Делитель, также известный как фактор или множитель, — это такое целое число m, на которое n делится без остатка. Например, делителями числа 12 являются 1, 2, 3, 4, 6 и 12.
В итоге я написал кое-что с помощью itertools, и в моем коде используется несколько интересных моментов из теории чисел. Я не знаю, буду ли я возвращаться к нему снова, но я надумал написать эту статью, потому что мои попытки решить озвученный выше вопрос перетекли в довольно забавное упражнение.
Простейший подход
Если мы хотим найти все числа, которые делят n без остатка, мы можем просто перебрать числа от 1 до n:
def get_all_divisors_brute(n):
for i in range(1, int(n / 2) + 1):
if n % i == 0:
yield i
yield n
На деле нам нужно дойти только до n/2, потому что все, что больше этого значения, гарантировано не может быть делителем n — если вы разделите n на что-то большее, чем n/2, результат не будет целым числом.
Этот код очень прост, и для малых значений n он работает достаточно хорошо, но он довольно неэффективен и медлителен в других случаях. По мере увеличения n время выполнения линейно увеличивается. Можем ли мы сделать лучше?
Факторизация
В моем проекте я работал в основном с факториалами. Факториал числа n, обозначаемый n! — это произведение всех целых чисел от 1 до n включительно. Например:
8! = 8 × 7 × 6 × 5 × 4 × 3 × 2 × 1
Поскольку факториалы состоят преимущественно из небольших множителей, я решил попробовать получить список делителей, определив сначала наименьшие из них. В частности, я искал простые множители, то есть те, которые также являются простыми числами. (Простое число — это число, единственными делителями которого являются оно само и 1. Например, 2, 3 и 5 являются простыми, а 4 и 6 — нет).
Вот функция, которая находит простые делители числа n:
def get_prime_divisors(n):
i = 2
while i * i <= n:
if n % i == 0:
n /= i
yield i
else:
i += 1
if n > 1:
yield n
Это похоже на предыдущую функцию, использующую перебор делителей: мы продолжаем пробовать множители, и если находим подходящий, то делим на него. В противном случае мы проверяем следующее число. Это довольно стандартный подход к поиску простых множителей.
Теперь мы можем использовать этот метод для получения факторизации числа, то есть для его записи в виде произведения простых чисел. Например, факторизация числа 8! выглядит следующим образом:
8! = 2^7 × 3^2 × 5 × 7
Вычисление такой факторизации относительно эффективно, особенно для факториалов, так как, поскольку все простые множители очень малы, вам не нужно делать много делений.
В теории чисел есть утверждение, называемое основной теоремой арифметики, которое гласит, что простые факторизации (разложения) уникальны: для любого числа n существует только один способ представить его в виде произведения простых множителей. (Я не буду приводить здесь доказательство, но вы можете найти его в Википедии).
Это дает нам способ находить делители путем перебора всех комбинаций простых множителей. Простые множители любого m делителя числа n должны входить в подмножество простых множителей n, иначе m не делило бы число n.
Переход от факторизации к делителям
Для начала разложим исходное число на простые множители с указанием «кратности», то есть мы должны получить список всех множителей и количество раз, которое каждый из них встречается в факторизации:
import collections
def get_all_divisors(n):
primes = get_prime_divisors(n)
primes_counted = collections.Counter(primes)
...
Затем, давайте продолжим и возведем каждое простое число во все степени, которые могут появиться в возможном делителе n.
def get_all_divisors(n):
...
divisors_exponentiated = [
[div ** i for i in range(count + 1)]
for div, count in primes_counted.items()
]
Например, для 8! представленный код выдаст нам следующее:
[
[1, 2, 4, 8, 16, 32, 64, 128], // 2^0, 2^1, ..., 2^7
[1, 3, 9], // 3^0, 3^1, 3^2
[1, 5],
[1, 7],
]
Затем, чтобы получить делители, мы можем использовать довольно удобную функцию itertools.product, которая принимает на вход итерабельные объекты и возвращает все возможные упорядоченные комбинации их элементов. В нашем случае она выбирает по одному числу из каждого списка с возведениями в степень, а затем, перемножая их вместе, мы получаем очередной делитель n.
import itertools
def calc_product(iterable):
acc = 1
for i in iterable:
acc *= i
return acc
def get_all_divisors(n):
...
for prime_exp_combination in itertools.product(*divisors_exponentiated):
yield calc_product(prime_exp_combination)
Таким образом, мы находим все делители n (хотя, в отличие от предыдущих функций, они не отсортированы).
Собираем все вместе
Сложив все это, мы получим следующую функцию для вычисления делителей n:
import collections
import itertools
def get_prime_divisors(n):
i = 2
while i * i <= n:
if n % i == 0:
n /= i
yield i
else:
i += 1
if n > 1:
yield n
def calc_product(iterable):
acc = 1
for i in iterable:
acc *= i
return acc
def get_all_divisors(n):
primes = get_prime_divisors(n)
primes_counted = collections.Counter(primes)
divisors_exponentiated = [
[div ** i for i in range(count + 1)]
for div, count in primes_counted.items()
]
for prime_exp_combination in itertools.product(*divisors_exponentiated):
yield calc_product(prime_exp_combination)
print(list(get_all_divisors(40320))) # 8!
Такая реализация очень эффективна, особенно когда у вас много маленьких простых множителей, как в случае с факториалами, с которыми я работал. Я не знаю, насколько хорошо она покажет себя в общем случае, и, если вы занимаетесь серьезными научными вычислениями, я уверен, что вы легко найдете уже реализованные и оптимизированные алгоритмы для такого рода вещей.
]]>Синтаксис:
lambda [аргументы] : выражение
Лямбда-функция может иметь ноль или более аргументов перед символом ‘:’. При вызове такой функции выполняется выражение, указанное после ‘:’.
Пример определения лямбда-функции:
get_cube = lambda x : x ** 3
Приведенная выше лямбда-функция начинается с ключевого слова lambda, за которым следует параметр x. Выражение x ** 3 после ‘:’ возвращает вызывающему коду значение куба переданного числа. Сама лямбда-функция lambda x : x ** 3 присваивается переменной get_cube для ее последующего вызова как именованной функции. Имя переменной становится именем функции, чтобы мы могли работать с ней как с обычной функцией.
Пример вызова лямбда-функции:
>>> get_cube(4)
64
Приведенное выше определение лямбда-функции аналогично следующей стандартной функции:
def get_cube(x):
return x ** 3
Выражение не обязательно должно всегда возвращать значение. Следующая лямбда-функция не возвращает ничего.
Пример лямбда-функции, не возвращающей значение:
>>> welcome = lambda user: print('Welcome, ' + name + '!')
>>> welcome('Anon')
Welcome, Anon!
Примечание:
Лямбда-функция может иметь только одно выражение. Очевидно, что она не может заменить функцию, тело которой содержит условия, циклы и т.д.
Следующая лямбда-функция содержит несколько параметров.
Пример лямбда-функции с тремя параметрами:
>>> get_prod = lambda a, b, c : a * b * c
>>> get_prod(3, 5, 7)
105
Также лямбда-функция может принимать любое количество параметров.
Пример лямбда-функции с неопределенным числом аргументов (используются только первые 3):
Лямбда-функция без параметров
Ниже приведен пример лямбда-функции без параметров.
>>> welcome = lambda : print('Welcome!')
>>> welcome()
Welcome!
Анонимная функция
Мы можем объявить лямбда-функцию и вызвать ее как анонимную функцию, не присваивая ее переменной.
Пример анонимной лямбда-функции:
>>> (lambda x: x**3)(10)
1000
Здесь lambda x: x3 определяет анонимную функцию и вызывает ее один раз, передавая аргументы в скобках (lambda x: x3)(10).
В Python функции, как и литералы, можно передавать в качестве аргументов.
Лямбда-функции особенно полезны, когда мы хотим отправить функцию на вход другой функции. Мы можем передать анонимную лямбда-функцию, не присваивая ее переменной, в качестве аргумента другой функции.
Пример передачи лямбда-функции в качестве параметра:
def run_task(task):
print('Before running the task')
task()
print('After running the task')
run_task(lambda : print('Task is complete!')) # передача анонимной функции
important_task = lambda : print('Important task is complete!')
run_task(important_task) # передача лямбда-функции
Вывод:
Before running the task
Task is complete!
After running the task
Before running the task
Important task is complete!
After running the task
Представленная выше функция run_task() определена с параметром task, который вызывается как функция внутри run_task(). run_task(lambda : print(‘Task is complete!’)) вызывает функцию run_task() с анонимной лямбда-функцией в качестве аргумента.
В Python есть встроенные функции, которые принимают в качестве аргументов другие функции. Функции map(), filter() и reduce() являются важными инструментами функционального программирования. Все они принимают на вход функцию. Такая функция-аргумент может быть обычной функцией или лямбда-функцией.
Пример передачи лямбда-функции в map():
>>> prime_cube_list = map(lambda x: x**3, [2, 3, 5, 7, 11]) # передача анонимной функции
>>> next(prime_cube_list)
8
>>> next(prime_cube_list)
27
>>> next(prime_cube_list)
125
>>> next(prime_cube_list)
343
>>> next(prime_cube_list)
1331
Давайте посмотрим на следующий фрагмент:
# Простая программа на Python для демонстрации
# работы yield
# Функция-генератор, которая выдает 2 при
# первом обращении, 4 — при втором и
# 8 — при третьем
def simple_generator():
yield 2
yield 4
yield 8
# Код для проверки simple_generator()
for value in simple_generator():
print(value)
Вывод:
2
4
8
Функция с return отправляет указанное значение обратно вызвавшему его коду, в то время как yield может создавать последовательность возвращаемых значений. Мы должны использовать yield, когда хотим обработать множество объектов, но не хотим хранить их все в памяти.
Yield применяется в генераторах Python. Такой генератор определяется как обычная функция, но всякий раз, когда ей нужно выдать значение, она делает это с помощью ключевого слова yield, а не return. Если тело def содержит yield, то функция автоматически становится генератором.
# Программа на Python для генерации степеней 2
# от 2 до 256
def get_next_num():
n = 2
# Бесконечный цикл для генерации степеней 2
while True:
yield n
n *= 2 # При последующем обращении к
# get_next_num() выполнение
# продолжится отсюда
# Код для проверки get_next_num()
for num in get_next_num():
if num > 256:
break
print(num)
Вывод:
2
4
8
16
32
64
128
256
Кубический корень обозначается символом «3√». В случае с квадратным корнем мы использовали только символ ‘√’ без указания степени, который также называется радикалом.
Например, кубический корень из 125, обозначаемый как 3√125, равен 5, так как при умножении 5 на само себя три раза получается 5 x 5 x 5 = 125 = 5^3.
Кубический корень в Python
Чтобы вычислить кубический корень в Python, используйте простое математическое выражение x ** (1. / 3.), результатом которого является кубический корень из x в виде значения с плавающей точкой. Для проверки, корректно ли произведена операция извлечения корня, округлите полученный результат до ближайшего целого числа и возведите его в третью степень, после сравните, равен ли результат x.
x = 8
cube_root = x ** (1./3.)
print(cube_root)
Вывод
2.0
В Python для того, чтобы возвести число в степень, мы используем оператор **. Указание степени, равной 1/3, в выражении с ** позволяет получить кубический корень данного числа.
Извлечение кубического корня из отрицательного числа в Python
Мы не можем найти кубический корень из отрицательных чисел указанным выше способом. Например, кубический корень из целого числа -64 должен быть равен -4, но Python возвращает 2+3.464101615137754j.
Чтобы найти кубический корень из отрицательного числа в Python, сначала нужно применить функцию abs(), а затем можно воспользоваться представленным ранее простым выражением с ** для его вычисления.
Давайте напишем полноценную функцию, которая будет проверять, является ли входное число отрицательным, а затем вычислять его кубический корень соответствующим образом.
def get_cube_root(x):
if x < 0:
x = abs(x)
cube_root = x**(1/3)*(-1)
else:
cube_root = x**(1/3)
return cube_root
print(round(get_cube_root(64)))
print(get_cube_root(-64))
Вывод
4
-3.9999999999999996
Как видите, нам нужно округлить результат, чтобы получить целочисленное значение кубического корня.
Использование функции Numpy cbrt()
Библиотека numpy предлагает еще один вариант нахождения кубического корня в Python, который заключается в использовании метода cbrt(). Функция np.cbrt() вычисляет кубический корень для каждого элемента переданного ей массива.
import numpy as np
cubes = [125, -64, 27, -8, 1]
cube_roots = np.cbrt(cubes)
print(cube_roots)
Вывод
[ 5. -4. 3. -2. 1.]
Функция np.cbrt() — самый простой способ получения кубического корня числа. Она не испытывает проблем с отрицательными входными данными и возвращает целочисленное число, например, -4 для переданного в качестве аргумента числа -64, в отличие от вышеописанных подходов.
]]>В этой статье мы рассмотрим несколько примеров использования циклов for с функцией range() в Python.
Циклы for в Python
Циклы for повторяют определённый код для некоторого набора значений.
Из документации Python можно узнать, что в нем циклы for работают несколько иначе, чем в таких языках, как JavaScript или C.
Цикл for присваивает итерируемой переменной каждое значение из предоставленного списка, массива или строки и повторяет код в теле цикла for для каждого установленного таким образом значения переменной-итератора.
В приведенном ниже примере мы используем цикл for для вывода каждого числа в нашем массиве.
# Простой пример цикла for
for i in [0, 1, 2, 3, 4, 5]:
print(i, end="; ") # выведет: 0; 1; 2; 3; 4; 5;
В тело цикла for можно включить и более сложную логику. В следующем примере мы выводим результат небольшого вычисления, основанного на значении переменной i.
# Пример посложнее
for i in [0, 1, 2, 3, 4, 5]:
x = (i-2)*(i+2) - i**2 + 4
print(x, end="; ") # выведет: 0; 0; 0; 0; 0; 0;
Когда значения в массиве для нашего цикла for представляют собой некоторую закономерную последовательность, мы можем использовать функцию Python range() вместо того, чтобы вписывать содержимое нашего массива вручную.
Функция Range в Python
Функция range() возвращает последовательность целых чисел на основе переданных ей аргументов. Дополнительную информацию можно найти в документации Python по функции range().
range(stop)
range(start, stop[, step])
Аргумент start — это первое значение в диапазоне. Если функция range() вызывается только с одним аргументом, то Python считает, что start = 0.
Аргумент stop — это верхняя граница диапазона. Важно понимать, что само граничное значение не включается в последовательность.
В примере ниже у нас есть диапазон, начинающийся со значения по умолчанию, равному 0, и включающий целые числа меньше 6.
# Использование range() с единственным аргументом
for i in range(6):
print(i, end="; ") # выведет: 0; 1; 2; 3; 4; 5;
В следующем примере мы задаем start = -2 и включаем целые числа меньше 4.
# В этот раз передаются два аргумента
for i in range(-2, 4):
print(i, end="; ") # выведет: -2; -1; 0; 1; 2; 3;
Необязательное значение step (шаг) управляет приращением между значениями последовательности. По умолчанию step = 1.
В нашем последнем примере мы используем диапазон целых чисел от -2 до 6 и задаем step = 2.
# Здесь используются все аргументы range()
for i in range(-2, 6, 2):
print(i, end="; ") # выведет: -2; 0; 2; 4;
Заключение
В этой статье мы рассмотрели циклы for в Python и функцию range().
Циклы for обеспечивают повторное выполнение блока кода для всех значений в указанном списке, массиве, строке или последовательности, определенной с помощью функции range().
Как было показано, мы можем использовать range(), чтобы упростить написание цикла for. При вызове данной функции вы обязаны указать stop значение, также вами могут быть определены начальное значение и шаг между целыми числами в возвращаемом диапазоне.
]]>В повседневной практике необходимость изменить одно или несколько значений в списке возникает довольно часто. Предположим, вы создаете меню для ресторана и замечаете, что неправильно определили один из пунктов. Чтобы исправить подобную ошибку, вам нужно просто заменить существующий элемент в списке.
Замена элемента в списке на Python
Вы можете заменить элемент в списке на Python, используя цикл for, обращение по индексу или list comprehension. Первые два метода изменяют существующий список, а последний создает новый с заданными изменениями.
Давайте кратко опишем каждый метод:
- Обращение по индексу: мы используем порядковый номер элемента списка для изменения его значения. Знак равенства используется для присвоения нового значения выбранному элементу.
- List comprehension или генератор списка создает новый список из существующего. Синтаксис list comprehension позволяет добавлять различные условия для определения значений в новом списке.
- Цикл For выполняет итерацию по элементам списка. Для внесения изменений в данном случае используется обращение по индексу. Мы применяем метод enumerate() для создания двух списков: с индексами и с соответствующими значениями элементов — и итерируем по ним.
В этом руководстве мы рассмотрим каждый из этих методов. Для более полного понимания приведенных подходов мы также подготовили примеры использования каждого из них.
Замена элемента в списке на Python: обращение по индексу
Самый простой способ заменить элемент в списке — это использовать синтаксис обращения к элементам по индексу. Такой способ позволяет выбрать один элемент или диапазон последовательных элементов, а с помощью оператора присваивания вы можете изменить значение в заданной позиции списка.
Представим, что мы создаем программу, которая хранит информацию о ценах в магазине одежды. Цена первого товара в нашем списке должна быть увеличена на $2.
Начнем с создания списка, который содержит цены на наши товары:
prices = [29.30, 10.20, 44.00, 5.99, 81.90]
Мы используем обращение по индексу для выбора и изменения первого элемента в нашем списке 29.30. Данное значение имеет нулевой индекс. Это связано с тем, что списки индексируются, начиная с нуля.
prices[0] = 31.30
print(prices)
Наш код выбирает элемент в нулевой позиции и устанавливает его значение равным 31.30, что на $2 больше прежней цены. Далее мы возвращаем список со скорректированной ценой первого товара:
[31.30, 10.20, 44.00, 5.99, 81.90]
Мы также можем изменить наш список, добавив два к текущему значению prices[0]:
prices[0] = prices[0] + 2
print(prices)
prices[0] соответствует первому элементу в нашем списке (тот, который находится в позиции с нулевым индексом).
Этот код выводит список с теми же значениями, что и в первом случае:
[31.30, 10.20, 44.00, 5.99, 81.90]
Замена элемента в списке на Python: list comprehension
Применение генератора списка в Python может быть наиболее изящным способом поиска и замены элемента в списке. Этот метод особенно полезен, если вы хотите создать новый список на основе значений существующего.
Использование list comprehension позволяет перебирать элементы существующего списка и образовывать из них новый список на основе определенного критерия. Например, из последовательности слов можно скомпоновать новую, выбрав только те, которые начинаются на «C».
Здесь мы написали программу, которая рассчитывает 30% скидку на все товары в магазине одежды, стоимость которых превышает $40. Мы используем представленный ранее список цен на товары:
prices = [29.30, 10.20, 44.00, 5.99, 81.90]
Далее мы применяем list comprehension для замены элементов в нашем списке:
sale_prices = [round(price - (price * 30 / 100), 2) if price > 40 else price for price in prices]
print(sale_prices)
Таким образом, наш генератор проходит по списку «prices» и ищет значения стоимостью более 40 долларов. К найденным товарам применяется скидка в 30%. Мы округляем полученные значения цен со скидкой до двух десятичных знаков после точки с помощью метода round().
Наш код выводит следующий список с новыми ценами:
[29.3, 10.2, 30.8, 5.99, 57.33]
Замена элемента в списке на Python: цикл for
Вы можете изменить элементы списка с помощью цикла for. Для этого нам понадобится функция Python enumerate(). Эта функция возвращает два списка: список с номерами индексов и список со значениями соответствующих элементов. Мы можем выполнить необходимые итерации по этим двум последовательностям с помощью единственного цикла for.
В этом примере мы будем использовать тот же список цен:
prices = [29.30, 10.20, 44.00, 5.99, 81.90]
Затем мы определим цикл for, который проходит по данному списку с помощью функции enumerate():
for index, item in enumerate(prices):
if item > 40:
prices[index] = round(prices[index] - (prices[index] * 30 / 100), 2)
print(prices)
В коде выше переменная «index» содержит позиционный номер элемента. В свою очередь «item» — это значение, хранящееся в элементе списка на данной позиции. Индекс и соответствующее значение, возвращаемые методом enumerate(), разделяются запятой.
Подобное получение двух или более значений из возвращаемого функцией кортежа называется распаковкой. Мы «распаковали» элементы двух списков из метода enumerate().
Здесь мы используем ту же формулу, что и ранее, для расчета 30% скидки на товары стоимостью более 40 долларов. Давайте запустим наш код и посмотрим, что получится:
[29.3, 10.2, 30.8, 5.99, 57.33]
Наш код успешно изменяет товары в списке «prices» в соответствии с нашей скидкой.
Заключение
Вы можете заменить элементы в списке на Python с помощью обращения по индексу, list comprehension или цикла for.
Если вы хотите изменить одно значение в списке, то наиболее подходящим будет обращение по индексу. Для замены нескольких элементов в списке, удовлетворяющих определенному условию, хорошим решением будет использование list comprehension. Хотя циклы for более функциональны, они менее элегантны, чем генераторы списков.
]]>Определение функции
Функция — это многократно используемый блок программных инструкции, предназначенный для выполнения определенной задачи. Для определения функции в Python используется ключевое слово def. Ниже приведен синтаксис определения функции.
Синтаксис:
def имя_функции(параметры):
"""docstring"""
инструкция1
инструкция2
...
...
return [выражение]
За ключевым словом def следует подходящий идентификатор (имя функции) и круглые скобки. В круглых скобках может быть дополнительно указан один или несколько параметров. Символ ‘:’ после круглых скобок начинает блок с отступом (тело функции).
Первой инструкцией в теле функции может быть строка, которая называется docstring. Она описывает функциональность функции/класса. Строка docstring не является обязательной.
В общем случае тело функции содержит одну или несколько инструкций, которые выполняют некоторые действия. В нем также может использоваться ключевое слово pass.
Последней командой в блоке функции зачастую является инструкция return. Она возвращает управление обратно вызвавшему функцию окружению. Если после оператора return стоит выражение, то его значение также передается в вызывающий код.
В следующем примере определена функция welcome().
Пример созданной пользователем функции:
def welcome():
"""This function prints 'Welcome!'"""
print('Welcome!')
Выше мы определили функцию welcome(). Первая инструкция — это docstring, в котором сообщается о том, что делает эта функция. Вторая — это метод print, который выводит указанную строку на консоль. Обратите внимание, что welcome() не содержит оператор return.
Чтобы вызвать определенную ранее функцию, просто используйте выражение, состоящее из ее имени и двух круглых скобок ‘()’, в любом месте кода. Например, приведенная выше функция может быть вызвана так: welcome().
Пример вызова определенной пользователем функции:
welcome()
Вывод:
Welcome!
По умолчанию все функции возвращают None, если отсутствует оператор return.
returned_value = welcome()
print(returned_value)
Вывод:
Welcome!
None
Функция help() выводит docstring, как показано ниже.
>>> help(welcome)
Help on function welcome in module __main__:
welcome()
This function prints 'Welcome!'
Параметры функции
Функции также могут принимать на вход один или несколько параметров (они же аргументы) и использовать их для вычислений, определенных внутри функционального блока. В таком случае параметрам/аргументам даются подходящие формальные имена. Для примера изменим функцию welcome(): теперь она принимает в качестве параметра строку user_name; также изменена инструкция с функцией print() для отображения более персонализированного приветствия.
Пример функции с аргументами:
def welcome(user_name):
print('Welcome, ' + user_name + '!')
welcome('Anon') # вызов функции с параметром
Вывод:
Welcome, Anon!
Именованные аргументы, используемые в определении функции, называются формальными параметрами. В свою очередь, объекты, передаваемые в функцию при ее вызове, называются фактическими аргументами/параметрами.
Параметры функции могут иметь аннотацию для указания типа аргумента с использованием синтаксиса parameter:type. Например, следующая аннотация указывает тип параметра string.
Пример использования аннотации типов:
def welcome(user_name:str):
print('Welcome, ' + user_name + '!')
welcome('Anon') # передача строки в функцию
# пройдет нормально
welcome(42) # а передача числа в функцию
# вызовет ошибку
Передача нескольких параметров
Функция может иметь множество параметров. Представленная ниже вариация welcome() принимает три аргумента.
Пример определения функции с несколькими параметрами:
def welcome(first_name:str, last_name:str):
print('Welcome, ' + first_name + ' ' + last_name + '!')
welcome('Anton', 'Chekhov') # передача аргументов в функцию
Вывод:
Welcome, Anton Chekhov!
Неизвестное количество аргументов
Функция в Python может иметь неизвестное заранее число параметров. Укажите * перед аргументом, если вы не знаете, какое количество параметров передаст пользователь.
Пример функции с неизвестным числом параметров (используются только первые 3):
def welcome(*name_parts):
message = 'Welcome, ' + name_parts[0] + " "
message += name_parts[1] + " " + name_parts[2]
print(message + "!")
welcome('Anton', 'Pavlovich', 'Chekhov')
Вывод:
Welcome, Anton Pavlovich Chekhov!
Следующая функция работает с любым количеством аргументов.
Пример функции, использующей все переданные ей параметры:
def welcome(*name_parts):
message = 'Welcome,'
for part in name_parts:
message += " " + part
print(message + "!")
welcome('Anton', 'Pavlovich', 'Chekhov',
'and', 'Fyodor', 'Mikhailovich', 'Dostoevsky')
Вывод:
Welcome, Anton Pavlovich Chekhov and Fyodor Mikhailovich Dostoevsky!
Аргументы-ключевые слова
Чтобы использовать функцию с параметрами, необходимо предоставить ей фактические аргументы в количестве, соответствующем числу формальных. С другой стороны, при вызове функции мы не обязаны соблюдать указанный в определении порядок параметров. Но в таком случае при передаче значений аргументов мы должны явно указать имена соответствующих формальных параметров. В следующем примере фактические значения передаются с использованием имен параметров.
def welcome(first_name:str, last_name:str):
print('Welcome, ' + first_name + ' ' + last_name + '!')
welcome(last_name='Chekhov', first_name='Anton') # передача
# аргументов в функцию в произвольном порядке
Вывод:
Welcome, Anton Chekhov!
Аргументы-ключевые слова **kwarg
Функция может иметь только один параметр с префиксом **. Он инициализирует новое упорядоченное отображение (словарь), содержащее все оставшееся без соответствующего формального параметра аргументы-ключевые слова.
Пример использования **kwarg:
def welcome(**name_parts):
print('Welcome, ' + name_parts['first_name'] + ' ' + name_parts['last_name'] + '!')
welcome(last_name='Chekhov', first_name='Anton')
welcome(last_name='Chekhov', first_name='Anton', age='28')
welcome(last_name='Chekhov') # вызовет KeyError
Вывод:
Welcome, Anton Chekhov!
Welcome, Anton Chekhov!
При использовании параметра ** порядок аргументов не имеет значения. Однако их имена должны быть идентичными. Доступ к аргументам-ключевым словам для получения переданных значений осуществляется с помощью такого выражения: имя_параметра_kwarg[‘имя_переданного_аргумента’].
Если функция обращается к аргументу-ключевому слову, но вызывающий код не передает этот параметр, то она вызовет исключение KeyError, как показано ниже.
Пример функции, вызывающей KeyError:
def welcome(**name_parts):
print('Welcome, ' + name_parts['first_name'] + ' ' + name_parts['last_name'] + '!')
welcome(last_name='Chekhov') # вызывет KeyError: необходимо предоставить аргумент 'first_name'
Вывод:
Traceback (most recent call last):
...
line 2, in welcome
print('Welcome, ' + name_parts['first_name'] + ' ' + name_parts['last_name'] + '!')
KeyError: 'first_name'
Параметры со значением по умолчанию
При определении функции ее параметрам могут быть присвоены значения по умолчанию. Такое значение заменяется на соответствующий фактический аргумент, если он был передан при вызове функции. Однако если фактический параметр не был предоставлен, то внутри функции будет использоваться значение по умолчанию.
Представленная ниже функция welcome() определена с параметром name, имеющим значение по умолчанию ‘Anon’. Оно будет заменено только в том случае, если вызывающей стороной будет передан какой-либо фактический аргумент.
Пример функции со значением по умолчанию:
def welcome(user:str = 'Anon'):
print('Welcome, ' + user + '!')
welcome()
welcome('Chekhov')
Вывод:
Welcome, Anon!
Welcome, Chekhov!
Функция с возвращаемым значением
Чаще всего нам нужен результат работы функции для использования в дальнейших вычислениях. Следовательно, когда функция завершает выполнение, она также должна возвращать какое-то результирующее значение.
Для того, чтобы передать подобное значение внешнему коду, функция должна содержать инструкцию с оператором return. В этом случае возвращаемое значение должно быть указано после return.
Пример функции с возвращаемым значением:
def get_product(a, b):
return a * b
Ниже показано, как при вызове функции get_product() получить результат ее работы.
Пример использования функции с возвращаемым значением:
result = get_product(6, 7)
print(result)
result = get_product(3, get_product(4, 5))
print(result)
Вывод:
42
60
Enum в Python
Перечисления — это наборы символических имен, связанных с уникальными константными значениями. Они используются для создания простых пользовательских типов данных, таких как времена года, недели, виды оружия в игре, планеты, оценки или дни. По соглашению имена перечислений начинаются с заглавной буквы и употребляются в единственном числе.
Модуль enum используется для создания перечислений в Python. Вы можете определить их с помощью ключевого слова class или с помощью функционального API.
Существуют специальные производные перечисления enum.IntEnum, enum.IntFlag и enum.Flag.
Простой пример использования enum в Python
Ниже приведен простой пример кода на Python, использующего перечисления.
#!/usr/bin/python3
from enum import Enum
class Weapon(Enum):
SWORD = 1
BOW = 2
DAGGER = 3
CLUB = 4
ranged_weapon = Weapon.BOW
print(ranged_weapon)
if ranged_weapon == Weapon.BOW:
print("It's a bow")
print(list(Weapon))
В примере у нас есть перечисление Weapon, которое имеет четыре различных значения: SWORD, BOW, DAGGER и CLUB. Чтобы получить доступ к одному из членов enum, мы должны указать название перечисления, за которым следует точка и имя интересующей нас символической константы.
class Weapon(Enum):
SWORD = 1
BOW = 2
DAGGER = 3
CLUB = 4
Перечисление Weapon создается нами с помощью ключевого слова class, то есть происходит наследование от базового класса enum.Enum. После этого мы явно задаем числа, соответствующие значениям перечисления.
ranged_weapon = Weapon.BOW
print(ranged_weapon)
Здесь символическая константа присваивается переменной и выводится на консоль.
if ranged_weapon == Weapon.BOW:
print("It's a bow")
Данный фрагмент демонстрирует использование Weapon.BOW в выражении if.
print(list(Weapon))
С помощью встроенной функции list мы получаем список всех возможных значений для перечисления Weapon.
Вывод:
Weapon.BOW
It's a bow
[, , , ]
Еще один пример использования enum в Python
В следующем примере представлена другая часть базовой функциональности перечислений в Python.
#!/usr/bin/python3
from enum import Enum
class Weapon(Enum):
SWORD = 1
BOW = 2
DAGGER = 3
CLUB = 4
weapon = Weapon.SWORD
print(weapon)
print(isinstance(weapon, Weapon))
print(type(weapon))
print(repr(weapon))
print(Weapon['SWORD'])
print(Weapon(1))
И снова мы имеем дело с enum Weapon, созданным с помощью класса.
print(weapon)
Здесь мы выводим человекочитаемое строковое представление одного из членов перечисления.
print(isinstance(weapon, Weapon))
С помощью метода isinstance мы проверяем, имеет ли переменная значение типа Weapon.
print(type(weapon))
Функция type выводит тип переменной.
print(repr(weapon))
Функция repr предоставляет дополнительную информацию о перечислении.
print(Weapon['SWORD'])
print(Weapon(1))
Доступ к символической константе можно получить как по ее имени, так и по значению (индексу).
Вывод:
Weapon.SWORD
True
Weapon.SWORD
Weapon.SWORD
Функциональное создание enum в Python
Перечисления Python также могут быть созданы с помощью функционального API.
from enum import Enum
Weapon = Enum('Weapon', 'SWORD BOW DAGGER CLUB', start=1)
weapon = Weapon.DAGGER
print(weapon)
if weapon == Weapon.DAGGER:
print("Dagger")
Есть несколько способов, как мы можем указать значения, используя функциональный API. В последующих примерах мы будем применять различные варианты их задания.
Weapon = Enum('Weapon', 'SWORD BOW DAGGER CLUB', start=1)
Здесь наименования символических констант задаются в строке, разделенные пробелами. Число, переданное в start, определяет начало нумерации значений для членов перечисления.
Вывод:
Weapon.DAGGER
Dagger
Итерирование enum в Python
Мы можем выполнять итерацию по перечислениям Python.
from enum import Enum
Weapon = Enum('Weapon', 'SWORD BOW DAGGER CLUB', start=10)
for weapon in Weapon:
print(weapon)
for weapon in Weapon:
print(weapon.name, weapon.value)
В этом примере мы создаем перечисление Weapon, где символьные константы задаются в виде списка строк.
for weapon in Weapon:
print(weapon)
В коде выше мы выполняем итерации по членам перечисления в цикле for.
for weapon in Weapon:
print(weapon.name, weapon.value)
Здесь мы выводим их имена и значения.
Вывод:
Weapon.SWORD
Weapon.BOW
Weapon.DAGGER
Weapon.CLUB
SWORD 10
BOW 11
DAGGER 12
CLUB 13
Автоматическое назначение имен для enum в Python
Значения символьных констант могут быть автоматически установлены с помощью функции auto().
#!/usr/bin/python3
from enum import Enum, auto
class Weapon(Enum):
SWORD = auto()
BOW = auto()
DAGGER = auto()
CLUB = auto()
for weapon in Weapon:
print(weapon.value)
В этом фрагменте мы создали перечисление Weapon, члены которого получают значения с помощью функции auto.
Вывод:
1
2
3
4
Уникальные значения enum в Python
Значения символьных констант могут быть принудительно уникальными с помощью декоратора @unique.
#!/usr/bin/python3
from enum import Enum, unique
@unique
class Weapon(Enum):
SWORD = 1
BOW = 2
DAGGER = 3
CLUB = 3
# CLUB = 4
for weapon in Weapon:
print(weapon)
Данный пример завершается с ошибкой ValueError: duplicate values found in : CLUB -> DAGGER, потому что члены CLUB и DAGGER имеют одинаковые значения. Если мы закомментируем декоратор @unique, пример выведет три члена; CLUB игнорируется.
Python enum __members__
Специальный атрибут members представляет собой упорядоченное отображение имен на символьные константы enum, доступное только для чтения.
#!/usr/bin/python3
from enum import Enum
Weapon = Enum('Weapon', [('SWORD', 1), ('BOW', 2),
('DAGGER', 3), ('CLUB', 4)])
for name, member in Weapon.__members__.items():
print(name, member)
В этом примере мы используем свойство members. Члены перечисления заданы списком кортежей с помощью функционального API.
Вывод:
SWORD Weapon.SWORD
BOW Weapon.BOW
DAGGER Weapon.DAGGER
CLUB Weapon.CLUB
enum.Flag
Enum.Flag — это базовый класс для создания пронумерованных констант, которые можно объединять с помощью побитовых операций без потери их принадлежности к Flag.
#!/usr/bin/python3
from enum import Flag, auto
class Permission(Flag):
READ = auto()
WRITE = auto()
EXECUTE = auto()
print(list(Permission))
print(Permission.READ | Permission.WRITE)
Пример выше показывает, как флаг может быть использован для проверки или установки разрешений.
Вывод:
[<Permission.READ: 1>, <Permission.WRITE: 2>, <Permission.EXECUTE: 4>]
Permission.WRITE|READЕсли вы считаете Colorama полезной, не забудьте поблагодарить ее авторов и сделать пожертвование. Спасибо!
Установка
pip install colorama
# или
conda install -c anaconda colorama
Описание
Управляющие символы ANSI давно используются для создания цветного текста и позиционирования курсора в терминале на Unix и Mac. Colorama делает возможным их использование на платформе Windows, оборачивая stdout, удаляя найденные ANSI-последовательности (которые будут выглядеть как тарабарщина при выводе) и преобразуя их в соответствующие вызовы win32 для изменения состояния командной строки. На других платформах Colorama ничего не меняет.
В результате мы получаем простой кроссплатформенный API для отображения цветного терминального текста из Python, а также следующий приятный побочный эффект: существующие приложения или библиотеки, использующие ANSI-последовательности для создания цветного вывода на Linux или Mac, теперь могут работать и на Windows, просто вызвав colorama.init().
Альтернативный подход заключается в установке ansi.sys на машины с Windows, что обеспечивает одинаковое поведение для всех приложений, работающих с командной строкой. Colorama предназначена для ситуаций, когда это не так просто (например, может быть, у вашего приложения нет программы установки).
Демо-скрипты в репозитории исходного кода библиотеки выводят небольшой цветной текст, используя последовательности ANSI. Сравните их работу в Gnome-terminal и в Windows Command-Prompt, где отображение осуществляется с помощью Colorama:
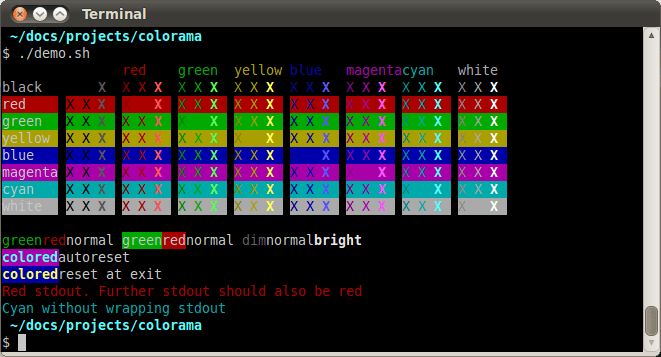
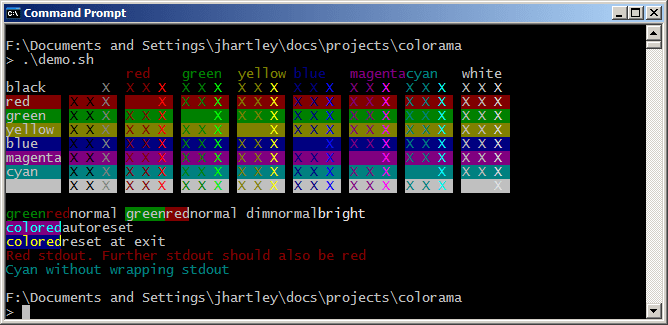
Эти скриншоты показывают, что в Windows Colorama не поддерживает ANSI ‘dim text’ (тусклый текст); он выглядит так же, как и ‘normal text’.
Использование
Инициализация
Приложения должны инициализировать Colorama с помощью:
from colorama import init
init()
В Windows вызов init() отфильтрует управляющие ANSI-последовательности из любого текста, отправленного в stdout или stderr, и заменит их на эквивалентные вызовы Win32.
На других платформах вызов init() не имеет никакого эффекта (если только вы не укажете другие дополнительные возможности; см. раздел «Аргументы Init», ниже). По задумке разработчиков такое поведение позволяет приложениям вызывать init() безоговорочно на всех платформах, после чего вывод ANSI должен просто работать.
Чтобы прекратить использование Colorama до выхода из программы, просто вызовите deinit(). Данный метод вернет stdout и stderr к их исходным значениям, так что Colorama будет отключена. Чтобы возобновить ее работу, используйте reinit(); это выгоднее, чем повторный вызов init() (но делает то же самое).
Цветной вывод
Кроссплатформенное отображение цветного текста может быть упрощено за счет использования константных обозначений для управляющих последовательностей ANSI, предоставляемых библиотекой Colorama:
from colorama import init
init()
from colorama import Fore, Back, Style
print(Fore.GREEN + 'зеленый текст')
print(Back.YELLOW + 'на желтом фоне')
print(Style.BRIGHT + 'стал ярче' + Style.RESET_ALL)
print('обычный текст')
При этом вы также можете использовать ANSI-последовательности напрямую в своем коде:
print('\033[31m' + 'красный текст')
print('\033[39m') # сброс к цвету по умолчанию
Еще одним вариантом является применение Colorama в сочетании с существующими ANSI библиотеками, такими как Termcolor или Blessings. Такой подход настоятельно рекомендуется для чего-то большего, чем тривиальное выделение текста:
from colorama import init
from termcolor import colored
# используйте Colorama, чтобы Termcolor работал и в Windows
init()
# теперь вы можете применять Termcolor для вывода
# вашего цветного текста
print(colored('Termcolor and Colorama!', 'red', 'on_yellow'))
Доступны следующие константы форматирования:
// цвет текста
Fore: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
// цвет фона
Back: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE, RESET.
// яркость текста и общий сброс
Style: DIM, NORMAL, BRIGHT, RESET_ALL
Style.RESET_ALL сбрасывает настройки цвета текста, фона и яркости. Colorama выполнит этот сброс автоматически при выходе из программы.
Позиционирование курсора
Библиотекой поддерживаются ANSI-коды для изменения положения курсора. Пример их генерации смотрите в demos/demo06.py.
Аргументы Init
init() принимает некоторые **kwargs для переопределения поведения по умолчанию.
init(autoreset=False):
Если вы постоянно осуществляете сброс указанных вами цветовых настроек после каждого вывода, init(autoreset=True) будет выполнять это по умолчанию:
from colorama import init, Fore
init(autoreset=True)
print(Fore.GREEN + 'зеленый текст')
print('автоматический возврат к обычному')
init(strip=None):
Передайте True или False, чтобы определить, должны ли коды ANSI удаляться при выводе. Поведение по умолчанию — удаление, если программа запущена на Windows или если вывод перенаправляется (не на tty).
init(convert=None):
Передайте True или False, чтобы определить, следует ли преобразовывать ANSI-коды в выводе в вызовы win32. По умолчанию Colorama будет их конвертировать, если вы работаете под Windows и вывод осуществляется на tty (терминал).
init(wrap=True):
В Windows Colorama заменяет sys.stdout и sys.stderr прокси-объектами, которые переопределяют метод .write() для выполнения своей работы. Если эта обертка вызывает у вас проблемы, то ее можно отключить, передав init(wrap=False). Поведение по умолчанию — обертывание, если autoreset, strip или convert равны True.
Когда обертка отключена, цветной вывод на платформах, отличных от Windows, будет продолжать работать как обычно. Для кроссплатформенного цветного отображения текста можно использовать AnsiToWin32 прокси, предоставляемый Colorama, напрямую:
import sys
from colorama import init, Fore, AnsiToWin32
init(wrap=False)
stream = AnsiToWin32(sys.stderr).stream
# Python 2
print >>stream, Fore.RED + 'красный текст отправлен в stderr'
# Python 3
print(Fore.RED + 'красный текст отправлен в stderr', file=stream)
Распознаваемые ANSI-последовательности
Последовательности ANSI обычно имеют вид:
ESC [ <параметр> ; <параметр> ... <команда>
Где <параметр> — целое число, а <команда> — один символ. В <команда> передается ноль или более параметров. Если параметры не представлены, это, как правило, синоним передачи одного нуля. В последовательности нет пробелов; они были добавлены здесь исключительно для удобства чтения.
Единственные ANSI-последовательности, которые Colorama преобразует в вызовы win32, это:
ESC [ 0 m # сбросить все (цвета и яркость)
ESC [ 1 m # яркий
ESC [ 2 m # тусклый (выглядит так же, как обычная яркость)
ESC [ 22 м # нормальная яркость
# FOREGROUND (цвет текста)
ESC [ 30 м # черный
ESC [ 31 м # красный
ESC [ 32 м # зеленый
ESC [ 33 м # желтый
ESC [ 34 m # синий
ESC [ 35 m # пурпурный
ESC [ 36 m # голубой
ESC [ 37 m # белый
ESC [ 39 m # сброс
# ФОН
ESC [ 40 m # черный
ESC [ 41 m # красный
ESC [ 42 м # зеленый
ESC [ 43 m # желтый
ESC [ 44 m # синий
ESC [ 45 m # пурпурный
ESC [ 46 m # голубой
ESC [ 47 m # белый
ESC [ 49 m # сброс
# позиционирование курсора
ESC [ y;x H # позиционирование курсора в позиции x, y (у направлена вниз)
ESC [ y;x f # позиционирование курсора в точке x, y
ESC [ n A # перемещение курсора на n строк вверх
ESC [ n B # перемещение курсора на n строк вниз
ESC [ n C # перемещение курсора на n символов вперед
ESC [ n D # перемещение курсора на n символов назад
# очистить экран
ESC [ режим J # очистить экран
# очистить строку
ESC [ режим K # очистить строку
Несколько числовых параметров команды ‘m’ могут быть объединены в одну последовательность:
ESC [ 36 ; 45 ; 1 m # яркий голубой текст на пурпурном фоне
Все другие ANSI-последовательности вида ESC [ <параметр> ; <параметр> … <команда> молча удаляются из вывода в Windows.
Любые другие формы ANSI-последовательностей, такие как односимвольные коды или альтернативные начальные символы, не распознаются и не удаляются. Однако было бы здорово добавить их. Вы можете сообщить разработчикам, если это будет полезно для вас, через Issues на GitHub.
Текущий статус и известные проблемы
Лично я тестировал библиотеку только на Windows XP (CMD, Console2), Ubuntu (gnome-terminal, xterm) и OS X.
Некоторые предположительно правильные ANSI-последовательности не распознаются (см. подробности ниже), но, насколько мне известно, никто еще не жаловался на это. Загадка.
См. нерешенные проблемы и список пожеланий: https://github.com/tartley/colorama/issues
Если у вас что-то не работает или делает не то, что вы ожидали, авторы библиотеки будут рады услышать об этом в списке проблем, указанном выше, также они с удовольствием ждут и предоставляют доступ к коммиту любому, кто напишет один или, может, пару рабочих патчей.
]]>Код #1: Демонстрация работы yield
# Код на Python3 для демонстрации
# использования ключевого слова yield
# генерация нового списка, состоящего
# только из четных чисел
def get_even(list_of_nums) :
for i in list_of_nums:
if i % 2 == 0:
yield i
# инициализация списка
list_of_nums = [1, 2, 3, 8, 15, 42]
# вывод начального списка
print ("До фильтрации в генераторе: " + str(list_of_nums))
# вывод только четных значений из списка
print ("Только четные числа: ", end = " ")
for i in get_even(list_of_nums):
print (i, end = " ")
Вывод
До фильтрации в генераторе: [1, 2, 3, 8, 15, 42]
Только четные числа: 2 8 42
Код #2
# Данная Python программа выводит
# числа от 1 до 15, возведенные в куб,
# используя yield и, следовательно, генератор
# Функция ниже будет бесконечно генерировать
# последовательность чисел в третьей степени,
# начиная с 1
def nextCube():
acc = 1
# Бесконечный цикл
while True:
yield acc**3
acc += 1 # После повторного обращения
# исполнение продолжится отсюда
# Ниже мы запрашиваем у генератора
# и выводим ровно 15 чисел
count = 1
for num in nextCube():
if count > 15:
break
print(num)
count += 1
Вывод:
1
8
27
64
125
216
343
512
729
1000
1331
1728
2197
2744
3375
Преимущества yield:
- Поскольку генераторы автоматически сохраняют и управляют состояниями своих локальных переменных, программист не должен заботиться о накладных расходах, связанных с выделением и освобождением памяти.
- Так как при очередном вызове генератор возобновляет свою работу, а не начинает с самого начала, общее время выполнения сокращается.
Недостатки yield:
- Иногда использование yield может вызвать ошибки, особенно если вызов функции не обрабатывается должным образом.
- За оптимизацию времени работы и используемой памяти приходится платить сложностью кода, поэтому иногда трудно сходу понять логику, лежащую в его основе.
Практическое применение
Один из вариантов практического применения генераторов заключается в том, что при обработке большого объема данных и поиске в нем, выгодно использовать yield, так как зачастую нам не нужно повторно осматривать уже проверенные объекты. Такой подход значительно сокращает затраченное программой время. В зависимости от конкретной ситуации существует множество различных вариантов использования yield.
# Код Python3 для демонстрации
# использования ключевого слова yield
# Поиск слова pythonru в тексте
# Импорт библиотеки для работы
# с регулярными выражениями
import re
# Этот генератор создает последовательность
# значений True: по одному на каждое
# найденное слово pythonru
# Также для наглядности он выводит
# обработанные слова
def get_pythonru (text) :
text = re.split('[., ]+', text)
for word in text:
print(word)
if word == "pythonru":
yield True
# Инициализация строки, содержащей текст для поиска
text = "В Интернете есть множество сайтов, \
но только один pythonru. \
Программа никогда не прочтет \
последнее предложение."
# Инициализация переменной с результатом
result = "не найден"
# Цикл произведет единственную итерацию
# в случае наличия в тексте pythonru и
# не сделает ни одной, если таких слов нет
for j in get_pythonru(text):
result = "найден"
break
print ('Результат поиска: %s' % result)
Вывод
В
Интернете
есть
множество
сайтов
но
только
один
pythonru
Результат поиска: найден
Сначала давайте вкратце рассмотрим, что такое список в Python и как найти в нем максимальное значение или просто наибольшее число.
Список в Python
В Python есть встроенный тип данных под названием список (list). По своей сути он сильно напоминает массив. Но в отличие от последнего данные внутри списка могут быть любого типа (необязательно одного): он может содержать целые числа, строки или значения с плавающей точкой, или даже другие списки.
Хранимые в списке данные определяются как разделенные запятыми значения, заключенные в квадратные скобки. Списки можно определять, используя любое имя переменной, а затем присваивая ей различные значения в квадратных скобках. Он является упорядоченным, изменяемым и допускает дублирование значений. Например:
list1 = ["Виктор", "Артем", "Роман"]
list2 = [16, 78, 32, 67]
list3 = ["яблоко", "манго", 16, "вишня", 3.4]
Далее мы рассмотрим возможные варианты кода на Python, реализующего поиск наибольшего элемента в списке, состоящем из сравниваемых элементов. В наших примерах будут использоваться следующие методы/функции:
- Встроенная функция
max() - Метод грубой силы (перебора)
- Функция
reduce() - Алгоритм Heap Queue (очередь с приоритетом)
- Функция
sort() - Функция
sorted() - Метод хвостовой рекурсии
№1 Нахождение максимального значения с помощью функции max()
Это самый простой и понятный подход к поиску наибольшего элемента. Функция Python max() возвращает самый большой элемент итерабельного объекта. Ее также можно использовать для поиска максимального значения между двумя или более параметрами.
В приведенном ниже примере список передается функции max в качестве аргумента.
list1 = [3, 2, 8, 5, 10, 6]
max_number = max(list1)
print("Наибольшее число:", max_number)
Наибольшее число: 10Если элементы списка являются строками, то сначала они упорядочиваются в алфавитном порядке, а затем возвращается наибольшая строка.
list1 = ["Виктор", "Артем", "Роман"]
max_string = max(list1, key=len)
print("Самая длинная строка:", max_string)
Самая длинная строка: Виктор№2 Поиск максимального значения перебором
Это самая простая реализация, но она немного медленнее, чем функция max(), поскольку мы используем этот алгоритм в цикле.
В примере выше для поиска максимального значения нами была определена функция large(). Она принимает список в качестве единственного аргумента. Для сохранения найденного значения мы используем переменную max_, которой изначально присваивается первый элемент списка. В цикле for каждый элемент сравнивается с этой переменной. Если он больше max_, то мы сохраняем значение этого элемента в нашей переменной. После сравнения со всеми членами списка в max_ гарантировано находится наибольший элемент.
def large(arr):
max_ = arr[0]
for ele in arr:
if ele > max_:
max_ = ele
return max_
list1 = [1,4,5,2,6]
result = large(list1)
print(result) # вернется 6
№3 Нахождение максимального значения с помощью функции reduce()
В функциональных языках reduce() является важной и очень полезной функцией. В Python 3 функция reduce() перенесена в отдельный модуль стандартной библиотеки под названием functools. Это решение было принято, чтобы поощрить разработчиков использовать циклы, так как они более читабельны. Рассмотрим приведенный ниже пример использования reduce() двумя разными способами.
В этом варианте reduce() принимает два параметра. Первый — ключевое слово max, которое означает поиск максимального числа, а второй аргумент — итерабельный объект.
from functools import reduce
list1 = [-1, 3, 7, 99, 0]
print(reduce(max, list1)) # вывод: 99
Другое решение показывает интересную конструкцию с использованием лямбда-функции. Функция reduce() принимает в качестве аргумента лямбда-функцию, а та в свою очередь получает на вход условие и список для проверки максимального значения.
from functools import reduce
list1 = [-1, 3, 7, 99, 0]
print(reduce(lambda x, y: x if x > y else y, list1)) # -> 99
№4 Поиск максимального значения с помощью приоритетной очереди
Heapq — очень полезный модуль для реализации минимальной очереди. Если быть более точным, он предоставляет реализацию алгоритма очереди с приоритетом на основе кучи, известного как heapq. Важным свойством такой кучи является то, что ее наименьший элемент всегда будет корневым элементом. В приведенном примере мы используем функцию heapq.nlargest() для нахождения максимального значения.
import heapq
list1 = [-1, 3, 7, 99, 0]
print(heapq.nlargest(1, list1)) # -> [99]
Приведенный выше пример импортирует модуль heapq и принимает на вход список. Функция принимает n=1 в качестве первого аргумента, так как нам нужно найти одно максимальное значение, а вторым аргументом является наш список.
№5 Нахождение максимального значения с помощью функции sort()
Этот метод использует функцию sort() для поиска наибольшего элемента. Он принимает на вход список значений, затем сортирует его в порядке возрастания и выводит последний элемент списка. Последним элементом в списке является list[-1].
list1 = [10, 20, 4, 45, 99]
list1.sort()
print("Наибольшее число:", list1[-1])
Наибольшее число: 99№6 Нахождение максимального значения с помощью функции sorted()
Этот метод использует функцию sorted() для поиска наибольшего элемента. В качестве входных данных он принимает список значений. Затем функция sorted() сортирует список в порядке возрастания и выводит наибольшее число.
list1=[1,4,22,41,5,2]
sorted_list = sorted(list1)
result = sorted_list[-1]
print(result) # -> 41
№7 Поиск максимального значения с помощью хвостовой рекурсии
Этот метод не очень удобен, и иногда программисты считают его бесполезным. Данное решение использует рекурсию, и поэтому его довольно сложно быстро понять. Кроме того, такая программа очень медленная и требует много памяти. Это происходит потому, что в отличие от чистых функциональных языков, Python не оптимизирован для хвостовой рекурсии, что приводит к созданию множества стековых фреймов: по одному для каждого вызова функции.
def find_max(arr, max_=None):
if max_ is None:
max_ = arr.pop()
current = arr.pop()
if current > max_:
max_ = current
if arr:
return find_max(arr, max_)
return max_
list1=[1,2,3,4,2]
result = find_max(list1)
print(result) # -> 4
Заключение
В этой статье мы научились находить максимальное значение из заданного списка с помощью нескольких встроенных функций, таких как max(), sort(), reduce(), sorted() и других алгоритмов. Мы написали свои код, чтобы попробовать метод перебора, хвостовой рекурсии и алгоритма приоритетной очереди.
Большинство моих однокурсников только и мечтали о том, как они наконец закончат универ и смогут заниматься чем-то по-настоящему крутым. Вместо скучных лекций и семинаров реальные проекты, которые действительно меняют мир вокруг.
Мне же во время учебы совсем не хватало времени на то, чтобы думать о том, что будет после диплома. Сейчас, в середине лета, наконец появилось время подумать о своем будущем.
Я решил подойти к делу обстоятельно, поэтому постарался структурировать все варианты (спойлер, их два основных), оценить все «за» и «против» и уже на основе этого мини исследования принимать решение. Надеюсь, кому-нибудь это тоже будет полезно и поможет увидеть новые возможности.
Вводные и первые выводы
Дано:
- выпускник технического вуза,
- хорошо разбираюсь в математике и знаю Python,
- рассматриваю переезд,
- хочу зарабатывать.
Основных гипотез у меня было две: работа или продолжение учебы в каком-либо виде с подработками.
Можно было еще рассмотреть варианты номер три и четыре — не делать ничего целый год или отправиться волонтером в какую-нибудь отдаленную часть света. Но если свериться с «Дано», становится понятно, что эти варианты не удовлетворяли условию моей задачи, поэтому не рассматривались.
Проверка гипотезы #1 — работа
С самого начала я был настроен на поиск удаленной работы, потому что этот вариант мне казался наиболее реальным. Знание Python и интерес к машинному обучению были на моей стороне, поэтому я вооружился чаем и начал изучать сайты с вакансиями.
За пару дней не осталось предложений в моём городе (Калининград), которые бы не попались мне два, а то и три раза. Я отправил 28 откликов на вакансии, показавшиеся мне интересными.
Основной критерий здесь был такой: если при прочтении текста вакансии я думал: «Классное место! Здесь мне будет интересно», то отправлял свое резюме.
- На мои запросы в течение недели пришло 12 ответов.
- 5 из них поблагодарили за интерес и обещали иметь меня ввиду.
- 7 пригласили на собеседование или предложили тестовые задания.
Мне показался этот результат вполне положительным. В итоге, у меня на руках были 3 перспективы получить работу.
Проверка гипотезы #2 — учеба и подработка
Эта гипотеза изначально не вызывала у меня уверенности.
Допустим, я смогу найти интересную магистратуру в моём городе — Калининграде. Но нужно будет еще искать работу, которую получится совместить с учебой. А значит, работать придётся больше, чем при варианте #1: учеба — работа — сон — учеба — и т.д. Я не против труда, но опасался, что просто не смогу качественно успевать на обоих фронтах.
И я до сих пор благодарю сам себя, что не остановился на гипотезе #1. В ней все хорошо, но я даже не думал, что смогу найти то, что полностью будет подходить под мой запрос.
Мой поиск привел меня на сайт МФТИ. Где я наткнулся на магистратуру «Системы машинного обучения для умного производства». Сразу скажу, что свой запрос на участие в отборе на грант я уже отправил. Но решил поделиться, потому что знаю, насколько иногда важно найти нужную информацию.
В общем, программу МФТИ запускает в этом году впервые в партнерстве с группой НЛМК. Это большая сталелитейная компания, которая сейчас активно проходит цифровизацию производства: это огромные площадки, где нужно продумывать и оцифровывать сотни процессов.
Я не просто так делаю на этом акцент. Первое, что меня заинтересовало в этой программе — работа под руководством IT-специалистов НЛМК над проектами компании. Ни через год или два, а с первого семестра учебы. Одна мысль о том, что во время магистратуры не придется довольствоваться только теорией, меня крайне впечатлила.
Следующий аргумент «за» — грант. Магистранты не платят за это обучение совсем. Как я понял, суть в том, что компания НЛМК готова выращивать свои кадры. Поэтому они берут тех, кто разбирается в программировании и математике, и обеспечивают им среду для роста. А за пару лет плотной работы с задачами НЛМК магистранты превращаются в спецов Data Science и инженеров искусственного интеллекта.
Кстати, о работе тоже переживать не придется. Студенты получают доход от 35 до 80 тыс. рублей и официальный опыт работы с первых дней учебы. В интервью с куратором программы Шамилем Ульбашевым я прочитал, что доход на последних курсах может расти до 140 тыс. рублей, это зависит от самого студента. Чем больше пользы приносишь, тем больше получаешь.
Смотрите, какой у меня итог:
- не платишь за учебу, при этом учишься в самых эффективных условиях: теорию отрабатываешь на реальных задачах,
- есть наставник и команда,
- получаешь доход 35-140 тыс. рублей, который зависит только от тебя.
Итог исследования
Надеюсь, что мой небольшой эксперимент поможет кому-нибудь понять, что возможностей на самом деле гораздо больше, чем кажется. За пару недель поисков я смог получить 3 потенциальных предложения о работе и найти магистратуру по моему технарскому профилю, в которой действительно захотелось учиться. Я даже готов двигать ради такой возможности в Москву!
Если кому-то интересно, вот сайт магистратуры, может, будем учиться вместе.
Удачи всем выпускникам в определении своего пути!
Автор: Игорь Макушев
]]>Новичкам не нужно жонглировать двоичными представлениями, чтобы научиться программировать на Python. Существует несколько инструментов для написания кода с простым и понятным интерфейсом. Они поощряют детей пробовать свои силы в программировании, тем самым удовлетворяя их потребность в изучении Python.
Вы можете обучать детей языку Python, не заставляя их выполнять утомительные задания по предварительному чтению гор специализированной литературы.
Python считается современным языком программирования и используется для разработки бесчисленных программных продуктов. С помощью него дети могут создавать свои приложения от простого вывода «Hello World!» до разработки анимации и игр. Программирование на Python развивает у ребенка интерес к изучению этой сферы.
Что такое Python?
Python — один из самых популярных языков программирования последнего времени. Как и любой другой язык программирования, Python помогает нам описывать различные компьютерные команды для получения желаемого результата. Синтаксис Python позволяет новичкам легко написать практически любой набор инструкций.
Например, если вы хотите отобразить «Hello!» на экране компьютера, необходимая для этого команда в Python будет выглядеть следующим образом:
print("Hello")
Такой простой набор команд и синтаксис облегчают детям изучение Python. Высокая читабельность — одна из тех особенностей языка, которая привела к его огромной популярности среди программистов. Кроме того, с помощью Python можно легко продемонстрировать важные концепции объектно-ориентированного программирования даже детям. Ниже перечислены другие полезные особенности Python.
- Встроенные структуры данных.
- Поощряет повторное использование кода.
- Наличие обширной стандартной библиотеки.
- Сверхбыстрый цикл редактирования-тестирования-отладки.
Python делает упор на простой подход к программированию, который можно интерпретировать и понять без изучения сложного синтаксиса. Кроме того, как было сказано выше, язык поддерживает повторное использование кода и разделение его на модули/пакеты. Все эти особенности делают его довольно эффективным языком программирования.
Почему дети должны изучать Python?
Поскольку этот язык известен своей легкостью восприятия, программирование на Python для детей может привить им страсть к написанию кода, не перегружая их.
В цифровую эпоху ничто не может превзойти важность навыков программирования. Поэтому среди других языков, таких как Java, C# и т.д., он является наиболее подходящим вариантом для изучения основ написания кода ребенком.
Причины, по которым дети должны изучать Python:
- Python — один из самых гибких языков программирования. Он имеет легко читаемый набор команд и синтаксис, который гораздо менее сложен, чем в других языках программирования. Эти команды представляют собой обычные английские слова, что делает изучение Python более доступным для детей.
- Детям не нужно прочесть множество учебников, чтобы начать писать код на Python. Изучение Python для детей — вполне выполнимая задача, даже если у них нет никаких предшествующих знаний о программировании.
- Python имеет обширную стандартную библиотеку, которую можно импортировать по необходимости. Дети могут осуществить многие свои идеи при создании приложений на Python, просто добавляя нужные библиотеки. Такой подход повышает доступность Python. Дети могут написать код любой программы на Python за меньшее число шагов, чем если бы им пришлось писать на Java или C.
- Python — очень дружелюбный к детям язык программирования. Они могут экспериментировать с различными фрагментами кода и постепенно собирать из них более осмысленные программы для создания собственных видеоигр и анимации.
- Совершенно очевидно, что язык программирования Python останется с нами надолго. Поэтому для детей довольно важно изучать Python из-за широкого спектра его применения. Знание Python также даст им преимущество при получении высшего образования в области науки о данных, автоматизации, машинного обучения и веб-разработки.
- Несмотря на различные усовершенствования, базовая структура языка Python остается неизменной. Поэтому изучение программирования на Python для малышей является большим плюсом, так как их навыки точно не устареют в будущем.
- Изучение Python также повысит способность детей к критическому мышлению. Да, последовательное рассуждение — это ключ к пониманию основных концепций программирования. Поэтому написание кода на Python для различных приложений позволит детям визуализировать и в итоге осмыслить сложные абстрактные понятия программирования. Это, в свою очередь, также улучшит их способность анализировать и решать математические задачи.
Как лучше всего детям изучать Python?
Освоение программирования на Python станет более достижимым для детей, если они будут следовать хорошим ориентированным на них видеоурокам. В Интернете можно найти несколько подобных курсов, обучающих малышей Python. Также они могут изучать основы программирования на Python, обращаясь к некоторым неплохим книгам. Например, из таких учебников дети могут узнать о переменных в Python и о том, как изменение переменной влияет на вывод программы.
Самое важное, о чем нужно помнить при написании кода на Python, — это синтаксис. Существуют различные инструменты для создания кода, которые позволяют детям изучить основные понятия программирования на Python. Для обучения синтаксису они могут практиковаться в создании небольших фрагментов кода в таких инструментах.
Часто дети отказываются от изучения языков программирования из-за сложных синтаксических структур. Однако с Python и его довольно простым синтаксисом эта проблема отпадает.
Очень важно поддерживать заинтересованность детей к обучению программированию, чтобы они могли развить хорошую концептуальную базу. Для этого необходимо разбить всю информацию по конкретной теме на кусочки и поощрять маленьких студентов самостоятельно решать упражнения по Python. Это, в свою очередь, делает изучение программирования на Python для детей более доступным, не вызывая у них потери интереса.
Чем больше они будут решать упражнений, тем лучше они смогут понять основные концепции и применение различных базовых элементов программирования, таких как инициализация переменных, условные операторы, циклы, функции и т.д.
- Python — практические задачи
- Основы программирования на языке Python в примерах и задачах
- Книга «1400 задач по программированию»
Установка может оказаться очень трудоемкой для некоторых сред программирования. С Python все обстоит совершенно иначе. Для установки в Windows требуется всего три шага. Дети могут установить Python на свои компьютеры, скачав программу с официального сайта. Родителям, вероятно, стоит помочь им при выборе версии, совместимой с используемой операционной системой.
После завершения установки ребенок сразу может приступить к увлекательному процессу создания кода с нуля. Лучший способ изучения Python для детей — это написание небольших фрагментов кода и последующий их запуск в терминале или текстовом редакторе.
Некоторые из лучших книг по Python для детей
Как только у ребенка появится интерес к программированию, самое время расширить его кругозор с помощью тематических книг. Ниже перечислены некоторые из лучших учебников для детей.
Вышеупомянутые книги весьма полезны для обучения детей основам программирования.
Книга «Python для детей. Самоучитель по программированию» написана в увлекательной форме, что поможет сохранить интерес маленьких студентов к изучению этого языка программирования. Она преподносит материал в очень легкой для понимания манере, которая побуждает ребенка глубже вникнуть в концепции Python.
Книга «Python для детей и родителей. Играй и программируй» также имеет очень интересный подход. Темы, освещенные в ней, подходят для изучения языка детьми и родителями.
Что дети могут делать с Python?
Начнем с того, что они могут отображать простые сообщения типа «Hello World!» или «Good Morning!» с помощью Python на начальном уровне. Также могут выполнять и выводить простые математические вычисления с помощью функции print. Например:
>>> print("Доброе утро!")
Доброе уро!
>>> print(12 + 10 - 2)
20
С помощью функции print в Python можно выводить не только отдельные слова, но и сообщения или значения переменных. Для этого детям придется сначала освоить процесс инициализации переменных. Например:
>>> print("Клубника и\nМалина")
Клубника и
Малина
>>> x = 2
>>> print(x)
2
Помимо базовой функции print, дети могут писать программы для различных веселых интерактивных игр. Существует множество онлайн-уроков по программированию на Python для школьников, где они могут научиться писать код для видеоигр.
Кроме того, ребенок может использовать Python для создания анимации. Однако для создания более сложных проектов ему придется узнать немного больше о циклах и условных операторах.
Дети также могут попробовать свои силы в различных инструментах с открытым исходным кодом, если они хотят выйти на новый уровень программирования. От вывода имен, сообщений и арифметических вычислений до создания веселых видеоигр и других полезных программ. Python позволяет детям исследовать и творить, воплощая свои мысли и идеи в жизнь.
Ресурсы для детей
Хотя существует несколько веб-сайтов, на которых подробно рассматриваются концепции, ни один из них не предназначен для детей. Такое обилие знаний им может показаться чрезвычайно подавляющим. Именно поэтому создано несколько индивидуальную программу обучения написанию кода детей. Эти курсы разработаны таким образом, чтобы любому ребенку было очень легко войти в мир программирования. Так что, если вы хотите научить своих детей языку Python, мы рекомендуем выбирать специализированные курсы.
]]>Spark предоставляет API для Scala, Java, Python и R. Система поддерживает повторное использование кода между рабочими задачами, пакетную обработку данных, интерактивные запросы, аналитику в реальном времени, машинное обучение и вычисления на графах. Она использует кэширование в памяти и оптимизированное выполнение запросов к данным любого размера.
У нее нет одной собственной файловой системы, такой как Hadoop Distributed File System (HDFS), вместо этого Spark поддерживает множество популярных файловых систем, таких как HDFS, HBase, Cassandra, Amazon S3, Amazon Redshift, Couchbase и т. д.
Преимущества использования Apache Spark:
- Он запускает программы в памяти до 100 раз быстрее, чем Hadoop MapReduce, и в 10 раз быстрее на диске, потому что Spark выполняет обработку в основной памяти рабочих узлов и предотвращает ненужные операции ввода-вывода.
- Spark крайне удобен для пользователя, поскольку имеет API-интерфейсы, написанные на популярных языках, что упрощает задачу для разработчиков: такой подход скрывает сложность распределенной обработки за простыми высокоуровневыми операторами, что значительно снижает объем необходимого кода.
- Систему можно развернуть, используя Mesos, Hadoop через Yarn или собственный диспетчер кластеров Spark.
- Spark производит вычисления в реальном времени и обеспечивает низкую задержку благодаря их резидентному выполнению (в памяти).
Давайте приступим.
Настройка среды в Google Colab
Чтобы запустить pyspark на локальной машине, нам понадобится Java и еще некоторое программное обеспечение. Поэтому вместо сложной процедуры установки мы используем Google Colaboratory, который идеально удовлетворяет наши требования к оборудованию, и также поставляется с широким набором библиотек для анализа данных и машинного обучения. Таким образом, нам остается только установить пакеты pyspark и Py4J. Py4J позволяет программам Python, работающим в интерпретаторе Python, динамически обращаться к объектам Java из виртуальной машины Java.
Итоговый ноутбук можно скачать в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/pyspark_beginner.ipynb
Команда для установки вышеуказанных пакетов:
!pip install pyspark==3.0.1 py4j==0.10.9Spark Session
SparkSession стал точкой входа в PySpark, начиная с версии 2.0: ранее для этого использовался SparkContext. SparkSession — это способ инициализации базовой функциональности PySpark для программного создания PySpark RDD, DataFrame и Dataset. Его можно использовать вместо SQLContext, HiveContext и других контекстов, определенных до 2.0.
Вы также должны знать, что SparkSession внутренне создает SparkConfig и SparkContext с конфигурацией, предоставленной с SparkSession. SparkSession можно создать с помощью SparkSession.builder, который представляет собой реализацию шаблона проектирования Builder (Строитель).
Создание SparkSession
Чтобы создать SparkSession, вам необходимо использовать метод builder().
getOrCreate()возвращает уже существующий SparkSession; если он не существует, создается новый SparkSession.master(): если вы работаете с кластером, вам нужно передать имя своего кластерного менеджера в качестве аргумента. Обычно это будет либоyarn, либоmesosв зависимости от настройки вашего кластера, а при работе в автономном режиме используетсяlocal[x]. Здесь X должно быть целым числом, большим 0. Данное значение указывает, сколько разделов будет создано при использовании RDD, DataFrame и Dataset. В идеалеXдолжно соответствовать количеству ядер ЦП.appName()используется для установки имени вашего приложения.
Пример создания SparkSession:
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark_Tutorial')\
.getOrCreate()
# где "*" обозначает все ядра процессора.
Чтение данных
Используя spark.read мы может считывать данные из файлов различных форматов, таких как CSV, JSON, Parquet и других. Вот несколько примеров получения данных из файлов:
# Чтение CSV файла
csv_file = 'data/stocks_price_final.csv'
df = spark.read.csv(csv_file)
# Чтение JSON файла
json_file = 'data/stocks_price_final.json'
data = spark.read.json(json_file)
# Чтение parquet файла
parquet_file = 'data/stocks_price_final.parquet'
data1 = spark.read.parquet(parquet_file)
Структурирование данных с помощью схемы Spark
Давайте прочитаем данные о ценах на акции в США с января 2019 года по июль 2020 года, которые доступны в датасетах Kaggle.
Код для чтения данных в формате файла CSV:
data = spark.read.csv(
'stocks_price_final.csv',
sep=',',
header=True,
)
data.printSchema()
Теперь посмотрим на схему данных с помощью метода PrintSchema.
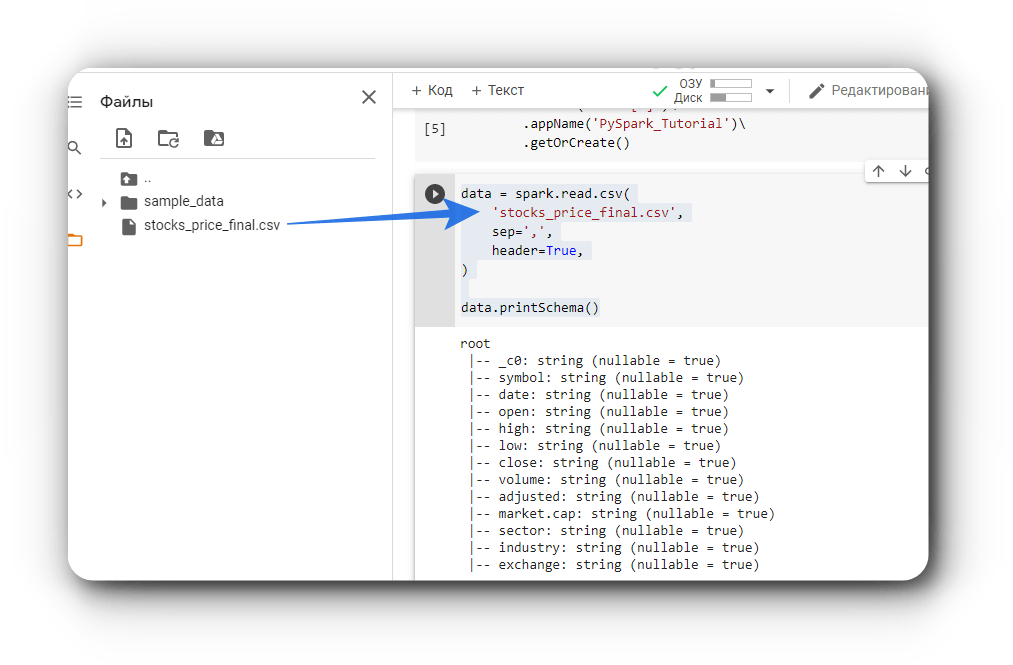
Схема Spark отображает структуру фрейма данных или датасета. Мы можем определить ее с помощью класса StructType, который представляет собой коллекцию объектов StructField. Они в свою очередь устанавливают имя столбца (String), его тип (DataType), допускает ли он значение NULL (Boolean), и метаданные (MetaData).
Это бывает довольно полезно, даже учитывая, что Spark автоматически выводит схему из данных, так как иногда предполагаемый им тип может быть неверным, или нам необходимо определить собственные имена столбцов и типы данных. Такое часто случается при работе с полностью или частично неструктурированными данными.
Давайте посмотрим, как мы можем структурировать наши данные:
from pyspark.sql.types import *
data_schema = [
StructField('_c0', IntegerType(), True),
StructField('symbol', StringType(), True),
StructField('data', DateType(), True),
StructField('open', DoubleType(), True),
StructField('high', DoubleType(), True),
StructField('low', DoubleType(), True),
StructField('close', DoubleType(), True),
StructField('volume', IntegerType(), True),
StructField('adjusted', DoubleType(), True),
StructField('market.cap', StringType(), True),
StructField('sector', StringType(), True),
StructField('industry', StringType(), True),
StructField('exchange', StringType(), True),
]
final_struc = StructType(fields = data_schema)
data = spark.read.csv(
'stocks_price_final.csv',
sep=',',
header=True,
schema=final_struc
)
data.printSchema()
В приведенном выше коде создается структура данных с помощью StructType и StructField. Затем она передается в качестве параметра schema методу spark.read.csv(). Давайте взглянем на полученную в результате схему структурированных данных:
root
|-- _c0: integer (nullable = true)
|-- symbol: string (nullable = true)
|-- data: date (nullable = true)
|-- open: double (nullable = true)
|-- high: double (nullable = true)
|-- low: double (nullable = true)
|-- close: double (nullable = true)
|-- volume: integer (nullable = true)
|-- adjusted: double (nullable = true)
|-- market.cap: string (nullable = true)
|-- sector: string (nullable = true)
|-- industry: string (nullable = true)
|-- exchange: string (nullable = true)Различные методы инспекции данных
Существуют следующие методы инспекции данных: schema, dtypes, show, head, first, take, describe, columns, count, distinct, printSchema. Давайте разберемся в них на примере.
schema(): этот метод возвращает схему данных (фрейма данных). Ниже показан пример с ценами на акции.
data.schema
# -------------- Вывод ------------------
# StructType(
# List(
# StructField(_c0,IntegerType,true),
# StructField(symbol,StringType,true),
# StructField(data,DateType,true),
# StructField(open,DoubleType,true),
# StructField(high,DoubleType,true),
# StructField(low,DoubleType,true),
# StructField(close,DoubleType,true),
# StructField(volume,IntegerType,true),
# StructField(adjusted,DoubleType,true),
# StructField(market_cap,StringType,true),
# StructField(sector,StringType,true),
# StructField(industry,StringType,true),
# StructField(exchange,StringType,true)
# )
# )
dtypesвозвращает список кортежей с именами столбцов и типами данных.
data.dtypes
#------------- Вывод ------------
# [('_c0', 'int'),
# ('symbol', 'string'),
# ('data', 'date'),
# ('open', 'double'),
# ('high', 'double'),
# ('low', 'double'),
# ('close', 'double'),
# ('volume', 'int'),
# ('adjusted', 'double'),
# ('market_cap', 'string'),
# ('sector', 'string'),
# ('industry', 'string'),
# ('exchange', 'string')]
head(n)возвращает n строк в виде списка. Вот пример:
data.head(3)
# ---------- Вывод ---------
# [
# Row(_c0=1, symbol='TXG', data=datetime.date(2019, 9, 12), open=54.0, high=58.0, low=51.0, close=52.75, volume=7326300, adjusted=52.75, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ'),
# Row(_c0=2, symbol='TXG', data=datetime.date(2019, 9, 13), open=52.75, high=54.355, low=49.150002, close=52.27, volume=1025200, adjusted=52.27, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ'),
# Row(_c0=3, symbol='TXG', data=datetime.date(2019, 9, 16), open=52.450001, high=56.0, low=52.009998, close=55.200001, volume=269900, adjusted=55.200001, market_cap='$9.31B', sector='Capital Goods', industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ')
# ]
show()по умолчанию отображает первые 20 строк, а также принимает число в качестве параметра для выбора их количества.first()возвращает первую строку данных.
data.first()
# ----------- Вывод -------------
# Row(_c0=1, symbol='TXG', data=datetime.date(2019, 9, 12), open=54.0, high=58.0, low=51.0,
# close=52.75, volume=7326300, adjusted=52.75, market_cap='$9.31B', sector='Capital Goods',
# industry='Biotechnology: Laboratory Analytical Instruments', exchange='NASDAQ')
take(n)возвращает первые n строк.describe()вычисляет некоторые статистические значения для столбцов с числовым типом данных.columnsвозвращает список, содержащий названия столбцов.
data.columns
# --------------- Вывод --------------
# ['_c0',
# 'symbol',
# 'data',
# 'open',
# 'high',
# 'low',
# 'close',
# 'volume',
# 'adjusted',
# 'market_cap',
# 'sector',
# 'industry',
# 'exchange']count()возвращает общее число строк в датасете.
data.count()
# возвращает количество строк данных
# -------- Вывод ---------
# 1292361distinct()— количество различных строк в используемом наборе данных.printSchema()отображает схему данных.
df.printSchema()
# ------------ Вывод ------------
# root
# |-- _c0: integer (nullable = true)
# |-- symbol: string (nullable = true)
# |-- data: date (nullable = true)
# |-- open: double (nullable = true)
# |-- high: double (nullable = true)
# |-- low: double (nullable = true)
# |-- close: double (nullable = true)
# |-- volume: integer (nullable = true)
# |-- adjusted: double (nullable = true)
# |-- market_cap: string (nullable = true)
# |-- sector: string (nullable = true)
# |-- industry: string (nullable = true)
# |-- exchange: string (nullable = true)Манипуляции со столбцами
Давайте посмотрим, какие методы используются для добавления, обновления и удаления столбцов данных.
1. Добавление столбца: используйте withColumn, чтобы добавить новый столбец к существующим. Метод принимает два параметра: имя столбца и данные. Пример:
data = data.withColumn('date', data.data)
data.show(5)
2. Обновление столбца: используйте withColumnRenamed, чтобы переименовать существующий столбец. Метод принимает два параметра: название существующего столбца и его новое имя. Пример:
data = data.withColumnRenamed('date', 'data_changed')
data.show(5)
3. Удаление столбца: используйте метод drop, который принимает имя столбца и возвращает данные.
data = data.drop('data_changed')
data.show(5)
Работа с недостающими значениями
Мы часто сталкиваемся с отсутствующими значениями при работе с данными реального времени. Эти пропущенные значения обозначаются как NaN, пробелы или другие заполнители. Существуют различные методы работы с пропущенными значениями, некоторые из самых популярных:
- Удаление: удалить строки с пропущенными значениями в любом из столбцов.
- Замена средним/медианным значением: замените отсутствующие значения, используя среднее или медиану соответствующего столбца. Это просто, быстро и хорошо работает с небольшими наборами числовых данных.
- Замена на наиболее частые значения: как следует из названия, используйте наиболее часто встречающееся значение в столбце, чтобы заменить отсутствующие. Это хорошо работает с категориальными признаками, но также может вносить смещение (bias) в данные.
- Замена с использованием KNN: метод K-ближайших соседей — это алгоритм классификации, который рассчитывает сходство признаков новых точек данных с уже существующими, используя различные метрики расстояния, такие как Евклидова, Махаланобиса, Манхэттена, Минковского, Хэмминга и другие. Такой подход более точен по сравнению с вышеупомянутыми методами, но он требует больших вычислительных ресурсов и довольно чувствителен к выбросам.
Давайте посмотрим, как мы можем использовать PySpark для решения проблемы отсутствующих значений:
# Удаление строк с пропущенными значениями
data.na.drop()
# Замена отсутствующих значений средним
data.na.fill(data.select(f.mean(data['open'])).collect()[0][0])
# Замена отсутствующих значений новыми
data.na.replace(old_value, new_vallue)
Получение данных
PySpark и PySpark SQL предоставляют широкий спектр методов и функций для удобного запроса данных. Вот список наиболее часто используемых методов:
- Select
- Filter
- Between
- When
- Like
- GroupBy
- Агрегирование
Select
Он используется для выбора одного или нескольких столбцов, используя их имена. Вот простой пример:
# Выбор одного столбца
data.select('sector').show(5)
# Выбор нескольких столбцов
data.select(['open', 'close', 'adjusted']).show(5)
Filter
Данный метод фильтрует данные на основе заданного условия. Вы также можете указать несколько условий, используя операторы AND (&), OR (|) и NOT (~). Вот пример получения данных о ценах на акции за январь 2020 года.
from pyspark.sql.functions import col, lit
data.filter( (col('data') >= lit('2020-01-01')) & (col('data') <= lit('2020-01-31')) ).show(5)
Between
Этот метод возвращает True, если проверяемое значение принадлежит указанному отрезку, иначе — False. Давайте посмотрим на пример отбора данных, в которых значения adjusted находятся в диапазоне от 100 до 500.
data.filter(data.adjusted.between(100.0, 500.0)).show()
When
Он возвращает 0 или 1 в зависимости от заданного условия. В приведенном ниже примере показано, как выбрать такие цены на момент открытия и закрытия торгов, при которых скорректированная цена была больше или равна 200.
data.select('open', 'close',
f.when(data.adjusted >= 200.0, 1).otherwise(0)
).show(5)
Like
Этот метод похож на оператор Like в SQL. Приведенный ниже код демонстрирует использование rlike() для извлечения имен секторов, которые начинаются с букв M или C.
data.select(
'sector',
data.sector.rlike('^[B,C]').alias('Колонка sector начинается с B или C')
).distinct().show()
GourpBy
Само название подсказывает, что данная функция группирует данные по выбранному столбцу и выполняет различные операции, такие как вычисление суммы, среднего, минимального, максимального значения и т. д. В приведенном ниже примере объясняется, как получить среднюю цену открытия, закрытия и скорректированную цену акций по отраслям.
data.select(['industry', 'open', 'close', 'adjusted'])\
.groupBy('industry')\
.mean()\
.show()
Агрегирование
PySpark предоставляет встроенные стандартные функции агрегации, определенные в API DataFrame, они могут пригодится, когда нам нужно выполнить агрегирование значений ваших столбцов. Другими словами, такие функции работают с группами строк и вычисляют единственное возвращаемое значение для каждой группы.
В приведенном ниже примере показано, как отобразить минимальные, максимальные и средние значения цен открытия, закрытия и скорректированных цен акций в промежутке с января 2019 года по январь 2020 года для каждого сектора.
from pyspark.sql import functions as f
data.filter((col('data') >= lit('2019-01-02')) & (col('data') <= lit('2020-01-31')))\
.groupBy("sector") \
.agg(f.min("data").alias("С"),
f.max("data").alias("По"),
f.min("open").alias("Минимум при открытии"),
f.max("open").alias("Максимум при открытии"),
f.avg("open").alias("Среднее в open"),
f.min("close").alias("Минимум при закрытии"),
f.max("close").alias("Максимум при закрытии"),
f.avg("close").alias("Среднее в close"),
f.min("adjusted").alias("Скорректированный минимум"),
f.max("adjusted").alias("Скорректированный максимум"),
f.avg("adjusted").alias("Среднее в adjusted"),
).show(truncate=False)
Визуализация данных
Для визуализации данных мы воспользуемся библиотеками matplotlib и pandas. Метод toPandas() позволяет нам осуществить преобразование данных в dataframe pandas, который мы используем при вызове метода визуализации plot(). В приведенном ниже коде показано, как отобразить гистограмму, отображающую средние значения цен открытия, закрытия и скорректированных цен акций для каждого сектора.
from matplotlib import pyplot as plt
sec_df = data.select(['sector',
'open',
'close',
'adjusted']
)\
.groupBy('sector')\
.mean()\
.toPandas()
ind = list(range(12))
ind.pop(6)
sec_df.iloc[ind ,:].plot(kind='bar', x='sector', y=sec_df.columns.tolist()[1:],
figsize=(12, 6), ylabel='Stock Price', xlabel='Sector')
plt.show()
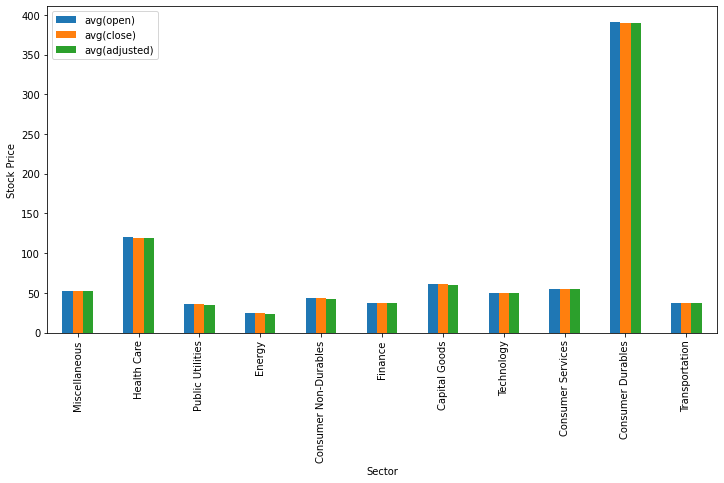
Теперь давайте визуализируем те же средние показатели, но уже по отраслям.
industries_x = data.select(['industry', 'open', 'close', 'adjusted']).groupBy('industry').mean().toPandas()
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')]
q.plot(kind='barh', x='industry', y=q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel='Industry')
plt.show()
Также построим временные ряды для средних цен открытия, закрытия и скорректированных цен акций технологического сектора.
industries_x = data.select(['industry', 'open', 'close', 'adjusted']).groupBy('industry').mean().toPandas()
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')]
q.plot(kind='barh', x='industry', y=q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel='Industry')
plt.show()
Запись/сохранение данных в файл
Метод write.save() используется для сохранения данных в различных форматах, таких как CSV, JSVON, Parquet и других. Давайте рассмотрим, как записать данные в файлы разных форматов. Мы можем сохранить как все строки, так и только выбранные с помощью метода select().
# CSV
data.write.csv('dataset.csv')
# JSON
data.write.save('dataset.json', format='json')
# Parquet
data.write.save('dataset.parquet', format='parquet')
# Запись выбранных данных в различные форматы файлов
# CSV
data.select(['data', 'open', 'close', 'adjusted'])\
.write.csv('dataset.csv')
# JSON
data.select(['data', 'open', 'close', 'adjusted'])\
.write.save('dataset.json', format='json')
# Parquet
data.select(['data', 'open', 'close', 'adjusted'])\
.write.save('dataset.parquet', format='parquet')
Заключение
PySpark — отличный инструмент для специалистов по данным, поскольку он обеспечивает масштабируемые анализ и ML-пайплайны. Если вы уже знакомы с Python, SQL и Pandas, тогда PySpark — хороший вариант для быстрого старта.
В этой статье было показано, как следует выполнять широкий спектр операций, начиная с чтения файлов и заканчивая записью результатов с помощью PySpark. Также мы охватили основные методы визуализации с использованием библиотеки matplotlib.
Мы узнали, что Google Colaboratory Notebooks — это удобное место для начала изучения PySpark без долгой установки необходимого программного обеспечения. Не забудьте ознакомиться с представленными ниже ссылками на ресурсы, которые могут помочь вам быстрее и проще изучить PySpark.
Также не стесняйтесь использовать предоставленный в статье код, доступ к которому можно получить, перейдя на Gitlab. Удачного обучения.
]]>В этом материале разберемся с этой ошибкой, и по каким еще причинам она возникает. Разберем несколько примеров, чтобы понять, как с ней справляться.
Ошибка «SyntaxError: unexpected EOF while parsing» возникает в том случае, когда программа добирается до конца файла, но не весь код еще выполнен. Это может быть вызвано ошибкой в структуре или синтаксисе кода.
EOF значит End of File. Представляет собой последний символ в Python-программе.
Python достигает конца файла до выполнения всех блоков в таких случаях:
- Если забыть заключить код в специальную инструкцию, такую как, циклы for или while, или функцию.
- Не закрыть все скобки на строке.
Разберем эти ошибки на примерах построчно.
Пример №1: незавершенные блоки кода
Циклы for и while, инструкции if и функции требуют как минимум одной строки кода в теле. Если их не добавить, результатом будет ошибка EOF.
Рассмотрим такой пример цикла for, который выводит все элементы рецепта:
ingredients = ["325г муки", "200г охлажденного сливочного масла", "125г сахара", "2 ч. л. ванили", "2 яичных желтка"]
for i in ingredients:
Определяем переменную ingredients, которая хранит список ингредиентов для ванильного песочного печенья. Используем цикл for для перебора по каждому из элементов в списке. Запустим код и посмотрим, что произойдет:
File "main.py", line 4
^
SyntaxError: unexpected EOF while parsingВнутри цикла for нет кода, что приводит к ошибке. То же самое произойдет, если не заполнить цикл while, инструкцию if или функцию.
Для решения проблемы требуется добавить хотя бы какой-нибудь код. Это может быть, например, инструкция print() для вывода отдельных ингредиентов в консоль:
for i in ingredients:
print(i)
Запустим код:
325г муки
200г охлажденного сливочного масла
125г сахара
2 ч. л. ванили
2 яичных желткаКод выводит каждый ингредиент из списка, что говорит о том, что он выполнен успешно.
Если же кода для такого блока у вас нет, используйте оператор pass как заполнитель. Выглядит это вот так:
for i in ingredients:
pass
Такой код ничего не возвращает. Инструкция pass говорит о том, что ничего делать не нужно. Такое ключевое слово используется в процессе разработке, когда разработчики намечают будущую структуру программы. Позже pass заменяются на реальный код.
Пример №2: незакрытые скобки
Ошибка «SyntaxError: unexpected EOF while parsing» также возникает, если не закрыть скобки в конце строки с кодом.
Напишем программу, которая выводит информацию о рецепте в консоль. Для начала определим несколько переменных:
name = "Капитанская дочка"
author = "Александр Пушкин"
genre = "роман"
Отформатируем строку с помощью метода .format():
print('Книга "{}" - это {}, автор {}'.format(name, genre, author)
Значения {} заменяются на реальные из .format(). Это значит, что строка будет выглядеть вот так:
Книга "НАЗВАНИЕ" - это ЖАНР, автор АВТОРЗапустим код:
File "main.py", line 7
^
SyntaxError: unexpected EOF while parsingНа строке кода с функцией print() мы закрываем только один набор скобок, хотя открытыми были двое. В этом и причина ошибки.
Решаем проблему, добавляя вторую закрывающую скобку («)») в конце строки с print().
print('Книга "{}" - это {}, автор {}'.format(name, genre, author))
Теперь на этой строке закрываются две скобки. И все из них теперь закрыты. Попробуем запустить код снова:
Книга "Капитанская дочка" это роман. Александр ПушкинТеперь он работает. То же самое произойдет, если забыть закрыть скобки словаря {} или списка [].
Выводы
Ошибка «SyntaxError: unexpected EOF while parsing» возникает, если интерпретатор Python добирается до конца программы до выполнения всех строк.
Для решения этой проблемы сперва нужно убедиться, что все инструкции, включая while, for, if и функции содержат код. Также нужно проверить, закрыты ли все скобки.
]]>Python используют чуть более 10 миллионов пользователей по всему миру, в 2020 году число новых разработчиков составило 1,6 миллиона человек. Python — второй по распространенности язык после JavaScript.
Откуда эта информация? Благодаря опросу Developer Nation, в котором дважды в год принимают участие более 36 000 разработчиков по всему миру. Их спрашивают о любимых (и не очень) языках программирования, библиотеках, фреймворках, инструментах разработчика и платформах. Опрос организовывает независимая аналитическая компания SlashData, которая специализируется на отслеживании глобальных тенденций в разработке за последние 10 лет.
Новый международный опрос Developer Nation уже начался, теперь и у вас есть шанс принять участие! Ответьте на вопросы о своих любимых инструментах и платформах для создания ПО. Внесите вклад в будущее программирования и выиграйте ценные призы.
Организаторы позаботились о локализации и добавили русскую версию.
Сделайте среду разработки, облачные сервисы и ML-инструменты лучше
Ваши ответы помогут тем, кто создает инструменты для разработчиков, сделать их удобнее и добавить необходимый функционал.
Если вы когда-либо хотели повлиять на экосистему разработчиков, то сейчас у вас есть шанс. Новое глобальное исследование Developer Nation, приглашает всех разработчиков и дизайнеров поделится мнением о популярных технологиях, платформах и инструментах в 13 различных областях разработки программного обеспечения:
- мобильные, десктопные, облачные и веб-приложения,
- IoT, ПО для электроники, встроенное ПО,
- виртуальная и дополненная реальность,
- приложения и расширения для сторонних платформ,
- игры,
- машинное обучение, искусственный интеллект, анализ данных.
Расскажите над какими проектами вы работаете и с какими трудностями сталкиваетесь. Если вы только учитесь, расскажите о трудностях в обучении. Пройти опрос ->
Выигрывайте ценные призы
Каждый год в опросе принимают участие более 36 000 разработчиков из 159 стран. Все зарегистрированные пользователи участвуют в розыгрыше призов. После прохождения опроса вы получаете шанс выиграть один из призов.
![[Опрос] Насколько популярен Python в 2021, главный приз — MacBook Pro](https://pythonru.com/wp-content/uploads/2021/06/pervoklassnye-prizy.png)
Респонденты могут выиграть:
- Ноутбук MacBook Pro 13,
- Samsung Galaxy S21 Plus,
- лицензию GitKraken Pro,
- гаджеты для рабочего места,
- сертификаты и лицензии на обучающие курсы,
- ваучеры Amazon
- и многое другое.
Кроме того, каждый, кто пройдет опрос, получит в подарок специальный набор для разработчиков (в электронном виде).
Поспешите, опрос заканчивается 4 августа. Пройти опрос ->
]]>Как научиться программированию на Python удаленно
Обучение по Python-разработке можно пройти в онлайн-школе. Это удобно:
- Вебинары сохраняются в записи. Вы сможете подключиться к онлайн-конференции или посмотреть урок в записи.
- Поскольку занятия проводят удаленно, не нужно тратить время на поездки. Такой формат обучения легко совмещать с работой.
- На курсе у вас будет наставник, который ответит на вопросы, поможет разобраться со сложным заданием. Вам не придется изучать форумы в поисках решения.
- Все видео и учебные материалы сохраняются в личном кабинете. Многие онлайн-школы оставляют доступ к ним навсегда.
Как проходит обучение в онлайн-школе:
- Вы смотрите лекции в режиме реального времени или в записи. Преподаватель на экране объясняет новую тему, отвечает на вопросы.
- После урока в личном кабинете появляется домашнее задание, которое нужно сделать за 4-7 дней. Это могут быть задачи на язык программирования Python, работа с тренажером и т. д.
- Готовую работу проверяет куратор. Вы узнаете, какие ошибки допустили, и получите рекомендации.
- На протяжении всего курса вы будете готовить дипломный проект, который добавите в портфолио.
Как выбрать онлайн-курс начинающему программисту
Выбирая курс Python-программирования для начинающих, обращайте внимание на следующие условия:
- Стоимость обучения. Некоторые онлайн-школы предоставляют рассрочку — можно оплачивать учебу частями.
- Включенные темы. Важно, чтобы было много практических занятий – так вы сможете подготовить портфолио.
- Какой документ выдает школа: электронный сертификат, диплом или удостоверение.
- Предусмотрена ли стажировка или помощь с поиском работы (карьерные консультации, рассылка резюме по базе партнеров, гарантированное трудоустройство и пр.).
Для поиска онлайн-курсов мы рекомендуем пользоваться специальными агрегаторами. Например, УчисьОнлайн.ру — здесь самая большая подборка курсов разных школ, которые можно сравнить по цене, длительности, формату занятий. А также на сервисе есть отзывы учеников. Лучшие курсы по Python мы нашли именно там, расскажем о них ниже.
Лучшие курсы обучения Python-программированию с нуля
Мы составили ТОП курсов для тех, кто хочет изучить программирование на Python с нуля:
- «Python-разработчик с нуля» от Нетологии. Вам покажут, как использовать Python для разных целей: от разработки сайтов до игр и приложений. Будет много практических уроков, на которых вы создадите 4 проекта для портфолио. После курса получите диплом о профессиональной переподготовке гос. образца.
- «Онлайн-курс по Python» от Hedu. На курсе вы познакомитесь с основами Python и напишете собственное приложение. Программа разработана специально для новичков: после каждого урока есть тест или домашнее задание с проверкой, на всех этапах обучения вас поддержит куратор. Школа выдает электронный сертификат, а при необходимости высылает оригинал по почте.
- «Python для начинающих программистов» от OTUS. Изучите синтаксис языка программирования Python, узнаете, как создаются сайты на Django, научитесь использовать библиотеки NumPy и Pandas для анализа данных. После каждого вебинара — проверочный тест. Курс является подготовительным и предназначен для самостоятельного прохождения.
Учебные программы для продвинутых разработчиков
В список лучших учебных курсов для продвинутых программистов входят следующие:
- «Мидл Python-разработчик» от Яндекс.Практикум. Вы освоите технологии, которые используются в backend-разработке, научитесь решать сложные задачи с базами данных, работать с фреймворками, получите опыт командной работы. Отработаете навыки на онлайн-тренажере, создадите несколько крупных проектов для портфолио, по которым профессиональный разработчик сделает код-ревью. Доступ к вводному блоку тем — бесплатно.
- «Python-разработчик PRO» от Geekbrains. Практический курс по программированию, на котором освоите фреймворк Django, создадите приложение с сервером, потренируетесь работать в команде. В конце обучения сможете пройти стажировку и получите опыт работы на проекте, который приближен к реальным условиям. По окончании онлайн-курса вам выдадут удостоверение о повышении квалификации гос. образца.
- «Python Developer. Professional» от OTUS. Вы на практике освоите технологии разработки высоконагруженных веб-приложений, систем контроля качества и аналитических систем. После прохождения курса получите сертификат, а также сможете пройти собеседование у партнера онлайн-школы. Видеоуроки, презентации лекций и примеры кодов останутся у вас навсегда.
Дистанционное обучение Python-разработке с трудоустройством
Кроме вышеперечисленных курсов, помощь с трудоустройством предусмотрена и на следующих:
- «Профессия Python-разработчик» от Skillbox. Вы с нуля изучите возможности Python и Django, сделаете несколько крупных проектов: сервис по доставке еды, интернет-магазин, сайт-задачник. В конце онлайн-курса у вас будет консультация с HR-менеджером, который поможет оформить резюме и портфолио, подготовит к собеседованию у партнеров. На защите дипломов будут присутствовать реальные работодатели.
- «Python-разработчик» от Яндекс.Практикум. Вы изучите язык Python и основные инструменты бэкенд-разработчика: Django, SQL, GITHub. В процессе обучения создадите несколько приложений: соцсеть, бот-ассистент и др. За 2 месяца до конца курса вы подготовите резюме и портфолио, начнете проходить собеседования.
- «Факультет Python-разработки» от Geekbrains. На курсе вы освоите web-разработку, научитесь писать веб-приложения и самостоятельно создадите интернет-магазин, сетевой чат, базу данных, веб-сайт и другие программы. Вместе с HR-консультантом составите резюме и откликнитесь на вакансии партнеров школы. Гарантия трудоустройства указана в договоре: если не сможете найти работу после курса – вам вернут деньги.
Где найти бесплатные онлайн-уроки по Python
В некоторых онлайн-школах есть бесплатные дистанционные программы обучения для новичков. Это вводные мини-курсы, на которых рассказывают об основах Python:
- «Python-разработка для начинающих» от Нетологии. После регистрации на сайте школы вам предоставят доступ к шести вебинарам. Вы изучите основы разработки на Python, самостоятельно сделаете 2 программы, а также получите подборку полезных статей, инструментов и чек-листов.
- «Python для непрограммистов» от Skillfactory. Игровой онлайн-тренажер поможет сделать первые шаги в программировании. Вы выполните несколько простых упражнений и напишете первый код.
- Виртуализация
- Контейнеризация (с помощью Docker)
- Docker
- Создание Dockerfile
- Docker Compose
- Настройка Django приложения в среде Docker с помощью Dockerfile и docker-compose
Условия
Чтобы справиться с этим руководством вам нужно иметь следующее:
- Git/GitHub
- PyCharm (или любой другой редактор кода)
- Опыт работы с Django
Готовый репозиторий с Django-приложением, как всегда на GitLab: https://gitlab.com/PythonRu/django-docker.
Что такое виртуализация
Обычно при развертывании веб-приложения в хостинге (например, DigitalOcean или Linode) вы настраиваете виртуальную машину или виртуальный компьютер, куда будет перенесен весь код с помощью git, FTP или другими средствами. Это называется виртуализацией.
Со временем разработчики начали видеть недостатки такого процесса — как минимум затраты на приспосабливание к изменениям в операционной системе. Им хотелось объединить среды разработки и производственную, вследствие чего и появилась идея контейнеризации.
Что такое контейнеры, и что в них такого особенного?
Контейнер, если говорить простыми словами, — это место для среды разработки, то есть, вашего приложения и тех зависимостей, которые требуются для его работы.
Контейнеры позволяют разработчику упаковывать приложение со всеми зависимостями и передавать его между разными средами без каких-либо изменений.
Поскольку контейнеризация — куда более портативное, масштабируемое и эффективное решение, такие платформы, как Docker, становятся популярным выбором разработчиков.
Введение в Docker
Docker — это набор инструментов, с помощью которого можно создавать, управлять и запускать приложения в контейнерах. Он позволяет запросто упаковывать и запускать приложения в виде портативных, независимых и легких контейнеров, которые способны работать где угодно.
Установка Docker
Для установки Docker на компьютере, воспользуйтесь инструкцией с официального сайта. У каждой операционной системы есть своя версия приложения.
Настройка приложения
Для этого руководства используем репозиторий приложения для опросов, написанного на Django. По мере продвижения в этом руководстве настроим Dockerfile, в котором будут обозначены инструкции для контейнера, внутри которого приложение и будет работать. После этого же настроим и файл docker-compose.yml для упрощения всего процесса.
На ПК с установленным git перейдите в выбранную папку и клонируйте следующий репозиторий из GitLab:
git clone https://gitlab.com/PythonRu/django-docker.gitПосле этого перейдите в корень этой папки и откройте ее в редакторе с помощью такой команды:
cd django-docker && code .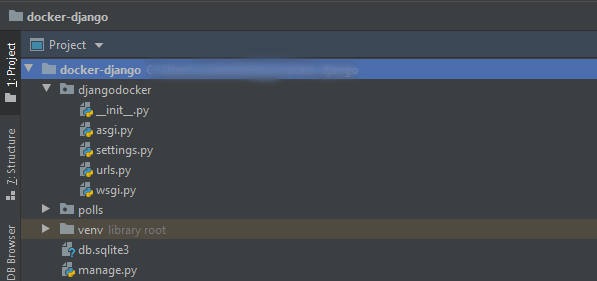
В этой папке создайте файл Dockerfile (регистр играет роль) без формата. Внутри него будут находиться настройки контейнера. Инструкции из него компьютер будет выполнять каждый раз при запуске команды docker build.
Следующий этап — создание файла requirements.txt, в котором перечислены все зависимости. Позже он будет использован для Dockerfile, в котором также требуется указывать все требуемые зависимости.
В файле requirements.txt добавьте Django версии 3.1.2 в таком формате:
Django==3.1.2Что такое Dockerfile
Идея написания Dockerfile может показаться сложной, но не забывайте, что это всего лишь инструкция (набор шагов) для создания собственных образов (images). Dockerfile будет содержать следующее:
- Базовый образ, на основе которого требуется построить свой. Он выступает своего рода фундаментом для вашего приложения. Это может быть операционная система, язык программирования (Python в нашем случае) или фреймворк.
- Пакеты и дополнительные инструменты для образа.
- Скрипты и файлы, которые требуется скопировать в образ. Обычно это и есть исходный код приложения.
При чтении или написании такого файла удобно держать в голове следующее:
- Строки с инструкциями обычно начинаются с ключевого слова, например:
RUN,FROM,COPY,WORKDIRи так далее. - Комментарии начинаются с символа
#. При выполнении инструкций из файла такие комментарии обычно игнорируются.
Создание Dockerfile
Приложение будет работать на основе официального образа Python. Напишем следующие инструкции:
# Указывает Docker использовать официальный образ python 3 с dockerhub в качестве базового образа
FROM python:3
# Устанавливает переменную окружения, которая гарантирует, что вывод из python будет отправлен прямо в терминал без предварительной буферизации
ENV PYTHONUNBUFFERED 1
# Устанавливает рабочий каталог контейнера — "app"
WORKDIR /app
# Копирует все файлы из нашего локального проекта в контейнер
ADD ./app
# Запускает команду pip install для всех библиотек, перечисленных в requirements.txt
RUN pip install -r requirements.txtФайл Docker Compose
Docker Compose — это отличный инструмент, помогающий определять и запускать приложения, для которых требуются несколько сервисов.
Обычно Docker Compose использует файл docker-compose.yml для настройки сервисов, которые приложение будет использовать. Запускаются эти сервисы с помощью команды docker-compose up. Это создает и запускает все сервисы из файла. В большинстве веб-приложений нужны, веб-сервер (такой как nginx) и база данных (например, PostgreSQL). В этом приложении будем использовать SQLite, поэтому внешняя база данных не потребуется.
Для использования особенностей Docker Compose нужно создать файл docker-compose.yml в той же папке, где находится Dockerfile и добавить туда следующий код:
version: '3.8'
services:
web:
build: .
command: python manage.py runserver localhost:8000
ports:
- 8000:8000Дальше разберем содержимое файла построчно:
version: '3.8'Эта строка сообщает Docker, какая версия docker-compose должна быть использована для запуска файла. На момент написания руководства последняя версия — 3.8, но обычно синтаксис не сильно меняется по мере выхода последующих.
После настройки docker-compose откройте терминал и запустите команду docker-compose up -d для запуска приложения. Дальше открывайте ссылку localhost:8000 в браузере, чтобы увидеть приложение в действии:
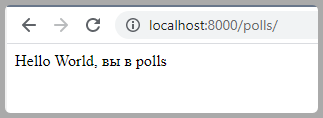
Для закрытия контейнера используется команда docker-compose down.
Выводы
Репозиторий проекта: https://gitlab.com/PythonRu/django-docker.
В этом руководстве вы познакомились с виртуализацией, контейнеризацией и другими терминами из мира Docker. Также вы теперь знаете, что такое Dockerfile, как его создавать для запуска контейнеризированного Django-приложения. Наконец, разобрались с настройкой docker-compose с помощью файла docker-compose.yml для сервисов, от которых зависит самое приложения.
Не существует единого правильного способа использовать Docker в Django-приложении, но считается хорошей практикой следовать официальным инструкциями, чтобы максимально обезопасить свое приложение.
]]>Если вам просто нужно найти количество конкретных элементов с списке, используйте метод .count()
>>> list_numbers = [1, 2, 2, 5, 5, 7, 4, 2, 1]
>>> print(list_numbers.count(2))
3
Существует несколько способов такого подсчета, и мы изучим каждый из них с помощью примеров. Итак, давайте начнем.
1. Использование цикла for для подсчета в списке Python
В этом фрагменте кода мы используем цикл for для подсчета элементов списка Python, удовлетворяющих условиям или критериям. Мы перебираем каждый элемент списка и проверяем условие, если оно истинно, то мы увеличиваем счетчик на 1. Это простой процесс сопоставления и подсчета для получения интересующего нас количества.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
count = 0
for item in list_numbers:
if item%5 == 0:
count += 1
print("количество элементов списка, удовлетворяющих заданному условию:", count)
количество элементов списка, удовлетворяющих заданному условию: 6
2. Применение len() со списковыми включениями для подсчета в списке Python
В представленном ниже фрагменте кода, мы используем списковые включения (list comprehension), чтобы создать новый список, элементы которого соответствует заданному условию, после чего мы получаем длину собранного списка. Это намного легче понять на примере, поэтому давайте перейдем к нему.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
element_count = len([item for item in list_numbers if item%5 == 0])
print(
"количество элементов списка, удовлетворяющих заданному условию:",
element_count
)
количество элементов списка, удовлетворяющих заданному условию: 6
Подсчет ненулевых элементов
В этом примере мы находим общее количество ненулевых элементов. Чтобы узнать число нулевых членов списка, мы можем просто изменить условие на if item == 0.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 0, 0, 0]
element_count = len([item for item in list_numbers if item != 0])
print(
"количество элементов списка, удовлетворяющих заданному условию:",
element_count
)
количество элементов списка, удовлетворяющих заданному условию: 7
3. sum() и выражение-генератор для подсчета в списке Python
В этом примере кода мы используем sum() с генераторным выражением. Каждый элемент списка проходит проверку условием и для тех элементов, которые ему удовлетворяют, возвращается значение True. Метод sum() в свою очередь подсчитывает общее число истинных значений.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
count = 0
count = sum(True for i in list_numbers if i % 5 == 0)
print(
"количество элементов списка, удовлетворяющих заданному условию:",
count
)
количество элементов списка, удовлетворяющих заданному условию: 6
4. sum() и map() для подсчета элементов списка Python с условиями или критериями
Функция map(fun, iterable) принимает два аргумента: итерируемый объект (это может быть строка, кортеж, список или словарь) и функцию, которая применяется к каждому его элементу, — и возвращает map-объект (итератор). Для применения одной функции внутри другой идеально подходит лямбда-функция. Таким образом, map() примет первый аргумент в виде лямбда-функции.
Здесь sum() используется с функцией map(), чтобы получить количество всех элементов списка, которые делятся на 5.
Давайте разберемся на примере, в котором переданная лямбда-функция предназначена для фильтрации членов списка, не кратных 5.
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
count = 0
count = sum(map(lambda item: item % 5 == 0, list_numbers))
print(
"количество элементов списка, удовлетворяющих заданному условию:",
count
)
количество элементов списка, удовлетворяющих заданному условию: 6
5. reduce() с лямбда-функцией для подсчета элементов списка Python с условием или критериями
Lambda — это анонимная (без имени) функция, которая может принимать много параметров, но тело функции должно содержать только одно выражение. Лямбда-функции чаще всего применяют для передачи в качестве аргументов в другие функции или для написания более лаконичного кода. В этом примере мы собираемся использовать функции sum(), map() и reduce() для подсчета элементов в списке, которые делятся на 5.
Приведенный ниже код наглядно демонстрирует это.
from functools import reduce
list_numbers = [78, 99, 66, 44, 50, 30, 45, 15, 25, 20]
result_count = reduce(
lambda count, item: count + (item % 5 == 0),
list_numbers,
0
)
print(
"количество элементов списка, удовлетворяющих заданному условию:",
result_count
)
количество элементов списка, удовлетворяющих заданному условию: 6Надеюсь, что вы узнали о различных подходах к подсчету элементов в списке Python с помощью условия или критериев для фильтрации данных.
Удачного обучения!
]]>Случайный лес имеет множество применений, таких как механизмы рекомендаций, классификация изображений и отбор признаков. Его можно использовать для классификации добросовестных соискателей кредита, выявления мошенничества и прогнозирования заболеваний. Он лежит в основе алгоритма Борута, который определяет наиболее значимые показатели датасета.
Алгоритм Random Forest
Давайте разберемся в алгоритме случайного леса, используя нетехническую аналогию. Предположим, вы решили отправиться в путешествие и хотите попасть в туда, где вам точно понравится.
Итак, что вы делаете, чтобы выбрать подходящее место? Ищите информацию в Интернете: вы можете прочитать множество различных отзывов и мнений в блогах о путешествиях, на сайтах, подобных Кью, туристических порталах, — или же просто спросить своих друзей.
Предположим, вы решили узнать у своих знакомых об их опыте путешествий. Вы, вероятно, получите рекомендации от каждого друга и составите из них список возможных локаций. Затем вы попросите своих знакомых проголосовать, то есть выбрать лучший вариант для поездки из составленного вами перечня. Место, набравшее наибольшее количество голосов, станет вашим окончательным выбором для путешествия.
Вышеупомянутый процесс принятия решения состоит из двух частей.
- Первая заключается в опросе друзей об их индивидуальном опыте и получении рекомендации на основе тех мест, которые посетил конкретный друг. В этой части используется алгоритм дерева решений. Каждый участник выбирает только один вариант среди знакомых ему локаций.
- Второй частью является процедура голосования для определения лучшего места, проведенная после сбора всех рекомендаций. Голосование означает выбор наиболее оптимального места из предоставленных на основе опыта ваших друзей. Весь этот процесс (первая и вторая части) от сбора рекомендаций до голосования за наиболее подходящий вариант представляет собой алгоритм случайного леса.
Технически Random forest — это метод (основанный на подходе «разделяй и властвуй»), использующий ансамбль деревьев решений, созданных на случайно разделенном датасете. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака.
Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс. В случае регрессии конечным результатом считается среднее значение всех выходных данных ансамбля. Метод случайного леса является более простым и эффективным по сравнению с другими алгоритмами нелинейной классификации.
Как работает случайный лес?
Алгоритм состоит из четырех этапов:
- Создайте случайные выборки из заданного набора данных.
- Для каждой выборки постройте дерево решений и получите результат предсказания, используя данное дерево.
- Проведите голосование за каждый полученный прогноз.
- Выберите предсказание с наибольшим количеством голосов в качестве окончательного результата.
Поиск важных признаков
Random forest также предлагает хороший критерий отбора признаков. Scikit-learn предоставляет дополнительную переменную при использовании модели случайного леса, которая показывает относительную важность, то есть вклад каждого показателя в прогноз. Библиотека автоматически вычисляет оценку релевантности каждого признака на этапе обучения. Затем полученное значение нормализируется так, чтобы сумма всех оценок равнялась 1.
Такая оценка поможет выбрать наиболее значимые показатели и отбросить наименее важные для построения модели.
Случайный лес использует критерий Джини, также известный как среднее уменьшение неопределенности (MDI), для расчета важности каждого признака. Кроме того, критерий Джини иногда называют общим уменьшением неопределенности в узлах. Он показывает, насколько снижается точность модели, когда вы отбрасываете переменную. Чем больше уменьшение, тем значительнее отброшенный признак. Таким образом, среднее уменьшение является необходимым параметром для выбора переменной. Также с помощью данного критерия можете быть отображена общая описательная способность признаков.
Сравнение случайных лесов и деревьев решений
- Случайный лес — это набор из множества деревьев решений.
- Глубокие деревья решений могут страдать от переобучения, но случайный лес предотвращает переобучение, создавая деревья на случайных выборках.
- Деревья решений вычислительно быстрее, чем случайные леса.
- Случайный лес сложно интерпретировать, а дерево решений легко интерпретировать и преобразовать в правила.
Создание классификатора с использованием Scikit-learn
Вы будете строить модель на основе набора данных о цветках ириса, который является очень известным классификационным датасетом. Он включает длину и ширину чашелистика, длину и ширину лепестка, и тип цветка. Существуют три вида (класса) ирисов: Setosa, Versicolor и Virginica. Вы построите модель, определяющую тип цветка из вышеперечисленных. Этот датасет доступен в библиотеке scikit-learn или вы можете загрузить его из репозитория машинного обучения UCI.
Начнем с импорта datasets из scikit-learn и загрузим набор данных iris с помощью load_iris().
from sklearn import datasets
# загрузка датасета
iris = datasets.load_iris()
Вы можете отобразить имена целевого класса и признаков, чтобы убедиться, что это нужный вам датасет:
print(iris.target_names)
print(iris.feature_names)
['setosa' 'versicolor' 'virginica']
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']Рекомендуется всегда хотя бы немного изучить свои данные, чтобы знать, с чем вы работаете. Здесь вы можете увидеть результат вывода первых пяти строк используемого набора данных, а также всех значений целевой переменной датасета.
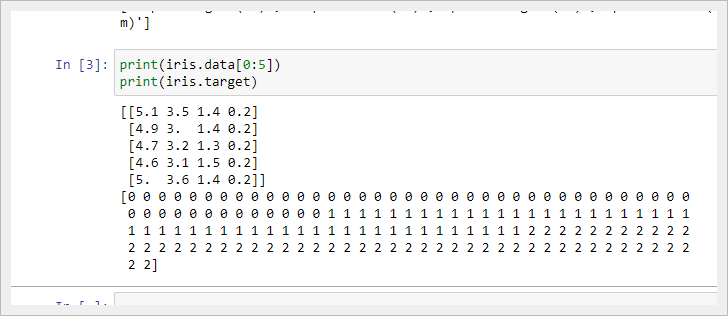
Ниже мы создаем dataframe из нашего набора данных об ирисах.
import pandas as pd
data=pd.DataFrame({
'sepal length':iris.data[:,0],
'sepal width':iris.data[:,1],
'petal length':iris.data[:,2],
'petal width':iris.data[:,3],
'species':iris.target
})
data.head()
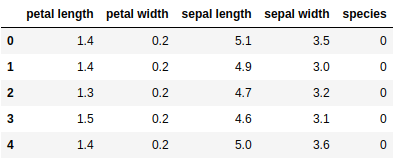
Далее мы разделяем столбцы на зависимые и независимые переменные (признаки и метки целевых классов). Затем давайте создадим выборки для обучения и тестирования из исходных данных.
from sklearn.model_selection import train_test_split
X = data[['sepal length', 'sepal width', 'petal length', 'petal width']]
y = data['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=85)
После этого мы сгенерируем модель случайного леса на обучающем наборе и выполним предсказания на тестовом.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
После создания модели стоит проверить ее точность, используя фактические и спрогнозированные значения.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
Accuracy: 0.9333333333333333Вы также можете сделать предсказание для единственного наблюдения. Предположим, sepal length=3, sepal width=5, petal length=4, petal width=2.
Мы можем определить, к какому типу цветка относится выбранный, следующим образом:
clf.predict([[3, 5, 4, 2]])
# результат - 2
Выше цифра 2 указывает на класс цветка «virginica».
Поиск важных признаков с помощью scikit-learn
В этом разделе вы определяете наиболее значимые признаки или выполняете их отбор в датасете iris. В scikit-learn мы можем решить эту задачу, выполнив перечисленные шаги:
- Создадим модель случайного леса.
- Используем переменную
feature_importances_, чтобы увидеть соответствующие оценки значимости показателей. - Визуализируем полученные оценочные значения с помощью библиотеки seaborn.
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
feature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)
feature_imp
petal width (cm) 0.470224
petal length (cm) 0.424776
sepal length (cm) 0.075913
sepal width (cm) 0.029087Вы также можете визуализировать значимость признаков. Такое графическое отображение легко понять и интерпретировать. Кроме того, визуальное представление информации является самым быстрым способом ее усвоения человеческим мозгом.
Для построения необходимых диаграмм вы можете использовать библиотеки matplotlib и seaborn совместно, потому что seaborn, построенная поверх matplotlib, предлагает множество специальных тем и дополнительных графиков. Matplotlib — это надмножество seaborn, и обе библиотеки одинаково необходимы для хорошей визуализации.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.barplot(x=feature_imp, y=feature_imp.index)
plt.xlabel('Важность признаков')
plt.ylabel('Признаки')
plt.title('Визуализация важных признаков')
plt.show()
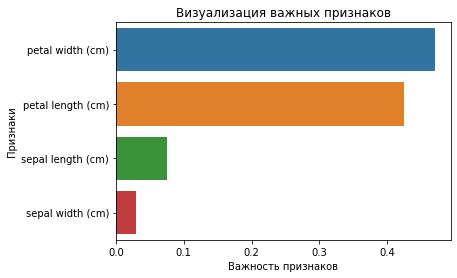
Повторная генерация модели с отобранными признаками
Далее мы удаляем показатель «sepal width» и используем оставшиеся 3 признака, поскольку ширина чашелистика имеет очень низкую важность.
from sklearn.model_selection import train_test_split
X = data[['petal length', 'petal width','sepal length']]
y = data['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=85)
После разделения вы сгенерируете модель случайного леса для выбранных признаков обучающей выборки, выполните прогноз на тестовом наборе и сравните фактические и предсказанные значения.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
from sklearn import metrics
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.9619047619047619
Вы можете заметить, что после удаления наименее важных показателей (ширины чашелистика) точность увеличилась, поскольку мы устранили вводящие в заблуждение данные и уменьшили шум. Кроме того, ограничив количество значимых признаков, мы сократили время обучения модели.
Преимущества Random Forest:
- Случайный лес считается высокоточным и надежным методом, поскольку в процессе прогнозирования участвует множество деревьев решений.
- Random forest не страдает проблемой переобучения. Основная причина в том, что случайный лес использует среднее значение всех прогнозов, что устраняет смещения.
- RF может использоваться в обоих типах задач (задачах классификации и регрессии).
- Случайный лес также может работать с отсутствующими значениями. Есть два способа решения такой проблемы в Random forest. В первом используется медианное значение для заполнения непрерывных переменных, а во втором вычисляется среднее взвешенное пропущенных значений.
- RF также рассчитывает относительную важность показателей, которая помогает в выборе наиболее значимых признаков для классификатора.
Недостатки Random Forest:
- Случайный лес довольно медленный, так как для работы алгоритм использует множество деревьев: каждому дереву в лесу передаются одни и те же входные данные, на основании которых оно должно вернуть свое предсказание. После чего также происходит голосование на полученных прогнозах. Весь этот процесс занимает много времени.
- Модель случайного леса сложнее интерпретировать по сравнению с деревом решений, где вы легко определяете результат, следуя по пути в дереве.
Заключение
Вы узнали об алгоритме Random forest и принципе его работы, о поиске важных признаков, о главных отличиях случайного леса от дерева решений, о преимуществах и недостатках данного метода. Также научились создавать и оценивать модели, находить наиболее значимые показатели в scikit-learn. Не останавливайся на этом!
Я рекомендую вам попробовать RF на разных наборах данных и прочитать больше о матрице ошибок.
]]>Почему крупные компании выбирают Django?
При создании сайта чаще всего требуется стандартный набор компонентов:
- Инструменты для управления аутентификацией пользователя (создание аккаунта, логин и так далее).
- Панель управления своим аккаунтом.
- Загрузка и скачивание файлов и так далее.
Если эти задачи повторяются из раза в раз, почему бы не упростить их и не уменьшить стоимость разработки? Веб-фреймворки — это коллекции компонентов, которые и предназначены для этих целей.
Одним из таких фреймворков является Django, который неустанно набирает популярность и используется даже в крупных компаниях.
Django считается лучшим веб-фреймворком на Python. Он подходит для создания сайтов, работающих с базами данными.
Изучая следующие примеры, разберем основные достоинства использования этой платформы. Используйте их не только как примеры, но также и как источники вдохновения для собственных проектов.
1. YouTube
Крупнейший видеохостинг — это часть компании Google, которая использует Python и Django во множестве своих проектов. YouTube — не исключение, ведь вся платформа написана с использованием этого фреймворка.
Изначально он создавался с помощью PHP, но по мере роста пришлось быстро перестраиваться, что и привело к тому, что разработчики присоединились к сообществу Django. И этот выбор был вполне оправдан, поскольку переход на новую технологию не только не остановил рост аудитории, но и привел к появлению новых особенностей.
2. Поиск Google
Google использует Python во множестве своих продуктов. Компания всегда видела потенциал этого языка и пыталась задействовать его как можно чаще. Так, Python в целом и Django в частности используются для главного проекта компании — поиска Google.
3. Dropbox
Один из крупнейших в мире сайтов для хранения данных, Dropbox, создал новый способ хранения данных — в облаке. Благодаря нему пользователи имеют возможность получать доступ к файлам из любого места (только находясь онлайн, конечно). Dropbox подходит для хранения документов, видео, изображений и других данных. И все это благодаря возможностям Python.
Фреймворк использовался для создания бэкенда и клиентской части, что позволило команде разработчиков выпустить продукт довольно быстро. С помощью Django разработчики добились того, что у пользователей есть возможность смотреть историю, синхронизировать аккаунт между устройствами и делиться своими файлами.
4. Instagram
Instagram — одна из крупнейших социальных сетей в мире. Она позволяет публиковать фотографии и погружаться в жизни не только друзей, но и знаменитостей со всего мира. В первую очередь это мобильное приложение, но если говорить о веб-версии, то она была создана с помощью Django.
Изначально Python был ядром технологического стека приложения. Команда использовала несколько версий языка и в конце остановилась на Python 3.5.
Instagram обрабатывает большие объемы данных и взаимодействий пользователей. Использование Django упрощает это все и позволяет сосредоточиться на UI и UX.
Именно большое количество инструментов позволило сооснователям Instagram разработать первую версию приложения всего за две недели. Майк Кригер рассказывал, что им было легко стартовать с Django, ведь последний не требовал опыта и не предполагал широких возможностей в плане кастомизации.
Instagram начал быстро расти и компания искала новые технологии, чтобы задействовать их, но в итоге они приняли решение остаться с Python и Django.
Бывший глава разработки рассказал:
Мы смогли добраться до отметки в сотни миллионов пользователей с помощью Python и Django, поэтому решили продолжать в том же направлении. Одна из причин — наши инженеры действительно любят Python. Поэтому они и хотят работать у нас.
Более того Instagram использует Sentry для мониторинга и составления отчетов о багах. И все это происходит в реальном времени.
5. Reddit
Reddit — крупнейший в мире проект с элементами новостной ленты и социальной сети. Пользователи могут публиковать разные посты, комментировать их и оценивать посты других. Большая часть сайта выполнена с помощью Python.
6. Pinterest
Pinterest очень похож на Instagram. На этом сайте пользователи могут делиться разными фотографиями, но только теми, которые соответствуют их интересам или определенной теме. Например, можно вести доску о самых быстрых автомобилях, подписаться на нее и после этого получать похожие фотографии.
Django — популярный фреймворк в среде платформ социальных медиа, ведь он позволяет работать с большими объемами данных, которые могут обрабатывать тысячи взаимодействий каждую секунду. У Pinterest 250 миллионов активных пользователей, поэтому важно обеспечивать производительность и пропускную способность. Все это есть в Django, что позволяет пользователям Pinterest следить друг за другом, делиться информацией и так далее.
7. Quora
Quora — портал, на котором пользователи могут задавать и отвечать на вопросы. С активностью они приобретают рейтинг, который позволяет активнее привлекать ответы на свои вопросы.
8. Yahoo Maps
В основном, Yahoo использует для своих проектов Node.js. Но для создания карт они решили использовать Python. Yahoo Maps — стандартное решение, которое позволяет проложить маршрут из точки A в точку B. Этот поисковый движок не так популярен в восточных странных, но пользуется популярностью на западе. Он считается надежным, поэтому его часто используют в повседневных поездках.
9. Spotify
Spotify — приложение, которое позволяет находить, слушать и делиться музыкой бесплатно. Оно очень удобное, поскольку позволяет быстро находить нужные треки и создавать плейлисты.
Как и iTunes, Spotify изменил то, как люди слушают музыку и делятся ею. С помощью Spotify получить доступ к своей медиатеке можно с любого устройства. Разработчики выбрали Django по двум причинам:
- Быстрый бэкенд
- Возможности для машинного обучения
Они не только используют возможности Python, но и создают новые. В Spotify также используют Java и C++, но последний — все меньше и меньше.
10. The Onion
The Onion — еще один пример отличного сервиса, созданного с помощью Django. Это сатирическое издание, у которого есть онлайн-версия. Публикации, дизайн и все функции созданы с помощью Django и Python.
Сегодня это одна из самых известных и читаемых газет в мире.
11. Disqus
Django — один из самых значимых проектов, созданных с помощью Python. Он позволяет реализовывать комментарии и дискуссии на сайтах, анализировать аудиторию, активность, а также менять то, как отображается реклама для них.
Использование Disqus не только позволило команде быстрее создать сайт, но также стремительно масштабировать его. Сегодня разработчики используют и другие фреймворки, но Django остается выбором №1 благодаря отличному сообществу и готовым компонентам.
С помощью Django команда Disqus также создала Sentry — внутренний инструмент для отслеживания багов, отладки и исправления критических ошибок.
12. Washington Post
Изначально Django был создан для поддержки контентного приложения для Lawrence Journal-World, The Washington Post, The Guardian, The New York Post и других сайтов новостных изданий. Django работает быстро и отлично масштабируется, что позволяет обрабатывать запросы аудитории любого масштаба.
13. Bitbucket
Облачный Git-репозиторий привлек миллионы разработчиков в 2008 году. С 17 миллионами запросов и 6 млн репозиториев в год это одно из крупнейших веб-приложений на Django.
Команда Bitbucket выбрала Django по нескольким причинам: тысячи разработчиков в сообществе и готовые решение.
14. Eventbrite
Eventbrite — популярная платформа для управления и продажи билетов на мероприятия. Изначально она была создана на чистом Python, но позже разработчики переключились на Django, чтобы справляться с ростом аудитории и объемом взаимодействия между ними.
15. Mozilla
Один из популярнейших браузеров, Mozilla, должен обрабатывать миллионы запросов каждый месяц. Учитывая это количество, нет ничего удивительного, что команда решила перейти с PHP + CakePHP на Python + Django. Сайт поддержки и дополнений Mozilla сегодня работают с помощью Django.
Почему веб-разработка на Django?
Когда у вас только появилась идея, нужно всего несколько минут, чтобы придать ей форму с помощью Django. Тот факт, что Django находится в свободном доступе, значительно упрощает процесс разработки и помогает разработчиков думать о дизайне и функциях.
Также это идеальный инструментов для стартапов. У Django есть множество преимуществ и недостатков, которые не были упомянуты в этом материале. Однако для проекта с дедлайном этот фреймворк подходит чуть ли не лучше всех. А для ускорения процесса разработки можно использовать собственные параметры.
]]>Представьте приложение для поиска по сети, которое открывает тысячу соединений. Можно открывать соединение, получать результат и переходить к следующему, двигаясь по очереди. Однако это значительно увеличивает задержку в работе программы. Ведь открытие соединение — операция, которая занимает время. И все это время последующие операции находятся в процессе ожидания.
А вот асинхронность предоставляет способ открытия тысячи соединений одновременно и переключения между ними. По сути, появляется возможность открыть соединение и переходить к следующему, ожидая ответа от первого. Так продолжается до тех пор, пока все не вернут результат.

На графике видно, что синхронный подход займет 45 секунд, в то время как при использовании асинхронности время выполнения можно сократить до 20 секунд.
Где асинхронность применяется в реальном мире?
Асинхронность больше всего подходит для таких сценариев:
- Программа выполняется слишком долго.
- Причина задержки — не вычисления, а ожидания ввода или вывода.
- Задачи, которые включают несколько одновременных операций ввода и вывода.
Это могут быть:
- Парсеры,
- Сетевые сервисы.
Разница в понятиях параллелизма, concurrency, поточности и асинхронности
Параллелизм — это выполнение нескольких операций за раз. Многопроцессорность — один из примеров. Отлично подходит для задач, нагружающих CPU.
Concurrency — более широкое понятие, которое описывает несколько задач, выполняющихся с перекрытием друг друга.
Поточность — поток — это отдельный поток выполнения. Один процесс может содержать несколько потоков, где каждый будет работать независимо. Отлично подходит для IO-операций.
Асинхронность — однопоточный, однопроцессорный дизайн, использующий многозадачность. Другими словами, асинхронность создает впечатление параллелизма, используя один поток в одном процессе.
Составляющие асинхронного программирования
Разберем различные составляющие асинхронного программирования подробно. Также используем код для наглядности.
Сопрограммы
Сопрограммы (coroutine) — это обобщенные формы подпрограмм. Они используются для кооперативных задач и ведут себя как генераторы Python.
Для определения сопрограммы асинхронная функция использует ключевое слово await. При его использовании сопрограмма передает поток управления обратно в цикл событий (также известный как event loop).
Для запуска сопрограммы нужно запланировать его в цикле событий. После этого такие сопрограммы оборачиваются в задачи (Tasks) как объекты Future.
Пример сопрограммы
В коде ниже функция async_func вызывается из основной функции. Нужно добавить ключевое слово await при вызове синхронной функции. Функция async_func не будет делать ничего без await.
import asyncio
async def async_func():
print('Запуск ...')
await asyncio.sleep(1)
print('... Готово!')
async def main():
async_func() # этот код ничего не вернет
await async_func()
asyncio.run(main())
Вывод:
Warning (from warnings module):
File "\AppData\Local\Programs\Python\Python38\main.py", line 8
async_func() # этот код ничего не вернет
RuntimeWarning: coroutine 'async_func' was never awaited
Запуск ...
... Готово!Задачи (tasks)
Задачи используются для планирования параллельного выполнения сопрограмм.
При передаче сопрограммы в цикл событий для обработки можно получить объект Task, который предоставляет способ управления поведением сопрограммы извне цикла событий.
Пример задачи
В коде ниже создается create_task (встроенная функция библиотеки asyncio), после чего она запускается.
import asyncio
async def async_func():
print('Запуск ...')
await asyncio.sleep(1)
print('... Готово!')
async def main():
task = asyncio.create_task (async_func())
await task
asyncio.run(main())
Вывод:
Запуск ...
... Готово!Циклы событий
Этот механизм выполняет сопрограммы до тех пор, пока те не завершатся. Это можно представить как цикл while True, который отслеживает сопрограммы, узнавая, когда те находятся в режиме ожидания, чтобы в этот момент выполнить что-нибудь другое.
Он может разбудить спящую сопрограмму в тот момент, когда она ожидает своего времени, чтобы выполниться. В одно время может выполняться лишь один цикл событий в Python.
Пример цикла событий
Дальше создаются три задачи, которые добавляются в список. Они выполняются асинхронно с помощью get_event_loop, create_task и await библиотеки asyncio.
import asyncio
async def async_func(task_no):
print(f'{task_no}: Запуск ...')
await asyncio.sleep(1)
print(f'{task_no}: ... Готово!')
async def main():
taskA = loop.create_task (async_func('taskA'))
taskB = loop.create_task(async_func('taskB'))
taskC = loop.create_task(async_func('taskC'))
await asyncio.wait([taskA,taskB,taskC])
if __name__ == "__main__":
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
except :
pass
Вывод:
taskA: Запуск ...
taskB: Запуск ...
taskC: Запуск ...
taskA: ... Готово!
taskB: ... Готово!
taskC: ... Готово!Future
Future — это специальный низкоуровневый объект, который представляет окончательный результат выполнения асинхронной операции.
Если этот объект подождать (await), то сопрограмма дождется, пока Future не будет выполнен в другом месте.
В следующих разделах посмотрим, на то, как Future используется.
Сравнение многопоточности и асинхронности
Прежде чем переходить к асинхронности попробуем проверить многопоточность на производительность и сравним результаты. Для этого теста будем получать данные по URL с разной частотой: 1, 10, 50, 100 и 500 раз соответственно. После этого сравним производительность обоих подходов.
Реализация
Многопоточность:
import requests
import time
from concurrent.futures import ProcessPoolExecutor
def fetch_url_data(pg_url):
try:
resp = requests.get(pg_url)
except Exception as e:
print(f"Возникла ошибка при получении данных из url: {pg_url}")
else:
return resp.content
def get_all_url_data(url_list):
with ProcessPoolExecutor() as executor:
resp = executor.map(fetch_url_data, url_list)
return resp
if __name__=='__main__':
url = "https://www.uefa.com/uefaeuro-2020/"
for ntimes in [1,10,50,100,500]:
start_time = time.time()
responses = get_all_url_data([url] * ntimes)
print(f'Получено {ntimes} результатов запроса за {time.time() - start_time} секунд')
Вывод:
Получено 1 результатов запроса за 0.9133939743041992 секунд
Получено 10 результатов запроса за 1.7160518169403076 секунд
Получено 50 результатов запроса за 3.842841625213623 секунд
Получено 100 результатов запроса за 7.662721633911133 секунд
Получено 500 результатов запроса за 32.575703620910645 секундProcessPoolExecutor — это пакет Python, который реализовывает интерфейс Executor. fetch_url_data — функция для получения данных по URL с помощью библиотеки request. После получения get_all_url_data используется, чтобы замапить function_url_data на список URL.
Асинхронность:
import asyncio
import time
from aiohttp import ClientSession, ClientResponseError
async def fetch_url_data(session, url):
try:
async with session.get(url, timeout=60) as response:
resp = await response.read()
except Exception as e:
print(e)
else:
return resp
return
async def fetch_async(loop, r):
url = "https://www.uefa.com/uefaeuro-2020/"
tasks = []
async with ClientSession() as session:
for i in range(r):
task = asyncio.ensure_future(fetch_url_data(session, url))
tasks.append(task)
responses = await asyncio.gather(*tasks)
return responses
if __name__ == '__main__':
for ntimes in [1, 10, 50, 100, 500]:
start_time = time.time()
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(fetch_async(loop, ntimes))
# будет выполняться до тех пор, пока не завершится или не возникнет ошибка
loop.run_until_complete(future)
responses = future.result()
print(f'Получено {ntimes} результатов запроса за {time.time() - start_time} секунд')
Вывод:
Получено 1 результатов запроса за 0.41477298736572266 секунд
Получено 10 результатов запроса за 0.46897053718566895 секунд
Получено 50 результатов запроса за 2.3057644367218018 секунд
Получено 100 результатов запроса за 4.6860511302948 секунд
Получено 500 результатов запроса за 18.013994455337524 секундНужно использовать функцию get_event_loop для создания и добавления задач. Чтобы использовать более одного URL, нужно применить функцию ensure_future.
Функция fetch_async используется для добавления задачи в объект цикла событий, а fetch_url_data — для чтения данных URL с помощью пакета session. Метод future_result возвращает ответ всех задач.
Результаты
Как можно увидеть, асинхронное программирование на порядок эффективнее многопоточности для этой программы.
Выводы
Асинхронное программирование демонстрирует более высокие результаты в плане производительности, задействуя параллелизм, а не многопоточность. Его стоит использовать в тех программах, где этот параллелизм можно применить.
]]>Известный пример — спам-фильтр для электронной почты. Gmail использует методы машинного обучения с учителем, чтобы автоматически помещать электронные письма в папку для спама в зависимости от их содержания, темы и других характеристик.
Две модели машинного обучения выполняют большую часть работы, когда дело доходит до задач классификации:
- Метод K-ближайших соседей
- Метод К-средних
Из этого руководства вы узнаете, как применять алгоритмы K-ближайших соседей и K-средних в коде на Python.
Модели K-ближайших соседей
Алгоритм K-ближайших соседей является одним из самых популярных среди ML-моделей для решения задач классификации.
Обычным упражнением для студентов, изучающих машинное обучение, является применение алгоритма K-ближайших соседей к датасету, категории которого неизвестны. Реальным примером такой ситуации может быть случай, когда вам нужно делать предсказания, используя ML-модели, обученные на секретных правительственных данных.
В этом руководстве вы изучите алгоритм машинного обучения K-ближайших соседей и напишите его реализацию на Python. Мы будем работать с анонимным набором данных, как в описанной выше ситуации.
Используемый датасет
Первое, что вам нужно сделать, это скачать набор данных, который мы будем использовать в этом руководстве. Вы можете скачать его на Gitlab.
Далее вам нужно переместить загруженный файл с датасетом в рабочий каталог. После этого откройте Jupyter Notebook — теперь мы можем приступить к написанию кода на Python!
Необходимые библиотеки
Чтобы написать алгоритм K-ближайших соседей, мы воспользуемся преимуществами многих Python-библиотек с открытым исходным кодом, включая NumPy, pandas и scikit-learn.
Начните работу, добавив следующие инструкции импорта:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Импорт датасета
Следующий шаг — добавление файла classified_data.csv в наш код на Python. Библиотека pandas позволяет довольно просто импортировать данные в DataFrame.
Поскольку датасет хранится в файле csv, мы будем использовать метод read_csv:
raw_data = pd.read_csv('classified_data.csv')
Отобразив полученный DataFrame в Jupyter Notebook, вы увидите, что представляют собой наши данные:
Стоит заметить, что таблица начинается с безымянного столбца, значения которого равны номерам строк DataFrame. Мы можем исправить это, немного изменив команду, которая импортировала наш набор данных в скрипт Python:
raw_data = pd.read_csv('classified_data.csv', index_col = 0)
Затем давайте посмотрим на показатели (признаки), содержащиеся в этом датасете. Вы можете вывести список имен столбцов с помощью следующей инструкции:
raw_data.columns
Получаем:
Index(['WTT', 'PTI', 'EQW', 'SBI', 'LQE', 'QWG', 'FDJ', 'PJF', 'HQE', 'NXJ',
'TARGET CLASS'],
dtype='object')Поскольку этот набор содержит секретные данные, мы понятия не имеем, что означает любой из этих столбцов. На данный момент достаточно признать, что каждый столбец является числовым по своей природе и поэтому хорошо подходит для моделирования с помощью методов машинного обучения.
Стандартизация датасета
Поскольку алгоритм K-ближайших соседей делает прогнозы относительно точки данных (семпла), используя наиболее близкие к ней наблюдения, существующий масштаб показателей в датасете имеет большое значение.
Из-за этого специалисты по машинному обучению обычно стандартизируют набор данных, что означает корректировку каждого значения x так, чтобы они находились примерно в одном диапазоне.
К счастью, библиотека scikit-learn позволяет сделать это без особых проблем.
Для начала нам нужно будет импортировать класс StandardScaler из scikit-learn. Для этого добавьте в свой скрипт Python следующую команду:
from sklearn.preprocessing import StandardScaler
Этот класс во многом похож на классы LinearRegression и LogisticRegression, которые мы использовали ранее в этом курсе. Нам нужно создать экземпляр StandardScaler, а затем использовать этот объект для преобразования наших данных.
Во-первых, давайте создадим экземпляр класса StandardScaler с именем scaler следующей инструкцией:
scaler = StandardScaler()
Теперь мы можем обучить scaler на нашем датасете, используя метод fit:
scaler.fit(raw_data.drop('TARGET CLASS', axis=1))
Теперь мы можем применить метод transform для стандартизации всех признаков, чтобы они имели примерно одинаковый масштаб. Мы сохраним преобразованные семплы в переменной scaled_features:
scaled_features = scaler.transform(raw_data.drop('TARGET CLASS', axis=1))
В качестве результата мы получили массив NumPy со всеми точками данных из датасета, но нам желательно преобразовать его в формат DataFrame библиотеки pandas.
К счастью, сделать это довольно легко. Мы просто обернем переменную scaled_features в метод pd.DataFrame и назначим этот DataFrame новой переменной scaled_data с соответствующим аргументом для указания имен столбцов:
scaled_data = pd.DataFrame(scaled_features, columns = raw_data.drop('TARGET CLASS', axis=1).columns)
Теперь, когда мы импортировали наш датасет и стандартизировали его показатели, мы готовы разделить этот набор данных на обучающую и тестовую выборки.
Разделение датасета на обучающие и тестовые данные
Мы будем использовать функцию train_test_split библиотеки scikit-learn в сочетании с распаковкой списка для создания обучающих и тестовых датасетов из нашего набора секретных данных.
Во-первых, вам нужно импортировать train_test_split из модуля model_validation библиотеки scikit-learn:
from sklearn.model_selection import train_test_split
Затем нам необходимо указать значения x и y, которые будут переданы в функцию train_test_split.
Значения x представляют собой DataFrame scaled_data, который мы создали ранее. Значения y хранятся в столбце "TARGET CLASS" нашей исходной таблицы raw_data.
Вы можете создать эти переменные следующим образом:
x = scaled_data
y = raw_data['TARGET CLASS']
Затем вам нужно запустить функцию train_test_split, используя эти два аргумента и разумный test_size. Мы будем использовать test_size 30%, что дает следующие параметры функции:
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, y, test_size = 0.3)
Теперь, когда наш датасет разделен на данные для обучения и данные для тестирования, мы готовы приступить к обучению нашей модели!
Обучение модели K-ближайших соседей
Начнем с импорта KNeighborsClassifier из scikit-learn:
from sklearn.neighbors import KNeighborsClassifier
Затем давайте создадим экземпляр класса KNeighborsClassifier и назначим его переменной model.
Для этого требуется передать параметр n_neighbors, который равен выбранному вами значению K алгоритма K-ближайших соседей. Для начала укажем n_neighbors = 1:
model = KNeighborsClassifier(n_neighbors = 1)
Теперь мы можем обучить нашу модель, используя метод fit и переменные x_training_data и y_training_data:
model.fit(x_training_data, y_training_data)
Теперь давайте сделаем несколько прогнозов с помощью полученной модели!
Делаем предсказания с помощью алгоритма K-ближайших соседей
Способ получения прогнозов на основе алгоритма K-ближайших соседей такой же, как и у моделей линейной и логистической регрессий, построенных нами ранее в этом курсе: для предсказания достаточно вызвать метод predict, передав в него переменную x_test_data.
В частности, вот так вы можете делать предсказания и присваивать их переменной predictions:
predictions = model.predict(x_test_data)
Давайте посмотрим, насколько точны наши прогнозы, в следующем разделе этого руководства.
Оценка точности нашей модели
В руководстве по логистической регрессии мы видели, что scikit-learn поставляется со встроенными функциями, которые упрощают измерение эффективности классификационных моделей машинного обучения.
Для начала импортируем в наш отчет две функции classification_report и confusion_matrix:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
Теперь давайте поработаем с каждой из них по очереди, начиная с classification_report. С ее помощью вы можете создать отчет следующим образом:
print(classification_report(y_test_data, predictions))
Полученный вывод:
precision recall f1-score support
0 0.92 0.91 0.91 148
1 0.91 0.92 0.92 152
accuracy 0.91 300
macro avg 0.91 0.91 0.91 300
weighted avg 0.91 0.91 0.91 300Точно так же вы можете сгенерировать матрицу ошибок:
print(confusion_matrix(y_test_data, predictions))
# Вывод:
# [[134 14]
# [ 12 140]]
Глядя на такие метрики производительности, похоже, что наша модель уже достаточно эффективна. Но ее еще можно улучшить.
В следующем разделе будет показано, как мы можем повлиять на работу модели K-ближайших соседей, выбрав более подходящее значение для K.
Выбор оптимального значения для K с помощью метода «Локтя»
В этом разделе мы будем использовать метод «локтя», чтобы выбрать оптимальное значение K для нашего алгоритма K-ближайших соседей.
Метод локтя включает в себя итерацию по различным значениям K и выбор значения с наименьшей частотой ошибок при применении к нашим тестовым данным.
Для начала создадим пустой список error_rates. Мы пройдемся по различным значениям K и добавим их частоту ошибок в этот список.
error_rates = []
Затем нам нужно создать цикл Python, который перебирает различные значения K, которые мы хотим протестировать, и на каждой итерации выполняет следующее:
- Создает новый экземпляр класса
KNeighborsClassifierиз scikit-learn. - Тренирует эту модель, используя наши обучающие данные.
- Делает прогнозы на основе наших тестовых данных.
- Вычисляет долю неверных предсказаний (чем она ниже, тем точнее наша модель).
Реализация описанного цикла для значений K от 1 до 100:
for i in np.arange(1, 101):
new_model = KNeighborsClassifier(n_neighbors = i)
new_model.fit(x_training_data, y_training_data)
new_predictions = new_model.predict(x_test_data)
error_rates.append(np.mean(new_predictions != y_test_data))
Давайте визуализируем, как изменяется частота ошибок при различных K, используя matplotlib — plt.plot(error_rates):
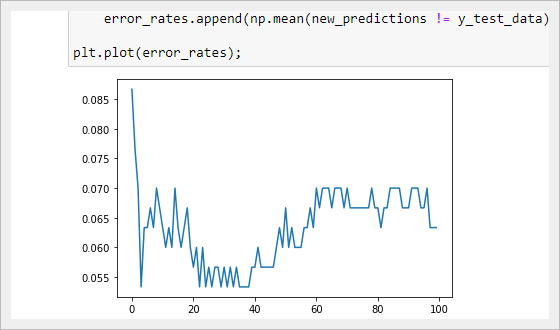
Как видно из графика, мы достигаем минимальной частоты ошибок при значении K, равном приблизительно 35. Это означает, что 35 является подходящим выбором для K, который сочетает в себе простоту и точность предсказаний.
Вы можете найти весь код в ноутбуке на GitLab:
https://gitlab.com/PythonRu/notebooks/-/blob/master/sklearn_kmeans_and_knn.ipynb
Модели кластеризации методом K-средних
Алгоритм кластеризации K-средних обычно является первой моделью машинного обучения без учителя, которую изучают студенты.
Он позволяет специалистам по машинному обучению создавать группы точек данных со схожими количественными характеристиками в датасете. Это полезно для решения таких задач, как формирование клиентских сегментов или определение городских районов с высоким уровнем преступности.
В этом разделе вы узнаете, как создать свой первый алгоритм кластеризации K-средних на Python.
Используемый датасет
В этом руководстве мы будем использовать набор данных, созданный с помощью scikit-learn.
Давайте импортируем функцию make_blobs из scikit-learn, чтобы сгенерировать необходимые данные. Откройте Jupyter Notebook и запустите свой скрипт Python со следующей инструкцией:
from sklearn.datasets import make_blobs
Теперь давайте воспользуемся функцией make_blobs, чтобы получить фиктивные данные!
В частности, вот как вы можете создать набор данных из 200 семплов, который имеет 2 показателя и 4 кластерных центров. Стандартное отклонение для каждого кластера будет равно 1.8.
raw_data = make_blobs(
n_samples = 200,
n_features = 2,
centers = 4,
cluster_std = 1.8
)
Если вы выведите объект raw_data, то заметите, что на самом деле он представляет собой кортеж Python. Первым его элементом является массив NumPy с 200 наблюдениями. Каждое наблюдение содержит 2 признака (как мы и указали в нашей функции make_blobs).
Теперь, когда наши данные созданы, мы можем перейти к импорту других необходимых библиотек с открытым исходным кодом в наш скрипт Python.
Импортируемые библиотеки
В этом руководстве будет использоваться ряд популярных библиотек Python с открытым исходным кодом, включая pandas, NumPy и matplotlib. Продолжим написание скрипта, добавив следующие импорты:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Первая группа библиотек в этом блоке кода предназначена для работы с большими наборами данных. Вторая группа предназначена для визуализации результатов.
Теперь перейдем к созданию визуального представления нашего датасета.
Визуализация датасета
В функции make_blobs мы указали, что в нашем наборе данных должно быть 4 кластерных центра. Лучший способ убедиться, что все действительно так, — это создать несколько простых точечных диаграмм.
Для этого мы воспользуемся функцией plt.scatter, передав в нее все значения из первого столбца нашего набора данных в качестве X и соответствующие значения из второго столбца в качестве Y:
Примечание: ваш датасет будет отличаться от моего, поскольку его данные сгенерированы случайным образом.
Представленное изображение, похоже, указывает на то, что в нашем датасете всего три кластера. Нам так кажется потому, что два кластера расположены очень близко друг к другу.
Чтобы исправить это, нужно сослаться на второй элемент кортежа raw_data, представляющий собой массив NumPy: он содержит индекс кластера, которому принадлежит каждое наблюдение.
Если при построении мы будем использовать уникальный цвет для каждого кластера, то мы легко различим 4 группы наблюдений. Вот код для этого:
plt.scatter(raw_data[0][:,0], raw_data[0][:,1], c=raw_data[1]);
Теперь мы видим, что в нашем наборе данных есть четыре уникальных кластера. Давайте перейдем к построению нашей модели на основе метода K-средних на Python!
Создание и обучение модели кластеризации K-средних
Для того, чтобы начать использовать метод K-средних, импортируем соответствующий класс из scikit-learn. Для этого добавьте в свой скрипт следующую команду:
from sklearn.cluster import KMeans
Затем давайте создадим экземпляр класса KMeans с параметром n_clusters=4 и присвоим его переменной model:
model = KMeans(n_clusters=4)
Теперь обучим нашу модель, вызвав на ней метод fit и передав первый элемент нашего кортежа raw_data:
model.fit(raw_data[0])
В следующем разделе мы рассмотрим, как делать прогнозы с помощью модели кластеризации K-средних.
Прежде чем двигаться дальше, я хотел бы указать на одно различие, которое вы, возможно заметили, между процессом построения модели, используя метод K-средних (он является алгоритмом кластеризации без учителя), и алгоритмами машинного обучения с учителем, с которыми мы работали ранее в данном курсе.
Оно заключается в том, что нам не нужно разбивать набор данных на обучающую и тестовую выборки. Это важное различие, так как вам никогда не нужно разделять таким образом датасет при построении моделей машинного обучения без учителя!
Применяем нашу модель кластеризации K-средних для получения предсказаний
Специалисты по машинному обучению обычно используют алгоритмы кластеризации, чтобы делать два типа прогнозов:
- К какому кластеру принадлежит каждая точка данных.
- Где находится центр каждого кластера.
Теперь, когда наша модель обучена, мы можем легко сгенерировать такие предсказания.
Во-первых, давайте предскажем, к какому кластеру принадлежит каждая точка данных. Для этого обратимся к атрибуту labels_ из объекта model с помощью оператора точки:
model.labels_
Таким образом мы получаем массив NumPy с прогнозами для каждого семпла:
array([3, 2, 1, 1, 3, 2, 1, 0, 0, 0, 0, 0, 3, 2, 1, 2, 1, 3, 3, 3, 3, 1,
1, 1, 2, 2, 3, 1, 3, 2, 1, 0, 1, 3, 1, 1, 3, 2, 0, 1, 3, 2, 3, 3,
0, 3, 2, 2, 3, 0, 0, 0, 1, 1, 2, 1, 2, 0, 1, 2, 2, 1, 2, 3, 0, 3,
0, 2, 0, 0, 1, 1, 0, 3, 2, 3, 2, 0, 1, 2, 0, 2, 0, 3, 3, 0, 3, 3,
0, 3, 2, 3, 2, 1, 2, 1, 3, 3, 2, 2, 0, 2, 0, 2, 0, 2, 1, 0, 0, 2,
3, 2, 1, 2, 3, 0, 1, 1, 1, 3, 2, 2, 3, 3, 2, 1, 3, 0, 0, 3, 0, 1,
1, 3, 1, 0, 1, 1, 0, 3, 2, 0, 3, 0, 1, 2, 1, 2, 1, 2, 2, 3, 2, 1,
0, 2, 3, 3, 2, 0, 1, 3, 3, 2, 0, 0, 0, 3, 1, 2, 0, 2, 3, 3, 2, 2,
3, 1, 0, 1, 2, 3, 1, 3, 1, 1, 0, 2, 1, 0, 2, 1, 3, 1, 3, 3, 1, 3,
0, 3])Чтобы узнать, где находится центр каждого кластера, аналогичным способом обратитесь к атрибуту cluster_centers_:
model.cluster_centers_
Получаем двумерный массив NumPy, содержащий координаты центра каждого кластера. Он будет выглядеть так:
array([[ 5.2662658 , -8.20493969],
[-9.39837945, -2.36452588],
[ 8.78032251, 5.1722511 ],
[ 2.40247618, -2.78480268]])Визуализация точности предсказаний модели
Последнее, что мы сделаем в этом руководстве, — это визуализируем точность нашей модели. Для этого можно использовать следующий код:
f, (ax1, ax2) = plt.subplots(1, 2, sharey=True,figsize=(10,6))
ax1.set_title('Наши предсказания')
ax1.scatter(raw_data[0][:,0], raw_data[0][:,1],c=model.labels_)
ax2.set_title('Реальные значения')
ax2.scatter(raw_data[0][:,0], raw_data[0][:,1],c=raw_data[1]);
Он генерирует две точечные диаграммы. Первая показывает кластеры, используя фактические метки из нашего датасета, а вторая основана на предсказаниях, сделанных нашей моделью. Вот как выглядит результат:
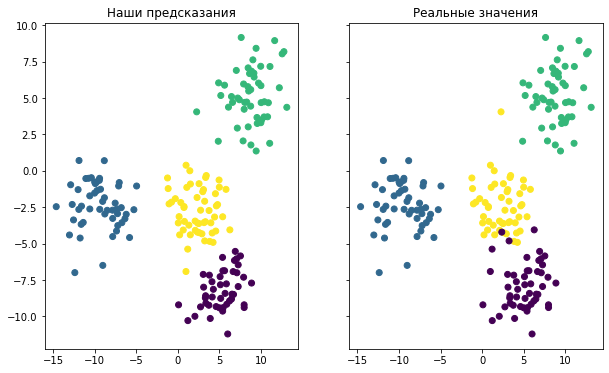
Хотя окраска двух графиков разная, вы можете видеть, что созданная модель довольно хорошо справилась с предсказанием кластеров в нашем наборе данных. Вы также можете заметить, что модель не идеальна: точки данных, расположенные на краях кластеров, в некоторых случаях классифицируются неверно.
И последнее, о чем следует упомянуть, говоря об оценке точности нашей модели. В этом примере мы знали, к какому кластеру принадлежит каждое наблюдение, потому что мы сами создали этот набор данных.
Такая ситуация встречается крайне редко. Метод К-средних обычно применяется, когда не известны ни количество кластеров, ни присущие им качества. Таким образом, специалисты по машинному обучению используют данный алгоритм, чтобы обнаружить закономерности в датасете, о которых они еще ничего не знают.
Вы можете найти весь код в ноутбуке на GitLab:
https://gitlab.com/PythonRu/notebooks/-/blob/master/sklearn_kmeans_and_knn.ipynb
Заключительные мысли
В этом руководстве вы научились создавать модели машинного обучения на Python, используя методы K-ближайших соседей и K-средних.
Вот краткое изложение того, что вы узнали о моделях K-ближайших соседей в Python:
- Как засекреченные данные являются распространенным инструментом для обучения студентов решению задач K-ближайших соседей.
- Почему важно стандартизировать набор данных при построении моделей K-ближайших соседей.
- Как разделить датасет на обучающую и тестирующую выборки с помощью функции
train_test_split. - Способ обучить вашу первую модель K-ближайших соседей и как получить сделанные ее прогнозы.
- Как оценить эффективность модели K-ближайших соседей.
- Метод локтя для выбора оптимального значения K в модели K-ближайших соседей.
А вот краткое изложение того, что вы узнали о моделях кластеризации K-средних в Python:
- Как сгенерировать фиктивные данные в scikit-learn с помощью функции
make_blobs. - Как создать и обучить модель кластеризации K-средних.
- То, что ML-методы без учителя не требуют, чтобы вы разделяли датасет на данные для обучения и данные для тестирования.
- Как создать и обучить модель кластеризации K-средних с помощью scikit-learn.
- Как визуализировать эффективность алгоритма K-средних, если вы изначально владеете информацией о кластерах.
Удовольствие от написания Python-кода заключается в возможности создавать короткие, лаконичные и читаемые классы, которые выражают большой объем логики в небольшом объеме кода, а не в сотнях строк, утомляющих читателя.
Гвидо ван РоссумЗа последние несколько лет технологии вокруг нас поменялись почти во всех аспектах. Мы живем в мире, где во главе угла стоит программное обеспечение, а за почти любой службой стоит какая-нибудь строчка кода. Индустрия путешествий, банкинг, образование, исследования, военная сфера — лишь немногие из тех, кто полагается на ПО.
Любой софт написан на каком-то языке программирования. А число последних лишь растет.
Однако одним из самых популярных в мире на сегодня является Python. В этом материале рассмотрим примеры реальных приложений, работающих на этом языке.
Реальные приложения на Python
Python сильно поменялся с момента создания в 1991 году Гвино ван Россумом. Это динамический, интерпретируемый, высокоуровневый язык программирования, с помощью которого можно создать массу разнообразных приложений. У него плавная кривая обучения и понятный синтаксис.
С помощью Python делают веб-приложения, видеоигры, занимаются Data Science и машинным обучения, разрабатывают софт, работающий в реальном мире, а также встроенные приложения и многое другое.
1. Веб-разработка
Наверняка все разработчики знают, что такое веб-разработка. Это квинтэссенция применимости Python. Также этот язык выделяет широкое разнообразие фреймворков и систем управления контентом (CMS), которые упрощают жизнь разработчика. Среди самых популярных решений — Django, Flask, Pyramid и Bottle. Среди CMS выделяются Django CMS, Plone CMS и Wagtail.
Веб-разработка на Python дает такие преимущества, как повышенная безопасность, масштабируемость и удобство в процессе работы. Также язык из коробки поддерживает такие протоколы, как HTML, XML, email-протоколы, FTP. У Python одна из крупнейших коллекций библиотек, упрощающих и улучшающих жизнь разработчика.
Посмотреть список сайтов, которые использую python можно на https://trends.builtwith.com/framework/Python.
2. Разработка игр
По аналогии с веб-разработкой в Python есть масса инструментов и библиотек для разработки игр. Кстати, а вы знали, что на этом языке программирования была написала популярная некогда Battlefield 2?
Для разработки игр используются такие библиотеки, как PyGame, Pycap, Construct, Panda3D, PySoy и PyOpenGL.
Также с помощью Python были разработаны такие проекты, как Sims 4, World of Tanks, Civilization IV и EVE Online. Можно вспомнить еще Mount & Blade, Doki Doki Literature Club, Frets on Fire и Disney’s Toontown Online.
3. Искусственный интеллект и машинное обучение
По данным GitHub Python расположился на втором месте среди языков, используемых для машинного обучения.
Искусственный интеллект и машинное обучение — очень популярные темы сегодня. С помощью них мы сегодня принимаем очень много решений. Python отчасти повлиял на такой рост популярность отрасли.
Стабильность и безопасность языка сделали его идеальным для интенсивных вычислений, без которых AI и ML не обходятся. А широкая коллекция библиотек помогает при разработке моделей и алгоритмов. Вот самые популярные библиотеки:
- SciPy для научных и технических вычислений.
- Pandas для анализа данных и манипуляции ими.
- Keras для нейронных сетей.
- TensorFlow для машинного обучения, особенно для глубоких нейронных сетей.
- NumPy для сложных математических функций и вычислений.
- Scikit-Learn для работы с разными моделями машинного обучения.
4. Графический интерфейс для настольных приложений
Иногда можно обойтись и без полноценного интерфейса, но для большинства проектов сегодня важен GUI. И для них в Python тоже есть множество решений.
При этом доступный синтаксис и модульная структура позволяют создавать быстрые и отзывчивые интерфейсы, делая еще и сам процесс разработки приятным. Среди самых популярных библиотек и фреймоворков — PyQt, Tkinter, Python GTK+, wxWidgets и Kivy.
5. Обработка изображений
Благодаря росту популярности машинного обучения, глубокого обучения и нейронных сетей выросла и роль инструментов для (предварительной) обработки изображений. Python в полной мере удовлетворяет этот спрос.
Среди самых популярных инструментов в Python можно выделить OpenCV, Scikit-Image, Python Imaging Library (PIL). Среди известных приложений, использующих Python — GIMP, Corel PaintShop, Blender и Houdini.
6. Обработка текста
Обработка текста — чуть ли не самый распространенный сценарий использования Python. Она руку идет с NLP (обработкой естественного языка), но не будем погружаться в эту тему сейчас. Обработка текста позволяет обрабатывать большие объемы текста, предоставляя гибкость структуры. Можно запросто сортировать строки, извлекать определенный текст, форматировать абзацы и так далее.
7. Бизнес приложения
Бизнес приложения во многом отличаются от обычного потребительского ПО. Во-первых, они предлагают ограниченный набор функций вместо десяток или даже сотен возможностей. Во-вторых, у них есть конкретная целевая группа (чаще всего ею выступает определенная организация).
Python отлично подходит для разработки таких высоконагруженных приложений.
Еще одной важной составляющей любого приложения является безопасность. И хотя почти все программы создаются с прицелом на безопасность, возможности Python в этом плане очень важны для бизнес-решений. Также Python позволяет писать масштабируемый код.
8. Образовательные и тренировочные программы
Python — отличная точка входа для каждого, кто хочет познакомиться с миром современного программирования. Все благодаря максимально простому синтаксису языка, который очень напоминает английский. Также изучается Python быстрее других языков. Именно поэтому этот язык один из основных кандидатов на то, чтобы быть первым языком программирования.
Есть масса обучающих ресурсов для получения начальных знаний по Python, но среди самых популярных можно выделить Coursera, edX, Udemy, Python Institute и Harvard.
9. Аудио и видео приложения
Эффективность Python позволяет использовать его для аудио и видео приложений. Для этого есть масса инструментов и библиотек. Сигнальная обработка, управление аудио, распознавание звуков — все это доступно с помощью таких библиотек, как Pyo, pyAudioANalysis, Dejavu и других.
Для видео же есть Scikit-video, OpenCV и SciPy. С их помощью можно управлять видеороликами и готовить их к использованию в других приложениях. На Python написаны Spotify, Netflix и YouTube.
10. Парсинг
В интернете просто невероятные объемы информации. И с помощью веб-парсеров данные на сайтах можно собирать, сохраняя их в одном месте. После этого их могут использовать исследователи, аналитики или организации для самых разных задач.
На Python есть такие библиотеки, как PythonRequest, BeautifulSoup, MechanicalSoup, Selenium и другие. Парсеры используются для отслеживания цены, аналитики, анализа в социальных медиа, проектах машинного обучения и в любых других проектах, где есть большие объемы данных.
11. Data Science и визуализация данных
Данные играют ключевую роль в современном мире. Они помогают понимать людей, их вкусы, собирать и анализировать интересные наблюдения. Это все — важная часть Data Science. В этой области требуется определить проблему, собрать данные, обработать их, изучить, проанализировать и визуализировать.
В экосистеме Python есть такие решения, как TensorFlow, PyTorch, Pandas, Scikit-Learn, NumPy, SciPy и многие другие.
Визуализация важна, когда данные нужно преподнести команде или держателям акций. Для этого в Python есть Plotly, Matplotlib, Seaborn, Ggplot, Geoplotlib и другие.
12. Научные и математические приложения
Мы уже определили, что в Python есть библиотеки для научных и математических вычислений, включая AI, ML и Data Science. Но даже если не брать эти сферы, язык пригодится, например, для работы с высокоуровневыми математическими функциями.
Стоит отметить такие инструменты, как Pandas, IPython, SciPy, Numeric Python, Matplotlib и другие. С помощью Python созданы такие приложения, как FreeCAD и Abaqus.
13. Разработка программного обеспечения
Python подходит не только для веб-разработки, научной разработки, создания игр или встраиваемых систем. По большому счету, это универсальное решение для софта любого типа. Все это возможно благодаря тому, что Python обеспечивает высокую скорость исполнения, хорошую совместимость, отличную поддержку со стороны сообщества, а также огромное количество библиотек. С помощью Python были созданы Roundup, Buildbot, SCons, Mercurial, Orbiter и Allura.
Часто разработчики используют Python как вспомогательный язык для управления проектами, контроля сборок и тестирования.
14. Операционные системы
Операционные системы — мозг любого компьютера. На Python, например, работают ОС, построенные на базе Linux. Как минимум, отдельные части таких систем.
В качестве примеров можно вспомнить Ubiquity Installer от Ubuntu, Anaconda Installer от Red Hat Enterprise. Также язык использовался для создания Gentoo Linux и системы управления пакетами Portage в Google Chrome OS. Вообще комбинация Python и C дает огромные преимущества при проектировании и разработке операционных систем.
15. CAD-приложения
CAD (computer aided design) приложения преимущественно используются в автомобильной, аэрокосмической и архитектурной сферах. Они помогают инженерам и дизайнерам проектировать продукты с точностью до миллиметров.
В среде Python из таких приложений есть FreeCAD, Fandango, PythonCAD, Blender и Vintech RCAM. Они предоставляют такие функции, как макрозапись, верстаки, симуляция роботов, скетчинг, поддержка мультиформатного импорта/экспорта, модули технического чертежа и многое другое.
16. Встроенные приложения
Одна из самых впечатляющих возможностей Python — работа на встроенном железе. Это такие устройства, которые предназначены для выполнения ограниченного набора действий. Встроенный софт — это тот, который отвечает за работу таких устройств. Среди самых популярных приложений MicroPython, Zerynth, PyMite и EmbeddedPython.
В качестве примера встроенных устройств можно вспомнить цифровые камеры, смартфоны, Raspberry Pi, промышленные роботы и другие, которые могут работать с помощью Python. Не все знают, но Python может использоваться как слой абстракции там, где на системном уровне работают C или C++.
Другие приложение на Python
- Консольные приложения
- Компьютерное зрение
- Робототехника
- Разработка языков
- Автоматическое тестирование
- Автоматизация
- Анализа данных
Вывод
Python — продвинутый и универсальный язык программирования, который быстро приобретает популярность среди разработчиков в разных отраслях. Его можно применить почти в любой сфере благодаря широкому набору библиотек.
Если вы только знакомитесь с программированием в целом, то этот материал должен был убедить вас выбрать в качестве первого языка Python. Благо, выучить его сегодня легко с помощью обилия книг, курсов, GitHub-репозиториев, популярных инструментов и библиотек.
]]>это последовательность символов в кавычках. Она может включать числа, буквы и
символы. С помощью Python строку можно разделить на список подстрок по
определенному разделителю. Это делается с помощью метода
split.
В этом материале разберем особенности его использования.
Что делает split в Python?
Функция split сканирует всю строку и разделяет ее в случае нахождения разделителя.
В строке должен быть как минимум один разделитель. Им может выступать в том
числе и символ пробела. Пробел — разделитель по умолчанию.
Если параметр на задать, то разделение будет выполнено именно по символу
пробела.
Синтаксис функции следующий:
string.split(separator*, maxsplit*)
Параметр separator — необязательный, но он позволяет задать разделитель
вручную.
Параметр maxsplit определяет максимальное количество разделений. Значение по
умолчанию — -1, будут выполнены все разделения.
Как разделить строку в Python
Метод .split() разделяет основную строку по разделителю и возвращает список строк.
my_st = "Пример строки Python"
print(my_st.split())
В примере выше была объявлена строка my_st. Она помещена в одинарные кавычки. Функция .split() разделяет ее на список таких строк:
['Пример', 'строки', 'Python']Вывод содержит список подстрок.
Еще один пример разбиения строки:
my_st = "синий,оранжевый,красный"
print(my_st.split(","))
В приведенном выше примере мы создали строку my_st с 3 подстроками. В этом случае именно запятая выступит параметром разделения в функции. Вывод будет следующий:
['синий', 'оранжевый', 'красный']Примеры разделения строки в Python
Разделение сроки по пробелу
Если не передать параметр разделителя, то .split() выполнит разделение по пробелу.
my_st = "Пример строки Python"
print(my_st.split())
Код вернет: ['Пример', 'строки', 'Python'].
Обратите внимание, что мы не указали разделитель, который нужно использовать при вызове функции .split(), поэтому в качестве разделителя используется пробел.
Разделение строки по запятой
Разделителем может выступать запятая (","). Это вернет список строк, которые
изначально были окружены запятыми.
my_st = "Например, строка Python"
print(my_st.split(","))
Вывод: ['Например', ' строка Python']. Результатом является список подстрок, разделенных по запятым в исходной строке.
Разделение строк по нескольким разделителям
В Python можно использовать даже несколько разделителей. Для этого просто требуется передать несколько символов в качестве разделителей функции split.
Возьмем в качестве примера ситуацию, где разделителями выступают одновременно : и ,. Задействуем функцию re.split().
import re
my_st = "Я\nучу; язык,программирования\nPython"
print(re.split(";|,|\n", my_st))
Вывод:
['Я', 'учу', ' язык', 'программирования', 'Python']Здесь мы используем модуль re и функции регулярных выражений. Переменной my_st была присвоена строка с несколькими разделителями, включая «\n», «;» и «,». А функция re.split() вызывается для этой строки с перечисленными выше разделителями.
Вывод — список подстрок, разделенных на основе оригинальной строки.
Как работает параметр maxsplit в функции split?
Этот параметр помогает задать максимальное число разделений. Разделить стоку можно, передав значение этого параметра. Например, если разделителем выступает символ пробела, а значение maxsplit — 1,
то строка будет разделена максимум на 2 подстроки.
languages = "Python,Java,Perl,PHP,Swift"
print(languages.split(",",1))
В строке languages хранится строка с перечислением разных языков. Функция split принимает запятую в качестве разделителя и значение 1 для параметра maxsplit. Это значит, что разделение будет выполнено только один раз.
['Python', 'Java,Perl,PHP,Swift']Следующий пример показывает, как выполнить разделение два раза. Здесь разделителем выступает пробел, а значение maxplit равно 2.
languages = "Python,Java,Perl,PHP,Swift"
print(languages.split(",",2))
['Python', 'Java', 'Perl,PHP,Swift']Как разделить строку посередине
Функция .split() не может разбить строку на две равных части.
Однако для этого можно использовать срезы (оператор :) и функцию len().
languages = "Python,Java,Perl,PHP,Swift"
mean_index = len(languages) // 2
print(f"Первая половина: {languages[:mean_index]}")
print(f"Вторая половина: {languages[mean_index:]}")
Вывод:
Первая половина: Python,Java,P
Вторая половина: erl,PHP,SwiftЗначение languages было разбито на две равных части. Для работы был использован оператор целочисленного деления.
Вывод
Вот что вы узнали:
- Функция
splitразбивает строку на подстроки по разделителю. - Параметр
maxsplitпозволяет указать максимально количество разделений. - Если разделитель не задать, то по умолчанию будет выбрано значение пробела.
- Срезы используются для деления строк на равные части.
Прочитав статью, вы узнаете как:
- Использовать функцию
runдля запуска внешнего процесса. - Получить стандартный вывод процесса и информацию об ошибках.
- Проверить код возврата процесса и вызвать исключение в случае сбоя.
- Запустить процесс, используя оболочку в качестве посредника.
- Установить время ожидания завершения процесса.
- Использовать класс
Popenнапрямую для создания конвейера (pipe) между двумя процессами.
Так как модуль subprocess почти всегда используют с Linux все примеры будут касаться Ubuntu. Для пользователей Windows советую скачать терминал Ubuntu 18.04 LTS.
Функция «run»
Функция run была добавлена в модуль subprocess только в относительно последних версиях Python (3.5). Теперь ее использование является рекомендуемым способом создания процессов и должно решать наиболее распространенные задачи. Прежде всего, давайте посмотрим на простейший случай применения функции run.
Предположим, мы хотим запустить команду ls -al; для этого в оболочке Python нам нужно ввести следующие инструкции:
>>> import subprocess
>>> process = subprocess.run(['ls', '-l', '-a'])
Вывод внешней команды ls отображается на экране:
total 12
drwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .
drwxr-xr-x 1 root root 4096 Apr 27 15:40 ..
-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history
-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout
-rw-r--r-- 1 cnc cnc 3771 Apr 27 15:40 .bashrcЗдесь мы просто использовали первый обязательный аргумент функции run, который может быть последовательностью, «описывающей» команду и ее аргументы (как в примере), или строкой, которая должна использоваться при запуске с аргументом shell=True (мы рассмотрим последний случай позже).
Захват вывода команды: stdout и stderr
Что, если мы не хотим, чтобы вывод процесса отображался на экране. Вместо этого, нужно чтобы он сохранялся: на него можно было ссылаться после выхода из процесса? В этом случае нам стоит установить для аргумента функции capture_output значение True:
>>> process = subprocess.run(['ls', '-l', '-a'], capture_output=True)
Как мы можем впоследствии получить вывод (stdout и stderr) процесса? Если вы посмотрите на приведенные выше примеры, то увидите, что мы использовали переменную process для ссылки на объект CompletedProcess, возвращаемый функцией run. Этот объект представляет процесс, запущенный функцией, и имеет много полезных свойств. Помимо прочих, stdout и stderr используются для «хранения» соответствующих дескрипторов команды, если, как уже было сказано, для аргумента capture_output установлено значение True. В этом случае, чтобы получить stdout, мы должны использовать:
>>> process = subprocess.run(['ls', '-l', '-a'], capture_output=True)
>>> process.stdout
b'total 12\ndrwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .\ndrwxr-xr-x 1 root root 4096 Apr 27 15:40 ..\n-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history\n-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout...По умолчанию stdout и stderr представляют собой последовательности байтов. Если мы хотим, чтобы они хранились в виде строк, мы должны установить для аргумента text функции run значение True.
Управление сбоями процесса
Команда, которую мы запускали в предыдущих примерах, была выполнена без ошибок. Однако при написании программы следует принимать во внимание все случаи. Так, что случится, если порожденный процесс даст сбой? По умолчанию ничего «особенного» не происходит. Давайте посмотрим на примере: мы снова запускаем команду ls, пытаясь вывести список содержимого каталога /root, который не доступен для чтения обычным пользователям:
>>> process = subprocess.run(['ls', '-l', '-a', '/root'])
Мы можем узнать, не завершился ли запущенный процесс ошибкой, проверив его код возврата, который хранится в свойстве returncode объекта CompletedProcess:
>>> process.returncode
2
Видите? В этом случае returncode равен 2, подтверждая, что процесс столкнулся с ошибкой, связанной с недостаточными правами доступа, и не был успешно завершен. Мы могли бы проверять выходные данные процесса таким образом чтобы при возникновении сбоя возникало исключение. Используйте аргумент check функции run: если для него установлено значение True, то в случае, когда внешний процесс завершается ошибкой, возникает исключение CalledProcessError:
>>> process = subprocess.run(['ls', '-l', '-a', '/root'])
ls: cannot open directory '/root': Permission deniedОбработка исключений в Python довольно проста. Поэтому для управления сбоями процесса мы могли бы написать что-то вроде:
>>> try:
... process = subprocess.run(['ls', '-l', '-a', '/root'], check=True)
... except subprocess.CalledProcessError as e:
... print(f"Ошибка команды {e.cmd}!")
...
ls: cannot open directory '/root': Permission denied
['ls', '-l', '-a', '/root'] failed!
>>>Исключение CalledProcessError, как мы уже сказали, возникает, когда код возврата процесса не является 0. У данного объекта есть такие свойства, как returncode, cmd, stdout, stderr; то, что они представляют, довольно очевидно. Например, в приведенном выше примере мы просто использовали свойство cmd, чтобы отобразить последовательность, которая использовалась для запуска команды при возникновении исключения.
Выполнение процесса в оболочке
Процессы, запущенные с помощью функции run, выполняются «напрямую», это означает, что для их запуска не используется оболочка: поэтому для процесса не доступны никакие переменные среды и не выполняются раскрытие и подстановка выражений. Давайте посмотрим на пример, который включает использование переменной $HOME:
>>> process = subprocess.run(['ls', '-al', '$HOME'])
ls: cannot access '$HOME': No such file or directoryКак видите, переменная $HOME не была заменена на соответствующее значение. Такой способ выполнения процессов является рекомендованным, так как позволяет избежать потенциальные угрозы безопасности. Однако, в некоторых случаях, когда нам нужно вызвать оболочку в качестве промежуточного процесса, достаточно установить для параметра shell функции run значение True. В таких случаях желательно указать команду и ее аргументы в виде строки:
>>> process = subprocess.run('ls -al $HOME', shell=True)
total 12
drwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .
drwxr-xr-x 1 root root 4096 Apr 27 15:40 ..
-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history
-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout
...Все переменные, существующие в пользовательской среде, могут использоваться при вызове оболочки в качестве промежуточного процесса. Хотя это может показаться удобным, такой подход является источником проблем. Особенно при работе с потенциально опасным вводом, который может привести к внедрению вредоносного shell-кода. Поэтому запуск процесса с shell=True не рекомендуется и должен использоваться только в безопасных случаях.
Ограничение времени работы процесса
Обычно мы не хотим, чтобы некорректно работающие процессы бесконечно исполнялись в нашей системе после их запуска. Если мы используем параметр timeout функции run, то можем указать количество времени в секундах, в течение которого процесс должен завершиться. Если он не будет завершен за это время, процесс будет остановлен сигналом SIGKILL. Который, как мы знаем, не может быть перехвачен. Давайте продемонстрируем это, запустив длительный процесс и предоставив timeout в секундах:
>>> process = subprocess.run(['ping', 'google.com'], timeout=5)
PING google.com (216.58.208.206) 56(84) bytes of data.
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=1 ttl=118 time=15.8 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=2 ttl=118 time=15.7 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=3 ttl=118 time=19.3 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=4 ttl=118 time=15.6 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=5 ttl=118 time=17.0 ms
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.8/subprocess.py", line 495, in run
stdout, stderr = process.communicate(input, timeout=timeout)
File "/usr/lib/python3.8/subprocess.py", line 1028, in communicate
stdout, stderr = self._communicate(input, endtime, timeout)
File "/usr/lib/python3.8/subprocess.py", line 1894, in _communicate
self.wait(timeout=self._remaining_time(endtime))
File "/usr/lib/python3.8/subprocess.py", line 1083, in wait
return self._wait(timeout=timeout)
File "/usr/lib/python3.8/subprocess.py", line 1798, in _wait
raise TimeoutExpired(self.args, timeout)
subprocess.TimeoutExpired: Command '['ping', 'google.com']' timed out after 4.999637200000052 seconds
В приведенном выше примере мы запустили команду ping без указания фиксированного числа пакетов ECHO REQUEST, поэтому она потенциально может работать вечно. Мы также установили время ожидания в 5 секунд с помощью параметра timeout. Как мы видим, ping была запущена, а по истечении 5 секунд возникло исключение TimeoutExpired и процесс был остановлен.
Функции call, check_output и check_call
Как мы уже говорили ранее, функция run является рекомендуемым способом запуска внешнего процесса. Она должна использоваться в большинстве случаев. До того, как она была представлена в Python 3.5, тремя основными функциями API высокого уровня, применяемыми для создания процессов, были call, check_output и check_call; давайте взглянем на них вкратце.
Прежде всего, функция call: она используется для выполнения команды, описанной параметром args; она ожидает завершения команды; ее результатом является соответствующий код возврата. Это примерно соответствует базовому использованию функции run.
Поведение функции check_call практически не отличается от run, когда для параметра check задано значение True: она запускает указанную команду и ожидает ее завершения. Если код возврата не равен 0, возникает исключение CalledProcessError.
Наконец, функция check_output. Она работает аналогично check_call, но возвращает вывод запущенной программы, то есть он не отображается при выполнении функции.
Работа на более низком уровне с классом Popen
До сих пор мы изучали функции API высокого уровня в модуле subprocess, особенно run. Все они под капотом используют класс Popen. Из-за этого в подавляющем большинстве случаев нам не нужно взаимодействовать с ним напрямую. Однако, когда требуется большая гибкость, без создания объектов Popen не обойтись.
Предположим, например, что мы хотим соединить два процесса, воссоздав поведение конвейера (pipe) оболочки. Как мы знаем, когда передаем две команды в оболочку, стандартный вывод той, что находится слева от пайпа «|», используется как стандартный ввод той, которая находится справа. В приведенном ниже примере результат выполнения двух связанных конвейером команд сохраняется в переменной:
$ output="$(dmesg | grep sda)"Чтобы воссоздать подобное поведение с помощью модуля subprocess без установки параметра shell в значение True, как мы видели ранее, мы должны напрямую использовать класс Popen:
dmesg = subprocess.Popen(['dmesg'], stdout=subprocess.PIPE)
grep = subprocess.Popen(['grep', 'sda'], stdin=dmesg.stdout)
dmesg.stdout.close()
output = grep.comunicate()[0]
Рассматривая данный пример, вы должны помнить, что процесс, запущенный с использованием класса Popen, не блокирует выполнение скрипта.
Первое, что мы сделали в приведенном выше фрагменте кода, — это создали объект Popen, представляющий процесс dmesg. Мы установили stdout этого процесса на subprocess.PIPE. Данное значение указывает, что пайп к указанному потоку должен быть открыт.
Затем мы создали еще один экземпляр класса Popen для процесса grep. В конструкторе Popen мы, конечно, указали команду и ее аргументы, но вот что важно, мы установили стандартный вывод процесса dmesg в качестве стандартного ввода для grep (stdin=dmesg.stdout), чтобы воссоздать поведение конвейера оболочки.
После создания объекта Popen для команды grep мы закрыли поток stdout процесса dmesg, используя метод close(). Это, как указано в документации, необходимо для того, чтобы первый процесс мог получить сигнал SIGPIPE. Дело в том, что обычно, когда два процесса соединены конвейером, если один справа от «|» (grep в нашем примере) завершается раньше, чем тот, что слева (dmesg), то последний получает сигнал SIGPIPE (пайп закрыт) и по умолчанию тоже заканчивает свою работу.
Однако при репликации пайплайна между двумя командами в Python возникает проблема. stdout первого процесса открывается как в родительском скрипте, так и в стандартном вводе другого процесса. Таким образом, даже если процесс grep завершится, пайп останется открытым в вызывающем процессе (нашем скрипте), поэтому dmesg никогда не получит сигнал SIGPIPE. Вот почему нам нужно закрыть поток stdout первого процесса в нашем основном скрипте после запуска второго.
Последнее, что мы сделали, — это вызвали метод communicate() объекта grep. Этот метод можно использовать для необязательной передачи данных в stdin процесса. Он ожидает завершения процесса и возвращает кортеж. Где первый элемент — это stdout (на который ссылается переменная output), а второй — stderr процесса.
Заключение
В этом руководстве мы увидели рекомендуемый способ создания внешних процессов в Python с помощью модуля subprocess и функции run. Использование этой функции должно быть достаточным для большинства случаев. Однако, когда требуется более высокий уровень гибкости, следует использовать класс Popen напрямую.
Как всегда, мы советуем вам взглянуть на документацию subprocess, чтобы получить полную информацию о функциях и классах, доступных в данном модуле.
Книги расскажут о фундаментальных концепциях контейнеров, оркестрации, OpenShift, непрерывного развертывания, cloud-native и т.д. Кроме того, я добавил несколько книг для людей, которые уже знакомы с Kubernetes и хотят попрактиковаться.
Независимо от того, являетесь ли вы новичком в мире Kubernetes или уже работаете DevOps инженером, эта подборка поможет выбрать наиболее подходящую книгу.
Если вы не знаете, что делает Kubernetes и как он работает, читайте статью Kubernetes для чайников, в ней подробно описаны принципы работы.
Лучшие книги по Kubernetes
Kubernetes в действии, второе издание — 2019
В самом начале эта книга поможет вам понять, что это такое и как с его помощью можно легко развернуть распределенные приложения на основе контейнеров. Автор будет постепенно знакомить вас с новыми возможностями.

После прочтения этой книги вы сможете контролировать, масштабировать и настраивать приложения с помощью Kubernetes.
Kubernetes. Лучшие практики. Построение эффективных приложений — 2021

Я бы сказал, что эта книга не для абсолютных новичков. Это отличный вариант для тех, кто хочет узнать о современных лучших практиках использования Kubernetes в реальных приложениях.
Вы узнаете различные паттерны для мониторинга и обеспечения безопасности ваших систем. Кроме того, я рекомендую эту книгу, если вы хотите понять сетевые политики платформы.
Kubernetes для DevOps: развертывание, запуск и масштабирование в облаке — 2020

Kubernetes, без сомнения, является отличным изобретением для «облачного мира». Авторы этой книги Джон Арундел и Джастин Домингус — настоящие эксперты по облачным технологиям. Они расскажут вам обо всех тонкостях экосистемы платформы.
Здесь вы научитесь создавать облачное нативное приложение с поддерживающей его инфраструктурой. Запустите собственные кластеры в облачных сервисах автоматического развёртывания таких, как SberCloud K8S. Вас познакомят с конвейером непрерывного развертывания, что очень важно для производственных приложений.
Паттерны Kubernetes. Шаблоны разработки собственных облачных приложений — 2020
Микросервисы и контейнеры значительно изменили способ создания и развертывания программных приложений. В этой книге Билджин Ибрам и Роланд Хасс, работающие в компании Red Hat, расскажут вам об общих методах разработки и внедрения облачных нативных приложений на платформе. Они предоставят вам популярные элементы, паттерны и принципы, которые повысят вашу производительность при создании реальных приложений.
Перед покупкой этой книги вы должны иметь некоторое базовое представление о Kubernetes. Она больше подходит для тех, кто ищет общие паттерны для облачных приложений.
Книга посвящена следующим категориям паттернов:
- Основополагающие паттерны
- Поведенческие паттерны
- Структурные паттерны
- Конфигурационные паттерны
- Продвинутые шаблоны
Введение в технологии контейнеров и Kubernetes — 2019
Главная особенность этой книги — знакомство с возможностями дистрибутива OpenShift (OKD) от Red Hat. Это один из самых популярных дистрибутивов Kubernetes. Вместе с ним рассматриваются механизмы работы контейнеров в Linux, основы работы с помощью Docker и Podman, а также сама система оркестрации контейнеров.

Книга подходит тем, кто уже знаком с GNU/Linux и хочет повысить уровень знаний контейнерных технологий и этой системы оркестровки.
Будущее Kubernetes
Вы только что ознакомились с подборкой лучших книг по этой платформе. Теперь я хотел бы упомянуть некоторые факты о ее доле на рынке. Это определенно побудит вас к изучению этой удивительной технологии.
Согласно отчету, опубликованному Cloud Native Computing Foundation (CNCF), контейнеры, используемые в производственной среде, выросли на 300% с 2016 года. Кроме того, использование платформы в производстве выросло до 83% по сравнению с 78% в прошлом году.
Kubernetes в основном используется компаниями корпоративного уровня, такими как Google, VMware, Deloitte и др. Доля рынка Kubernetes постоянно растет, это создает новые вакансии для инженеров DevOps.
]]>Gensim может работать с большими текстовыми коллекциями. Этим она отличается от других программных библиотек машинного обучения, ориентированных на обработку в памяти. GenSim также предоставляет эффективные многоядерные реализации различных алгоритмов для увеличения скорости обработки. В нее добавлены более удобные средства для обработки текста, чем у конкурентов, таких как Scikit-learn, R и т. д.
В этом руководстве будут рассмотрены следующие концепции:
- Создание корпуса из заданного датасета.
- Матрицы TFIDF в Gensim.
- Создание биграммы и триграммы с помощью Gensim.
- Модели Word2Vec, с использованием Gensim.
- Модели Doc2Vec, с использованием Gensim.
- Создание тематической модели с LDA.
- Создание тематической модели с LSI.
Прежде чем двигаться дальше, давайте разберемся, что означают следующие термины:
- Корпус: коллекция текстовых документов.
- Вектор: форма представления текста.
- Модель: алгоритм, используемый для генерации представления данных.
- Тематическое моделирование: инструмент интеллектуального анализа информации, который используется для извлечения семантических тем из документов.
- Тема: повторяющаяся группа слов, часто встречающихся вместе.
Например:
У вас есть документ, состоящий из таких слов, как:
bat, car, racquet, score, glass, drive, cup, keys, water, game, steering, liquid.
Их можно сгруппировать по разным темам:
| Тема 1 | Тема 2 | Тема 3 |
|---|---|---|
| glass | bat | car |
| cup | racquet | drive |
| water | score | keys |
| liquid | game | sterring |
Некоторые из методов тематического моделирования:
- Латентно-семантический анализ (LSI)
- Латентное размещение Дирихле (LDA)
Теперь, когда у нас есть базовое понимание терминологии, давайте перейдем к использованию пакета Gensim. Сначала установите библиотеку с помощью следующих команд:
pip install gensim
# или
conda install gensimШаг 1. Создайте корпус из заданного датасета
Вам необходимо выполнить следующие шаги, чтобы создать свою коллекцию документов:
- Загрузите выбранный датасет.
- Проведите предварительную обработку вашего набора данных.
- Создайте словарь.
- Создайте Bag of Words.
1.1 Загрузите выбранный датасет:
У вас может быть файл .txt в качестве набора данных или вы также можете загрузить необходимые датасеты с помощью API Gensim Downloader.
import os
# прочитать текстовый файл как объект
doc = open('sample_data.txt', encoding ='utf-8')
Gensim Downloader API – это модуль, доступный в библиотеке Gensim, который представляет собой API для скачивания, получения информации и загрузки датасетов/моделей.
import gensim.downloader as api
# проверка имеющихся моделей и датасетов
info_datasets = api.info()
print(info_datasets)
# информация ы конкретном наборе данных
dataset_info = api.info("text8")
# загрузка набора данных "text8"
dataset = api.load("text8")
# загрузка предварительно обученной модели
word2vec_model = api.load('word2vec-google-news-300')
Здесь мы будем использовать текстовый файл как необработанный набор данных, которые представляют собой текст со страницы Википедии.
1.2 Предварительная обработка набора данных
В NLP под предварительной обработкой текста понимают процесс очистки и подготовки текстовых данных. Для этого мы воспользуемся функцией simple_preprocess(), которая возвращает список токенов после их токенизации и нормализации.
import gensim
import os
from gensim.utils import simple_preprocess
# прочитать текстовый файл как объект
doc = open('nlp-wiki.txt', encoding ='utf-8')
# предварительная обработка файла для получения списка токенов
tokenized = []
for sentence in doc.read().split('.'):
# функция simple_preprocess возвращает список слов каждого предложения
tokenized.append(simple_preprocess(sentence, deacc = True))
print(tokenized)
doc.close()
Токенизированный вывод:
[['the', 'history', 'of', 'natural', 'language', 'processing', 'generally', 'started', 'in', 'the', 'although', 'work', 'can', 'be', 'found', 'from', 'earlier', 'periods'], ['in', 'alan', 'turing', 'published', 'an', 'article', 'titled', 'intelligence', 'which', 'proposed', 'what', 'is', 'now', 'called', 'the', 'turing', 'test', 'as', 'criterion', 'of', 'intelligence'], ['the', 'georgetown', 'experiment', 'in', 'involved', 'fully', 'automatic', 'translation', 'of', 'more', 'than', 'sixty', 'russian', 'sentences', 'into', 'english'], ['the', 'authors', 'claimed', 'that', 'within', 'three', 'or', 'five', 'years', 'machine', 'translation', 'would', 'be', 'solved', 'problem'],
...1.3 Создание словаря
Теперь у нас есть предварительно обработанные данные, которые можно преобразовать в словарь с помощью функции corpora.Dictionary(). Этот словарь представляет собой коллекцию уникальных токенов.
from gensim import corpora
# сохранение извлеченных токенов в словарь
my_dictionary = corpora.Dictionary(tokenized)
print(my_dictionary)
Dictionary(410 unique tokens: ['although', 'be', 'can', 'earlier', 'found']...)
1.3.1 Сохранение словаря
Вы можете сохранить (или загрузить) свой словарь на диске напрямую, а также в виде текстового файла, как показано ниже:
# сохраните словарь на диске
my_dictionary.save('my_dictionary.dict')
# загрузите обратно
load_dict = corpora.Dictionary.load('my_dictionary.dict')
# сохраните словарь в текстовом файле
from gensim.test.utils import get_tmpfile
tmp_fname = get_tmpfile("dictionary")
my_dictionary.save_as_text(tmp_fname)
# загрузите текстовый файл с вашим словарем
load_dict = corpora.Dictionary.load_from_text(tmp_fname)
1.4 Создание Bag of Words
Когда у нас есть словарь, мы можем создать корпус Bag of Words с помощью функции doc2bow(). Эта функция подсчитывает число вхождений и генерирует целочисленный идентификатор для каждого слова. Результат возвращается в виде разреженного вектора.
# преобразование в слов Bag of Word
bow_corpus =[my_dictionary.doc2bow(doc, allow_update = True) for doc in tokenized]
print(bow_corpus)
[[(0, 1), (1, 1), (2, 1),
...
(407, 1), (408, 1), (409, 1)], []]
1.4.1 Сохранение корпуса на диск
Код для сохранения/загрузки вашего корпуса:
from gensim.corpora import MmCorpus
from gensim.test.utils import get_tmpfile
output_fname = get_tmpfile("BoW_corpus.mm")
# сохранение корпуса на диск
MmCorpus.serialize(output_fname, bow_corpus)
# загрузка корпуса
load_corpus = MmCorpus(output_fname)
Шаг 2: Создание матрицы TF-IDF в Gensim
TF-IDF (Term Frequency – Inverse Document Frequency) – это часто используемая модель обработки естественного языка, которая помогает вам определять самые важные слова для каждого документа в корпусе. Она была разработана для коллекций небольшого размера.
Некоторые слова могут не являться стоп-словами, но при этом довольно часто встречаться в документах, имея малую значимость. Следовательно, эти слова необходимо удалить или снизить их важность. Модель TFIDF берет текст, написанный на одном языке, и гарантирует, что наиболее распространенные слова во всем корпусе не будут отображаться в качестве ключевых слов.
Вы можете построить модель TFIDF, используя Gensim и корпус, который вы разработали ранее, следующий образом:
from gensim import models
import numpy as np
# Вес слова в корпусе Bag of Word
word_weight =[]
for doc in bow_corpus:
for id, freq in doc:
word_weight.append([my_dictionary[id], freq])
print(word_weight)
Вес слов перед применением TF-IDF:
[['although', 1], ['be', 1], ['can', 1], ['earlier', 1],
...
['steps', 1], ['term', 1], ['transformations', 1]]Код (применение модели TF-IDF):
# создать модель TF-IDF
tfIdf = models.TfidfModel(bow_corpus, smartirs ='ntc')
# TF-IDF вес слова
weight_tfidf =[]
for doc in tfIdf[bow_corpus]:
for id, freq in doc:
weight_tfidf.append([my_dictionary[id], np.around(freq, decimals=3)])
print(weight_tfidf)
Вес слов после применением TF-IDF:
[['although', 0.339], ['be', 0.19], ['can', 0.237], ['earlier', 0.339],
...
['steps', 0.191], ['term', 0.191], ['transformations', 0.191]]
Вы можете видеть, что словам, часто встречающимся в документах, теперь присвоены более низкие веса.
Шаг 3. Создание биграмм и триграмм с помощью Gensim
Многие слова употребляются в тексте вместе. Такие сочетания имеют другое значение, чем составляющие их слова по отдельности.
Например:
Beatboxing -> слова beat и boxing имеют собственные смысловые вариации, но вместе они представляют совсем иное значение.
Биграмма — группа из двух слов.
Триграмма — группа из трех слов.
Здесь мы будем использовать датасет text8, который можно загрузить с помощью API downloader Gensim. Код построения биграмм и триграмм:
import gensim.downloader as api
from gensim.models.phrases import Phrases
# загрузка набора данных "text8"
dataset = api.load("text8")
# извлечь список слов из датасета
data =[]
for word in dataset:
data.append(word)
# Биграм с использованием модели фразера
bigram_model = Phrases(data, min_count=3, threshold=10)
print(bigram_model[data[0]])
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working_class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans_culottes', 'of', 'the', 'french_revolution', 'whilst', 'the', 'term', 'is', 'still' ...Для создания триграмм мы просто передаем полученную выше биграммную модель той же функции.
# Триграмма с использованием модели фразы
trigram_model = Phrases(bigram_model[data], threshold=10)
# Триграмма
print(trigram_model[bigram_model[data[0]]])
['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early' ...Шаг 4: Создайте модель Word2Vec с помощью Gensim
Алгоритмы ML/DL не могут использовать текст напрямую, поэтому нам нужно некоторое числовое представление, чтобы эти алгоритмы могли обрабатывать данные. В простых приложениях машинного обучения используются CountVectorizer и TFIDF, которые не сохраняют связь между словами.
Word2Vec — метод преобразования текста для создания векторных представлений (Word Embeddings), которые отображают все слова, присутствующие в языке, в векторное пространство заданной размерности. Мы можем выполнять математические операции с этими векторами, которые помогают сохранить связь между словами.
Пример: queen — women + man = king.
Готовые векторно-семантические модели, такие как word2vec, GloVe, fasttext и другие можно загрузить с помощью API загрузчика Gensim. Иногда векторные представления определенных слов из вашего документа могут отсутствовать в упомянутых пакетах. Но вы можете решить данную проблему, обучив свою модель.
4.1) Обучение модели
import gensim.downloader as api
from multiprocessing import cpu_count
from gensim.models.word2vec import Word2Vec
# загрузка набора данных "text8"
dataset = api.load("text8")
# извлечь список слов из датасета
data =[]
for word in dataset:
data.append(word)
# Разделим данные на две части
data_1 = data[:1200] # используется для обучения модели
data_2 = data[1200:] # используется для обновления модели
# Обучение модели Word2Vec
w2v_model = Word2Vec(data_1, min_count=0, workers=cpu_count())
# вектор слов для слова "время"
print(w2v_model.wv['time'])
Вектор для слова «time»:
[-0.04681756 -0.08213229 1.0628034 -1.0186515 1.0779341 -0.89710116
0.6538859 -0.81849015 -0.29984367 0.55887854 2.138567 -0.93843514
...
-1.4128548 -1.3084044 0.94601256 0.27390406 0.6346426 -0.46116787
0.91097695 -3.597664 0.6901859 1.0902803 ]Вы также можете использовать функцию most_similar(), чтобы найти слова, похожие на переданное.
# слова, похожие на "time"
print(w2v_model.wv.most_similar('time'))
# сохранение и загрузка модели
w2v_model.save('Word2VecModel')
model = Word2Vec.load('Word2VecModel')
Cлова, наиболее похожие на «time»:
[('moment', 0.6137239933013916), ('period', 0.5904807448387146), ('stage', 0.5393826961517334), ('decade', 0.51670902967453), ('lifetime', 0.4878680109977722), ('once', 0.4843854010105133), ('distance', 0.4821343719959259), ('breteuil', 0.4815649390220642), ('preestablished', 0.47662678360939026), ('point', 0.4757876396179199)]4.2) Обновление модели
# построим словарный запас по образцу из последовательности предложений
w2v_model.build_vocab(data_2, update=True)
# обучение вектора слов
w2v_model.train(data_2, total_examples=w2v_model.corpus_count, epochs=w2v_model.epochs)
print(w2v_model.wv['time'])
На выходе вы получите новые веса для слов.
Шаг 5: Создание модели Doc2Vec с помощью Gensim
В отличие от модели Word2Vec, модель Doc2Vec генерирует векторное представление для всего документа или группы слов. С помощью этой модели мы можем найти взаимосвязь между различными документами, как показано ниже:
Если натренировать модель на литературе типа «Алиса в Зазеркалье». Мы можем сказать, что
Алиса в Зазеркалье == Алиса в Стране чудес.
5.1) Обучите модель
import gensim
import gensim.downloader as api
from gensim.models import doc2vec
# получить датасета
dataset = api.load("text8")
data =[]
for w in dataset:
data.append(w)
# Для обучения модели нам нужен список целевых документов
def tagged_document(list_of_ListOfWords):
for x, ListOfWords in enumerate(list_of_ListOfWords):
yield doc2vec.TaggedDocument(ListOfWords, [x])
# тренировочные данные
data_train = list(tagged_document(data))
# вывести обученный набор данных
print(data_train[:1])
Вывод – обученный датасет.
5.2) Обновите модель
# Инициализация модели
d2v_model = doc2vec.Doc2Vec(vector_size=40, min_count=2, epochs=30)
# расширить словарный запас
d2v_model.build_vocab(data_train)
# Обучение модели Doc2Vec
d2v_model.train(data_train, total_examples=d2v_model.corpus_count, epochs=d2v_model.epochs)
# Анализ выходных данных
analyze = d2v_model.infer_vector(['violent', 'means', 'to', 'destroy'])
print(analyze)
Вывод обновленной модели:
[-3.79053354e-02 -1.03341974e-01 -2.85615563e-01 1.37473553e-01
1.79868549e-01 3.42468806e-02 -1.68495290e-02 -1.86038092e-01
...
-1.20517321e-01 -1.48323074e-01 -5.70210926e-02 -2.15077385e-01]Шаг 6. Создание тематической модели с помощью LDA
LDA – популярный метод тематического моделирования, при котором каждый документ рассматривается как совокупность тем в определенной пропорции. Нам нужно вывести полезные качества тем, например, насколько они разделены и значимы. Темы хорошего качества зависят от:
- качества обработки текста,
- нахождения оптимального количества тем,
- настройки параметров алгоритма.
Выполните следующие шаги, чтобы создать модель.
6.1 Подготовка данных
Это делается путем удаления стоп-слов и последующей лемматизации ваших данных. Чтобы выполнить лемматизацию с помощью Gensim, нам нужно сначала загрузить пакет шаблонов и стоп-слова.
pip install pattern
# в python консоле
>>> import nltk
>>> nltk.download('stopwords')import gensim
from gensim import corpora
from gensim.models import LdaModel, LdaMulticore
import gensim.downloader as api
from gensim.utils import simple_preprocess
import nltk
from nltk.stem.wordnet import WordNetLemmatizer
# nltk.download('stopwords')
from nltk.corpus import stopwords
import re
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s')
logging.root.setLevel(level=logging.INFO)
# загрузка stopwords
stop_words = stopwords.words('english')
# добавление stopwords
stop_words = stop_words + ['subject', 'com', 'are', 'edu', 'would', 'could']
lemmatizer = WordNetLemmatizer()
# загрузка датасета
dataset = api.load("text8")
data = [w for w in dataset]
# подготовка данных
processed_data = []
for x, doc in enumerate(data[:100]):
doc_out = []
for word in doc:
if word not in stop_words: # для удаления стоп-слов
lemmatized_word = lemmatizer.lemmatize(word) # лемматизация
if lemmatized_word:
print
doc_out.append(lemmatized_word)
else:
continue
processed_data.append(doc_out) # processed_data это список слов
# вывод образца
print(processed_data[0][:10])
['anarchism', 'originated', 'term', 'abuse', 'first', 'used', 'early', 'working', 'class', 'radical']6.2 Создание словаря и корпуса
Обработанные данные теперь будут использоваться для создания словаря и корпуса.
dictionary = corpora.Dictionary(processed_data)
corpus = [dictionary.doc2bow(l) for l in processed_data]
6.3 Обучение LDA-модели
Мы будем обучать модель LDA с 5 темами, используя словарь и корпус, созданные ранее. Здесь используется функция LdaModel(), но вы также можете использовать функцию LdaMulticore(), поскольку она позволяет выполнять параллельную обработку.
# Обучение
LDA_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=5)
# сохранение модели
LDA_model.save('LDA_model.model')
# показать темы
print(LDA_model.print_topics(-1))
Слова, которые встречаются в более чем одной теме и имеют малое значение, могут быть добавлены в список запрещенных слов.
6.4 Интерпретация вывода
Модель LDA в основном дает нам информацию по трем направлениям:
- Темы в документе
- К какой теме принадлежит каждое слово
- Значение фи
Значением фи является вероятность того, что слово относится к определенной теме. Для выбранного слова сумма значений фи дает количество раз, оно встречается в документе.
# вероятность принадлежности слова к теме
LDA_model.get_term_topics('fire')
bow_list =['time', 'space', 'car']
# сначала преобразуйте в bag of words
bow = LDA_model.id2word.doc2bow(bow_list)
# интерпретация данных
doc_topics, word_topics, phi_values = LDA_model.get_document_topics(bow, per_word_topics=True)
Шаг 7. Создание тематической модели с помощью LSI
Чтобы создать модель с LSI, просто выполните те же шаги, что и с LDA.
Только для обучения используйте функцию LsiModel() вместо LdaMulticore() или LdaModel().
from gensim.models import LsiModel
# Обучение модели с помощью LSI
LSI_model = LsiModel(corpus=corpus, id2word=dictionary, num_topics=7, decay=0.5)
# темы
print(LSI_model.print_topics(-1))
Заключение
Это только некоторые из возможностей библиотеки Gensim. Пользоваться ими очень удобно, особенно когда вы занимаетесь NLP. Вы, конечно, можете применять их по своему усмотрению.
]]>При использовании SQLAlchemy ORM взаимодействие с базой данных происходит через объект Session. Он также захватывает соединение с базой данных и транзакции. Транзакция неявно стартует как только Session начинает общаться с базой данных и остается открытой до тех пор, пока Session не коммитится, откатывается или закрывается.
Для создания объекта session можно использовать класс Session из sqlalchemy.orm.
from sqlalchemy import create_engine
from sqlalchemy.orm import Session
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
Создавать объект Session нужно будет каждый раз при взаимодействии с базой.
Конструктор Session принимает определенное количество аргументов, которые определяют режим его работы. Если создать сессию таким способом, то в дальнейшем конструктор Session нужно будет вызывать с одним и тем же набором параметров.
Чтобы упростить этот процесс, SQLAlchemy предоставляет класс sessionmaker, который создает класс Session с аргументами для конструктора по умолчанию.
from sqlalchemy.orm import Session, sessionmaker
session = sessionmaker(bind=engine)
Нужно просто вызвать sessionmaker один раз в глобальной области видимости.
Получив доступ к этому классу Session раз, можно создавать его экземпляры любое количество раз, не передавая параметры.
session = Session()Обратите внимание на то, что объект Session не сразу устанавливает соединение с базой данных. Это происходит лишь при первом запросе.
Вставка(добавление) данных
Для создания новой записи с помощью SQLAlchemy ORM нужно выполнить следующие шаги:
- Создать объект
- Добавить его в сессию
- Сохранить сессию
Создадим два новых объекта Customer:
c1 = Customer(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com'
)
c2 = Customer(
first_name = 'Valeriy',
last_name = 'Golyshkin',
username = 'Fortioneaks',
email = 'fortioneaks@gmail.com'
)
print(c1.first_name, c2.last_name)
session.add(c1)
session.add(c2)
print(session.new)
session.commit()
Первый вывод: Dmitriy Golyshkin.
Два объекта созданы. Получить доступ к их атрибутам можно с помощью оператора точки (.).
Дальше в сессию добавляются объекты.
session.add(c1)
session.add(c2)Но добавление объектов не влияет на запись в базу, а лишь готовит объекты к сохранению в следующем коммите. Проверить это можно, получив первичные ключи объектов.
Значение атрибута id обоих объектов — None. Это значит, что они еще не сохранены в базе данных.
Вместо добавления одного объекта за раз можно использовать метод add_all(). Он принимает список объектов, которые будут добавлены в сессию.
session.add_all([c1, c2])Добавление объекта в сессию несколько раз не приводит к ошибкам. В любой момент на имеющиеся объекты можно посмотреть с помощью session.new.
IdentitySet([<__main__.Customer object at 0x000001BD25928C40>, <__main__.Customer object at 0x000001BD25928C70>])Наконец, для сохранения данных используется метод commit():
session.commit()После сохранения транзакции ресурсы соединения, на которые ссылается объект Session, возвращаются в пул соединений. Последующие операции будут выполняться в новой транзакции.
Сейчас таблица Customer выглядит вот так:
Пока что покупатели ничего не приобрели. Поэтому c1.orders и c2.orders вернут пустой список.
[] []Добавим еще потребителей в таблицу customers:
from sqlalchemy import create_engine
from sqlalchemy.orm import Session, sessionmaker
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
c3 = Customer(
first_name = "Vadim",
last_name = "Moiseenko",
username = "Antence73",
email = "antence73@mail.com",
)
c4 = Customer(
first_name = "Vladimir",
last_name = "Belousov",
username = "Andescols",
email = "andescols@mail.com",
)
c5 = Customer(
first_name = "Tatyana",
last_name = "Khakimova",
username = "Caltin1962",
email = "caltin1962@mail.com",
)
c6 = Customer(
first_name = "Pavel",
last_name = "Arnautov",
username = "Lablen",
email = "lablen@mail.com",
)
session.add_all([c3, c4, c5, c6])
session.commit()
Также добавим продукты в таблицу items:
i1 = Item(name = 'Chair', cost_price = 9.21, selling_price = 10.81, quantity = 5)
i2 = Item(name = 'Pen', cost_price = 3.45, selling_price = 4.51, quantity = 3)
i3 = Item(name = 'Headphone', cost_price = 15.52, selling_price = 16.81, quantity = 50)
i4 = Item(name = 'Travel Bag', cost_price = 20.1, selling_price = 24.21, quantity = 50)
i5 = Item(name = 'Keyboard', cost_price = 20.1, selling_price = 22.11, quantity = 50)
i6 = Item(name = 'Monitor', cost_price = 200.14, selling_price = 212.89, quantity = 50)
i7 = Item(name = 'Watch', cost_price = 100.58, selling_price = 104.41, quantity = 50)
i8 = Item(name = 'Water Bottle', cost_price = 20.89, selling_price = 25, quantity = 50)
session.add_all([i1, i2, i3, i4, i5, i6, i7, i8])
session.commit()
Создадим заказы:
o1 = Order(customer = c1)
o2 = Order(customer = c1)
line_item1 = OrderLine(order = o1, item = i1, quantity = 3)
line_item2 = OrderLine(order = o1, item = i2, quantity = 2)
line_item3 = OrderLine(order = o2, item = i1, quantity = 1)
line_item3 = OrderLine(order = o2, item = i2, quantity = 4)
session.add_all([o1, o2])
session.new
session.commit()
В данном случае в сессию добавляются только объекты Order (o1 и o2). Order и OrderLine связаны отношением один-ко-многим. Добавление объекта Order в сессию неявно добавляет также и объекты OrderLine. Но даже если добавить последние вручную, ошибки не будет.
Вместо передачи объекта Order при создании экземпляра OrderLine можно сделать следующее:
o3 = Order(customer = c1)
orderline1 = OrderLine(item = i1, quantity = 5)
orderline2 = OrderLine(item = i2, quantity = 10)
o3.line_items.append(orderline1)
o3.line_items.append(orderline2)
session.add_all([o3,])
session.new
session.commit()
После коммита таблицы orders и order_lines будут выглядеть вот так:
Если сейчас получить доступ к атрибуту orders объекта Customer, то вернется не-пустой список.
[<Order:1>, <Order:2>]С другой стороны отношения можно получить доступ к объекту Customer, которому заказ принадлежит через атрибут customer объекта Order — o1.customer.
Сейчас у покупателя c1 три заказа. Чтобы посмотреть все пункты в заказе нужно использовать атрибут line_items объекта Order.
c1.orders[0].line_items, c1.orders[1].line_items
([<OrderLine:1>, <OrderLine:2>], [<OrderLine:3>, <OrderLine:4>])Для получения элемента заказа используйте item.
for ol in c1.orders[0].line_items:
ol.id, ol.item, ol.quantity
print('-------')
for ol in c1.orders[1].line_items:
ol.id, ol.item, ol.quantity
Вывод:
(1, <Item:1-Chair>, 3)
(2, <Item:2-Pen>, 2)
-------
(3, <Item:1-Chair>, 1)
(4, <Item:2-Pen>, 4)
Все это возможно благодаря отношениям relationship() моделей.
Получение данных
Чтобы сделать запрос в базу данных используется метод query() объекта session. Он возвращает объект типа sqlalchemy.orm.query.Query, который называется просто Query. Он представляет собой инструкцию SELECT, которая будет использована для запроса в базу данных. В следующей таблице перечислены распространенные методы класса Query.
| Метод | Описание |
|---|---|
| all() | Возвращает результат запроса (объект Query) в виде списка |
| count() | Возвращает общее количество записей в запросе |
| first() | Возвращает первый результат из запроса или None, если записей нет |
| scalar() | Возвращает первую колонку первой записи или None, если результат пустой. Если записей несколько, то бросает исключение MultipleResultsFound |
| one | Возвращает одну запись. Если их несколько, бросает исключение MutlipleResultsFound. Если данных нет, бросает NoResultFound |
| get(pk) | Возвращает объект по первичному ключу (pk) или None, если объект не был найден |
| filter(*criterion) | Возвращает экземпляр Query после применения оператора WHERE |
| limit(limit) | Возвращает экземпляр Query после применения оператора LIMIT |
| offset(offset) | Возвращает экземпляр Query после применения оператора OFFSET |
| order_by(*criterion) | Возвращает экземпляр Query после применения оператора ORDER BY |
| join(*props, **kwargs) | Возвращает экземпляр Query после создания SQL INNER JOIN |
| outerjoin(*props, **kwargs) | Возвращает экземпляр Query после создания SQL LEFT OUTER JOIN |
| group_by(*criterion) | Возвращает экземпляр Query после добавления оператора GROUP BY к запросу |
| having(criterion) | Возвращает экземпляр Query после добавления оператора HAVING |
Метод all()
В базовой форме метод query() принимает в качестве аргументов один или несколько классов модели или колонок. Следующий код вернет все записи из таблицы customers.
from sqlalchemy import create_engine
from sqlalchemy.orm import Session
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
session = Session(bind=engine)
print(session.query(Customer).all())
[<Customer:1-Moseend>,
<Customer:2-Fortioneaks>,
<Customer:3-Antence73>,
<Customer:4-Andescols>,
<Customer:5-Caltin1962>,
<Customer:6-Lablen>]Так же можно получить записи из таблиц items и orders.
Чтобы получить сырой SQL, который используется для выполнения запроса в базу данных, примените sqlalchemy.orm.query.Query следующим образом: print(session.query(Customer)).
SELECT
customers. ID AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customersВызов метода all() на большом объекте результата не очень эффективен. Вместо этого стоит использовать цикл for для перебора по объекту Query:
q = session.query(Customer)
for c in q:
print(c.id, c.first_name)
Предыдущие запросы вернули данные из всех колонок таблицы. Предотвратить это можно, передав названия колонок явно в метод query():
print(session.query(Customer.id, Customer.first_name).all())
Вывод:
[(1, 'Dmitriy'),
(2, 'Valeriy'),
(3, 'Vadim'),
(4, 'Vladimir'),
(5, 'Tatyana'),
(6, 'Pavel')]Обратите внимание на то, что каждый элемент списка — это кортеж, а не экземпляр модели.
Метод count()
count() возвращает количество элементов в результате.
session.query(Item).count()
# Вывод - 8
Метод first()
first() возвращает первый результат запроса или None, если последний не вернул данных.
session.query(Order).first()
# Вывод - Order:1
Метод get()
get() возвращает экземпляр с соответствующим первичным ключом или None, если такой объект не был найден.
session.query(Customer).get(1)
# Вывод - Customer:1-Moseend
Метод filter()
Этот метод позволяет отфильтровать результаты, добавив оператор WHERE. Он принимает колонку, оператор и значение. Например:
session.query(Customer).filter(Customer.first_name == 'Vadim').all()Этот запрос вернет всех покупателей, чье имя — Vadim. А вот SQL-эквивалент этого запроса:
print(session.query(Customer).filter(Customer.first_name == 'Vadim'))
SELECT
customers.id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
WHERE
customers.first_name = %(first_name_1)sСтрока %(first_name_1)s в операторе WHERE — это заполнитель, который будет заменен на реальное значение (Vadim) при выполнении запроса.
Можно передать несколько фильтров в метод filter() и они будут объединены с помощью оператора AND. Например:
session.query(Customer).filter(Customer.id <= 5, Customer.last_name == "Arnautov").all()
Этот запрос вернет всех покупателей, чей первичный ключ меньше или равен 5, а фамилия начинается с "Ar".
session.query(Customer).filter(Customer.id <= 5, Customer.last_name.like("Ar%")).all()
Еще один способ комбинировать условия — союзы (and_(), or_() и not_()). Некоторые примеры:
# все клиенты с именем Vadim и Tatyana
session.query(Customer).filter(or_(
Customer.first_name == 'Vadim',
Customer.first_name == 'Tatyana'
)).all()
# найти всех с именем и Pavel фамилией НЕ Yatsenko
session.query(Customer).filter(and_(
Customer.first_name == 'Pavel',
not_(
Customer.last_name == 'Yatsenko',
)
)).all()
Следующий перечень демонстрирует, как использовать распространенные операторы сравнения с методом filter().
IS NULL
session.query(Order).filter(Order.date_placed == None).all()IS NOT NULL
session.query(Order).filter(Order.date_placed != None).all()
IN
session.query(Customer).filter(Customer.first_name.in_(['Pavel', 'Vadim'])).all()NOT INT
session.query(Customer).filter(Customer.first_name.notin_(['Pavel', 'Vadim'])).all()BETWEEN
session.query(Item).filter(Item.cost_price.between(10, 50)).all()NOT BETWEEN
session.query(Item).filter(not_(Item.cost_price.between(10, 50))).all()
LIKE
session.query(Item).filter(Item.name.like("%r")).all()
Метод like() выполняет поиск с учетом регистра. Для поиска совпадений без учета регистра используйте ilike().
session.query(Item).filter(Item.name.ilike("w%")).all()
NOT LIKE
session.query(Item).filter(not_(Item.name.like("W%"))).all()
Метод limit()
Метод limit() добавляет оператор LIMIT к запросу. Он принимает количество записей, которые нужно вернуть.
session.query(Customer).limit(2).all()
session.query(Customer).filter(Customer.username.ilike("%Andes")).limit(2).all()
SQL-эквивалент:
SELECT
customers. id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
LIMIT %(param_1)s Метод offset()
Метод offset() добавляет оператор OFFSET к запросу. Он принимает в качестве аргумента значение смещения. Часто используется с оператором limit().
session.query(Customer).limit(2).offset(2).all()
SQL-эквивалент:
SELECT
customers. ID AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_addrees,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
LIMIT %(param_1)s OFFSET %(param_2)sМетод order_by()
Метод order_by() используется для сортировки результата с помощью оператора ORDER BY. Он принимает названия колонок, по которым необходимо сортировать результат. По умолчанию сортирует по возрастанию.
session.query(Item).filter(Item.name.ilike("wa%")).all()
session.query(Item).filter(Item.name.ilike("wa%")).order_by(Item.cost_price).all()
Чтобы сортировать по убыванию используйте функцию desc():
from sqlalchemy import desc
session.query(Item).filter(Item.name.ilike("wa%")).order_by(desc(Item.cost_price)).all()
Метод join()
Метод join() используется для создания SQL INNER JOIN. Он принимает название таблицы, с которой нужно выполнить SQL JOIN.
Используем join(), чтобы найти всех покупателей, у которых как минимум один заказ.
session.query(Customer).join(Order).all()
SQL-эквивалент:
SELECT
customers.id AS customers_id,
customers.first_name AS customers_first_name,
customers.last_name AS customers_last_name,
customers.username AS customers_username,
customers.email AS customers_email,
customers.address AS customers_address,
customers.town AS customers_town,
customers.created_on AS customers_created_on,
customers.updated_on AS customers_updated_on
FROM
customers
JOIN orders ON customers.id = orders.customer_id
Этот оператор часто используется для получения данных из одной или нескольких таблиц в одном запросе. Например:
session.query(Customer.id, Customer.username, Order.id).join(Order).all()
Можно создать SQL JOIN для более чем двух таблиц, объединив несколько методов join() следующим образом:
session.query(Table1).join(Table2).join(Table3).join(Table4).all()
Вот еще один пример, который использует 3 объединения для нахождения всех пунктов в первом заказе Dmitriy Yatsenko.
session.query(
Customer.first_name,
Item.name,
Item.selling_price,
OrderLine.quantity
).join(Order).join(OrderLine).join(Item).filter(
Customer.first_name == 'Dmitriy',
Customer.last_name == 'Yatsenko',
Order.id == 1,
).all()
Метод outerjoin()
Метод outerjoin() работает как join(), но создает LEFT OUTER JOIN.
session.query(
Customer.first_name,
Order.id,
).outerjoin(Order).all()
В этом запросе левой таблицей является customers. Это значит, что он вернет все записи из customers и только те, которые соответствуют условию, из orders.
Создать FULL OUTER JOIN можно, передав в метод full=True. Например:
session.query(
Customer.first_name,
Order.id,
).outerjoin(Order, full=True).all()
Метод group_by()
Результаты группируются с помощью group_by(). Этот метод принимает одну или несколько колонок и группирует записи в соответствии со значениями в колонке.
Следующий запрос использует join() и group_by() для подсчета количества заказов, сделанных Dmitriy Yatsenko.
from sqlalchemy import func
session.query(func.count(Customer.id)).join(Order).filter(
Customer.first_name == 'Dmitriy',
Customer.last_name == 'Yatsenko',
).group_by(Customer.id).scalar()
Метод having()
Чтобы отфильтровать результаты на основе значений, которые возвращают агрегирующие функции, используется метод having(), добавляющий оператор HAVING к инструкции SELECT. По аналогии с where() он принимает условие.
session.query(
func.count("*").label('username_count'),
Customer.town
).group_by(Customer.username).having(func.count("*") > 2).all()
Работа с дубликатами
Для работы с повторяющимися записями используется параметр DISTINCT. Его можно добавить к SELECT с помощью метода distinct(). Например:
from sqlalchemy import distinct
session.query(Customer.first_name).filter(Customer.id < 10).all()
session.query(Customer.first_name).filter(Customer.id < 10).distinct().all()
session.query(
func.count(distinct(Customer.first_name)),
func.count(Customer.first_name)
).all()
Приведение
Приведение (конвертация) данных от одного типа к другому — распространенная операция, которая выполняется с помощью функции cast() из библиотеки sqlalchemy.
from sqlalchemy import cast, Date, distinct, union
session.query(
cast(func.pi(), Integer),
cast(func.pi(), Numeric(10,2)),
cast("2010-12-01", DateTime),
cast("2010-12-01", Date),
).all()
Объединения
Для объединения запросов используется метод union() объекта Query. Он принимает один или несколько запросов. Например:
s1 = session.query(Item.id, Item.name).filter(Item.name.like("Wa%"))
s2 = session.query(Item.id, Item.name).filter(Item.name.like("%e%"))
s1.union(s2).all()
[(2, 'Pen'),
(4, 'Travel Bag'),
(3, 'Headphone'),
(5, 'Keyboard'),
(7, 'Watch'),
(8, 'Water Bottle')]По умолчанию union() удаляет все повторяющиеся записи из результата. Для их сохранения используйте union_all().
s1.union_all(s2).all()Обновление данных
Для обновления объекта просто установите новое значение атрибуту, добавьте объект в сессию и сохраните ее.
i = session.query(Item).get(8)
i.selling_price = 25.91
session.add(i)
session.commit()
Таким образом можно обновлять только один объект за раз. Для обновления нескольких записей за раз используйте метод update() объекта Query. Он возвращает общее количество обновленных записей. Например:
session.query(Item).filter(
Item.name.ilike("W%")
).update({"quantity": 60}, synchronize_session='fetch')
session.commit()
Удаление данных
Для удаления объекта используйте метод delete() объекта сессии. Он принимает объект и отмечает его как удаленный для следующего коммита.
i = session.query(Item).filter(Item.name == 'Monitor').one()
session.delete(i)
session.commit()
<Item:6-Monitor>Этот коммит удаляет Monitor из таблицы items.
Для удаления нескольких записей за раз используйте метод delete() объекта Query.
session.query(Item).filter(
Item.name.ilike("W%")
).delete(synchronize_session='fetch')
session.commit()
Этот коммит удаляет все элементы, название которых начинается с W.
Сырые(raw) запросы
ORM предоставляет возможность использовать сырые SQL-запросы с помощью функции text(). Например:
from sqlalchemy import text
session.query(Customer).filter(text("first_name = 'Vladimir'")).all()
session.query(Customer).filter(text("username like 'Cal%'")).all()
session.query(Customer).filter(text("username like 'Cal%'")).order_by(text("first_name, id desc")).all()
Транзакции
Транзакция — это способ выполнения набора SQL-инструкций так, что выполняются или все вместе, или ни одна из них. Если хотя бы одна инструкция из транзакции была провалена, база данных возвращается к предыдущему состоянию.
В базе данных есть два заказа, в процессе отгрузки заказа есть такие этапы:
- В колонке
date_placedтаблицыordersустанавливается дата отгрузки. - Количество заказанных товаров вычитается из
items.
Оба действия должны быть выполнены как одно, чтобы убедиться, что данные в таблицах корректны.
В следующем коде определяем метод dispatch_order(), который принимает order_id в качестве аргумента и выполняет описанные выше задачи в одной транзакции.
def dispatch_order(order_id):
# проверка того, правильно ли указан order_id
order = session.query(Order).get(order_id)
if not order:
raise ValueError("Недействительный order_id: {}.".format(order_id))
try:
for i in order.line_items:
i.item.quantity = i.item.quantity - i.quantity
order.date_placed = datetime.now()
session.commit()
print("Транзакция завершена.")
except IntegrityError as e:
print(e)
print("Возврат назад...")
session.rollback()
print("Транзакция не удалась.")
dispatch_order(1)
В первом заказе 3 стула и 2 ручки. dispatch_order() с идентификатором заказа 1 даст следующий вывод:
Транзакция завершена.«Я не думаю, что мы подходим друг другу. Похоже, наши мысли работают по-разному.
Будто ты написана на Python, а он — на Java»
Но, поскольку они входят в группу самых популярных языков программирования, стоит обратить внимание на сходства, различия, преимущества, недостатки и идеальные варианты использования для каждого из них.
Во-первых, Java и Python имеют некоторые общие характеристики, как и ключевые различия. Оба являются мощными языками программирования с большими преданными сообществами и огромным набором библиотек, поддерживаемых легионами разработчиков. Если вы затрудняетесь что-то сделать, используя нативные возможности языка, вы, вероятно, легко найдете библиотеку, реализующую необходимый функционал.
Но Java и Python также сильно отличаются, с какой стороны ни посмотреть. Некоторые из этих различий объективны и не подлежат обсуждению. В то время как другие связаны с взглядами и предпочтениями разработчика или продиктованы средой программирования.
Например, Java — это компилируемый язык, а Python — интерпретируемый. Это различие дает каждому языку определенные преимущества и недостатки. Довольно часто бушуют споры о том, выполняется ли скомпилированный код быстрее, чем, интерпретируемый. При этом реальное положение вещей имеет тенденцию меняться от случая к случаю. Будет ли один язык выполняться быстрее другого, зависит, помимо прочего, от окружения, в котором они используются. Например, Python более приспособлен к работе в массово распараллеленном режиме на графических процессорах.
Два языка также имеют значительные синтаксические различия. Например, при написании кода на Java для определения его структуры используются фигурные скобки. В Python для выполнения тех же задач применяются отступы.
FreeCodeCamp называет код на Python: «аккуратным, читаемым и хорошо структурированным. Здесь корректная расстановка отступов нужна не только для красоты — она оказывает прямое влияние на порядок выполнения программы».
Такие структурные различия могут повлиять на то, как разработчики смотрят на языки и на скорость, с которой они программируют. Теоретически это также влияет на уровень навыков, необходимых для изучения языка. Однако в большинстве случаев проблема действительно сводится к личным предпочтениям. Более того, многие разработчики привыкли использовать IDE, среды программирования и шаблоны. Это делает проблему гораздо менее значимой.
Программисты бесконечно спорят и о других качествах этих языков. Например, некоторые утверждают, что разработчик может быть до десяти раз более продуктивным в Python. Потому что он поддерживает, среди прочего, динамическую типизацию. Другие придерживаются противоположных взглядов на проблему производительности. Большинство приводимых сторонами аргументов сводятся к не слишком полезному сравнению квадратного с круглым.
Какой язык в конечном итоге будет более продуктивным, обычно зависит от накопленного программистом опыта, стиля кодирования и требований к разработке.
Не стоит забывать, что языковые инструменты в конечном итоге превращают все, что создают программисты, в машинный код. Таким образом, выбор языка — это не вопрос того, какой код понравится машине больше. Это вопрос удовлетворения требований разработчика по удобному описанию задач машине в терминах, понятных прежде всего самому разработчику.
Тенденции в Java и Python
Хотя Java сейчас не на пике популярности, он по-прежнему один из самых используемых языков программирования. С другой стороны, Python показал астрономический рост, особенно в развитых странах с высоким уровнем дохода. Согласно некоторым источникам, Python в конечном итоге превзойдет Java по популярности.
Причины такого удивительного подъема заключаются в повышенной продуктивности разработки, языковой гибкости, разнообразии поддерживаемых библиотек, огромном сообществе и простоте обучения. Python также широко используется в таких горячих областях, как data science и искусственный интеллект. А также при создании веб-приложений, настольных приложений, сетевых серверов и медиа-инструментов.
Между тем популярность Java, возможно, снизилась из-за ее невысокой репутации в области безопасности. Сайты технических новостей, такие как The Register, с наслаждением критикуют Java. The Hill утверждает, что 88% приложений на Java имеют проблемы с безопасностью. Конечно, плохая репутация языка во многом объясняется недостатками Java-плагина для браузера. В остальном потенциальные уязвимости в Java не намного хуже, чем у других языков.
В любом случае безопасность Python тоже далека от идеала, но она пользуется большим вниманием и поддержкой со стороны специалистов в этой области. А простота использования языка может облегчить менее опытным разработчикам написание надежного кода.
Однако было бы неразумно думать о Java как о языке «из далекого прошлого». Разработчики Java продолжают добавлять новые функции. Они делают язык меньше, быстрее и гибче при использовании в крупномасштабной разработке. Мощная виртуальная машина Java (JVM) упрощает создание кроссплатформенных приложений. Java продолжает процветать в создании большого традиционного ПО, чем сегодня занимается большинство предприятий.
Более того, язык используется в 90% компаний из Fortune 500! Как ни крути, огромное количество установленных Java-приложений (как и вакансий на должность Java-разработчика) в ближайшее время точно никуда не исчезнут.
Java и Python также используют очень разные модели потоков. Python GIL или глобальная блокировка интерпретатора означает, что, в отличие от Java, Python фактически является однопоточным. Он может работать только на одном CPU-ядре одновременно. С другой стороны, использовать GPU с Python относительно легко по сравнению с аналогичным процессом в Java.
Таким образом, приложение на Python, работающее в параллельном режиме на 5120-ядерном графическом процессоре, скорее всего, оставит далеко позади полностью оптимизированное приложение на Java, запущенное на 8-ядерном CPU.
Возможно, из-за широкого диапазона позиций Java-разработчиков, было замечено, что Python-программисты обычно зарабатывают больше денег, чем Java-разработчики: 116000 долларов против 102000 долларов на Indeed и 99000 долларов против 96000 долларов на StackOverflow.
Проблема «грамотного программирования»
Кривая обучения языку программирования во многом зависит от ваших текущих знаний. От того, как вы планируете его использовать, и среды обучения. Например, если вы знакомы с программированием на C, C ++ или JavaScript и намерены писать код для стандартного приложения, процесс изучения Java будет относительно простым.
Однако, если вы никогда раньше не программировали и собираетесь использовать язык, например, для обработки каких-то научных данных, тогда вам лучше подойдет Python. В школах обучают именно этому языку. Он помогает людям очень быстро нарабатывать основные принципы написания качественного кода и имеет широкий спектр применений.
Представление кода также становится все более важным отличием между двумя языками. В прошлом разработчики использовали код в основном для создания приложений. Написанные программы обычно читались только другими разработчиками (и машинами). Долгое время лаконичный синтаксис Java имел преимущество.
Однако теперь, когда люди с разными взглядами и навыками используют языки программирования для достижения самых разных целей. Не обязательно для разработки приложений.. Python лидирует в этом качестве, потому что он полностью поддерживает грамотный подход к программированию. Literate programming — основанный Стэнфордским ученым-программистом Дональдом Кнутом.
При использовании методов грамотного программирования в одном документе содержится код, пояснительный текст, графики, изображения и всевозможные другие материалы, но при этом код остается полностью исполняемым в соответствующей среде разработки. Это позволяет докладчику или непрограммисту использовать среду способом, который немногие разработчики распознают как «написание кода».
Грамотное программирование часто применяется для:
- Демонстраций
- Взаимодействия между разработчиками
- Исследований
- Обучения
- Презентаций
Python напрямую поддерживает такой подход через IDE, такие как Leo и Jupyter Notebook. Вы также можете добавить эту поддержку в другие редакторы, такие как Atom, используя специальные инструкции. Напротив, аналогичный функционал в среде с использованием Java может казаться принудительно склеенным. И кривая обучения для него, как правило, выше.
Сравнение производительности
Некоторые разработчики считают, что «интерпретируемый» всегда означает «медленный». Пользователи Java часто говорят:
«Конечно, пишите код на Python или на чем-то еще, но, когда вам нужно будет масштабировать приложение, его придется переписать на Java».
Довольно сложно проводить сравнение языков по скорости, так как производительность сильно зависит от окружения. Вы можете провесит ряд тестов, которые отдадут предпочтение одному из языков. Но результаты, имеющие решающее значение, — это полученные вами в реальных проектах.
Кроме того, вы должны учитывать такие моменты, как необходимые приложению библиотеки и стиль программирования, используемый при разработке (по крайней мере, с Python). Данный вопрос более актуален для Python, так как он поддерживает несколько парадигм программирования.
Сравнивая производительность написанных на нем приложений с использованием функционального программирования и объектно-ориентированного, результаты, вероятно, будут отличаться труднопредсказуемым образом.
Также важно учитывать, как разные версии языка влияют на производительность. В реальном мире не всегда имеет смысл сравнивать только последние их выпуски. Если мы говорим о Java, то большинство приложений отстают от текущей версии на 2-3 обновления. Что касается Python, Python 3.x обычно работает быстрее, чем 2.x.
Поэтому, хотя это может показаться контрпродуктивным, некоторые программисты (и другие пользователи), занимающиеся data science, по-прежнему предпочитают использовать Python 2.x вместо 3.x из-за определенных библиотек. Обратите внимание, что сообщество Python изо всех сил пытается перейти 3 версию и в настоящее время отказалась от поддержки 2х.
В конце концов, производительность — невероятно сложный показатель. Какой язык работает быстрее всего, обычно зависит от окружения. От того, как код был написан, как он используется и запускается. Не говоря о влиянии библиотек и других внешних факторов.
Доля рынка и сообщество
Также довольно сложно сравнивать относительную популярность различных языков программирования. Но в большинстве попыток такого ранжирования — либо здесь, либо на сайтах рейтингов, Java обычно выходит на первое место. Python не отстает и находится где-то в первой пятерке.
Важно отметить, что оба языка поддерживаются большими и активными сообществами пользователей. Группы пользователей Java (JUG) существуют по всему миру. (Это геолокационное приложение позволяет вам найти ближайший к вам JUG.) Java-программисты также могут посещать крупные мероприятия, такие как JavaOne.
Сообщество Python не уступает по размаху: 1637 пользовательских Python-групп в 191 городе и 37 странах. В них участвуют более 860000 человек. События Python варьируются от встреч PyLadies, где женщины могут встречаться и программировать вместе, до PyCon и многих других.
Однако, как отмечалось ранее, истинная цель языка программирования — служить потребностям разработчика в передаче конкретной задачи машине наиболее простым и понятным способом. Для некоторых разработчиков простота означает наименьшее количество строк кода или максимальную скорость приложения.
Но проблема выходит далеко за рамки любого из этих соображений. Например, если вы специалист по данным, работающий над проектом машинного обучения, Python будет лучшим выбором. Java занимает третье место в этой группе.
Гибкость также имеет значение. При работе с Python у вас есть доступ к нескольким парадигмам программирования, которые вы можете смешивать и сопоставлять по мере необходимости в одном приложении.
Java поддерживает только один стиль: объектно-ориентированное программирование. Обратите внимание, Python поддерживает применение разных подходов в одном приложении. Это означает, вы можете использовать тот, который лучше всего решает конкретную подзадачу. И не будите полагаться на одну парадигму, независимо от того, насколько она отвечает вашим текущим потребностям.
Мультиязычность путь к победе
Дело в том, что не существует единственного лучшего языка программирования. Но каждый из них может удовлетворять некоторым требованиям, имеющим значение в данный момент времени, для конкретного проекта.
В идеале разработчики должны знать несколько языков, чтобы им не приходилось использовать язык, который плохо подходит для обозначенных целей. Такой подход облегчает адаптацию к большому числу ситуаций. Например, присоединение к команде, занимающейся обновлением приложения, написанного на языке, который вы бы не выбрали при создании данного проекта с нуля.
Тем не менее, можно сделать некоторые обобщения относительно языков программирования:
- Python был бы моим личным выбором для задач, связанных с data science, искусственным интеллектом и машинным обучением.
- Когда нужно написать ПО для пользователей, особенно десктопные и кроссплатформенные приложения, Java будет лучшим выбором.
- Оба языка являются отличным выбором для создания серверного приложения.
Независимо от того, близки ли вам эти предпочтения, надеюсь, что представленное сравнение поможет вам сделать собственный выбор, какой из языков программирования подходит лучше именно вам.
]]>В этом руководстве поговорим об ошибке «NameError name is not defined». Разберем несколько примеров и разберемся, как эту ошибку решать.
Что такое NameError?
NameError возникает в тех случаях, когда вы пытаетесь использовать несуществующие имя переменной или функции.
В Python код запускается сверху вниз. Это значит, что переменную нельзя объявить уже после того, как она была использована. Python просто не будет знать о ее существовании.
Самая распространенная NameError выглядит вот так:
NameError: name 'some_name' is not definedРазберем частые причина возникновения этой ошибки.
Причина №1: ошибка в написании имени переменной или функции
Для человека достаточно просто сделать опечатку. Также просто для него — найти ее. Но это не настолько просто для Python.
Язык способен интерпретировать только те имена, которые были введены корректно. Именно поэтому важно следить за правильностью ввода всех имен в коде.
Если ошибку не исправить, то возникнет исключение. Возьмем в качестве примера следующий код:
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
print(boooks)
Он вернет:
Traceback (most recent call last):
File "main.py", line 3, in <module>
print(boooks)
NameError: name 'boooks' is not definedДля решения проблемы опечатку нужно исправить. Если ввести print(books), то код вернет список книг.
Таким образом при возникновении ошибки с именем в первую очередь нужно проверить, что все имена переменных и функций введены верно.
Причина №2: вызов функции до объявления
Функции должны использоваться после объявления по аналогии с переменными. Это связано с тем, что Python читает код сверху вниз.
Напишем программу, которая вызывает функцию до объявления:
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
print_books(books)
def print_books(books):
for b in books:
print(b)
Код вернет:
Traceback (most recent call last):
File "main.py", line 3, in <module>
print_books(books)
NameError: name 'print_books' is not definedНа 3 строке мы пытаемся вызвать print_books(). Однако эта функция объявляется позже.
Чтобы исправить эту ошибку, нужно перенести функцию выше:
def print_books(books):
for b in books:
print(b)
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
print_books(books)
Причина №3: переменная не объявлена
Программы становятся больше, и порой легко забыть определить переменную. В таком случае возникнет ошибка. Причина в том, что Python не способен работать с необъявленными переменными.
Посмотрим на программу, которая выводит список книг:
for b in books:
print(b)
Такой код вернет:
Traceback (most recent call last):
File "main.py", line 1, in <module>
for b in books:
NameError: name 'books' is not definedПеременная books объявлена не была.
Для решения проблемы переменную нужно объявить в коде:
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
for b in books:
print(b)
Причина №4: попытка вывести одно слово
Чтобы вывести одно слово, нужно заключить его в двойные скобки. Таким образом мы сообщаем Python, что это строка. Если этого не сделать, язык будет считать, что это часть программы. Рассмотрим такую инструкцию print():
print(Books)
Этот код пытается вывести слово «Books» в консоль. Вместо этого он вернет ошибку:
Traceback (most recent call last):
File "main.py", line 1, in <module>
print(Books)
NameError: name 'Books' is not definedPython воспринимает «Books» как имя переменной. Для решения проблемы нужно заключить имя в скобки:
print("Books")
Теперь Python знает, что нужно вывести в консоли строку, и код возвращает Books.
Причина №5: объявление переменной вне области видимости
Есть две области видимости переменных: локальная и глобальная. Локальные переменные доступны внутри функций или классов, где они были объявлены. Глобальные переменные доступны во всей программе.
Если попытаться получить доступ к локальной переменной вне ее области видимости, то возникнет ошибка.
Следующий код пытается вывести список книг вместе с их общим количеством:
def print_books():
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
for b in books:
print(b)
print(len(books))
Код возвращает:
Traceback (most recent call last):
File "main.py", line 5, in <module>
print(len(books))
NameError: name 'books' is not definedПеременная books была объявлена, но она была объявлена внутри функции print_books(). Это значит, что получить к ней доступ нельзя в остальной части программы.
Для решения этой проблемы нужно объявить переменную в глобальной области видимости:
books = ["Near Dark", "The Order", "Where the Crawdads Sing"]
def print_books():
for b in books:
print(b)
print(len(books))
Код выводит название каждой книги из списка books. После этого выводится общее количество книг в списке с помощью метода len().
ORM построен на базе SQLAlchemy Core, поэтому имеющиеся знания должны пригодиться.
ORM позволяет быть более продуктивным, но также добавляет дополнительную сложность в запросы. Однако для большинства приложений преимущества перевешивают проигрыш в производительности.
Прежде чем двигаться дальше удалите все таблицы из sqlalchemy-tuts с помощью следующей команды: metadata.drop_all(engine).
Создание моделей
Модель — это класс Python, соответствующий таблице в базе данных, а его свойства — это колонки.
Чтобы класс был валидной моделью, нужно соответствовать следующим требованиям:
- Наследоваться от декларативного базового класса с помощью вызова функции
declarative_base(). - Объявить имя таблицы с помощью атрибута
__tablename__. - Объявить как минимум одну колонку, которая должна быть частью первичного ключа.
Последние два пункта говорят сами за себя, а вот для первого нужны детали.
Базовый класс управляет каталогом классов и таблиц. Другими словами, декларативный базовый класс — это оболочка над маппером и MetaData. Маппер соотносит подкласс с таблицей, а MetaData сохраняет всю информацию о базе данных и ее таблицах. По аналогии с Core в ORM методы create_all() и drop_all() объекта MetaData используются для создания и удаления таблиц.
Следующий код показывает, как создать модель Post, которая используется для сохранения постов в блоге.
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric
from sqlalchemy.ext.declarative import declarative_base
from datetime import datetime
Base = declarative_base()
class Post(Base):
__tablename__ = 'posts'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
slug = Column(String(100), nullable=False)
content = Column(String(50), nullable=False)
published = Column(String(200), nullable=False, unique=True)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
Разберем построчно:
- На 1-4 строках импортируются нужные классы и функции.
- В 6 строке создается базовый класс с помощью вызова функции
declarative_base(). - На 10-16 строках колонки объявляются как атрибуты класса.
Стоит обратить внимание на то, что для создания колонок используется тот же класс Column, что и для SQLAlchemy Core. Единственное отличие в том, что первым аргументом является тип, а не название колонки. Аргументы-ключевые слова, в свою очередь, переданные в Column(), работают одинаково в ORM и Core.
Поскольку ORM построен на базе Core, SQLAlchemy использует определение модели для создания объекта Table и связи его с моделью с помощью функции mapper(). Это завершает процесс маппинга модели Post с соответствующим экземпляром Table. Теперь модель Post можно использовать для управления базой данных и для осуществления запросов к ней.
Классический маппинг
После прошлого раздела может создаться впечатление, что для использования SQLAlchemy ORM нужно переписать все экземпляры Table в виде моделей. Но это не так.
Можно запросто мапить любые Python классы на экземпляры Table с помощью функции mapper(). Например:
from sqlalchemy import MetaData, Table, Integer, String, Column, Text, DateTime, Boolean
from sqlalchemy.orm import mapper
from datetime import datetime
metadata = MetaData()
post = Table('post', metadata,
Column('id', Integer(), primary_key=True),
Column('title', String(200), nullable=False),
Column('slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('published', Boolean(), default=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
class Post(object):
pass
mapper(Post, post)
Этот класс принимает два аргумента: класс для маппинга и объект Table.
После этого у класса Post будут атрибуты, соответствующие колонкам таблицы. Таким образом у Post сейчас следующие атрибуты:
post.idpost.titlepost.slugpost.contentpost.publishedpost.created_onpost.updated_on
Код в списке выше эквивалентен модели Post, которая была объявлена выше.
Теперь вы должны лучше понимать, что делает declarative_base().
Добавление ключей и ограничений
При использовании ORM ключи и ограничения добавляются с помощью атрибута __table_args__.
from sqlalchemy import Table, Index, Integer, String, Column, Text, \
DateTime, Boolean, PrimaryKeyConstraint, \
UniqueConstraint, ForeignKeyConstraint
from sqlalchemy.ext.declarative import declarative_base
from datetime import datetime
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer)
username = Column(String(100), nullable=False)
email = Column(String(100), nullable=False)
password = Column(String(200), nullable=False)
__table_args__ = (
PrimaryKeyConstraint('id', name='user_pk'),
UniqueConstraint('username'),
UniqueConstraint('email'),
)
class Post(Base):
__tablename__ = 'posts'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
slug = Column(String(100), nullable=False)
content = Column(String(50), nullable=False)
published = Column(String(200), nullable=False, default=False)
user_id = Column(Integer(), nullable=False)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
__table_args__ = (
ForeignKeyConstraint(['user_id'], ['users.id']),
Index('title_content_index' 'title', 'content'), # composite index on title and content
)
Отношения
Один-ко-многим
Отношение один-ко-многим создается за счет передачи внешнего ключа в дочерний класс. Например:
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book")
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
Строчка author_id = Column(Integer, ForeignKey('authors.id')) устанавливает отношение один-ко-многим между моделями Author и Book.
Функция relationship() добавляет атрибуты в модели для доступа к связанным данным. Как минимум — название класса, отвечающего за одну сторону отношения.
Строчка books = relationship("Book") добавляет атрибут books классу Author.
Имея объект a класса Author, получить доступ к его книгам можно через a.books. А если нужно получить автора книги через объект Book?
Для этого можно определить отдельное отношение relationship() в модели Author:
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book")
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author")
Теперь через объект b класса Book можно получить автора b.author.
Как вариант можно использовать параметры backref для определения названия атрибута, который должен быть задан на другой стороне отношения.
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Book", backref="book")
Relationship можно задавать на любой стороне отношений. Поэтому предыдущий код можно записать и так:
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author", backref="books")
Один-к-одному
Установка отношения один-к-одному в SQLAlchemy почти не отличается от одного-ко-многим. Единственное отличие в том, что нужно передать дополнительный аргумент uselist=False в функцию relationship(). Например:
class Person(Base):
__tablename__ = 'persons'
id = Column(Integer(), primary_key=True)
name = Column(String(255), nullable=False)
designation = Column(String(255), nullable=False)
doj = Column(Date(), nullable=False)
dl = relationship('DriverLicense', backref='person', uselist=False)
class DriverLicense(Base):
__tablename__ = 'driverlicense'
id = Column(Integer(), primary_key=True)
license_number = Column(String(255), nullable=False)
renewed_on = Column(Date(), nullable=False)
expiry_date = Column(Date(), nullable=False)
person_id = Column(Integer(), ForeignKey('persons.id'))
Имея объект p класса Person, p.dl вернет объект DriverLicense. Если не передать uselist=False в функцию, то установится отношение один-ко-многим между Person и DriverLicense, а p.dl вернет список объектов DriverLicense вместо одного. При этом uselist=False никак не влияет на атрибут persons объекта DriverLicense. Он вернет объект Person как и обычно.
Многие-ко-многим
Для отношения многие-ко-многим нужна отдельная таблица. Она создается как экземпляр класса Table и затем соединяется с моделью с помощью аргумента secondary функции relationship().
author_book = Table('author_book', Base.metadata,
Column('author_id', Integer(), ForeignKey("authors.id")),
Column('book_id', Integer(), ForeignKey("books.id"))
)
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship("Author", secondary=author_book, backref="books")
Один автор может написать одну или несколько книг. Так и книга может быть написана одним или несколькими авторами. Поэтому здесь требуется отношение многие-ко-многим.
Для представления этого отношения была создана таблица author_book.
Через объект a класса Author можно получить все книги автора с помощью a.books. По аналогии через b класса Book можно вернуть список авторов b.authors.
В этом случае relationship() была объявлена в модели Book, но это можно было сделать и с другой стороны.
Может потребоваться хранить дополнительную информацию в промежуточной таблице. Для этого нужно определить эту таблицу как класс модели.
class Author_Book(Base):
__tablename__ = 'author_book'
id = Column(Integer, primary_key=True)
author_id = Column(Integer(), ForeignKey("authors.id"))
book_id = Column(Integer(), ForeignKey("books.id"))
extra_data = Column(String(100))
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
books = relationship("Author_Book", backref='author')
class Book(Base):
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(100), nullable=False)
copyright = Column(SmallInteger, nullable=False)
authors = relationship("Author_Book", backref="book")
Создание таблиц
По аналогии с SQLAlchemy Core в ORM есть метод create_all() экземпляра MetaData, который отвечает за создание таблицы.
Base.metadata.create_all(engine)Для удаления всех таблиц есть drop_all.
Base.metadata.drop_all(engine)Пересоздадим таблицы с помощью моделей и сохраним их в базе данных, вызвав create_all(). Вот весь код для этой операции:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric, SmallInteger
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
from datetime import datetime
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
Base = declarative_base()
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer(), primary_key=True)
first_name = Column(String(100), nullable=False)
last_name = Column(String(100), nullable=False)
username = Column(String(50), nullable=False)
email = Column(String(200), nullable=False)
created_on = Column(DateTime(), default=datetime.now)
updated_on = Column(DateTime(), default=datetime.now, onupdate=datetime.now)
orders = relationship("Order", backref='customer')
class Item(Base):
__tablename__ = 'items'
id = Column(Integer(), primary_key=True)
name = Column(String(200), nullable=False)
cost_price = Column(Numeric(10, 2), nullable=False)
selling_price = Column(Numeric(10, 2), nullable=False)
quantity = Column(Integer())
class Order(Base):
__tablename__ = 'orders'
id = Column(Integer(), primary_key=True)
customer_id = Column(Integer(), ForeignKey('customers.id'))
date_placed = Column(DateTime(), default=datetime.now)
line_items = relationship("OrderLine", backref='order')
class OrderLine(Base):
__tablename__ = 'order_lines'
id = Column(Integer(), primary_key=True)
order_id = Column(Integer(), ForeignKey('orders.id'))
item_id = Column(Integer(), ForeignKey('items.id'))
quantity = Column(SmallInteger())
item = relationship("Item")
Base.metadata.create_all(engine)
Популярность отрасли постоянно растет. В 2015 только 17% компаний использовали возможности аналитики Big Data, а в 2017 это значение выросло до 53%.
Чтобы присоединиться к этой группе, нужно знать как минимум один язык программирования, используемый для data science.
В этом материале разберем Python и то, как он используется для анализа данных.
Подходит ли Python для анализа данных?
Python появился еще в 1990 году, но начал приобретать популярность не так давно. В 2020 Python стал четвертым в списке самых используемых языков программирования после JavaScript, HTML/CSS и SQL — его используют 44,1% разработчиков.
Python — это интерпретируемый, высокоуровневый объектно-ориентированный язык общего назначения, используемый для разработки API, искусственного интеллекта, веб-разработки, интернета вещей и так далее.
Отчасти Python стал так популярен благодаря специалистам в области data science. Это один из самых простых языков для изучения. Он предлагает множество библиотек, которые применяются на всех этапах анализа данных. Поэтому язык однозначно подходит для этих целей.
Как Python используется для анализа данных?
Python отлично работает на всех этапах. В первую очередь в этом помогают различные библиотеки. Поиск, обработка, моделирование (вместе с визуализацией) — 3 самых популярных сценария использования языка для анализа данных.
Поиск данных
Инженеры используют Scrapy и BeautifulSoup для поиска данных с помощью Python.С помощью Scrapy можно создавать программы, которые собирают структурированные данные в сети. Также его можно использовать для сбора данных из API.
BeautifulSoup применяется там, где получить данные из API не выходит; он собирает данные и расставляет их в определенном формате.
Обработка и моделирование данных
На этом этапе в числе самых используемых библиотек NumPy и Pandas. NumPy (Numerical Python) используется для сортировки больших наборов данных. Он упрощает математические операции и их векторизацию на массивах. Pandas предлагает два структуры данных: Series (список элементов) и Data Frames (таблица с несколькими колонками). Эта библиотека конвертирует данные в Data Frame, позволяя удалять и добавлять новые колонки, а также выполнять разные операции.
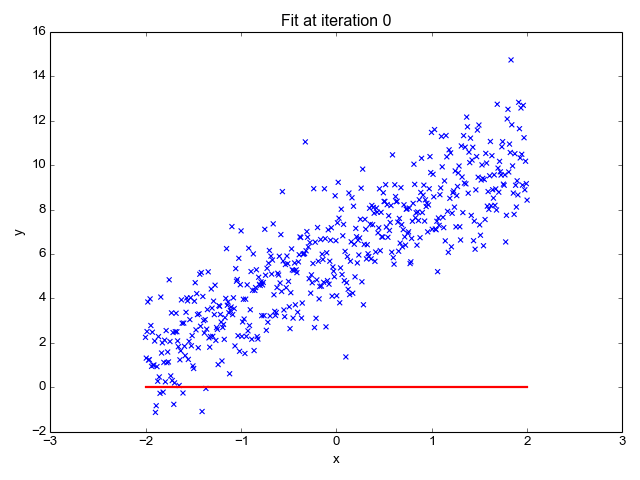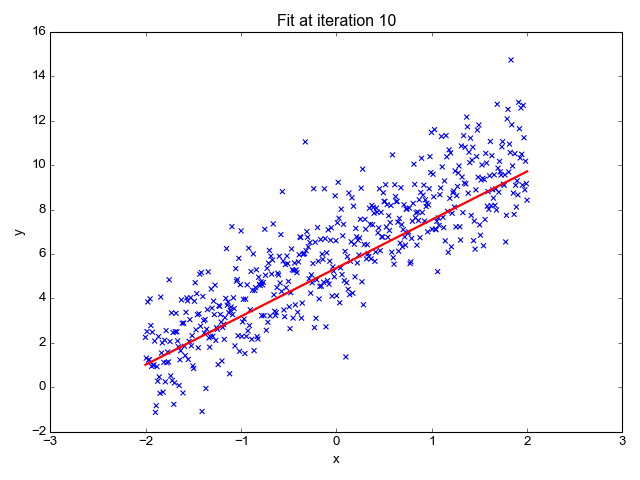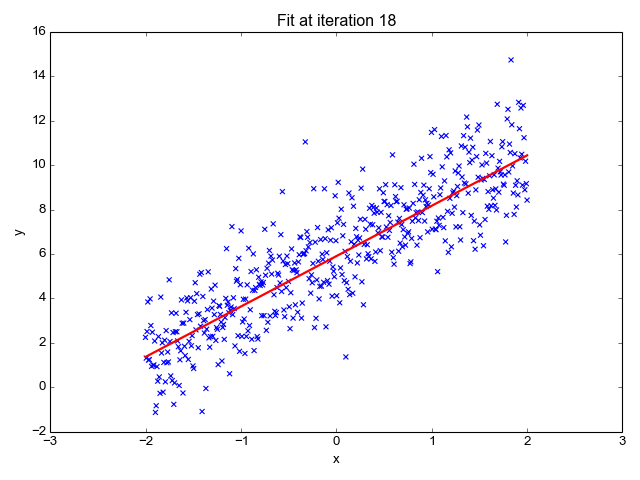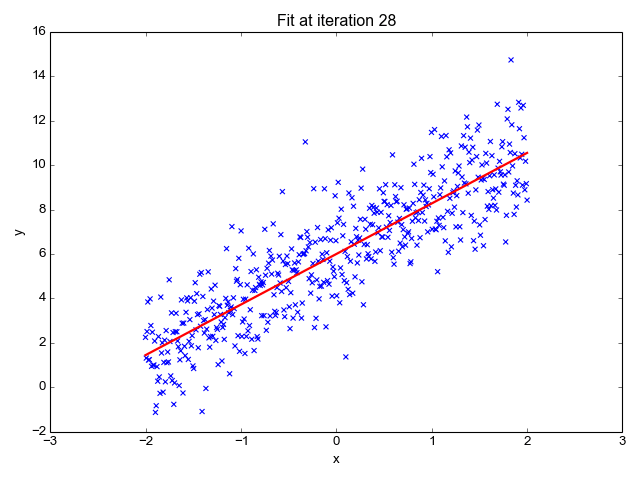
Визуализация данных
Matplotlib и Seaborn широко используются для визуализации данных. Они помогают конвертировать огромные списки чисел в удобные графики, гистограммы, диаграммы, тепловые карты и так далее.
Конечно, библиотек куда больше. Python предлагает бесчисленное количество инструментов для проектов в сфере анализа данных и может помочь при выполнении любых задач в процессе.
Преимущества и недостатки Python для анализа данных
Почти невозможно найти идеальный язык для анализа данных, поскольку у каждого есть свои достоинства и недостатки. Один лучше подходит для визуализации, а другой лучше работает с большими объемами данных. Выбор зависит и от личных предпочтений разработчика. Посмотрим на преимущества и недостатки Python для анализа данных.
Преимущества Python
Отличное сообщество
Программирование никогда не было простым, и даже разработчики с большим количеством опыта сталкиваются с проблемами. К счастью, у каждого языка есть сообщество, помогающее находить верные решения. На GitHub, например, более 90000 репозиториев с Python-проектами. Поэтому почти всегда можно найти ответ на интересующий вопрос.
Легко изучается
Python — один из самых простых языков для изучения благодаря его простому синтаксису и читаемости. Он также требует куда меньшего количества строк кода. Разработчик может не думать о самом коде, а о том, что тот делает. Заниматься отладкой на Python тоже намного проще.
Гибкий и масштабируемый
Python используется в самых разных отраслях благодаря его гибкости и широкому набору инструментов.
Разнообразие библиотек
Для Python существует огромное количество библиотек, которые можно использовать на разных этапах анализа данных. Плюс, большая часть из них — бесплатные. Это все влияет на простоту работы с данными с помощью Python.
Недостатки
Динамическая типизация
Python — язык общего назначения и был создан не только для анализа данных. Разрабатывать с динамической типизацией куда проще, однако это замедляет поиск ошибок в данных, связанных с разными типами.
Где учится анализу данных
Один из лучших курсов — годовая программа Профессия Data Scientist: анализ данных от Skillbox. Аналитики из Ivi, QIWI, Rambler и Epam обучают работе с данными и комментируют домашние задания.
Программа курса:
- Python для Data Science
- Аналитика. Начальный уровень
- Статистика и теория вероятностей
- Основы математики для Data Science
- Аналитика. Средний уровень
- Универсальные знания программиста
- Английский для IT-специалистов
После прохождения курса вы реализуете дипломный проект и получите помощь с трудоустройством. Сейчас действует скидка и рассрочка, подробности на сайте Skillbox.
Альтернативы Python для анализа данных
Хотя Python и считается одним из главных языков для анализа данных, существуют и другие варианты. Каждый из таких языков предназначен для выполнения конкретной задачи (поиска данных, визуализации или работы с большими объемами данных), а некоторые и вовсе были разработаны специально для анализа данных и статистических вычислений.
R
R — второй по популярности язык для анализа данных, который часто сравнивают с Python. Он был разработан для статистических вычислений и графики, что отлично подходит для анализа данных. В нем есть инструменты для визуализации данных. Он совместим с любыми статистическими приложениями, работает офлайн, а разработчикам предлагаются различные пакеты для управления данными и создания графиков.
SQL
Широко используемый язык для запросов данных и редактирования. Это также отличный инструмент для хранения и получения данных. SQL прекрасно работает с большими базами данных и способен получать данные из сети быстрее остальных языков.
Julia
Julia был разработан для data science и научных вычислений. Это относительно новый язык, который быстро приобретает популярность среди специалистов в области. Главная его цель — преодолеть недостатки Python и стать выбором №1 среди инженеров. Julia — компилируемый язык, что подразумевает более высокую производительность. Однако синтаксис похож на Python, пусть и с акцентом на математику. В Julia можно использовать библиотеки из Python, C и Forton. Также язык славится параллельными вычислениями, которые работают быстрее и сложнее чем в Python.
Scala
Scala и фреймворк Spark часто используются для работы с большими базами данных. Для этого даже не обязательно загружать все данные — можно работать кусками. Scala работает на JVM и может быть встроен в enterprise-код. Предлагает массу инструментов для обработки данных, которые работают быстрее, чем у Python и R.
Это 4 самых популярных языка среди специалистов в сфере data science. Однако стоит также отметить MATLAB для статистического анализа, TensorFlow для BigData, графов и параллельных вычислений, а также JavaScript для визуализации.
Выводы
Данные — важная часть любого бизнеса. Для анализа данных сегодня существует масса языков, включая R, SQL, Julia и Scala. Каждый из них выполняет определенный набор задач и справляется с ним лучше остальных. В целом, нет одного идеального языка для проекта.
Тем не менее Python остается самым популярным языков программирования для анализа данных. Он предлагает массу библиотек, имеет огромное сообщество и легко изучается.
]]>Проще говоря, AJAX позволяет обновлять веб-страницы асинхронно, негласно обмениваясь данными с веб-сервером. Это означает, что обновление частей веб-страницы возможно без перезагрузки всей страницы.
Мы можем делать запросы AJAX из шаблонов Django, используя JQuery. AJAX методы библиотеки jQuery позволяют нам запрашивать текст, HTML, XML или JSON с удаленного сервера, используя как HTTP Get, так и HTTP Post. Полученные данные могут быть загружены непосредственно в выбранные HTML-элементы вашей веб-страницы.
В этом руководстве мы узнаем, как выполнять AJAX HTTP GET и POST запросы из шаблонов Django.
Требования к знаниям
Я предполагаю, что у вас есть базовые знания о Django. Поэтому я не буду вдаваться в настройку проекта. Это очень простой проект с приложением под названием AJAX, в котором я использую bootstrap и Django crispy form для стилизации.
Репозиторий Gitlab — https://gitlab.com/PythonRu/django-ajax
Выполнение AJAX GET запросов с помощью Django и JQuery
Метод HTTP GET используется для получения данных с сервера.
В этом разделе мы создадим страницу регистрации, где мы будем проверять доступность имени пользователя с помощью JQuery и AJAX в шаблонах Django. Это очень распространенное требование для большинства современных приложений.
# ajax/views.py
from django.contrib.auth.models import User
from django.contrib.auth.decorators import login_required
from django.http import JsonResponse
from django.contrib.auth.forms import UserCreationForm
from django.contrib.auth import login, authenticate
from django.shortcuts import render, redirect
from django.views.generic.edit import CreateView
from django.urls import reverse_lazy
@login_required(login_url='signup')
def home(request):
return render(request, 'home.html')
class SignUpView(CreateView):
template_name = 'signup.html'
form_class = UserCreationForm
success_url = reverse_lazy('home')
def form_valid(self, form):
valid = super().form_valid(form)
login(self.request, self.object)
return valid
def validate_username(request):
"""Проверка доступности логина"""
username = request.GET.get('username', None)
response = {
'is_taken': User.objects.filter(username__iexact=username).exists()
}
return JsonResponse(response)
Итак, у нас есть три представления, первым является home, которое отображает довольно простой шаблон домашней страницы.
Далее идет SignUpView, унаследованный от класса CreateView. Он нужен для создания пользователей с помощью встроенного Django-класса UserCreationForm, который предоставляет очень простую форму для регистрации. При успешном ее прохождении происходит вход в систему, и пользователь перенаправляется на домашнюю страницу.
Наконец, validate_username — это наше AJAX представление, которое возвращает объект JSON с логическим значением из запроса, проверяющего, существует ли введенное имя пользователя.
Класс JsonResponse возвращает HTTP-ответ с типом содержимого application/json, преобразуя переданный ему объект в формат JSON. Поэтому, если имя пользователя уже существует в базе данных, он вернет JSON-объект, показанный ниже.
{'is_taken': true}# ajax/urls.py
from django.urls import path
from .views import home, SignUpView, validate_username
urlpatterns = [
path('', home, name='home'),
path('signup', SignUpView.as_view(), name='signup'),
path('validate_username', validate_username, name='validate_username')
]
# dj_ajax/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('ajax/', include('ajax.urls'))
]
{# home.html #}
<h1>Привет, {{ user.username }}!</h1>
{# signup.html #}
{% load crispy_forms_tags %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css" crossorigin="anonymous">
</head>
<body>
<div class="container mt-5 w-50">
<form id="signupForm" method="POST">
{% csrf_token %}
{{ form|crispy }}
<input type="submit" name="signupSubmit" class="btn btn-success btn-lg" />
</form>
</div>
{% block javascript %}
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script>
$(document).ready(function () {
// отслеживаем событие отправки формы
$('#id_username').keyup(function () {
// создаем AJAX-вызов
$.ajax({
data: $(this).serialize(), // получаяем данные формы
url: "{% url 'validate_username' %}",
// если успешно, то
success: function (response) {
if (response.is_taken == true) {
$('#id_username').removeClass('is-valid').addClass('is-invalid');
$('#id_username').after('<div class="invalid-feedback d-block" id="usernameError">This username is not available!</div>')
}
else {
$('#id_username').removeClass('is-invalid').addClass('is-valid');
$('#usernameError').remove();
}
},
// если ошибка, то
error: function (response) {
// предупредим об ошибке
console.log(response.responseJSON.errors)
}
});
return false;
});
})
</script>
{% endblock javascript %}
</body>
</html>
Для лучшего понимания давайте подробно разберем все части представленного шаблона.
Внутри тега head мы загружаем bootstrap, используя CDN. Вы также можете сохранить библиотеку себе на диск и отдавать ее клиенту из статических папок.
<form id="signupForm" method="POST">
{% csrf_token %}
{{ form|crispy }}
<input type="submit" name="signupSubmit" class="btn btn-success btn-lg" />
</form>
Затем мы создаем форму Django, используя для стилизации тег crispy.
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
Далее внутри блока javascript мы запрашиваем JQuery от google CDN, вы также можете загрузить ее локально.
$(document).ready(function () {
( .... )
})
Затем у нас есть еще один скрипт с методом ready(). Код, написанный внутри метода $(document).ready(), будет запущен, когда DOM страницы будет готов для выполнения JavaScript.
$('#id_username').keyup(function () {
// создаем AJAX-вызов
$.ajax({
data: $(this).serialize(), // получаяем данные формы
url: "{% url 'validate_username' %}",
// если успешно, то
success: function (response) {
if (response.is_taken == true) {
$('#id_username').removeClass('is-valid').addClass('is-invalid');
$('#id_username').after('<div class="invalid-feedback d-block" id="usernameError">Это имя пользователя недоступно!</div>')
}
else {
$('#id_username').removeClass('is-invalid').addClass('is-valid');
$('#usernameError').remove();
}
},
// если ошибка, то
error: function (response) {
// предупредим об ошибке
console.log(response.responseJSON.errors)
}
});
return false;
});
Метод ajax запускается функцией keyup. Он принимает на вход объект с параметрами запроса. После успешного завершения запросов запускается одна из колбэк-функций success или error. При успешном вызове мы используем условный оператор для добавления и удаления классов is-valid/is-invalid поля ввода. А return false в конце скрипта предотвращает отправку форм, таким образом останавливая перезагрузку страницы.
Сохраните файлы и запустите сервер, вы должны увидеть AJAX в действии.
Выполнение AJAX POST запросов с помощью Django и JQuery
Метод HTTP POST используется для отправки данных на сервер.
В этом разделе мы узнаем, как делать POST-запросы с помощью JQuery и AJAX в шаблонах Django.
Мы создадим контактную форму и сохраним данные, предоставленные пользователем, в базу данных с помощью JQuery и AJAX.
# ajax/models.py
from django.db import models
class Contact(models.Model):
name = models.CharField(max_length=100)
email = models.EmailField()
message = models.TextField()
def __str__(self):
return self.name
# ajax/forms.py
from django import forms
from .models import Contact
class ContactForm(forms.ModelForm):
class Meta:
model = Contact
fields = '__all__'
# ajax/urls.py
...
from .views import home, SignUpView, validate_username, contact_form
urlpatterns = [
...
path('contact-form/', contact_form, name='contact_form')
]
# ajax/views.py
...
from .forms import ContactForm
...
def contact_form(request):
form = ContactForm()
if request.method == "POST" and request.is_ajax():
form = ContactForm(request.POST)
if form.is_valid():
name = form.cleaned_data['name']
form.save()
return JsonResponse({"name": name}, status=200)
else:
errors = form.errors.as_json()
return JsonResponse({"errors": errors}, status=400)
return render(request, "contact.html", {"form": form})
В представлении мы проверяем ajax-запрос с помощью метода request.is_ajax(). Если форма корректно заполнена, мы сохраняем ее в базе данных и возвращаем объект JSON с кодом состояния и именем пользователя. Для недопустимой формы мы отправим клиенту найденные ошибки с кодом 400, что означает неверный запрос (bad request).
{# contact.html #}
{% load crispy_forms_tags %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Contact us</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.2/css/bootstrap.min.css" crossorigin="anonymous">
</head>
<body>
<div class="container mt-5 w-50">
<form id="contactForm" method="POST">
{% csrf_token %}
{{ form|crispy }}
<input type="submit" name="contact-submit" class="btn btn-success btn-lg" />
</form>
</div>
{% block javascript %}
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script>
$(document).ready(function () {
// отслеживаем событие отправки формы
$('#contactForm').submit(function () {
// создаем AJAX-вызов
$.ajax({
data: $(this).serialize(), // получаем данные формы
type: $(this).attr('method'), // GET или POST
url: "{% url 'contact_form' %}",
// если успешно, то
success: function (response) {
alert("Спасибо, что обратились к нам " + response.name);
},
// если ошибка, то
error: function (response) {
// предупредим об ошибке
alert(response.responseJSON.errors);
console.log(response.responseJSON.errors)
}
});
return false;
});
})
</script>
{% endblock javascript %}
</body>
</html>
Давайте разобьем шаблон на более мелкие модули, чтобы лучше понять его.
Сначала мы импортируем bootstrap в head, используя CDN. Затем внутри body мы создаем форму с тегом crispy для стилизации.
После этого в первом javascript-блоке мы загружаем JQuery из CDN. Далее внутри функции $(document).ready() мы добавили наш AJAX метод.
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script>
$(document).ready(function () {
// отслеживаем событие отправки формы
$('#contactForm').submit(function () {
// создаем AJAX-вызов
$.ajax({
data: $(this).serialize(), // получаем данные формы
type: $(this).attr('method'), // GET или POST
url: "{% url 'contact_form' %}",
// если успешно, то
success: function (response) {
alert("Спасибо, что обратились к нам " + response.name);
},
// если ошибка, то
error: function (response) {
// предупредим об ошибке
alert(response.responseJSON.errors);
console.log(response.responseJSON.errors)
}
});
return false;
});
})
</script>
При отправке формы мы вызываем метод ajax(), который сериализует ее данные и отправляет их по заданному URL-адресу. В случае успеха мы показываем диалоговое окно с сообщением, сгенерированным на основе полученного имени пользователя.
Выполнение AJAX POST запросов с использованием представлений на основе классов
Нам нужно просто вернуть объект JSON из метода form_valid() класса FormView. Вы также можете использовать другие стандартные представления, основанные на классах, переопределив метод post().
# ajax/views.py
...
from django.views.generic.edit import CreateView, FormView
...
class ContactFormView(FormView):
template_name = 'contact.html'
form_class = ContactForm
def form_valid(self, form):
"""
Если форма валидна, вернем код 200
вместе с именем пользователя
"""
name = form.cleaned_data['name']
form.save()
return JsonResponse({"name": name}, status=200)
def form_invalid(self, form):
"""
Если форма невалидна, возвращаем код 400 с ошибками.
"""
errors = form.errors.as_json()
return JsonResponse({"errors": errors}, status=400)
Будем использовать таблицу созданную в предыдущей статье.
Вставка (добавление) записей
Есть несколько способов вставить записи в базу данных. Основной — метод insert() экземпляра Table. Его нужно вызвать, после чего использовать метод values() и передать значения для колонок в качестве аргументов-ключевых слов:
ins = customers.insert().values(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com',
address = 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
town = ' Vladivostok'
)
print(ins)
Чтобы увидеть, какой SQL код будет сгенерирован в результате, достаточно вывести ins:
INSERT INTO customers (first_name, last_name, username, email, address, town, created_on, updated_on) VALUES (:first_name, :last_name, :username, :email, :address, :town, :created_on, :updated_on)Стоит обратить внимание на то, что внутри оператора VALUES находятся связанные параметры (параметры в формате :name), а не сами значения, переданные в метод values().
И только при выполнении запроса в базе данных диалект заменит их на реальные значения. Они также будут экранированы, что исключает вероятность SQL-инъекций.
Посмотреть на то, какие значения будут на месте связанных параметров, можно с помощью такой инструкции: ins.compile().params.
Вывод:
{'first_name': 'Dmitriy',
'last_name': 'Yatsenko',
'username': 'Moseend',
'email': 'moseend@mail.com',
'address': 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
'town': ' Vladivostok',
'created_on': None,
'updated_on': None}Инструкция создана, но не отправлена в базу данных. Для ее вызова нужно вызвать метод execute() на объекте Connection:
ins = customers.insert().values(
first_name = 'Dmitriy',
last_name = 'Yatsenko',
username = 'Moseend',
email = 'moseend@mail.com',
address = 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23',
town = ' Vladivostok'
)
conn = engine.connect()
r = conn.execute(ins)
Этот код вставляет следующую запись в таблицу customers:

Метод execute() возвращает объект типа ResultProxy. Последний предоставляет несколько атрибутов, один из которых называется inserted_primary_key. Он возвращает первичный ключ вставленной записи.
Еще один способ создания инструкции для вставки — использование функции insert() из библиотеки sqlalchemy.
from sqlalchemy import insert
ins = insert(customers).values(
first_name = 'Valeriy',
last_name = 'Golyshkin',
username = 'Fortioneaks',
email = 'fortioneaks@gmail.com',
address = 'Narovchatova, bld. 8, appt. 37',
town = 'Magadan'
)
conn = engine.connect()
r = conn.execute(ins)
print(r.inserted_primary_key)
Вывод: (2,).
Вставка (добавление) нескольких записей
Вместо того чтобы передавать значения в метод values() в качестве аргументов-ключевых слов, их можно передать в метод execute().
from sqlalchemy import insert
conn = engine.connect()
ins = insert(customers)
r = conn.execute(ins,
first_name = "Vadim",
last_name = "Moiseenko",
username = "Antence73",
email = "antence73@mail.com",
address = 'Partizanskiy Prospekt, bld. 28/А, appt. 51',
town = ' Vladivostok'
)
Метод execute() достаточно гибкий, потому что он позволяет вставить несколько записей, передав значения в качестве списка словарей, где каждый — значения для одной строки:
r = conn.execute(ins, [
{
"first_name": "Vladimir",
"last_name": "Belousov",
"username": "Andescols",
"email":"andescols@mail.com",
"address": "Ul. Usmanova, bld. 70, appt. 223",
"town": " Naberezhnye Chelny"
},
{
"first_name": "Tatyana",
"last_name": "Khakimova",
"username": "Caltin1962",
"email":"caltin1962@mail.com",
"address": "Rossiyskaya, bld. 153, appt. 509",
"town": "Ufa"
},
{
"first_name": "Pavel",
"last_name": "Arnautov",
"username": "Lablen",
"email":"lablen@mail.com",
"address": "Krasnoyarskaya Ul., bld. 35, appt. 57",
"town": "Irkutsk"
},
])
print(r.rowcount)
Вывод: 3.
Прежде чем переходить к следующему разделу, добавим также записи в таблицы items, orders и order_lines:
items_list = [
{
"name":"Chair",
"cost_price": 9.21,
"selling_price": 10.81,
"quantity": 6
},
{
"name":"Pen",
"cost_price": 3.45,
"selling_price": 4.51,
"quantity": 3
},
{
"name":"Headphone",
"cost_price": 15.52,
"selling_price": 16.81,
"quantity": 50
},
{
"name":"Travel Bag",
"cost_price": 20.1,
"selling_price": 24.21,
"quantity": 50
},
{
"name":"Keyboard",
"cost_price": 20.12,
"selling_price": 22.11,
"quantity": 50
},
{
"name":"Monitor",
"cost_price": 200.14,
"selling_price": 212.89,
"quantity": 50
},
{
"name":"Watch",
"cost_price": 100.58,
"selling_price": 104.41,
"quantity": 50
},
{
"name":"Water Bottle",
"cost_price": 20.89,
"selling_price": 25.00,
"quantity": 50
},
]
order_list = [
{
"customer_id": 1
},
{
"customer_id": 1
}
]
order_line_list = [
{
"order_id": 1,
"item_id": 1,
"quantity": 5
},
{
"order_id": 1,
"item_id": 2,
"quantity": 2
},
{
"order_id": 1,
"item_id": 3,
"quantity": 1
},
{
"order_id": 2,
"item_id": 1,
"quantity": 5
},
{
"order_id": 2,
"item_id": 2,
"quantity": 5
},
]
r = conn.execute(insert(items), items_list)
print(r.rowcount)
r = conn.execute(insert(orders), order_list)
print(r.rowcount)
r = conn.execute(insert(order_lines), order_line_list)
print(r.rowcount)
Вывод:
8
2
5Получение записей
Для получения записей используется метод select() на экземпляре объекта Table:
s = customers.select()
print(s)
Вывод:
SELECT customers.id, customers.first_name, customers.last_name, customers.username, customers.email, customers.address, customers.town, customers.created_on, customers.updated_on
FROM customersТакой запрос вернет все записи из таблицы customers. Вместо этого можно также использовать функцию select(). Она принимает список или колонок, из которых требуется получить данные.
from sqlalchemy import select
s = select([customers])
print(s)
Вывод буде тот же.
Для отправки запроса нужно выполнить метод execute():
from sqlalchemy import select
conn = engine.connect()
s = select([customers])
r = conn.execute(s)
print(r.fetchall())
Вывод:
[(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583)), (2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109)),...)]Метод fetchall() на объекте ResultProxy возвращает все записи, соответствующие запросу. Как только результаты будут исчерпаны, последующие запросы к fetchall() вернут пустой список.
Метод fetchall() загружает все результаты в память сразу. В случае большого количества данных это не очень эффективно. Как вариант, можно использовать цикл для перебора по результатам:
s = select([customers])
rs = conn.execute(s)
for row in rs:
print(row)
Вывод:
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
...
(7, 'Pavel', 'Arnautov', 'Lablen', 'lablen@mail.com', 'Krasnoyarskaya Ul., bld. 35, appt. 57', 'Irkutsk', datetime.datetime(2021, 4, 22, 10, 32, 45, 364619), datetime.datetime(2021, 4, 22, 10, 32, 45, 364619))Дальше список часто используемых методов и атрибутов объекта ResultProxy:
| Метод/Атрибут | Описание |
| fetchone() | Извлекает следующую запись из результата. Если других записей нет, то последующие вызовы вернут None |
| fetchmany(size=None) | Извлекает набор записей из результата. Если их нет, то последующие вызовы вернут None |
| fetchall() | Извлекает все записи из результата. Если записей нет, то вернется None |
| first() | Извлекает первую запись из результата и закрывает соединение. Это значит, что после вызова метода first() остальные записи в результате получить не выйдет, пока не будет отправлен новый запрос с помощью метода execute() |
| rowcount | Возвращает количество строк в результате |
| keys() | Возвращает список колонок из источника данных |
| scalar() | Возвращает первую колонку первой записи и закрывает соединение. Если результата нет, то возвращает None |
Следующие сессии терминала демонстрируют рассмотренные выше методы и атрибуты в действии, где s = select([customers]).
fetchone()
r = conn.execute(s)
print(r.fetchone())
print(r.fetchone())
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
(2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109))fetchmany()
r = conn.execute(s)
print(r.fetchmany(2))
print(len(r.fetchmany(5))) # вернется 4, потому что у нас всего 6 записей
[(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583)), (2, 'Valeriy', 'Golyshkin', 'Fortioneaks', 'fortioneaks@gmail.com', 'Narovchatova, bld. 8, appt. 37', 'Magadan', datetime.datetime(2021, 4, 21, 17, 54, 30, 209109), datetime.datetime(2021, 4, 21, 17, 54, 30, 209109))]
4first()
r = conn.execute(s)
print(r.first())
print(r.first()) # вернется ошибка
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
Traceback (most recent call last):
...
sqlalchemy.exc.ResourceClosedError: This result object is closed.rowcount
r = conn.execute(s)
print(r.rowcount)
# вернется 6
keys()
r = conn.execute(s)
print(r.keys())
RMKeyView(['id', 'first_name', 'last_name', 'username', 'email', 'address', 'town', 'created_on', 'updated_on'])scalar()
r = conn.execute(s)
print(r.scalar())
# вернется 1
Важно отметить, что fetchxxx() и first() возвращают не кортежи или словари, а объекты типа LegacyRow, что позволяет получать доступ к данным в записи с помощью названия колонки, индекса или экземпляра Column. Например:
r = conn.execute(s)
row = r.fetchone()
print(row)
print(type(row))
print(row['id'], row['first_name']) # доступ к данным по названию колонки
print(row[0], row[1]) # доступ к данным по индексу
print(row[customers.c.id], row[customers.c.first_name]) # доступ к данным через объект класса
print(row.id, row.first_name) # доступ к данным, как к атрибуту
Вывод:
(1, 'Dmitriy', 'Yatsenko', 'Moseend', 'moseend@mail.com', 'Shemilovskiy 2-Y Per., bld. 8/10, appt. 23', ' Vladivostok', datetime.datetime(2021, 4, 21, 17, 33, 35, 172583), datetime.datetime(2021, 4, 21, 17, 33, 35, 172583))
<class 'sqlalchemy.engine.row.LegacyRow'>
1 Dmitriy
1 Dmitriy
1 Dmitriy
1 DmitriyДля получения данных из нескольких таблиц нужно передать список экземпляров Table, разделенных запятыми в функцию select():
Этот код вернет Декартово произведение записей из обоих таблиц. О SQL JOIN поговорим позже отдельно.
Фильтр записей
Для фильтрования записей используется метод where(). Он принимает условие и добавляет оператор WHERE к SELECT:
s = select([items]).where(
items.c.cost_price > 20
)
print(s)
r = conn.execute(s)
print(r.fetchall())
Запрос вернет все элементы, цена которых выше 20.
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.cost_price > :cost_price_1
[(4, 'Travel Bag', Decimal('20.10'), Decimal('24.21'), 50),
(5, 'Keyboard', Decimal('20.12'), Decimal('22.11'), 50),
(6, 'Monitor', Decimal('200.14'), Decimal('212.89'), 50),
(7, 'Watch', Decimal('100.58'), Decimal('104.41'), 50),
(8, 'Water Bottle', Decimal('20.89'), Decimal('25.00'), 50)]Дополнительные условия можно задать, просто добавив несколько вызовов метода where().
s = select([items]).\
where(items.c.cost_price + items.c.selling_price > 50).\
where(items.c.quantity > 10)
При использовании такого способа операторы просто объединяются при помощи AND. А как использовать OR или NOT?
Для этого есть:
- Побитовые операторы
- Союзы
Побитовые операторы
Побитовые операторы &, | и ~ позволяют объединять условия с операторами AND, OR или NOT из SQL.
Предыдущий запрос можно записать вот так с помощью побитовых операторов:
s = select([items]).\
where(
(items.c.cost_price + items.c.selling_price > 50) &
(items.c.quantity > 10)
)
Условия заключены в скобки. Это нужно из-за того, что побитовые операторы имеют более высокий приоритет по сравнению с операторами + и >.
s = select([items]).\
where(
(items.c.cost_price > 200 ) |
(items.c.quantity < 5)
)
print(s)
s = select([items]).\
where(
~(items.c.quantity == 50)
)
print(s)
s = select([items]).\
where(
~(items.c.quantity == 50) &
(items.c.cost_price < 20)
)
print(s)
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.cost_price > :cost_price_1 OR items.quantity < :quantity_1
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity != :quantity_1
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity != :quantity_1 AND items.cost_price < :cost_price_1Союзы
Условия можно объединять и с помощью функций-союзов and_(), or_() и not_(). Это предпочтительный способ добавления условий в SQLAlchemy.
from sqlalchemy import select, and_, or_, not_
select([items]).\
where(
and_(
items.c.quantity >= 50,
items.c.cost_price < 100,
)
)
select([items]).\
where(
or_(
items.c.quantity >= 50,
items.c.cost_price < 100,
)
)
select([items]).\
where(
and_(
items.c.quantity >= 50,
items.c.cost_price < 100,
not_(
items.c.name == 'Headphone'
),
)
)
Другие распространенные операторы сравнения
Следующий список демонстрирует как использовать остальные операторы сравнения при определении условий в SQLAlchemy
IS NULL
select([orders]).where(
orders.c.date_shipped == None
)
IS NOT NULL
select([orders]).where(
orders.c.date_shipped != None
)
IN
select([customers]).where(
customers.c.first_name.in_(["Valeriy", "Vadim"])
)
NOT IN
select([customers]).where(
customers.c.first_name.notin_(["Valeriy", "Vadim"])
)
BETWEEN
select([items]).where(
items.c.cost_price.between(10, 20)
)
NOT BETWEEN
from sqlalchemy import not_
select([items]).where(
not_(items.c.cost_price.between(10, 20))
)
LIKE
select([items]).where(
items.c.name.like("Wa%")
)
Метод like() выполняет сравнение с учетом регистра. Для сравнения без учета регистра используйте ilike().
NOT LIKE
select([items]).where(
not_(items.c.name.like("wa%"))
)
Сортировка результата c order_by
Метод order_by() добавляет оператор ORDER BY к инструкции SELECT. Он принимает одну или несколько колонок для сортировки. Для каждой колонки можно указать, выполнять ли сортировку по возрастанию (asc()) или убыванию (desc()). Если не указать ничего, то сортировка будет выполнена в порядке по возрастанию. Например:
s = select([items]).where(
items.c.quantity > 10
).order_by(items.c.cost_price)
print(s)
print(conn.execute(s).fetchall())
Вывод:
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items
WHERE items.quantity > :quantity_1 ORDER BY items.cost_price
[(3, 'Headphone', Decimal('15.52'), Decimal('16.81'), 50),
(4, 'Travel Bag', Decimal('20.10'), Decimal('24.21'), 50),
(5, 'Keyboard', Decimal('20.12'), Decimal('22.11'), 50),
(8, 'Water Bottle', Decimal('20.89'), Decimal('25.00'), 50),
(7, 'Watch', Decimal('100.58'), Decimal('104.41'), 50),
(6, 'Monitor', Decimal('200.14'), Decimal('212.89'), 50)]Запрос возвращает записи, отсортированные по cost_price по возрастанию. Это эквивалентно следующему:
from sqlalchemy import asc
s = select([items]).where(
items.c.quantity > 10
).order_by(asc(items.c.cost_price))
rs = conn.execute(s)
rs.fetchall()
Для сортировки результатов по убыванию используйте функцию desc(). Пример:
from sqlalchemy import desc
s = select([items]).where(
items.c.quantity > 10
).order_by(desc(items.c.cost_price))
conn.execute(s).fetchall()
Вот еще один пример сортировки по двух колонкам: quantity по возрастанию и cost_price по убыванию.
s = select([items]).order_by(
items.c.quantity,
desc(items.c.cost_price)
)
conn.execute(s).fetchall()
Ограничение результатов c limit
Метод limit() добавляет оператор LIMIT в инструкцию SELECT. Он принимает целое число, определяющее число записей, которые должны вернуться. Например:
s = select([items]).order_by(
items.c.quantity
).limit(2)
print(s)
print(conn.execute(s).fetchall())
Вывод:
SELECT items.id, items.name, items.cost_price, items.selling_price, items.quantity
FROM items ORDER BY items.quantity
LIMIT :param_1
[(2, 'Pen', Decimal('3.45'), Decimal('4.51'), 3),
(1, 'Chair', Decimal('9.21'), Decimal('10.81'), 5)]Чтобы задавать «сдвиг» (начальное положение) в LIMIT, нужно использовать метод offset():
s = select([items]).order_by(
items.c.quantity
).limit(2).offset(2)
Ограничение колонок
Инструкции SELECT, созданные ранее, возвращают данные из всех колонок. Ограничить количество полей, возвращаемых запросом можно, передав название полей в виде списка в функцию select(). Например:
s = select([items.c.name, items.c.quantity]).where(
items.c.quantity == 50
)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT items.name, items.quantity
FROM items
WHERE items.quantity = :quantity_1
RMKeyView(['name', 'quantity'])
[('Headphone', 50), ('Travel Bag', 50), ('Keyboard', 50), ('Monitor', 50), ('Watch', 50), ('Water Bottle', 50)]Запрос возвращает данные только из колонок name и quantity таблицы items.
По аналогии с SQL можно выполнять вычисления на вернувшихся строках до того, как они попадут в вывод. Например:
select([
items.c.name,
items.c.quantity,
items.c.selling_price * 5
]).where(
items.c.quantity == 50
)
Обратите внимание на то, что items.c.selling_price * 5 — это не реальная колонка, поэтому создается анонимное имя anon_1.
Колонке или выражению можно присвоить метку с помощью метода label(), который работает, добавляя оператор AS к SELECT.
select([
items.c.name,
items.c.quantity,
(items.c.selling_price * 5).label('price')
]).where(
items.c.quantity == 50
)
Доступ к встроенным функциям
Для доступа к встроенным функциям базы данных используется объект func. Следующий список показывает, как использовать функции для работы с датой/временем, математическими операциями и строками в базе данных PostgreSQL.
from sqlalchemy.sql import func
c = [
## функции даты/времени ##
func.timeofday(),
func.localtime(),
func.current_timestamp(),
func.date_part("month", func.now()),
func.now(),
## математические функции ##
func.pow(4,2),
func.sqrt(441),
func.pi(),
func.floor(func.pi()),
func.ceil(func.pi()),
## строковые функции ##
func.lower("ABC"),
func.upper("abc"),
func.length("abc"),
func.trim(" ab c "),
func.chr(65),
]
s = select(c)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
RMKeyView(['timeofday_1', 'localtime_1', 'current_timestamp_1', 'date_part_1', 'now_1', 'pow_1', 'sqrt_1', 'pi_1', 'floor_1', 'ceil_1', 'lower_1', 'upper_1', 'length_1', 'trim_1', 'chr_1'])
[('Thu Apr 22 12:33:07.655488 2021 EEST', datetime.time(12, 33, 7, 643174), datetime.datetime(2021, 4, 22, 12, 33, 7, 643174, tzinfo=psycopg2.tz.FixedOffsetTimezone(offset=180, name=None)), 4.0, datetime.datetime(2021, 4, 22, 12, 33, 7, 643174, tzinfo=psycopg2.tz.FixedOffsetTimezone(offset=180, name=None)), 16.0, 21.0, 3.14159265358979, 3.0, 4.0, 'abc', 'ABC', 3, 'ab c', 'A')]Также можно получить доступ к агрегирующим функциям из объекта object.
c = [
func.sum(items.c.quantity),
func.avg(items.c.quantity),
func.max(items.c.quantity),
func.min(items.c.quantity),
func.count(customers.c.id),
]
s = select(c)
rs = conn.execute(s)
print(rs.fetchall())
# вывод: [(1848, Decimal('38.5000000000000000'), 50, 3, 48)]
Группировка результатов с group_by
Группировка результатов выполняется с помощью оператора GROUP BY. Он часто используется в союзе с агрегирующими функциями. GROUP BY добавляется к SELECT с помощью метода group_by(). Последний принимает одну или несколько колонок и группирует строки по значениям в этих колонках. Например:
c = [
func.count("*").label('count'),
customers.c.town
]
s = select(c).group_by(customers.c.town)
print(conn.execute(s).fetchall())
Вывод:
[(1, 'Ufa'), (1, 'Irkutsk'), (2, ' Vladivostok'), (1, 'Magadan'), (1, ' Naberezhnye Chelny')]Этот запрос возвращает количество потребителей в каждом городе.
Чтобы отфильтровать результат на основе значений агрегирующих функций, используется метод having(), добавляющий оператор HAVING к SELECT. По аналогии с where() он принимает условие.
c = [
func.count("*").label('count'),
customers.c.town
]
s = select(c).group_by(customers.c.town).having(func.count("*") > 2)
Объединения (joins)
Экземпляр Table предоставляет два метода для создания объединений (joins):
join()— создает внутренний joinouterjoin()— создает внешний join (LEFT OUTER JOIN, если точнее)
Внутренний join возвращает только те колонки, которые соответствуют условию объединения, а внешний — также некоторые дополнительные.
Оба метода принимают экземпляр Table, определяют условие объединения на основе отношений во внешних ключах и возвращают конструкцию JOIN.
>>> print(customers.join(orders))
customers JOIN orders ON customers.id = orders.customer_idЕсли методы не могут определить условия объединения, или нужно предоставить другое условие, то это делается через передачу условия объединения в качестве второго аргумента.
customers.join(items,
customers.c.address.like(customers.c.first_name + '%')
)Когда в функции select() указываются таблицы или список колонок, SQLAlchemy автоматически размещает эти таблицы в операторе FROM. Но при использовании объединения таблицы, которые нужны во FROM, точно известны, поэтому используется select_from(). Этот же метод можно применять и для запросов, не использующих объединения. Например:
s = select([
customers.c.id,
customers.c.first_name
]).select_from(customers)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT customers.id, customers.first_name
FROM customers
RMKeyView(['id', 'first_name'])
[(1, 'Dmitriy'), (2, 'Valeriy'), (4, 'Vadim'), (5, 'Vladimir'), (6, 'Tatyana'), (7, 'Pavel')]Используем эти знания, чтобы найти все заказы, размещенные пользователем Dmitriy Yatsenko.
select([
orders.c.id,
orders.c.date_placed
]).select_from(
orders.join(customers)
).where(
and_(
customers.c.first_name == "Dmitriy",
customers.c.last_name == "Yatsenko",
)
)
Последний запрос возвращает id и date_placed заказа. Было бы неплохо также знать товары и их общее количество.
Для этого нужно сделать 3 объединения вплоть до таблицы items.
s = select([
orders.c.id.label('order_id'),
orders.c.date_placed,
order_lines.c.quantity,
items.c.name,
]).select_from(
orders.join(customers).join(order_lines).join(items)
).where(
and_(
customers.c.first_name == "Dmitriy",
customers.c.last_name == "Yatsenko",
)
)
print(s)
rs = conn.execute(s)
print(rs.keys())
print(rs.fetchall())
SELECT orders.id AS order_id, orders.date_placed, order_lines.quantity, items.name
FROM orders JOIN customers ON customers.id = orders.customer_id JOIN order_lines ON orders.id = order_lines.order_id JOIN items ON items.id = order_lines.item_id
WHERE customers.first_name = :first_name_1 AND customers.last_name = :last_name_1
RMKeyView(['order_id', 'date_placed', 'quantity', 'name'])
[(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Chair'),
(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 2, 'Pen'),
(1, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 1, 'Headphone'),
(2, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Chair'),
(2, datetime.datetime(2021, 4, 22, 10, 34, 39, 548608), 5, 'Pen')]
А вот как создавать внешнее объединение.
select([
customers.c.first_name,
orders.c.id,
]).select_from(
customers.outerjoin(orders)
)
Экземпляр Table, передаваемый в метод outerjoin(), располагается с правой стороны внешнего объединения. В результате последний запрос вернет все записи из таблицы customers (левой таблицы) и только те, которые соответствуют условию объединения из таблицы orders (правой).
Если нужны все записи из таблицы order, но лишь те, которые соответствуют условию, из orders, стоит использовать outerjoin():
select([
customers.c.first_name,
orders.c.id,
]).select_from(
orders.outerjoin(customers)
)
Также можно создать FULL OUTER JOIN, передав full=True в метод outerjoin(). Например:
select([
customers.c.first_name,
orders.c.id,
]).select_from(
orders.outerjoin(customers, full=True)
)
Обновление записей
Обновление данных выполняется с помощью функции update(). Например, следующий запрос обновляет selling_price и quantity для Water Bottle и устанавливает значения 30 и 60 соответственно.
from sqlalchemy import update
s = update(items).where(
items.c.name == 'Water Bottle'
).values(
selling_price = 30,
quantity = 60,
)
print(s)
rs = conn.execute(s)
Вывод:
UPDATE items SET selling_price=:selling_price, quantity=:quantity WHERE items.name = :name_1Удаление записей
Для удаления данных используется функция delete().
from sqlalchemy import delete
s = delete(customers).where(
customers.c.username.like('Vladim%')
)
print(s)
rs = conn.execute(s)
Вывод:
DELETE FROM customers WHERE customers.username LIKE :username_1Этот запрос удалит всех покупателей, чье имя пользователя начинается с Vladim.
Работа с дубликатами
Для обработки повторяющихся записей в результатах используется параметр DISTINCT. Его можно добавить в SELECT с помощью метода distinct(). Например:
# без DISTINCT
s = select([customers.c.town]).where(customers.c.id < 10)
print(s)
rs = conn.execute(s)
print(rs.fetchall())
# с DISTINCT
s = select([customers.c.town]).where(customers.c.id < 10).distinct()
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT customers.town
FROM customers
WHERE customers.id < :id_1
[(' Vladivostok',), ('Magadan',), (' Vladivostok',), (' Naberezhnye Chelny',), ('Ufa',), ('Irkutsk',)]
SELECT DISTINCT customers.town
FROM customers
WHERE customers.id < :id_1
[(' Vladivostok',), ('Ufa',), ('Irkutsk',), ('Magadan',), (' Naberezhnye Chelny',)]
Вот еще один пример использования distinct() с агрегирующей функцией count().Здесь считается количество уникальных городов в таблице customers.
select([
func.count(distinct(customers.c.town)),
func.count(customers.c.town)
])
Конвертация данных с cast
Приведение (конвертация) данных из одного типа в другой — это распространенная операция, которая выполняется с помощью функции cast() из библиотеки sqlalchemy.
from sqlalchemy import func, cast, Date
s = select([
cast(func.pi(), Integer),
cast(func.pi(), Numeric(10,2)),
cast("2010-12-01", DateTime),
cast("2010-12-01", Date),
])
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT CAST(pi() AS INTEGER) AS pi, CAST(pi() AS NUMERIC(10, 2)) AS anon__1, CAST(:param_1 AS DATETIME) AS anon_1, CAST(:param_2 AS DATE) AS anon_2
[(3, Decimal('3.14'), datetime.datetime(2010, 12, 1, 0, 0), datetime.date(2010, 12, 1))]Union
Оператор UNION позволяет объединять результаты нескольких SELECT. Для добавления его к функции select() используется вызов union().
from sqlalchemy import union, desc
u = union(
select([items.c.id, items.c.name]).where(items.c.name.like("Wa%")),
select([items.c.id, items.c.name]).where(items.c.name.like("%e%")),
).order_by(desc("id"))
print(u)
rs = conn.execute(u)
print(rs.fetchall())
Вывод:
SELECT items.id, items.name
FROM items
WHERE items.name LIKE :name_1 UNION SELECT items.id, items.name
FROM items
WHERE items.name LIKE :name_2 ORDER BY id DESC
[(8, 'Water Bottle'), (7, 'Watch'), (5, 'Keyboard'), (4, 'Travel Bag'), (3, 'Headphone'), (2, 'Pen')]По умолчанию union() удаляет все повторяющиеся записи из результата. Для их сохранения стоит использовать union_all().
from sqlalchemy import union_all, desc
union_all(
select([items.c.id, items.c.name]).where(items.c.name.like("Wa%")),
select([items.c.id, items.c.name]).where(items.c.name.like("%e%")),
).order_by(desc("id"))
Создание подзапросов
Данные можно получать и из нескольких таблиц с помощью подзапросов.
Следующий запрос возвращает идентификатор и название элементов, отсортированных по Dmitriy Yatsenko в его первом заказе:
s = select([items.c.id, items.c.name]).where(
items.c.id.in_(
select([order_lines.c.item_id]).select_from(customers.join(orders).join(order_lines)).where(
and_(
customers.c.first_name == 'Dmitriy',
customers.c.last_name == 'Yatsenko',
orders.c.id == 1
)
)
)
)
print(s)
rs = conn.execute(s)
print(rs.fetchall())
Вывод:
SELECT items.id, items.name
FROM items
WHERE items.id IN (SELECT order_lines.item_id
FROM customers JOIN orders ON customers.id = orders.customer_id JOIN order_lines ON orders.id = order_lines.order_id
WHERE customers.first_name = :first_name_1 AND customers.last_name = :last_name_1 AND orders.id = :id_1)
[(1, 'Chair'), (2, 'Pen'), (3, 'Headphone')]Тот же запрос можно написать и с использованием объединений:
select([items.c.id, items.c.name]).select_from(customers.join(orders).join(order_lines).join(items)).where(
and_(
customers.c.first_name == 'Dmitriy',
customers.c.last_name == 'Yatsenko',
orders.c.id == 1
)
)
«Сырые» запросы
SQLAlchemy предоставляет возможность выполнять сырые SQL-запросы с помощью функции text(). Например, следующая инструкция SELECT возвращает все заказы с товарами для Dmitriy Yatsenko.
from sqlalchemy.sql import text
s = text(
"""
SELECT
orders.id as "Order ID", items.id, items.name
FROM
customers
INNER JOIN orders ON customers.id = orders.customer_id
INNER JOIN order_lines ON order_lines.order_id = orders.id
INNER JOIN items ON items.id= order_lines.item_id
where customers.first_name = :first_name and customers.last_name = :last_name
"""
)
print(s)
rs = conn.execute(s, first_name='Dmitriy', last_name='Yatsenko')
print(rs.fetchall())
Вывод:
SELECT
orders.id as "Order ID", items.id, items.name
FROM
customers
INNER JOIN orders ON customers.id = orders.customer_id
INNER JOIN order_lines ON order_lines.order_id = orders.id
INNER JOIN items ON items.id= order_lines.item_id
where customers.first_name = :first_name and customers.last_name = :last_name
[(1, 1, 'Chair'), (1, 2, 'Pen'), (1, 3, 'Headphone'), (2, 1, 'Chair'), (2, 2, 'Pen')]Обратите внимание на то, что инструкция включает пару связанных параметров: first_name и last_name. Сами значения для них передаются уже в метод execute().
Эту же функцию можно встроить в select(). Например:
select([items]).where(
text("items.name like 'Wa%'")
).order_by(text("items.id desc"))
Выполнить сырой SQL можно и просто передав его прямо в execute(). Например:
rs = conn.execute("select * from orders;")
rs.fetchall()
Транзакции
Транзакция — это способ выполнять наборы SQL-инструкций так, чтобы выполнились или все, или ни одна из них. Если хотя бы одна из инструкций, участвующих в транзакции, проходит с ошибкой, база данных возвращается к состоянию, которое было до ее начала.
Сейчас в базе данных два заказа. Для совершения заказа нужно выполнить следующие два действия:
- Удалить заказанные товары из
items - Обновить колонку
date_shippedс датой
Оба действия должны быть выполнены как одно целое, чтобы быть уверенными в том, что данные корректные.
Объект Connection предоставляет метод begin(), который инициирует транзакцию и возвращает соответствующий объект Transaction. Последний в свою очередь предоставляет методы rollback() и commit() для отката до прежнего состояния или сохранения текущего состояния.
В следующем списке метод dispatch_order() принимает order_id в качестве аргумента и выполняет упомянутые выше действия с помощью транзакции.
from sqlalchemy import func, update
from sqlalchemy.exc import IntegrityError
def dispatch_order(order_id):
# проверка того, правильно ли указан order_id
r = conn.execute(select([func.count("*")]).where(orders.c.id == order_id))
if not r.scalar():
raise ValueError("Недействительный order_id: {}".format(order_id))
# брать товары в порядке очереди
s = select([order_lines.c.item_id, order_lines.c.quantity]).where(
order_lines.c.order_id == order_id
)
rs = conn.execute(s)
ordered_items_list = rs.fetchall()
# начало транзакции
t = conn.begin()
try:
for i in ordered_items_list:
u = update(items).where(
items.c.id == i.item_id
).values(quantity = items.c.quantity - i.quantity)
rs = conn.execute(u)
u = update(orders).where(orders.c.id == order_id).values(date_shipped=datetime.now())
rs = conn.execute(u)
t.commit()
print("Транзакция завершена.")
except IntegrityError as e:
print(e)
t.rollback()
print("Транзакция не удалась.")
dispatch_order(1)
Первый заказ включает 5 стульев и 2 ручки. Вызов функции dispatch_order() с идентификатором заказа 1 вернет такой результат.
Транзакция завершена.
Теперь items и order_lines должны выглядеть следующим образом:
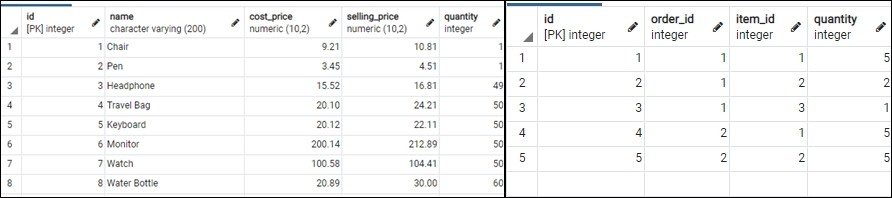
В следующем заказе 5 стульев и 4 ручки, но в запасе остались лишь 1 стул и 1 ручка.
Запустим dispatch_order(2) для второго заказа.
(psycopg2.errors.CheckViolation) ОШИБКА: новая строка в отношении "items" нарушает ограничение-проверку "quantity_check"
DETAIL: Ошибочная строка содержит (1, Chair, 9.21, 10.81, -4).
[SQL: UPDATE items SET quantity=(items.quantity - %(quantity_1)s) WHERE items.id = %(id_1)s]
[parameters: {'quantity_1': 5, 'id_1': 1}]
(Background on this error at: http://sqlalche.me/e/14/gkpj)
Транзакция не удалась.
Выполнение закончилось с ошибкой, потому что в запасе недостаточно ручек. В итоге база данных вернулась к состоянию до начала транзакции.
]]>Теория ROC-кривой
Полное название ROC — Receiver Operating Characteristic (рабочая характеристика приёмника). Впервые она была создана для использования радиолокационного обнаружения сигналов во время Второй мировой войны. США использовали ROC для повышения точности обнаружения японских самолетов с помощью радара. Поэтому ее называют рабочей характеристикой приемника.
AUC или area under curve — это просто площадь под кривой ROC. Прежде чем мы перейдем к тому, что такое ROC-кривая, нужно вспомнить, что такое матрица ошибок.
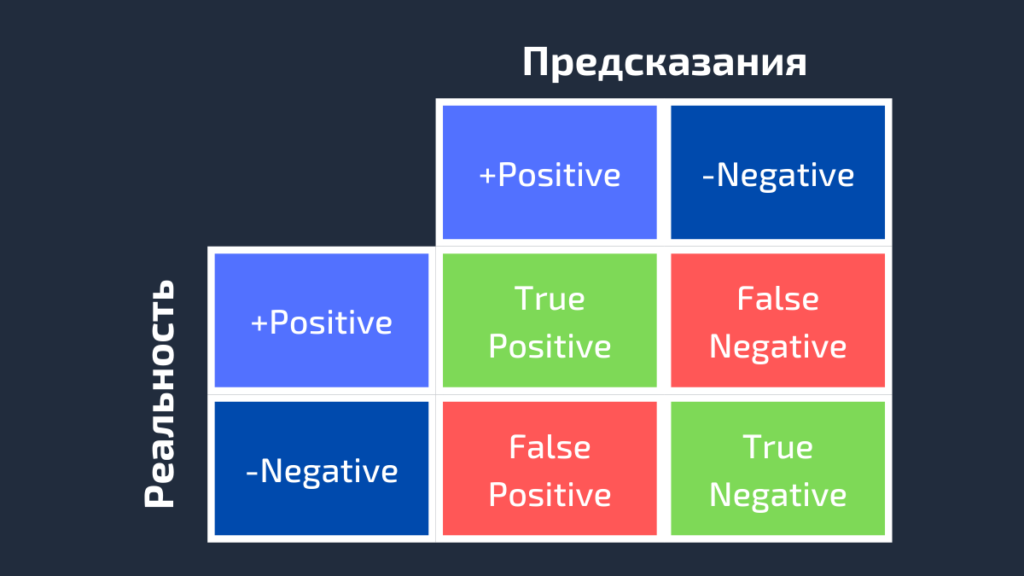
Как видно из рисунка выше, матрица ошибок — это комбинация вашего прогноза (1 или 0) и фактического значения (1 или 0). В зависимости от результата предсказания и того, корректна ли была проведена классификация, матрица разделена на 4 части. Например, true positive (истинно положительный) результат — это количество случаев, в которых вы правильно классифицируете семпл как положительный. А false positive (ложноположительный) — это число случаев, в которых вы ошибочно классифицируете семпл как положительный.
Матрица ошибок содержит только абсолютные числа. Однако, используя их, мы можем получить множество других метрик, основанных на процентных соотношениях. True Positive Rate (TPR) и False Positive Rate (FPR) — две из них.
True Positive Rate (TPR) показывает, какой процент среди всех positive верно предсказан моделью.
TPR = TP / (TP + FN).
False Positive Rate (FPR): какой процент среди всех negative неверно предсказан моделью.
FPR = FP / (FP + TN).
Хорошо, давайте теперь перейдем к кривой ROC!
Что такое ROC-кривая?
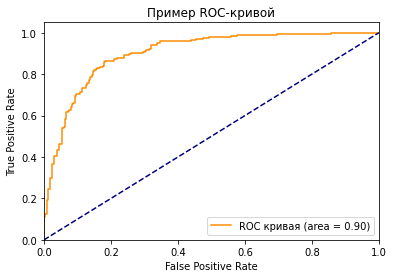
Как вы можете видеть на графике, кривая ROC — это просто отношение TPR к FPR. Теперь вам все понятно, в заключение…
Поверили?
Если серьезно, вы можете прочитать намного больше информации из диаграммы. Первый вопрос, который я хочу здесь обсудить: у нас же есть только один набор TPR, FPR, посчитанный на основе сделанных моделью предсказаний. Так откуда взялось такое количество точек для построения целого графика?
Все следует из того, как работает модель классификации. Когда вы строите классификационную модель, такую как дерево решений, и хотите определить, будут ли акции расти в цене или падать на основе входных данных. Модель сначала рассчитает вероятность увеличения или уменьшения, используя предоставленные вами исторические данные. После этого, основываясь на пороговом значении, она решит, будет ли результат увеличиваться или уменьшаться.
Да, ключевое слово здесь — порог. Разные пороговые значения создают разные TPR и FPR. Они представляют те самые точки, что образуют кривую ROC. Вы можете выбрать «Увеличение» в качестве предсказания модели, если полученная на основе исторических данных вероятность роста акций больше 50%. Также можете изменить пороговое значение и отобразить «Увеличение», только если соответствующая вероятность больше 90%. Если вы установите 90% порог вместо 50%, вы будете более уверены в том, что выбранные для «Увеличения» акции действительно вырастут. Но так вы можете упустить некоторые потенциально выгодные варианты.
Что значит синяя пунктирная линия на графике?
Как мы знаем, чем больше площадь под кривой (AUC), тем лучше классификация. Идеальная или наилучшая кривая — это вертикальная линия от (0,0) до (0,1), которая тянется до (1,1). Это означает: модель всегда может различить положительные и отрицательные случаи. Однако, если вы выбираете класс случайным образом для каждого семпла, TPR и FPR должны увеличиваться с одинаковой скоростью. Синяя пунктирная линия показывает кривую TPR и FPR при случайном определении positive или negative для каждого случая. Для этой диагональной линии площадь под кривой (AUC) составляет 0.5.
Что произойдет с TPR, FPR и ROC-кривой, если изменить пороговое значение?
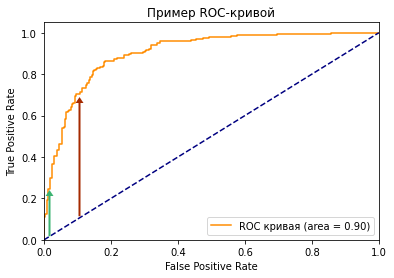
Посмотрите на две точки на ROC-кривой. Зеленая точка имеет очень высокий порог, это означает, что только если вы уверены на 99%, можете классифицировать случай как positive. Красная точка имеет относительно более низкий порог. Это означает, что вы можете классифицировать случай как positive, если вы уверены на 90%.
Как изменяются TPR и FPR при движении от зеленой точки к красной?
И TPR, и FPR увеличиваются. Когда вы уменьшаете порог, модель будет определять больше положительных случаев. Таким образом, TP увеличивается, как и TP/(TP + FN). С другой стороны, вы неизбежно ошибочно классифицируете некоторые отрицательные случаи как положительные из-за снижения порога, и поэтому FP и FP/(FP + TN) также увеличиваются.
Мы видим, что TPR и FPR положительно коррелируют. Вам нужно балансировать между максимальным охватом positive случаев и минимизацией неправильной классификации negative случаев.
Как выбрать оптимальную точку на кривой ROC?
Трудно определить оптимальную точку, потому что нужно выбрать наиболее подходящее пороговое значение, учитывая сферу применения модели. Однако общее правило — максимизировать разницу (TPR-FPR), которая на графике представлена вертикальным расстоянием между оранжевой и синей пунктирной линией.
Почему площадь под кривой ROC – хорошая метрика для оценки модели классификации?
Хорошая метрика модели машинного обучения должна отображать истинную и постоянную способность модели к прогнозированию. Это означает, что, если я изменю тестовый набор данных, он не должен давать другой результат.
ROC-кривая учитывает не только результаты классификации, но и вероятность предсказания всех классов. Например, если результат корректно классифицирован на основе 51% вероятности, то он, скорее всего, будет классифицирован неверно, если вы воспользуетесь другим тестовым датасетом. Кроме того, ROC-кривая также учитывает эффективность модели при различных пороговых значениях. Она является комплексной метрикой для оценки того, насколько хорошо разделяются случаи в разных группах.
Какое значение AUC является приемлемым для модели классификации?
Как я показал ранее, для задачи двоичной классификации при определении классов случайным образом, вы можете получить 0.5 AUC. Следовательно, если вы решаете задачу бинарной классификации, разумное значение AUC должно быть > 0.5. У хорошей модели классификации показатель AUC > 0.9, но это значение сильно зависит от сферы ее применения.
Как рассчитать AUC и построить ROC-кривую в Python?
Если вы просто хотите рассчитать AUC, вы можете воспользоваться пакетом metrics библиотеки sklearn (ссылка).
Если вы хотите построить ROC-кривую для результатов вашей модели, вам стоит перейти сюда.
Вот код для построения графика ROC, который я использовал в этой статье.
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import roc_auc_score
from matplotlib import pyplot as plt
# генерируем датасет на 2 класса
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# разделяем его на 2 выборки
trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2)
# обучаем модель
model = LogisticRegression(solver='lbfgs')
model.fit(trainX, trainy)
# получаем предказания
lr_probs = model.predict_proba(testX)
# сохраняем вероятности только для положительного исхода
lr_probs = lr_probs[:, 1]
# рассчитываем ROC AUC
lr_auc = roc_auc_score(testy, lr_probs)
print('LogisticRegression: ROC AUC=%.3f' % (lr_auc))
# рассчитываем roc-кривую
fpr, tpr, treshold = roc_curve(testy, lr_probs)
roc_auc = auc(fpr, tpr)
# строим график
plt.plot(fpr, tpr, color='darkorange',
label='ROC кривая (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Пример ROC-кривой')
plt.legend(loc="lower right")
plt.show()
Вам нужны следующие входные данные: фактическое значение y и вероятность предсказания. Обратите внимание, что функция roc_curve требует только вероятность для положительного случая, а не для обоих классов. Если вам нужно решить задачу мультиклассовой классификации, вы также можете использовать этот пакет, и в приведенной выше ссылке есть пример того, как построить график.
]]>List comprehension — это упрощенный подход к созданию списка, который задействует цикл for, а также инструкции if-else для определения того, что в итоге окажется в финальном списке.
Преимущества list comprehension
У list comprehension есть три основных преимущества.
- Простота. List comprehension позволяют избавиться от циклов for, а также делают код более понятным. В JavaScript, например, есть нечто похожее в виде
map()иfilter(), но новичками они воспринимаются сложнее. - Скорость. List comprehension быстрее for-циклов, которые он и заменяет. Это один из первых пунктов при рефакторинге Python-кода.
- Принципы функционального программирования. Это не так важно для начинающих, но функциональное программирование — это подход, при котором изменяемые данные не меняются. Поскольку list comprehensions создают новый список, не меняя существующий, их можно отнести к функциональному программированию.
Создание первого list comprehension
List comprehension записывается в квадратных скобках и задействует цикл for. В процессе создается новый список, куда добавляются все элементы оригинального. По мере добавления элементов их можно изменять.
Для начала возьмем простейший пример: создадим список из цифр от 1 до 5, используя функцию range().
>>> nums = [n for n in range(1,6)]
>>> print(nums)
[1, 2, 3, 4, 5]
В этом примере каждое значение диапазона присваивается переменной n. Каждое значение возвращается неизменным и добавляется в новый список. Это — та самая n перед циклом for.
В качестве итерируемого объекта не обязательно должна быть функция range(). Это может быть любое итерируемое значение.
List comprehension с изменением
Теперь пойдем чуть дальше и добавим изменение для каждого значения в цикле.
>>> nums = [1, 2, 3, 4, 5]
>>> squares = [n*n for n in nums]
>>> print(squares)
[1, 4, 9, 16, 25]
В этом примере два изменения по сравнению с прошлым кодом. Во-первых, в качестве источника используется уже существующий список. Во-вторых, list comprehension создает список, где каждое значение — это возведенное в квадрат значения оригинального списка.
List comprehension с if
Теперь добавим проверку с помощью if, чтобы не добавлять все значения.
>>> nums = [1, 2, 3, 4, 5]
>>> odd_squares = [n*n for n in nums if n%2 == 1]
>>> print(odd_squares)
[1, 9, 25]
Инструкция if идет после цикла — в данном случае порядок играет роль.
List comprehension с вложенным циклом for
В последнем примере рассмотрим пример со вложенным циклом for.
>>> matrix = [[x for x in range(1, 4)] for y in range(1, 4)]
>>> print(matrix)
[[1, 2, 3], [1, 2, 3], [1, 2, 3]]
Может показаться, что здесь все стало чуть сложнее. Но достаточно разбить код на несколько строк, чтобы увидеть, что нет ничего особенного.
matrix = [
[x for x in range(1, 4)]
for y in range(1, 4)
]
print(matrix)
Последний пример. Создадим список дней рождения из списка словарей. Для этого используем знакомые тактики.
people = [{
"first_name": "Василий",
"last_name": "Марков",
"birthday": "9/25/1984"
}, {
"first_name": "Регина",
"last_name": "Павленко",
"birthday": "8/21/1995"
}]
birthdays = [
person[term]
for person in people
for term in person
if term == "birthday"
]
print(birthdays)
В этом примере мы сперва перебираем people, присваивая каждый словарь person. После этого перебираем каждый идентификатор в словаре, присваивая ключи term. Если значение term равно birthday, то значение person[term] добавляет в list comprehension.
['9/25/1984', '8/21/1995']Теперь можете попробовать поработать с list comprehension на собственных примерах. Это сделает код более быстрым и компактным.
]]>Таблицы в SQLAlchemy представлены в виде экземпляров класса Table. Его конструктор принимает название таблицы, метаданные и одну или несколько колонок. Например:
from sqlalchemy import MetaData, Table, String, Integer, Column, Text, DateTime, Boolean
from datetime import datetime
metadata = MetaData()
blog = Table('blog', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('published', Boolean(), default=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
Разберем код построчно:
- Импортируем несколько классов из sqlalchemy, которые используются для создания таблицы.
- Импортируем класс datetime из модуля datetime.
- Создаем объекта
MetaData. Он содержит всю информацию о базе данных и таблицах. ЭкземплярMetaDataиспользуется для создания или удаления таблиц в базе данных. - Наконец, создается схема таблицы. Колонки создаются с помощью экземпляра
Column. Конструктор этого класса принимает название колонки и тип данных. Также можно передать дополнительные аргументы для обозначения ограничений (constraints) и конструкций SQL. Вот самые популярные ограничения:
| Ограничение | Описание |
primary_key | Булево. Если значение равно True, отмечает колонку как первичный ключ таблицы. Для создания составного ключа, нужно просто установить значение True для каждой колонки. |
nullable | Булево. Если False, то добавляет ограничение NOT NULL. Значение по умолчанию равно True. |
default | Определяет значение по умолчанию, если при вставке данных оно не было передано. Может быть как скалярное значение, так и вызываемое значение Python. |
onupdate | Значение по умолчанию для колонки, которое устанавливается, если ничего не было передано при обновлении записи. Может принимать то же значение, что и default. |
unique | Булево. Если True, следит за тем, чтобы значение было уникальным. |
index | Булево. Если True, создает индексируемую колонку. По умолчанию False. |
auto_increment | Добавляет параметр auto_increment для колонки. Значение по умолчанию равно auto. Это значит, что значение основного ключа будет увеличиваться каждый раз при добавлении новой записи. Если нужно увеличить значение для каждого элемента составного ключа, то этот параметр нужно задать как True для всех колонок ключа. Для отключения поведения нужно установить значение False |
Типы колонок
Тип определяет то, какие данные колонка сможет хранить. SQLAlchemy предоставляет абстракцию для большого количества типов. Однако всего есть три категории:
- Общие типы
- Стандартные SQL-типы
- Типы отдельных разработчиков
Общие типы
Тип Generic указывает на те типы, которые поддерживаются большинством баз данных. При использовании такого типа SQLAlchemy подбирает наиболее подходящий при создании таблицы. Например, в прошлом примере была определена колонка published. Ее тип — Boolean. Это общий тип. Для базы данных PostgreSQL тип будет boolean. А для MySQL — SMALLINT, потому что там нет Boolean. В Python же этот тип данных представлен типом bool (True или False).
Следующая таблица описывает основные типы в SQLAlchemy и ассоциации в Python и SQL.
| SQLAlchemy | Python | SQL |
|---|---|---|
BigInteger | int | BIGINT |
Boolean | bool | BOOLEAN или SMALLINT |
Date | datetime.date | DATE |
DateTime | datetime.datetime | DATETIME |
Integer | int | INTEGER |
Float | float | FLOAT или REAL |
Numeric | decimal.Decimal | NUMERIC |
Text | str | TEXT |
Получить эти типы можно из sqlalchemy.types или sqlalchemy.
Стандартные типы SQL
Типы в этой категории происходят из самого SQL. Их поддерживает небольшое количество баз данных.
from sqlalchemy import MetaData, Table, Column, Integer, ARRAY
metadata = MetaData()
employee = Table('employees', metadata,
Column('id', Integer(), primary_key=True),
Column('workday', ARRAY(Integer)),
)
Доступ к ним можно также получить из sqlalchemy.types или sqlalchemy. Однако для разделения стандартные типы записаны в верхнем регистре. Например, есть тип ARRAY, который пока поддерживается только PostgreSQL.
Типы производителей
В пакете sqlalchemy можно найти типы, которые используются в конкретных базах данных. Например, в PostgreSQL есть тип INET для хранения сетевых данных. Для его использования нужно импортировать sqlalchemy.dialects.
from sqlalchemy import MetaData, Table, Column, Integer
from sqlalchemy.dialects import postgresql
metadata = MetaData()
comments = Table('comments', metadata,
Column('id', Integer(), primary_key=True),
Column('ipaddress', postgresql.INET),
)
Реляционные отношения (связи)
Таблицы в базе данных редко существуют сами по себе. Чаще всего они связаны с другими через специальные отношения. Существует три типа отношений:
- Один-к-одному
- Один-ко-многим
- Многие-ко-многим
Разберемся, как определять эти отношения в SQLAlchemy.
Отношение один-ко-многим
Две таблицы связаны отношением один-ко-многим, если запись в первой таблице связана с одной или несколькими записями второй. На изображении ниже такая связь существует между таблицей users и posts.
Для создания отношения нужно передать объект ForeignKey, в котором содержится название колонки в функцию-конструктор Column.
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', ForeignKey("users.id")),
)
В этом коде определяется внешний ключ для колонки user_id таблицы posts. Это значит, что эта колонка может содержать только значения из колонки id таблицы users.
Вместо того чтобы передавать название колонки в качестве строки, можно передать объект Column прямо в конструктор ForeignKey. Например:
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', Integer(), ForeignKey(user.c.id)),
)
user.c.id ссылается на колонку id таблицы users. Важно лишь запомнить, что определение колонки (user.c.id) должно идти до ссылки на нее (posts.c.user_id).
Отношение один-к-одному
Две таблицы имеют связь один-к-одному, если запись в одной таблице связана только с одной записью в другой. На изображении ниже таблица employees связана с employee_details. Первая включает публичные записи о сотрудниках, а вторая — частные.
from sqlalchemy import MetaData, Table, Column, Integer, String, DateTime, ForeignKey
metadata = MetaData()
employees = Table('employees', metadata,
Column('employee_id', Integer(), primary_key=True),
Column('first_name', String(200), nullable=False),
Column('last_name', String(200), nullable=False),
Column('dob', DateTime(), nullable=False),
Column('designation', String(200), nullable=False),
)
employee_details = Table('employee_details', metadata,
Column('employee_id', ForeignKey('employees.employee_id'), primary_key=True),
Column('ssn', String(200), nullable=False),
Column('salary', String(200), nullable=False),
Column('blood_group', String(200), nullable=False),
Column('residential_address', String(200), nullable=False),
)
Для создания такой связи одна и та же колонка должна выступать одновременно основным и внешним ключом в employee_details.
Отношение многие-ко-многим
Две таблицы имеют связь многие-ко-многим, если запись в первой таблице связана с одной или несколькими таблицами во второй. Вместе с тем, запись во второй таблице связана с одной или несколькими в первой. Для таких отношений создается таблица ассоциаций. На изображении ниже отношение многие-ко-многим существует между таблицами posts и tags.
from sqlalchemy import MetaData, Table, Column, Integer, String, Text, ForeignKey
metadata = MetaData()
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
)
tags = Table('tags', metadata,
Column('id', Integer(), primary_key=True),
Column('tag', String(200), nullable=False),
Column('tag_slug', String(200), nullable=False),
)
post_tags = Table('post_tags', metadata,
Column('post_id', ForeignKey('posts.id')),
Column('tag_id', ForeignKey('tags.id'))
)
Процесс установки отношений почти не отличается от такового в SQL. Все потому что используется SQLAlchemy Core, который позволяет делать почти то же, что доступно в SQL.
Ограничения (constraint) на уровне таблицы
В прошлых разделах мы рассмотрели, как добавлять ограничения и индексы для колонки, передавая дополнительные аргументы в функцию-конструктор Column. По аналогии с SQL можно также определять ограничения с индексами и на уровне таблицы. В следующей таблице перечислены основные constraint и классы для их создания:
| Ограничения/индексы | Название класса |
| Основной ключ | PrimaryKeyConstraint |
| Внешний ключ | ForeignKeyConstraint |
| Уникальный ключ | UniqueConstraint |
| Проверочный ключ | CheckConstraint |
| Индекс | Index |
Получить доступ к этим классам можно через sqlalchemy.schema или sqlalchemy. Вот некоторые примеры использования:
Добавления Primary Key с помощью PrimaryKeyConstraint
parent = Table('parent', metadata,
Column('acc_no', Integer()),
Column('acc_type', Integer(), nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('acc_no', name='acc_no_pk')
)Здесь создается первичный ключ для колонки acc_no. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('acc_no', Integer(), primary=True),
Column('acc_type', Integer(), nullable=False),
Column('name', String(16), nullable=False),
)Преимущественно PrimaryKeyConstraint используется для создания составного основного ключа (такого ключа, который использует несколько колонок). Например:
parent = Table('parent', metadata,
Column('acc_no', Integer, nullable=False),
Column('acc_type', Integer, nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('acc_no', 'acc_type', name='uniq_1')
)Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('acc_no', Integer, nullable=False, primary_key=True),
Column('acc_type', Integer, nullable=False, primary_key=True),
Column('name', String(16), nullable=False),
)Создание Foreign Key с помощью ForeignKeyConstraint
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False)
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('parent_id', Integer, nullable=False),
Column('name', String(40), nullable=False),
ForeignKeyConstraint(['parent_id'],['parent.id'])
)Создаем внешний ключ в колонке parent_it, которая ссылается на колонку id таблицы parent. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False)
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('parent_id', ForeignKey('parent.id'), nullable=False),
Column('name', String(40), nullable=False),
)Но реальную пользу ForeignKeyConstraint приносит при определении составного внешнего ключа (который также задействует несколько колонок). Например:
parent = Table('parent', metadata,
Column('id', Integer, nullable=False),
Column('ssn', Integer, nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('id', 'ssn', name='uniq_1')
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(40), nullable=False),
Column('parent_id', Integer, nullable=False),
Column('parent_ssn', Integer, nullable=False),
ForeignKeyConstraint(['parent_id','parent_ssn'],['parent.id', 'parent.ssn'])
)Обратите внимание на то, что просто передать объект ForeignKey в отдельные колонки не получится — это приведет к созданию нескольких внешних ключей.
Создание Unique Constraint с помощью UniqueConstraint
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('ssn', Integer, nullable=False),
Column('name', String(16), nullable=False),
UniqueConstraint('ssn', name='unique_ssn')
)Определим ограничение уникальности для колонки ssn. Необязательное ключевое слово name позволяет задать имя для этого constraint. Такой код эквивалентен следующему:
parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('ssn', Integer, unique=True, nullable=False),
Column('name', String(16), nullable=False),
)UniqueConstraint часто используется для создания ограничения уникальности на нескольких колонках. Например:
parent = Table('parent', metadata,
Column('acc_no', Integer, primary_key=True),
Column('acc_type', Integer, nullable=False),
Column('name', String(16), nullable=False),
UniqueConstraint('acc_no', 'acc_type', name='uniq_1')
)В этом примере ограничения уникальности устанавливаются на acc_no и acc_type, в результате чего комбинация значений этих двух колонок всегда должна быть уникальной.
Создание ограничения проверки с помощью CheckConstraint
Ограничение CHECK позволяет создать условие, которое будет срабатывать при вставке или обновлении данных. Если проверка пройдет успешно, данные успешно сохранятся в базе данных. В противном случае возникнет ошибка.
Добавить это ограничение можно с помощью CheckConstraint.
employee = Table('employee', metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(100), nullable=False),
Column('salary', Integer(), nullable=False),
CheckConstraint('salary < 100000', name='salary_check')
)Создание индексов с помощью Index
Аргумент-ключевое слово index также позволяет добавлять индекс для отдельных колонок. Для работы с ним есть класс Index:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
Index('idx_col1', 'first_name')
)В этом примере индекс создается для колонки first_name. Такой код эквивалентен следующему:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False, index=True),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
)Если запросы включают поиск по определенному набору полей, то увеличить производительность можно с помощью составного индекса (то есть, индекса для нескольких колонок). В этом основное назначение Index:
a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
Index('idx_col1', 'first_name', 'last_name')
)Связь с таблицами и колонками с помощью MetaData
Объект MetaData содержит всю информацию о базе данных и таблицах внутри нее. С его помощью можно получать доступ к объектам таблицы, используя такие два атрибута:
| Атрибут | Описание |
| tables | Возвращает объект-словарь типа immutabledict, где ключом выступает название таблицы, а значением — объект с ее данными |
| sorted_tables | Возвращает список объектов Table, отсортированных по порядку зависимости внешних ключей. Другими словами, таблицы с зависимостями располагаются перед самими зависимостями. Например, если у таблицы posts есть внешний ключ, указывающий на колонку id таблицы users, то таблица users будет расположена перед posts |
Вот два описанных атрибута в действии:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, Column, Text, DateTime, Boolean, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', Integer(), ForeignKey("users.id")),
)
for t in metadata.tables:
print(metadata.tables[t])
print('-------------')
for t in metadata.sorted_tables:
print(t.name)
Ожидаемый вывод:
users
posts
-------------
users
postsПосле получения доступа к экземпляру Table можно получать доступ к любым деталям о колонках:
print(posts.columns) # вернуть список колонок
print(posts.c) # как и post.columns
print(posts.foreign_keys) # возвращает множество, содержащий внешние ключи таблицы
print(posts.primary_key) # возвращает первичный ключ таблицы
print(posts.metadata) # получим объект MetaData из таблицы
print(posts.columns.post_title.name) # возвращает название колонки
print(posts.columns.post_title.type) # возвращает тип колонки
Ожидаемый вывод:
ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, posts.user_id)
ImmutableColumnCollection(posts.id, posts.post_title, posts.post_slug, posts.content, posts.user_id)
{ForeignKey('users.id')}
PrimaryKeyConstraint(Column('id', Integer(), table=<posts>, primary_key=True, nullable=False))
MetaData()
post_title
VARCHAR(200)Создание таблиц
Для создания таблиц, хранящихся в экземпляре MetaData, вызовите метод MetaData.create_all() с объектом Engine.
metadata.create_all(engine)Этот метод создает таблицы только в том случае, если они не существуют в базе данных. Это значит, что его можно вызвать безопасно несколько раз. Также стоит отметить, что вызов метода после определения схемы не изменит ее. Для этого нужно использовать инструмент миграции под названием Alembic.
Удалить все таблицы можно с помощью MetaData.drop_all().
В дальнейшем будем работать с базой данных для приложения в сфере электронной коммерции. Она включает 4 таблицы:
- customers — хранит всю информацию о потребителях. Имеет следующие колонки:
- id — первичный ключ
- first_name — имя покупателя
- last_name — фамилия покупателя
- username — уникальное имя покупателя
- email — уникальный адрес электронной почты
- address — адрес
- town — город
- created_on — дата и время создания аккаунта
- updated_on — дата и время обновления аккаунта
- items — хранит информацию о товарах. Колонки:
- id — первичный ключ
- name — название
- cost_price — себестоимость товара
- selling_price — цена продажи
- quantity — количество товаров в наличии
- orders — информация о покупках потребителей. Колонки:
- id — первичный ключ
- customer_id — внешний ключ, указывающий на колонку
idтаблицы customers - date_placed — дата и время размещения заказа
- date_shipped — дата и время отгрузки заказа
- order_lines — подробности каждого товара в заказе. Колонки:
- id — первичный ключ
- order_id — внешний ключ, указывающий на
idтаблицы orders - item_id — внешний ключ, указывающий на
idтаблицы items - quantity — количество товаров в заказе
А вот и весь код для создания этих таблиц:
from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric, CheckConstraint
from datetime import datetime
metadata = MetaData()
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
customers = Table('customers', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('last_name', String(100), nullable=False),
Column('username', String(50), nullable=False),
Column('email', String(200), nullable=False),
Column('address', String(200), nullable=False),
Column('town', String(50), nullable=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
items = Table('items', metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(200), nullable=False),
Column('cost_price', Numeric(10, 2), nullable=False),
Column('selling_price', Numeric(10, 2), nullable=False),
Column('quantity', Integer(), nullable=False),
CheckConstraint('quantity > 0', name='quantity_check')
)
orders = Table('orders', metadata,
Column('id', Integer(), primary_key=True),
Column('customer_id', ForeignKey('customers.id')),
Column('date_placed', DateTime(), default=datetime.now),
Column('date_shipped', DateTime())
)
order_lines = Table('order_lines', metadata,
Column('id', Integer(), primary_key=True),
Column('order_id', ForeignKey('orders.id')),
Column('item_id', ForeignKey('items.id')),
Column('quantity', Integer())
)
metadata.create_all(engine)
Базу данных
sqlalchemy_tutsмы создали в предыдущем уроке: https://pythonru.com/biblioteki/ustanovka-i-podklyuchenie-sqlalchemy-k-baze-dannyh
В следующем материале рассмотрим, как выполнять CRUD-операции в базе данных с помощью SQL.
]]>Для работы с LightGBM доступны API на C, Python или R. Фреймворк также предоставляет CLI, который позволяет нам использовать библиотеку из командной строки. Оценщики (estimators) LightGBM оснащены множеством гиперпараметров для настройки модели. Кроме этого, в нем уже реализован большой набор функций оптимизации/потерь и оценочных метрики.
В рамках данного руководства мы рассмотрим Python API данного фреймворка. Мы постараемся объяснить и охватить большую часть этого API. Основная цель работы — ознакомить читателей с основными функциональными возможностями lightgbm, необходимыми для начала работы с ним.
Существуют и другие библиотеки (xgboost, catboost, scikit-learn), которые также обеспечивают реализацию деревьев решений с градиентным бустингом.
Давайте начнем.
Ноутбук с кодом в репозитории: https://gitlab.com/PythonRu/notebooks/-/blob/master/LightGBM_python.ipynb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import lightgbm as lgb
import sklearn
import warnings
warnings.filterwarnings("ignore")
print("Версия LightGBM : ", lgb.__version__)
print("Версия Scikit-Learn : ", sklearn.__version__)
Версия LightGBM : 3.2.1
Версия Scikit-Learn : 0.23.2Загрузка датасетов
Мы будем использовать доступные в sklearn три набора данных (показаны ниже) для этого руководства.
- Boston Housing Dataset — это выборка для задач регрессии, которая содержит информацию о различных характеристиках домов в Бостоне и их цене в долларах. Она будет использоваться нами при решении регрессионных проблем.
- Breast Cancer Dataset — это датасет для задач классификации, содержащий информацию о двух типах опухолей. Он будет применяться для объяснения методов бинарной классификации.
- Wine Dataset — это набор данных классификации, содержащий информацию об ингредиентах, используемых в создании вин трех типов. Используется нами для объяснения задач мультиклассификации.
Ниже мы загрузили все три упомянутых датасета, вывели их описания для ознакомления с признаками(features) и размерами соответствующих выборок. Каждый датасет как pandas DataFrame. Посмотрим на них:
Boston Housing Dataset
from sklearn.datasets import load_boston
boston = load_boston()
for line in boston.DESCR.split("\n")[5:29]:
print(line)
boston_df = pd.DataFrame(data=boston.data, columns = boston.feature_names)
boston_df["Price"] = boston.target
boston_df.head()
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | Price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
Breast Cancer Dataset
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
for line in breast_cancer.DESCR.split("\n")[5:31]:
print(line)
breast_cancer_df = pd.DataFrame(data=breast_cancer.data, columns = breast_cancer.feature_names)
breast_cancer_df["TumorType"] = breast_cancer.target
breast_cancer_df.head()
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
The mean, standard error, and "worst" or largest (mean of the three
worst/largest values) of these features were computed for each image,
resulting in 30 features. For instance, field 0 is Mean Radius, field
10 is Radius SE, field 20 is Worst Radius.
- class:
- WDBC-Malignant
- WDBC-Benign| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | … | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | TumorType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | … | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | … | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | … | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | … | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | … | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Wine Dataset
from sklearn.datasets import load_wine
wine = load_wine()
for line in wine.DESCR.split("\n")[5:29]:
print(line)
wine_df = pd.DataFrame(data=wine.data, columns = wine.feature_names)
wine_df["WineType"] = wine.target
wine_df.head()
**Data Set Characteristics:**
:Number of Instances: 178 (50 in each of three classes)
:Number of Attributes: 13 numeric, predictive attributes and the class
:Attribute Information:
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
- class:
- class_0
- class_1
- class_2| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | WineType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 | 0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 | 0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 | 0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 | 0 |
Обучение модели на train()
Самый простой способ создать оценщик (estimator) в lightgbm — использовать метод train(). Он принимает на вход оценочный параметр в виде словаря и обучающий датасет. Затем train тренирует оценщик и возвращает объект типа Booster, который является обученным оценщиком: его можно использовать для будущих предсказаний.
Ниже приведены некоторые из важных параметров метода train().
params— это словарь, определяющий параметры алгоритма деревьев решений с градиентным бустингом. Нам просто нужно предоставить целевую функцию для начала работы в зависимости от типа задачи (классификация/регрессия). Позже мы ознакомимся с часто используемым списком параметров, которые можно передать в этот словарь.train_set— этот параметр принимает объект типаDatasetфреймворка lightgbm, который содержит информацию о показателях и целевых значениях. Это внутренняя структура данных, разработанная lightgbm для обертывания данных.num_boost_round— указывает количество деревьев бустинга, которые будут использоваться в ансамбле. Ансамбль — это группа деревьев с градиентным бустингом, которую мы обычно называем оценщиком. Значение по умолчанию равно 100.valid_sets— принимает списокDatasetобъектов, которые являются выборками для валидации. Эти проверочные датасеты оцениваются после каждого цикла обучения.valid_names— принимает список строк той же длины, что и уvalid_sets, определяющих имена для каждой проверочной выборки. Эти имена будут использоваться при выводе оценочных метрик для валидационных наборов данных, а также при их построении.categorical_feature— принимает список строк/целых чисел или строку auto. Если мы передадим список строк/целых чисел, тогда указанные столбцы из набора данных будут рассматриваться как категориальные.verbose_eval— принимает значения типаboolилиint. Если мы установим значениеFalseили 0, тоtrainне будет выводить результаты расчета метрик на проверочных выборках, которые мы передали. Если нами было указано True, он будет печатать их для каждого раунда. При передаче целого числа, большего 1,trainотобразит результаты повторно после указанного количества раундов.
Dataset
Dataset представляет собой внутреннюю структуру данных lightgbm для хранения данных и меток. Ниже приведены важные параметры класса.
data— принимает массив библиотеки numpy, dataframe pandas, разреженные матрицы (sparse matrix) scipy, список массивов numpy, фрейм таблицы данных h2o в качестве входного значения, хранящего значения признаков (features).label— принимает массив numpy, pandas series или dataframe с одним столбцом. Данный параметр определяет целевые значения. Мы также можем установить дляlabelзначениеNone, если у нас нет таких значений. По умолчанию —None.feature_name— принимает список строк, определяющих имена показателей.categorical_feature— имеет то же значение, что и указанное выше в параметре методаtrain(). Мы можем определить категориальный показатель здесь или вtrain.
Регрессия
Первая проблема, которую мы решим с помощью lightgbm, — это простая задача регрессии с использованием датасета Boston housing, который был загружен нами ранее. Мы разделили этот набор данных на обучающую/тестовую выборки и создали из них экземпляр Dataset. Затем мы вызвали метод lightgbm.train(), предоставив ему датасеты для обучения и проверки. Мы установили количество итераций бустинга равным 10, поэтому для решения задачи будет создано 10 деревьев.
После завершения обучения train вернет экземпляр типа Booster, который мы позже сможем использовать для будущих предсказаний. Поскольку мы передали проверочный датасет в качестве входных данных, метод выведет значение l2 для валидации после каждой итерации обучения. Обратите внимание, что по умолчанию lightgbm минимизирует потерю l2 для задачи регрессии.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression"},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Размеры Train/Test: (379, 13) (127, 13) (379,) (127,)
[LightGBM] [Warning] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000840 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 961
[LightGBM] [Info] Number of data points in the train set: 379, number of used features: 13
[LightGBM] [Info] Start training from score 22.134565
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[1] valid_0's l2: 92.7815
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[2] valid_0's l2: 80.7846
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[3] valid_0's l2: 70.6207
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[4] valid_0's l2: 61.6287
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[5] valid_0's l2: 55.0184
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[6] valid_0's l2: 49.3809
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[7] valid_0's l2: 44.3784
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[8] valid_0's l2: 40.2941
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[9] valid_0's l2: 36.8559
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[10] valid_0's l2: 33.9026Ниже мы сделали прогнозы по тренировочным и тестовым данным с использованием обученной модели. Затем рассчитали R2 метрики для них, используя соответствующий метод sklearn. Обратите внимание, метод predict() принимает массив numpy, dataframe pandas, scipy sparse matrix или фрейм таблицы данных h2o в качестве входных данных для предсказаний.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression"},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Test R2 Score : 0.68
Train R2 Score : 0.74raw_score— это логический параметр, при котором, если он установлен вTrue, результатом выполнения будут необработанные прогнозы. Для задач регрессии это не имеет никакого значения, но при классификации predict вернет значения функции, а не вероятности.pred_leaf— этот параметр принимает логические значения. Если заданоTrue, то будет возвращаться индекс листа каждого дерева, который был спрогнозирован для конкретного семпла. Размер вывода будетn_samples x n_trees.pred_contrib— возвращает массив показателей для каждого наблюдения. Результатом будет являться массив размера(n_features + 1)для каждого семпла, где последнее значение является ожидаемым значением, а первые n_features являются вкладом показателей в этот прогноз. Мы можем добавить вклад каждого показателя к последнему ожидаемому значению и получить фактический прогноз. Обычно такие значения называют SHAP.
idxs = booster.predict(X_test, pred_leaf=True)
print("Размерность: ", idxs.shape)
idxs
Размерность: (127, 10)
array([[10, 11, 12, ..., 5, 13, 6],
[ 3, 3, 3, ..., 3, 4, 2],
[ 2, 8, 2, ..., 2, 2, 3],
...,
[ 3, 3, 3, ..., 3, 4, 2],
[ 5, 0, 0, ..., 13, 0, 13],
[ 0, 5, 14, ..., 0, 3, 1]])shap_vals = booster.predict(X_test, pred_contrib=True)
print("Размерность: ", shap_vals.shape)
print("\nЗначения Shap для нулевого семпла: ", shap_vals[0])
print("\nПредсказания с использованием значений SHAP: ", shap_vals[0].sum())
print("Предсказания без SHAP: ", test_preds[0])
Размерность: (127, 14)
Значения Shap для нулевого семпла: [-1.04268359e+00 0.00000000e+00 5.78385997e-02 0.00000000e+00
-5.09776692e-01 -1.81771187e+00 -5.44789659e-02 -2.41017058e-02
9.10266200e-03 -6.42845196e-03 5.32678196e-03 0.00000000e+00
-4.62999363e+00 2.21345647e+01]
Предсказания с использованием значений SHAP: 14.121657826104853
Предсказания без SHAP: 14.121657826104858Мы можем вызвать метод num_trees() в экземпляре бустера, чтобы получить количество деревьев в ансамбле. Обратите внимание: если мы не прекратим обучение раньше, число деревьев будет таким же, как num_boost_round. Но если мы прервем тренировку, тогда их количество будет отличаться от num_boost_round.
Позже в этом руководстве мы объясним, как можно остановить обучение, если производительность ансамбля не улучшается при оценке на проверочном наборе.
Экземпляр бустера имеет еще один важный метод feature_importance(), который может возвращать нам важность признаков на основе значений выигрыша (booster.feature_importance(importance_type="gain")) и разделения (booster.feature_importance(importance_type="split")) деревьев.
(array([4.56516126e+03, 0.00000000e+00, 1.49124010e+03, 0.00000000e+00,
1.20125020e+03, 6.15448327e+04, 4.08311499e+02, 8.27205796e+02,
2.62632999e+01, 4.70000000e+01, 2.03512299e+02, 0.00000000e+00,
4.28531050e+04])
array([21, 0, 7, 0, 9, 29, 7, 15, 1, 1, 4, 0, 44]))Бинарная классификация
В этом разделе объясняется, как мы можем, используя метод train(), создать бустер для задачи бинарной классификации. Обучаем модель на наборе данных о раке груди, а затем оцениваем ее точность, используя метрику из sklearn. Мы установили objective значение binary для информирования метода train() о том, что предоставленные нами данные предназначены для решения задачи бинарной классификации. Также установили параметр verbosity равным -1, чтобы предотвратить вывод сообщений во время обучения. Он по-прежнему будет печатать результаты оценки проверочного датасета, которые тоже можно отключить, передав для параметра verbose_eval значение False.
Обратите внимание, что для задач классификации метод бустера predict() возвращает вероятности. Мы добавили логику для преобразования вероятностей в целевой класс.
По умолчанию при решении задач бинарной классификации LightGBM использует для оценки бинарную логистическую функцию потери на проверочной выборке. Мы можем добавить параметр metric в словарь, который передается методу train(), с названиями любых метрик, доступных в lightgbm, и он будет использовать эти метрики. Позже мы более подробно обсудим перечень предоставляемых lightgbm метрик.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=breast_cancer.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=breast_cancer.feature_names.tolist())
booster = lgb.train({"objective": "binary", "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's binary_logloss: 0.600128
[2] valid_0's binary_logloss: 0.537151
[3] valid_0's binary_logloss: 0.48676
[4] valid_0's binary_logloss: 0.443296
[5] valid_0's binary_logloss: 0.402604
[6] valid_0's binary_logloss: 0.37053
[7] valid_0's binary_logloss: 0.339712
[8] valid_0's binary_logloss: 0.316836
[9] valid_0's binary_logloss: 0.297812
[10] valid_0's binary_logloss: 0.278683
Test Accuracy: 0.95
Train Accuracy: 0.97Мультиклассовая классификация
В рамках этого раздела объясняется, как использовать метод train() для задач мультиклассовой классификации. Мы применяем его на выборке данных о вине, которая имеет три разных типа вина в качестве целевой переменной. Мы установили objective в значение multiclass. Всякий раз, когда нами используется метод train() для решения такой задачи, нам необходимо предоставить целочисленный параметр num_class, определяющим количество классов.
Метод predict() возвращает вероятности для каждого класса в случае мультиклассовых задач. Мы добавили логику для выбора класса с наибольшим значением вероятности в качестве фактического предсказания.
LightGBM по умолчанию использует для оценки мультиклассовую логистическую функцию потери на проверочном датасете при решении проблем бинарной классификации.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=wine.feature_names)
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=wine.feature_names)
booster = lgb.train({"objective": "multiclass", "num_class":3, "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = np.argmax(test_preds, axis=1)
train_preds = np.argmax(train_preds, axis=1)
print("\nTest Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (133, 13) (45, 13) (133,) (45,)
[1] valid_0's multi_logloss: 0.951806
[2] valid_0's multi_logloss: 0.837812
[3] valid_0's multi_logloss: 0.746033
[4] valid_0's multi_logloss: 0.671446
[5] valid_0's multi_logloss: 0.60648
[6] valid_0's multi_logloss: 0.54967
[7] valid_0's multi_logloss: 0.499026
[8] valid_0's multi_logloss: 0.458936
[9] valid_0's multi_logloss: 0.419804
[10] valid_0's multi_logloss: 0.385265
Test Accuracy: 0.98
Train Accuracy: 1.00Список важных параметров LightGBM
Теперь мы перечислим важные параметры lightgbm, которые могут быть предоставлены в виде словаря при вызове метода train(). Мы можем использовать те же параметры для оценщиков (LGBMModel, LGBMRegressor и LGBMClassifier), которые доступны в lightgbm, с той лишь разницей, что нам не нужно формировать словарь — мы можем передать их напрямую при создании экземпляра. Мы рассмотрим работу с оценщиками в следующем разделе.
objective— этот параметр позволяет нам определить целевую функцию, используемую для текущей задачи. Его значением по умолчанию является regression. Ниже приведен список часто используемых значений этого параметра.regressionregression_l1tweediebinarymulticlassmulticlassovacross_entropy- Другие доступные целевые функции
metric— данный параметр принимает метрики для расчета на оценочных наборах данных (в случае если эти выборки предоставлены как значение параметраeval_set/validation_sets). Мы можем предоставить более одной метрики, и все они будут посчитаны на проверочных датасетах. Ниже приведен список наиболее часто используемых значений этого параметра.rmsel2l1tweediebinary_loglossmulti_loglossauccross_entropy- Другие доступные метрики
boosting— этот параметр принимает одну из нижеперечисленных строк, определяющих, какой алгоритм использовать.gbdt— значение по умолчанию. Дерево решений с градиентным бустингомrf— Случайный лесdart— Dropout на множественных аддитивных регрессионных деревьяхgoss— Односторонняя выборка на основе градиента
num_iterations— данный параметр является псевдонимом дляnum_boost_round, который позволяет нам указать число деревьев в ансамбле для создания оценщика. По умолчанию 100.learning_rate— этот параметр используется для определения скорости обучения. По умолчанию 0.1.num_class— если мы работаем с задачей мультиклассовой классификации, то этот параметр должен содержать количество классов.num_leaves— данный параметр принимает целое число, определяющее максимальное количество листьев, разрешенное для каждого дерева. По умолчанию 31.num_threads— принимает целое число, указывающее количество потоков, используемых для обучения. Мы можем установить его равным числу ядер системы.seed— позволяет нам указать инициализирующее значение для процесса обучения, что предоставляет нам возможность повторно генерировать те же результаты.max_depth— этот параметр позволяет нам указать максимальную глубину, разрешенную для деревьев в ансамбле. По умолчанию -1, что позволяет деревьям расти как можно глубже. Мы можем ограничить это поведение, установив этот параметр.min_data_in_leaf— данный параметр принимает целочисленное значение, определяющее минимальное количество точек данных (семплов), которые могут храниться в одном листе дерева. Этот параметр можно использовать для контроля переобучения. Значение по умолчанию 20.bagging_fraction— этот параметр принимает значение с плавающей запятой от 0 до 1, которое позволяет указать, насколько большая часть данных будет случайно отбираться при обучении. Этот параметр может помочь предотвратить переобучение. По умолчанию 1.0.feature_fraction— данный параметр принимает значение с плавающей запятой от 0 до 1, которое информирует алгоритм о выборе этой доли показателей из общего числа для обучения на каждой итерации. По умолчанию 1.0, поэтому используются все показатели.extra_trees— этот параметр принимает логические значения, определяющие, следует ли использовать чрезвычайно рандомизированное дерево или нет.early_stopping_round— принимает целое число, указывающее, что мы должны остановить обучение, если оценочная метрика, рассчитанная на последнем проверочном датасете, не улучшается на протяжении определенного параметром числа итераций.monotone_constraints— этот параметр позволяет нам указать, должна ли наша модель обеспечивать увеличение, уменьшение или отсутствие связи отдельного показателя с целевым значением. Использование данного параметра объясняется в разделе «Монотонные ограничения».monotone_constraints_method— этот параметр принимает одну из нижеперечисленных строк, определяющих тип накладываемых монотонных ограничений.basic— базовый метод монотонных ограничений, который может чрезмерно ограничивать модель.intermediate— это более сложный метод ограничений, который немного менее ограничивает, чем базовый метод, но может занять больше времени.advanced— это расширенный метод ограничений, который менее ограничивает, чем базовый и промежуточный методы, но может занять больше времени.
interaction_constraints— этот параметр принимает список списков, в которых отдельные списки определяют индексы показателей, которым разрешено взаимодействовать друг с другом. Такое взаимодействие подробно объясняется в разделе «Ограничения взаимодействия показателей».verbosity— этот параметр принимает целочисленное значение для управления логированием сообщений при обучении.- < 0 — отображаются только фатальные ошибки.
- 0 — отображаются сообщения об ошибках/предупреждениях и перечисленные выше.
- 1 — отображаются информационные сообщения и перечисленные выше.
- > 1 — отображается отладочная информация и перечисленные выше.
is_unbalance— это логический параметр, который должен иметь значениеTrue, если данные не сбалансированы. Его следует использовать с задачами бинарной и мультиклассовой классификации.device_type— принимает одну из следующих строк, определяющих тип используемого для обучения оборудования.cpugpucuda
force_col_wise— этот параметр принимает логическое значение, определяющее, следует ли принудительно строить гистограмму по столбцам при обучении. Если в данных слишком много столбцов, установка для этого параметра значенияTrueповысит скорость процесса обучения за счет уменьшения использования памяти.force_row_wise— этот параметр принимает логическое значение, определяющее, следует ли принудительно строить гистограмму по строкам при обучении. Если в данных слишком много строк, установка для этого параметра значенияTrueповысит скорость процесса обучения за счет уменьшения использования памяти.
Стоит учитывать, что это не полный список параметров, доступных при работе с lightgbm, а только перечисление некоторых наиболее важных. Если вы хотите узнать обо всех параметрах, перейдите по ссылке ниже.
Полный список параметров LightGBM.
LGBMModel
Класс LGBMModel — это обертка для класса Booster, которая предоставляет подобный scikit-learn API для обучения и прогнозирования в lightgbm. Он позволяет нам создать объект оценщика со списком параметров в качестве входных данных. Затем мы можем вызвать метод fit() для обучения, передав ему тренировочные данные, и метод predict() для предсказания.
Параметры, которые мы передали в виде словаря аргументу params функции train(), теперь можно напрямую передать конструктору LGBMModel для создания модели. LGBMModel позволяет нам выполнять задачи как классификации, так и регрессии, указав цель (objective) задачи.
Регрессия
Ниже на простом примере объясняется, как мы можем использовать LGBMModel для выполнения задач регрессии с данными о жилье в Бостоне. Сначала нами был создан экземпляр LGBMModel с целью (objective) регрессии и числом деревьев, равным 10. Параметр n_estimators является псевдонимом параметра num_boost_round метода train().
Затем мы вызвали метод fit() для обучения модели, передав ему тренировочные данные. Обратите внимание, что он принимает в качестве входных данных массивы numpy, а не объект Dataset фреймворка lightgbm. Мы также предоставили набор данных, который будет использоваться в качестве оценочного датасета, и метрики, которые будут рассчитываться на нем. Параметры метода fit() почти такие же, как и у train().
Наконец, мы вызвали метод predict(), чтобы сделать прогнозы.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="regression", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
from sklearn.metrics import r2_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("\nTest R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Размеры Train/Test Sizes: (379, 13) (127, 13) (379,) (127,)
[1] valid_0's rmse: 9.70598 valid_0's l2: 94.206
[2] valid_0's rmse: 9.04855 valid_0's l2: 81.8763
[3] valid_0's rmse: 8.51309 valid_0's l2: 72.4727
[4] valid_0's rmse: 8.04785 valid_0's l2: 64.7678
[5] valid_0's rmse: 7.6032 valid_0's l2: 57.8086
[6] valid_0's rmse: 7.21651 valid_0's l2: 52.078
[7] valid_0's rmse: 6.88971 valid_0's l2: 47.4681
[8] valid_0's rmse: 6.63273 valid_0's l2: 43.9931
[9] valid_0's rmse: 6.40727 valid_0's l2: 41.0532
[10] valid_0's rmse: 6.21095 valid_0's l2: 38.5759
Test R2 Score: 0.65
Train R2 Score: 0.74Бинарная классификация
Ниже мы объясняем на простом примере, как мы можем использовать LGBMModel для задач классификации. У нас есть обученная модель с набором данных по раку груди. Обратите внимание, что метод predict() возвращает вероятности. Мы включили логику для вычисления класса по вероятностям.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="regression", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
from sklearn.metrics import r2_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("\nTest R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Размеры Train/Test Sizes: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's binary_logloss: 0.578847
[2] valid_0's binary_logloss: 0.524271
[3] valid_0's binary_logloss: 0.480868
[4] valid_0's binary_logloss: 0.441691
[5] valid_0's binary_logloss: 0.410361
[6] valid_0's binary_logloss: 0.381543
[7] valid_0's binary_logloss: 0.353827
[8] valid_0's binary_logloss: 0.33609
[9] valid_0's binary_logloss: 0.319685
[10] valid_0's binary_logloss: 0.30735
Test Accuracy: 0.90
Train Accuracy: 0.98LGBMRegressor
LGBMRegressor — еще одна обертка-оценщик вокруг класса Booster, предоставляемая lightgbm и имеющая тот же API, что и у оценщиков sklearn. Как следует из названия, он предназначен для задач регрессии.
LGBMRegressor почти такой же, как LGBMModel, с той лишь разницей, что он предназначен только для задач регрессии. Ниже мы объяснили использование LGBMRegressor на простом примере с использованием набора данных о жилье в Бостоне. Обратите внимание, что LGBMRegressor предоставляет метод score(), который рассчитывает для нас оценку R2, которую мы до сих пор получали с использованием метрик sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
print("Размеры Train/Test Sizes: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMRegressor(objective="regression_l2", n_estimators=10,)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric=["rmse", "l2", "l1"])
print("Test R2 Score: %.2f"%booster.score(X_train, Y_train))
print("Train R2 Score: %.2f"%booster.score(X_test, Y_test))
Размеры Train/Test Sizes: (379, 13) (127, 13) (379,) (127,)
[1] valid_0's rmse: 8.31421 valid_0's l2: 69.1262 valid_0's l1: 6.0334
[2] valid_0's rmse: 7.61825 valid_0's l2: 58.0377 valid_0's l1: 5.54499
[3] valid_0's rmse: 7.00797 valid_0's l2: 49.1116 valid_0's l1: 5.14472
[4] valid_0's rmse: 6.45103 valid_0's l2: 41.6158 valid_0's l1: 4.7527
[5] valid_0's rmse: 5.97644 valid_0's l2: 35.7178 valid_0's l1: 4.41064
[6] valid_0's rmse: 5.55884 valid_0's l2: 30.9007 valid_0's l1: 4.11807
[7] valid_0's rmse: 5.20092 valid_0's l2: 27.0495 valid_0's l1: 3.85392
[8] valid_0's rmse: 4.88393 valid_0's l2: 23.8528 valid_0's l1: 3.63833
[9] valid_0's rmse: 4.63603 valid_0's l2: 21.4928 valid_0's l1: 3.45951
[10] valid_0's rmse: 4.40797 valid_0's l2: 19.4302 valid_0's l1: 3.27911
Test R2 Score: 0.75
Train R2 Score: 0.76LGBMClassifier
LGBMClassifier — еще одна обертка-оценщик вокруг класса Booster, которая предоставляет API, подобный sklearn, для задач классификации. Он работает точно так же, как LGBMModel, но только для задач классификации. Он также предоставляет метод score(), который оценивает точность переданных ему данных.
Обратите внимание, что LGBMClassifier предсказывает фактические метки классов для задач классификации с помощью метода predict(). Он предоставляет метод pred_proba(), если нам нужны вероятности целевых классов.
Бинарная классификация
Ниже мы приводим простой пример того, как мы можем использовать LGBMClassifier для задач бинарной классификации. Наше объяснение основано на его применении к датасету по раку груди.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
booster = lgb.LGBMClassifier(objective="binary", n_estimators=10)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),])
print("Test Accuracy: %.2f"%booster.score(X_test, Y_test))
print("Train Accuracy: %.2f"%booster.score(X_train, Y_train))
Test Accuracy: 0.97
Train Accuracy: 0.97Мультиклассовая классификация
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target)
booster = lgb.LGBMClassifier(objective="multiclassova", n_estimators=10, num_class=3)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),])
print("Test Accuracy: %.2f"%booster.score(X_test, Y_test))
print("Train Accuracy: %.2f"%booster.score(X_train, Y_train))
Test Accuracy: 0.96
Train Accuracy: 1.00Далее мы объясняем использование LGBMClassifier для задач мультиклассовой классификации с использованием набора данных Wine.
Обратите внимание, что LGBMModel, LGBMRegressor и LGBMClassifier предоставляют атрибут с названием booster_, возвращающий экземпляр класса Booster, который мы можем сохранить на диск после обучения и позже загрузить для прогнозирования.
Сохранение и загрузка модели
Теперь мы покажем, как сохранить обученную модель на диск, чтобы использовать ее позже для прогнозов. Lightgbm предоставляет нижеперечисленные методы для сохранения и загрузки моделей.
save_model()— этот метод принимает имя файла, в котором сохраняется модель.model_to_string()— данный метод возвращает строковое представление модели, которое мы затем можем сохранить в текстовый файл.lightgbm.Booster()— этот конструктор позволяет нам создать экземпляр классаBooster. У него есть два важных параметра, которые могут помочь нам загрузить модель из файла или из строки.model_file— этот параметр принимает имя файла, из которого загружается обученная модель.model_str— данный параметр принимает строку, содержащую информацию об обученной модели. Нам нужно передать этому параметру строку, которая была сгенерирована с помощьюmodel_to_string()после загрузки из файла.
Ниже мы объясняем на простых примерах, как использовать вышеупомянутые методы для сохранения моделей на диск, а затем загрузки с него.
Обратите внимание, что для сохранения модели, обученной с использованием LGBMModel, LGBMRegressor и LGBMClassifier, нам сначала нужно получить их экземпляр Booster с помощью атрибута booster_ оценщика, а затем сохранить его. LGBMModel, LGBMRegressor и LGBMClassifier не предоставляют функций сохранения и загрузки. Они доступны только с экземпляром Booster.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression", "verbosity": -1},
train_set=train_dataset, valid_sets=(test_dataset,),
verbose_eval=False,
feature_name=boston.feature_names.tolist(),
num_boost_round=10)
booster.save_model("lgb.model")
loaded_booster = lgb.Booster(model_file="lgb.model")
test_preds = loaded_booster.predict(X_test)
train_preds = loaded_booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.62
Train R2 Score: 0.76Кросс-валидация
Lightgbm позволяет нам выполнять кросс-валидацию с помощью метода cv(). Он принимает параметры модели в виде словаря, как метод train(). Затем мы можем предоставить набор данных для выполнения перекрестной проверки. По умолчанию данный метод производит 5-кратную кросс-валидацию. Мы можем изменить кратность, установив параметр nfold. Он также принимает разделитель данных sklearn, такой как KFold, StratifiedKFold, ShuffleSplit и StratifiedShuffleSplit. Мы можем предоставить эти разделители данных параметру folds метода cv().
Метод cv() возвращает словарь, содержащий информацию о среднем значении и стандартном отклонении потерь для каждого цикла обучения. Мы даже можем попросить метод вернуть экземпляр CVBooster, установив для параметра return_cvbooster значение True. Объект CVBooster содержит информацию о кросс-валидации.
from sklearn.model_selection import StratifiedShuffleSplit
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=breast_cancer.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=breast_cancer.feature_names.tolist())
lgb.cv({"objective": "binary", "verbosity": -1},
train_set=test_dataset, num_boost_round=10,
nfold=5, stratified=True, shuffle=True,
verbose_eval=True)
cv_output = lgb.cv({"objective": "binary", "verbosity": -1},
train_set=test_dataset, num_boost_round=10,
metrics=["auc", "average_precision"],
folds=StratifiedShuffleSplit(n_splits=3),
verbose_eval=True,
return_cvbooster=True)
for key, val in cv_output.items():
print("\n" + key, " : ", val)
auc-mean : [0.9766666666666666, 0.9833333333333334, 0.9833333333333334, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
auc-stdv : [0.020548046676563275, 0.023570226039551608, 0.023570226039551608, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
average_precision-mean : [0.9833333333333334, 0.9888888888888889, 0.9888888888888889, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
average_precision-stdv : [0.013608276348795476, 0.015713484026367772, 0.015713484026367772, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
cvbooster : <lightgbm.engine.CVBooster object at 0x000001CDFDA4FA00>Построение графиков
Lightgbm предоставляет нижеперечисленные функции для построения графиков — plot_importance().
Этот метод принимает экземпляр класса Booster и с его помощью отображает важность показателей. Ниже мы создали график важности показателей, используя бустер, ранее обученный для задачи регрессии. У данного метода есть параметр important_type. Если он установлен в значение split, то график будет отображать количество раз каждый показатель использовался для разбиения. Также если установлено значение gain, то будет показан выигрыш от соответствующих разделений. Значение параметра important_type по умолчанию split.
Метод plot_importance() имеет еще один важный параметр max_num_features, который принимает целое число, определяющее, сколько признаков включить в график. Мы можем ограничить их количество с помощью этого параметра. Таким образом, на графике будет показано только указанное количество основных показателей.
lgb.plot_importance(booster, figsize=(8,6));
plot_metric()
Этот метод отображает результаты расчета метрики. Нам нужно предоставить экземпляр бустера методу, чтобы построить оценочною метрику, рассчитанную на наборе данных для оценки.
plot_split_value_histogram()
Этот метод принимает на вход экземпляр класса Booster и имя/индекс показателя. Затем он строит гистограмму значений разделения (split value) для выбранного признака.
plot_tree()
Этот метод позволяет построить отдельное дерево ансамбля. Нам нужно указать экземпляр бустера и индекс дерева, которое мы хотим построить.
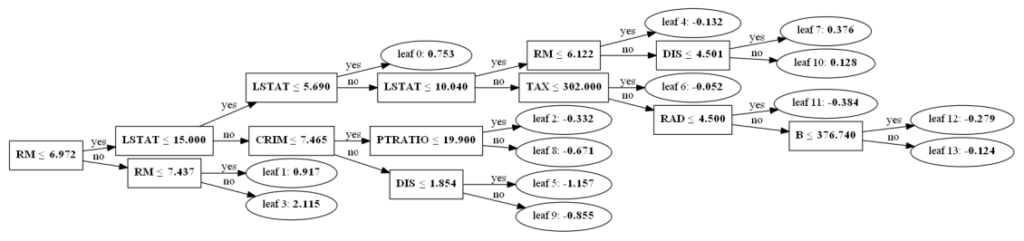
Ранняя остановка обучения
Ранняя остановка обучения — это процесс, при котором мы прекращаем обучение, если оценочная метрика, рассчитанная на оценочном датасете, не улучшается в течение указанного числа раундов. Lightgbm предоставляет параметр early_stopping_rounds как часть методов train() и fit(). Этот параметр принимает целочисленное значение, указывающее, что процесс обучения должен остановится, если результаты вычисления метрики не улучшились за указанное число итераций.
Обратите внимание, что для того, чтобы данный процесс работал, нам нужен набор данных для оценки, поскольку принятие решения об остановке обучения основано на результатах расчета метрики на оценочном датасете.
Ниже мы показываем использование параметра early_stopping_rounds для задач регрессии и классификации на простых примерах.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target)
print("Размеры Train/Test: ", X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)
booster = lgb.LGBMModel(objective="binary", n_estimators=100, metric="auc")
booster.fit(X_train, Y_train,
eval_set=[(X_test, Y_test),],
early_stopping_rounds=3)
from sklearn.metrics import accuracy_score
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Размеры Train/Test: (426, 30) (143, 30) (426,) (143,)
[1] valid_0's auc: 0.979158
Training until validation scores don't improve for 3 rounds
[2] valid_0's auc: 0.979592
[3] valid_0's auc: 0.979592
[4] valid_0's auc: 0.988168
[5] valid_0's auc: 0.988602
[6] valid_0's auc: 0.98947
[7] valid_0's auc: 0.992727
[8] valid_0's auc: 0.995766
[9] valid_0's auc: 0.994572
[10] valid_0's auc: 0.995115
[11] valid_0's auc: 0.995332
Early stopping, best iteration is:
[8] valid_0's auc: 0.995766
Test Accuracy: 0.92
Train Accuracy: 0.96Lightgbm также предоставляет возможность ранней остановки обучения с помощью функции early_stopping(). Мы можем передать число раундов в функцию early_stopping() и использовать возвращаемую ее функцию обратного вызова в качестве входного параметра callbacks методов train() или fit(). Обратные вызовы рассматриваются более подробно в одном из следующих разделов.
Ограничения взаимодействия показателей
Когда lightgbm завершил обучение на датасете, отдельный узел в этих деревьях представляет некоторое условие, основанное на некотором значении показателя. Когда во время предсказания мы используем отдельное дерево, мы начинаем с его корневого узла, проверяя условие конкретного показателя, указанное в данном узле, с соответствующим значением показателя из нашего семпла. Решения принимаются нами на основе значений признаков из наблюдения и условий, представленных в дереве. Таким образом, мы идем по определенному пути, пока не достигнем листа дерева, где сможем сделать окончательный прогноз.
По умолчанию любой узел может быть связан с любым показателем в качестве условия. Этот процесс принятия окончательного решения путем прохождения узлов дерева, проверяя условие на соответствующих признаках, называется взаимодействием показателей, так как предиктор пришел к конкретному узлу после оценки условия предыдущего узла. Lightgbm позволяет нам определять ограничения на то, какой признак взаимодействует с каким. Мы можем предоставить список индексов, и указанные показатели будут взаимодействовать только друг с другом. Этим признакам не будет разрешено взаимодействовать с другими, и это ограничение будет применяться при создании деревьев в процессе обучения.
Ниже мы объясняем на простом примере, как наложить ограничение взаимодействия показателей на оценщик в lightgbm. Оценщики Lightgbm предоставляют параметр с названием interaction_constraints, который принимает список списков, где отдельные списки являются индексами признаков, которым разрешено взаимодействовать друг с другом.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.90, random_state=42)
train_dataset = lgb.Dataset(X_train, Y_train, feature_name=boston.feature_names.tolist())
test_dataset = lgb.Dataset(X_test, Y_test, feature_name=boston.feature_names.tolist())
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse",
'interaction_constraints':[[0,1,2,11,12], [3, 4],[6,10], [5,9], [7,8]]},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
test_preds = [1 if pred > 0.5 else 0 for pred in test_preds]
train_preds = [1 if pred > 0.5 else 0 for pred in train_preds]
print("Test Accuracy: %.2f"%accuracy_score(Y_test, test_preds))
print("Train Accuracy: %.2f"%accuracy_score(Y_train, train_preds))
Монотонные ограничения
Lightgbm позволяет нам указывать монотонные ограничения для модели, которые определяют, связан ли отдельный показатель с увеличением/уменьшением целевого значения, или не связан вовсе. Таким образом, у нас есть возможность использовать монотонные значения -1, 0 и 1, тем самым заставляя модель устанавливать уменьшающуюся, нулевую и увеличивающуюся взаимосвязь показателя с целью. Мы можем предоставить список той же длины, что и количество признаков, указав 1, 0 или -1 для монотонной связи, используя параметр monotone_constraints. Ниже объясняется, как обеспечить монотонные ограничения в lightgbm.
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse",
'monotone_constraints':(1,0,1,-1,1,0,1,0,-1,1,1, -1, 1)},
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
Пользовательская функция цели/потерь
Lightgbm также позволяет определить целевую функцию, подходящую именно нам. Для этого нужно создать функцию, которая принимает список прогнозируемых и фактических меток в качестве входных данных и возвращает первую и вторую производные функции потерь, вычисленные с использованием предсказанных и фактических значений. Далее мы можем передать параметру objective оценщика определенную нами функцию цели/потерь. В случае использования метода train() мы должны предоставить ее через параметр fobj.
Ниже нами была разработана целевая функция средней квадратической ошибки (MSE). Затем мы передали ее параметру objective LGBMModel.
def first_grad(predt, dmat):
'''Вычисли первую производную для MSE.'''
y = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
return 2*(y-predt)
def second_grad(predt, dmat):
'''Вычисли вторую производную для MSE.'''
y = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
return [1] * len(predt)
def mean_sqaured_error(predt, dmat):
''''Функция MSE.'''
predt[predt < -1] = -1 + 1e-6
grad = first_grad(predt, dmat)
hess = second_grad(predt, dmat)
return grad, hess
booster = lgb.LGBMModel(objective=mean_sqaured_error, n_estimators=10,)
booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test),], eval_metric="rmse")
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.78
Train R2 Score: 0.82Пользовательская функция оценки
Lightgbm позволяет нам определять нашу собственную оценочную метрику, если мы не хотим использовать метрики, предоставленные фреймворком. Для этого мы должны написать функцию, которая принимает на вход список предсказаний и фактических целевых значений. Она будет возвращать строку, определяющую название метрики, результат ее расчета и логическое значение, выражающее, стоит ли стремится к максимизации данной метрики или к ее минимизации. В случае, когда чем выше значение метрики, тем лучше, должно быть возвращено True, иначе — False.
Нам нужно указать ссылку на эту функцию в параметре feval, если мы используем метод train() для разработки нашего оценщика. При передаче в fit() нам нужно присвоить данную ссылку параметру eval_metric.
Далее объясняется на простых примерах, как можно использовать пользовательские оценочные метрики с lightgbm.
def mean_absolute_error(preds, dmat):
actuals = dmat.get_label() if isinstance(dmat, lgb.Dataset) else dmat
err = (actuals - preds).sum()
is_higher_better = False
return "MAE", err, is_higher_better
booster = lgb.train({"objective": "regression", "verbosity": -1, "metric": "rmse"},
feval=mean_absolute_error,
train_set=train_dataset, valid_sets=(test_dataset,),
num_boost_round=10)
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score: %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score: %.2f"%r2_score(Y_train, train_preds))
Test R2 Score: 0.71
Train R2 Score: 0.76Функции обратного вызова
Lightgbm предоставляет пользователям список функций обратного вызова для разных целей, которые выполняются после каждой итерации обучения. Ниже приведен список доступных колбэков:
early_stopping(stopping_rounds)— эта функция обратного вызова принимает целое число, указывающее, следует ли останавливать обучение, если результаты расчета метрики на последнем оценочном датасете не улучшаются на протяжении указанного числа итераций.print_evaluation(period, show_stdv)— данный колбэк принимает целочисленные значения, определяющие, как часто должны выводиться результаты оценки. Полученные значения оценочной метрики печатаются через указанное число итераций.record_evaluation(eval_result)— эта функция получает на вход словарь, в котором будут записаны результаты оценки.reset_parameter()— данная функция обратного вызова позволяет нам сбрасывать скорость обучения после каждой итерации. Она принимает массив, размер которого совпадает с их количеством, или функцию, возвращающую новую скорость обучения для каждой итерации.
Параметр callbacks методов train() и fit() принимает список функций обратного вызова.
Ниже на простых примерах показано, как мы можем использовать различные колбэки. Функция обратного вызова early_stopping() также была рассмотрена в разделе «Ранняя остановка обучения» этого руководства.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target)
booster = lgb.LGBMModel(objective=mean_sqaured_error, n_estimators=10,)
booster.fit(X_train, Y_train,
eval_set=[(X_test, Y_test),], eval_metric="rmse",
callbacks=[lgb.reset_parameter(learning_rate=np.linspace(0.1,1,10).tolist())])
test_preds = booster.predict(X_test)
train_preds = booster.predict(X_train)
print("Test R2 Score : %.2f"%r2_score(Y_test, test_preds))
print("Train R2 Score : %.2f"%r2_score(Y_train, train_preds))
[1] valid_0's rmse: 20.8416
[2] valid_0's rmse: 12.9706
[3] valid_0's rmse: 6.60998
[4] valid_0's rmse: 4.28918
[5] valid_0's rmse: 3.96958
[6] valid_0's rmse: 3.89009
[7] valid_0's rmse: 3.80177
[8] valid_0's rmse: 3.88698
[9] valid_0's rmse: 4.2917
[10] valid_0's rmse: 4.39651
Test R2 Score : 0.82
Train R2 Score : 0.94На этом заканчивается наше небольшое руководство, объясняющее API LightGBM. Не стесняйтесь поделиться с нами своим мнением в разделе комментариев.
]]>Основные особенности функций в Python:
- Используются чтобы избегать повторений в коде,
- Используются для разделения кода на мелкие модули
- Позволяют скрывать код и создавать ясность для понимания модулей,
- Позволяют повторно использовать код и сохранять память,
- Код из функции можно выполнить только по ее имени,
- Простой синтаксис:
def имя_функции(параметры):.
Правила создания функций:
- Для объявления функции в Python используется ключевое слово
def. - Название функции должно начинаться с символа латинского алфавита в любом регистре или нижнего подчеркивания.
- В каждой функции есть двоеточие и отступ, после которого записывается сам код программы.
- Зарезервированные ключевые слова не могут использоваться в качестве названия функции.
- Функция может содержать несколько параметров или не иметь их совсем.
Создание функции в Python
Для создания нужно написать ключевое слово def. Синтаксис следующий:
def function_name():
# логика функции
return result # возврат значенияСоздадим и вызовем реальную функцию в Python:
def my_fun():
print("Как вызвать функцию в Python?")
my_fun() # вызов функции
Вывод: Как вызвать функцию в Python?.
Вызов функции в Python
После создания функции ее можно вызвать, написав имя или присвоив ее переменной:
def my_fun():
x = 22 ** 5
return x
# 1. Вызов функции
my_fun()
# 2. Вызов функции и присвоение результат переменной
a = my_fun()
# 3. Вызов функции и вывод результат в консоль
print(my_fun())
Создадим простую функцию, которая ничего не возвращает и вызовем ее.
def my_fun():
print("Hello World")
print("Функция вызвана")
my_fun()
Вывод:
Hello World
Функция вызванаВ этом примере вызов функции my_fun() привел к выводу двух строк.
Вызов вложенных функций в Python
Одна функция внутри другой — это вложенные функции. Создавать вложенные функции можно с помощью того же ключевого слова def. После создания функции нужно вызвать как внешнюю, так и внутреннюю. Создадим программу, чтобы разобраться с этим на примере.
def out_fun():
print("Привет, это внешняя функция")
def in_fun():
print("Привет, это внутренняя функция")
in_fun()
out_fun()
Вывод:
Привет, это внешняя функция
Привет, это внутренняя функцияЗдесь функция in_fun() определена внутри out_fun(). Для вызова in_fun() нужно сперва вызвать out_fun(). После этого out_fun() начнет выполняться, что приведет к вызову in_fun().
Внутренняя функция не будет выполняться, если не вызвать внешнюю.
Еще один пример. Программа для вывода результата сложения двух чисел с помощью вложенных функций в Python.
def fun1():
a = 6
def fun2(b):
a = 4
print ("Сумма внутренней функции", a + b)
print("Значение внешней переменной a", a)
fun2(4)
fun1()
Вывод:
Значение внешней переменной a 6
Сумма внутренней функции 8Функции как объекты первого класса
В Python функции — это объекты первого класса. У них есть те же свойства и методы, что и обычных объектов. Так, функцию можно присвоить переменной, передать ее в качестве аргумента, сохранить в структуре данных и вернуть в качестве результата работы другой функции. Все данные в Python представлены в качестве объектов или отношений.
Особенности функций как объектов первого класса:
- Функции можно присваивать переменным.
- Функция может быть примером объекта.
- Функцию можно вернуть из функции.
- У функций те же свойства и методы, что и у объектов.
- Функцию можно передать в качестве аргумента при вызове другой функции.
Разберем на примере:
def my_object(text):
return text.upper()
print(my_object("Вызов my_object"))
upper = my_object
print(upper("Вызов upper"))
Вывод:
ВЫЗОВ MY_OBJECT
ВЫЗОВ UPPERНапишем программу для вызова функции в классе (точнее, это будет метод класса).
class Student:
no = 101
name = "Владимир"
def show(self):
print("№ {}\nИмя {}".format(self.no, self.name))
stud = Student()
stud.show()
Вывод:
№ 101
Имя ВладимирУстановка SQLAlchemy
Для установки SQLAlchemy введите следующее:
pip install sqlalchemyЧтобы проверить успешность установки введите следующее в командной строке:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.8'
Установка DBAPI
По умолчанию SQLAlchemy работает только с базой данных SQLite без дополнительных драйверов. Для работы с другими базами данных необходимо установить DBAPI-совместимый драйвер в соответствии с базой данных.
Что такое DBAPI?
DBAPI — это стандарт, который поощряет один и тот же API для работы с большим количеством баз данных. В следующей таблице перечислены все DBAPI-совместимые драйверы:
| База данных | DBAPI драйвер |
|---|---|
| MySQL | PyMySQL, MySQL-Connector, CyMySQL, MySQL-Python (по умолчанию) |
| PostgreSQL | psycopg2 (по умолчанию), pg8000, |
| Microsoft SQL Server | PyODBC (по умолчанию), pymssql |
| Oracle | cx-Oracle (по умолчанию) |
| Firebird | fdb (по умолчанию), kinterbasdb |
Все примеры в этом руководстве протестированы в PostgreSQL, но вы можете выбрать базу данных по вкусу. Для установки DBAPI psycopg2 для PostgreSQL введите следующую команду:
pip install psycopg2Подготовка к подключению
Первый шаг для подключения к базе данных — создания объекта Engine. Именно он отвечает за взаимодействие с базой данных. Состоит из двух элементов: диалекта и пула соединений.
Диалект SQLAlchemy
SQL — это стандартный язык для работы с базами данных. Однако и он отличается от базы к базе. Производители баз данных редко придерживаются одной и той же версии и предпочитают добавлять свои особенности. Например, если вы используете Firebird, то для получения id и name для первых 5 строк из таблицы employees нужна следующая команда:
select first 10 id, name from employeesА вот как получить тот же результат для MySQL:
select id, name from employees limit 10
Чтобы обрабатывать эти различия нужен диалект. Диалект определяет поведение базы данных. Другими словами он отвечает за обработку SQL-инструкций, выполнение, обработку результатов и так далее. После установки соответствующего драйвера диалект обрабатывает все отличия, что позволяет сосредоточиться на создании самого приложения.
Пул соединений SQLAlchemy
Пул соединений — это стандартный способ кэширования соединений в памяти, что позволяет использовать их повторно. Создавать соединение каждый раз при необходимости связаться с базой данных — затратно. А пул соединений обеспечивает неплохой прирост производительности.
При таком подходе приложение при необходимости обратиться к базе данных вытягивает соединение из пула. После выполнения запросов подключение освобождается и возвращается в пул. Новое создается только в том случае, если все остальные связаны.
Для создания движка (объекта Engine) используется функция create_engine() из пакета sqlalchemy. В базовом виде она принимает только строку подключения. Последняя включает информацию об источнике данных. Обычно это приблизительно следующий формат:
dialect+driver://username:password@host:port/databasedialect— это имя базы данных (mysql, postgresql, mssql, oracle и так далее).driver— используемый DBAPI. Этот параметр является необязательным. Если его не указать будет использоваться драйвер по умолчанию (если он установлен).usernameиpassword— данные для получения доступа к базе данных.host— расположение сервера базы данных.port— порт для подключения.database— название базы данных.
Вот код для создания движка некоторых популярных баз данных:
from sqlalchemy import create_engine
# Подключение к серверу MySQL на localhost с помощью PyMySQL DBAPI.
engine = create_engine("mysql+pymysql://root:pass@localhost/mydb")
# Подключение к серверу MySQL по ip 23.92.23.113 с использованием mysql-python DBAPI.
engine = create_engine("mysql+mysqldb://root:pass@23.92.23.113/mydb")
# Подключение к серверу PostgreSQL на localhost с помощью psycopg2 DBAPI
engine = create_engine("postgresql+psycopg2://root:pass@localhost/mydb")
# Подключение к серверу Oracle на локальном хосте с помощью cx-Oracle DBAPI.
engine = create_engine("oracle+cx_oracle://root:pass@localhost/mydb"))
# Подключение к MSSQL серверу на localhost с помощью PyODBC DBAPI.
engine = create_engine("oracle+pyodbc://root:pass@localhost/mydb")
Формат строки подключения для базы данных SQLite немного отличается. Поскольку это файловая база данных, для нее не нужны имя пользователя, пароль, порт и хост. Вот как создать движок для базы данных SQLite:
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sqlite3.db') # используя относительный путь
engine = create_engine('sqlite:////path/to/sqlite3.db') # абсолютный путь
Подключение к базе данных
Но создание движка — это еще не подключение к базе данных. Для получения соединения нужно использовать метод connect() объекта Engine, который возвращает объект типа Connection.
from sqlalchemy import create_engine
# 1111 это мой пароль для пользователя postgres
engine = create_engine("postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts")
engine.connect()
print(engine)
Но если запустить его, то будет следующая ошибка:
sqlalchemy.exc.OperationalError: (psycopg2.OperationalError)
(Background on this error at: http://sqlalche.me/e/14/e3q8)Проблема в том, что предпринимается попытка подключиться к несуществующей базе данных. Для создания базы данных PostgreSQL нужно выполнить следующий код:
import psycopg2
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT
# Устанавливаем соединение с postgres
connection = psycopg2.connect(user="postgres", password="1111")
connection.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
# Создаем курсор для выполнения операций с базой данных
cursor = connection.cursor()
sql_create_database =
# Создаем базу данных
cursor.execute('create database sqlalchemy_tuts')
# Закрываем соединение
cursor.close()
connection.close()
Запустите скрипт еще раз, чтобы получить нужный вывод:
Engine(postgresql+psycopg2://postgres:***@localhost/sqlalchemy_tuts)Дополнительные аргументы
В следующей таблице перечислены дополнительные аргументы-ключевые слова, которые можно передать в функцию create_engine().
| Аргумент | Описание |
echo | Булево значение. Если задать True, то движок будет сохранять логи SQL в стандартный вывод. По умолчанию значение равно False |
pool_size | Определяет количество соединений для пула. По умолчанию — 5 |
max_overflow | Определяет количество соединений вне значения pool_size. По умолчанию — 10 |
encoding | Определяет кодировку SQLAlchemy. По умолчанию — UTF-8. Однако этот параметр не влияет на кодировку всей базы данных |
isolation_level | Уровень изоляции. Эта настройка контролирует степень изоляции одной транзакции. Разные базы данных поддерживают разные уровни. Для этого лучше ознакомиться с документацией конкретной базы данных |
Вот скрипт, в котором использованы дополнительные аргументы-ключевые слова при создании движка:
from sqlalchemy import create_engine
engine = create_engine(
"postgresql+psycopg2://postgres:1111@localhost/sqlalchemy_tuts",
echo=True, pool_size=6, max_overflow=10, encoding='latin1'
)
engine.connect()
print(engine)
Запустите его, чтобы получить следующий вывод:
2021-04-16 15:12:59,983 INFO sqlalchemy.engine.Engine select version()
2021-04-16 15:13:00,023 INFO sqlalchemy.engine.Engine [raw sql] {}
2021-04-16 15:13:00,028 INFO sqlalchemy.engine.Engine select current_schema()
2021-04-16 15:13:00,038 INFO sqlalchemy.engine.Engine [raw sql] {}
2021-04-16 15:13:00,038 INFO sqlalchemy.engine.Engine show standard_conforming_strings
2021-04-16 15:13:00,048 INFO sqlalchemy.engine.Engine [raw sql] {}
Engine(postgresql+psycopg2://postgres:***@localhost/sqlalchemy_tuts)Зачем использовать SQLAlchemy
Самая важная особенность SQLAlchemy — это ее ORM. ORM или Object Relational Mapper (объектно-реляционное отображение) позволяет работать с базой данных с помощью объектно-ориентированного кода, не используя SQL-запросы. Еще одна особенность SQLAlchemy — код приложения будет оставаться тем же вне зависимости от используемой базы данных. Это позволяет с легкостью мигрировать с одной базы данных на другую, не переписывая код.
У SQLAlchemy есть компонент, который называется SQLAlchemy Core. Это абстракция над традиционным SQL. Он предоставляет SQL Expression Language, позволяющий генерировать SQL-инструкции с помощью конструкций Python.
В отличие от ORM, который сосредоточен на моделях и объектах, Core фокусируется на таблицах, колонках, индексах и так далее (по аналогии с обычным SQL). SQL Expression Language очень похож на SQL, однако он стандартизирован, поэтому его можно использовать в разных базах данных. SQLAlchemy ORM и Core можно использовать независимо друг от друга. Под капотом SQLAlchemy ORM использует Core.
Так что использовать: Core или ORM?
Смысл ORM — упрощение процесса работы с базой данных. В процессе добавляется некая сложность, однако она незаметна, если работать с не очень большими объемами данных. Для большинства проектов ORM будет достаточно, однако там, где имеется много данных, стоит работать с чистым SQL.
Кто использует SQLAlchemy
- Hulu
- Fedora Project
- Dropbox
- OpenStack
- и многие другие.
Уроки по SQLAlchemy
Чтобы разобраться с руководством, нужно иметь базовые знания в Python и SQL.
]]>В бой. Импортируем рабочие библиотеки и датасет:
from sklearn.datasets import load_boston
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import learning_curve
from sklearn.metrics import make_scorer
%matplotlib inline
np.random.seed(42)
boston_data = load_boston()
boston_df = pd.DataFrame(boston_data.data, columns=boston_data.feature_names)
target = boston_data.target
Вот краткое описание нашего датасета:
- CRIM — уровень преступности на душу населения по городам.
- ZN — доля земли под жилую застройку, разделенная на участки площадью более 25 000 кв. футов.
- INDUS — доля акров, которые принадлежат предприятиям, не связанным с розничной торговлей, на город.
- CHAS — фиктивная переменная реки Чарльз (1, если участок соединен с рекой; 0 в противном случае).
- NOX — концентрация оксидов азота (в десятимиллионных долях).
- RM — среднее количество комнат в доме.
- AGE — доля занимаемых зданий, построенных до 1940 г.
- DIS — взвешенные расстояния до пяти бостонских центров занятости.
- RAD — индекс доступности радиальных автомобильных дорог.
- TAX — полная ставка налога на имущество за каждые 10000 долларов стоимости.
- PTRATIO — соотношение учеников и учителей по городам.
- B — 1000 (Bk — 0,63) , где Bk — доля граждан афроамериканского происхождения по городам.
- LSTAT — процент более низкого статуса населения.
- TARGET —медианное значение стоимости занимаемых домов в тысячах долларов США.
Задача данной выборки сводится к прогнозированию целевого показателя (медианной стоимости недвижимости), используя приведенные выше показатели (все, кроме TARGET).
Полный ноутбук с кодом статьи: https://gitlab.com/PythonRu/notebooks/-/blob/master/linear_regression_sklearn.ipynb
Линейная регрессия
Как мы можем подойти к этой проблеме?
Для нашего первого прохода давайте упростим задачу. Допустим, мы просто хотим использовать признак LSAT для прогнозирования TARGET.
plt.scatter(boston_df['LSTAT'], target);

По оси X у нас есть LSTAT, а по оси Y — TARGET. Просто взглянув на это, можно увидеть отрицательную взаимосвязь: когда LSTAT растет, TARGET падает.
Функция оценки/стоимости
Как мы можем решить проблему предсказания TARGET на основе LSTAT? Хорошая отправная точка для размышлений: допустим, мы разрабатываем множество моделей для прогнозирования целевого показателя, как нам выбрать лучшую из них? Как только мы найдем подходящее для сравнения значение, наша задача — минимизировать/максимизировать его.
Это чрезвычайно полезно, если вы можете свести проблему к единственной оценочной метрике. Тогда это очень упрощает цикл разработки модели. Однако в реальном мире прийти к такому упрощению может быть непросто. Иногда не совсем понятно, что вы хотите, чтобы ваша модель максимизировала/минимизировала. Но это проблема для другой статьи.
Поэтому для нашей задачи предлагаю использовать среднюю квадратическую ошибку (mean squared error) в качестве оценочной метрики. Для лучшего понимания смысла MSE, давайте определимся с терминологией:

Таким образом, MSE:

По сути, для каждой точки мы вычитаем предсказанное нами значение из фактического. Затем, поскольку нас не волнует направление ошибки, мы возводим разницу в квадрат. Наконец, мы вычисляем среднее всех этих значений. Таким образом, мы хотим, чтобы среднее расстояние между предсказанными и фактическими показателями было минимальным.
Вам может быть интересно, почему мы возводили разницу в квадрат вместо того, чтобы брать абсолютное значение. Оказывается, что для некоторых из представленных ниже математических операций возведение в квадрат работает лучше. Кроме того, это метод максимального правдоподобия. Тем не менее, такой подход приводит к тому, что крупные ошибки имеют более сильное влияние на среднее значение, поскольку мы возводим в квадрат каждое отклонение.
Наша модель
Теперь, когда у нас есть функция оценки, как найти способ ее минимизировать? В этом посте мы рассмотрим модель линейной регрессии. Она выглядит следующим образом:

Где j — количество имеющихся у нас предсказателей (независимых переменных), значения бета — это наши коэффициенты. А бета 0 является смещением (intercept). По сути, данная модель представляет собой линейную комбинацию наших предсказателей с intercept.
Теперь, когда у нас есть модель и функция оценки, наша задача состоит в том, чтобы найти бета-значения, которые минимизируют MSE для наших данных. Для линейной регрессии на самом деле существует решение в замкнутой форме, называемое нормальным уравнением. Однако в этом посте мы собираемся использовать другую технику — градиентный спуск.
Градиентный спуск
Градиентный спуск — это метод, который мы позаимствовали из оптимизации. Очень простой, но мощный алгоритм, который можно использовать для поиска минимума функции.
- Выберите случайное начальное значение.
- Делайте шаги, пропорциональные отрицательному градиенту в текущей точке.
- Повторяйте, пока не достигните предела.
Этот метод найдет глобальный минимум, если функция выпуклая. В противном случае мы можем быть уверены только в том, что достигнем локальный минимум.
Первый вопрос, на который нам нужно ответить: является ли наша функция оценки выпуклой? Давайте посмотрим:
mses = []
lstat_coef = range(-20, 23)
for coef in lstat_coef:
pred_values = np.array([coef * lstat for lstat in boston_df.LSTAT.values])
mses.append(np.sum((target - pred_values)**2))
plt.plot(lstat_coef, mses);
Для построения графика выше мы взяли диапазон значений коэффициентов для LSTAT, и для каждого из них рассчитали MSE на основе наших данных. Если мы затем отобразим полученные значения, мы получим приведенную выше кривую — выглядит довольно выпуклой! И оказывается, что наша функция MSE с нашей моделью линейной регрессии всегда будет выпуклой! Это означает: мы можем использовать градиентный спуск, чтобы найти оптимальные коэффициенты для нашей модели!
Одна из причин того, что градиентный спуск более распространен, чем нормальное уравнение для машинного обучения, заключается в том, что он намного лучше масштабируется по мере увеличения количества показателей. Это также стандартный метод оптимизации, который используется повсюду в машинном обучении. Поэтому понимание того, как он работает, чрезвычайно важно.
Градиенты
Если вы снова посмотрите на наш псевдокод для градиентного спуска, вы увидите, что на самом деле все, что нам нужно сделать, это вычислить градиенты. Итак, что такое градиенты? Это просто частные производные по коэффициентам. Для каждого имеющегося коэффициента нам нужно будет вычислить производную MSE по этому коэффициенту. Давайте начнем!
Для начала запишем выражение для MSE, подставив функцию оценки со смещением и единственной переменной LSTAT:
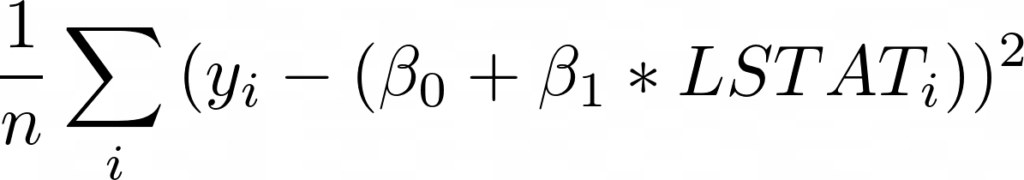
Теперь, взяв производную по бета 0, мы получим (умноженное на -1):

И для бета 1:
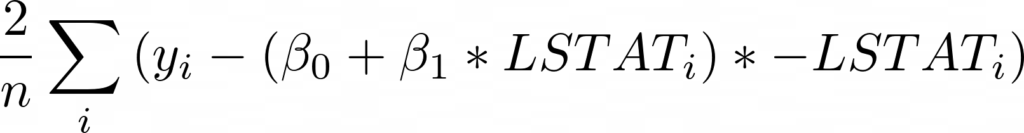
Теперь давайте запустим наш алгоритм градиентного спуска и убедимся, что MSE действительно уменьшается:
beta_0 = 0
beta_1 = 0
learning_rate = 0.001
lstat_values = boston_df.LSTAT.values
n = len(lstat_values)
all_mse = []
for _ in range(10000):
predicted = beta_0 + beta_1 * lstat_values
residuals = target - predicted
all_mse.append(np.sum(residuals**2))
beta_0 = beta_0 - learning_rate * ((2/n) * np.sum(residuals) * -1)
beta_1 = beta_1 - learning_rate * ((2/n) * residuals.dot(lstat_values) * -1)
plt.plot(range(len(all_mse)), all_mse);
Первый график, представленный выше, показывает значение MSE, когда мы запускаем градиентный спуск. Как и следовало ожидать, MSE уменьшается со временем по мере выполнения алгоритма. Это означает, что мы постоянно приближаемся к оптимальному решению.
На графике видно, что мы вполне могли завершить работу раньше. MSE переходит в прямую (почти не изменяется) примерно после 4000 итераций.
print(f"Beta 0: {beta_0}")
print(f"Beta 1: {beta_1}")
plt.scatter(boston_df['LSTAT'], target)
x = range(0, 40)
plt.plot(x, [beta_0 + beta_1 * l for l in x]);
Итак, запуск градиентного спуска показал, что оптимальное смещение составляет 34.55, а оптимальный наклон равен -0,95. На приведенном выше графике эта линия показана поверх наших данных, она выглядит как аппроксимирующая прямая.
Скорость обучения
Один параметр, который нам еще предстоит обсудить, — это скорость обучения. Эта скорость — гиперпараметр, используемый для определения того, насколько большие шаги мы делаем от направления градиента. Как узнать, какое значение выбрать? Как правило, можно попробовать множество вариантов. Вот некоторые из них, которые были предложены Andrew Ng: .001, .003, .01, .03, .1, .3, 1, 3.
Выбор слишком малого значения приводит к более медленной сходимости. Выбор слишком большого значения может привести к перешагиванию через минимум и расхождению.
Существуют также другие оптимизаторы градиентного спуска, которые более сложны и адаптируют скорость обучения за вас. Это также то, что вы можете делать самостоятельно, постепенно снижая скорость обучения.
Когда прекратить итерацию?
В моем коде я просто выполняю наш цикл 10000 раз. Почему 10000? Никакой реальной причины, кроме моей уверенности в том, что этого достаточно, чтобы достичь минимума. Такой подход точно нельзя назвать лучшей практикой. Вот несколько более разумных идей:
- Следите за оценкой после каждого цикла, и когда ее очередное изменение меньше некоторого граничного значения — скажем, 0.001 — останавливайтесь.
- Используйте проверочный датасет (validation set) и отслеживайте число ошибок, например, с помощью MSE. Когда метрика перестанет уменьшаться, остановитесь.
Нормализация данных
При работе с градиентным спуском вы хотите, чтобы все ваши данные были нормализованы. Вычтите среднее значение и разделите на стандартное отклонение для всех ваших тренировочных показателей. Обычно это ускоряет обучение и снижает вероятность застревания в локальном оптимуме, если функция оценки не является выпуклой.
Другие виды градиентного спуска
Показанный здесь градиентный спуск представляет собой классическую форму, что означает: каждое обновление коэффициента использует все данные для вычисления градиентов. Существует также стохастический градиентный спуск. Ему необходима только 1 строка данных (1 наблюдение) для пересчета коэффициентов в каждом цикле.
Такой способ намного лучше масштабируется, так как нужно обработать только одну строку данных за раз перед обновлением. Также он является более неопределенным, поскольку вы пытаетесь перемещаться с использованием градиента, рассчитанного на основе единственного наблюдения.
Другой тип градиентного спуска — это мини-пакетный градиентный спуск. Эта форма представляет собой компромисс между двумя, где вы выбираете размер пакета. Скажем, 32 (или, что еще лучше, пакетный график, который начинается с небольших пакетов и увеличивается с увеличением количества эпох), и каждая итерация вашего градиентного спуска использует 32 случайные строки данных для вычисления градиента (алгоритм воспользуется всеми строками перед повторной выборкой раннее обработанных). В результате мы получаем некоторую масштабируемость, но и некоторую неопределенность.
Такое случайное поведение оказывается полезным для функций оценки, которые не являются выпуклыми (глубокое обучение), поскольку оно может помочь модели избежать локального минимума. Это наиболее распространенный метод для невыпуклых функций оценки.
Допущения нашей модели
Всякий раз, когда вы имеете дело с моделью, хорошо знать, какие допущения она делает. Университет Дьюка написал об этом целую статью:
https://people.duke.edu/~rnau/testing.htm
Реализация линейной регрессии в Scikit-Learn
Теперь, когда мы немного разбираемся в теории и реализации, давайте обратимся к библиотеке scikit-learn, чтобы на самом деле использовать линейную регрессию на наших данных. Написание моделей с нуля довольно полезно для обучения, но на практике вам, как правило, гораздо лучше использовать проверенную и широко используемую библиотеку.
Для начала нужно нормализовать данные:
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(boston_df)
scaled_df = scaler.transform(boston_df)
У Scikit-learn довольно удобный API. Он предоставляет множество моделей, и все они имеют функции fit и predict. Вы можете вызвать fit с вашими X и y данными для обучения модели, а затем использовать predict для получения предсказанных значений на основе новых данных. Scikit-learn также предоставляет множество метрик, которые вы можете использовать для оценки, такие как MSE. Здесь я вычисляю среднеквадратическую ошибку (RMSE). Так мы можем использовать шкалу нашего целевого показателя, что, легче для понимания.
SGDRegressor выполняет линейную регрессию с использованием градиентного спуска и принимает следующие аргументы: tol(сообщает модели, когда следует прекратить итерацию) и eta0(начальная скорость обучения).
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
linear_regression_model.fit(scaled_df, target)
predictions = linear_regression_model.predict(scaled_df)
mse = mean_squared_error(target, predictions)
print("RMSE: {}".format(np.sqrt(mse)))
RMSE в итоге составила 4.68… для нашей обучающей выборки с использованием scikit-learn.
Полиномиальные переменные
Рассматривая построенный выше график стоимости от LSTAT, вы могли заметить, что между данными показателями существует полиномиальная связь. Линейная регрессия хорошо подходит в случае линейной зависимости, но, если вы добавите полиномиальные показатели, такие как LSTAT, вы сможете установить более сложные отношения. SKLearn упрощает данный процесс:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(2, include_bias=False)
poly_df = poly.fit_transform(boston_df)
scaled_poly_df = scaler.fit_transform(poly_df)
print(f"shape: {scaled_poly_df.shape}")
linear_regression_model.fit(scaled_poly_df, target)
predictions = linear_regression_model.predict(scaled_poly_df)
mse = mean_squared_error(target, predictions)
print("RMSE: {}".format(np.sqrt(mse)))
shape: (506, 104)
RMSE: 3.243477309312183Функция PolynomialFeatures сгенерировала новую матрицу показателей, состоящую из всех их полиномиальных комбинаций со степенью меньше или равной указанной (в нашем примере 2). Затем мы нормализовали эти данные и скормили их нашей модели. Так мы получили улучшенную тренировочную RMSE, равную 3.24. Однако обратите внимание, что эти результаты, представленные в иллюстративных целях, используют только тренировочную выборку.
Категориальные переменные
Линейная регрессия — одна из моделей, с которой нужно быть осторожным, когда у вас есть качественные данные. Если у вас переменные со значениями 1, 2 и 3, которые на самом деле означают «Мужской», «Женский», «Нет ответа», не передавайте их модели таким образом, даже если они являются числами.
Если бы вы это сделали, модель присвоила бы такому показателю коэффициент — возможно, 0.1. Это будет означать, что принадлежность к женскому полу увеличивает предсказанное значение на 0.1. А отсутствие ответа — на 0.2. Но, возможно, метка «Женский» должна повысить результат на 1.2, а «Нет ответа» — всего на 0.001. Чтобы решить данную проблему, вы должны преобразовать такие значения в фиктивные переменные, чтобы каждая категория имела свой собственный вес. Вы можете узнать, как это сделать с помощью scikit-learn, здесь.
Интерпретация вашей модели
Линейная регрессия — это отличная статистическая модель, которая существует уже давно. Есть много статистических методов, которые можно использовать для ее оценки и интерпретации. Мы не будем рассматривать их все и на самом деле сосредоточимся на очень простых подходах, которые, возможно, более распространены в машинном обучении, чем в статистике.
Во-первых, давайте посмотрим на коэффициенты, которым научилась наша модель (по всем показателям):
linear_regression_model.fit(scaled_df, target)
sorted(list(zip(boston_df.columns, linear_regression_model.coef_)),
key=lambda x: abs(x[1]))
[('AGE', -0.09572161737815363),
('INDUS', -0.21745291834072922),
('CHAS', 0.7410105153873195),
('B', 0.8435653632801421),
('CRIM', -0.850480180062872),
('ZN', 0.9500420835249525),
('TAX', -1.1871976153182786),
('RAD', 1.7832553590229068),
('NOX', -1.8352515775847786),
('PTRATIO', -2.0059298125382456),
('RM', 2.8526547965775757),
('DIS', -2.9865347158079887),
('LSTAT', -3.724642983604627)]Что они означают? Каждый коэффициент представляет собой среднее изменение цены на жилье при изменении соответствующего показателя на единицу с условием, что все остальные показатели остаются неизменными. Например, если значения других показателей не затрагиваются, то увеличение LSTAT на единицу снижает наш целевой показатель (цену на жилье) на 3.72, а увеличение RM увеличивает его на 2.85.
Таким образом, если вы хотите повысить стоимость дома, то может быть стоит начать с увеличения RM и уменьшения LSTAT. Я говорю «может быть», потому что линейная регрессия рассматривает корреляции. Судя по нашим данным, такая взаимосвязь имеет место быть, что само по себе не означает обязательное наличие причинно-следственной связи между показателями.
Доверительные интервалы
Часто в машинном обучении очень полезно иметь доверительный интервал вокруг ваших оценок. Есть разные способы сделать это, но одним довольно общим методом является использование bootstrap.
Bootstrap — это случайная выборка на основе наших данных, и эта выборка того же размера, что и исходные данные. Так мы можем создать несколько представлений одних и тех же данных. Давайте создадим 1000 bootstrap-семплов наших данных.
from sklearn.utils import resample
n_bootstraps = 1000
bootstrap_X = []
bootstrap_y = []
for _ in range(n_bootstraps):
sample_X, sample_y = resample(scaled_df, target)
bootstrap_X.append(sample_X)
bootstrap_y.append(sample_y)
Затем мы обучим модель на каждом из полученных датасетов и получим следующие коэффициенты:
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
coeffs = []
for i, data in enumerate(bootstrap_X):
linear_regression_model.fit(data, bootstrap_y[i])
coeffs.append(linear_regression_model.coef_)
coef_df = pd.DataFrame(coeffs, columns=boston_df.columns)
coef_df.plot(kind='box')
plt.xticks(rotation=90);
На представленной диаграмме размаха показан диапазон значений коэффициентов, которые мы получили для каждого показателя для всех моделей, которые мы обучили. AGE — особенно интересен, потому что значения коэффициентов были как положительными, так и отрицательными, что является хорошим признаком того, что, вероятно, нет никакой связи между возрастом и стоимостью.
Кроме того, мы можем увидеть, что LSTAT имеет большой разброс в значениях коэффициентов, в то время как PTRATIO имеет относительно небольшую дисперсию, что повышает доверие к нашей оценке этого коэффициента.
Мы даже можем немного углубиться в полученные коэффициенты для LSTAT:
print(coef_df['LSTAT'].describe())
coef_df['LSTAT'].plot(kind='hist');
count 1000.000000
mean -3.686064
std 0.713812
min -6.032298
25% -4.166195
50% -3.671628
75% -3.202391
max -1.574986
Name: LSTAT, dtype: float64
Теперь мы можем с большой уверенностью сказать, что фактический коэффициент LSTAT отрицателен и почти наверняка находится между -2 и -5.5.
Разделение на обучающий/тестовый датасеты и кросс-валидация
До этого момента мы тренировались на всех имеющихся данных. Это может иметь смысл, потому что мы хотим максимизировать их полезность, используя как можно больше данных для обучения. С другой стороны, из-за такого подхода нам становится труднее оценивать, насколько хорошо работает наша модель. Причина этого в том, что, если мы продолжим рассчитывать MSE, используя тренировочные данные, мы можем обнаружить, что при применении модели на незнакомых ей данных, она работает довольно плохо.
Эта идея называется переобучением (overfitting). По сути, такая модель работает намного лучше с обучающими данными, чем с новыми. Она была чрезмерно натренирована на обнаружение уникальных характеристик обучающего множества, которые не являются общими закономерностями, присущими генеральной совокупности.
Другая сторона проблемы называется bias. Модель имеет высокий bias, когда она плохо обучена. В этом случае MSE будет высокой как для тренировочных данных, так и для данных, не показанных во время обучения.
В ML всегда существует компромисс между смещением (bias) и дисперсией (overfitting). По мере того, как ваши модели становятся более сложными, возрастает риск переобучения на тренировочных данных.
Теперь, когда мы знаем о проблемах с вычислением MSE, используя только обучающее множество, что мы можем сделать, чтобы лучше судить о способности модели к обобщению? А также диагностировать overfitting и bias? Типичным решением является разделение наших данных на две части: обучающий и тестовый датасеты.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled_df,
target,
test_size=0.33,
random_state=42)
Теперь, когда у нас есть два отдельных набора данных, мы можем тренировать модель на обучающем множестве и вычислять метрики, используя оба датасета (лучше всего использовать ваши тестовые данные после настройки модели):
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01)
linear_regression_model.fit(X_train, y_train)
train_predictions = linear_regression_model.predict(X_train)
test_predictions = linear_regression_model.predict(X_test)
train_mse = mean_squared_error(y_train, train_predictions)
test_mse = mean_squared_error(y_test, test_predictions)
print("Train MSE: {}".format(train_mse))
print("Test MSE: {}".format(test_mse))
Train MSE: 23.068773005090424
Test MSE: 21.243935754712375Отлично! Теперь у нас есть MSE как для тренировочных данных, так и для данных тестирования. И оба значения довольно близки, что говорит об отсутствии проблемы с переобучением. Но достаточно ли они низкие? Большие значения предполагают наличие высокого bias.
Один из способов разобраться в этом — построить график обучения. Кривая обучения отображает нашу функцию ошибок (MSE) с различными объемами данных, используемых для тренировки. Вот наш график:
# Источник: http://scikit-learn.org/0.15/auto_examples/plot_learning_curve.html
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Train примеры")
plt.ylabel("Оценка")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, scoring=make_scorer(mean_squared_error))
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Train score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="C-V score")
plt.legend(loc="best")
return plt
plot_learning_curve(linear_regression_model,
"Кривая обучения",
X_train,
y_train,
cv=5);

Вы можете видеть, что с менее чем 50 обучающими примерами тренировочная MSE неплохая, а кросс-валидация оставляет желать лучшего — довольно плохая (мы еще не говорили о кросс-валидации, так что пока думайте об этом как о тестировании). Если бы у нас было только такое количество данных, это выглядело бы как явная проблема высокой дисперсии (переобучения).
По мере увеличения наших данных мы начинаем улучшать оба результата, и они становятся очень похожими, что говорит о том, что у нас нет проблемы переобучения. Как правило, при высокой дисперсии на этом графике две линии будут находится довольно далеко друг от друга, и кажется, что, если мы продолжим добавлять больше данных, они могут сойтись.
Этот график больше похож на проблему с большим смещением (bias), поскольку две наши кривые очень близки и сглаживаются. Однако трудно сказать наверняка, потому что, возможно, мы только что достигли наилучшего возможного MSE. В таком случае это не будет проблемой высокого смещения. Такой результат был бы ей только в том случае, если бы наши кривые выровнялись при значении MSE выше оптимального. В реальной жизни вы не знаете, какова оптимальная MSE, поэтому вам нужно немного поразмышлять, считаете ли вы, что уменьшение bias улучшит ваш результат — но лучше просто попробуйте!
Устранение проблем высоких bias/variance
Итак, теперь, когда вы диагностировали проблему смещения или дисперсии, как ее исправить?
Для высокой дисперсии:
- Получите больше данных для обучения
- Попробуйте меньший набор показателей
- Используйте менее сложную модель
- Добавьте регуляризацию
Для высокого смещения:
- Попробуйте увеличить число показателей
- Перейдите на более сложную модель
Кросс-валидация и настройка гиперпараметров
Ранее мы упоминали этот термин: кросс-валидация. Давайте поговорим об этом сейчас. На данный момент мы узнали, что неплохо разделить данные на наборы для обучения и тестирования, чтобы лучше понять, насколько хорошо работает модель. Это замечательно, но представьте, что мы хотим протестировать несколько разных моделей или протестировать разные параметры нашей модели — например, другую скорость обучения или толерантность. Как бы нам решить, какая модель или какой параметр лучше? Будем ли мы обучать все на тренировочных данных и тестировать все на наших тестовых данных?
Надеюсь, вы понимаете, что это не имеет смысла, потому что тогда мы, по сути, оказались бы в том же месте, что и раньше, без возможности проверить, насколько хорошо мы справляемся с ранее неизвестными данными. Итак, мы хотим сохранить датасет для тестирования незапятнанным в том смысле, что в идеальном мире мы бы запускали наши тесты на нем только после того, как провели все необходимые эксперименты и были уверены в том, что нашли самую лучшую модель.
Похоже, нам нужен третий набор данных – датасет для валидации. По сути, мы можем разбить наши обучающие данные на две части: обучающий и проверочный датасеты. Все модели будут обучены на тренировочном множестве, а затем протестированы на нашем проверочном наборе. Затем мы выберем модель, которая лучше всего справляется с проверкой, и посмотрим, насколько удачно она пройдет тестирование. Результаты тестирования покажут, как хорошо наша модель будет работать с незнакомыми данными, и на этом мы завершим процесс разработки.
Примечание: в статье предполагается, что используемые тестовые и проверочные датасеты представляют собой репрезентативные выборки из нашей совокупности. Например, если средняя цена дома в вашем проверочном множестве составляет 1 миллион, а для генеральной совокупности соответствующее значение равно 300 тысячам, у вас плохая выборка. Часто мы случайным образом делим имеющиеся данные на три выборки, но всегда полезно подтвердить, что эти наборы являются репрезентативными. В противном случае вы обнаружите, что ваша модель, которая хорошо зарекомендовала себя при проверке и тестировании, плохо работает на реальных данных.
На практике вместо создания единого множества для проверки мы часто используем k-блочную кросс-валидацию.
Это означает, что мы выбираем значение k, скажем 3. Затем мы берем наши обучающие данные и делим их на 3 части. Мы случайным образом выбираем 2 блока для тренировки, а затем используем оставшийся для тестирования. Повторяем этот процесс еще 2 раза, так чтобы все наблюдения были использованы как для обучения, так и для проверки, и каждое из них применялось для валидации только один раз. После этого усредняем все три оценки (в нашем случае MSE), чтобы получить общую оценку для конкретной модели. Затем мы можем повторить этот процесс для других моделей, чтобы найти лучшую.
Вот видео, которое более наглядно описывает этот подход (с русскими субтитрами): https://www.youtube.com/watch?v=TIgfjmp-4BA
Этот процесс довольно просто реализуется с помощью sklearn:
from sklearn.model_selection import RandomizedSearchCV
param_dist = {"eta0": [ .001, .003, .01, .03, .1, .3, 1, 3]}
linear_regression_model = SGDRegressor(tol=.0001)
n_iter_search = 8
random_search = RandomizedSearchCV(linear_regression_model,
param_distributions=param_dist,
n_iter=n_iter_search,
cv=3,
scoring='neg_mean_squared_error')
random_search.fit(X_train, y_train)
print("Лучшие параметры: {}".format(random_search.best_params_))
print("Лучшая оценка MSE: {}".format(random_search.best_score_))
Лучшие параметры: {'eta0': 0.001}
Лучшая оценка MSE: -25.64219216972172Здесь мы фактически использовали рандомизированный поиск (RandomizedSearchCV), который обычно лучше, чем поиск по всем возможным значениям. Часто вы хотите попробовать много разных параметров для множества различных регуляторов, и сеточный поиск (перебор всех возможных комбинаций) вам не подходит.
Обычно вы хотите использовать рандомизированный поиск (случайный выбор комбинаций), как мы сделали выше. Хотя, поскольку у нас было только небольшое количество значений, мы заставили его работать как сеточный поиск, установив n_iter_search равным числу вариантов, которые мы хотели попробовать.
Мы также установили cv=3, чтобы иметь 3 блока и использовали отрицательную MSE, потому что функции CV в scikit-learn пытаются максимизировать значение.
Вы можете узнать больше о случайном и «сеточном» вариантах поиска здесь: https://scikit-learn.org/stable/modules/grid_search.html.
Кроме того, в scikit-learn есть много других CV функций, которые полезны, особенно если вы хотите протестировать разные модели с одинаковыми блоками. Вот некоторая документация: https://scikit-learn.org/stable/modules/cross_validation.html.
Регуляризация
В качестве средства борьбы с высокой дисперсией я упомянул регуляризацию. Вы можете думать о ней как о методе, который используется для наказания модели за обучение сложным взаимосвязям. Для линейной регрессии она принимает форму трех популярных подходов. Все эти методы сосредоточены на идее ограничения того, насколько большими могут быть коэффициенты наших показателей.
Идея состоит в том, что если мы переоцениваем влияние предсказателя (большое значение коэффициента), то, вероятно, мы переобучаемся. Примечание: у нас все еще могут быть просто большие коэффициенты. Регуляризация говорит о том, что уменьшение MSE должно оправдывать увеличение значений коэффициентов.
- Регуляризация L1 (Lasso): вы добавляете сумму абсолютных значений коэффициентов к функции оценки. Этот метод может принудительно обнулить коэффициенты, что затем может быть средством выбора показателей.
- Регуляризация L2 (Ridge): вы добавляете сумму квадратов значений коэффициентов к функции оценки.
- Эластичная сетка: вы добавляете обе и выбираете, как их утяжелить.
Каждый из этих методов принимает весовой множитель, который говорит вам, насколько сильное влияние регуляризация будет иметь на функцию оценки. В scikit-learn такой параметр называется альфа. Альфа равный 0 не добавит штрафа, в то время как высокое его значение будет сильно наказывать модель за наличие больших коэффициентов. Вы можете использовать кросс-валидацию, чтобы найти хорошее значение для альфа.
Sklearn упрощает это:
from sklearn.linear_model import ElasticNetCV
clf = ElasticNetCV(l1_ratio=[.1, .5, .7, .9, .95, .99, 1], alphas=[.1, 1, 10])
clf.fit(X_train, y_train)
train_predictions = clf.predict(X_train)
test_predictions = clf.predict(X_test)
print("Train MSE: {}".format(mean_squared_error(y_train, train_predictions)))
print("Test MSE: {}".format(mean_squared_error(y_test, test_predictions)))
Train MSE: 23.58766002758097
Test MSE: 21.54591803491954Здесь мы использовали функцию ElasticNetCV, которая имеет встроенную кросс-валидацию, чтобы выбрать лучшее значение для альфы. l1_ratio — это вес, который придается регуляризации L1. Оставшийся вес применяется к L2.
Итог
Если вы зашли так далеко, поздравляю! Это была тонна информации, но я обещаю, что, если вы потратите время на ее усвоение, у вас будет очень твердое понимание линейной регрессии и многих вещей, которые она может делать!
Кроме того, здесь вы можете найти весь код статьи.
]]>В Python есть несколько методов для удаления элементов из списка: remove(), pop() и clear(). Помимо них также существует ключевое слово del.
Рассмотрим их все.
Пример списка:
my_list = ['Python', 50, 11.50, 'Alex', 50, ['A', 'B', 'C']]
Индекс начинается с 0. В списке my_list на 0-ой позиции находится строка «Python». Далее:
- Целое число 50
- Число с плавающей точкой 11.50
- Снова строка — «Alex»
- Еще одно число 50
- Список из строк «A», «B» и «C»
Метод remove()
Метод remove() — это встроенный метод, который удаляет первый совпадающий элемент из списка.
Синтаксис: list.remove(element).
Передается элемент, который нужно удалить из списка.
Метод не возвращает значений.
Как использовать:
- Если в списке есть повторяющиеся элементы, первый совпадающий будет удален.
- Если элемента нет, будет брошена ошибка с сообщением о том, что элемент не найден.
- Метод не возвращает значений.
- В качестве аргумента нужно передать валидное значение.
Пример: использование метод remove() для удаления элемента из списка
В этом списке есть строки и целые числа. Есть повторяющиеся элементы: строка «Mars» и число 12.
my_list = [12, 'USA', 'Sun', 14, 'Mars', 12, 'Mars']
my_list.remove(12) # удаляем элемент 12 в начале
print(my_list)
my_list.remove('Mars') # удаляем первый Mars из списка
print(my_list)
my_list.remove(100) # ошибка
print(my_list)
Вывод:
['USA', 'Sun', 14, 'Mars', 12, 'Mars']
['USA', 'Sun', 14, 12, 'Mars']
Traceback (most recent call last):
File "wb.py", line 6, in <module>
my_list.remove(100) # ошибка
ValueError: list.remove(x): x not in listМетод pop()
Этот метод удаляет элемент на основе переданного индекса.
Синтаксис: list.pop(index).
Принимает лишь один аргумент — индекс.
- Для удаления элемента списка нужно передать его индекс. Индексы в списках стартуют с 0. Для получения первого передайте 0. Для удаления последнего передайте -1.
- Этот аргумент не является обязательным. Значение по умолчанию равно -1, поэтому по умолчанию будет удален последний элемент.
- Если этот индекс не найден или он вне диапазона, то метод выбросит исключение
IndexError: pop index.
Возвращает элемент, удаленный из списка по индексу. Сам же список обновляется и больше не содержит этот элемент.
Пример: использования метода pop() для удаления элемента
Попробуем удалить элемент с помощью pop:
- По индексу
- Не передавая индекс
- Передав индекс вне диапазона
Удалим из списка «Sun». Индекс начинается с 0, поэтому индекс для «Sun» будет 2.
my_list = [12, 'USA', 'Sun', 14, 'Mars', 12, 'Mars']
# Передавая индекс как 2, чтобы удалить Sun
name = my_list.pop(2)
print(name)
print(my_list)
# метод pop() без индекса - возвращает последний элемент
item = my_list.pop()
print(item)
print(my_list)
# передача индекса за пределами списка
item = my_list.pop(15)
print(item)
print(my_list)
Вывод:
Sun
[12, 'USA', 14, 'Mars', 12, 'Mars']
Mars
[12, 'USA', 14, 'Mars', 12]
Traceback (most recent call last):
File "wb.py", line 14, in <module>
item = my_list.pop(15)
IndexError: pop index out of rangeМетод clear()
Метод clear() удаляет все элементы из списка.
Синтаксис: list.clear().
Нет ни параметров, ни возвращаемого значения.
Пример
Метод clear() очистит данный список. Посмотрим:
my_list = [12, 'USA', 'Sun', 14, 'Mars', 12, 'Mars']
element = my_list.clear()
print(element)
print(my_list)
Вывод:
None
[]Ключевое слово del
Для удаления элемента из списка можно использовать ключевое слово del с названием списка после него. Также потребуется передать индекс того элемента, который нужно удалить.
Синтаксис: del list[index].
Также можно выбрать элементы в определенном диапазоне и удалить их с помощью del. Для этого нужно передать начальное и конечное значение диапазона.
Синтаксис: del list[start:stop].
Вот пример того как с помощью del можно удалить первый, последний и сразу несколько элементов списка:
my_list = list(range(7))
print("Исходный список", my_list)
# Чтобы удалить первый элемент
del my_list[0]
print("После удаления первого элемента", my_list)
# Чтобы удалить элемент по индексу
del my_list[5]
print("После удаления элемента", my_list)
# Чтобы удалить несколько элементов
del my_list[1:5]
print("После удаления нескольких элементов", my_list)
Вывод:
Исходный список [0, 1, 2, 3, 4, 5, 6]
После удаления первого элемента [1, 2, 3, 4, 5, 6]
После удаления элемента [1, 2, 3, 4, 5]
После удаления нескольких элементов [1]Как удалить первый элемент списка
Для этого можно использовать методы remove(), pop(). В случае с remove потребуется передать индекс первого элемента, то есть 0. Также можно использовать ключевое слово del.
Пример показывает применение всех этих способов.
my_list = ['A', 'B', 'C', 'D', 'E', 'F']
print("Список", my_list)
my_list.remove('A')
print("С использованием remove()", my_list)
my_list = ['A', 'B', 'C', 'D', 'E', 'F']
my_list.pop(0)
print("С использованием pop()", my_list)
my_list = ['A', 'B', 'C', 'D', 'E', 'F']
del my_list[0]
print("С использованием del", my_list)
Вывод:
Список ['A', 'B', 'C', 'D', 'E', 'F']
С использованием remove() ['B', 'C', 'D', 'E', 'F']
С использованием pop() ['B', 'C', 'D', 'E', 'F']
С использованием del ['B', 'C', 'D', 'E', 'F']Как удалить несколько элементов из списка
Методы remove() и pop() могут удалить только один элемент. Для удаления нескольких используется метод del.
Например, из списка ['A', 'B', 'C', 'D', 'E', 'F'] нужно удалить элементы B, C и D. Вот как это делается с помощью del.
my_list2 = ['A', 'B', 'C', 'D', 'E', 'F']
print("Список", my_list2)
del my_list2[1:4]
print("С использованием del", my_list2)
Вывод:
Список ['A', 'B', 'C', 'D', 'E', 'F']
С использованием del ['A', 'E', 'F']Как удалить элемент из списка с помощью индекса в Python
Для удаления элемента по индексу используйте pop(). Для этого также подойдет ключевое слово del.
# Использование del для удаления нескольких элементов из списка
my_list1 = ['A', 'B', 'C', 'D', 'E', 'F']
print("Список", my_list1)
element = my_list1.pop(2)
print("Используя pop", my_list1)
# Использование del для удаления нескольких элементов из списка
my_list2 = ['A', 'B', 'C', 'D', 'E', 'F']
del my_list2[2]
print("Используя del", my_list2)
Вывод:
Список ['A', 'B', 'C', 'D', 'E', 'F']
Используя pop ['A', 'B', 'D', 'E', 'F']
Используя del ['A', 'B', 'D', 'E', 'F']Выводы
В Python есть много способов удаления данных из списка. Это методы remove(), pop(), clear() и ключевое слово del.
remove()— удаляет первый встреченный элемент в списке, который соответствует условию.pop()— удаляет элемент по индексу.clear()— удаляет все элементы списка.
В этом руководстве рассмотрим особенности Python, и его ключевые отличия от C++.
Особенности C++
- Компилируемый язык
- Строго типизируемый с учетом регистра
- Не зависит от устройства — портативный и модульный
- Быстрый и эффективный
- Мощный
- Использует указатели и имеет огромную библиотеку функций
- Поддерживает следующие особенности ООП:
- Классы и объекты
- Абстракция
- Инкапсуляция
- Полиморфизм
- Наследование
Особенности Python
- Понятный синтаксис и простой в изучении
- Легко масштабируемый
- Бесплатный, с открытым исходным кодом и кроссплатформенный
- Объектно-ориентированный с высоким уровнем надежности и отличной читаемостью
- Может использоваться для прототипирования и тестирования, чтобы позже переходить к разработке на других высокоуровневых языках
- Предлагается с крупной библиотекой, включающей XML-парсеры и многое другое
Теперь посмотрим на основные отличия:
| Параметр | C++ | Python |
|---|---|---|
| Компиляция | Компилируемый | Интерпретируемый |
| Простота в использовании | Писать код непросто | Легко писать код |
| Статическая/динамическая типизация | Статически типизируемый | Динамически типизируемый |
| Портативность | Не портативный | Портативный |
| Сборка мусора | Не поддерживает сборку мусора | Поддерживает сборку мусора |
| Установка | Простая установка | Сложный в установке |
| Типы | Типы данных проверяются при компиляции | Привязывается к значениям, проверяемым во время работы программы |
| Область видимости переменных | Ограничены в пределах блоков и циклов | Доступны вне циклов или блоков |
| Быстрое прототипирование | Невозможно | Возможно |
| Функции | Ограничены по типу параметров и возвращаемому типу | Нет ограничений по типу параметров и возвращаемому типу |
| Эффективность | Сложно поддерживать | Легко поддерживать |
| Сложность синтаксиса | Использует блоки и точки с запятой | Нет блоков и точек с запятой (используются отступы) |
| Скорость выполнения | Быстрый | Медленный |
| Производительность | Высокая производительность | Низкая производительность |
| Популярность | Более популярный во встроенных и энтерпрайз-системах | Наиболее популярен в машинном обучении |
| Простота и удобство использования | Сложен в изучении и используется в низкоуровневых приложениях | Простой, используется в машинном обучении и веб-приложениях |
Ключевые отличия C++ и Python
Дальше перечислены основные отличия C++ и Python с точки зрения языков программирования.
Компиляция
Python — интерпретируемый язык. Файлы с расширением .py не нужно компилировать. Можно передавать код прямо в интерпретатор Python и получать результат.
C++ — это компилируемый язык. Компилятор создает код из написанного программистом, который потом выполняется для получения результата.
Использование
У C++ много разных функций и относительно сложный синтаксис. Код на этом языке писать не так просто.
У Python синтаксис очень простой, поэтому программы выглядят намного проще и их легче писать.
Статическая/динамическая типизация
C++ — статически типизируемый язык. Таким образом типы данных проверяются во время компиляции. Благодаря этому исходный код при работе защищен от ошибок.
Python же предрасположен к ошибкам, ведь типы там проверяются уже при работе программы.
Портативность
Python портативен. Он также кроссплатформенный, что позволяет запускать код на разных устройствах.
C++ не является портативным, поэтому для каждой платформы код нужно специально компилировать: «Написал код однажды, компилируй везде».
Сборка мусора/управление памятью
В C++ памятью нужно управлять вручную. Здесь нет автоматической сборки мусора.
Python же поддерживает автоматическую сборку мусора. Управление памятью в нем осуществляется автоматически.
Быстрое прототипирование
С помощью Python можно заниматься быстрым прототипированием, чтобы потом создавать приложения на других языках программирования.
Недоступно для C++.
Область видимости переменных
Код в C++ разделяется с помощью фигурных скобок в циклах. Область видимости переменных ограничена этими блоками.
В Python область видимости переменных не ограничена ничем. Переменные доступны в рамках одной конструкции.
Установка
C++ можно легко установить на Windows, а вот с Python посложнее. Некоторые библиотеки не совместимы с Windows.
Типы
В C++ типы данных привязываются к именам и проверяются при компиляции. Это уменьшает количество возможных ошибок при работе.
В Python же типы данных проверяются уже во время работы программы. Из-за этого количество ошибок в этом языке может быть больше.
Функции
Функции — это блоки кода с одним или несколькими параметрами и возвращаемым значением. У каждого параметра и возвращаемого значения есть свой тип.
В C++ типы всех значений должны совпадать с тем, что передается. В Python таких ограничений нет.
Эффективность
Код на C++ сложнее поддерживать, поскольку он становится только сложнее с ростом размера приложений.
У Python же наоборот более чистый код и понятный синтаксис. Его поддерживать значительно легче.
Сложность синтаксиса
В C++ есть четкое разделение блоков с помощью фигурных скобок, а также точек с запятой. Таким образом этот код отлично организован.
В Python же нет ни скобок, ни точек с запятой. Там используются отступы.
Скорость выполнения
Программы на C++ работают быстрее. Именно поэтому этот язык используется в тех сферах, где скорость имеет значение, например, в играх.
Python же медленнее. Код на Python работает даже медленнее Java-приложений.
Производительность
C++ — статически типизируемый язык, поэтому при работе с программой возникает меньше ошибок. Такой код работает быстрее. Это делает C++ высокопроизводительным языком.
Python динамический, поэтому при работе с ним чаще происходят ошибки, а общая производительность ниже в сравнении с C++.
Зато в машинном обучении Python почти нет равных.
Простота и удобство в использовании
Python дает возможность писать простой и понятный код. Это позволяет разрабатывать сложные приложения для машинного обучения, не задумываясь об особенностях синтаксиса.
Также Python легче изучать. О C++ такого сказать нельзя. Это низкоуровневый язык, который больше подходит компьютерам, чем людям.
У Python в этом плане преимущество, особенности если говорить о приложениях для машинного обучения.
Ключевые достоинства Python
- Одно из главных достоинств Python — простой и понятный синтаксис. Программистам с C++ он будет понятен почти сразу, пусть изначально может и не хватать скобок и точек с запятой.
- У Python огромная стандартная библиотека с ридерами/райтерами для CSV, ZIP и других форматов, XML-парсеры, инструменты для работы с сетью и так далее.
- Язык подходит для создания веб-приложений.
- Поддерживает duck-typing, когда можно создавать и вызывать объект, не волнуясь о том какого он типа.
- Лучше всего подходит для машинного обучения.
Преимущества C++ над Python
- Главное преимущество C++ — производительность. Его скорость работы намного выше в сравнении с Python.
- C++ подходит почти для всех платформ, а также для встроенных систем, в то время как Python работает только на отдельных платформах, поддерживающих высокоуровневые языки.
- C++ более предсказуем благодаря статической типизации. Это же влияет и на производительность.
- При работе с C++ можно изучать низкоуровневое программирование, ведь язык близок к железу. В случае с Python это не сработает.
Часто задаваемые вопросы
Лучше учить C++ вместо Python?
Программист должен выбрать, что ему учить. Это также зависит от потребностей. Если вас интересует системное или низкоуровневое программирование, то обратите внимание на C++.
Если же ближе машинное обучение, то Python подойдет больше. Также можно познакомиться с веб-программированием на примере Ruby, JavaScript, Angular и так далее.
Все зависит от интересов и потребностей. Плюс, никогда не будет лишним знать несколько языков программирования.
Python лучше чем C++
Да. Если говорить о простоте синтаксиса и легкости освоения. Python можно взять просто для того, чтобы познакомиться с программированием. Там нет точек с запятой, указателей, шаблонов, STL, типов и так далее.
Если вы хотите познакомиться с основами программирования, то Python явно лучше C++. Однако последний выигрывает в плане производительности, скорости работы, широты применения и так далее.
Может ли Python заменить C++
Нет. C и C++ образуют основу программирования. По сути, даже Python построен на базе C. Поэтому не может быть такого, что Python заменит один из этих языков.
Он может оказаться впереди в тех сферах, где нет взаимодействия с устройствами, производительности, серьезного управления ресурсами и так далее.
Что лучше, если выбирать из C++, Python и Java
У всех трех языков есть свои преимущества и недостатки. C++ славится своей производительностью, скоростью и управлением памятью. В Java основное — это его платформа. В то же время для Python главное простота, читаемость и поддержка со стороны сообщества.
Личные предпочтения помогут сделать выбор. Без этого невозможно сказать, какой язык лучше.
Почему C++ быстрее Python
По следующим причинам:
- Хороший C++ код исполняется в CPU быстрее, чем Python
- Нет этапа интерпретации, когда каждое выражение построчно оценивается
- Нет постоянно работающего сборщика мусора
- Есть больше контроля над системными вызовами
- Можно запросто писать машинный код
Это все и влияет на более высокую производительность кода C++. Вот что влияет на более медленную работу Python:
- Язык интерпретируется, а не компилируется
- В Python нет примитивов. Все представлено в виде объектов встроенных типов
- Списки содержат объекты разных типов. Это требует дополнительного места для определения будущих элементов в списке
Выводы
C++ и Python — разные языки с разным набором функций и областями применения. У Python более простой синтаксис, хорошая читаемость, однако он проигрывает C++ в плане производительности и скорости.
Python подходит для машинного обучения, а C++ — для широкого спектра приложений, включая системное программирование.
]]>abs(x) в Python возвращает абсолютное значение аргумента x, который может быть целым или числом с плавающей точкой, или же объектом, реализующим функцию __abs__(). Для комплексных чисел функция возвращает их величину. Абсолютное значение любого числового значения -x или +x — это всегда соответствующее положительное +x.
| Аргумент | x | целое число, число с плавающей точкой, комплексное число, объект, реализующий __abs__() |
| Возвращаемое значение | |x| | возвращает абсолютное значение входящего аргумента |
Пример abs() с целым числом
Следующий код демонстрирует, как получить абсолютное значение 42 положительного числа 42.
x = 42
abs_x = abs(x)
print(f"Абсолютное значение {x} это {abs_x}")
# Вывод: Абсолютное значение 42 это 42
Вывод: «Абсолютное значение 42 это 42».
То же самое, но уже с отрицательным -42.
x = -42
abs_x = abs(x)
print(f"Абсолютное значение {x} это {abs_x}")
# Вывод: Абсолютное значение -42 это 42
Пример с числом float
Вот как получить абсолютное значение 42.42 и для -42.42:
x = 42.42
abs_x = abs(x)
print(f"Абсолютное значение {x} это {abs_x}")
# Абсолютное значение 42.42 это 42.42
x = -42.42
abs_x = abs(x)
print(f"Абсолютное значение {x} это {abs_x}")
# Абсолютное значение -42.42 это 42.42
Комплексное число
Абсолютное значение комплексного числа (3+10j).
complex_number = (3+10j)
abs_complex_number = abs(complex_number)
print(f"Абсолютное значение {complex_number} это {abs_complex_number}")
# Абсолютное значение (3+10j) это 10.44030650891055
abs() vs fabs()
abs(x) вычисляет абсолютное значение аргумента x. По аналогии функция fabs(x) модуля math вычисляет то же значение. Разница лишь в том, что math.fabs(x) возвращает число с плавающей точкой, а abs(x) вернет целое число, если в качестве аргумента было целое число. Fabs расшифровывается как float absolute value.
Пример c fabs():
x = 42
print(abs(x))
# 42
import math
print(math.fabs(x))
# 42.0
abs() vs. np.abs()
И abs() в Python, и np.abs() в NumPy вычисляют абсолютное значение числа, но есть два отличия. np.abs(x) всегда возвращает число с плавающей точкой. Также np.abs(x) принимает массив NumPy, вычисляя значение для каждого элемента коллекции.
Пример:
x = 42
print(abs(x))
# 42
import numpy as np
print(np.fabs(x))
# 42.0
a = np.array([-1, 2, -4])
print(np.abs(a))
# [1 2 4]
abs и np.abs абсолютно идентичны. Нет разницы какой использовать. У первой преимущество лишь в том, что ее вызов короче.
Вывод
Функция abs() — это встроенная функция, возвращающая абсолютное значение числа. Она принимает целые, с плавающей точкой и комплексные числа на вход.
Если передать в abs() целое число или число с плавающей точкой, то функция вернет не-отрицательное значение n и сохранит тип. Для целого числа — целое число. Для числа с плавающей точкой — число с плавающей точкой.
>>> abs(20)
20
>>> abs(20.0)
20.0
>>> abs(-20.0)
20.0
Комплексные числа состоят из двух частей и могут быть записаны в форме a + bj, где a и b — это или целые числа, или числа с плавающей точкой. Абсолютное значение a + bj вычисляется математически как math.sqrt(a**2 + b**2).
>>> abs(3 + 4j)
5.0
>>> math.sqrt(3**2 + 4**2)
5.0
Таким образом, результат всегда положительный и всегда является числом с плавающей точкой.
]]>Django REST Framework — это набор инструментов для создания REST API с помощью Django. В этом руководстве рассмотрим, как правильно его использовать. Создадим эндпоинты(точки доступа к ресурсам) для пользователей, постов в блоге, комментариев и категорий.
Также рассмотрим аутентификацию, чтобы только залогиненный пользователь мог изменять данные приложения.
Вот чему вы научитесь:
- Добавлять новые и существующие модели Django в API.
- Сериализовать модели с помощью встроенных сериализаторов для распространенных API-паттернов.
- Создавать представления и URL-паттерны.
- Создавать отношения многие-к-одному и многие-ко-многим.
- Аутентифицировать пользовательские действия.
- Использовать созданный API Django REST Framework.
Код урока можно скачать в репозитории https://gitlab.com/PythonRu/blogapi.
Требования
У вас в системе должен быть установлен Python 3, желательно 3.8. Также понадобится опыт работы с REST API. Вы должны быть знакомы с реляционными базами данными, включая основные и внешние ключи, модели баз данных, миграции, а также отношения многие-к-одному и многие-ко-многим.
Наконец, потребуется опыт работы с Python и Django.
Настройка проекта
Для создания нового API-проекта для начала создайте виртуальную среду Python в своей рабочей директории. Для этого запустите следующую команду в терминале:
python3 -m venv env
source env/bin/activateВ Windows это будет source env\Scripts\activate.
Не забывайте запускать все команды из этого руководства в виртуальной среде. Убедиться в том, что она активирована можно благодаря надписи (env) в начале строки приглашения к вводу в терминале.
Чтобы деактивировать среду, введите deactivate.
После этого установите Django и REST Framework в среду:
pip install django==3.1.7 djangorestframework==3.12.4Создайте новый проект «blog» и новое приложение «api»:
django-admin startproject blog
cd blog
django-admin startapp api
Из корневой директории «blog» (там где находится файл «manage.py»), синхронизируйте базу данных. Это запустит миграции для admin, auth, contenttypes и sessions.
python manage.py migrateВам также понадобится пользователь admin для взаимодействия с панелью управления Django и API. Из терминала запустите следующее:
python manage.py createsuperuser --email admin@example.com --username admin
Установите любой пароль (у него должно быть как минимум 8 символов). Если вы введете слишком простой пароль, то можете получить ошибку.
Для настройки, добавьте rest_framework и api в файл конфигурации (blog/blog/settings.py):
INSTALLED_APPS = [
...
'rest_framework',
'api.apps.ApiConfig',
]
Добавление ApiConfig позволит добавлять параметры конфигурации в приложение. Другие настройки для этого руководства не потребуются.
Наконец, запустите локальный сервер с помощью команды python manage.py runserver.
Перейдите по ссылке http://127.0.0.1:8000/admin и войдите в админ-панель сайта. Нажмите на «Users», чтобы увидеть пользователя и добавить новых при необходимости.

Создание API для пользователей
Теперь с пользователем «admin» можно переходить к созданию самого API. Это предоставит доступ только для чтения списку пользователей из списка API-эндпоинтов.
Сериализатор для User
REST Framework Django использует сериализаторы, чтобы переводить наборы запросов и экземпляры моделей в JSON-данные. Сериализация также определяет, какие данные вернет API в ответ на запрос клиента.
Пользователи Django создаются из модели User, которая определена в django.contrib.auth. Для создания сериализатора для модели добавьте следующее в blog/api/serializers.py (файл нужно создать):
from rest_framework import serializers
from django.contrib.auth.models import User
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ['id', 'username']
По примеру импортируйте модель User из Django вместе с набором сериализаторов из REST Framework Django.
Теперь создайте класс UserSerializer, который должен наследоваться от класса ModelSerializer.
Определите модель, которая должна ассоциироваться с сериализатором (model = User). Массив fields определяет, какие поля модели должны быть включены. Например, можно добавлять поля first_name и last_name.
Класс ModelSerializer генерирует поля сериализатора, которые основаны на соответствующих свойствах модели. Это значит, что не нужно вручную указывать все атрибуты для поля сериализации, поскольку они вытягиваются напрямую из модели.
Этот сериализатор также создает простые методы create() и update(). При необходимости их можно переписать.
Ознакомиться подробнее с работой ModelSerializer можно на официальном сайте.
Представления для User
Есть несколько способов создавать представления в REST Framework Django. Чтобы получить возможность повторного использования кода и избегать повторений, используйте классовые представления.
REST Framework предоставляет несколько обобщенных представлений, основанных на классе APIView. Они представляют собой самые распространенные паттерны.
Например, ListAPIView используется для эндпоинтов с доступом только для чтения. Он предоставляет метод-обработчик get. ListCreateAPIView используется для эндпоинтов с разрешением чтения-записи, а также обработчики get и post.
Для создания эндпоинта только для чтения, который возвращал бы список пользователей, добавьте следующее в blog/api/views.py:
from rest_framework import generics
from . import serializers
from django.contrib.auth.models import User
class UserList(generics.ListAPIView):
queryset = User.objects.all()
serializer_class = serializers.UserSerializer
class UserDetail(generics.RetrieveAPIView):
queryset = User.objects.all()
serializer_class = serializers.UserSerializer
В первую очередь здесь импортируется generics коллекция представлений, а также модель User и UserSerialized из предыдущего шага. Представление UserList предоставляет доступ только для чтения (через get) к списку пользователей, а UserDetails — к одному пользователю.
Названия представлений должны быть в следующем формате: {ModelName}List и {ModelName}Details для коллекции объектов и одного объекта соответственно.
Для каждого представления переменная queryset содержит коллекцию экземпляров модели, которую возвращает User.objects.all(). Значением serializer_class должно быть UserSerializer, который и сериализует данные модели User.
Пути к эндпоинтам будут настроены на следующем шаге.
URL-паттерны
С моделью, сериализатором и набором представлений для User финальным шагом будет создание эндпоинтов (которые в Django называются URL-паттернами) для каждого представления.
В первую очередь добавьте следующее в blog/api/urls.py (этот файл тоже нужно создать):
from django.urls import path
from rest_framework.urlpatterns import format_suffix_patterns
from . import views
urlpatterns = [
path('users/', views.UserList.as_view()),
path('users/<int:pk>/', views.UserDetail.as_view()),
]
urlpatterns = format_suffix_patterns(urlpatterns)
Здесь импортируется функция path и также коллекция представлений приложения api.
Функция path создает элемент, который Django использует для показа страницы приложения. Для этого Django в первую очередь ищет нужный элемент с соответствующим URL (например, users/) для запрошенного пользователем. После этого он импортирует и вызывает соответствующее представление (то есть, UserList)
Последовательность <int:pk> указывает на целочисленное значение, которое является основным ключом (pk). Django захватывает эту часть URL и отправляет в представление в виде аргумента-ключевого слова.
В этом случае основным ключом для User является поле id, поэтому http://127.0.0.1:8000/users/1 вернет id со значением 1.
Прежде чем можно будет взаимодействовать с этими URL-паттернами (и теми, которые будут созданы позже) их нужно добавить в проект. Добавьте следующее в blog/blog/urls.py:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('api.urls')),
]
Чтобы убедиться, что все элементы работают корректно, перейдите по ссылке http://127.0.0.1:8000/users, чтобы увидеть список пользователей приложения.
В этом руководстве используется графическое представление API из Django REST Framework для демонстрации эндпоинтов. Интерфейс предоставляет элементы аутентификации и формы, имитирующие фронтенд-клиент. Для тестирования API также можно использовать cURL или httpie.
Обратите внимание на то, что значение пользователя admin равно 1. Можете перейти к нему, открыв для этого http://127.0.0.1:8000/users/1.
В итоге класс модели Django сериализуется с помощью UserSerializaer. Он предоставляет данные представлениям UserList и UserDetail, доступ к которым можно получить с помощью паттернов users/ и users/<int:pk>.
Создание API для Post
После базовой настройки можно приступать к созданию полноценного API для блога с эндпоинтами для постов, комментариев и категорий. Начнем с API для Post.
Модель Post
В blog/api/models.py создайте модель Post, которая наследуется от класса Model из Django и определите ее поля:
from django.db import models
class Post(models.Model):
created = models.DateTimeField(auto_now_add=True)
title = models.CharField(max_length=100, blank=True, default='')
body = models.TextField(blank=True, default='')
owner = models.ForeignKey('auth.User', related_name='posts', on_delete=models.CASCADE)
class Meta:
ordering = ['created']
Типы полей соответствуют таковым в реляционных базах данные. Можете ознакомиться со страницей Models на официальном сайте фреймворка.
Обратите внимание на то, что тип ForeignKey создает отношение многие-к-одному между текущей моделью и моделью, указанной в первом аргументе (auth.User — то есть, модель User, с которой вы работаете).
В этом случае пользователь может иметь много статей, но у поста может быть всего один владелец. Поле owner может быть использовано во фронтенд-приложении для получения пользователя и отображения его имени в качестве автора поста.
Аргумент related_name позволяет задать другое имя доступа к текущей модели (posts) вместо стандартного (post_set). Список постов будет добавлен в сериализатор User на следующем шаге для завершения отношения многие-к-одному.
Каждый раз при обновлении модели запускайте следующие команды для обновления базы данных:
python manage.py makemigrations api
python manage.py migrateПоскольку мы работаем с моделями Django, таким как User, посты можно изменить из административной панели Django, зарегистрировав ее в blog/api/admin.py:
from django.contrib import admin
from .models import Post
admin.site.register(Post)
Позже их можно будет создавать и через графическое представление API.
Перейдите на http://127.0.0.1:8000/admin, кликните на Posts и добавьте новые посты. Вы заметите, что поля title и body в форме соответствуют типам CharField и TextField из модели Post.
Также можно выбрать owner среди существующих пользователей. При создании поста в API пользователя выбирать не нужно. Owner будет задан автоматически на основе данных залогиненного пользователя. Это настроим в следующем шаге.
Сериализатор Post
Чтобы добавить модель Post в API, нужно повторить шаги добавления модели User.
Сначала нужно сериализовать данные модели Post. В blog/api/serializers.py добавьте следующее:
from rest_framework import serializers
from django.contrib.auth.models import User
from .models import Post
class PostSerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
class Meta:
model = Post
fields = ['id', 'title', 'body', 'owner']
class UserSerializer(serializers.ModelSerializer):
posts = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = User
fields = ['id', 'username', 'posts']
Импортируйте модель Post из приложения api и создайте PostSerializer, который будет наследоваться от класса ModelSerializer. Задайте модель и поля, которые будут использоваться сериализатором.
ReadOnlyField — это класс, возвращающий данные без изменения. В этом случае он используется для возвращения поля username вместо стандартного id.
Дальше добавьте поле posts в UserSerializer. Отношение многие-к-одному между постами и пользователями определено моделью Post в прошлом шаге. Название поля (posts) должно быть равным аргументу related_field поля Post.owner. Замените posts на post_set (значение по умолчанию), если вы не задали значение related_field в прошлом шаге.
PrimaryKeyRelatedField представляет список публикаций в этом отношении многие-к-одному (many=True указывает на то, что постов может быть больше чем один).
Если не задать read_only=True поле posts будет иметь права записи по умолчанию. Это значит, что будет возможность вручную задавать список статей, принадлежащих пользователю при его создании. Вряд ли это желаемое поведение.
Перейдите по ссылке http://127.0.0.1:8000/users, чтобы увидеть поле posts каждого пользователя.
Обратите внимание на то, что список
posts— это, по сути, список id. Вместо этого можно возвращать список URL с помощьюHyperLinkModelSerializer.
Представления Post
Следующий шаг — создать набор представлений для Post API. Добавьте следующее в blog/api/views.py:
...
from .models import Post
...
class PostList(generics.ListCreateAPIView):
queryset = Post.objects.all()
serializer_class = serializers.PostSerializer
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class PostDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Post.objects.all()
serializer_class = serializers.PostSerializer
ListCreateAPIView и RetrieveUpdateDestroyAPIView предоставляют самые распространенные обработчики API-методов: get и post для списка (ListCreateAPIView) и get, update и delete для одной сущности (RetrieveUpdateDestroyAPIView).
Также нужно перезаписать функцию по умолчанию perform_create, чтобы задать поле owner текущего пользователя (значение self.request.user).
URL-паттерны Post
Чтобы закончить с эндпоинтами для Post API создайте URL-паттерны Post. Добавьте следующее в массив urlpatterns в blog/api/urls.py:
urlpatterns = [
...
path('posts/', views.PostList.as_view()),
path('posts/<int:pk>/', views.PostDetail.as_view()),
]
Объединение представлений с этими URL-паттернами создает эндпоинты:
get posts/,post posts/,get posts/<int:pk>/,put posts/<int:pk>/- и
delete posts/<int:pk>/.
Чтобы протестировать их, перейдите на http://127.0.0.1:8000/posts и создайте публикации. Я взял несколько статей из Медиума.
Перейдите на один пост (например, http://127.0.0.1:8000/posts/1 и нажмите DELETE. Чтобы поменять название поста, обновите поле «title» и нажмите PUT.
После этого перейдите на http://127.0.0.1:8000/posts, чтобы увидеть список существующих публикаций или создать новый. Убедитесь, что вы залогинены, потому что при создании поста его автор создается на основе данных текущего пользователя.

Настройка разрешений
Для удобства добавим кнопку «Log in» в графическое представление API с помощью следующего кода в blog/urls.py:
urlpatterns = [
...
path('api-auth/', include('rest_framework.urls')),
]
Теперь можно заходить под разными аккаунтами, чтобы проверять работу разрешений и изменять посты через интерфейс.
Сейчас можно создать пост, будучи зарегистрированным, но для удаления или изменения данных этого не требуется — даже если пост вам не принадлежит. Попробуйте зайти под другим аккаунтом, и вы сможете удалить посты, принадлежащие admin.
Чтобы аутентифицировать пользователя и быть уверенным в том, что только владелец поста может обновлять и удалять его, нужно добавить разрешения.
Начните с этого кода в blog/api/permisisions.api (файл необходимо создать):
from rest_framework import permissions
class IsOwnerOrReadOnly(permissions.BasePermission):
def has_object_permission(self, request, view, obj):
if request.method in permissions.SAFE_METHODS:
return True
return obj.owner == request.user
Разрешение IsOwnerOrReadOnly проверяет, является ли пользователь владельцем этого объекта. Таким образом только при этом условии можно будет обновлять или удалять пост. Не-владельцы смогут получать пост, потому что это действие только для чтения.
Также есть встроенное разрешение IsAuthenticatedOrReadOnly. С ним любом аутентифицированный пользователь может выполнять любой запрос, а остальные — только на чтение.
Добавьте эти разрешения в представления Post:
from rest_framework import generics, permissions
...
from .serializers import PostSerializer
from .permissions import IsOwnerOrReadOnly
...
class PostList(generics.ListCreateAPIView):
queryset = Post.objects.all()
serializer_class = PostSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly]
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class PostDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Post.objects.all()
serializer_class = PostSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly,
IsOwnerOrReadOnly]
Представлению PostList требуется разрешение IsAuthenticatedOrReadOnly, потому что пользователь должен аутентифицироваться, чтобы создать пост, а вот просматривать список может любой пользователь.
Для PostDetails нужны оба разрешения, поскольку обновлять или удалять пост должен только залогиненный пользователь, а также его владелец. Для получения поста прав не нужно. Вернитесь на http://127.0.0.1:8000/posts. Зайдите в учетную запись admin и другие, чтобы проверить, какие действия доступны аутентифицированным и анонимным пользователям.
Будучи разлогиненным, вы не должны иметь возможность создавать, удалять или обновлять посты. При аутентификации вы не должны иметь право удалять или редактировать чужие посты.
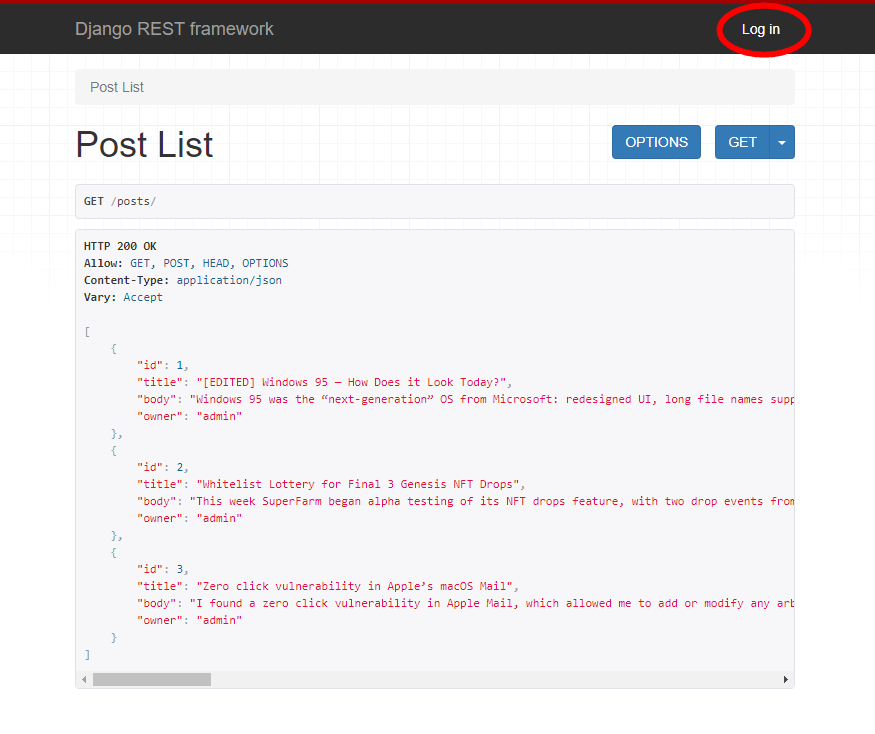
Создание API для Comments
Теперь у вас есть базовый API для постов. Можно добавить в систему комментарии.
Комментарий — это текст, который пользователь добавляет в ответ на пост другого пользователя. К одному можно оставить несколько комментариев, а у поста может быть несколько комментариев от разных пользователей. Это значит, что нужно настроить две пары отношений многие-к-одному: между комментариями и пользователями, а также между комментариями и постами.
Модель Comment
Сначала создайте модель в blog/api/models.py:
...
class Comment(models.Model):
created = models.DateTimeField(auto_now_add=True)
body = models.TextField(blank=False)
owner = models.ForeignKey('auth.User', related_name='comments', on_delete=models.CASCADE)
post = models.ForeignKey('Post', related_name='comments', on_delete=models.CASCADE)
class Meta:
ordering = ['created']
Модель Comment похожа на Post и имеет отношение многие-к-одному с пользователями через поле owner. У комментария есть отношение многие-к-одному с одним постом через поле post.
Запустите миграции базы данных:
python manage.py makemigrations api
python manage.py migrateСериализатор Comment
Для создания API комментариев нужно добавить модель Comment в PostSerializer и UserSerializer, чтобы убедиться, что связанные комментарии отправляются вместе с данными о пользователе и посте.
Обновите код в blog/api/serializers.py:
...
from .models import Post, Comment
class PostSerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
comments = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = Post
fields = ['id', 'title', 'body', 'owner', 'comments']
class UserSerializer(serializers.ModelSerializer):
posts = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
comments = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = User
fields = ['id', 'username', 'posts', 'comments']
Процесс напоминает добавление posts в UserSerializer. Это настраивает часть «многие» отношения многие-к-одному между комментариями и пользователем, а также между комментариями и постом. Список комментариев должен быть доступен только для чтения (read_only=True)
Теперь добавим CommentSerializer в тот же файл:
...
class CommentSerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
class Meta:
model = Comment
fields = ['id', 'body', 'owner', 'post']
Обратите внимание на то, что поле post не меняется. После добавления поля post в массив fields он будет сериализоваться по умолчанию (согласно ModelSerializer). Это эквивалентно post=serializers.PrimaryKeyRelatedField(queryset=Post.objects.all()).
Это значит, что у поля post есть право на запись по умолчанию: при создании комментария настраивается, какому посту он принадлежит.
Представления комментариев
Наконец, создадим представления и паттерны для комментариев. Процесс похож на тот, что был при настройке API Post.
Добавьте этот код в blog/api/views.py:
...
from .models import Post, Comment
...
class CommentList(generics.ListCreateAPIView):
queryset = Comment.objects.all()
serializer_class = serializers.CommentSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly]
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class CommentDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Comment.objects.all()
serializer_class = serializers.CommentSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly,
IsOwnerOrReadOnly]
Представления похожи на PostList и PostDetails.
URL-Паттерны комментариев
Чтобы закончить API комментариев, определите URL-паттерны в blog/api/urls.py:
urlpatterns = [
...
path('comments/', views.CommentList.as_view()),
path('comments/<int:pk>/', views.CommentDetail.as_view()),
]
Теперь по ссылке http://127.0.0.1:8000/comments можете увидеть список существующих комментариев и создавать новые.
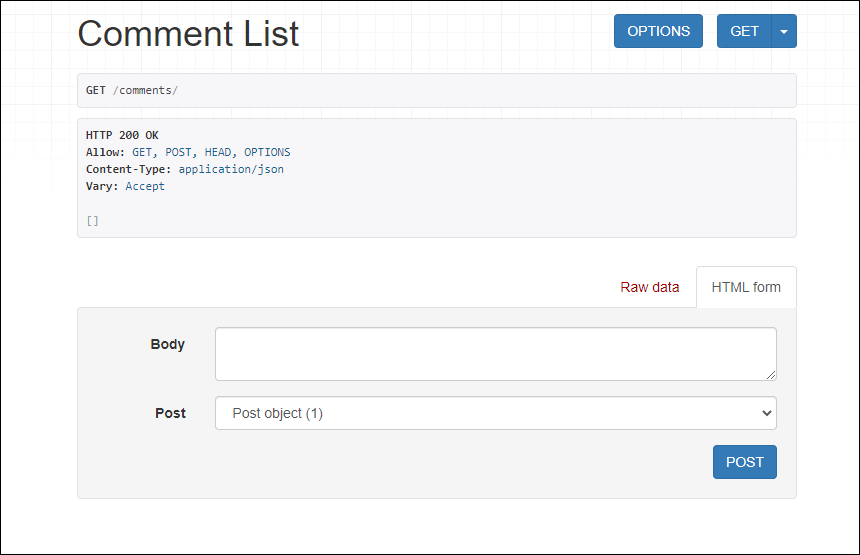
Также обратите внимание на то, что при создании нужно выбрать пост из списка существующих.
Создание API для Category
Финальный элемент блога — система категорий.
Пост может принадлежать к одной или нескольким категориям. Также одна категория может принадлежать нескольким постам, значит это отношение многие-ко-многим.
Модель категории
Создайте модель Category в blog/api/models.py:
urlpatterns = [
...
path('comments/', views.CommentList.as_view()),
path('comments/<int:pk>/', views.CommentDetail.as_view()),
]
Здесь класс ManyToManyField создает отношение многие-ко-многим между текущей моделью и моделью из первого аргумента. Как и в случае с классом ForeignKey отношение завершает сериализатор.
Обратите внимание на то, что verbose_name_plural определяет, как правильно писать название модели во множественном числе. Это нужно, например, для административной панели. Так, вы можете указать, что во множественном числе правильно писать categories, а не categorys.
Запустите миграции базы данных:
python manage.py makemigrations api
python manage.py migrateСериализатор Category
Процесс создания похож на описанный в прошлых шагах. Сперва создайте сериализатор для Category, добавив код в blog/api/serializers.py:
...
from .models import Post, Comment, Category
...
class CategorySerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
posts = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = Category
fields = ['id', 'name', 'owner', 'posts']
class PostSerializer(serializers.ModelSerializer):
owner = serializers.ReadOnlyField(source='owner.username')
comments = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = Post
fields = ['id', 'title', 'body', 'owner', 'comments', 'categories']
class UserSerializer(serializers.ModelSerializer):
posts = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
comments = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
categories = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = User
fields = ['id', 'username', 'posts', 'comments', 'categories']
Не забудьте добавить имя поля categories в список полей PostSerializer и UserSerializer. Обратите внимание на то, что UserSerializer.categories можно отметить как read_only=True. Это поле представляет список всех созданных категорий.
С другой стороны, поле PostSerializer.categories будет иметь право на запись по умолчанию. То же самое, что указать categories = serializers.PrimaryKeyRelatedField(many=True, queryset=Category.objects.all()). Это позволит пользователю выбирать одну или нескольких категорий для поста.
Представления для категории
Дальше создайте представления в blog/api/views.api:
...
from .models import Post, Comment, Category
...
class CategoryList(generics.ListCreateAPIView):
queryset = Category.objects.all()
serializer_class = serializers.CategorySerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly]
def perform_create(self, serializer):
serializer.save(owner=self.request.user)
class CategoryDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Category.objects.all()
serializer_class = serializers.PostSerializer
permission_classes = [permissions.IsAuthenticatedOrReadOnly,
IsOwnerOrReadOnly]
По аналогии с прошлыми.
URL-паттерны категорий
Наконец, добавьте этот код в blog/api/urls.py:
...
from .models import Post, Comment, Category
urlpatterns = [
...
path('categories/', views.CategoryList.as_view()),
path('categories/<int:pk>/', views.CategoryDetail.as_view()),
]
Теперь отправляйтесь на http://127.0.0.1:8000/categories и создайте пару категорий. А на http://127.0.0.1:8000/posts создайте пост и выберите для него категории.
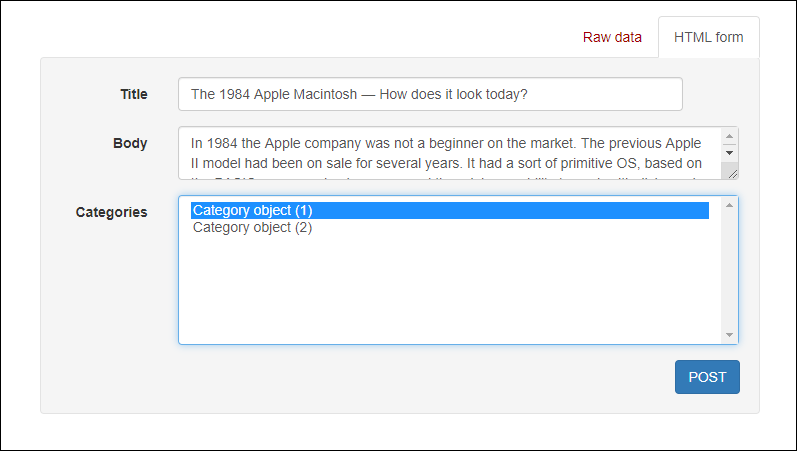
Выводы
Теперь у вас есть API блога с аутентификацией и многими распространенными паттернами API. Есть эндпоинты для получения, создания, обновления и удаления постов, категорий и комментариев. Также настроены отношения многие-к-одному и многие-ко-многим между этими ресурсами.
Чтобы расширить возможности своего API, переходите к официальной документации Django REST Framework. А ссылку на код этого урока можно найти в начале статьи.
]]>При этом Python — очень важный инструмент в арсенале любого разработчика. Для помощи вам я создал лучшее руководство по вопросам и ответам на собеседовании по Python, чтобы понять глубину и реальное их предназначение.
Помимо этих вопросов, вам также вероятно предоставят фрагменты кода, прочитав которые вы должны будете определить результирующее значение (или его отсутствие). Такие задания невозможно предсказать, и успешность их прохождения будет зависеть от вашего опыта программирования. Давайте начнем с самых популярных вопросов и ответов на собеседовании по Python.
Вопросы и ответы на собеседовании по Python 2021
1) В чем разница между модулем и пакетом в Python?
Каждый программный файл Python представляет собой модуль, который импортирует другие модули как объекты. Таким образом, модуль — это способ структурирования вашей программы. Папка с программой на Python называется пакетом модулей.
2) Какие встроенные типы доступны в Python?
Это один из наиболее распространенных вопросов на собеседовании. В Python есть изменяемые и неизменяемые встроенные типы.
К изменяемым относятся:
- Списки,
- Множества,
- Словари.
Представителями неизменяемых типов являются:
- Строки,
- Кортежи,
- Числа.
3) Что такое лямбда-функция в Python?
Лямбда часто используется как встраиваемая функция и представляет собой единственное анонимное функциональное выражение. Она применяется для создания нового объекта функции и его возврата во время выполнения.
Лямбда — это анонимная функция в Python, которая может принимать неограниченное количество аргументов и может иметь любое число параметров. Однако лямбда-функция может иметь только одно выражение или инструкцию. Обычно она используется в ситуациях, когда требуется анонимная функция в течение короткого периода времени. Лямбда-функции можно использовать одним из двух способов:
Пример лямбда-функции:
a = lambda x,y : x+y
print(a(5, 6))
# Вывод: 11
4) Что означает пространство имен?
Пространство имен представляет собой систему имен, которая используется для обеспечения уникальности наименования всех объектов в программе, чтобы избежать возможных конфликтов. В Python эти пространства имен реализованы как словари с именем в качестве ключа и объектом в качестве значения. В результате разные пространства могут давать своим объектам одинаковые имена.
Ниже приведены три типа пространств имен в Python:
- Локальное пространство имен — включает локальные имена внутри функции. Локальное пространство имен временно создается во время вызова функции и очищается при возврате из нее.
- Глобальное пространство имен — состоит из имен различных импортированных пакетов/модулей, которые в настоящее время используются в проекте. Глобальное пространство имен создается при импорте пакета в скрипт, и оно доступно до тех пор, пока скрипт не закончит выполнение.
- Встроенное пространство имен — оно включает встроенные функции Python и встроенные имена для различных типов исключений.
5) Объясните разницу между списком и кортежем?
Список изменяемый, а кортеж — нет. Кортежи можно хешировать, как в случае создания ключей для словарей.
6) Чем отличается pickling от unpickling?
Любое руководство по вопросам и ответам на собеседовании по Python не будет полным без этого вопроса. В Python модуль pickle принимает любой объект Python, преобразует его в строковое представление и выгружает его в файл с помощью функции dump. Такой процесс известен как pickling. Для этого процесса используется функция pickle.dump().
С другой стороны, процесс извлечения исходного объекта Python из сохраненного строкового представления называется unpickling. Для этого процесса используется функция pickle.load().
7) Что такое декораторы в Python?
Декоратор Python — это некоторое обновление синтаксиса Python, сделанное для более простого изменения функций.
8) Разница между генераторами и итераторами?
В Python итераторы используются для перебора группы элементов (например, в списке). Генераторы представляют собой способ реализации итераторов. В них применяется yield для возврата выражения из функции, но в остальном генератор ведет себя как обычная функция.
9) Как преобразовать число в строку?
Один из самых распространенных вопросов на собеседовании. Мы можем использовать встроенную функцию str(). Для восьмеричного или шестнадцатеричного представления числа мы можем использовать другие встроенные функции, такие как oct() или hex().
10) Как используется оператор // в Python?
Использование оператора // между двумя числами дает частное при делении числителя на знаменатель. Он также называется оператором деления без остатка.
11) Есть ли в Python инструкция Switch или Case, как в C?
Нет. Однако мы можем создать нашу собственную функцию Switch и использовать ее.
12) Что такое функция range() и каковы ее параметры?
Функция range() используется для создания списка из чисел. Разрешены только целые числа, поэтому переданные аргументы могут быть как отрицательными, так и положительными. Допустимы следующие параметры:
range(stop)
Где «stop» — это количество целых чисел для генерации, начиная с 0. Пример: list(range(5)) == [0,1,2,3,4]
Другие параметры: range([start], stop[, step]):
- Start: устанавливает первое число в последовательности.
- Stop: указывает верхний предел для последовательности.
- Step: коэффициент приращения в последовательности.
13) Как используется %s?
%s — это спецификатор формата, который преобразует любое значение в строку.
14) Обязательно ли функция Python должна возвращать значение?
Нет
15) Есть ли в Python функция main()?
Да, есть. Она выполняется автоматически всякий раз, когда мы запускаем скрипт. Если вы хотите изменить этот естественный порядок вещей, используйте оператор if.
16) Что такое GIL?
GIL или Global Interpreter Lock — это мьютекс, используемый для ограничения доступа к объектам Python. Он синхронизирует потоки и предотвращает их одновременное выполнение.
17) Какой метод использовался до оператора «in» для проверки наличия ключа в словаре?
Метод has_key().
18) Как изменить тип данных списка?
Чтобы преобразовать список в кортеж, мы используем функцию tuple().
Чтобы превратить его в множество — функцию set().
Для преобразования в словарь — dict().
Для превращения в строку — join().
19) Каковы ключевые особенности Python?
Это один из распространенных вопросов на собеседовании. Python — это язык программирования общего назначения высокого уровня с открытым исходным кодом. Поскольку это язык программирования общего назначения, и он поставляется с большим набором библиотек, вы можете использовать Python для разработки практически любого типа приложений.
Некоторые из его ключевых особенностей:
- Интерпретированный,
- С динамической типизацией,
- Объектно-ориентированный,
- Англоязычный синтаксис.
20) Объясните управление памятью в Python.
В Python диспетчер памяти заботится об управлении памятью. Он выделяет ее в виде пространства в куче, в которой хранятся все объекты Python и структуры данных. В языке существуют 4 встроенных структуры данных. Данное пространство недоступно для программиста напрямую. Однако базовый API позволяет разработчику получить доступ к некоторым инструментам для написания кода.
Кроме того, Python оснащен встроенным сборщиком мусора, который освобождает неиспользуемую память из пространства кучи.
21) Что такое PYTHONPATH?
PYTHONPATH — это переменная окружения, которая используется для включения дополнительных каталогов при импорте модуля/пакета. Каждый раз, когда модуль/пакет импортируется, PYTHONPATH используется для проверки наличия добавляемых модулей в существующих каталогах. Обычно интерпретатор использует PYTHONPATH, чтобы определить, какой модуль загрузить.
22) Чувствителен ли Python к регистру?
Язык программирования считается чувствительным к регистру, если он различает такие идентификаторы, как «myname» и «Myname». Проще говоря, он заботится, являются ли символы строчными или прописными.
Давайте посмотрим на пример:
>>> myname="John"
>>> Myname
Traceback (most recent call last):
File "", line 1, in
Myname
NameError: name 'Myname' is not defined
Возникновение ошибки NameError означает, что Python чувствителен к регистру.
23) Объясните использование функций help() и dir().
В Python функция help() используется для отображения документации по модулям, классам, функциям, ключевым словам и так далее. Если help() не получает параметров, она запускает интерактивную справочную утилиту на консоли.
Функция dir() возвращает допустимый список атрибутов и методов объекта, к которому она вызывается. Поскольку функция предназначена для получения наиболее релевантных данных (вместо отображения полной информации), она ведет себя по-разному с разными объектами:
- Для модулей/библиотек функция
dir()возвращает список всех атрибутов, содержащихся в этом модуле. - Для объектов класса
dir()вернет список всех допустимых атрибутов и базовых атрибутов. - Когда ей не передаются никакие параметры, функция
dir()возвращает список атрибутов в текущей области видимости.
24) Что такое модули Python?
Назовите некоторые наиболее часто используемые встроенные модули в Python?
Модули Python — это файлы, содержащие код на Python, который представляет собой либо функциональные классы, либо переменные. Модули являются файлами Python с расширением .py. Они могут включать в себя набор функций, классов или переменных, которые определены и реализованы. Вы можете импортировать и инициализировать модуль с помощью инструкции import. Изучив руководство по Python, вы можете узнать больше о модулях в Python.
Вот некоторые из наиболее часто используемых встроенных модулей в Python:
Операционные системы
- os,
- sys,
- math,
- random,
- datetime,
- JSON.
25) Объясните, что означает «self» в Python.
В Python «self» — это ключевое слово, применяемое для определения экземпляра или объекта класса. В отличие от Java, где self не является обязательным, в Python он используется как первый параметр. Self помогает отличать методы и атрибуты класса от его локальных переменных.
Переменная self в методе __init__ ссылается к созданному объекту или экземпляру, тогда как в других методах она указывает на объект или экземпляр, метод которого был вызван.
Хотите получить работу Python-разработчика?
Тогда вам нужно выполнить следующий алгоритм:
- Записаться на курс от Skillbox «Профессия Python-разработчик»;
- Познакомиться с индивидуальным наставником, который поможет вам создать свою первую программу на Python и получить реальный опыт разработки;
- Пройти 7 блоков обучения с разным уровнем сложности, знание которых можно приравнять к году работы;
- Защитить диплом перед реальными заказчиками. Это не сложно, так как к концу обучения у вас будет 2 проекта на Github и глубокое понимание Python;
- Вместе с опытными HR-специалистами составить резюме и подготовится к собеседованию;
- Пройти собеседования на подобранные для вас вакансии Центром карьеры Skillbox.
Переходите по ссылке и перенимайте знания у профи: Профессия Python-разработчик.
]]>
√25 = ±5
Для отрицательного числа результат извлечения квадратного корня включает комплексные числа, обсуждение которых выходит за рамки данной статьи.
Математическое представление квадрата числа
Все мы в детстве узнали, что, когда число умножается само на себя, мы получаем его квадрат. Также квадрат числа можно представить как многократное умножение этого числа. Попробуем разобраться в этом на примере.
Предположим, мы хотим получить квадрат 5. Если мы умножим число (в данном случае 5) на 5, мы получим квадрат этого числа. Для обозначения квадрата числа используется следующая запись:
52 = 25
При программировании на Python довольно часто возникает необходимость использовать функцию извлечения квадратного корня. Есть несколько способов найти квадратный корень числа в Python.
1. Используя оператор возведения в степень
num = 25
sqrt = num ** (0.5)
print("Квадратный корень из числа "+str(num)+" это "+str(sqrt))
Вывод:
Квадратный корень из числа 25 это 5.0Объяснение: Мы можем использовать оператор «**» в Python, чтобы получить квадратный корень. Любое число, возведенное в степень 0.5, дает нам квадратный корень из этого числа.
2. Использование math.sqrt()
Квадратный корень из числа можно получить с помощью функции sqrt() из модуля math, как показано ниже. Далее мы увидим три сценария, в которых передадим положительный, нулевой и отрицательный числовые аргументы в sqrt().
a. Использование положительного числа в качестве аргумента.
import math
num = 25
sqrt = math.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа 25 это 5.0.
b. Использование ноля в качестве аргумента.
import math
num = 0
sqrt = math.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа 0 это 0.0.
c. Использование отрицательного числа в качестве аргумента.
import math
num = -25
sqrt = math.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод:
Traceback (most recent call last):
File "C:\wb.py", line 3, in <module>
sqrt = math.sqrt(num)
ValueError: math domain errorОбъяснение: Когда мы передаем отрицательное число в качестве аргумента, мы получаем следующую ошибку «math domain error». Из чего следует, что аргумент должен быть больше 0. Итак, чтобы решить эту проблему, мы должны использовать функцию sqrt() из модуля cmath.
3. Использование cmath.sqrt()
Ниже приведены примеры применения cmath.sqrt().
а. Использование отрицательного числа в качестве аргумента.
import cmath
num = -25
sqrt = cmath.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа -25 это 5j.
Объяснение: Для отрицательных чисел мы должны использовать функцию sqrt() модуля cmath, которая занимается математическими вычислениями над комплексными числами.
b. Использование комплексного числа в качестве аргумента.
import cmath
num = 4 + 9j
sqrt = cmath.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа (4+9j) это (2.6314309606938298+1.7100961671491028j).
Объяснение: Для нахождения квадратного корня из комплексного числа мы также можем использовать функцию cmath.sqrt().
4. Использование np.sqrt()
import numpy as np
num = -25
sqrt = np.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод:
...
RuntimeWarning: invalid value encountered in sqrt
Квадратный корень из числа -25 это nan5. Использование scipy.sqrt()
import scipy as sc
num = 25
sqrt = sc.sqrt(num)
print("Квадратный корень из числа " + str(num) + " это " + str(sqrt))
Вывод: Квадратный корень из числа 25 это 5.0.
Объяснение: Как и функция sqrt() модуля numpy, в scipy квадратный корень из положительных, нулевых и комплексных чисел может быть успешно вычислен, но для отрицательных возвращается nan с RunTimeWarning.
6. Использование sympy.sqrt()
import sympy as smp
num = 25
sqrt = smp.sqrt(num)
print("Квадратный корень из числа "+str(num)+" это "+str(sqrt))
Вывод: Квадратный корень из числа 25 это 5.
Объяснение: sympy — это модуль Python для символьных вычислений. С помощью функции sympy.sqrt() мы можем получить квадратный корень из положительных, нулевых, отрицательных и комплексных чисел. Единственная разница между этим и другими методами заключается в том, что, если при использовании sympy.sqrt() аргумент является целым числом, то результат также является целым числом, в отличие от других способов, в которых возвращаемое значение всегда число с плавающей точкой, независимо от типа данных аргумента.
Заключение
Наконец, мы подошли к завершению этой статьи. В начале мы кратко затронули использование квадратного корня в математике. Затем мы обсудили принципы внутреннего устройства функции извлечения квадратного корня и ее возможную реализацию. В завершении мы рассмотрели различные методы применения этой функции в Python.
]]>Наличие готовых датасетов является огромным преимуществом, потому что вы можете сразу приступить к созданию моделей, не тратя время на получение, очистку и преобразование данных — на что специалисты по данным тратят много времени.
Даже после того, как вся подготовительная работа выполнена, применение выборок Scikit-Learn поначалу может показаться вам немного запутанным. Не волнуйтесь, через несколько минут вы точно узнаете, как использовать датасеты, и встанете на путь исследования мира искусственного интеллекта. В этой статье предполагается, что у вас установлены python, scikit-learn, pandas и Jupyter Notebook (или вы можете воспользоваться Google Collab). Давайте начнем.
Введение в Scikit-Learn datasets
Scikit-Learn предоставляет семь наборов данных, которые они называют игровыми датасетами. Не дайте себя обмануть словом «игровой». Эти выборки довольно объемны и служат хорошей отправной точкой для изучения машинного обучения (далее ML). Вот несколько примеров доступных наборов данных и способы их использования:
- Цены на жилье в Бостоне — используйте ML для прогнозирования цен на жилье на основе таких атрибутов, как количество комнат, уровень преступности в городе.
- Датасет диагностики рака молочной железы (Висконсин) — используйте ML для диагностики рака как доброкачественного (не распространяется на остальную часть тела) или злокачественного (распространяется).
- Распознавание вина — используйте ML для определения типа вина по химическим свойствам.
В этой статье мы будем работать с “Breast Cancer Wisconsin” (рак молочной железы, штат Висконсин) датасетом. Мы импортируем данные и разберем, как их читать. В качестве бонуса мы построим простую модель машинного обучения, которая сможет классифицировать сканированные изображения рака как злокачественные или доброкачественные.
Чтобы узнать больше о предоставленных выборках, нажмите здесь для перехода на документацию Scikit-Learn.
Как импортировать модуль datasets?
Доступные датасеты можно найти в sklearn.datasets. Давайте импортируем необходимые данные. Сначала мы добавим модуль datasets, который содержит все семь выборок.
from sklearn import datasets
У каждого датасета есть соответствующая функция, используемая для его загрузки. Эти функции имеют единый формат: «load_DATASET()», где DATASET — названием выборки. Для загрузки набора данных о раке груди мы используем load_breast_cancer(). Точно так же при распознавании вина мы вызовем load_wine(). Давайте загрузим выбранные данные и сохраним их в переменной data.
data = datasets.load_breast_cancer()
До этого момента мы не встретили никаких проблем. Но упомянутые выше функции загрузки (такие как load_breast_cancer()) не возвращают данные в табличном формате, который мы привыкли ожидать. Вместо этого они передают нам объект Bunch.
Не знаете, что такое Bunch? Не волнуйтесь. Считайте объект Bunch причудливым аналогом словаря от библиотеки Scikit-Learn.
Давайте быстро освежим память. Словарь — это структура данных, в которой данные хранятся в виде ключей и значений. Думайте о нем как о книге с аналогичным названием, к которой мы привыкли. Вы ищете интересующее вас слово (ключ) и получаете его определение (значение). У программистов есть возможность делать ключи и соответствующие значения какими угодно (могут быть словами, числами и так далее).
Например, в случае хранения персональных контактов ключами являются имена, а значениями — телефонные номера. Таким образом, словарь в Python не ограничивается его типичной репрезентацией, но может быть применен ко всему, что вам нравится.
Что в нашем Bunch-словаре?
Предоставленный Sklearn словарь Bunch — достаточно мощный инструмент. Давайте узнаем, какие ключи нам доступны.
print(data.keys())
Получаем следующие ключи:
data— это необходимые для предсказания данные (показатели, полученные при сканировании, такие как радиус, площадь и другие) в массиве NumPy.target— это целевые данные (переменная, которую вы хотите предсказать, в данном случае является ли опухоль злокачественной или доброкачественной) в массиве NumPy.
Значения этих двух ключей предоставляют нам необходимые для обучения данные. Остальные ключи (смотри ниже) имеют пояснительное предназначение. Важно отметить, что все датасеты в Scikit-Learn разделены на data и target. data представляет собой показатели, переменные, которые используются моделью для тренировки. target включает в себя фактические метки классов. В нашем случае целевые данные — это один столбец, в котором опухоль классифицируется как 0 (злокачественная) или 1 (доброкачественная).
feature_names— это названия показателей, другими словами, имена столбцов вdata.target_names— это имя целевой переменной или переменных, другими словами, название целевого столбца или столбцов.DESCR— сокращение от DESCRIPTION, представляет собой описание выборки.filename— это путь к файлу с данными в формате CSV.
Чтобы посмотреть значение ключа, вы можете ввести data.KEYNAME, где KEYNAME — интересующий ключ. Итак, если мы хотим увидеть описание датасета:
print(data.DESCR)
Вот небольшая часть полученного результата (полная версия слишком длинная для добавления в статью):
.. _breast_cancer_dataset:
Breast cancer wisconsin (diagnostic) dataset
--------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
...Вы также можете узнать информацию о выборке, посетив документацию Scikit-Learn. Их документация намного более читабельна и точна.
Работа с датасетом
Теперь, когда мы понимаем, что возвращает функция загрузки, давайте посмотрим, как можно использовать датасет в нашей модели машинного обучения. Прежде всего, если вы хотите изучить выбранный набор данных, используйте для этого pandas. Вот так:
# импорт pandas
import pandas as pd
# Считайте DataFrame, используя данные функции
df = pd.DataFrame(data.data, columns=data.feature_names)
# Добавьте столбец "target" и заполните его данными.
df['target'] = data.target
# Посмотрим первые пять строк
df.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | … | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | … | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | … | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | … | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | … | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | … | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Вы загрузили обучающую выборку в Pandas DataFrame, которая теперь полностью готова к изучению и использованию. Чтобы действительно увидеть возможности этого датасета, запустите:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 569 entries, 0 to 568
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mean radius 569 non-null float64
1 mean texture 569 non-null float64
2 mean perimeter 569 non-null float64
3 mean area 569 non-null float64
4 mean smoothness 569 non-null float64
5 mean compactness 569 non-null float64
6 mean concavity 569 non-null float64
7 mean concave points 569 non-null float64
8 mean symmetry 569 non-null float64
9 mean fractal dimension 569 non-null float64
10 radius error 569 non-null float64
11 texture error 569 non-null float64
12 perimeter error 569 non-null float64
13 area error 569 non-null float64
14 smoothness error 569 non-null float64
15 compactness error 569 non-null float64
16 concavity error 569 non-null float64
17 concave points error 569 non-null float64
18 symmetry error 569 non-null float64
19 fractal dimension error 569 non-null float64
20 worst radius 569 non-null float64
21 worst texture 569 non-null float64
22 worst perimeter 569 non-null float64
23 worst area 569 non-null float64
24 worst smoothness 569 non-null float64
25 worst compactness 569 non-null float64
26 worst concavity 569 non-null float64
27 worst concave points 569 non-null float64
28 worst symmetry 569 non-null float64
29 worst fractal dimension 569 non-null float64
30 target 569 non-null int32
dtypes: float64(30), int32(1)
memory usage: 135.7 KBНесколько вещей, на которые следует обратить внимание:
- Нет пропущенных данных, все столбцы содержат 569 значений. Это избавляет нас от необходимости учитывать отсутствующие значения.
- Все типы данных числовые. Это важно, потому что модели Scikit-Learn не принимают качественные переменные. В реальном мире, когда получаем такие переменные, мы преобразуем их в числовые. Датасеты Scikit-Learn не содержат качественных значений.
Следовательно, Scikit-Learn берет на себя работу по очистке данных. Эти наборы данных чрезвычайно удобны. Вы получите удовольствие от изучения машинного обучения, используя их.
Обучение на датесете из sklearn.datasets
Наконец, самое интересное. Далее мы построим модель, которая классифицирует раковые опухоли как злокачественные и доброкачественные. Это покажет вам, как использовать данные для ваших собственных моделей. Мы построим простую модель K-ближайших соседей.
Во-первых, давайте разделим выборку на две: одну для тренировки модели — предоставление ей данных для обучения, а вторую — для тестирования, чтобы посмотреть, насколько хорошо модель работает с данными (результаты сканирования), которые она раньше не видела.
X = data.data
y = data.target
# разделим данные с помощью Scikit-Learn's train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
Это дает нам два датасета — один для обучения и один для тестирования. Приступим к тренировке модели.
from sklearn.neighbors import KNeighborsClassifier
logreg = KNeighborsClassifier(n_neighbors=6)
logreg.fit(X_train, y_train)
logreg.score(X_test, y_test)
Получили на выходе 0.923? Это означает, что модель точна на 92%! Всего за несколько минут вы создали модель, которая классифицирует результаты сканирования опухолей с точностью 90%. Конечно, в реальном мире все сложнее, но это хорошее начало.
Ноутбук с кодом вы можете скачать здесь.
Вы многому научитесь, пытаясь построить модели с использованием datasets из Scikit-Learn. Удачного обучения искусственному интеллекту!
]]>Установка PyInstaller не отличается от установки любой другой библиотеки Python.
pip install PyInstaller
Вот так можно проверить версию PyInstaller.
pyinstaller --versionЯ использую PyInstaller версии 4.2.
Создание exe файла с помощью PyInstaller
PyInstaller собирает в один пакет Python-приложение и все необходимые ему библиотеки следующим образом:
- Считывает файл скрипта.
- Анализирует код для выявления всех зависимостей, необходимых для работы.
- Создает файл spec, который содержит название скрипта, библиотеки-зависимости, любые файлы, включая те параметры, которые были переданы в команду PyInstaller.
- Собирает копии всех библиотек и файлов вместе с активным интерпретатором Python.
- Создает папку BUILD в папке со скриптом и записывает логи вместе с рабочими файлами в BUILD.
- Создает папку DIST в папке со скриптом, если она еще не существует.
- Записывает все необходимые файлы вместе со скриптом или в одну папку, или в один исполняемый файл.
Если использовать параметр команды onedir или -D при генерации исполняемого файла, тогда все будет помещено в одну папку. Это поведение по умолчанию. Если же использовать параметр onefile или -F, то все окажется в одном исполняемом файле.
Возьмем в качестве примера простейший скрипт на Python c названием simple.py, который содержит такой код.
import time
name = input("Введите ваше имя ")
print("Ваше имя ", name)
time.sleep(5)
Создадим один исполняемый файл. В командной строке введите:
pyinstaller --onefile simple.py
После завершения установки будет две папки, BUILD и DIST, а также новый файл с расширением .spec. Spec-файл будет называться так же, как и файл скрипта.
Python создает каталог распространения, который содержит основной исполняемый файл, а также все динамические библиотеки.
Вот что произойдет после запуска файла.
Добавление файлов с данными, которые будут использоваться exe-файлом
Есть CSV-файл netflix_titles.csv, и Python-script, который считывает количество записей в нем. Теперь нужно добавить этот файл в бандл с исполняемым файлом. Файл Python-скрипта назовем просто simple1.py.
import time
# pip install pandas
import pandas as pd
def count_records():
data = pd.read_csv('netflix_titles.csv')
print("Всего фильмов:", data.shape[0])
if __name__ == "__main__":
count_records()
time.sleep(5)
Создадим исполняемый файл с данными в папке.
pyinstaller --add-data "netflix_titles.csv;." simple1.py
Параметр --add-data позволяет добавить файлы с данными, которые нужно сохранить в одном бандле с исполняемым файлом. Этот параметр можно применить много раз.
Синтаксис add-data:
- add-data <source;destination> — Windows.
- add-data <source:destination> — Linux.
Можно увидеть, что файл теперь добавляется в папку DIST вместе с исполняемым файлом.
Также, открыв spec-файл, можно увидеть раздел datas, в котором указывается, что файл netflix_titles.csv копируется в текущую директорию.
...
a = Analysis(['simple1.py'],
pathex=['E:\\myProject\\pyinstaller-tutorial'],
binaries=[],
datas=[('netflix_titles.csv', '.')],
...Запустим файл simple1.exe, появится консоль с выводом: Всего фильмов: 7787.
Добавление файлов с данными и параметр onefile
Если задать параметр --onefile, то PyInstaller распаковывает все файлы в папку TEMP, выполняет скрипт и удаляет TEMP. Если вместе с add-data указать onefile, то нужно считать данные из папки. Путь папки меняется и похож на «_MEIxxxxxx-folder».
import time
import sys
import os
# pip install pandas
import pandas as pd
def count_records():
os.chdir(sys._MEIPASS)
data = pd.read_csv('netflix_titles.csv')
print("Всего фильмов:", data.shape[0])
if __name__ == "__main__":
count_records()
time.sleep(5)
Скрипт обновлен для чтения папки TEMP и файлов с данными. Создадим exe-файл с помощью onefile и add-data.
pyinstaller --onefile --add-data "netflix_titles.csv;." simple1.pyПосле успешного создания файл simple1.exe появится в папке DIST.
Можно скопировать исполняемый файл на рабочий стол и запустить, чтобы убедиться, что нет никакой ошибки, связанной с отсутствием файла.
Дополнительные импорты с помощью Hidden Imports
Исполняемому файлу требуются все импорты, которые нужны Python-скрипту. Иногда PyInstaller может пропустить динамические импорты или импорты второго уровня, возвращая ошибку ImportError: No module named…
Для решения этой ошибки нужно передать название недостающей библиотеки в hidden-import.
Например, чтобы добавить библиотеку os, нужно написать вот так:
pyinstaller --onefile --add-data "netflix_titles.csv;." — hidden-import "os" simple1.pyФайл spec
Файл spec — это первый файл, который PyInstaller создает, чтобы закодировать содержимое скрипта Python вместе с параметрами, переданными при запуске.
PyInstaller считывает содержимое файла для создания исполняемого файла, определяя все, что может понадобиться для него.
Файл с расширением .spec сохраняется по умолчанию в текущей директории.
Если у вас есть какое-либо из нижеперечисленных требований, то вы можете изменить файл спецификации:
- Собрать в один бандл с исполняемым файлы данных.
- Включить другие исполняемые файлы: .dll или .so.
- С помощью библиотек собрать в один бандл несколько программы.
Например, есть скрипт simpleModel.py, который использует TensorFlow и выводит номер версии этой библиотеки.
import time
import tensorflow as tf
def view_model():
print(tf.__version__)
if __name__ == "__main__" :
model = view_model()
time.sleep(5)
Компилируем модель с помощью PyInstaller:
pyinstaller -F simpleModel.pyПосле успешной компиляции запускаем исполняемый файл, который возвращает следующую ошибку.
...
File "site-packages\tensorflow_core\python_init_.py", line 49, in ImportError: cannot import name 'pywrap_tensorflow' from 'tensorflow_core.python' Исправим ее, обновив файл spec. Одно из решений — создать файл spec.
$ pyi-makespec simpleModel.py -F
wrote E:\pyinstaller-tutorial\simpleModel.spec
now run pyinstaller.py to build the executable
Команда pyi-makespec создает spec-файл по умолчанию, содержащий все параметры, которые можно указать в командной строке. Файл simpleModel.spec создается в текущей директории.
Поскольку был использован параметр --onefile, то внутри файла будет только раздел exe.
...
exe = EXE(pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='simpleModel',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
upx_exclude=[],
runtime_tmpdir=None,
console=True )Если использовать параметр по умолчанию или onedir, то вместе с exe-разделом будет также и раздел collect.
Можно открыть simpleModel.spec и добавить следующий текст для создания хуков.
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
import os
spec_root = os.path.realpath(SPECPATH)
options = []
from PyInstaller.utils.hooks import collect_submodules, collect_data_files
tf_hidden_imports = collect_submodules('tensorflow_core')
tf_datas = collect_data_files('tensorflow_core', subdir=None, include_py_files=True)
a = Analysis(['simpleModel.py'],
pathex=['E:\\myProject\\pyinstaller-tutorial'],
binaries=[],
datas=tf_datas + [],
hiddenimports=tf_hidden_imports + [],
hookspath=[],
...Создаем хуки и добавляем их в hidden imports и раздел данных.
Хуки
Файлы хуков расширяют возможность PyInstaller обрабатывать такие требования, как необходимость включать дополнительные данные или импортировать динамические библиотеки.
Обычно пакеты Python используют нормальные методы для импорта своих зависимостей, но в отдельных случаях, как например TensorFlow, существует необходимость импорта динамических библиотек. PyInstaller не может найти все библиотеки, или же их может быть слишком много. В таком случае рекомендуется использовать вспомогательный инструмент для импорта из PyInstaller.utils.hooks и собрать все подмодули для библиотеки.
Скомпилируем модель после обновления файла simpleModel.spec.
pyinstaller simpleModel.spec
Скопируем исполняемый файл на рабочий стол и увидим, что теперь он корректно отображает версию TensorFlow.
Вывод:
PyInstaller предлагает несколько вариантов создания простых и сложных исполняемых файлов из Python-скриптов:
- Исполняемый файл может собрать в один бандл все требуемые данные с помощью параметра
--add-data. - Исполняемый файл и зависимые данные с библиотеками можно собрать в один файл или папку с помощью
--onefileили--onedirсоответственно. - Динамические импорты и библиотеки второго уровня можно включить с помощью
hidden-imports. - Файл spec позволяет создать исполняемый файл для обработки скрытых импортов и других файлов данных с помощью хуков.
В этом руководстве обсуждается матрица ошибок и то, как рассчитываются precision, recall и accuracy метрики.
Здесь мы рассмотрим:
- Матрицу ошибок для двоичной классификации.
- Матрицу ошибок для мультиклассовой классификации.
- Расчет матрицы ошибок с помощью Scikit-learn.
- Accuracy, Precision и Recall.
- Precision или Recall?
Матрица ошибок для бинарной классификации
В бинарной классификации каждая выборка относится к одному из двух классов. Обычно им присваиваются такие метки, как 1 и 0, или положительный и отрицательный (Positive и Negative). Также могут использоваться более конкретные обозначения для классов: злокачественный или доброкачественный (например, если проблема связана с классификацией рака), успех или неудача (если речь идет о классификации результатов тестов учащихся).
Предположим, что существует проблема бинарной классификации с классами positive и negative. Вот пример достоверных или эталонных меток для семи выборок, используемых для обучения модели.
positive, negative, negative, positive, positive, positive, negativeТакие наименования нужны в первую очередь для того, чтобы нам, людям, было проще различать классы. Для модели более важна числовая оценка. Обычно при передаче очередного набора данных на выходе вы получите не метку класса, а числовой результат. Например, когда эти семь семплов вводятся в модель, каждому классу будут назначены следующие значения:
0.6, 0.2, 0.55, 0.9, 0.4, 0.8, 0.5На основании полученных оценок каждой выборке присваивается соответствующий класс. Такое преобразование числовых результатов в метки происходит с помощью порогового значения. Данное граничное условие является гиперпараметром модели и может быть определено пользователем. Например, если порог равен 0.5, тогда любая оценка, которая больше или равна 0.5, получает положительную метку. В противном случае — отрицательную. Вот предсказанные алгоритмом классы:
positive (0.6), negative (0.2), positive (0.55), positive (0.9), negative (0.4), positive (0.8), positive (0.5)Сравните достоверные и полученные метки — мы имеем 4 верных и 3 неверных предсказания. Стоит добавить, что изменение граничного условия отражается на результатах. Например, установка порога, равного 0.6, оставляет только два неверных прогноза.
Реальность: positive, negative, negative, positive, positive, positive, negative
Предсказания: positive, negative, positive, positive, negative, positive, positiveДля получения дополнительной информации о характеристиках модели используется матрица ошибок (confusion matrix). Матрица ошибок помогает нам визуализировать, «ошиблась» ли модель при различении двух классов. Как видно на следующем рисунке, это матрица 2х2. Названия строк представляют собой эталонные метки, а названия столбцов — предсказанные.
Четыре элемента матрицы (клетки красного и зеленого цвета) представляют собой четыре метрики, которые подсчитывают количество правильных и неправильных прогнозов, сделанных моделью. Каждому элементу дается метка, состоящая из двух слов:
- True или False.
- Positive или Negative.
True, если получено верное предсказание, то есть эталонные и предсказанные метки классов совпадают, и False, когда они не совпадают. Positive или Negative — названия предсказанных меток.
Таким образом, всякий раз, когда прогноз неверен, первое слово в ячейке False, когда верен — True. Наша цель состоит в том, чтобы максимизировать показатели со словом «True» (True Positive и True Negative) и минимизировать два других (False Positive и False Negative). Четыре метрики в матрице ошибок представляют собой следующее:
- Верхний левый элемент (True Positive): сколько раз модель правильно классифицировала Positive как Positive?
- Верхний правый (False Negative): сколько раз модель неправильно классифицировала Positive как Negative?
- Нижний левый (False Positive): сколько раз модель неправильно классифицировала Negative как Positive?
- Нижний правый (True Negative): сколько раз модель правильно классифицировала Negative как Negative?
Мы можем рассчитать эти четыре показателя для семи предсказаний, использованных нами ранее. Полученная матрица ошибок представлена на следующем рисунке.
Вот так вычисляется матрица ошибок для задачи двоичной классификации. Теперь посмотрим, как решить данную проблему для большего числа классов.
Матрица ошибок для мультиклассовой классификации
Что, если у нас более двух классов? Как вычислить эти четыре метрики в матрице ошибок для задачи мультиклассовой классификации? Очень просто!
Предположим, имеется 9 семплов, каждый из которых относится к одному из трех классов: White, Black или Red. Вот достоверные метки для 9 выборок:
Red, Black, Red, White, White, Red, Black, Red, WhiteПосле загрузки данных модель делает следующее предсказание:
Red, White, Black, White, Red, Red, Black, White, RedДля удобства сравнения здесь они расположены рядом.
Реальность: Red, Black, Red, White, White, Red, Black, Red, White Предсказания: Red, White, Black, White, Red, Red, Black, White, RedПеред вычислением матрицы ошибок необходимо выбрать целевой класс. Давайте назначим на эту роль класс Red. Он будет отмечен как Positive, а все остальные отмечены как Negative.
Positive, Negative, Positive, Negative, Negative, Positive, Negative, Positive, Negative Positive, Negative, Negative, Negative, Positive, Positive, Negative, Negative, Positive11111111111111111111111После замены остались только два класса (Positive и Negative), что позволяет нам рассчитать матрицу ошибок, как было показано в предыдущем разделе. Стоит заметить, что полученная матрица предназначена только для класса Red.
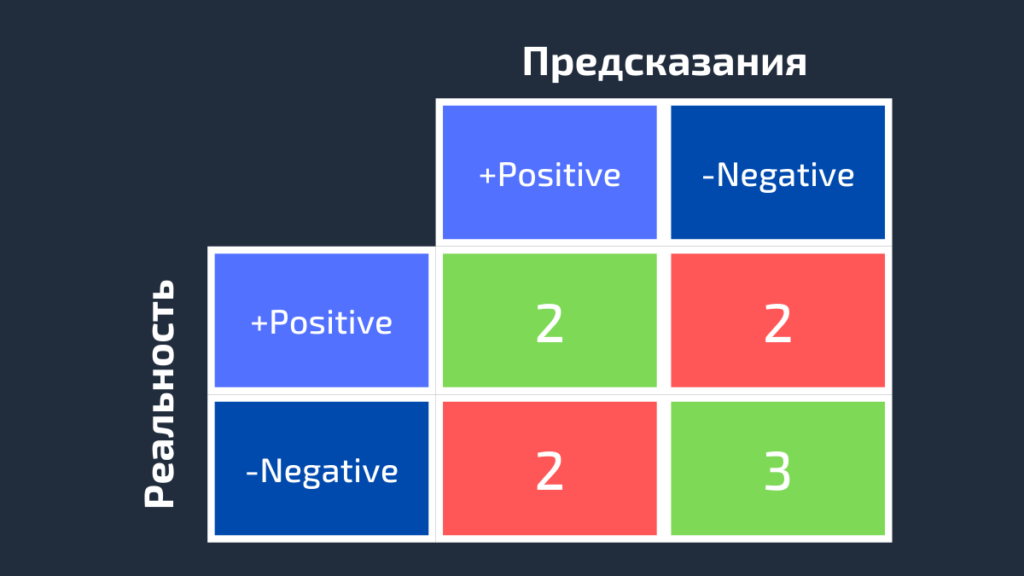
Далее для класса White заменим каждое его вхождение на Positive, а метки всех остальных классов на Negative. Мы получим такие достоверные и предсказанные метки:
Negative, Negative, Negative, Positive, Positive, Negative, Negative, Negative, Positive Negative, Positive, Negative, Positive, Negative, Negative, Negative, Positive, NegativeНа следующей схеме показана матрица ошибок для класса White.
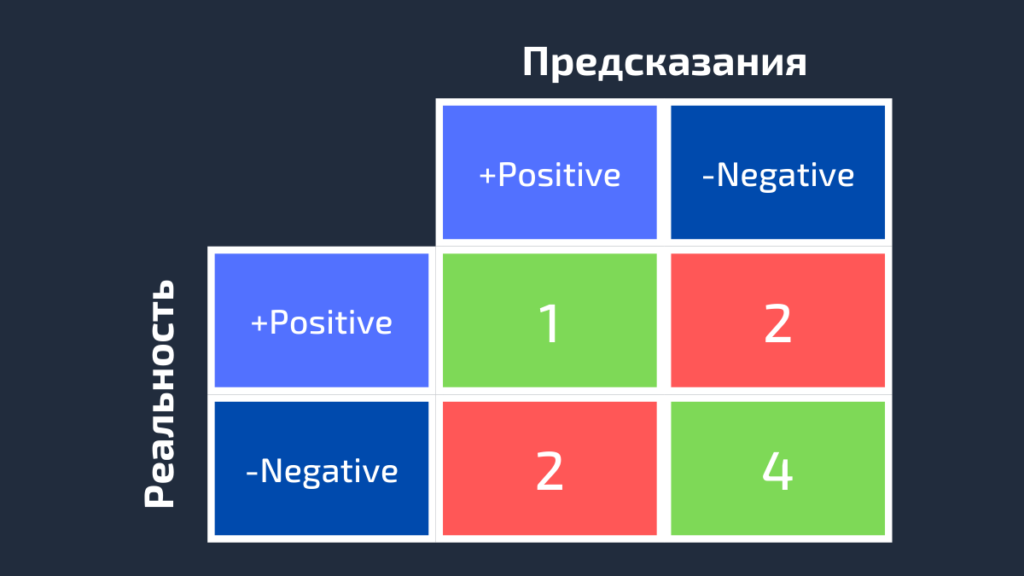
Точно так же может быть получена матрица ошибок для Black.
Расчет матрицы ошибок с помощью Scikit-Learn
В популярной Python-библиотеке Scikit-learn есть модуль metrics, который можно использовать для вычисления метрик в матрице ошибок.
Для задач с двумя классами используется функция confusion_matrix(). Мы передадим в функцию следующие параметры:
y_true: эталонные метки.y_pred: предсказанные метки.
Следующий код вычисляет матрицу ошибок для примера двоичной классификации, который мы обсуждали ранее.
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
print(r)
array([[1, 2],
[1, 3]], dtype=int64)Обратите внимание, что порядок метрик отличается от описанного выше. Например, показатель True Positive находится в правом нижнем углу, а True Negative — в верхнем левом углу. Чтобы исправить это, мы можем перевернуть матрицу.
import numpy
r = numpy.flip(r)
print(r)
array([[3, 1],
[2, 1]], dtype=int64)Чтобы вычислить матрицу ошибок для задачи с большим числом классов, используется функция multilabel_confusion_matrix(), как показано ниже. В дополнение к параметрам y_true и y_pred третий параметр labels принимает список классовых меток.
import sklearn.metrics
import numpy
y_true = ["Red", "Black", "Red", "White", "White", "Red", "Black", "Red", "White"]
y_pred = ["Red", "White", "Black", "White", "Red", "Red", "Black", "White", "Red"]
r = sklearn.metrics.multilabel_confusion_matrix(y_true, y_pred, labels=["White", "Black", "Red"])
print(r)
array([
[[4 2]
[2 1]]
[[6 1]
[1 1]]
[[3 2]
[2 2]]], dtype=int64)Функция вычисляет матрицу ошибок для каждого класса и возвращает все матрицы. Их порядок соответствует порядку меток в параметре labels. Чтобы изменить последовательность метрик в матрицах, мы будем снова использовать функцию numpy.flip().
print(numpy.flip(r[0])) # матрица ошибок для класса White
print(numpy.flip(r[1])) # матрица ошибок для класса Black
print(numpy.flip(r[2])) # матрица ошибок для класса Red
# матрица ошибок для класса White
[[1 2]
[2 4]]
# матрица ошибок для класса Black
[[1 1]
[1 6]]
# матрица ошибок для класса Red
[[2 2]
[2 3]]В оставшейся части этого текста мы сосредоточимся только на двух классах. В следующем разделе обсуждаются три ключевых показателя, которые рассчитываются на основе матрицы ошибок.
Accuracy, Precision и Recall
Как мы уже видели, матрица ошибок предлагает четыре индивидуальных показателя. На их основе можно рассчитать другие метрики, которые предоставляют дополнительную информацию о поведении модели:
- Accuracy
- Precision
- Recall
В следующих подразделах обсуждается каждый из этих трех показателей.
Метрика Accuracy
Accuracy — это показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен. Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Рассчитаем accuracy с помощью Scikit-learn на основе ранее полученной матрицы ошибок. Переменная acc содержит результат деления суммы True Positive и True Negative метрик на сумму всех значений матрицы. Таким образом, accuracy, равная 0.5714, означает, что модель с точностью 57,14% делает верный прогноз.
import numpy
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
r = numpy.flip(r)
acc = (r[0][0] + r[-1][-1]) / numpy.sum(r)
print(acc)
# вывод будет 0.571
В модуле sklearn.metrics есть функция precision_score(), которая также может вычислять accuracy. Она принимает в качестве аргументов достоверные и предсказанные метки.
acc = sklearn.metrics.accuracy_score(y_true, y_pred)
Стоит учесть, что метрика accuracy может быть обманчивой. Один из таких случаев — это несбалансированные данные. Предположим, у нас есть всего 600 единиц данных, из которых 550 относятся к классу Positive и только 50 — к Negative. Поскольку большинство семплов принадлежит к одному классу, accuracy для этого класса будет выше, чем для другого.
Если модель сделала 530 правильных прогнозов из 550 для класса Positive, по сравнению с 5 из 50 для Negative, то общая accuracy равна (530 + 5) / 600 = 0.8917. Это означает, что точность модели составляет 89.17%. Полагаясь на это значение, вы можете подумать, что для любой выборки (независимо от ее класса) модель сделает правильный прогноз в 89.17% случаев. Это неверно, так как для класса Negative модель работает очень плохо.
Precision
Precision представляет собой отношение числа семплов, верно классифицированных как Positive, к общему числу выборок с меткой Positive (распознанных правильно и неправильно). Precision измеряет точность модели при определении класса Positive.
Когда модель делает много неверных Positive классификаций, это увеличивает знаменатель и снижает precision. С другой стороны, precision высока, когда:
- Модель делает много корректных предсказаний класса Positive (максимизирует True Positive метрику).
- Модель делает меньше неверных Positive классификаций (минимизирует False Positive).
Представьте себе человека, который пользуется всеобщим доверием; когда он что-то предсказывает, окружающие ему верят. Метрика precision похожа на такого персонажа. Если она высока, вы можете доверять решению модели по определению очередной выборки как Positive. Таким образом, precision помогает узнать, насколько точна модель, когда она говорит, что семпл имеет класс Positive.
Основываясь на предыдущем обсуждении, вот определение precision:
Precision отражает, насколько надежна модель при классификации Positive-меток.
На следующем изображении зеленая метка означает, что зеленый семпл классифицирован как Positive, а красный крест – как Negative. Модель корректно распознала две Positive выборки, но неверно классифицировала один Negative семпл как Positive. Из этого следует, что метрика True Positive равна 2, когда False Positive имеет значение 1, а precision составляет 2 / (2 + 1) = 0.667. Другими словами, процент доверия к решению модели, что выборка относится к классу Positive, составляет 66.7%.
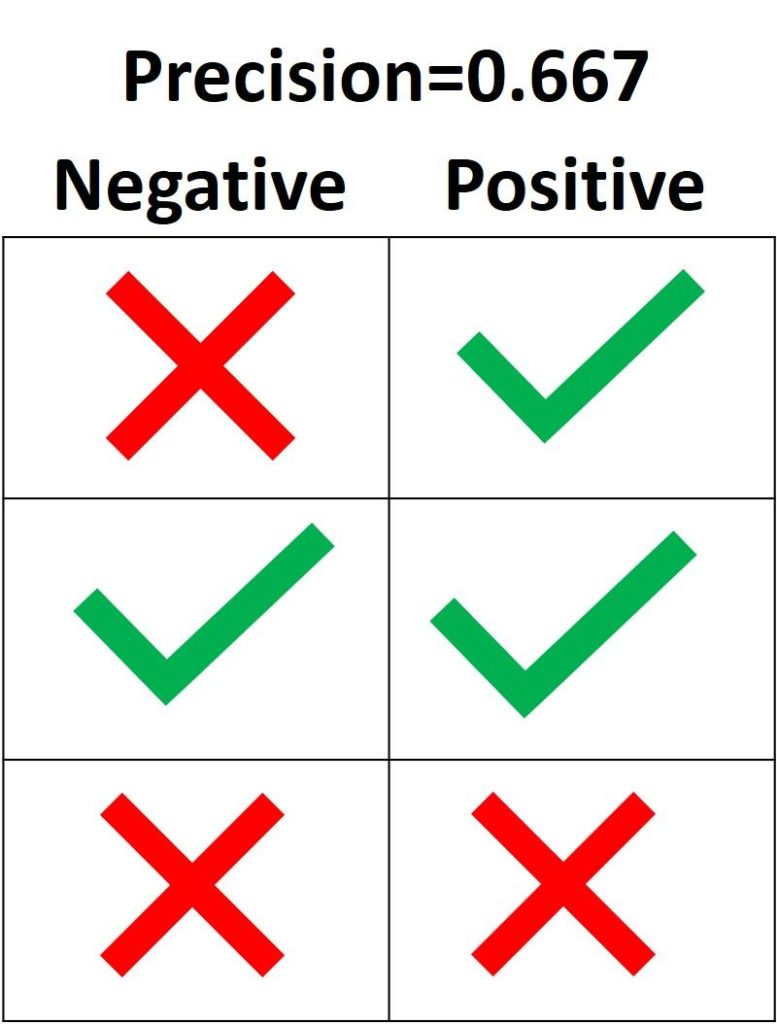
Цель precision – классифицировать все Positive семплы как Positive, не допуская ложных определений Negative как Positive. Согласно следующему рисунку, если все три Positive выборки предсказаны правильно, но один Negative семпл классифицирован неверно, precision составляет 3 / (3 + 1) = 0.75. Таким образом, утверждения модели о том, что выборка относится к классу Positive, корректны с точностью 75%.
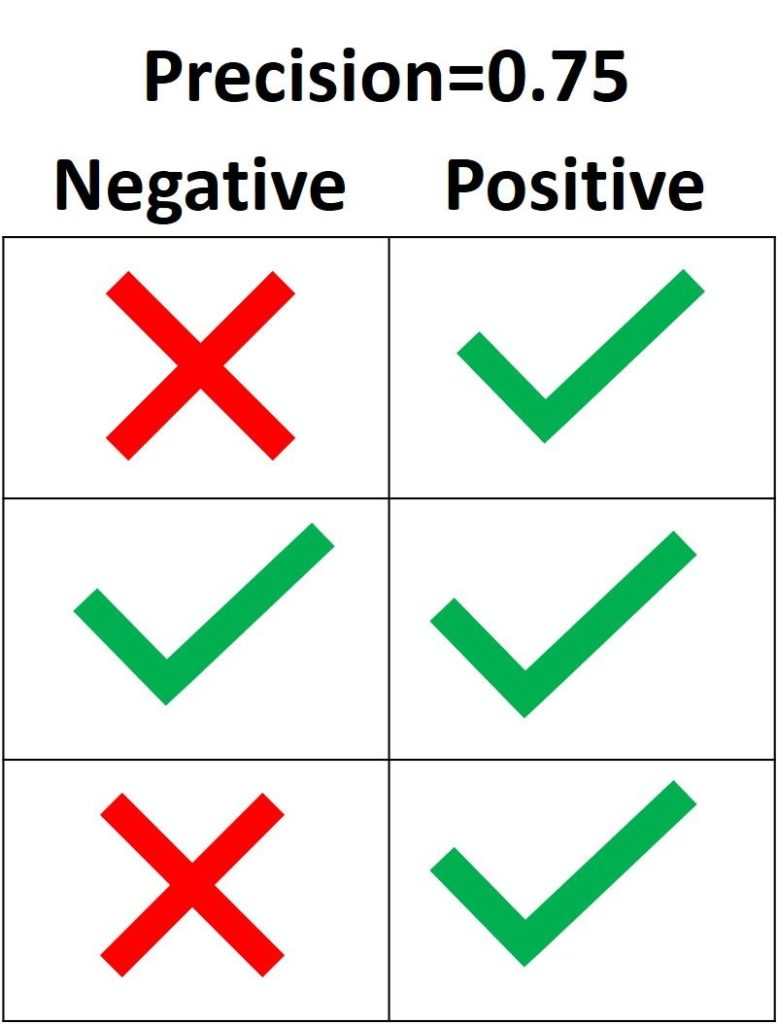
Единственный способ получить 100% precision — это классифицировать все Positive выборки как Positive без классификации Negative как Positive.
В Scikit-learn модуль sklearn.metrics имеет функцию precision_score(), которая получает в качестве аргументов эталонные и предсказанные метки и возвращает precision. Параметр pos_label принимает метку класса Positive (по умолчанию 1).
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
precision = sklearn.metrics.precision_score(y_true, y_pred, pos_label="positive")
print(precision)
Вывод: 0.6666666666666666.
Recall
Recall рассчитывается как отношение числа Positive выборок, корректно классифицированных как Positive, к общему количеству Positive семплов. Recall измеряет способность модели обнаруживать выборки, относящиеся к классу Positive. Чем выше recall, тем больше Positive семплов было найдено.
Recall заботится только о том, как классифицируются Positive выборки. Эта метрика не зависит от того, как предсказываются Negative семплы, в отличие от precision. Когда модель верно классифицирует все Positive выборки, recall будет 100%, даже если все представители класса Negative были ошибочно определены как Positive. Давайте посмотрим на несколько примеров.
На следующем изображении представлены 4 разных случая (от A до D), и все они имеют одинаковый recall, равный 0.667. Представленные примеры отличаются только тем, как классифицируются Negative семплы. Например, в случае A все Negative выборки корректно определены, а в случае D – наоборот. Независимо от того, как модель предсказывает класс Negative, recall касается только семплов относящихся к Positive.

Из 4 случаев, показанных выше, только 2 Positive выборки определены верно. Таким образом, метрика True Positive равна 2. False Negative имеет значение 1, потому что только один Positive семпл классифицируется как Negative. В результате recall будет равен 2 / (2 + 1) = 2/3 = 0.667.
Поскольку не имеет значения, как предсказываются объекты класса Negative, лучше их просто игнорировать, как показано на следующей схеме. При расчете recall необходимо учитывать только Positive выборки.

Что означает, когда recall высокий или низкий? Если recall имеет большое значение, все Positive семплы классифицируются верно. Следовательно, модели можно доверять в ее способности обнаруживать представителей класса Positive.
На следующем изображении recall равен 1.0, потому что все Positive семплы были правильно классифицированы. Показатель True Positive равен 3, а False Negative – 0. Таким образом, recall вычисляется как 3 / (3 + 0) = 1. Это означает, что модель обнаружила все Positive выборки. Поскольку recall не учитывает, как предсказываются представители класса Negative, могут присутствовать множество неверно определенных Negative семплов (высокая False Positive метрика).

С другой стороны, recall равен 0.0, если не удается обнаружить ни одной Positive выборки. Это означает, что модель обнаружила 0% представителей класса Positive. Показатель True Positive равен 0, а False Negative имеет значение 3. Recall будет равен 0 / (0 + 3) = 0.
Когда recall имеет значение от 0.0 до 1.0, это число отражает процент Positive семплов, которые модель верно классифицировала. Например, если имеется 10 экземпляров Positive и recall равен 0.6, получается, что модель корректно определила 60% объектов класса Positive (т.е. 0.6 * 10 = 6).
Подобно precision_score(), функция repl_score() из модуля sklearn.metrics вычисляет recall. В следующем блоке кода показан пример ее использования.
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
recall = sklearn.metrics.recall_score(y_true, y_pred, pos_label="positive")
print(recall)
Вывод: 0.6666666666666666.
После определения precision и recall давайте кратко подведем итоги:
- Precision измеряет надежность модели при классификации Positive семплов, а recall определяет, сколько Positive выборок было корректно предсказано моделью.
- Precision учитывает классификацию как Positive, так и Negative семплов. Recall же использует при расчете только представителей класса Positive. Другими словами, precision зависит как от Negative, так и от Positive-выборок, но recall — только от Positive.
- Precision принимает во внимание, когда семпл определяется как Positive, но не заботится о верной классификации всех объектов класса Positive. Recall в свою очередь учитывает корректность предсказания всех Positive выборок, но не заботится об ошибочной классификации представителей Negative как Positive.
- Когда модель имеет высокий уровень recall метрики, но низкую precision, такая модель правильно определяет большинство Positive семплов, но имеет много ложных срабатываний (классификаций Negative выборок как Positive). Если модель имеет большую precision, но низкий recall, то она делает высокоточные предсказания, определяя класс Positive, но производит всего несколько таких прогнозов.
Некоторые вопросы для проверки понимания:
- Если recall равен 1.0, а в датасете имеются 5 объектов класса Positive, сколько Positive семплов было правильно классифицировано моделью?
- Учитывая, что recall составляет 0.3, когда в наборе данных 30 Positive семплов, сколько представителей класса Positive будет предсказано верно?
- Если recall равен 0.0 и в датасете14 Positive-семплов, сколько корректных предсказаний класса Positive было сделано моделью?
Precision или Recall?
Решение о том, следует ли использовать precision или recall, зависит от типа вашей проблемы. Если цель состоит в том, чтобы обнаружить все positive выборки (не заботясь о том, будут ли negative семплы классифицированы как positive), используйте recall. Используйте precision, если ваша задача связана с комплексным предсказанием класса Positive, то есть учитывая Negative семплы, которые были ошибочно классифицированы как Positive.
Представьте, что вам дали изображение и попросили определить все автомобили внутри него. Какой показатель вы используете? Поскольку цель состоит в том, чтобы обнаружить все автомобили, используйте recall. Такой подход может ошибочно классифицировать некоторые объекты как целевые, но в конечном итоге сработает для предсказания всех автомобилей.
Теперь предположим, что вам дали снимок с результатами маммографии, и вас попросили определить наличие рака. Какой показатель вы используете? Поскольку он обязан быть чувствителен к неверной идентификации изображения как злокачественного, мы должны быть уверены, когда классифицируем снимок как Positive (то есть с раком). Таким образом, предпочтительным показателем в данном случае является precision.
Вывод
В этом руководстве обсуждалась матрица ошибок, вычисление ее 4 метрик (true/false positive/negative) для задач бинарной и мультиклассовой классификации. Используя модуль metrics библиотеки Scikit-learn, мы увидели, как получить матрицу ошибок в Python.
Основываясь на этих 4 показателях, мы перешли к обсуждению accuracy, precision и recall метрик. Каждая из них была определена и использована в нескольких примерах. Модуль sklearn.metrics применяется для расчета каждого вышеперечисленного показателя.
]]>join в Python отвечает за объединение списка строк с помощью определенного указателя. Часто это используется при конвертации списка в строку. Например, так можно конвертировать список букв алфавита в разделенную запятыми строку для сохранения.
Метод принимает итерируемый объект в качестве аргумента, а поскольку список отвечает этим условиям, то его вполне можно использовать. Также список должен состоять из строк. Если попробовать использовать функцию для списка с другим содержимым, то результатом будет такое сообщение: TypeError: sequence item 0: expected str instance, int found.
Посмотрим на короткий пример объединения списка для создания строки.
vowels = ["a", "e", "i", "o", "u"]
vowels_str = ",".join(vowels)
print("Строка гласных:", vowels_str)
Этот скрипт выдаст такой результат:
Строка гласных: a,e,i,o,uПочему join() — метод строки, а не списка?
Многие часто спрашивают, почему функция join() относится к строке, а не к списку. Разве такой синтаксис не было бы проще запомнить?
vowels_str = vowels.join(",")Это популярный вопрос на StackOverflow, и вот простой ответ на него:
Функция
join()может использоваться с любым итерируемым объектом, но результатом всегда будет строка, поэтому и есть смысл иметь ее в качестве API строки.
Объединение списка с несколькими типами данных
Посмотрим на программу, где предпринимается попытка объединить элементы списка разных типов:
names = ['Java', 'Python', 1]
delimiter = ','
single_str = delimiter.join(names)
Вывод:
Traceback (most recent call last):
File "test.py", line 3, in <module>
single_str = delimiter.join(names)
TypeError: sequence item 2: expected str instance, int foundЭто лишь демонстрация того, что join нельзя использовать для объединения элементов разного типа. Только строковые значения.
Что бы избежать этой ошибки, превратите все элементы списка в строки:
names = ['Java', 'Python', 1]
names = [str(i) for i in names]
Разбитие строки с помощью join
Также функцию join() можно использовать, чтобы разбить строку по определенному разделителю.
>>> print(",".join("Python"))
P,y,t,h,o,n
Если передать в качестве аргумента функции строку, то она будет разбита по символам с определенным разделителем.
Обратное преобразование строки в список
Помимо join() есть и функция split(), которая используется для разбития строки. Она работает похожим образом. Посмотрим на код:
names = ['Java', 'Python', 'Go']
delimiter = ','
single_str = delimiter.join(names)
print('Строка: {0}'.format(single_str))
split = single_str.split(delimiter)
print('Список: {0}'.format(split))
Вывод:
Строка: Java,Python,Go
Список: ['Java', 'Python', 'Go']Вот и все что нужно знать об объединении и разбитии строк.
]]>Что такое librosa?
Librosa — это пакет Python для анализа музыки и аудио. Он предоставляет строительные блоки для создания структур, которые помогают получать информацию о музыке.
Установка librosa в Python
Установим библиотеку с помощью команды pip:
pip install librosa
Для примера я скачал файл mp3-файл из https://www.bensound.com/ и конвертировал его в ogg для комфортной работы. Загрузим короткий ogg-файл (это может быть любой музыкальный файл в формате ogg):
import librosa
y, sr = librosa.load('bensound-happyrock.ogg')
Обработка аудио в виде временных рядов
В последней строке функция load считывает ogg-файл в виде временного рядя. Где, sr обозначает sample_rate.
- Time series (временной ряд) представлен массивом.
sample_rate— это количество сэмплов на секунду аудио.
По умолчанию звук микшируется в моно. Но его можно передискретизировать во время загрузки до 22050 Гц. Это делается с помощью дополнительных параметров в функции librosa.load.
Извлечение признаков из аудиофайла
У сэмпла есть несколько важных признаков. Есть фундаментальное понятие ритма в некоторых формах, а остальные либо имеют свою нюансы, либо связаны:
- Темп: скорость, с которой паттерны повторяются. Темп измеряется в битах в минуту (BPM). Если у музыки 120 BPM, это значит, что каждую минуту в ней 120 битов (ударов).
- Бит: отрезок времени. Это ритм, выстукиваемый в песне. Так, в одном такте 4 бита, например.
- Такт: логичное деление битов. Обычно в такте 3 или 4 бита, хотя возможны и другие варианты.
- Интервал: в программах для редактирования чаще всего встречаются интервалы. Обычно есть последовательность нот, например, 8 шестнадцатых одинаковой длины. Обычно интервал — 8 нот, триплеты или четверные.
- Ритм: список музыкальных звуков. Все ноты и являются ритмом.
Из аудио можно получить темп и биты:
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
print(tempo)
print(beat_frames)
89.10290948275862
[ 3 40 75 97 132 153 183 211 246 275 303 332 361 389
...
4438 4466]Мел-кепстральные коэффициенты (MFCC)
Мел-кепстральные коэффициенты — один из важнейших признаков в обработке аудио.
MFCC — это матрица значений, которая захватывает тембральные аспекты музыкального инструменты: например, отличия в звучании металлической и деревянной гитары. Другими метриками эта разница не захватывается, но это ближайшее к тому, что может различать человек.
mfcc = librosa.feature.mfcc(y=y, sr=sr, hop_length=8192, n_mfcc=12)
# pip install seaborn matplotlib
import seaborn as sns
from matplotlib import pyplot as plt
mfcc_delta = librosa.feature.delta(mfcc)
sns.heatmap(mfcc_delta)
plt.show()
Здесь мы создаем тепловую карту данных MFCC, которая обеспечивает такой результат:
Нормализация ее в хроматограмму даст такой результат:
chromagram = librosa.feature.chroma_cqt(y=y, sr=sr)
sns.heatmap(chromagram)
plt.show()
Это лишь основы о том, что можно получить из аудиоданных для обучаемых алгоритмов. Много продвинутых примеров есть в документации librosa.
]]>Если неправильно организовать отступы, пробелы или табуляции в программе, то вернется ошибка IndentationError: expected an intended block.
В этом руководстве рассмотрим, что это за ошибка и когда она появляется. Разберем пример и посмотрим, как решить эту проблему.
IndentationError: expected an indented block
Языки программирования, такие как C и JavaScript, не требуют отступов. В них для структуризации кода используются фигурные скобы. В Python этих скобок нет.
Структура программы создается с помощью отступов. Без них интерпретатор не сможет корректно распознавать разные блоки кода. Возьмем такой код в качестве примера:
def find_average(grades):
average = sum(grades) / len(grades)
print(average)
return average
Откуда Python знает, какой код является частью функции find_average(), а какой — основной программы? Вот почему так важны отступы.
Каждый раз, когда вы забываете поставить пробелы или символы табуляции, Python напоминает об этом с помощью ошибки отступа.
Пример возникновения ошибки отступа
Напишем программу, которая извлекает все бублики из списка с едой в меню. Они после этого будут добавлены в отдельный список.
Для начала создадим список всей еды:
lunch_menu = ["Бублик с сыром", "Сэндвич с сыром", "Cэндвич с огурцом", "Бублик с лососем"]
Меню содержит два сэндвича и два бублика. Теперь напишем функцию, которая создает новый список бубликов на основе содержимого списка lunch_menu:
def get_bagels(menu):
bagels = []
for m in menu:
if "Бублик" in m:
bagels.append(m)
return bagels
get_bagels() принимает один аргумент — список меню, по которому она пройдется в поиске нужных элементов. Она проверяет, содержит ли элемент слово «Бублик», и в случае положительного ответа добавит его в новый список.
Наконец, функцию нужно вызвать и вывести результат:
bagels = get_bagels(lunch_menu)
print(bagels)
Этот код вызывает функцию get_bagels() и выводит список бубликов в консоль. Запустим код и посмотрим на результат:
File "test.py", line 4
bagels = []
^
IndentationError: expected an indented block
Ошибка отступа.
Решение ошибки IndentationError
Ошибка отступа сообщает, что отступ был установлен неправильно. Его нужно добавить на 4 строке. Посмотрим на код:
def get_bagels(menu):
bagels = []
Значение переменной bagels должно присваиваться внутри функции, но этого не происходит, что и приводит к ошибке. Для решения проблемы нужно добавить отступ:
def get_bagels(menu):
bagels = []
Теперь запустим код:
['Бублик с сыром', 'Бублик с лососем']Код нашел все бублики и добавил их в новый список. После этого вывел его в консоль.
Вывод
Ошибка IndentationError: expected an indented block возникает, если забыть добавить отступ в коде. Для исправления нужно проверить все отступы, которые должны присутствовать.
]]>В данной статье обсуждаются три конкретных особенности, которые следует учитывать при разделении набора данных, подходы к решению связанных проблем и практическая реализация на Python.
Для наших примеров мы будем использовать модуль train_test_split библиотеки Scikit-learn, который очень полезен для разделения датасетов, независимо от того, будете ли вы применять Scikit-learn для выполнения других задач машинного обучения. Конечно, можно выполнить такие разбиения каким-либо другим способом (возможно, используя только Numpy). Библиотека Scikit-learn включает полезные функции, позволяющее сделать это немного проще.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.67,
random_state=42)
Возможно, вы использовали этот модуль для разделения данных в прошлом, но при этом не приняли во внимание некоторые детали.
Случайное перемешивание строк
Первое, на что следует обратить внимание: перемешаны ли ваши экземпляры? Это следует делать пока нет причин не перетасовывать данные (например, они представляют собой временные интервалы). Мы должны убедиться в том, что наши экземпляры не разбиты на выборки по классам. Это потенциально вносит в нашу модель некоторую нежелательную предвзятость.
Например, посмотрите, как одна из версий набора данных iris, упорядочивает свои экземпляры при загрузке:
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
print(f"Классы датасета: {iris.target}")
Классы датасета: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]Если такой набор данных с тремя классами при равном числе экземпляров в каждом разделить на две выборки: 2/3 для обучения и 1/3 для тестирования, то полученные поднаборы будут иметь нулевое пересечение классовых меток. Это, очевидно, недопустимо при изучении признаков для предсказания классов. К счастью, функция train_test_split по умолчанию автоматически перемешивает данные (вы можете переопределить это, установив для параметра shuffle значение False).
- В функцию должны быть переданы как вектор признаков, так и целевой вектор (X и y).
- Для воспроизводимости вы должны установить аргумент
random_state. - Также необходимо определить либо
train_size, либоtest_size, но оба они не нужны. Если вы явно устанавливаете оба параметра, они должны составлять в сумме 1.
Вы можете убедится, что теперь наши классы перемешаны.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.67,
random_state=42)
print(f"Классы в y_train:\n{y_train}")
print(f"Классы в y_test:\n{y_test}")
Классы в y_train:
[1 2 1 0 2 1 0 0 0 1 2 0 0 0 1 0 1 2 0 1 2 0 2 2 1 1 2 1 0 1 2 0 0 1 1 0 2
0 0 1 1 2 1 2 2 1 0 0 2 2 0 0 0 1 2 0 2 2 0 1 1 2 1 2 0 2 1 2 1 1 1 0 1 1
0 1 2 2 0 1 2 2 0 2 0 1 2 2 1 2 1 1 2 2 0 1 2 0 1 2]
Классы в y_test:
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0 1 2 2 1 2]Стратификация (равномерное распределение) классов
Данное размышление заключается в следующем. Равномерно ли распределено количество классов в наборах данных, разделенных для обучения и тестирования?
import numpy as np
print(f"Количество строк в y_train по классам: {np.bincount(y_train)}")
print(f"Количество строк в y_test по классам: {np.bincount(y_test)}")
Количество строк в y_train по классам: [31 35 34]
Количество строк в y_test по классам: [19 15 16]Это не равная разбивка. Главная идея заключается в том, получает ли наш алгоритм равные возможности для изучения признаков каждого из представленных классов и последующего тестирования результатов обучения, на равном числе экземпляров каждого класса. Хотя это особенно важно для небольших наборов данных, желательно постоянно уделять внимание данному вопросу.
Мы можем задать пропорцию классов при разделении на обучающий и проверяющий датасеты с помощью параметра stratify функции train_test_split. Стоит отметить, что мы будем стратифицировать в соответствии распределению по классам в y.
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.67,
random_state=42,
stratify=y)
print(f"Количество строк в y_train по классам: {np.bincount(y_train)}")
print(f"Количество строк в y_test по классам: {np.bincount(y_test)}")
Количество строк в y_train по классам: [34 33 33]
Количество строк в y_test по классам: [16 17 17]Сейчас это выглядит лучше, и представленные числа говорят нам, что это наиболее оптимально возможное разделение.
Дополнительное разделение
Третье соображение относится к проверочным данным (выборке валидации). Есть ли смысл для нашей задачи иметь только один тестовый датасет. Или мы должны подготовить два таких набора — один для проверки наших моделей во время их точной настройки, а еще один — в качестве окончательного датасета для сравнения моделей и выбора лучшей.
Если мы определим 2 таких набора, это будет означать, что одна выборка, будет храниться до тех пор, пока все предположения не будут проверены, все гиперпараметры не настроены, а все модели обучены для достижения максимальной производительности. Затем она будет показана моделям только один раз в качестве последнего шага в наших экспериментах.
Если вы хотите использовать датасеты для тестирования и валидации, создать их с помощью train_test_split легко. Для этого мы разделяем весь набор данных один раз для выделения обучающей выборки. Затем еще раз, чтобы разбить оставшиеся данные на датасеты для тестирования и валидации.
Ниже, используя набор данных digits, мы разделяем 70% для обучения и временно назначаем остаток для тестирования. Не забывайте применять методы, описанные выше.
from sklearn.datasets import load_digits
digits = load_digits()
X, y = digits.data, digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=0.7,
random_state=42,
stratify=y)
print(f"Количество строк в y_train по классам: {np.bincount(y_train)}")
print(f"Количество строк в y_test по классам: {np.bincount(y_test)}")
Количество строк в y_train по классам: [124 127 124 128 127 127 127 125 122 126]
Количество строк в y_test по классам: [54 55 53 55 54 55 54 54 52 54]Обратите внимание на стратифицированные классы в полученных наборах. Затем мы повторно делим тестовый датасет.
X_test, X_val, y_test, y_val = train_test_split(X_test, y_test,
train_size=0.5,
random_state=42,
stratify=y_test)
print(f"Количество строк в y_test по классам: {np.bincount(y_test)}")
print(f"Количество строк в y_val по классам: {np.bincount(y_val)}")
Количество строк в y_test по классам: [27 27 27 27 27 28 27 27 26 27]
Количество строк в y_val по классам: [27 28 26 28 27 27 27 27 26 27]Обратите внимание на стратификацию классов по всем наборам данных, которая является оптимальной.
Теперь вы готовы обучать, проверять и тестировать столько моделей машинного обучения, сколько вы сочтете нужным для ваших данных.
Еще один совет: вы можете подумать об использовании перекрестной валидации вместо простой стратегии обучение/тестирование или обучение/валидация/тестирование. Мы рассмотрим вопросы кросс-валидации в следующий раз.
]]>- Как настроить Celery с Django.
- Как протестировать Celery-задачу в Django-оболочке.
- Где контролировать работу Celery-приложения.
Вы можете использовать на исходный код проекта из этого репозитория.
Зачем приложению на Django нужен Celery
Celery нужен для запуска задач в отдельном рабочем процессе (worker), что позволяет немедленно отправить HTTP-ответ пользователю в веб-процессе (даже если задача в рабочем процессе все еще выполняется). Цикл обработки запроса не будет заблокирован, что повысит качество взаимодействия с пользователем.
Ниже приведены некоторые примеры использования Celery:
- Вы создали приложение с функцией отправки комментариев, в которых пользователь может использовать символ @, чтобы упомянуть другого пользователя, после чего последний получит уведомление по электронной почте. Если пользователь упоминает 10 человек в своем комментарии, веб-процессу необходимо обработать и отправить 10 электронных писем. Иногда это занимает много времени (сеть, сервер и другие факторы). В данном случае Celery может организовать отправку писем в фоновом режиме, что в свою очередь позволит вернуть HTTP-ответ пользователю без ожидания.
- Нужно создать миниатюру загруженного пользователем изображения? Такую задачу стоит выполнить в рабочем процессе.
- Вам необходимо делать что-то периодически, например, генерировать ежедневный отчет, очищать данные истекшей сессии. Используйте Celery для отправки задач рабочему процессу в назначенное время.
Когда вы создаете веб-приложение, постарайтесь сделать время отклика не более, чем 500мс (используйте New Relic или Scout APM), если пользователь ожидает ответа слишком долго, выясните причину и попытайтесь устранить ее. В решении такой проблемы может помочь Celery.
Celery или RQ
RQ (Redis Queue) — еще одна библиотека Python, которая решает вышеуказанные проблемы.
Логика работы RQ схожа с Celery (используется шаблон проектирования производитель/потребитель). Далее я проведу поверхностное сравнение для лучшего понимания, какой из инструментов более подходит для задачи.
- RQ (Redis Queue) проста в освоении, направлена на снижение барьера в использовании асинхронного рабочего процесса. В ней отсутствуют некоторые функции, и она работает только с Redis и Python.
- Celery предоставляет больше возможностей, поддерживает множество различных серверных конфигураций. Одним из минусов такой гибкости является более сложная документация, что довольно часто пугает новичков.
Я предпочитаю Celery, поскольку он замечательно подходит для решения многих проблем. Данная статья написана мной, чтобы помочь читателю (особенно новичку) быстро изучить Celery!
Брокер сообщений и бэкенд результатов
Брокер сообщений — это хранилище, которое играет роль транспорта между производителем и потребителем.
Из документации Celery рекомендуемым брокером является RabbitMQ, потому что он поддерживает AMQP (расширенный протокол очереди сообщений).
Так как во многих случаях нам не нужно использовать AMQP, другой диспетчер очереди, такой как Redis, также подойдет.
Бэкенд результатов — это хранилище, которое содержит информацию о результатах выполнения Celery-задач и о возникших ошибках.
Здесь рекомендуется использовать Redis.
Как настроить Celery
Celery не работает на Windows. Используйте Linux или терминал Ubuntu в Windows.
Далее я покажу вам, как импортировать Celery worker в ваш Django-проект.
Мы будем использовать Redis в качестве брокера сообщений и бэкенда результатов, что немного упрощает задачу. Но вы свободны в выборе любой другой комбинации, которая удовлетворяет требованиям вашего приложения.
Используйте Docker для подготовки среды разработки
Если вы работаете в Linux или Mac, у вас есть возможность использовать менеджер пакетов для настройки Redis (brew, apt-get install), однако я хотел бы порекомендовать вам попробовать применить Docker для установки сервера redis.
- Вы можете скачать Docker-клиент здесь.
- Затем попробуйте запустить службу Redis
$ docker run -p 6379: 6379 --name some-redis -d redis
Команда выше запустит Redis на 127.0.0.1:6379.
- Если вы намерены использовать RabbitMQ в качестве брокера сообщений, вам нужно изменить только приведенную выше команду.
- Закончив работу с проектом, вы можете закрыть Docker-контейнер — окружение вашей рабочей машины по-прежнему будет чистым.
Теперь импортируем Celery в наш Django-проект.
Создание Django-проекта
Рекомендую создать отдельное виртуальное окружение и работать в нем.
$ pip install django==3.1
$ django-admin startproject celery_django
$ python manage.py startapp pollsНиже представлена структура проекта.
├── celery_django
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
└── polls
├── __init__.py
├── admin.py
├── apps.py
├── migrations
│ └── __init__.py
├── models.py
├── tests.py
└── views.pyФайл celery.py
Давайте приступим к установке и настройке Celery.
pip install celery==4.4.7 redis==3.5.3 flower==0.9.7
Создайте файл celery_django/celery.py рядом с celery_django/wsgi.py.
"""
Файл настроек Celery
https://docs.celeryproject.org/en/stable/django/first-steps-with-django.html
"""
from __future__ import absolute_import
import os
from celery import Celery
# этот код скопирован с manage.py
# он установит модуль настроек по умолчанию Django для приложения 'celery'.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celery_django.settings')
# здесь вы меняете имя
app = Celery("celery_django")
# Для получения настроек Django, связываем префикс "CELERY" с настройкой celery
app.config_from_object('django.conf:settings', namespace='CELERY')
# загрузка tasks.py в приложение django
app.autodiscover_tasks()
@app.task
def add(x, y):
return x / y
Файл __init__.py
Давайте продолжим изменять проект, в celery_django/__init__.py добавьте.
from __future__ import absolute_import, unicode_literals
# Это позволит убедиться, что приложение всегда импортируется, когда запускается Django
from .celery import app as celery_app
__all__ = ('celery_app',)
Дополнение settings.py
Поскольку Celery может читать конфигурацию из файла настроек Django, мы внесем в него следующие изменения.
CELERY_BROKER_URL = "redis://127.0.0.1:6379/0"
CELERY_RESULT_BACKEND = "redis://127.0.0.1:6379/0"
Есть кое-что, о чем следует помнить.
При изучении документации Celery вы вероятно увидите, что broker_url — это ключ конфигурации, который вы должны установить для диспетчера сообщений, однако в приведенном выше celery.py:
app.config_from_object('django.conf: settings', namespace = 'CELERY')сообщает Celery, чтобы он считывал значение из пространства именCELERY, поэтому, если вы установите простоbroker_urlв своем файле настроек Django, этот параметр не будет работать. Правило применяется для всех ключей конфигурации в документации Celery.- Некоторые конфигурационные ключи различаются между Celery 3 и Celery 4, так что, пожалуйста, загляните в документацию при настройке.
Отправка заданий Celery
После завершение работы с конфигурацией все готово к использованию Celery. Мы будем запускать некоторые команды в отдельном терминале, но я рекомендую вам взглянуть на Tmux, когда у вас будет время.
Сначала запустите Redis-клиент, потом celery worker в другом терминале, celery_django — это имя Celery-приложения, которое вы установили в celery_django/celery.py.
$ celery worker -A celery_django --loglevel=info
-------------- celery@DESKTOP-111111 v4.4.7 (cliffs)
--- ***** -----
-- ******* ---- Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.27 2021-03-15 15:03:44
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: celery_django:0x7ff07f818ac0
- ** ---------- .> transport: redis://127.0.0.1:6379/0
- ** ---------- .> results: redis://127.0.0.1:6379/0
- *** --- * --- .> concurrency: 4 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. celery_django.celery.add
Далее запустим приложение в новом терминале, которое поможет нам отслеживать Celery-задачу (я расскажу об этом чуть позже).
$ flower -A celery_django --port=5555
[I 210315 16:11:39 command:135] Visit me at http://localhost:5555
[I 210315 16:11:39 command:142] Broker: redis://127.0.0.1:6379/0
[I 210315 16:11:39 command:143] Registered tasks:
['celery.accumulate',
'celery.backend_cleanup',
'celery.chain',
'celery.chord',
'celery.chord_unlock',
'celery.chunks',
'celery.group',
'celery.map',
'celery.starmap',
'celery_django.celery.add']
[I 210315 16:11:39 mixins:229] Connected to redis://127.0.0.1:6379/0
Затем откройте http://localhost:5555/. Вы должны увидеть информационную панель, на которой отображаются детали выполнения рабочего процесса Celery.
Теперь войдем в Django shell и попробуем отправить Celery несколько задач.
$ python manage.py migrate
$ python manage.py shell
...
>>> from celery_django.celery import add
>>> task = add.delay(1, 2)Рассмотрим некоторые моменты:
- Мы используем
xxx.delayдля отправки сообщения брокеру. Рабочий процесс получает эту задачу и выполняет ее. - Когда вы нажимаете клавишу enter для ввода
task = add.delay(1, 2), кажется, что команда быстро завершает выполнение (отсутствие блокировки), но метод добавления все еще активен в рабочем процессе Celery. - Если вы проверите вывод терминала, где был запущен Celery, то увидите что-то вроде этого:
[2021-03-15 15:04:32,859: INFO/MainProcess] Received task: celery_django.celery.add[e1964774-fd3b-4add-96ff-116e3578de
de]
[2021-03-15 15:04:32,882: INFO/ForkPoolWorker-1] Task celery_django.celery.add[e1964774-fd3b-4add-96ff-116e3578dede] s
ucceeded in 0.013418699999988348s: 0.5
Рабочий процесс получил задачу в 15:04:32, и она была успешно выполнена.
Думаю, теперь у вас уже есть базовое представление об использовании Celery. Попробуем ввести еще один блок кода.
>>> print(task.state, task.result)
SUCCESS 0.5
Затем давайте попробуем вызвать ошибку в Celery worker и посмотрим, что произойдет.
>>> task = add.delay(1, 0)
>>> type(task)
celery.result.AsyncResult
>>> task.state
'FAILURE'
>>> task.result
ZeroDivisionError('division by zero')
Как видите, результатом вызова метода delay является экземпляр AsyncResult.
Мы можем использовать его следующим образом:
- Проверить состояние задачи.
- Узнать возвращенное значение (результат) или сведения об исключении.
- Получить другие метаданные.
Мониторинг Celery с помощью Flower
Flower позволяет отобразить информацию о работу Celery более наглядно на веб-странице с дружественным интерфейсом. Это значительно упрощает понимание происходящего, поэтому я хочу обратить внимание на Flower, прежде чем углубиться в дальнейшее рассмотрение Celery.
URL-адрес панели управления: http://127.0.0.1:5555/. Откройте страницу задач — Tasks.
При изучении Celery довольно полезно использовать Flower для лучшего понимания деталей.
Когда вы развертываете свой проект на сервере, Flower не является обязательным компонентом. Я имею в виду, что вы можете напрямую использовать команды Celery, чтобы управлять приложением и проверять статус рабочего процесса.
Заключение
В этой статье я рассказал об основных аспектах Celery. Надеюсь, что после прочтения вы стали лучше понимать процесс работы с ним. Исходный код проекта доступен по ссылке в начале статьи.
]]>В библиотеке Pandas есть несколько функций для решения этой проблемы, и value_counts — одна из них. Она возвращает объект, содержащий уникальные значения из dataframe Pandas в отсортированном порядке. Однако многие забывают об этой возможности и используют параметры по умолчанию. В этом материале посмотрим, как получить максимум пользы от value_counts, изменив параметры по умолчанию.
Что такое функция value_counts()?
Функция value_counts() используется для получения Series, содержащего уникальные значения. Она вернет результат, отсортированный в порядке убывания, так что первый элемент в коллекции будет самым встречаемым. NA-значения не включены в результат.
Синтаксисdf['your_column'].value_counts() — вернет количество уникальных совпадений в определенной колонке.
Важно заметить, что value_counts работает только с series, но не dataframe. Поэтому нужно указать одни квадратные скобки df['your_column'], а не пару df[['your_column']].
Параметры:
normalize(bool, по умолчанию False) — еслиTrue, то возвращаемый объект будет содержать значения относительно частоты встречаемых значений.sort(bool, по умолчанию True) — сортировка по частоте.ascending(bool, по умолчанию False) — сортировка по возрастанию.bins(int) — вместе подсчета значений группирует их по отрезкам, но это работает только с числовыми данными.- dropna (bool, по умолчанию True) — не включать количество NaN.
Загрузка данных для демонстрации
Рассмотрим, как использовать этот метод на реальных данных. Возьмем в качестве примера датасет из курса Coursera на Kaggle.
Для начала импортируем нужные библиотеки и сами данные. Это нужно в любом проекте. После этого проанализируем данные в notebook Jupyter.
# импорт библиотеки
import pandas as pd
# Загрузка данных
df = pd.read_csv('Downloads/coursea_data.csv', index_col=0)
# проверка данных из csv
df.head(10)
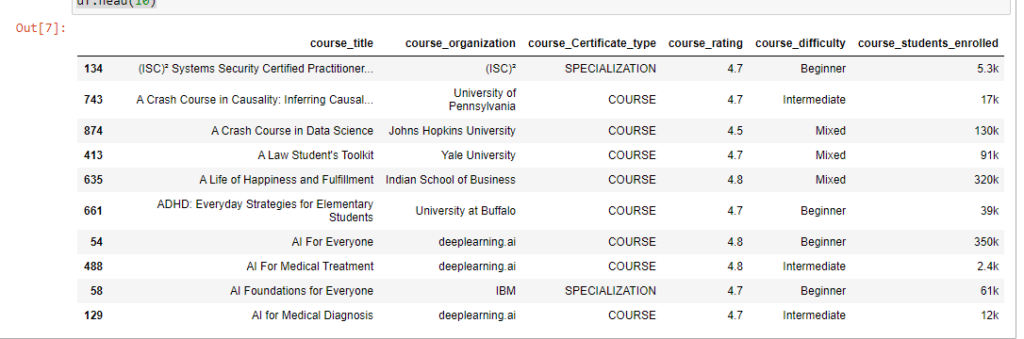
Проверьте, сколько записей в датасете и есть ли у нас пропуски.
df.info()
Результат показывает, что в наборе 981 запись, и нет ни одного NA.
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 134 to 163
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 course_title 891 non-null object
1 course_organization 891 non-null object
2 course_Certificate_type 891 non-null object
3 course_rating 891 non-null float64
4 course_difficulty 891 non-null object
5 course_students_enrolled 891 non-null object
dtypes: float64(1), object(5)
memory usage: 48.7+ KB1. value_counts с параметрами по умолчанию
Теперь можно начинать использовать функцию value_counts. Начнем с базового применения функции.
Синтаксис: df['your_column'].value_counts().
Получим количество каждого значения для колонки «course_difficulty».
Функция value_counts вернет количество совпадений всех уникальных значений по заданному индексу без пропусков. Это позволит увидеть, что больше всего курсов с уровнем сложности «Начинающий», после этого идут «Средний» и «Смешанный». А «Сложный» на последнем месте.
df['course_difficulty'].value_counts()
---------------------------------------------------
Beginner 487
Intermediate 198
Mixed 187
Advanced 19
Name: course_difficulty, dtype: int64Теперь время поработать с параметрами.
2. Сортировка по возрастанию
По умолчанию value_counts() возвращает данные по убыванию. Изменит поведение можно, задав значение True для параметра ascending.
Синтаксис: df['your_column'].value_counts(ascending=True).
df['course_difficulty'].value_counts(ascending=True)
---------------------------------------------------
Advanced 19
Mixed 187
Intermediate 198
Beginner 487
Name: course_difficulty, dtype: int643. Сортировка в алфавитном порядке
В определенных случаях может существовать необходимость отсортировать записи в алфавитном порядке. Это делается с помощью добавления sort_index(ascending=True) после value_counts().
По умолчанию функция сортирует «course_difficulty» по количеству совпадений, а с sort_index сортирует по индексу (имени колонки, для которой и используется функция):
df['course_difficulty'].value_counts().sort_index(ascending=True)
---------------------------------------------------
Advanced 19
Beginner 487
Intermediate 198
Mixed 187
Name: course_difficulty, dtype: int64Если же требуется отобразить value_counts() в обратном алфавитном порядке, то нужно изменить направление сортировки: .sort_index(ascending=False).
4. Сортировка по значению, а затем по алфавиту
Для этого примера используем другой датасет.
df_fruit = pd.DataFrame({
'fruit':
['хурма']*5 + ['яблоки']*5 + ['бананы']*3 +
['персики']*3 + ['морковь']*3 + ['абрикосы'] + ['манго']*2
})
Так, нужно получить вывод, отсортированный в первую очередь по количеству совпадений значений, а потом уже и по алфавиту. Это можно сделать, объединив value_counts() c sort_index(ascending=False) и sort_values(ascending=False).
df_fruit['fruit'].value_counts()\
.sort_index(ascending=False)\
.sort_values(ascending=False)
-------------------------------------------------
хурма 5
яблоки 5
бананы 3
морковь 3
персики 3
манго 2
абрикосы 1
Name: fruit, dtype: int645. Относительная частота уникальных значений
Иногда нужно получить относительные значения, а не просто количество. С параметром normalize=True объект вернет относительную частоту уникальных значений. По умолчанию значение этого параметра равно False.
Синтаксис: df['your_column'].value_counts(normalize=True).
df['course_difficulty'].value_counts(normalize=True)
-------------------------------------------------
Beginner 0.546577
Intermediate 0.222222
Mixed 0.209877
Advanced 0.021324
Name: course_difficulty, dtype: float646. value_counts() для разбивки данных на дискретные интервалы
Еще один трюк, который часто игнорируют. value_counts() можно использовать для разбивки данных на дискретные интервалы с помощью параметра bin. Это работает только с числовыми данными. Принцип напоминает pd.cut. Посмотрим как это работает на примере колонки «course_rating». Сгруппируем значения колонки на 4 группы.
Синтаксис: df['your_column'].value_counts(bin=количество групп).
df['course_rating'].value_counts(bins=4)
-------------------------------------------------
(4.575, 5.0] 745
(4.15, 4.575] 139
(3.725, 4.15] 5
(3.297, 3.725] 2
Name: course_rating, dtype: int64Бинниг позволяет легко получить инсайты. Так, можно увидеть, что большая часть людей оценивает курс на 4.5. И лишь несколько курсов имеют оценку ниже 4.15.
7. value_counts() с пропусками
По умолчанию количество значений NaN не включается в результат. Но это поведение можно изменить, задав значение False для параметра dropna. Поскольку в наборе данных нет нулевых значений, в этом примере это ни на что не повлияет. Но сам параметр следует запомнить.
Синтаксис: df['your_column'].value_counts(dropna=False).
8. value_counts() как dataframe
Как уже было отмечено, value_counts() возвращает Series, а не Dataframe. Если же нужно получить результаты в последнем виде, то для этого можно использовать функцию .to_frame() после .value_counts().
Синтаксис: df['your_column'].value_counts().to_frame().
Это будет выглядеть следующим образом:
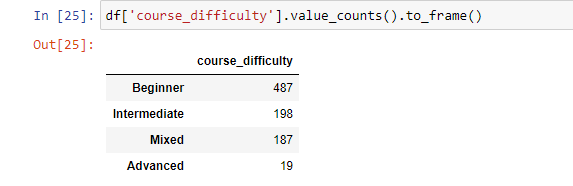
Если нужно задать имя для колонки или переименовать существующую, то эту конвертацию можно реализовать другим путем.
value_counts = df['course_difficulty'].value_counts()
# преобразование в df и присвоение новых имен колонкам
df_value_counts = pd.DataFrame(value_counts)
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = ['unique_values', 'counts for course_difficulty']
df_value_counts
Groupby и value_counts
Groupby — очень популярный метод в Pandas. С его помощью можно сгруппировать результат по одной колонке и посчитать значения в другой.
Синтаксис: df.groupby('your_column_1')['your_column_2'].value_counts().
Так, с помощью groupby и value_counts можно посчитать количество типов сертификатов для каждого уровня сложности курсов.
df.groupby('course_difficulty')['course_Certificate_type'].value_counts()
-------------------------------------------------
course_difficulty course_Certificate_type
Advanced SPECIALIZATION 10
COURSE 9
Beginner COURSE 282
SPECIALIZATION 196
PROFESSIONAL CERTIFICATE 9
Intermediate COURSE 104
SPECIALIZATION 91
PROFESSIONAL CERTIFICATE 3
Mixed COURSE 187
Name: course_Certificate_type, dtype: int64Это мульти-индекс, позволяющий иметь несколько уровней индексов в dataframe. В этом случае сложность курса соответствует нулевому уровню индекса, а тип сертификата — первому.
Фильтрация значений по минимум и максимум
Работая с набором данных, может потребоваться вернуть количество ограниченных вхождений с помощью value_counts().
Синтаксис: df['your_column'].value_counts().loc[lambda x : x > 1].
Этот код отфильтрует все значения уникальных данных и покажет только те, где значение больше единицы.
Для примера ограничим рейтинг курса значением 4.
df.groupby('course_difficulty')['coudf['course_rating']\
.value_counts().loc[lambda x: x > 4]
-------------------------------------------------
4.8 256
4.7 251
4.6 168
4.5 80
4.9 68
4.4 34
4.3 15
4.2 10
Name: course_rating, dtype: int64value_counts() — удобный инструмент, позволяющий делать удобный анализ в одну строку.
Тест на знание функции value_counts
Что такое отладка
Независимо от профессионализма, каждый разработчик имеет дело с ошибками — это является частью работы. Отладка ошибок — непростая задача; изначально много времени занимает процесс обнаружения ошибки и ее устранения. Следовательно, каждый разработчик должен знать как устранять ошибки.
В Django, процесс отладки можно сильно упростить. Вам только необходимо установить и подключить Django Debug Toolbar в приложение.
Теперь, когда мы знаем, почему отладка так важна, давайте настроим ее в проекте.
Подготовка приложения для демонстрации
Код примера есть в репозитории на GitLab.
Чтобы использовать панель инструментов отладки, нам нужен сайт. Если у вас есть свой проект, вы можете использовать его. В противном случае создайте новый и добавьте следующее представление и соответствующий путь.
Команды для создания нового приложения:
$ pip install django
$ django-admin startproject debug-tool
$ cd debug_tool
$ python manage.py startapp app# app/views.py
from django.http import HttpResponse
def sample_view(request):
html = '<body><h1>Django sample_view</h1><br><p>Отладка sample_view</p></body>'
return HttpResponse(html)
Убедитесь в присутствии тега <body>. В противном случае инструмент отладчика не будет отображаться на страницах, шаблоны которых не имеют этого тега.
URL путь для кода будет:
# debug_tool/urls.py
from app import views as app_views
urlpatterns = [
path('admin/', admin.site.urls),
path('sample/', app_views.sample_view),
]
Теперь вы сможете повторять за мной.
Django Debug Toolbar
Рассмотрим инструменты, которые представлены в панели:
- Version: Предоставляет версию Django, которую мы используем.
- Time: Сообщает время, затраченное на загрузку веб-страницы.
- Setting: Показывает настройки страницы.
- Request: Показывает все запросы — views, файлы, куки и т.д.
- SQL: Список запросов к базе данных.
- Static Files: Предоставляет информацию о статических файлах.
- Templates: Предоставляет информацию о шаблонах.
- Cache: Сообщает информацию о существующем кэш.
- Loggin: Показывает количество зарегистрированных логов.
Установка Debug Toolbar в Django
Теперь установим библиотеку и настроим все необходимое для нее. Следуйте пошаговой инструкции:
1) Установка библиотеки
Для установки django-debug-toolbar, используем команду pip install. Запустите следующий код в терминале/оболочке ОС:
pip install django-debug-toolbar2) Добавление в INSTALLED_APPS
В settings.py добавьте следующую строку в раздел INSTALLED_APPS.
Проверьте, что бы debug_toolbar был добавлен после django.contrib.staticfiles.
# debug_tool/settings.py
INSTALLED_APPS = [
...
'debug_toolbar',
]
Также убедитесь, что в файле settings.py присутствует следующая строка STATIC_URL = '/static/'. Обычно она находится в конце модуля и не требует добавления.
Если ее нет, просто добавьте в конец файла.
3) Импорт в urls.py
Чтобы использовать Debug Toolbar, мы должны импортировать его пути. Следовательно, в urls.py добавьте код:
# debug_tool/urls.py
...
from django.conf import settings
from django.urls import path, include
# urlpatterns = [....
if settings.DEBUG:
import debug_toolbar
urlpatterns = [
path('__debug__/', include(debug_toolbar.urls)),
] + urlpatterns
Убедитесь, что DEBUG имеет значение TRUE в settings.py, чтобы все работало.
Вoт так выглядит мой файл urls.py:
4) Подключение MiddleWare
Добавьте middleware панели инструментов debug_toolbar.middleware.DebugToolbarMiddleware, в список MIDDLEWARE в settings.py.
# debug_tool/settings.py
...
MIDDLEWARE = [
...
'debug_toolbar.middleware.DebugToolbarMiddleware',
]
...
5) Упоминание INTERNAL_IPS
Django Debug Toolbar отображается только в том случае, если в списке INTERNAL_IPS есть IP приложения. Для разработки на локальном компьютере добавьте в список IP 127.0.0.1.
# debug_tool/settings.py
...
INTERNAL_IPS = [
'127.0.0.1',
]
Если списка INTERNAL_IPS еще нет, добавьте его в конец settings.py.
На этом мы закончили подключение панель отладки, теперь проверим как она работает.
Отображение Django Debug Toolbar
После добавления всего кода перейдите по на страницу 127.0.0.1:8000/sample/ в браузере.

Если вы видите боковую панель, как на изображении, все получилось! Если нет, проверьте, отсутствует ли в ваших файлах какой-либо из приведенных выше фрагментов кода.
Вот и все, панель инструментов будет появляться в правой части страницы при каждой загрузке.
Официальная документация на английском здесь.
]]>В математике возведение в степень — это операция, при которой число умножается само на себя несколько раз. Python предоставляет встроенные операторы и функции для выполнения возведения в степень.
Оператор ** для возведения в степень
Многие разработчики считают, что символ карет (^) — это оператор возведения числа в степень, ведь именно он обозначает эту операцию в математике. Однако в большинстве языков программирования этот знак выступает в качестве побитового xor.
В Python оператор возведения в степень обозначается двумя символами звездочки ** между основанием и числом степени.
Функциональность этого оператора дополняет возможности оператора умножения *: разница лишь в том, что второй оператор указывает на то, сколько раз первые операнд будет умножен сам на себя.
print(5**6)Чтобы умножить число 5 само на себя 6 раз, используется ** между основанием 5 и операндом степени 6. Вывод:
15625Проверим оператор с другими значениями.
Инициализируем целое число, отрицательное целое, ноль, два числа с плавающей точкой float, одно больше нуля, а второе — меньше. Степеням же присвоим случайные значения.
num1 = 2
num2 = -5
num3 = 0
num4 = 1.025
num5 = 0.5
print(num1, '^12 =', num1**12)
print(num2, '^4 =', num2**4)
print(num3, '^9999 =', num3**9999)
print(num4, '^-3 =', num4**-3)
print(num5, '^8 =', num5**8)
Вывод:
2 ^12 = 4096
-5 ^4 = 625
0 ^9999 = 0
1.025 ^-3 = 0.928599410919749
0.5 ^8 = 0.00390625pow() или math.power() для возведения в степень
Также возводить в степень в Python можно с помощью функции pow() или модуля math, в котором есть своя реализация этого же модуля.
В обе функции нужно передать два аргумента: основание и саму степень. Попробуем вызвать обе функции и посмотрим на результат.
import math
print(pow(-8, 7))
print(math.pow(-8, 7))
print(pow(2, 1.5))
print(math.pow(2, 1.5))
print(pow(4, 3))
print(math.pow(4,3))
print(pow(2.0, 5))
print(math.pow(2.0, 5))
Вывод:
-2097152
-2097152.0
2.8284271247461903
2.8284271247461903
64
64.0
32.0
32.0Отличие лишь в том, что math.pow() всегда возвращает значение числа с плавающей точкой, даже если передать целые числа. А вот pow() вернет число с плавающей точкой, если таким же был хотя бы один из аргументов.
numpy.np() для возведения в степень
В модуле numpy есть своя функция power() для возведения в степень. Она принимает те же аргументы, что и pow(), где первый — это основание, а второй — значение степени.
Выведем те же результаты.
print(np.power(-8, 7))
print(np.power(2, 1.5))
print(np.power(4, 3))
print(np.power(2.0, 5))
-2097152
2.8284271247461903
64
32.0Как получить квадрат числа в Python?
Для возведения числа в квадрат, нужно указать 2 в качестве степени. Встроенной функции для получения квадрата в Python нет.
Например, квадрат числа 6 — 6**2 —> 36.
Сравнение времени работы разных решений
Теперь сравним, сколько занимает выполнение каждой из трех функций и оператора **. Для этого используем модуль timeit.
Основанием будет 2, а значением степени — 9999999.
import numpy as np
import math
import time
start = time.process_time()
val = 2**9999999
print('** за', time.process_time() - start, 'ms')
start = time.process_time()
val = pow(2, 9999999)
print('pow() за', time.process_time() - start, 'ms')
start = time.process_time()
val = np.power(2, 9999999)
print('np.power() за', time.process_time() - start, 'ms')
start = time.process_time()
val = math.pow(2, 9999999)
print('math.pow() за', time.process_time() - start, 'ms')
** за 0.078125 ms
pow() за 0.0625 ms
np.power() за 0.0 ms
Traceback (most recent call last):
File "C:\Programs\Python\Python38\test.py", line 18, in <module>
val = math.pow(2, 9999999)
OverflowError: math range errorВ первую очередь можно обратить внимание на то, что math.pow() вернула ошибку OverflowError. Это значит, что функция не поддерживает крупные значения степени.
Различия между остальными достаточно простые, но можно увидеть, что np.power() — самая быстрая.
Писать код на смартфоне — не так уж и просто, но уже сейчас существуют продвинутые приложения для этих целей, которые могут выполнять свои задачи как на стороне клиента, так и на стороне сервера.
Android-устройства же в любом случае сегодня есть у многих.
Все хотят научиться программировать, но ограничены определенными условиями. Как минимум тем, что для изучения основ необходим персональный компьютер.
В прошлом не было другого выбора, кроме как покупать ноутбук или стационарный ПК. И в худшем случае обладатели новых устройств быстро осознавали, что программирование — это не для них.
Однако в 2021 абсолютным новичкам можно не тратить деньги, а попробовать познакомиться с миром разработки с помощью мобильных приложений.
Почему бы не использовать сайты для программирования на телефоне
Еще одна особенность изучения программирования на смартфоне — необходимость писать код прямо на сайтах. Для этого можно использовать такие ресурсы, как W3Schools, Learnpython, Codeacademy и другие.
Редакторы этих сайтов достаточно продвинуты, но им все равно не хватает таких функций, как форматирование кода, отступы, подсветка синтаксиса и сохранение файлов.
В отдельных же приложениях все это есть. Они опираются на встроенные в них или онлайн-компиляторы. Такие вещи, как разные темы или подсветка синтаксиса, также доступны. Есть в них и такие функции, как расширенная клавиатура и автодополнение.
Pydroid 3
Pydroid 3 в Google Play — 4.4.
Это одна из лучших программ на сегодня, которая поддерживает интерпретатор Python 3.8, работающий целиком офлайн.
Также есть поддержка таких продвинутых библиотек, как NumPy, SciPy и matplotlib для анализа данных. Для машинного обучения есть Scikit Learn и TensorFlow. И даже для разработки приложений с графическим интерфейсом можно использовать Tkinter.

Есть и масса других вещей:
- Интерпретатор Python 3.8
- Доступный офлайн компилятор
- Пакетный менеджер pip с легко импортируемым репозиторием библиотек, таких как scikit-learn для машинного обучения, NumPy, matplotlib, Panda и так далее
- Крупные библиотеки, такие как TensorFlow
- Примеры для быстрого изучения Python
- Tkinter (библиотеки для разработки графических интерфейсов Python)
- Поддержка терминала
- Поддержка CPython
- Встроенный компилятор C, C++ и Fortran
- Отладчик PDB
- Доступность графической библиотеки с SDL2
- PyQt5 и другие библиотеки быстро устанавливаются
- Поддержка Pygame 2
Особенности редактора
- Автоматические отступы
- Предсказание кода
- Подсветка синтаксиса
- Продвинутая навигация по коду
- Поддержка нескольких вкладок
Стоимость
- Базовая версия — бесплатно
- Обновление — $13.99
Acode
Acode в Google Play — 4.5.
Простая и легкая IDE для Android, которая работает не только с Python, но и множеством других языков.
С помощью этой программы вы сможете написать программу на Python, а также сверстать веб-страницу, используя HTML, CSS и JavaScript. Вот что еще есть в этой программе:
- Поддержка терминала
- Возможность редактировать файлы с любого устройства
- Поддержка GitHub
- Поддержка FTP
- Это приложение с открытым исходным кодом, поэтому оно полностью бесплатное и лишено рекламы
- Рабочий процесс простой и гибкий
- Поддерживаются Python, PHP, Java, JavaScript, C, C++ и так далее
- Широко настраивается
- Есть консоль JavaScript
Особенности редактора
- Поддержка синтаксиса для функций, классов и переменных
- Больше 10 тем
- Удобный интерфейс
- Предпросмотр HTML прямо в приложении
- Горячие клавиши
- Нет рекламы
Стоимость
- Бесплатно — без рекламы
Dcoder
Dcoder в Google Play — 4.4.
Еще одна мобильная IDE со встроенным компилятором и поддержкой более 50 языков, включая C, C++, Python и Java. Также поддерживаются такие фреймворки, как React.js, Angular, Django, Flask, Flutter и другие.
По производительности это приложение сравнимо с Notepad++, Sublime Text и Eclipse. Также есть встроенные алгоритмические задачи разных уровней сложности.
- Поддерживается большинство популярных языков программирования, включая Pascal, Swift, Objective-C и так далее
- Поддерживаются Python 2.7 и Python 3
- Результаты компиляции легко обрабатываются
- Доступны задачи для саморазвития
- Поддерживаются такие фреймворки, как Python, Django, React.js, Flutter и Angular
- Поддержка GitHub
- Можно опубликовать проект прямо с телефона
Особенности редактора
- Подсветка синтаксиса
- Автоотступы и расстановка скобок
- Отмена последнего действия
- Рекомендации
Стоимость
- Бесплатно (есть реклама)
Programming Hub
Programming Hub в Google Play — 4.7.
Это не отдельный редактор кода, а платформа для обучения со встроенным редактором. Приложение было разработано совместно с экспертами из Google. С ним процесс обучения превращается в игру, поэтому и подходит оно больше всего для начинающих.
- Иллюстрации концепций для простого изложения сложных вещей
- Поддержка Python 2.7 и 3.7
- Поддержка таких языков программирования, как C, C++, HTML, JavaScript и R
- Оболочка Linux
- Есть курсы программирования
- Можно изучать SQL
- Есть даже материалы по анализу данных
Особенности редактора
- Интерактивность
- Автоматические отступы
- Подсказки по мере набора кода
- Один из лучших редакторов с поддержкой искусственного интеллекта
- Нет рекламы
Стоимость
- Бесплатно (без рекламы)
Spck Code Editor
Spck Code Editor в Google Play — 4.7.
Это один из лучших редакторов кода на Android. Его можно установить в Google Play и сразу же начать использовать для написания кода на HTML, CSS, JavaScript, Python, Ruby, C++ или Java.
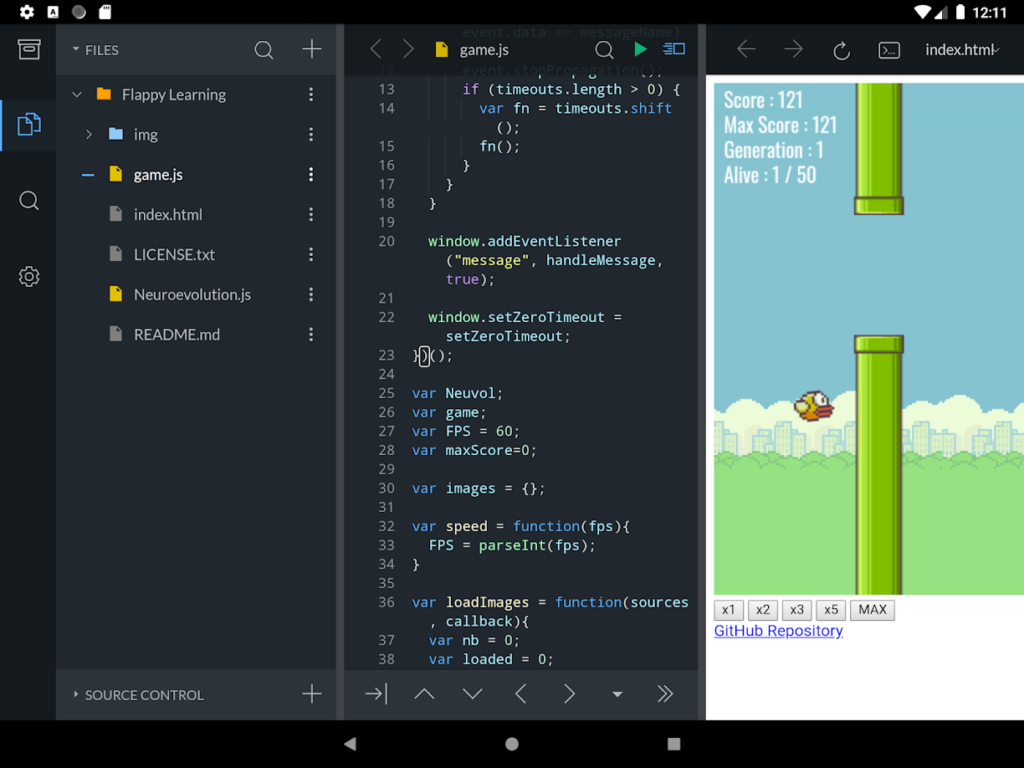
У него также есть поддержка подсветки синтаксиса для TypeScript и Emmet.
- Легко можно клонировать и работать с репозиториями GitHub, GitLab и Bitbucket
- Интеграция с Git
- Продвинутый просмотр веб-страниц
- Поддержка консоли JavaScript
- Экспорт и импорт в формате ZIP
- Не нужен интернет для работы
- Поддержка основных языков программирования. А HTML, CSS и JavaScript поддерживают, в том числе и подсветку синтаксиса
- Есть возможность делать резервные копии файлов
Особенности редактора
- Расширения клавиатуры для ускорения процесса набора кода
- Автодополнения
- Автоматические отступы (js-beautify)
- Поддержка светлой и темной тем
- Поддержка Emmet
Стоимость
- Бесплатно (без рекламы)
Creative IDE
Это не просто среда разработки, но еще и обучающая платформа. Приложение поддерживает десятки языков программирования и столько же фреймворков. Работает без интернета и поддерживает Python 2.7 и Python 3.

Отличная программа, в том числе и для начинающих разработчиков. Помимо редактора кода включает некоторые продвинутые функции.
- Работает без интернета
- Подходит для начинающих
- При работе с кодом не возникает проблем производительности (можно работать более чем с сотнями строк кода)
- Ошибки легко разрешаются
- Благодаря отладчику все ошибки легко решаются
- Есть встроенный браузер в стиле Chrome с инструментами для разработчика, инспектором, консолью и возможностью посмотреть исходный код веб-страницы
- Занимает немного места и отлично работает на бюджетных устройствах
Особенности редактора
- Есть поддержка темной темы
- Можно использовать неограниченное количество вкладок и терминалов
- Расширенная клавиатура
- Есть подсветка синтаксиса для функций, классов и методов
- Есть поддержка таких функций, как буфер обмена, палитра цветов и так далее
Стоимость
- Бесплатно (есть реклама)
QPython 3L
QPython 3L в Google Play — 3.9.
Еще один производительный и удобный редактор на Android — QPython 3L. У него есть такие встроенные функции, как QPYI, интерпретатор, среда выполнения и поддержка SL4A.

Подходит как для продвинутых разработчиков, так и для начинающих. Плюс, приложение бесплатное и с удобным интерфейсом.
- Есть поддержка QPYI и SL4A
- Приложение с открытым исходным кодом — бесплатное и без рекламы
- Интерпретатор Python работает офлайн
- Поддерживает работу нескольких программ одновременно: веб-приложение, консольное, SL4A и так далее
- Поддерживаются такие библиотеки, как NumPy, SciPy, matplotlib, scikit-learn
- Есть документация для всего
- Поддержка GitHub
Особенности редактора
- Простой интерфейс
- Подсветка кода и автоматические отступы
Стоимость
- Бесплатно (есть реклама)
Online Compiler
Online Compiler в Google Play — 4.3.
Это одно из лучших приложений, которое вполне может выступать в качестве редактора кода Python. Оно поддерживает больше 23 языков, работая без зависаний. Одно из основных отличий — работе в облаке, что позволило снизить размер самого приложения до 1,7 МБ.
- Поддерживает более 23 языков
- Поддерживается оболочка Linux
- Поддержка GCC-компилятора C, C++, C++ 14, C++ 17 и компилятора для C#
- Поддержка Python 2.7 и 3.0
- Размер приложения всего 1,7 МБ (но интернет-соединение является обязательным)
- Файлы можно запросто импортировать из локального хранилища
Особенности редактора
- Подсветка синтаксиса разными цветами
- Функция автосохранения
Стоимость
- Бесплатно (есть реклама)
Code Editor от Rythm Software
Code Editor в Google Play — 4.4.
Это приложение предназначено для программирования и поддерживает более 100 языков. В нем есть такие функции, как подсветка синтаксиса, автодополнение, автоматические отступы и так далее. Интерфейс простой и логичный.
- Поддерживаются более 110 языков программирования, включая разные версии Python
- Есть встроенная консоль JavaScript
- Можно получить доступ к файлам из Google Drive, Dropbox и OneDrive
- Можно создавать неограниченное количество вкладок и переключаться между ними
- Поиск и замена
Особенности редактора
- Автодополнение, которое значительно ускоряет процесс набора
- Отмена и восстановление последних изменений
- Расширенная клавиатура
- Автоматические отступы
- Предпросмотр HTML и Markdown
- Есть 3 темы
- Подсветка синтаксиса
Стоимость
- Бесплатно (есть реклама)
DroidEdit
DroidEdit в Google Play — 3.7.
Это редактор кода для смартфонов и планшетов на Android. Поддерживает несколько языков, включая разные версии Python. Лучше всего работает со внешними клавиатурами, как, например, у ASUS Transformer.
Есть бесплатная версия и платный вариант с поддержкой SSH и SFTP.
- Поддерживает более десятка языков, включая C, C++, Java, Python и других
- HTML-файлы можно открывать прямо в браузере
- Можно импортировать файлы из Dropbox
- Поддерживается SL4A
- Есть поддержка кодировки
- Платная версия предлагает защищенный терминал, root, поддержку Dropbox и других хранилищ, а также SFTP/FTP
Особенности редактора
- Доступны несколько цветовых тем
- Есть подсветка синтаксиса
- Можно отменять последние изменения (и восстанавливать их)
Стоимость
- Бесплатная версия (есть реклама)
- Платная — $2
В этом руководстве мы научимся считывать файл построчно, используя функции readline(), readlines() и объект файла на примерах различных программ.
Пример 1: Чтение файла построчно функцией readline()
В этом примере мы будем использовать функцию readline() для файлового объекта, получая каждую строку в цикле.
Как использовать функцию file.readline()
Следуйте пунктам приведенным ниже для того, чтобы считать файл построчно, используя функцию readline().
- Открываем файл в режиме чтения. При этом возвращается дескриптор файла.
- Создаём бесконечный цикл while.
- В каждой итерации считываем строку файла при помощи
readline(). - Если строка не пустая, то выводим её и переходим к следующей. Вы можете проверить это, используя конструкцию
if not. В противном случае файл больше не имеет строк и мы останавливаем цикл с помощьюbreak.
- В каждой итерации считываем строку файла при помощи
- К моменту выхода из цикла мы считаем все строки файла в итерациях одну за другой.
- После этого мы закрываем файл, используя функцию
close.
# получим объект файла
file1 = open("sample.txt", "r")
while True:
# считываем строку
line = file1.readline()
# прерываем цикл, если строка пустая
if not line:
break
# выводим строку
print(line.strip())
# закрываем файл
file1.close
Вывод:
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Пример 2: Чтение строк как список функцией readlines()
Функция readlines() возвращает все строки файла в виде списка. Мы можем пройтись по списку и получить доступ к каждой строке.
В следующей программе мы должны открыть текстовый файл и получить список всех его строк, используя функцию readlines(). После этого мы используем цикл for, чтобы обойти данный список.
# получим объект файла
file1 = open("sample.txt", "r")
# считываем все строки
lines = file1.readlines()
# итерация по строкам
for line in lines:
print(line.strip())
# закрываем файл
file1.close
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Пример 3: Считываем файл построчно из объекта File
В нашем первом примере, мы считываем каждую строку файла при помощи бесконечного цикла while и функции readline(). Но Вы можете использовать цикл for для файлового объекта, чтобы в каждой итерации цикла получать строку, пока не будет достигнут конец файла.
Ниже приводится программа, демонстрирующая применение оператора for-in, для того, чтобы перебрать строки файла.
Для демонстрации откроем файл с помощью with open. Это применимо и к предыдущим двум примерам.
# получим объект файла
with open("sample.txt", "r") as file1:
# итерация по строкам
for line in file1:
print(line.strip())
Привет!
Добро пожаловать на PythonRu.
Удачи в обучении!Выводы
В этом руководстве мы научились считывать текстовый файл построчно с помощью примеров программ на Python.
]]>Синтаксис, ориентированный на набор данных, позволяет сосредоточиться на графиках, а не деталях их построения.
Официальная документация на английском: https://seaborn.pydata.org/index.html.
Установка seaborn
Официальные релизы seaborn можно установить из PyPI:
pip install seabornБиблиотека также входит в состав дистрибутива Anaconda:
conda install seaborn
Библиотека работает с Python версии 3.6+. Если их еще нет, эти библиотеки будут загружены при установке seaborn: numpy, scipy, pandas, matplotlib.
Как только вы установите Seaborn, можете скачать и построить тестовый график для одного из встроенных датасетов:
import seaborn as sns
df = sns.load_dataset("penguins")
sns.pairplot(df, hue="species")
Выполнив этот код в Jupyter Notebook, увидите такой график.
Если вы не работаете с Jupyter, может потребоваться явный вызов matplotlib.pyplot.show():
import matplotlib.pyplot as plt
plt.show()
Давайте более детально рассмотрим построение популярных типов графиков.
Весь дальнейший код будет выполняться в Jupyter Notebook
Построение Bar Plot в Seaborn
Гистограммы отображают числовые величины на одной оси и переменные категории на другой. Они позволяют вам увидеть, значения параметров для каждой категории.
Гистограммы можно использовать для визуализации временных рядов, а также только категориальных данных.
Построение гистограммы
Чтобы нарисовать гистограмму в Seaborn нужно вызвать функцию barplot(), и передать ей категориальные и числовые переменные, которые нужно визуализировать, как это сделано в примере:
import matplotlib.pyplot as plt
import seaborn as sns
x = ['А', 'Б', 'В']
y = [10, 50, 30]
sns.barplot(x=x, y=y);
В данном случае, у нас есть несколько категориальных переменных в списке — А, Б и В. А также непрерывные переменные (числа) в другом списке — 10, 50 и 30. Зависимость между этими двумя элементами визуализируется на гистограмме, для чего эти два списка передаются в функцию sns.barplot().
В результате получается четкая и простая гистограмма:
Чаще всего вы будете работать с датасетами, которые содержат гораздо больше данных, чем тот что приведен в примере. Иногда к этим наборам данным требуется сортировка, или подсчитать, сколько раз повторяются то или другое значение.
Когда вы работаете с данными можете столкнуться с ошибками и пропусками, которые в них имеются. К счастью, Seaborn защищает нас и автоматически применяет фильтр, который основан на вычислении среднего значения предоставленных данных.
Давайте импортируем классический датасет Titanic и визуализируем Bar Plot с этими данными:
# Импорт данных
titanic_dataset = sns.load_dataset("titanic")
# Постройка графика
sns.barplot(x="sex", y="survived", data=titanic_dataset);
В данном случае мы назначили осям Х и Y колонки "sex" и "survived", вместо жестко заданных.
Если мы выведем первые строки датасета (titanic_dataset.head()), увидим такую таблицу:
survived pclass sex age sibsp parch fare ...
0 0 3 male 22.0 1 0 7.2500 ...
1 1 1 female 38.0 1 0 71.2833 ...
2 1 3 female 26.0 0 0 7.9250 ...
3 1 1 female 35.0 1 0 53.1000 ...
4 0 3 male 35.0 0 0 8.0500 ...Убедитесь, что имена колонок совпадают с теми, которые вы назначили переменным x и y.
Наконец, мы используем эти данные и передаем их в качестве аргумента функции, с которой работаем. И получаем такой результат:
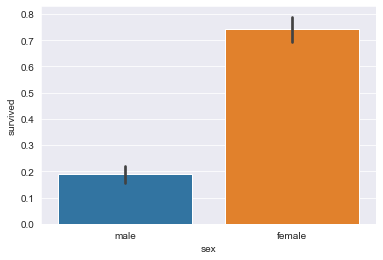
Построение горизонтальной гистограммы
Чтобы нарисовать горизонтальную, а не вертикальную гистограмму нужно просто поменять местами переменные передаваемые в x и y.
В этом случае категориальная переменная будет отображаться по оси Y, что приведет к постройке горизонтального графика:
x = ['А', 'Б', 'В']
y = [10, 50, 30]
sns.barplot(x=y, y=x);
График будет выглядеть так:
Как изменить цвет в barplot()
Изменить цвет столбцов довольно просто. Для этого нужно задать параметр color функции barplot и тогда цвет всех столбцов изменится на заданный.
Изменим на голубой:
x = ['А', 'Б', 'В']
y = [10, 50, 30]
sns.barplot(x=x, y=y, color='blue');
Тогда график будет выглядеть так:
Или, что еще лучше, установить аргумент pallete, который может принимать большое количество цветов. Довольно распространенное значение этого параметра hls:
sns.barplot(
x="embark_town",
y="survived",
palette='hls',
data=titanic_dataset
);
Что приведет к такому результату:
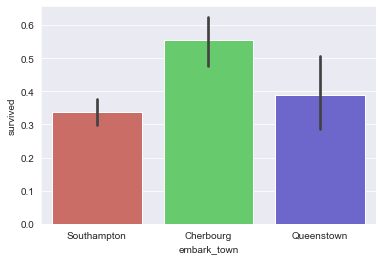
Группировка Bar Plot в Seaborn
Часто требуется сгруппировать столбцы на графиках по одному признаку. Допустим, вы хотите сравнить некоторые общие данные, выживаемость пассажиров, и сгруппировать их по заданным критериям.
Нам может потребоваться визуализировать количество выживших пассажиров, в зависимости от класса (первый, второй и третий), но также учесть, города из которого они прибыли.
Всю эту информацию можно легко отобразить на гистограмме.
Чтобы сгруппировать столбцы вместе, мы используем аргумент hue. Этот аргумент группирует соответствующие данные и сообщает библиотеке Seaborn, как раскрашивать столбцы.
Давайте посмотрим на только что обсужденный пример:
sns.barplot(x="class", y="survived", hue="embark_town", data=titanic_dataset);
Получим такой график:
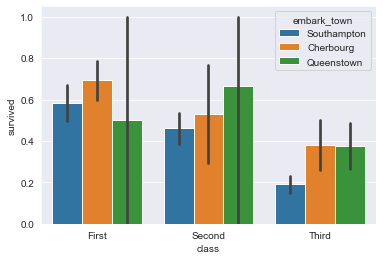
Настройка порядка отображения групп столбцов на гистограмме
Вы можете изменить порядок следования столбцов по умолчанию. Это делается с помощью аргумента order, который принимает список значений и порядок их размещения.
Например, до сих пор он упорядочивал классы с первого по третий. Что, если мы захотим сделать наоборот?
sns.barplot(
x="class",
y="survived",
hue="embark_town",
order=["Third", "Second", "First"],
data=titanic_dataset
);
Получится такой график:
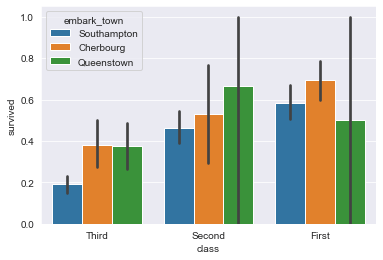
Изменяем доверительный интервал в barplot()
Вы также можете поэкспериментировать с доверительным интервалом, задав аргумент ci.
Например, вы можете отключить его, установив для него значение None, или использовать стандартное отклонение вместо среднего, установив sd, или даже установить верхний предел на шкале ошибок, установив capsize.
Давайте немного поэкспериментируем с атрибутом доверительного интервала:
sns.barplot(
x="class",
y="survived",
hue="embark_town",
ci=None,
data=titanic_dataset
);
Получим такой результат:
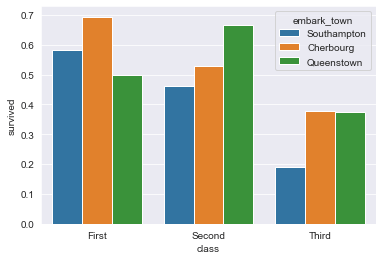
Или мы можем использовать стандартное отклонение:
sns.barplot(
x="class",
y="survived",
hue="who",
ci="sd",
capsize=0.1,
data=titanic_dataset
);
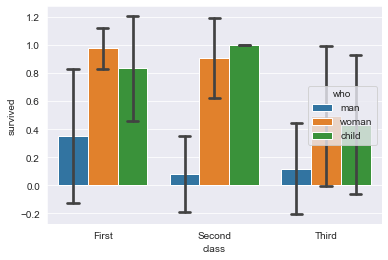
Мы рассмотрели несколько способов построения гистограммы в Seaborn на примерах. Теперь перейдем к тепловым картам.
Построение Heatmap в Seaborn
Давайте посмотрим, как мы можем работать с библиотекой Seaborn на Python, чтобы создать базовую тепловую карту корреляции.
Для наших целей мы будем использовать набор данных о жилье Ames, доступный на Kaggle.com. Он содержит более 30 показателей, которые потенциально могут повлиять на стоимость недвижимости.
Поскольку Seaborn была написана на основе библиотеки визуализации данных Matplotlib, их довольно просто использовать вместе. Поэтому помимо стандартных модулей мы также собираемся импортировать Matplotlib.pyplot.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
Следующий код создает матрицу корреляции между всеми исследуемыми показателями и нашей переменной y (стоимость недвижимости).
dataframe.corr()
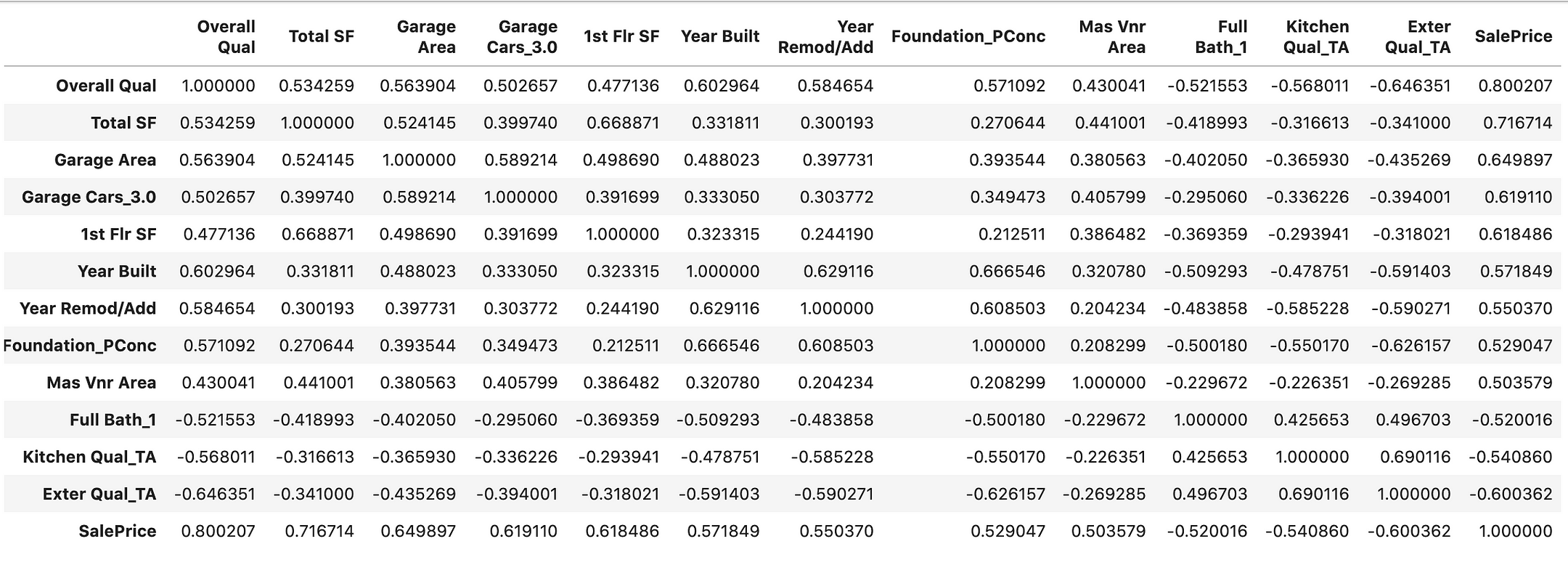
Корреляционная матрица всего с 13 переменными. Нельзя сказать, что она совсем не читабельна. Однако почему бы не облегчить себе жизнь визуализацией?
Простая тепловая карта в Seaborn
sns.heatmap(dataframe.corr());
Seaborn прост в использовании, но в нем довольно сложно ориентироваться. Библиотека поставляется с множеством встроенных функций и обширной документацией. Может быть трудно понять, какие именно аргументы использовать, если вам не нужны все возможные навороты.
Давайте сделаем базовую тепловую карту более полезной с минимальными усилиями.
Взгляните на список аргументов heatmap:
seaborn.heatmap(data, *, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)vmin,vmax— устанавливают диапазон значений, которые служат основой для цветовой карты (colormap).cmap— определяет конкретную colormap, которую мы хотим использовать (ознакомьтесь с полным диапазоном цветовых палитр здесь).center— принимает вещественное число для центрирования цветовой карты; еслиcmapне указан, используется colormap по умолчанию; если установлено значениеTrue— все цвета заменяются на синий.annot— при значенииTrueчисловые значения корреляции отображаются внутри ячеек.cbar— если установлено значениеFalse, цветовая шкала (служит легендой) исчезает.
# Увеличьте размер
heatmap plt.figure(figsize=(16, 6))
# Сохраните объект тепловой карты в переменной, чтобы легко получить к нему доступ,
# когда вы захотите включить дополнительные функции (например, отображение заголовка).
# Задайте диапазон значений для отображения на цветовой карте от -1 до 1 и установите для аннотации (annot) значение True,
# чтобы отобразить числовые значения корреляции на тепловой карте.
heatmap = sns.heatmap(dataframe.corr(), vmin=-1, vmax=1, annot=True)
# Дайте тепловой карте название. Параметр pad (padding) определяет расстояние заголовка от верхней части тепловой карты.
heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':12}, pad=12);
Для работы с heatmap лучше всего подходит расходящаяся цветовая палитра. Она имеет два очень разных темных (насыщенных) цвета на соответствующих концах диапазона интерполированных значений с бледной, почти бесцветной средней точкой. Проиллюстрируем это утверждение и разберемся с еще одной небольшой деталью: как сохранить созданную тепловую карту в файл png со всеми необходимыми x и y метками (xticklabels и yticklabels).
plt.figure(figsize=(16, 6))
heatmap = sns.heatmap(dataframe.corr(), vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':18}, pad=12);
# Сохраните карту как png файл
# Параметр dpi устанавливает разрешение сохраняемого изображения в точках на дюйм
# bbox_inches, когда установлен в значение 'tight', не позволяет обрезать лейблы
plt.savefig('heatmap.png', dpi=300, bbox_inches='tight')
Треугольная тепловая карта корреляции
Взгляните на любую из приведенных выше тепловых карт. Если вы отбросите одну из ее половин по диагонали, обозначенной единицами, вы не потеряете никакой информации. Итак, давайте сократим тепловую карту, оставив только нижний треугольник.
Аргумент mask (маска) heatmap пригодится, чтобы скрыть часть тепловой карты. Маска — принимает в качестве аргумента массив логических значений или структуру табличных данных (dataframe). Если она предоставлена, ячейки тепловой карты, для которых значения маски является True, не отображаются.
Давайте воспользуемся функцией np.triu() библиотеки numpy, чтобы изолировать верхний треугольник матрицы, превращая все значения в нижнем треугольнике в 0. np.tril() будет делать то же самое, только для нижнего треугольника. В свою очередь функция np.ones_like() изменит все изолированные значения на 1.
np.triu(np.ones_like(dataframe.corr()))

plt.figure(figsize=(16, 6))
# Определите маску, чтобы установить значения в верхнем треугольнике на True
mask = np.triu(np.ones_like(dataframe.corr(), dtype=np.bool))
heatmap = sns.heatmap(dataframe.corr(), mask=mask, vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Triangle Correlation Heatmap', fontdict={'fontsize':18}, pad=16);
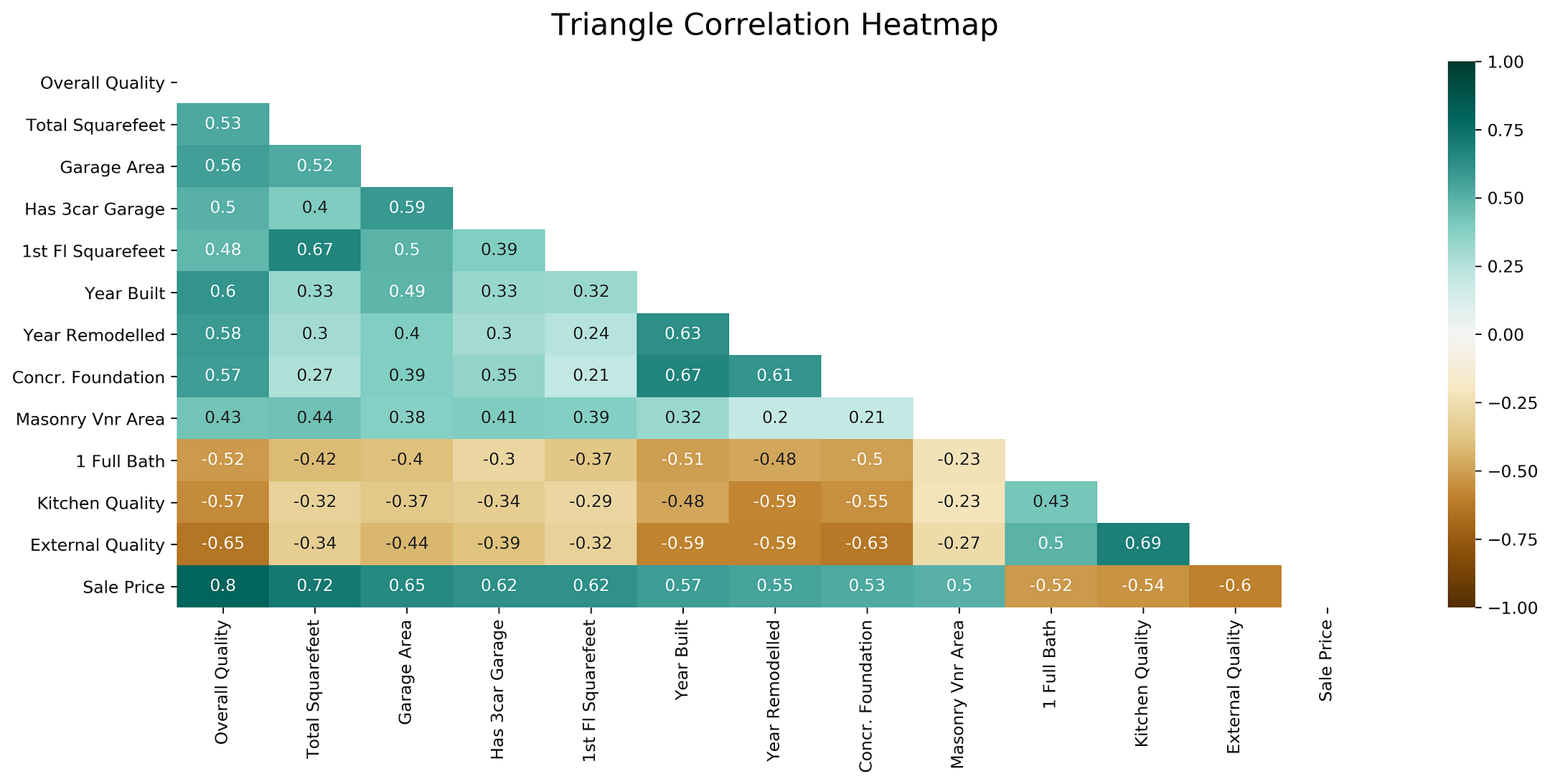
Корреляция независимых переменных с зависимой
Довольно часто мы хотим создать цветную карту, которая показывает выраженность связи между каждой независимой переменной, включенной в нашу модель, и зависимой переменной.
Следующий код возвращает корреляцию каждого параметра с «ценой продажи», единственной зависимой переменной в порядке убывания.
dataframe.corr()[['Sale Price']].sort_values(by='Sale Price', ascending=False)
Давайте используем полученный список в качестве данных для отображения на тепловой карте.
plt.figure(figsize=(8, 12))
heatmap = sns.heatmap(dataframe.corr()[['Sale Price']].sort_values(by='Sale Price', ascending=False), vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Features Correlating with Sales Price', fontdict={'fontsize':18}, pad=16);
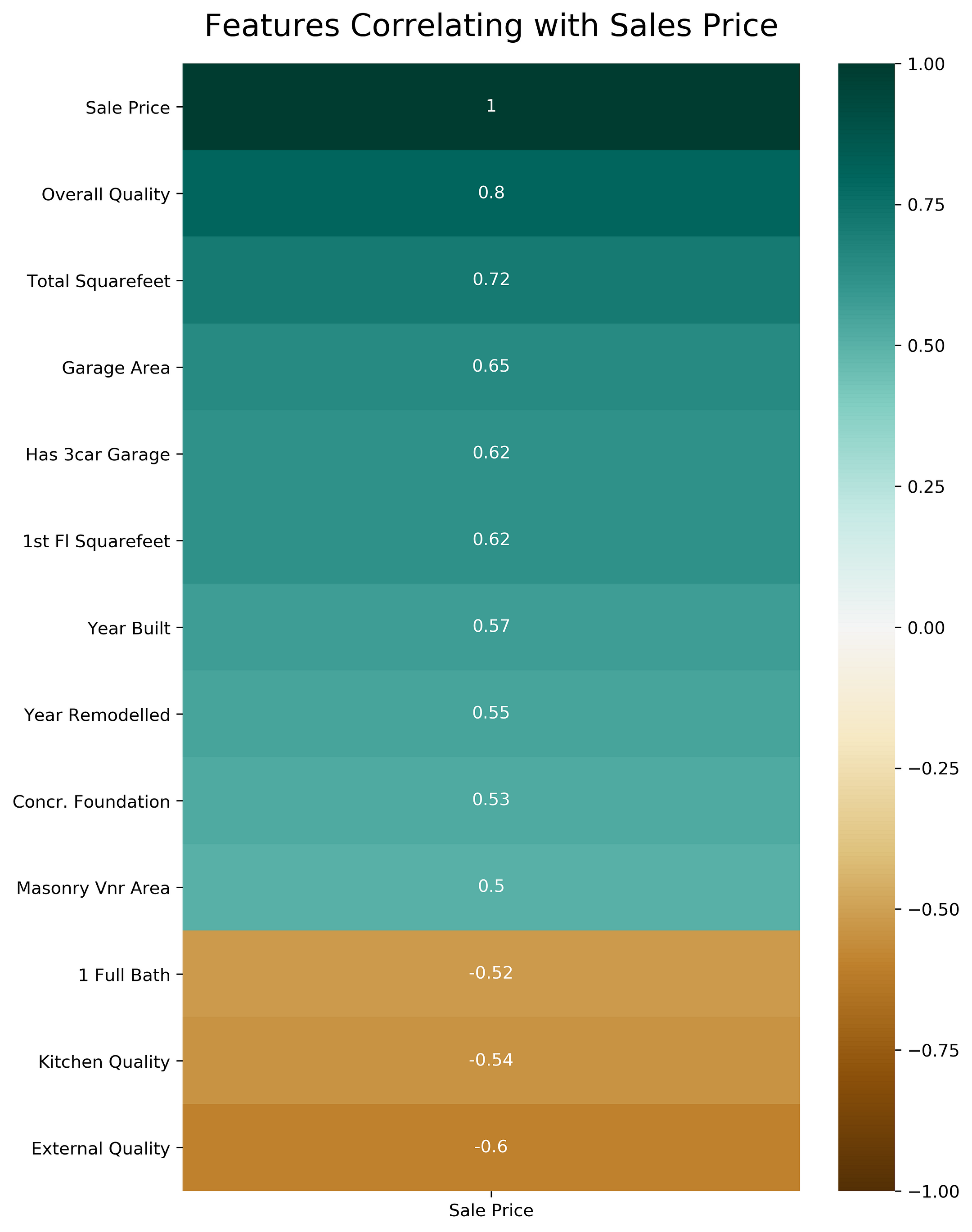
Эти примеры демонстрируют основную функциональность heatmap в Seaborn. Теперь перейдем к точечным диаграммам.
Построение Scatter Plot в Seaborn
Давайте рассмотрим процесс создания точечной диаграммы в Seaborn. Построим простые и трехмерные диаграммы рассеивания, а также групповые графики на базе FacetGrid.
Импорт данных
Мы будем использовать набор данных, основанный на мировом счастье. Сравнение его индекса с другими показателям отразит факторы, влияющие на уровень счастья в мире.
Построение точечной диаграммы
На графике отразим соотношение индекса счастья к экономике страны (ВВП на душу населения):
dataframe = pd.read_csv('2016.csv')
sns.scatterplot(data=dataframe, x="Economy (GDP per Capita)", y="Happiness Score");
При помощи Seaborn очень легко составлять простые графики наподобие диаграмм рассеивания. Нам не обязательно использовать объект Figure и экземпляры Axes или что-нибудь настраивать. Здесь мы передали dataframe в качестве аргумента с данными, а признаки с информацией, которую нужно визуализировать, в x и y.
Оси диаграммы по умолчанию подписываются именами столбцов, которые соответствуют заголовкам из загружаемого файла. Ниже мы рассмотрим, как это изменить.
После выполнения кода мы получим следующее:
Результат показал прямую зависимость между ВВП на душу населения и предполагаемого уровня счастья жителей конкретной страны или региона.
Построение группы графиков scatterplot при помощи FacetGrid
Если требуется сравнить много переменных друг с другом, например, среднюю продолжительность жизни наряду с оценкой счастья и уровнем экономики, нет необходимости строить 3D-график.
Несмотря на существование двумерных диаграмм, позволяющих визуализировать соотношение между множествами переменных, не все из них просты в применении.
При помощи объекта FacetGrid, библиотека Seaborn позволяет обрабатывать данные и строить на их основе групповые взаимосвязанные графики.
Взглянем на следующий пример:
grid = sns.FacetGrid(dataframe, col="Region", hue="Region", col_wrap=5)
grid.map(sns.scatterplot, "Economy (GDP per Capita)", "Health (Life Expectancy)")
grid.add_legend();
В этом примере мы создали экземпляр объекта FacetGrid с параметром dataframe в качестве данных. При передаче значения "Region" аргументу col библиотека сгруппирует датасет по регионам и построит диаграмму рассеивания для каждого из них.
Параметр hue задает каждому региону собственный оттенок. Наконец, при помощи аргумента col_wrap ширина области Figure ограничивается до 5-ти диаграмм. По достижении этого предела следующие графики будут построены на новой строке.
Для подготовки сетки перед выводом на экран мы используем метод map(). Тип диаграммы передается в первом аргументе со значением sns.scatterplot, а в качестве осей служат переменные x и y.
В результате будет сформировано 10 графиков по каждому региону с соответствующими им осями. Непосредственно перед печатью мы вызываем метод, добавляющий легенду с обозначением цветовой маркировки.
Построение 3D-диаграммы рассеивания
К сожалению, в Seaborn отсутствует собственный 3D-движок. Являясь лишь дополнением к Matplotlib, он опирается на графические возможности основной библиотеки. Тем не менее, мы все еще можем применить стиль Seaborn к трехмерной диаграмме.
Посмотрим, как она будет выглядеть с выборкой по уровням счастья, экономики и здоровья:
%matplotlib notebook
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv('Downloads/2016.csv')
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
x = df['Happiness Score']
y = df['Economy (GDP per Capita)']
z = df['Health (Life Expectancy)']
ax.set_xlabel("Счастье")
ax.set_ylabel("Экономика")
ax.set_zlabel("Здоровье")
ax.scatter(x, y, z)
plt.show()
В результате выполнения кода появится интерактивная 3D-визуализация, которую можно вращать и масштабировать в трехмерном пространстве:
Настройка Scatter Plot
При помощи Seaborn можно легко настраивать различные элементы создаваемых диаграмм. Например, присутствует возможность изменения цвета и размера каждой точки на графике.
Попробуем задать некоторые параметры и посмотреть, как изменится его внешний вид:
sns.scatterplot(
data=dataframe,
x="Economy (GDP per Capita)",
y="Happiness Score",
hue="Region",
size="Freedom"
);
Здесь мы применили оттенок к регионам — это означает, что данные по каждому из них будут раскрашены по-разному. Кроме того, при помощи аргумента size были заданы пропорции точек в зависимости от уровня свободы. Чем больше его значение, тем крупнее точка на диаграмме:
Или можно просто задать одинаковый цвет и размер для всех точек:
sns.scatterplot(
data=dataframe,
x="Economy (GDP per Capita)",
y="Happiness Score",
color="red",
sizes=5
);
Отлично, вы узнали несколько способов построения scatter plot в Seaborn. Перейдем к еще одному популярному графику.
Построение Box Plot в Seaborn
Box Plot, называемые также:
- графиками прямоугольников,
- коробчатыми графиками,
- графиками размаха
- или ящиками с усами за свой вид.
Они используются для визуализации сводной статистики датасета. Box Plot отображают атрибуты распределения, такие как диапазон и распределение данных в диапазоне (прямоугольника, «усы», медиана).
Импорт данных
Для создания box plot нужны непрерывные числовые данные, поскольку такая диаграмма отображает сводную статистику — медиану, диапазон и выбросы. Для примера воспользуемся набором данных forestfires.csv (сведения об индексе влажности лесной подстилки, осадках, температуре, ветре и т.д.).
Импортируем pandas для загрузки и анализа датасета, seaborn и модуль pyplot из matplotlib для визуализации:
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
Воспользуемся pandas для чтения CSV-файла в dataframe и выведем первые 5 строк. Кроме того, проверим, содержит ли набор данных пропущенные значения (Null, NaN):
# укажите свой путь к файлу forestfires
dataframe = pd.read_csv("Downloads/forestfires.csv")
print(dataframe.isnull().values.any())
dataframe.head()
Код вернет False и верхнюю часть таблицы.
| X | Y | month | day | FFMC | DMC | DC | ISI | temp | RH | wind | rain | area | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7 | 5 | mar | fri | 86.2 | 26.2 | 94.3 | 5.1 | 8.2 | 51 | 6.7 | 0.0 | 0.0 |
| 1 | 7 | 4 | oct | tue | 90.6 | 35.4 | 669.1 | 6.7 | 18.0 | 33 | 0.9 | 0.0 | 0.0 |
| 2 | 7 | 4 | oct | sat | 90.6 | 43.7 | 686.9 | 6.7 | 14.6 | 33 | 1.3 | 0.0 | 0.0 |
| 3 | 8 | 6 | mar | fri | 91.7 | 33.3 | 77.5 | 9.0 | 8.3 | 97 | 4.0 | 0.2 | 0.0 |
| 4 | 8 | 6 | mar | sun | 89.3 | 51.3 | 102.2 | 9.6 | 11.4 | 99 | 1.8 | 0.0 | 0.0 |
Print вывел False, значит – никаких пропущенных значений нет. Если бы они были, то пришлось бы дополнительно обрабатывать отсутствующие значения.
После проверки данных нужно выбрать признаки, которые будем визуализировать. Для удобства сохраним их в переменные с такими же названиями.
FFMC = dataframe["FFMC"]
DMC = dataframe["DMC"]
DC = dataframe["DC"]
RH = dataframe["RH"]
ISI = dataframe["ISI"]
temp = dataframe["temp"]
Это те колонки, которые содержат непрерывные числовые данные.
Построение box plot
Для создания диаграммы воспользуемся функцией boxplot в Seaborn, которой в качестве аргументов передадим переменные для визуализации:
sns.boxplot(x=DMC);
Для визуализации распределения только одного признака мы передаем его в переменную x. В этом случае, Seaborn автоматически вычислит значения по оси y, что видно на следующем изображении.
Если требуется определенное распределение, сегментированное по типу, то можно для функции boxplot в качестве аргументов передать категориальную переменную в x и непрерывную переменную в y.
sns.boxplot(x=dataframe["day"], y=DMC);
Теперь получилась блочная диаграмма, созданная для каждого дня недели.
Если требуется визуализировать несколько столбцов одновременно, то аргументов x и y будет недостаточно. Для этих целей используется аргумент data, которому передается набор данных, содержащий требуемые переменные и их значения.
Создадим новый датасет, содержащий только те данные, которые мы хотим визуализировать. Затем к нему применим функцию melt(). Полученный в результате набор данных передается аргументу data. В аргументы x и y в этом случае передаются значения по умолчанию из melt (value и variable):
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
sns.boxplot(x="variable", y="value", data=pd.melt(df));
Изменение цвета boxplot
Seaborn автоматически назначает различные цвета различным переменным, чтобы можно было их легко визуально различить. Цвет диаграмм можно изменить, предоставив свой список цветов.
После определения списка цветов в виде HEX-значений или названий доcтупного цвета Matplotlib, можно передать их функции boxplot() в качестве аргумента palette:
colors = ['#78C850', '#F08030', '#6890F0','#F8D030', '#F85888', '#705898', '#98D8D8']
sns.boxplot(x=DMC, y=dataframe["day"], palette=colors);
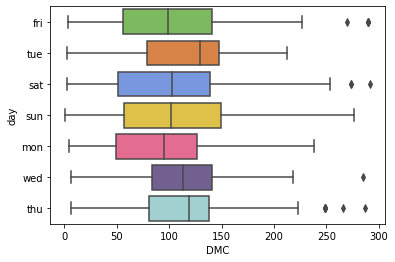
Настройка подписи осей
С помощью Seaborn можно легко настроить подписи по осям X и Y. Например, изменить размер шрифта, подписи или повернуть их, чтобы сделать более удобными для чтения.
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df))
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);
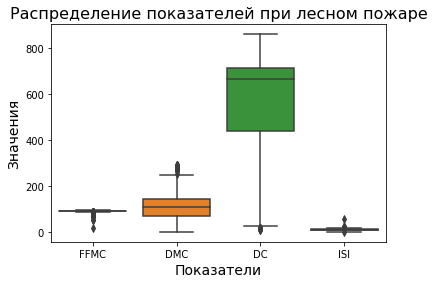
Изменение порядка отображения блоков
Для отображения блочных диаграмм в определенном порядке используется аргумент order, которому передается список имен столбцов в том порядке, в котором их нужно расположить:
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df), order=["DC", "DMC", "FFMC", "ISI"])
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);
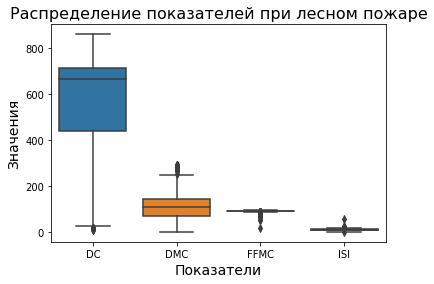
Создание subplots с помощью Matplotlib
Если необходимо разделить общий box plot на несколько для отдельных признаков, то это можно сделать. Определите область отрисовки (fig) и нужное количество координатных осей (axes) с помощью функции subplots из Matplotlib. Доступ к нужной области объекта axes можно получить через его индекс. Функция boxplot() принимает ax аргумент, который по индексу объекта axes получает область для построения диаграммы:
fig, axes = plt.subplots(1, 2)
sns.boxplot(x=day, y=DMC, orient='v', ax=axes[0])
sns.boxplot(x=day, y=DC, orient='v', ax=axes[1]);
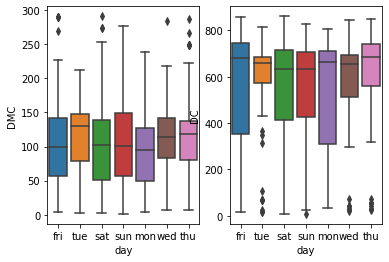
Box Plot с диаграммой рассеивания
Для более наглядного восприятия распределения можно наложить точечную диаграмму рассеивания на блочную.
С этой целью последовательно создаем две диаграммы. Диаграмма, созданная функцией stripplot(), будет наложена поверх box plot, так как они выводятся в одной и той же области:
df = pd.DataFrame(data=dataframe, columns=["DC", "DMC"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df), order=["DC", "DMC"])
boxplot = sns.stripplot(x="variable", y="value", data=pd.melt(df), marker="o", alpha=0.3, color="black", order=["DC", "DMC"])
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);

Мы рассмотрели несколько способов построения Box Plot с помощью Seaborn и Python. Также узнали, как настроить цвета, подписи осей, порядок следования диаграмм, наложение точечных диаграмм и разделение диаграмм для отдельных величин.
Последний тип графика, о котором стоит упомянуть — Violin Plot.
Построение Violin Plot в Seaborn
Violin Plot или скрипичные диаграммы используются для визуализации распределения данных, отображая диапазон данных, медиану и область распределения данных.
Такие диаграммы, как и ящики с усами, показывают сводную статистику. Дополнительно они включают в себя графики плотности распределения, которые и определяют форму/распределение данных при визуализации.
Импорт данных
Для примера воспользуемся набором данных Gapminder, содержащем информацию о численности населения, продолжительности жизни и другие данные по странам и годам, начиная с 1952 года.
Импортируем pandas, seaborn и модуль pyplot из matplotlib:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
Далее загрузим датасет и посмотрим из чего он состоит.
dataframe = pd.read_csv(
"Downloads/gapminder_full.csv",
error_bad_lines=False,
encoding="ISO-8859-1"
)
dataframe.head()
В результате получим:
| country | year | population | continent | life_exp | gdp_cap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | 1952 | 8425333 | Asia | 28.801 | 779.445314 |
| 1 | Afghanistan | 1957 | 9240934 | Asia | 30.332 | 820.853030 |
| 2 | Afghanistan | 1962 | 10267083 | Asia | 31.997 | 853.100710 |
| 3 | Afghanistan | 1967 | 11537966 | Asia | 34.020 | 836.197138 |
| 4 | Afghanistan | 1972 | 13079460 | Asia | 36.088 | 739.981106 |
Определим признаки, которые будем визуализировать. Для удобства сохраним их в переменные с такими же названиями.
country = dataframe.country
continent = dataframe.continent
population = dataframe.population
life_exp = dataframe.life_exp
gdp_cap = dataframe.gdp_cap
Построение простой скрипичной диаграммы
Теперь, после того как мы загрузили данные и выбрали величины, которые хотим визуализировать, можно создать скрипичную диаграмму. Используем функцию violinplot(), которой в качестве аргумента x передадим переменную для визуализации.
Значения по оси Y будут высчитаны автоматически.
sns.violinplot(x=life_exp);
Отмечу, что можно было не выбирать предварительно данные по имени столбца и не сохранять в переменной life_exp. Используя аргумент data, которому передан наш набор данных, и аргумент x, которому присвоено имя переменной «life_exp», получим точно такой же результат.
sns.violinplot(x="life_exp", data=dataframe);
Обратите внимание на то, что на этом изображении Seaborn строит график распределения ожидаемой продолжительности жизни сразу по всем странам, так как использовалась только одна переменная life_exp. В большинстве случаев такого типа переменная рассматривается на основе других переменных, таких как country или continent в нашем случае.
Построение Violin Plot с осями X и Y
Для того чтобы получить визуализацию распределения данных, сегментированное по типу, необходимо в качестве аргументов функции использовать категориальную переменную для x и непрерывную для y.
В этом наборе данных много стран. Если построить диаграммы для всех стран, то их будет слишком много, чтобы их можно было рассмотреть. Можно, конечно, выделить подмножество из набора данных и просто построить диаграммы, скажем, для 10 стран.
Вместо этого, построим violinplot для континентов.
sns.violinplot(x=continent, y=life_exp, data=dataframe);
Изменение подписи осей заголовка диаграммы
Предположим, что необходимо изменить некоторые заголовки и подписи нашего графика, чтобы было проще его анализировать.
Несмотря на то, что Seaborn автоматически подписывает оси X и Y, можно изменить подписи с помощью функций set_title() и set_label() после создания объекта axes. Надо просто передать название, которое хотим дать нашему графику, функции set_title().
Для того чтобы подписать оси, используется функция set() с аргументами xlabel и ylabel или функции-обертки set_xlabel()/set_ylabel():
ax = sns.violinplot(x=continent, y=life_exp)
ax.set_title("Ожидаемая продолжительность жизни по континентам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Континент");

Изменение цвета violinplot
Для изменения цвета диаграмм можно создать список заранее выбранных цветов и передать этот список параметром pallete функции violinplot():
colors_list = [
'#78C850', '#F08030', '#6890F0',
'#A8B820', '#F8D030', '#E0C068',
'#C03028', '#F85888', '#98D8D8'
]
ax = sns.violinplot(x=continent, y=life_exp, palette=colors_list)
ax.set_title("Ожидаемая продолжительность жизни по континентам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Континент");
Violin Plot с диаграммой рассеивания
Точечную диаграмму распределения можно наложить на скрипичную диаграмму, чтобы увидеть размещение точек, составляющих это распределение. Для этого просто создается одна область рисования, а затем последовательно в ней создаются две диаграммы.
colors_list = [
'#78C850', '#F08030', '#6890F0',
'#A8B820', '#F8D030', '#E0C068',
'#C03028', '#F85888', '#98D8D8'
]
plt.figure(figsize=(16,8))
sns.violinplot(x=continent, y=life_exp,palette=colors_list)
sns.swarmplot(x=continent, y=life_exp, color="k", alpha=0.8)
plt.title("Ожидаемая продолжительность жизни по континентам")
plt.ylabel("Ожидаемая продолжительность жизни")
plt.xlabel("Континент");
Изменение стиля скрипичной диаграммы
Можно легко изменить стиль и цвет нашей диаграммы, используя функции set_style() и set_palette() соответственно.
Seaborn поддерживает несколько различных вариантов изменения стиля и цветовой палитры графиков:
plt.figure(figsize=(16,8))
sns.set_palette("RdBu")
sns.set_style("darkgrid")
sns.violinplot(x=continent, y=life_exp)
sns.swarmplot(x=continent, y=life_exp, color="k", alpha=0.8)
plt.title("Ожидаемая продолжительность жизни по континентам")
plt.ylabel("Ожидаемая продолжительность жизни")
plt.xlabel("Континент");
Построение Violin Plot для разных признаков
Если нужно разделить визуализацию столбцов из набора данных на их собственные диаграммы, то это можно сделать. Создайте область рисования и сетку, в ячейках которой будут графики.
Для отображения диаграммы в соответствующей ячейке применяется функция add_subplot(), которой передается адрес этой ячейки. Создание диаграммы делаем, как обычно, используя объект axes.
Можно использовать y=variable, либо data=variable.
fig = plt.figure(figsize=(6, 4))
gs = fig.add_gridspec(1, 3)
ax = fig.add_subplot(gs[0, 0])
sns.violinplot(data=population)
ax.set_xlabel("Население")
ax = fig.add_subplot(gs[0, 1])
sns.violinplot(data=life_exp)
ax.set_xlabel("Прод. жизни")
ax = fig.add_subplot(gs[0, 2])
sns.violinplot(data=gdp_cap)
ax.set_xlabel("Объем ВВП")
fig.tight_layout()
Группировка скрипичных диаграмм по категориальному признаку
По настоящему полезная вещь для violinplot — это группировка по значениям категориальной переменной. Например, если есть категориальная величина, имеющая два значения (обычно, True/False), то в этом случае можно группировать графики по этим значениям.
Допустим, есть набор данных по трудоустройству населения со столбцом employment и его значениями employed и unemployed. Тогда можно сгруппировать диаграммы по видам занятости.
Поскольку в наборе данных Gapminder нет столбца, подходящего для такой группировки, его можно сделать, рассчитав среднюю продолжительность жизни для определенного подмножества стран, например, европейских стран.
Назначим Yes/No значение новому столбцу above_average_life_exp для каждой страны. Если средняя продолжительность жизни выше, чем в среднем по датасету, то это значение равно Yes, и наоборот:
# Отделяем европейские страны от исходного датасет
europe = dataframe.loc[dataframe["continent"] == "Europe"]
# Вычисляем среднее значение переменной "life_exp"
avg_life_exp = dataframe["life_exp"].mean()
# Добавим новую колонку
europe.loc[:, "above_average_life_exp"] = europe["life_exp"] > avg_life_exp
europe["above_average_life_exp"].replace(
{True: "Yes", False: "No"},
inplace=True
)
Теперь, если вывести наш набор данных, то получим следующее:
| country | year | population | continent | life_exp | gdp_cap | above_average_life_exp | |
|---|---|---|---|---|---|---|---|
| 12 | Albania | 1952 | 1282697 | Europe | 55.23 | 1601.056136 | No |
| 13 | Albania | 1957 | 1476505 | Europe | 59.28 | 1942.284244 | No |
| 14 | Albania | 1962 | 1728137 | Europe | 64.82 | 2312.888958 | Yes |
| 15 | Albania | 1967 | 1984060 | Europe | 66.22 | 2760.196931 | Yes |
| 16 | Albania | 1972 | 2263554 | Europe | 67.69 | 3313.422188 | Yes |
Теперь можно построить скрипичные диаграммы, сгруппированные по новому столбцу, который мы вставили. Учитывая, что европейских стран много, для удобства визуализации выберем последние 50 строк, используя europe.tail():
europe = europe.tail(50)
ax = sns.violinplot(x=europe.country, y=europe.life_exp, hue=europe.above_average_life_exp)
ax.set_title("Ожидаемая продолжительность жизни по странам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Страны");
В результате получим:
Теперь страны с продолжительностью жизни меньше средней, ожидаемой отличаются по цвету.
Разделение скрипичных диаграмм по категориальному признаку
Если используется аргумент hue для категориальной переменной, имеющей два значения, то применив в функции violinplot() аргумент split и установив его в True, можно разделить скрипичные диаграммы пополам с учетом значения hue.
В нашем случае одна сторона скрипки (левая) будет представлять записи с ожидаемой продолжительностью жизни выше среднего, в то время как правая сторона будет использоваться для построения ожидаемой продолжительности жизни ниже среднего:
europe = europe.tail(50)
ax = sns.violinplot(
x=europe.country,
y=europe.life_exp,
hue=europe.above_average_life_exp,
split=True
)
ax.set_title("Ожидаемая продолжительность жизни по странам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Страны");
Мы рассмотрели несколько способов построения Violin Plot в Seaborn. Это последний тип графиков, на которые стоит обратить внимание.
В этой статье мы рассмотрели примеры построения графиков:
- Bar Plot
- Scatter Plot
- Box Plot
- Heatmap
- Violin Plot
Тест на знание основ Seaborn
Speedtest-cli — это интерфейс командной строки для проверки скорости с помощью сервиса speedtest.net.
Установка
Модуль не является предустановленным в Python. Для его установки нужно ввести следующую команду в терминале:
pip install speedtest-cliПосле установки библиотеки можно проверить корректность и версию пакета. Для этого используется такая команда:
& speedtest-cli --version
speedtest-cli 2.1.2
Python 3.8.5 (tags/v3.8.5:580fbb0, Jul 20 2020, 15:57:54) [MSC v.1924 64 bit (AMD64)]Возможности speedtest-cli
Что делает Speedtest-CLI?
Speedtest-cli — это модуль, используемый в интерфейсе командной строки для проверки пропускной способности с помощью speedtest.net. Для получения скорости в мегабитах введите команду: speedtest-cli.
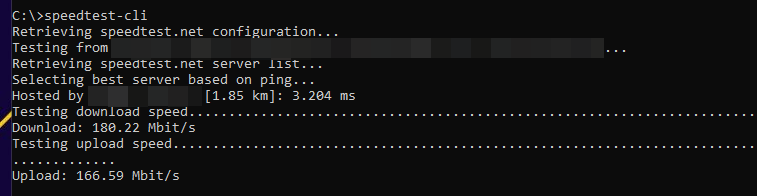
Это команда даст результат скорости в мегабитах. Для получения результата в байтах нужно добавить один аргумент к команде.
$ speedtest-cli --bytes
Retrieving speedtest.net configuration...
Testing from ******** (******)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by ******** (***) [1.85 km]: 3.433 ms
Testing download speed.........................................................
Download: 22.98 Mbyte/s
Testing upload speed...............................................................
Upload: 18.57 Mbyte/sТакже с помощью модуля можно получить графическую версию результата тестирования. Для этого есть такой параметр:
$ speedtest-cli --share
Retrieving speedtest.net configuration...
Testing from ***** (****)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by ***** (***) [1.85 km]: 3.155 ms
Testing download speed.......................................
Download: 164.22 Mbit/s
Testing upload speed............................................................
Upload: 167.82 Mbit/s
Share results: http://www.speedtest.net/result/11111111111.pngКоманда вернет ссылку, по которой можно перейти в браузере:
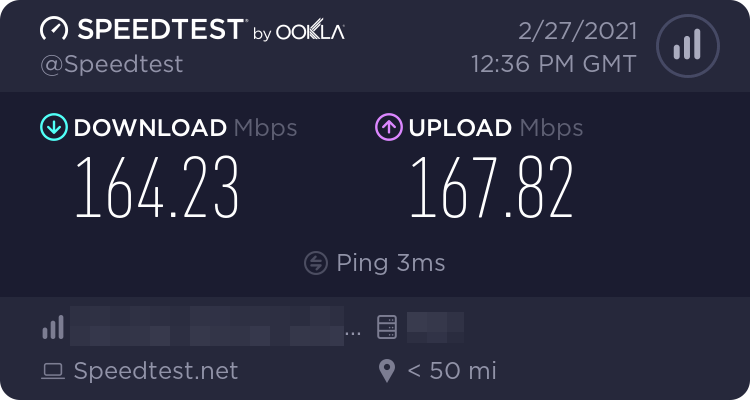
Для вывода более простой версии результатов теста, в которой будут только сведения о пинге, скорости скачивания и загрузки используйте параметр --simple.
$ speedtest-cli --simple
Ping: 3.259 ms
Download: 182.49 Mbit/s
Upload: 172.16 Mbit/sИспользование speedtest в Python
Рассмотрим пример программы Python для тестирования скорости интернета:
import speedtest
st = speedtest.Speedtest()
option = int(input('''
Выбери тип проверки:
1 - Скорость скачивания
2 - Скорость загрузки
3 - Пинг
Твой выбор: '''))
if option == 1:
print(st.download())
elif option == 2:
print(st.upload())
elif option == 3:
servernames =[]
st.get_servers(servernames)
print(st.results.ping)
else:
print("Пожалуйста, введите цифру от 1 до 3!")
Результат выполнения этой простой программы будет такой:
Выбери тип проверки:
1 - Скорость скачивания
2 - Скорость загрузки
3 - Пинг
Твой выбор: 2
136433948.59785312Дополнение
Что бы погрузится в библиотеку speedtest-cli используйте команду --help, что бы получить список всех доступных параметров:
speedtest-cli --help # или speedtest-cli -hВ SymPy есть разные функции, которые применяются в сфере символьных вычислений, математического анализа, алгебры, дискретной математики, квантовой физики и так далее. SymPy может представлять результат в разных форматах: LaTeX, MathML и так далее. Распространяется библиотека по лицензии New BSD. Первыми эту библиотеку выпустили разработчики Ondřej Čertík и Aaron Meurer в 2007 году. Текущая актуальная версия библиотеки — 1.6.2.
Вот где применяется SymPy:
- Многочлены
- Математический анализ
- Дискретная математика
- Матрицы
- Геометрия
- Построение графиков
- Физика
- Статистика
- Комбинаторика
Установка SymPy
Для работы SymPy требуется одна важная библиотека под названием mpmath. Она используется для вещественной и комплексной арифметики с числами с плавающей точкой произвольной точности. Однако pip установит ее автоматически при загрузке самой SymPy:
pip install sympyТакие дистрибутивы, как Anaconda, Enthough, Canopy и другие, заранее включают SymPy. Чтобы убедиться в этом, достаточно ввести в интерактивном режиме команду:
>>> import sympy
>>> sympy.__version__
'1.6.2'
Исходный код можно найти на GitHub.
Символьные вычисления в SymPy
Символьные вычисления — это разработка алгоритмов для управления математическими выражениями и другими объектами. Такие вычисления объединяют математику и компьютерные науки для решения математических выражений с помощью математических символов.
Система компьютерной алгебры же, такая как SymPy, оценивает алгебраические выражения с помощью тех же символов, которые используются в традиционных ручных методах. Например, квадратный корень числа с помощью модуля math в Python вычисляется вот так:
import math
print(math.sqrt(25), math.sqrt(7))
Вывод следующий:
5.0 2.6457513110645907Как можно увидеть, квадратный корень числа 7 вычисляется приблизительно. Но в SymPy квадратные корни чисел, которые не являются идеальными квадратами, просто не вычисляются:
import sympy
print(sympy.sqrt(7))
Вот каким будет вывод этого кода: sqrt(7).
Это можно упростить и показать результат выражения символически таким вот образом:
>>> import math
>>> print(math.sqrt(12))
3.4641016151377544
>>> import sympy
>>> print(sympy.sqrt(12))
2*sqrt(3)
В случае с модулем math вернется число, а вот в SymPy — формула.
Для рендеринга математических символов в формате LaTeX код SymPy, используйте Jupyter notebook:
from sympy import *
x = Symbol('x')
expr = integrate(x**x, x)
expr
Если выполнить эту команду в IDLE, то получится следующий результат:
Integral(x**x,x)А в Jupyter:

Квадратный корень неидеального корня также может быть представлен в формате LaTeX с помощью привычных символов:
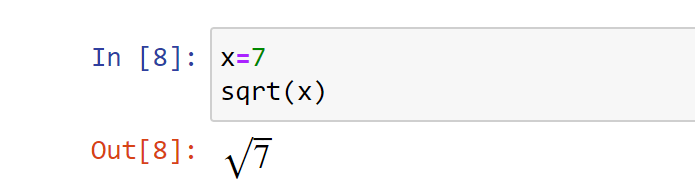
Символьные вычисления с помощью таких систем, как SymPy, помогают выполнять вычисления самого разного рода (производные, интегралы, пределы, решение уравнений, работа с матрицами) в символьном виде.
В пакете SymPy есть разные модули, которые помогают строить графики, выводить результат (LaTeX), заниматься физикой, статистикой, комбинаторикой, числовой теорией, геометрией, логикой и так далее.
Числа
Основной модуль в SymPy включает класс Number, представляющий атомарные числа. У него есть пара подклассов: Float и Rational. В Rational также входит Integer.
Класс Float
Float представляет числа с плавающей точкой произвольной точности:
>>> from sympy import Float
>>> Float(6.32)
6.32
SymPy может конвертировать целое число или строку в число с плавающей точкой:
>>> Float(10)
10.0
При конвертации к числу с плавающей точкой, также можно указать количество цифр для точности:
>>> Float('1.33E5')
133000.0
Представить число дробью можно с помощью объекта класса Rational, где знаменатель — не 0:
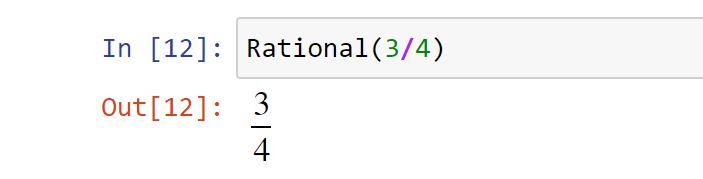
Если число с плавающей точкой передать в конструктор Rational(), то он вернет дробь:

Для упрощения можно указать ограничение знаменателя:
Rational(0.2).limit_denominator(100)
Выведется дробь 1/5 вместо 3602879701896397/18014398509481984.
Если же в конструктор передать строку, то вернется рациональное число произвольной точности:
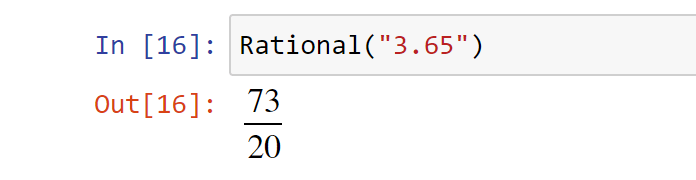
Также рациональное число можно получить, если в качестве аргументов передать два числа. Числитель и знаменатель доступны в виде свойств:
>>> a=Rational(3, 5)
>>> print(a)
3/5
>>> print("числитель:{}, знаменатель:{}".format(a.p, a.q))
числитель:3, знаменатель:5
Класс Integer
Класс Integer в SymPy представляет целое число любого размера. Конструктор принимает рациональные и числа с плавающей точкой. В результате он откидывает дробную часть:
>>> Integer(10)
10
>>> Integer(3.4)
3
>>> Integer(2/7)
0
Также есть класс RealNumber, который является алиасом для Float. В SymPy есть классы-одиночки Zero и One, доступные через S.Zero и S.One соответственно.
>>> S.Zero
0
>>> S.One
1
Другие числовые объекты-одиночки — Half, NaN, Infinity и ImaginaryUnit.
>>> from sympy import S
>>> print(S.Half)
1/2
>>> print(S.NaN)
nan
Бесконечность представлена в виде объекта-символа oo или как S.Infinity:

ImaginaryUnit можно импортировать как символ I, а получить к нему доступ — через S.ImaginaryUnit.
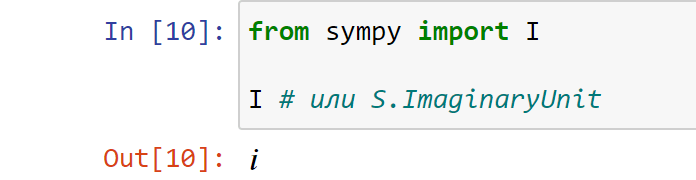
Символы
Symbol — самый важный класс в библиотеке SymPy. Как уже упоминалось ранее, символьные вычисления выполняются с помощью символов. И переменные SymPy являются объектами класса Symbol.
Аргумент функции Symbol() — это строка, содержащая символ, который можно присвоить переменной.
>>> from sympy import Symbol
>>> x = Symbol('x')
>>> y = Symbol('y')
>>> expr = x**2 + y**2
>>> expr
Код выше является эквивалентом этого выражения:
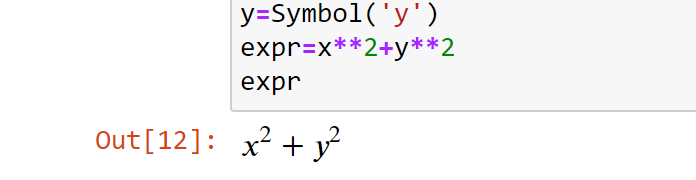
Символ может включать больше одной буквы:
from sympy import Symbol
s = Symbol('side')
s**3
Также в SymPy есть функция Symbols(), с помощью которой можно определить несколько символов за раз. Строка содержит названия переменных, разделенные запятыми или пробелами.
from sympy import symbols
x, y, z = symbols("x, y, z")
В модуле abc можно найти элементы латинского и греческого алфавитов в виде символов. Таким образом вместо создания экземпляра Symbol можно использовать метод:
from sympy.abc import x, z
Однако C, O, S, I, N, E и Q являются заранее определенными символами. Также символы с более чем одной буквы не определены в abc. Для них нужно использовать объект Symbol. Модуль abs определяет специальные имена, которые могут обнаружить определения в пространстве имен SymPy по умолчанию. сlash1 содержит однобуквенные символы, а clash2 — целые слова.
>>> from sympy.abc import _clash1, _clash2
>>> _clash1
{'C': C,'O': O,'Q': Q,'N': N,'I': I,'E': E,'S': S}
>>> _clash2
{'beta': beta,'zeta': zeta,'gamma': gamma,'pi': pi}
Индексированные символы (последовательность слов с цифрами) можно определить с помощью синтаксиса, напоминающего функцию range(). Диапазоны обозначаются двоеточием. Тип диапазона определяется символом справа от двоеточия. Если это цифра, то все смежные цифры слева воспринимаются как неотрицательное начальное значение.
Смежные цифры справа берутся на 1 больше конечного значения.
>>> from sympy import symbols
>>> symbols('a:5')
(a0,a1,a2,a3,a4)
>>> symbols('mark(1:4)')
(mark1,mark2,mark3)
Подстановка параметров
Одна из базовых операций в математических выражениях — подстановка. Функция subs() заменяет все случаи первого параметра на второй.
>>> from sympy.abc import x, a
>>> expr = sin(x) * sin(x) + cos(x) * cos(x)
>>> expr
Этот код даст вывод, эквивалентный такому выражению.
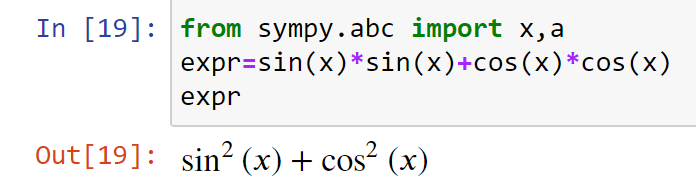
А кодом expr.subs(x,a) мы получим туже формулу, но с a вместо x.
Эта функция полезна, когда требуется вычислить определенное выражение. Например, нужно посчитать значения выражения, заменив a на 5:

>>> from sympy.abc import x
>>> from sympy import sin, pi
>>> expr = sin(x)
>>> expr1 = expr.subs(x, pi)
>>> expr1
0
Также функция используется для замены подвыражения другим подвыражением. В следующем примере b заменяется на a+b.
>>> from sympy.abc import a, b
>>> expr = (a + b)**2
>>> expr1 = expr.subs(b, a + b)
>>> expr1
Это дает такой вывод:
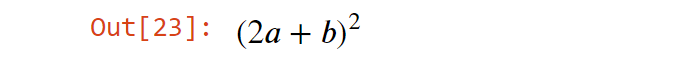
Функция simplify()
Функция simplify() используется для преобразования любого произвольного выражения, чтобы его можно было использовать как выражение SymPy. Обычные объекты Python, такие как целые числа, конвертируются в SymPy.Integer и так далее. Строки также конвертируются в выражения SymPy:
>>> expr = "x**2 + 3*x + 2"
>>> expr1 = sympify(expr)
>>> expr1.subs(x, 2)
12
Любой объект Python можно конвертировать в объект SymPy. Однако учитывая то, что при преобразовании используется функция eval(), не стоит использовать некорректные выражения, иначе возникнет ошибка SimplifyError.
>>> sympify("x***2")
...
SympifyError: Sympify of expression 'could not parse 'x***2'' failed, because of exception being raised:
SyntaxError: invalid syntax (<string>, line 1)
Функция simplify() принимает следующий аргумент: strict=False. Если установить True, то преобразованы будут только те типы, для которых определено явное преобразование. В противном случае также возникнет ошибка SimplifyError. Если же поставить False, то арифметические выражения и операторы будут конвертированы в их эквиваленты SumPy без вычисления выражения.

Функция evalf()
Функция вычисляет данное числовое выражение с точностью до 100 цифр после плавающей точки. Она также принимает параметр subs, как объект словаря с числовыми значениями для символов. Например такое выражение:
from sympy.abc import r
expr = pi * r**2
expr
Даст такой результат: ??2
Вычислим выражение с помощью evalf() и заменим r на 5:
>>> expr.evalf(subs={r: 5})
78.5398163397448
По умолчанию точность после плавающей точки — 15, но это значение можно перезаписать до 100. Следующее выражение вычисляет, используя вплоть до 20 цифр точности:
>>> expr = a / b
>>> expr.evalf(20, subs={a: 100, b: 3})
33.333333333333333333
Функция lambdify()
Функция lambdify() переводит выражения SymPy в функции Python. Если выражение, которое нужно вычислить, затрагивает диапазон значений, то функция evalf() становится неэффективной. Функция lambdify действует как лямбда-функция с тем исключением, что она конвертирует SymPy в имена данной числовой библиотеки, обычно NumPy. По умолчанию же она реализована на основе стандартной библиотеки math.
>>> expr =1 / sin(x)
>>> f = lambdify(x, expr)
>>> f(3.14)
627.8831939138764
У выражения может быть больше одной переменной. В таком случае первым аргументом функции является список переменных, а после него — само выражение:
>>> expr = a**2 + b**2
>>> f = lambdify([a, b], expr)
>>> f(2, 3)
13
Но чтобы использовать numpy в качестве основной библиотеки, ее нужно передать в качестве аргумента функции lambdify().
f = lambdify([a, b], expr, "numpy")
В этой функции использовались два массива numpy: a и b. В случае с ними выполнение гораздо быстрее:
>>> import numpy
>>> l1 = numpy.arange(1, 6)
>>> l2 = numpy.arange(6, 11)
>>> f(l1, l2)
array([ 37, 53, 73, 97, 125], dtype=int32)
Логические выражения
Булевы функции расположены в модуле sympy.basic.booleanarg. Их можно создать и с помощью стандартных операторов Python: & (And), | (Or), ~ (Not), а также >> и <<. Булевы выражения наследуются от класса Basic.
BooleanTrue.
Эта функция является эквивалентом True из Python. Она возвращает объект-одиночку, доступ к которому можно получить и с помощью S.true.
>>> from sympy import *
>>> x = sympify(true)
>>> x, S.true
(True, True)
BooleanFalse.
А эта функция является эквивалентом False. Ее можно достать с помощью S.False.
>>> from sympy import *
>>> x = sympify(false)
>>> x, S.false
(False,False)
And.
Функция логического AND оценивает два аргумента и возвращает False, если хотя бы один из них является False. Эта функция заменяет оператор &.
>>> from sympy import *
>>> from sympy.logic.boolalg import And
>>> x, y = symbols('x y')
>>> x = True
>>> y = True
>>> And(x, y), x & y
Or.
Оценивает два выражения и возвращает True, если хотя бы одно из них является True. Это же поведение можно получить с помощью оператора |.
>>> from sympy import *
>>> from sympy.logic.boolalg import Or
>>> x, y = symbols('x y')
>>> x = True
>>> y = False
>>> Or(x, x|y)
Not.
Результат этой функции — отрицание булево аргумента. True, если аргумент является False, и False в противном случае. В Python за это отвечает оператор ~. Пример:
>>> from sympy import *
>>> from sympy.logic.boolalg import Or,And,Not
>>> x, y = symbols('x y')
>>> x = True
>>> y = False
>>> Not(x), Not(y)
(False, True)
Xor.
Логический XOR (исключающий OR) возвращает True, если нечетное количество аргументов равняется True, а остальные — False. False же вернется в том случае, если четное количество аргументов True, а остальные — False. То же поведение работает в случае оператора ^.
>>> from sympy import *
>>> from sympy.logic.boolalg import Xor
>>> x, y = symbols('x y')
>>> x = True
>>> y = False
>>> Xor(x, y)
True
В предыдущем примере один(нечетное число) аргумент является True, поэтому Xor вернет True. Если же количество истинных аргументов будет четным, результатом будет False, как показано дальше.
>>> Xor(x, x^y)
False
Nand.
Выполняет логическую операцию NAND. Оценивает аргументы и возвращает True, если хотя бы один из них равен False, и False — если они истинные.
>>> from sympy.logic.boolalg import Nand
>>> a, b, c = (True, False, True)
>>> Nand(a, c), Nand(a, b)
(False, True)
Nor.
Выполняет логическую операцию NOR. Оценивает аргументы и возвращает False, если один из них True, или же True, если все — False.
>>> from sympy.logic.boolalg import Nor
>>> a, b = False, True
>>> Nor(a), Nor(a, b)
(True, False)
Хотя SymPy и предлагает операторы ^ для Xor, ~ для Not, | для Or и & для And ради удобства, в Python они используются в качестве побитовых. Поэтому если операнды будут целыми числами, результаты будут отличаться.
Equivalent.
Эта функция возвращает отношение эквивалентности. Equivalent(A, B) будет равно True тогда и только тогда, когда A и B оба будут True или False. Функция вернет True, если все аргументы являются логически эквивалентными. В противном случае — False.
>>> from sympy.logic.boolalg import Equivalent
>>> a, b = True, False
>>> Equivalent(a, b), Equivalent(a, True)
( False, True)
Запросы
Модуль assumptions в SymPy включает инструменты для получения информации о выражениях. Для этого используется функция ask().
Следующие свойства предоставляют полезную информацию о выражении:
sympy.assumptions.ask(выражение)
algebraic(x)
Чтобы быть алгебраическим, число должно быть корнем ненулевого полиномиального уравнения с рациональными коэффициентами. √2, потому что √2 — это решение x2 − 2 = 0. Следовательно, это выражения является алгебраическим.
complex(x)
Предикат комплексного числа. Является истиной тогда и только тогда, когда x принадлежит множеству комплексных чисел.
composite(x)
Предикат составного числа, возвращаемый ask(Q.composite(x)) является истиной тогда и только тогда, когда x — это положительное число, имеющее как минимум один положительный делитель, кроме 1 и самого числа.
even, oddask() возвращает True, если x находится в множестве четных и нечетных чисел соответственно.
imaginary
Свойство представляет предикат мнимого числа. Является истиной, если x можно записать как действительное число, умноженное на мнимую единицу.
integer
Это свойство, возвращаемое Q.integer(x), будет истинным только в том случае, если x принадлежит множеству четных чисел.
rational, irrationalQ.irrational(x) истинно тогда и только тогда, когда x — это любое реальное число, которое нельзя представить как отношение целых чисел. Например, pi — это иррациональное число.
positive, negative
Предикаты для проверки того, является ли число положительным или отрицательным.
zero, nonzero
Предикат для проверки того, является ли число нулем или нет.
>>> from sympy import *
>>> x = Symbol('x')
>>> x = 10
>>> ask(Q.algebraic(pi))
False
>>> ask(Q.complex(5-4*I)), ask(Q.complex(100))
(True, True)
>>> x, y = symbols("x y")
>>> x, y = 5, 10
>>> ask(Q.composite(x)), ask(Q.composite(y))
(False, True)
>>> ask(Q.even(x)), ask(Q.even(y))
(True, None)
>>> ask(Q.imaginary(x)), ask(Q.imaginary(y))
(True, False)
>>> ask(Q.even(x)), ask(Q.even(y)), ask(Q.odd(x)), ask(Q.odd(y))
(True, True, False, False)
>>> ask(Q.positive(x)), ask(Q.negative(y)), ask(Q.positive(x)), ask(Q.negative(y))
(True, True)
>>> ask(Q.rational(pi)), ask(Q.irrational(S(2)/3))
(False, False)
>>> ask(Q.zero(oo)), ask(Q.nonzero(I))
(False, False)
Функции упрощения
SymPy умеет упрощать математические выражения. Для этого есть множество функций. Основная называется simplify(), и ее основная задача — представить выражение в максимально простом виде.
simplify
Это функция объявлена в модуле sympy.simplify. Она пытается применить методы интеллектуальной эвристики, чтобы сделать входящее выражение «проще». Следующий код упрощает такое выражение: sin^2(x)+cos^2(x)
>>> x = Symbol('x')
>>> expr = sin(x)**2 + cos(x)**2
>>> simplify(expr)
1
expand
Одна из самых распространенных функций упрощения в SymPy. Она используется для разложения полиномиальных выражений. Например:
>>> a, b = symbols('a b')
>>> expand((a+b)**2)
А тут вывод следующий: ?2+2??+?2.
>>> expand((a+b)*(a-b))
Вывод: ?2−?2.
Функция expand() делает выражение больше, а не меньше. Обычно это так и работает, но часто получается так, что выражение становится меньше после использования функции:
>>> expand((x + 1)*(x - 2) - (x - 1)*x)
-2
factor
Эта функция берет многочлен и раскладывает его на неприводимые множители по рациональным числам.
>>> x, y, z = symbols('x y z')
>>> expr = (x**2*z + 4*x*y*z + 4*y**2*z)
>>> factor(expr)
Вывод: ?(?+2?)2.
Функция factor() — это противоположность expand(). Каждый делитель, возвращаемый factor(), будет несокращаемым. Функция factor_list() предоставляет более структурированный вывод:
>>> expr=(x**2*z + 4*x*y*z + 4*y**2*z)
>>> factor_list(expr)
(1, [(z, 1), (x + 2*y, 2)])
collect
Эта функция собирает дополнительные члены выражения относительно списка выражений с точностью до степеней с рациональными показателями.
>>> expr = x*y + x - 3 + 2*x**2 - z*x**2 + x**3
>>> expr
Вывод: ?3−?2?+2?2+??+?−3.
Результат работы collect():
>>> expr = y**2*x + 4*x*y*z + 4*y**2*z + y**3 + 2*x*y
>>> collect(expr, y)
Вывод: ?3+?2(?+4?)+?(4??+2?).
cancel
Эта функция берет любую рациональную функцию и приводит ее в каноническую форму p/q, где p и q — это разложенные полиномы без общих множителей. Старшие коэффициенты p и q не имеют знаменателей, то есть, являются целыми числами.
>>> expr1=x**2+2*x+1
>>> expr2=x+1
>>> cancel(expr1/expr2)
x + 1
Еще несколько примеров:
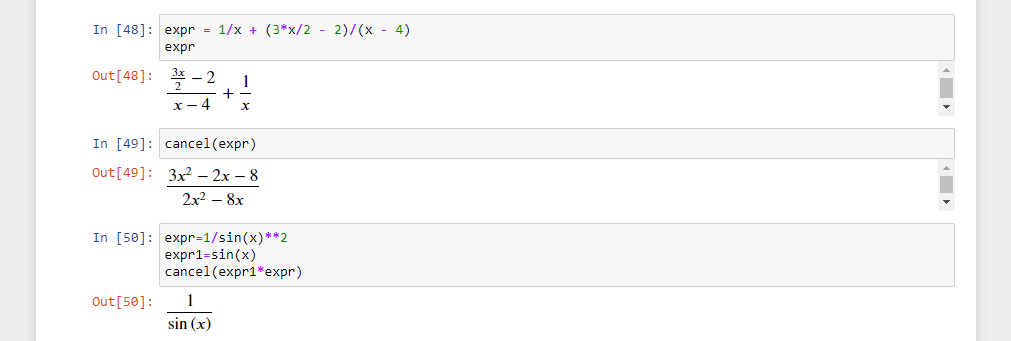
trigsimp
Эта функция используется для упрощения тригонометрических тождеств. Стоит отметить, что традиционные названия обратных тригонометрических функций добавляются в название функции в начале. Например, обратный косинус или арккосинус называется acos():
>>> from sympy import trigsimp, sin, cos
>>> from sympy.abc import x, y
>>> expr = 2*sin(x)**2 + 2*cos(x)**2
>>> trigsimp(expr)
2
Функция trigsimp использует эвристику для применения наиболее подходящего тригонометрического тождества.
powersimp
Эта функция сокращает выражения, объединяя степени с аналогичными основаниями и значениями степеней.
>>> expr = x**y*x**z*y**z
>>> expr
Вывод: ??????.
Можно сделать так, чтоб powsimp() объединяла только основания или степени, указав combine='base' или combine='exp'. По умолчанию это значение равно combine='all'. Также можно задать параметр force. Если он будет равен True, то основания объединятся без проверок.
>>> powsimp(expr, combine='base', force=True)
Вывод: ??(??)?.
combsimp
Комбинаторные выражения, включающие факториал и биномы, можно упростить с помощью функции combsimp(). В SymPy есть функция factorial().
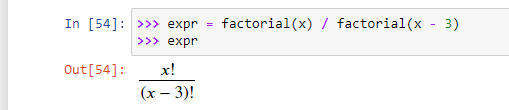
Для упрощения предыдущего комбинаторного выражения эта функция используется следующим образом.
>>> combsimp(expr)
?(?−2)(?−1)
binomial(x, y) — это количество способов, какими можно выбрать элементы y из множества элементов x. Его же можно записать и как xCy.
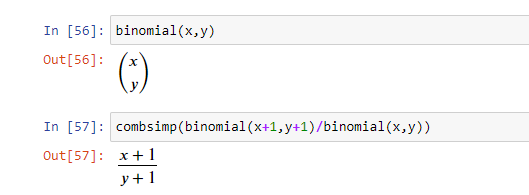
logcombine
Эта функция принимает логарифмы и объединяет их с помощью следующих правил:
log(x) + log(y) == log(x*y)— оба положительные.a*log(x) == log(x**a)если x является положительным и вещественным.
>>> logcombine(a*log(x) + log(y) - log(z))
?log(?)+log(?)−log(?)
Если здесь задать значение параметра force равным True, то указанные выше предположения будут считаться выполненными, если нет предположений о величине.
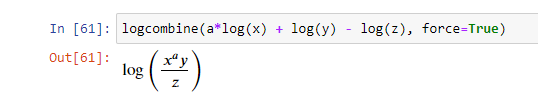
Производные
Производная функции — это ее скорость изменения относительно одной из переменных. Это эквивалентно нахождению наклона касательной к функции в точке. Найти дифференцирование математических выражений в форме переменных можно с помощью функции diff() из SymPy.
>>> from sympy import diff, sin, exp
>>> from sympy.abc import x, y
>>> expr = x*sin(x*x) + 1
>>> expr
Вывод: ?sin(?2)+1.
Чтобы получить несколько производных, нужно передать переменную столько раз, сколько нужно выполнить дифференцирование. Или же можно просто указать это количество с помощью числа.
>>> diff(x**4, x, 3)
24?
Также можно вызвать метод diff() выражения. Он работает по аналогии с функцией.
>>> expr = x*sin(x*x) + 1
>>> expr.diff(x)
Вывод: 2?2cos(?2)+sin(?2).
Неоцененная производная создается с помощью класса Derivative. У него такой же синтаксис, как и функции diff(). Для оценки же достаточно использовать метод doit.

Интеграция
SymPy включает и модуль интегралов. В нем есть методы для вычисления определенных и неопределенных интегралов выражений. Метод integrate() используется для вычисления обоих интегралов. Для вычисления неопределенного или примитивного интеграла просто передайте переменную после выражения.
Для вычисления определенного интеграла, передайте аргументы следующим образом:
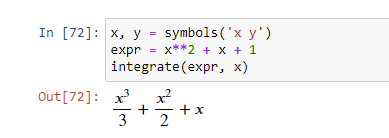
Пример определенного интеграла:
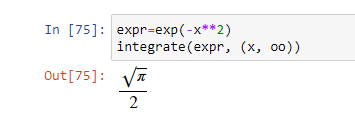
С помощью объекта Integral можно создать неоцененный интеграл. Он оценивается с помощью метода doit().
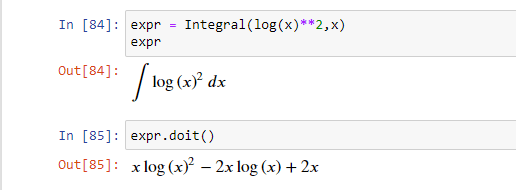
Трансформации интегралов
SymPy поддерживает разные виды трансформаций интегралов:
- laplace_tranfsorm.
- fourier_transform.
- sine_tranfsorm.
- cosine_transform.
- hankel_transform.
Эти функции определены в модуле sympy.integrals.transforms. Следующие примеры вычисляют преобразования Фурье и Лапласа соответственно:

>>> from sympy.integrals import laplace_transform
>>> from sympy.abc import t, s, a
>>> laplace_transform(t**a, t, s)
(s**(-a)*gamma(a + 1)/s, 0, re(a) > -1)
Матрицы
В математике матрица — это двумерный массив чисел, символов или выражений. Теория манипуляций матрицами связана с выполнением арифметических операций над матричными объектами при соблюдении определенных правил.
Линейная трансформация — одно из важнейших применений матрицы. Она часто используется в разных научных областях, особенно связанных с физикой. В SymPy есть модуль matrices, который работает с матрицами. В нем есть класс Matrix для представления матрицы.
Примечание: для выполнения кода в этом разделе нужно сперва импортировать модуль matrices следующим образом.
>>> from sympy.matrices import Matrix
>>> m=Matrix([[1, 2, 3], [2, 3, 1]])
>>> m
⎡1 2 3⎤
⎣2 3 1⎦
Матрица — это изменяемый объект. Также в модуле есть класс ImmutableMatrix для получения неизменяемой матрицы.
Базовое взаимодействие
Свойство shape возвращает размер матрицы.
>>> m.shape
(2, 2)
Методы row() и col() возвращают колонку или строку соответствующего числа.
>>> m.row(0)
[1 2 3]
>>> m.col(1)
⎡2⎤
⎣3⎦
Оператор slice из Python можно использовать для получения одного или большего количества элементов строки или колонки.
У класса Matrix также есть методы row_del() и col_del(), которые удаляют указанные строку/колонку из выбранной матрицы.
>>> m.row(1)[1:3]
[3, 1]
>>> m.col_del(1)
>>> m
⎡1 3⎤
⎣2 1⎦
По аналогии row_insert() и col_insert() добавляют строки и колонки в обозначенные индексы:
>>> m1 = Matrix([[10, 30]])
>>> m = m.row_insert(0, m1)
>>> m
⎡10 30⎤
⎢ 1 3 ⎥
⎣ 2 1 ⎦
Арифметические операции
Привычные операторы +, — и * используются для сложения, умножения и деления.
>>> M1 = Matrix([[3, 0], [1, 6]])
>>> M2 = Matrix([[4, 5], [6, 4]])
>>> M1 + M2
⎡7 5 ⎤
⎣7 10 ⎦
Умножение матрицы возможно лишь в том случае, если количество колонок первой матрицы соответствует количеству колонок второй. Результат будет иметь такое же количество строк, как у первой матрицы и столько же колонок, сколько есть во второй.
Для вычисления определителя матрицы используется метод det(). Определитель — это скалярное значение, которое может быть вычислено из элементов квадратной матрицы.
>>> M = Matrix([[4, 5], [6, 4]])
>>> M.det()
-14
Конструкторы матрицы
SymPy предоставляет множество специальных типов классов матриц. Например, Identity, матрица из единиц, нолей и так далее. Эти классы называются eye, zeroes и ones соответственно. Identity — это квадратная матрица, элементы которой по диагонали равны 1, а остальные — 0.
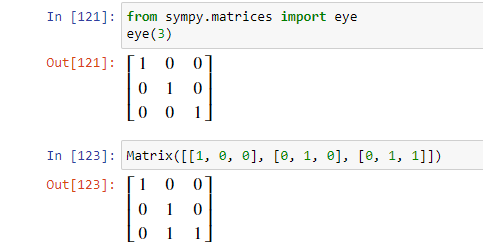
В матрице diag элементы по диагонали инициализируются в соответствии с предоставленными аргументами.
>>> from sympy.matrices import diag
>>> diag(1, 3)
⎡1 0 ⎤
⎣0 3 ⎦
Все элементы в матрице zero инициализируются как нули.
>>> from sympy.matrices import zeros
>>> zeros(2, 3)
⎡0 0 0⎤
⎣0 0 0⎦
По аналогии в матрице ones элементы равны 1:
>>> from sympy.matrices import zeros
>>> ones(2, 3)
⎡1 1 1⎤
⎣1 1 1⎦
Класс Function
В пакете SymPy есть класс Function, определенный в модуле sympy.core.function. Это базовый класс для всех математических функций, а также конструктор для неопределенных классов.
Следующие категории функций наследуются от класса Function:
- Функции для комплексных чисел
- Тригонометрические функции
- Функции целого числа
- Комбинаторные функции
- Другие функции
Функции комплексных чисел
Набор этих функций определен в модуле sympy.functions.elementary.complexes.
re — Эта функция возвращает реальную часть выражения:
>>> from sympy import *
>>> re(5+3*I)
5
>>> re(I)
0
im — Возвращает мнимую часть выражения:
>>> im(5+3*I)
3
>>> im(I)
1
sign — Эта функция возвращает сложный знак выражения..
Для реального выражения знак будет:
- 1, если выражение положительное,
- 0, если выражение равно нулю,
- -1, если выражение отрицательное.
Если выражение мнимое, то знаки следующие:
- l, если выражение положительное,
- -l, если выражение отрицательное.
>>> sign(1.55), sign(-1), sign(S.Zero)
(1,-1,0)
>>> sign (-3*I), sign(I*2)
(-I, I)
Функция abs возвращает абсолютное значение комплексного числа. Оно определяется как расстояние между основанием (0, 0) и точкой на комплексной плоскости. Эта функция является расширением встроенной функции abs() и принимает символьные значения.
Например, Abs(2+3*I), вернет √13.
conjugate — Функция возвращает сопряжение комплексного числа. Для поиска меняется знак мнимой части.
>>> conjugate(4+7*I)
4−7?
Тригонометрические функции
В SymPy есть определения всех тригонометрических соотношений: синуса, косинуса, тангенса и так далее. Также есть обратные аналоги: asin, acos, atan и так далее. Функции вычисляют соответствующее значение данного угла в радианах.
>>> sin(pi/2), cos(pi/4), tan(pi/6)
(1, sqrt(2)/2, sqrt(3)/3)
>>> asin(1), acos(sqrt(2)/2), atan(sqrt(3)/3)
(pi/2, pi/4, pi/6)
Функции целого числа
Набор функций для работы с целым числом.
Одномерная функция ceiling, возвращающая самое маленькое целое число, которое не меньше аргумента. В случае с комплексными числами округление до большего целого для целой и мнимой части происходит отдельно.
>>> ceiling(pi), ceiling(Rational(20, 3)), ceiling(2.6+3.3*I)
(4, 7, 3 + 4*I)
floor — Возвращает самое большое число, которое не больше аргумента. В случае с комплексными числами округление до меньшего целого для целой и мнимой части происходит отдельно.
>>> floor(pi), floor(Rational(100, 6)), floor(6.3-5.9*I)
(3, 16, 6 - 6*I)
frac — Функция представляет долю x.
>>> frac(3.99), frac(10)
(0.990000000000000, 0)
Комбинаторные функции
Комбинаторика — это раздел математики, в котором рассматриваются выбор, расположение и работа в конечной и дискретной системах.
factorial — Факториал очень важен в комбинаторике. Он обозначает число способов, которыми могут быть представлены объекты.
Кватернион
В математика числовая система кватернион расширяет комплексные числа. Каждый объект включает 4 скалярные переменные и 4 измерения: одно реальное и три мнимых.
Кватернион можно представить в виде следующего уравнения: q = a + bi + cj + dk, где a, b, c и d — это реальные числа, а i, j и k — квартенионные единицы, так что i2 == j2 == k2 = ijk.
Класс Quaternion расположен в модуле sympy.algebras.quaternion.
>>> from sympy.algebras.quaternion import Quaternion
>>> q = Quaternion(2, 3, 1, 4)
>>> q
2+3?+1?+4?
Кватернионы используются как в чистой, так и в прикладной математике, а также в компьютерной графике, компьютерном зрении и так далее.

add()
Этот метод класса Quaternion позволяет сложить два объекта класса:
>>> q1=Quaternion(1,2,4)
>>> q2=Quaternion(4,1)
>>> q1.add(q2)
5+3?+4?+0?
Также возможно добавить число или символ к объекту Quaternion.
>>> q1+2
3+2?+4?+0?
>>> q1+x
(?+1)+2?+4?+0?
mul()
Этот метод выполняет умножение двух кватернионов.
>>> q1 = Quaternion(1, 2)
>>> q2 = Quaternion(2, 4, 1)
>>> q1.mul(q2)
(−6)+8?+1?+2?
inverse()
Возвращает обратный кватернион.
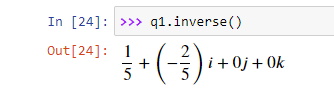
pow()
Возвращает степень кватерниона.
>>> q1.pow(2)
(−3)+4?+0?+0?
exp()
Вычисляет экспоненту кватерниона.
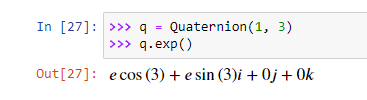
Уравнения
Поскольку символы = и == определены как символ присваивания и равенства в Python, их нельзя использовать для создания символьных уравнений. Для этого в SymPy есть функция Eq().
>>> x, y = symbols('x y')
>>> Eq(x, y)
?=?
Поскольку x=y возможно только в случае x-y=0, уравнение выше можно записать как:
>>> Eq(x-y, 0)
x−y=0
Модуль solver из SymPy предлагает функцию solveset():
solveset(equation,variable,domain)Параметр domain по умолчанию равен S.Complexes. С помощью функции solveset() можно решить алгебраическое уравнение.
>>> solveset(Eq(x**2-9, 0), x)
{−3,3}
>>> solveset(Eq(x**2-3*x, -2), x)
{1,2}
Линейное уравнение
Для решения линейных уравнений нужно использовать функцию linsolve().
Например, уравнения могут быть такими:
- x-y=4
- x+1=1
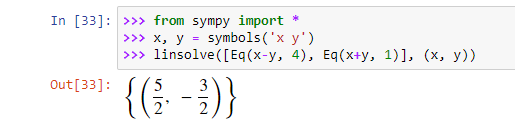
Функция linsolve() также может решать линейные уравнения в матричной форме:
>>> a, b = symbols('a b')
>>> a = Matrix([[1, -1], [1, 1]])
>>> b = Matrix([4, 1])
>>> linsolve([a, b], y)
Вывод будет тот же.
Нелинейное уравнение
Для таких уравнений используется функция nonlinsolve(). Пример такого уравнения:
>>> a, b = symbols('a b')
>>> nonlinsolve([a**2 + a, a - b], [a, b])
{(−1, −1),(0, 0)}
Дифференциальное уравнение
Для начала создайте функцию, передав cls=Function в функцию symbols. Для решения дифференциальных уравнений используйте dsolve.
>>> x = ymbol('x')
>>> f = symbols('f', cls=Function)
>>> f(x)
?(?)
Здесь f(x) — это невычисленная функция. Ее производная:
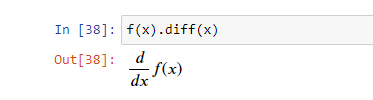
Сначала создается объект Eq, соответствующий следующему дифференциальному уравнению.
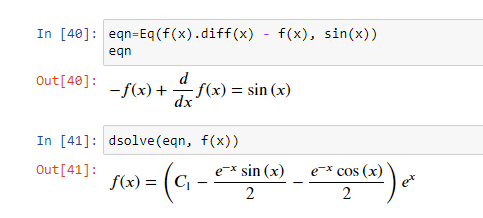
Графики
SymPy использует библиотеку matplotlib в качестве бэкенда для рендеринга двухмерных и трехмерных графиков математических функций. Убедитесь, что на вашем устройстве установлена matplotlib. Если нет, установите с помощью следующей команды.
pip install matplotlib
Функции для работы с графиками можно найти в модуле sympy.plotting:
plot— двухмерные линейные графики.plot3d— трехмерные линейные графики.plot_parametric— двухмерные параметрические графики.plot3d_parametric— трехмерные параметрические графики.
Функция plot() возвращает экземпляр класса Plot. Сам график может включать одно или несколько выражений SymPy. По умолчанию в качестве бэкенда используется matplotlib, но вместе нее можно взять texplot, pyglet или API Google Charts.
plot(expr,range,kwargs)
где expr — это любое валидное выражение SymPy. Если не сказано другое, то по умолчанию значение range равно (-10, 10).
Следующий график показывает квадрат для каждого значения в диапазоне от -10 до 10.
>>> from sympy.plotting import plot
>>> from sympy import *
>>> x = Symbol('x')
>>> plot(x**2, line_color='red')
Чтобы нарисовать несколько графиков для одного диапазона, перед кортежем нужно указать несколько выражений.
>>> plot(sin(x), cos(x), (x, -pi, pi))
Также для каждого выражения можно задать отдельный диапазон.
plot((expr1,range1),(expr2,range2))
Также в функции plot() можно использовать следующие необязательные аргументы-ключевые слова.
line_color— определяет цвет линии графика.title— название графика.xlabel— метка для оси X.ylabel— метка для оси Y.
>>> plot((sin(x), (x,-pi,pi)), line_color='red', title='Пример графика SymPy')
Функция plot3d() рендерит трехмерный график.
>>> from sympy.plotting import plot3d
>>> x, y = symbols('x y')
>>> plot3d(x*y, (x, -10, 10), (y, -10, 10))
По аналогии с двухмерным трехмерный график может включать несколько графиков для отдельных диапазонов:
>>> plot3d(x*y, x/y, (x, -5, 5), (y, -5, 5))
Функция plot3d_parametric_line() рендерит трехмерный линейный параметрический график:
>>> from sympy.plotting import plot3d_parametric_line
>>> plot3d_parametric_line(cos(x), sin(x), x, (x, -5, 5))
Чтобы нарисовать параметрический объемный график, используйте plot3d_parametric_surface().
Сущности
Модуль geometry в SymPy позволяет создавать двухмерные сущности, такие как линия, круг и так далее. Информацию о них можно получить через проверку коллинеарности или поиск пересечения.
Point
Класс point представляет точку Евклидового пространства. Следующие примеры проверяют коллинеарность точек:
>>> from sympy.geometry import Point
>>> from sympy import *
>>> x = Point(0, 0)
>>> y = Point(2, 2)
>>> z = Point(4, 4)
>>> Point.is_collinear(x, y, z)
True
>>> a = Point(2, 3)
>>> Point.is_collinear(x, a)
False
>>> x.distance(y)
2√2
Метод distance() класса Point вычисляет расстояние между двумя точками.
Line
Сущность Line можно получить из двух объектов Point. Метод intersection() возвращает точку пересечения двух линий.
>>> from sympy.geometry import Point, Line
>>> p1, p2 = Point(0, 5), Point(5, 0)
>>> l1 = Line(p1,p2)
>>> l2 = Line(Point(0, 0), Point(5, 5))
>>> l1.intersection(l2)
[Point2D(5/2, 5/2)]
>>> l1.intersection(Line(Point(0,0), Point(2,2)))
[Point2D(5/2, 5/2)]
>>> x, y = symbols('x y')
>>> p = Point(x, y)
>>> p.distance(Point(0, 0))
Вывод: √?2+?2
Triangle
Эта функция создает сущность Triangle из трех точек.
Ellipse
Эллиптическая геометрическая сущность создается с помощью объекта Point, который указывает на центр, а также горизонтальный и вертикальный радиусы.
ellipse(center,hradius,vradius)
>>> from sympy.geometry import Ellipse, Line
>>> e = Ellipse(Point(0, 0), 8, 3)
>>> e.area
24?
- vradius может быть получен косвенно с помощью параметра eccentricity.
apoapsis— это наибольшее расстояние между фокусом и контуром.- метод
equationэллипса возвращает уравнение эллипса.
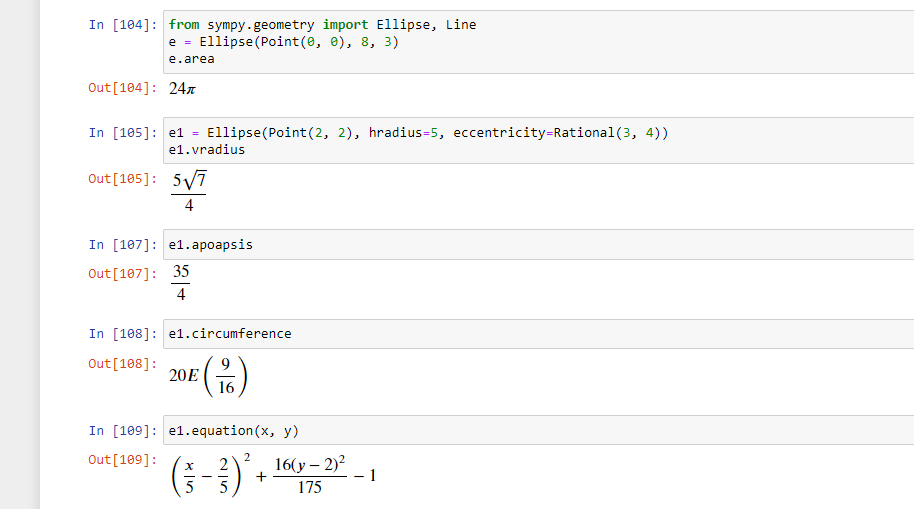
Множества
В математике множество — это четко определенный набор объектов, которые могут быть числами, буквами алфавита или даже другими множествами. Set — это также один из встроенных типов в Python. В SymPy же есть модуль sets. В нем можно найти разные типы множеств и операции поиска пересекающихся элементов, объединения и так далее.
Set — это базовый класс для любого типа множества в Python. Но стоит отметить, что в SymPy он отличается от того, что есть в Python. Класс interval представляет реальные интервалы, а граничное свойство возвращает объект FiniteSet.
>>> from sympy import Interval
>>> s = Interval(1, 10).boundary
>>> type(s)
sympy.sets.sets.FiniteSet
FiniteSet — это коллекция дискретных чисел. Ее можно получить из любой последовательности, будь то список или строка.
>>> from sympy import FiniteSet
>>> FiniteSet(range(5))
{{0,1,…,4}}
>>> numbers = [1, 3, 5, 2, 8]
>>> FiniteSet(*numbers)
{1,2,3,5,8}
>>> s = "HelloWorld"
>>> FiniteSet(*s)
{?,?,?,?,?,?,?}
По аналогии со встроенным множеством, Set из SymPy также является коллекцией уникальных объектов.
ConditionSet — это множество элементов, удовлетворяющих заданному условию.
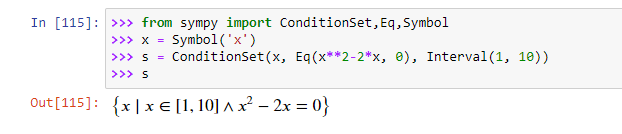
Union — составное множество. Оно включает все элементы из двух множеств. Если же какие-то повторяются, то в результирующем множестве будет только одна копия.
>>> from sympy import Union
>>> l1 = [3, 7]
>>> l2 = [9, 7, 1]
>>> a = FiniteSet(*l1)
>>> b = FiniteSet(*l2)
>>> Union(a, b)
{1,3,7,9}
Intersection же включает только те элементы, которые есть в обоих множествах.
>>> from sympy import Intersection
>>> Intersection(a, b)
{7}
ProductSet представляет декартово произведение элементов из обоих множеств.
>>> from sympy import ProductSet
>>> l1 = [1, 2]
>>> l2 = [2, 3]
>>> a = FiniteSet(*l1)
>>> b = FiniteSet(*l2)
>>> set(ProductSet(a, b))
{(1, 2), (1, 3), (2, 2), (2, 3)}
Complement(a, b) исключает те элементы, которых нет в b.
>>> from sympy import Complement
>>> l1 = [3, 1]
>>> a = FiniteSet(*l1)
>>> b = FiniteSet(*l2)
>>> Complement(a, b), Complement(b, a)
(FiniteSet(1), FiniteSet(2))
SymmetricDifference хранит только необщие элементы обоих множеств.
>>> from sympy import SymmetricDifference
>>> l1 = [3, 1]
>>> a = FiniteSet(*l1)
>>> b = FiniteSet(*l2)
>>> SymmetricDifference(a, b)
{1,2}
Вывод в консоль
В SymPy есть несколько инструментов для вывода. Вот некоторые из них:
- str,
- srepr,
- ASCII pretty printer,
- Unicode pretty printer,
- LaTeX,
- MathML,
- Dot.
Объекты SymPy также можно отправить как ввод в другие языки программирования, такие как C, Fortran, JavaScript, Theano.
SymPy использует символы Юникод для рендеринга вывода. Если вы используете консоль Python для работы с SymPy, то лучше всего применять функцию init_session().
>>> from sympy import init_session
>>> init_session()
Python console for SymPy 1.6.2 (Python 3.8.5-64-bit) (ground types: python)
...
Выполним эти команды:
>>> from __future__ import division
>>> from sympy import *
>>> x, y, z, t = symbols('x y z t')
>>> k, m, n = symbols('k m n', integer=True)
>>> f, g, h = symbols('f g h', cls=Function)
>>> init_printing()
>>> Integral(sqrt(1/x), x)
⌠
⎮ ___
⎮ ╱ 1
⎮ ╱ ─ dx
⎮ ╲╱ x
⌡
Если нет LaTeX, но есть matplotlib, то последняя будет использоваться в качестве движка рендеринга. Если и matplotlib нет, то применяется Unicode pretty printer. Однако Jupyter notebook использует MathJax для рендеринга LaTeX.
В терминале, который не поддерживает Unicode, используется ASCII pretty printer (как в выводе из примера).
Для ASCII printer есть функция pprinter() с параметром use_unicode=False.
>>> pprint(Integral(sqrt(1/x), x), use_unicode=False)
/
|
| ___
| / 1
| / - dx
| \/ x
|
/Также доступ к Unicode printer можно получить из pprint() и pretty(). Если терминал поддерживает Unicode, то он используется автоматически. Если поддержку определить не удалось, то можно передать use_unicode=True, чтобы принудительно использовать Unicode.
Для получения LaTeX-формата используйте функцию latex().
>>> print(latex(Integral(sqrt(1/x), x)))
\int \sqrt{\frac{1}{x}}\, dx
Также доступен printer mathml. Для него есть функция pint_mathml().
>>> from sympy.printing.mathml import print_mathml
>>> print_mathml(Integral(sqrt(1/x),x))
<apply>
<int/>
<bvar>
<ci>x</ci>
</bvar>
<apply>
<root/>
<apply>
<power/>
<ci>x</ci>
<cn>-1</cn>
</apply>
</apply>
</apply>
>>> mathml(Integral(sqrt(1/x),x))
<apply><int/><bvar><ci>x</ci></bvar><apply><root/><apply><power/><ci>x</ci><cn
>-1</cn></apply></apply></apply>Фреймворк — это интерфейс или инструмент, позволяющий разработчикам просто создавать модели машинного обучения, не погружаясь в лежащие в основе алгоритмы.
Библиотека — это набор файлов, содержащих код, который можно импортировать в свое приложение.
Фреймворк может быть набором библиотек, необходимых для построения модели без понимания особенностей лежащих в основе алгоритмов. Однако разработчикам нужно знать, каким образом эти алгоритмы работают, чтобы корректно интерпретировать результат.
#10 Matplotlib
Matplotlib — это интерактивная кроссплатформенная библиотека для создания двумерных диаграмм. С ее помощью можно создавать качественные графики и диаграммы в нескольких форматах.
Преимущества:
- Гибкость. Поддерживает Python и IPython, скрипты Python, Jupyter Notebook, сервера веб-приложений и многие инструменты с интерфейсом (GTK+, Tkinter, Qt и wxPython).
- Предоставляет интерфейс в стиле MATLAB для создания диаграмм
- Объектно-ориентированный интерфейс предоставляет полный контроль над свойствами осей, шрифтов, стилями линий и так далее.
- Совместим с разными графическими движками и операционными системами.
- Часто используется в других библиотеках, таких как Pandas.
Недостатки:
- Наличие двух разных интерфейсов (объектно-ориентированного и в стиле MATLAB) может запутать начинающего разработчика.
- Matplotlib — это библиотека для визуализации, а не для анализа данных. Для последнего ее нужно совмещать с другими, например, Pandas.
Официальная документация: https://matplotlib.org/stable/index.html.
Уроки по matplotlib на русском: Установка matplotlib и архитектура графиков / plt 1.
#9 Natural Language Toolkit (NLTK)

NLTK — это фреймворк и набор библиотек для разработки системы символической и статистической обработки естественного языка (natural language processing, NLP). Стандартный инструмент для NLP в Python.
Преимущества:
- Библиотека содержит графические инструменты, а также примеры данных.
- Включает книгу и набор примеров для начинающих.
- Предоставляет поддержку разных ML-операций, таких как классификация, парсинг, токенизация и так далее.
- Работает как платформа для прототипирования и создания исследовательских систем.
- Совместима с несколькими языками.
Недостатки:
- Для работы с NLTK нужно понимать, как работать со строками. Однако в этом может помочь документация.
- Токенизация происходит за счет разбития текста на предложения. Это отрицательно влияет на производительность.
Официальная документация: https://www.nltk.org/.
#8 Pandas

Это библиотека Python для высокопроизводительных и одновременно понятных структур данных и инструментов анализа данных в Python.
Преимущества:
- Выразительные, быстрые и гибкие структуры данных.
- Поддерживает операции агрегации, конкатенации, итерации, переиндексации и визуализации.
- Гибкая и совместимая с другими библиотеками Python.
- Интуитивное управление данными с минимальным набором команд.
- Поддерживает широкий спектр коммерческих и академических областей.
- Производительная.
Недостатки:
- Построена на основе matplotlib, что значит, что начинающий должен быть знаком с обеими, чтобы понимать, что лучше использовать для решения конкретной проблемы.
- Меньше подходит для n-размерных массивов и статистического моделирования. Для этого лучше использовать NumPy, SciPy или SciKit Learn.
Официальная документация: https://pandas.pydata.org/pandas-docs/stable/index.html.
Краткая документация с примерами: Введение в библиотеку pandas: установка и первые шаги / pd 1.
Уроки по Pandas на русском: Основы Pandas №1 // Чтение файлов, DataFrame, отбор данных.
#7 Scikit-Learn

Эта библиотека построена на основе matplotlib, NumPy и SciPy. Она предоставляет несколько инструментов для анализа и добычи данных.
Преимущества:
- Простая и эффективная.
- Быстро улучшается и обновляется.
- Разнообразие алгоритмов, включая кластерный и факторный анализ, а также метод главных компонент.
- Может извлекать данные из изображений и текста.
- Может использоваться для NLP.
Недостатки:
- Предназначена для обучения с учителем и не очень хорошо работает в обучении без учителя (например, в Deep Learning).
Официальная документация: https://scikit-learn.org/stable/.
#6 Seaborn

Библиотека для создания статистических графиков в Python. Построена на базе matplotlib и имеет интеграцию со структурами данных pandas.
Преимущества
- Предлагает более визуально привлекательные графики по сравнению с matplotlib.
- Предлагает встроенные графики, которых нет в matplotlib.
- Использует меньше кода для визуализации.
- Отличная интеграция с Pandas: комбинация из визуализации данных и анализа.
Недостатки:
- Построена на основе matplotlib, поэтому нужно понимать, какую из библиотек использовать в том или ином случае.
- Полагается на темы по умолчанию, поэтому результат не настолько настраиваемый, как у matplotlib.
Официальная документация: https://seaborn.pydata.org/.
#5 NumPy

NumPy добавляет обработку многомерных массивов и матриц в Python, а также крупные наборов данных для высокоуровневых математических функций. Обычно используется для научных вычислений. Следовательно, это один из самых используемых пакетов Python для машинного обучения.
Преимущества:
- Интуитивная и интерактивная.
- Предлагает преобразования Фурье, возможности для генерации сложных чисел и другие инструменты для интеграции таких компьютерных языков, как C/C++ и Fortran.
- Универсальность — другие библиотеки для машинного обучения, такие как scikit-learn и TensorFlow, используют массивы NumPy в качестве исходных значений; а у Pandas — NumPy под капотом.
- Серьезный вклад сообщества в развитие.
- Упрощает сложные математические реализации.
Недостатки:
- Может быть чересчур сложным — не стоит использовать, если вам с головой хватает обычных списков Python.
Официальная документация: https://numpy.org/.
Уроки по NumPy на русском: Введение и установка библиотеки NumPy / np 1.
#4 Keras

Очень популярная библиотека для машинного обучения в Python, предоставляющая высокоуровневое API нейронной сети, работающее поверх TensorFlow, CNTK или Theano.
Преимущества:
- Отличное решение для экспериментов и быстрого прототипирования.
- Портативная.
- Предлагает легкое представление нейронных сетей.
- Удобно использовать для моделирования и визуализации.
Недостатки:
- Медленная, поскольку требует создания вычислительного графа перед выполнением операций.
Официальная документация: https://keras.io/.
Уроки по Keras на русском: Преимущества и ограничения Keras / keras 1.
#3 SciPy

Популярная библиотека с разными модулями для оптимизации, линейной алгебры, интеграции и статистики.
Преимущества:
- Подходит для управления изображениями.
- Предоставляет простую обработку математических операций.
- Предлагает эффективные математические операции, включая интеграцию и оптимизацию.
- Поддерживает сигнальную обработку.
Недостатки:
- Под названием SciPy скрываются как стек, так и библиотека. При этом библиотека является частью стека. Это может сбивать с толку.
Официальная документация: https://www.scipy.org/.
Введение в SciPy на русском: Руководство по SciPy: что это, и как ее использовать.
#2 Pytorch

Популярная библиотека, построенная на базе Torch, которая, в свою очередь, сделана на C и завернута в Lua. Изначально создавалась Facebook, но сейчас используется в Twitter, Salefsorce и многих других организациях.
Преимущества:
- Содержит инструменты и библиотеки компьютерного зрения, натуральной обработки речи, глубокого обучения и другого.
- Разработчики могут выполнять вычисления на тензорах с помощью ускорения GPU.
- Помогает создавать вычислительные диаграммы.
- Процесс моделирования простой и прозрачный.
- Стандартный режим «define-by-run» больше напоминает классическое программирование.
- Использует привычные инструменты отладки, такие как pdb, ipdb или отладчик PyCharm.
- Использует массу готовых моделей и модулей, которые можно комбинировать между собой.
Недостатки:
- Поскольку PyTorch относительно новый, не так много онлайн-ресурсов. Это усложняет процесс обучения с нуля, хотя он все равно достаточно интуитивный.
- Не настолько готов к полноценной работе в сравнении с TensorFlow.
Официальная документация: https://pytorch.org/.
#1 TensorFlow

Изначально разработанная Google, TensorFlow — это высокопроизводительная библиотека для вычислений с помощью графа потока данных.
Под капотом это в большей степени фреймворк для создания и работы вычислений, использующих тензоры. Чаще всего TensorFlow используется в нейронных сетях и глубоком обучении. Это делает библиотеку одной из самых популярных.
Преимущества:
- Поддерживает обучение с подкреплением и другие алгоритмы.
- Предоставляет абстракцию вычислительного графа.
- Огромное сообщество.
- Предоставляет TensorBoard — инструмент для визуализации моделей прямо в браузере.
- Готов к работе.
- Может быть развернут на нескольких CPU и GPU.
Недостатки:
- Намного медленнее остальных фреймворков, использующих CPU/GPU.
- Крутая кривая обучения по сравнению с PyTorch.
- Вычислительные графы могут быть медленными.
- Не поддерживается коммерчески.
- Не слишком большой набор инструментов.
Официальная документация: https://www.tensorflow.org/.

Выводы
Теперь вы знаете разницу в библиотеках и фреймворках Python. Можете оценить преимущества и недостатки самых популярных библиотек машинного обучения.
]]>Пул соединений — это кэшированные соединения с базой данных, которые создаются и поддерживаются таким образом, чтобы не было необходимости пересоздавать их для новых запросов.
Реализация и использование пула соединений в приложении Python, работающим с базой данных PostgreSQL, дает несколько преимуществ.
Основное — улучшение времени и производительности. Как известно, создание соединения с базой данных PostgreSQL — операция, потребляющая ресурсы и время. А с помощью пула можно уменьшить время запроса и ответа для приложений, работающих с базой данных в Python. Рассмотрим, как его реализовать.
В модуле psycopg2 есть 4 класса для управления пулом соединений. С их помощью можно легко создавать пул и управлять им. Как вариант, того же результата можно добиться с помощью реализации абстрактного класса.
Классы psycopg2 для управления пулом соединений
В модуле psycopg2 есть четыре класса для управления пулом соединений:
- AbstractConnectionPool.
- SimpleConnectionPool.
- ThreadedConnectionPool.
- PersistentConnectionPool.
Примечание:
SimpleConnectionPool,ThreadedConnectionPoolиPersistentConnectionPoolявляются подклассамиAbstractConnectionPoolи реализуют методы из него.
Рассмотрим каждый из них по отдельности.
AbstractConnectionPool
Это базовый класс, реализующий обобщенный код пула, основанный на ключе.
psycopg2.pool.AbstractConnectionPool(minconn, maxconn, *args, **kwargs)AbstractConnectionPool — это абстрактный класс. Наследуемые должны реализовывать объявленные в нем методы. Если хотите создать собственную реализацию пула соединений, то нужно наследоваться от него и реализовать эти методы.
minconn — это минимальное требуемое количество объектов соединения. *args, *kwargs — аргументы, которые нужны для метода connect(), отвечающего за подключение к базе данных PostgreSQL.
SimpleConnectionPool
Это подкласс AbstractConnectionPool, реализующий его методы. Его уже можно использовать для пула соединений.
Этот класс подходит только для однопоточных приложений. Это значит, что если вы хотите создать пул соединений с помощью этого класса, то его нельзя будет передавать между потоками.
Синтаксис:
psycopg2.pool.SimpleConnectionPool(minconn, maxconn, *args, **kwargs)ThreadedConnectionPool
Он также является подклассом класса AbstractConnectionPool и реализует его методы.
Этот класс используется в многопоточной среде, т.е. пул, созданный с помощью этого класса, можно разделить между несколькими потоками.
psycopg2.pool.ThreadedConnectionPool(minconn, maxconn, *args, **kwargs)PersistentConnectionPool
Еще один подкласс AbstractConnectionPool, реализующий его методы.
Этот класс используется в многопоточных приложениях с пулом, распределяющим постоянные соединения разным потокам.
Как и предполагает название, каждый поток получает одно соединение из пула. Таким образом, у одного потока может быть не больше одного соединения из пула.
Пул соединений генерирует ключ с помощью идентификатора потока. Это значит, что для каждого потока при вызовах соединение не меняется.
Примечание: этот класс преимущественно предназначен для взаимодействия с Zope и, вероятно, не подходит для обычных приложений.
Синтаксис:
psycopg2.pool.PersistentConnectionPool(minconn, maxconn, *args, **kwargs)Посмотрим, как создать пул соединений.
Методы psycopg2 для управления пулом соединений
Следующие методы представлены в модуле Psycopg2 и используются для управления.
getconn(key=None)— для получения доступного соединения из пула. Параметрkeyнеобязательный. При использовании этого параметраgetconn()возвращает соединение, связанное с этим ключом. Key используется в классеPersistentConnectionPool.putconn(connection, key=None, close=False)— для возвращения соединения обратно в пул. Если параметрcloseравенTrue, то соединение удаляется и из пула. Если при получении соединения был использован ключ, то его же нужно передать при возвращении соединения.closeall()— закрывает все используемые соединения пула.
Создание пула соединений с помощью psycopg2
В этом примере используем SimpleConnectionPool для создания пула. Перед этим стоит рассмотреть аргументы, которые требуются для работы.
Нужно указать минимальное и максимальное количество соединений, имя пользователя, пароль, хост и базу данных.
minconn— это нижний лимит количества подключений.maxconn— максимальное количество возможных подключений.*args,**kwargs— аргументы для методаconnect(), необходимые для создания объекта соединений. Тут требуется указать имя хоста, пользователя, пароль, базу данных и порт.
Пример создания и управления пулом соединений PostgreSQL
Рассмотрим, как использовать класс SimpleConnectionPool для создания и управления пулом соединений из Python.
import psycopg2
from psycopg2 import pool
try:
# Подключиться к существующей базе данных
postgresql_pool = psycopg2.pool.SimpleConnectionPool(1, 20,
user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
if postgresql_pool:
print("Пул соединений создан успешно")
# Используйте getconn() для получения соединения из пула соединений.
connection = postgresql_pool.getconn()
if connection:
print("Соединение установлено")
cursor = connection.cursor()
cursor.execute("select * from mobile")
mobile_records = cursor.fetchall()
print ("Отображение строк с таблицы mobile")
for row in mobile_records:
print(row)
cursor.close()
# Используйте этот метод, чтобы отпустить объект соединения
# и отправить обратно в пул соединений
postgresql_pool.putconn(connection)
print("PostgreSQL соединение вернулось в пул")
except (Exception, psycopg2.DatabaseError) as error :
print ("Ошибка при подключении к PostgreSQL", error)
finally:
if postgresql_pool:
postgresql_pool.closeall
print("Пул соединений PostgreSQL закрыт")
Вывод:
Пул соединений создан успешно
Соединение установлено
Отображение строк с таблицы mobile
(1, 'IPhone 12', 800.0)
(2, 'Google Pixel 2', 900.0)
PostgreSQL соединение вернулось в пул
Пул соединений PostgreSQL закрытРазберем пример. В метод были переданы следующие значения:
- Minimum connection = 1. Это значит, что в момент создания пула создается как минимум одно соединение.
- Maximum connection = 20. Всего можно использовать 20 соединений с PostgreSQL.
- Другие параметры для подключения.
- Конструктор класса
SimpleConnectionPoolвозвращает экземпляр пула. - С помощью
getconn()делается запрос на подключение из пула - После этого выполняются операции в базе данных.
- И в конце закрываются все активные и пассивные объекты соединения для закрытия приложения.
Создание многопоточного пула соединений
Создадим пул соединений, который будет работать в многопоточной среде. Это можно сделать с помощью класса ThreadedConnectionPool.
import psycopg2
from psycopg2 import pool
try:
# Подключиться к существующей базе данных
postgresql_pool = psycopg2.pool.ThreadedConnectionPool(5, 20,
user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
if postgresql_pool:
print("Пул соединений создан успешно")
# Используйте getconn() для получения соединения из пула соединений.
connection = postgresql_pool.getconn()
if connection:
print("Соединение установлено")
cursor = connection.cursor()
cursor.execute("select * from mobile")
mobile_records = cursor.fetchall()
print ("Отображение строк с таблицы mobile")
for row in mobile_records:
print(row)
cursor.close()
# Используйте этот метод, чтобы отпустить объект соединения
# и отправить обратно в пул соединений
postgresql_pool.putconn(connection)
print("PostgreSQL соединение вернулось в пул")
except (Exception, psycopg2.DatabaseError) as error :
print ("Ошибка при подключении к PostgreSQL", error)
finally:
if postgresql_pool:
postgresql_pool.closeall
print("Пул соединений PostgreSQL закрыт")
Вывод будет таким же:
Во-первых, Heroku очень редко используют в продакшене. Его платные тарифы сильно выше стоимости аренды сервера.
Во-вторых, крупные кампании дают виртуальные машины бесплатно на год. Этого достаточно, что бы 4 года не платить за работу сервера.
Получение VPS
Как я уже написал, есть возможность получить VPS бесплатно на год. Выбирайте любой:
- AWS Amazon, продукт Amazon EC2.
- Azure Microsoft, продукт Виртуальные машины Linux.
- Google Cloud, продукт Compute Engine.
- Alibaba Cloud, продукт Elastic Compute Service.
Только не активируйте все сразу, это разовое предложение.
Не буду подробно описывать, как развернуть VPS, у этих платформ документации на высоком уровне. Если у вас трудности с английским и переводчиками, начинайте с Azure. У них много русской документации. Скажу только, что крайне желательно выбирать OS Ubuntu 18.04.
Процесс получения бесплатного периода и создание виртуальной машины достаточно тернист. Если вы никогда не делали это ранее, будьте готов потратить 1-2 часа на знакомство с облачными решениями.
Я буду использовать VPS с почасовой оплатой от reg.ru. Это дешевое и простое решение. Для обучения и демонстрации можно запускать на несколько часов по цене от 0,32 ₽/час. А постоянная работа подобного бота будет стоить 215 рублей в месяц.
Подключение к виртуальной машине
Для подключения к VPS нужно знать ip (IPv4), логин (обычно «root») и пароль.
С Linux и MacOS можно подключится из терминала. Введите команду, логин и ip сервера.
ssh root@123.123.123.23Для windows можно скачать терминал Ubuntu. Если такой вариант не подходит, используйте PuTTY (порт: 22). Вот так выглядит консоль. Для подключения требуется ввести «yes» и пароль.
После входа я узнал какая версия python установлена командой python -V. Из коробки стоит 3.6.9, а проект на 3.8.5, нужно обновить.
Подготовка сервера
- Установим необходимую версию python. Внимательно вводите эти команды по очереди, это процесс кастомной установки.
$ sudo apt update
$ sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev libsqlite3-dev wget libbz2-dev
$ wget https://www.python.org/ftp/python/3.8.5/Python-3.8.5.tgz
$ tar -xf Python-3.8.5.tgz
$ cd Python-3.8.5
$ ./configure --enable-optimizations
$ make # ~15 минут
$ sudo make altinstall
$ cd /homeНемного деталей. Я скачал архив, распаковал и установил python 3.8.5. Будет готов подождать пока выполнится команды make. Введите python3.8 -V и убедитесь, что можно продолжать:
/home# python3.8 -V
Python 3.8.5 2. Создадим проект. Установим и создадим виртуально окружение. Выполняйте команды по очереди:
$ python3.8 -m pip install --upgrade pip
$ pip install virtualenv
$ mkdir fonlinebot
$ cd fonlinebot
$ virtualenv venv
$ source venv/bin/activate
$ python -V
$ deactivateМы установили pip и virtualenv. Затем создали папку «fonlinebot», создали в ней виртуальное окружение и проверили его.

3. Установим и запустим Redis-server. Для установки и проверки в Ubuntu введите эти команды:
$ sudo apt install redis-server
$ redis-cli
127.0.0.1:6379> pingПолучите PONG, значит redis запущен. Устанавливать удаленный доступ и пароль в этом руководстве я не буду. Эта служба доступна только конкретной машине, что полностью покрывает задачу.
4. Переменные окружения. Теперь нужно спрятать токен и API-ключ в переменные. Выполните команду nano /etc/environment и вставьте эти строки со своими значениями в кавычках.
fonlinebot_token="замените_на_токен"
fonlinebot_api_key="замените_на_ключ_апи"Затем нажмите CTRL+O -> Enter -> CTRL+X для сохранения. Перезапустите машину: sudo reboot, что бы переменить настройки.
5. Подготовка кода бота. Отредактируйте файл config.py. Раскомментируем настройки логирования и установим переменные окружения.
# fonlinebot/config.py
#...
import datetime
import os
formatter = '[%(asctime)s] %(levelname)8s --- %(message)s (%(filename)s:%(lineno)s)'
logging.basicConfig(
filename=f'bot-from-{datetime.datetime.now().date()}.log',
filemode='w',
format=formatter,
datefmt='%Y-%m-%d %H:%M:%S',
level=logging.WARNING
)
TOKEN = os.environ.get("fonlinebot_token")
#...
'x-rapidapi-key': os.environ.get("fonlinebot_api_key"),
#...
Скрывать секретную информацию (токены, пароли) обязательно. Нельзя выкладывать файлы с паролями на гитхаб, stackoverflow или отправлять сторонним разработчикам.
Половина работы сделана. Теперь нужно загрузить файлы на сервер.
Загрузка файлов на VPS
Скачайте и установите WinSCP. Это программа для загрузки проекта на VPS. Альтернативный вариант Filezilla. Вариант для повышения скиллов — Git.
Откройте и установите соединение с сервером:
Далее перенесите файлы проекта (без venv и файлов Pycharm) в папку home/fonlinebot/.
Готово? Запустим бота с сервера.
$ cd /home/fonlinebot/ # перейдем в папку проекта
$ source venv/bin/activate # активируем окружение
$ pip install -r requirements.txt # установим зависимости
$ python main.py # запустим ботаТеперь перейдите в Телеграм и протестируйте работу. Отвечает? Хорошо, остановите его (ctrl+c) и деактивируйте виртуальное окружение (deactivate)
Финишная прямая проекта. После закрытия терминала, бот остановится. После перезапуска сервера, он не запустится. Настроем автономную работу.
Беспрерывная работа бота
Создадим собственную службу для постоянной работы бота и перезапуска в случае падения.
nano /lib/systemd/system/fonlinebot.serviceС настройками:
[Unit]
Description=Football online bot
After=network.target
[Service]
EnvironmentFile=/etc/environment
ExecStart=/home/fonlinebot/venv/bin/python main.py
ExecReload=/home/fonlinebot/venv/bin/python main.py
WorkingDirectory=/home/fonlinebot/
KillMode=process
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
Затем нажмите CTRL+O -> Enter -> CTRL+X для сохранения. Что это за настройки?
Настройки службы, нам важны эти:
Description— описание службы.EnvironmentFile— путь к файлу с переменными.ExecStartиExecReload— это команды для запуска и перезапуска бота.WorkingDirectory— путь к папке в которой файл запуска main.py.
Для запуска службы выполните эти 2 команды.
systemctl enable fonlinebot
systemctl start fonlinebotТеперь вернемся в бот и посмотрим как он отвечает.
Если бот не отвечает, проверьте статус и логи. Здесь сложно предвидеть ошибку:
systemctl status fonlinebot # статус
journalctl -u fonlinebot.service # логиПроект готов, отличная работа! Все этапы разработки на Gitlab.
Заключение
Мы проделали большую работу: создали бота, настроили его взаимодействие с внешним api и загрузили на сервера. В процессе затронули кнопки, меню, callback и ошибки.
Вот несколько идей для продолжения проекта:
- более детальная статистика матча,
- админка для получения ошибок и отправки сообщения всем пользователям,
- сбор статистики активности пользователей.
- переход на вебхук.
Удачи!
]]>С другой стороны, переменная, объявленная внутри определенного блока кода, будет видна только внутри этого же блока — она называется локальной.
Разберемся с этими понятиями на примере.
Пример локальных и глобальных переменных
def sum():
a = 10 # локальные переменные
b = 20
c = a + b
print("Сумма:", c)
sum()
Вывод: Сумма: 30.
Переменная объявлена внутри функции и может использоваться только в ней. Получить доступ к этой локальной функции в других нельзя.
Для решения этой проблемы используются глобальные переменные.
Теперь взгляните на этот пример с глобальными переменными:
a = 20 # определены вне функции
b = 10
def sum():
c = a + b # Использование глобальных переменных
print("Сумма:", c)
def sub():
d = a - b # Использование глобальных переменных
print("Разница:", d)
sum()
sub()
Вывод:
Сумма: 30
Разница: 10В этом коде были объявлены две глобальные переменные: a и b. Они используются внутри функций sum() и sub(). Обе возвращают результат при вызове.
Если определить локальную переменную с тем же именем, то приоритет будет у нее. Посмотрите, как в функции msg это реализовано.
def msg():
m = "Привет, как дела?"
print(m)
msg()
m = "Отлично!" # глобальная переменная
print(m)
Вывод:
Привет, как дела?
Отлично!Здесь была объявлена локальная переменная с таким же именем, как и у глобальной. Сперва выводится значение локальной, а после этого — глобальной.
Ключевое слово global
Python предлагает ключевое слово global, которое используется для изменения значения глобальной переменной в функции. Оно нужно для изменения значения. Вот некоторые правила по работе с глобальными переменными.
Правила использования global
- Если значение определено на выходе функции, то оно автоматически станет глобальной переменной.
- Ключевое слово
globalиспользуется для объявления глобальной переменной внутри функции. - Нет необходимости использовать
globalдля объявления глобальной переменной вне функции. - Переменные, на которые есть ссылка внутри функции, неявно являются глобальными.
Пример без использования глобального ключевого слова.
c = 10
def mul():
c = c * 10
print(c)
mul()
Вывод:
line 5, in mul
c = c * 10
UnboundLocalError: local variable 'c' referenced before assignmentЭтот код вернул ошибку, потому что была предпринята попытка присвоить значение глобальной переменной. Изменять значение можно только с помощью ключевого слова global.
c = 10
def mul():
global c
c = c * 10
print("Значение в функции:", c)
mul()
print("Значение вне функции:", c)
Вывод:
Значение в функции: 100
Значение вне функции: 100Здесь переменная c была объявлена в функции mul() с помощью ключевого слова global. Ее значение умножается на 10 и становится равным 100. В процессе работы программы можно увидеть, что изменение значения внутри функции отражается на глобальном значении переменной.
Глобальные переменные в модулях Python
Преимущество использования ключевого слова global — в возможности создавать глобальные переменные и передавать их между модулями. Например, можно создать name.py, который бы состоял из глобальных переменных. Если их изменить, то изменения повлияют на все места, где эти переменные встречаются.
1. Создаем файл name.py для хранения глобальных переменных:
a = 10
b = 20
msg = "Hello World"
2. Создаем файл change.py для изменения переменных:
import name
name.a = 15
name.b = 25
name.msg = "Dood bye"
Меняем значения a, b и msg. Эти переменные были объявлены внутри name, и для их изменения модуль нужно было импортировать.
3. В третий файл выводим значения измененных глобальных переменных.
import name
import change
print(name.a)
print(name.b)
print(name.msg)
Значение изменилось. Вывод:
15
25
Dood byeGlobal во вложенных функциях
Можно использовать ключевое слово global во вложенных функциях.
def add():
a = 15
def modify():
global a
a = 20
print("Перед изменением:", a)
print("Внесение изменений")
modify()
print("После изменения:", a)
add()
print("Значение a:", a)
Вывод:
Перед изменением: 15
Внесение изменений
После изменения: 15
Значение a: 20В этом коде значение внутри add() принимает значение локальной переменной x = 15. В modify() оно переназначается и принимает значение 20 благодаря global. Это и отображается в переменной функции add().
Полный код бота из этого урока на gitlab.
Выбор API для результатов матчей
Обычно я использую Rapid API для получения данных, там много бесплатных предложений. Под нашу задачу хорошо подходит Football Pro. Они дают 100 запросов в день, и возможность получить все результаты за раз.
Зарегистрируйтесь на Rapid Api, создайте приложение и оформите подписку на базовый (бесплатный) план. Сервис бесплатный, но для продолжения требуется карта.
После подписки вы получите уникальный ключ, который мы позже добавим в настройки.
Бесплатно можно делать только 100 запросов в сутки. При превышении лимита с вас будут брать деньги. Хотя мы будем останавливать работу при достижении лимита, я не несу ответственность за возможные списания.
Обновление настроек для API
Добавим переменные для запросов. Ключ можно найти на вкладке «Endpoints» внизу в поле «X-RapidAPI-Key». Остальные строки можно копировать у меня. Мы будем запрашивать данные по указанному адресу с заголовками для авторизации и параметрами для фильтрации.
# fonlinebot/config.py
# ...
SOCCER_API_URL = "https://football-pro.p.rapidapi.com/api/v2.0/livescores"
SOCCER_API_HEADERS = {
'x-rapidapi-key': "ваш уникальный ключ",
'x-rapidapi-host': "football-pro.p.rapidapi.com"
}
SOCCER_API_PARAMS = {
"tz": "Europe/Moscow",
"include": "localTeam,visitorTeam"
}
# ...
В этом же файле нужно отредактировать данные лиг. Я предлагаю уже готовые, вы можете выбрать другие (Id здесь):
# fonlinebot/config.py
# ...
BOT_LEAGUES = {
"82": "Немецкая Бундеслига",
"384": "Итальянская Серия А",
"564": "Испанская Ла Лига",
"462": "Португальская Примейра Лига",
"72": "Чемпионат Нидерландов",
"2": "Лига Чемпионов",
"5": "Лига Европы",
"8": "Английская Премьер-лига",
"301": "Французская Лига 1",
"486": "Российская Премьер-лига"
}
# Флаги для сообщений, emoji-код
BOT_LEAGUE_FLAGS = {
"82": ":Germany:",
"384": ":Italy:",
"564": ":Spain:",
"462": ":Portugal:",
"72": ":Netherlands:",
"2": ":European_Union:",
"5": ":trophy:",
"8": ":England:",
"301": ":France:",
"486": ":Russia:"
}
# ...
Вместо тестовых 1,2,3 я добавил реальные id лиг. Вместе с этим обновились и некоторые лиги. Запустим и проверим:
Отлично, теперь можно следить за Лигой Чемпионов.
Получение данных с внешнего API
В прошлой части руководства я заложил будущую логику, хранение результатов по трем лигам в одном ключе. Так как у нас всего 10 лиг и нет разницы в запросе по трем лигам или всем сразу лучше результаты по каждой хранить отдельно. Это сэкономит запросы.
Посмотрим в каком виде приходят данные в ответе с помощью интерфейса сервиса. Во вкладке «Endpoints» слева выберем «Fixtures of Today» и нажмем «Test Endpoint». Ответ появится в правом столбце.
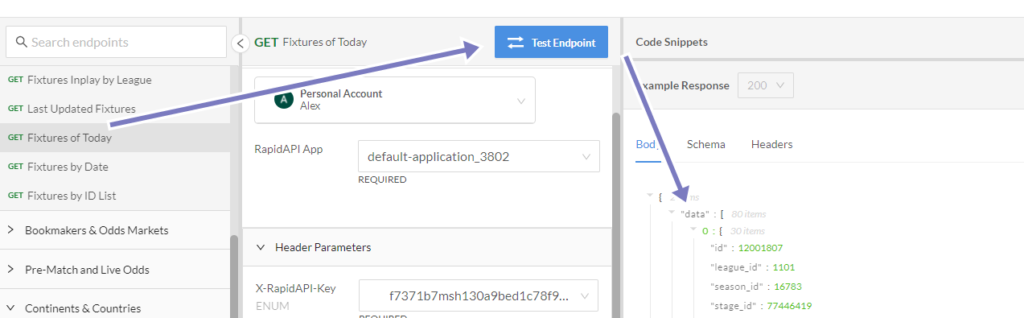
Вот эти строки мы будем использовать для каждого матча:
{
...
"league_id":998
...
"scores":{
...
"ht_score":"0-0"
"ft_score":"1-1"
...
}
"time":{
"status":"FT"
"starting_at":{
"time":"08:00:00"
...
}
"minute":90
...
"added_time":NULL
...
}
...
"localTeam":{
"data":{
...
"name":"Hadiya Hosaena"
...
}
}
"visitorTeam":{
"data":{
...
"name":"Kedus Giorgis"
...
}
}
}Для отправки запросов нужно установить библиотеку requests: pip install requests==2.25.1.
Напишем функцию, которая делает запрос к API. Иногда в ответ мы будем получать ошибки, нужно быть готовым. Отправим логи об ошибке и вернем ее.
TODO для вас. Настройте отправку сообщения админу, если fetch_results вернула словарь с ключом "error".
# fonlinebot/app/service.py
import requests
import logging
from config import BOT_LEAGUES, BOT_LEAGUE_FLAGS, MINUTE, \
SOCCER_API_URL, SOCCER_API_HEADERS, SOCCER_API_PARAMS
# ...
def limit_control(headers):
"""Контроль бесплатного лимита запросов"""
if headers.get("x-ratelimit-requests-remaining") is None:
logging.error(f"Invalid headers response {headers}")
if int(headers['x-ratelimit-requests-remaining']) <= 5:
cache.setex(
"limit_control",
int(headers['x-ratelimit-requests-reset']),
msg.limit_control
)
def fetch_results() -> dict:
SOCCER_API_PARAMS['leagues'] = ",".join(BOT_LEAGUES.keys())
try:
resp = requests.get(SOCCER_API_URL,
headers=SOCCER_API_HEADERS,
params=SOCCER_API_PARAMS)
except requests.ConnectionError:
logging.error("ConnectionError")
return {"error": "ConnectionError"}
limit_control(resp.headers)
if resp.status_code == 200:
return resp.json()
else:
logging.warning(f"Data retrieval error [{resp.status_code}]. Headers: {resp.headers} ")
return {"error": resp.status_code}
#...
Для контроля бесплатных запросов я добавил функцию limit_control. Когда останется меньше 6ти запросов, в кеш добавится соответствующая запись. Теперь бот будет проверять наличие этой записи в кеше, прежде чем отправлять запрос.
Проверку разместим в generate_results_answer. Если запись есть, мы вернем предупреждение.
# fonlinebot/app/service.py
#...
async def generate_results_answer(ids: list) -> str:
"""Функция создaет сообщение для вывода результатов матчей"""
limit = cache.get("limit_control")
if limit is not None:
return limit
results = await get_last_results(ids)
if results == [[]]*len(ids):
return msg.no_results
elif msg.fetch_error in results:
return msg.fetch_error
else:
text_results = results_to_text(results)
return msg.results.format(matches=text_results)
#...
А теперь обновите «bot.py» и «dialogs.py».
# fonlinebot/app/bot.py
#...
@dp.callback_query_handler(lambda c: c.data.startswith('update_results'))
async def update_results(callback_query: types.CallbackQuery):
"""Обновление сообщения результатов"""
if cache.get(f"last_update_{callback_query.from_user.id}") is None:
user_leagues = callback_query.data.split("#")[1:]
answer = await s.generate_results_answer(user_leagues)
if answer == msg.limit_control:
return await callback_query.answer(answer, show_alert=True)
else:
cache.setex(f"last_update_{callback_query.from_user.id}", MINUTE, "Updated")
await bot.edit_message_text(
answer,
callback_query.from_user.id,
message_id=int(cache.get(f"last_msg_{callback_query.from_user.id}")),
reply_markup=s.results_kb(user_leagues)
)
# игнорируем обновление, если прошло меньше минуты
await callback_query.answer(msg.cb_updated)
#...
Я дописал в функцию 2 строки для проверки answer. Если в ответе текст превышения лимита мы показываем предупреждение.
# fonlinebot/app/dialogs.py
#...
limit_control: str = "Лимит запросов исчерпан. Возвращайтесь завтра."
fetch_error: str = "Ошибка получения данных, попробуйте позже."
#...
Можете добавить такую запись на минуту и убедиться.
cache.setex("limit_control", 60, msg.limit_control)
На самом деле лимит начисляется каждые 24 часа с момента подписки. Если вы подписались в 13:00, значит это время обновления остатка. В заголовках ответа по ключу
x-ratelimit-requests-resetможно получить остаток времени в секундах.
Очистка данных API и сохранение
Теперь напишем функцию которая распарсит ответ для сохранения в кеш.
TODO для вас. Не всегда нужно обновлять матчи. Например, мы в 8 утра получили список и первый матч начнется в 19.00. До начала первого матча результаты не изменятся, здесь можно сэкономить запросы.
# fonlinebot/app/service.py
#...
async def parse_matches() -> dict:
"""Функция сбора матчей по API"""
data = {}
matches = fetch_results()
if matches.get("error", False):
return matches
for m in matches['data']:
if not data.get(str(m['league_id']), False):
data[str(m['league_id'])] = [m]
else:
data[str(m['league_id'])].append(m)
return data
#...
Эту функцию мы вызываем в get_last_results, если не нашли результатов в кеше. Давайте туда допишем сохранение последних результатов:
# fonlinebot/app/service.py
#...
async def save_results(matches: dict):
"""Сохранение результатов матчей"""
for lg_id in BOT_LEAGUES.keys():
cache.jset(lg_id, matches.get(lg_id, []), MINUTE)
async def get_last_results(league_ids: list) -> list:
last_results = [cache.jget(lg_id) for lg_id in league_ids]
if None in last_results:
all_results = await parse_matches()
if all_results.get("error", False):
return [msg.fetch_error]
else:
await save_results(all_results)
last_results = [all_results.get(lg_id, []) for lg_id in league_ids]
return last_results
#...
Если по какой-то лиге у нас нет записи, мы обращаемся к API и сохраняем результат на 1 минуту.
Запись логов в файл
Появились важные логи, которые помогут исправлять ошибки получения данных. Добавим настройки логирования: формат и запись в файл.
# fonlinebot/config.py
#...
formatter = '[%(asctime)s] %(levelname)8s --- %(message)s (%(filename)s:%(lineno)s)'
logging.basicConfig(
# TODO раскомментировать на сервере
# filename=f'bot-from-{datetime.datetime.now().date()}.log',
# filemode='w',
format=formatter,
datefmt='%Y-%m-%d %H:%M:%S',
# TODO logging.WARNING
level=logging.DEBUG
)
#...
Теперь строка будет выглядеть так. Появилось время и место лога:
[2021-02-05 11:38:29] INFO --- Database connection established (database.py:38)Для настройки логирования много вариантов, мы не будет подробно на этом останавливать. Уроки посвящены телеграм боту.
Красивый вывод сообщения пользователю
Хорошо, мы получили список словарей с множеством данных. Его нужно превратить в текст формата:
Английская Премьер-лига Окончен Тоттенхэм 0:1 (0:1) Челси
Форматирование реализуем в results_to_text.
# fonlinebot/app/service.py
#...
def add_text_time(time: dict) -> str:
"""Подбор текста в зависимости от статуса матча
Все статусы здесь:
https://sportmonks.com/docs/football/2.0/getting-started/a/response-codes/85#definitions
"""
scheduled = ["NS"]
ended = ["FT", "AET", "FT_PEN"]
live = ["LIVE", "HT", "ET", "PEN_LIVE"]
if time['status'] in scheduled and time['starting_at']['time'] is not None:
# обрезаем секунды
return time['starting_at']['time'][:-3]
elif time['status'] in ended:
return "Окончен"
elif time['status'] in live and time['minute'] is not None:
if time['extra_minute'] is not None:
return time['minute'] + time['extra_minute']
return time['minute']
else:
# для других статусов возвращаем заглушку
return "--:--"
def results_to_text(matches: list) -> str:
"""
Функция генерации сообщения с матчами
Получает list[list[dict]]]
Возвращает текст:
| Английская Премьер-лига |
| Окончен Тоттенхэм 0:1 (0:1) Челси |
...
"""
text = ""
for lg_matches in matches:
if not lg_matches:
continue
lg_flag = BOT_LEAGUE_FLAGS[str(lg_matches[0]['league_id'])]
lg_name = BOT_LEAGUES[str(lg_matches[0]['league_id'])]
text += f"{emojize(lg_flag)} {lg_name}\n"
for m in lg_matches:
text += f"{add_text_time(m['time']):>7} "
if m['localteam_id'] == m['winner_team_id']:
text += f"*{m['localTeam']['data']['name']}* "
else:
text += f"{m['localTeam']['data']['name']} "
if m['time']['minute'] is not None:
text += f"{m['scores']['localteam_score']}-{m['scores']['visitorteam_score']} "
else:
text += "— "
if m['scores']['ht_score'] is not None:
text += f"({m['scores']['ht_score']}) "
if m['visitorteam_id'] == m['winner_team_id']:
text += f"*{m['visitorTeam']['data']['name']}*\n"
else:
text += f"{m['visitorTeam']['data']['name']}\n"
text += "\n"
return text
#...
Функция циклом проходит по лигам и матчам, формирует читаемый вывод. Перед запуском нужно добавить параметр parse_mode в сообщения, для выделения жирным команд-победителей.
# fonlinebot/app/bot.py
#...
async def get_results(message: types.Message):
#...
await message.answer(answer,
reply_markup=s.results_kb(user_leagues),
parse_mode=types.ParseMode.MARKDOWN)
# ...
async def update_results(callback_query: types.CallbackQuery):
# ...
await bot.edit_message_text(
answer,
callback_query.from_user.id,
message_id=int(cache.get(f"last_msg_{callback_query.from_user.id}")),
parse_mode=types.ParseMode.MARKDOWN,
reply_markup=s.results_kb(user_leagues)
)
Запустим и проверим, как работает бот:
TODO для вас.
1. Получение данных может длится несколько секунд, добавьте chat_action. Это текст, который отображается сверху во время выполнения кода.
2. Не всегда обновление результатов меняет сообщение, это приводит к ошибке. Пусть сообщение не редактируется, если текст дублирует старый.
Теперь допишем немного тестов и пойдем деплоить.
Тестирование бота
Будем проверять работоспособность API и контроль лимита.
# fonlinebot/test.py
#...
import requests
import config
#...
class TestService(IsolatedAsyncioTestCase):
#...
def test_limit_control(self):
test_data = {'x-ratelimit-requests-reset': "60",
'x-ratelimit-requests-remaining': "0"}
service.limit_control(test_data)
self.assertIsNotNone(cache.get("limit_control"))
class TestAPI(unittest.TestCase):
def test_api_response(self):
result = service.fetch_results()
self.assertIsNotNone(result.get('data', None))
def test_api_headers(self):
config.SOCCER_API_PARAMS['leagues'] = ",".join(config.BOT_LEAGUES.keys())
resp = requests.get(
config.SOCCER_API_URL,
headers=config.SOCCER_API_HEADERS,
params=config.SOCCER_API_PARAMS
)
self.assertIsNotNone(resp.headers.get('x-ratelimit-requests-reset', None))
Бот готов! Код этого урока в начале статьи.
]]>Подготовка
В большинстве случаев выполнять операцию в базе данных нужно лишь после завершения некой другой операции. Например, в банковской системе перевести сумму со счета А на счет Б можно только после снятия средств со счета А.
В транзакции или все операции выполняются, или не выполняется ни одна из них. Таким образом требуется выполнить все операции в одной транзакции, чтобы она была успешной.
Вот о чем дальше пойдет речь:
- Включение и выключение режима автокомита (автосохранения).
- Транзакции для сохранения изменений в базе данных.
- Поддержка свойства ACID транзакции.
- Откат всех операций в случае неудачи.
- Изменение уровня изоляции транзакции PostgreSQL из Python.
Управление транзакциями psycopg2
Транзакции PostgreSQL обрабатываются объектом соединения. Он отвечает за сохранение изменений или откат в случае неудачи.
С помощью объекта cursor выполняются операции в базе данных. Можно создать неограниченное количество объектов cursor из объекта connection. Если любая из команд объекта cursor завершается неудачно, или же транзакция отменяется, то следующие команды не выполняются вплоть до вызова метода connection.rollback().
- Объект соединения отвечает за остановку транзакции. Это можно сделать с помощью методов
commit()лиrollback(). - После использования метода
commit()изменения сохраняются в базе данных. - С помощью метода
rollback()можно откатить изменения.
Примечание: вызов метода
closе()или любого другого, отвечающего за уничтожение объекта соединения, приводит к неявному вызовуrollback(), вследствие чего все изменения откатываются.
Connection.autocommit
По умолчанию соединение работает в режиме автоматического сохранения, то есть свойство auto-commit равно True. Это значит, что при успешном выполнении запроса изменения немедленно сохраняются в базу данных, а откат становится невозможным.
Для выполнения запросов в транзакции это свойство нужно отключить. Для этого нужно сделать connection.autocommit=False. В этом случае будет возможность откатить выполненный запрос к оригинальному состоянию в случае неудачи.
Синтаксис autocommit:
connection.autocommit=True or FalseсConnection.commit
Если все операции в транзакции завершены, используйте connection.commit() для сохранения изменений в базе данных. Если метод не использовать, то все эффекты взаимодействия с данными не будут применены.
Синтаксис commit:
connection.commit()Connection.rollback
Если в транзакции хотя бы одна операция завершается неудачно, то отменить изменения можно с помощью connection.rollback().
Синтаксис rollback:
connection.rollback()Пример управления транзакциями PostgreSQL из Python
- Отключите режим автосохранения (auto-commit).
- Если все операции были выполнены успешно, используйте
connection.commit()для их сохранения в базе данных. - Если какая-то из операций была завершена неудачно, то откатиться к последнему состоянию можно с помощью
connection.rollback().
Примечание: транзакция остается открытой до явного вызова
commit()илиrollback().
Давайте понизим цену на один телефон и повысим на второй.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
connection.autocommit=False
cursor = connection.cursor()
amount = 200
query = """select price from mobile where id = 1"""
cursor.execute(query)
record = cursor.fetchone() [0]
price_a = int(record)
price_a -= amount
# Понизить цену у первого
sql_update_query = """update mobile set price = %s where id = 1"""
cursor.execute(sql_update_query,(price_a,))
query = """select price from mobile where id = 2"""
cursor.execute(query)
record = cursor.fetchone() [0]
price_b = int(record)
price_b += amount
# Повысить цену у второго
sql_update_query = """Update mobile set price = %s where id = 2"""
cursor.execute(sql_update_query, (price_b,))
# совершение транзакции
connection.commit()
print("Транзакция успешно завершена")
except (Exception, psycopg2.DatabaseError) as error :
print ("Ошибка в транзакции. Отмена всех остальных операций транзакции", error)
connection.rollback()
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вы получите следующий вывод после успешного завершения всех операций в транзакции.
Транзакция успешно завершена
Соединение с PostgreSQL закрытоЕсли хотя бы одна из операций будет завершена с ошибкой, то вывод будет таким.
Ошибка в транзакции. Отмена всех остальных операций транзакции
Соединение с PostgreSQL закрытоИнструкция With для управления транзакциями
Для создания транзакции внутри определенного блока в коде используйте инструкцию with.
Что делает инструкция with?Соединения и объекта cursor в psycopg2 — это всего лишь контекстные менеджеры, которые можно использовать с with. Основное преимущество в том, что это позволяет не писать явно commit или rollback.
Синтаксис:
with psycopg2.connect(connection_arguments) as conn:
with conn.cursor() as cursor:
cursor.execute(Query)
Когда соединение выходит из блока with, а запрос выполняется без ошибок или исключений, транзакция сохраняется. Если же в процессе возникла проблема, то транзакция откатывается.
При выходе за пределы блока соединение не закрывается, но объекты cursor и любые другие связанные объекты — да. Соединение можно использовать в более чем одном with, и каждый блок with — это всего лишь транзакция.
В этом примере выполним транзакцию в платформе для онлайн-торговки. Приобретем один товар, уменьшим баланс покупателя и переведем соответствующую сумму на счет компании.
import psycopg2
from psycopg2 import Error
connection = psycopg2.connect(**params)
with connection:
with connection.cursor() as cursor:
# Поиск цены товара
query = """select price from itemstable where itemid = 876"""
cursor.execute(query)
record = cursor.fetchone() [0]
item_price = int(record)
# Получение остатка на счету
query = """select balance from ewallet where userId = 23"""
cursor.execute(query)
record = cursor.fetchone() [0]
ewallet_balance = int(record)
new_ewallet_balance -= item_price
# Обновление баланса с учетом расхода
sql_update_query = """Update ewallet set balance = %s where id = 23"""
cursor.execute(sql_update_query,(new_ewallet_balance,))
# Зачисление на баланс компании
query = """select balance from account where accountId = 2236781258763"""
cursor.execute(query)
record = cursor.fetchone()
account_balance = int(record)
new_account_balance += item_price
# Обновление счета компании
sql_update_query = """Update account set balance = %s where id = 132456"""
cursor.execute(sql_update_query, (new_account_balance,))
print("Транзакция успешно завершена")
Уровни изоляции psycopg2
В системах баз данных с помощью уровней изоляции можно определить какой уровень целостности транзакции будет виден остальным пользователям и системам.
Например, когда пользователь выполняет действие или операцию, которые еще не завершены, подробности о них доступны другим пользователям, которые могут выполнить последовательные действия. Например, потребитель приобретает товар. Информация об этом становится известна другим системам, что нужно для подготовки счета, квитанции и подсчетов скидки, что ускоряет весь процесс.
Если уровень изоляции низкий, множество пользователей может получить доступ к одним и тем же данным одновременно. Однако это же может привести и к некоторым проблемам вплоть до утраченных обновлений. Поэтому нужно учитывать все. Более высокий уровень изоляции может заблокировать других пользователей или транзакции до завершения.
psycopg2.extensions предоставляет следующие уровня изоляции:
- psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT,
- psycopg2.extensions.ISOLATION_LEVEL_READ_UNCOMMITTED,
- psycopg2.extensions.ISOLATION_LEVEL_READ_COMMITTED,
- psycopg2.extensions.ISOLATION_LEVEL_REPEATABLE_READ,
- psycopg2.extensions.ISOLATION_LEVEL_SERIALIZABLE,
- psycopg2.extensions.ISOLATION_LEVEL_DEFAULT.
Как задать уровни изоляции
Это можно сделать с помощью класса connection:
conn.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)Также можно использовать метод connection.set_session.
connectio.set_session(isolation_level=None, readonly=None, deferrable=None, autocommit=None)
В этом случае isolation_level могут быть READ UNCOMMITED, REPEATABLE READ, SERIALIZE или другие из списка констант.
«Рыба» кода бота
Сразу запишем функции в «bot.py», которые понадобятся. Предварительно удалите test_message:
# fonlinebot/app/bot.py
# ...
dp.middleware.setup(LoggingMiddleware())
@dp.message_handler(commands=['start'])
async def start_handler(message: types.Message):
"""Обработка команды start. Вывод текста и меню"""
...
@dp.message_handler(commands=['help'])
async def help_handler(message: types.Message):
"""Обработка команды help. Вывод текста и меню"""
...
@dp.callback_query_handler(lambda c: c.data == 'main_window')
async def show_main_window(callback_query: types.CallbackQuery):
"""Главный экран"""
...
@dp.message_handler(lambda message: message.text == msg.btn_online)
@dp.message_handler(commands=['online'])
async def get_results(message: types.Message):
"""Обработка команды online и кнопки Онлайн.
Запрос матчей. Вывод результатов"""
...
@dp.callback_query_handler(lambda c: c.data.startswith('update_results'))
async def update_results():
"""Обновление сообщения результатов"""
...
@dp.message_handler(lambda message: message.text == msg.btn_config)
async def get_config(message: types.Message):
"""Обработка кнопки Настройки.
Проверка выбора лиг. Вывод меню изменений настроек"""
...
@dp.callback_query_handler(lambda c: c.data.startswith('edit_config'))
async def set_or_update_config(user_id: str):
"""Получение или обновление выбранных лиг"""
...
@dp.callback_query_handler(lambda c: c.data[:6] in ['del_le', 'add_le'])
async def update_leagues_info(callback_query: types.CallbackQuery):
"""Добавление/удаление лиги из кеша, обновление сообщения"""
...
@dp.callback_query_handler(lambda c: c.data == 'save_config')
async def save_config(callback_query: types.CallbackQuery):
"""Сохранение пользователя в базу данных"""
....
@dp.callback_query_handler(lambda c: c.data == 'delete_config')
async def delete_config(user_id: str):
"""Удаление пользователя из базы данных"""
...
@dp.message_handler()
async def unknown_message(message: types.Message):
"""Ответ на любое неожидаемое сообщение"""
...
async def on_shutdown(dp):
# ...
Это не окончательная версия, я мог что-то упустить. В процессе добавим недостающие.
Каждая функция обернута декоратором, так мы общаемся с Телегармом:
@dp.message_handler(commands=['start'])— декоратор ожидает сообщения-команды (которые начинаются с/). В этом примере он ожидает команду/start.@dp.callback_query_handler(lambda c: c.data == 'main_window')— ожидает callback и принимает lambda-функцию для его фильтрации. Callback отправляется inline-кнопками. В примере мы ожидаем callback со значением'main_window'.@dp.message_handler(lambda message: message.text == msg.btn_config)— этот декоратор похож на предыдущий, но ожидает сообщение от пользователя. В примере мы будем обрабатывать сообщение с текстом изmsg.btn_config.
Итак. Пользователь нажимает команду старт, получает приветственное сообщение. В нем мы предлагаем выбрать 3 лиги и мониторить результаты по ним. Получить результаты можно командой или кнопкой меню. Так же мы даем возможность изменить выбранные соревнования или удалить свои данные из бота.
Полный код бота из этого урока на gitlab.
Добавление команд в бота
Изначально команды не настроены. Пользователи могут вводить их, но специально меню нет. Для добавления нужно снова написать https://t.me/botfather команду /setcommands. Выберите своего бота и добавьте этот текст:
start - Запуск и перезапуск бота
help - Возможности бота
online - Результаты матчей
В ответ получите «Success! Command list updated. /help». Теперь можно перейти в своего бота и проверить:
Ответы на команды
Взаимодействие с ботом начинается с команды /start. Нужно поприветствовать и предложить следующий шаг. Эта команда будет возвращать текст с клавиатурой. Точно так же работает и /help.
Добавим обработку этих команд в «bot.py», обновите start_handler help_handler:
# fonlinebot/app/bot.py
# ...
from config import TOKEN, YEAR, MINUTE
import app.service as s
# ...
@dp.message_handler(commands=['start'])
async def start_handler(message: types.Message):
"""Обработка команды start. Вывод текста и меню"""
# проверка, есть ли пользователь в базе
user_league_ids = await s.get_league_ids(message.from_user.id)
if not user_league_ids:
await message.answer(msg.start_new_user)
# добавление id сообщения настроек
cache.setex(f"last_msg_{message.from_user.id}", YEAR, message.message_id+2)
await set_or_update_config(user_id=message.from_user.id)
else:
await message.answer(msg.start_current_user,
reply_markup=s.MAIN_KB)
@dp.message_handler(commands=['help'])
async def help_handler(message: types.Message):
"""Обработка команды help. Вывод текста и меню"""
await message.answer(msg.help, reply_markup=s.MAIN_KB)
# ...
Я добавил импорт import app.service as s. В этом модуле клавиатура и функция проверки пользователя. start_handler проверяет есть ли пользователь в кеше или базе данных, и отправляет ему соответствующий текст.
Перед отправкой текста для выбора лиг, я сохранил его будущий id. Получил номер последнего сообщения (это сама команда «start») и добавил 2 пункта: +1 за наш ответ на команду и +1 за само сообщения выбора лиг. Зная id сообщения, его можно редактирвать.
Теперь напишем клавиатуру и get_league_ids в модуль «service».
# fonlinebot/app/service.py
from aiogram.types import ReplyKeyboardMarkup, KeyboardButton, \
InlineKeyboardMarkup, InlineKeyboardButton
from emoji import emojize
from config import BOT_LEAGUES, BOT_LEAGUE_FLAGS
from database import cache, database as db
from app.dialogs import msg
MAIN_KB = ReplyKeyboardMarkup(
resize_keyboard=True,
one_time_keyboard=True
).row(
KeyboardButton(msg.btn_online),
KeyboardButton(msg.btn_config)
)
async def get_league_ids(user_id: str) -> list:
"""Функция получает id лиг пользователя в базе данных"""
leagues = cache.lrange(f"u{user_id}", 0, -1)
if leagues is None:
leagues = await db.select_users(user_id)
if leagues is not None:
leagues = leagues.split(',')
[cache.lpush(f"u{user_id}", lg_id) for lg_id in leagues]
else:
return []
return leagues
MAIN_KB — основная клавиатура, как на скриншоте выше. Разберем подробнее:
ReplyKeyboardMarkup— объект, который создает клавиатуру.- Параметр
resize_keyboard=Trueуменьшает ее размер. - А с
one_time_keyboard=Trueклавиатура будет скрываться, после использования. .row— метод для группировки кнопок в строку.KeyboardButton(msg.btn_online)иKeyboardButton(msg.btn_config)— кнопки с заданным текстом.
Осталось только добавить текста сообщений в dialogs. Вставьте этот код в класс Messages.
# fonlinebot/app/dialogs.py
# ...
start_new_user: str = "Привет. Я могу сообщать тебе результаты матчей online."
start_current_user: str = "Привет. С возвращением! " \
"Используй команды или меню внизу для продолжения."
help: str = """
Этот бот получает результаты матчей за последние 48 часов.
Включая режим LIVE.
- Что бы выбрать/изменить лиги нажмите "Настройки".
- Для проверки результатов нажмите "Онлайн".
Бот создан в учебных целях, для сайта pythonru.com
"""
Выбор, изменение и удаление лиг

Сначала внесем правки в наши вспомогательные модули.
В «dababase» в класс Database добавим новый метод insert_or_update_users.
# fonlinebot/database.py
#...
async def insert_or_update_users(self, user_id: int, leagues: str):
user_leagues = await self.select_users(user_id)
if user_leagues is not None:
await self.update_users(user_id, leagues)
else:
await self.insert_users(user_id, leagues)
#...
В настройки добавим переменные метрик времени:
# fonlinebot/config.py
#...
MINUTE = 60
YEAR = 60*60*24*366
И допишем текста для блока настроек:
# fonlinebot/app/dialogs.py
# ...
league_row: str = "{i}. {flag} {name}"
config: str = "Сейчас выбраны:\n{leagues}"
btn_back: str = "<- Назад"
btn_go: str = "Вперед ->"
btn_save: str = "Сохранить"
config_btn_edit: str = "Изменить"
config_btn_delete: str = "Удалить данные"
data_delete: str = "Данные успешно удалены"
set_leagues: str = "Выбери 3 лиги для отслеживания.\nВыбраны:\n{leagues}"
main: str = "Что будем делать?"
db_saved: str = "Настройки сохранены"
cb_not_saved: str = "Лиги не выбраны"
cb_limit: str = "Превышен лимит. Максимум 3 лиги."
# ...
На этом подготовка окончена, пора написать логику добавления лиг. В модуль «service» добавим две inline-клавиатуры.
Inline-клавиатура привязана к конкретному сообщению. С их помощью можно отправлять и обрабатывать сигналы боту.
# fonlinebot/app/service.py
# ...
CONFIG_KB = InlineKeyboardMarkup().row(
InlineKeyboardButton(msg.btn_back, callback_data='main_window'),
InlineKeyboardButton(msg.config_btn_edit, callback_data='edit_config#')
).add(InlineKeyboardButton(msg.config_btn_delete, callback_data='delete_config'))
def leagues_kb(active_leagues: list, offset: int = 0):
kb = InlineKeyboardMarkup()
league_keys = list(BOT_LEAGUES.keys())[0+offset:5+offset]
for lg_id in league_keys:
if lg_id in active_leagues:
kb.add(InlineKeyboardButton(
f"{emojize(':white_heavy_check_mark:')} {BOT_LEAGUES[lg_id]}",
callback_data=f'del_league_#{offset}#{lg_id}'
))
else:
kb.add(InlineKeyboardButton(
BOT_LEAGUES[lg_id],
callback_data=f'add_league_#{offset}#{lg_id}'
))
kb.row(
InlineKeyboardButton(
msg.btn_back if offset else msg.btn_go,
callback_data="edit_config#0" if offset else "edit_config#5"),
InlineKeyboardButton(msg.btn_save, callback_data="save_config")
)
return kb
# ...
В клавиатуре CONFIG_KB 3 кнопки. Класс кнопки InlineKeyboardButton принимает текст и параметр callback_data. Именно callback нам отправит Телеграм после нажатия на кнопку. Вот так выглядит эта клавиатура:
А leagues_kb генерирует более сложную клавиатуру, с пагинацией. Мы выводим 5 лиг, кнопку «далее/назад» и «сохранить». Функция принимает выбранные лиги и отступ. Отступ нужен, для вывода лиг постранично.
Когда юзер нажимает на лигу, мы добавляем ее в кеш, нажимает повторно — удаляем. Обратите внимание, я генерирую динамическую строку в callback_data. Подставляю параметры offset и lg_id, что бы использовать при обработке.
Теперь напишем функцию красивого вывода списка лиг и обновления этого списка в кеше:
# fonlinebot/app/service.py
# ...
async def get_league_names(ids: list) -> str:
"""Функция собирает сообщение с названиями лиг из id"""
leagues_text = ""
for i, lg_id in enumerate(ids, start=1):
if i != 1:
leagues_text += '\n'
leagues_text += msg.league_row.format(
i=i,
flag=emojize(BOT_LEAGUE_FLAGS.get(lg_id, '-')),
name=BOT_LEAGUES.get(lg_id, '-')
)
return leagues_text
def update_leagues(user_id: str, data: str):
"""Функция добавляет или удаляет id лиги для юзера"""
league_id = data.split("#")[-1] # data ~ add_league_#5#345
if data.startswith("add"):
cache.lpush(f"u{user_id}", league_id)
else:
cache.lrem(f"u{user_id}", 0, league_id)
Настройка общения с Телеграмом
В файле бота допишем функции для меню настроек.
# fonlinebot/app/bot.py
@dp.callback_query_handler(lambda c: c.data == 'main_window')
async def show_main_window(callback_query: types.CallbackQuery):
"""Главный экран"""
await callback_query.answer()
await bot.send_message(callback_query.from_user.id, msg.main, reply_markup=s.MAIN_KB)
dp.message_handler(lambda message: message.text == msg.btn_config)
async def get_config(message: types.Message):
"""Обработка кнопки Настройки.
Проверка выбора лиг. Вывод меню изменений настроек"""
user_league_ids = await s.get_league_ids(message.from_user.id)
if user_league_ids:
cache.setex(f"last_msg_{message.from_user.id}", YEAR, message.message_id+2)
leagues = await s.get_league_names(user_league_ids)
await message.answer(msg.config.format(leagues=leagues),
reply_markup=s.CONFIG_KB)
else:
cache.setex(f"last_msg_{message.from_user.id}", YEAR, message.message_id+1)
await set_or_update_config(user_id=message.from_user.id)
@dp.callback_query_handler(lambda c: c.data == 'delete_config')
async def delete_config(callback_query: types.CallbackQuery):
"""Удаление пользователя из базы данных"""
await db.delete_users(callback_query.from_user.id)
cache.delete(f"u{callback_query.from_user.id}")
await callback_query.answer()
cache.incr(f"last_msg_{callback_query.from_user.id}")
await bot.send_message(callback_query.from_user.id,
msg.data_delete,
reply_markup=s.MAIN_KB)
Функция get_config вызывается после нажатия на «Настройки». Если у пользователя выбраны лиги, она возвращает стандартное сообщение и меню настроек. В другом случае будет вызвана set_or_update_config для выбора лиг.
Одновременно я добавил удаление данных и главный экран.
Создавать и редактировать список будем в одной функции. Ей понадобятся параметры из строки callback. Например, пользователь нажал «вперед ->» и Телеграм прислал "edit_config#5". Мы разделили строку по # и взяли последнее значение (‘5’). Так будут передаваться параметры между сообщениями.
# fonlinebot/app/bot.py
@dp.callback_query_handler(lambda c: c.data.startswith('edit_config'))
async def set_or_update_config(callback_query: types.CallbackQuery = None,
user_id=None, offset=""):
"""Получение или обновление выбранных лиг"""
# если пришел callback, получим данные
if callback_query is not None:
user_id = callback_query.from_user.id
offset = callback_query.data.split("#")[-1]
league_ids = await s.get_league_ids(user_id)
leagues = await s.get_league_names(league_ids)
# если это первый вызов функции, отправим сообщение
# если нет, отредактируем сообщение и клавиатуру
if offset == "":
await bot.send_message(
user_id,
msg.set_leagues.format(leagues=leagues),
reply_markup=s.leagues_kb(league_ids)
)
else:
msg_id = cache.get(f"last_msg_{user_id}")
await bot.edit_message_text(
msg.set_leagues.format(leagues=leagues),
user_id,
message_id=msg_id
)
await bot.edit_message_reply_markup(
user_id,
message_id=msg_id,
reply_markup=s.leagues_kb(league_ids, int(offset))
)
Не хватает еще реакции на нажатие по названию лиг и кнопке «сохранить».
# fonlinebot/app/bot.py
dp.callback_query_handler(lambda c: c.data[:6] in ['del_le', 'add_le'])
async def update_leagues_info(callback_query: types.CallbackQuery):
"""Добавление/удаление лиги из кеша, обновление сообщения"""
offset = callback_query.data.split("#")[-2]
s.update_leagues(callback_query.from_user.id, callback_query.data)
await set_or_update_config(user_id=callback_query.from_user.id, offset=offset)
await callback_query.answer()
@dp.callback_query_handler(lambda c: c.data == 'save_config')
async def save_config(callback_query: types.CallbackQuery):
"""Сохранение пользователя в базу данных"""
leagues_list = await s.get_league_ids(callback_query.from_user.id)
if len(leagues_list) > 3:
# не сохраняем, если превышен лимит лиг
await callback_query.answer(msg.cb_limit, show_alert=True)
elif leagues_list:
await db.insert_or_update_users(
callback_query.from_user.id,
",".join(leagues_list)
)
await callback_query.answer()
await bot.send_message(
callback_query.from_user.id,
msg.db_saved,
reply_markup=s.MAIN_KB
)
else:
# не сохраняем если список пустой
await callback_query.answer(msg.cb_not_saved)
Готово. Теперь можете запустить бота и добавить лиги в настройках.
Сообщение с результатами матчей
Так как работа с API еще не настроена, напишем заглушку для этих процессов.
# fonlinebot/app/bot.py
@dp.message_handler(lambda message: message.text == msg.btn_online)
@dp.message_handler(commands=['online'])
async def get_results(message: types.Message):
"""Обработка команды online и кнопки Онлайн.
Запрос матчей. Вывод результатов"""
user_leagues = await s.get_league_ids(message.from_user.id)
cache.setex(f"last_msg_{message.from_user.id}", YEAR, message.message_id+1)
if not user_leagues:
await set_or_update_config(user_id=message.from_user.id)
else:
answer = await s.generate_results_answer(user_leagues)
cache.setex(f"last_update_{message.from_user.id}", MINUTE, "Updated")
await message.answer(answer, reply_markup=s.results_kb(user_leagues))
@dp.callback_query_handler(lambda c: c.data.startswith('update_results'))
async def update_results(callback_query: types.CallbackQuery):
"""Обновление сообщения результатов"""
if cache.get(f"last_update_{callback_query.from_user.id}") is None:
user_leagues = callback_query.data.split("#")[1:]
answer = await s.generate_results_answer(user_leagues)
cache.setex(f"last_update_{callback_query.from_user.id}", MINUTE, "Updated")
await bot.edit_message_text(
answer,
callback_query.from_user.id,
message_id=int(cache.get(f"last_msg_{callback_query.from_user.id}"))
)
# игнорируем обновление, если прошло меньше минуты
await callback_query.answer(msg.cb_updated)
get_results получает лиги и фиксирует id сообщения для редактирования. Если у пользователя нет сохраненных лиг — вызывает set_or_update_config, в другом случает генерируем ответ с матчами и кнопкой «обновить».

Функция обновления результатов выполняет логику только если прошло больше минуты с момента последнего обновления. Для этого после каждого получения ответа с результатами мы добавляем запись в кеш со сроком хранения 1 минута.
Допишем зависимости:
# fonlinebot/app/dialogs.py
#...
results: str = "Все результаты за сегодня\n{matches}"
no_results: str = "Сегодня нет матчей"
update_results: str = "Обновить результаты"
cb_updated: str = f"{emojize(':white_heavy_check_mark:')} Готово"
#...
Кнопку обновления и генерацию ответа в «service.py».
# fonlinebot/app/service.py
from config import BOT_LEAGUES, BOT_LEAGUE_FLAGS, MINUTE
#...
def results_kb(leagues: list):
params = [f"#{lg}" for lg in leagues]
kb = InlineKeyboardMarkup()
kb.add(InlineKeyboardButton(
msg.update_results,
callback_data=f"update_results{''.join(params)}"
))
return kb
async def generate_results_answer(ids: list) -> str:
"""Функция создaет сообщение для вывода результатов матчей"""
results = await get_last_results(ids)
if results:
text_results = results_to_text(results)
return msg.results.format(matches=text_results)
else:
return msg.no_results
def ids_to_key(ids: list) -> str:
"""Стандартизация ключей для хранения матчей"""
ids.sort()
return ",".join(ids)
async def parse_matches(ids: list) -> list:
"""Функция получения матчей по API"""
# логику напишем в следующей части
return []
async def get_last_results(league_ids: list) -> list:
lg_key = ids_to_key(league_ids)
last_results = cache.jget(lg_key)
if last_results is None:
last_results = await parse_matches(league_ids)
if last_results:
# добавляем новые матчи, если они есть
cache.jset(lg_key, last_results, MINUTE)
return last_results
def results_to_text(matches: list) -> str:
"""
Функция генерации сообщения с матчами
"""
# логику напишем в следующей части
...
#...
Функция generate_results_answer получает матчи, преобразовывает данные в текст и возвращает его. Если матчей нет, возвращает соответствующий текст.
Что бы сэкономить ресурсы мы проверяем наличие матчей в кеше и только потом обращаемся к API.
Обработка неизвестных сообщений
Люди будут писать текст, который мы не обрабатываем. Обновите класс Messages:
# fonlinebot/app/dialogs.py
#...
unknown_text: str = "Ничего не понятно, но очень интересно.\nПопробуй команду /help"
#...
И unknown_message.
# fonlinebot/app/bot.py
#...
@dp.message_handler()
async def unknown_message(message: types.Message):
"""Ответ на любое неожидаемое сообщение"""
await message.answer(msg.unknown_text, reply_markup=s.MAIN_KB)
#...
Убедимся, что все работает:
Отлично. Мы написали бота с клавиатурами, кешированием и базой данных. Теперь пора добавить тестов.
Обновление тестов
Добавим класс TestService для контроля функции get_league_ids и get_last_results.
# fonlinebot/test.py
from app import bot, service
#...
class TestService(IsolatedAsyncioTestCase):
async def test_get_league_ids(self):
ids = await service.get_league_ids("1111")
self.assertEqual(type(ids), list)
async def test_get_last_results(self):
results = await service.get_last_results(["1", "2", "3"])
self.assertEqual(type(results), list)
#...
Ссылка на репозиторий с кодом в начале статьи. Удачи!
Что дальше?
Осталась малая часть работы. В следующей части мы найдем подходящий API и настроем обработку получения результатов: добавление внешнего API.
]]>Virtualenv — простой и рекомендованный способ настройки среды Python.
Отличия virtualenv и venv
Venv — это пакет, который идет по умолчанию с Python 3.3+. В версии Python 2 его нет.
Virtualenv — более продвинутая библиотека. По ссылке можно ознакомиться с основными отличиями.
Виртуальную среду можно создать и с помощью venv, но все-таки рекомендуется установить и использовать virtualenv для полноценной работы.
Установка virtualenv с помощью pip
Для установки virtualenv с Python нужно использовать pip. Желательно предварительно обновить этот инструмент.
python -m pip install --upgrade pipИли используйте python3, если python ссылается на 2 версию.
После обновления можно установить и virtualenv:
pip install virtualenv # или pip3Создание виртуальной среды
1. Перейдите в директорию, в которой вы хотите создать виртуальную среду(например папка проекта).
~$ cd test
~/test$2. Создайте виртуальную среду, при необходимости указав конкретную версию Python. Следующая команда создает virtualenv с именем venv_name и использует флаг -p, чтобы указать полный путь к версии Python:
virtualenv -p /usr/bin/python venv_name
# или
virtualenv venv_nameНазвать среду можно как угодно
После выполнения команды вы увидите логи:
Running virtualenv with interpreter /usr/bin/python
Already using interpreter /usr/bin/python
Using base prefix '/usr'
New python executable in /home/username/test/venv_name/bin/python
Installing setuptools, pip, wheel...
done.Эта команда создает локальную копию среды. Работая с ней, важно не забывать об активации, чтобы использовались нужные версии конкретных инструментов и пакетов.
Если при установке возникла ошибка setuptools pip failed with error code 1` error, используйте следующую команду, чтобы решить проблему:
pip install --upgrade setuptools # или pip33. Для активации новой виртуальной среды используйте команду:
source venv_name/bin/activateПосле этого название текущей среды отобразится слева от символа ввода: (venv_name) username@desctop:~/test$
Теперь при установке любого пакета с помощью pip он будет размещаться в папках этой среды, изолированно от глобальной установки.
Деактивации virtualenv
После завершения работы деактивировать виртуальную среду можно с помощью команды deactivate.
Введите ее и приставка venv_name пропадет. Вы вернетесь к использованию глобально версии python.
Удаление виртуальной среды
Для удаления виртуальной среды достаточно просто удалить папку проекта. Для этого используется следующая команда:
rm -rf venv_nameРешение популярных ошибок
Ошибки при создании virtualenv. При попытке создать virtualenv с Python 3.7 могут возникнуть следующие ошибки.
AttributeError: module 'importlib._bootstrap' has no attribute 'SourceFileLoader'
OSError: Command /home/username/venv/bin/python3 -c "import sys, pip; sys...d\"] + sys.argv[1:]))" setuptools pip failed with error code 1Для их исправления нужно добавить следующую строку в .bash_profile.
export LC_ALL="en_US.UTF-8"Использование полного пути к виртуальной среде. Может быть такое, что при использовании команды virtualenv будет использована не та версия. Для решения проблемы нужно лишь задать полные пути как к virtualenv, так и к Python в системе.
А получить их можно с помощью этой команды:
/home/username/opt/python-3.8.0/bin/virtualenv -p /home/username/opt/python-3.8.0/bin/python3 venvКогда локальная версия будет готова, разместим бота на сервере. Вместо Heroku, я выбрал отдельную виртуальную машину, что бы бот не засыпал. Это ближе к реальности.
Вся разработка разбита на этапы:
- Локальная установка библиотек и Redis.
- Регистрация и получение токена.
- Настройка , подключение к базам данных.
- Написание основной функциональности бота.
- Регистрации, выбор и настройка внешнего апи футбольных матчей.
- Добавление сбора результатов матчей и интеграция в бота.
- Деплой, публикация на сервере:
- Регистрация дешевого или бесплатного VPS.
- Запуск Редис-клиента.
- Запуск и настройка бота на сервере.
Рабочая версия бота запущена в телеграме до конца февраля @FonlineBOT. Бот отключен.
Вводные данные
Материал рассчитан на уровень Начинающий+, нужно понимать как работают классы и функции, знать основы базы данных и async/await. Если знаний мало, крайне желательно писать код в Pycharm, бесплатная версия подходит.
Используйте указанные версии библиотек, что бы проект работал без изменений. При установке иных версий вы можете получать ошибки, связанные с совместимостью.
Версия Python - 3.8+
aiogram==2.11.2
emoji==1.1.0
redis==3.5.3
ujson==4.0.1
uvloop==0.14.0 # не работает и не требуется на WindowsРепозиторий с кодом этой для этой части бота:
https://gitlab.com/PythonRu/fonlinebot/-/tree/master/first_step
Локальная установка библиотек для бота и Redis
Для начала нужно создать проект «fonlinebot» с виртуальным окружение. В Pycharm это делается так:
Затем установить библиотеки в виртуальном окружении. Сразу понадобятся 4: для бота, работы с redis, ускорения и emoji в сообщениях.
pip install aiogram==2.11.2 redis==3.5.3 ujson==4.0.1 emoji==1.1.0Установка Redis локально
Redis — это резидентная база данных (такая, которая хранит записи прямо в оперативной памяти) в виде пар ключ-значение. Чтение и запись в память происходит намного быстрее, чем в случае с дисками, поэтому такой подход отлично подходит для хранения второстепенных данных.
Из недавней статьи — Redis для приложений на Python
Для установки Redis на Linux/Mac следуйте этим инструкциям: https://redis.io/download#from-source-code. Для запуска достаточно ввести src/redis-server.
Что бы установить на Windows скачайте и распакуйте архив отсюда. Для запуска откройте «redis-server.exe».
Теперь нужно убедиться, что все работает. Создайте файл «main.py» в корне проекта и выполните этот код:
# fonlinebot/main.py
import redis
r = redis.StrictRedis()
print(r.ping())
Вывод будет True, в другом случае ошибка.
Регистрация бота и получение токена
Для регистрации напишем https://t.me/botfather команду /newbot. Далее он просит ввести имя и адрес бота. Если данные корректны, выдает токен. Учтите, что адрес должен быть уникальным, нельзя использовать «fonlinebot» снова.
На время разработки сохраним токен в файл. Создайте «config.py» в папке проекта для хранения настроек и запишите токен TOKEN = "ВАШ ТОКЕН"
Настройка бота
Теперь нужно связать бота с redis и базой данных, проверить работоспособность.
Создадим необходимые модули и файлы. В папке «fonlinebot» к созданным ранее «main.py» и «config.py» добавим: «database.py», «requirements.txt» и папку «app». В папку «app» добавьте: «bot.py», «dialogs.py», «service.py». Вот такая структура получится:

Разделив бот на модули, его удобнее поддерживать и дорабатывать.
- «main.py» — для запуска бота.
- «config.py» — хранит настройки, ключи доступов и другую статическую информацию.
- «database.py» — для работы с базой данных и кешем(redis).
- «requirements.txt» — хранит зависимости проекта, для запуска на сервере.
- «app» — папка самого бота.
- «bot.py» — для взаимодействия бота с юзерами, ответы на сообщения.
- «dialogs.py» — все текстовые ответы бота.
- «service.py» — бизнес логика, получение и обработка данных о матчах.
Пришло время перейти к программированию. Запишем в «requirements.txt» наши зависимости:
aiogram==2.11.2
emoji==1.1.0
redis==3.5.3
ujson==4.0.1
uvloop==0.14.0Так как большая часть программирует на Windows, uvloop мы не устанавливали локально. Установим его на сервере.
В «config.py» к токену добавим данные бота и подключения к redis.
# fonlinebot/config.py
import ujson
import logging
logging.basicConfig(level=logging.INFO)
TOKEN = "здесь должен быть токен"
BOT_VERSION = 0.1
# База данных хранит выбранные юзером лиги
BOT_DB_NAME = "users_leagues"
# Тестовые данные поддерживаемых лиг
BOT_LEAGUES = {
"1": "Бундеслига",
"2": "Серия А",
"3": "Ла Лига",
"4": "Турецкая Суперлига",
"5": "Чемпионат Нидерландов",
"6": "Про-лига Бельгии",
"7": "Английская Премьер-лига",
"8": "Лига 1",
}
# Флаги для сообщений, emoji-код
BOT_LEAGUE_FLAGS = {
"1": ":Germany:",
"2": ":Italy:",
"3": ":Spain:",
"4": ":Turkey:",
"5": ":Netherlands:",
"6": ":Belgium:",
"7": ":England:",
"8": ":France:",
}
# Данные redis-клиента
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
# По умолчанию пароля нет. Он будет на сервере
REDIS_PASSWORD = None
Информацию о лигах в будущем можно будет вынести в отдельный json файл. Эта версия бота будет поддерживать не более 10 вариантов, я явно их записал.
Добавление базы данных
Теперь добавим классы для работы с базой данных sqlite и redis. База данных нужна для сохранения предпочтений по лигам юзеров.
Юзер будет выбирать 3 чемпионата для отслеживания, бот сохранит их в БД и использует для запроса результатов.
Кеш(redis) будет сохранять результаты матчей, что бы уменьшить количество запросов к API и ускорить время ответов. Как правило, бесплатные API лимитирует запросы.
# fonlinebot/database.py
import os
import logging
import sqlite3
import redis
import ujson
import config
# класс наследуется от redis.StrictRedis
class Cache(redis.StrictRedis):
def __init__(self, host, port, password,
charset="utf-8",
decode_responses=True):
super(Cache, self).__init__(host, port,
password=password,
charset=charset,
decode_responses=decode_responses)
logging.info("Redis start")
def jset(self, name, value, ex=0):
"""функция конвертирует python-объект в Json и сохранит"""
r = self.get(name)
if r is None:
return r
return ujson.loads(r)
def jget(self, name):
"""функция возвращает Json и конвертирует в python-объект"""
return ujson.loads(self.get(name))
Класс Cache наследуется от StrictRedis. Мы добавляем 2 метода jset, jget для сохранения списков и словарей python в хранилище redis. Изначально он не работает с ними.
Теперь добавим класс, который будет создавать базы данных и выполнять функции CRUD.
# fonlinebot/database.py
#...
class Database:
""" Класс работы с базой данных """
def __init__(self, name):
self.name = name
self._conn = self.connection()
logging.info("Database connection established")
def create_db(self):
connection = sqlite3.connect(f"{self.name}.db")
logging.info("Database created")
cursor = connection.cursor()
cursor.execute('''CREATE TABLE users
(id INTEGER PRIMARY KEY,
leagues VARCHAR NOT NULL);''')
connection.commit()
cursor.close()
def connection(self):
db_path = os.path.join(os.getcwd(), f"{self.name}.db")
if not os.path.exists(db_path):
self.create_db()
return sqlite3.connect(f"{self.name}.db")
def _execute_query(self, query, select=False):
cursor = self._conn.cursor()
cursor.execute(query)
if select:
records = cursor.fetchone()
cursor.close()
return records
else:
self._conn.commit()
cursor.close()
async def insert_users(self, user_id: int, leagues: str):
insert_query = f"""INSERT INTO users (id, leagues)
VALUES ({user_id}, "{leagues}")"""
self._execute_query(insert_query)
logging.info(f"Leagues for user {user_id} added")
async def select_users(self, user_id: int):
select_query = f"""SELECT leagues from leagues
where id = {user_id}"""
record = self._execute_query(select_query, select=True)
return record
async def update_users(self, user_id: int, leagues: str):
update_query = f"""Update leagues
set leagues = "{leagues}" where id = {user_id}"""
self._execute_query(update_query)
logging.info(f"Leagues for user {user_id} updated")
async def delete_users(self, user_id: int):
delete_query = f"""DELETE FROM users WHERE id = {user_id}"""
self._execute_query(delete_query)
logging.info(f"User {user_id} deleted")
Sqlite подходит для тестовых проектов. В будущем потребуется переход на внешнюю базу данных и асинхронная работа. Что бы не переписывать всю логику работы с базой, я сразу добавил асинхронный синтаксис.
Файл базы данных будет создаваться один раз, автоматически. Теперь нужно создать экземпляры классов:
# fonlinebot/database.py
#...
# создание объектов cache и database
cache = Cache(
host=config.REDIS_HOST,
port=config.REDIS_PORT,
password=config.REDIS_PASSWORD
)
database = Database(config.BOT_DB_NAME)
Добавление текстовых сообщений
Для шаблонов сообщений создадим неизменяемый dataclass. Здесь будут все текстовые ответы. А dataclass удобно использовать при вызове аргументов.
# fonlinebot/app/dialogs.py
from dataclasses import dataclass
@dataclass(frozen=True)
class Messages:
test: str = "Привет {name}. Работаю..."
msg = Messages()
Создание бота
В файле «bot.py» создадим бота. Импортируем зависимости, создадим объект бота и первое сообщение.
# fonlinebot/app/bot.py
from aiogram import Bot, types
from aiogram.contrib.middlewares.logging import LoggingMiddleware
from aiogram.dispatcher import Dispatcher
from config import TOKEN
from app.dialogs import msg
from database import database as db
# стандартный код создания бота
bot = Bot(token=TOKEN)
dp = Dispatcher(bot)
dp.middleware.setup(LoggingMiddleware())
@dp.message_handler()
async def test_message(message: types.Message):
# имя юзера из настроек Телеграма
user_name = message.from_user.first_name
await message.answer(msg.test.format(name=user_name))
Функция test_message принимает любое сообщение и отвечает на него. Кроме этого, нужно закрывать соединение с базой данных перед завершением работы. Добавим в конец файла on_shutdown.
# fonlinebot/app/bot.py
# ...
async def on_shutdown(dp):
logging.warning('Shutting down..')
# закрытие соединения с БД
db._conn.close()
logging.warning("DB Connection closed")
Первый запуск бота
Для запуска используем файл «main.py». Импортируем бота и настроим пулинг:
# fonlinebot/main.py
from aiogram import executor
from app import bot
executor.start_polling(bot.dp,
skip_updates=True,
on_shutdown=bot.on_shutdown)
Теперь запустим проект. Если вы в Pycharm, откройте вкладку «Terminal» и введите python main.py. Что бы запустить бота без Pycharm:
- перейдите в папку проекта,
- активируйте виртуальное окружение,
- запустите скрипт (
python main.py).
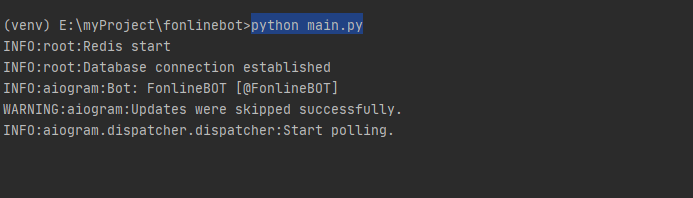
Теперь откроем телеграм и проверим.
Отлично, работает! Теперь самое время написать несколько базовых тестов, что бы избежать проблем в будущем.
Тестирование бота
В процессе написания проекта код будем изменяться. Что бы избежать появления новых ошибок после размещения на сервере, нужно сразу написать несколько тестов.
Добавьте модуль «test.py» в папку fonlinebot. На этом этапе достаточно 4 теста, вы можете добавить свои.
# fonlinebot/test.py
import unittest
import aiohttp
from unittest import IsolatedAsyncioTestCase
from database import cache, database
from app import bot
class TestDatabase(IsolatedAsyncioTestCase):
async def test_crud(self):
await database.insert_users(1111, "1 2 3")
self.assertEqual(await database.select_users(1111), ('1 2 3',))
await database.delete_users(1111)
self.assertEqual(await database.select_users(1111), None)
class TestCache(unittest.TestCase):
def test_connection(self):
self.assertTrue(cache.ping())
def test_response_type(self):
cache.setex("test_type", 10, "Hello")
response = cache.get("test_type")
self.assertEqual(type(response), str)
class TestBot(IsolatedAsyncioTestCase):
async def test_bot_auth(self):
bot.bot._session = aiohttp.ClientSession()
bot_info = await bot.bot.get_me()
await bot.bot._session.close()
self.assertEqual(bot_info["username"], "FonlineBOT")
if __name__ == '__main__':
unittest.main()
Мы проверим CRUD функции базы данных, запишем тестовые данные и удалим. Проверим соединение с redis и ботом.
Запуск теста такой же как и бота, изменяется только имя файла python main.py.

На скриншоте видно уведомление об ошибке после завершения тестирования. Это известная проблема aiohttp на windows, можно игнорировать.
Ошибки, которые можно встретить
aiogram.utils.exceptions.Unauthorized: Unauthorized— неверный токен бота. Токен нужно сохранить как строку, его структура «цифры:буквы-и-цифры», проверьте.redis.exceptions.ConnectionError: Error 10061 connecting to ...— redis-server не запущен.sqlite3.IntegrityError: UNIQUE constraint failed: ...— вы пытаетесь добавить значение в базу данных, которое уже существует.
На этом подготовка проекта окончена. Переходите ко второй части: Написание ядра бота.
]]>Подготовка базы данных
Перед выполнением следующей программы убедитесь, что у вас есть следующее:
- Имя пользователя и пароль для подключения к базе данных.
- Название хранимой процедуры или функции, которые нужно выполнить.
Для этого примера была создана функция get_production_deployment, которая возвращает список записей о сотрудниках, участвовавших в написании кода.
CREATE OR REPLACE FUNCTION filter_by_price(max_price integer)
RETURNS TABLE(id INT, model TEXT, price REAL) AS $$
BEGIN
RETURN QUERY
SELECT * FROM mobile where mobile.price <= max_price;
END;
$$ LANGUAGE plpgsql;Теперь посмотрим, как это выполнить.
import psycopg2
from psycopg2 import Error
def create_func(query):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
cursor.execute(query)
connection.commit()
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
postgresql_func = """
CREATE OR REPLACE FUNCTION filter_by_price(max_price integer)
RETURNS TABLE(id INT, model TEXT, price REAL) AS $$
BEGIN
RETURN QUERY
SELECT * FROM mobile where mobile.price <= max_price;
END;
$$ LANGUAGE plpgsql;
"""
create_func(postgresql_func)
Этот код добавит функцию в базу данных.
Детали вызова функции и хранимой процедуры PostgreSQL
Используем модуль psycopg2 для вызова функции PostgreSQL в Python. Дальше требуется выполнить следующие шаги:
- Метод
connect()вернет новый объект соединения. С его помощью и можно общаться с базой. - Создать объект
Cursorс помощью соединения. Именно он позволит выполнять запросы к базе данных. - Выполнить функцию или хранимую процедуру с помощью метода
cursor.callproc(). На этом этапе нужно знать ее название, а также параметры IN и OUT. Синтаксис метода следующий.cursor.callproc('filter_by_price',[IN and OUT parameters,])
Параметры следует разделить запятыми. - Этот метод возвращает либо строки базы данных, либо количество измененных строк. Все зависит от назначения самой функции.
Пример выполнения функции и хранимой процедуры
Посмотрим на демо. Процедура filter_by_price уже создана. В качестве параметра IN она принимает идентификатор приложения, а возвращает ID, модель и цену телефона.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# хранимая процедура
cursor.callproc('filter_by_price',[999,])
print("Записи с ценой меньше или равной 999")
result = cursor.fetchall()
for row in result:
print("Id = ", row[0], )
print("Model = ", row[1])
print("Price = ", row[2])
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
После предыдущего урока у меня осталось всего 2 записи, вывод вернул одну. Вторая с ценой 1000:
Записи с ценой меньше или равной 999
Id = 2
Model = Google Pixel 2
Price = 700.0
Соединение с PostgreSQL закрытоПосле этого обрабатываем результаты с помощью fetchone. Также можно использовать методы fetchall, fetchmany() в зависимости от того, что должна вернуть функция.
Также cursor.callproc() внутри вызывает метод execute() для вызова процедуры. Так что ничего не мешает использовать его явно:
cursor.execute("SELECT * FROM filter_by_price({price}); ".format(price=1000))Работать с датой и временем с помощью встроенного модуля datetime в большом проекте — непростая задача. Учитывая количество изменений, которые требуется применить, при получении «сырых» данных.
Для этих целей был создан модуль dateutil. Он предоставляет расширения для методов, уже имеющихся в datetime.
Установка модуля dateutil в Python
Прежде чем начинать работать с модулем dateutil нужно его установить с помощью следующей строки:
pip install python-dateutilВ этом примере используется пакетный менеджер pip, но ничего не мешает использовать Anaconda.
Работа с модулем
После установки можно начинать работать с самим модулем.
Dateutil разбит на несколько подклассов:
- easter,
- parser,
- relativedelta,
- rrule,
- tz
- и некоторые другие.
Их не так много, но в этом материале разберем лишь некоторые из них.
Импорт нужных методов
После установки модуля нужно выбрать требуемые методы. В верхней части кода нужные элементы сперва необходимо импортировать.
# нужно импортировать модуль datetime
from datetime import datetime, date
from dateutil.relativedelta import relativedelta, FR, TU
from dateutil.easter import easter
from dateutil.parser import parse
from dateutil import rrule
Это позволит использовать их для запуска примеров.
Datetime и relativedata
Итак, dateutil зависит от модуля datetime. Он использует его объекты.
Подкласс relativedelta расширяет возможности модуля datetime, предоставляя функции для работы с датами и временем относительно полученных данных.
Это значит, что вы можете добавлять дни, месяца и года к текущему объекту datetime. Также есть возможность работать с интервалами.
# Создание нескольких объектов datetime для работы
dt_now = datetime.now()
print("Дата и время прямо сейчас:", dt_now)
dt_today = date.today()
print("Дата сегодня:", dt_today)
Дата и время прямо сейчас: 2021-02-06 12:06:58.192574
Дата сегодня: 2021-02-06Попробуем поработать с полученной информацией с помощью относительных дат.
# Следующий месяц
print(dt_now + relativedelta(months=+1))
# Следующий месяц, плюс одна неделя
print(dt_now + relativedelta(months=+1, weeks=+1))
# Следующий месяц, плюс одна неделя, в 17:00.
print(dt_now + relativedelta(months=+1, weeks=+1, hour=17))
# Следующая пятница
print(dt_today + relativedelta(weekday=4))
2021-03-06 12:11:53.648565
2021-03-13 12:11:53.648565
2021-03-13 17:11:53.648565
2021-02-12С помощью базовых операций можно получить самую разную информацию.
# Узнаем последний вторник месяца
print(dt_today + relativedelta(day=31, weekday=TU(-1)))
# Мы также можем напрямую работать с объектами datetime
# Пример: Определение возраста.
birthday = datetime(1965, 12, 2, 12, 46)
print("Возраст:", relativedelta(dt_now, birthday).years)
Например, в примере выше удалось получить years объекта relativedelta.
2021-02-23
Возраст: 55К тому же с полученным объектом можно проводить самые разные манипуляции.
Datetime и easter
Подкласс easter используется для вычисления даты и времени с учетом разных календарей.
Этот подкласс довольно компактный и включает всего один аргумент с тремя вариантами:
- Юлианский календарь
EASTER_JULIAN=1. - Григорианский календарь
EASTER_ORTHODOX=2. - Западный календарь
EASTER_WESTERN=3.
Вот как это будет выглядеть в коде:
print("Юлианский календарь:", easter(2021, 1))
print("Григорианский календарь:", easter(2021, 2))
print("Западный календарь:", easter(2021, 3))
Юлианский календарь: 2021-04-19
Григорианский календарь: 2021-05-02
Западный календарь: 2021-04-04Datetime и parser
Подкласс parser добавляет продвинутый парсер даты и времени, с помощью которого можно парсить разные форматы даты и времени.
print(parse("Thu Sep 25 10:36:28 BRST 2003"))
# Мы также можем игнорировать часовой пояс
print(parse("Thu Sep 25 10:36:28 BRST 2003", ignoretz=True))
# Мы можем не указывать часовой пояс или год.
print(parse("Thu Sep 25 10:36:28"))
# Мы можем подставить переменные
default = datetime(2020, 12, 25)
print(parse("10:36", default=default))
Его можно использовать с разными явными аргументами, например, часовыми поясами. А с помощью переменных разные элементы можно удалить из финального результата.
2003-09-25 10:36:28
2003-09-25 10:36:28
2021-09-25 10:36:28
2020-12-25 10:36:00Datetime и rrule
Подкласс rrule использует пользовательский ввод для предоставлении информации о повторяемости объекта datetime.
# Вывод 5 дней от даты старта
print(list(rrule.rrule(rrule.DAILY, count=5, dtstart=parse("20201202T090000"))))
# Вывод 3 дней от даты старта с интервалом 10
print(list(rrule.rrule(rrule.DAILY, interval=10, count=3, dtstart=parse("20201202T090000"))))
# Вывод 3 дней с интервалом неделя
print(list(rrule.rrule(rrule.WEEKLY, count=3, dtstart=parse("20201202T090000"))))
# Вывод 3 дней с интервалом месяц
print(list(rrule.rrule(rrule.MONTHLY, count=3, dtstart=parse("20201202T090000"))))
# Вывод 3 дней с интервалом год
print(list(rrule.rrule(rrule.YEARLY, count=3, dtstart=parse("20201202T090000"))))
Важная особенность модуля dateuitl — возможность работать с запланированными задачами и функциями календаря с помощью этого подкласса.
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2020, 12, 3, 9, 0), datetime.datetime(2020, 12, 4, 9, 0), datetime.datetime(2020, 12, 5, 9, 0), datetime.datetime(2020, 12, 6, 9, 0)]
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2020, 12, 12, 9, 0), datetime.datetime(2020, 12, 22, 9, 0)]
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2020, 12, 9, 9, 0), datetime.datetime(2020, 12, 16, 9, 0)]
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2021, 1, 2, 9, 0), datetime.datetime(2021, 2, 2, 9, 0)]
[datetime.datetime(2020, 12, 2, 9, 0), datetime.datetime(2021, 12, 2, 9, 0), datetime.datetime(2022, 12, 2, 9, 0)]Выводы
Теперь вы знаете, что модуль dateutil дает возможность расширить количество информации, получаемой от datetime, что позволяет удобнее с ней работать.
]]>Для создания программ используют языки программирования. Python — один из самых популярных сегодня, язык общего назначения, используемый в самых разных сценариях. Умение программировать с помощью Python — крайне полезный навык.
В этом руководстве рассмотрим рекомендации относительно того, как учить Python и на чем сделать акценты в процессе.
Зачем учить Python?
Python используется для самых разных сценариев — от создания веб-приложений до анализа данных и решения математических проблем. Его любят как опытные программисты, так и начинающие. И есть масса причин начать учить этот язык.
Зная Python, вы будете востребованным. Умение программировать поможет «оставаться на плаву» по мере того, как мир развивается. Одна только работа в сфере разработки программного обеспечения должна вырасти на 21% за следующие 10 лет.
Бюро статистики труда США оценивает этот показатель как «намного стремительнее среднего». Учитывая количество разработчиков, использующих Python, знание этого языка поможет заложить фундамент в этом направлении.
Python похож на английский. Многие разработчики отмечают, что Python легко учить, потому что он похож на английский. И это правда, ведь язык был спроектирован, чтобы быть лаконичным. Если вы только учитесь программировать, то Python — отличный выбор для старта.
Python широко используется. Такие организации, как Quora, YouTube, Dropbox и IBM всерьез полагаются на Python в своем бизнесе, потому что он гибкий, мощный и простой. Вы также можете использовать язык для решения сложных проблем.
За сколько можно выучить Python?
Скорость изучения Python зависит от вашего расписания и того, что вы понимаете под словом «учить».
Существует не так уж и много людей, о которых можно было бы сказать, что они знают Python всецело. Объем знаний сильно зависит от того, для чего вам нужны эти знания.
Если вы хотите стать специалистом по машинному обучению, то перед вами лежит довольно долгий путь. Но начнем с того, сколько займет знакомство с базовым пониманием языка.
В среднем изучение основ занимает 6-8 недель. Это позволит понимать большую часть строк, написанных с помощью этого языка. Если же у вас в планах data science или любая другая специализированная отрасль, то лучше сразу закладывать месяцы и даже годы.
Можно расписать план обучения приблизительно на 5-6 месяцев. Это подойдет в первую очередь тем, кто работает полный день, и может проводить у компьютера 2-3 часа. Сегодня вы учите что-то, а завтра — практикуетесь.
Однако важно практиковаться каждый день, чтобы быть уверенным в том, что вам удастся получить нужные знания за определенный промежуток времени. В любом случае этот режим легко подстраивать, пожертвовав, например, временем, которое вы тратите на просмотр сериалов.
Для чего нужен Python?
Python — это язык программирования общего назначения, что значит, что он используется в самых разных отраслях. Чаще всего его применяют:
- в веб-разработке,
- при анализе данных,
- в машинном обучении и нейросетях,
- для парсинга/сбора данных,
- в тестировании ПО,
- реже в других областях.
Для Python есть внушительный набор библиотек, которые расширяют язык. Это подразумевает наличие огромного числа сообществ, использующих Python для самых разных целей. matplotlib, например, нужна для data science, а Click — для написания скриптов.
За сколько можно выучить основы?
Изучение основ Python займет как минимум три месяца. При условии уделения минимум 10 часов обучения в неделю.
Но три — это не конкретное число. Если вы захотите погрузиться в какую либо из библиотек, то быстро обнаружите, что общее время увеличивается. Одну только matplotlib можно учить несколько недель, и это всего одна библиотека.
Чем больше времени вы посвящаете обучению, тем быстрее вы будете учиться. Базовые вещи можно разобрать и за несколько дней. Но если вы хотите писать сложные и длинные программы, то сразу ориентируетесь на три месяца.
Лучший способ изучить Python бесплатно
Итак, вы решили изучать Python. Теперь разберемся с тем, как сделать это быстро.
Учитывая количество разработчиков, использующих этот язык, недостатка в обучающих материалах нет. Однако ресурсы — это не главное. Вот что еще вам потребуется.
Шаг 1: определение мотивации
Прежде чем начать изучать программирование на Python, определитесь с мотивацией. Это может показаться не столь важным, однако стоит понимать, с какой целью вы учитесь.
Пусть Python и является относительно легким языком, сам процесс обучения требует времени и энергии. И наличие мотивации поможет оставаться сфокусированным.
Вы хотите начать карьеру разработчика? Или стремитесь разбираться в современных технологиях? Это — хорошие причины, чтобы начать.
Шаг 2: изучите основы Python
Вы можете быть искушены идеей сразу же приступить к разработке сайта, но такой подход не работает. Вы будите тратить часы на устранение ошибок, возможно, разочаруетесь в программировании. Решите — «это не мое».
Для начала лучше изучить основы. А время для собственных проектов всегда будет.
Давайте рассмотрим план изучения Python с нуля:
- Синтаксис:
- Как создаются программы Python.
- Переменные.
- Типы данных.
- Вывод инструкций в консоль.
- Арифметика (базовая математика).
- Комментарии.
- Условные конструкции.
Они помогают управлять потоком программы. Именно с их помощью можно сказать программе, чтобы она выполнила ту или иную задачу при соответствии условию. Например, выполнить какое-то действие после авторизации пользователя. - Циклы.
Разрабатывая программу, вам может потребоваться выполнить одну и ту же логику несколько раз. Например, при создании викторины вы хотите дать пользователю 5 попыток. Цикл — это структура Python, позволяющая запустить определенный код указанное количество раз. - Функции.
Важная структура Python. С их помощью можно избежать повторений. Используя функции, программисты могут создавать код, который проще переиспользовать.
Например, можно создать функцию, которая складывает два числа. И в следующий раз при необходимости выполнить операцию сложения достаточно будет просто ее вызвать.
Вот что нужно знать касательно функций в Python:- Как они работают.
- Формальные и реальные параметры.
- Системные и пользовательские функции.
- Импорт библиотек.
- Основы объектно-ориентированного программирования.
- Списки и словари. После изучения функций можно изучить типы данных для последовательностей.
1. Списки хранят коллекции похожих данных в одной переменной. Например, список в Python может хранить перечень обуви, продаваемой в определенном магазине. В другом могут быть компании, доставляющие продукты в рестораны. С помощью списков можно хранить похожую информацию в одном месте. Это же позволяет потом проще управлять такими данными.
2. Словари похожи на списки. С их помощью данные можно хранить в формате ключ-значение. Ключ выступает в качестве ярлыка для хранящегося значения.
Вот что нужно знать о списках:- Основы списков.
- Как они индексируются.
- Основы словарей.
- Сравнение списков и словарей.
- Структуры данных в Python.
- Как получить часть списка.
- Как перебрать элементы списка.
- Объекты и классы.
- Python — это объектно-ориентированный язык. Классы — это «чертежи» объектов. Они определяют, как именно объекты будут структурированы, и что они смогут хранить. Разработчики используют классы, чтобы избежать повторений и увеличить эффективность кода.
- Объекты — это экземпляры класса. Например, класс может определять структуру игрока. Объектом же будет выступать сам игрок. Этот объект будет хранить имя игрока и дату, когда тот зарегистрировался для участия.
- Работа с файлами.
Файлы повсеместно используются в Python-программах для хранения и получения информации. - Другие подтемы.
Это лишь некоторые из тем Python, но, освоив их, вы уже будете развиваться как профессиональный разработчик. Дальше в процессе вам будут встречаться все более сложные и продвинутые темы.
Онлайн-курсы по Python
Бесплатный доступ к курсам Skillbox
- Основы Python,
- Веб-верстка для начинающих,
- Разработчик игр на Unity с нуля,
- и еще более 30 курсов по IT-направлениям для каждого.
Онлайн-университет Skillbox открывает 7 дней бесплатного доступа к курсам и интенсивам. Я всегда рекомендую попробовать начать программировать бесплатно. Вы будите уверены, что это действительно вам нравится: получается, подходит язык и хочется писать код всю жизнь.
Udemy — глобальная платформа для обучения онлайн
- Полное руководство по Python 3: от новичка до специалиста.
- Data Science и Machine Learning на Python 3 с нуля.
- Разработка Telegram ботов на Python.
- Полный курс по веб разработке с нуля на Python + Django.
- Парсинг и анализ данных на Python: от азов до автоматизации.
Udemy — глобальная платформа для обучения и преподавания онлайн, где миллионы студентов получают доступ к необходимым знаниям, которые помогают им добиться успеха. Только по теме «python» доступно почти 2000 курсов для начинающих.
Сайты-справочники и ютуб
PythonRu.com
На нашем сайте более 300 статей и уроков по программированию на python. Вы можете узнать что-то конкретное или пройти серию уроков. Например:
- Уроки Python для начинающих.
- Стрелялка с Pygame.
- 19 уроков по Flask.
- Блог на Django — 35 уроков.
- Введение в библиотеку pandas.
- База данных SQLite в python.
Русскоязычные Youtube каналы
Ютуб один из лучших вариантов изучения программирования. Не спешите учить python «за час», лучше посмотрите эти каналы:
- Python программирование / Уроки для начинающих (3 млн просмотров),
- Язык программирования PYTHON для начинающих (1.2 млн просмотров),
- Базовый Python 3 (185 тыс. просмотров),
- Основы Python (105 тыс. просмотров).
Исключительно видео формат не все воспринимают. Если на ютубе не получилось, не опускайте руки, пробуйте текстовые материалы.
Python на Хабре
Множество статей «от разработчиков для разработчиков». Здесь вы найдете последние новости, обзоры и исследования которые касаются Python. Кроме этого, на Хабре есть несколько переводов курсов зарубежных авторов.
Книги по Python
Изучаем Python. Программирование игр, визуализация данных, веб-приложения
Эта книга посвящена основам Python: инструкциям if, кортежам и так далее. Из нее вы также узнаете о том, как использовать сторонние библиотеки.
Python. Книга рецептов
Эта книга содержит набор рецептов для Python-программиста. Из нее вы узнаете о том, как использовать язык в разных сценариях. Она также включает код, который поможет в изучении синтаксиса.
Автоматизация рутинных задач с помощью Python
Эта книга нужна тем, кто хочет расширить свои знания Python и уже знаком с основами. С ее помощью вы научитесь писать простые, но мощные скрипты, которые автоматизируют скучную рутину.
После изучения основных тем можно переходить к изучению машинного обучения и data science.
Большая часть современных руководств посвящена Python 3, потому что Python 2 уже отжил свое.
Шаг 3: создание проектов
Лучший способ научиться программировать — разрабатывать собственные проекты. Это помогает применять полученные знания и учиться, пробуя новое.
Чем больше вы пишите на Python, тем больше учитесь. Вы ставите цель, следуете ей и одновременно получаете новые навыки.
И даже это еще не все. Это также помогает развивать свое портфолио. А с его помощью вы сможете предлагать свои услуги работодателям.
Но прежде чем вы начнете создавать что-то масштабное, попробуйте с чего-нибудь попроще. Главное — создавать что-то, что развивает ваши способности.
Советы по созданию первых проектов
Единственное, что ограничивает вас в отношении собственного проекта — это воображение. Вы можете создать что угодно: сайт, чтобы рассказывать о любимых фильмах, алгоритм для предсказывания цены на авокадо и что-либо еще. Если же придумать что-нибудь не получается, то вот некоторые советы:
- Посмотрите, что создают другие разработчики.
- Поищите открытый исходный код, в развитии которого можно было бы поучаствовать. У GitHub даже есть руководство на эту тему.
- Займитесь волонтерством и предоставьте свои навыки местной некоммерческой организации.
- Добавьте новые функции в уже существующее приложение.
- Присоединитесь к сообществу разработчиков в slack или телеграме, чтобы знать, чем они занимаются.
Главное — начинать с малого. Например, вы можете создать трекер привычек. Вот еще несколько идей для проекта:
- Инструмент, предсказывающий стоимость акций.
- Сайт для показа рейтинга фильмов.
- Приложение, чтобы делиться любимыми книгами с друзьями.
- Телеграм бота для списка дел.
- Приложение для отслеживания привычек.
- Игру гонки.
- Консольный покер или блэкджек.
- Сайт для сокращения ссылок.
- Инструмент, который агрегирует интересующий вас контент.
Шаг 4: Развивайтесь для создания более сложных проектов
Создав несколько простых проектов, вы готовы переходить к боле сложным. Это может быть в том числе функциональное расширение уже существующих.
Предположим, ваш первый проект был сайтом со списком фильмов. Следующим шагом может быть добавление возможности пользователям создавать собственные списки.
Вот какие вопросы стоит задавать себе, рассматривая идеи для проектов:
- Можно ли улучшить что-то в уже существующей программе?
- Добавить в проект новые функции?
- Добавить платежную систему, чтобы позволить пользователям покупать доступ?
- Использовать внешние данные для улучшения программы?
- Задействовать сторонние библиотеки?
Вам всегда должно быть интересно работать над проектами. Если столкнулись с препятствием, просите о помощи. Для улучшения навыков нужно просто практиковаться.
Выводы
В начале своего пути изучите основы языка. Познакомьтесь с синтаксисом, условными конструкциями, циклами и списками.
После этого переходите к созданию простых проектов. Это поможет развивать навыки на практике и добавлять результаты в свое портфолио.
Изучение Python требует настойчивости, усилий и времени. Однако этот навык вы сможете использовать в самых разных сферах своей жизни.
]]>В итоге разберем, как использовать cursor.executemany() для выполнения вставки, обновления или удаления нескольких строк в один запрос.
Операция Insert
В этом разделе рассмотрим, как выполнять команду Insert для вставки одной или нескольких записей в таблицу PostgreSQL из Python с помощью Psycopg2.
Для выполнения запроса нужно сделать следующее:
- Установить psycopg2 с помощью pip.
- Установить соединение с базой данных из Python.
- Создать запрос Insert. Для этого требуется знать название таблицы и ее колонок.
- Выполнить запрос с помощью
cursor.execute(). В ответ вы получите количество затронутых строк. - После выполнения запроса нужно закоммитить изменения в базу данных.
- Закрыть объект
cursorи соединение с базой данных. - Также важно перехватить любые исключения, которые могут возникнуть в процессе.
- Наконец, можно проверить результаты, запросив данные из таблицы.
Теперь посмотрим реальный пример.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgres_insert_query = """ INSERT INTO mobile (ID, MODEL, PRICE)
VALUES (%s,%s,%s)"""
record_to_insert = (5, 'One Plus 6', 950)
cursor.execute(postgres_insert_query, record_to_insert)
connection.commit()
count = cursor.rowcount
print (count, "Запись успешно добавлена в таблицу mobile")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
1 Запись успешно добавлена в таблицу mobile
Соединение с PostgreSQL закрыто- В этом примере использовался запрос с параметрами для передачи значений во время работы программы. А в конце изменения сохранились с помощью
cursor.commit. - С помощью запроса с параметрами можно передавать переменные python в качестве параметров на месте
%s.
Операция Update
В этом разделе вы узнаете, как обновлять значение в одной или нескольких колонках для одной или нескольких строк таблицы. Для этого нужно изменить запрос к базе данных.
# Задать новое значение price в строке с id для таблицы mobile
Update mobile set price = %s where id = %sПосмотрим на примере обновления одной строки таблицы:
import psycopg2
from psycopg2 import Error
def update_table(mobile_id, price):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
print("Таблица до обновления записи")
sql_select_query = """select * from mobile where id = %s"""
cursor.execute(sql_select_query, (mobile_id,))
record = cursor.fetchone()
print(record)
# Обновление отдельной записи
sql_update_query = """Update mobile set price = %s where id = %s"""
cursor.execute(sql_update_query, (price, mobile_id))
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно обновлена")
print("Таблица после обновления записи")
sql_select_query = """select * from mobile where id = %s"""
cursor.execute(sql_select_query, (mobile_id,))
record = cursor.fetchone()
print(record)
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
update_table(3, 970)
Убедимся, что обновление сработало. Вывод:
Таблица до обновления записи
(3, 'Samsung Galaxy S21', 900.0)
1 Запись успешно обновлена
Таблица после обновления записи
(3, 'Samsung Galaxy S21', 970.0)
Соединение с PostgreSQL закрытоУдаление строк и колонок
В этом разделе рассмотрим, как выполнять операцию удаления данных из таблицы с помощью программы на Python и Psycopg2.
# Удалить из таблицы ... в строке с id ...
Delete from mobile where id = %sМожно сразу перейти к примеру. Он выглядит следующим образом:
import psycopg2
from psycopg2 import Error
def delete_data(mobile_id):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Удаление записи
sql_delete_query = """Delete from mobile where id = %s"""
cursor.execute(sql_delete_query, (mobile_id,))
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно удалена")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
delete_data(4)
delete_data(5)
Убедимся, что запись исчезла из таблицы.
1 Запись успешно удалена
Соединение с PostgreSQL закрыто
1 Запись успешно удалена
Соединение с PostgreSQL закрытоCursor.executemany() запросов нескольких строк
Метод cursor.executemany() делает запрос в базу данных со всеми параметрами.
Очень часто нужно выполнить один и тот же запрос с разными данными. Например, обновить информацию о посещаемости студентов. Скорее всего, данные будут разные, но SQL останется неизменным.
Используйте cursor.executemany() для вставки, обновления и удаления нескольких строк в один запрос.
Синтаксис executemany():
executemany(query, vars_list)- В этом случае запросом может быть любая DML-операция (вставка, обновление, удаление).
vars_list— это всего лишь список кортежей, которые передаются в запрос.- Каждый кортеж содержит одну строку для вставки или удаления.
Теперь посмотрим, как использовать этот метод.
Вставка нескольких строк в таблицу PostgreSQL
Можно выполнить вставку нескольких строк с помощью SQL-запроса. Для этого используется запрос с параметрами и метод executemany().
import psycopg2
from psycopg2 import Error
def bulk_insert(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
sql_insert_query = """ INSERT INTO mobile (id, model, price)
VALUES (%s,%s,%s) """
# executemany() для вставки нескольких строк
result = cursor.executemany(sql_insert_query, records)
connection.commit()
print(cursor.rowcount, "Запись(и) успешно вставлена(ы) в таблицу mobile")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
records_to_insert = [ (4,'LG', 800) , (5,'One Plus 6', 950)]
bulk_insert(records_to_insert)
Проверим результат, вернув данные из таблицы.
2 Запись(и) успешно вставлена(ы) в таблицу mobile
Соединение с PostgreSQL закрытоПримечание: для этого запроса был создан список записей, включающий два кортежа. Также использовались заменители. Они позволяют передать значения в запрос уже во время работы программы.
Обновление нескольких строк в одном запросе
Чаще всего требуется выполнить один и тот же запрос, но с разными данными. Например, обновить зарплату сотрудников. Сумма будет отличаться, но не запрос.
Обновить несколько колонок таблицы можно с помощью cursor.executemany() и запроса с параметрами (%). Посмотрим на примере.
import psycopg2
from psycopg2 import Error
def update_in_bulk(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Обновить несколько записей
sql_update_query = """Update mobile set price = %s where id = %s"""
cursor.executemany(sql_update_query, records)
connection.commit()
row_count = cursor.rowcount
print(row_count, "Записи обновлены")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
update_in_bulk([(750, 4), (950, 5)])
Вывод:
2 Записи обновлены
Соединение с PostgreSQL закрытоПроверим результат.

Используйте cursor.rowcount, чтобы получить общее количество строк, измененных методом executemany().
Удаление нескольких строк из таблицы
В этом примере используем запрос Delete с заменителями, которые подставляют ID записей для удаления. Также есть список записей для удаления. В списке есть кортежи для каждой строки. В примере их два, что значит, что удалены будут две строки.
import psycopg2
from psycopg2 import Error
def delete_in_bulk(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
delete_query = """Delete from mobile where id = %s"""
cursor.executemany(delete_query, records)
connection.commit()
row_count = cursor.rowcount
print(row_count, "Записи удалены")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
delete_in_bulk([(5,), (4,), (3,)])
Убедимся, что запрос был выполнен успешно.
3 Записи удалены
Соединение с PostgreSQL закрытоФункция input() возвращает все в виде строки, поэтому нужно выполнить явную конвертацию, чтобы получить целое число. Для этого пригодится функция int().
# вывод суммы двух чисел, введенных пользователем
num_1 = int(input("Введите первое число: "))
num_2 = int(input("Введите второе число: "))
print("Тип num_1:", type(num_1))
print("Тип num_2:", type(num_2))
result = num_1 + num_2
print("Сумма введенных чисел:", result)
int(string) конвертирует переданную строку в целое число.
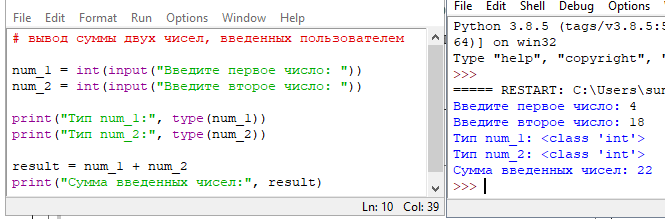
Ввода числа float
По аналогии можно использовать функцию float().
float_1 = float(input("Введите число: "))
print("Тип float_1:", type(float_1))
result = float_1 ** 2
print("Число в квадрате:", result)
Вывод примера:
Введите число: 1.8
Тип float_1: <class 'float'>
Число в квадрате: 3.24Ввод чисел в строку через пробел
Но что произойдет, если вы не знаете количество элементов ввода?
Предположим, что от пользователя нужно получить список чисел и вернуть их сумму. При этом вы не знаете количество элементов в этом списке. Как же запросить ввод для него?
Для этого можно использовать split и функции map. Метод split() делит введенную строку на список подстрок. После этого map() выполняет функцию int() для каждого элемента списка.
entered_list = input("Введите список чисел, разделенных пробелом: ").split()
print("Введенный список:", entered_list)
num_list = list(map(int, entered_list))
print("Список чисел: ", num_list)
print("Сумма списка:", sum(num_list))
Введите список чисел, разделенных пробелом: 1 34 4 6548
Введенный список: ['1', '34', '4', '6548']
Список чисел: [1, 34, 4, 6548]
Сумма списка: 6587В коде выше:
input()возвращает список, содержащий числа, разделенные запятыми.split()возвращает список строк, разделенных пробелами.map()выполняет операциюint()для всех элементов списка и возвращает объектmap.list()конвертирует объектmapснова в список.
Есть альтернативный способ получить список:
entered_list = input("Введите список чисел, разделенных пробелом: ").split()
num_list = [int(i) for i in entered_list]
print("Список чисел: ", num_list)
Обработка ошибок при пользовательском вводе
Часто при конвертации типов возникает исключение ValueError.
Это происходит в тех случаях, когда введенные пользователем данные не могут быть конвертированы в конкретный тип.
Например, пользователь вводит случайную строку в качестве возраста.
num = int(input("Введите возраст: "))
Функция int() ожидает целочисленное значение, обернутое в строку. Любое другое значение приводит к ошибке. Вот что будет, если, попробовать ввести «Двадцать»:
Введите возраст: Двадцать
---------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-10-1fa1cb611d10> in <module>
----> 1 num_1 = int(input('Введите возраст: '))
ValueError: invalid literal for int() with base 10: 'Двадцать'Чтобы убедиться, что пользователь вводит только подходящую информацию, нужно обработать массу подобных ошибок. Для этого будем использовать перехват исключений.
try:
num = int(input("Введите число: "))
print("Все верно. Число:", num)
except ValueError:
print("Это не число.")
Посмотрим, как ввод «Двадцать» сработает теперь:
Введите число: Двадцать
Это не число.В этом примере если пользователь вводит нечисловое значение, то возникает исключение. Однако оно перехватывается инструкцией except, которая в ответ выводит: «Это не число». Благодаря использованию конструкции try-except программа не прекратит работать при некорректном вводе.
- Рекурсивную функцию поиска факториала.
- Как рекурсивные функции работают в коде.
- Действительно ли рекурсивные функции выполняют свои задачи лучше итеративных?
Рекурсивные функции
Рекурсивная функция — это та, которая вызывает сама себя.
В качестве простейшего примера рассмотрите следующий код:
def factorial_recursive(n):
if n == 1:
return n
else:
return n*factorial_recursive(n-1)
Вызывая рекурсивную функцию здесь и передавая ей целое число, вы получаете факториал этого числа (n!).
Вкратце о факториалах
Факториал числа — это число, умноженное на каждое предыдущее число вплоть до 1.
Например, факториал числа 7:
7! = 7*6*5*4*3*2*1 = 5040
Вывести факториал числа можно с помощью функции:
num = 3
print(f"Факториал {num} это {factorial_recursive(num)}")
Эта функция выведет: «Факториал 3 это 6». Еще раз рассмотрим эту рекурсивную функцию:
def factorial_recursive(n):
...По аналогии с обычной функцией имя рекурсивной указывается после def, а в скобках обозначается параметр n:
def factorial_recursive(n):
if n == 1:
return n
else:
return n*factorial_recursive(n-1)Благодаря условной конструкции переменная n вернется только в том случае, если ее значение будет равно 1. Это еще называют условием завершения. Рекурсия останавливается в момент удовлетворения условиям.
def factorial_recursive(n):
if n == 1:
return n
else:
return n*factorial_recursive(n-1)В коде выше выделен фрагмент самой рекурсии. В блоке else условной конструкции возвращается произведение n и значения этой же функции с параметром n-1.
Это и есть рекурсия. В нашем примере это так сработало:
3 * (3-1) * ((3-1)-1) # так как 3-1-1 равно 1, рекурсия остановиласьДетали работы рекурсивной функции
Чтобы еще лучше понять, как это работает, разобьем на этапы процесс выполнения функции с параметром 3.
Для этого ниже представим каждый экземпляр с реальными числами. Это поможет «отследить», что происходит при вызове одной функции со значением 3 в качестве аргумента:
# Первый вызов
factorial_recursive(3):
if 3 == 1:
return 3
else:
return 3*factorial_recursive(3-1)
# Второй вызов
factorial_recursive(2):
if 2 == 1:
return 2
else:
return 2*factorial_recursive(2-1)
# Третий вызов
factorial_recursive(1):
if 1 == 1:
return 1
else:
return 1*factorial_recursive(1-1)
Рекурсивная функция не знает ответа для выражения 3*factorial_recursive(3–1), поэтому она добавляет в стек еще один вызов.
Как работает рекурсия
/\ factorial_recursive(1) - последний вызов || factorial_recursive(2) - второй вызов || factorial_recursive(3) - первый вызов
Выше показывается, как генерируется стек. Это происходит благодаря процессу LIFO (last in, first out, «последним пришел — первым ушел»). Как вы помните, первые вызовы функции не знают ответа, поэтому они добавляются в стек.
Но как только в стек добавляется вызов factorial_recursive(1), для которого ответ имеется, стек начинает «разворачиваться» в обратном порядке, выполняя все вычисления с реальными значениями. В процессе каждый из слоев выпадает в процессе.
- factorial_recursive(1) завершается, отправляет 1 в
- factorial_recursive(2) и выпадает из стека.
- factorial_recursive(2) завершается, отправляет 2*1 в
- factorial_recursive(3) и выпадает из стека. Наконец, инструкция else здесь завершается, возвращается 3 * 2 = 6, и из стека выпадает последний слой.
Рекурсия в Python имеет ограничение в 3000 слоев.
>>> import sys
>>> sys.getrecursionlimit()
3000
Рекурсивно или итеративно?
Каковы же преимущества рекурсивных функций? Можно ли с помощью итеративных получить тот же результат? Когда лучше использовать одни, а когда — другие?
Важно учитывать временную и пространственную сложности. Рекурсивные функции занимают больше места в памяти по сравнению с итеративными из-за постоянного добавления новых слоев в стек в памяти. Однако их производительность куда выше.
Рекурсия может быть медленной, если реализована неправильно
Тем не менее рекурсия может быть медленной, если ее неправильно реализовать. Из-за этого вычисления будут происходить чаще, чем требуется.
Написание итеративных функций зачастую требуется большего количества кода. Например, дальше пример функции для вычисления факториала, но с итеративным подходом. Выглядит не так изящно, не правда ли?
def factorial_iterative(num):
factorial = 1
if num < 0:
print("Факториал не вычисляется для отрицательных чисел")
else:
for i in range (1, num + 1):
factorial = factorial*i
print(f"Факториал {num} это {factorial}")
Цели:
- Получить все строки из базы данных PostgreSQL с помощью
fetchall()и ограниченное количество записей, используяfetchmany()иfetchone(). - Использовать переменные Python в операторе
whereдля передачи динамических значений.
Подготовка
Перед началом работы нужно убедиться, что у вас есть следующее:
- Имя пользователя и пароль для подключения к PostgreSQL
- Название базы данных, из которой требуется получить данные
В этом материале воспользуемся таблицей «mobile», которая была создана в первом руководстве по работе с PostgreSQL в Python. Если таблицы нет, то ее нужно создать.
Шаги для выполнения запроса SELECT из Python-программы
- Установить psycopg2 с помощью pip.
- Создать соединение с базой данных PostgreSQL.
- Создать инструкцию с запросом SELECT для получения данных из таблицы PostgreSQL.
- Выполнить запрос с помощью
cursor.execute()и получить результат. - Выполнить итерацию по объекту с помощью цикла и получить значения всех полей (колонок) базы данных для каждой строки.
- Закрыть объекты cursor и connection.
- Перехватить любые SQL-исключения, которые могут произойти в процессе.
Запить тестовых данных
Запишем несколько строк в базу данных, что бы потренироваться их получать.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Выполнение SQL-запроса для вставки данных в таблицу
insert_query = """ INSERT INTO mobile (ID, MODEL, PRICE) VALUES
(1, 'IPhone 12', 1000),
(2, 'Google Pixel 2', 700),
(3, 'Samsung Galaxy S21', 900),
(4, 'Nokia', 800)"""
cursor.execute(insert_query)
connection.commit()
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Пример получения данных с помощью fetchall()
В этом примере рассмотрим, как получить все строки из таблицы:
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgreSQL_select_Query = "select * from mobile"
cursor.execute(postgreSQL_select_Query)
print("Выбор строк из таблицы mobile с помощью cursor.fetchall")
mobile_records = cursor.fetchall()
print("Вывод каждой строки и ее столбцов")
for row in mobile_records:
print("Id =", row[0], )
print("Модель =", row[1])
print("Цена =", row[2], "\n")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
Выбор строк из таблицы mobile с помощью cursor.fetchall
Вывод каждой строки и ее столбцов
Id = 1
Модель = IPhone 12
Цена = 1000.0
Id = 2
Модель = Google Pixel 2
Цена = 700.0
Id = 3
Модель = Samsung Galaxy S21
Цена = 900.0
Id = 4
Модель = Nokia
Цена = 800.0
Соединение с PostgreSQL закрытоПримечание: в этом примере использовалась команда
cursor.fetchall()для получения всех строк из базы данных.
Используйте cursor.execute() для выполнения запроса:
cursor.fetchall()— для всех строк.cursor.fetchone()— для одной.cursor.fetchmany(SIZE)— для определенного количества.
Передача переменных Python в качестве параметров запроса
В большинстве случаев требуется передавать переменные Python в запросы SQL для получения нужного результата. Например, приложение может передать ID пользователя для получения подробностей о нем из базы данных. Для этого требуется использовать запрос с параметрами.
Запрос с параметрами — это такой запрос, где применяются заполнители (%s) на месте параметров, а значения подставляются уже во время работы программы. Таким образом эти запросы компилируются всего один раз.
import psycopg2
from psycopg2 import Error
def get_mobile_details(mobile_id):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgresql_select_query = "select * from mobile where id = %s"
cursor.execute(postgresql_select_query, (mobile_id,))
mobile_records = cursor.fetchall()
for row in mobile_records:
print("Id =", row[0], )
print("Модель =", row[1])
print("Цена =", row[2])
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
get_mobile_details(2)
get_mobile_details(3)
Вывод:
Id = 2
Модель = Google Pixel 2
Цена = 700.0
Соединение с PostgreSQL закрыто
Id = 3
Модель = Samsung Galaxy S21
Цена = 900.0
Соединение с PostgreSQL закрытоПолучение определенного количества строк
Если таблица содержит тысячи строк, то получение всех из них может занять много времени. Но существует альтернатива в виде cursor.fetchmany().
Вот ее синтаксис:
cursor.fetchmany([size=cursor.arraysize])size— это количество строк, которые требуется получить.- этот метод делает запрос на определенное количество строк из результата запроса.
fetchmany()возвращает список кортежей, содержащих строки. fetchmany()возвращает пустой список, если строки не были найдены. Количество строк зависит от аргумента SIZE. ОшибкаProgrammingErrorвозникает в том случае, если предыдущий вызов execute() не дал никаких результатов.
fetchmany() вернет меньше строк, если в таблице их меньше, чем было указано в аргументе SIZE.
Пример получения ограниченного количества строк из таблицы PostgreSQL с помощью cursor.fetchmany():
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgresql_select_query = "select * from mobile"
cursor.execute(postgresql_select_query)
mobile_records = cursor.fetchmany(2)
print("Вывод двух строк")
for row in mobile_records:
print("Id =", row[0], )
print("Модель =", row[1])
print("Цена =", row[2], "\n")
mobile_records = cursor.fetchmany(2)
print("Вывод следующих двух строк")
for row in mobile_records:
print("Id =", row[0], )
print("Модель =", row[1])
print("Цена =", row[2], "\n")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
Вывод двух строк
Id = 1
Модель = IPhone 12
Цена = 1000.0
Id = 2
Модель = Google Pixel 2
Цена = 700.0
Вывод следующих двух строк
Id = 3
Модель = Samsung Galaxy S21
Цена = 900.0
Id = 4
Модель = Nokia
Цена = 800.0
Соединение с PostgreSQL закрытоИспользование cursor.fetchone
- Используйте
cursor.fetchone()для получения одной строки из таблицы PostgreSQL. - Также можно использовать этот же метод для получения следующей строки из результатов запроса.
- Он может вернуть и
none, если в результате не оказалось записей cursor.fetchall()иfetchmany()внутри также используют этот метод.
Пример получения одной строки из базы данных PostgreSQL:
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
postgresql_select_query = "select * from mobile"
cursor.execute(postgresql_select_query)
mobile_records_one = cursor.fetchone()
print ("Вывод первой записи", mobile_records_one)
mobile_records_two = cursor.fetchone()
print("Вывод второй записи", mobile_records_two)
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод первой записи (1, 'IPhone 12', 1000.0)
Вывод второй записи (2, 'Google Pixel 2', 700.0)
Соединение с PostgreSQL закрытоЧто такое статические файлы в Django?
Изображения, JS и CSS-файлы называются статическими файлами или ассетами проекта Django.
Код из урока: https://gitlab.com/PythonRu/django_static
1. Создадим папку для статических файлов
В папке проекта Django создайте новую папку «static». В примере выше она находится в директории «dstatic».
2. Укажите статический URL Django в настройках
Теперь убедитесь, что статические файлы Django django.contrib.staticfiles указаны в списке установленных приложений в settings.py.
# dstatic > dstatic > settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
Они должны быть там по умолчанию.
После этого пролистайте в нижнюю часть файла настроек и укажите статический URL, если такого еще нет. Вы также можете указать статическую папку, чтобы Django знал, где искать статические файлы.
# dstatic > dstatic > settings.py
STATIC_URL = '/static/'
STATICFILES_DIRS = [
os.path.join(BASE_DIR, "static"),
]
Не забудьте импортировать библиотеку os после добавления кода выше.
После завершения базовой настройки рассмотрим, как добавлять и показывать изображения в шаблонах, а также как подключить свои JavaScript и CSS файлы.
3. Создайте папку для изображений
Создайте папку в «static» специально для изображений. Назовите ее «img». Главное после этого правильно ссылаться на нее в шаблонах.
4. Загрузите статический файл в свой HTML-шаблон
Теперь в выбранном шаблоне (например, в «home.html») загрузите статический файл в верхней части страницы.
Важно добавить
{% load static %}до того, как добавлять изображение. В противном случае оно не будет загружено.
Использование тега static в шаблоне
После этого вы можете использовать тег «static» в шаблоне для работы с источником изображения.
dstatic > templates > home.html
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Home</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css" rel="stylesheet">
</head>
<body>
<div class="container">
<h1 class="text-center">Привет Django</h1>
<img class="w-50 mx-auto d-block" src="{% static 'img/example.png' %}" alt="photo">
</div>
</body>
</html>
Стоит отметить, что этот файл использует также Bootstrap CDN. Результат:

5. Создание папки и файла JavaScript
Если нужно добавить кастомные JS-файлы в проект, создайте папку «js» внутри «static».
Можно также использовать элемент <script> внутри шаблона, но создание отдельного JS-файла улучшит организацию проекта и поможет проще находить все скрипты в одном месте.
Создание файла script.js
В папке static > js создайте файл «script.js», в котором будут храниться все функции JavaScript.
$(window).scroll(function() {
if ($(document).scrollTop() > 600 && $("#myModal").attr("displayed") === "false") {
$('#myModal').modal('show');
$("#myModal").attr("displayed", "true");
}
});
6. Загрузите скрипт в шаблон
Теперь для подключения JS-файла к проекту добавьте файл в «header.html». Файл должен вызываться так же, как и в случае с изображениями.
Не забудьте и о {% load static %} в верхней части страницы для корректной работы тегов.
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Home</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css" rel="stylesheet">
<script src="{% static 'js/script.js' %}"></script>
</head>
<body>
<div class="container">
<h1 class="text-center">Привет Django</h1>
<img class="w-50 mx-auto d-block" src="{% static 'img/example.png' %}" alt="photo">
</div>
</body>
</html>
7. Создание папки и файла для CSS
Также можно подключить CSS-файлы. Для этого создайте папку «css» внутри «static». Вы также можете использовать элемент <style> и вложить все стили туда.
Но в случае создания отдельных классовых атрибутов, которые затем используются в разных шаблонах, лучше создавать отдельные папки и файлы.
Создание файла стилей css
Создайте файл «stylesheet.css» в static > css. Там будут храниться все ваши стили.
.custom {
color:#007bff;
background:#000000;
font-size:20px;
}
8. Загрузите ссылку на CSS в шаблон
Для подключения собственных стилей к проекту, добавьте HTML-элемент <link> в «header.html». Файл вызывается так же, как изображения и JS-файлы.
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Home</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css" rel="stylesheet">
<link rel="stylesheet" href="{% static 'css/stylesheet.css'%}" type="text/css">
<script src="{% static 'js/script.js' %}"></script>
</head>
<body>
<div class="container custom">
<h1 class="text-center">Привет Django</h1>
<img class="w-50 mx-auto d-block" src="{% static 'img/example.png' %}" alt="photo">
</div>
</body>
</html>
И снова не забудьте о {% load static %} в верхней части страницы. Если не добавить эту строку, то будет ошибка.
Если класс custom добавить к container вы увидите изменения:

Ошибки, связанные с загрузкой статических файлов Django
Если вы получили ошибку «Invalid block tag on line 8: ‘static’, expected ‘endblock’. Did you forget to register or load this tag?», то вы наверняка забыли добавить тег загрузки статических файлов в верхней части страницы: {% load static %} до вызова самого изображения.
{% load static %}
<img src="{% static 'img/photo.jpg' %}">
Такая ошибка «Could not parse the remainder: ‘/photo.jpg’ from ‘img/photo.jpg’» значит, что вы забыли добавить кавычки вокруг ссылки на изображения. В этом случае нужно использовать две пары кавычек: одни для всего содержимого src, а вторые — для ссылки на изображение.
<img src="{% static img/photo.jpg %}"> {# ошибка #}
<img src="{% static 'img/photo.jpg' %}"> {# верно #}
«Invalid block tag on line 9: »static/img/photo.jpg», expected ‘endblock’. Did you forget to register or load this tag?» говорит о том, что вы случайно добавили тег static в URL.
<img src="{% 'static/img/photo.jpg' %}"> {# ошибка #}
<img src="{% static 'img/photo.jpg' %}"> {# верно #}
Если страница не загружается, и появляется следующая ошибка: «django.core.exceptions.ImproperlyConfigured: You’re using the staticfiles app without having set the required STATIC_URL setting», то это указывает на то, что вы забыли указать статический URL в файле настроек. Его нужно задать в settings.py и сохранить документ.
STATIC_URL = '/static/'Наконец, если вы не получаете ошибку, но изображение не отображается, то убедитесь, что вы правильно используете тег.
<img src="{ static img/photo.jpg }"> {# ошибка #}
<img src="{% static 'img/photo.jpg' %}"> {# верно #}
find(). Он помогает найти индекс первого совпадения подстроки в строке. Если символ или подстрока не найдены, find возвращает -1.
Синтаксис
string.find(substring,start,end)Метод find принимает три параметра:
substring(символ/подстрока) — подстрока, которую нужно найти в данной строке.start(необязательный) — первый индекс, с которого нужно начинать поиск. По умолчанию значение равно 0.end(необязательный) — индекс, на котором нужно закончить поиск. По умолчанию равно длине строки.
Поиск символов методом find() со значениями по умолчанию
Параметры, которые передаются в метод, — это подстрока, которую требуются найти, индекс начала и конца поиска. Значение по умолчанию для начала поиска — 0, а для конца — длина строки.
В этом примере используем метод со значениями по умолчанию.
Метод find() будет искать символ и вернет положение первого совпадения. Даже если символ встречается несколько раз, то метод вернет только положение первого совпадения.
>>> string = "Добро пожаловать!"
>>> print("Индекс первой буквы 'о':", string.find("о"))
Индекс первой буквы 'о': 1
Поиск не с начала строки с аргументом start
Можно искать подстроку, указав также начальное положение поиска.
В этом примере обозначим стартовое положение значением 8 и метод начнет искать с символа с индексом 8. Последним положением будет длина строки — таким образом метод выполнит поиска с индекса 8 до окончания строки.
>>> string = "Специалисты назвали плюсы и минусы Python"
>>> print("Индекс подстроки 'али' без учета первых 8 символов:", string.find("али", 8))
Индекс подстроки 'али' без учета первых 8 символов: 16
Поиск символа в подстроке со start и end
С помощью обоих аргументов (start и end) можно ограничить поиск и не проводить его по всей строке. Найдем индексы слова «пожаловать» и повторим поиск по букве «о».
>>> string = "Добро пожаловать!"
>>> start = string.find("п")
>>> end = string.find("ь") + 1
>>> print("Индекс первой буквы 'о' в подстроке:", string.find("о", start, end))
Индекс первой буквы 'о' в подстроке: 7
Проверка есть ли символ в строке
Мы знаем, что метод find() позволяет найти индекс первого совпадения подстроки. Он возвращает -1 в том случае, если подстрока не была найдена.
>>> string = "Добро пожаловать!"
>>> print("Есть буква 'г'?", string.find("г") != -1)
Есть буква 'г'? False
>>> print("Есть буква 'т'?", string.find("т") != -1)
Есть буква 'т'? True
Поиск последнего вхождения символа в строку
Функция rfind() напоминает find(), а единое отличие в том, что она возвращает максимальный индекс. В обоих случаях же вернется -1, если подстрока не была найдена.
В следующем примере есть строка «Добро пожаловать!». Попробуем найти в ней символ «о» с помощью методов find() и rfind().
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом rfind:", string.rfind("о"))
Поиск 'о' методом rfind: 11
Вывод показывает, что find() возвращает индекс первого совпадения подстроки, а rfind() — последнего совпадения.
Второй способ поиска — index()
Метод index() помогает найти положение данной подстроки по аналогии с find(). Единственное отличие в том, что index() бросит исключение в том случае, если подстрока не будет найдена, а find() просто вернет -1.
Вот рабочий пример, показывающий разницу в поведении index() и find():
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом index:", string.index("о"))
Поиск 'о' методом index: 1
В обоих случаях возвращается одна и та же позиция. А теперь попробуем с подстрокой, которой нет в строке:
>>> string = "Добро пожаловать"
>>> print("Поиск 'г' методом find:", string.find("г"))
Поиск 'г' методом find: 1
>>> print("Поиск 'г' методом index:", string.index("г"))
Traceback (most recent call last):
File "pyshell#21", line 1, in module
print("Поиск 'г' методом index:", string.index("г"))
ValueError: substring not found
В этом примере мы пытались найти подстроку «г». Ее там нет, поэтому find() возвращает -1, а index() бросает исключение.
Поиск всех вхождений символа в строку
Чтобы найти общее количество совпадений подстроки в строке можно использовать ту же функцию find(). Пройдемся циклом while по строке и будем задействовать параметр start из метода find().
Изначально переменная start будет равна -1, что бы прибавлять 1 у каждому новому поиску и начать с 0. Внутри цикла проверяем, присутствует ли подстрока в строке с помощью метода find.
Если вернувшееся значение не равно -1, то обновляем значением count.
Вот рабочий пример:
my_string = "Добро пожаловать"
start = -1
count = 0
while True:
start = my_string.find("о", start+1)
if start == -1:
break
count += 1
print("Количество вхождений символа в строку: ", count )
Количество вхождений символа в строку: 4Выводы
- Метод
find()помогает найти индекс первого совпадения подстроки в данной строке. Возвращает -1, если подстрока не была найдена. - В метод передаются три параметра: подстрока, которую нужно найти,
startсо значением по умолчанию равным 0 иendсо значением по умолчанию равным длине строки. - Можно искать подстроку в данной строке, задав начальное положение, с которого следует начинать поиск.
- С помощью параметров
startиendможно ограничить зону поиска, чтобы не выполнять его по всей строке. - Функция
rfind()повторяет возможностиfind(), но возвращает максимальный индекс (то есть, место последнего совпадения). В обоих случаях возвращается -1, если подстрока не была найдена. index()— еще одна функция, которая возвращает положение подстроки. Отличие лишь в том, чтоindex()бросает исключение, если подстрока не была найдена, аfind()возвращает -1.find()можно использовать в том числе и для поиска общего числа совпадений подстроки.
Здесь не инструкции по установки локального сервера, так как это не касается python. Скачайте и установите PostgreSQL с официального сайта https://www.postgresql.org/download/. Подойдут версии 10+, 11+, 12+.
Вот список разных модулей Python для работы с сервером базы данных PostgreSQL:
- Psycopg2,
- pg8000,
- py-postgreql,
- PyGreSQL,
- ocpgdb,
- bpsql,
- SQLAlchemy. Для работы SQLAlchemy нужно, чтобы хотя бы одно из перечисленных выше решений было установлено.
Примечание: все модули придерживаются спецификации Python Database API Specification v2.0 (PEP 249). Этот API разработан с целью обеспечить сходство разных модулей для доступа к базам данных из Python. Другими словами, синтаксис, методы и прочее очень похожи во всех этих модулях.
В этом руководстве будем использовать Psycopg2, потому что это один из самых популярных и стабильных модулей для работы с PostgreSQL:
- Он используется в большинстве фреймворков Python и Postgres;
- Он активно поддерживается и работает как с Python 3, так и с Python 2;
- Он потокобезопасен и спроектирован для работы в многопоточных приложениях. Несколько потоков могут работать с одним подключением.
В этом руководстве пройдемся по следующим пунктам:
- Установка Psycopg2 и использование его API для доступа к базе данных PostgreSQL;
- Вставка, получение, обновление и удаление данных в базе данных из приложения Python;
- Дальше рассмотрим управление транзакциями PostgreSQL, пул соединений и методы обработки исключений, что понадобится для разработки сложных программ на Python с помощью PostgreSQL.
Установка Psycopg2 с помощью pip
Для начала нужно установить текущую версию Psycopg2 для использования PostgreSQL в Python. С помощью команды pip можно установить модуль в любую операцию систему: Windows, macOS, Linux:
pip install psycopg2Также можно установить конкретную версию программы с помощью такой команды:
pip install psycopg2=2.8.6Если возникает ошибка установки, например «connection error: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:598)», то ее можно решить, сделав files.pythonhosted.org доверенным хостом:
python -m pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org --trusted-host pypi.python.org psycopg2
Модуль psycopg2 поддерживает:
- Python 2.7 и Python 3, начиная с версии 3.4.
- Сервер PostgreSQL от 7.4 до 12.
- Клиентскую библиотеку PostgreSQL от 9.1.
Проверка установки Psycopg2
После запуска команды должны появиться следующие сообщения:
- Collecting psycopg2
- Downloading psycopg2-2.8.6
- Installing collected packages: psycopg2
- Successfully installed psycopg2-2.8.6
При использовании anaconda подойдет следующая команда.
conda install -c anaconda psycopg2Подключение к базе данных PostgreSQL из Python
В этом разделе рассмотрим, как подключиться к PostgreSQL из Python с помощью модуля Psycopg2.
Вот какие аргументы потребуются для подключения:
- Имя пользователя: значение по умолчанию для базы данных PostgreSQL – postgres.
- Пароль: пользователь получает пароль при установке PostgreSQL.
- Имя хоста: имя сервера или IP-адрес, на котором работает база данных. Если она запущена локально, то нужно использовать localhost или 127.0.0.0.
- Имя базы данных: в этом руководстве будем использовать базу
postgres_db.
Шаги для подключения:
- Использовать метод
connect()с обязательными параметрами для подключения базы данных. - Создать объект cursor с помощью объекта соединения, который возвращает метод
connect. Он нужен для выполнения запросов. - Закрыть объект cursor и соединение с базой данных после завершения работы.
- Перехватить исключения, которые могут возникнуть в процессе.
Создание базы данных PostgreSQL с Psycopg2
Для начала создадим базу данных на сервере. Во время установки PostgreSQL вы указывали пароль, его нужно использовать при подключении.
import psycopg2
from psycopg2 import Error
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT
try:
# Подключение к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432")
connection.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
# Курсор для выполнения операций с базой данных
cursor = connection.cursor()
sql_create_database = 'create database postgres_db'
cursor.execute(sql_create_database)
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Пример кода для подключения к базе данных PostgreSQL из Python
Для подключения к базе данных PostgreSQL и выполнения SQL-запросов нужно знать название базы данных. Ее нужно создать прежде чем пытаться выполнить подключение.
import psycopg2
from psycopg2 import Error
try:
# Подключение к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
# Курсор для выполнения операций с базой данных
cursor = connection.cursor()
# Распечатать сведения о PostgreSQL
print("Информация о сервере PostgreSQL")
print(connection.get_dsn_parameters(), "\n")
# Выполнение SQL-запроса
cursor.execute("SELECT version();")
# Получить результат
record = cursor.fetchone()
print("Вы подключены к - ", record, "\n")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
После подключения появится следующий вывод:
Информация о сервере PostgreSQL
{'user': 'postgres', 'dbname': 'postgres_db', 'host': '127.0.0.1', 'port': '5432', 'tty': '', 'options': '', 'sslmode': 'prefer', 'sslcompression': '0', 'krbsrvname': 'postgres', 'target_session_attrs': 'any'}
Вы подключены к - ('PostgreSQL 10.13, compiled by Visual C++ build 1800, 64-bit',)
Соединение с PostgreSQL закрытоРазбор процесса подключения в деталях
import psycopg2 — Эта строка импортирует модуль Psycopg2 в программу. С помощью классов и методов модуля можно взаимодействовать с базой.
from psycopg2 import Error — С помощью класса Error можно обрабатывать любые ошибки и исключения базы данных. Это сделает приложение более отказоустойчивым. Этот класс также поможет понять ошибку в подробностях. Он возвращает сообщение об ошибке и ее код.
psycopg2.connect() — С помощью метода connect() создается подключение к экземпляру базы данных PostgreSQL. Он возвращает объект подключения. Этот объект является потокобезопасным и может быть использован на разных потоках.
Метод connect() принимает разные аргументы, рассмотренные выше. В этом примере в метод были переданы следующие аргументы: user = "postgres", password = "1111", host = "127.0.0.1", port = "5432", database = "postgres_db".
cursor = connection.cursor() — С базой данных можно взаимодействовать с помощью класса cursor. Его можно получить из метода cursor(), который есть у объекта соединения. Он поможет выполнять SQL-команды из Python.
Из одного объекта соединения можно создавать неограниченное количество объектов cursor. Они не изолированы, поэтому любые изменения, сделанные в базе данных с помощью одного объекта, будут видны остальным. Объекты cursor не являются потокобезопасными.
После этого выведем свойства соединения с помощью connection.get_dsn_parameters().
cursor.execute() — С помощью метода execute объекта cursor можно выполнить любую операцию или запрос к базе данных. В качестве параметра этот метод принимает SQL-запрос. Результаты запроса можно получить с помощью fetchone(), fetchmany(), fetchall().
В этом примере выполняем SELECT version(); для получения сведений о версии PosgreSQL.
Блок try-except-finally — Разместим код в блоке try-except для перехвата исключений и ошибок базы данных.
cursor.close() и connection.close() — Правильно всегда закрывать объекты cursor и connection после завершения работы, чтобы избежать проблем с базой данных.
Создание таблицы PostgreSQL из Python
В этом разделе разберем, как создавать таблицу в PostgreSQL из Python. В качестве примера создадим таблицу Mobile.
Выполним следующие шаги:
- Подготовим запрос для базы данных
- Подключимся к PosgreSQL с помощью
psycopg2.connect(). - Выполним запрос с помощью
cursor.execute(). - Закроем соединение с базой данных и объект
cursor.
Теперь рассмотрим пример.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
# Создайте курсор для выполнения операций с базой данных
cursor = connection.cursor()
# SQL-запрос для создания новой таблицы
create_table_query = '''CREATE TABLE mobile
(ID INT PRIMARY KEY NOT NULL,
MODEL TEXT NOT NULL,
PRICE REAL); '''
# Выполнение команды: это создает новую таблицу
cursor.execute(create_table_query)
connection.commit()
print("Таблица успешно создана в PostgreSQL")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
Таблица успешно создана в PostgreSQL
Соединение с PostgreSQL закрытоПримечание: наконец, коммитим изменения с помощью метода commit().
Соответствие типов данных Python и PostgreSQL
Есть стандартный маппер для конвертации типов Python в их эквиваленты в PosgreSQL и наоборот. Каждый раз при выполнении запроса PostgreSQL из Python с помощью psycopg2 результат возвращается в виде объектов Python.
| Python | PostgreSQL |
|---|---|
| None | NULL |
| bool | bool |
| float | real double |
| int long | smallint integer bigint |
| Decimal | numeric |
| str unicode | varchar text |
| date | date |
| time | time timetz |
| datetime | timestamp timestamptz |
| timedelta | interval |
| list | ARRAY |
| tuple namedtuple | Composite types IN syntax |
| dict | hstore |
Константы и числовые преобразования
При попытке вставить значения None и boolean (True, False) из Python в PostgreSQL, они конвертируются в соответствующие литералы SQL. То же происходит и с числовыми типами. Они конвертируются в соответствующие типы PostgreSQL.
Например, при выполнении запроса на вставку числовые объекты, такие как int, long, float и Decimal, конвертируются в числовые представления из PostgreSQL. При чтении из таблицы целые числа конвертируются в int, числа с плавающей точкой — во float, а десятичные — в Decimal.
Выполнение CRUD-операций из Python
Таблица mobile уже есть. Теперь рассмотрим, как выполнять запросы для вставки, обновления, удаления или получения данных из таблицы в Python.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Выполнение SQL-запроса для вставки данных в таблицу
insert_query = """ INSERT INTO mobile (ID, MODEL, PRICE) VALUES (1, 'Iphone12', 1100)"""
cursor.execute(insert_query)
connection.commit()
print("1 запись успешно вставлена")
# Получить результат
cursor.execute("SELECT * from mobile")
record = cursor.fetchall()
print("Результат", record)
# Выполнение SQL-запроса для обновления таблицы
update_query = """Update mobile set price = 1500 where id = 1"""
cursor.execute(update_query)
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно удалена")
# Получить результат
cursor.execute("SELECT * from mobile")
print("Результат", cursor.fetchall())
# Выполнение SQL-запроса для удаления таблицы
delete_query = """Delete from mobile where id = 1"""
cursor.execute(delete_query)
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно удалена")
# Получить результат
cursor.execute("SELECT * from mobile")
print("Результат", cursor.fetchall())
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
1 запись успешно вставлена
Результат [(1, 'Iphone12', 1100.0)]
1 Запись успешно удалена
Результат [(1, 'Iphone12', 1500.0)]
1 Запись успешно удалена
Результат []
Соединение с PostgreSQL закрытоПримечание: не забывайте сохранять изменения в базу данных с помощью
connection.commit()после успешного выполнения операции базы данных.
Работа с датой и временем из PostgreSQL
В этом разделе рассмотрим, как работать с типами date и timestamp из PostgreSQL в Python и наоборот.
Обычно при выполнении вставки объекта datetime модуль psycopg2 конвертирует его в формат timestamp PostgreSQL.
По аналогии при чтении значений timestamp из таблицы PostgreSQL модуль psycopg2 конвертирует их в объекты datetime Python.
Для этого примера используем таблицу Item. Выполните следующий код, чтобы подготовить таблицу.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
# Создайте курсор для выполнения операций с базой данных
cursor = connection.cursor()
# SQL-запрос для создания новой таблицы
create_table_query = '''CREATE TABLE item (
item_id serial NOT NULL PRIMARY KEY,
item_name VARCHAR (100) NOT NULL,
purchase_time timestamp NOT NULL,
price INTEGER NOT NULL
);'''
# Выполнение команды: это создает новую таблицу
cursor.execute(create_table_query)
connection.commit()
print("Таблица успешно создана в PostgreSQL")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Рассмотрим сценарий на простом примере. Здесь мы читаем колонку purchase_time из таблицы и конвертируем значение в объект datetime Python.
import psycopg2
import datetime
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Выполнение SQL-запроса для вставки даты и времени в таблицу
insert_query = """ INSERT INTO item (item_Id, item_name, purchase_time, price)
VALUES (%s, %s, %s, %s)"""
item_purchase_time = datetime.datetime.now()
item_tuple = (12, "Keyboard", item_purchase_time, 150)
cursor.execute(insert_query, item_tuple)
connection.commit()
print("1 элемент успешно добавлен")
# Считать значение времени покупки PostgreSQL в Python datetime
cursor.execute("SELECT purchase_time from item where item_id = 12")
purchase_datetime = cursor.fetchone()
print("Дата покупки товара", purchase_datetime[0].date())
print("Время покупки товара", purchase_datetime[0].time())
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
1 элемент успешно добавлен
Дата покупки товара 2021-01-16
Время покупки товара 20:16:23.166867
Соединение с PostgreSQL закрытоModuleNotFoundError: No module named ...:
- Модуль Python не установлен.
- Есть конфликт в названиях пакета и модуля.
- Есть конфликт зависимости модулей Python.
Рассмотрим варианты их решения.
Модуль не установлен
В первую очередь нужно проверить, установлен ли модуль. Для использования модуля в программе его нужно установить. Например, если попробовать использовать numpy без установки с помощью pip install будет следующая ошибка:
Traceback (most recent call last):
File "", line 1, in
ModuleNotFoundError: No module named 'numpy'Для установки нужного модуля используйте следующую команду:
pip install numpy
# или
pip3 install numpyИли вот эту если используете Anaconda:
conda install numpyУчтите, что может быть несколько экземпляров Python (или виртуальных сред) в системе. Модуль нужно устанавливать в определенный экземпляр.
Конфликт имен библиотеки и модуля
Еще одна причина ошибки No module named — конфликт в названиях пакета и модуля. Предположим, есть следующая структура проекта Python:
demo-project
└───utils
__init__.py
string_utils.py
utils.pyЕсли использовать следующую инструкцию импорта файла utils.py, то Python вернет ошибку ModuleNotFoundError.
>>> import utils.string_utils
Traceback (most recent call last):
File "C:\demo-project\utils\utils.py", line 1, in
import utils.string_utils
ModuleNotFoundError: No module named 'utils.string_utils';
'utils' is not a package
В сообщении об ошибке сказано, что «utils is not a package». utils — это имя пакета, но это также и имя модуля. Это приводит к конфликту, когда имя модуля перекрывает имя пакета/библиотеки. Для его разрешения нужно переименовать файл utils.py.
Конфликт зависимостей модулей Python
Иногда может существовать конфликт модулей Python, который и приводит к ошибке No module named.
Следующее сообщение явно указывает, что _numpy_compat.py в библиотеке scipy пытается импортировать модуль numpy.testing.nosetester.
Traceback (most recent call last):
File "C:\demo-project\venv\
Lib\site-packages\
scipy\_lib\_numpy_compat.py", line 10, in
from numpy.testing.nosetester import import_nose
ModuleNotFoundError: No module named 'numpy.testing.nosetester'Ошибка ModuleNotFoundError возникает из-за того, что модуль numpy.testing.nosetester удален из библиотеки в версии 1.18. Для решения этой проблемы нужно обновить numpy и scipy до последних версий.
pip install numpy --upgrade
pip install scipy --upgrade Почему Redis?
Обычно при упоминании Redis у многих возникают ассоциации с базами данных NoSQL, но это в корне неверно. У Redis нет с ними ничего общего: ни в плане своего позиционирования, ни в плане исполнения. MongoDB, например, хранит данные на диске.
Выделение места для записей подразумевает, что эти данные должны быть сохранены: аккаунты пользователей, записи в блог, разрешения и так далее. Большая часть данных любых приложений относится к этой категории.
Тем не менее есть и исключения. Было бы крайне неэффективно хранить, например, содержимое корзины пользователя или информацию о последней посещенной странице. В краткосрочной перспективе такая информация была бы полезной, но нагружать ею базы данных, основанные на транзакционных системах — не очень разумно. Благо, существует такое понятие как RAM (ОЗУ или оперативное запоминающее устройство).
Redis — это резидентная база данных (такая, которая хранит записи прямо в оперативной памяти) в виде пар ключ-значение. Чтение и запись в память происходит намного быстрее, чем в случае с дисками, поэтому такой подход отлично подходит для хранения второстепенных данных.
Это улучшает пользовательский опыт, но одновременно делает базы данных чистыми. Если же в будущем решается, что такие данные тоже нужно хранить, то их всегда можно записать на диск (например, в базу данных SQL).
В этом руководстве познакомимся с библиотекой Python для Redis под названием redis-py. В среде Python его называют просто redis. Официальная документация этой библиотеки — просто одна страница с перечислением всех методов в алфавитном порядке.
Если вы планируете использовать Redis с каким-либо из фреймворков, то рекомендуется выбирать конкретную библиотеку: например, Flask-Redis, а не redis-py. Однако все они преимущественно повторяют синтаксис redis-py и имеют несколько минимальных отличий.
Установка Redis
Что бы протестировать работу Redis рекомендую использовать облачное решение. Зарегистрируйтесь на Redis Labs, они дают бесплатный сервер для обучения и тестирования.
- Пройдите регистрацию.
- Подтвердите почту.
- Создайте подписку (сервер).

4. Создайте базу данных:
После активации приложения вам понадобятся хост(Endpoint) и пароль (Default User Password).
Далее установим redis:
pip install redisСтрока подключения к Redis
Как и в случае с обычными базами данных подключить экземпляр Redis можно с помощью строки подключения. Вот как такая выглядит в Redis:
redis://:hostname.redislabs.com@mypassword:12345/0Разберем по пунктам:
[CONNECTION_METHOD]:[HOSTNAME]@[PASSWORD]:[PORT]/[DATABASE]
CONNECTION_METHOD— это суффикс, который нужен во всех URI Redis. Он определяет способ подключения к приложению.redis://— стандартное соединение,rediss://— подключается по SSL,redis-socket://— зарезервированный тип для сокетов Unix иredis-sentinel://— тип подключения для кластеров Redis с высоким уровнем доступности.HOSTNAME— URL или IP приложения Redis. Если вы используете облачное решение, то, скорее всего, вам нужен адрес AWS EC2. (Такова особенность современного капитализма, где все весь мелкий бизнес — это реселлеры с заранее настроенным ПО).PASSWORD— у приложения Redis есть пароль, но нет пользователей. Скорее всего, это связано с тем, что в случае с резидентной базой данных сложно было хранить их имена.PORT— выбранный порт.DATABASE— если не уверены, что здесь указать, просто напишите 0.
Создание клиента Redis
URI есть. Теперь нужно подключиться к Redis, создав объект клиента:
import redis
r = redis.StrictRedis(
host='redis-17449.c55.eu-central-1-1.ec2.cloud.redislabs.com', # из Endpoint
port=17449, # из Endpoint
password='qwerty' # ваш пароль
)
Но почему StrictRedis, вы можете спросить? Есть два вида создания клиентов Redis: redis.Redis() и redis.StrictRedis(). StrictRedis пытается правильно применять типы данных. Старые экземпляры так не умеют. redis.Redis() — обратно совместимая с устаревшими экземплярами Redis версия с любыми наборами данных, а redis.StrictRedis() — нет. Если сомневаетесь — используйте StrictRedis.
Есть множество других аргументов, которые можно (и нужно) передать в redis.StrictRedis(), чтобы упростить себе жизнь. Обязательно передайте decode_responses=True, ведь это избавит необходимости явно расшифровывать каждое значение из базы. Также не лишним будет указать кодировку:
import redis
r = redis.StrictRedis(
host='redis-17449.c55.eu-central-1-1.ec2.cloud.redislabs.com',
port=17449,
password='qwerty',
charset="utf-8",
decode_responses=True
)
Пример использования Redis
Хранилище ключ-значение Redis очень напоминает словари Python, отсюда и расшифровка — Remote Dictionary Service (удаленный сервис словарей). Ключи — это всегда строки, но значениями могут быть разные типы данных. Заполним приложение Redis несколькими записями, чтобы лучше понять, как они работают:
import redis
import time
r = redis.StrictRedis(
host='redis-17449.c55.eu-central-1-1.ec2.cloud.redislabs.com',
port=17449,
password='qwerty',
charset="utf-8",
decode_responses=True
)
r.set('ip_address', '127.0.0.0')
r.set('timestamp', int(time.time()))
r.set('user_agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11)')
r.set('last_page_visited', 'home')
r.set([KEY], [VALUE]) — это основной синтаксис, чтобы задавать одиночные значения. Первый параметр — это ключ, а второй — присваиваемое ему значение.
По аналогии с обычными базами данных подключение к Redis осуществляется с помощью графического интерфейса, по типу TablePlus для проверки данных. Вот как выглядит тестовая база после выполнения кода выше:
| KEY | VALUE | TYPE | TTL |
|---|---|---|---|
| user_agent | Mozilla/5.0 (Macintosh; Intel Mac OS X 11) | STRING | -1 |
| last_page_visited | home | STRING | -1 |
| ip_address | 127.0.0.0 | STRING | -1 |
| timestamp | 1610803181 | STRING | -1 |
Кажется, операция прошла успешно. Узнать кое-что о Redis можно, просто взглянув на таблицу. Начнем с колонки type.
Типы данных в Redis
В Redis могут храниться данные 5 типов:
STRING(строка) — любое значение, сохраняемое с помощьюr.set(), хранится в виде строки. Вы также можете обратить внимание на то, что значениеtimestampбудет целым числом в Python, но здесь оно выступает строкой. Вы можете подумать, что это не очень удобно, но строки в Redis — это чуть больше, чем может показаться на первый взгляд. Во-первых, они являются бинарно-безопасными, что значит, что с их помощью можно хранить почти что угодно, вплоть до изображений и сериализованных объектов. У строк также есть несколько встроенных функций, которые позволяют управлять ими так, будто бы это целые числа (например INC для инкремента).LIST(список) — списки являются изменяемыми массивами строк в Redis, которые сортируются в порядке появления. После создания списка новые элементы могут добавляться в конец с помощью командыRPUSHили в начало с помощьюLPUSH. Можно также ограничить максимальное количество элементов в списке с помощью командыLTRIM. Если вы знакомы с методом вытеснения из кэша LRU, например, то должны быть знакомы с этой командой.SET(множество) — несортированный набор строк. По аналогии с множествами в Python в Redis элементы не могут повторяться. У множеств также есть уникальные функции по объединению и пересечению, что позволяет эффективно и быстро объединять данные из разных наборов.ZSET— те же множества, но уже сортированные. Однако в них по-прежнему могут храниться только уникальные значения. После создания порядок в них можно менять, что удобно для ранжирования уникальных элементов, например. СтруктураZSETпохожа на сортированные словари в Python за исключением того, что у них есть ключ для каждого значения (что было бы ненужным, ведь все множества уникальны).HASH(хэши) — хэши в Redis являются парами ключ-значение. Эта структура позволяют присваивать ключам значение из ключа и значения. Однако вложенными хэши быть не могут.
Срок хранения данных
В базе данных Redis есть четвертая колонка под названием ttl. В нашем примере для всех записей в ней было значение -1. Когда же там положительное значение, то оно указывает на количество секунд до истечения срока действия данных. Redis — отличное хранилище для временно полезных данных, однако не таких, которые нужны в долгосрочной перспективе. Вот когда полезно устанавливать срок действия — это позволяет не нагружать приложение информацией, которая быстро становится нерелевантной.
Вернемся к примеру, где хранится информация о сессии пользователя и зададим срок действия данных:
...
r.set('last_page_visited', 'home', 86400)
В этот раз передадим третье значение в r.set(). Оно указывает на количество секунд, которое должно пройти до истечения срока действия данных. Снова проверим базу данных:
| KEY | VALUE | TYPE | TTL |
|---|---|---|---|
| user_agent | Mozilla/5.0 (Macintosh; Intel Mac OS X 11) | STRING | -1 |
| last_page_visited | home | STRING | 86400 |
| ip_address | 127.0.0.0 | STRING | -1 |
| timestamp | 1610803181 | STRING | -1 |
Работа с каждым типом данных
Теория — это прекрасно, но мы знаем, зачем вы здесь: чтобы воспользоваться кодом, который можно будет применить в своем приложении. Рассмотрим несколько примеров распространенного использования 5 типов данных в Redis.
Строки
Если строки включают целые числа, то есть несколько методов, с помощью которых можно их изменять так, будто бы это целые числа. Это incr(), decr() и incrby():
# Создать строковое значение
r.set('index', '1')
print(f"index: {r.get('index')}")
# Увеличить строку на 1
r.incr('index')
print(f"index: {r.get('index')}")
# Уменьшить строку на 1
r.decr('index')
print(f"index: {r.get('index')}")
# Увеличить строку на 3
r.incrby('index', 3)
print(f"index: {r.get('index')}")
Это присвоит значение ‘1’ ключу index, увеличит его на 1, уменьшит на 1 и в итоге увеличит еще на 3:
index: 1
index: 2
index: 1
index: 4Списки
Добавим элементы в список Redis с помощью комбинации .lpush() и rpush(), а также удалим их оттуда с помощью .lpop(). Классика:
r.lpush('my_list', 'A')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Добавить вторую строку в список справа
r.rpush('my_list', 'B')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Вставить третью строку в список справа
r.rpush('my_list', 'C')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Удалить из списка 1 экземпляр, значение которого "C"
r.lrem('my_list', 1, 'C')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Вставить строку в наш список слева
r.lpush('my_list', 'C')
print(f"my_list: {r.lrange('my_list', 0, -1)}")
# Вытащить первый элемент нашего списка и переместить его в конец
r.rpush('my_list', r.lpop('my_list'))
print(f"my_list: {r.lrange('my_list', 0, -1)}")
Вот как будет выглядеть список на разных этапах:
my_list: ['A']
my_list: ['A', 'B']
my_list: ['A', 'B', 'C']
my_list: ['A', 'B']
my_list: ['C', 'A', 'B']
my_list: ['A', 'B', 'C']Множества
Множества являются мощным инструментом отчасти благодаря их способности взаимодействовать между собой. Дальше создаются два отдельных множества и на них применяются операции .sunion() и .sinter():
# Добавить элемент в set 1
r.sadd('my_set_1', 'Y')
print(f"my_set_1: {r.smembers('my_set_1')}")
# Добавить элемент в set 1
r.sadd('my_set_1', 'X')
print(f"my_set_1: {r.smembers('my_set_1')}")
# Добавить элемент в set 2
r.sadd('my_set_2', 'X')
print(f"my_set_2: {r.smembers('my_set_2')}")
# Добавить элемент в set 2
r.sadd('my_set_2', 'Z')
print(f"my_set2: {r.smembers('my_set_2')}")
# Объединение set 1 и set 2
print(f"sunion: {r.sunion('my_set_1', 'my_set_2')}")
# Пересечение set 1 и set 2
print(f"sinter: {r.sinter('my_set_1', 'my_set_2')}")
Первая объединяет наборы без повторов, а вторая — выбирает общие элементы:
my_set_1: {'Y'}
my_set_1: {'X', 'Y'}
my_set_2: {'X'}
my_set2: {'X', 'Z'}
sunion: {'X', 'Y', 'Z'}
sinter: {'X'}Сортированные множества
Добавление элементов в сортированное множество с помощью .zadd() предполагает интересный синтаксис. Обратите внимание на то, что для добавления записей требуется словарь в формате {[VALUE]: [INDEX]}:
# Создали отсортированный set с 3 значениями
r.zadd('top_songs_set', {'Never Change - Jay Z': 1,
'Rich Girl - Hall & Oats': 2,
'The Prayer - Griz': 3})
print(f"top_songs_set: {r.zrange('top_songs_set', 0, -1)}")
# Добавили элемент в set с конфликтующим значением
r.zadd('top_songs_set', {"Can't Figure it Out - Bishop Lamont": 3})
print(f"top_songs_set: {r.zrange('top_songs_set', 0, -1)}")
# Индекс сдвига значения
r.zincrby('top_songs_set', 3, 'Never Change - Jay Z')
print(f"top_songs_set: {r.zrange('top_songs_set', 0, -1)}")
У элементов в сортированном множестве никогда не может быть одного и того же индекса, так что при попытке добавить элемент на место существующего индекса, текущий элемент (и все после него) сдвигаются, чтобы дать место новому. Также есть возможность менять индексы после их создания:
top_songs_set: ['Never Change - Jay Z', 'Rich Girl - Hall & Oats', 'The Prayer - Griz']
top_songs_set: ['Never Change - Jay Z', 'Rich Girl - Hall & Oats', "Can't Figure it Out - Bishop Lamont", 'The Prayer - Griz']'
top_songs_set: ['Rich Girl - Hall & Oats', "Can't Figure it Out - Bishop Lamont", 'The Prayer - Griz', 'Never Change - Jay Z']Хэши
Это просто добавление и получение данных из хэшей:
record = {
"name": "PythonRu",
"description": "Redis tutorials",
"website": "https://pythonru.com/"
}
r.hmset('business', record)
print(f"business: {r.hgetall('business')}")
Вывод такой же, как и ввод:
business: {'name': 'PythonRu', 'description': 'Redis tutorials', 'website': 'https://pythonru.com/'}Где используется?
Словари — распространенная структура данных в Python. Они используются в самых разных ситуациях. Вот некоторые из методов и функций словарей:
.keys()— используется для вывода ключей словаря..items()— используется для создания кортежей с ключами и значениями..get()— метод для получения значения по ключу..clear()— очистить словарь..copy()— скопировать весь словарь.len()— получить длину словаря.type()— узнать тип.min()— получить ключ с минимальным значением.max()— получить ключ с максимальным значением.
Рекомендации по работе со словарями
- Словари создаются с помощью фигурных скобок.
- Пары из ключа и значения разделяются запятыми.
- Ключи и значения разделяются между собой двоеточием
- Ключи в словаре могут быть только строками, целыми числами или числами с плавающей точкой. А вот значения могут быть любого типа
- Важно не забывать использовать кавычки для строки-ключа
Дальше пример словаря, где в качестве ключей используются строки, а в качестве значений — целые числа.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages)
{"Андрей": 32, "Виктор": 29, "Максим": 18}
Все строки в словаре заключены в кавычки. В следующем примере ключами уже являются целые числа, а значениями — строки.
>>> p_ages = {32: "Андрей", 29: "Виктор", 18: "Максим"}
>>> print(p_ages)
{32: "Андрей", 29: "Виктор", 18: "Максим"}
В этот раз кавычки нужно использовать для значений, которые тут представлены в виде строк. Доступ к значениям словаря можно получить по его ключам.
Так, для получения значения ключа «Виктор» нужно использовать такой синтаксис:
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> p_ages["Максим"]
18
>>> p_ages["Андрей"]
32
Merge и Update
Начиная с версии Python 3.9, в языке появились новые операторы, которые облегчают процесс слияния словарей.
- Merge (
|): этот оператор позволяет объединять два словаря с помощью одного символа |. - Update (
|=): с помощью такого оператора можно обновить первый словарь значением второго (с типом dict)
Вот основные отличия этих двух операторов:
- «|» создает новый словарь, объединяя два, а «|=» обновляет первый словарь.
- Оператор merge (|) упрощает процесс объединения словарей и работы с их значениями.
- Оператор update (|=) используется для обновления словарей.
>>> dict1 = {"x": 1, "y":2}
>>> dict2 = {"a":11, "b":22}
>>> dict3 = dict1 | dict2
>>> print(dict3)
{"x":1, "y":2, "a":11, "b":22}
>>> dict1 = {"x": 1, "y":2}
>>> dict2 = {"a":11, "b":22}
>>> dict2 |= dict1
>>> print(dict2)
{"x":1, "y":2, "a":11, "b":22}
Примечание: при наличии пересекающихся ключей (а в словарях Python может быть только один уникальный ключ) останется ключ второго словаря, а первый просто заменится.
Функция №1: .keys()
.keys() — это удобный метод, который возвращает все ключи в словаре. Дальше посмотрим на пример с использованием метода keys.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages.keys())
dict_keys(['Андрей', 'Виктор', 'Максим'])
Функция №2: .items()
.items() возвращает список кортежей, каждый из которых является парой из ключа и значения. Полезность этой функции станет понятна на более поздних этапах работы в качестве программиста, а пока достаточно просто запомнить эту функцию.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> a = p_ages.items()
>>> print(a)
dict_items([('Андрей', 32), ('Виктор', 29), ('Максим', 18)])
Метод .items() пригодится при необходимости использовать индексацию для доступа к данным.
Функция №3: .get()
.get() — полезный метод для получения значений из словаря по ключу. Получим доступ к возрасту с помощью метода .get().
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages.get("Андрей"))
32
Функция №4: .clear()
Метод .clear() очищает словарь ото всех элементов.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> p_ages.clear()
>>> print(p_ages)
{}
Функция №5: .copy()
Метод .copy() возвращает копию словаря.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages.copy())
{"Андрей": 32, "Виктор": 29, "Максим": 18}
Функция №6: len()
Метод len() возвращает количество элементов словаря.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(len(p_ages))
3
Полезно знать
- Метод
get()— более продвинутый по сравнению с подходом получения значения по ключу.
Если добавить в метод второй параметр, то он вернет переданное значение в случае, когда ключ не будет найден. Если второй параметр не указывать, получитеNone. - Если попробовать использовать новые операторы (| и |=) в старых версиях python, то вернется ошибка TypeError. Это касается в том числе и dict comprehension.
>>> p_ages = {"Андрей": 32, "Виктор": 29, "Максим": 18}
>>> print(p_ages.get("Михаил", "Не найдено"))
Не найдено
>>> print(p_ages.get("Андрей", "Не найдено"))
32
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Выведите значение возраста из словаря person.
# данный код
person = {"name": "Kelly", "age":25, "city": "New york"}
# требуемый вывод:
# 252. Значениями словаря могут быть и списки. Допишите словарь с ключами BMW, ВАЗ, Tesla и списками из 3х моделей в качестве значений.
# данный код
models_data = {..., "Tesla": ["Modes S", ...]}
print(models_data["Tesla"][0])
# требуемый вывод:
# Modes S- Исправьте ошибки в коде, что бы получить требуемый вывод.
# данный код
d1 = {"a": 100. "b": 200. "c":300}
d2 = {a: 300, b: 200, d:400}
print(d1["b"] == d2["b"])
# требуемый вывод:
# TrueФайл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_8.py.
Тест по словарям
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
Конец. Что делать дальше?
Это краткая серия знакомит с программированием на python. Если вы решали задачи, проходили тесты, справлялись с ошибками и не потеряли мотивацию стать разработчиком — стоит продолжать!
Вы можете учится основам, например на бесплатных курсах от Нетологии или практиковаться на вебинарах Skillbox.
Для перехода на следующий уровень напишите свою программу: калькулятор, игру, api. Самостоятельно или с поддержкой менторов из Twitter и EPAM на программе Профессия Python-разработчик.
]]>Отображение панелей с вкладками с помощью Notebook
Класс ttk.Notebook — еще один новый виджет из модуля ttk. Он позволяет добавлять разные виды отображения приложения в одном окне, предлагая после этого выбрать желаемый с помощью клика по соответствующей вкладке.
Панели с вкладками — это удобный вариант повторного использования графического интерфейса для тех ситуаций, когда содержимое нескольких областей не должно отображаться одновременно.
Следующее приложение показывает список дел, разбитый по категориям. В этом примере данные доступны только для чтения (для упрощения):
Создаем ttk.Notebook с фиксированными размерами, и затем проходимся по словарю с заранее определенными данными. Он выступит источником вкладок и названий для каждой области:
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Ttk Notebook")
todos = {
"Дом": ["Постирать", "Сходить за продуктами"],
"Работа": ["Установить Python", "Учить Tkinter", "Разобрать почту"],
"Отпуск": ["Отдых!"]
}
self.notebook = ttk.Notebook(self, width=250, height=100, padding=10)
for key, value in todos.items():
frame = ttk.Frame(self.notebook)
self.notebook.add(frame, text=key, underline=0,
sticky=tk.NE + tk.SW)
for text in value:
ttk.Label(frame, text=text).pack(anchor=tk.W)
self.label = ttk.Label(self)
self.notebook.pack()
self.label.pack(anchor=tk.W)
self.notebook.enable_traversal()
self.notebook.bind("<<NotebookTabChanged>>", self.select_tab)
def select_tab(self, event):
tab_id = self.notebook.select()
tab_name = self.notebook.tab(tab_id, "text")
text = "Ваш текущий выбор: {}".format(tab_name)
self.label.config(text=text)
if __name__ == "__main__":
app = App()
app.mainloop()
При клике по вкладке метка в нижней части экрана обновляет содержимое, показывая название текущей вкладки.
Как работает этот виджет
Виджет ttk.Notebook создается с фиксированными шириной, высотой и внешними отступами.
Каждый ключ из словаря todos используется в качестве названия вкладки, а список значений добавляется в виде меток в ttk.Frame, который представляет собой область окна:
self.notebook = ttk.Notebook(self, width=250, height=100, padding=10)
for key, value in todos.items():
frame = ttk.Frame(self.notebook)
self.notebook.add(frame, text=key,
underline=0, sticky=tk.NE+tk.SW)
for text in value:
ttk.Label(frame, text=text).pack(anchor=tk.W)
После этого у виджета ttk.Notebook вызывается метод enable_traversal(). Это позволяет пользователям переключаться между вкладками с помощью Ctrl + Shift + Tab и Ctrl + Tab соответственно.
Благодаря этому также можно переключиться на определенную вкладку, зажав Alt и подчеркнутый символ: Alt + H для вкладки Home, Alt + W — для Work, а Alt + V — для Vacation.
Виртуальное событие "<<NotebookTabChanged>>" генерируется автоматически при изменении выбора. Оно связывается с методом select_tab(). Стоит отметить, что это событие автоматически срабатывает при добавлении вкладки в ttk.Notebook:
self.notebook.pack()
self.label.pack(anchor=tk.W)
self.notebook.enable_traversal()
self.notebook.bind("<<NotebookTabChanged>>", self.select_tab)
При упаковке элементов необязательно размещать дочерние элементы ttk.Notebook, поскольку это делается автоматически с помощью вызова geometry manager:
def select_tab(self, event):
tab_id = self.notebook.select()
tab_name = self.notebook.tab(tab_id, "text")
self.label.config(text=f"Ваш текущий выбор: {tab_name}")
Если нужно получить текущий дочерний элемент ttk.Notebook, то для этого не нужно использовать дополнительные структуры данных для маппинга индекса вкладки и окна виджета.
Метод nametowidget() доступен для всех классов виджетов, так что с его помощью можно легко получить объект виджета, соответствующий определенному имени:
def select_tab(self, event):
tab_id = self.notebook.select()
frame = self.nametowidget(tab_id)
# ...
Применение стилей Ttk
У тематических виджетов есть отдельный API для изменения внешнего вида. Прямо задавать параметры нельзя, потому что они определены в классе ttk.Style.
В этом разделе разберем, как изменять виджеты и добавлять им стили.
Для добавления дополнительных настроек нужен объект ttk.Style, который предоставляет следующие методы:
configure(style, opts)— меняет внешний видoptsдляstyleвиджета. Именно здесь задаются такие параметры, как фон, отступы и анимации.map(style, query)— меняет динамический видstyleвиджета. Аргументquery— аргумент-ключевое слово, где каждый ключ отвечает за параметр стиля, а значение — список кортежей в виде(state, value). Это значит, что значение каждого параметра определяется его текущим состоянием.
Например, отметим следующие примеры для двух ситуаций:
import tkinter as tk
import tkinter.ttk as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Tk themed widgets")
style = ttk.Style(self)
style.configure("TLabel", padding=10)
style.map("TButton",
foreground=[("pressed", "grey"), ("active", "white")],
background=[("pressed", "white"), ("active", "grey")]
)
# ...
Теперь каждый ttk.Label отображается с внутренним отступом 10, а у ttk.Button динамические стили: серая заливка с белым фоном, когда состояние кнопки — pressed и белая заливка с серым фоном — когда active.
Как работают стили
Создавать ttk.Style довольно просто. Нужно лишь создать экземпляр с родительским виджетом в качестве первого параметра.
После этого можно задать настройки стиля для виджетов с помощью символа T в верхнем регистре и названия виджета: Tbutton для ttk.Button, Tlabel для ttk.Label и так далее. Однако есть и исключения, поэтому рекомендуется сверяться с помощью интерпретатора Python, вызывая winfo_class() для экземпляра виджета.
Также можно добавить префикс, чтобы указать, что этот стиль должен быть не по умолчанию, а явно задаваться для определенных виджетов:
style.configure("My.TLabel", padding=10)
# ...
label = ttk.Label(master, text="Какой-то текст", style="My.TLabel")
Создание виджета выбора даты
Если нужно позволить пользователям выбирать дату в приложении, то можно попробовать оставить текстовую подсказку, которая бы побудила их написать строку в формате даты. Еще одно решение — добавить несколько числовых полей для ввода дня, месяца и года, но в этом случае понадобятся несколько правил валидации.
В отличие от других фреймворков для создания графических интерфейсов, в Tkinter нет класса для этих целей, но можно воспользоваться знаниями тематических виджетов для создания виджета календаря.
В этом материале пошагово разберем процесс создания виджета выбора даты с помощью виджетов Ttk:
Это рефакторинг решения https://svn.python.org/projects/sandbox/trunk/t tk-gsoc/samples/ttkcalendar.py, который не требует внешних зависимостей.
Помимо модулей tkinter также нужны модули calendar и datetime из стандартной библиотеки. Это поможет моделировать данные виджета и взаимодействовать с ними.
Заголовок виджета показывает стрелки для перемещения между месяцами. Их внешний вид зависит от текущих выбранных стилей Tk. Тело виджета состоит из таблицы ttk.Treeview с экземпляром Canvas, который подсвечивает ячейку выбранной даты:
import calendar
import datetime
import tkinter as tk
import tkinter.ttk as ttk
import tkinter.font as tkfont
from itertools import zip_longest
class TtkCalendar(ttk.Frame):
def __init__(self, master=None, **kw):
now = datetime.datetime.now()
fwday = kw.pop('firstweekday', calendar.MONDAY)
year = kw.pop('year', now.year)
month = kw.pop('month', now.month)
sel_bg = kw.pop('selectbackground', '#ecffc4')
sel_fg = kw.pop('selectforeground', '#05640e')
super().__init__(master, **kw)
self.selected = None
self.date = datetime.date(year, month, 1)
self.cal = calendar.TextCalendar(fwday)
self.font = tkfont.Font(self)
self.header = self.create_header()
self.table = self.create_table()
self.canvas = self.create_canvas(sel_bg, sel_fg)
self.build_calendar()
# ...
def main():
root = tk.Tk()
root.title('Календарь Tkinter')
ttkcal = TtkCalendar(firstweekday=calendar.SUNDAY)
ttkcal.pack(expand=True, fill=tk.BOTH)
root.mainloop()
if __name__ == '__main__':
main()
Полный код в файле lesson_23/creating_widget.py на Gitlab.
Как создается виджет
Этот класс TtkCalendar можно кастомизировать, передавая параметры в виде аргументов-ключевых слов. Их можно получать при инициализации, указав кое-какие значения по умолчанию, например, текущие месяц и год:
def __init__(self, master=None, **kw):
now = datetime.datetime.now()
fwday = kw.pop('firstweekday', calendar.MONDAY)
year = kw.pop('year', now.year)
month = kw.pop('month', now.month)
sel_bg = kw.pop('selectbackground', '#ecffc4')
sel_fg = kw.pop('selectforeground', '#05640e')
super().__init__(master, **kw)
После этого задаются атрибуты для хранения информации:
selected— хранит значение выбранной даты.date— дата, представляющая текущий месяц, который показывается на календаре.calendar— григорианский календарь с информацией о неделях и названиями месяцев.
Визуальные элементы виджета внутри создаются с помощью методов create_header() и create_table(), речь о которых пойдет дальше.
Также используется экземпляр tkfont.Font для определения размера шрифта.
После инициализации этих атрибутов визуальные элементы календаря выравниваются с помощью вызова метода build_calendar():
self.selected = None
self.date = datetime.date(year, month, 1)
self.cal = calendar.TextCalendar(fwday)
self.font = tkfont.Font(self)
self.header = self.create_header()
self.table = self.create_table()
self.canvas = self.create_canvas(sel_bg, sel_fg)
self.build_calendar()
Метод create_header() использует ttk.Style для отображения стрелок, которые нужны для переключения между месяцами. Он возвращает метку названия текущего месяца:
def create_header(self):
left_arrow = {'children': [('Button.leftarrow', None)]}
right_arrow = {'children': [('Button.rightarrow', None)]}
style = ttk.Style(self)
style.layout('L.TButton', [('Button.focus', left_arrow)])
style.layout('R.TButton', [('Button.focus', right_arrow)])
hframe = ttk.Frame(self)
btn_left = ttk.Button(hframe, style='L.TButton',
command=lambda: self.move_month(-1))
btn_right = ttk.Button(hframe, style='R.TButton',
command=lambda: self.move_month(1))
label = ttk.Label(hframe, width=15, anchor='center')
hframe.pack(pady=5, anchor=tk.CENTER)
btn_left.grid(row=0, column=0)
label.grid(row=0, column=1, padx=12)
btn_right.grid(row=0, column=2)
return label
Колбек move_month() скрывает текущий выбор, выделенный с помощью поля полотна и добавляет параметр offset текущему месяцу, чтобы задать атрибут date с предыдущим или следующим месяцем. После этого календарь снова перерисовывается, показывая уже дни нового месяца:
def move_month(self, offset):
self.canvas.place_forget()
month = self.date.month - 1 + offset
year = self.date.year + month // 12
month = month % 12 + 1
self.date = datetime.date(year, month, 1)
self.build_calendar()
Тело календаря создается в create_table() с помощью виджета ttk.Treeview, который показывает каждую неделю текущего месяца в одной строке:
def create_table(self):
cols = self.cal.formatweekheader(3).split()
table = ttk.Treeview(self, show='', selectmode='none',
height=7, columns=cols)
table.bind('<Map>', self.minsize)
table.pack(expand=1, fill=tk.BOTH)
table.tag_configure('header', background='grey90')
table.insert('', tk.END, values=cols, tag='header')
for _ in range(6):
table.insert('', tk.END)
width = max(map(self.font.measure, cols))
for col in cols:
table.column(col, width=width, minwidth=width, anchor=tk.E)
return table
Полотно, подсвечивающее выбор, создается с помощью метода create_canvas(). Поскольку оно выравнивает размер в зависимости от размеров выбранного элемента, то оно же скрывается при изменении размеров окна:
def create_canvas(self, bg, fg):
canvas = tk.Canvas(self.table, background=bg,
borderwidth=0, highlightthickness=0)
canvas.text = canvas.create_text(0, 0, fill=fg, anchor=tk.W)
handler = lambda _: canvas.place_forget()
canvas.bind('<ButtonPress-1>', handler)
self.table.bind('<Configure>', handler)
self.table.bind('<ButtonPress-1>', self.pressed)
return canvas
Календарь строится за счет перебора недель и позиций элементов таблицы ttk.Treeview. С помощью функции zip_longest() из модуля itertools перебираем коллекцию, оставляя на месте недостающих дней пустые строки.
Это поведение нужно для первой и последней недель месяца, ведь именно там часто можно найти пустые слоты:
def build_calendar(self):
year, month = self.date.year, self.date.month
month_name = self.cal.formatmonthname(year, month, 0)
month_weeks = self.cal.monthdayscalendar(year, month)
self.header.config(text=month_name.title())
items = self.table.get_children()[1:]
for week, item in zip_longest(month_weeks, items):
week = week if week else []
fmt_week = ['%02d' % day if day else '' for day in week]
self.table.item(item, values=fmt_week)
При клике по элементу таблицы обработчик события pressed() задает выделение и меняет полотно для выделения выбора:
def pressed(self, event):
x, y, widget = event.x, event.y, event.widget
item = widget.identify_row(y)
column = widget.identify_column(x)
items = self.table.get_children()[1:]
if not column or not item in items:
# клик на заголовок или за пределами столбцов
return
index = int(column[1]) - 1
values = widget.item(item)['values']
text = values[index] if len(values) else None
bbox = widget.bbox(item, column)
if bbox and text:
self.selected = '%02d' % text
self.show_selection(bbox)
Метод show_selection() размещает полотно в пределах выбранного элемента, так что текст помещается внутри:
def show_selection(self, bbox):
canvas, text = self.canvas, self.selected
x, y, width, height = bbox
textw = self.font.measure(text)
canvas.configure(width=width, height=height)
canvas.coords(canvas.text, width - textw, height / 2 - 1)
canvas.itemconfigure(canvas.text, text=text)
canvas.place(x=x, y=y)
Наконец, параметр selection позволяет получить выбранную дату в виде объекта datetime.date. Он не используется в примере, но нужен для работы API в классе TtkCalendar:
@property
def selection(self):
if self.selected:
year, month = self.date.year, self.date.month
return datetime.date(year, month, int(self.selected))
Перед работой с программой нужно убедиться, что у вас есть база данных из прошлых уроков sqlite_python.db.
В этом примере будет использоваться таблица new_developers.
Пример вставки/получения объекта DateTime
Обычно при выполнении запроса на вставку объекта datetime модуль sqlite3 в Python конвертирует его в строковый формат. То же самое происходит при получении данных из таблицы — они возвращаются в строковом формате. Разберем на простом примере.
import sqlite3, datetime
def add_developer(dev_id, name, joining_date):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_create_table_query = '''CREATE TABLE new_developers (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
joiningDate timestamp);'''
cursor = sqlite_connection.cursor()
cursor.execute(sqlite_create_table_query)
# вставить данные разработчика
sqlite_insert_with_param = """INSERT INTO 'new_developers'
('id', 'name', 'joiningDate')
VALUES (?, ?, ?);"""
data_tuple = (dev_id, name, joining_date)
cursor.execute(sqlite_insert_with_param, data_tuple)
sqlite_connection.commit()
print("Разработчик успешно добавлен \n")
# получить данные разработчика
sqlite_select_query = """SELECT name, joiningDate from new_developers where id = ?"""
cursor.execute(sqlite_select_query, (1,))
records = cursor.fetchall()
for row in records:
developer= row[0]
joining_date = row[1]
print(developer, "присоединился", joining_date)
print("тип даты", type(joining_date))
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
add_developer(1, 'Mark', datetime.datetime.now())
Вывод:
Подключен к SQLite
Разработчик успешно добавлен
Mark присоединился 2020-12-28 10:58:48.828803
тип даты <class 'str'>
Соединение с SQLite закрытоКак можно видеть, в таблицу был вставлен объект даты, но после получения он стал строкой. Однако это не мешает конвертировать результат обратно в объект даты.
Для этого используется detect_types с PARSE_DECLTYPES и PARSE_COLNAMES в качестве аргументов в методе connect модуля sqlite3.
sqlite3.PARSE_DECLTYPES
Эта константа используется как значение параметра detect_types метода connect().
Если использовать этот параметр в методе connect(), то модуль sqlite3 будет парсить тип каждой получаемой колонки.
После парсинга используется словарь конвертации типов для поиска выполнения конкретной функции конвертации.
sqlite3.PARSE_COLNAMES
Эта константа нужна для того же параметра.
При ее использовании интерфейс SQLite сохранит значения имени каждой возвращаемой колонки. После этого можно аналогично использовать словарь для конвертации в нужный тип.
Посмотрим на следующий пример. В нем при считывании объекта datetime из таблицы SQLite нужно получить объединяющий тип — datetime.
import sqlite3, datetime
def add_developer(dev_id, name, joining_date):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db',
detect_types=sqlite3.PARSE_DECLTYPES |
sqlite3.PARSE_COLNAMES)
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_create_table_query = '''CREATE TABLE new_developers2 (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
joiningDate timestamp);'''
cursor = sqlite_connection.cursor()
cursor.execute(sqlite_create_table_query)
# вставить данные разработчика
sqlite_insert_with_param = """INSERT INTO 'new_developers2'
('id', 'name', 'joiningDate')
VALUES (?, ?, ?);"""
data_tuple = (dev_id, name, joining_date)
cursor.execute(sqlite_insert_with_param, data_tuple)
sqlite_connection.commit()
print("Разработчик успешно добавлен \n")
# получить данные разработчика
sqlite_select_query = """SELECT name, joiningDate from new_developers2 where id = ?"""
cursor.execute(sqlite_select_query, (1,))
records = cursor.fetchall()
for row in records:
developer= row[0]
joining_date = row[1]
print(developer, "присоединился", joining_date)
print("тип даты", type(joining_date))
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
add_developer(1, 'Mark', datetime.datetime.now())
Вывод:
Подключен к SQLite
Разработчик успешно добавлен
Mark присоединился 2020-12-28 11:11:01.304116
тип даты <class 'datetime.datetime'>
Соединение с SQLite закрытоВ результате вернувшиеся данные из таблицы представлены типом datetime.datetime.
Индекс начинается с нуля, как и в случае списков, а отрицательный индекс — с -1. Этот индекс указывает на последний элемент кортежа.
Где используется?
Кортежи — распространенная структура данных для хранения последовательностей в Python.
.index()— используется для вывода индекса элемента..count()— используется для подсчета количества элементов в кортеже.sum()— складывает все элементы кортежа.min()— показывает элемент кортежа с наименьшим значением.max()— показывает элемент кортежа с максимальным значением.len()— показывает количество элементов кортежа.
Рекомендации по работе с кортежами
- Кортежи создаются с помощью круглых скобок:
(); - Элементы внутри кортежей разделяются запятыми;
- Важно соблюдать особенности синтаксиса, характерные для каждого отдельного типа данных в кортеже — кавычки для строк, числа и булевые значения без кавычек и так далее.
Дальше — кортеж, включающий элементы разных типов:
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup)
('Лондон', 'Пекин', 44, True)
Доступ к элементам: получить элементы кортежа можно с помощью соответствующего индекса в квадратных скобках.
Например, для получения элемента «Лондон» нужно использовать следующий индекс: p_tup[0]
А для 44: p_tup[2]
Последний элемент следующего кортежа — булево True. Доступ к нему мы получаем с помощью функции print.
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup[3])
True
Пример получения первого элемента кортежа.
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup[0])
'Лондон'
Советы:
- Обратное индексирование: по аналогии с элементами списка элементы кортежа также можно получить с помощью обратного индексирования. Оно начинается с -1. Это значение указывает на последний элемент.
Так, для получения последнего элементp_tupнужно писатьp_tup[-1].p_tup[-2]вернет второй элемент с конца и так далее. - Главное отличие кортежей от списков — они неизменяемые. Кортежам нельзя добавлять или удалять элементы.
Поэтому эта структура используется, когда известно, что элементы не будут меняться в процессе работы программы.
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup[-1])
True
Функция .index()
.index() — полезный метод, используемый для получения индекса конкретного элемента в кортеже.
Посмотрим на примере.
>>> p_tup = ("Лондон", "Пекин", 44, True)
>>> print(p_tup.index("Лондон"))
0
Функция .count()
Метод .count() подходит для определения количества вхождений определенного элемента в кортеже.
В примере ниже можно увидеть, что считается количество вхождений числа 101 в списке p_cup. Результат — 2.
>>> p_tup = (5, 101, 42, 3, 101)
>>> print(p_tup.count(101))
2
Функция sum()
Функция sum() возвращает общую сумму чисел внутри кортежа.
>>> lucky_numbers = (5, 55, 4, 3, 101, 42)
>>> print(sum(lucky_numbers))
210
Функция min()
Функция min() вернет элемент с самым маленьким значением в кортеже.
>>> lucky_numbers = (5, 55, 4, 3, 101, 42)
>>> print(min(lucky_numbers))
5
Функция max()
Функция max() вернет элемент с максимальным значением в кортеже.
>>> lucky_numbers = (5, 55, 4, 3, 101, 42)
>>> print(max(lucky_numbers))
101
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Создайте кортеж с цифрами от 0 до 9 и посчитайте сумму.
# данный код
numbers =
print(sum(numbers))
# требуемый вывод:
# 452. Введите статистику частотности букв в кортеже.
# данный код
long_word = (
'т', 'т', 'а', 'и', 'и', 'а', 'и',
'и', 'и', 'т', 'т', 'а', 'и', 'и',
'и', 'и', 'и', 'т', 'и'
)
print("Количество 'т':", )
print("Количество 'a':", )
print("Количество 'и':", )
# требуемый вывод:
# Колличество 'т': 5
# Колличество 'а': 3
# Колличество 'и': 11- Допишите скрипт для расчета средней температуры.
Постарайтесь посчитать количество дней на основеweek_temp. Так наш скрипт сможет работать с данными за любой период.
# данный код
week_temp = (26, 29, 34, 32, 28, 26, 23)
sum_temp =
days =
mean_temp = sum_temp / days
print(int(mean_temp))
# требуемый вывод:
# 28Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_7.py.
Тест по кортежам
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>- В качестве бинарных данных могут выступать файлы с любым расширением, изображения, видео или другие медиа;
- BLOB-данные можно считывать из таблицы SQLite.
Перед выполнением операций над BLOB-данными убедитесь, что вы знаете название таблицы SQLite. Для хранения этой информации нужно или создать новую, или изменить существующую, добавив колонку соответствующего типа.
В этом примере будет использоваться таблица new_employee. Ее можно создать с помощью следующего скрипта:
CREATE TABLE new_employee (id INTEGER PRIMARY KEY, name TEXT NOT NULL, photo BLOB NOT NULL, resume BLOB NOT NULL);Эта таблица содержит две BLOB-колонки:
- Колонка
photoдля хранения изображения сотрудника. - Колонка
resumeдля хранения файла резюме.
Но стоит также разобраться с тем, что же такое BLOB.
Что такое BLOB
BLOB (large binary object — «большой бинарный объект») — это тип данных, который используется для хранения «тяжелых» файлов, таких как изображения, видео, музыка, документы и так далее. Перед сохранением в базе данных эти файлы нужно конвертировать в бинарные данные — то есть, массив байтов.
Вставка изображений и файлов в таблицу
Вставим изображение и резюме сотрудника в таблицу new_employee. Для этого требуется выполнить следующие шаги:
- Установить SQLite-соединение с базой данных из Python;
- Создать объект cursor из объекта соединения;
- Создать INSERT-запрос. На этом этапе нужно знать названия таблицы и колонки, в которую будет выполняться вставка;
- Создать функцию для конвертации цифровых данных (например, изображений или файлов) в бинарные;
- Выполнить INSERT-запрос с помощью
cursor.execute(); - После успешного завершения операции закоммитить сохранения в базу данных;
- Закрыть объект
cursorи соединение; - Перехватить любые SQL-исключения.
Посмотрим на пример:
import sqlite3
def convert_to_binary_data(filename):
# Преобразование данных в двоичный формат
with open(filename, 'rb') as file:
blob_data = file.read()
return blob_data
def insert_blob(emp_id, name, photo, resume_file):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_insert_blob_query = """INSERT INTO new_employee
(id, name, photo, resume) VALUES (?, ?, ?, ?)"""
emp_photo = convert_to_binary_data(photo)
resume = convert_to_binary_data(resume_file)
# Преобразование данных в формат кортежа
data_tuple = (emp_id, name, emp_photo, resume)
cursor.execute(sqlite_insert_blob_query, data_tuple)
sqlite_connection.commit()
print("Изображение и файл успешно вставлены как BLOB в таблиу")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
insert_blob(1, "Smith", "smith.jpg", "smith_resume.docx")
insert_blob(2, "David", "david.jpg", "david_resume.docx")
Вывод:
Подключен к SQLite
Изображение и файл успешно вставлены как BLOB в таблиу
Соединение с SQLite закрыто
Подключен к SQLite
Изображение и файл успешно вставлены как BLOB в таблиу
Соединение с SQLite закрытоВот как выглядит таблица после вставки данных:
- В примере были вставлены id сотрудника, имя, фото и файл с резюме. Для последних двух были переданы местоположения файлов, так что программа смогла считать их и конвертировать в бинарные данные
- Как можно явно увидеть, изображение и файл конвертировались в бинарный формат в процессе чтения данных в режиме
rb. И только после этого данные были вставлены в колонку BLOB. Также был использован запрос с параметрами для вставки динамических данных в таблицу.
Получение изображения и файла, сохраненных в виде BLOB
Предположим, данные, которые хранятся в виде BLOB в базе данных, нужно получить, записать в файл на диске и открыть в привычном виде. Как это делается?
В этом примере считаем изображение сотрудника и файл с резюме из SQLite-таблицы.
Для этого нужно проделать следующие шаги:
- Установить SQLite-соединение с базой данных из Python;
- Создать объект
cursorиз объекта соединения; - Создать SELECT-запрос для получения BLOB-колонок из таблицы;
- Использовать
cursor.fetchall()для получения всех строк и перебора по ним; - Создать функцию для конвертации BLOB-данных в нужный формат и записать готовые файлы на диск;
- Закрыть объект
cursorи соединение.
import sqlite3, os
def write_to_file(data, filename):
# Преобразование двоичных данных в нужный формат
with open(filename, 'wb') as file:
file.write(data)
print("Данный из blob сохранены в: ", filename, "\n")
def read_blob_data(emp_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_fetch_blob_query = """SELECT * from new_employee where id = ?"""
cursor.execute(sql_fetch_blob_query, (emp_id,))
record = cursor.fetchall()
for row in record:
print("Id = ", row[0], "Name = ", row[1])
name = row[1]
photo = row[2]
resume_file = row[3]
print("Сохранение изображения сотрудника и резюме на диске \n")
photo_path = os.path.join("db_data", name + ".jpg")
resume_path = os.path.join("db_data", name + "_resume.txt")
write_to_file(photo, photo_path)
write_to_file(resume_file, resume_path)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
read_blob_data(1)
read_blob_data(2)
Вывод:
Подключен к SQLite
Id = 1 Name = Smith
Сохранение изображения сотрудника и резюме на диске
Данный из blob сохранены в: db_data\Smith.jpg
Данный из blob сохранены в: db_data\Smith_resume.txt
Соединение с SQLite закрыто
Подключен к SQLite
Id = 2 Name = David
Сохранение изображения сотрудника и резюме на диске
Данный из blob сохранены в: db_data\David.jpg
Данный из blob сохранены в: db_data\David_resume.txt
Соединение с SQLite закрытоИзображения и файлы действительно сохранились на диске.

Примечание: для копирования бинарных данных на диск они сперва должны быть конвертированы в нужный формат. В этом примере форматами были .jpg и .txt.
]]>В этом материале рассмотрим класс ttk.Treeview, с помощью которого можно выводить информацию в иерархической или форме таблицы.
Каждый элемент, добавленный к классу ttk.Treeview разделяется на одну или несколько колонок. Первая может содержать текст и иконку, которые показывают, может ли элемент быть раскрыт, чтобы показать вложенные элементы. Оставшиеся колонки показывают значения для каждой строки.
Первая строка класса ttk.Treeview состоит из заголовков, которые определяют каждую колонку с помощью имени. Их можно скрыть.
С помощью ttk.Treeview создадим таблицу из списка контактов, которые хранятся в CSV-файле:
Создадим виджет ttk.Treeview с тремя колонками, в каждой из которых будут поля каждого из контактов: имя, фамилия и адрес электронной почты.
Контакты загружаются из CSV-файла с помощью модуля csv, и после этого добавляется связывание для виртуального элемента <<TreeviewSelect>>, который генерируется при выборе одного или большего количества элементов:
import csv
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self, path):
super().__init__()
self.title("Ttk Treeview")
columns = ("#1", "#2", "#3")
self.tree = ttk.Treeview(self, show="headings", columns=columns)
self.tree.heading("#1", text="Фамилия")
self.tree.heading("#2", text="Имя")
self.tree.heading("#3", text="Почта")
ysb = ttk.Scrollbar(self, orient=tk.VERTICAL, command=self.tree.yview)
self.tree.configure(yscroll=ysb.set)
with open("../lesson_13/contacts.csv", newline="") as f:
for contact in csv.reader(f):
self.tree.insert("", tk.END, values=contact)
self.tree.bind("<<TreeviewSelect>>", self.print_selection)
self.tree.grid(row=0, column=0)
ysb.grid(row=0, column=1, sticky=tk.N + tk.S)
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=1)
def print_selection(self, event):
for selection in self.tree.selection():
item = self.tree.item(selection)
last_name, first_name, email = item["values"][0:3]
text = "Выбор: {}, {} <{}>"
print(text.format(last_name, first_name, email))
if __name__ == "__main__":
app = App(path=".")
app.mainloop()
Если запустить эту программу, то каждый раз при выборе контакта данные о нем будут выводиться в стандартный вывод.
Как работает виджет Treeview
Для создания ttk.Treeview с несколькими колонками нужно указать идентификатор каждой с помощью параметра columns. После этого можно настроить текст заголовка с помощью метода heading().
Используем идентификаторы #1, #2 и #3, поскольку первая колонка, включающая иконку раскрытия и текст, всегда генерируется с идентификатором #0.
Также параметру show передается значение «headings», чтобы обозначить, что нужно скрыть колонку #0, потому что вложенных элементов тут не будет.
Следующие значения являются валидными для параметра show:
tree— отображает колонку #0;headings— отображает строку заголовка;tree headings— отображает и колонку #0, и строку заголовка (является значением по умолчанию);""— не отображает ни колонку #0, ни строку заголовка.
После этого к виджету ttk.Treeview добавляется вертикальный скроллбар:
columns = ("#1", "#2", "#3")
self.tree = ttk.Treeview(self, show="headings", columns=columns)
self.tree.heading("#1", text="Фамилия")
self.tree.heading("#2", text="Имя")
self.tree.heading("#3", text="Почта")
ysb = ttk.Scrollbar(self, orient=tk.VERTICAL, command=self.tree.yview)
self.tree.configure(yscroll=ysb.set)
Для загрузки контактов в таблицу файл нужно обработать с помощью функции render() из модуля CSV. В процессе строка, прочтенная на каждой итерации, добавляется к ttk.Treeview.
Это делается с помощью метода insert(), который получает родительский узел и положение для размещения элемента.
Поскольку все контакты показываются как элементы верхнего уровня, передаем пустую строку в качестве первого параметра и константу END, чтобы обозначить, что каждый элемент добавляется на последнюю позицию.
Также можно использовать другие аргументы-ключевые слова для метода insert(). Здесь используется параметр values, который принимает последовательность значений — они и отображаются в каждой колонке Treeview:
with open("../lesson_13/contacts.csv", newline="") as f:
for contact in csv.reader(f):
self.tree.insert("", tk.END, values=contact)
self.tree.bind("<<TreeviewSelect>>", self.print_selection)
<<TreeviewSelect>> — это виртуальное событие, которое генерируется при выборе одного или нескольких элементов из таблицы. В обработчике print_selection() получаем текущее выделение с помощью метода selection(), и для каждого результата выполняем следующие шаги:
- С помощью метода
item()получаем словарь параметров и значений выбранного элемента. - Получаем первые три значения словаря
item, которые соответствуют фамилии, имени и адресу электронной почты контакта. - Значения форматируются и выводятся в стандартный вывод:
def print_selection(self, event):
for selection in self.tree.selection():
item = self.tree.item(selection)
last_name, first_name, email = item["values"][0:3]
text = "Выбор: {}, {} <{}>"
print(text.format(last_name, first_name, email))
Это были базовые особенности класса ttk.Treeview, поскольку работа велась с обычной таблицей. Однако приложение можно расширить и с помощью более продвинутых особенностей этого класса.
Использование тегов в элементах Treeview
Тэги доступны для элементов ttk.Treeview, благодаря чему существует возможность связать последовательности события с конкретными строками таблицы Contacts.
Предположим, что есть необходимость открывать новое окно для добавления информации об электронной почте по двойному клику. Однако это должно работать только для записей, в которых поле email уже заполнено.
Это можно реализовать, добавляя тег с условием при вставке. После этого нужно вызывать tag_bind() на экземпляре виджета с последовательностью "<Double-Button-1>" — здесь можно просто сослаться на реализацию функции-обработчика send_email_to_contact() по имени:
columns = ("Фамилия", "Имя", "Почта")
tree = ttk.Treeview(self, show="headings", columns=columns)
for contact in csv.reader(f):
email = contact[2]
tags = ("dbl-click",) if email else ()
self.tree.insert("", tk.END, values=contact, tags=tags)
tree.tag_bind("dbl-click", "<Double-Button-1>", send_email_to_contact)
По аналогии с тем, что происходит при связывании событий с элементами Canvas, важно не забывать добавлять элементы с тегами к ttk.Treeview до вызова tag_bind(), потому что связывания добавляются только к существующим совпадающим элементам.
Заполнение вложенных элементов в Treeview
ttk.Treeview может использоваться и как обычная таблица, но также — содержать структуры с определенной иерархией. Визуально это напоминает дерево, у которого можно раскрывать определенные узлы.
Это удобно для отображения результатов рекурсивных вызовов и нескольких уровней вложенных элементов. В этом материале рассмотрим сценарий работы с такой структурой.
Для демонстрации рекурсивного добавления элементов в виджет ttk.Treeview создадим базовый браузер файловой системы. Раскрываемые узлы будут представлять собой папки, а после раскрытия они будут показывать вложенные файлы и папки:
Дерево изначально будет заполняться с помощью метода populate_node(), который содержит записи текущей директории. Если запись сама является директорией, то она добавляет дочерний раскрываемый узел.
Когда такой узел раскрывается, он «лениво» загружает содержимое с помощью еще одного вызова populate_node(). В этот раз, вместо добавления элементов в качестве узлов верхнего уровня, они вкладываются внутрь открытого узла:
import os
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self, path):
super().__init__()
self.title("Ttk Treeview")
abspath = os.path.abspath(path)
self.nodes = {}
self.tree = ttk.Treeview(self)
self.tree.heading("#0", text=abspath, anchor=tk.W)
ysb = ttk.Scrollbar(self, orient=tk.VERTICAL,
command=self.tree.yview)
xsb = ttk.Scrollbar(self, orient=tk.HORIZONTAL,
command=self.tree.xview)
self.tree.configure(yscroll=ysb.set, xscroll=xsb.set)
self.tree.grid(row=0, column=0, sticky=tk.N + tk.S + tk.E + tk.W)
ysb.grid(row=0, column=1, sticky=tk.N + tk.S)
xsb.grid(row=1, column=0, sticky=tk.E + tk.W)
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=1)
self.tree.bind("<<TreeviewOpen>>", self.open_node)
self.populate_node("", abspath)
def populate_node(self, parent, abspath):
for entry in os.listdir(abspath):
entry_path = os.path.join(abspath, entry)
node = self.tree.insert(parent, tk.END, text=entry, open=False)
if os.path.isdir(entry_path):
self.nodes[node] = entry_path
self.tree.insert(node, tk.END)
def open_node(self, event):
item = self.tree.focus()
abspath = self.nodes.pop(item, False)
if abspath:
children = self.tree.get_children(item)
self.tree.delete(children)
self.populate_node(item, abspath)
if __name__ == "__main__":
app = App(path="../")
app.mainloop()
Запуск предыдущего примера выведет иерархию файловой системы в зависимости от того, где запустить этот файл. Однако можно явно указать директорию с помощью аргумента path конструктора App.
Как работают выпадающие элементы
В этом примере будем использовать модуль os, который является частью стандартной библиотеки Python и предоставляет удобный способ для выполнения запросов к операционной системе.
Первый раз модуль используется для перевода начального пути в абсолютный, а также для инициализации словаря nodes, который будет хранить соответствия между расширяемыми элементами и путями к директориям, которые те представляют:
import os
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self, path):
# ...
abspath = os.path.abspath(path)
self.nodes = {}
Например, os.path.abspath(".") вернет абсолютную версию пути к папке, откуда был запущен скрипт. Этот подход лучше использования относительных путей, потому что он помогает не думать о возможных проблемах при работе с путями.
Дальше инициализируется экземпляр ttk.Treeview с вертикальным и горизонтальным скроллбарами. Параметр text иконки заголовка будет тем самым абсолютным путем:
self.tree = ttk.Treeview(self)
self.tree.heading("#0", text=abspath, anchor=tk.W)
ysb = ttk.Scrollbar(self, orient=tk.VERTICAL,
command=self.tree.yview)
xsb = ttk.Scrollbar(self, orient=tk.HORIZONTAL,
command=self.tree.xview)
self.tree.configure(yscroll=ysb.set, xscroll=xsb.set)
После этого виджеты размещаются с помощью geometry manager Grid. Экземпляр ttk.Treeview нужно сделать автоматически изменяемым горизонтально и вертикально.
После этого выполняется связывание виртуального события "<<TreeviewOpen>>", которое генерируется при открытии раскрываемого элемента в обработчике open_node(). populate_node() вызывается для загрузки записей конкретной директории:
self.tree.bind("<<TreeviewOpen>>", self.open_node)
self.populate_node("", abspath)
Стоит обратить внимание на то, что первый вызов этого метода выполняется с пустой строкой для родительской директории, что значит, что у нее не будет родителей, и ее стоит отображать как элемент верхнего уровня.
В методе populate_node() перечисляем названия записей директорий с помощью вызова os.listdir(). Для каждого названия после этого выполняем следующие действия:
- Вычисляем абсолютный путь к записи. В UNIX-системах это делается за счет объединения строк слэшем, а в Windows используются обратные слэши. Благодаря
os.path.join()с путями можно работать безопасно, не думая об особенностях платформ. - Вставляем строку
entryкак последний дочерний элемент конкретного узлаparent. Всегда отмечаем их закрытыми, чтобы «лениво» загружать вложенные элементы только тогда, когда те потребуются. - Если абсолютный путь записи указывает на директорию, то добавляется связь для узла и пути в атрибут
nodes, а также добавляется пустой дочерний элемент, позволяющий раскрывать его:
def populate_node(self, parent, abspath):
for entry in os.listdir(abspath):
entry_path = os.path.join(abspath, entry)
node = self.tree.insert(parent, tk.END, text=entry, open=False)
if os.path.isdir(entry_path):
self.nodes[node] = entry_path
self.tree.insert(node, tk.END)
При нажатии на такой элемент обработчик open_node() получает выбранный элемент с помощью вызова метода focus() экземпляра ttk.Treeview.
Идентификатор элемента используется для получения абсолютного пути, который был добавлен до этого в атрибут nodes. Чтобы ошибка KeyError не появлялась, если узел не существует в словаре, используем метод pop(), который возвращает второй параметр в качестве значения по умолчанию — False.
Если узел существует, очищаем «фейковый» элемент расширяемого узла. Вызов self.tree.get_children(item) возвращает идентификаторы дочерних элементов item. После этого они удаляются с помощью вызова self.tree.delete(children).
После очистки элемента добавляем реальные дочерние элементы с помощью метода populate_node() и item в качестве родителя:
def open_node(self, event):
item = self.tree.focus()
abspath = self.nodes.pop(item, False)
if abspath:
children = self.tree.get_children(item)
self.tree.delete(children)
self.populate_node(item, abspath)
Популярность специалистов на рынке труда высока, в особенности в направлениях, связанных с анализом данных и машинным обучением. Давайте рассмотрим, в какой школе лучше всего осваивать представленный язык.
Топ-10 онлайн-курсов
Хотите освоить перспективную и востребованную профессию программиста на Python или тесно связанную с выбранным языком — тогда нужно заняться образованием прямо сейчас! Представляем 10 интересных и эффективных курсов для новичков, которые помогут освоить тонкости разработки и получить работу мечты:
Профессия Python-разработчик
Годичная программа по изучению популярного языка программирования Python от Skillbox. На занятиях вы научитесь складывать числа, выводить на монитор тест и создавать модульные программы. С первого урока студенты пишут код.
Краткая программа курса:
- Python
- Python Advanced
- Веб-верстка
- Python-фреймворк
- Django
- Универсальные знания программиста
- Английский для IT-специалистов
- Система контроля версий Git
Бонус от онлайн-школы — 2 месяца английского языка в подарок!
Python-разработчик
Альтернативный вариант предыдущему курсу. Сокращенная программа обучения — 6 месяцев. На уроках вы научитесь основам программирования и продвинутому использованию Python.
Краткая программа курса:
- Настройка окружения
- Базовые структуры данных
- Основные операторы
- Функции подробнее
- Модули и пакеты
- Пространства имён и области видимости
- Классы и объекты
- Библиотеки для работы с ресурсами
- Бонусный модуль Python Advanced. Flask: начало
- Бонусный модуль Python Advanced.
- Основы работы в Linux
- Бонусный модуль Python Advanced.
- Основы культуры CI
Профессия Fullstack-разработчик на Python

Стань Fullstack-разработчиком на Python вместе с опытными преподавателями школы SkillFactory. Вы сможете прокачать свои знания за 15 месяцев и сразу начать работать по специальности. На занятиях вы получите базовые знания о программировании, освоите бекэнд на Python и фронтенд JavaScript.
Краткая программа курса:
- Программирование на Python
- Создаем веб-приложение на Django
- Подключаем веб-приложение к базе данных
- Верстаем страницы и изучаем фронтенд-разработку на Javascript
- Пишем приложение на React
- Знакомимся с основами Devops и размещаем проект на сервере и в облаке
- Карьерный трек
- Финальный проект
Новогодняя акция — скидка 50% на курсы!
Курс Python Basic

Станьте опытным Python-разработчиком с нуля вместе с командой онлайн-академии ITEA. Вы научитесь создавать логические структуры программ и писать чистый код за короткое время. Всего за 10 занятий вы освоите профессию будущего под руководством топовых преподавателей-практиков.
Краткая программа курса:
- Зачем нужны компьютерные программы
- Переменные, выражения и инструкции Python
- Управление потоком выполнения
- Итерации
- Функции и модули
- Строки
- Основы работы с системой контроля версий
- Файлы
- Коллекции
- Элементы функционального программирования
- Объектно-ориентированное программирование
Специальная скидка 40% от академии на все курсы!
Python Advanced

Углубиться в основы программирования на Python и изучить все аспекты разработки на популярном языке можно в академии ITEA. Пройдя учебный курс, вы сможете эффективно подготовиться к работе на фрилансе или в IT-компании. В онлайн-академии вы научитесь использовать все возможности языка программирования на практике.
Краткая программа курса:
- Функции
- Объектно-ориентированный подход
- Управление созданием экземпляров класса
- Приемы объектно-ориентированного программирования
- Модули и пакеты
- Работа с файлами
- Встроенные пакеты Python
- Networking
- Многопоточность в Python
- Процессы в Python
- Асинхронное программирование
- SQL
- Object Relational Mapping
- NoSQL-базы данных
- Веб-разработка
В академии можно пройти бесплатный пробный урок, оплачивать обучение частями, а также получить скидку в 40%!
Python / Django

Продвинутый курс от ITEA подойдет всем, кто хочет научиться создавать уникальные проекты в мире web-разработки. Действенная программа подготовки поможет вам быстро освоить Django, если знаете углубленно Python.
Краткая программа курса:
- Введение в Django
- Базы данных. Модели
- Система URL-адресов
- Шаблонизатор
- Практика
- Формы, валидаторы форм
- Class-based views
- Аутентификация/авторизация/регистрация пользователей
- Отправка сообщений на почту/телеграмм
- Практика
- Создание rest-api
- Введение в front end
- Библиотека jquery. Фреймворк Vue.js
Для всех будущих студентов действует специальное предложение от онлайн-академии — скидка в 40% на курсы!
Python Developer. Basic

Изучите ключевые механизмы работы с Python для решения разных задач в IT-сфере в онлайн-школе OTUS. На занятиях студенты проходят синтаксис, овладевают фундаментальными приемами разработки на востребованном языке программирования.
Краткая программа курса:
- Синтаксис и базовые операторы Python
- ООП. Классы, исключения
- Батарейки идут в комплекте. Взаимодействие с внешним миром
- Асинхронное программирование, работа с базами данных
- Python для Data Science
- Веб-разработка. Знакомство
- Контейнеризация, сборка проекта
- Веб-разработка на Django
- Разработка API и парсинг сайтов
- DevOps
- Проектная работа
Пройдите тестирование на сайте и запишитесь на курс по специальной цене!
Python разработка — с нуля до профессионала

Пройдите онлайн-курс в Udemy, чтобы с нуля освоить перспективную профессию. Занятия построены максимально просто и доступно даже для новичков. Вы начнете с базиса и пройдете весь путь разработчика: от теории и созданию собственных приложений.
Краткая программа курса:
- Введение
- Основы
- Коллекции, циклы и логика
- Функции и модули
- ООП
- Что нового в питон 3.8
- Введение в SQL
30-дневная гарантия возврата денег, если курс не подойдет!
Основы языка Python

Курс «Основы языка Python» от Geekbrains подойдет всем, кто желает познакомиться с новым инструментом программирования – как опытным разработчикам, так и новичкам. Студенты пройдут путь от базовых понятий до построения собственных приложений с применением объектно-ориентированного подхода.
Краткая программа курса:
- Вступление
- Введение в Python
- Встроенные типы и операции с ними
- Работа с файлами. Кодировки
- Практикум. Консольный файловый менеджер
PythonBoost

Экспресс-интенсив по изучению основ Python. На онлайн-уроках вы узнаете фундаментальные особенности языка программирования и поймете, в каком направлении двигаться дальше.
Краткая программа курса:
- Первое знакомство и настройка окружения
- Базовые структуры данных
- Условия if/elif/else
- Циклы
- Функции
- ООП. Классы, объекты
- Тестирование
- Материалы для дальнейшего изучения
Скидка на обучение — 1000 рублей!
Желаем удачи в изучению востребованного языка программирования Python! Это будет нелегкий путь, но поставив перед собой цели и двигаясь к ним под руководством опытных преподавателей, вы станете на шаг ближе к освоению востребованной и перспективной профессии!
]]>В отличие от словарей у списков есть индексный порядок. Это значит, что каждый элемент в списке имеет индекс, который не поменяется, если его не изменить вручную. В случае других структур, таких как словари, это может быть иначе. Например, у словарей нет индексов для их ключей, поэтому нельзя просто указать на второй или третий элемент, ведь такого порядка не существует. Эту структуру данных стоит воспринимать как мешок перемешанных вещей без конкретного порядка.
Индексация: важно отметить, что индексация списков начинается с 0 (нуля). Это значит, что первый элемент в списке на самом деле является нулевым в мире Python. Об этом очень важно помнить.
Изменяемость: списки являются изменяемым типом, что значит, что можно добавлять или удалять их элементы. Посмотрим на примерах.
Где используется?
Списки — распространенная структура данных в Python. Они используются для самых разных целей.
| Метод | Действие |
|---|---|
| .append() | метод для добавления элементов в список |
| .insert() | для добавления элементов в конкретное место в списке |
| .index() | для получения индекса элемента |
| .clear() | для очистки списка |
| .remove() | для удаления элемента списка |
| .reverse() | чтобы развернуть список в обратном порядке |
| .count() | для подсчета количества элементов в списке |
| sum() | для сложения элементов списка |
| min() | показывает элемент с самым низким значением в списке |
| max() | элемент с самым высоким значением в списке |
Рекомендации по работе со списками
- Списки создаются с помощью квадратных скобок [].
- Элементы списка нужно разделять запятыми.
- Правила синтаксиса, характерные для определенных типов данных, нужно соблюдать внутри списка. Так, если у строки должны быть кавычки, то их нужно использовать и внутри списка, а для чисел и значений булево типа их не нужно использовать.
Дальше идет список, включающий значения разных типов. Это отличный пример, демонстрирующий нюансы списков. Посмотрим.
>>> p_datatypes = ["Python", "апельсин", 23, 51, False, "False", "22"]
>>> print(p_datatypes)
"Python", "апельсин", 23, 51, False, "False", "22"
- Во-первых, видно, что внутри находятся значения разных типов. Это строка, целое число, булево значение и снова строка.
- Последние два элемента списка — это строки, хотя они могут напоминать булев тип и целое число. Однако использование кавычек прямо указывает на то, что это строки в Python.
- Наконец, если посмотреть на индексы элементов, то можно увидеть, что нулевой элемент — это «Python», а шестой — «22». Оба являются строками. Хотя элементов 7, последним индексом является 6.
Доступ к элементам: доступ к элементам списка можно получить с помощью их индекса, указанного в квадратных скобках.
Например, для получения первого элемента («Python») нужно написать следующим образом: p_datatypes[0]. Для получения элемента 23: p_datatypes[2].
Посмотрим на другие примеры. Последний элемент следующего списка — булево значение False. Получим доступ к нему внутри функции print.
>>> p_datatypes = ["Python", "апельсин", 23, False]
>>> print(p_datatypes[3])
False
А вот получение первого элемента из списка.
>>> p_datatypes = ["Python", "апельсин", 23, False]
>>> print(p_datatypes[0])
'Python'
Обратное индексирование
- Обратное индексирование. Элементы списка также можно вызывать, начиная с конца — это называется обратным индексированием. В отличие от обычного индексирования, обратное начинается не с 0, а с -1.
Для получения последнего элемента списка p_datatypes:p_datatypes[-1]. - Аналогично
p_datatypes[-2]вернет второй элемент с конца и так далее.
Этот подход имеет свои преимущества в определенных ситуациях. Куда практичнее и эффективнее использовать обратное индексирование, ведь благодаря этому можно не считать количество элементов в списке. Еще одно преимущество становится заметным при изменяемой длине списка. В этом случае снова не придется считать элементы с самого начала, чтобы добраться до финального.
>>> p_datatypes = ["Python", "апельсин", 23, False]
>>> print(p_datatypes[-1])
False
Методы и функции списков
Метод №1: .append()
append() — это, наверное, самый используемый метод списков. Он используется для добавления элементов к списку. Теперь посмотрим на пример, где метод .append() используется для добавления нового элемента в конец списка.
>>> p_datatypes = ["Python", "апельсин"]
>>> p_datatypes.append("BMW")
>>> print(p_datatypes)
["Python", "апельсин", "BMW"]
Метод №2: .insert()
.insert() — еще один полезный метод для списков. Он используется для вставки элемента в список по индексу.
Посмотрим на примере — .insert() принимает два аргумента: индекс, куда нужно вставить новый элемент, и сам элемент.
>>> p_datatypes = ["Python", "апельсин"]
>>> p_datatypes.insert(1, “BMW”)
>>> print(p_datatypes)
["Python", "BMW", "апельсин"]
Метод №3 .index()
.index() помогает определить индекс элемента. Дальше идет пример получения индекса конкретного элемента.
>>> lst = [1, 33, 5, 55, 1001]
>>> a = lst.index(55)
>>> print(a)
3
Метод №4: .clear()
Метод .clear() удаляет все элементы списка.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> lucky_numbers.clear()
>>> print(lucky_numbers)
[]
Метод №5: .remove()
Метод .remove() удаляет конкретный элемент списка.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> lucky_numbers.remove(101)
>>> print(lucky_numbers)
[5, 55, 4, 3, 42]
Метод №6: .reverse()
Метод .reverse() разворачивает порядок элементов в списке.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> lucky_numbers.reverse()
>>> print(lucky_numbers)
[42, 101, 3, 4, 55, 5]
Метод №7: .count()
Метод .count() используется, чтобы подсчитать, как часто конкретный элемент встречается в списке.
В следующем примере мы считаем, как часто в списке встречается число 5. Результат — 1, что значит, что число 5 встретилось всего один раз.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(lucky_numbers.count(5))
1
В этом же случае в списке нет 1, поэтому и вывод будет 0.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(lucky_numbers.count(1))
0
Функция №8: sum()
Функция sum() вернет общую сумму всех чисел в списке.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(sum(lucky_numbers))
210
Функция №9: min()
Функция min() покажет элемент с минимальным значением в списке. Посмотрим пример.
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(min(lucky_numbers))
3
Функция №10: max()
Функция max() покажет элемент с максимальным значением в списке. Пример:
>>> lucky_numbers = [5, 55, 4, 3, 101, 42]
>>> print(max(lucky_numbers))
101
Продвинутые рекомендации
Вот еще некоторые функции и методы списков, особенности которых мы рассмотрим позже:
- .sort()
- .find()
- .pop()
- len() — используется и в других структурах данныхю.
- zip()
- map()
- filter()
- List Comprehension (очень практичный и удобный способ работы со списками)
Как перемешать элементы списка
Перемешать элементы в списке можно с помощью библиотеки random.
Это стандартная библиотека Python, которая предлагает разные полезные элементы (среди самых используемых — randrange и randint).
В этой библиотеке также есть метод shuffle, который можно использовать после импорта random: random.shuffle(список).
>>> import random
>>> lst = [1,2,3,4,5,6,7,8,9,10]
>>> random.shuffle(lst)
>>> print(lst)
[7,3,5,2,6,8,4,1,9]
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Допишите код, что бы вывести последний элемент списка.
# данный код
sample = ["abc", "xyz", "aba", 1221]
# требуемый вывод:
# 12212. Допишите код, что бы вывести расширенный список.
# данный код
sample = ["Green", "White", "Black"]
print(sample)
# требуемый вывод:
# ["Red", "Green", "White", "Black", "Pink", "Yellow"]3. Исправьте ошибки в коде, что бы посчитать сумму элементов в списке.
# данный код
sample = ["11", "33", "50"]
print(sample.sum())
# требуемый вывод:
# 94Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_6.py.
Тест по спискам
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>CREATE FUNCTION и CREATE PROCEDURE с этой базой данных работать не будут. В этом материале рассмотрим, как создавать или переиспользовать SQL-функции из Python.
C API базы данных SQLite дает возможность создавать пользовательские функции или переопределять поведение существующих. Модуль sqlite3 — это всего лишь оболочка для этого C API, которая предоставляет возможность создавать или переопределять SQLite-функции из Python.
В этой статье мы рассмотрим:
- Использовать
connection.create_function()из sqlite3 в Python для создания и переопределения функций в SQLite; - Использовать
connection.create_aggregate()для создания агрегатных функций в SQLite.
Создание SQL-функций из Python для SQLite
В определенных случаях возникает необходимость совершать определенные вещи при выполнении SQL-запроса, особенно, если это обновление или получение данных. В таких случаях на помощь приходят пользовательские функции. Например, при получении имени пользователя нужно, чтобы оно вернулось в верхнем регистре.
В SQLite есть масса встроенных функций: LENGTH, LOWER, UPPER, SUBSTR, REPLACE и другие. Добавим к этому списку TOTITLE для конвертации любой строки и в строку с заглавными буквами.
Для начала нужно разобраться с connection.create_function().
Синтаксис:
create_function(name, num_params, func)Функция принимает три аргумента:
name— имя функцииnum_params— количество параметров, которые функция принимаетfunc— функция Python, которая вызывается внутри запроса
Эта функция создает пользовательскую функцию, которую можно использовать в инструкциях SQL, ссылаясь на ее name.
Примечание: если в качестве параметра num_params передать значение -1, то функция будет принимать любое количество аргументов. connection.create_function() может возвращать любые типы, поддерживаемые SQLite: bytes, str, int, float и None.
Создадим новую функцию в SQLite с помощью connection.create_function().
import sqlite3
def _to_title_case(string):
return str(string).title()
def get_developer_name(dev_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_connection.create_function("TOTILECASE", 1, _to_title_case)
select_query = "SELECT TOTILECASE(name) FROM sqlitedb_developers where id = ?"
cursor.execute(select_query, (dev_id,))
name = cursor.fetchone()
print("Имя разработчика", name)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
get_developer_name(2)
Вывод:
Подключен к SQLite
Имя разработчика ('Viktoria',)
Соединение с SQLite закрытоРазбор примера в подробностях
В прошлом разделе была создана функция _to_title_case, которая принимает строку в качестве входящего значения и конвертирует ее в строку с заглавными буквами.
import sqlite3:
- Эта строка импортирует модуль sqlite3 в программу.
- С помощью классов и методов модуля sqlite3 можно взаимодействовать с базой данных SQLite.
sqlite3.connect() и connection.cursor():
- С помощью
sqlite3.connect()устанавливается соединение с базой данных. - Дальше метод
connection.cursor()используется для получения объектаcursorиз объекта соединения.
сonnection.create_function():
- После этого вызывается
create_functionиз классаconnection. В нее передаются три аргумента: название функции, количество параметров, которые будет принимать_to_title_caseи функция Python, которая будет вызываться как SQL-функция. - После этого функция TOTITLECASE вызывается в запросе SELECT для получения имени разработчика в виде строки с заглавными буквами.
cursor.execute():
- Выполняем запрос с помощью метода
execute()объектаcursorи получаем имя с помощьюcursor.fetchone().
Наконец, объекты cursor и connection закрываются в блоке finally после завершения операции обновления.
Переопределение существующих функций SQLite
Иногда нужно переопределить уже существующие функции. Например, при возвращении имени пользователя необходимо, чтобы оно было в верхнем регистре.
В качестве демонстрации конвертируем встроенную в SQLite функцию LOWER в UPPER, чтобы при ее вызове она превращала входящие данные в верхний регистр.
Создадим новое определение для функции lower() с помощью метода connection.create_function(). Таким образом мы перезаписываем уже существующую реализацию функции lower().
import sqlite3
def lower(string):
return str(string).upper()
def get_developer_name(dev_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_connection.create_function("lower", 1, lower)
select_query = "SELECT lower(name) FROM sqlitedb_developers where id = ?"
cursor.execute(select_query, (dev_id,))
name = cursor.fetchone()
print("Имя разработчика", name)
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
get_developer_name(1)
Вывод:
Подключен к SQLite
Имя разработчика ('OLEG',)
Соединение с SQLite закрытоТематические виджеты Tk — это отдельная коллекция виджетов Tk, которые выглядят и ощущаются как нативные, и могут быть кастомизированы с помощью API.
Эти классы определены в модуле tkinter.ttk. Помимо новых виджетов, таких как Treeview и Notebook, этот модуль предлагает альтернативную реализацию классических виджетов Tk: Button, Label и Frame.
В этом материале рассмотрим, как использовать эти классы, как их стилизовать и как применять новые классы виджетов.
Набор тематических виджетов Tk был представлен в Tk 8.5, что не должно быть проблемой, ведь установка Python как минимум версии 3.6 добавляет интерпретатор Tcl/Tk версии 8.6.
Убедиться в этом можно, набрав на любой платформе в командной строке python –mtkinter. После этого запустится следующая программа с указанием текущей версии Tcl/Tk:
Замена классов базовых виджетов
В качестве первого пункта знакомства с тематическими виджетами Tkinter посмотрим, как использовать уже знакомые (Button, Label, Entry и так далее), но взятые из другого модуля, сохраняя то же поведение в приложении.
Хотя это не даст аналогичных возможностей в плане настройки стилей, достаточно обратить внимание на визуальные отличия, которые привносят нативные дизайн и «ощущения» этих тематических виджетов.
На следующем скриншоте можно увидеть различия между тематическим виджетом и стандартным виджетом Tkinter:
Создадим приложение с первого скриншота, но рассмотрим, как легко переключаться между разными стилями.
Стоит отметить, что это поведение сильно зависит от платформы. В этом конкретном случае тематический виджет повторяет внешний вид виджетов с Windows 10.
Чтобы начать использовать тематические виджеты нужны импортировать модуль tkinter.ttk и привычным образом использовать виджеты из него в приложении:
import tkinter as tk
import tkinter as ttk
class App(tk.Tk):
greetings = ("Привет", "Ciao", "Hola")
def __init__(self):
super().__init__()
self.title("Тематические виджеты Tk")
var = tk.StringVar()
var.set(self.greetings[0])
label_frame = ttk.LabelFrame(self, text="Выберите приветствие")
for greeting in self.greetings:
radio = ttk.Radiobutton(label_frame, text=greeting,
variable=var, value=greeting)
radio.pack()
frame = ttk.Frame(self)
label = ttk.Label(frame, text="Введите ваше имя")
entry = ttk.Entry(frame)
command = lambda: print("{}, {}!".format(var.get(), entry.get()))
button = ttk.Button(frame, text="Приветствовать", command=command)
label.grid(row=0, column=0, padx=5, pady=5)
entry.grid(row=0, column=1, padx=5, pady=5)
button.grid(row=1, column=0, columnspan=2, pady=5)
label_frame.pack(side=tk.LEFT, padx=10, pady=10)
frame.pack(side=tk.LEFT, padx=10, pady=10)
if __name__ == "__main__":
app = App()
app.mainloop()
Если же в будущем потребуется переключиться к обычным виджетам Tkinter, то достаточно заменить все ttk. на tk..
Как работает замена виджетов
Чтобы начать использовать тематически виджеты нужно импортировать модуль tkinter.ttk с помощь синтаксиса import … as. Это позволит быстро отличать стандартные виджеты благодаря имени tk и тематические — с именем ttk:
import tkinter as tk
import tkinter as ttk
Вы могли заметить, что для замены виджетов из модуля tkinter на аналогичные им из tkinter.ttk достаточно просто поменять алиас:
import tkinter as tk
import tkinter as ttk
# ...
entry_1 = tk.Entry(root)
entry_2 = ttk.Entry(root)
В этом примере мы делаем это с помощью виджетов ttk.Frame, ttk.Label, ttk.Entry, ttk.LabelFrame и ttk.Radiobutton. Эти классы принимают почти те же базовые параметры, что и эквиваленты из Tkinter. На самом деле, они являются их подклассами.
Тем не менее эта смена довольно простая, потому что в этом случае не переносятся никакие особенности стиля: например, foreground и background. В тематических виджетах эти ключевые слова используются в классе ttk.Style, речь о котором пойдет дальше.
Создание редактируемого выпадающего списка с Combobox
Выпадающие списки — это удобный способ выбора значения с помощью отображения вертикального списка значений только тогда, когда они нужны. Традиционно пользователям также позволяют добавить свой вариант, которого нет в списке.
Эта функциональность комбинируется с классом ttk.Combobox, который выглядит и ощущается как нативные (для конкретной платформы) выпадающие списки.
Следующее приложение будет состоять из простого выпадающего списка с парой кнопок для подтверждения или сброса содержимого.
Если одно из имеющихся значений выбирается и нажимается кнопка Submit, то текущее значение Combobox выводится в стандартный вывод:
Это приложение создает экземпляр ttk.Combobox при инициализации, передавая заранее определенную последовательность значений, которые можно будет выбирать из списка:
import tkinter as tk
import tkinter.ttk as ttk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Ttk Combobox")
colors = ("Purple", "Yellow", "Red", "Blue")
self.label = ttk.Label(self, text="Пожалуйста, выберите цвет")
self.combo = ttk.Combobox(self, values=colors)
btn_submit = ttk.Button(self, text="Разместить",
command=self.display_color)
btn_clear = ttk.Button(self, text="Очистить",
command=self.clear_color)
self.combo.bind("<>", self.display_color)
self.label.pack(pady=10)
self.combo.pack(side=tk.LEFT, padx=10, pady=5)
btn_submit.pack(side=tk.TOP, padx=10, pady=5)
btn_clear.pack(padx=10, pady=5)
def display_color(self, *args):
color = self.combo.get()
print("Ваш выбор", color)
def clear_color(self):
self.combo.set("")
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает виджет Combobox
Традиционно виджет ttk.Combobox добавляется в приложение через передачу экземпляра Tk в качестве первого параметра в конструктор. Параметр values определяет список выбираемых вариантов, которые будут отображаться по клику.
Также выполняется связывание виртуального события <<ComboboxSelected>> при выборе одного из значений списка:
self.label = ttk.Label(self, text="Пожалуйста, выберите цвет")
self.combo = ttk.Combobox(self, values=colors)
btn_submit = ttk.Button(self, text="Разместить",
command=self.display_color)
btn_clear = ttk.Button(self, text="Очистить",
command=self.clear_color)
self.combo.bind("<<ComboboxSelected>>", self.display_color)
Тот же метод вызывается при клике по кнопке Submit, так что она получает значение, введенное пользователем.
display_color() принимает переменный список аргументов с помощью синтаксиса *, что позволяет безопасно обрабатывать опциональные аргументы. Это происходит, потому что событие передается внутрь при вызове через связывание. Однако функция не получает параметры при вызове через колбек кнопки.
Внутри этого метода мы получаем текущее значение Combobox с помощью метода get() и выводим его:
def display_color(self, *args):
color = self.combo.get()
print("Ваш выбор", color)
Наконец, clear_color() очищает содержимое Combobox с помощью вызова set() с пустой строкой:
def clear_color(self):
self.combo.set("")
С помощью этих методов вы знаете, как взаимодействовать с выбранным значением в экземпляре Combobox.
Класс ttk.Combobox расширяет ttk.Entry, который, в свою очередь, расширяет класс Entry из модуля tkinter.
Это значит, что можно использовать уже рассмотренные методы из класса Entry, если потребуется:
combobox.insert(0, "Добавьте это в начало: ")
Вот этот код более понятен чем combobox.set("Добавьте это в начало: " + combobox.get()).
Инициализировать список, кортеж и словарь можно несколькими способами. Один из наиболее распространенных — присвоить соответствующие символы переменной. Для списка эти символы — [], для кортежа — (), а для словаря — {}. Если присвоить эти символы без значений внутри, то будут созданы соответствующие пустые структуры данных.
Функции, которые будут использоваться дальше, являются альтернативными способами создания списков, кортежей и словарей. Их необязательно знать, но лучше запомнить, ведь они могут встретиться в коде других разработчиков.
Где используется
Структуры данных используются во всех аспектах программирования.
- Списки: содержат значения. Ими могут быть числа, строки, имена и так далее:
- Модели автомобилей;
- Имена собак;
- Посещенные страны;
- Посетители магазина и так далее;
- Кортежи: этот тип данных очень похож на список, но с одним исключением. После создания кортежа его значения нельзя менять. Списки — изменяемые, а кортежи — нет. Это может понадобиться в определенных случаях для достижения безопасности или просто удобства. В кортежах могут, например, храниться:
- Все месяцы года;
- Дисциплины Олимпийских игр;
- Штаты США;
Важно только отметить, что кортежи не являются вообще неизменяемыми, ведь вы всегда можете переписать код, поменяв или удалив определенные значения. Речь идет о том, что значения не могут быть изменены после создания — во время работы программы.
- Словари — это пары из ключа и значения. Словари также являются изменяемыми. Это удобная структура данных, которая подходит для сохранения значения с определенными дополнительными параметрами, например:
- Данные клиента включая список его покупок
- Названия стран + их количество олимпийских медалей
- Автомобильные бренды и их модели
- Страны с количеством ДТП с летальным исходом
- Функции
list()иdict()очень простые. Они помогают создавать соответствующие структуры данных.
Рекомендации по работе со структурами данных
- List(), dict() и float() используют круглые скобки, потому что они являются функциями;
- Скобки сами по себе представляют кортеж, и их не стоит путать со скобками в функциях, например, list();
- При создании пустого списка нужно использовать квадратные, а не круглые скобки:
[].
Функция №1: list()
У функции list() очень простой сценарий применения.
C помощью скобок создается список. После этого выводится переменная с присвоенным ей пустым списком. Выводится «[]», что указывает пусть и на пустой, но список. После этого выводится подтверждение того, что это действительно список.
>>> my_first_list = []
>>> print(my_first_list )
>>> print(type(my_first_list ))
[]
<class 'list'>
В следующем примере можно добиться того же результата, что и в первом, но уже с помощью функции list().
>>> my_first_list = list()
>>> print(my_first_list)
>>> print(type(my_first_list))
[]
<class 'list'>
Функция №2: dict()
Рассмотрим функцию dict(), с помощью которой можно создать словарь Python.
>>> my_first_dictionary = {}
>>> print(my_first_dictionary)
>>> print(type(my_first_dictionary))
{}
<class 'dict'>
И вот еще один пример создания пустого словаря. Тот же результат, но с помощью функции dict().
>>> my_first_dictionary = dict()
>>> print(my_first_dictionary)
>>> print(type(my_first_dictionary))
{}
<class 'dict'>
Функция №3: tuple()
Функция tuple() для создания кортежа Python. Пример с присваиванием переменной пустого кортежа.
>>> my_first_tuple = ()
>>> print(my_first_tuple)
>>> print(type(my_first_tuple))
()
<class 'tuple'>
И снова тот же результат, но уже с помощью функции tuple().
>>> my_first_tuple = tuple()
>>> print(my_first_tuple)
>>> print(type(my_first_tuple))
()
<class 'tuple'>
Советы:
- Кортеж — отличная альтернатива списку для тех ситуаций, когда в дальнейшем не требуется менять значения внутри этой структуры данных.
- Словари — идеальная структура для хранения пар ключ-значение.
Создадим список со значениями внутри.
>>> mylist = ["лыжные ботинки", "лыжи", "перчатки"]
>>> print(mylist)
>>> print(type(mylist))
["лыжные ботинки", "лыжи", "перчатки"]
<class 'list'>
В этом примере список состоит из 3 строковых значений. Но все три типа — списки, словари и кортежи — могут включать разные типы данных.
Теперь создадим словарь с этими значениями.
>>> mydict = {"лыжные ботинки": 3, "лыжи": 2, "перчатки": 5}
>>> print(mydict)
>>> print(type(mydict))
{"лыжные ботинки": 3, "лыжи": 2, "перчатки": 5}
<class 'dict'>
В этом примере создается словарь. Он присвоен переменной mydict, которая состоит из 3 ключей: “лыжные ботинки”, “лыжи” и “перчатки”. Каждому ключу присвоено свое значение: 3, 2 и 5 соответственно.
Теперь создадим список со значениями разных типов.
>>> mylist = ["карабины", False, "порошок", 666, 25.25]
>>> print(mylist)
>>> print(type(mylist))
["карабины", False, "порошок", 666, 25.25]
<class 'list'>
В этом примере список включает 5 значений четырех разных типов: строка, булев тип, строка, целое число и число с плавающей точкой.
Наконец, создадим пример кортежа.
>>> mytuple = ("карабины", False, "порошок", 666, 25.25)
>>> print(mytuple)
>>> print(type(mytuple))
("карабины", False, "порошок", 666, 25.25)
<class 'tuple'>
Единственное отличие здесь в том, что используются круглые (), а не квадратные [] скобки.
Мы кратко рассмотрели структуры данных, в следующих уроках разберем каждый подробно.
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Создайте пустой список, определите его тип и выведите в консоль.
# данный код
gift_list=
answer_1=
print(answer_1)
# требуемый вывод:
# <class 'list'>2. Допишите код, чтобы gift_list был заполненным кортежем. Порядок элементов значения не имеет.
gifts=
print(gifts)
# требуемый вывод:
# ("Камера", "Наушники", "Часы")3. Исправьте ошибки в коде, для получения требуемого вывода.
stats = {1 - 10, 220, 3 - 30, 4 - 40, 5 - 50 6 - 60}
print(stat)
# требуемый вывод:
# {1: 10, 2: 20, 3: 30, 4: 40, 5: 50, 6: 60}Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_5.py.
Тест по конвертации типов данных
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>В этой статье мы рассмотрим:
- Удаление одной, нескольких или всех строк или колонок из SQLite-таблицы с помощью Python;
- Использование запроса с параметрами для выполнения операции удаления из SQLite;
- Коммит и отмена последней операции;
- Массовое удаление в один запрос.
Подготовка
Перед выполнением следующих операций нужно знать название таблицы SQLite, а также ее колонок. В этом материале будет использоваться таблица sqlitedb_developers.
Пример удаления одной строки из SQLite-таблицы
Сейчас таблица sqlitedb_developers содержит шесть строк, а удалять будем разработчика, чей id равен 6. Вот что для этого нужно сделать:
- Присоединиться к SQLite из Python;
- Создать объект
Cursorс помощью полученного в прошлом шаге объекта соединения SQLite; - Создать DELETE-запрос для SQLite. Именно на этом этапе нужно знать названия таблицы и колонок;
- Выполнить DELETE-запрос с помощью
cursor.execute(); - После выполнения запроса необходимо закоммитить изменения в базу данных;
- Закрыть соединение с базой данных;
- Также важно не забыть перехватить исключения, которые могут возникнуть;
- Наконец, проверить результат операции.
Пример:
import sqlite3
def delete_record():
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_delete_query = """DELETE from sqlitedb_developers where id = 6"""
cursor.execute(sql_delete_query)
sqlite_connection.commit()
print("Запись успешно удалена")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
delete_record()
Вывод: таблица sqlitedb_developers после удаления строки из Python.
Подключен к SQLite
Запись успешно удалена
Соединение с SQLite закрытоРазбор примера в подробностях
import sqlite3:
- На этой строке модуль sqlite3 импортируется в программу;
- С помощью классов и методов sqlite3 можно взаимодействовать с базой данных SQLite.
sqlite3.connect() и connection.cursor():
- С помощью
sqlite3.connect()устанавливается соединение с базой данных SQLite из Python; - Дальше используется
sqliteConnection.cursor()для получения объектаCursor.
После этого создается DELETE-запрос для удаления шестой строки в таблице (для разработчика с id равным 6). В запросе этот разработчик упоминается.
cursor.execute():
- Выполняется операция из DELETE-запроса с помощью метода
execute()объектаCursor; - После успешного удаления записи изменения коммитятся в базу данных с помощью
connection.commit().
Наконец, закрываются Cursor и SQLite-соединение в блоке finally.
Примечание: если выполняется несколько операций удаления, и есть необходимость отменить все изменения в случае неудачи хотя бы с одной из них, нужно использовать функцию
rollback()класса соединения для отмены. Эту функцию стоит применять внутри блокаexcept.
Использование переменных в запросах для удаления строки
В большинстве случаев удалять строки из таблицы SQLite нужно с помощью ключа, который передается уже во время работы программы. Например, когда пользователь удаляет свою подписку, запись о нем нужно удалить из таблицы.
В таких случаях требуется использовать запрос с параметрами. В таких запросах на месте будущих значений ставятся заполнители (?). Это помогает удалять записи, получая значения во время работы программы, и избегать проблем SQL-инъекций. Вот пример с удалением разработчика с id=5.
import sqlite3
def delete_sqlite_record(dev_id):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sql_update_query = """DELETE from sqlitedb_developers where id = ?"""
cursor.execute(sql_update_query, (dev_id, ))
sqlite_connection.commit()
print("Запись успешно удалена")
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
delete_sqlite_record(5)
Вывод: таблица sqlitedb_developers после удаления строки с помощью запроса с параметрами.
Подключен к SQLite
Запись успешно удалена
Соединение с SQLite закрытоРазберем последний пример:
- Запрос с параметрами использовался, чтобы получить id разработчика во время работы программы и подставить его на место
?. Он определяет id записи, которая будет удалена. - После этого создается кортеж данных с помощью переменных Python.
- Дальше DELETE-запрос вместе с данными передается в метод
cursor.execute(). - Наконец, изменения сохраняются в базе данных с помощью метода
commit()классаConnection.
Операция Delete для удаления нескольких строк
В примере выше был использован метод execute() объекта Cursor для удаления одной записи, но часто приходится удалять сразу несколько одновременно.
Вместо выполнения запроса DELETE каждый раз для каждой записи, можно выполнить операцию массового удаления в одном запросе. Удалить несколько записей из SQLite-таблицы в один запрос можно с помощью метода cursor.executemany().
Метод cursor.executemany(query, seq_param) принимает два аргумента: SQL-запрос и список записей для удаления.
Посмотрим на следующий пример. В нем удаляются сразу три разработчика.
import sqlite3
def delete_multiple_records(ids_list):
try:
sqlite_connection = sqlite3.connect('sqlite_python.db')
cursor = sqlite_connection.cursor()
print("Подключен к SQLite")
sqlite_update_query = """DELETE from sqlitedb_developers where id = ?"""
cursor.executemany(sqlite_update_query, ids_list)
sqlite_connection.commit()
print("Удалено записей:", cursor.rowcount)
sqlite_connection.commit()
cursor.close()
except sqlite3.Error as error:
print("Ошибка при работе с SQLite", error)
finally:
if sqlite_connection:
sqlite_connection.close()
print("Соединение с SQLite закрыто")
ids_to_delete = [(4,),(3,)]
delete_multiple_records(ids_to_delete)
Подключен к SQLite
далено записей: 2
Соединение с SQLite закрытоРазберем последний пример:
- После соединения с базой данных SQLite готовится SQL-запрос с параметрами и одним заполнителем. Вместе с ним также передается список id в формате кортежа.
- Каждый элемент списка — это всего лишь кортеж каждой строки. Каждый кортеж содержит id разработчика. В этом примере три кортежа — то есть, три разработчика.
- Дальше вызывается
cursor.executemany(sqlite_delete_query, ids_list)для удаления нескольких записей из таблицы. И запрос, и список id передаютсяcursor.executemany()в качестве аргументов. - Чтобы увидеть количество затронутых записей, можно использовать метод
cursor.rowcount. Наконец, изменения сохраняются в базу данных с помощью методаcommitклассаConnection.
Определение пересечений между элементами
В продолжение предыдущего материала о поиске ближайшего элемента стоит отметить, что существует также возможность определять, пересекается ли один прямоугольник с другим. Этого можно добиться благодаря тому, что все элементы заключены в прямоугольные контейнеры. А для определения пересечений используется метод find_overlapping() из класса Canvas.
Это приложение расширяет возможности предыдущего за счет четырех новых прямоугольников, добавленных на полотно. Подсвечиваться будет тот, с которым пересечется синий. Управлять последним можно с помощью клавиш стрелок:

Поскольку код во многом повторяет предыдущий, отметим лишь те части кода, которые отвечают за создание новых прямоугольников и вызов метода canvas.find_overlapping():
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Обнаружение пересечений между предметами")
self.canvas = tk.Canvas(self, bg="white")
self.canvas.pack()
self.update()
self.width = w = self.canvas.winfo_width()
self.height = h = self.canvas.winfo_height()
pos = (w / 2 - 15, h / 2 - 15, w / 2 + 15, h / 2 + 15)
self.item = self.canvas.create_rectangle(*pos, fill="blue")
positions = [(60, 60), (w - 60, 60), (60, h - 60), (w - 60, h - 60)]
for x, y in positions:
self.canvas.create_rectangle(x - 10, y - 10, x + 10, y + 10,
fill="green")
self.pressed_keys = {}
self.bind("<KeyPress>", self.key_press)
self.bind("<KeyRelease>", self.key_release)
self.process_movements()
def key_press(self, event):
self.pressed_keys[event.keysym] = True
def key_release(self, event):
self.pressed_keys.pop(event.keysym, None)
def process_movements(self):
all_items = self.canvas.find_all()
for item in filter(lambda i: i is not self.item, all_items):
self.canvas.itemconfig(item, fill="green")
x0, y0, x1, y1 = self.canvas.coords(self.item)
items = self.canvas.find_overlapping(x0, y0, x1, y1)
for item in filter(lambda i: i is not self.item, items):
self.canvas.itemconfig(item, fill="yellow")
off_x, off_y = 0, 0
speed = 3
if 'Right' in self.pressed_keys:
off_x += speed
if 'Left' in self.pressed_keys:
off_x -= speed
if 'Down' in self.pressed_keys:
off_y += speed
if 'Up' in self.pressed_keys:
off_y -= speed
pos_x = x0 + (x1 - x0) / 2 + off_x
pos_y = y0 + (y1 - y0) / 2 + off_y
if 0 <= pos_x <= self.width and 0 <= pos_y <= self.height:
self.canvas.move(self.item, off_x, off_y)
self.after(10, self.process_movements)
if __name__ == "__main__":
app = App()
app.mainloop()
Как определяются пересечения
До пересечения цвет заполнения всех прямоугольников на полотне, кроме управляемого пользователем, будет зеленым. Идентификаторы этих элементов можно получить с помощью метода canvas.find_all():
def process_movements(self):
all_items = self.canvas.find_all()
for item in filter(lambda i: i is not self.item, all_items):
self.canvas.itemconfig(item, fill="green")
Когда цвета элемента сброшены, вызываем canvas.find_overlapping() для получения всех элементов, которые пересекаются с двигающимся. Он, в свою очередь, из цикла исключен, а цвет остальных пересекающихся элементов (если такие имеются) меняется на желтый:
def process_movements(self):
# ...
x0, y0, x1, y1 = self.canvas.coords(self.item)
items = self.canvas.find_overlapping(x0, y0, x1, y1)
for item in filter(lambda i: i is not self.item, items):
self.canvas.itemconfig(item, fill="yellow")
Метод продолжает выполнение, перемещая синий прямоугольник на заданный показатель сдвига, и планируя себя же снова с помощью process_movements().
Если нужно определить, когда движущийся элемент полностью перекрывает другой (а не частично), то стоит воспользоваться методом canvas.find_enclosed() вместо canvas.find_overlapping() с теми же параметрами.
Удаление элементов с полотна
Помимо добавления и изменения элементов полотна их также можно удалять с помощью метода delete() класса Canvas. Хотя в принципах его работы нет каких-либо особенностей, существуют кое-какие паттерны, которые будут рассмотрены дальше.
Стоит учитывать, что чем больше элементов на полотне, тем дольше Tkinter будет рендерить виджет. Таким образом важно удалять неиспользуемые для улучшения производительности.
В этом примере создадим приложение, которое случайным образом выбирает несколько кругов на полотне. Каждый кружок будет удаляться по клику. Одна кнопка в нижней части виджета сбрасывает состояние полотна, а вторая — удаляет все элементы.

Чтобы случайным образом размещать элементы на полотне, будем генерировать координаты с помощью функции randint модуля random. Цвет элемента будет выбираться случайным образом с помощью вызова choice и определенного набора цветов.
После генерации элементы можно будет удалить с помощью обработчика on_click или кнопки Clearitems, которая, в свою очередь, вызывает функцию обратного вызова clear_all. Внутри этот метод вызывает canvas.delete() с нужными параметрами:
import random
import tkinter as tk
class App(tk.Tk):
colors = ("red", "yellow", "green", "blue", "orange")
def __init__(self):
super().__init__()
self.title("Удаление элементов холста")
self.canvas = tk.Canvas(self, bg="white")
frame = tk.Frame(self)
generate_btn = tk.Button(frame, text="Создавать элементы",
command=self.generate_items)
clear_btn = tk.Button(frame, text="Удалить элементы",
command=self.clear_items)
self.canvas.pack()
frame.pack(fill=tk.BOTH)
generate_btn.pack(side=tk.LEFT, expand=True, fill=tk.BOTH)
clear_btn.pack(side=tk.LEFT, expand=True, fill=tk.BOTH)
self.update()
self.width = self.canvas.winfo_width()
self.height = self.canvas.winfo_height()
self.canvas.bind("<Button-1>", self.on_click)
self.generate_items()
def on_click(self, event):
item = self.canvas.find_withtag(tk.CURRENT)
self.canvas.delete(item)
def generate_items(self):
self.clear_items()
for _ in range(10):
x = random.randint(0, self.width)
y = random.randint(0, self.height)
color = random.choice(self.colors)
self.canvas.create_oval(x, y, x + 20, y + 20, fill=color)
def clear_items(self):
self.canvas.delete(tk.ALL)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает удаление элементов
Метод canvas.delete() принимает один аргумент, который может быть идентификатором элемента или тегом, и удаляет один или несколько соответствующих элементов (поскольку тег может быть использован несколько раз).
В обработчике on_click() можно увидеть пример удаления элемента по идентификатору:
def on_click(self, event):
item = self.canvas.find_withtag(tk.CURRENT)
self.canvas.delete(item)
Стоит также отметить, что если сейчас кликнуть по пустой точке, то canvas.find_withtag(tk.CURRENT) вернет None, но когда это значение будет передано в canvas.delete(), то ошибки не будет. Это объясняется тем, что параметр None не совпадает ни с одним идентификатором или тегом. Таким образом это валидный параметр, хоть в результате никакое действие и не выполняется.
В функции обратного вызова clear_items() можно найти другой пример удаления элементов. Здесь вместо передачи идентификатора элемента используется тег ALL, который соответствует всем элементам и удаляет их с полотна:
def clear_items(self):
self.canvas.delete(tk.ALL)
Можно обратить внимание на то, что тег ALL работает «из коробки», поэтому его не нужно добавлять каждому элементу полотна.
Связывание событий с элементами полотна
Вы уже знаете, как связывать события с виджетами, но то же самое можно делать и с элементами. Это помогает писать более специфичные и простые обработчики событий. Такой намного удобнее, чем связывать все события с экземпляром Canvas и потом определять, какое из них нужно в текущий момент.
Следующее приложение показывает, как реализовать функциональность drag and drop для элементов полотна. Это распространенная особенность, которая способна значительно упростить программы.
Создадим несколько элементов (прямоугольник и овал), которые можно будет перетаскивать с помощью мыши. Разная форма поможет заметить, как события кликов корректно применяются к элементам, даже когда они пересекаются между собой:
import tkinter as tk
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Drag and drop")
self.dnd_item = None
self.canvas = tk.Canvas(self, bg="white")
self.canvas.pack()
self.canvas.create_rectangle(30, 30, 60, 60, fill="green",
tags="draggable")
self.canvas.create_oval(120, 120, 150, 150, fill="red",
tags="draggable")
self.canvas.tag_bind("draggable", "<ButtonPress-1>",
self.button_press)
self.canvas.tag_bind("draggable", "<Button1-Motion>",
self.button_motion)
def button_press(self, event):
item = self.canvas.find_withtag(tk.CURRENT)
self.dnd_item = (item, event.x, event.y)
def button_motion(self, event):
x, y = event.x, event.y
item, x0, y0 = self.dnd_item
self.canvas.move(item, x - x0, y - y0)
self.dnd_item = (item, x, y)
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает drag and drop
Для связывания событий с элементами используется метод tag_bind() из класса Canvas. Это добавляет связывание для всех элементов, которые соответствуют конкретному элементу — тегу draggable в этом случае.
И хотя метод называется tag_bind() вместо тега в него можно передавать также идентификатор:
self.canvas.tag_bind("draggable", "<ButtonPress-1>",
self.button_press)
self.canvas.tag_bind("draggable", "<Button1-Motion>",
self.button_motion)
Также стоит отметить, что новое поведение затронет только уже существующие элементы, поэтому если позже добавить новые с тегом draggable, то к ним связывание применено не будет.
Метод button_press() — это обработчик, который запускается после нажатия на элемент. Традиционный паттерн для получения соответствующего элемента — вызов canvas.find_withtag(tk.CURRENT).
Идентификатор элемента, а также координаты x и y события click хранятся в поле dnd_item. Эти значения позже будут использованы для перемещения элемента в соответствии с движением мыши:
def button_press(self, event):
item = self.canvas.find_withtag(tk.CURRENT)
self.dnd_item = (item, event.x, event.y)
Метод button_motion() обрабатывает события движения мыши до тех пор, пока зажата основная кнопка.
Для определения дистанции, на которую должен быть перемещен элемент, нужно вычислить разницу текущей позиции с предыдущими координатами. Эти значения передаются в метод canvas.move() и снова сохраняются в поле dnd_item:
def button_motion(self, event):
x, y = event.x, event.y
item, x0, y0 = self.dnd_item
self.canvas.move(item, x - x0, y - y0)
self.dnd_item = (item, x, y)
Существуют вариации этой drag & drop функциональности, которые также задействуют обработчик последовательности <ButtonRelease-1>. Она сбрасывает текущий элемент.
Однако использовать его необязательно, потому что после того как это событие происходит, связывание <Button1-Motion> не запустится до очередного клика по элементу. Это также помогает избежать проверки того, не является ли None значением dnd_item в начале обработчика button_motion().
Также этот пример можно улучшить, добавив базовую валидацию. Например, можно проверять, чтобы пользователь не мог вытащить элемент за пределы видимой области полотна.
Для этого используются паттерны, которые рассматривались в прошлых примерах. С их помощью можно вычислять ширину и высоту полотна и убедиться, что финальное положение элемента находится в пределах валидного диапазона с помощью цепочки операторов сравнения. В качестве шаблона для этого можно использовать следующий код:
final_x, final_y = pos_x + off_x, pos_y + off_y
if 0 <= final_x <= canvas_width and 0 <= final_y <= canvas_height:
canvas.move(item, off_x, off_y)
Рендер полотна в файл PostScript
Класс Canvas нативно поддерживает сохранение содержимого с помощью языка PostScript и метода postscript(). Он сохраняет графическое представление элементов полотна (линий, прямоугольников, овалов и так далее), но не его виджетов или изображений.
Изменим прошлый пример, который динамически генерирует этот тип простых элементов, и добавим функциональность для сохранения полотна в файл PostScript.
Возьмем уже знакомый код и добавим в него кусок для вывода содержимого полотна в файл PostScript:
import tkinter as tk
from lesson_18.drawing import LineForm
class App(tk.Tk):
def __init__(self):
super().__init__()
self.title("Базовый холст")
self.line_start = None
self.form = LineForm(self)
self.render_btn = tk.Button(self, text="Render canvas",
command=self.render_canvas)
self.canvas = tk.Canvas(self, bg="white")
self.canvas.bind("<Button-1>", self.draw)
self.form.grid(row=0, column=0, padx=10, pady=10)
self.render_btn.grid(row=1, column=0)
self.canvas.grid(row=0, column=1, rowspan=2)
def draw(self, event):
x, y = event.x, event.y
if not self.line_start:
self.line_start = (x, y)
else:
x_origin, y_origin = self.line_start
self.line_start = None
line = (x_origin, y_origin, x, y)
arrow = self.form.get_arrow()
color = self.form.get_color()
width = self.form.get_width()
self.canvas.create_line(*line, arrow=arrow,
fill=color, width=width)
def render_canvas(self):
self.canvas.postscript(file="output.ps", colormode="color")
if __name__ == "__main__":
app = App()
app.mainloop()
Как работает рендеринг в .ps
Основное нововведение — это кнопка Render canvas с функцией обратного вызова render_canvas().
Она вызывает метод postscript() для экземпляра canvas с аргументами file и colormode. Эти параметры определяют путь к расположению файла, а также информацию о цвете. Вторым параметром может быть color для полностью цветного вывода, gray — для использования оттенков серого или mono — для конвертации цветов в черный и белый:
def render_canvas(self):
self.canvas.postscript(file="output.ps", colormode="color")
Все параметры, которые можно передать в postscript(), стоит искать в официальной документации Tk/Tcl по ссылке https://www.tcl.tk/m an/tcl8.6/TkCmd/canvas.htm#M61. Стоит напомнить, что PostScript — язык печати, поэтому большая часть его параметров касается настроек страницы.
Поскольку файлы PostScript не так популярны, как другие форматы файлов, возможно, возникнет необходимость конвертировать готовый файл во что-то более знакомое — например, PDF.
Для этого нужен сторонний софт, такой как, например, Ghostscript, который распространяется по лицензии GNU APGL. Интерпретатор и инструмент рендеринга можно вызвать из программы для автоматической конвертации результатов PostScript в PDF.
Установить программу можно с сайта https://w ww.ghostscript.com/download/gsdnld.html. Дальше нужно только добавить папки bin и lib из установки в переменную path операционной системы.
Затем остается изменить приложение Tkinter для вызова программы ps2pdf в качестве подпроцеса и удалить файл output.ps после завершения выполнения:
import os
import subprocess
import tkinter as tk
class App(tk.Tk):
# ...
def render_canvas(self):
output_filename = "output.ps"
self.canvas.postscript(file=output_filename, colormode="color")
process = subprocess.run(["ps2pdf", output_filename, "output.pdf"],
shell=True)
os.remove(output_filename)
type() возвращает тип объекта. Ее назначение очевидно, и на примерах можно понять, зачем эта функция нужна.
Также в этом материале рассмотрим другие функции, которые могут помочь в процессе конвертации типа данных. Некоторые из них — это int(), float() или str().
type() — это базовая функция, которая помогает узнать тип переменной. Получившееся значение можно будет выводить точно так же, как обычные значения переменных с помощью print.
Где используется
- Функция
type()используется для определения типа переменной. - Это очень важная информация, которая часто нужна программистам.
- Например, программа может собирать данные, и будет необходимость знать тип этих данных.
- Часто требуется выполнять определенные операции с конкретными типами данных: например, арифметические вычисления на целых или числах с плавающей точкой или поиск символа в строках.
- Иногда будут условные ситуации, где с данными нужно будет обращаться определенным образом в зависимости от их типа.
- Будет и много других ситуаций, где пригодится функция
type().
Рекомендации по работе с типами данных
- Типы
intиfloatможно конвертировать вstr, потому что строка может включать не только символы алфавита, но и цифры. - Значения типа
strвсегда представлены в кавычках, а дляint,floatиboolони не используются. - Строку, включающую символы алфавита, не выйдет конвертировать в целое или число с плавающей точкой.
Примеры конвертации типов данных
>>> game_count = 21
>>> print(type(game_count))
<class 'int'>
В следующих материалах речь пойдет о более сложных типах данных, таких как списки, кортежи и словари. Их обычно называют составными типами данных, потому что они могут состоять из значений разных типов. Функция type() может использоваться для определения их типов также.
>>> person1_weight = 121.25
>>> print(type(person1_weight))
<class 'float'>
Функция int()
С помощью функции int() можно попробовать конвертировать другой тип данных в целое число.
В следующем примере можно увидеть, как на первой строке переменной inc_count присваивается значение в кавычках.
Из-за этих кавычек переменная регистрирует данные как строку. Дальше следуют команды print для вывода оригинального типа и значения переменной, а затем — использование функции int() для конвертации переменной к типу int.
После этого две функции print показывают, что значение переменной не поменялось, но тип данных — изменился.
Можно обратить внимание на то, что после конвертации выведенные данные не отличаются от тех, что были изначально. Так что без использования type() вряд ли удастся увидеть разницу.
>>> inc_count = "2256"
>>> print(type(inc_count))
>>> print(inc_count)
>>> inc_count = int(inc_count)
>>> print(type(inc_count))
>>> print(inc_count)
<class 'str'>
2256
<class 'int'>
2256
Функция float()
Функция float() используется для конвертации данных из других типов в тип числа с плавающей точкой.
>>> inc_count = "2256"
>>> print(type(inc_count))
>>> print(inc_count)
>>> inc_count = float(inc_count)
>>> print(type(inc_count))
>>> print(inc_count)
<class 'str'>
2256
<class 'float'>
2256.0
Функция str()
Как и int() с float() функция str() помогает конвертировать данные в строку из любого другого типа.
>>> inc_count = 2256
>>> print(type(inc_count))
>>> print(inc_count)
>>> inc_count = str(inc_count)
>>> print(type(inc_count))
>>> print(inc_count)
<class 'int'>
2256
<class 'str'>
2256
Советы:
- Не любой тип можно конвертировать в любой другой. Например, если строка состоит только из символов алфавита, то при попытке использовать с ней
int()приведет к ошибке. - Зато почти любой символ или число можно привести к строке. Это будет эквивалентно вводу цифр в кавычках, поскольку именно так создаются строки в Python.
Как можно увидеть в следующем примере, поскольку переменная состоит из символов алфавита, Python не удается выполнить функцию int(), и он возвращает ошибку.
>>> my_data = "Что-нибудь"
>>> my_data = int(my_data)
ValueError: invalid literal for int() with base 10: 'Что-нибудь'
Задачи к уроку
Попробуйте решить задачи к этому уроку для закрепления знаний.
1. Измените и дополните код, что бы переменная salary_type хранила результат функции type() со значением int.
# данный код
salary = "50000"
salary_type =
print(salary_type)
# требуемый вывод:
# <class 'int'>2. Исправьте ошибку в коде, что бы получить требуемый вывод.
# данный код
mark = int("5+")
print(mark, "баллов")
# требуемый вывод:
# 5+ баллов3. Конвертируйте переменные и введите только целые числа через дефис.
# данный код
score1 = 50.5648
score2 = 23.5501
score3 = 96.560
print()
# требуемый вывод:
# 50-23-96Файл со всем заданиями: https://gitlab.com/PythonRu/python-dlya-nachinayushih/-/blob/master/lesson_4.py.
Тест по конвертации типов данных
Пройдите тест к этому уроку для проверки знаний. В тесте 5 вопросов, количество попыток неограниченно.
Если нашли ошибку, опечатку или знаете как улучшить этот урок, пишите на почту. Ее можно найти внизу сайта.
]]>