoo.csv!

Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
pd.read_csv('zoo.csv', delimiter=',')

Готово! Это файл zoo.csv, перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv
Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:

Если кликнуть на него…

…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
pd.read_csv('pandas_tutorial_read.csv', delimete=';')
Данные загружены в pandas!

Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
pd.read_csv('pandas_tutorial_read.csv', delimiter=';',
names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'])

Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл
.csvчерез URL напрямую. В этом случае данные не загрузятся на сервер данных.
pd.read_csv(
'https://pythonru.com/downloads/pandas_tutorial_read.csv',
delimiter=';',
names=['my_datetime', 'event', 'country',
'user_id', 'source', 'topic']
)
Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
article_read = pd.read_csv(
'pandas_tutorial_read.csv',
delimiter=';',
names = ['my_datetime', 'event', 'country',
'user_id', 'source', 'topic']
)
После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!

Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
article_read.head()

Или последние 5 строк:
article_read.tail()

Или 5 случайных строк:
article_read.sample(5)

Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
article_read[['country', 'user_id']]

Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
- article_read.user_id
- article_read[‘user_id’]

Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
article_read[article_read.source == 'SEO']
Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли 'SEO' значением колонки article_read.source? Результат всегда будет булевым значением (True или False).

Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read.

Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
article_read.head()[['country', 'user_id']]
Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
article_read[['country', 'user_id']].head()
В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
pd.read_csv(
'pandas_tutorial_read.csv',
delimiter=';',
names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic']
)[['country', 'user_id']].head()
Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2. Выведите первые 5 строк!
Вперед!
.
.
.
.
.
А вот и решение!
Его можно преподнести одной строкой:
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head()
Или, чтобы было понятнее, можно разбить на несколько строк:
ar_filtered = article_read[article_read.country == 'country_2']
ar_filtered_cols = ar_filtered[['user_id','topic', 'country']]
ar_filtered_cols.head()
В любом случае, логика не отличается. Сначала берется оригинальный dataframe (article_read), затем отфильтровываются строки со значением для колонки country — country_2 ([article_read.country == 'country_2']). Потому берутся три нужные колонки ([['user_id', 'topic', 'country']]) и в конечном итоге выбираются только первые пять строк (.head()).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
]]>